1. Introduction
We model the surplus of an insurance portfolio with a diffusion approximation
. We assume that the insurer has the possibility of investing in an independent asset given by a Black–Scholes model
. That is, at time
, the surplus from insurance business
and the price of the risky asset
are given by
for
,
, and independent Brownian motions
,
.
is a constant representing the initial capital. The insurer may decide on the invested amount
at every point in time
. The surplus process
under the investment strategy
takes the form
which we can compare with (
Schmidli 2008, Section 2.2.2). By
, we denote the running maximum process with
. The process
with
is the (absolute) drawdown of
. It should be noted that these definitions allow for a positive initial offset
of the surplus with respect to the historical maximum. The target of our analysis is to find an optimal investment strategy that minimises the expected discounted time spent with a large drawdown y
Here,
and
are preference parameters and
denotes the set of admissible investment strategies
A, which is specified in the next section. The notation
is used for the expected value under the condition
, as usual. The preference parameter
has the economic interpretation of weighing immediate drawdowns more than drawdowns in the far future. Since drawdowns imply a reduction of the surplus, this is in line with the concept of the time value of money. If a large
is chosen, drawdowns occurring very soon have a much stronger impact on the value function than prospective drawdowns. This reflects a short-term-orientated decision-making by the insurer. On the other hand, a small discounting parameter indicates that future and current drawdowns are almost equally damaging from the insurer’s point of view. The parameter
d is the critical size of drawdowns that are perceived as large and, thus, unfavourable by the insurer. That is, drawdowns exceeding
d are assessed to have an adverse effect on the insurance company. The choice of this parameter would, in reality, depend on many internal and external factors, such as capital requirement, total capital, or corporate strategy. For example, if
d is small in comparison to the total surplus, the value function essentially measures the time within “peaks” of the surplus process. One could think of this as the surplus being forced to grow most of the time. If
d is large, the state
can likely be associated with low values of the surplus
, so the unfavourable state of being under-capitalised for a long time is penalised. The function given in (
2) is strongly related to the optimal control problem of minimising the Laplace transform of the process’ first passage through
d:
Since
is positive, one could think of this as maximising the time in which the drawdown is smaller than
d and the surplus has not exited the uncritical area close to the historical maximum. The difference between the two problems is that the first one will result in a strategy for an infinite time horizon, while the latter stops at the first time the drawdown is critically large. As mentioned above, our analysis shows that the problems are closely related. However, especially for long-term liabilities or if a drawdown will likely occur soon (for example, if
), problem (
2) contains more information than (
3).
Drawdowns and related path functionals have attracted a lot of attention in the last 20 years. They are particularly popular in financial mathematics and economics, where they are used as a one-sided, path-dependent, and dynamic risk indicator. For instance, the “conditional drawdown at risk” is considered by
Chekhlov et al. (
2005) in the context of portfolio optimisation. Another more recent example is found in (
Maier-Paape and Zhu 2018), where a risk measure depending on the proportional drawdown (which measures the percentage loss) is constructed. In addition to measuring risks, drawdowns and maximum drawdowns have also been linked to market crashes (compare (
Sornette 2003) and (
Zhang and Hadjiliadis 2012)) and have been used to quantify performance (
Hamelink and Hoesli 2004).
Much research has been conducted on drawdowns of actuarial and financial models as probabilistic objects as well. Distributional properties of the drawdowns of standard and arithmetic Brownian motions were investigated by
Douady et al. (
2000),
Graversen and Shiryaev (
2000), and
Salminen and Vallois (
2007). Other articles deal with first passage times, such as
defined in (
3). An example covering a broad scope is due to
Mijatović and Pistorius (
2012), who studied the joint distribution of the first passage time and related quantities for spectrally negative Lévy processes. Another example containing results specifically for one-dimensional diffusions is (
Zhang 2015). In (
Landriault et al. 2015), the frequency of drawdowns larger than a critical level is examined for an arithmetic Brownian motion. In (
Landriault et al. 2017), the magnitude of the drawdown and the so-called “time to recover” are considered. The term “time to recover” refers to the duration until the historical running maximum is re-reached, which is related to our problem for small values of
d.
Wang et al. (
2020) analysed a Gerber–Shiu-type expected penalty function for the drawdown, extending the classical results of
Gerber and Shiu (
1998).
A popular approach in the field of stochastic optimisation aims to minimise ruin probabilities, severity of ruin, or functionals thereof (see, for example, (
Browne 1995)). However, ruin is a rare and extreme event, which is why ruin-related quantities merely serve as a conceptual measure of risk. In reality, it is more likely that an economic unit will aim to enhance its capital or to prevent diminishment. This motivates the consideration of optimisation problems related to drawdowns. In the context of portfolio selection,
Grossman and Zhou (
1993) introduced a utility maximisation problem under “drawdown constraints”. This means that one admits only those portfolios that prevent large drawdowns of the wealth process. Their results were extended by
Cvitanic and Karatzas (
1995),
Elie and Touzi (
2008), and
Cherny and Obloj (
2013). Another possibility is to put drawdowns into the focus of the optimisation and introduce drawdown-based value functions. A prominent example is the minimisation of the probability that a large (proportional) drawdown occurs.
Chen et al. (
2015) consider this problem for an investment model. Angoshtari, Bayraktar, and Young published a series of papers dealing with the optimisation of drawdown probabilities under investment and consumption (compare
Angoshtari et al. (
2015,
2016a,
2016b)).
Han et al. (
2018,
2019) examined problems connected to the minimisation of the probability of a drawdown under proportional reinsurance.
However, the above literature does not take into account the length of a drawdown. Intuitively, it is clear that a drawdown has, in general, a negative connotation. Even if the business is profitable, frequent drawdowns can affect the value of a company negatively through an indirect psychological impact on managers, policyholders, shareholders, and potential partners. The following simple example illustrates the situation. Imagine that the surplus of the company under consideration increases from 100 to 130 EUR and then drops by 28 EUR. Despite the positive profit, one cannot help feeling a disappointment about the relative loss. Similar psychological effects have been observed in the context of decreasing dividend payments (compare (
Albrecher et al. 2018)). An additional factor playing an influential role is the duration of a drawdown. If the surplus recovers shortly after the drawdown, inattentive policyholders might not notice the changes. However, a long-lasting drawdown can be interpreted as a consequence of flawed business decisions or general managerial inefficiency. The present manuscript contributes to the existing research by analysing the optimal control problems (
2) and (
3), which reflect both aspects, the severity and the duration of a drawdown. Differently from (
Brinker and Schmidli 2020), we allow the possibility of investment. With this in mind, the following results can be seen as a first step towards understanding optimal investment decisions based on multiple drawdown key indicators.
The rest of this paper is organised as follows. In the next section, we specify the model we are working with. With
Section 3, the main part of this paper is devoted to solving the optimal control problem (
3). We use a fixed-point argument to show that the Hamilton–Jacobi–Bellman equation (HJB equation) associated with the problem has a unique solution. We identify this solution as the value function (
3) and conclude that the optimal strategy is a monotone function of the current drawdown. Neither the value function nor the optimal investment strategy can explicitly be calculated, but fixed-point iteration allows us to calculate both in numerical examples. In the last section, we use these results to solve the original problem given in (
2). Our ansatz is the natural extension to the strategy maximising the time until a large drawdown occurs: Under the assumption that the initial drawdown exceeds
d, we find the strategy minimising the time with large drawdown. In principle, one could repeat the steps of
Section 3 with slight modifications to prove existence of a solution to the connected HJB equation. However, in this case, we explicitly obtain the solution using a different approach. The key argument is that the drawdown process behaves like a diffusion without reflection above the critical level
d. The optimal strategy turns out to be constant such that well-known results on passage times of arithmetic Brownian motions apply. We connect the return functions of the two subproblems and verify that their composition is the solution to our original problem (
2). We draw conclusions from our results and give numerical examples for the expected discounted time spent in drawdown.
2. The Model and Its Parameters
Throughout the paper, we work on a complete probability space equipped with the natural filtration generated by the two-dimensional Brownian motion . We assume that the investment strategies are càdlàg and adapted with values in the bounded interval . It will turn out that this restriction of the maximally invested amount is necessary for the problem to be well defined. The inclusion of zero in this interval means that it is possible not to invest. Moreover, we assume that either , or if , then there exists with . This means that either the insurance portfolio is expected to be profitable or that it is possible to invest in such a way that is expected to generate profits. The reason we include the case is that insurance premiums are calculated in advance, and if adjustments are contractually permitted, they are usually tied to certain key dates or other conditions. That means that, particularly for long-term liabilities, it is possible that unexpectedly severe or frequent claims occur in contract portfolios or divisions. Even though insurers evaluate risks regarding their profitability before issuing contracts, there are prominent examples, such as life insurance policies with high guaranteed fixed interest rates or the insurance of flood risk, which have turned out to be non-profitable. In this case, drawdown-minimising strategies might be used to prevent or shorten “negative tours” from the previous level.
In order to define the set of admissible strategies
, we first observe that the controlled drawdown process and running maximum together form a solution to the Skorohod problem for
(compare, for example, (
Pilipenko 2014)). That is, the pair
solves
for all ,
L is non-decreasing with ,
for all ,
Almost surely for all
:
One important implication of the third condition is that whenever
L increases,
Y must be equal to zero. If a solution
to the reflected equation (
4) is known, the surplus process
is given by
. In case the strategy
A is of feedback form
depending on the current drawdown through a function
, (
4) is a reflected stochastic differential equation. Hence, we define
as the set of strategies
A, which are càdlàg and adapted processes with values in the interval
, such that a solution to (
4) exists and is unique. It is clear that the process under the strategy
,
, exists and we will use this strategy of “doing nothing” as a reference in our numerical examples. Concerning the “well-posedness” of the problem (
2) for all parameter sets, it is important that the discounting factor
is strictly positive. Otherwise, the integral might not exist if the drawdown process spends infinite time above the level
d. For example, if
,
tends to infinity as
almost surely and the indicator function will ultimately be equal to one. So, in this case, the value of the strategy of never investing is not finite. On the other hand, as the indicator function is at most equal to one, the return of all strategies is bounded from above by
. This implies that (
2) is well posed for every
. The value function
V of the optimal control problem (
3) is bounded from above by 1.
3. Maximising the Time to Drawdown
Assume that initially, the surplus process is uncritically close to the running maximum, meaning that
. Intuitively, and since immediate drawdowns have a larger weight than future drawdowns, the optimal strategy is to maximise the time
in the uncritical area. In fact, one can reason this intuition with a dynamic programming principle, as was done in (
Brinker and Schmidli 2020) for the optimisation of reinsurance. Hence, we consider the following auxiliary problem. We let the function
be defined as in (
3) for
. This is the Laplace transform of the first time the drawdown process hits
d, and it clearly becomes minimal when
is maximised. The boundary condition
has to be fulfilled. By the theory of stochastic control, this problem is connected to the HJB equation:
We start with some heuristics on the function V. If the initial drawdown is with , there are two possible scenarios. If the drawdown process arrives at y before exiting the interval , it will then spend the same time in the favourable area as a process of initial drawdown y. However, it is also possible that the drawdown overshoots the critical level d before reaching y. In this case, the process leaves the favourable area earlier. Now, intuitively, this means that the time the process spends in should be smaller when the initial drawdown is larger. Comparing small values x and y, we expect that y is reached quickly and that it is almost impossible for the drawdown to exceed d before. On the other hand, if x and y are close to the boundary d, it is easier for the paths to “slip” out of the interval, so in this case, the effect should be stronger. In other words, we presume that V is an increasing and convex function. At this point, this is just an educated guess, since our heuristics neither took the preference factor into account, nor the time passing until y is visited for the first time. We prove at end of this section that, in fact, V has those properties. In order to see which other characteristics we are looking for, we start with a verification theorem.
Theorem 1. Let be a twice continuously differentiable, non-decreasing function with . Moreover, assume that f solves (5) with pointwise optimiser . Then, , and the strategy with , , is optimal. Proof. By Itô’s formula, we have for an arbitrary strategy
:
Now, since the running maximum only increases at times where the drawdown is zero and
, the first integral is equal to zero. By continuity (and hence boundedness over compacts) of the derivative of
f, the two stochastic integrals are martingales. The last integral is non-negative. Thus, taking expectations, we find
By the boundedness of f, we can take the limit to find . Taking the infimum over the set of admissible strategies, we conclude . As we will see below, it follows from the HJB equation that is an admissible strategy. Thus, repeating the above argumentation for the strategy , we see that f is the value of this strategy and that . □
Example 1 (
).
If , investing in the second active only results in an increased volatility without any expected steady income. Therefore, we expect that it is never optimal to buy units of the risky asset in this case. The HJB equation becomes particularly simple under this assumption:Solving this ordinary differential equation, we findas a candidate solution. A quick calculation shows that this function is increasing and strictly convex, such that becomes minimal at . f solves (5) and is verified by Theorem 1. In the following, we consider the more complicated case . We focus on the case , where holding the risky asset leads to expected profits. The case (where short selling leads to expected profits) can be treated analogously. This is because we could consider the Brownian motion , the positive drift component , and the strategy to transform the problem: An optimal strategy for the model with can be obtained by mirroring an optimal strategy for the case of positive drift around the x-axis. In view of Theorem 1, our ansatz is to show the existence of a solution to the HJB equation on the interval .
3.1. Construction of a Solution to (5)
Throughout this subsection, we assume that
holds. We denote by
the space of continuous functions that are defined on the closed interval
endowed with the supremum norm
. We roughly follow the approach in (
Belkina et al. 2014) by defining an operator, the fixed point of which is a solution to the HJB equation. This idea works for the presented problem, even though the results in (
Belkina et al. 2014) apply to the classical risk model under a different value function. Assume that
V is, in fact, an increasing solution to the HJB equation and that we know the optimiser
at a certain point
x. Then, rearranging the terms of the HJB equation, we have
For any other
, the equation holds with “≥” in place of “=”. This inspires the definition of the operator
with
for all functions
.
represents the unknown value
. Since the value
is known, it might seem counter-intuitive not to write
. In the following, we will see that the above is more useful. We observe that for every
,
is finite for every
. We will now show that for every
, there exists a unique
, such that
holds with initial condition
. We use a fixed-point argument, so our first step is to construct a contraction. As a preparation, we need the following Lemmas.
Lemma 1. For , we define the function by attains a global maximum. As , converges to zero uniformly in a. In particular, there exists such that , where m denotes the global maximum of .
Proof. A direct calculation shows that
attains its global maximum at
m, where
Both converge as . Hence, converges and for . □
The first part of Lemma 1 is used to define the Lipschitz constant in the next result.
Lemma 2. For an arbitrary , , and , we define throughfor . Let and m be defined as in Lemma 1. The operator fulfilsfor all , so it is Lipschitz-continuous with respect to the uniform norm on . Proof. For all
, we define
Now,
is continuous for all
and, hence, uniformly continuous on the compact set
. Thus, the maximum
of the uniformly continuous functions is continuous as well. Next, we show that all operators
are Lipschitz-continuous with a common constant. Let
. We have
Since
becomes maximal at
m, we have found
as common Lipschitz-constant. This bound is not necessarily sharp, since we only consider
a from the bounded interval
. Now, we show the Lipschitz-continuity of
. We consider again
. We fix
and assume that
. By definition of
and
, for every
, there is some
, such that
. We have
and, hence,
Similarly, we could have derived the same upper bound in the case
. The left-hand side does not depend on
, such that we can let
. Hence, we have
for every
. We can now take the supremum on the left-hand side to conclude that
is Lipschitz-continuous with respect to the uniform norm. □
Remark 1. Lemma 2 implies that maps onto itself and is Lipschitz-continuous with respect to the uniform norm on when , .
Now, we use the second part of Lemma 1 for defining a contraction.
Lemma 3. Let ϵ be chosen sufficiently small, such that . Let be defined as in Lemma 2 and let λ be given. The map withis a contraction, and thus has a unique fixed point u. u is continuously differentiable on with . Moreover, . Proof. is a well-defined map from a complete space to itself. To conclude that it is also a contraction, we take
and observe:
The properties of the fixed point follow from the definitions of and , respectively. □
Now, we compose the solutions on the subintervals to construct a function on .
Lemma 4. For every Λ, there exists a unique continuously differentiable function , such that and .
Proof. We divide the interval
into
N parts, choosing a large enough
N such that
fulfils
. We define the operators
for
, and by Lemma 3, the latter has the unique fixed point
with
and continuous derivative
. Now, we let
Inductively, we define on
and
for
, where
denotes the unique fixed point of
. From the definition of the sequence
, we conclude that the composition
is continuous. From the definition of the sequence
, we get that the derivative is also continuous and given by
If is a -function with and , then it is continuously differentiable, and is a fixed point of . Because this functional is a contraction, . Repeating this argument for all subintervals , we find . □
We reverse our hypothetical calculations for V to show that the anti-derivative of the constructed function solves the HJB equation.
Theorem 2. Let u be defined as in Lemma 4. The anti-derivative is twice continuously differentiable. It holds that and . The function is the unique solution to and the HJB equation with these initial conditions.
Proof. Differentiability, initial values and uniqueness are a direct consequence from the definition of
U and Lemma 4. Let
denote the maximiser of
. We have
which is equivalent to
Since (
7) holds with “≥” in place of “=” for all
,
U solves the HJB equation. In the same way as in the beginning of this subsection, we obtain that every solution
to the HJB equation matching the initial conditions is a solution to
. This implies uniqueness for the HJB equation. □
In the next two Lemmas, we derive properties of the function U and the optimiser a on the condition that the initial value is positive.
Lemma 5. Let U be defined as in Theorem 2 for . For all , it holds that and U is strictly convex. The optimiser is continuous and non-negative with and , where is continuously differentiable. If, additionally, , then is strictly increasing.
Proof. We have by
:
so
and
. By the continuity of
, it follows that
is strictly increasing, at least in a small environment
,
. On
, it holds that
. If we define
, we have
by continuity. Again, as in (
9),
. This is not possible because
is defined as the first time that
enters the negative half plane, meaning that it must be decreasing at this time. Hence,
for
. Now, suppose that there was
such that
. Then,
for all
. This is a contradiction: The first term must be positive and the second term is non-negative, at least for
, by assumption. We conclude:
for all
. It follows directly that the optimiser is non-negative:
All variables inducing a negative counter are already excluded, and all values of with a positive counter are dominated by the value at . Moreover, since U solves the HJB equation and is increasing and convex, the optimiser takes the form . Continuity of implies continuity of a.
Deriving the right-hand side of (
10) with respect to
a shows that the maximum is attained at
or on the boundary
. From this representation of
in terms of
U and
, it follows that
is continuously differentiable.
Now, we show that the second derivative increases in the special case. If
, it holds that
for every
if
. By (
10), this implies that
and
is strictly increasing. □
Lemma 6. We assume that the conditions of Lemma 5 hold and define - 1.
If , it holds that and a is strictly increasing up to the point where it reaches , and is constant from there on. is continuously differentiable on with existing limits and .
- 2.
If , there exists . It holds that for and for . is continuously differentiable on and on with existing limits , , , and .
Proof. Since
and
, we have
for sufficiently small
x by Lemma 5. We let
. In particular, by
and
, we have
for all
. We firstly show that
is increasing at least in a small environment of zero. We have
and
, so there exists
such that
for all
. This means that
is strictly decreasing on this interval. Hence,
is decreasing in
x for every
a, meaning that
is decreasing. However, then,
is increasing for
.
Now, either (
13) holds for all
and
is strictly increasing up to
, or there exists at least one point
with
. We write
. Then,
is strictly increasing up to
. Using that
, we conclude from the HJB equation that
So, by the non-negativity of the optimiser, . This is a contradiction in the case , so is strictly increasing on with . If , we get that is strictly increasing on with .
In the case , the optimiser is constant for . This is shown via direct calculation using the ansatz , where the constants fulfil and . In the second case of , it holds that with constant optimiser for , if exists. This means that the optimiser is strictly increasing on . Once it reaches , it is “trapped” there and constant for all .
By
, it follows that
a is continuously differentiable on
if
. The limit
exists because
is strictly increasing, continuous, and bounded from above. To show that
is finite, we make the following observation. Since
a is differentiable and the denominator of (
7) is positive, the third derivative of
U exists and is continuous on
. This means that the derivative of
a takes the form
. Suppose that
. Then, it must hold that
because
U is strictly convex. However, on the other hand, it holds that
which follows from differentiating the HJB equation after plugging in the optimiser
. Now, if we let
, the bracket term on the left-hand side converges to a positive value. The right-hand side also converges, which contradicts the unboundedness of the third derivative. Hence,
. If
,
a is continuously differentiable on
and on
. If the latter interval is non-empty, the derivative is equal to zero. Existence of the limits
,
follows in the same way as in the case
. □
Remark 2. - 1.
This Lemma implies that U calculated with also solves the HJB equation for the unbounded case where the strategy may be chosen from the interval .
- 2.
We note that throughout the considerations above, was arbitrary. The uniqueness implies that if and is the solution defined on , then . Moreover, the optimiser a does not depend on d.
Now, we relate the constructed solution to the value function V and an optimal strategy.
3.2. Solution to the Optimisation Problem
In view of Theorem 1, our natural candidate for the value function is the solution to the HJB equation, which is equal to one at
. Thus, for
and
defined as in Theorem 2, we let
Theorem 3. If , f defined in (14) is the unique solution to the HJB equation (5) with and . f is strictly increasing except at zero, and is strictly convex. The pointwise optimiser has the properties stated in Lemmas 5 and 6. Moreover, for all , and the strategy with , , is optimal. Proof. The properties of
f follow by Lemma 5. We observe that
f solves the HJB equation under the initial conditions
and
, as it is a positive multiple of the solution
U. The optimiser remains the same. Since
is continuously differentiable, except possibly at one point
, and the derivative is bounded for
, it is Lipschitz-continuous on
. This implies that (
4) has a unique strong solution (compare, for example, (
Pilipenko 2014), Theorem 2.1.1). The verification of
f being the value function and
being optimal follow from Theorem 1. □
Thus, we have shown that V is strictly increasing except at zero, and is strictly convex. The optimal strategy is the feedback strategy defined in Theorem 1 with optimiser . The function a fulfils and is strictly increasing until either or is reached. This means that if the drawdown is small, nothing is invested, and as the drawdown approaches the critical line, slightly more is invested. This holds true for the case . Analogously, we could have shown:
Theorem 4. If , V is the unique solution to the HJB equation (5) with and . V is strictly increasing except at zero, and is strictly convex. The pointwise optimiser fulfils and is continuously differentiable except possibly at one positive point. It is strictly decreasing until it is constant and bounded from below by In the next subsection, we consider some numerical examples.
3.3. Numerical Examples
We assume that the technical discounting factor is
. The relatively small
reflects a long-term strategy, as this would be preferable, for example, in the context of life insurance. We define
as the critical size in these numerical examples. However, as noted in Remark 2, the choice of
d does not affect the shape of the function
.
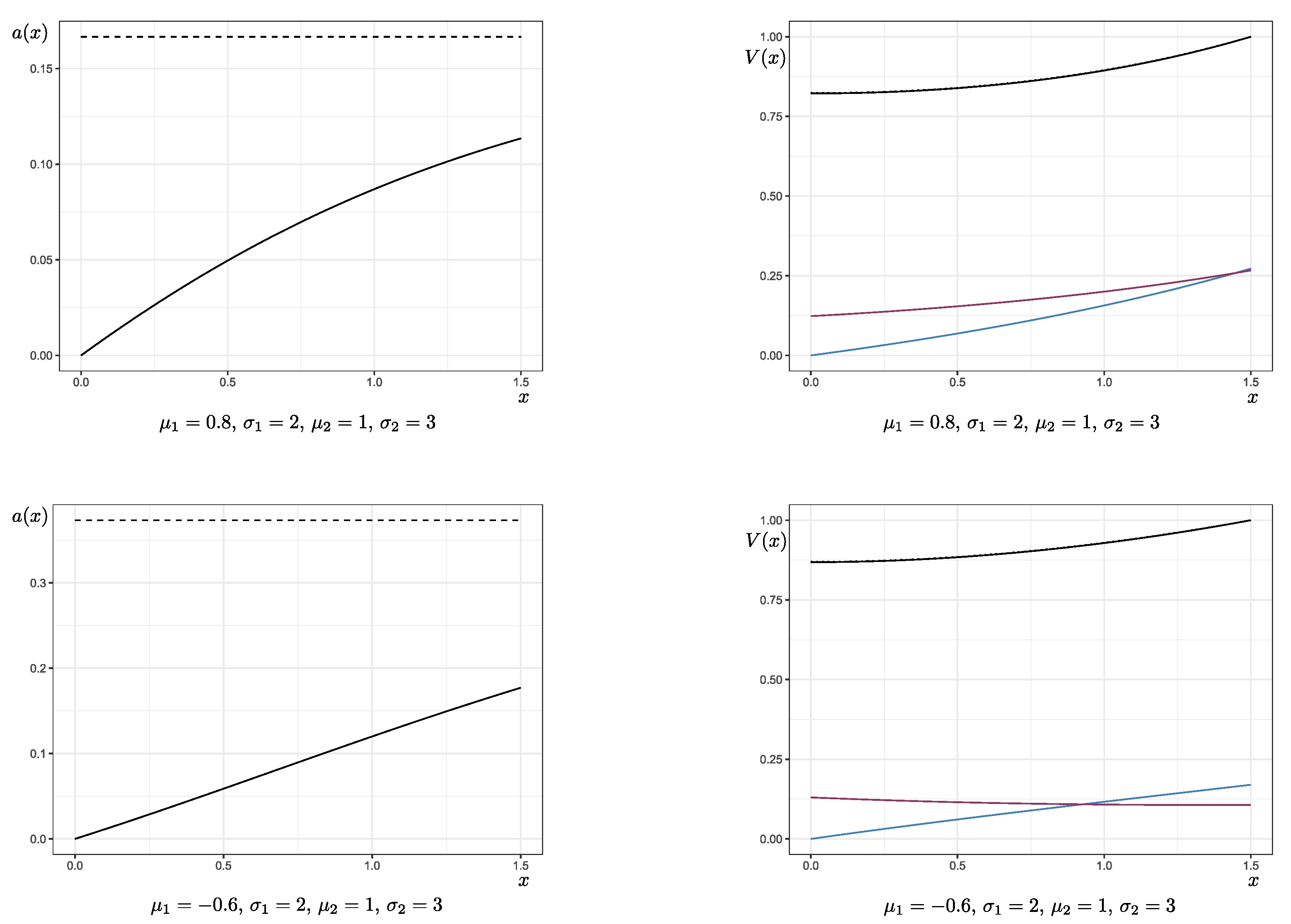
Figure 1 shows the optimal strategy inducing function
and Laplace transform
of the first passage through
d for different combinations of
,
,
, and
. In the graphs of the first row, the income from the insurance business is already expected to be profitable (
,
). The goal of the insurer is to elongate the time until the first significant drawdown occurs via investment in a risky asset, which yields a higher return at the cost of increased uncertainty (
,
). In comparison, the second row displays the functions in the same situation, but for the case where the insurance portfolio consists of non-profitable contracts (
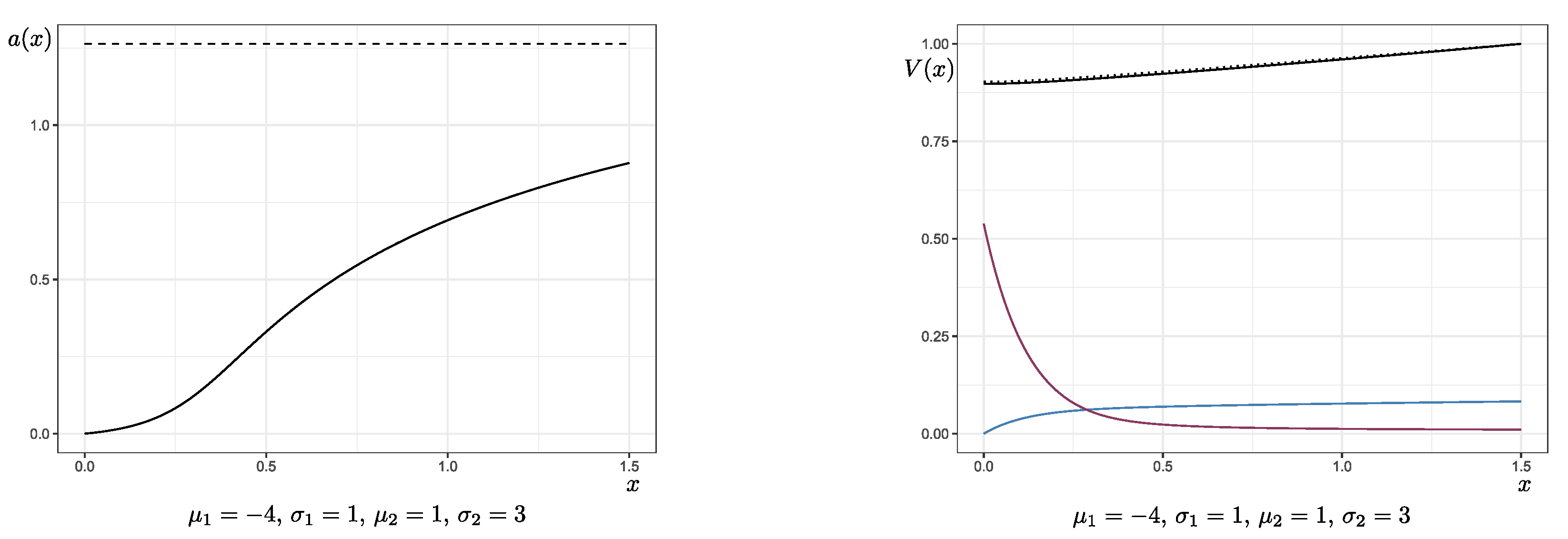
). The graphs in the third row belong to an example of extremely negative drift,
,
,
, and
, which is mainly included to show the variation in shape of the function
. In all cases, it holds that
and
, and the solutions were obtained via fixed-point iteration.
According to Lemma 6, the function
is strictly increasing with
and bounded from above by the constant
. If the drawdown approaches the critical value
d, the amount invested increases up to the level
. The drift from the investment is supposed to keep the process’ paths in the uncritical area.
is the critical value for which the added volatility from the investment is too risky and may push the process over the critical line. In the numerical examples, it can be observed that, if the drift of the original portfolio
is negative, the investment function
grows larger in a shorter time. If, for regulatory reasons, it held that
, the function
a would retain its shape, except for staying at
once this level is reached (see
Section 4.1 for an example with
). As shown in Theorem 3 the value function is increasing and convex in all cases. Moreover, only in the case of
, the second derivative of
V is increasing as well. For a comparison, the Laplace transform of the first passage through
d under the strategy of never investing, that is,
for all
, is pictured in the graphs on the right-hand side (dotted lines). We see here that
V is only slightly smaller. However, this effect will be striking for the solution of the general problem.
4. Minimising the Expected Time with Large Drawdown
Since we have already found the optimal strategy that maximises the time with a small drawdown, it is natural to extend this with the strategy that minimises the time with a large drawdown: for . We start by considering constant strategies. As it turns out, this is sufficient for the case of a large initial drawdown.
Since the drawdown process under the constant strategy a behaves like an arithmetic Brownian motion of drift and variance as long as it is above d, the value of this strategy inherits its structure from the Laplace transform of the hitting time of a Brownian motion:
Lemma 7. For define and is the negative solution to . The value of the strategy A, which is constant and equal to a, is given by for all .
Theorem 5. If holds in combination with or with and , the best constant strategy is . Otherwise, is the best constant strategy. If holds in combination with or with and , the best constant strategy is . Otherwise, is the best constant strategy. Let denote the respective optimiser. It holds that for and is optimal.
Proof. We conclude from the previous Lemma that we have to maximise
. Since
itself is hard to handle as a function of
a, we consider the functions
instead. For every
a,
, so the function is strictly decreasing up to its first zero. It holds that
, so there can be at most one negative solution to
. We start with the case
. For all
a with
, it holds that
for all
. For
with
,
. In either case, it holds that
, which implies that
.
Now, we assume . Let . Similarly as before, we have for all . On the other hand, for all . By , we conclude that lies below or for all , and thus cannot induce the maximum. We still have to compare the values on the boundary if . It holds that iff . This means that the optimiser is , in case . The case follows analogously.
Now, let
denote the optimiser in the respective cases. We conclude that for every
a, it holds that
with equality in the case
. Thus,
solves
for
. The assertion is verified in the same way as in the proof of Theorem 1. □
Now, to solve our original problem, we connect the solutions to the two subproblems. Our ansatz for the optimal strategy is
with
for
. In the case that this is continuous, the existence of the controlled surplus process follows as in the proof of Theorem 3. Otherwise, weak existence of the controlled drawdown follows by Theorem 4.1 of (
Rozkosz and Slominski 1997). In the non-degenerate case of
, a construction similar to the one in Theorem 4.2 of (
Semrau 2009) ensures pathwise uniqueness (choose
,
, and use that
is bounded away from zero). The Yamada–Watanabe-type Theorem 333 of (
Situ 2005) therefore implies strong existence and uniqueness.
Theorem 6. Let denote the maximal time to drawdown from the previous section and let denote the minimal time in drawdown. We define It holds that and , defined as in (16), is an optimal strategy. Proof. We have already seen that
f solves (
5) on
with
, where the second derivative is assumed to be one-sided for
. Equation (
15) implies that this differential equation can be extended on
in the sense that
f solves
f can be written as the difference of two convex functions (with a bounded derivative), so by Theorem 4.3 in (
Björk 2015), it follows that
is a martingale for every
. The integrand is larger than or equal to
. By taking expectations and letting
, we conclude that
for every
. In particular,
is a martingale, so the assertion follows again, as in the proof of Theorem 1. □
We consider numerical examples for the expected discounted time in drawdown and finish with some concluding remarks.
4.1. Numerical Examples and Remarks
The numerical examples were obtained by solving the subproblems of finding the functions
V and
W and then connecting the solutions. Again, we let
and
.
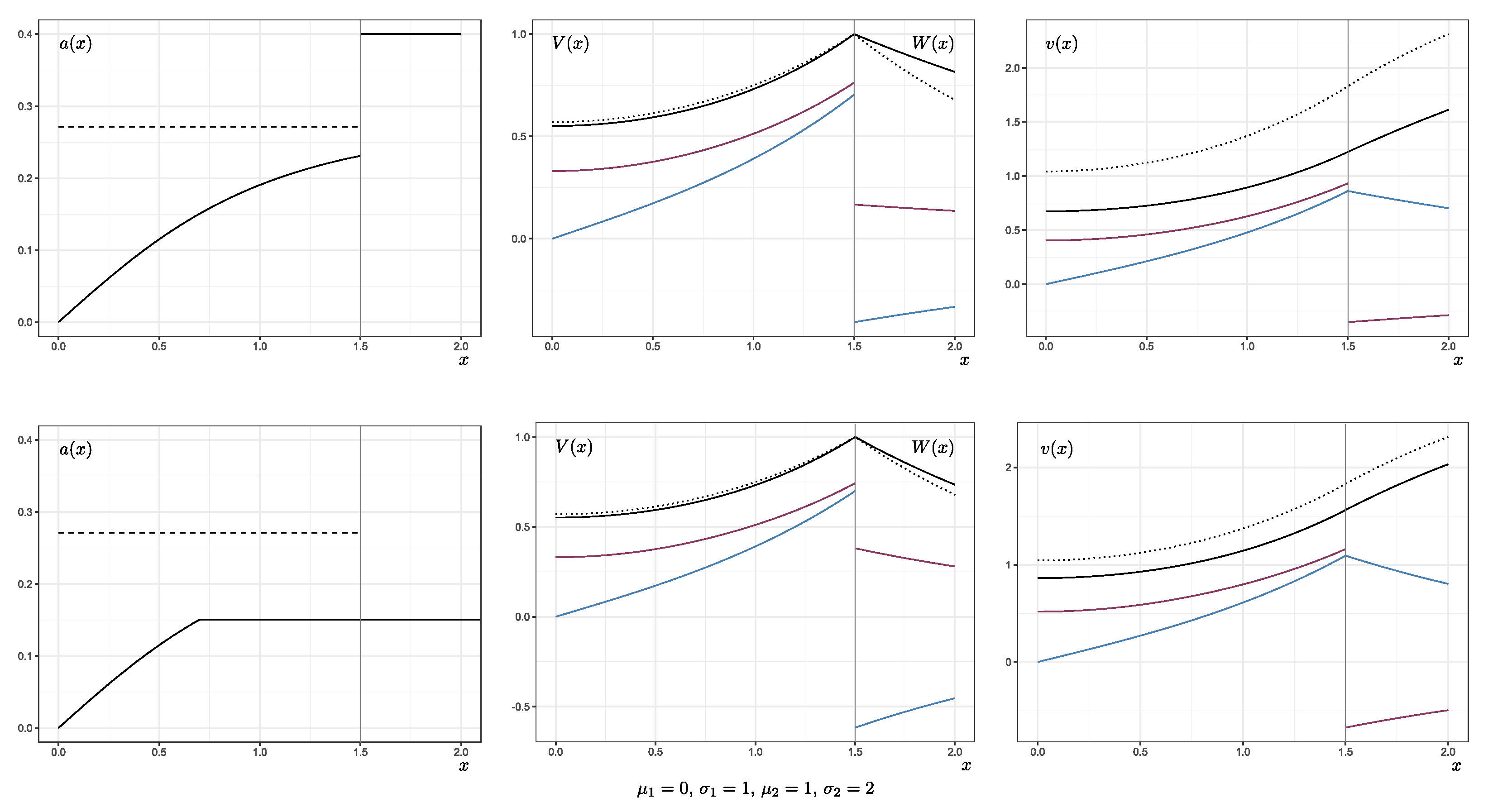
Figure 2 shows the function inducing the optimal strategy given in (
16), Laplace transforms of the passage times, and the value function
v for the parameters
,
,
,
, and
and
. That is, the insurance portfolio is not expected to generate profits and the insurer is allowed to invest a small amount in a risky asset to minimise the time in drawdown of this portfolio. In the uncritical area, the invested amount depends on the current drawdown through the function
a. Independently from the bounds
and
, the optimal strategy always lies within the finite interval
(here:
). If the maximal amount
is smaller than
, the graph of the function
a is flattened at the top.
is antiproportional to
, meaning that, to minimise drawdowns, less should be invested if investment is risky. The presented solution is optimal for arbitrarily large
and
. In the critical area, the investment is chosen maximally to force the processes paths back into the uncritical area. Hence, it is necessary to restrict investment in this case.
Again, as in
Figure 1, the blue lines represent the first and the red lines represent the second derivatives of the functions of
Figure 2. The middle graphs of the figure display the two different functions
defined for
and
defined for
. They are the solutions to the subproblems of maximising the time in the uncritical area below
d and minimising the time in the critical area above
d. As they are expressed via Laplace transforms of the passage time of
d, both fulfil the boundary condition
. Since they solve different optimal control problems, the first and second derivatives will not coincide in general. The graphs on the right display the function
. The function was constructed such that it is once continuously differentiable. However, as a solution to Equation (
17), it cannot be twice continuously differentiable in any small environment of
d because the right-hand side is discontinuous at this point.
In comparison to the strategy of never investing (represented by the dotted line in the second and third columns of
Figure 2), the expected time in drawdown is visibly reduced by investing optimally.
The minimisation of drawdowns prevents negative tours from the favourable area close to the maximum. As soon as the process reaches a new running maximum, the favourable area slides upwards. On the other hand, the choice of implies that the absolute growth is kept relatively small.
This observation seems counter-intuitive at first sight: Close to zero, it should be “safer” to invest without causing critical drawdowns. However, under the optimal strategy, the insurer never invests when the drawdown is small—even if that results in a negative drift. In fact, accepting a few more technicalities, one can extend the proofs of the previous subsection to show that if , there exists an optimiser of similar shape, but with close to zero. We do not consider this scenario here because an obligatory minimum investment is not realistic. However, this technical observation adds to the impression that, with a small drawdown, the insurer invests as little as possible. This means that the optimal strategy elongating the time to drawdown merely equilibrates the process close to the previously reached maximum at the cost of missing out on possible profits. Though this is not ideal from an economical point of view, stability might be preferable over unbounded profits for single insurance portfolios or in certain scenarios (especially if they are expected to cause losses without investment). The benefit of stabilised paths can outweigh the generation of higher profits at higher (drawdown) risk. For this reason, we expect the approach to work best if either large drawdowns are very likely to occur (because of a high volatility or expected unprofitability of a certain portfolio) or if there is a minimum capital requirement that, for regulatory reasons or due to management decisions, is more important than the generation of profits.
A variation of the model and idea for possible future research is to consider the case where the portfolio should be self-financing in the sense that the invested amount at time
t lies within the interval
. This paper studies how to prevent drawdowns for certain portfolios or divisions that are allowed to be non-profitable. Therefore, financing the investments from an external source—for example, through profits generated in other business lines—is a reasonable model assumption. However, if one seeks to optimise the entire surplus of the company, external financing becomes less realistic. An interesting question arising from this is how drawdowns of the company’s compound surplus may be prevented through investment if there are profitable and non-profitable business lines and external financing is not allowed. Another extension would be to relax the strong assumption of independence and to work with correlated Brownian motions
and
as in (
Browne 1995). Moreover, one could study the problem where reinsurance and investment are simultaneously used to minimise the expected time in drawdown.



{kind=link}
{kind=link}
{kind=link}
{kind=link}


