One-Year Change Methodologies for Fixed-Sum Insurance Contracts


Abstract
:1. Introduction
2. The Probabilistic Model
2.1. The Case of a Multi-Step n
- (i)
- at an intermediate step i, the number of exposures is and the number of losses obtained at this step is given by:(the equality in distribution is discussed and proved in Appendix A) setting , and is, conditionally on , a binomial rv , which we denote as
- (ii)
- up to an intermediate step i, the total number of exposures is and the total number of losses is given byand is, conditionally on , a binomial rv:Here, we have and
- (iii)
- at the end of the multi-steps process under condition (H), the total number of exposures is n and the total number of losses is, as in the one-step caseThis is what is called the ultimate loss, once the process is completed.
2.2. Random Variables of Interest
- the ultimate loss , which is ,
- the expected ultimate loss, given the information up to the step i (for :the s being independent of the s. Note that we can also definewhich corresponds to the expected loss at ultimate. Note that Equation (8) defines a martingale. Note also that it is a real number (although the rvs are integer valued).
- the variation of the expected ultimate loss between two successive steps defines exactly the one year change, when choosing yearly steps:Here is also a real rv. When , the is closely related to the solvency capital required as defined in the Solvency II framework, which reflects the risk of changes in the technical provision in one year. The difference lies in that does not take into account the risk margin change. However, this is of minor importance in the SCR estimation because the risk margin change is of a smaller order of magnitude. Indeed, in practice, it is commonly accepted that the risk margin, which represents the risk loading for the market value of the liability, is approximately constant from one year to the other. We note here that the s are the innovation of the martingale defined in Equation (8).
3. Analytical Expressions of Quantities to Be Studied
3.1. Incremental Pattern and Capital
3.2. Moments of
- (i)
- (ii)
- (iii)
- For ,where .
- (a)
- As a consequence of the Proposition 2, the moments of are given by
- (b)
- The conditional variance of the ultimate is
- (a)
- Thus, the unconditional moments of D are given by
- (b)
- As an immediate consequence of Equation (24), one can write the conditional variance of the ultimate as
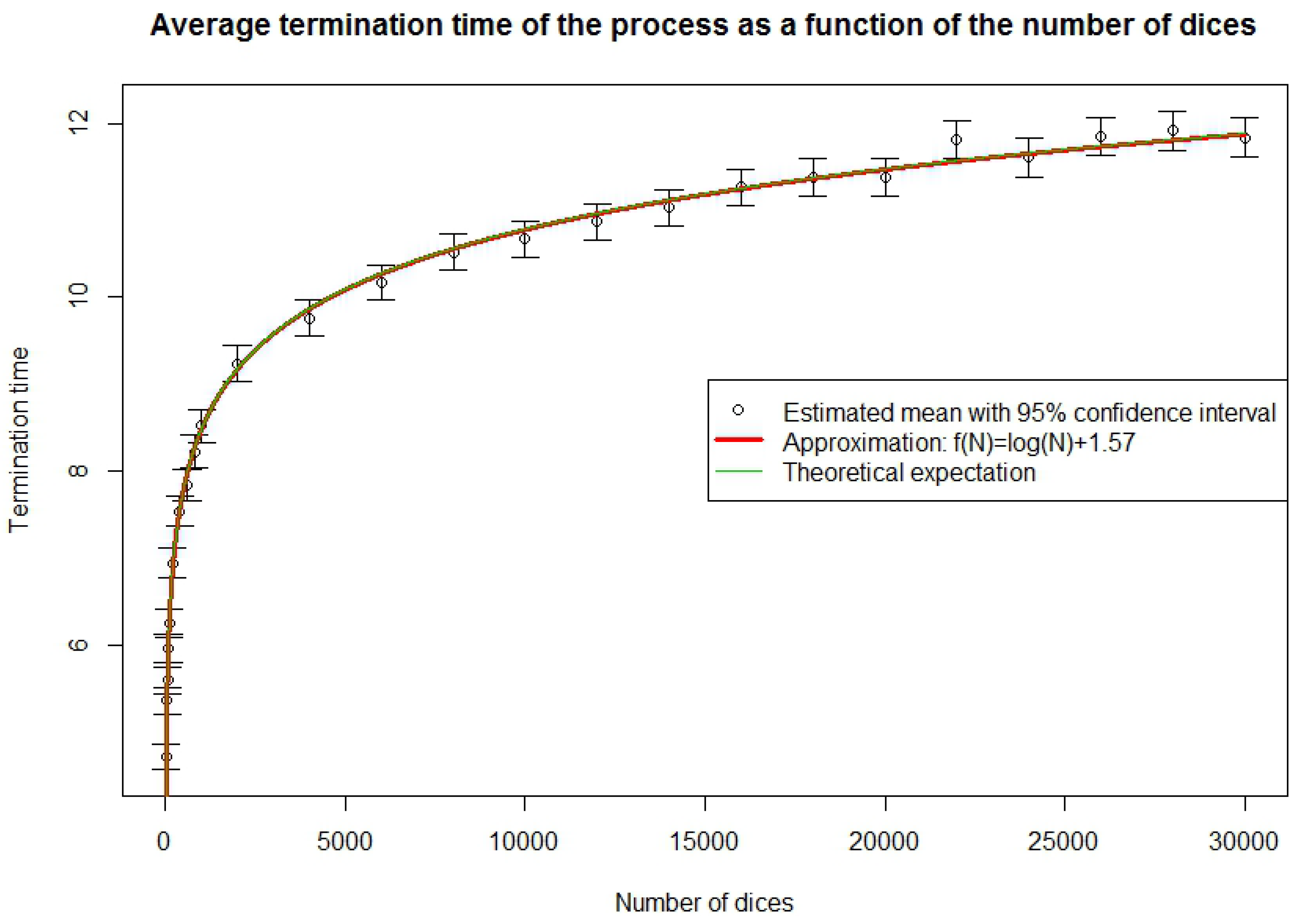
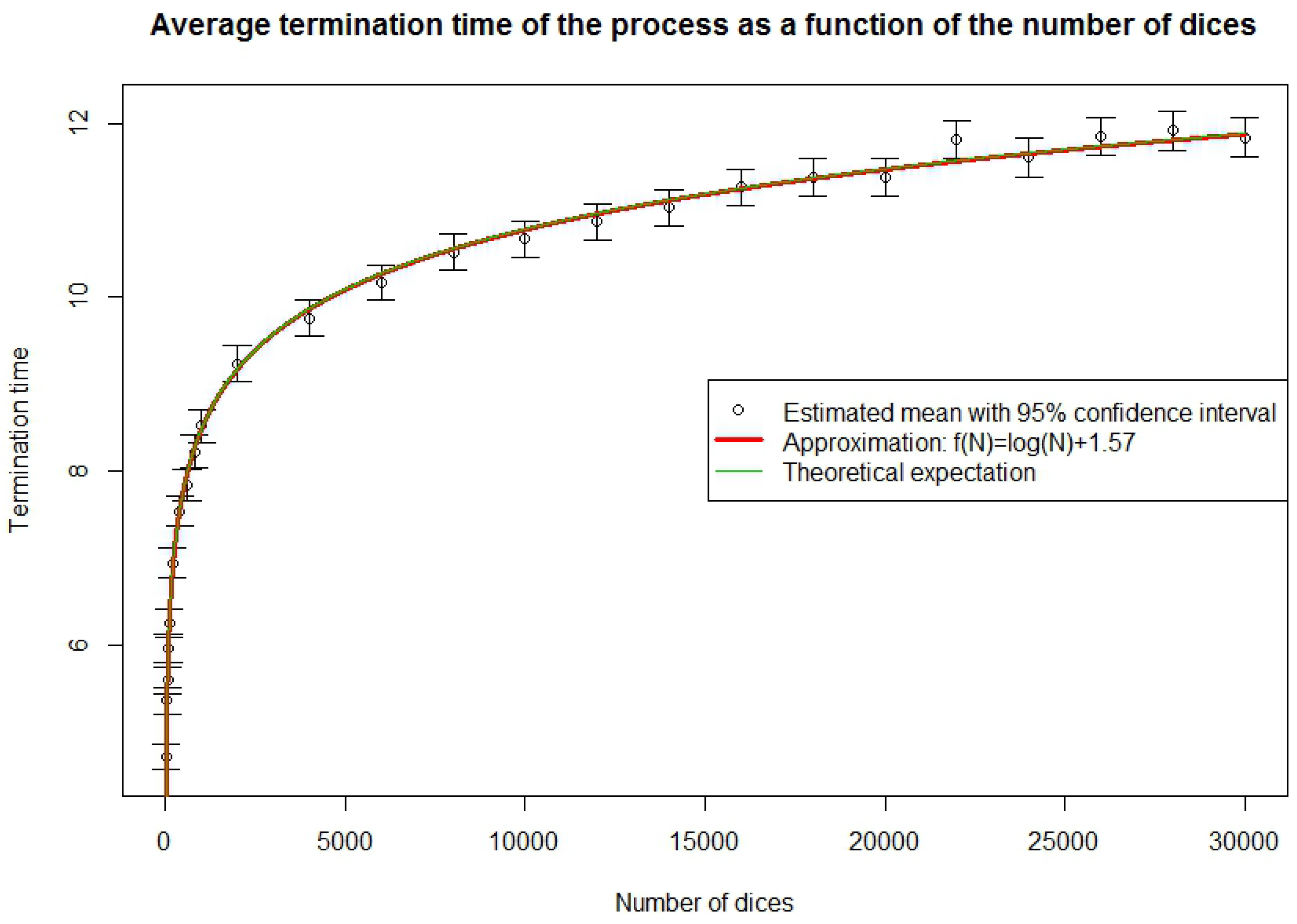
3.3. Completion Time
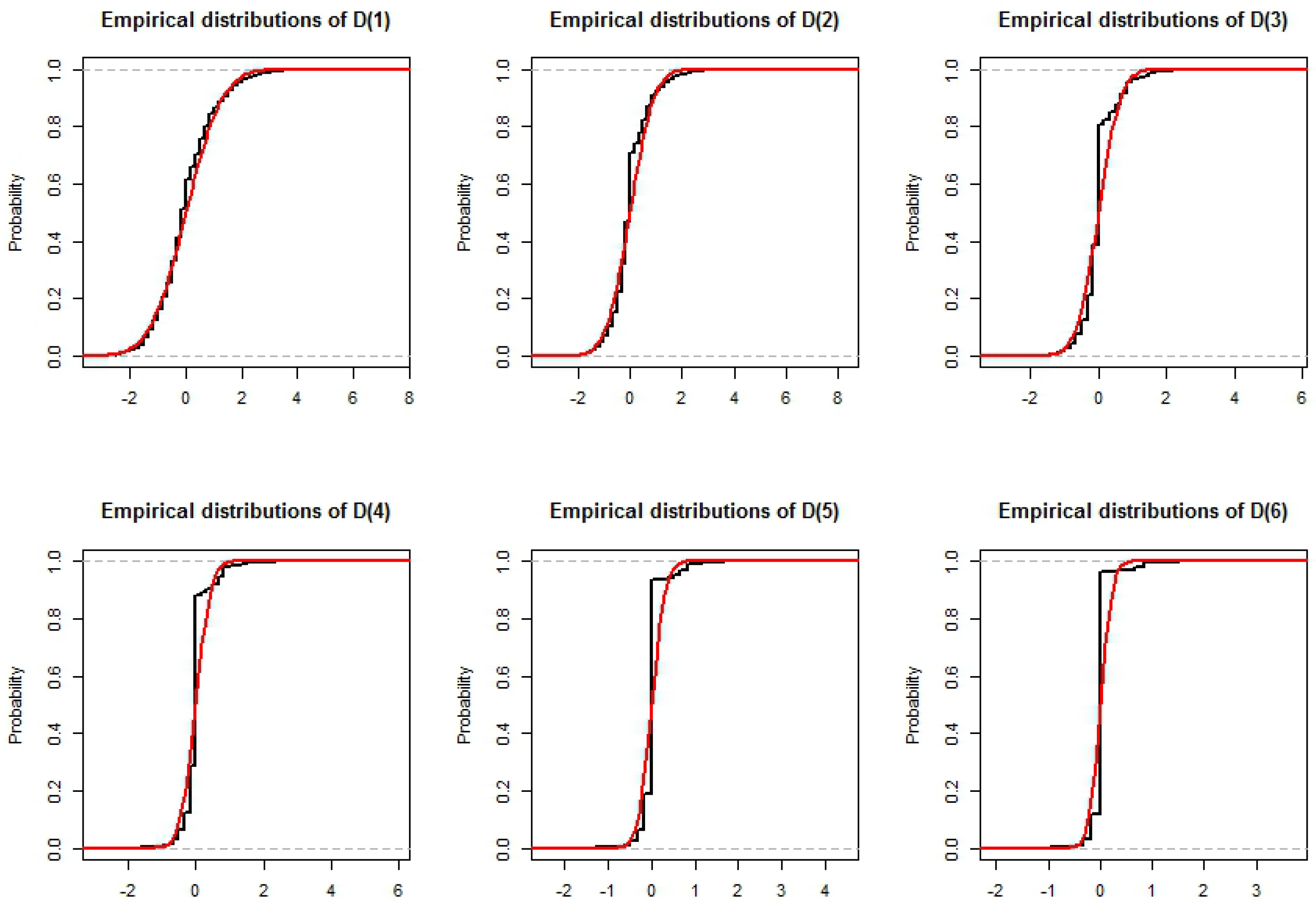
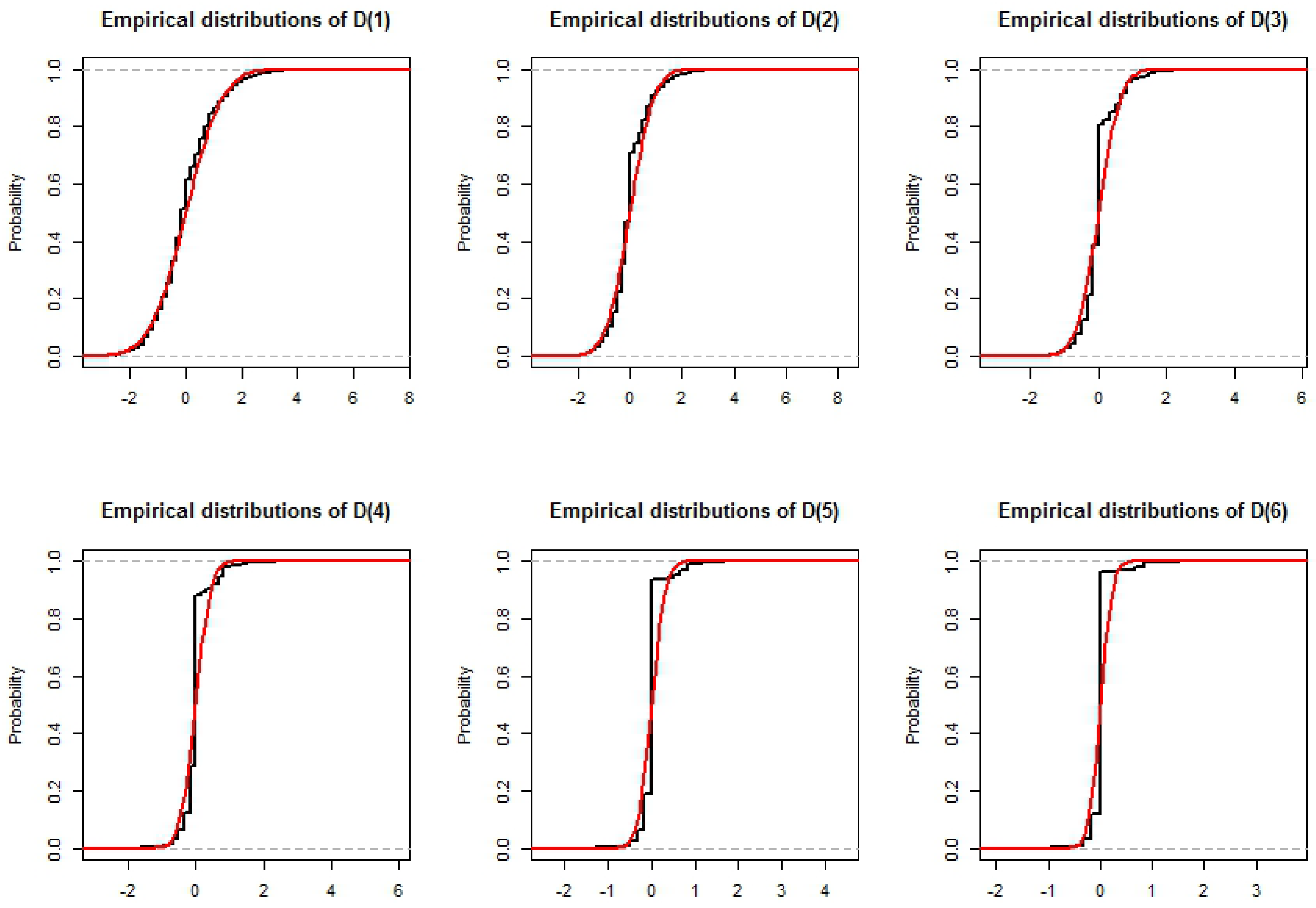
3.4. Distribution of the
3.5. Simulation of the Completion Time
4. Capital Requirements
4.1. Triangles
4.2. Methodology and Results’ Comparison
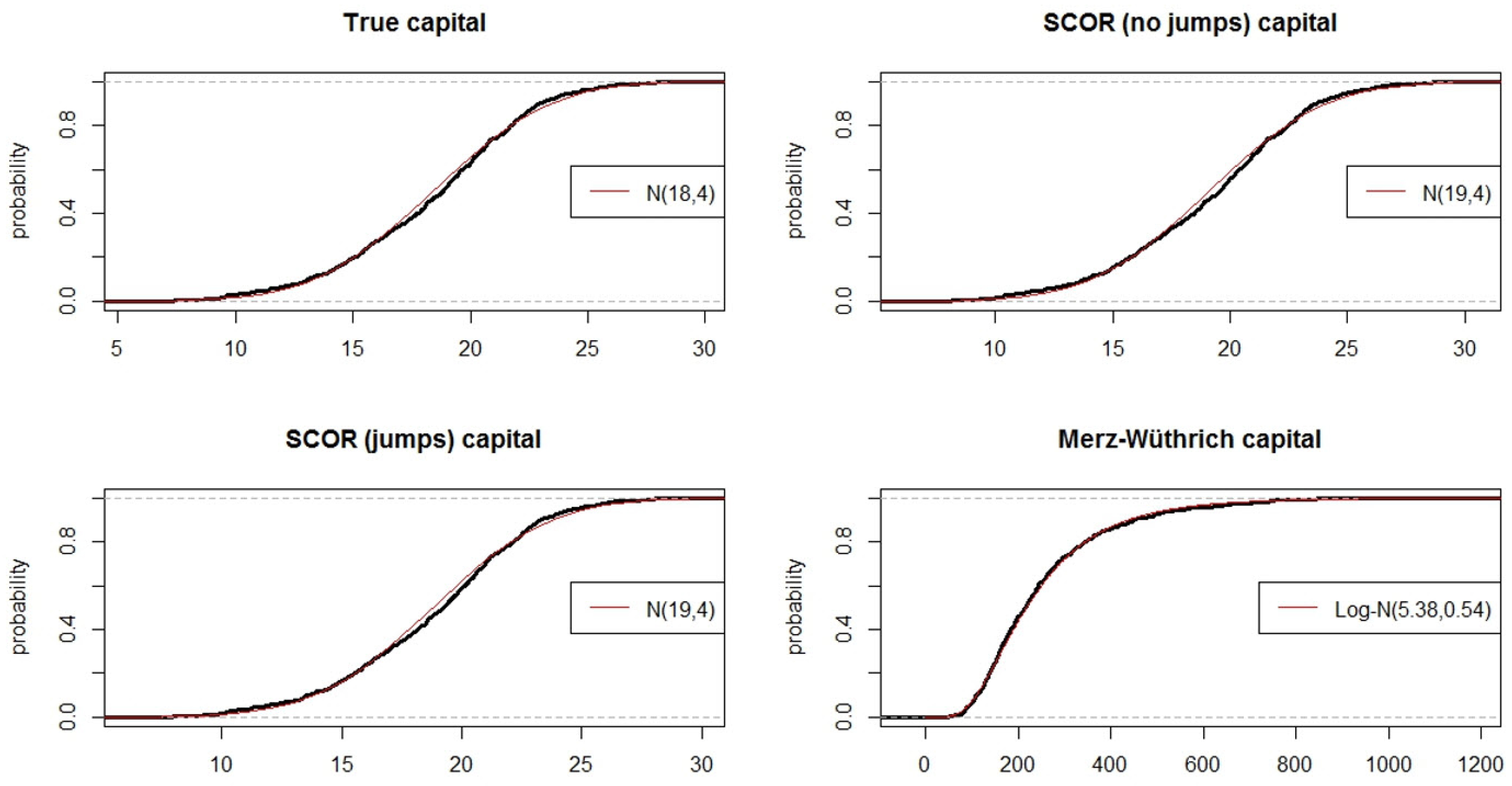
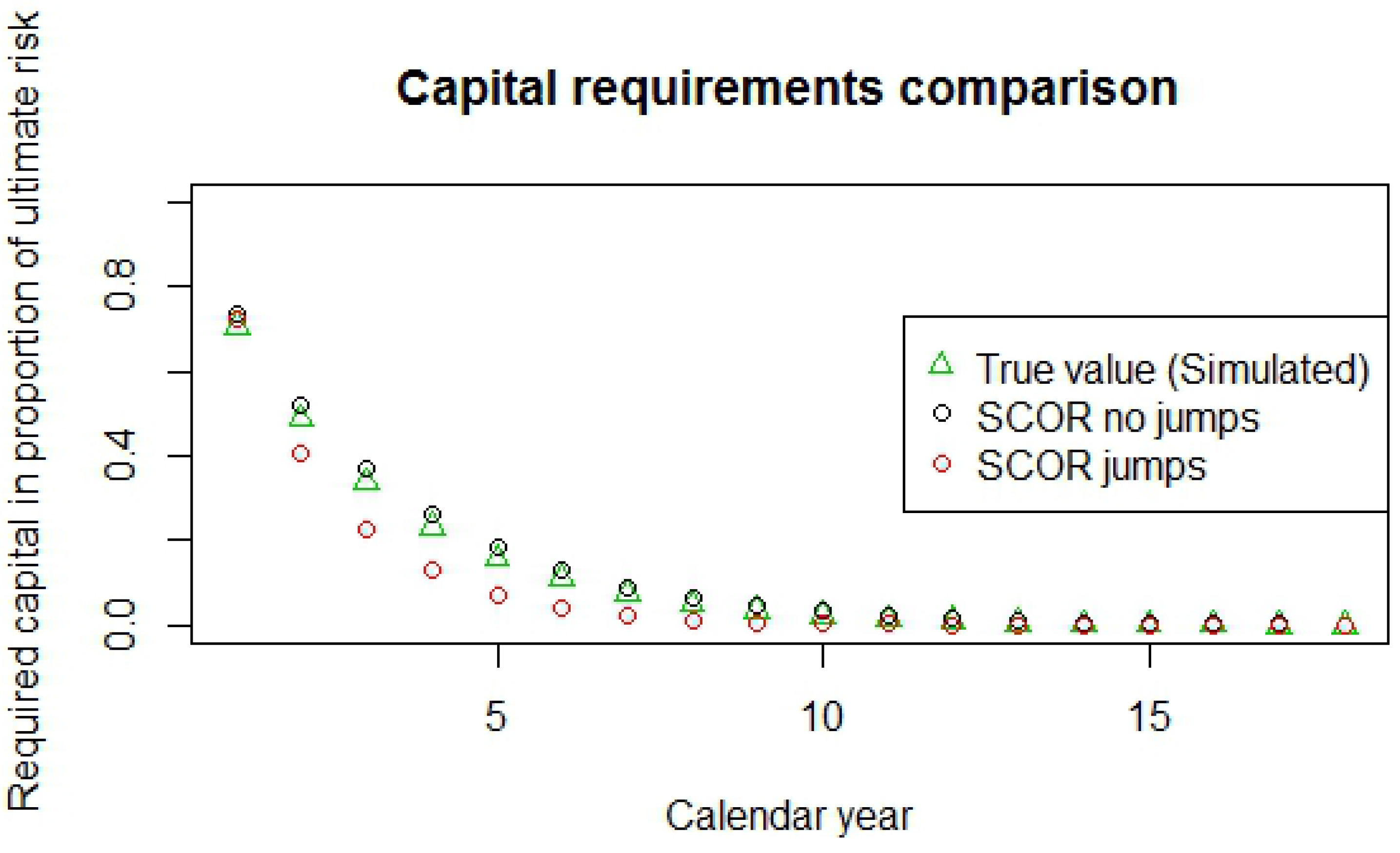
4.2.1. First Year Capital Comparison
4.2.2. Risk Margin Comparison
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proof of an Equality in Distribution
Appendix B. The Distributions of Ni and of D(i)
Appendix C. The Reserves in Our Model
Appendix D. Presentation of the Methods to Compute the One-Year Change Volatility
Appendix D.1. Merz–Wüthrich Method
- Independence across rows of the triangle.
- There exists a sequence of factors , such that
- There exists a sequence of factors , such that

Appendix D.2. The COT Method
- The evolutions of the claims losses and of the best estimates are stochastic processes as described in Ferriero (2016); roughly speaking, the relative losses evolve from the start to the end as a Brownian motion, except during a random time interval in which they evolve as a fractional Brownian motion, and the consequently best estimates evolve as the conditional expectation of the ultimate loss plus a sudden reserves jump, which may happen as a result of systematic under-estimations of the losses.
- The volatility, measured in standard deviations, of the attritional claims losses is small relative to the ultimate loss size.
Appendix E. Numerical Stability

{kind=link}
{kind=link}
{kind=link}
{kind=link}
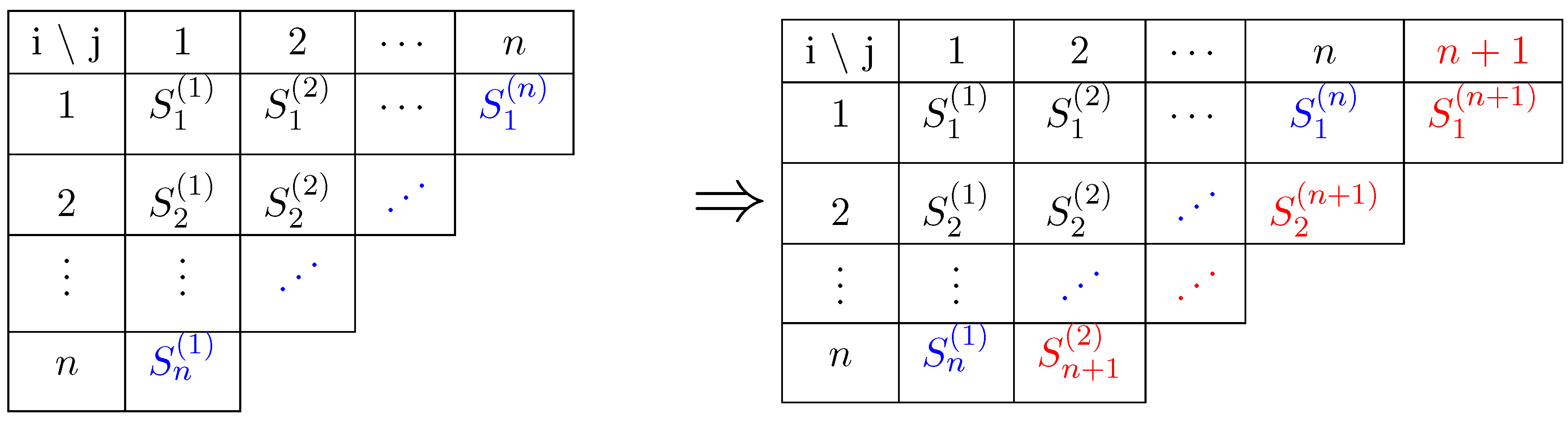{kind=link}
| R | Mean | Standard Dev. | Confidence Interval | Variation |
|---|---|---|---|---|
| 10 | 3.279 | 0.176 | [2.935, 3.624] | |
| 20 | 3.294 | 0.122 | [3.055, 3.533] | |
| 50 | 3.287 | 0.077 | [3.136, 3.438] | |
| 100 | 3.291 | 0.057 | [3.180, 3.402] | |
| 200 | 3.289 | 0.042 | [3.206, 3.372] | |
| 500 | 3.281 | 0.027 | [3.228, 3.333] | |
| 1000 | 3.284 | 0.018 | [3.248, 3.320] | |
| 2000 | 3.283 | 0.013 | [3.258, 3.308] | |
| 5000 | 3.282 | 0.009 | [3.265, 3.300] | |
| 10,000 | 3.283 | 0.006 | [3.272, 3.294] | |
| 20,000 | 3.283 | 0.004 | [3.275, 3.291] |
Appendix F. Capital Properties of the Model
| Number of rvs | Number of Steps | Mean | Standard Dev. | Min. Obs. | Max. Obs. |
|---|---|---|---|---|---|
| 10,000 | 16 | 0.3137 | 0.00395 | 0.3067 | 0.3267 |
| 20,000 | 17 | 0.3129 | 0.00472 | 0.3049 | 0.3286 |
| 30,000 | 17 | 0.3130 | 0.00444 | 0.3056 | 0.3278 |
| 40,000 | 18 | 0.3125 | 0.00372 | 0.3064 | 0.3257 |
| 50,000 | 18 | 0.3129 | 0.00465 | 0.3040 | 0.3244 |
| 60,000 | 18 | 0.3123 | 0.00412 | 0.3041 | 0.3240 |
| 70,000 | 18 | 0.3123 | 0.00422 | 0.3057 | 0.3279 |
| 80,000 | 18 | 0.3118 | 0.00440 | 0.3039 | 0.3264 |
| 90,000 | 18 | 0.3125 | 0.00465 | 0.3041 | 0.3284 |
| 100,000 | 19 | 0.3118 | 0.00383 | 0.3033 | 0.3231 |
References
- Bornhuetter, Ronald L., and Ronald E. Ferguson. 1972. The Actuary and IBNR. Proceedings of the Casualty Actuarial Society 59: 181–95. [Google Scholar]
- Busse, Marc, Michel M. Dacorogna, and Marie Kratz. 2013. Does Risk Diversification Always Work? The Answer through Simple Modelling. SCOR Paper No 24. Available online: http://www.scor.com/en/sgrc/scor-publications/scor-papers.html (accessed on 10 May 2013).
- Busse, Marc, Ulrich Müller, and Michel Dacorogna. 2010. Robust estimation of reserve risk. Astin Bulletin 40: 453–89. [Google Scholar]
- Dacorogna, Michel M., and Christoph Hummel. 2008. Alea Jacta Est, An Illustrative Example of Pricing Risk. SCOR Technical Newsletter. Zurich: SCOR Global P&C. [Google Scholar]
- Ferriero, Alessandro. 2016. Solvency capital estimation, reserving cycle and ultimate risk. Insurance: Mathematics and Economics 68: 162–68. [Google Scholar] [CrossRef]
- Huber, Peter J. 1981. Robust Statistics. Chichester: Wiley. [Google Scholar]
- Mack, Thomas. 1993. Distribution-free calculation of the standard error of chain ladder reserve estimates. Astin Bulletin 23: 213–55. [Google Scholar] [CrossRef]
- Mack, Thomas. 2008. The Prediction Error of Bornhuetter-Fergusonn. Astin Bulletin 38: 87–103. [Google Scholar] [CrossRef]
- Merz, Michael, and Mario V. Wüthrich. 2008. Modelling the claims development result for solvency purposes. Casualty Actuarial Society, 542–68. [Google Scholar]
- Mikosch, Thomas. 2004. Non-Life Insurance Mathematics: An Introduction with Stochastic Processes. Berlin: Springer Verlag. [Google Scholar]
- Rousseeuw, Peter J., and Annick M. Leroy. 1987. Robust Regression and Outlier Detection. New York: Wiley. [Google Scholar]
- Schmidt, Klaus D., and Mathias Zocher. 2008. The Bornhuetter-Ferguson principle. Variance 2: 85–110. [Google Scholar]
- Wüthrich, Mario V., and Michael Merz. 2008. Stochastic Claims ReservingMethods in Insurance. Chichester: Wiley-Finance. [Google Scholar]
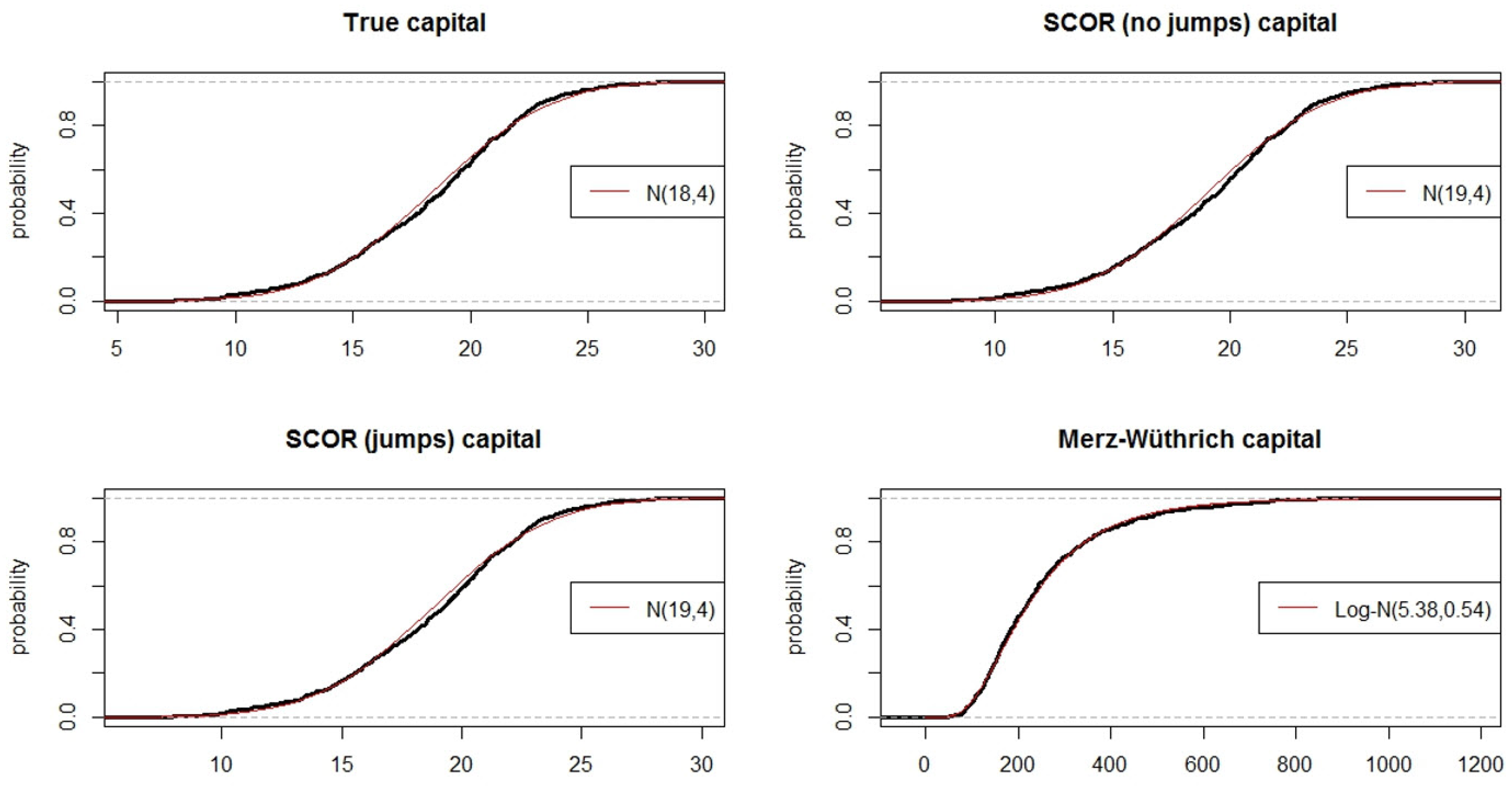
| Method | Mean | Std. Dev. | MAD | MRAD | Rob. MAD | Rob. MRAD |
|---|---|---|---|---|---|---|
| Theoretical value | 18.37 | 3.92 | 0 | 0% | 0 | 0% |
| SCOR, without jumps | 19.08 | 3.93 | 0.71 | 4.14% | 0.71 | 3.93% |
| SCOR, with jumps | 18.81 | 3.86 | 0.43 | 2.47% | 0.44 | 2.42% |
| Merz–Wüthrich | 252.89 | 149.6 | 234.5 | 1365.6% | 213.9 | 1217.8% |
| Standard Corr | True Value | SCOR, No Jumps | SCOR, Jumps | Merz–Wüthrich |
| True value | 100% | 99.98% | 99.97% | −37.64% |
| SCOR, no jumps | 100% | 99.99% | −37.65% | |
| SCOR, jumps | 100% | −37.64% | ||
| Merz–Wüthrich | 100% | |||
| MVE Corr | True Value | SCOR, No Jumps | SCOR, Jumps | Merz–Wüthrich |
| True value | 100% | 99.98% | 99.97% | −46.56% |
| SCOR, no jumps | 100% | 99.99% | −46.61% | |
| SCOR, jumps | 100% | −46.60% | ||
| Merz–Wüthrich | 100% |
| Method | Mean | Std. Dev. | MAD | MRAD |
|---|---|---|---|---|
| True value (simulation) | 5.89 | 1.27 | 0 | 0% |
| SCOR, without jumps | 6.49 | 1.34 | 0.61 | 10.57% |
| SCOR, with jumps | 4.32 | 0.89 | 1.57 | 26.52% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dacorogna, M.; Ferriero, A.; Krief, D. One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks 2018, 6, 75. https://doi.org/10.3390/risks6030075
Dacorogna M, Ferriero A, Krief D. One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks. 2018; 6(3):75. https://doi.org/10.3390/risks6030075
Chicago/Turabian StyleDacorogna, Michel, Alessandro Ferriero, and David Krief. 2018. "One-Year Change Methodologies for Fixed-Sum Insurance Contracts" Risks 6, no. 3: 75. https://doi.org/10.3390/risks6030075
APA StyleDacorogna, M., Ferriero, A., & Krief, D. (2018). One-Year Change Methodologies for Fixed-Sum Insurance Contracts. Risks, 6(3), 75. https://doi.org/10.3390/risks6030075