A User-Friendly Algorithm for Detecting the Influence of Background Risks on a Model



{kind=link}
{kind=link}
Abstract
:1. Introduction
2. The Model
3. The Algorithm
- Case 1:
- The pivot is not approaching .
- (i)
- If decisively tends to a limit other than , then we advise the decision maker about the absence of the risk.
- (ii)
- If seems to tend to a limit other than but there is some doubt as to whether this is true, then we check if the supporter is asymptotically bounded, and if yes, then we advise the decision maker about the absence of the risk.
- Case 2:
- The pivot is approaching .
- (i)
- If the supporter tends to infinity, then we advise the decision maker about the presence of the risk.
- (ii)
- If the supporter is asymptotically bounded, then and are likely to be insufficiently different to have already triggered Case 1 above, and we thus advise the decision maker about the absence of the risk.
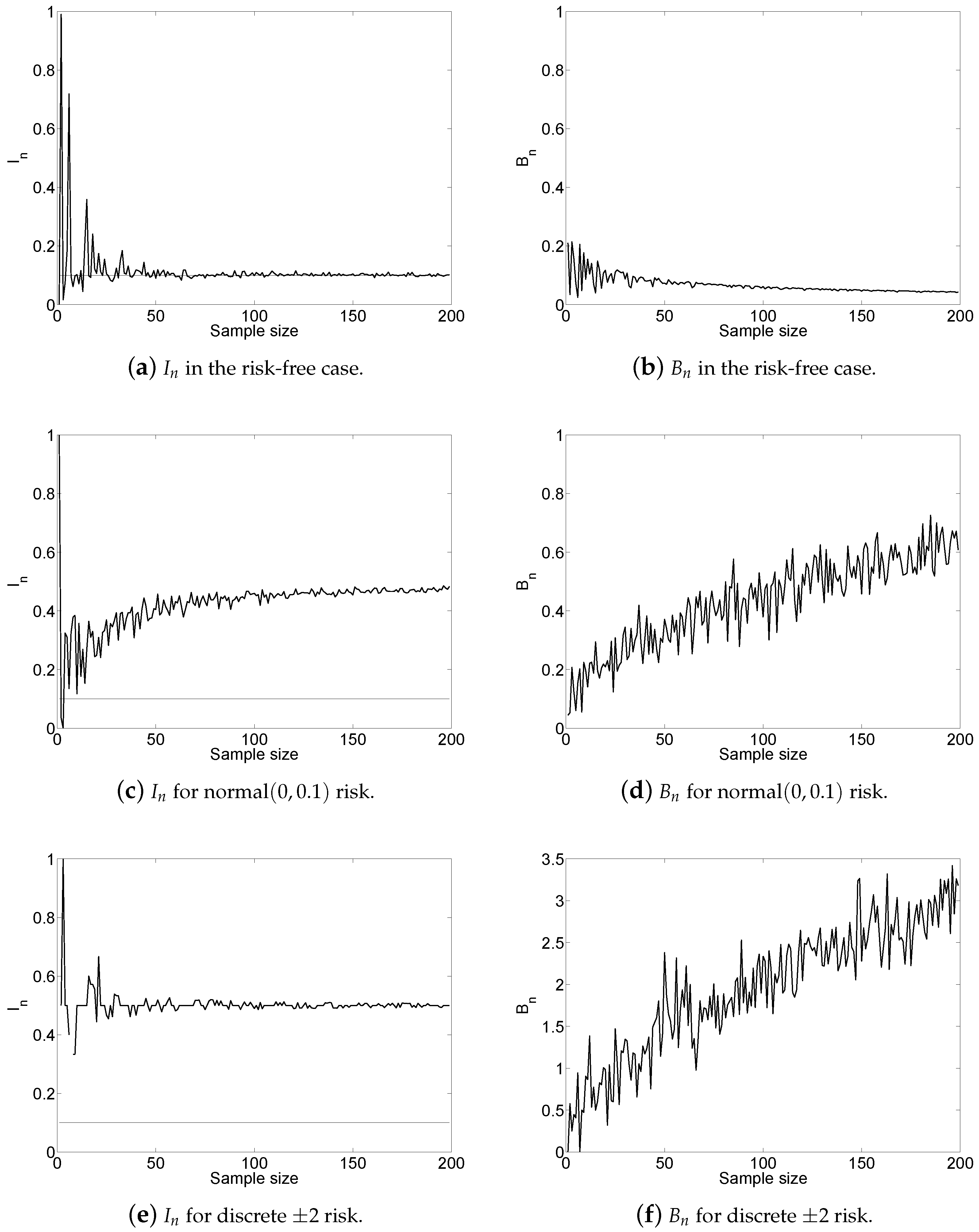
4. Asymptotics of the Pivot
5. Growth of the Supporter
6. Concluding Notes
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Box, George Edward Pelham, Gwilym Meirion Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2015. Time Series Analysis: Forecasting and Control, 5th ed. New York: Wiley. [Google Scholar]
- Cárdenas, Alvaro A., Saurabh Amin, Zong-Syun Lin, Yu-Lun Huang, Chi-Yen Huang, and Shankar Sastry. 2011. Attacks against process control systems: Risk assessment, detection, and response. Paper presented at the 6th ACM Symposium on Information, Computer and Communications Security, Hong Kong, March 22–24; pp. 355–66. [Google Scholar]
- Chen, Lingzhi, Youri Davydov, Nadezhda Gribkova, and Ričardas Zitikis. 2018. Estimating the index of increase via balancing deterministic and random data. Mathematical Methods of Statistics 27: 83–102. [Google Scholar] [CrossRef]
- David, Herbert A., and Haikady N. Nagaraja. 2003. Order Statistics, 3rd ed. New York: Wiley. [Google Scholar]
- Davydov, Youri, and Ričardas Zitikis. 2017. Quantifying non-monotonicity of functions and the lack of positivity in signed measures. Modern Stochastics: Theory and Applications 4: 219–31. [Google Scholar] [CrossRef]
- Debar, Hervé, Marc Dacier, and Andreas Wespi. 1999. Towards a taxonomy of intrusion-detection systems. Computer Networks 31: 805–22. [Google Scholar] [CrossRef]
- Finkelshtain, Israel, Offer Kella, and Marco Scarsini. 1999. On risk aversion with two risks. Journal of Mathematical Economics 31: 239–50. [Google Scholar] [CrossRef]
- Franke, Günter, Harris Schlesinger, and Richard C. Stapleton. 2006. Multiplicative background risk. Management Science 52: 146–53. [Google Scholar] [CrossRef]
- Franke, Günter, Harris Schlesinger, and Richard C. Stapleton. 2011. Risk taking with additive and multiplicative background risks. Journal of Economic Theory 146: 1547–68. [Google Scholar] [CrossRef]
- Furman, Edward, Ruodu Wang, and Zitikis ardas. 2017. Gini-type measures of risk and variability: Gini shortfall, capital allocations, and heavy-tailed risks. Journal of Banking and Finance 83: 70–84. [Google Scholar] [CrossRef]
- Furman, Edward, Alexey Kuznetsov, and Ričardas Zitikis. 2018. Weighted risk capital allocations in the presence of systematic risk. Insurance: Mathematics and Economics 79: 75–81. [Google Scholar]
- Giorgi, Giovanni. 1993. A fresh look at the topical interest of the Gini concentration ratio. Metron 51: 83–98. [Google Scholar]
- Gribkova, Nadezhda, and Ričardas Zitikis. 2018. Assessing transfer functions in control systems. arXiv, arXiv:1805.10633. [Google Scholar]
- Guo, Xu, Andreas Wagener, Wing-Keung Wong, and Lixing Zhu. 2018. The two-moment decision model with additive risks. Risk Management 20: 77–94. [Google Scholar] [CrossRef]
- Guo, Xu, Raymond Honfu Chan, Wing-Keung Wong, and Lixing Zhu. 2018. Mean-variance, mean-VaR, and mean-CVaR models for portfolio selection with background risk. Risk Management. [Google Scholar] [CrossRef]
- He, Youbiao, Gihan J. Mendis, and Jin Wei. 2017. Real-rime detection of false data injection attacks in smart grid: A deep learning-based intelligent mechanism. IEEE Transactions on Smart Grid 8: 2505–16. [Google Scholar] [CrossRef]
- Huang, Yi, Jin Tang, Yu Cheng, Husheng Li, Kristy A. Campbell, and Zhu Han. 2016. Real-time detection of false data injection in smart grid networks: An adaptive CUSUM method and analysis. IEEE Systems Journal 10: 532–43. [Google Scholar] [CrossRef]
- Hug, Gabriela, and Joseph Andrew Giampapa. 2012. Vulnerability assessment of AC state estimation with respect to false data injection cyber-attacks. IEEE Transactions on Smart Grid 3: 1362–70. [Google Scholar] [CrossRef]
- Liang, Gaoqi, Junhua Zhao, Fengji Luo, Steven R. Weller, and Zhao Yang Dong. 2017. A review of false data injection attacks against modern power systems. IEEE Transactions on Smart Grid 8: 1630–38. [Google Scholar] [CrossRef]
- Nachman, David. 1982. Preservation of “more risk averse” under expectations. Journal of Economic Theory 28: 361–68. [Google Scholar] [CrossRef]
- Onoda, Takashi. 2016. Probabilistic models-based intrusion detection using sequence characteristics in control system communication. Neural Computing and Applications 27: 1119–27. [Google Scholar] [CrossRef]
- Perote, Javier, and Juan Perote-Peña. 2004. Strategy-proof estimators for simple regression. Mathematical Social Sciences 47: 153–76. [Google Scholar] [CrossRef]
- Perote, Javier, Juan Perote-Peña, and Marc Vorsatz. 2015. Strategic behavior in regressions: An experimental study. Theory and Decision 79: 517–46. [Google Scholar] [CrossRef]
- Potluri, Sasanka, Christian Diedrich, and Girish Kumar Reddy Sangala. 2017. Identifying false data injection attacks in industrial control systems using artificial neural networks. Paper presented at the 22nd IEEE International Conference on Emerging Technologies and Factory Automation, Limassol, Cyprus, December 21; pp. 1–8. [Google Scholar]
- Pratt, John W. 1998. Aversion to one risk in the presence of others. Journal of Risk and Uncertainty 1: 395–413. [Google Scholar] [CrossRef]
- Premathilaka, Nalaka Arjuna, Achala Chathuranga Aponso, and Naomi Krishnarajah. 2013. Review on state of art intrusion detection systems designed for the cloud computing paradigm. Paper presented at 47th International Carnahan Conference on Security Technology, Medellin, Colombia, October 8–11; pp. 1–6. [Google Scholar]
- Semenikhine, Vadim, Edward Furman, and Jianxi Su. 2018. On a multiplicative multivariate gamma distribution with applications in insurance. Risks 6: 79. [Google Scholar] [CrossRef]
- Su, Jianxi. 2016. Multiple Risk Factors Dependence Structures with Applications to Actuarial Risk Management. Ph.D. Dissertation, York University, Toronto, ON, Canada. [Google Scholar]
- Su, Jianxi, and Edward Furman. 2017a. A form of multivariate Pareto distribution with applications to financial risk measurement. ASTIN Bulletin 47: 331–57. [Google Scholar] [CrossRef]
- Su, Jianxi, and Edward Furman. 2017b. Multiple risk factor dependence structures: Distributional properties. Insurance: Mathematics and Economics 76: 56–68. [Google Scholar] [CrossRef]
- Yitzhaki, Shlomo, and Edna Schechtman. 2013. The Gini Methodology: A Primer on a Statistical Methodology. New York: Springer. [Google Scholar]
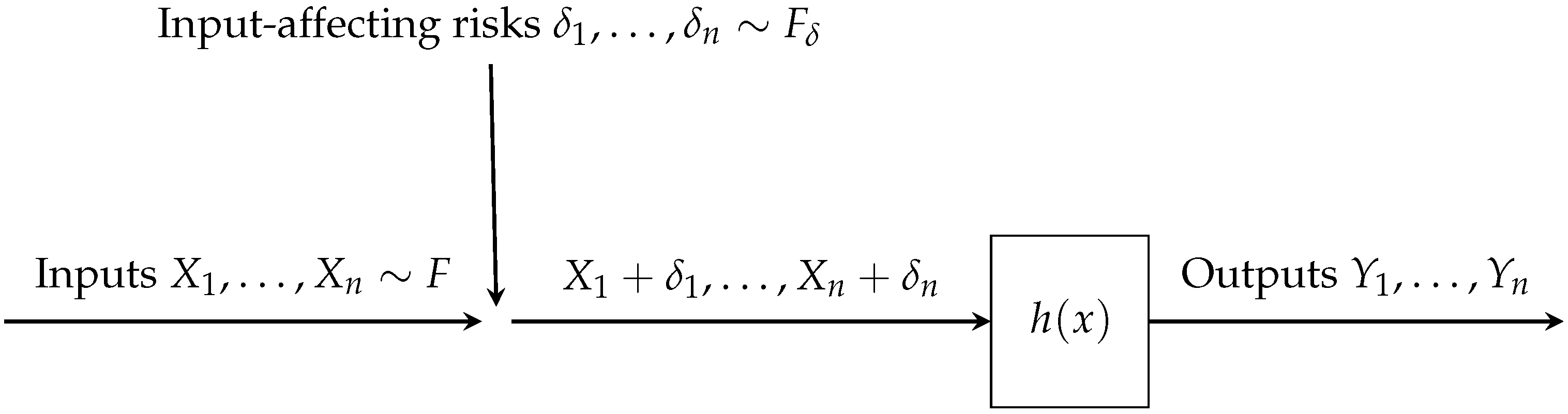
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gribkova, N.; Zitikis, R. A User-Friendly Algorithm for Detecting the Influence of Background Risks on a Model. Risks 2018, 6, 100. https://doi.org/10.3390/risks6030100
Gribkova N, Zitikis R. A User-Friendly Algorithm for Detecting the Influence of Background Risks on a Model. Risks. 2018; 6(3):100. https://doi.org/10.3390/risks6030100
Chicago/Turabian StyleGribkova, Nadezhda, and Ričardas Zitikis. 2018. "A User-Friendly Algorithm for Detecting the Influence of Background Risks on a Model" Risks 6, no. 3: 100. https://doi.org/10.3390/risks6030100
APA StyleGribkova, N., & Zitikis, R. (2018). A User-Friendly Algorithm for Detecting the Influence of Background Risks on a Model. Risks, 6(3), 100. https://doi.org/10.3390/risks6030100