Evaluation of the Kou-Modified Lee-Carter Model in Mortality Forecasting: Evidence from French Male Mortality Data

Abstract
1. Introduction
2. The Model Specification
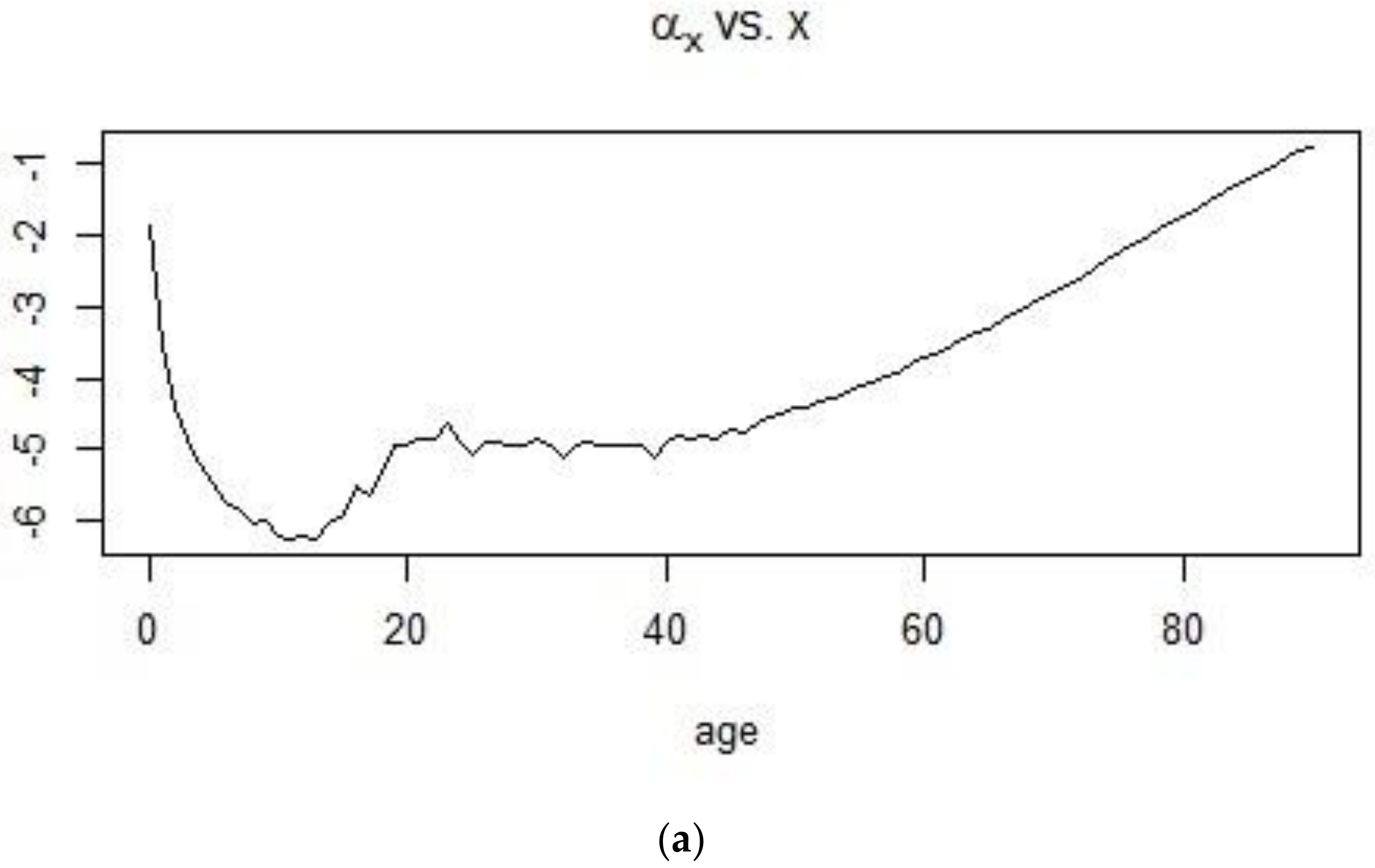
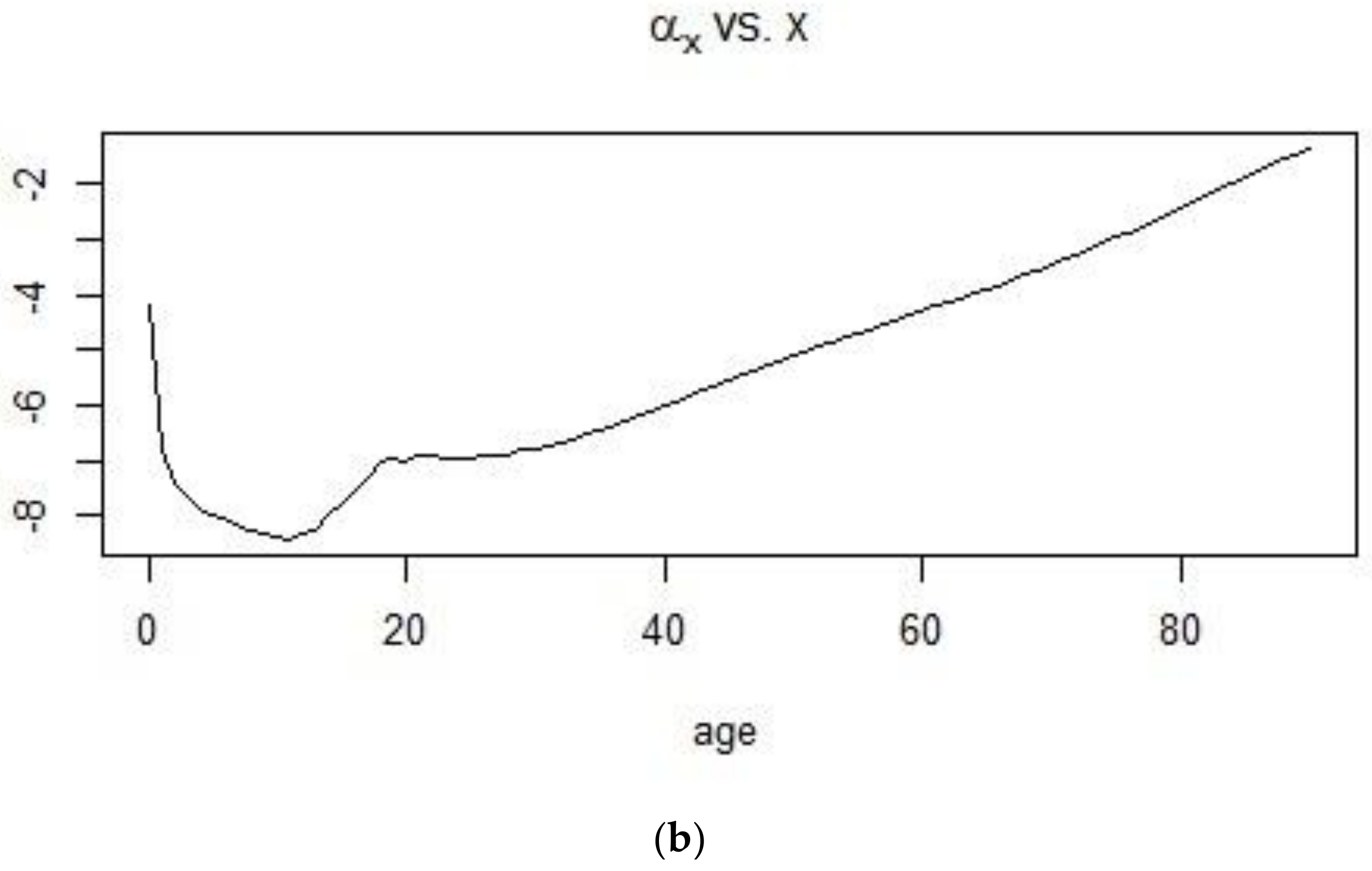
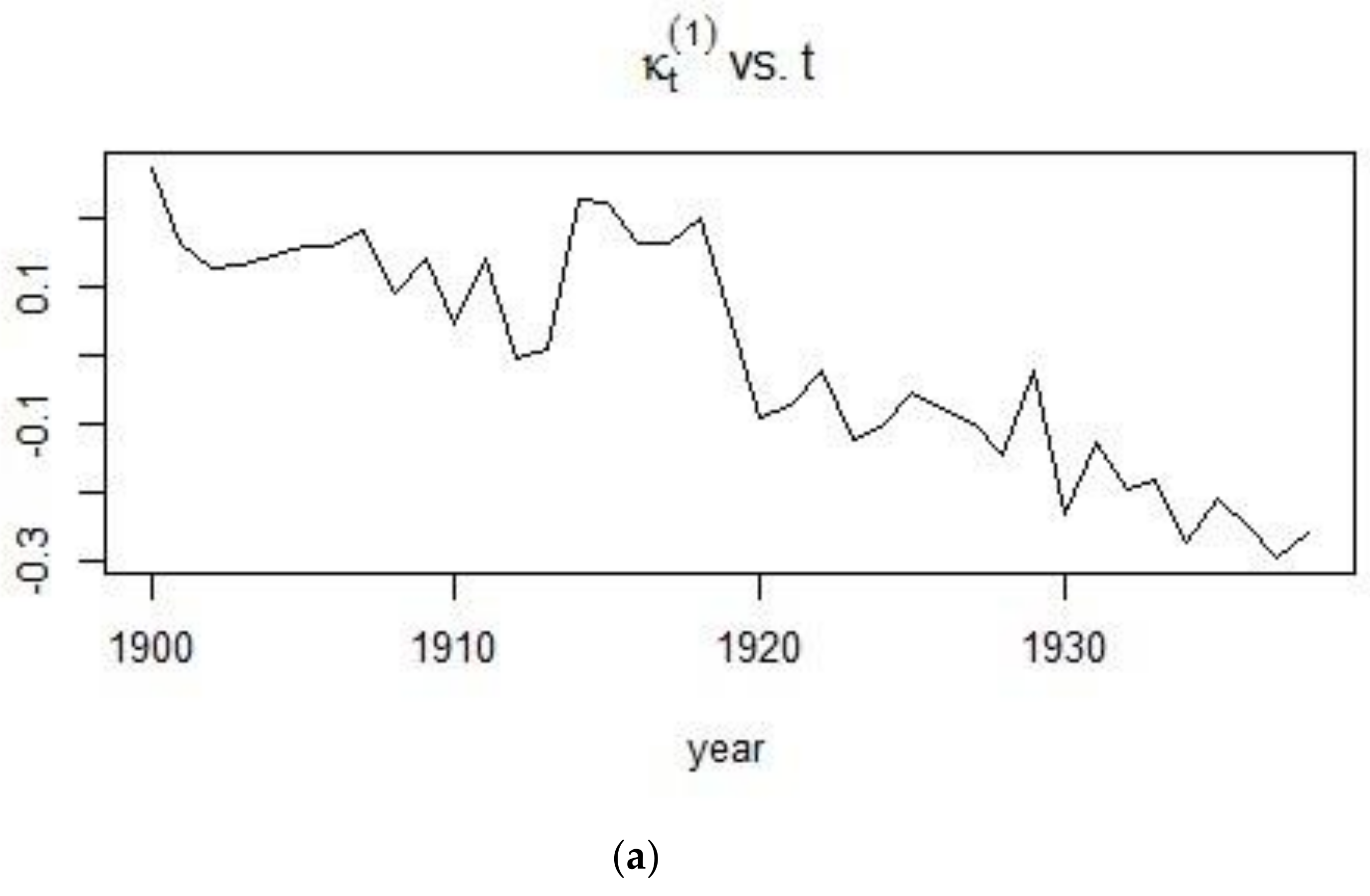
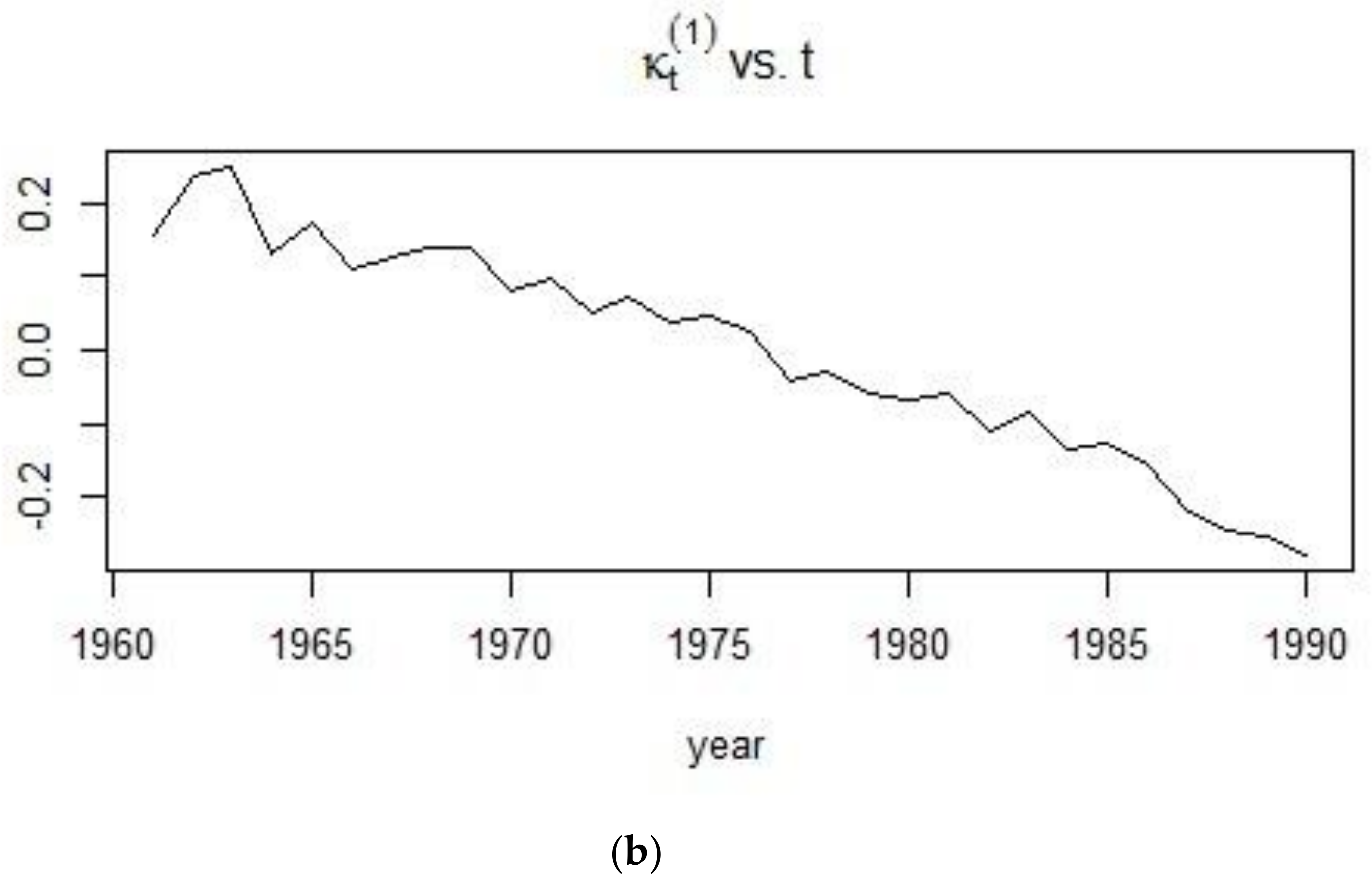
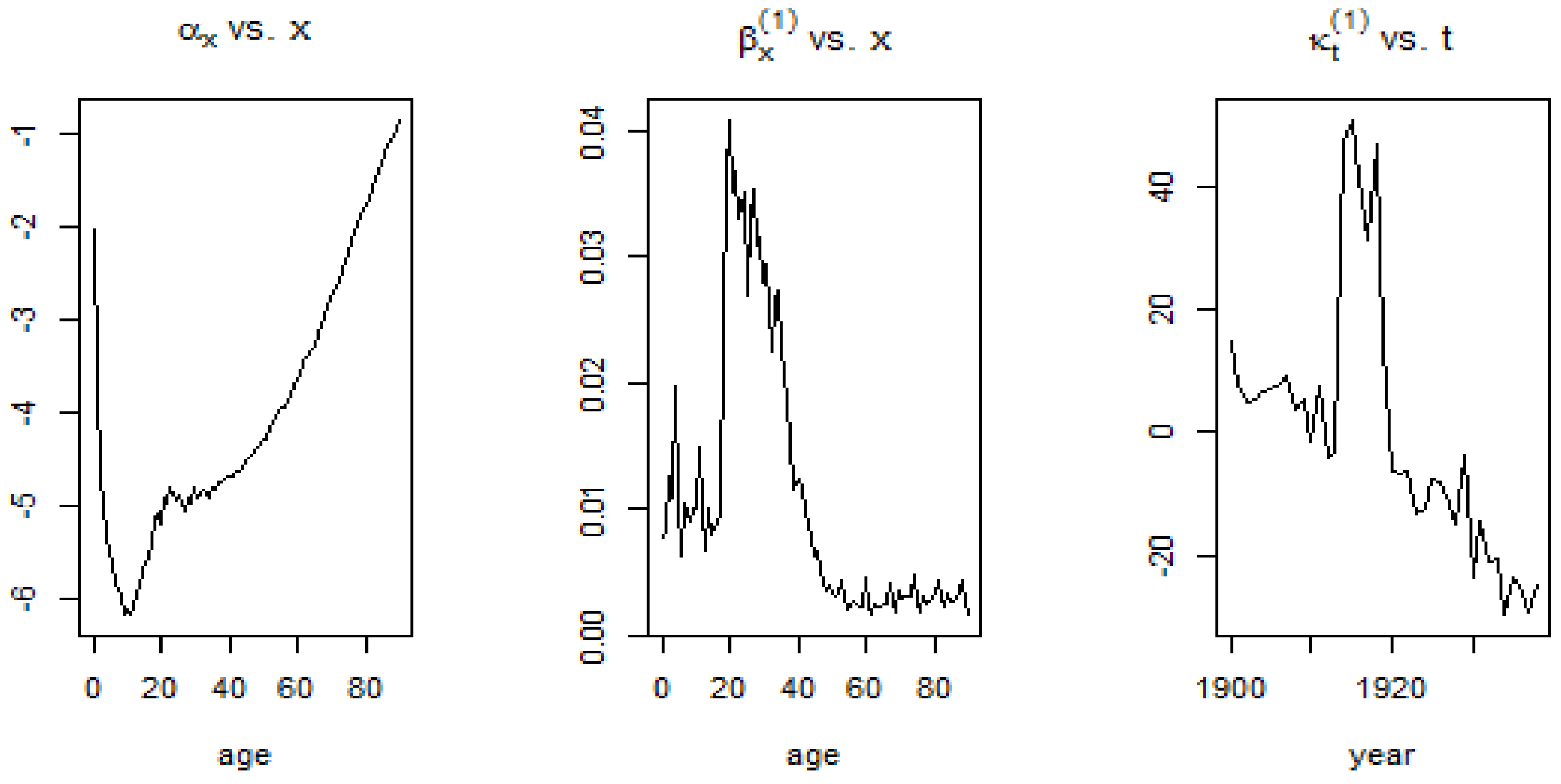
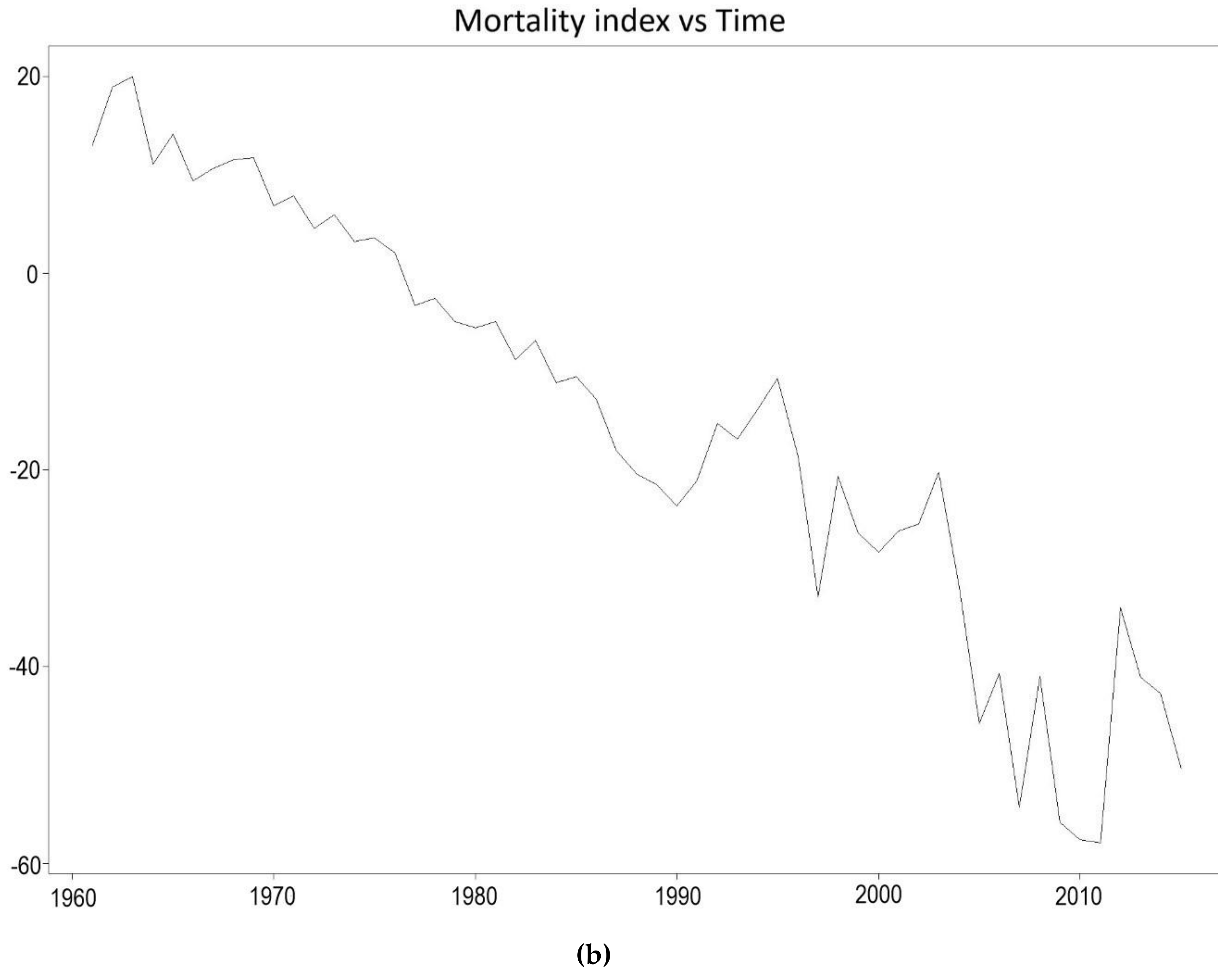
2.1. The Lee-Carter Model
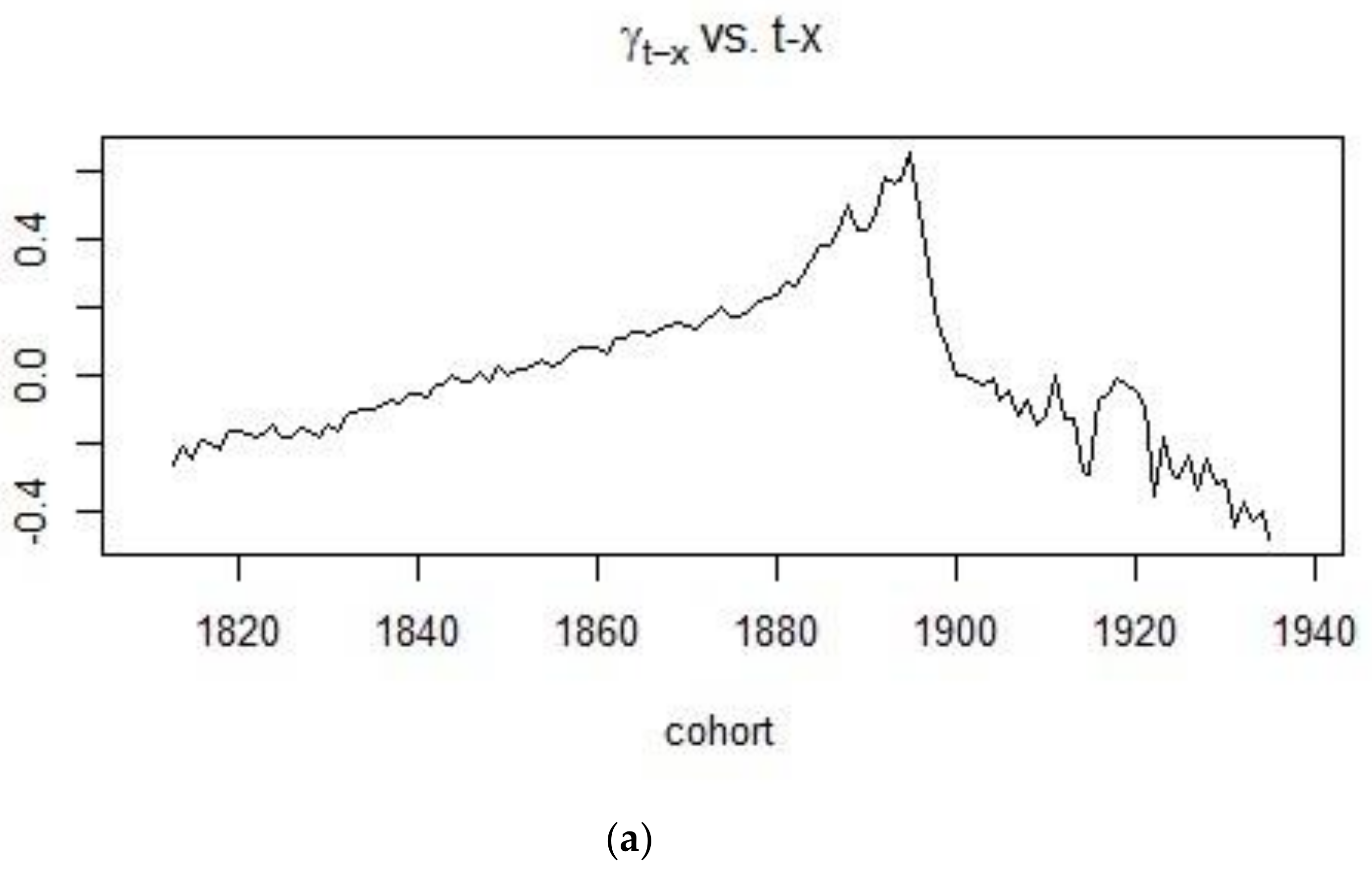
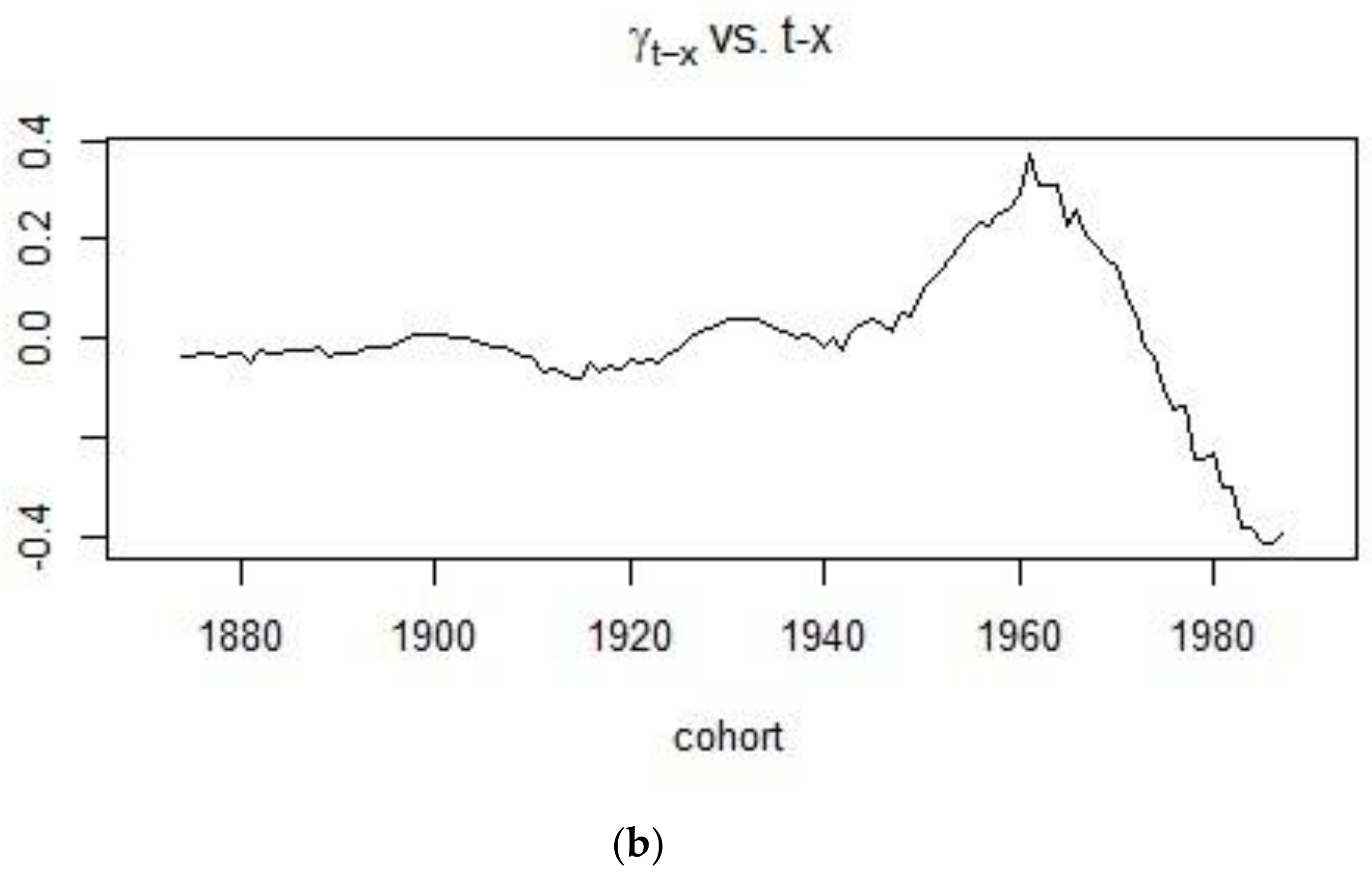
2.2. The Age-Period-Cohort Model
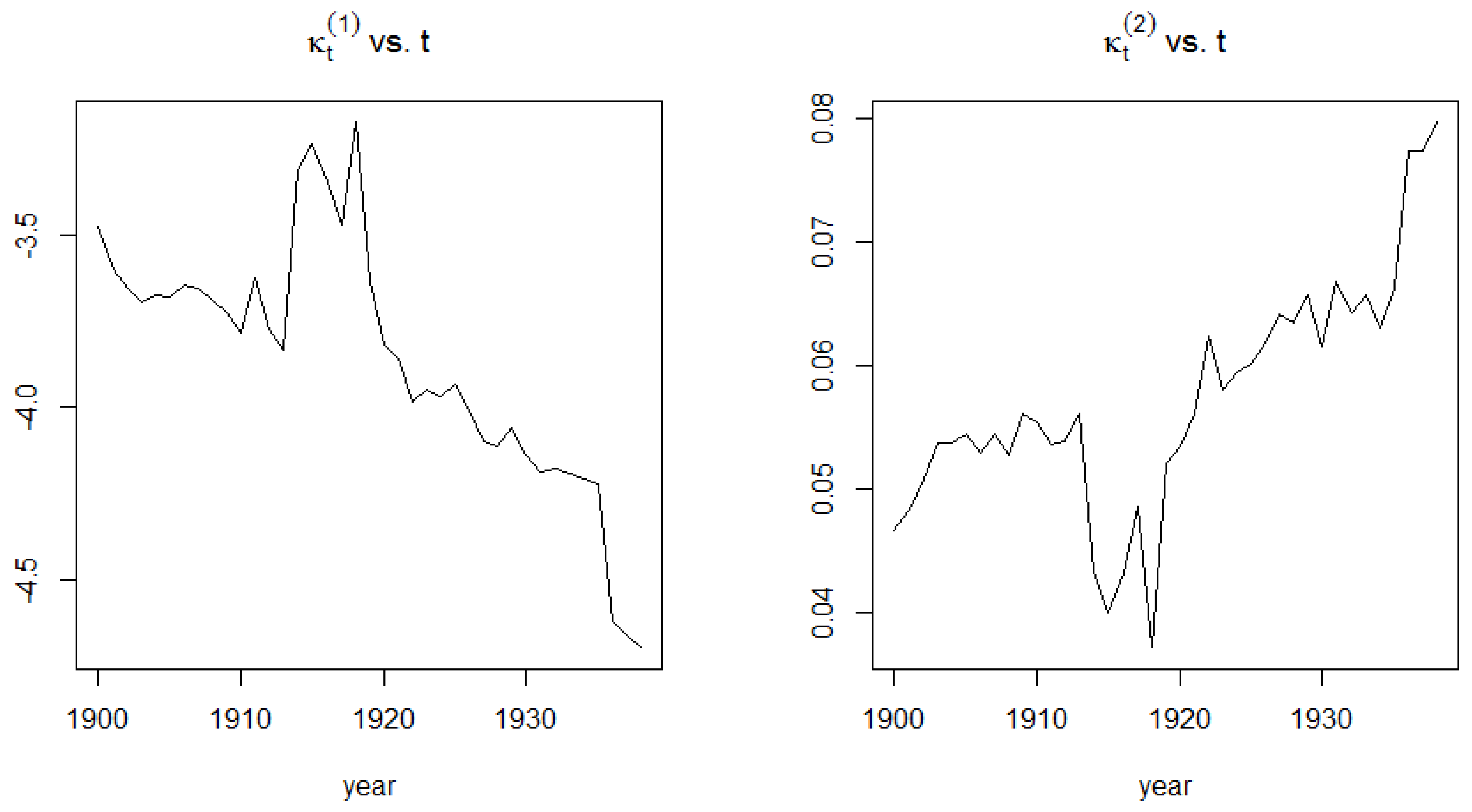
2.3. The Cairns-Blake-Dowd Model
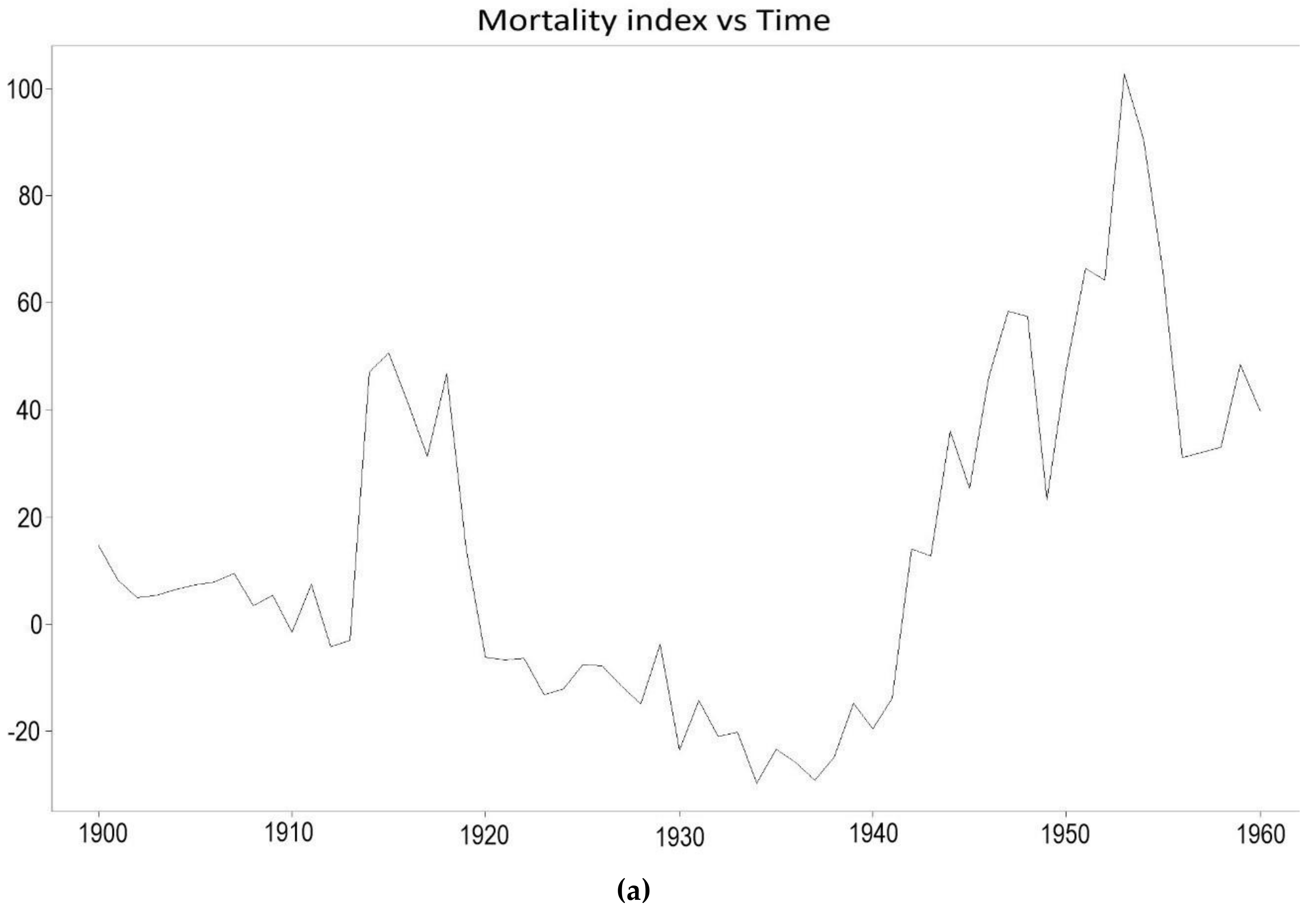
2.4. The Kou-Modified Lee-Carter Model
2.4.1. Equivalence of the PBJD Model and DEJD Process
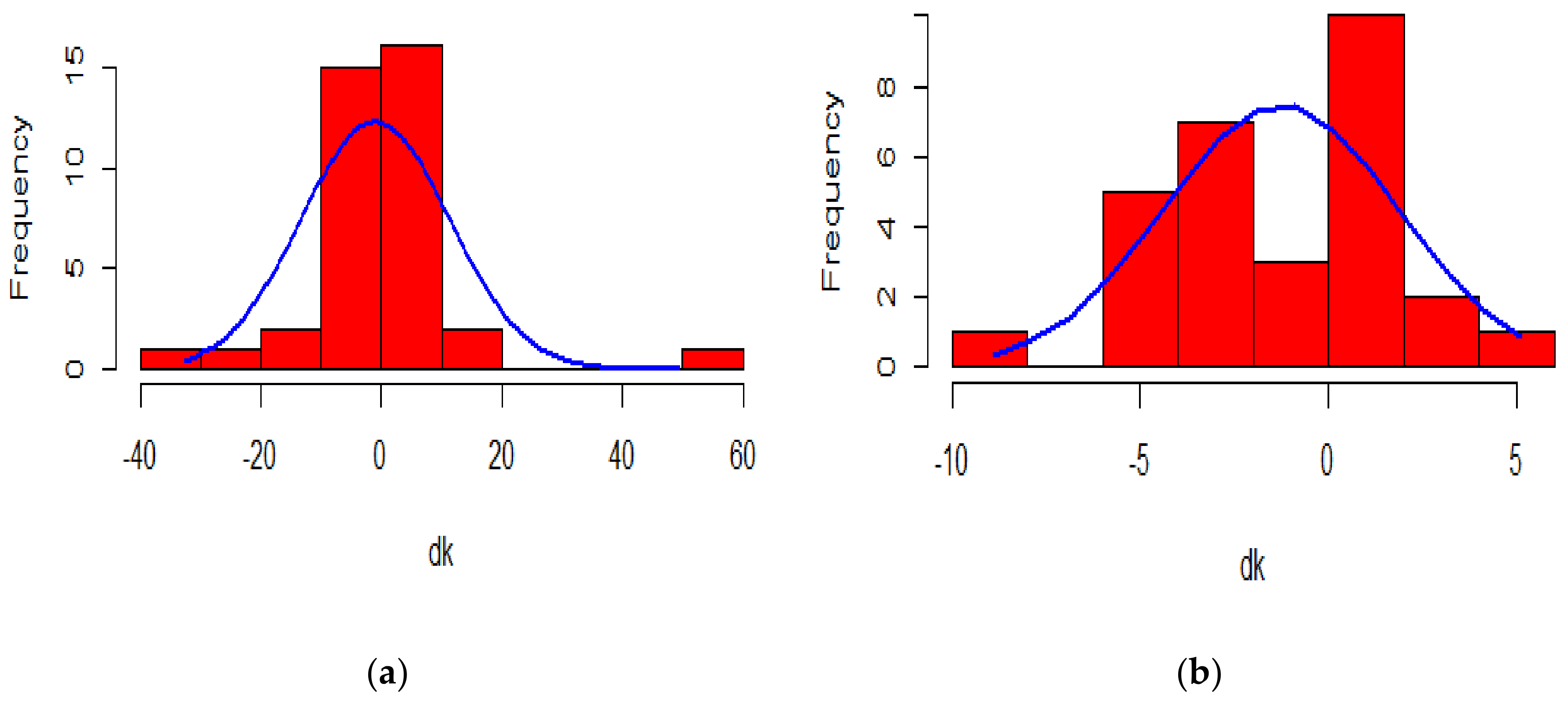
2.4.2. Parameter Estimation
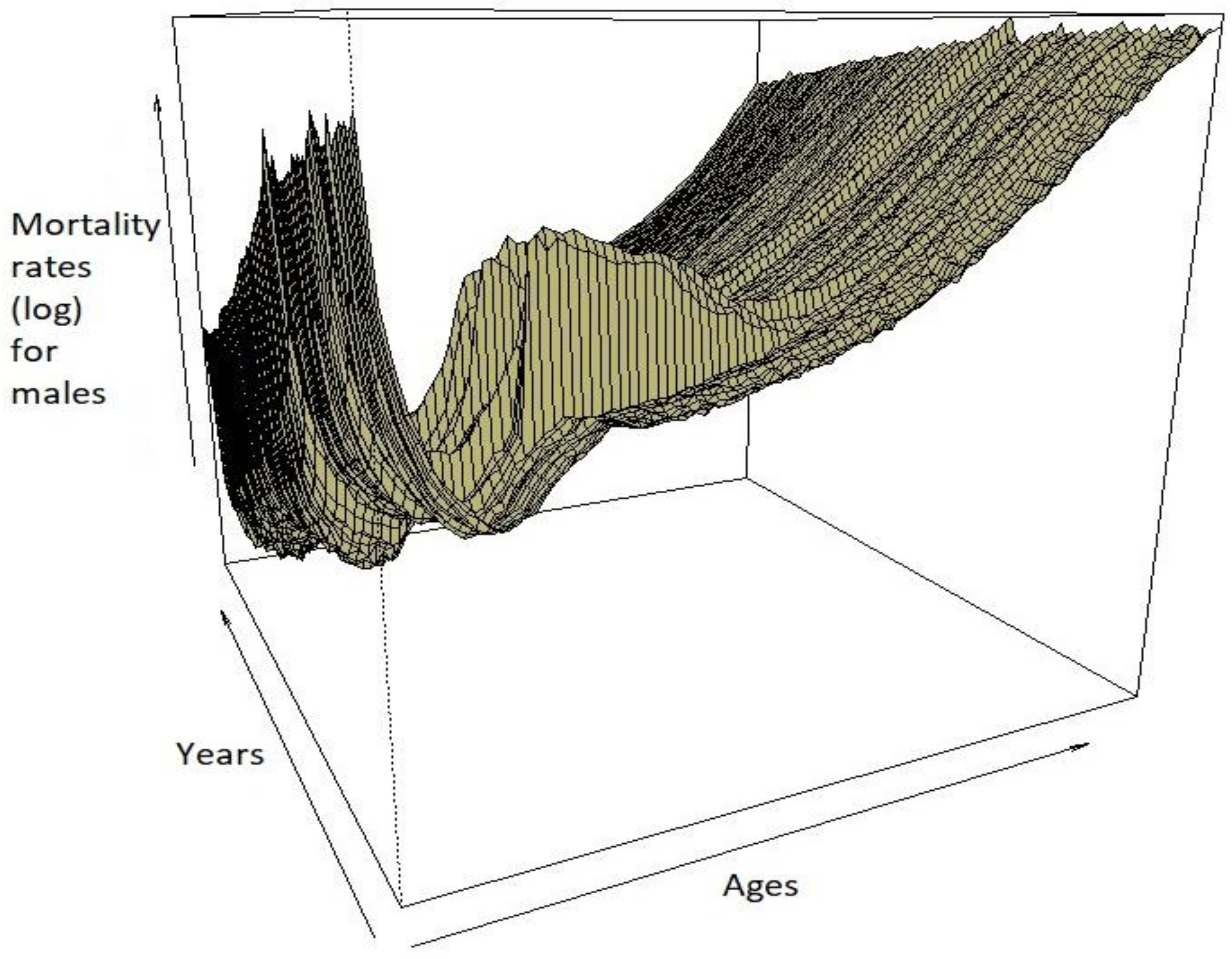
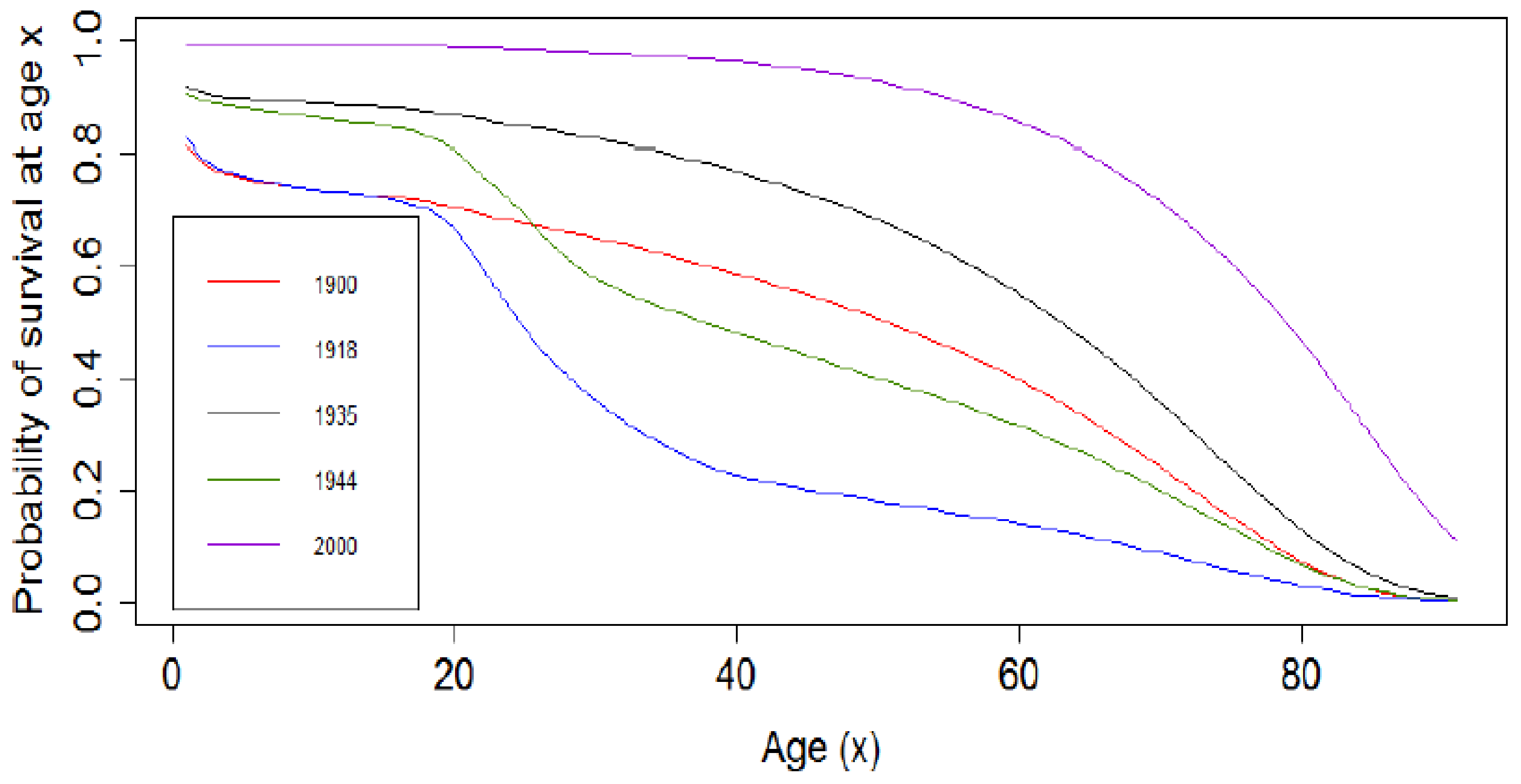
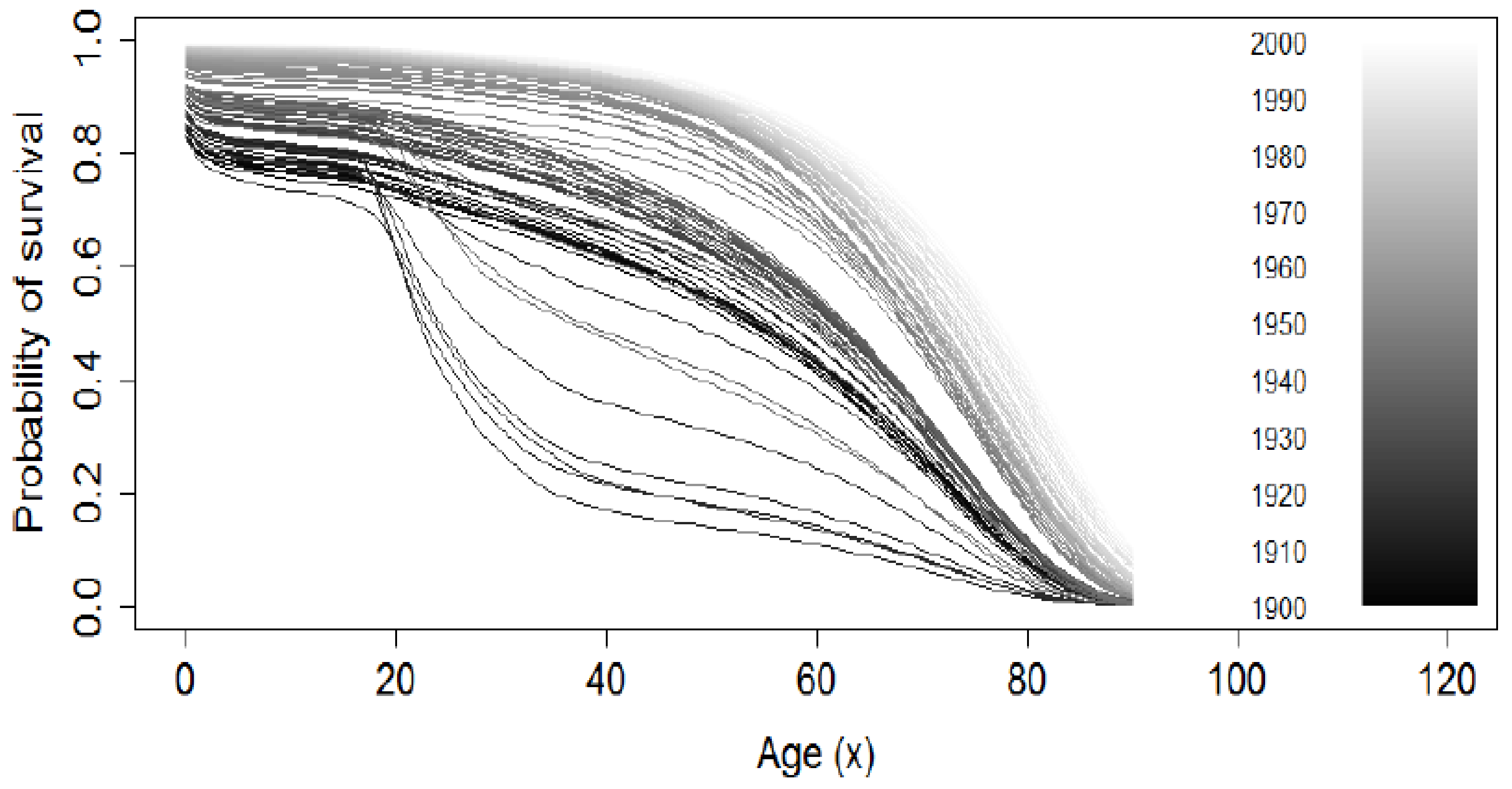
3. Mortality Data
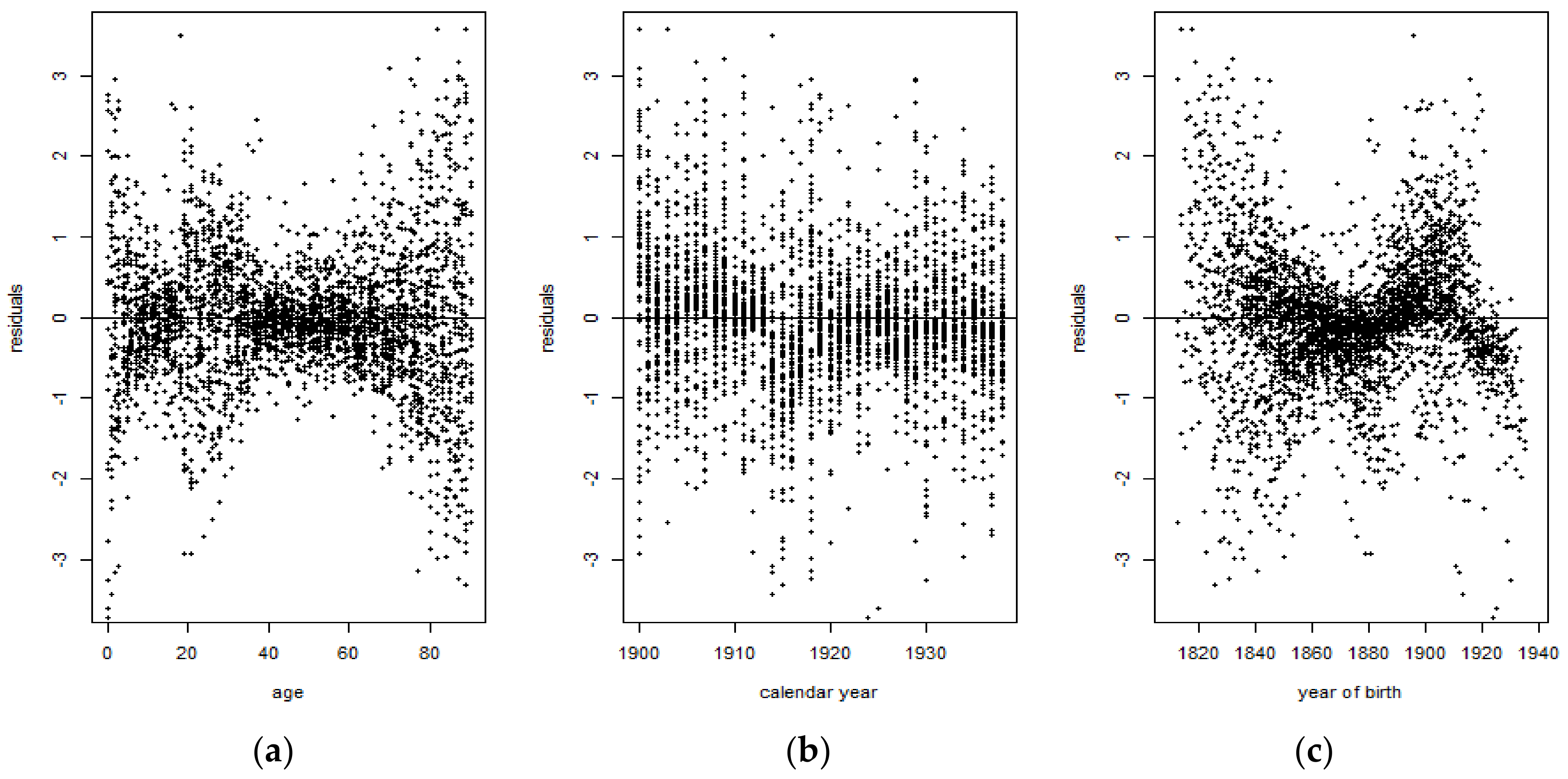
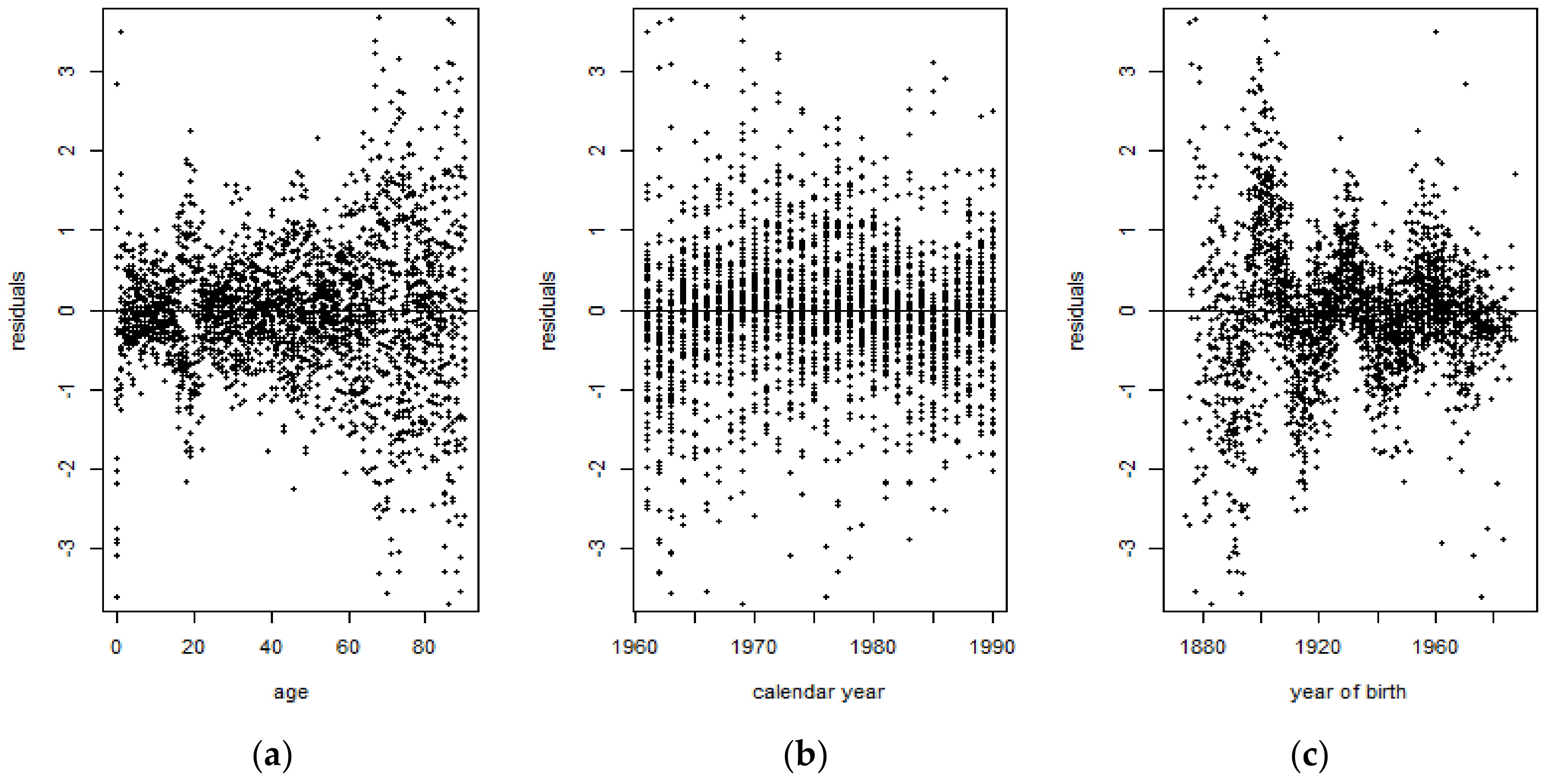
3.1. Data Analysis
3.2. The Backtesting Procedure
4. Application of the Models
4.1. Application of the APC Model
4.2. Application of the CBD Model
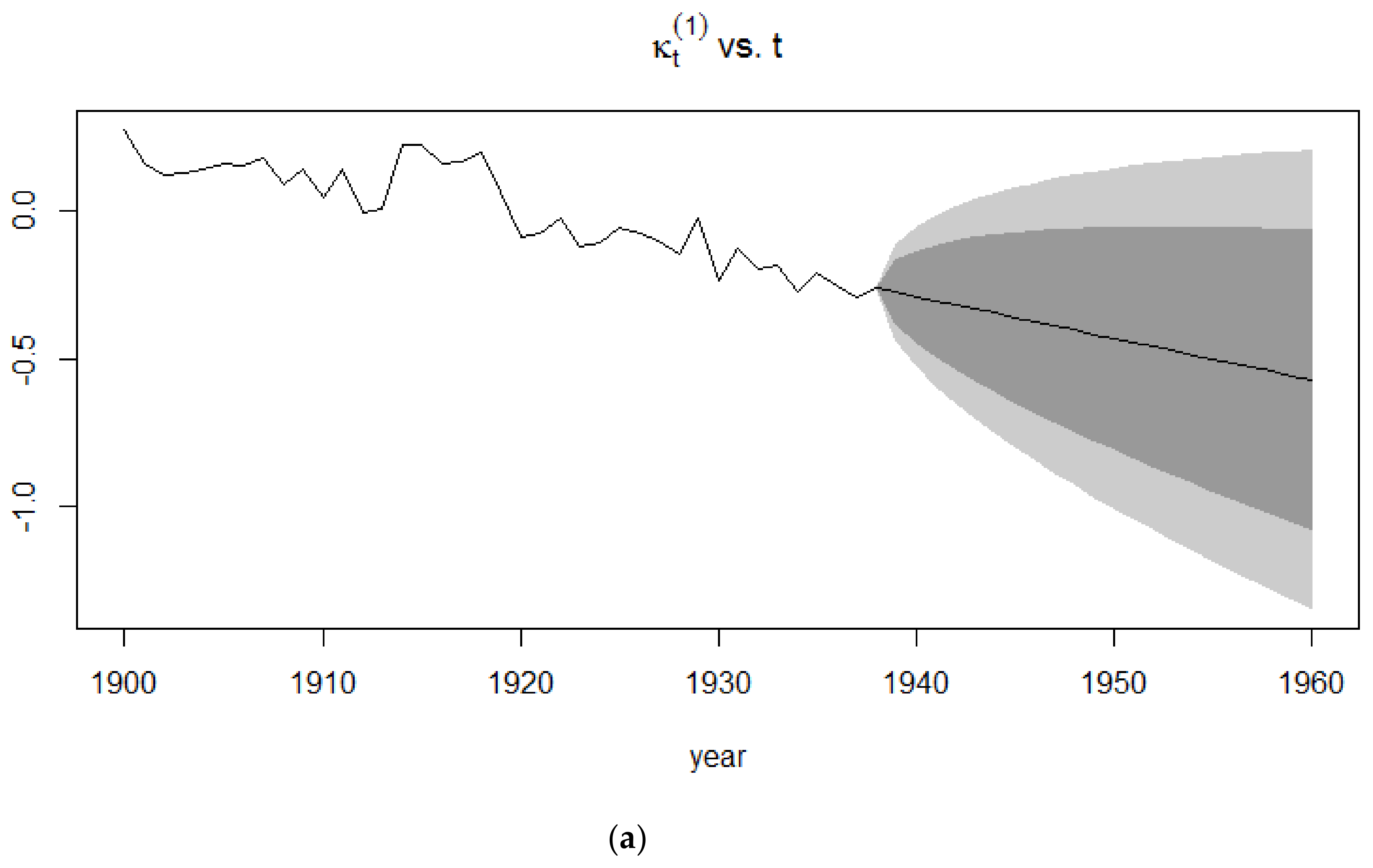
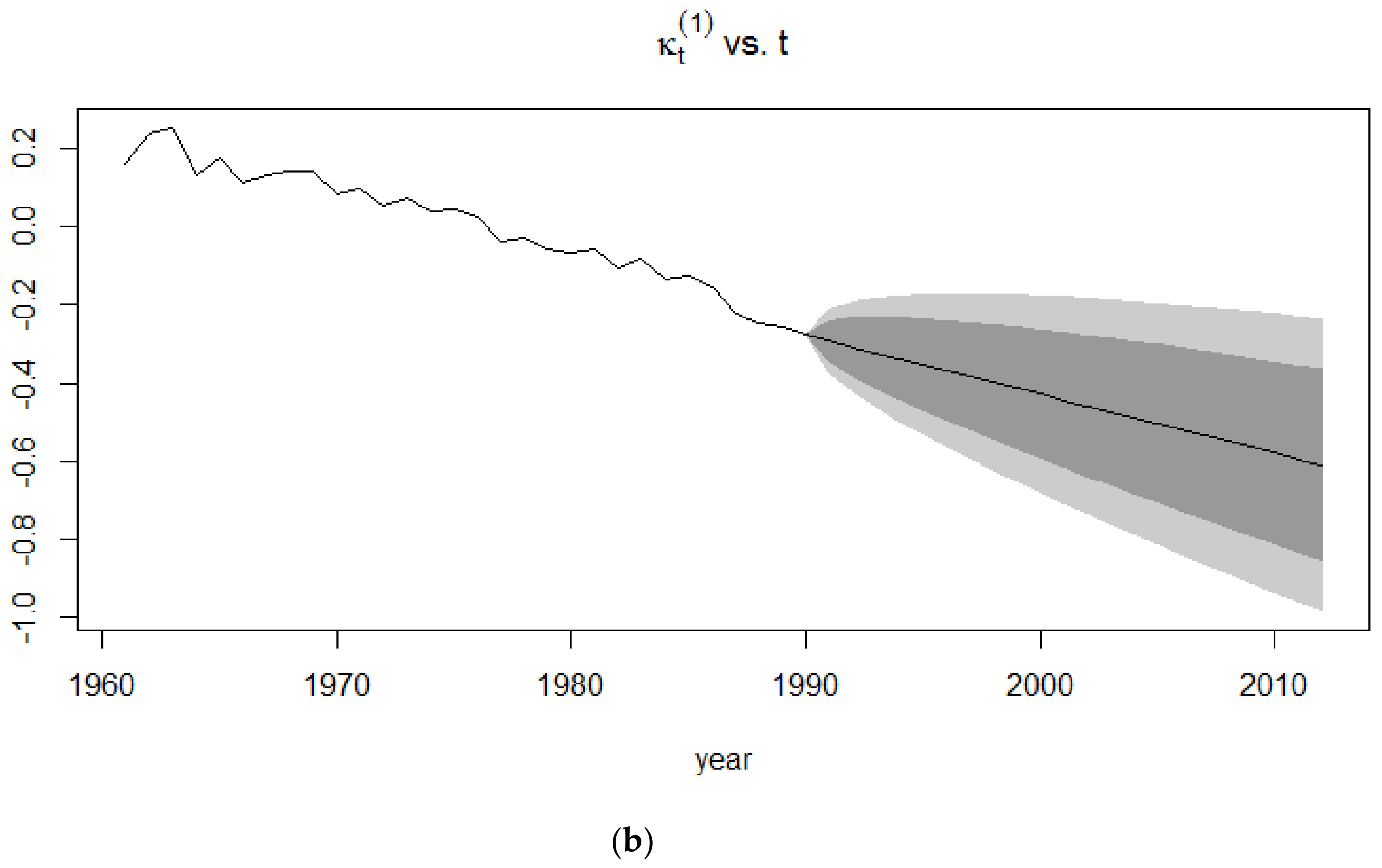
4.3. Application of the Lee-Carter Model
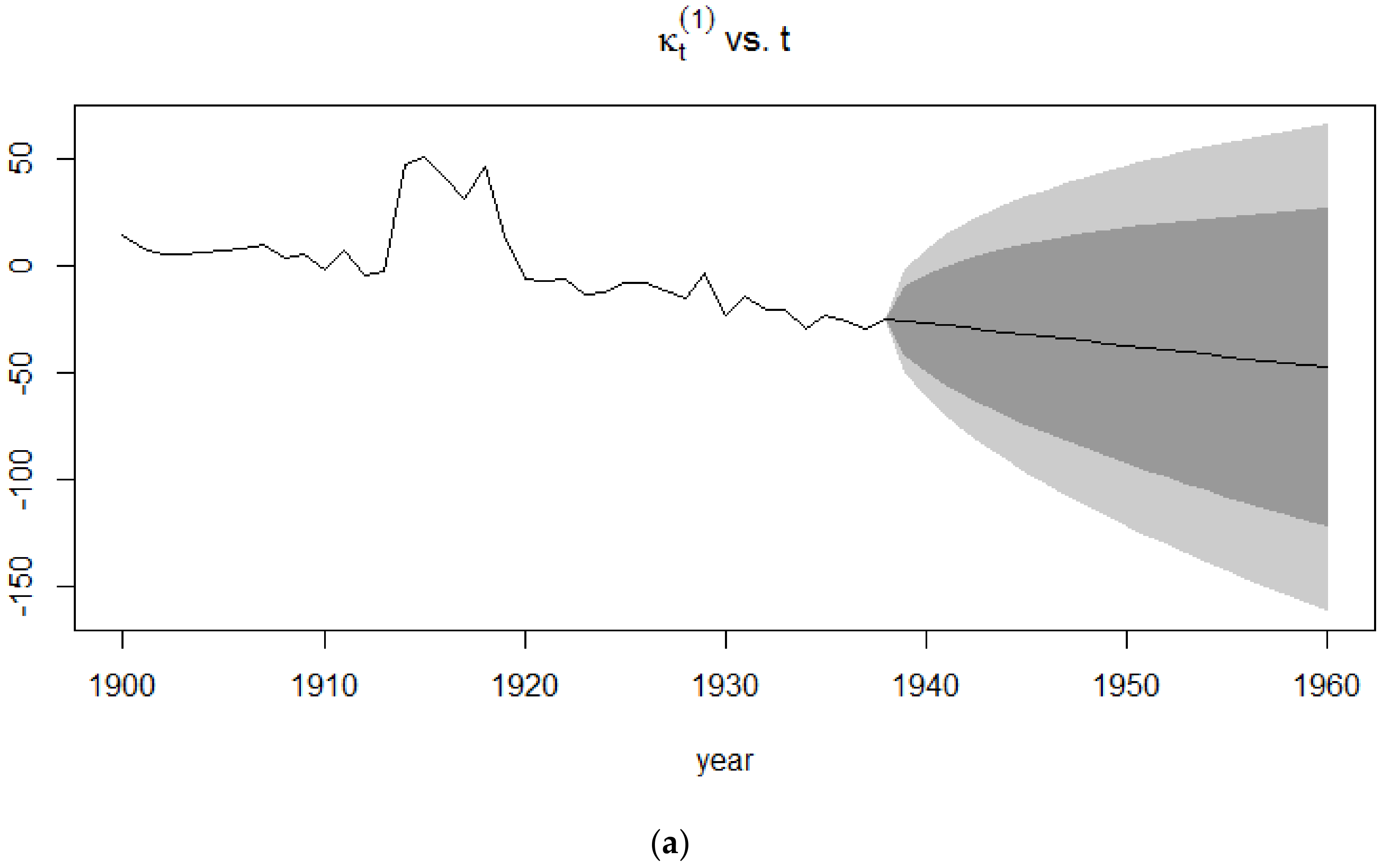
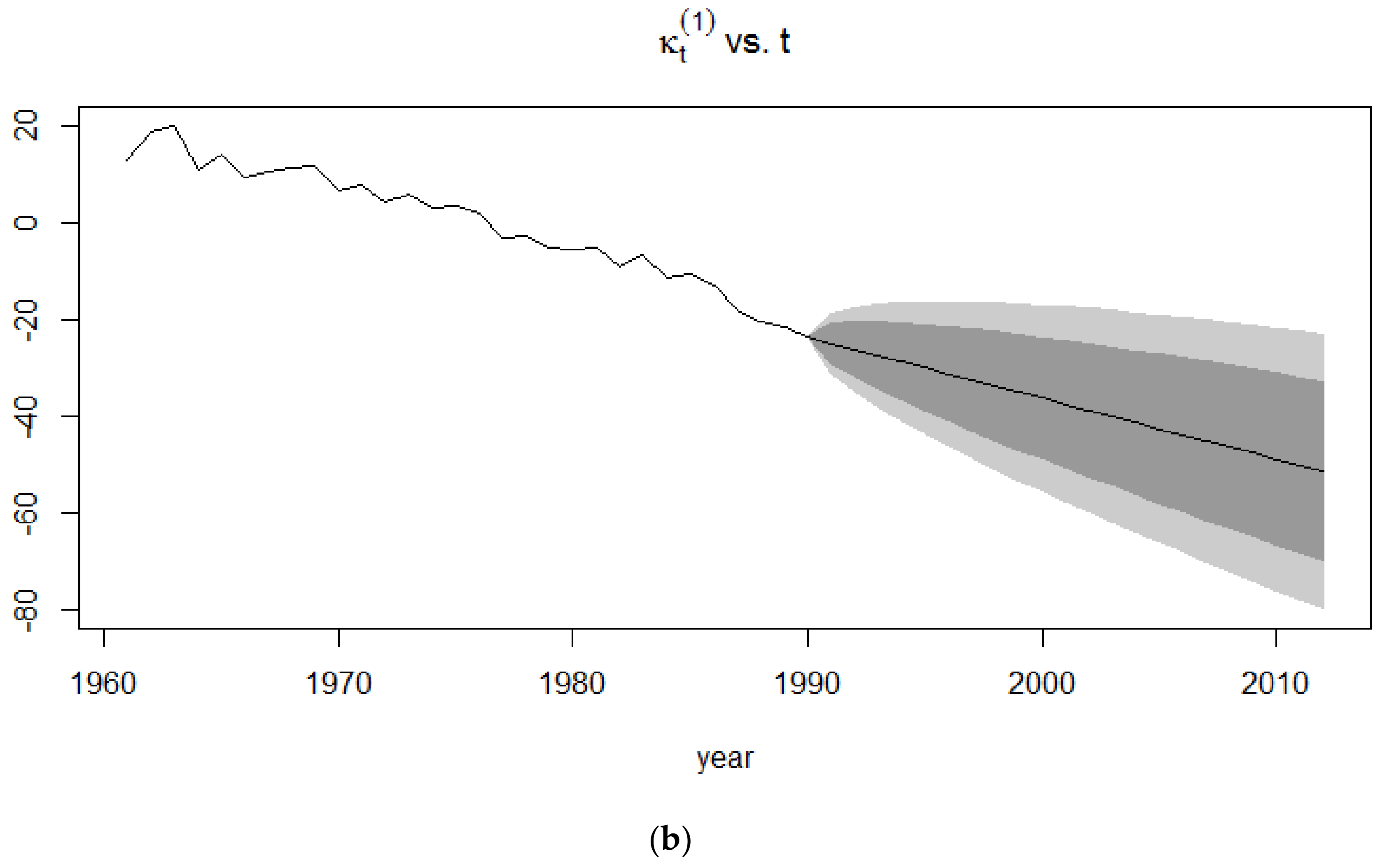
4.3.1. Random Walk with Drift
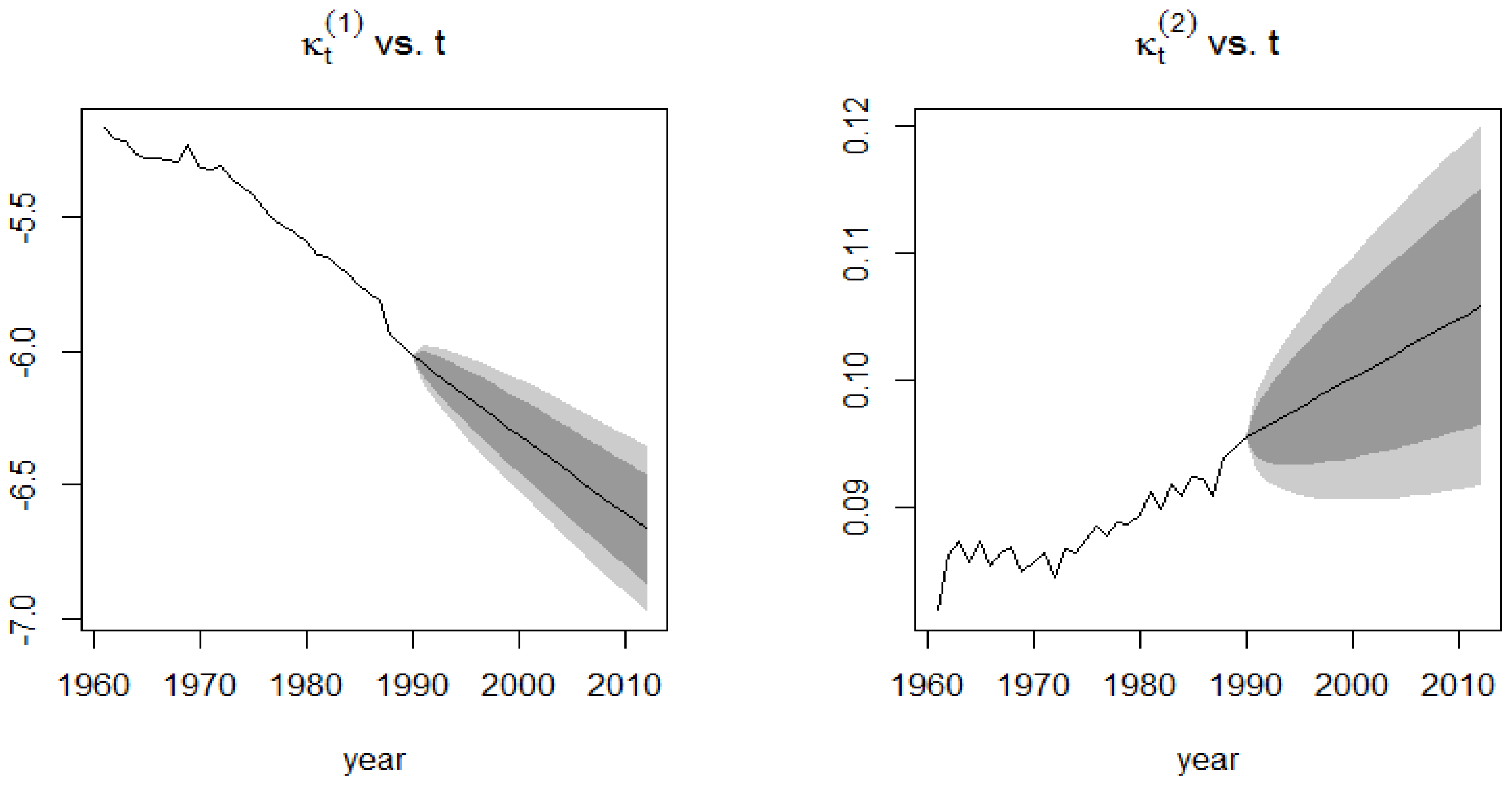
4.3.2. Application of the Kou Model on the Lee-Carter Mortality Index
5. Performance Metrics
6. Results
7. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. SVD Procedure Used in the Lee-Carter Model
References
- Aït-Sahalia, Yacine, Lars Peter Hansen, and José A. Scheinkman. 2004. Operator methods for continuous-time Markov processes. Available online: https://perso.univ-rennes1.fr/jian-feng.yao/gdt/docs/ahs04.pdf (accessed on 12 October 2018).
- Blake, David, and William Burrows. 2001. Survivor Bonds: Helping to Hedge Mortality Risk. The Journal of Risk and Insurance 68: 339–48. [Google Scholar] [CrossRef]
- Booth, Heather, and Leonie Tickle. 2008. Mortality modelling and forecasting: A review of methods. Annals of Actuarial Science 3: 3–43. [Google Scholar] [CrossRef]
- Box, George E.P., and Gwilym M. Jenkins. 1976. Time Series Analysis, Control, and Forecasting. San Francisco: Holden Day. [Google Scholar]
- Brass, William. 1971. Mortality models and their uses in demography. Transactions of the Faculty of Actuaries 33: 123–142. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Michel Denuit, and Jeroen K. Vermunt. 2002. Measuring the Longevity Risk in Mortality Projections. Bulletin of the Swiss Association of Actuaries 2: 105–30. [Google Scholar]
- Cairns, Andrew J.G., David Blake, and Kevin Dowd. 2006. Pricing Death: Frameworks for the Valuation and Securitization of Mortality Risk. ASTIN Bulletin 36: 79–120. [Google Scholar] [CrossRef]
- Cairns, Andrew J.G., David P. Blake, Kevin Dowd, Guy Coughlan, and David Epstein. 2007. A Quantitative Comparison of Stochastic Mortality Models Using Data from England & Wales and the United States. University Business. Available online: https://ssrn.com/abstract=1340389 (accessed on 12 October 2018).
- Chen, Hua, and Samuel H. Cox. 2009. Modelling Mortality with Jumps: Applications to Mortality Securitization. Journal of Risk and Insurance 76: 727–51. [Google Scholar] [CrossRef]
- Chen, Hua, and J. David Cummins. 2010. Longevity Bond Premiums: The Extreme Value Approach and Risk Cubic Pricing. Insurance: Mathematics and Economics 46: 150–61. [Google Scholar] [CrossRef]
- Chuang, Shuo Li, and Patrick L. Brockett. 2014. Modelling and Pricing Longevity Derivatives Using Stochastic Mortality Rates and the Esscher Transform. North American Actuarial Journal 18: 22–37. [Google Scholar] [CrossRef]
- Cox, Samuel H., Yijia Lin, and Shaun Wang. 2006. Multivariate Exponential Tilting and Pricing Implications for Mortality Securitization. Journal of Risk and Insurance 73: 719–36. [Google Scholar] [CrossRef]
- De Moivre, Abraham. 1725. Annuities upon Lives: Or, the Valuation of Annuities upon Any Number of Lives; as also, of Reversions. To which is Added, An Appendix Concerning the Expectations of Life, and Probabilities of Survivorship. Oxford: Oxford University Press. [Google Scholar]
- Deaton, Angus S., and Christina Paxson. 2004. Mortality, Income, and Income Inequality over Time in Britain and the United States. In Perspectives on the Economics of Aging. Chicago: University of Chicago Press. [Google Scholar]
- Deng, Yinglu, Patrick L. Brockett, and Richard D. MacMinn. 2012. Longevity/Mortality Risk Modelling and Securities Pricing. Journal of Risk and Insurance 79: 697–721. [Google Scholar] [CrossRef]
- Dowd, Kevin, Andrew J.G. Cairns, David Blake, Guy D. Coughlan, David Epstein, and Marwa Khalaf-Allah. 2008. Backtesting Stochastic Mortality Models: An Ex-Post Evaluation of Multi-Periodi-Ahead Density Forecasts. CRIS Discussion Paper Series; Nottingham, UK: Centre for Risk Insurance Studies, Nottingham University Business School. [Google Scholar]
- Gompertz, Benjamin. 1825. On the nature of the law of human mortality and on a new method of determining the value of life contingencies. Philosophical Transactions of the Royal Society 115: 513–83. [Google Scholar] [CrossRef]
- Giacometti, Rosella, Sergio Ortobelli, and Maria Ida Bertocchi. 2009. Impact of Different Distributional Assumptions in Forecasting Italian Mortality Rates. Investment Management and Financial Innovations 6: 65–72. [Google Scholar]
- Girosi, Federico, and Gary King. 2007. Understanding the Lee-Carter Mortality Forecasting Method. Working paper. Cambridge, MA, USA: Harvard University. [Google Scholar]
- Hainaut, Donatien, and Pierre Devolder. 2008. Mortality Modelling with Lévy Processes. Insurance: Mathematics and Economics 42: 409–18. [Google Scholar] [CrossRef]
- Hansen, Lars Peter. 1982. Large Sample Properties of Generalized Method of Moments Estimators. Econometrica 50: 1029–54. [Google Scholar] [CrossRef]
- Hyndman, Rob J., and Anne B. Koehler. 2006. Another Look at Measures of Forecast Accuracy. International Journal of Forecasting 22: 679–88. [Google Scholar] [CrossRef]
- Kendall, Maurice, and Alan Stuart. 1977. Distribution theory. In The Advanced Theory of Statistics, 4th ed. London: Griffin, vol. 1. [Google Scholar]
- Kou, Steven G. 2002. A Jump-Diffusion Model for Option Pricing. Management Science 48: 1086–101. [Google Scholar] [CrossRef]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modelling and Forecasting US Sex Differentials in Mortality. International Journal of Forecasting 8: 393–411. [Google Scholar]
- Maccheroni, Carlo, and Samuel Nocito. 2017. Backtesting the Lee-Carter and the Cairns-Blake-Dowd Stochastic Mortality Models on Italian Death Rates. Risks 5: 34. [Google Scholar] [CrossRef]
- Merton, Robert C. 1976. Option Pricing When Underlying Stock Returns Are Discontinuous. Journal of Financial Economics 3: 125–44. [Google Scholar] [CrossRef]
- Mitchell, Daniel, Patrick Brockett, Rafael Mendoza-Arriaga, and Kumar Muthuraman. 2013. Modelling and Forecasting Mortality Rates. Insurance: Mathematics and Economics 52: 275–85. [Google Scholar]
- Ramezani, Cyrus A., and Yong Zeng. 1998. Maximum Likelihood Estimation of Asymmetric Jump-Diffusion Processes: Application to Security Prices. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Ramezani, Cyrus A., and Yong Zeng. 2007. Maximum Likelihood Estimation of the Double Exponential Jump-Diffusion Process. Annals of Finance 3: 487–507. [Google Scholar] [CrossRef]
- Ramezani, Cyrus A., and Yong Zeng. 2004. An empirical assessment of the double exponential jump-diffusion process. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Renshaw, Arthur E., and Steven Haberman. 2006. A Cohort-Based Extension to the Lee-Carter Model for Mortality Reduction Factors. Insurance: Mathematics and Economics 38: 556–70. [Google Scholar] [CrossRef]
- Sorensen, Michael. 1991. Likelihood methods for diffusions with jumps. Statistical Inference in Stochastic Processes 3: 67–105. [Google Scholar]
- Wilmoth, John R. 1993. Computational Methods for Fitting and Extrapolating the Lee-Carter Model of Mortality Change. Technical report. Berkeley: University of California. [Google Scholar]
- Wilmoth, John R. 1990. Variation in vital rates by age, period, and cohort. Sociological methodology 20: 295–335. [Google Scholar] [CrossRef] [PubMed]
- Wilmoth, John R., and Hans Lundström. 1996. Extreme Longevity in Five Countries: Presentation of Trends with Special Attention to Issues of Data Quality. European Journal of Population 12: 63–93. [Google Scholar] [CrossRef] [PubMed]
| 1 | Data downloaded on September 2017. Source: https://www.mortality.org/. |

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1900–1960 Period | ||||
|---|---|---|---|---|
| Models | Average RMSE | Average MAE | Average MPE | Average MAPE |
| APC | 0.013063 | 0.006709 | 12.8334 | 16.30235 |
| CBD | 0.014837 | 0.007495 | 15.08032 | 18.38768 |
| Lee-Carter | 0.012102 | 0.006798 | 13.65589 | 15.49652 |
| Lee-Carter Kou-Modified Mortality Index | 0.003029 | 0.003153 | 10.27675 | 13.58456 |
| 1961–2015 Period | ||||
|---|---|---|---|---|
| Models | Average RMSE | Average MAE | Average MPE | Average MAPE |
| APC | 0.008016 | 0.016184 | 16.03057 | 18.92784 |
| CBD | 0.013744 | 0.02708 | 25.13116 | 26.68533 |
| Lee-Carter | 0.006764 | 0.00852 | 13.48385 | 15.88327 |
| Lee-Carter Kou-Modified Mortality Index | 0.018139 | 0.030101 | 28.11825 | 30.23325 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alijean, M.A.C.; Narsoo, J. Evaluation of the Kou-Modified Lee-Carter Model in Mortality Forecasting: Evidence from French Male Mortality Data. Risks 2018, 6, 123. https://doi.org/10.3390/risks6040123
Alijean MAC, Narsoo J. Evaluation of the Kou-Modified Lee-Carter Model in Mortality Forecasting: Evidence from French Male Mortality Data. Risks. 2018; 6(4):123. https://doi.org/10.3390/risks6040123
Chicago/Turabian StyleAlijean, Marie Angèle Cathleen, and Jason Narsoo. 2018. "Evaluation of the Kou-Modified Lee-Carter Model in Mortality Forecasting: Evidence from French Male Mortality Data" Risks 6, no. 4: 123. https://doi.org/10.3390/risks6040123
APA StyleAlijean, M. A. C., & Narsoo, J. (2018). Evaluation of the Kou-Modified Lee-Carter Model in Mortality Forecasting: Evidence from French Male Mortality Data. Risks, 6(4), 123. https://doi.org/10.3390/risks6040123