1. Introduction
The theme of this tutorial is not to develop an analysis of all possible variants of quantile time series model: their model properties and relevant estimation approaches. Hence, the paper is not addressing the concerns of estimation of these models, as there is existing literature on these aspects in many cases. We provide references to relevant works on these aspects in several classes of models presented.
Instead, the focus is rather to provide a unified framework to construct such models for practitioners. Therefore, the emphasis of the paper is on the properties of the models and links between such models from a constructive perspective. As such, the tutorial takes a considered perspective on popular classes of quantile time series model structure that have been developed in the literature. It first introduces the key papers in the literature that have led to developments in some important classes of models. The second aspect of this paper is to provide an overview of various different model components that one can consider when developing a quantile times series models. This is the novelty introduced in this paper, where existing models are viewed from a different perspective and core components of relevance to general quantile time series modelling are decomposed and represented in components that allow development of new models and extensions of existing models.
In this regard, the theme of the overview is to decompose quantile time series modelling into a few core model components and then to go into detail on choices developed in the literature relating to these particular components. In viewing quantile time series modelling from this perspective, we are able to easily introduce new aspects to the modelling such as modifications to the quantile error function as well as nonlinear transformations of relevance to broader classes of quantile time series model.
In particular, in this paper, we consider classes of univariate quantile regression models developed in the context of time series modelling. We begin by providing a brief overview of different classes of parametric quantile time series regression models. Quantile valued time series models can be of many different types with regard to their regression structure: function on scalar or vector regressions; function on function regressions; and scalar on function regressions.
We then explore novel applications of quantile time series modelling in applications of relevance to life insurance contexts. In particular, we explore a range of mortality and demographic data sets via quantile time series regressions. The purpose of this is to illustrate for actuarial practitioners how one may utilise such time series modelling techniques to explore relevant demographic and mortality related time series data sets. The outputs of this analysis can be directly useful in insurance applications for instance in life insurance applications in annuities pricing and risk management as well as pension policy development. We do not go into detail on these particular areas of application; instead, we focus on modelling and comparison of different quantile time series models on these real mortality and demographic data sets obtained for England, Wales, Scotland and Northern Ireland.
In general, when studying such data sets, we note that one can separate such data sets typically into four categories
1:
Demographic data: which includes factors such as age, sex, migration patterns, ethnicity and marital status in populations. Typically, this comes from census type data sets.
Health event data: this involves recordings of health events affecting individuals or populations which can include births, deaths, health conditions, primary care interactions, secondary care interactions and health hazards;
Circumstantial data: focuses on aspects of individuals’ and populations’ circumstances that may affect the wider determinants of health, including socio-economic, lifestyle, and environmental data. Such data in this type of category can include education data; employment data; housing data and environmental data;
National reference data: which includes data not collected for the sole purpose of health analysis; however, it can be used in connection with health data.
In this manuscript, we will focus on data reflecting demographic data and health event data. In
Section 9, we provide a detailed overview of which data sets are considered. This will then be followed by the analysis of numerous quantile time series models, both linear and nonlinear, applied to these data sets. At each stage, a detailed description of the fitted model properties is provided in order to act as a guide for practitioners unfamiliar with such modelling approaches in demography and insurance.
In addition, more recently, in
Bernardi et al. (
2016a), they extended the Bayesian family of Asymmetric Laplace distribution (ALD) quantile regression models to the family of Skewed Exponential Power (SEP) models. Their intention was to account for application settings in which the assumptions and model properties that standard ALD models impose was extended, allowing for greater skewness and kurtosis ranges to be feasibly expressed. In similar context, with the perspective of generalizing the distributional properties of the resulting quantile regression and its distributional tail properties, in
Lancaster and Jae Jun (
2010), they study applications of Bayesian exponentially tilted empirical likelihood to make inference about quantile regressions.
From the perspective of covariate selection and shrinkage in Bayesian quantile regressions, there is also a sequence of papers on regularization methods for quantile regressions, such as
Li et al. (
2010). In such works, the authors demonstrate that regularization methods such as lasso are effective in Bayesian quantile regression contexts. For a good overview of the past 40 years of quantile regression modelling over a wide spectrum of quantile models and modelling domains, see the discussions in
Koenker (
2017).
Quantile regression has also begun to be explored in more general regression settings such as for panel data applications, where bootstrap procedures are developed in such quantile regression contexts (see
Galvao and Montes-Rojas (
2015) and references therein).
The application of quantile regression models in financial risk and insurance has also recently begun to develop in works such as (
Dong et al. 2015;
Peters et al. 2016) and discussions in Operational risk contexts in (
Cruz et al. 2015;
Peters and Shevchenko 2015). Furthermore, there are Bayesian applications in econometrics. For instance,
Hu et al. (
2013) develop a Bayesian partially collapsed Gibbs sampler approach to fitting single-index models for conditional quantile regressions. In
Bernardi et al. (
2016b), they consider the challenge of model combining or model averaging in dynamic quantile regression settings, which they termed the general dynamic model averaging framework.
We now shift the focus from general quantile regression background to a particular focus on time series contexts. Specification of quantile function time series and regression can be decomposed into three main components:
The conditional distribution of the regression time series model. This defines a conditional quantile function of the dependent variable, given the explanatory variables, primarily comprised in our case of time series past observations of the process. However, in general, the conditioning arguments may also include additional exogenous covariates perhaps with distributed lags;
The structural component of the regression model. This component includes specification of the choice of link function and functional form expressing how covariates enter to the regression structure. The link function connected the linear or nonlinear predictor regression structure to the moments or parameters of the conditional quantile function;
The actual choice of independent variables (regressors), that is, the covariates in the regression model and possible lagged and transformed structures. This could include distributed lags, projections, feature extraction as well as basis function transformations of the covariates.
1.1. Outline and Contributions
In
Section 2, we overview important developments in the context of quantile regression modelling with a particular focus on quantile times series models.
In
Section 3,
Section 4 and
Section 5, we present a general modelling framework for developing a wide class of quantile time series models that is detailed in a constructive manner involving four key ingredients. The first is the structural form of the quantile regression or time series model (linear or nonlinear maps), the second is the choice of quantile error function, the third is the choice of lag structure for the endogenous variables that characterize the quantile time series structure and the fourth is the choice of endogenous covariates and their lag structures. Then, we introduce examples in the case of non-parametric and parametric linear and nonlinear quantile time series models.
In
Section 6, we characterize the class of quantile error function families in categories of location-scale, shape-scale and some special heavy tailed families of quantile functions. We conclude this section with discussion on truncated quantile error models for time series constructions with restricted supports.
In
Section 7 and
Section 8, we detail how to develop transformation of these basic families of parametric quantile error models to other significantly more flexible families of quantile error models based on two classes of mappings: the
Tukey Elongation Maps and secondly the
Rank Transmutation Map framework. We note that these general transformations may also be used to construct other aspects of the quantile time series model, not just the quantile error function.
In
Section 9, we will explore applications of the general quantile time series model constructions on a range of demographic and mortality data. The focus will be to explore with applications the properties of some of the models discussed in the tutorial overview and to explore their application relevance for future developments in new insurance domains such as life-insurance modelling. We then conclude.
1.2. Notation
In this section, we briefly introduce some core notation used throughout the manuscript. We denote random variables by upper script and their realization by lower script. We denote vectors by bold and scalars by non-bold. Furthermore, we use the notation to refer to the quantile function of a random variable obtained as the t-th time instance of a time series . We will typically refer to the quantile level by variable . The generic notation used for static model parameters in any of the introduced time series models will be denoted by vector unless otherwise discussed. Furthermore, we will utilize the notation to denote the natural sigma-algebra of the observed time series given by . We will therefore denote by the conditional quantile function of random variable condition on the information set , i.e., the observations of the time series until time given by and the static model parameters generically denoted by .
Furthermore, we will in general denote functional coefficients of the quantile time series structure by functions which will multiply lagged values of the time series. We will impose additional structure on these functions as required. When we consider the coefficients of lagged covariates, for a given quantile level u, we will also denote them by notations and for u-th quantile coefficients. These could, for instance, be coefficients for the endogenous autoregressive (AR) structures and exogenous distributed lag structures, respectively, or for trend and volatility terms. In addition, we will denote by the quantile error function, which represents white noise sequence with distributional static parameters generically denoted by . Additional notation used in the paper is introduced and defined where required.
2. Developments of Quantile Time Series Models
In its earliest form, quantile regression as introduced by
Koenker and Bassett (
1978) generalizes the notion of sample quantiles to linear and nonlinear regression models including the least absolute deviation estimation as its special case. In developing such a regression framework, one is able to develop estimation methods for conditional quantile functions at any (or all) probability levels. Such conditional quantile regression structures are now increasingly studied as they have been shown to present new information, compared to classical generalized linear model (GLM) regressions or linear mean regressions (see discussions in
Koenker (
2000)).
In (
Koenker and Xiao 2006;
Koenker 2017), the background of time series developments in quantile models is discussed for the class of quantile Autoregressive (QAR) models. Such QAR models are characterized by a parametric form, in the univariate time series
setting, by:
with notation as defined in
Section 1.2.
To understand how to go from a time series model to a quantile time series model, consider the following relationship detailed in Example 1. This example illustrates the relationship between a functional, random coefficient AR time series model and its equivalent form expressed as a quantile time series model. Of course, any time series model, even without a structure of random functional coefficients can also admit a quantile time series model. However, in general the direct link between such a model and the coefficients of each model, the underlying time series model and the quantile time series model may not be easy to obtain in an explicit closed-form.
Example 1 (Relating Functional time series with Random Coefficients to Quantile time series)
. Consider a functional time series model with random coefficients in an AR structure given bywith for all t and where . We need only then assume thatis a monotone increasing function of . Note: one way to construct such a solution is to consider a positive valued time series, such that , then if each coefficient is specified as a quantile function which is scale invariant, one has that the resulting linear combination is a quantile function. Furthermore, one can write the equivalent conditional quantile function time series model as follows:which is obtained by use of the following general rule for any monotone increasing function g and standard uniform random variable U:where we use the fact that for a uniform random variable the distribution and quantile function satisfy the linear relationship, such that . Such an example was illustrated in
Koenker and Xiao (
2006) where they point out that one can also consider, from a regression perspective, an alternative formulation of such functional regressions with scalar or vector on function regression. In particular, one can define a scalar (vector) on function regression version of the QAR model, with co-monotonic random functional coefficients, denoted as the random coefficients by
for i.i.d.
. Such QAR models, in which the autoregressive coefficients are expressed as monotone functions of a single, scalar random variable are interesting as they allow one to capture
“systematic influences of conditioning variables on the location, scale and shape of the conditional distribution of the response, and therefore constitute a significant extension of classical constant coefficient linear time series models in which the effect of conditioning is confined to a location shift.”
Furthermore, such quantile time series models can also be more robust to outliers and heavy tailed noise (see discussions in
Fitzenberger et al. (
2013)).
In the time series context, recent studies have also begun to develop properties specifically for QAR models, such as the notion of the quantile correlation (QACF) and quantile partial correlation (QPACF), defined in
Li et al. (
2015). These are natural quantile extensions of autocovariance and autocorrelation given by:
In addition, an analogous QPACF can be obtained from the quantile based correlation and is given according to the expression in (
Li et al. 2015, Equation (2.2)). Multivariate extensions have also been considered in
Han et al. (
2016) where they consider multiple QAR time series models, and develop the notion of cross-quantilogram. This provides a way to measure the quantile dependence between multiple quantile time series.
Variants of non-stationary QAR models have also been explored in
Aue et al. (
2017). This involves developing locally stationary QAR models through piece-wise, local in time constructions,
and they extend the standard QAR model to have a definition specific to each of the
k segments. A detailed discussion of model selection and segmentation approaches is provided that performs local segmentation of the space and model selection per quantile level.
In the above discussion, we have not mentioned specific choices for the base quantile function
, this is a topic we will discuss in detail in later sections of this manuscript. However, we note that there are many ways to construct and decide upon such a reference quantile function. Recent developments in this context include the flexible class of non-parametric estimators proposed in
Stephanou et al. (
2017). In this work, they propose a simple non-parametric L-estimator class of kernel representations of the error quantile, based on the class of Hermite Askey-orthogonal polynomials. This builds on earlier works by (
Cai 2002;
Cai and Xu 2008) where non-parametric quantile time series modelling was studied via the inverse of weighted Nadaraya–Watson estimators of the conditional distribution function.
In addition to classes of QAR model, quantile time series regressions have been studied in both linear and nonlinear autoregressive settings in (
Bloomfield and Steiger 1984;
Cai 2010b;
Cai et al. 2013;
Weiss 1991;
Davis and Dunsmuir 1997). The development of autoregressive conditional heteroscedasticity ARCH and GARCH models in quantile time series settings has also been undertaken by (
Koenker and Zhao 1996;
Lee and Noh 2013). Although the focus in this paper does not concern statistical estimation of quantile regression models, we believe it is still useful to mention that in frequentist estimation techniques for AR-ARCH type quantile models, identification in parameter estimation can be a challenge (see discussion in
Noh and Lee (
2015)). These authors demonstrate how a simple AR(1)-ARCH(1) model parametrized as follows:
with
i.i.d. random variables satisfying
and
, when re-expressed as a quantile regression form will have parameter identification issues. To see this, consider the reformulated AR(1)-ARCH(1) model represented as a quantile regression time series form as follows
where
. One may observe that since the
u-th quantile of
is unknown, then the parameters in Equation (
10) are not identifiable. Fortunately, this issue can be overcome with appropriate re-parametrization of the model (see discussion in
Lee and Noh (
2013)).
The re-parametrized form, which is identifiable, is obtained by setting
,
with
,
and
. In such a re-parametrization, one has re-expressed the ARCH model as a conditional scale model with no scale constraints on the i.i.d. innovations. The resulting conditional quantile time series model is then given by
General results for parametrizations that extend beyond the AR-ARCH models to ARMA-AGARCH models which are identifiable are also developed in
Noh and Lee (
2015).
These developments were then presented in a general framework that is widely utilized, known as the Conditional Autoregressive VaR model (CAViaR) of
Engle and Manganelli (
2004). This model class has been extended to study explicitly models which have both conditional location and scale components (see
Noh and Lee (
2015)).
In
Cai (
2016) and then later in
Noh and Lee (
2015), the authors developed general classes of conditional location-scale quantile time series models based on time series models of the generic form:
where
and
were functions they used to denote
and
for some measurable functions
;
denotes the true model parameter;
is a model parameter space;
are i.i.d. random variables with an unknown common distribution function
.
In fact, such ideas for quantile regression were previously well developed and explained in the location and scale class of quantile regression models in
Gilchrist (
2000). The equivalent quantile time series models may be presented according to the general location-scale generalized form given by
where model parameters
with
,
and generic quantile error function denoted by
.
Special cases of such models had previously also been considered in works such as
Cai et al. (
2013) who developed the quantile time series version of the double AR(p) models of
Ling (
2007) given by
where
for
,
and
is independent of
for all
t.
As noted in
Cai et al. (
2013), this is a special case of the ARMA-ARCH models proposed by
Weiss (
1984); however, it is structurally distinct from the ARCH models proposed by
Engle (
1982) when one considers settings in which
. A further extension developed includes the Double-QAR(p,q) model of
Cai et al. (
2013) given by
where model parameters
with
and
. In this particular study, the quantile error distribution was selected as a flexible quantile sub-family of the generalized lambda family of distributions developed in
Freimer et al. (
1988).
Other forms of nonlinear quantile time series models have been explored, such as the class of quantile self-exciting threshold autoregressive time series models proposed in
Cai and Stander (
2008). Such models are the quantile time series extension of self-exciting threshold autoregressive time series (SETAR) models, often referred to as the class of QSETAR models. These are generally characterized by the QAR model extension given by:
where we consider the following state-space threshold partitions
and denote by
the indicator function taking value one, when the arguments condition is satisfied and zero otherwise.
Other classes of nonlinear quantile time series models developed include those studied in (
Peters et al. 2016;
Dong et al. 2015;
Chen et al. 2017) where they proposed nonlinear quantile models of the form
which characterize the class of quantile models equivalent to distributed lag ARDL models with exogenous covariates. Furthermore, these models were also extended in
Chen et al. (
2017) to quantile state-space models (QSSM) that they termed the AQUA class. In
Peters et al. (
2016), several classes of transform function
were explored based on the Tukey class of elongation transforms, including popular sub-classes of g-and-h, G-and-K, G-and-J, G-G, and H-H transforms. An efficient R-package for estimation and description of its functionality is provided by
Prangle (
2017).
In terms of forecasting of quantile time series models, there are multiple approaches one can adopt (see discussions in
Cai (
2010a)). Furthermore, there is a branch of quantile time series models relating to extreme value theory (see a detailed discussion in
McNeil and Frey (
2000)). To complete this section, we make the following example to illustrate a general mapping from a time series model to a quantile time series model.
Example 2 (Relating General Nonlinear Stochastic Volatility Time Series Models to Quantile Time Series Models)
. Consider a functional time series model characterized by the general structural formfor time t and where is an i.i.d. sequence of uniform random variables and where which we assume satisfies that is a monotone increasing function in . Furthermore, we assume a general parametric linear or nonlinear map of lagged values of the process and time t for the trend such that parametrized by model parameters generically denoted by and a nonlinear stochastic volatility structure given by functional form such that with generic model parameters . Then, in this case, one has the general equivalent conditional quantile function time series model can be obtained, under the restrictions that for , given by To obtain this representation, we use the fact that a positive scaling of a quantile function is a quantile function, such that for all on has that is a quantile function. Furthermore, any linear combination of quantile functions is also a quantile function and we apply the rule that a linear translation of a quantile is a quantile function. Finally, we are back to the condition that we may then apply again the following general rule for any monotone increasing function g and standard uniform random variable U:where we use the fact that for a uniform random variable the distribution and quantile function satisfy the linear relationship such that . Remark 1. The above example is intended to be illustrative of the general approach one can adopt to moving from time series models to the equivalent relationship in a quantile time series model. However, one must in general still be cautious to consider such general model structures from the perspective of estimation and appropriate identification considerations.
3. General Construction of Quantile Time Series Regression Models
In the literature, it is common to develop quantile time series models dependent only on endogenous variables in the regression structure. In other words, the vast majority of time series quantile regression models discussed are constructed from conditional distributions which are based on information filtration, denoted which is constructed from the sigma-algebra naturally generated by the time series signal under consideration.
However, in many practical settings, it will be of interest to extend the class of quantile time series models such as the QAR models to include lagged endogenous covariates of different forms. A first natural extension would be to begin by developing the conditional quantile function forming the time series to also be dependent explicitly on a second filtration of observed exogenous covariates, which will be denoted by , where .
In such cases, one can construct a range of extensions of the QAR model, for instance, such as the two illustrative examples below:
where in the second case one may wish to impose that
for all
to ensure the resulting conditional quantile function is well defined. These illustrative models are based on linear relationships in the quantile time series regressions. However, we will also consider the general class of nonlinear and linear cases generically presented by the following parametric conditional quantile relationship
which involves some form of quantile preserving map defined in detail in the following sections. We will overview several classes of such mappings from the literature, including classical approaches based on location-scale, shape-scale maps as well as more advanced approaches such as the Rank Transmutation Maps (RTM) and the Elongation transforms of Tukey.
Remark 2 (Characterizing Generalized Quantile time series Models)
. To characterize this general class of quantile time series models, we will consider defining six attributes:
- 1.
choice of mapping function which can be linear or nonlinear on the quantile error function or on the quantile function time series “trend” structure;
- 2.
the choice of quantile error function —if in the parametric model context;
- 3.
the inclusion or not of lagged observations of the time series of interest , obtained by the natural filtration generated by the realization of the process (denoted ), which enter in the model in either the location or the scale or both;
- 4.
the inclusion or not of lagged exogenous covariates generically denoted by set of vectors , obtained by the natural filtration generated by the realization of the process (denoted ), which enter in the model in either the location or the scale or both;
- 5.
the choice of parametric vs. non-parametric model, through either an explicit specification of a quantile error function for the model, or a non-parametric approach when no quantile function is explicitly considered;
- 6.
function on function regressions, when one models the entire quantile function by considering all quantile levels or some sub-set of this range, versus individual quantile regressions for a specific target quantile level u.
In the following sub-sections, we discuss each of these components in turn, starting with the distributional aspects of the quantile regression models we consider. In this regard, the models of particular focus in this tutorial are the following classes of quantile model:
the Asymmetric Laplace (AL) distribution;
the regularly varying and heavy tailed classes of power-law distributions, which may for instance be characterized by models whose hazard rate
given by
satisfies the condition for instance in the right tail that
one, two, three and four parameter parametric distributional models often occurring as sub-members of the Pearson family and the Exponential family and is dispersion extensions.
the Rank Transmutation composite quantile function maps
the Tukey g-and-h elongation transform family,
which we extend to classes of quantile time series models.
We begin with an overview of some core examples of non-parametric quantile time series models and how these relate to the Asymmetric Laplace parametric model. We then proceed with more detailed illustrations of parametric modelling of quantile time series.
4. Nonparametric Quantile Time Series Models
In this case, we will consider the sub-class of regression quantile time series models given by
where we drop from the transformation
the component corresponding to the quantile error distribution specification
, hence making the model non-parametric in nature.
4.1. Examples of Linear Nonparametric Quantile Time Series Models
In a non-parametric quantile regression time series approach, one seeks to estimate regression coefficients without the need to make any assumptions on the distribution of the response, or equivalently the residuals. To understand this, we will first introduce a simple quantile AR process. We will focus on the family of models to begin with that have a linear transformation i.e., where the mapping is considered to be a simple linear function of the coefficients. Furthermore, we will consider a specific target quantile level u in the initial set-up below, not a functional regression structure.
Definition 1 (Non-Parametric Quantile Autoregressive QAR(p) Time Series)
. Consider the time series ; then, the quantile time series model is defined according to the conditional quantile functions as follows: One may consider to be the natural filtration generated by the observed time series up to the current time point, or it may contain additional structure such as lagged covariates. The location of the u-th quantile level is determined by coefficient scaled lagged previous values of the time series, where the coefficients can be quantile level specific. The coefficients are characterized as the solution to the system of equations, for all given by:when such a solution exists. Remark 3. Note, in this non-parametric specification, no distributional assumption is being made regarding the conditional distribution for , so, at this stage, one may wonder how can the coefficients be estimated. The answer involves reformulating the coefficients as the solution of a loss function minimization, which does not require any distributional assumptions to be made on the time series marginal or conditional distributions.
This reformulation is given by the quantile loss function. Hence, we may analogously obtain estimates of the quantile model parameters, non-parametrically by solving the following loss function minimization:and . Furthermore, it has been shown in (
Koenker and Hallock 2001;
Koenker and Machado 1999;
Yu and Moyeed 2001) that under this loss function
for quantile regression, the parameter estimates of
, which may be obtained by minimizing the loss function in (
28) will be equivalent to the maximum likelihood estimates of
when the conditional distribution of
follows the Asymmetric Laplace proxy distribution given in Definition 2.
Definition 2 (Asymmetric Laplace Distribution)
. A random variable has an Asymmetric Laplace (AL) law if it has the following distribution and densitywhere , is the location; is the scale parameter; and p is the asymmetry parameter. The mean, variance, skewness and kurtosis of this model are given by: Note, when
, we have that the AL distribution simplifies to the well known Laplace distribution. Hence, we may now observe that this family of distributions contains, embedded in the exponential argument, exactly the component required for minimization in the quantile regression loss function. This allows us to write the problem of solving for the coefficients of the model in Definition 1 given by:
for the location parameter or mode
, the scale parameter
and the skewness parameter
equals to the quantile level
u. Since the pdf (
32) contains the loss function (
28), it is clear that parameter estimates that maximize Equation (
32) will minimize Equation (
28).
In this formulation, the AL distribution represents the conditional distribution of the observed dependent variables (responses) given the covariates. More precisely, the location parameter of the AL distribution links the coefficient vector and associated covariates in the linear time series regression model to the location of the AL distribution.
4.2. Examples of Nonlinear Nonparametric Quantile Time Series Models
A natural extension of the QAR(p) class of quantile time series models is to consider the nonlinear class of non-parametric models. Here, we are treating the mapping as comprised of a combination of nonlinear and potentially also linear components.
Under the representation presented for the QAR(p) model, and its embedding within the AL family for estimation convenience, it is straightforward to extend the quantile regression model to allow for heteroscedasticity in the response, which may vary as a function of the quantile level u under study. To achieve this, one can simply add a regression structure linked to the scale parameter in the same manner as was done for the location parameter.
This would correspond to what we will call the Dynamic Volatility QAR(p) time series model given in the following definition.
Definition 3 (Examples of Non-Parametric Dynamic Volatility Quantile Autoregressive DV-QAR(p,q) Time Series)
. Consider the time series ; then, the DV-QAR(p) quantile time series model is defined according to the conditional quantile functions as follows:withwhere denotes information set or filtration that defines the time series dynamic. For instance, may be the natural filtration generated by the observed time series up to the current time point, or it may contain additional structure such as lagged covariates. The notation, , corresponds to the quantile level, and location of the u-th quantile level is dictated by coefficient lagged previous values of the time series, where the coefficients can be quantile level specific. The coefficients are characterized as the solution to the system of equations, for all given by:subject to the constraint for the filtration given bywhen such a solution exists. Remark 4. This second constraint in the above definition of the DV-QAR(p) process imposes the restriction that the time series process will admit a representation in which the original time series will be heteroskedastic with a volatility given by the functional specification: In terms of fitting such a DV-QAR(p) model, it will be convenient to observe the following relationship between this non-parametric model and its embedding withing a parametric AL distributional model.
Remark 5 (Embedding of the non-parametric DV-QAR(p) within Scale-Location Varying Asymmetric Laplace Model)
. Equivalently, we assume that conditionally follows an AL distribution denoted by . Then,where , the location and scale dynamic functions are given by Discussion on the parametric regression model, in particular, the choice of link function and structure of regression terms will be undertaken in later sections.
Note: this representation has the following advantages:
the parameters can be estimated by maximum-likelihood under the AL distribution family; and
importantly, it links the quantile process to a linear (when ) AR process with a driving noise sequence given by an AL error with appropriately chosen asymmetry parameter for corresponding to the target quantile level.
Other examples of nonlinear time series models have been proposed in the literature such as the double-AR time series structures of
Cai et al. (
2013), which we modify below to the non-parametric specification, embedded within an AL distribution estimation framework as noted in the DV-QAR(p,q) models above.
Definition 4 (Non-Parametric Dynamic Volatility Quantile Double Autoregressive DV-QDAR(p,q) Time Series)
. Consider the time series ; then, the DV-QDAR(p) quantile time series model is defined according to the conditional quantile functions as follows:withwhere denotes information set or filtration that defines the time series dynamic. For instance, may be the natural filtration generated by the observed time series up to the current time point, or it may contain additional structure such as lagged covariates. The location of the u-th quantile level is influenced by coefficient lagged previous values of the time series, where the coefficients can be quantile level specific, and in this example, we consider for all . As in the previous examples, the coefficients of the DV-QDAR(p,q) model are again characterized as solutions to the following system of equations, for all
given by:
subject to the constraint for the filtration
given by
when such a solution exists.
As demonstrated previously, the scale or volatility function has been specifically written in a form that naturally admits its embedding within an AL distribution family. This can greatly assist in developing the estimation, as one can directly avoid the estimation under the complicated nonlinear coupled and constrained system of equations above, replacing this with standard maximum likelihood of the AL distribution family for two of its parameters μ and σ.
6. Parametric Quantile Time Series Models: Error Quantile Functions
In this section, we will introduce a key component of the the generic parametric quantile time series model framework we propose based on representation:
which focuses on the modelling choices of the quantile error function
.
We begin by first exploring below the choice of quantile error functions that are closed-form and flexible enough to be used in a range of parametric quantile time series modelling contexts. Following from these specifications, we then discuss different examples of transformations to obtain conditional quantile functions.
In explaining different families of models for we will also introduce two highly flexible choices of mapping function that can either be applied to known parametric quantile error functions to obtain more flexible families of error quantile function or they can be applied to the quantile time series relationship to produce nonlinear quantile time series models.
It is also important to talk about families of quantile functions that admit parametric representations, as can be expected in many cases a random variable Y may have a well-defined and closed form expression for its distribution function ; however, its quantile function given by may not be easily obtainable as a function in closed form. However, there are several important and practical cases for different classes of parametric models for which one can obtain both functions in closed form, these are discussed below and presented in the context of quantile error models. This is the analog in time series settings of thinking about the quantile function of the generic notation for the driving noise in the time series.
We will separate the quantile error models into three categories:
Location and Scale families of quantile function;
Shape and Scale families of quantile function; and
Heavy tailed families of quantile function.
6.1. Location and Scale Quantile Error Families
In this section, we discuss a few examples of quantile error model that practitioners can consider in the class of location scale models. We will present four core models which represent a range of light and heavy tailed structure as well as asymmetric structures around the mode of the error distribution.
Definition 7 (Gaussian Quantile Function)
. The quantile function for a Gaussian random variable is given bywhere the error function is given by Such a model is of relevance if a practitioner believes that there are no extreme observations in the time series that is being considered for fitting. In addition, this model has a symmetric consideration in the tails.
Definition 8 (Cauchy Quantile Function)
. The quantile function for a Cauchy random variable is given by Unlike the Gaussian case, here we consider a heavy tailed error quantile function. Such a model is of relevance if a practitioners believes there is likely to be extreme observations in the time series that is being considered for fitting. In addition, this model has a symmetric consideration in the tails.
Definition 9 (Asymmetric Laplace Quantile Function)
. The quantile function for a Asymmetric Laplace random variable is given by Note that the shape parameter p of the AL distribution gives the magnitude and direction of skewness. AL distribution is skewed to left when and skewed to right when and hence it can model the left skewness of most log transformed loss data directly through this shape parameter p.
This model is a compromise between the two previous models. The ALD is popular in practice due to it convenient parametric structure for quantile loss functions; however, from the perspective of distributional properties, it allows for a light to intermediate tail behaviour. In addition, it allows for asymmetric distributional properties in the left and right tails of the error distribution. It does not however allow for heavy tailed features and often it may be beneficial to consider heavy tails as well as asymmetry. One way to achieve this was studied extensively in
Zhu and Zinde-Walsh (
2009) where they discuss the relationship between popular families of models the Exponential Power distributions (EPD), the Skewed Exponential Power distributions (SEPD) and the Asymmetric Exponential Power distributions (AEPD). Other models developed to achieve such features include the skewed exponential power (SEP) distribution of
Bernardi et al. (
2016a). The SEP model has found wide application uptake in volatility modelling contexts (see examples in (
Marín and Sucarrat 2012;
DiCiccio and Monti 2004) and references therein).
Definition 10 (Skewed Exponential Power Quantile Function)
. If the error random variable is considered distributed according to a Skewed Exponential Power distribution, , then its density is given bywith the location parameter, and the scale and shape parameters, respectively. In addition, the parameter controls the skewness of the distribution. Furthermore, we denote by the functionwhere is the complete gamma function. When represented in this density form, one can observe that the location parameter μ will directly correspond to the τ level quantile. One can also express the quantile function in the following form where it can be obtained from the more general family AEPD quantile function, given bywhere and To obtain the SEP distribution from the AEP, one selects and .
Practitioners can gain an intuition for this model by recognizing that it is related directly to sub-families of the skewed Laplace distribution and the skewed normal distributions.
6.2. Shape and Scale Quantile Error Families
This section will introduce light tailed through to ultra-heavy tailed models. The advantage of such heavy tailed models is that they may provide the ability to capture extreme observations in the observed time series more accurately. Another perspective on such models is that they may allow for a robustification to outliers of quantile time series modelling.
A flexible and popular choice of shape scale families that admits a parametric quantile function is the Weibull example.
Definition 11 (Weibull Quantile Function)
. The quantile function for a Weibull random variable with shape and scale is given by As a second case of shape-scale family of models is the well known transform of the location-scale Gaussian case, given by the Log-Normal model quantile error function.
Definition 12 (Log-Normal Quantile Function)
. The quantile function for a Log-Normal random variable with and is given by The next example of shape scale family of models involves variations of a power law error quantile function, given by modifications of the Pareto quantile function.
Definition 13 (Pareto Quantile Function)
. The quantile function for a Pareto random variable with distribution given byis given by This general class of quantile error function has been previously extended to multi-parameter versions, for instance those studied in the works of (
Cai 2010b;
Dong et al. 2015). Below, we present a simple example of such quantile models that one may adopt for a quantile error function given by the polynomial power-Pareto (PP) quantile error function model.
Definition 14 (Polynomial Power Pareto Quantile Error Function)
. Consider the following distribution function for a random variable with density given bywhere is an implicit function of the following structure which can be obtained by solving the system of equations defined for each observation The resulting quantile distribution of this model is the combination of a power distribution with a Pareto distribution, which enables us to model both the main body and the tails of a distribution. In considering the PP model, the quantile function of is comprised of two components:
component 1: a power distribution where and with a corresponding quantile function, then given by for ; and
component 2: a Pareto distribution function where and with a corresponding quantile function then given by .
One may use the fact that the product of the two quantile functions will remain a strictly valid quantile function, thereby producing the new quantile function family known as the Polynomial-Power Pareto model. The resulting structural form given by the inverse cdf of the Pareto distribution with an additional polynomial power term: The type two generalized beta distribution (GB2) has attractive features for modelling, as it has a positive support
and nests a number of important distributions as its special cases. The GB2 distribution has four parameters, which allows it to be expressed in various flexible densities. For instance, this family contains sub-families of models given by the Generalized Gamma (GG) family and the standard shape scale family of the Gamma distribution. See discussions in
Dong and Chan (
2013) for a more detailed description of GB2 distribution including its pdf and distribution family.
Definition 15 (Type 2 Generalized Beta Quantile Error Function)
. If follows a GB2 distribution, then it can be characterized by the density given bywhere and q are shape parameters and b is the scale parameter. We may rewrite the GB2 model as a generalized Beta distribution with pdfvia the transformation . The GB2 is directly relevant for quantile regression models since one may also find its quantile function in closed form according to the following expression:where . We note that, in general, when we know the mean function of the model as well as the quantile function, we may either perform a mean regression to estimate the parameters or a quantile regression—these two different approaches will in general produce different results for the resulting parameter estimates of the model, except in symmetric distribution settings when the median is considered. In this case, one would obtain a more robust regression (less sensitive to outliers) than obtained from the mean regression. In all other cases, these results will differ, however, having fit either the quantile model, or the mean regression model, we may reverse back to get the quantile model from a mean fit or the mean implied by the quantile regression fit and compare their differences, as indicated for the GB2 model below.
Remark 9 (Link Between GB2 Quantile Error Function and Mean Regressions)
. In mean regression, b can be linked to the mean μ of the distribution as follows:where μ is for instance a log-link to a linear function of covariates μ in (66) according to the relationship: Then, the variance is given by: We would argue that, from a parsimony perspective, practitioners would be best suited to first try the simple two parameter families to assess the quality of their fitted quantile time series models, if the resulting model fit is adequate then these would suffice. If, however, the fit is not adequate, then one may generalize to the three and four parameter families that also admit heavy tailed features and general skewness structure.
6.3. Truncated Error Quantile Functions
It will often in practice be beneficial to work with models for which the random variable of interest will be restricted to one of the possible domains , or . In this case, the model constructed will require the quantile error function to also be restricted to this domain. This is easily achieved in many cases and we will illustrate this below with examples of truncated quantile error families.
To proceed, we consider a standard distribution
(such as LogNormal, Gamma, etc.) with a corresponding density function
. However, one may be interested in modeling a time series restricted above some threshold
only. Then, one can consider a distribution truncated below L formally defined as
with a corresponding truncated density function
Note that this truncated density is a proper density function, that is, .
In principle, assuming the mapping
is restricted in its range to the interval
, this would not necessarily require explicitly that
be restricted to the same interval; however, in practice, it would be natural to consider such cases. Therefore, we briefly outline how this is easily achieved in parametric quantile error models generically as follows, for
as follows:
where
and
is the same functional form as the inverse of
with the appropriate restriction from the indicator and adjustment to quantile level from the normalization from the truncation.
Similarly, one can model below
L using a distribution truncated above
L:
As above, we can easily tackle this case also in parametric quantile error models generically as follows, for
as follows:
where
.
If there is a need to model in a specific range
, one can use distribution
truncated below
L and above
U:
The truncated quantile error model can be obtained as follows:
where
and
is the same functional form as the inverse of
with the appropriate restriction from the indicator and adjustment to quantile level from the normalization from the truncation.
7. Generalized Elongation Deformation Quantile Error Families
In this section, we discuss the family of quantile deformation models generally known in statistics as the family of Tukey elongation transforms (see detailed overview of such models in (
Peters et al. 2016;
Peters and Sisson 2006)). This family of models can be considered to be a generalization of the family of Rank Transmutation Maps (RTMs) discussed in
Shaw and Buckley (
2009). Others who have addressed similar issues to do with distortion transforms to map quantile functions of a base distribution to another class of distributions include the early work of
De Helguero (
1908). Other related works on distortion of density functions (as opposed to directly the quantile) were developed by (
Vicari and Kotz 2005;
Azzalini 2005;
Genton 2005).
Here, we discuss several distributional families relevant to modelling that can only be specified via the transformation of another standard random variable, for example a Gaussian. Examples of such models which are typically defined through their quantile functions include the Johnson family, with base distribution given by Gaussian or logisitic, and the Tukey family with base distribution typically given by a Gaussian or logistic.
The advantage of models such as the g-and-h family for modelling is the fact that they provide a very flexible range of skew, kurtosis, and heavy-tailed features while also being specified as a rather simple transformation of standard Gaussian random variates, making simulation under such models efficient and simple.
7.1. Tukey Class of Elongation Maps
Tukey suggested several nonlinear transformations of a reference random variable, typically considered to be symmetric and often selected to be a standard normal random variable in practical model applications, which will be denoted below by . There are then several sub-families of elongation transform that each produce different transformations of the reference quantile function of random variable W that induce specific skew and kurtosis features, relative to the base model.
One of the most well known of these classes of transformation is the g-and-h transformations which involve a skewness transformation of type g and a kurtosis transformation of type h. If one replaces the kurtosis transformation of the type h with the type k, one obtains the g-and-k family of distributions discussed by
Rayner and MacGillivray (
2002). If the type h transformation is replaced by the type j transformation, one obtains the g-and-j transformations of
Fischer and Klein (
2004).
The generic specification of the Tukey transformation is provided in Definition 16. These types of transformations were labeled elongation transformations, where the notion of elongation was noted to be closely related to tail properties such as heavy-tailedness (see discussions in
Hoaglin (
2006)). In considering such a class of elongation transformations to obtain a distribution, one is comparing the tail strength of the new distribution with that of the base distribution (such as a Gaussian or logistic). In this regard, one can think of tail strength or heavy-tailedness as an absolute concept, whereas the notion of elongation strength is a relative concept. In the following, we will first consider relative elongation compared to a base distribution for a generic random variable
W. It should be clear that such a measure of relative tail behavior is independent of location and scale.
Remark 10 (Desirable Properties of Quantile Elongation Transformation)
. An elongation transformation should also satisfy the following properties:
- 1.
Preservation of Symmetry: it is desirable that should one wish equi-probable tails on the left and right, then the mapping should be able to preserve symmetry, say around the mode, such that will hold under certain parameter settings;
- 2.
Deformation Around the Mode Controlled: the base distribution for the random variable’s quantile function being transformed should not be significantly transformed/deformed in the center, such that for w around the mode;
- 3.
Additional Relative Skewness and Relative Kurtosis: to increase the heaviness of the tails of the resulting distribution relative to the base distribution, it is important to assume that is a strictly monotonically increasing transform that is convex, that is, one has the transform satisfying for that and .
One such transformation family satisfying these properties is the Tukey transformations.
Definition 16 (Tukey transformations)
. Consider a Gaussian random variable and transformation then the resultant transformed error variable ϵ will be from a Tukey law if the corresponding transformation is given byfor a parameter . Under this transformation, we also have directly in closed form the quantile function of the error random variable ϵ in terms of the quantile function of the base random variable W as follows:with translation and scaling constants a, b for quantile levels . In application, it may often be desirable to enforce a constraint that the tails of the resulting distribution, after transformation, are heavier than the Gaussian distribution. In this case, one should consider a transformation , which is positive, symmetric, and strictly monotonically increasing for positive values of . In addition, it will be desirable to obtain this property of heavy tails relative to the Gaussian to also consider setting the parameter . As discussed, a series of kurtosis transformations is proposed in the literature. The Tukey transformations of types h, k, and j are provided in Definition 17.
Definition 17 (Tukey’s kurtosis transformations of types h, k and j)
. The h-type transformation, denoted by , is given by The k-type transformation, denoted by , is given by The j-type transformation, denoted by , is given by In addition to the kurtosis transformations, there are skewness transformations that have been developed in the Tukey family, such as the g-type transformation.
Definition 18 (Tukey’s skewness transformation)
. The g-type transformation, denoted by , is given by The generalized g-type transformation, denoted by , is given by To nest all these transformations within one class of transformations, the work of
Fischer (
2010) proposed a power series representation denoted by the subscript
a given in Equation (
82). This suggestion, though it nested the other families of distributions, is not practical for use as it involves the requirement of estimating a very large (infinite) number of parameters
to obtain the data-generating mechanism:
It was further observed in
Fischer (
2010) that this nesting structure may be replaced with a different form, given by the general transformation taking the form given in Equation (
83):
Then, it is clear that the original h-, k-, and j-type transformations are recovered with , , and . Further details of these transformations is provided in future sections where these classes of transformation are also applied to develop conditional quantile time series models.
7.1.1. Properties of the g-and-h Quantile Error Family
One can obtain the moments of Tukey family of distributions, with generically denoted Tukey quantile transform given by
, as the solution to the following integrals, where the n-th moment is given with respect to the transformed moments of the base density as follows:
From such a result, one may now express the moments of the g-and-h distributed random variable according to the result in Proposition 1.
Proposition 1 (Moments of the g-and-h density)
. Consider the g-and-h distributed random variable with constant parameters g and . The n-th integer moment is given with respect to the standard Normal distribution and the n-th power of the transformed quantile function given byto produce moments according to the relationshipwhich will exist if . One can also observe more generally that, under the g-and-h transform, the following identity holds with regard to powers of the standard Gaussian, , such thatwhich will produce moments given by Furthermore, it was shown by Dutta and Babbel (2002) that, when it exists, one can obtain the general expression Proof. This result follows from direct application of the binomial series expansion result for polynomial integer powers, followed by the moment of the
i-th integer order integration result derived in
Dutta and Babbel (
2002). ☐
Remark 11. We note the following properties of moments for the g (h = 0) and the h (g = 0) distributions, respectively. In the case of g distribution, since the g-distribution is a horizontally shifted LogNormal distribution, then the moments of the g-distribution take the same form as those of a LogNormal model with appropriate adjustment for the translation. The h-distributional family is symmetric (except the double h-h family); consequently, all odd-order moments for the h-subfamily are zero (see further discussion in Dutta and Babbel (2002)). Furthermore, using these moment identities, one can easily then find the skew, kurtosis, and coefficient of variations for model families such as the g-and-h, the g-distributions and h-distributions. In addition to these simple population summaries of the g-and-h model, one could also consider other generalized properties of quantile-based functionals of asymmetry and kurtosis (see
Balanda and MacGillivray 1990;
Rayner and MacGillivray 2002;
Balanda and MacGillivray 1988).
7.1.2. Tail Behaviour of the g-and-h Quantile Error Family
In terms of the tail behavior of the g-and-h family of distributions, the properties of such severity models have been studied by numerous authors such as (
Morgenthaler and Tukey 2000;
Degen et al. 2007). In particular, the tail property (index of regular variation) for the g-and-h family of distributions was first studied for the h-distribution by
Morgenthaler and Tukey (
2000) and later for the g-and-h distribution by (
Degen et al. 2007, see Proposition 2). In addition, the second-order regular variation properties of the g-and-h family of distributions were studied by
Degen et al. (
2007).
In order to study the properties of regular variation of the g-and-h family of loss distribution models, it is first important to recall some basic definitions. First, we note that a positive measurable function
is regularly varying if it satisfies the conditions in Definition 19 (see discussion in
Karatzas and Shreve (
1991)).
Definition 19 (Regularly varying function)
. A positive measurable function is regularly varying (at infinity) with an index if it satisfies:
We note that, when , then the function is said to be slowly varying (at infinity). From this definition, one can show that a random variable has a regularly varying distribution if it satisfies the condition in Definition 20.
Definition 20 (Regularly varying random variable)
. A loss random variable X with distribution taking positive support is said to be regularly varying with index if the right tail distribution is regularly varying with index .
The following important features can be noted about regularly varying distributions as shown in Theorem 1 (see detailed discussion in
Bingham et al. (
1989)).
Theorem 1 (Properties of regularly varying distributions)
. Given a loss distribution satisfying for all , the following conditions on can be used to verify that it is regularly varying such that :
Many additional properties are described for such heavy tailed distribution and density functions. Here, we will utilize the above stated conditions to assess the regular variation properties of the right tail of the g-and-h family of loss models. In particular, we will see if a single distributional parameter characterizes the heavy tailed feature as captured by the notion of regular variation index, or if the relationship is more complex.
Proposition 2 (Index of regular variation of g-and-h distribution)
. Consider the random variable and a random variable ϵ, which has severity distribution given by the g-and-h distribution with parameters , denoted , with and density (distribution) (and . Then, the index of regular variation is obtained by considering the following limit:for where the function is given by Hence, one can state that .
The asymptotic tail behavior of the h-family of Tukey distributions was studied by
Morgenthaler and Tukey (
2000) and is given in Proposition 4.
Proposition 4 (h-type tail behaviour)
. Consider the h-type transformation, where is a standard Gaussian random variable and the random variable ϵ has severity distribution given by the h-distribution with parameters , denoted according to Then, the asymptotic tail index of the h-type distribution is then given by . This is equivalent to the g-and-h family for .
This shows that the h-type family has a Pareto heavy-tailed property, hence the restriction that moments will only exist on the order of less than
. The g-family of distributions can be shown to be sub-exponential in the tail behavior but not regularly varying. It was shown (
Degen et al. 2007, Theorem 2.2) that one can obtain an explicit form for the function of slow variation in the g-and-h family as detailed in Theorem 2.
Theorem 2 (Slow variation representation of g-and-h severity models)
. Consider the random variable and a random variable ϵ, which has distribution given by the g-and-h with parameters , denoted , with and and density (distribution) (and . Then, for some slowly varying function given as by From this explicit Karamata representation developed by
Degen et al. (
2007), it was also shown that one can obtain the second-order regular variation properties of the g-and-h family.
The implications of these findings are that the g-and-h distribution, under the parameter restrictions
and
, belongs to the domain of attraction of an Extreme Value Distribution, such that
with distribution
F satisfying
where
. As a consequence, by the Pickands–Balkema–de Haan Theorem, discussed in detail in
Embrechts et al. (
2013) and recently in
Cruz et al. (
2015), one can state that there exists an Extreme Value Index (EVI) constant γ and a positive measurable function
such that the following result between the excess distribution of the g-and-h (denoted by
and the generalized Pareto distribution (GPD) is satisfied in the tails
For discussion on the rate of convergence in the tails, see
Raoult and Worms (
2003) and the application of this theorem to the g-and-h case by
Degen et al. (
2007), where it is shown that the order of convergence is given by
for functions
Hence, the conclusion from this analysis regarding the tail convergence of the excess distribution of the g-and-h family toward the GPD
is given explicitly by
Remark 12. The implications of this slow rate of convergence are that, when data are obtained from a process, if a goodness-of-fit test suggests that one may not reject the null hypothesis that these data came from a g-and-h distribution, then one should avoid performing estimation of the extreme quantiles, such as those used to measure the capital via the Value-at-Risk, via methods based on Peaks Over Threshold (POT) or Extreme Value Theory (EVT) based penultimate approximations.
Proposition 5 (Index of regular variation of the generalized g-and-h distribution)
. Consider the random variable and a random variable ϵ, which has distribution given by the generalized g-and-h distribution with parameters , denoted , with and density (distribution) (and . Recall that we have, for the generalized g-and-h loss model, the function with and given by Using this, we can then find the index of regular variation at given as follows: We note that this result is not unexpected since the g transform in each case drives the skewness and not the kurtosis. We can also obtain this analysis for the g-and-k model, this yields that the g-and-k does not admit a finite limit in either sign of the parameter g, showing that such a model is not regularly varying, as we see in the case of the g-and-h models. However, even though this is the case, we can still assess the relative heavy tailedness of the g-and-k models compared to the base distribution under the Tukey k-transform.
9. Illustrations of Quantile Time Series Models for Mortality and Demographic Actuarial Applications
In this section, we explore a range of mortality and demographic data sets via quantile time series regressions. The outputs of this analysis can be directly useful in insurance applications for instance in life insurance applications in annuities pricing and risk management as well as pension policy development. We do not go into detail on these particular areas of application in this manuscript; instead, we focus on modelling and comparison of different quantile time series models on real mortality and demographic data sets obtained for England, Wales, Scotland and Northern Ireland.
The intention of these application illustrations is not to be exhaustive on all the different models explored in previous sections; instead, we focus on providing examples of illustrations of these new regression techniques to show actuaries and practitioners how they may be readily applied in practical settings to explain some of the properties of the linear vs. nonlinear parametric and non-parametric models.
In this manuscript, we will focus on data reflecting Demographic data and health event data. In particular, the data we consider includes several different time series data sets from the following sources with the following attributes:
the Human Mortality Database
2, which provides records of annual data for aggregated births, aggregated deaths by age group with yearly stratification and population sizes. We took a specific focus on England, Wales, Scotland and Norther Ireland.
the United Kingdom Office of National Statistics data
3, where we obtained weekly mortality records from 2010 to 2017. Furthermore, we also obtained decompositions of the annual death counts for England and Wales between 2001 and 2013 for avoidable mortality events and alcohol related deaths.
the National Archives also provide the number of deaths annually by sex, age group and underlying cause from periods of 1901 to 2017
4.
the National Records of Scotland data
5, where we obtained weekly birth and death recordings for Scotland as well as the weekly recorded deaths due to respiratory disease, from 2004 to 2017. In addition, the monthly recorded births and deaths by geographical area in Scotland was obtained from 1990 to 2017.
the National Records of Scotland data
6, where we obtained weekly death recordings as well as monthly death records from 2006 to 2017 for Northern Ireland. Furthermore, alcohol related deaths were also obtained monthly from 2006 to 2017 for Norther Ireland.
The illustrations of quantile time series modelling on these data sets will be undertaken by data type and regions. Since this manuscript is intentionally not focused on aspects of estimation of quantile time series models, we will utilise existing R packages to perform estimation of the models explored in this section. All of the model illustrations performed in the following sections were estimated with standard quantile regression and time series packages in R based on ‘rq’ and ‘nlrq’ function outputs.
9.1. Annual Births for Males and Females: England and Wales, Scotland and Northern Ireland
We begin with analysis of the Human Mortality Data Base data sets of annual births by year. The data is presented in
Figure 1.
9.1.1. Examples of Linear Parametric QAR Modelling
We first select the order of the time series regression based on AIC criterion considering one to five lags. In
Table 1, we present the results for the AIC vs. lag for Male and Female births over time.
We see that, for all cases, both male and female time series prefer lag structure, according to AIC assessment, of order 5 with the exception of Northern Ireland male births where a lag of 4 was selected. Therefore, we first proceed with a linear quantile time series analysis to assess the lag 5 linear QAR model. We present the fitted quantile time series results in
Figure 2. We note that the results are presented for males only as the female results in this case are very similar. The plots show the estimated AR(5) model quantile residuals for decile values
. First, we show the lag 1 to lag 5 estimated quantile regression coefficients versus the quantile level in
Figure 2.
We can also assess the statistical significance of the fitted coefficients to see if they are statistically different from zero, even though AIC has suggested a model order of 5. For instance, as an illustration, we will consider the case of the model for and the first and second deciles.
For the QAR(5) model , the coefficients corresponding to lag 2 and lag 3 are basically on the border of being statistically significant according to the upper bound of a 95% confidence interval of the coefficient including 0. However, lags 4 and 5 are clearly not statistically significant as their 95% confidence intervals of the estimated coefficients clearly contain zero. In this case, one could consider including a comparison of a QAR(3) model. Furthermore, it is evident from the estimated coefficient for the lag one coefficient that the model is very close to the boundary of a random walk type behaviour for these low quantiles. Actually, this type of behaviour is seen throughout the entire range of decile fits in this data. In the case of the model for , one sees that all coefficients on lags 2 to 5 are clearly not statistically significant when one looks at whether their 95% confidence intervals on the coefficient estimates contain 0.
In addition, in order to assess the quality of the fitted QAR(5) quantile models at each quantile level, we also plot the studentised residuals of each model fit as a function of the quantile level in
Figure 3.
We see from these plots that the fitted QAR(5) models for each of the deciles
through to
have studentized residuals that are very well behaved. This indicates that the fitted models are doing a reasonable job at capturing the quantile time series dynamics of the births data. To finish this aspect of the illustrations, we will also fit the England and Wales data with a QAR(1) model to see how it performs relative to the QAR(5), since we found that the coefficients for lags 2 to 5 were not statistically significant. We show the fitting results for the QAR(1) model for the male births from England and Wales in
Figure 4.
The top subplot in
Figure 4 again confirms that the fitted model is very close to a random walk type behaviour across all decile levels, except for very low quantile levels. In this QAR(1) model analysis, the bottom subplot shows the fitted lines are superimposed in gray. In this case, we see in the top subplot that AR coefficients are basically very close to constant across quantiles and one would then expect fitted lines that are parallel to each other as the only change is the quantile level fitted. There is a slight fanning happening for quantile levels around the median, but this is very close to uniform behaviour across all quantiles.
We learn from this analysis that there has been a steady decline in the birth rates of males in Scotland, which is more pronounced in the last few decades than the declines seen in Northern Ireland. We will therefore focus further on the Scottish case study.
9.1.2. Examples of Nonlinear Non-Parametric QAR Modelling
We proceed next with an illustration of nonlinear quantile time series models for the total weekly births for Scotland from 2004 to 2018. We consider fitting both linear and nonlinear quantile regression models to this weekly data. We will use a QAR(1) linear model as a comparative reference, which was suitable for the yearly aggregate data. In
Figure 5, we see the fitted QAR(1) coefficients for the first lag as a function of quantile level are significantly different when looking at weekly observation patterns compared to the annual aggregate data.
In particular, we now see a pronounced deviation away from the random walk type behaviour observed in the annual counts models. Furthermore, we see that strength of the serial dependence present in the quantile time series of births is diminishing in strength as we move from low to high quantile levels, as reflected by the estimated magnitude of the first lag coefficient. Furthermore, we see that this change in coefficient of the lag one QAR models as a function of quantile level results in the fitted regressions fanning out much more than at the annual aggregate level where we saw almost parallel line relationships with the quantile level.
We will now demonstrate how to improve such a fit with nonlinear non-parametric quantile regression modelling in R using the nlrq package and the lprq local polynomial quantile regression function where we explore the effect of the bandwidth parameter h. In this case, we use the weekly time as the input covariate, constructing a model with local nonlinear polynomial transforms for and distributed lags for of week index for the regression variable.
We see that the fit of the median regression is reasonable; however, a stronger bandwidth is required to ensure that certain points don’t have too great a leverage effect on the local polynomial median quantile regression.
Next, we plot in
Figure 6 and
Figure 7 the fitted quantile regressions for a range of quantile levels
with bandwidth
and we only consider the temporal weekly covariate in the nonlinear non-parametric quantile regression.
9.2. Annual Deaths for England and Wales, Scotland and Northern Ireland
Next, we analyse the Human Mortality Data Base data sets of annual deaths by year and by age group. The data is presented in
Figure 8 where we explore particular age groups
.
Examples of Linear vs. Nonlinear Parametric QAR Modelling
In this section, we undertake a study of the first differences of the annual deaths for a range of ages for England and Wales, Scotland and Northern Ireland. We will consider a range of parametric nonlinear models of the following forms:
We present the results below for England and Wales as similar results were obtained for Scotland and Northern Ireland. The results for the fitted QARI(1,1) model are presented in
Figure 9 annual deaths for ages 20, 65 and 75 years old males. We also show the fitted quantile time series models for 0.1, 0.5 and 0.9 quantiles for an age group of 20 years in
Figure 10.
The fits of the QAR(1,1) model for the 0.1 and 0.9 quantile models are clearly having difficulty in the fit quality of the interval where the deaths suddenly declined in the great war periods between 1910–1940. There is also an evident asymmetry in the volatility of the fitted QARI(1,1) model for the compared to the case of . We also observe that both of the extreme quantile time series models struggle to differentiate the change that occurred in the deaths after the great wars and the behaviour before. We will therefore explore some examples of nonlinear quantile regression models.
Next, we explore in
Figure 11 the nonlinear parametric Double QARI model described above, where we select values of
and we compare this model fit to the linear QAR(1) model for the median
. We see that, when the coefficient
b is small, the model for the median time series regression is significantly skewed; however, as
b increases, it becomes less skewed and produces a more reactive fit to the periods of large death count change relative to the results obtained from the linear QAR(1) median time series model. One would need to be careful to assess the model output in this case to ensure that over fitting was not a problem. This can be achieved by looking at the residuals of the regression fits and standard model selection criterion.
Next, we illustrate the difference between the QARI(1,1) linear model to the Tukey G transform model explained in Definition 18. We note that the behaviour of the median regression performance of this model for values of
g has a highly nonlinear relationship with the parameter
g and the degree of responsivity that the median regression has produced when fit to the data. For instance, we plot in
Figure 12 the choices of
and
, where we see that, for smaller values of
g, one effectively recovers a model almost identical to the QARI(1,1) linear time series model with a slight deviation around 1920. However, for
, we see that the model is skewed in the median response and can be significantly more responsive to individual death yearly fluctuations than the QARI(1,1) model.
We note that the simple Tukey G model as presented can only be skewed in one direction; hence, we see that the values below the median have little influence on the result compared to the samples above the median. In these examples, we have seen the behaviours of nonlinear quantile regression models versus simple linear regressions.
9.3. Alcohol Related Age-Standardised Death Rates per 100,000 Population of the UK
In this example, we study the time series for alcohol related deaths in the UK for males and females between the period 1994 to 2016 (see
Figure 13). In this set of examples, we study a model that may be interpreted according to the class of nonlinear quantile time series models for the Rank Transmutation Maps (RTMs), which we demonstrate on the two real data sets. The particular example considered is a Weibul model growth curve model given by
where
and
are the lower and upper asymptotes of the curve,
k is the growth rate and
δ controls the
x coordinate for the point of inflection.
We then consider the fitted results for male and female alcohol annual related deaths over time under the Weibul growth curve quantile regression model, for 0.1, 0.5 and 0.9 quantile levels. The results of the nonlinear quantile regression are provided in
Figure 14. In both cases, the Weibull RTM quantile model provides a reliable fit at the quantile levels studied.
9.4. Male Population Size 65–69: England and Wales
As a further illustration of the quantile time series models discussed in this tutorial, we will also consider fitting quantile time series models for the official recorded annual population size for males in age groups 65–69 between 1911 and the year 2000.
In this illustration, a nonlinear quantile regression based on a logistic growth model is considered. This is a form of RTM model with a logistic distribution. In its most basic form, it is a logistic growth curve often termed the “S” shaped sigmoid curve, with equation:
where
is the
x-value of the sigmoid’s midpoint,
L is the curve’s maximum value, and
k is the steepness of the curve. In this model, we utilised it for the nonlinear quantile regression function. The results of the fit are presented in
Figure 15 for each of the three age groups.

















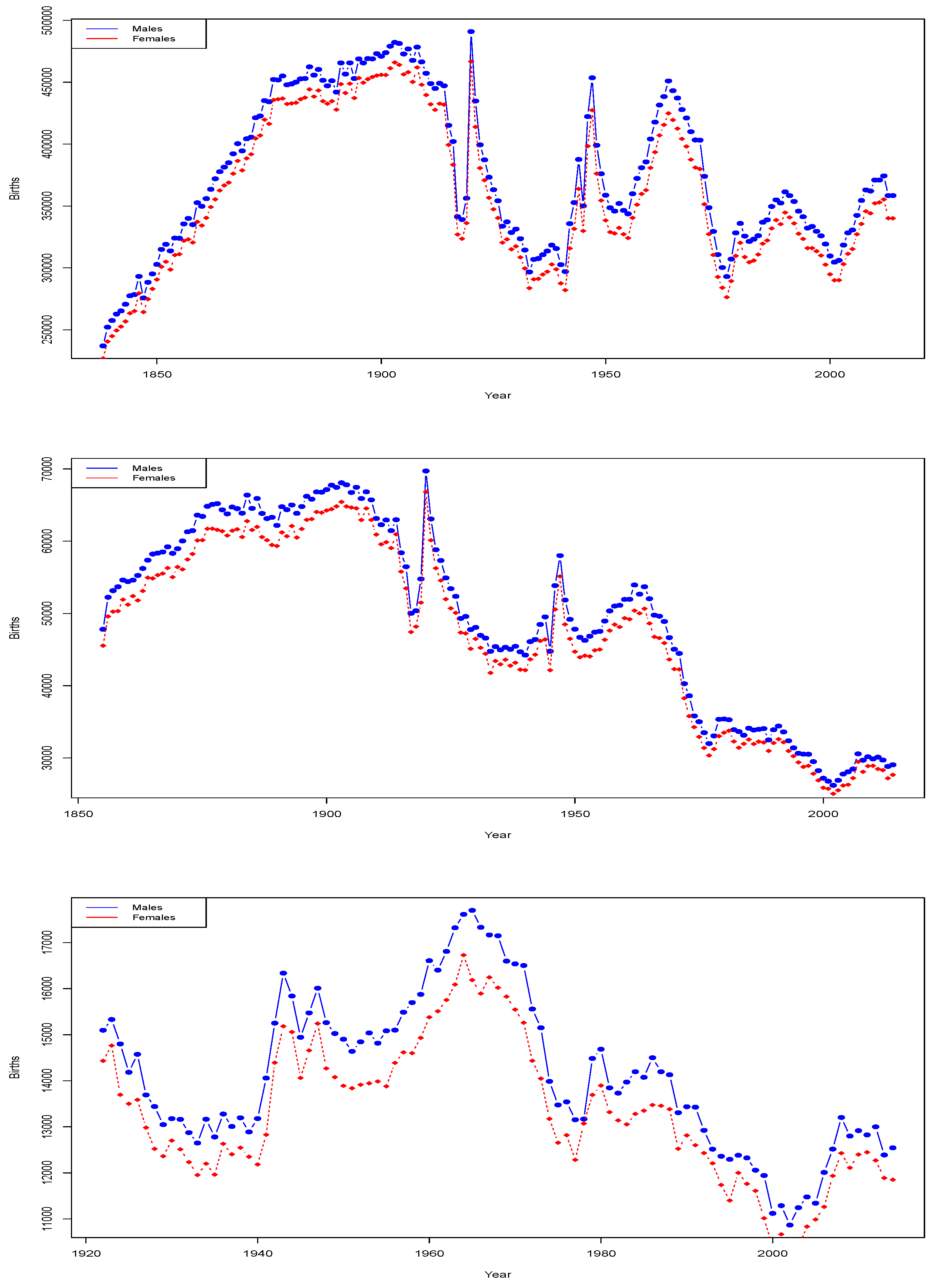{kind=link}
{kind=link}
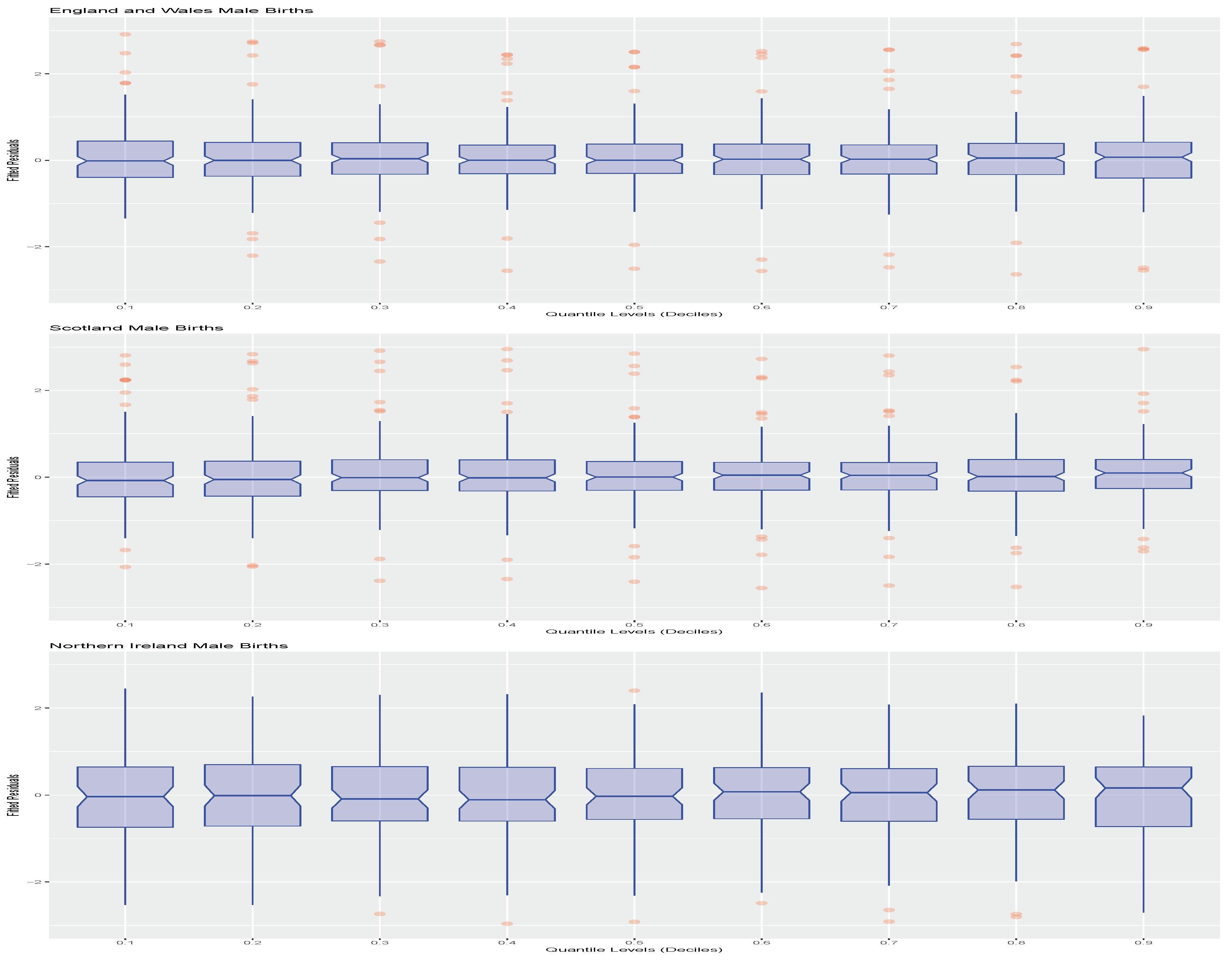{kind=link}
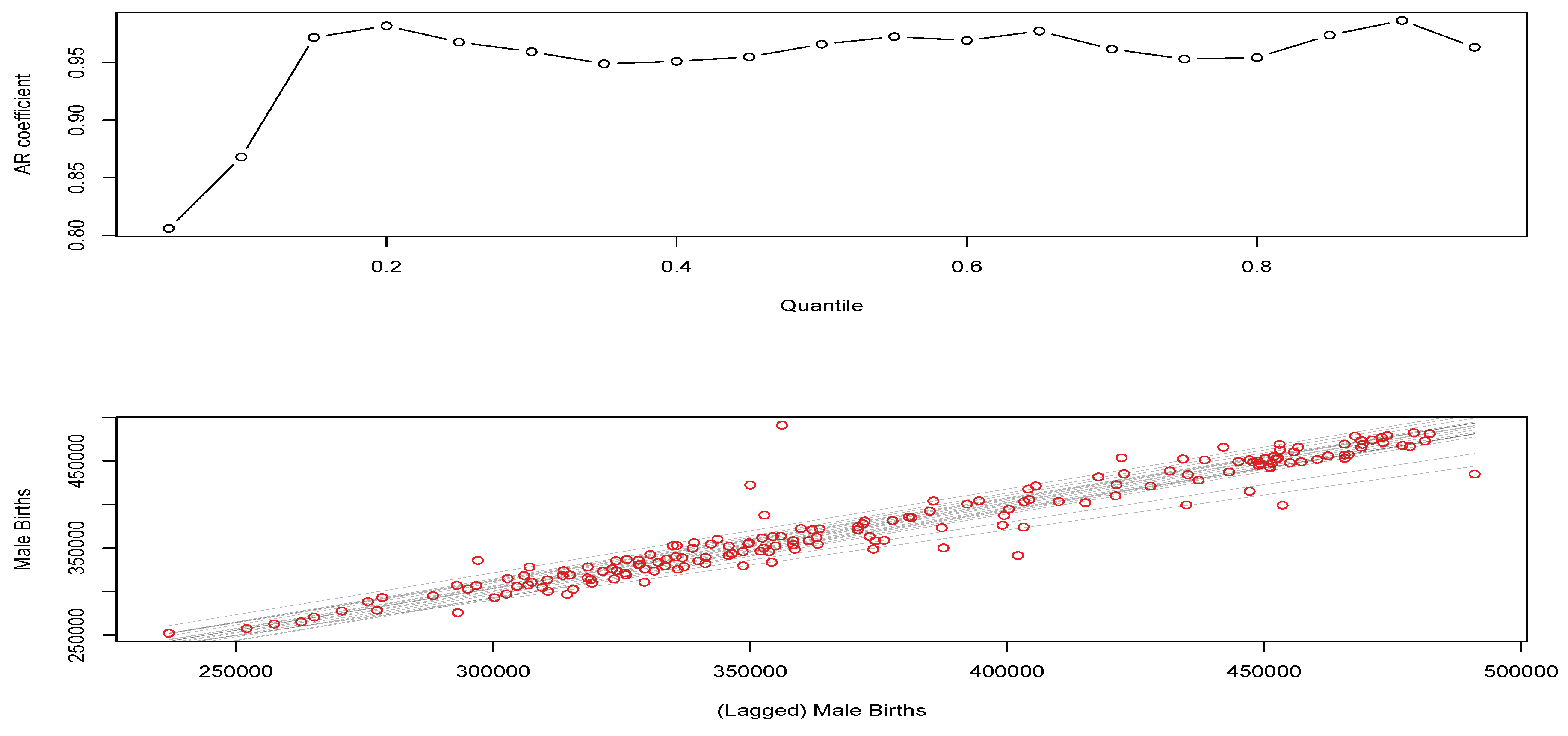{kind=link}
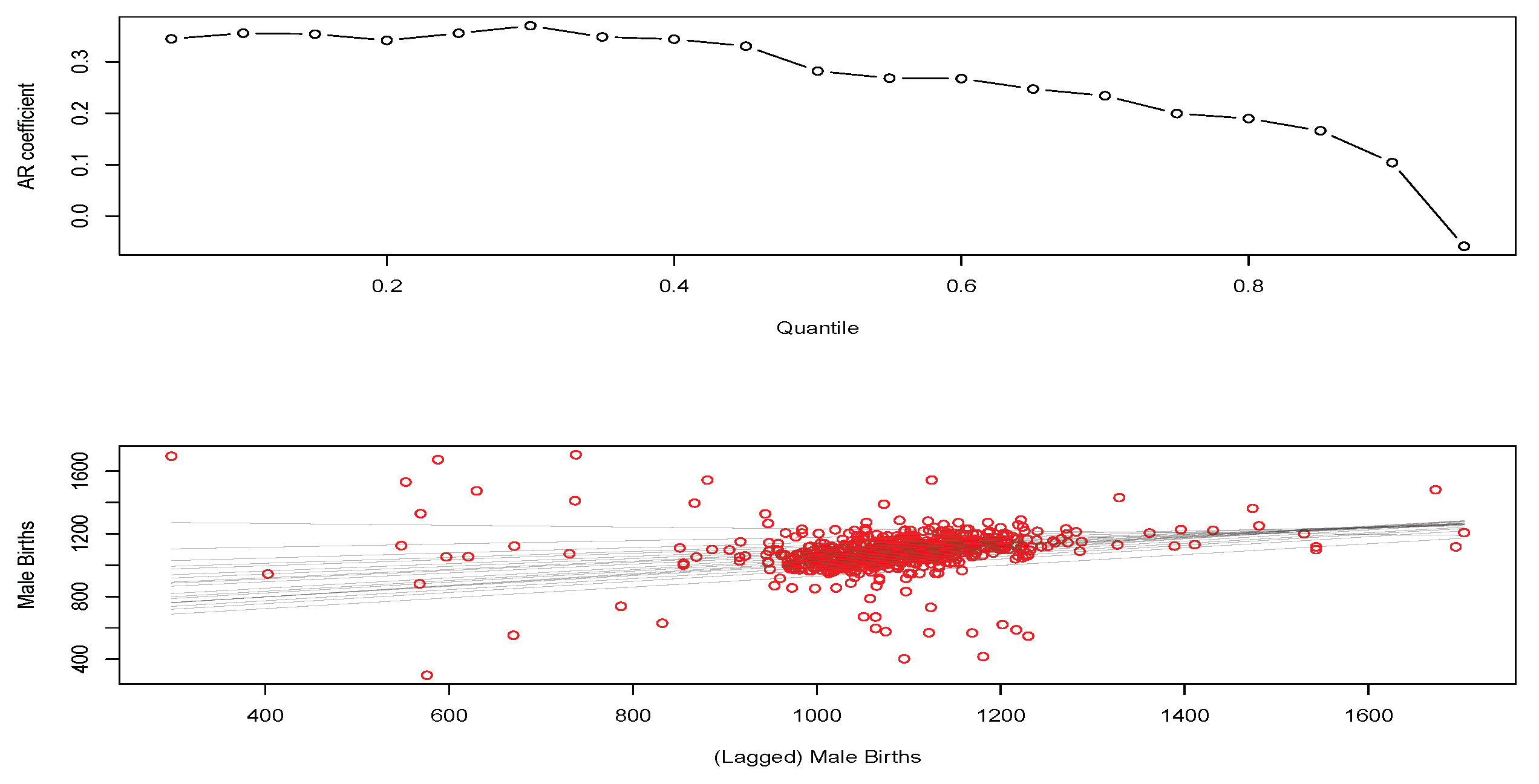{kind=link}
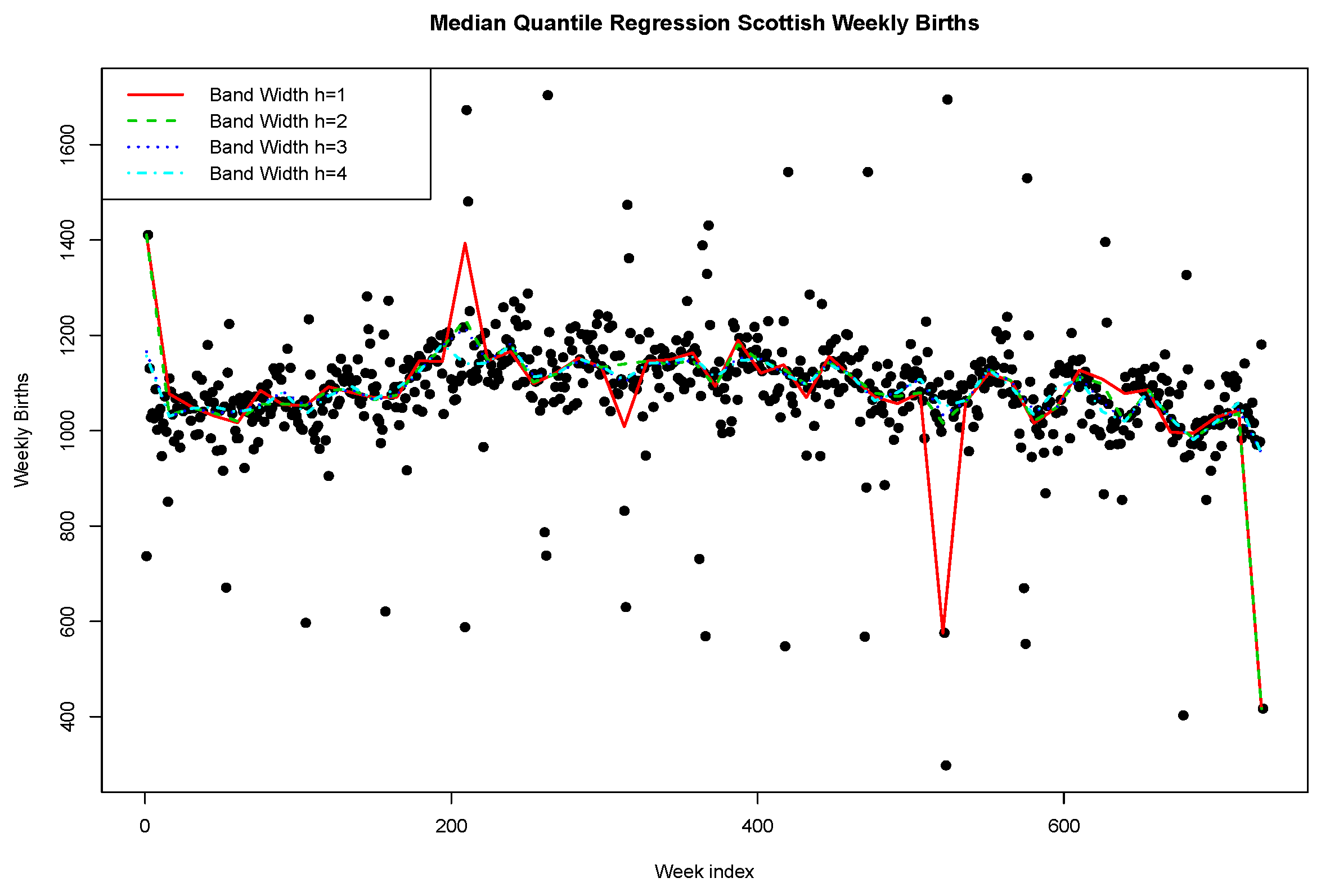{kind=link}
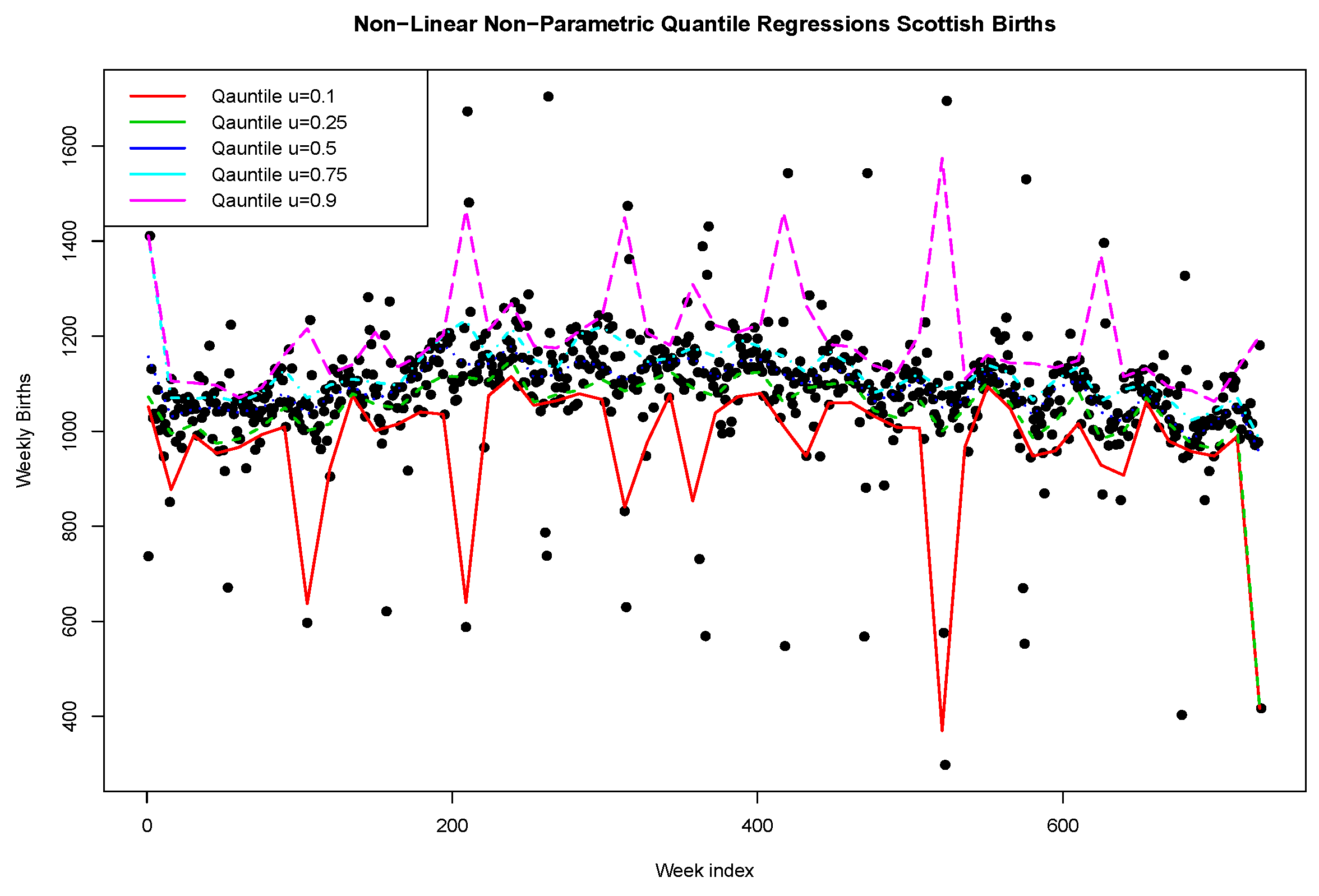{kind=link}
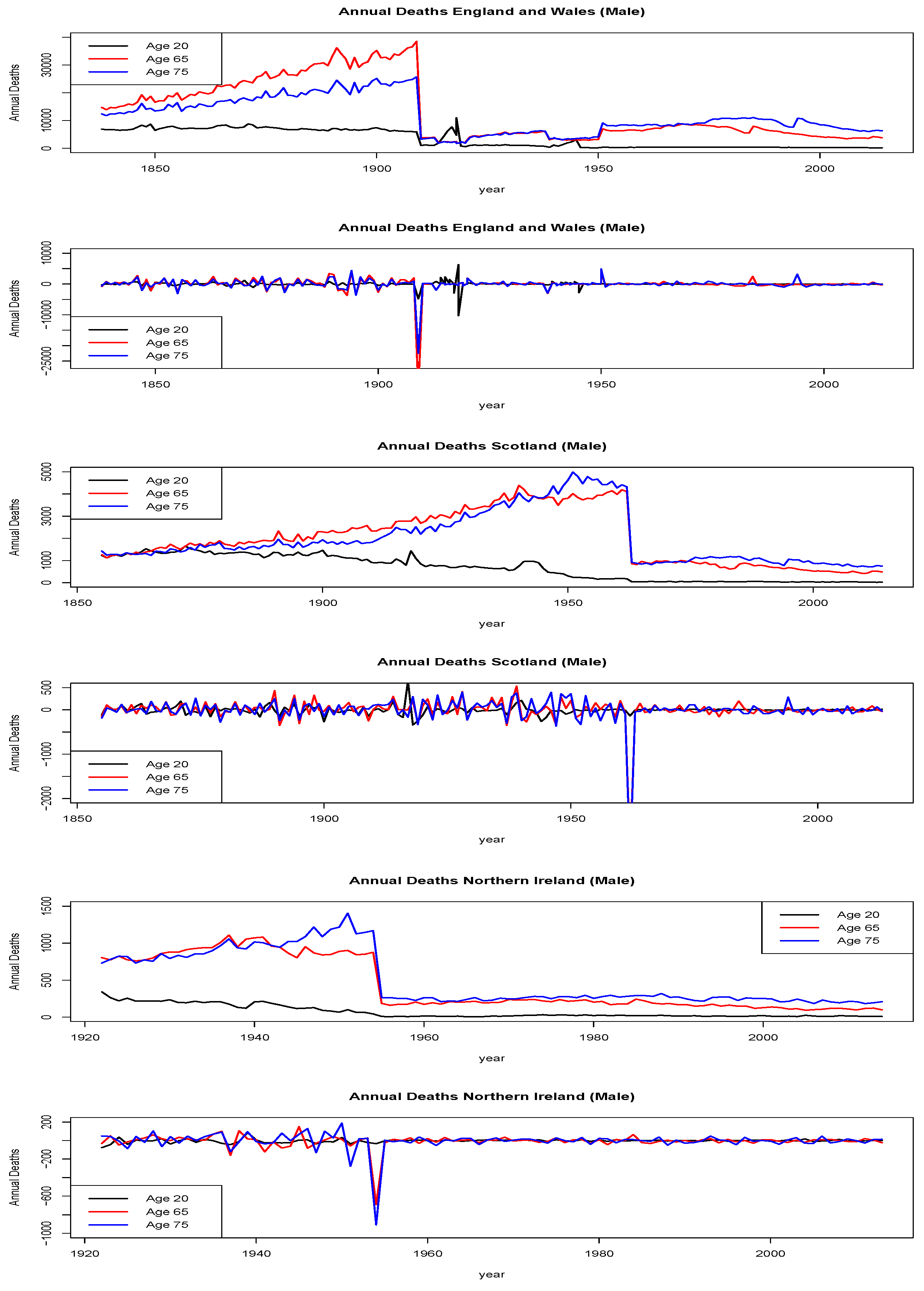{kind=link}
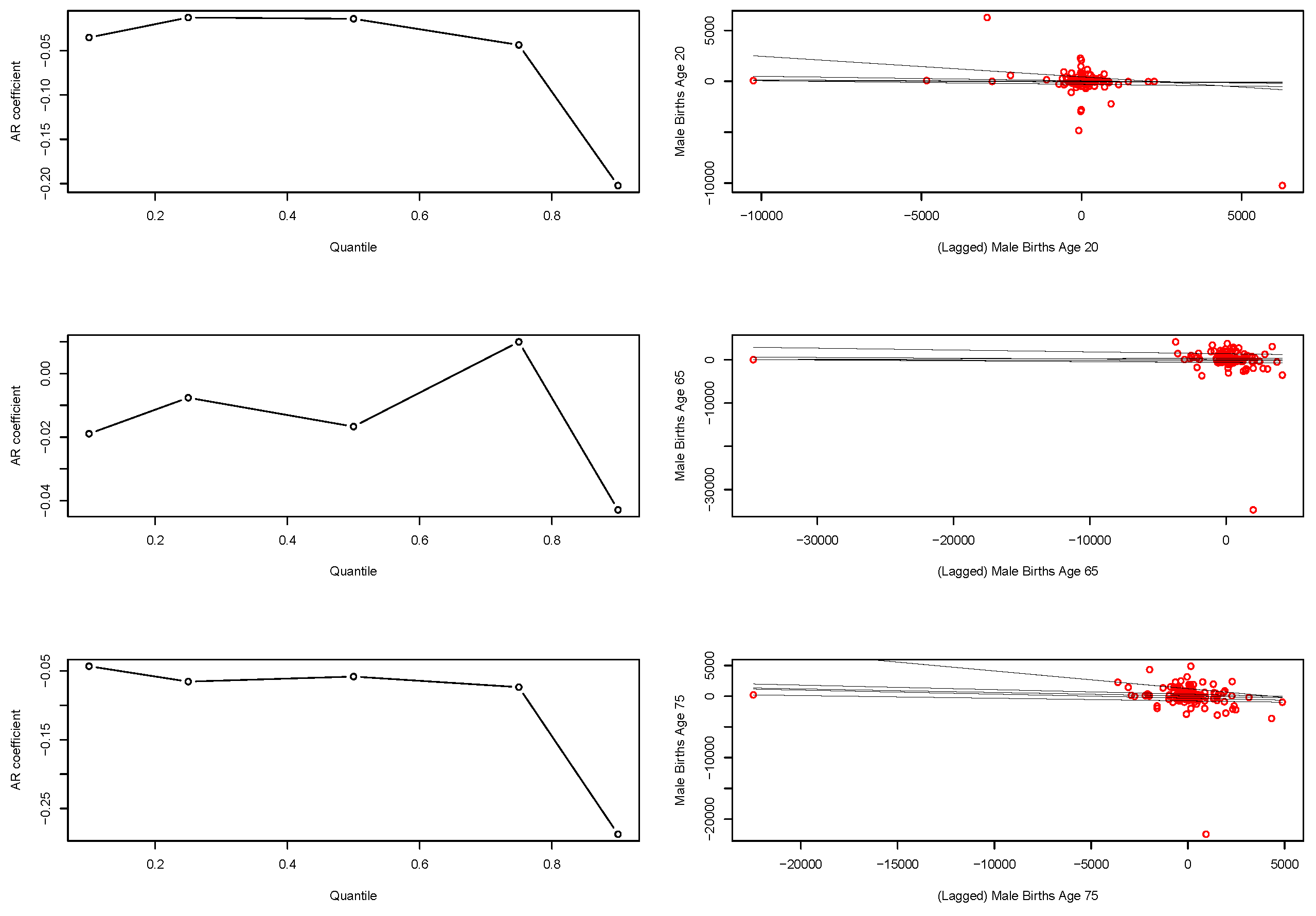{kind=link}
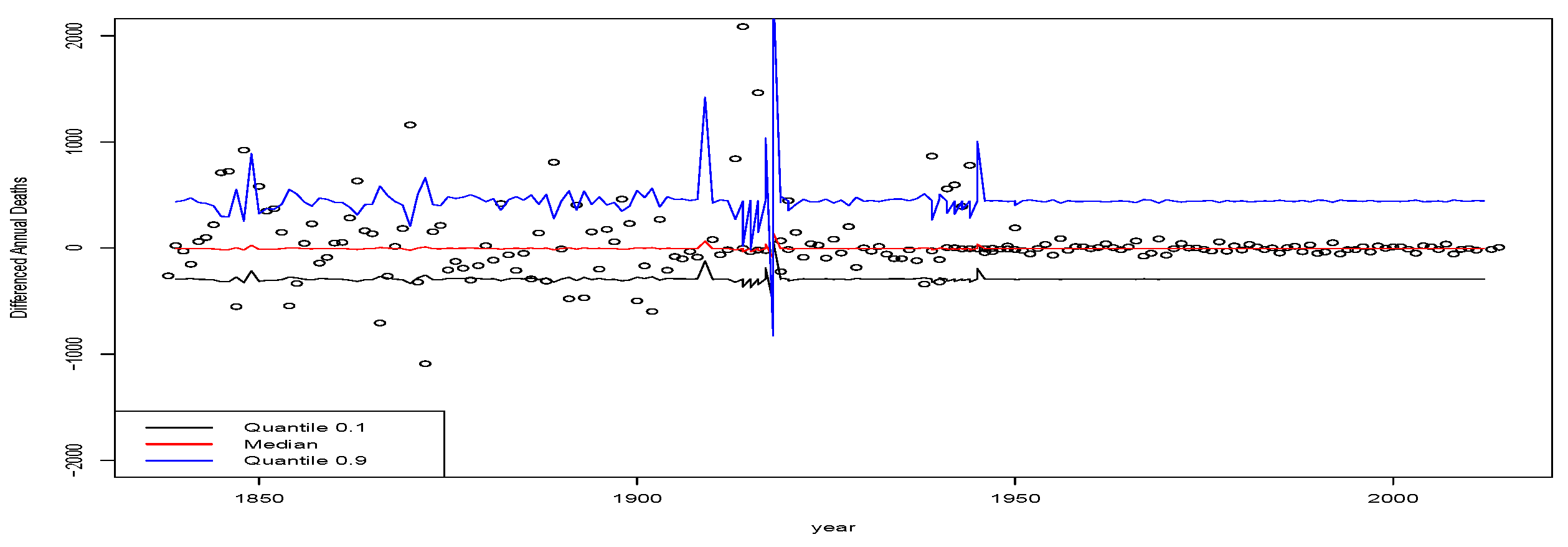{kind=link}
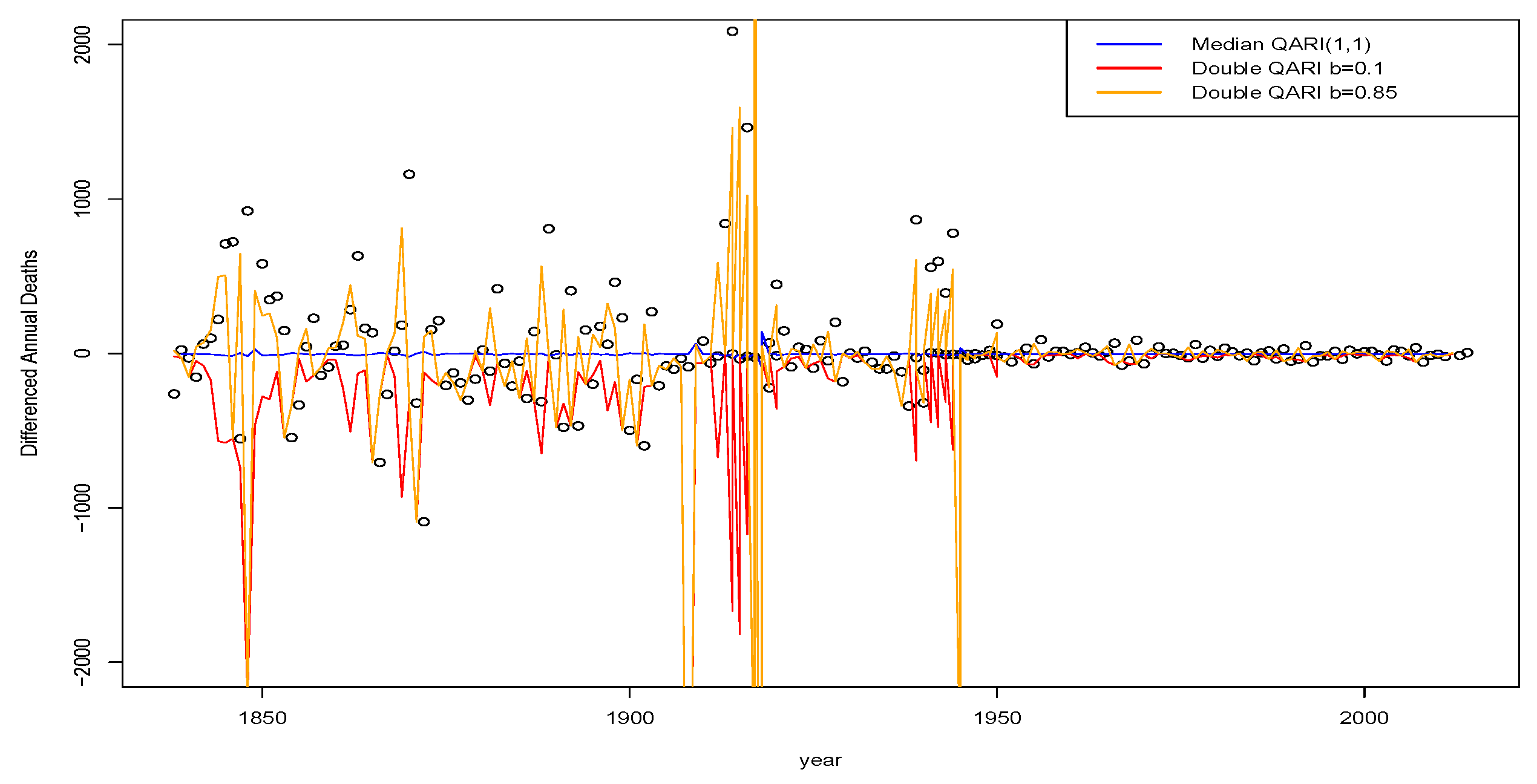{kind=link}
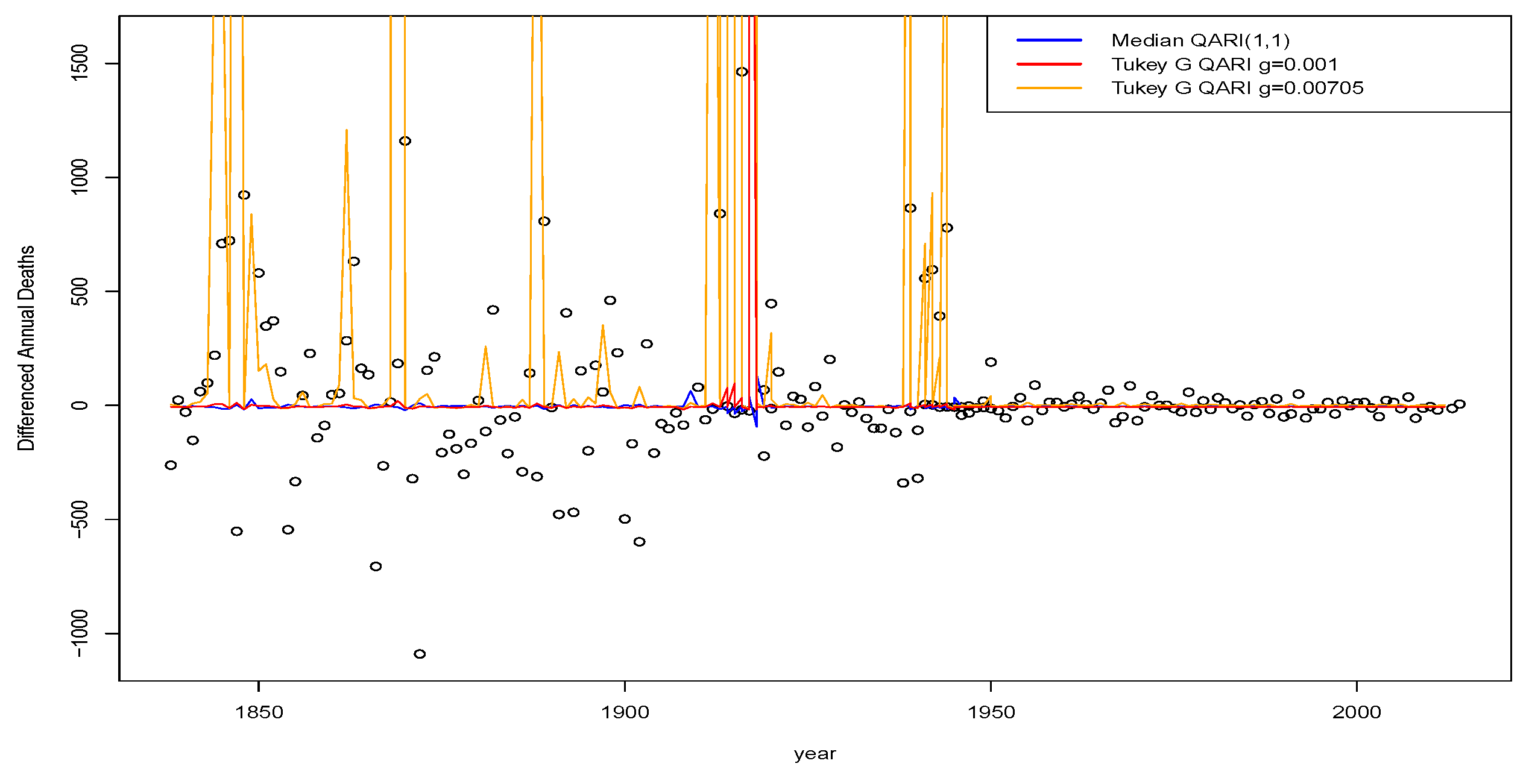{kind=link}
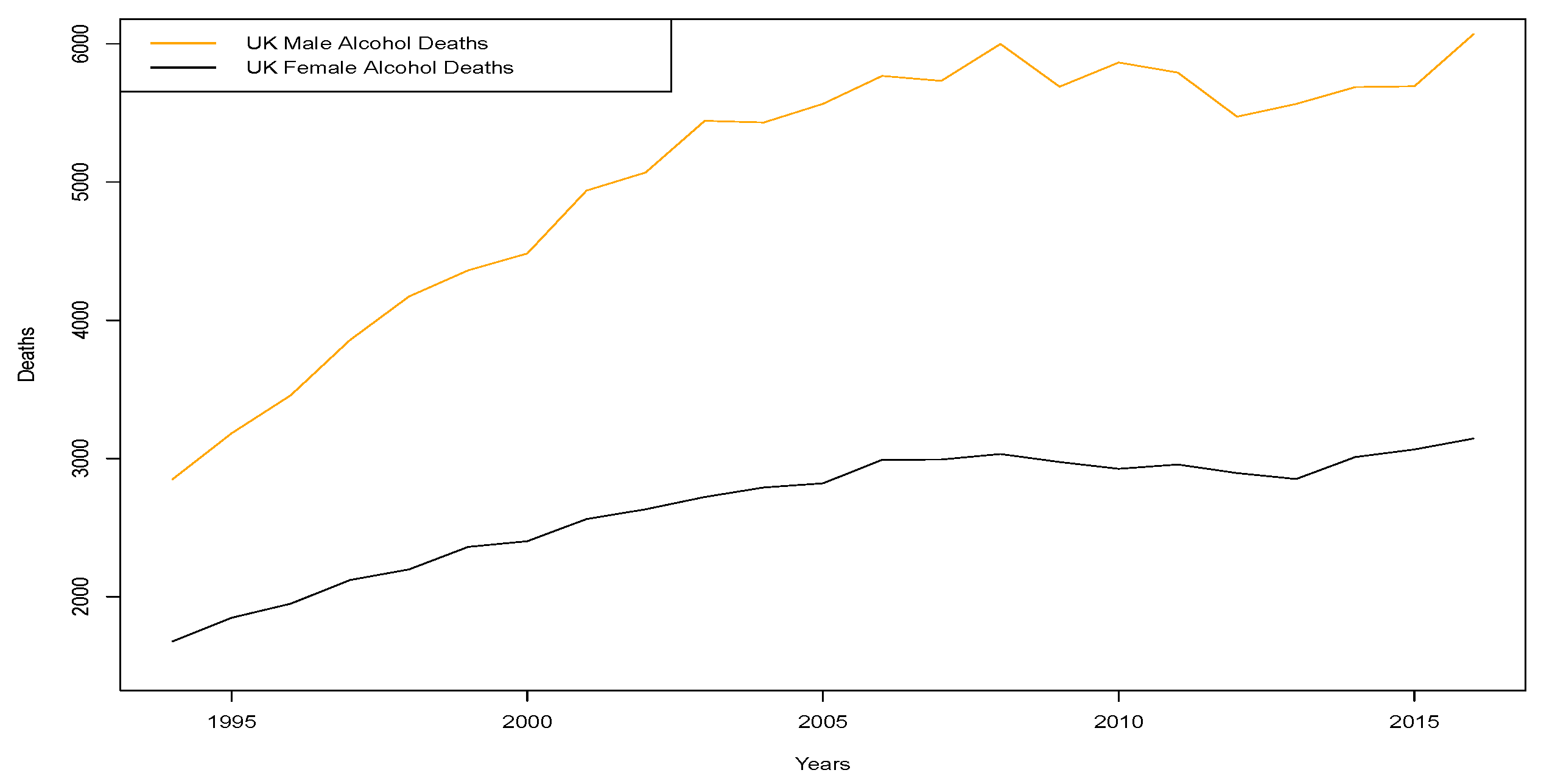{kind=link}
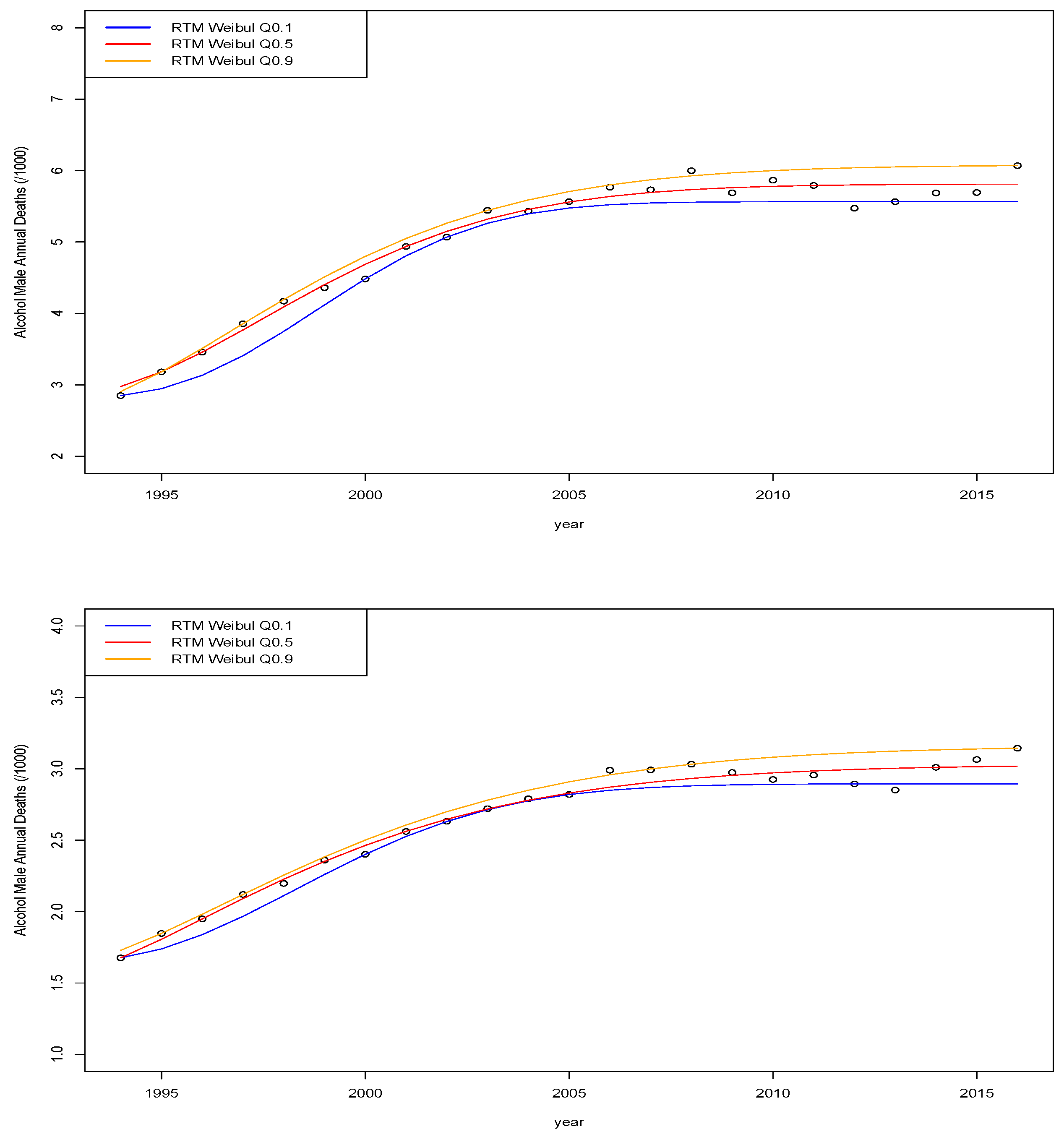{kind=link}
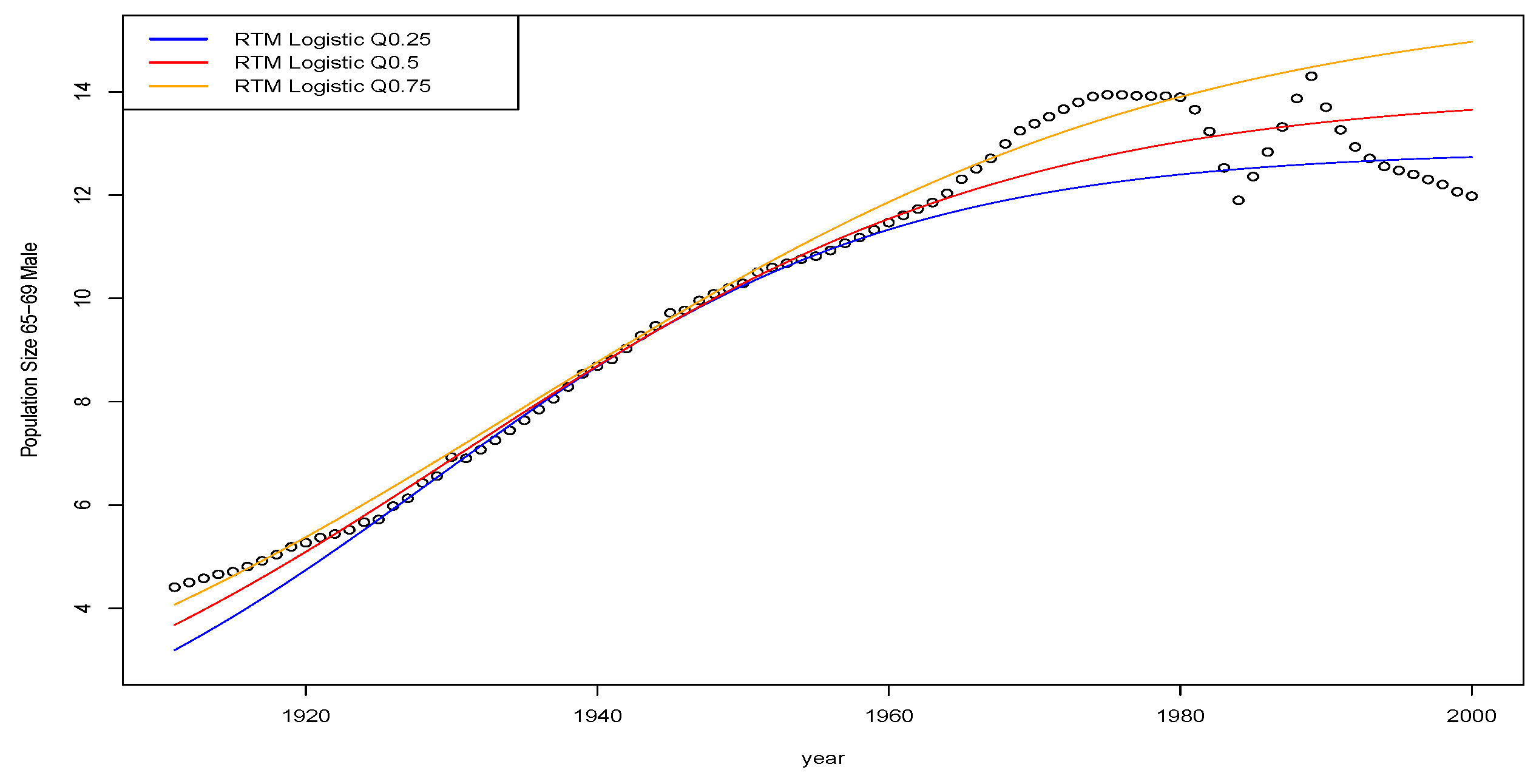{kind=link}