Peer-To-Peer Lending: Classification in the Loan Application Process


Abstract
:1. Introduction
2. Background
2.1. Peer-To-Peer Lending Companies
2.2. How Does It Work?
2.3. Loan Application Processing
2.4. Related Works on Peer-To-Peer Lending
3. Methods and Performance Metric
3.1. Logistic Regression—A Benchmark
3.2. Our Approach
- Each feature is transformed for finding the nonlinear dependence of the likelihood of loan approval using a feature-wise spline regression.
- Nonlinear score functions are estimated by applying logistic regression or maximizing the Buffered AUC or AUC with transformed features.
Transforming Features via Cubic Spline Regression
3.3. AUC and Optimization
3.4. bAUC and Optimization
4. Case Study
4.1. Data Preparation
- Amount Requested: The total amount requested by the borrower.
- Application Date: The date when the borrower applied for the loan.
- Notes Offered by Prospectus/Loan Title10: The loan title or purpose description provided by the borrower.
- Risk Score: For applications prior to November 5, 2013 the risk score is the borrower’s FICO score. For applications after November 5, 2013, the risk score is the borrower’s vantage score.
- Debt-To-Income Ratio (DTI): A ratio calculated using the borrower’s total monthly debt payments on the total debt obligations, excluding mortgage and the requested LC loan, divided by the borrower’s self-reported monthly income.
- Zip Code: The first three digits of the zip code provided by the borrower in the loan application.
- State: The state provided by the borrower in the loan application.
- Employment Length: Employment length in years. Values are between 0 and 10 where 0 means “less than one year” and 10 means “ten or more years”.
- Policy Code: policy codes 1 and 2 correspond to publicly available and not available new products.
4.2. Numerical Results
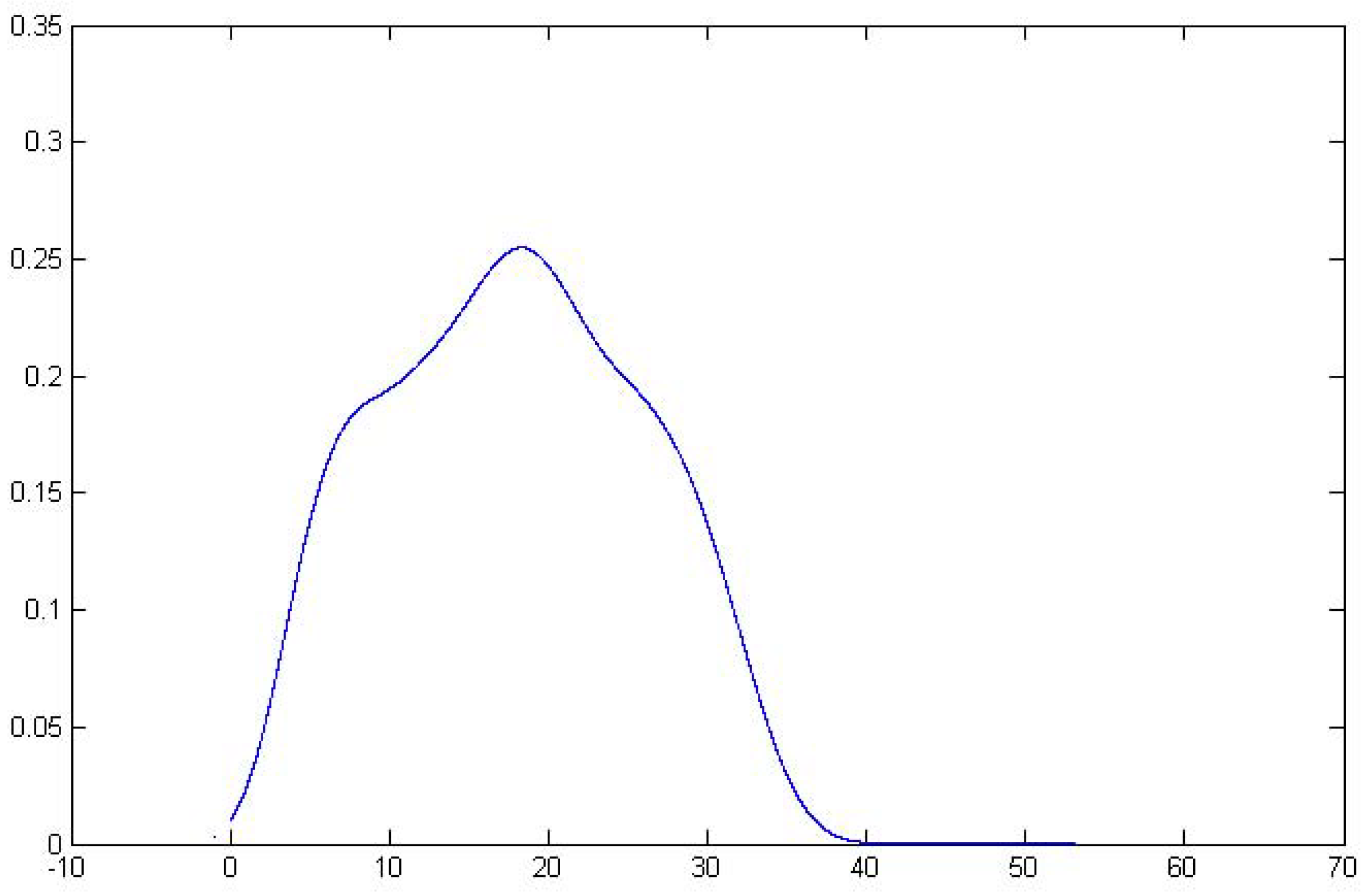
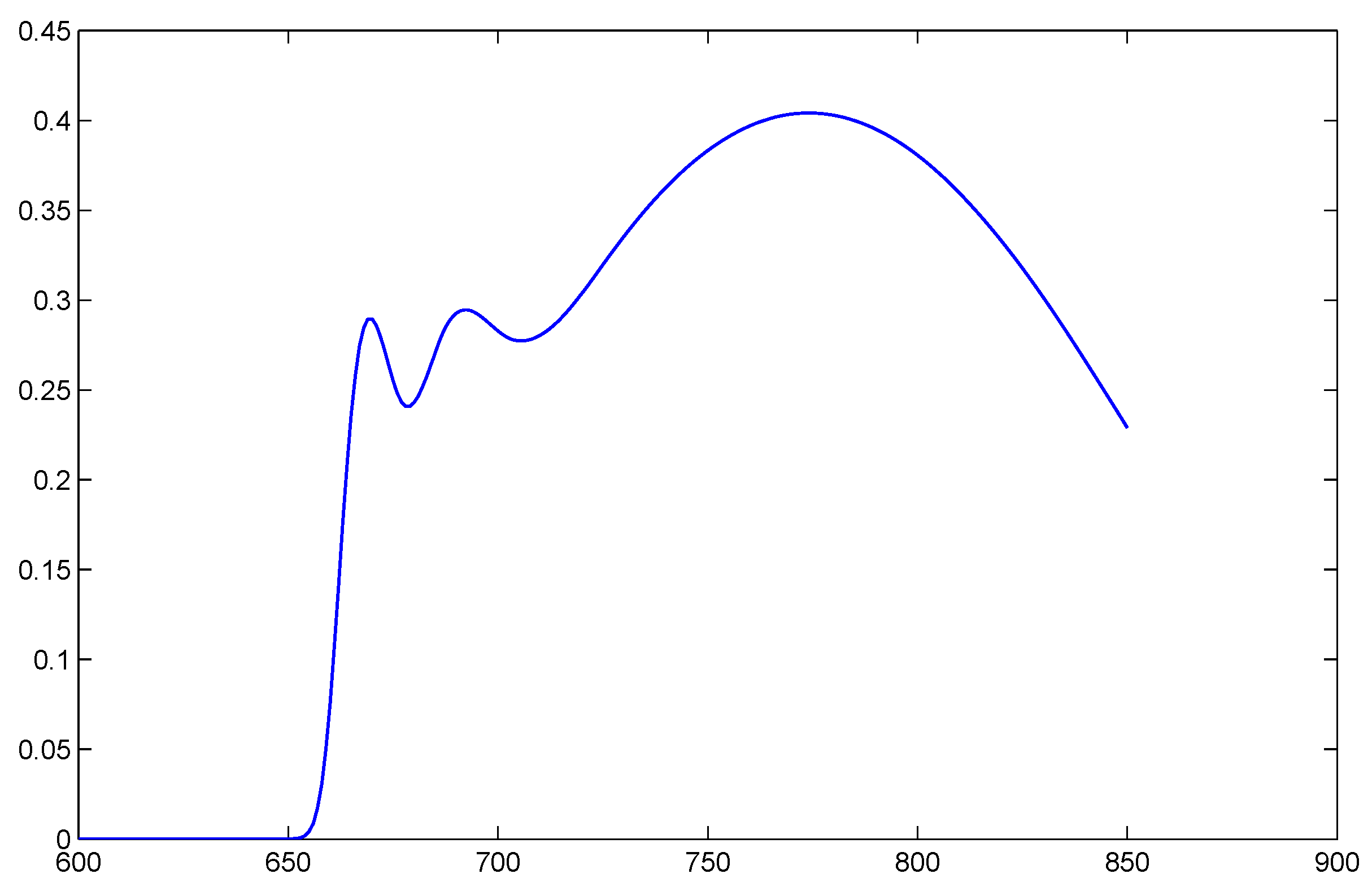
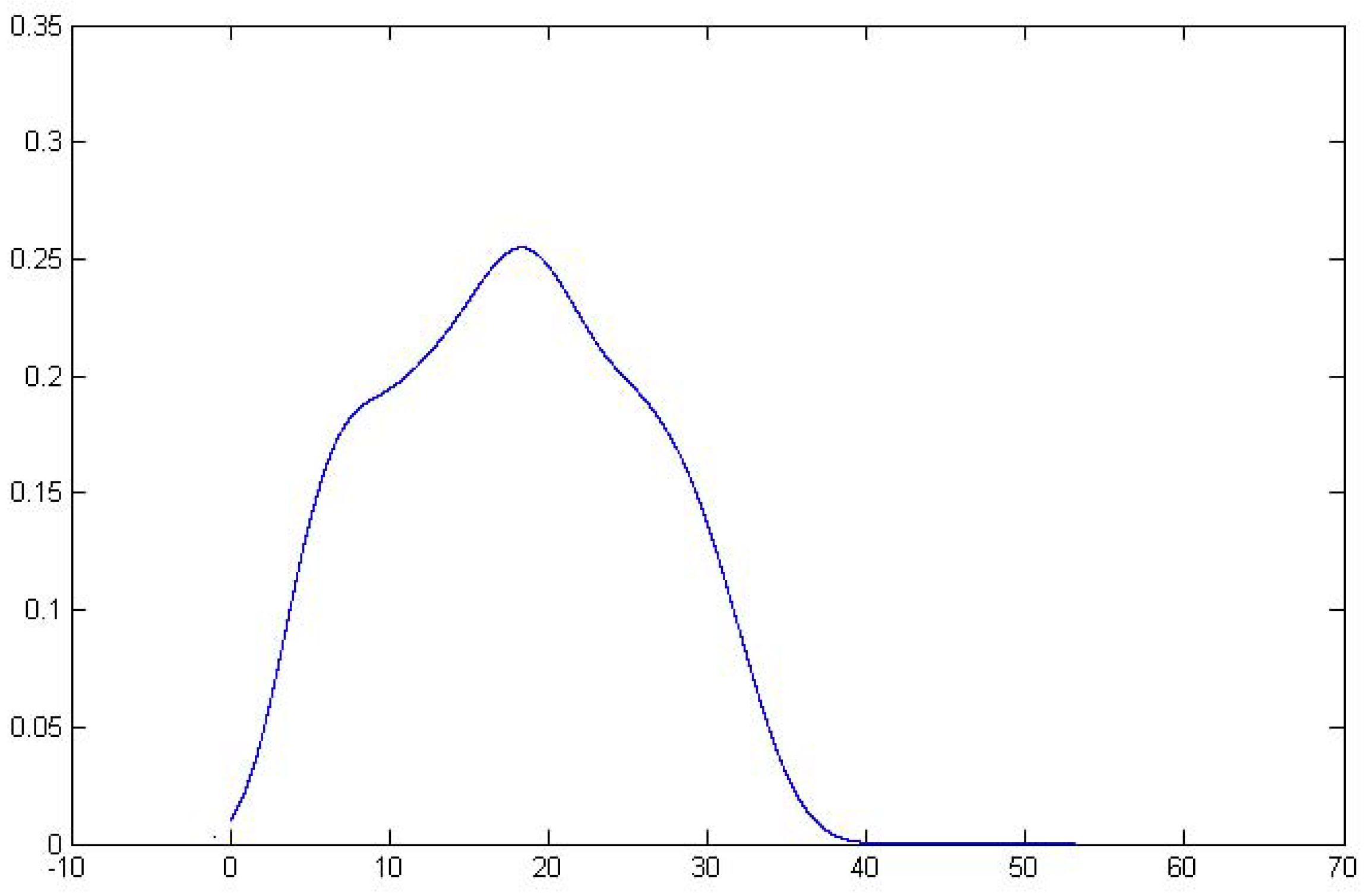
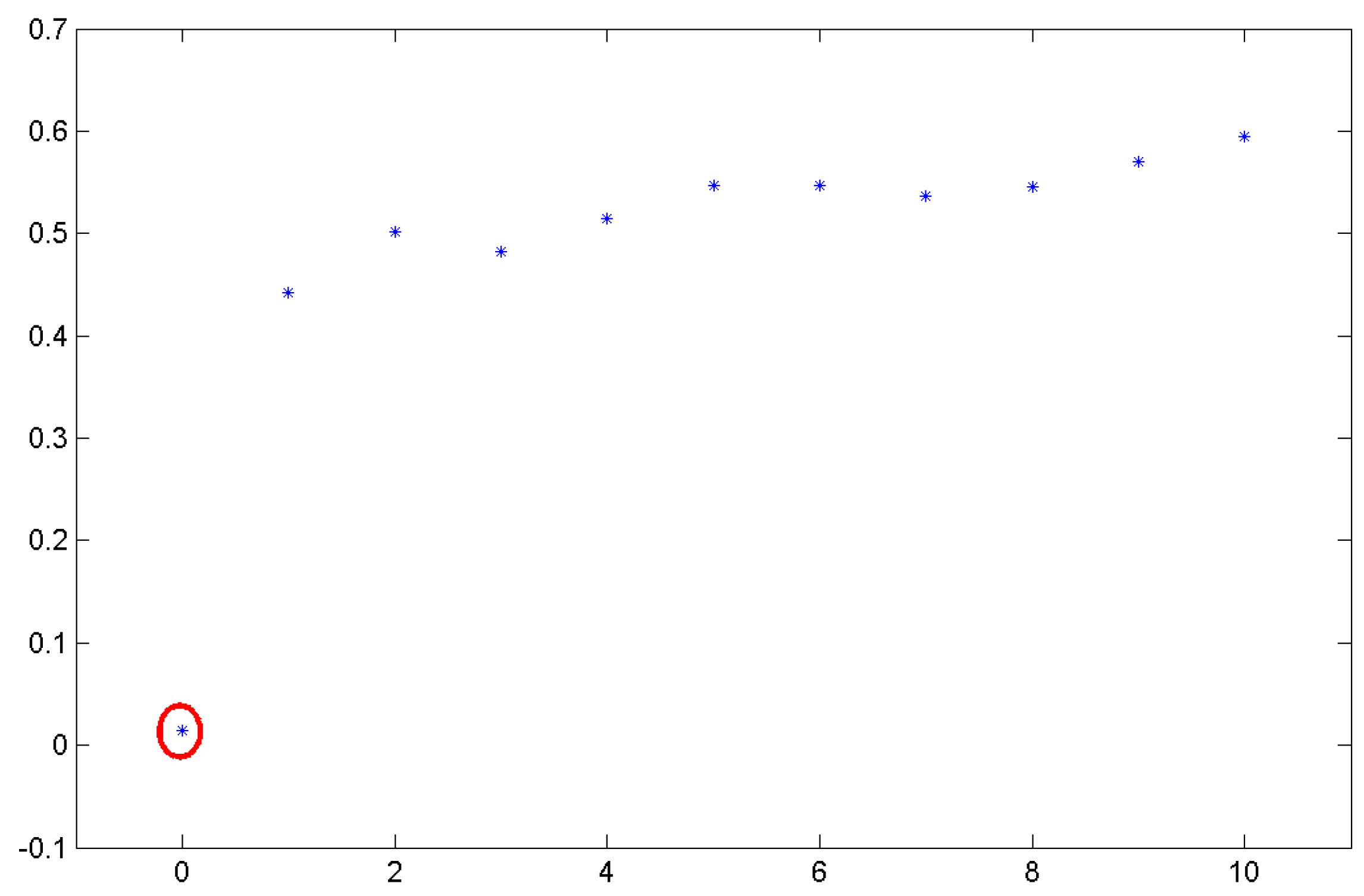
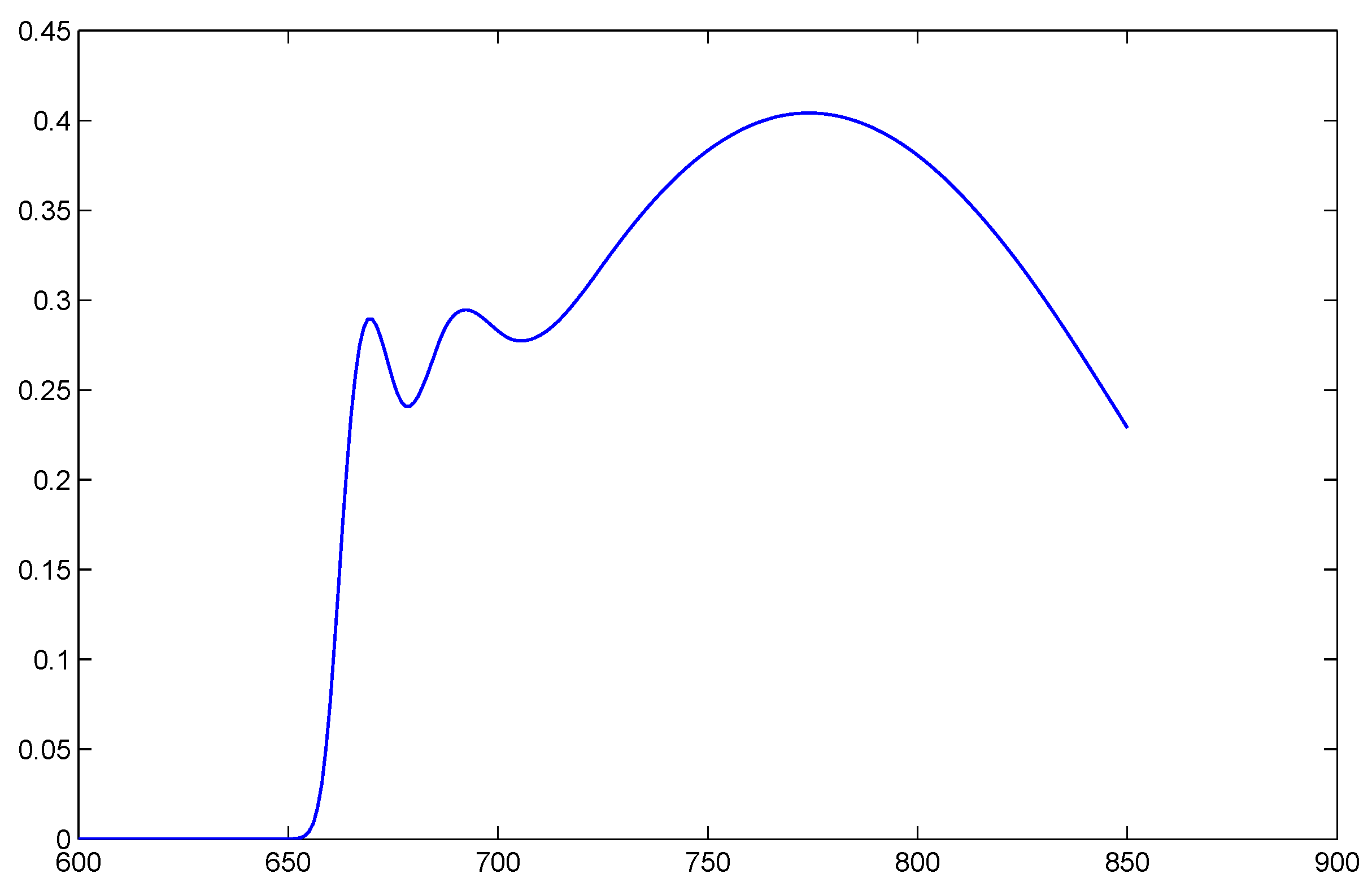
Spline Transformation of Features
4.3. Classification Results
4.3.1. In-Sample Evaluations
Model with One Feature: Debt-To-Income Ratio
Model with Two Features: Debt-To-Income Ratio and Employment Length
Model with 3 Features: Debt-to-Income Ratio, Employment Length, and Risk Score
4.3.2. Out-Of-Sample-Evaluations
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Portfolio Safeguard (PSG) Codes
Appendix A.1. PSG Code for Spline Generation
maximize
logexp_sum(spline_sum(matrix_par, matrix_DTI))
Appendix A.2. PSG Code for bPOE Minimization (Maximization of bAUC)
minimize
bPOE(0,L(matrix_F3_with_label1)-L(matrix_F3_with_label0))
constraint: = 3.0E+02
linear(matrix_plane)
Appendix A.3. PSG Code for Probability of Exceedance Minimization (Maximization of AUC)
minimize
pr_pen(0,L(matrix_F3_with_label1)-L(matrix_F3_with_label0))
constraint: = 3.0E+02
linear(matrix_plane)
Appendix A.4. PSG Text Code for Cross-Validation of Logistic Regression
for matrix_fact_in, matrix_fact_out, num = crossvalidation(4, matrix_allscenarios)
Problem: problem_num, maximize
logexp_sum(matrix_fact_in)
end for
References
- Ahlberg, J. Harold, Edwin Norman Nilson, and Joseph Leonard Walsh. 2016. The Theory of Splines and Their Applications: Mathematics in Science and Engineering: A Series of Monographs and Textbooks. Amsterdam: Elsevier, vol. 38. [Google Scholar]
- Aiolli, Fabio. 2014. Convex auc optimization for top-n recommendation with implicit feedback. Paper presented at the 8th ACM Conference on Recommender Systems, Foster City, CA, USA, October 6–10; pp. 293–296. [Google Scholar]
- Artzner, Philippe, Freddy Delbaen, Jean-Marc Eber, David Heath, and Hyejin Ku. 2002. Coherent multiperiod risk measurement. ETH, Preprint. [Google Scholar]
- Berger, Sven C., and Fabian Gleisner. 2009. Emergence of financial intermediaries in electronic markets: The case of online p2p lending. BuR Business Research 2: 39–65. [Google Scholar] [CrossRef]
- Bradley, Andrew P. 1997. The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognition 30: 1145–59. [Google Scholar] [CrossRef]
- Chen, Dongyu, Fujun Lai, and Zhangxi Lin. 2014. A trust model for online peer-to-peer lending: A lender’s perspective. Information Technology and Management 15: 239–54. [Google Scholar] [CrossRef]
- Collier, Benjamin C., and Robert Hampshire. 2010. Sending mixed signals: Multilevel reputation effects in peer-to-peer lending markets. Paper presented at the 2010 ACM Conference on Computer Supported Cooperative Work, Hangzhou, China, March 19–23; pp. 197–206. [Google Scholar]
- Davis, Justin R., and Stan Uryasev. 2016. Analysis of tropical storm damage using buffered probability of exceedance. Natural Hazards 83: 465–83. [Google Scholar] [CrossRef]
- Ding, Jie, Jinbo Huang, Yong Li, and Meichen Meng. 2018. Is there an effective reputation mechanism in peer-to-peer lending? Evidence from China. Finance Research Letters. [Google Scholar] [CrossRef]
- Doucette, John, and Malcolm I. Heywood. 2008. Gp classification under imbalanced data sets: Active sub-sampling and auc approximation. In European Conference on Genetic Programming. Berlin/Heidelberg: Springer, pp. 266–77. [Google Scholar]
- Einhorn, David, and Aaron Brown. 2008. Private profits and socialized risk. Global Association of Risk Professionals 42: 10–26. [Google Scholar]
- Emekter, Riza, Yanbin Tu, Benjamas Jirasakuldech, and Min Lu. 2015. Evaluating credit risk and loan performance in online peer-to-peer (p2p) lending. Applied Economics 47: 54–70. [Google Scholar] [CrossRef]
- Fawcett, Tom. 2006. An introduction to roc analysis. Pattern Recognition Letters 27: 861–74. [Google Scholar] [CrossRef]
- Freedman, David A. 2009. Statistical Models: Theory and Practice. Cambridge: Cambridge University Press. [Google Scholar]
- Habermann, Shelby J. 1979. Analysis of Qualitative Data: Introductory Topics. Cambridge: Academic Press. [Google Scholar]
- Hanley, James A., and Barbara J. McNeil. 1982. The meaning and use of the area under a receiver operating characteristic (roc) curve. Radiology 143: 29–36. [Google Scholar] [CrossRef] [PubMed]
- Hoblit, Frederic M. 1988. Gust Loads on Aircraft: Concepts and Applications. Reston: American Institute of Aeronautics and Astronautics. [Google Scholar]
- Hosmer, David W., Jr., Stanley Lemeshow, and Rodney X. Sturdivant. 2013. Applied Logistic Regression. Hoboken: John Wiley & Sons, vol. 398. [Google Scholar]
- Hulme, Michael K., and Collette Wright. 2006. Internet based social lending: Past, present and future. Social Futures Observatory 11: 1–115. [Google Scholar]
- Iyer, Rajkamal, Asim Ijaz Khwaja, Erzo FP Luttmer, and Kelly Shue. 2009. Screening in New Credit Markets: Can Individual Lenders Infer Borrower Creditworthiness in Peer-To-Peer Lending? Rochester: SSRN. [Google Scholar]
- Jiang, Cuiqing, Zhao Wang, Ruiya Wang, and Yong Ding. 2018. Loan default prediction by combining soft information extracted from descriptive text in online peer-to-peer lending. Annals of Operations Research 266: 511–29. [Google Scholar] [CrossRef]
- Lai, Linda S. L., and Efraim Turban. 2008. Groups formation and operations in the web 2.0 environment and social networks. Group Decision and Negotiation 17: 387–402. [Google Scholar] [CrossRef]
- Larsen, Nicklas, Helmut Mausser, and Stanislav Uryasev. 2002. Algorithms for optimization of value-at-risk. In Financial Engineering, E-Commerce and Supply Chain. Berlin/Heidelberg: Springer, pp. 19–46. [Google Scholar]
- Lending Academy. 2010. Available online: http://www.lendacademy.com/ (accessed on 1 November 2018).
- LendingClub. 2006. Available online: https://www.lendingclub.com/ (accessed on 1 November 2018).
- Lin, Mingfeng. 2009. Peer-to-peer lending: An empirical study. AMCIS 2009 Doctoral Consortium 17: 1–7. [Google Scholar]
- Lin, Mingfeng, Nagpurnanand R. Prabhala, and Siva Viswanathan. 2013. Judging borrowers by the company they keep: Friendship networks and information asymmetry in online peer-to-peer lending. Management Science 59: 17–35. [Google Scholar] [CrossRef]
- Ma, Ben-jiang, Zheng-long Zhou, and Feng-ying Hu. 2017. Pricing mechanisms in the online peer-to-peer lending market. Electronic Commerce Research and Applications 26: 119–30. [Google Scholar] [CrossRef]
- Mafusalov, Alexander, Alexander Shapiro, and Stan Uryasev. 2018. Estimation and asymptotics for buffered probability of exceedance. European Journal of Operational Research 270: 826–36. [Google Scholar] [CrossRef]
- Mafusalov, Alexander, and Stan Uryasev. 2018. Buffered probability of exceedance: Mathematical properties and optimization. SIAM Journal on Optimization 28: 1077–103. [Google Scholar] [CrossRef]
- Mi, Jackson J., Tianxiao Hu, and Luke Deer. 2018. User data can tell defaulters in p2p lending. Annals of Data Science 5: 59–67. [Google Scholar] [CrossRef]
- Miura, Kakeru, Satoshi Yamashita, and Shinto Eguchi. 2010. Area under the curve maximization method in credit scoring. The Journal of Risk Model Validation 4: 3. [Google Scholar] [CrossRef]
- Norton, Matthew, Alexander Mafusalov, and Stan Uryasev. 2017. Soft margin support vector classification as buffered probability minimization. The Journal of Machine Learning Research 18: 2285–327. [Google Scholar]
- Norton, Matthew, and Stan Uryasev. 2016. Maximization of auc and buffered auc in binary classification. Mathematical Programming, 1–38. [Google Scholar] [CrossRef]
- Puro, Lauri, Jeffrey E. Teich, Hannele Wallenius, and Jyrki Wallenius. 2010. Borrower decision aid for people-to-people lending. Decision Support Systems 49: 52–60. [Google Scholar] [CrossRef]
- Rockafellar, Ralph Tyrrell, and Johannes O. Royset. 2018. Superquantile/cvar risk measures: Second-order theory. Annals of Operations Research 262: 3–28. [Google Scholar] [CrossRef]
- Rockafellar, Ralph Tyrrell, and Stanislav Uryasev. 2000. Optimization of conditional value-at-risk. Journal of Risk 2: 21–42. [Google Scholar] [CrossRef]
- Shang, Danjue, Victor Kuzmenko, and Stan Uryasev. 2018. Cash flow matching with risks controlled by buffered probability of exceedance and conditional value-at-risk. Annals of Operations Research 260: 501–14. [Google Scholar] [CrossRef]
- Smith, Andrew M. 1999. Sec cease-and-desist orders. Administrative Law Review 51: 1197. [Google Scholar]
- Tsai, Kevin, Sivagami Ramiah, and Sudhanshu Singh. 2014. Peer Lending Risk Predictor. Stanford University CS229. Stanford: Stanford University. [Google Scholar]
- Tukey, John W. 1977. Exploratory Data Analysis. Reading: Sage, vol. 2. [Google Scholar]
- Wang, Hui, Martina Greiner, and Jay E Aronson. 2009. People-to-people lending: The emerging e-commerce transformation of a financial market. In Value Creation in E-Business Management. Berlin/Heidelberg: Springer, pp. 182–95. [Google Scholar]
- Wu, Jinghua, and Yun Xu. 2011. A decision support system for borrower’s loan in p2p lending. JCP 6: 1183–90. [Google Scholar] [CrossRef]
- Yu, Haihong, MengHan Dan, Qingguo Ma, and Jia Jin. 2018. They all do it, will you? Event-related potential evidence of herding behavior in online peer-to-peer lending. Neuroscience Letters 681: 1–5. [Google Scholar] [CrossRef] [PubMed]
| 1 | Portfolio Safeguard (PSG), http://www.aorda.com. |
| 2 | ZOPA, http://www.zopa.com/. |
| 3 | PROSPER Marketplace, https://www.prosper.com/. |
| 4 | LendingClub, https://www.lendingclub.com/. |
| 5 | |
| 6 | |
| 7 | Logistics regression likelihood for one dimensional spline is defined in “Example 3. Logarithms Exponents Sum”: http://www.aorda.com/html/PSG_Help_HTML/index.html?risk_function_argument.htm. |
| 8 | The essential supremum of the random value X is the smallest number a such that probability of the set equals zero. |
| 9 | The case study presented in this section (data, codes, and calculation results) is posted at this link http://www.ise.ufl.edu/uryasev/research/testproblems/financial_engineering/%20classification-in-loan-application-process%20/. |
| 10 | In some of the sets, this column is Notes Offered by Prospectus, and in others it is Loan Title. |
| 11 | In MATLAB, ROC is the area between the ROC curve and the random classifier slope; link to MATLAB documentation: https://www.mathworks.com/help/bioinfo/ref/rankfeatures.html?searchHighlight=Rankfeatures&s_tid=doc_srchtitle. |
| 12 | Data, codes, and calculation results in Text, MATLAB, and R environments. Logistic regression with untransformed features (PROBLEM 0); logistic regression with spline transformed features (PROBLEM 2); maximization of bAUC (PROBLEM 3); maximization of AUC (PROBLEM 4), see link http://www.ise.ufl.edu/uryasev/research/testproblems/financial_engineering/%20classification-in-loan-application-process%20/. |
| 13 | “PROBLEM 4” contains codes for generation of data and solving four-cross validation logistic regression problems in Text, MATLAB, and R environments: http://www.ise.ufl.edu/uryasev/research/testproblems/advanced-statistics/case-sudy-logistic-regression-and-regularized-logistics-regression-applied-to-estimating-the-probability-of-cesarean-section/. |
| 14 | “PROBLEM 1: problem_Logexp_Sum” contains codes and data for spline transformation in Text, MATLAB and R environments: http://www.ise.ufl.edu/uryasev/research/testproblems/financial_engineering/%20classification-in-loanapplication-process%20/. |
| 15 | “PROBLEM 4” contains codes for generation of data and solving four-cross validation logistic regression problems in Text, MATLAB, and R environments: http://www.ise.ufl.edu/uryasev/research/testproblems/advanced-statistics/case-sudylogistic-regression-and-regularized-logistics-regression-applied-to-estimating-the-probability-of-cesarean-section/. |


{kind=link}
{kind=link}
{kind=link}
| Ranking | Feature |
|---|---|
| 1 | Debt-To-Income Ratio |
| 2 | Employment Length |
| 3 | Risk Score |
| 4 | Amount Requested |
| Year | Logistic Regression without Feature Transformation | Logistic Regression | bAUC Maximization | AUC Maximization |
|---|---|---|---|---|
| 2012 | 0.535968 | 0.665422 | 0.725245 | 0.725259 |
| 2013 | 0.545397 | 0.729693 | 0.729692 | 0.729707 |
| 2014 | 0.538125 | 0.724710 | 0.724709 | 0.724711 |
| Year | Logistic Regression without Feature Transformation | Logistic Regression | bAUC Maximization | AUC Maximization |
|---|---|---|---|---|
| 2012 | 0.905332 | 0.932214 | 0.932377 | 0.932436 |
| 2013 | 0.907454 | 0.934874 | 0.935178 | 0.935191 |
| 2014 | 0.942253 | 0.973168 | 0.973479 | 0.973494 |
| Year | Logistic Regression without Feature Transformation | Logistic Regression | bAUC Maximization | AUC Maximization |
|---|---|---|---|---|
| 2012 | 0.931074 | 0.954391 | 0.954673 | 0.954727 |
| 2013 | 0.934141 | 0.960136 | 0.960204 | 0.960204 |
| 2014 | 0.937744 | 0.982057 | 0.982079 | 0.982097 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Gotoh, J.-y.; Uryasev, S. Peer-To-Peer Lending: Classification in the Loan Application Process. Risks 2018, 6, 129. https://doi.org/10.3390/risks6040129
Wei X, Gotoh J-y, Uryasev S. Peer-To-Peer Lending: Classification in the Loan Application Process. Risks. 2018; 6(4):129. https://doi.org/10.3390/risks6040129
Chicago/Turabian StyleWei, Xinyuan, Jun-ya Gotoh, and Stan Uryasev. 2018. "Peer-To-Peer Lending: Classification in the Loan Application Process" Risks 6, no. 4: 129. https://doi.org/10.3390/risks6040129
APA StyleWei, X., Gotoh, J.-y., & Uryasev, S. (2018). Peer-To-Peer Lending: Classification in the Loan Application Process. Risks, 6(4), 129. https://doi.org/10.3390/risks6040129