A General Framework for Portfolio Theory. Part II: Drawdown Risk Measures



Abstract
1. Introduction
2. Setup
- (a)
- Since implies that , Assumption 1 also yields the existence of a period resulting in a gain for each , i.e.,
- (b)
- Note that with Assumption 1 automatically follows, i.e., all trading systems are linearly independent.
- (c)
- It is not important whether or not the trading systems are “profitable”, since we allow short positions (cf. Assumption 1 in Hermes and Maier-Paape (2017)).
3. Randomly Drawing Trades
- (a)
- (b)
- .
- (a)
- For andholds, where
- (b)
- For all and withi.e., is always an upper bound for the expectation of the down-trade log series.
- (a)
- (b)
- Furthermore, is continuous in s and (in s even positive homogeneous) and
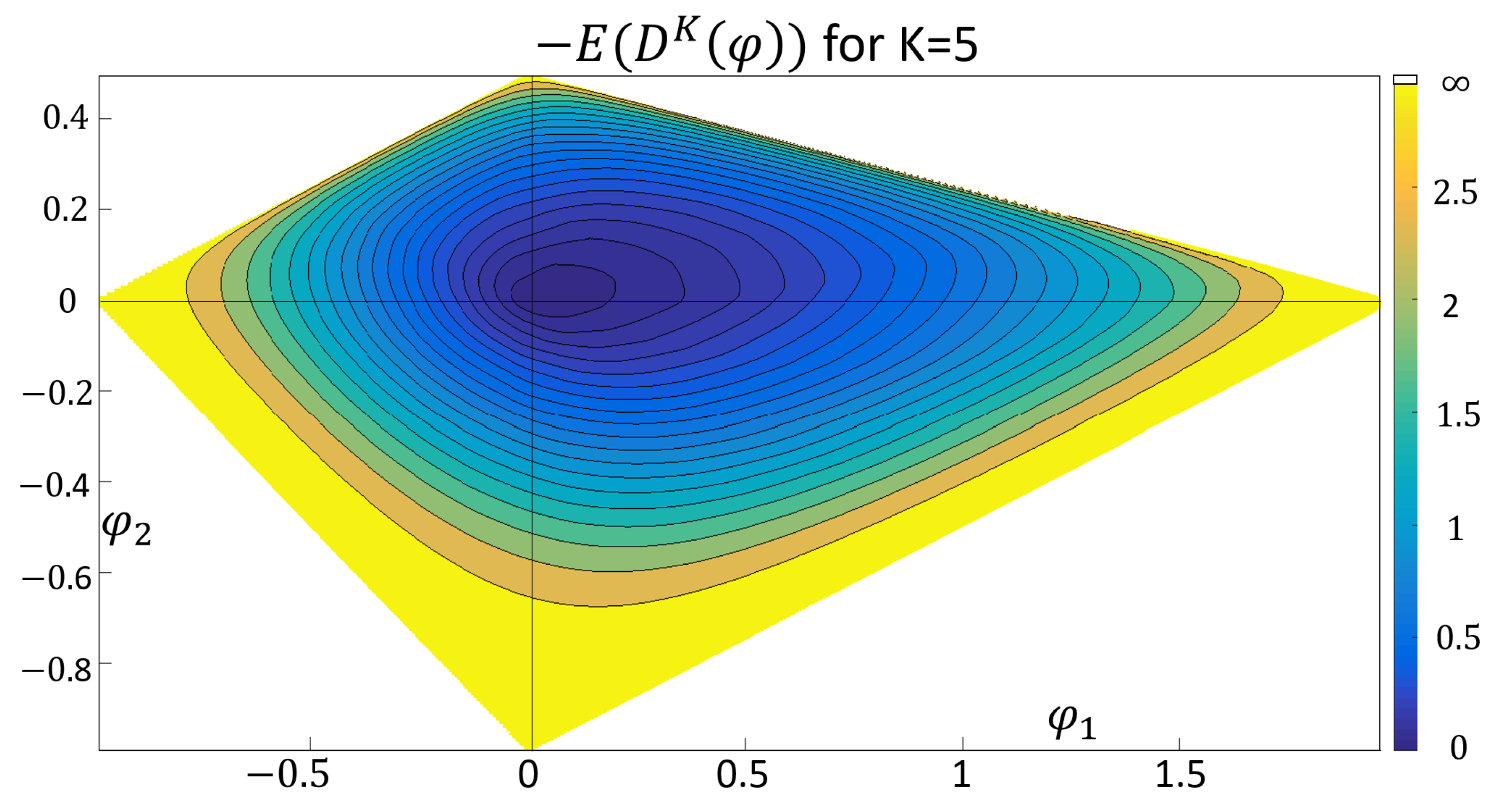
4. Admissible Convex Risk Measures
- (a)
- for all .
- (b)
- is a convex and continuous function.
- (c)
- For any the function restricted to the set is strictly increasing in s, and hence, in particular, for all .
- (a)
- Note that the risk measures from the above are functions of a portfolio vector , whereas in classical financial mathematics, usually the risk measure is a function of a random variable. For instance, the deviation measure of Rockafellar et al. (2006) is described in terms of the random payoff variable generated by the portfolio vector. However, viewed as a function of the portfolio vector, it is equivalent to a convex risk measure, as defined here (satisfying only (a) and (b) of Definition 3, but which is moreover positive homogeneous).
- (b)
- Another nontrivial example of a convex risk measure is the conditional value at risk (CVaR), cf. references Rockafellar and Uryasev (2002) and Rockafellar et al. (2006).
- (a)
- The function with , for some symmetric positive definite matrix is an admissible strictly convex risk measure (ASCRM).
- (b)
- with from (a) is an admissible convex risk measure which is moreover positive definite. For instance, the standard deviation of the payoff variable generated by the portfolio return is of that form (cf. Maier-Paape and Zhu (2018), Corollary 1).
- (c)
- For a fixed vector , with for , both,define admissible convex risk measures (ACRM).
- (a)
- The set , is convex and contains . Furthermore, if is bounded and , we have
- (b1)
- The boundary of is characterized by .
- (b2)
- is a codimension one manifold which varies continuously in α.
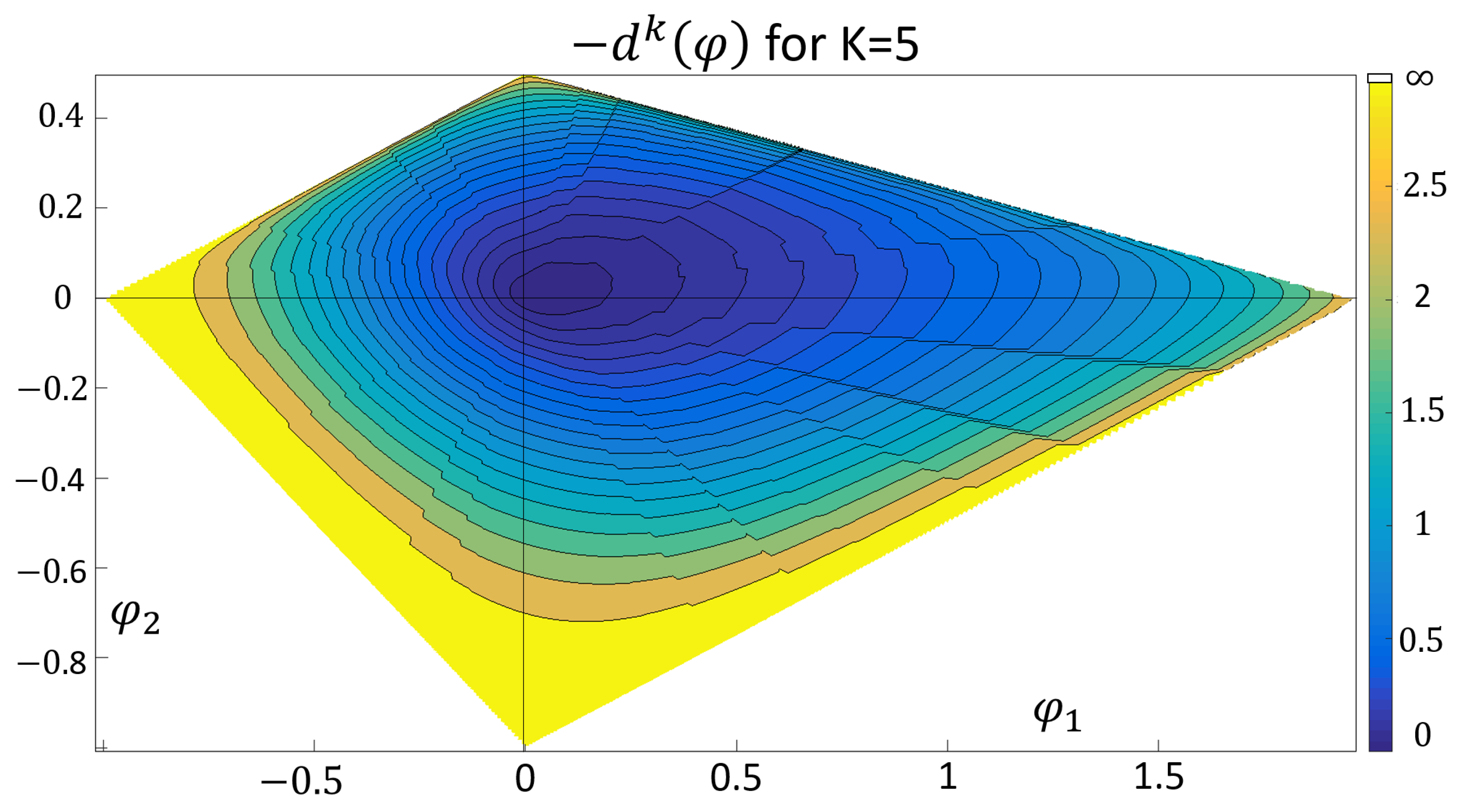
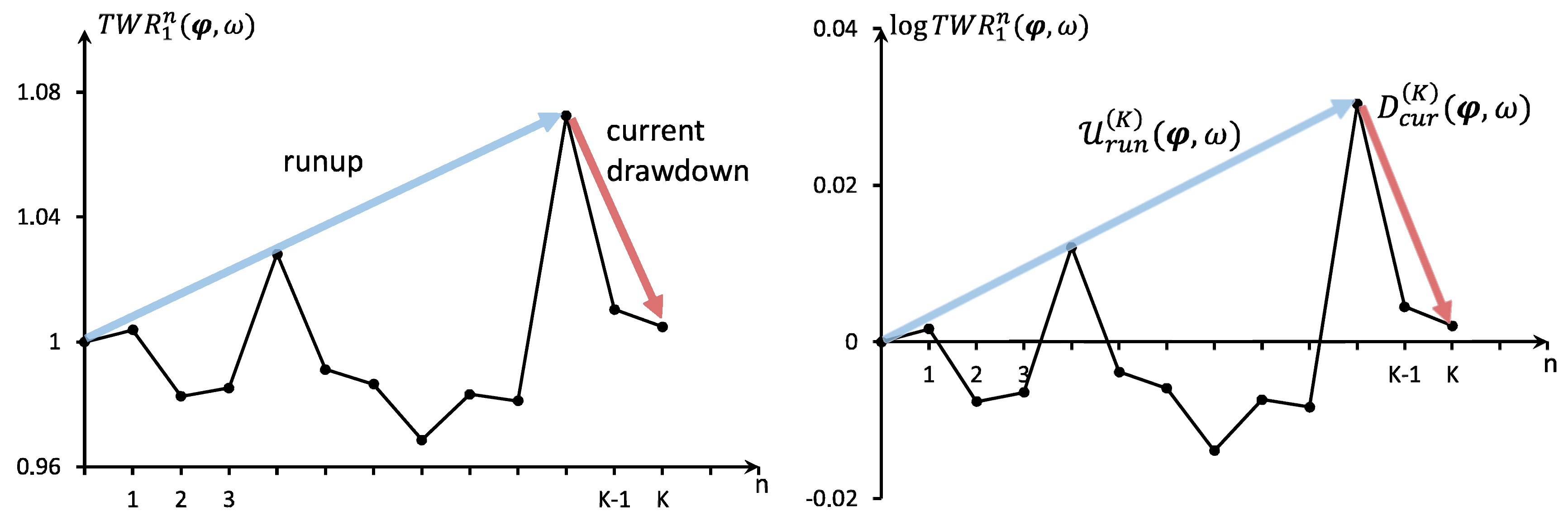
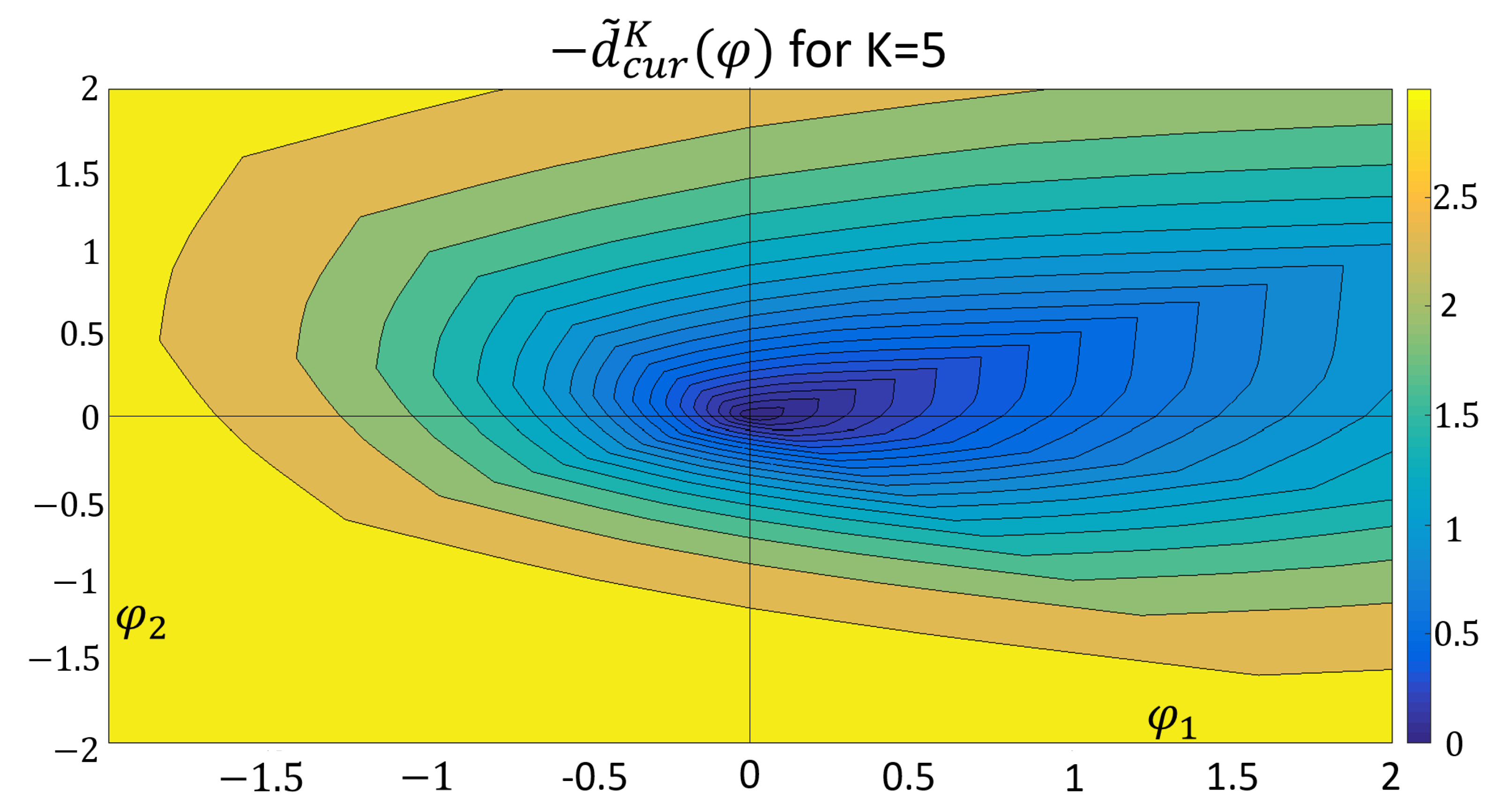
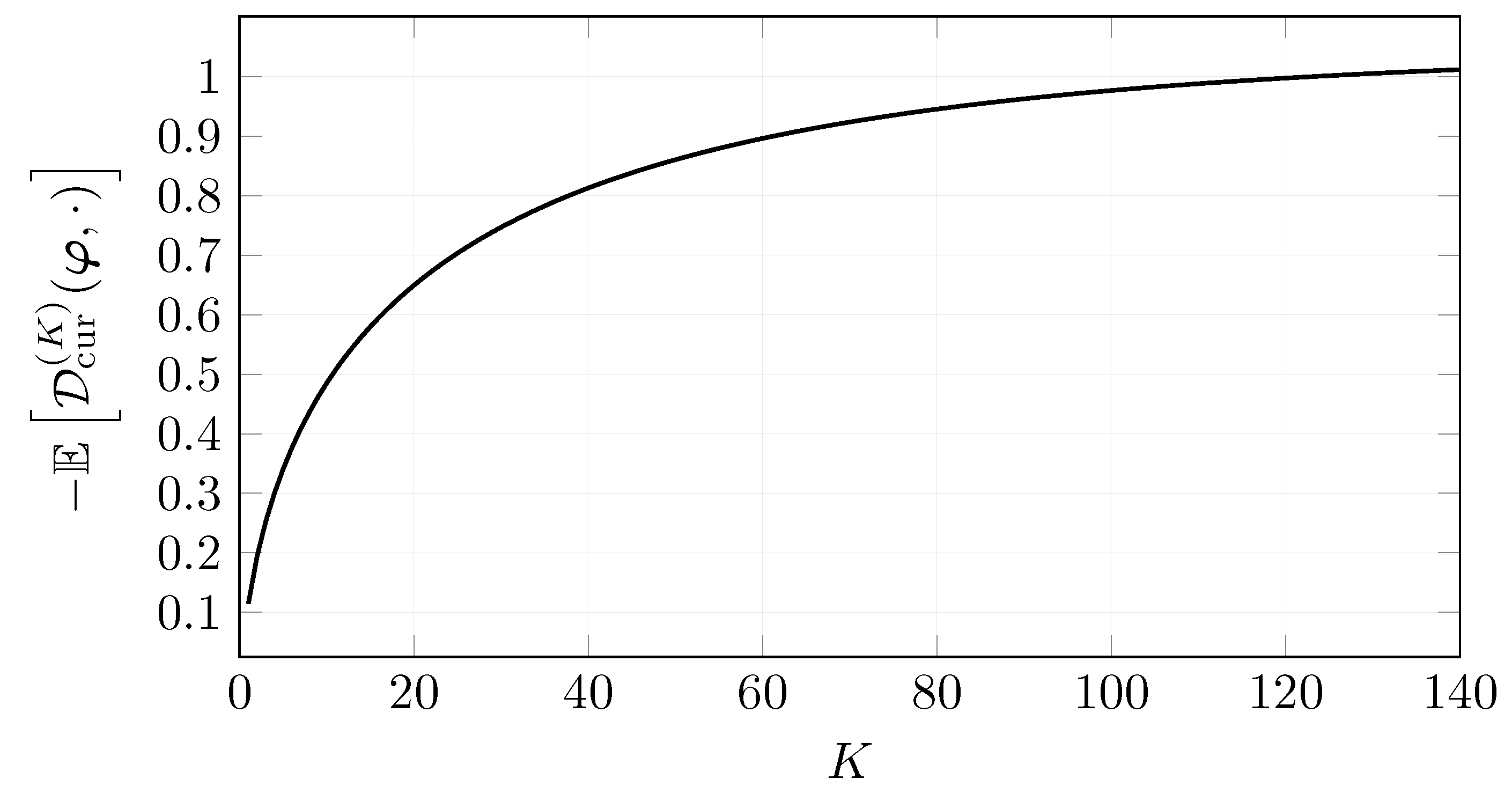
5. The Current Drawdown
- (a)
- in case
- (b)
- and otherwise, choose such thatwhere should be minimal with that property.
- (a)
- in case
- (b)
- and otherwise, choose such thatwhere should be minimal with that property.
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| ACRM | Admissible Convex Risk Measure |
| ASCRM | Admissible Strictly Convex Risk Measure |
| TWR | Terminal Wealth Relative |
| HPR | Holding Period Return |
Appendix A. Transfer of a One Period Financial Market to the TWR Setup

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x0 | portion of capital invested in bond |
| portion of capital invested in m-th risky asset, m = 1, … , M |
| cash position of the depot | |
| invested money in m-th asset, m = 1, … , M | |
| amount of shares of m-th asset to be bought at t = 0, m = 1, … , M |
| ϕm | portion of capital invested in m-th risky asset, m = 1, … , M |
- (r1)
- depends only on the risky part of the portfolio .
- (r1n)
- if and only if .
- (r2)
- is convex in .
- (r3)
- The two approximations and furthermore yield positive homogeneousfor all .
- (a)
- (No Nontrivial Riskless Portfolio) We say a portfolio x is riskless ifWe say the market has no nontrivial riskless portfolio if a riskless portfolio x with does not exist.
- (b)
- (No Arbitrage) We say x is an arbitrage if it is riskless and there exists some such thatWe say market has no arbitrage if an arbitrage portfolio does not exist.
- (c)
- (Nontrivial Bond Replicating Portfolio) We say that is a nontrivial bond replicating portfolio if and
- (i)
- The market has no arbitrage portfolio and there is no nontrivial bond replicating portfolio.
- (i)*
- The market has no nontrivial riskless portfolio.
- (ii)
- For every nontrivial portfolio (i.e., with ), there exists some such that
- (ii)*
- For every risky portfolio , some exists such that
- (iii)
- The market has no arbitrage and the matrixhas rank M, in particular, .
References
- Chekhlov, Alexei, Stanislav Uryasev, and Michael Zabarankin. 2003. Portfolio optimization with drawdown constraints. In Asset and Liability Management Tools. Edited by Bernd Scherer. London: Risk Books, pp. 263–78. [Google Scholar]
- Chekhlov, Alexei, Stanislav Uryasev, and Michael Zabarankin. 2005. Drawdown measure in portfolio optimization. International Journal of Theoretical and Applied Finance 8: 13–58. [Google Scholar] [CrossRef]
- Föllmer, Hans, and Alexander Schied. 2002. Stochastic Finance, 1st ed. Berlin: De Gruyter. [Google Scholar]
- Goldberg, Lisa R., and Ola Mahmoud. 2017. Drawdown: from Practice to Theory and Back Again. Mathematics and Financial Economics 11: 275–97. [Google Scholar] [CrossRef]
- Hermes, Andreas. 2016. A Mathematical Approach to Fractional Trading: Using the Terminal Wealth Relative with Discrete and Continuous Distributions. Ph.D. thesis, RWTH Aachen University, Aachen, Germany. [Google Scholar] [CrossRef]
- Hermes, Andreas, and Stanislaus Maier-Paape. 2017. Existence and uniqueness for the multivariate discrete terminal wealth relative. Risks 5: 44. [Google Scholar] [CrossRef]
- Kelly, John L., Jr. 1956. A new interpretation of information rate. Bell System Technical Journal 35: 917–26. [Google Scholar] [CrossRef]
- Maier-Paape, Stanislaus. 2013. Existence Theorems for Optimal Fractional Trading. Report No. 67. Aachen: Institut für Mathematik, RWTH Aachen University. Available online: https://www.instmath.rwth-aachen.de/Preprints/maierpaape20131008.pdf (accessed on 6 August 2018).
- Maier-Paape, Stanislaus. 2015. Optimal f and diversification. International Federation of Technical Analysts Journal 15: 4–7. [Google Scholar]
- Maier-Paape, Stanislaus. 2018. Risk averse fractional trading using the current drawdown. Journal of Risk 20: 1–25. [Google Scholar] [CrossRef]
- Maier-Paape, Stanislaus, and Qiji Jim Zhu. 2018. A general framework for portfolio theory. Part I: Theory and various models. Risks 6: 53. [Google Scholar] [CrossRef]
- Markowitz, Harry M. 1959. Portfolio Selection: Efficient Diversification of Investment. New York: John Wiley & Sons. [Google Scholar]
- Rockafellar, Ralph T., and Stanislav Uryasev. 2002. Conditional value–at–risk for general loss distributions. Journal of Banking and Finance 26: 1443–71. [Google Scholar] [CrossRef]
- Rockafellar, Ralph T., Stanislav Uryasev, and Michael Zabarankin. 2006. Generalized deviations in risk analysis. Finance and Stochastics 10: 51–74. [Google Scholar] [CrossRef]
- Rockafellar, Ralph T., Stanislav Uryasev, and Michael Zabarankin. 2006. Master funds in portfolio analysis with general deviation measures. Journal of Banking and Finance 30: 743–78. [Google Scholar] [CrossRef]
- Sharpe, William F. 1964. Capital asset prices: A theory of market equilibrium under conditions of risk. Journal of Finance 19: 425–42. [Google Scholar]
- Vince, Ralph. 1992. The Mathematics of Money Management, Risk Analysis Techniques for Traders. New York: John Wiley & Sons. [Google Scholar]
- Vince, Ralph. 1995. The New Money Management: A Framework for Asset Allocation. New York: John Wiley & Sons. [Google Scholar]
- Vince, Ralph. 2009. The Leverage Space Trading Model: Reconciling Portfolio Management Strategies and Economic Theory. New York: John Wiley & Sons. [Google Scholar]
- Vince, Ralph, and Qiji Jim Zhu. 2015. Optimal betting sizes for the game of blackjack. Risk Journals: Portfolio Management 4: 53–75. [Google Scholar] [CrossRef]
- Tharp, Van K. 2008. Van Tharp’s Definite Guide to Position Sizing. Cary: The International Institute of Trading Mastery. [Google Scholar]
- Zabarankin, Michael, Konstantin Pavlikov, and Stanislav Uryasev. 2014. Capital asset pricing model (capm) with drawdown measure. European Journal of Operational Research 234: 508–17. [Google Scholar] [CrossRef]
- Zhu, Qiji Jim. 2007. Mathematical analysis of investment systems. Journal of Mathematical Analysis and Applications 326: 708–20. [Google Scholar] [CrossRef]
- Zhu, Qiji Jim. 2012. Convex analysis in financial mathematics. Nonlinear Analysis, Theory Method and Applications 75: 1719–36. [Google Scholar] [CrossRef]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maier-Paape, S.; Zhu, Q.J. A General Framework for Portfolio Theory. Part II: Drawdown Risk Measures. Risks 2018, 6, 76. https://doi.org/10.3390/risks6030076
Maier-Paape S, Zhu QJ. A General Framework for Portfolio Theory. Part II: Drawdown Risk Measures. Risks. 2018; 6(3):76. https://doi.org/10.3390/risks6030076
Chicago/Turabian StyleMaier-Paape, Stanislaus, and Qiji Jim Zhu. 2018. "A General Framework for Portfolio Theory. Part II: Drawdown Risk Measures" Risks 6, no. 3: 76. https://doi.org/10.3390/risks6030076
APA StyleMaier-Paape, S., & Zhu, Q. J. (2018). A General Framework for Portfolio Theory. Part II: Drawdown Risk Measures. Risks, 6(3), 76. https://doi.org/10.3390/risks6030076