1. Introduction
Many countries, both developed and developing, have experienced large reductions in mortality rates and significant improvements in life expectancy in recent decades. However, the decline in the mortality rate varies across countries, as well as across regions within countries. While subnational mortality rates and life expectancies often exhibit similar trends and levels, there are also large regional disparities. For example, in the United States, there are large inequalities in mortality (
Montez et al. 2016); male life expectancy at birth in major cities such as San Francisco and Washington DC increased by 13.7 years during the period 1990–2015, whereas it only increased by 4.8 years for the entire country (
Fenelon and Boudreaux 2019). In developing countries also, subnational mortality rates and life expectancies show substantial variations (e.g.,
Schmertmann and Gonzaga 2018 for Brazil, and
Li et al. 2020 for China). The differences in life expectancy can pose challenges to the actuarial fairness of private annuity products and public pension schemes (
Lee and Sanchez-Romero 2019). Therefore, subnational mortality projections are important both for insurance companies to improve the fairness of annuity products and for policymakers to evaluate pension fairness and design pension reforms.
However, subnational mortality modelling is often difficult due to limited data. For many developed countries, a relatively long time series of subnational mortality data are available (see, e.g., the United States Mortality Database, the Canadian Human Mortality Database, the French Human Mortality Database), but the available mortality datasets often have missing values at lower and higher ages at the subnational level. For developing countries, subnational mortality data are typically scarce or even unavailable.
This study proposes a new model in a Bayesian hierarchical framework to estimate and project subnational and national mortality rates based on sparse and missing data. The model uses common factors to pool information at the national level and within regions consisting of several provinces. Its forecast intervals reflect provincial- and regional-level uncertainty. We illustrate the use of the model based on a new mortality database containing data from four censuses conducted in Chinese provinces over the period 1982–2010. We also apply the model to state-level mortality in the United States based on subnational mortality data from the period 1999–2018, which has missing values at the subnational level. We project and compare the national and subnational life expectancy of China and the United States. The proposed model can also be applied to model subnational mortality and life expectancy in other countries, especially those with a limited number of data points. All model codes are available upon request from the authors.
A growing body of literature has been developing stochastic mortality models for multiple populations. For instance,
Li and Lee (
2005) apply the Lee–Carter model (
Lee and Carter 1992) to a group of populations, allowing each population to have its own age pattern and level of mortality but imposing shared rates of change by age; this approach has had several extensions (e.g.,
Danesi et al. 2015;
Dowd et al. 2011;
Kleinow 2015). Other functional methods have also been used in modelling several related populations. For example, De
Beer (
2012) uses a relational model called the “tool for projecting age-specific rates using the linear splines (TOPALS)” to smooth, estimate, and project the mortality rates of 26 European countries.
Hyndman et al. (
2013) apply the product-ratio functional method to forecast male and female mortality in Switzerland, whereas
Bergeron-Boucher et al. (
2017) employ compositional data analysis to forecast mortality in 15 European countries.
More recently, Bayesian methods have been used to model subnational mortality. In contrast to the Lee–Carter model or other stochastic two-stage models, which estimate parameters and forecast in two separate steps, the Bayesian framework has the following strengths. First, it has higher statistical efficiency, as it permits estimations and forecasts to be conducted in one step (
Fung et al. 2017). Second, it can handle missing data. Based on this point,
Alexander et al. (
2017) develop a model under a Bayesian hierarchical framework to model incomplete subnational mortality rates in the United States and France. Third, the Bayesian framework is highly flexible and can adapt to almost all models. For example,
Schmertmann and Gonzaga (
2018) use the Bayesian framework to combine demographic estimation techniques and TOPALS in subnational mortality modelling and apply their model to Brazil.
There is limited research on developing stochastic mortality models for China, especially at the subnational level.
Zhao (
2012) proposes a modified Lee–Carter model for analysing short-base-period data and applies the model to (country-level) mortality data for China for the period 2000–2008. Using the model developed by
Zhao (
2012) and data for 2000–2008,
Zhao et al. (
2013) assess China’s mortality rates at the country level and in three subnational groups (cities, towns, and counties).
Huang and Browne (
2017) propose a modified continuous mortality investigation (CMI) mortality projections model that borrows information from international experience and apply the model to country-level mortality data for China for the period 1997–2011. Applying this modified CMI model,
Huang (
2017) forecasts the sex–age-specific mortality rates in the same three subnational groups (cities, towns, and counties) considered by
Zhao et al. (
2013).
Li et al. (
2019) develop a Bayesian approach to handle missing data points and data from different sources to model China’s (country-level) mortality based on data for 1981–2014. Using the provincial-level dataset from 1982 to 2010 introduced in this paper,
Lu et al. (
2020) extend the Cairns–Blake–Dowd model (
Cairns et al. 2006) to a Bayesian framework and introduce the reporting probability to study the effect of the underreporting of deaths on subnational mortality modelling and projections.
We make two main contributions to the literature. First, we propose a new model based on principal components under a Bayesian hierarchical framework to model and project subnational mortality in one stage. The proposed method allows for three geographical levels (province, region, and country) and shares information in regions through common regional and common country-level factors. The model estimates and forecasts the country- and provincial-level mortality rates simultaneously. Owing to the information-sharing structure, the new model copes with sparse and missing data. Second, we illustrate the model based on a new mortality database from four censuses for 30 Chinese provinces conducted during the period 1982–2010, which we compiled using online and archived resources. Our model captures the specific patterns within the sparse and irregular data for China. We also show that the model can be applied to more comprehensive subnational data: we apply the model to the United States using subnational data from the Centers for Disease Control and Prevention (CDC) from 1999 to 2018.
The proposed model provides a good fit and reasonable forecasts for China and its provinces, performing better, with lower values of the root mean square error (RMSE), than the Li–Lee model (
Li and Lee 2005), which we choose as a benchmark. The sensitivity analyses show that the forecasts are relatively robust to the method for grouping provinces into regions. The model performs well with missing data both in China and the United States. Based on the mortality forecast, we compute the subnational life expectancy for China and the United States. Based on the currently available data, which do not cover the COVID-19 pandemic, the model projects that both countries have the same national life expectancy at age 60 and similar subnational heterogeneity. However, the life expectancy at age 60 for China has larger forecast intervals because of the relatively few data points.
The remainder of this paper is organised as follows.
Section 2 introduces the proposed model.
Section 3 describes the subnational mortality database for China and the United States.
Section 4 presents and compares the results of the model based on Chinese subnational data.
Section 5 computes and compares the national and subnational life expectancies of China and the United States.
Section 6 provides conclusions and ideas for future research.
2. Method
The proposed model models the mortality rates at the country (national) and provincial (state) levels together, with
denoting the number of deaths at age
x in province
i at time
t (
t =
t1, …,
tT) and
representing the deaths at age
x in the country at time
t. We assumed that the number of deaths follows a Poisson distribution, which is a common assumption in the literature (e.g.,
Czado et al. 2005;
Alexander et al. 2017):
where
is the mortality rate and
is the population at risk at age
x and time
t in province
i, whereas
and
are the same variables at the country level, respectively. We applied the following consistency conditions to obtain the data for the entire country and ensured that the mortality rates at the country and provincial levels were consistent:
We modelled the provincial-level mortality rate and the country-level mortality rate as functions of principal components whose prior information is estimated by singular value decomposition (SVD).
In multi-population mortality modelling, common factors are usually used to maintain coherence (e.g.,
Kleinow 2015;
Li and Lee 2005). We followed this approach and used common factors at different geographical levels based on the principal components.
Alexander et al. (
2017) suggest that the first three principal components allow for a reasonably flexible fit and demographic interpretation at the same time and use the first three principal components in their study. Analysing Chinese subnational mortality curves, we found that three principal components provide good fits (and do not overfit) for the national and all available provincial mortality curves compared with two principal components and four principal components. Thus, we used the first three principal components as the provincial, regional and common factors in our model.
Most multi-population models emphasise coherence and model similar mortality trajectories together. However, in countries with subnational mortality disparities, such as China, all subnational areas need to be modelled together, despite the different mortality profiles. In that case, the differences in subnational mortality are substantial and can dominate the common patterns. To account for the different mortality characteristics across provinces (or states), we proposed using the first principal component as provincial-level factors to capture the dominant provincial mortality patterns. Given that provinces within a certain region experience similar levels of economic development and mortality, we introduced a regional common factor based on the second principal component to account for regional mortality similarities. The common country-level factors based on the third principal component determine the common patterns among all provinces and maintain coherence.
Following previous studies (e.g.,
Lee and Carter 1992;
Zhao 2012), we modelled the mortality rates on the log scale. Thus,
and
were modelled with provincial-level, region-level, and common principal components:
where
,
,
, and
(
p = 1, 2) are the principal components and
,
,
, and
(
p = 1, 2) are the corresponding coefficients of each principal component at time
t. The first factors,
and
, are provincial-level factors for the individual province
i; the second factors,
and
, are common factors within the
kth (
k = 1, …,
K) region; and the third factors,
and
, are common country-level factors for all provinces. By using common country-level factors, all provinces share the same information.
We estimated
and
by drawing from the following normal distribution:
where
is the prior, which is the first principal component computed by the SVD of the mortality matrix for the entire country.
We modelled the provincial-level
by using the following prior distribution:
where the prior
is the
pth (
p = 1, 2, 3) principal component computed by the SVD of the mortality matrix for the entire country.
Provinces in the same region share the same
, which is estimated as:
The common
for the entire country and its provinces were drawn from the following distribution:
The random walk process is commonly used to describe the dynamics of the period effects in multi-population and Bayesian mortality models, such as in
Li and Lee (
2005) and
Czado et al. (
2005). Therefore, we modelled the coefficients using the random walk process. As initial values, we allowed the provincial level
and the region level
to pool information within region
k:
where
is the population-weighted mean of the first coefficient in the
kth region (
k = 1, 2, …,
K) computed by the SVD.
The initial values of
and
and (
p = 1, 2) pool information across all provinces with the following priors:
where the prior
(
p = 1, 2, 3) is the population-weighted mean computed by the SVD of the mortality matrix of all provinces. Owing to population weighting, provinces with larger populations have a more significant effect on
.
The subsequent
,
,
, and
(
t >
t1) are as follows:
where
is the time gap between
and
, which means that the model allows for data to be collected at irregular time intervals (rather than annually);
is the drift for province
i,
is the common drift shared by the provinces in the
kth region, and
,
, and
are the common drifts shared by the entire country.
The drifts are modelled from normal distributions:
where
,
, and
are the priors, computed by the mean of
(
p = 1, 2),
is the prior computed by the regional mean of
(
i ∈
kth region), and
is the prior provincial factor computed by the SVD of the provincial mortality.
The terms
and
are normally distributed random errors:
The variances are assigned conjugated inverse gamma (IG) priors, which are commonly used in the literature (see, e.g.,
Khana et al. 2018;
Kogure et al. 2009;
Li 2014). Thus we used
as priors for all assumed prior variances, for example,
.
Here, we considered the temporal and provincial uncertainty, and forecasted the future values of
and
by drawing from normal distributions:
where
n is the number of future years to forecast.
and
are forecasted as:
is forecasted by:
The future mortality rates of the provinces and the entire country are forecasted as:
4. Results for China
In this section, we analyse the estimation and forecast of the proposed model in detail based on new subnational mortality data for males in China. Four Chinese census datasets from 1982 onwards for 30 provinces for males aged 0 to 90+ years were used in the estimation. The proposed model will be applied to the subnational mortality data for the United States in
Section 5.
We evaluated the performance of the proposed model, denoted as model
Mp, by comparing it to the Li–Lee model (
Li and Lee 2005). The Li–Lee model is widely used as a benchmark to evaluate the performance of multi-population models.
Li and Lee (
2005) model the mortality of multi populations using a common factor and an individual factor. To compare model
Mp with the Li–Lee model in one framework, we used the Bayesian framework to estimate and forecast the Li–Lee model, denoted as model
MLL. The Li–Lee model is designed for a group of populations with similar mortality rates. However, the provincial mortality rates in China have substantial variations. To compare model
Mp with model
MLL, we assumed that the provincial mortality rates could be modelled together in model
MLL. The original Li–Lee model proposes using a first-order autoregressive model (AR(1)) or random walk without drift to forecast the second period term. However, as our data only had a time series of 4 points with uneven time intervals, AR(1) generated discontinuous forecasts in 2011. Hence, we used the random walk without drift to forecast the individual factor in model
MLL. Prior information for the parameters of model
MLL was obtained by applying the original Li–Lee model. We show the estimation and forecast results for model
Mp and model
MLL in the following subsections.
We completed the estimation and forecasts using R and JAGS through the R package rjags (
Plummer 2019). We generated samples from the posterior distributions via the Markov chain Monte Carlo (MCMC) algorithm using Gibbs sampling. For each model, we generated samples with two chains and thinned the chains by sampling every 10th observation to reduce sample autocorrelation. The Gibbs sampling converged within 5000 iterations. After a burn-in of 20,000 iterations and convergence tests, we estimated the posterior distributions based on the last 20,000 recorded samples.
4.1. Model Performance
We evaluated the performance of models
Mp and
MLL based on the
RMSE, calculated as:
where
is the observed mortality rate,
is the estimated mortality rate,
is the number of age groups,
N is the number of provinces, and
T is the last year in the sample range. The
RMSE values of the models are shown in
Table 1. The proposed model
Mp has a lower
RMSE, which indicates a better fit compared with model
MLL.
4.2. Parameters
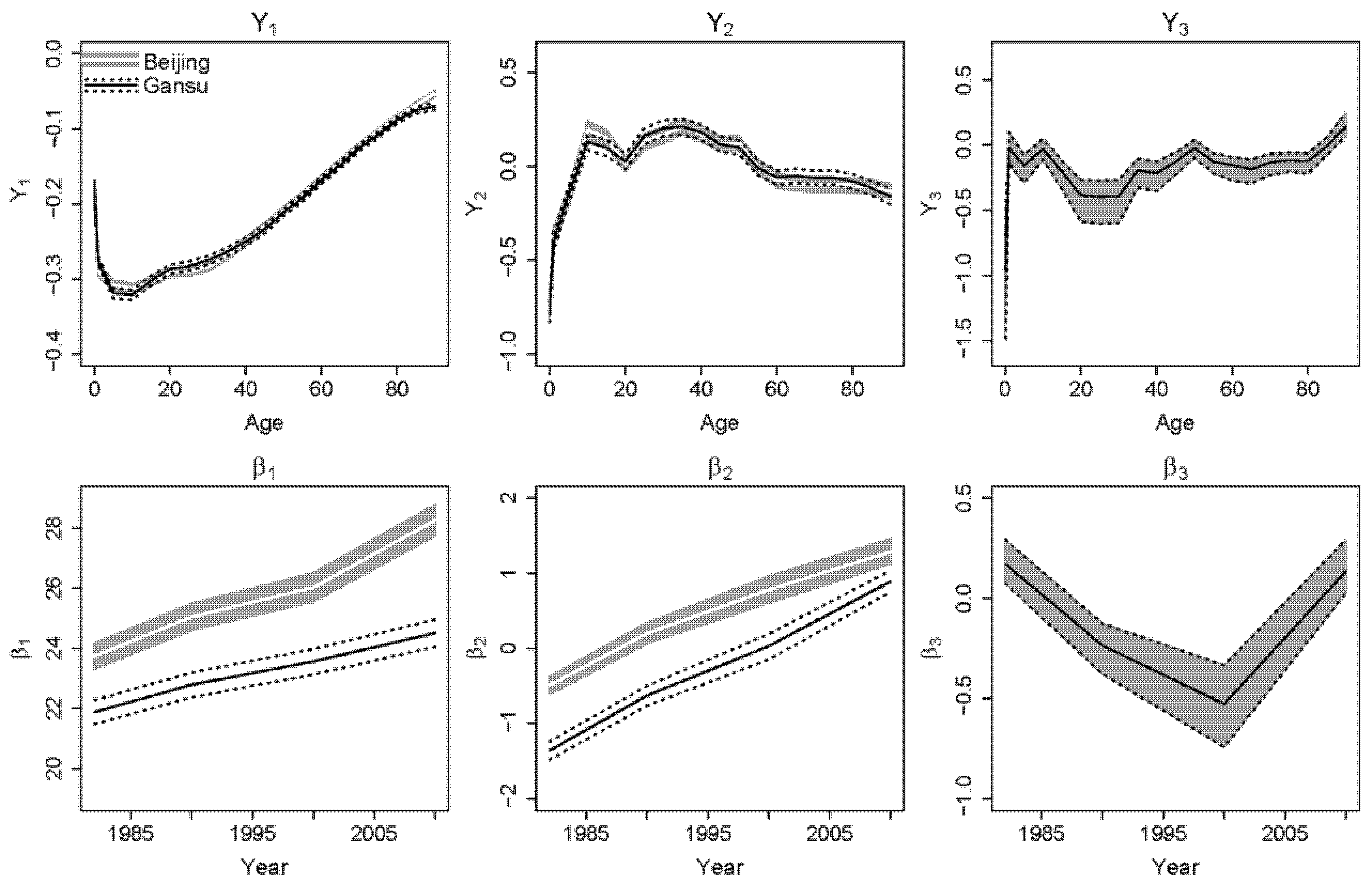
Figure 1 shows the estimated parameters of two representative provinces:
5 Beijing, a developed eastern province; and Gansu, a less developed western province. The white lines and grey shading show the estimated medians and the 95% posterior intervals of Beijing, respectively. The black lines show the estimated median of Gansu. The dashed lines delineate the corresponding 95% posterior interval.
Figure 1 illustrates that the proposed model allows for province-specific estimated values for
and
(
p = 1, 2) and assumes the same values for
and
because of the information-sharing structure. The first principal component
reflects the overall shape of the mortality curve. Gansu has higher
than Beijing at ages 20–40, but lower
at age 80+ (which is likely due to underreported mortality data for Gansu). The effect of underreported mortality data in Gansu is discussed in
Lu et al. (
2020). Beijing has a higher and steeper
, indicating a faster improvement in overall mortality in the eastern provinces than in the western provinces. The second principal component
reflects the common regional difference in mortality compared to the overall mortality curve. For Beijing and Gansu, the shapes of
are similar. Beijing has a higher level of
than Gansu, whereas Gansu has a steeper trend in
than Beijing. The third factors,
and
, reflect the common national differences in mortality compared with the regional differences and the overall mortality curve—they are the same for all provinces.
The results for the remaining provinces can be summarized as follows: different provinces have different levels of and different shapes of ; provinces in different regions have different levels of and different shapes of ; and all provinces have the same and .
4.3. Estimation Results
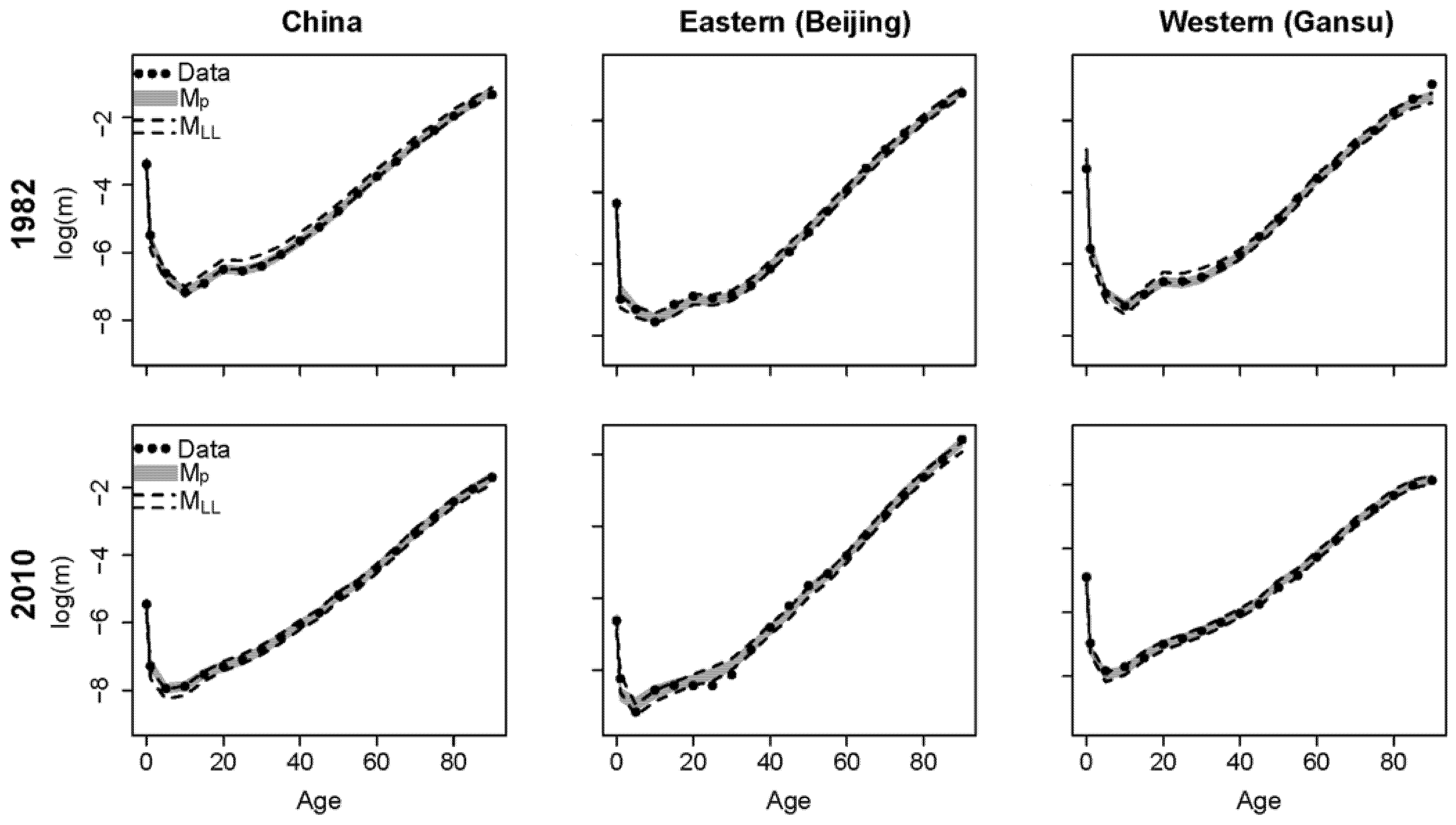
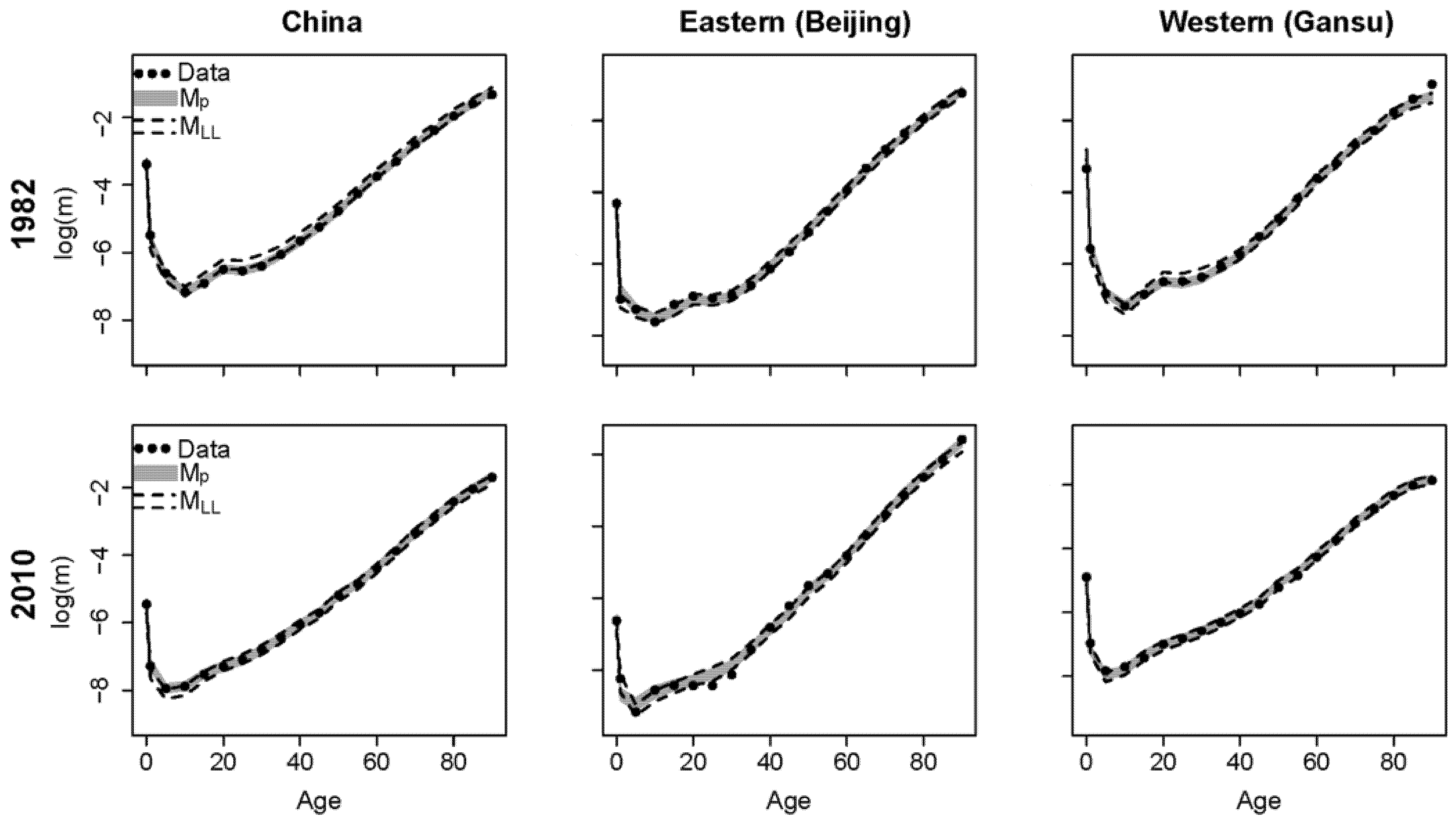
Our proposed model Mp estimates national and subnational mortality simultaneously, whereas the Li–Lee model MLL only estimates subnational mortality. Thus, we used the population-weighted average to calculate the national mortality estimates for model MLL. As the estimation results are similar for all four census years and provinces, we show the results for China, Beijing, and Gansu in the first and last census years.
The fan charts in
Figure 2 show the estimated mortality rates from the proposed model and the Li–Lee model
MLL for China, Beijing, and Gansu in census years 1982 and 2010. The black dots are the historical data, the grey intervals are the 95% posterior intervals of the proposed model, and the intervals between the black dashed lines are the 95% posterior intervals of model
MLL.
Figure 2 shows that the proposed model reproduces the historical mortality rates of China and the provinces well and covers the historical data better than model
MLL.
We used mortality data from the 1% sample survey data for China and its provinces to assess the quality of in-sample and out-of-sample forecasts. As noted in
Section 2, the 1% sample survey data are relatively volatile at the province level due to small sample sizes, making the random errors dominate the goodness of fit. Keeping regions identical to those mentioned previously, we used the average data of every region in the sample survey to reduce the data volatility and analyse the in- and out-of-sample forecasts. The regional average of the sample survey data is weighted and calculated by the total deaths divided by the total population at risk within the region:
, where
is the number of provinces within the region and
is the year of the sample survey. The regional average estimations of model
Mp and model
MLL are calculated by the population-weighted average of the estimated log-scale mortality within the region.
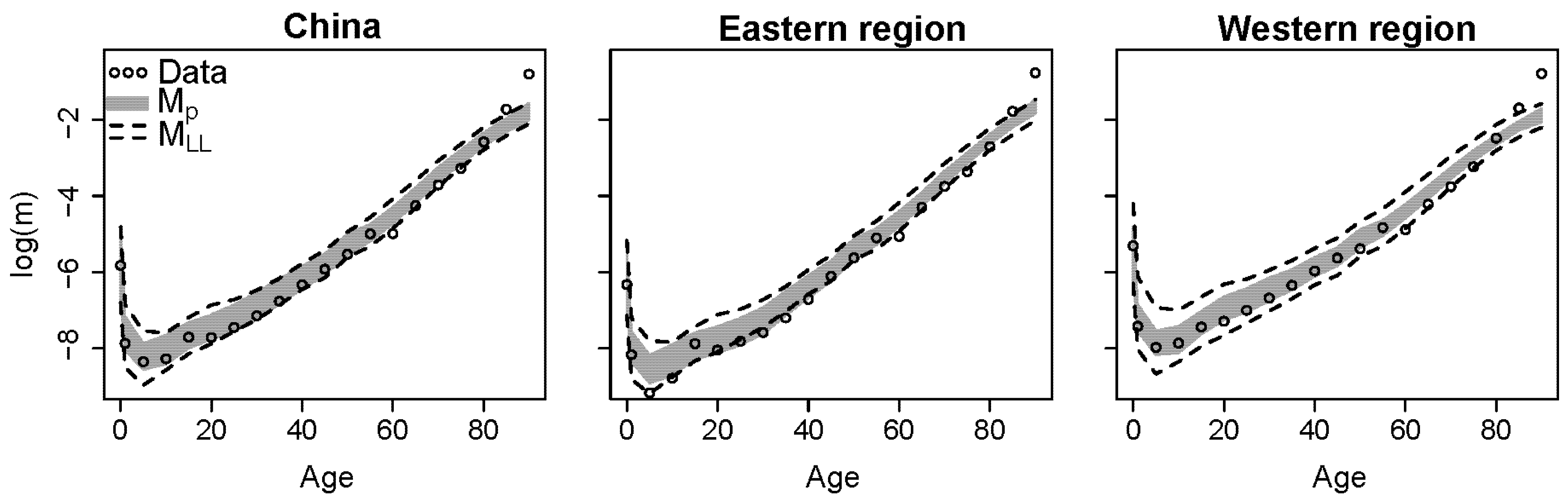
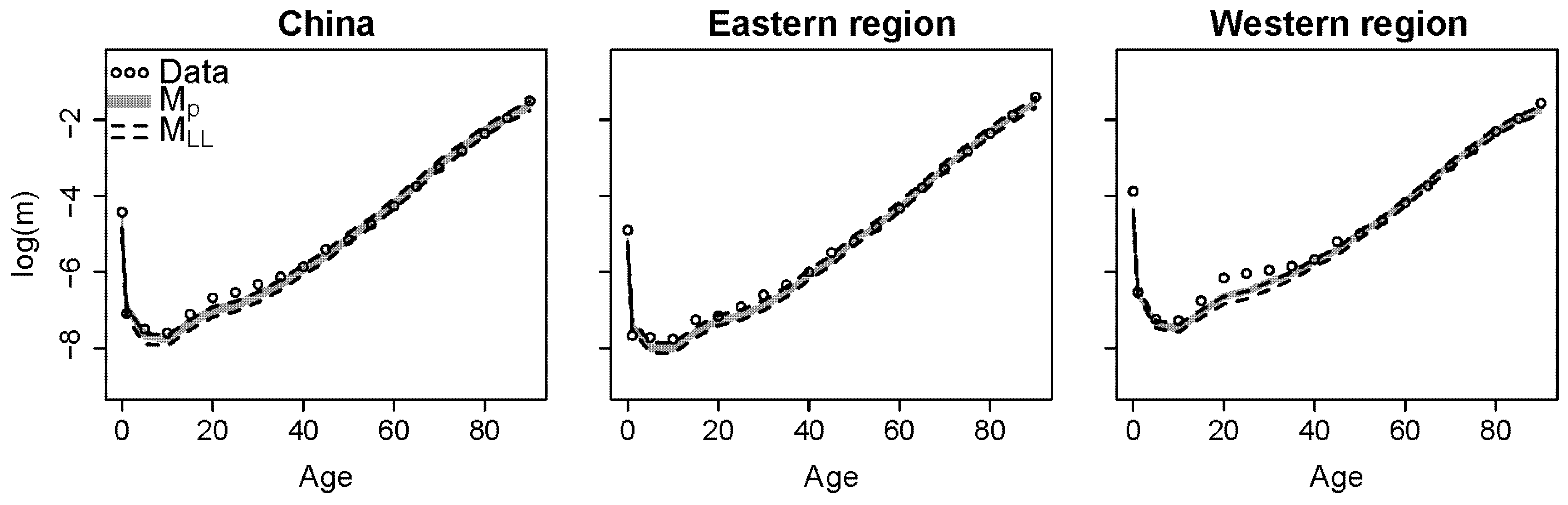
The larger the region, the less volatile the regional average. Therefore, we show the average of the two largest regions, the eastern and western regions, and the corresponding sample survey data in 2005 in
Figure 3. The hollow dots are the regional average of the sample survey data; and the grey intervals and the intervals between the black dashed lines are the 95% posterior intervals of the regional average of the proposed model and model
MLL, respectively. The proposed model has higher estimates of mortality rates for ages 10–40 in the western region than the Li–Lee model
MLL and reflects mortality patterns in the western region better. We conclude that both models
Mp and
MLL generate reasonable in-sample forecasts for China and its regions.
4.4. Performance on Missing Data
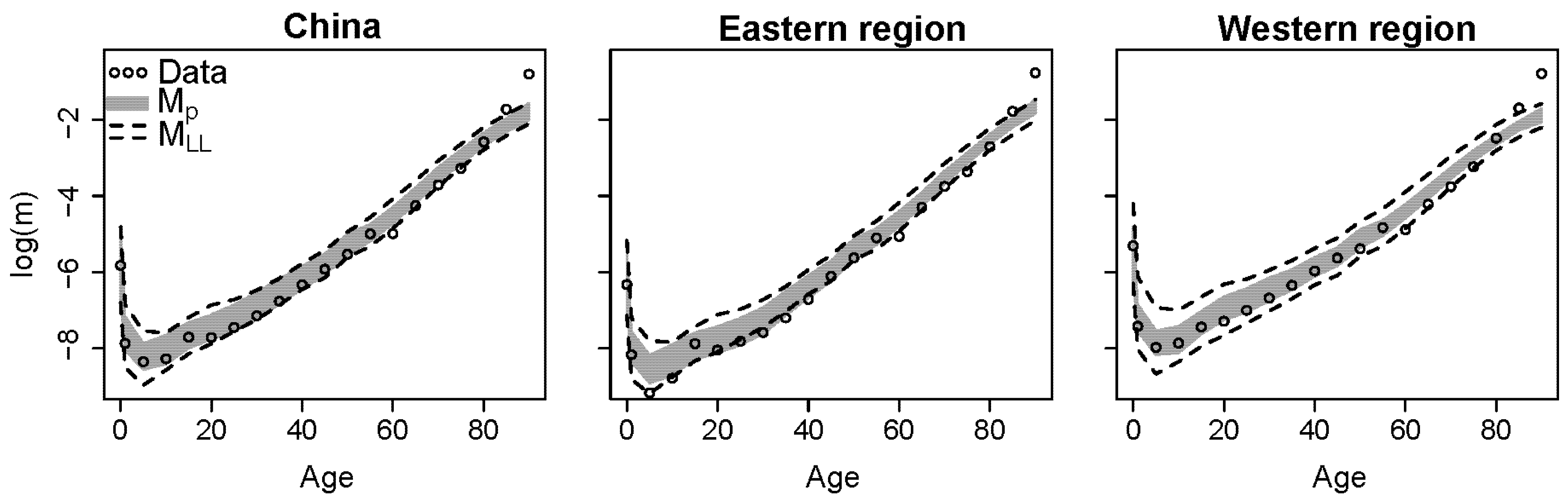
The proposed model handles missing data well. Although the provincial mortality data for Tibet in 1982 are missing, the models can still estimate mortality using information from the other provinces.
Figure 4 shows the estimation results for Tibet in 1982. The white lines show the estimated median mortality rates and the grey interval is the corresponding 95% posterior interval for the proposed model. The intervals are wider than for other provinces (e.g., the provinces shown in
Figure 2) because of larger uncertainty due to missing data.
4.5. Model Forecast
We used the national and regional average mortality of the 2015 sample survey data to evaluate the out-of-sample forecast performance of the proposed model.
Figure 5 shows the out-of-sample forecast for China and its eastern and western regions in 2015. The proposed model generates narrower forecast intervals than the Li–Lee model
MLL.
Table 2 shows the RMSE values of the proposed model and model
MLL in 2015. The proposed model has a lower RMSE for China and its regions than model
MLL.
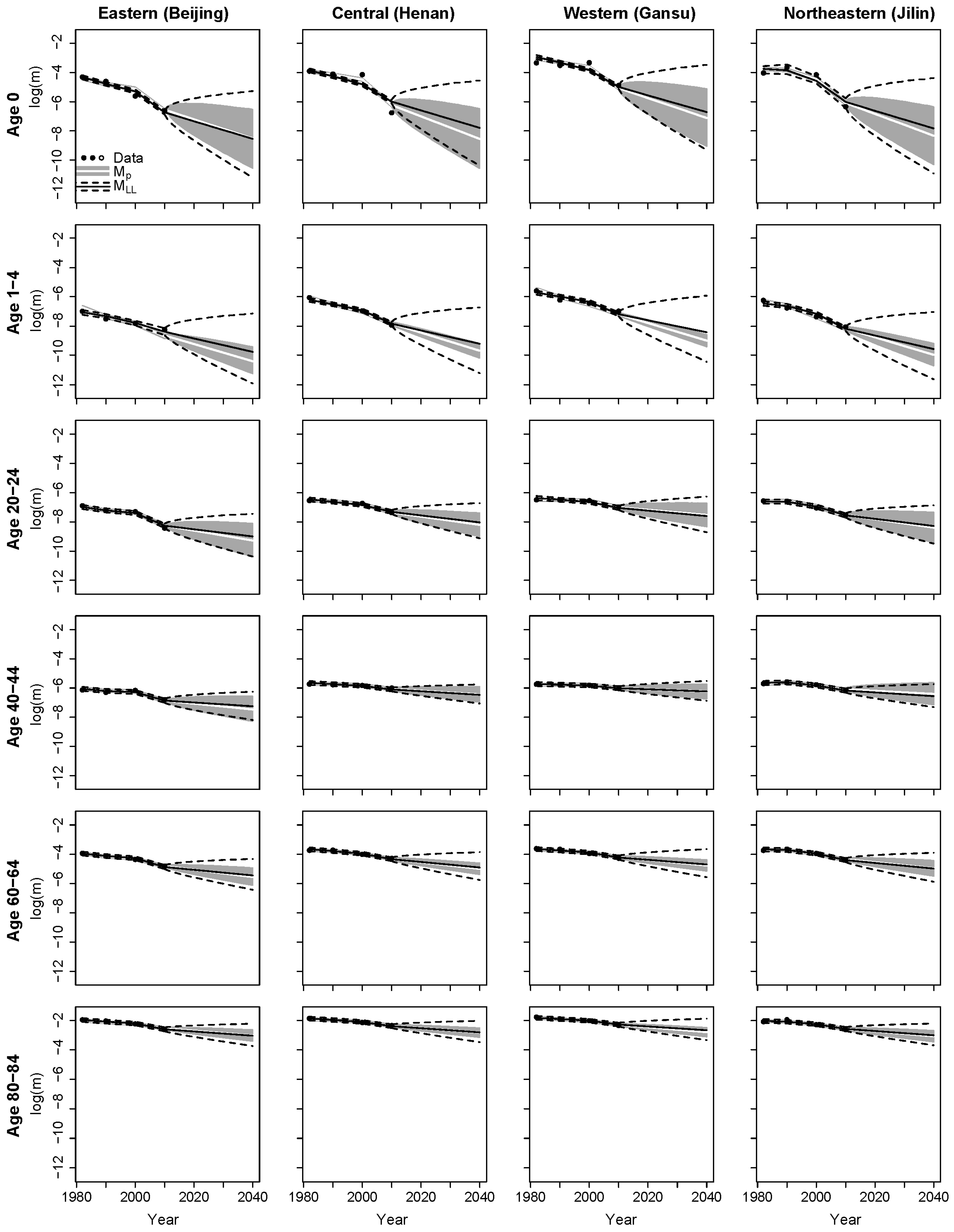
Figure 6 displays the estimation and forecast results for the different age groups in the four provinces representing the four regions.
6 The proposed model and the Li–Lee model
MLL have different estimates, forecast trends, and forecast intervals at younger ages (below age 4). However, the estimates and forecast trends are similar at other ages.
As the proposed model uses provincial and regional uncertainty in forecasts, the intervals in
Figure 6 show that the provincial forecasts of the proposed model have smaller uncertainty than model
MLL, which uses the overall uncertainty of all provinces. The forecast intervals of both models show that infant mortality has the largest uncertainty, which decreases as the age increases.
The provincial forecasts of the proposed model have different levels of uncertainty for the same age groups. When comparing different regions, the eastern region (the first column) and the north-eastern region (the last column) have larger uncertainties, indicating that provincial variations are also larger in these two regions. However, the forecasts for the central region (the second column) and the western region (the third column) have lower uncertainties, indicating smaller provincial variations in these regions. Moreover, model MLL has larger and equal widths of intervals for different regions. From the forecast uncertainty perspective, the proposed model captures different levels of uncertainty for the different regions.
The estimates for 1982–2010 and the forecast results for 2011–2040 for the entire country are shown in
Figure 7. The proposed model generates a better fit for the historical trends than model
MLL. The proposed model has steeper forecast trends than model
MLL, especially for infants and young children (aged 1–4 years). Although the proposed model has narrower forecast intervals than model
MLL, both the proposed model and model
MLL cover the 2015 sample survey data equally well.
4.6. Sensitivity Analysis
4.6.1. Grouping Assumption
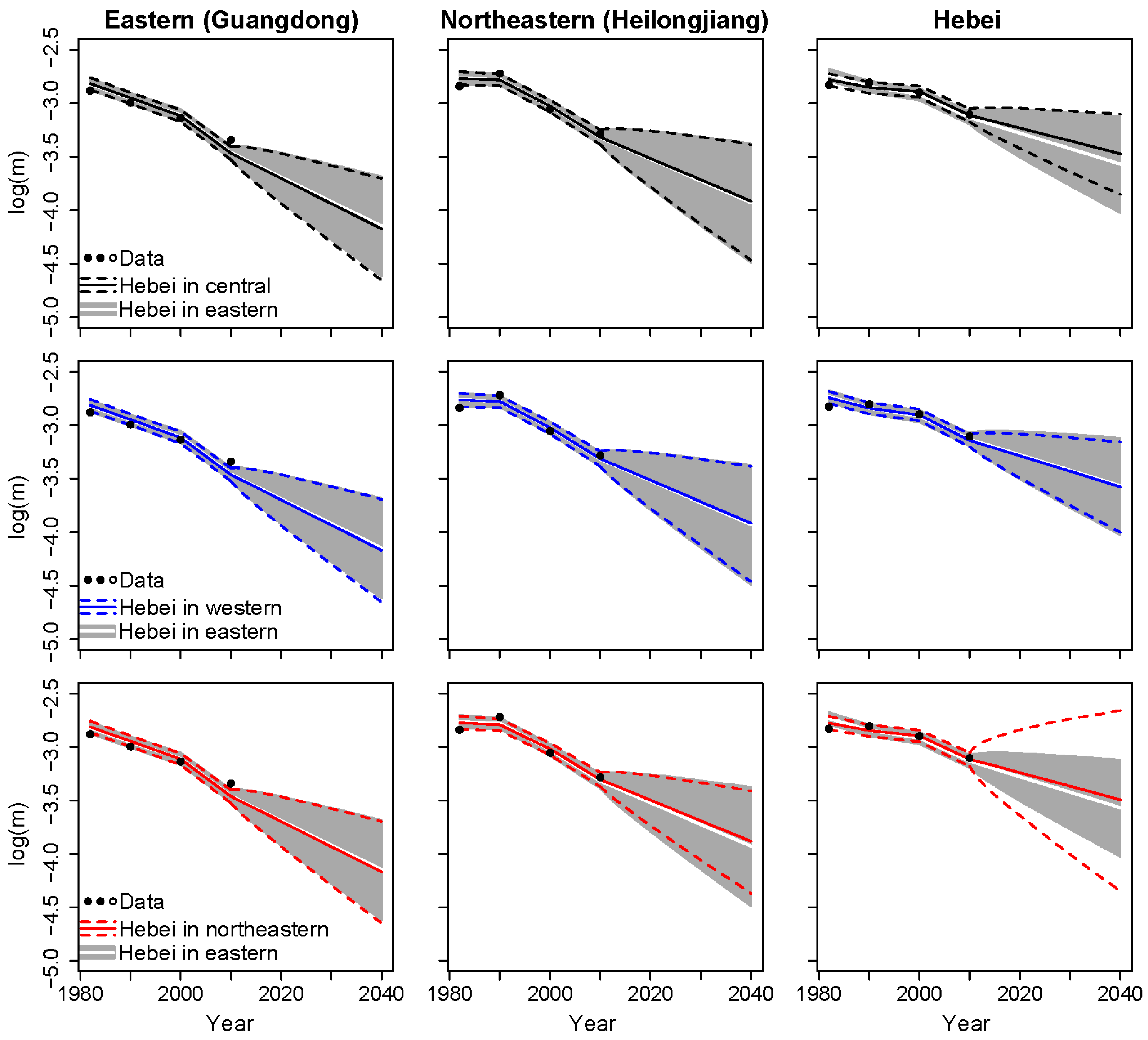
In the main analysis, we used the official classification developed by the NBS to group the provinces into regions based on their geographical and economic characteristics. However, this regional grouping assumption may be questioned, and other grouping assumptions may lead to different forecasts. As such, we conduct sensitivity analyses on alternative regional grouping assumptions in the following.
In the main analysis, Hebei province is included within the most developed (i.e., eastern) region in our proposed model. However, Hebei’s economic development (e.g., GDP per capita;
NBS 2019) and life expectancy (
Zhou et al. 2016) are similar to those of less developed regions. Since Hebei lies adjacent to the central, north-eastern, and western regions, it can be included within any of these groups. In the following, we use different grouping assumptions to derive forecasts for the proposed model with a random walk process. Specifically, we compare the results based on the original grouping, where Hebei is part of the eastern region, with three alternative grouping assumptions: (1) Hebei is in the central region; (2) Hebei is in the western region; and (3) Hebei is in the north-eastern region.
Figure 8 shows the forecast results based on the original grouping and the other three grouping assumptions. The forecast results are similar for the different age groups, so we consider the results at ages 70–74 for Guangdong as representative of the eastern region. We also show the results from Heilongjiang (which is in the north-eastern region) in
Figure 8 as the north-eastern region has the least number of provinces and it is interesting to observe the changes when Hebei is included.
The first column in
Figure 8 shows that the forecast trends and intervals are basically the same when Hebei is excluded from the eastern region. The second column in
Figure 8 shows that, when Hebei is included in the north-eastern region, the forecast trend of Heilongjiang is slightly less steep and the forecast interval is slightly narrower than in the original grouping. Overall, the differences are limited when the grouping assumption is changed. The third column in
Figure 8 shows that the fit and forecasts for Hebei change according to which region it is included in. When Hebei is included in the central region, the slope of the forecast trend is less steep than in the original grouping, whereas the forecast interval is narrower than the original grouping assumption and other new grouping assumptions, indicating that Hebei’s mortality rates are more similar to those in the central region.
4.6.2. Number of Principal Components
In the main analysis, the proposed model is constructed with three principal components. Here, we compare the model performance of the proposed model and an alternative model constructed using two principal components (denoted as MPC2).
Based on the structure of the proposed model described in
Section 2, the alternative model constructed with two principal components (model
MPC2) is given as follows:
where
and
are the common factors across all provinces. The parameters are estimated and forecasted as for the main proposed model described in
Section 2.
We compare the RMSE of the alternative model
MPC2, the proposed model
Mp, and the Li–Lee model
MLL in
Table 3. The alternative model
MPC2 has larger errors in fittings and forecasts than the proposed model and model
MLL.
Figure 9 shows the estimations and forecasts of
MPC2 and
Mp. The blue solid and dashed lines are the fitting and forecast intervals of model
MPC2, respectively. The proposed model
Mp reproduces better historical mortality trends than the alternative model
MPC2, especially for ages 0–4.
MPC2 generates narrower forecast intervals than
Mp.
5. Life Expectancy in China and the United States
5.1. Life Expectancy in China
Based on the provincial mortality forecast of model Mp for China, we calculated the provincial life expectancy. Life expectancy at pension eligibility age is an important reference for pension systems. In China, the normal retirement age for males is 60. In the following, we calculate the provincial-level life expectancy at age 60 for China and evaluate the subnational heterogeneity in life expectancy.
Figure 10 shows the provincial life expectancy at age 60 in China (
) in 2030. The areas shaded grey are the 95% intervals of
, the darker grey short lines are the medians of
, and the grey dashed line is the national
calculated based on the national mortality projection. The model predicts that the median
will be 24.6 years in 2030 (up from to 22.5 years in 2020).
The provincial in 2030 varies across regions. Most of the provinces in the eastern region have a higher than the national , whereas most of the provinces in the western region have a lower than the national . Hainan, a southern island and holiday destination, has the highest median of 27.7 years. The provinces in the north-eastern region have wider intervals than others.
To summarize, we calculated the national and subnational life expectancy at retirement in 2030 for China based on subnational mortality forecasts. The median life expectancy at pension eligibility age in China () is 24.6 years in 2030, with the median provincial life expectancy ranging from 21.3 years to 27.7 years. In the following subsection, we apply our proposed model to estimate subnational life expectancies in the United States and compare them with China.
5.2. Life Expectancy in the United States
We applied the proposed model described in
Section 2 to subnational mortality in the United States based on five-year age group data (0 to 80–84 years old) from 1999 to 2018. After obtaining estimations and projections of subnational mortality rates in the United States, we used the Kannisto model (
Kannisto 1994) to extrapolate the mortality rates to age 90+ years and calculate the national and subnational life expectancy in the United States.
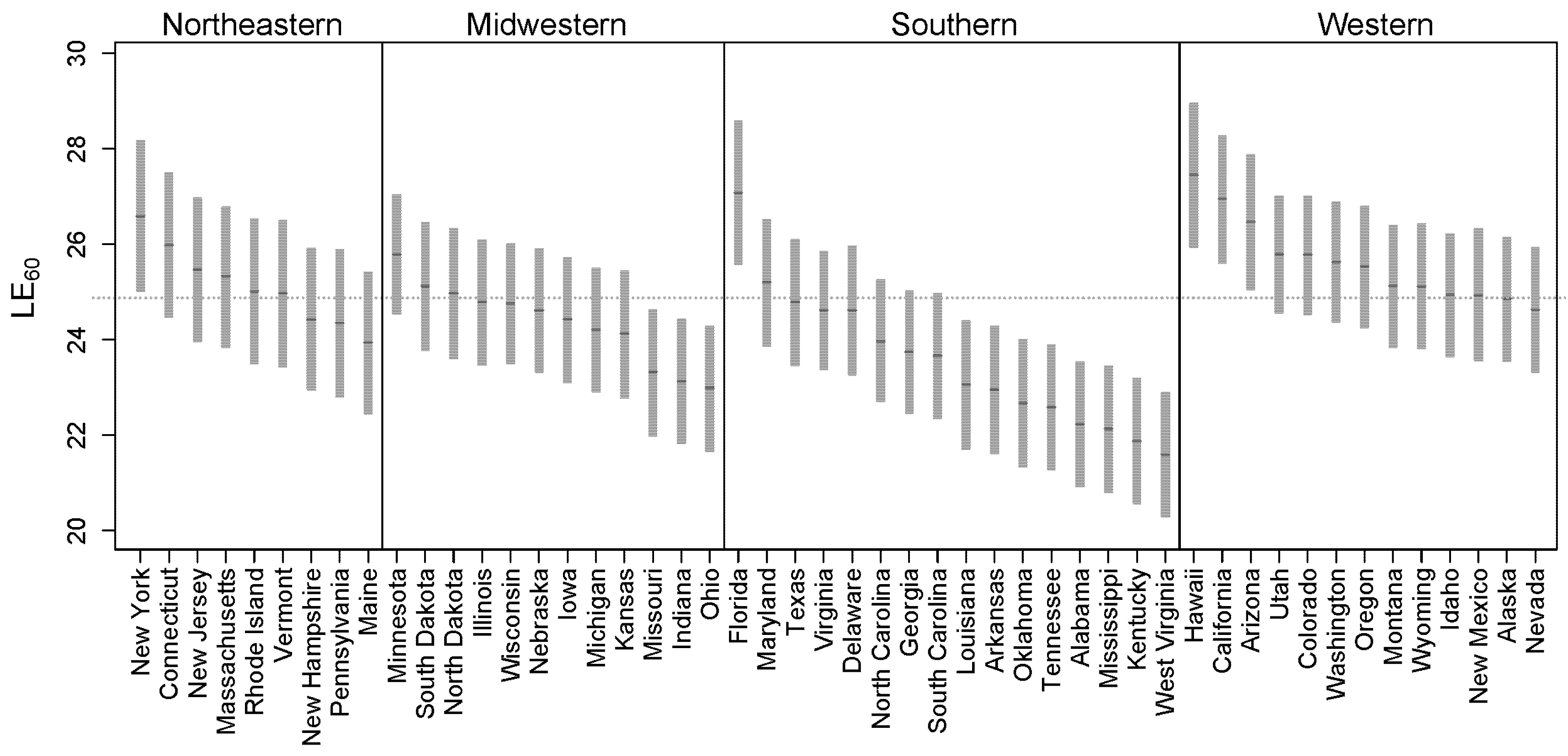
Figure 11 shows the projected state-level life expectancy at age 60 for the United States (
) in 2030. The grey shaded areas are the 95% intervals of , the darker grey short lines are the medians of
, and the grey dashed line is the national
projected by the model. In 2030, the median
is 24.9 years (up from to 23.2 years in 2020), which is 0.3 years higher than China.
The median ranges from 21.6 to 27.5 years. Most of the states in the western region have a higher than , with Hawaii having the highest . However, most of the states in the midwestern and southern regions have a lower than .
China has the same level of national life expectancy at age 60 as the United States. Based on the model results, in 2020, the national life expectancy at age 60 is 22.5 and 23.2 years for China and the United States, respectively. In 2030, predicted by our model, the national life expectancy at age 60 will be 24.6 and 24.9 years for China and the United States, respectively. In 2030, the median subnational life expectancy at age 60 for these two countries is at the same level, with 21.3 and 27.7 years, and 21.6 and 27.5 years for China and the United States, respectively. The comparison indicates that in 2030, China will approach the same level of life expectancy at age 60 as the United States. However, the forecast intervals of subnational life expectancy at age 60 are wider in China than they are in the United States due to fewer available historical data points.
6. Conclusions
This paper describes a new model in a Bayesian hierarchical framework to estimate subnational mortality rates and forecast mortality at both subnational and national levels. We propose a Bayesian hierarchical model based on principal components and random walk processes. The model uses the three levels of country, region, and province, with the information pooling and sharing structure through provincial-level factors, common region-level factors, and common country-level factors. Our study employs a new database of provincial-level mortality data for China from 1982 to 2010 and uses US subnational mortality data from 1999 to 2018. We note that the available time series for provincial mortality data in China are very limited and that both China and the United States have missing data for some provinces/states.
We evaluated the performance of our proposed model in detail based on new subnational mortality data for China. The evaluation results show that the proposed model copes with missing data and provides a good fit for the census and sample survey years, and reasonable forecasts at both the provincial and country levels. The forecast intervals are of equal width for all provinces within any one age group because of the model’s information-sharing structure. The proposed new model has a better fit and provides more accurate provincial-level forecasts with the intervals better reflecting the provincial and regional uncertainty than the Li–Lee model MLL. The results of the sensitivity analyses show that the forecasts are relatively robust when changing the grouping assumptions, and confirm that three principal components perform better than two. Overall, the proposed model provides good estimates and reasonable forecasts, and we recommend using the models in both national and subnational mortality modelling.
Based on the mortality forecast, we computed national and subnational life expectancy for China and the United States. The model predicts that the two countries will have the same level of national life expectancy at age 60 in 2030, and that the heterogeneity in subnational life expectancy in the two countries will also be of similar magnitude. However, China has larger forecast intervals for life expectancy at age 60 due to limited data points.
The model we have developed is based on principal components, considering the parsimony and flexibility of this approach. The Bayesian framework can incorporate other functional forms, for example, the Cairns–Blake–Dowd model (
Cairns et al. 2006) or models that include cohort effects. Future work may also consider other estimation methods, such as the Kalman filter, to improve the model fit. Finally, it would also be of interest to study regional annuity pricing and pension liabilities based on the proposed model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}