A Bayesian Approach to Measurement of Backtest Overfitting


Abstract
1. Introduction
- First, is it sufficient to apply the standard single p-test to the best strategy?
- If not, how should we modify the test to incorporate the multiple test effects?
- What is the expected future, i.e., true out-of-sample (OOS) performance (return, SR, etc.) of the best strategy selected on the in-sample (IS), i.e., historical dataset?
- What is the haircut, i.e., the percentage reduction, of the expected OOS performance compared to the IS performance?
- What is the probability of loss, if the strategy is implemented over a future period?
- What is the expected OOS rank of the IS best strategy among the candidate strategies?
- What is the probability that the selected model will in fact underperform most of the candidate models?
- What is the probability that we have selected a false model (false discovery rate—FDR)?
2. An Overview of the Existing Approaches
2.1. Classical Approaches
2.2. Stationary Bootstrap
2.3. Combinatorial Symmetric Cross-Validation
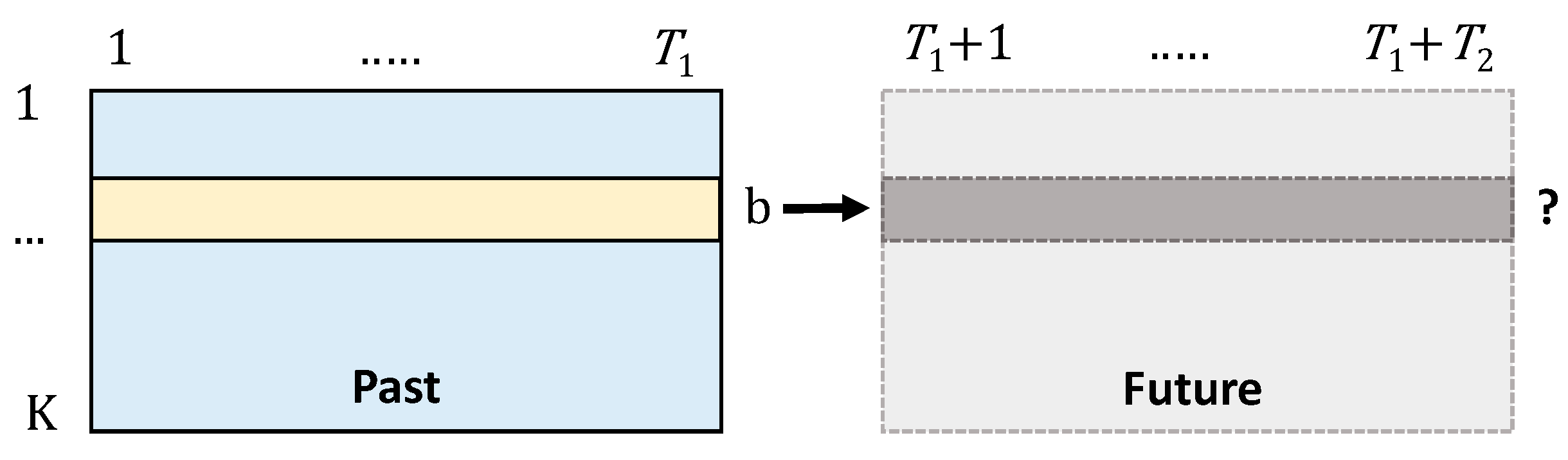
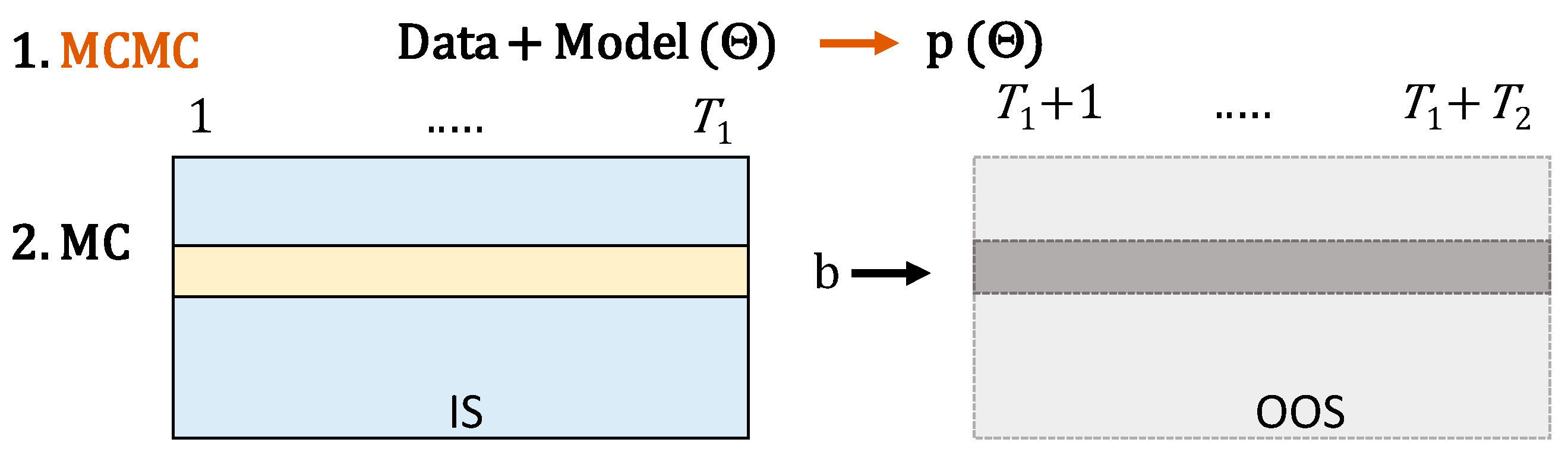
3. Bayesian Simulation Approach
3.1. The Naïve Model 1
- Sample from .
- Independently sample cross-sections .
- Determine the index of the best strategy on the basis of the backtest statistics calculated from the matrix of backtested returns for .
- Calculate and store the performance indicators, , in the OOS period Alternatively, store the selected strategy “true” performance indicators, i.e., .
3.2. Model 2—Bimodal Means Distribution
- Given , set , and estimate as above, i.e.,
- Given , estimate . Set , , , , and , where creates a matrix with diagonal elements given by the vector in the argument, and sample
- Given and , estimate . For set equal to with the exception of the diagonal element , and setting . Let
- We may allowencoding negative significant mean return, zero return, or significant positive return. In this case, the mean parameter of the prior distributionmust be strictly positive. In the Gibb’s sampler above, we just need to modify step 3 in a straightforward manner.
- The hyper-parametersforandmight be estimated within the MCMC procedure. In this case, the Gibb’s sampler can be extended as follows:
- 4.
- Samplegiven:
whereandis a conjugate prior distribution (e.g.,.- 5
- Samplegivenand. Here, we just use the meanswhere the signal is positive and the normal Gibb’s sampler. Since the set may be empty, we need to use proper conjugate priors, e.g.,and
For, setand. Then,If. then we have to sample on the basis of conjugate priorsandonly.
4. Numerical Study
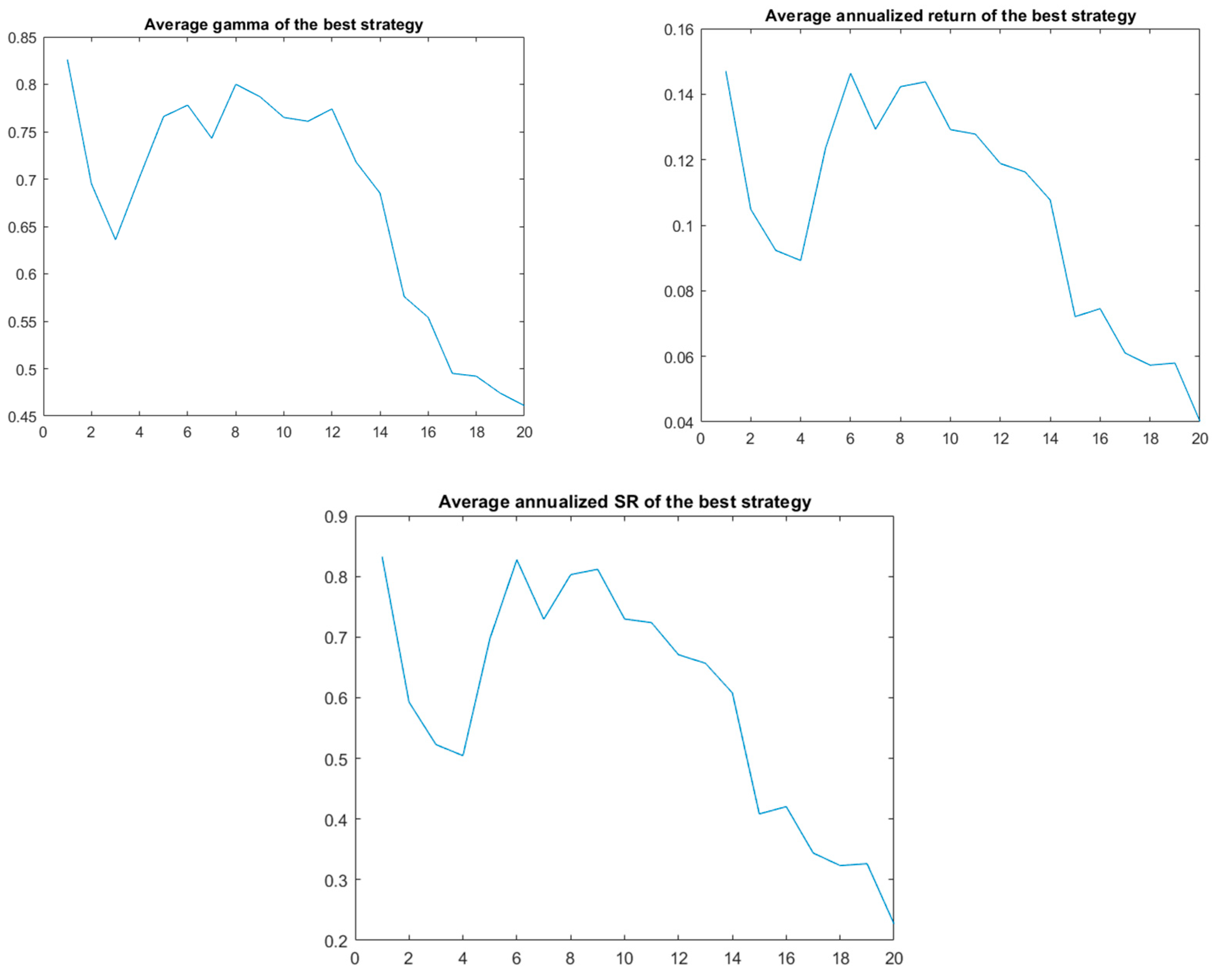
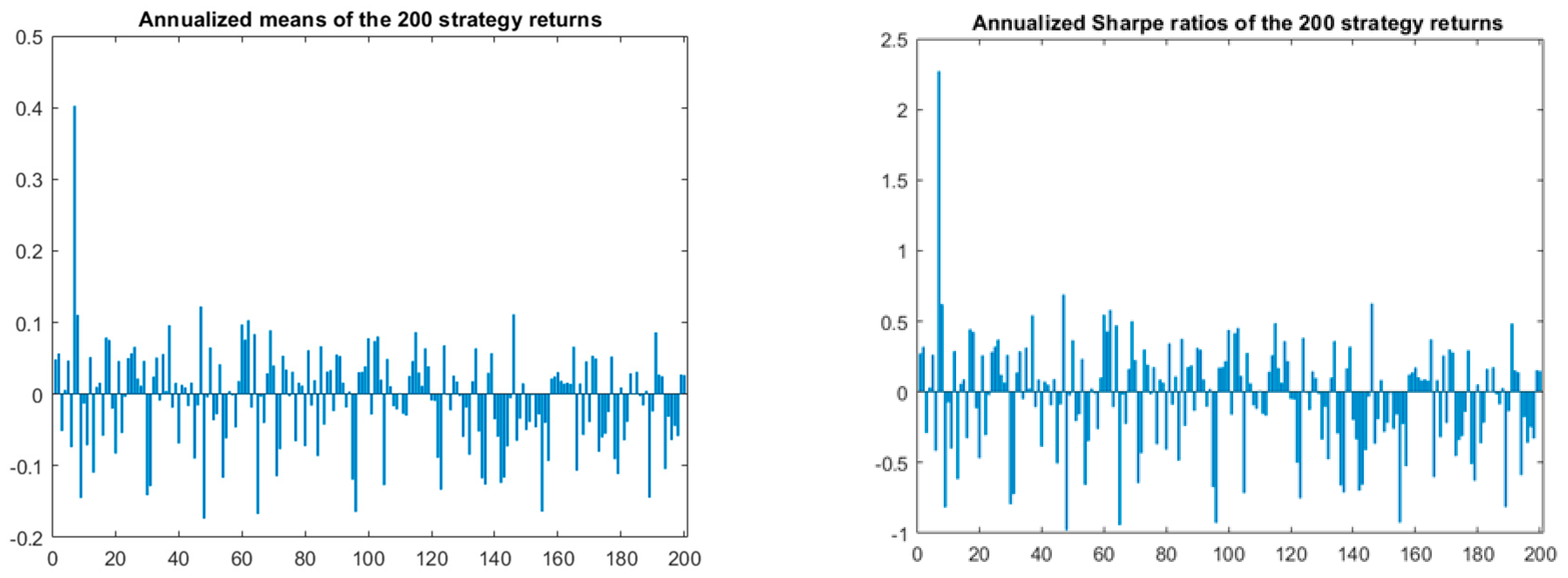
4.1. Technical Strategies Selection
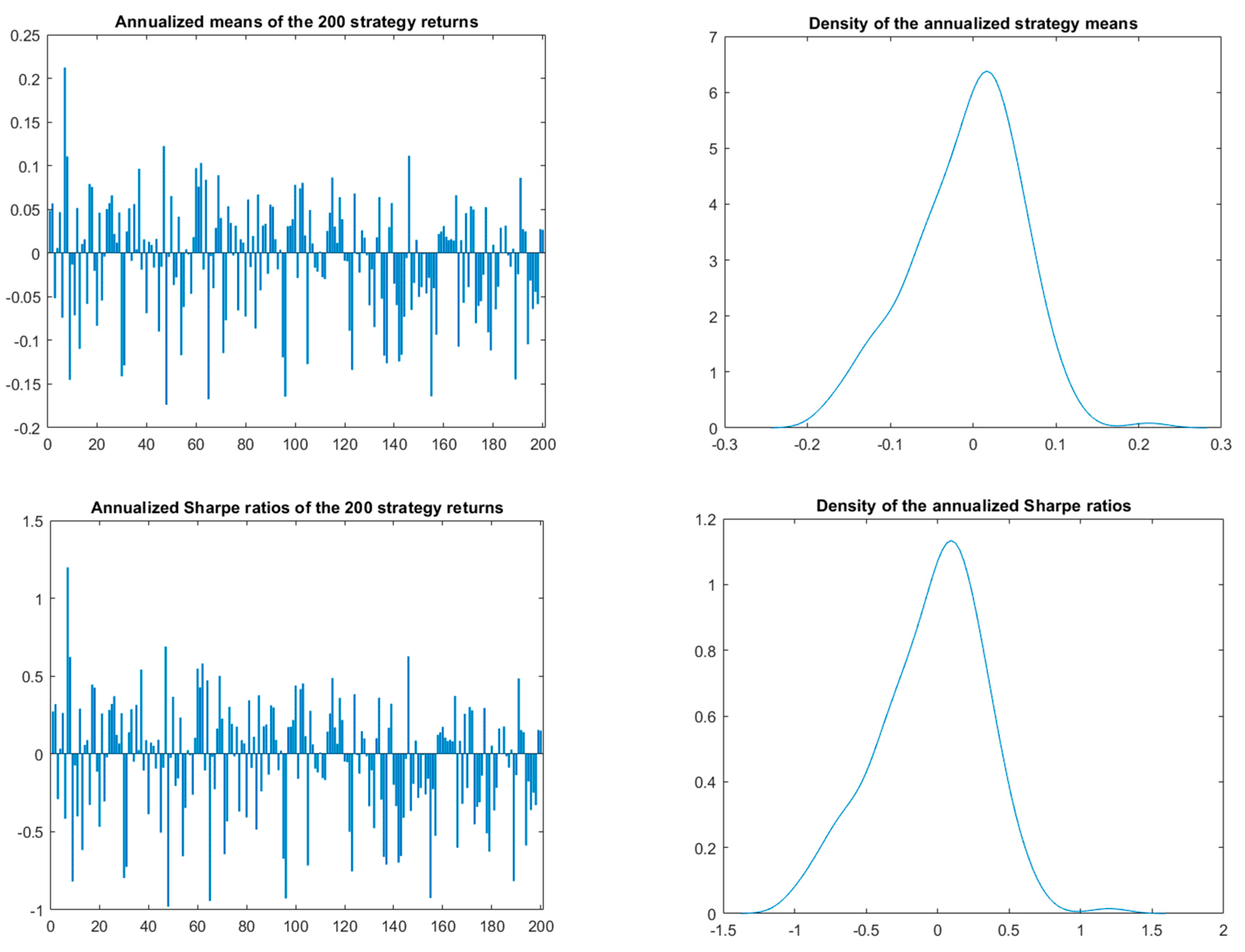
4.2. Single and Multiple p-Value Testing
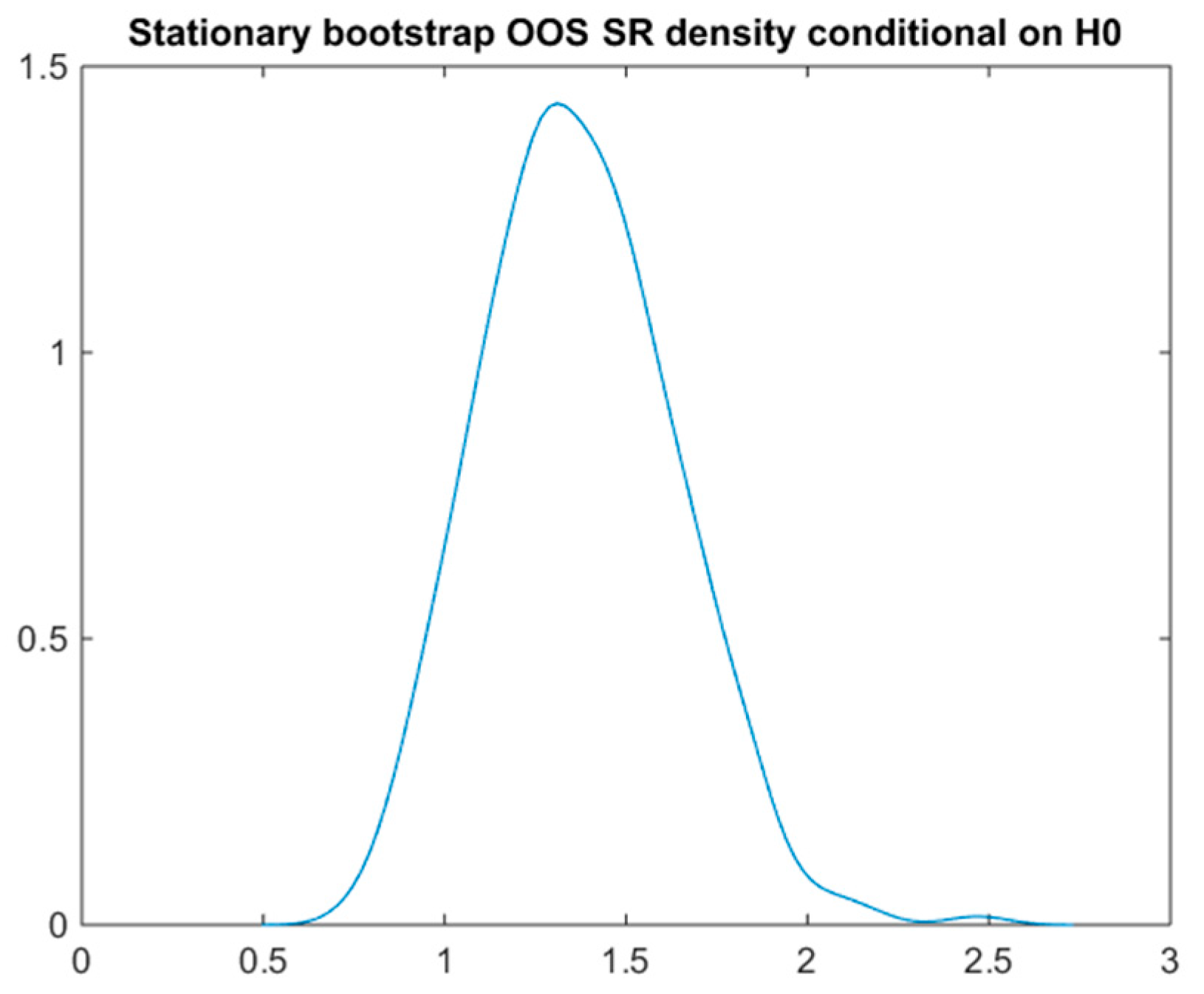
4.3. Multivariate Normal Simulation and the Stationary Bootstrap According to the Null Hypothesis
4.4. Stationary Bootstrap Two-Stage Simulation
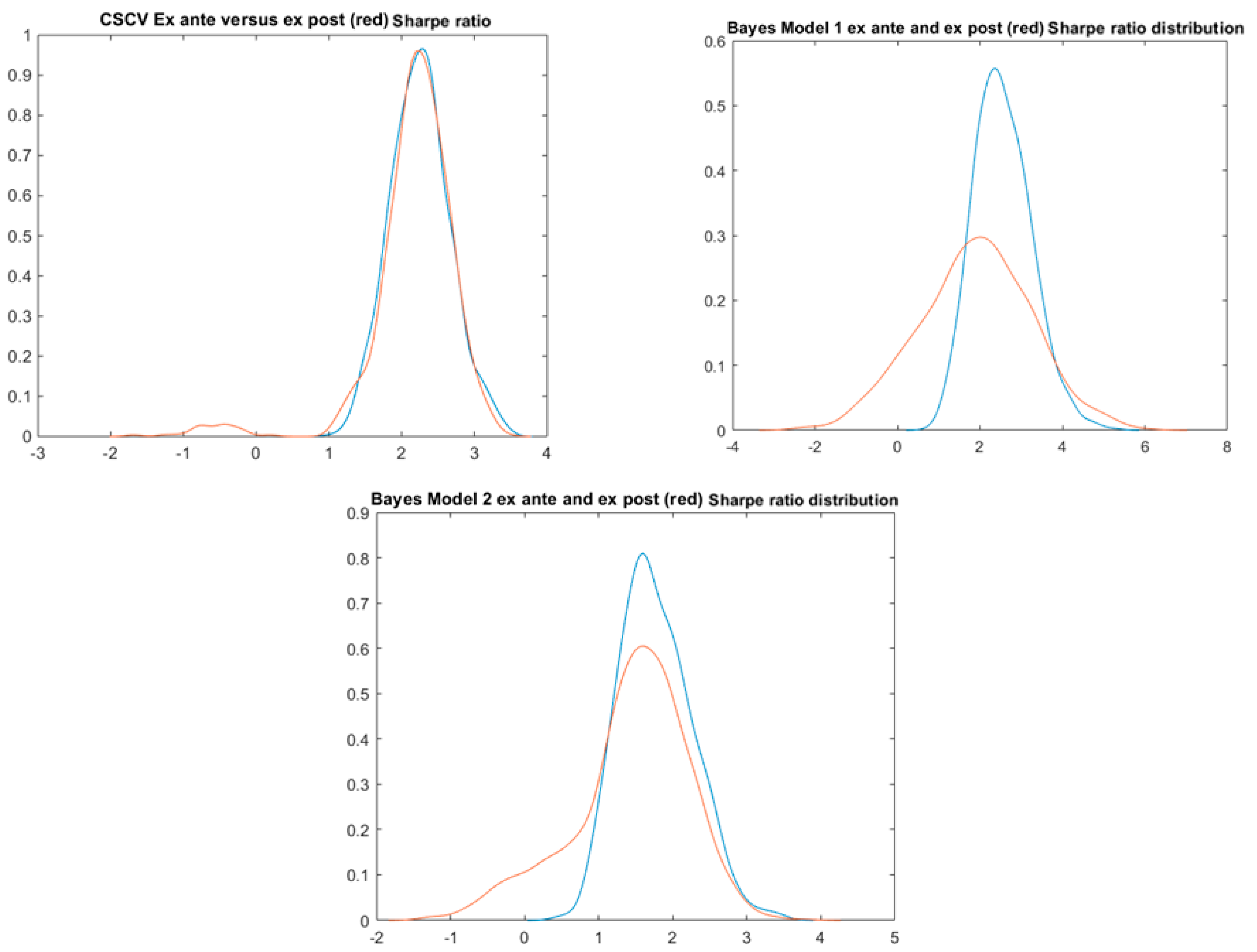
4.5. Combinatorial Symmetric Cross-Validation
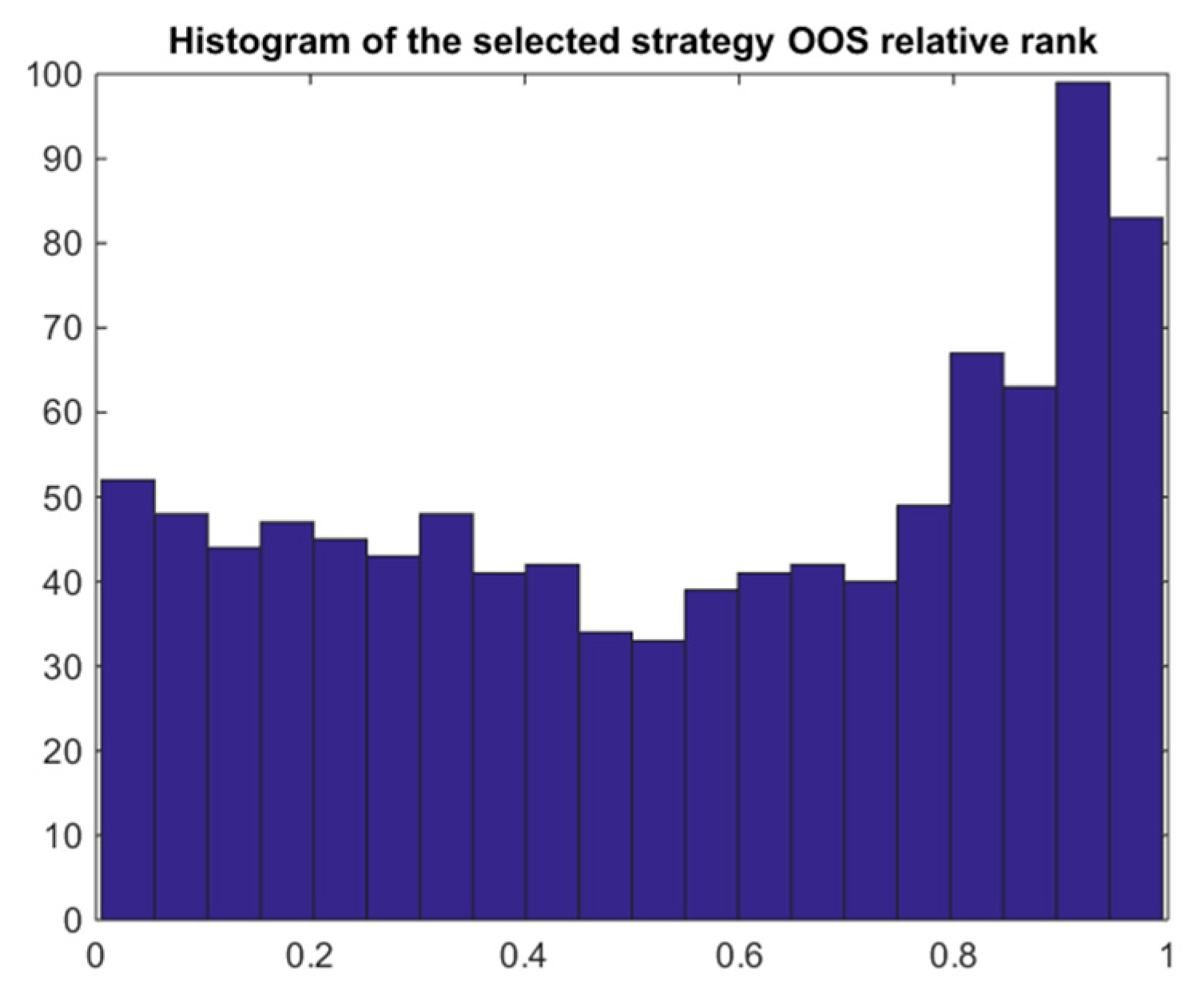
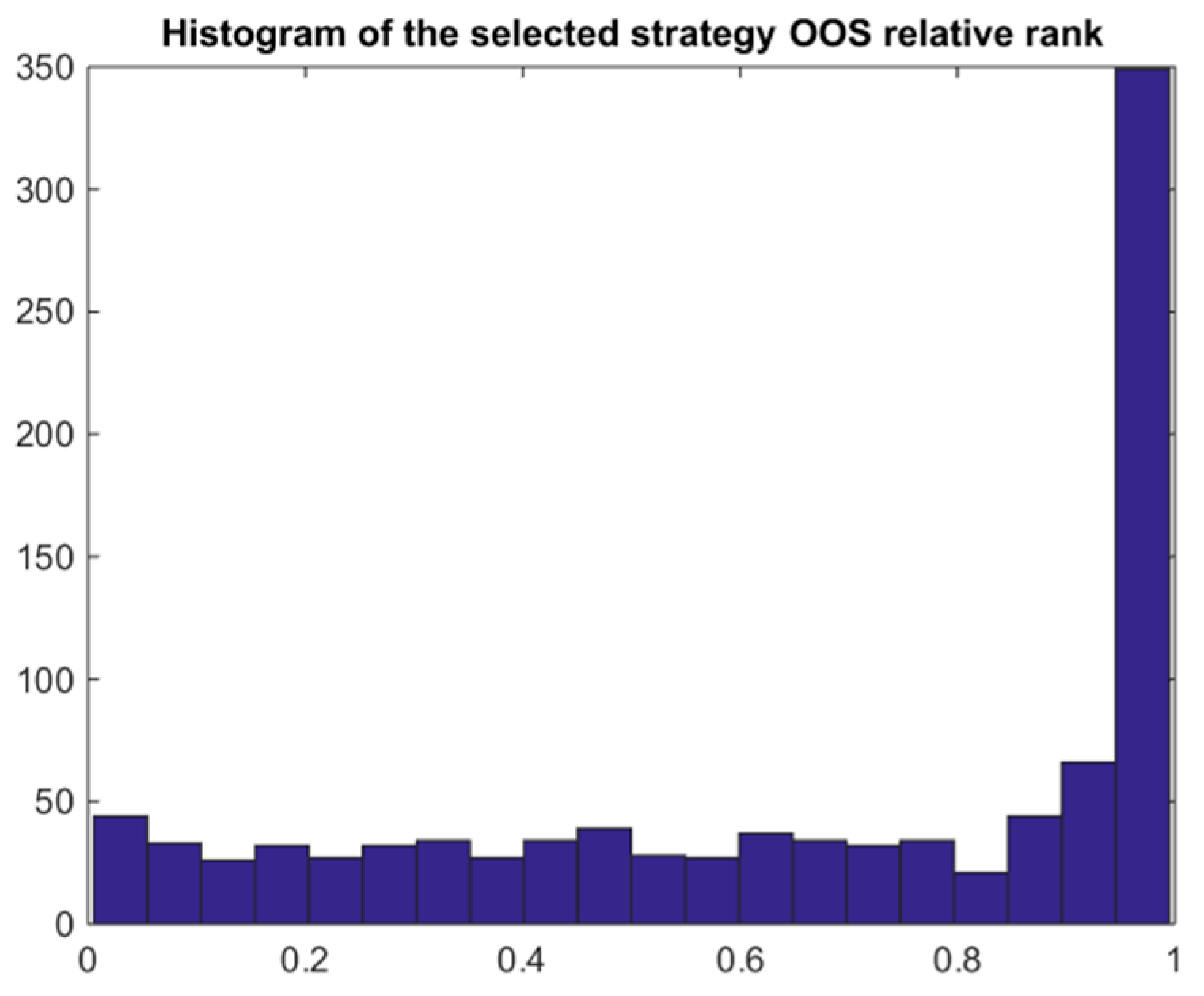
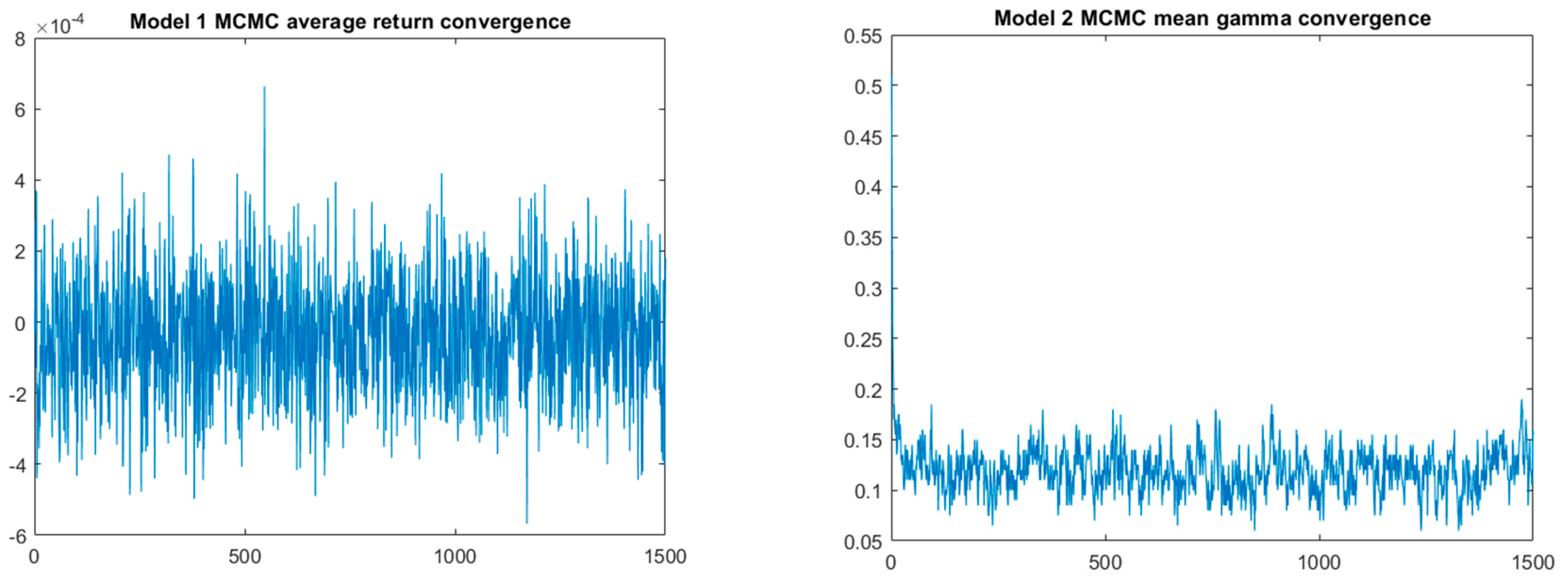
4.6. The Naïve Bayes Model 1
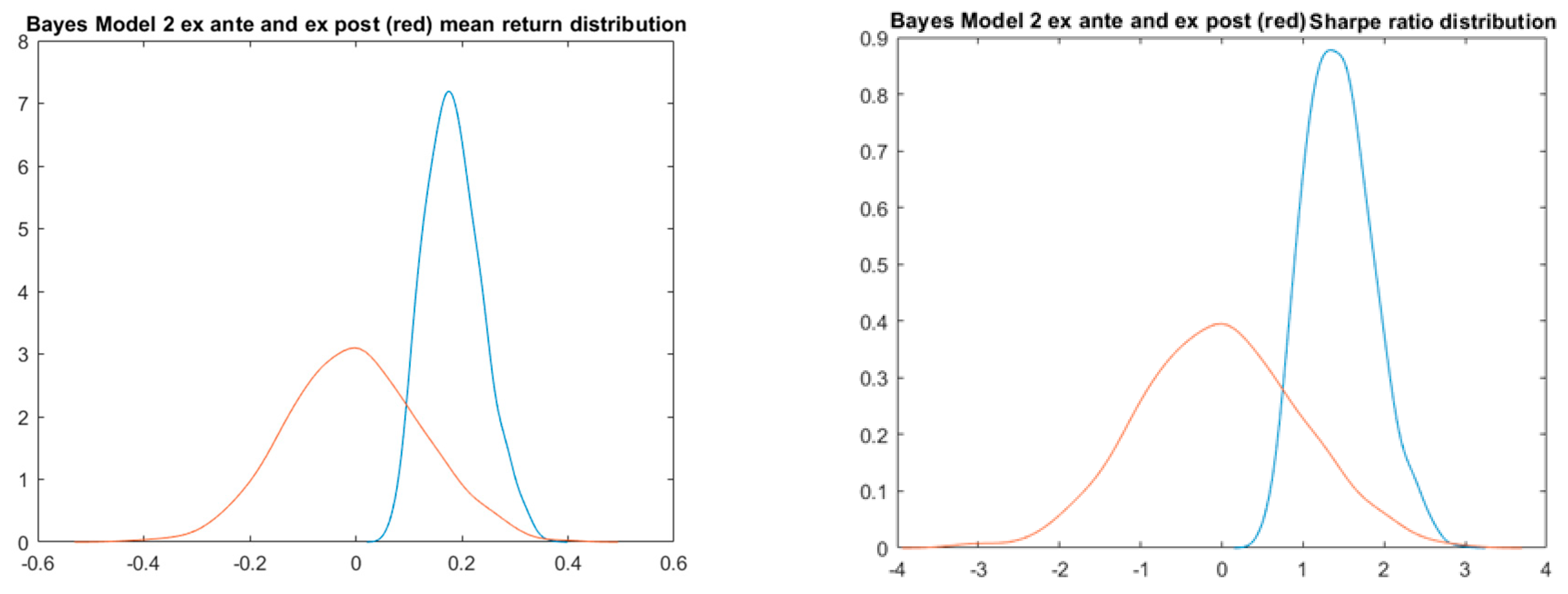
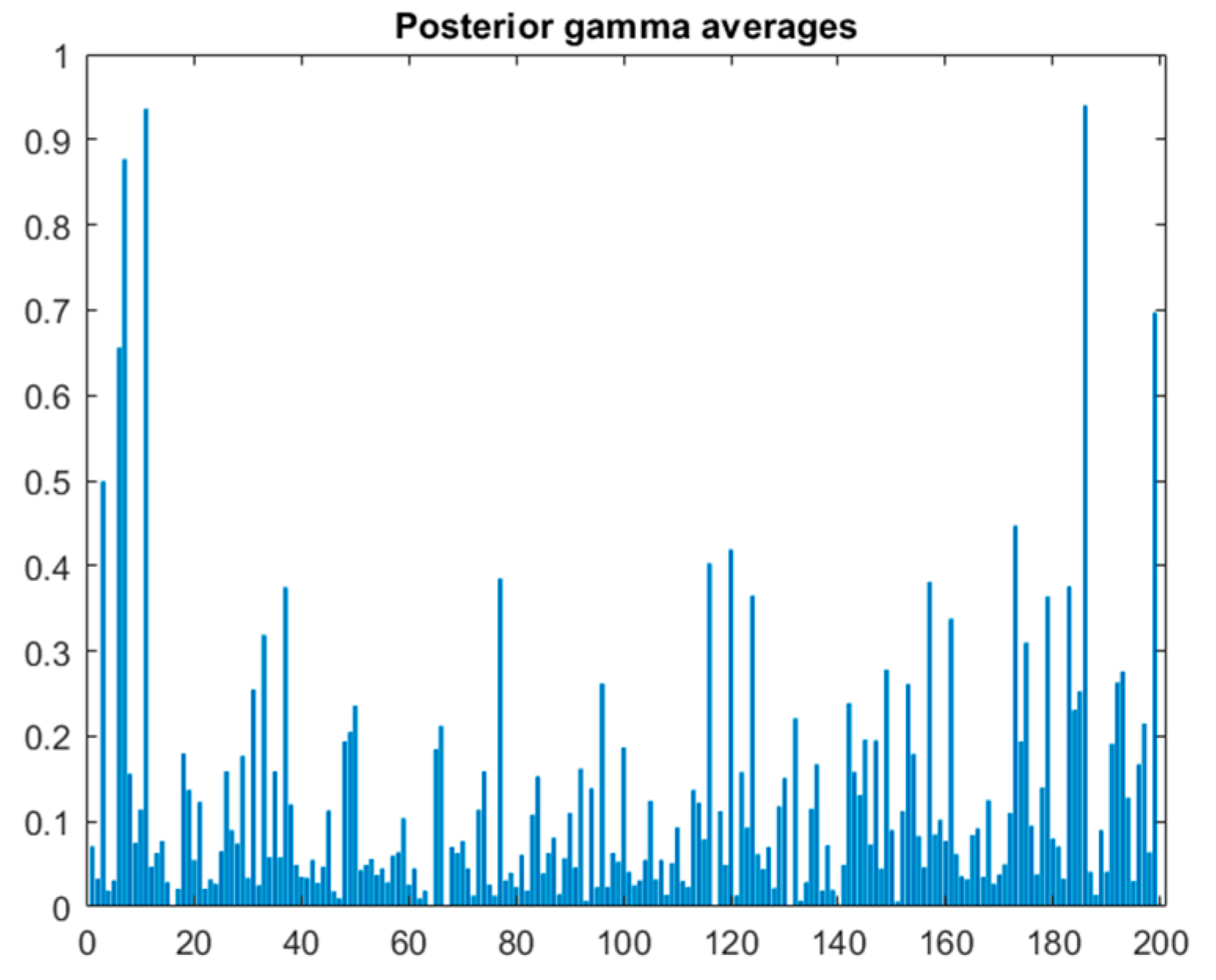
4.7. Bayes Bimodal Mean Returns Model 2
4.8. Testing with Modified Mean Returns
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Andrews, Isaiah, and Maximilian Kasy. 2019. Identification of and correction for publication bias. American Economic Review 109: 2766–94. [Google Scholar]
- Bailey, David H., Jonathan Borwein, Marcos Lopez de Prado, and Qiji Jim Zhu. 2014. Pseudomathematics and financial charlatanism: The effects of backtest over fitting on out-of-sample performance. Notices of the AMS 61: 458–71. [Google Scholar] [CrossRef]
- Bailey, David H., Jonathan Borwein, Marcos Lopez de Prado, and Qiji Jim Zhu. 2016. The Probability of Backtest Overfitting. Available online: https://ssrn.com/abstract=2840838 (accessed on 21 June 2016).
- Chen, Andrew Y., and Tom Zimmermann. 2020. Publication bias and the cross-section of stock returns. The Review of Asset Pricing Studies 10: 249–89. [Google Scholar] [CrossRef]
- De Prado, Marcos Lopez. 2015. The future of empirical finance. The Journal of Portfolio Management 41: 140–44. [Google Scholar] [CrossRef]
- Harvey, Campbell R., and Yan Liu. 2013. Multiple Testing in Economics. Available online: https://ssrn.com/abstract=2358214 (accessed on 28 April 2017).
- Harvey, Campbell R., and Yan Liu. 2014. Evaluating trading strategies. The Journal of Portfolio Management 40: 108–18. [Google Scholar] [CrossRef]
- Harvey, Campbell R., and Yan Liu. 2015. Backtesting. The Journal of Portfolio Management 42: 13–28. [Google Scholar] [CrossRef]
- Harvey, Campbell R., and Yan Liu. 2017. Lucky Factors. Available online: https://ssrn.com/abstract=2528780 (accessed on 28 June 2017). [CrossRef]
- Harvey, Campbell R., and Yan Liu. 2020. False (and missed) discoveries in financial economics. The Journal of Finance 75: 2503–53. [Google Scholar] [CrossRef]
- Harvey, Campbell R., Yan Liu, and Heqing Zhu. 2016. … and the cross-section of expected returns. The Review of Financial Studies 29: 5–68. [Google Scholar] [CrossRef]
- López de Prado, Marcos, and Michael J. Lewis. 2019. Detection of false investment strategies using unsupervised learning methods. Quantitative Finance 19: 1555–65. [Google Scholar] [CrossRef]
- Lynch, Scott M. 2007. Introduction to Applied Bayesian Statistics and Estimation for Social Scientists. Berlin/Heidelberg: Springer, p. 359. [Google Scholar]
- Politis, Dimitris N., and Joseph P. Romano. 1994. The stationary bootstrap. Journal of the American Statistical Association 89: 1303–13. [Google Scholar]
- Scott, James G., and James O. Berger. 2006. An exploration of aspects of Bayesian multiple testing. Journal of Statistical Planning and Inference 136: 2144–62. [Google Scholar] [CrossRef]
- Streiner, David L., and Geoffrey R. Norman. 2011. Correction for multiple testing: Is there a resolution? Chest 140: 16–18. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, Ryan, Allan Timmermann, and Halbert White. 1999. Data-snooping, technical trading rule performance, and the bootstrap. The Journal of Finance 54: 1647–91. [Google Scholar] [CrossRef]
- White, Halbert. 2000. A reality check for data snooping. Econometrica 68: 1097–126. [Google Scholar] [CrossRef]
| 1 | By an investment strategy, we mean a rule that dynamically determines a portfolio of assets that can be long or short according to information available at the beginning of the period t over which the investment is held. The return over the period is net of the cost of borrowings needed to set up the portfolio (i.e., the strategy is self-financing). For example, an investment strategy may just determine at the end of each trading day whether a long or short position is taken in a specific index futures contract for the next day. |
| 2 | A strategy with a significant negative t-ratio can be considered as a discovery as well since we can revert it in order to achieve systematic positive returns. |
| 3 | For example, 18% annualized volatility of returns is translated to volatility of the posterior annualized mean return. |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adjusted p-Value (FDR) | Ex Ante av. SR/Mean | Adjusted Expected SR/Mean | SR/Mean Hair Cut | Probability of Loss | Mean OOS Rank | PBO | |
|---|---|---|---|---|---|---|---|
| Boferroni method | 1.00 | 1.199 | 0 | 100% | - | - | |
| Šidák’s correction | 0.968 | 1.199 | 0.02 | 98.3% | - | - | |
| Mult. norm. MC adj. | 0.352 | 1.199 | 0.4668 | 61% | - | - | |
| Stationary bootstrap | 0.728 | 1.110/0.194 | 0.297/0.051 | 73.2%/74% | 0.328 | 55% | 0.444 |
| CSCV | - | 1.382/0.244 | 0.336/0.058 | 75.7%/76.4% | 0.371 | 66.8% | 0.323 |
| Bayes mod. 1 | - | 2.102/0.371 | 1.014/0.180 | 51.8%/51.5% | 0.171 | 75.7% | 0.168 |
| Bayes mod. 2 | 0.549 | 1.201/0.213 | 0.211/0.037 | 82.5%/82.5% | 0.380 | 60% | 0.395 |
| Adjusted p-Value (FDR) | Ex Ante av. SR | Adjusted Expected SR | Hair Cut | Probability of Loss | Mean Rank | PBO | |
|---|---|---|---|---|---|---|---|
| Boferroni method | 0.0014 | 2.2707 | 1.6121 | 29% | - | - | |
| Šidák’s correction | 0.0014 | 2.2707 | 1.6122 | 29% | - | - | |
| Multivariate norm. MC adj. | 0.0004 | 2.2707 | 1.783 | 21.5% | - | - | |
| CSCV | - | 2.257 | 2.196 | 2.7% | 0.014 | 98.5% | 0.01 |
| Bayes mod. 1 | - | 2.549 | 1.887 | 26% | 0.092 | 87.1% | 0.087 |
| Bayes mod. 2 | 0.11 | 1.776 | 1.442 | 18.8% | 0.067 | 92.1% | 0.059 |
| Adjusted p-Value (FDR) | Ex Ante av. SR | Adjusted Expected SR | Hair Cut | Probability of Loss | Mean Rank | PBO | |
|---|---|---|---|---|---|---|---|
| Boferroni method | 1 | 0.1536 | 0 | 100% | - | - | |
| Šidák’s correction | 1 | 0.1536 | 0 | 100% | - | - | |
| Multivariate norm. MC adj. | 0.997 | 0.1536 | 0.002 | 98.7% | - | - | |
| CSCV | - | 1.027 | −0.960 | 193.5% | 1.00 | 1.2% | 1 |
| Bayes mod. 1 | - | 1.975 | 0.607 | 69.3% | 0.286 | 67.1% | 0.265 |
| Bayes mod. 2 | 0.887 | 1.127 | 0.062 | 94.5% | 0.447 | 53.2% | 0.450 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Witzany, J. A Bayesian Approach to Measurement of Backtest Overfitting. Risks 2021, 9, 18. https://doi.org/10.3390/risks9010018
Witzany J. A Bayesian Approach to Measurement of Backtest Overfitting. Risks. 2021; 9(1):18. https://doi.org/10.3390/risks9010018
Chicago/Turabian StyleWitzany, Jiří. 2021. "A Bayesian Approach to Measurement of Backtest Overfitting" Risks 9, no. 1: 18. https://doi.org/10.3390/risks9010018
APA StyleWitzany, J. (2021). A Bayesian Approach to Measurement of Backtest Overfitting. Risks, 9(1), 18. https://doi.org/10.3390/risks9010018