The Cascade Bayesian Approach: Prior Transformation for a Controlled Integration of Internal Data, External Data and Scenarios

Abstract
:1. Introduction
2. A Bayesian Inference in Two Steps for Severity Estimation
- Prior by the scenarios and the likelihood component by external data as follows:
- The aforementioned posterior function is then sampled and used as prior, and the likelihood component is informed by internal data as follows:
3. Carrying Out the Cascade Approach in Practice
3.1. The Data Sets
3.2. The Priors
- Lognormal—a Gaussian and a gamma distribution,
- Weibull—gamma distributions for both the scale and the shape,
- Generalized Pareto distribution—a beta distribution for the shape and a gamma distribution on the scale.
3.3. Estimation
- One can choose conjugate priors for the parameters in the first step of the Bayesian inference estimation. In this case, the (joint) distribution of the posterior parameters is directly known, and it is possible to sample directly from this distribution to recreate the marginal posterior distributions for each severity parameter. These may then be used to generate the posterior empirical densities required to compute a Bayesian point estimator of the parameters. The admissible estimators are the median, mean and mode of the posterior distribution. The mode (also called maximum a posteriori (MAP)) can be seen as the ’most probable estimator’ and ultimately coincides with the maximum likelihood estimator (Lehmann and Casella 1998). Despite having good asymptotic properties, finding the mode of an empirical distribution is not a trivial matter and often requires some additional techniques and hypotheses (e.g., smoothing). This paper, therefore, uses posterior means as point estimators. To the best of our knowledge, the only conjugate priors for continuous distributions were studied by Shevchenko (2011), for the Lognormal severity case. Conjugate approach requires some assumptions that may not be sustainable in practice, particularly for priors that are modelled with ’uncommon’ distributions (e.g., inverse-Chi-squared). This might lead to difficulties in the step known as ’elicitation’, i.e., calibrating the prior hyper-parameters from the chosen scenario values.
- Another solution is to release the conjugate prior assumption and use a Markov chain Monte Carlo approach in the first step to sample from the first posterior. One can then use a parametric or non-parametric method to compute the corresponding densities. This enables the posterior function to be evaluated (see Equation (6)). Maximising this function directly gives the MAP estimators of the severity parameters (see above). Even if this method is sufficient for computing values for the global parameters, it misses the purpose of the Bayesian inference, which is to provide distribution as a final result instead of a single value. In addition, it may also suffer from all the drawbacks that an optimisation algorithm may suffer (e.g., non-convex functions, sensitivity to starting values, etc.)
- The final alternative is to use a Markov chain Monte Carlo (MCMC) approach at each step of the aforementioned cascade Bayesian inference. This method is more challenging to implement but is the most powerful one, as it generates the entire distribution of the final severity parameters from which any credibility intervals and/or other statistics may be evaluated.
4. Results
- Scenarios’ severity is derived from the calibration of the prior distributions with the scenario values. The theoretical means obtained from the calibrated priors provide scenario severity estimates.
- Intermediate severity refers to the estimation of the severity of the first obtained posterior, i.e., the mean of the posterior distribution obtained from scenario values updated with external loss data.
- Similarly, final severity represents the severity estimation of the second and last posterior distribution, which includes scenarios, external and internal loss data. A 95% Bayesian confidence interval (also known as a credible interval) derived from this final posterior distribution is also provided. It is worth noticing that this interval, which is formally defined as containing 95% of the distribution mass, is not unique and is chosen here as the narrowest possible interval. It is, therefore, not necessarily symmetric around the posterior mean estimator.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Epanechnikov Kernel
Appendix B. Least Square Cross Validation
Appendix C. The Metropolis–Hastings Algorithm
- Initialise with any value within a support of .
- For
- (a)
- Set
- (b)
- Generate a proposal from
- (c)
- Accept proposal with the acceptance probability:i.e., simulate U from the uniform distribution function and set if . Note that the normalization constant of the posterior does not contribute here.
- Next, l (i.e., do an increment, ), and return to step 2.
Appendix D. Risk Measure Evaluation
References
- Álvarez, Gene. 2001. Operational Risk Quantification Mathematical Solutions for Analyzing Loss Data. Available online: https://www.bis.org/bcbs/ca/galva.pdf (accessed on 26 April 2018).
- Bayes, Thomas. 1763. An Essay towards Solving a Problem in the Doctrine of Chances. By the Late Rev. Mr. Bayes, F. R. S. Communicated by Mr. Price, in a Letter to John Canton, A. M. F. R. S. Philosophical Transactions (1683–1775) 53: 370–418. [Google Scholar] [CrossRef]
- BCBS. 2001. Working Paper on the Regulatory Treatment of Operational Risk. Basel: Bank for International Settlements. [Google Scholar]
- BCBS. 2010. Basel III: A Global Regulatory Framework for More Resilient Banks and Banking Systems. Basel: Bank for International Settlements. [Google Scholar]
- Berger, James O. 1985. Statistical Decision Theory and Bayesian Analysis. New York: Springer. [Google Scholar]
- Böcker, Klaus, and Claudia Klüppelberg. 2010. Operational VaR: A Closed-Form Approximation. Risk 18: 90–93. [Google Scholar]
- Bowman, Adrian W. 1984. An alternative method of cross-validation for the smoothing of density estimates. Biometrika 71: 353–60. [Google Scholar] [CrossRef]
- Box, George E. P., and George C. Tiao. 1992. Bayesian Inference in Statistical Analysis. New York, Chichester and Brisbane: Wiley Classics Library, JohnWiley & Sons. [Google Scholar]
- Chernobai, Anna S., Svetlozar T. Rachev, and Frank J. Fabozzi. 2007. Operational Risk: A Guide to Basel II Capital Requirements, Models, and Analysis. New York: John Wiley & Sons. [Google Scholar]
- Cowell, Robert G., Richard J. Verrall, and Y. K. Yoon. 2007. Modeling operational risk with bayesian networks. Journal of Risk and Insurance 74: 795–827. [Google Scholar] [CrossRef]
- Cruz, Marcelo G. 2004. Operational Risk Modelling and Analysis. London: Risk Books. [Google Scholar]
- Cruz, Marcelo G., Gareth W. Peters, and Pavel V. Shevchenko. 2014. Fundamental Aspects of Operational Risk and Insurance Analytics: A Handbook of Operational Risk. Hoboken: John Wiley & Sons. [Google Scholar]
- Frachot, Antoine, Pierre Georges, and Thierry Roncalli. 2001. Loss Distribution Approach for Operational Risk. Working paper. Paris: GRO, Crédit Lyonnais. [Google Scholar]
- Gilks, Walter R., Sylvia Richardson, and David Spiegelhalter. 1996. Markov Chain Monte Carlo in Practice. London: Chapman & Hall/CRC. [Google Scholar]
- Guegan, Dominique, and Bertrand K. Hassani. 2013. Multivariate vars for operational risk capital computation: A vine structure approach. International Journal of Risk Assessment and Management 17: 148–70. [Google Scholar] [CrossRef]
- Guégan, Dominique, and Bertrand Hassani. 2013. Using a time series approach to correct serial correlation in operational risk capital calculation. The Journal of Operational Risk 8: 31. [Google Scholar] [CrossRef]
- Guégan, Dominique, and Bertrand Hassani. 2014. A mathematical resurgence of risk management: An extreme modeling of expert opinions. Frontiers in Finance & Economics 11: 25–45. [Google Scholar]
- Guégan, Dominique, Bertrand K. Hassani, and Cédric Naud. 2011. An efficient threshold choice for the computation of operational risk capital. The Journal of Operational Risk 6: 3–19. [Google Scholar] [CrossRef]
- Hassani, Bertrand, and Bertrand K. Hassani. 2016. Scenario Analysis in Risk Management. Cham: Springer. [Google Scholar]
- Lehmann, Erich L., and George Casella. 1998. Theory of Point Estimation, 2nd ed. Berlin: Springer. [Google Scholar]
- Leone, Paola, and Pasqualina Porretta. 2018. Operational risk management: Regulatory framework and operational impact. In Measuring and Managing Operational Risk. Cham: Palgrave Macmillan, pp. 25–93. [Google Scholar]
- Mizgier, Kamil J., and Maximilian Wimmer. 2018. Incorporating single and multiple losses in operational risk: A multi-period perspective. Journal of the Operational Research Society 69: 358–71. [Google Scholar] [CrossRef]
- Parent, Eric, and Jacques Bernier. 2007. Le Raisonnement Bayésien, Modelisation Et Inférence. Paris: Springer. [Google Scholar]
- Peters, Gareth William, and Scott Sisson. 2006. Bayesian inference, Monte Carlo sampling and operational risk. Journal of Operational Risk 1. [Google Scholar] [CrossRef]
- Peters, Gareth W., and Pavel V. Shevchenko. 2015. Advances in Heavy Tailed Risk Modeling: A Handbook of Operational Risk. Hoboken: John Wiley & Sons. [Google Scholar]
- Rudemo, Mats. 1982. Empirical choice of histograms and kernel density estimators. Scandinavian Journal of Statistics 9: 65–78. [Google Scholar]
- Shevchenko, Pavel V. 2011. Modelling Operational Risk Using Bayesian Inference. Berlin: Springer. [Google Scholar]
- Valdés, Rosa María Arnaldo, V. Fernando Gómez Comendador, Luis Perez Sanz, and Alvaro Rodriguez Sanz. 2018. Prediction of aircraft safety incidents using Bayesian inference and hierarchical structures. Safety Science 104: 216–30. [Google Scholar] [CrossRef]
| 1. | External loss data usually overlap with both internal data and scenario analysis and are therefore represented as a link between the two previous components. |
| 2. | It is generally accepted that capital calculations are not particularly sensitive to the choice of the frequency distribution (Álvarez 2001). |
| 3. | These parameters are omitted here for simplicity of notation, these are the parameters of the densities used as a prior distribution (e.g., a Gamma or Beta distribution). |
| 4. | These take into account the three different data sources. |
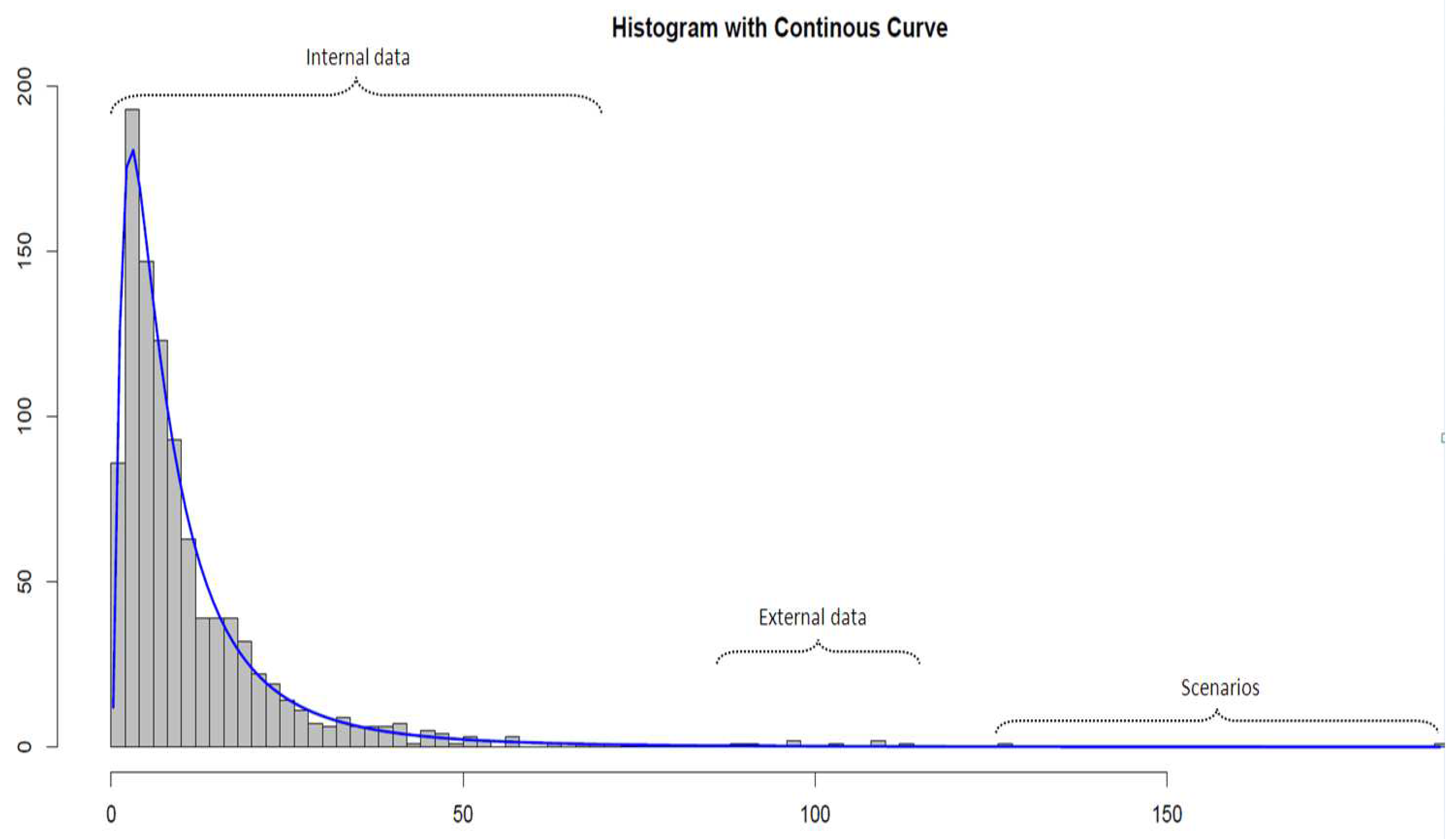
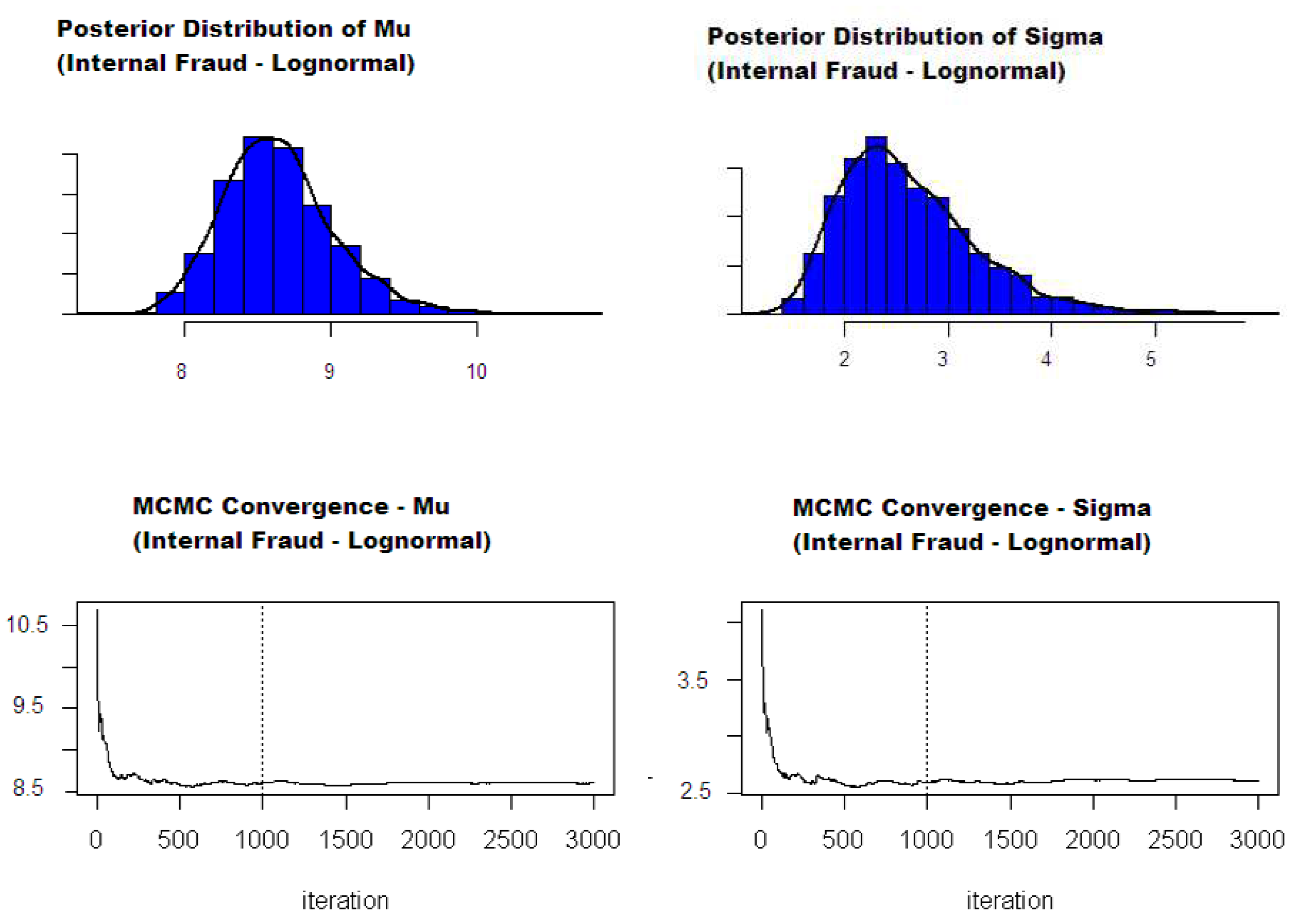
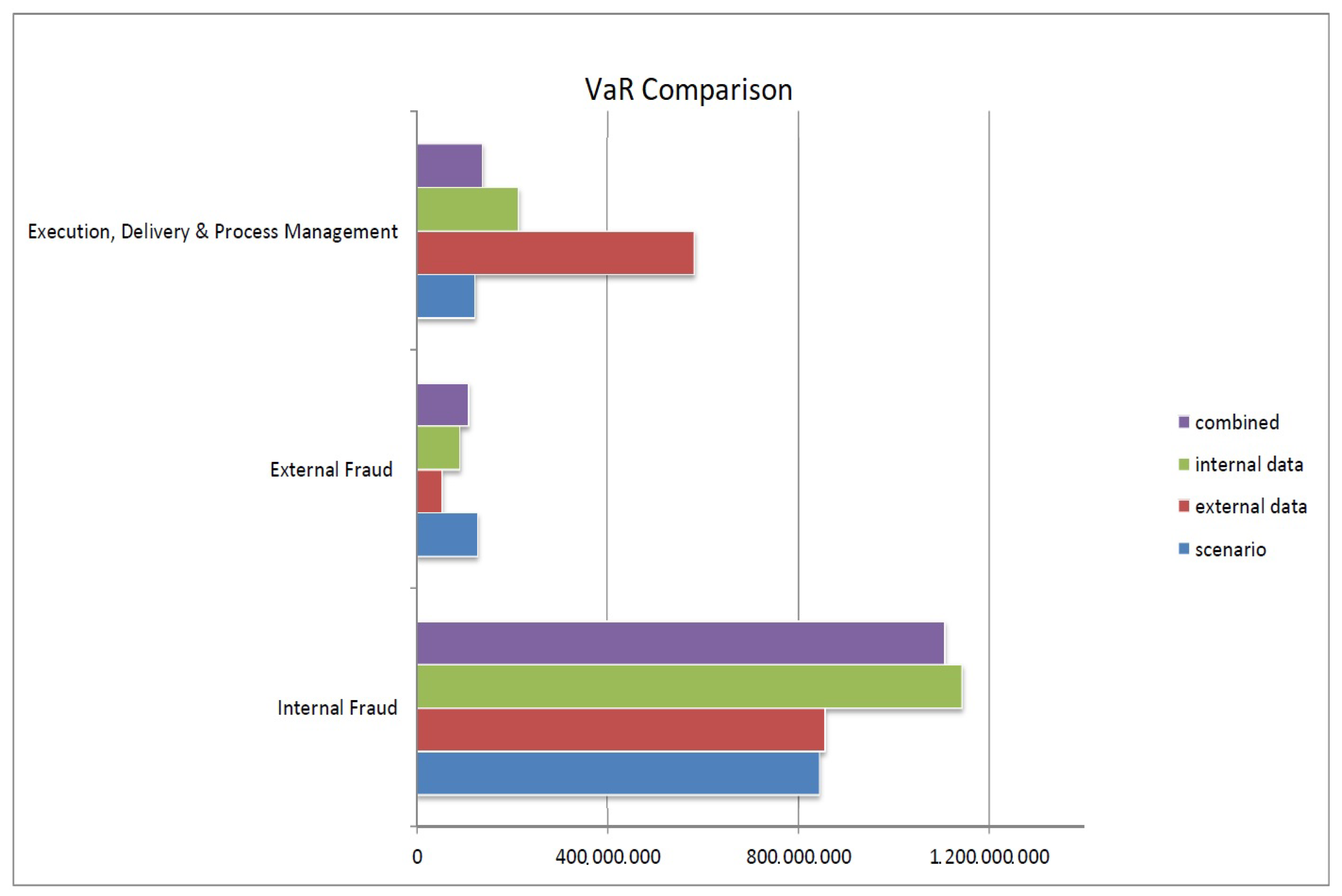

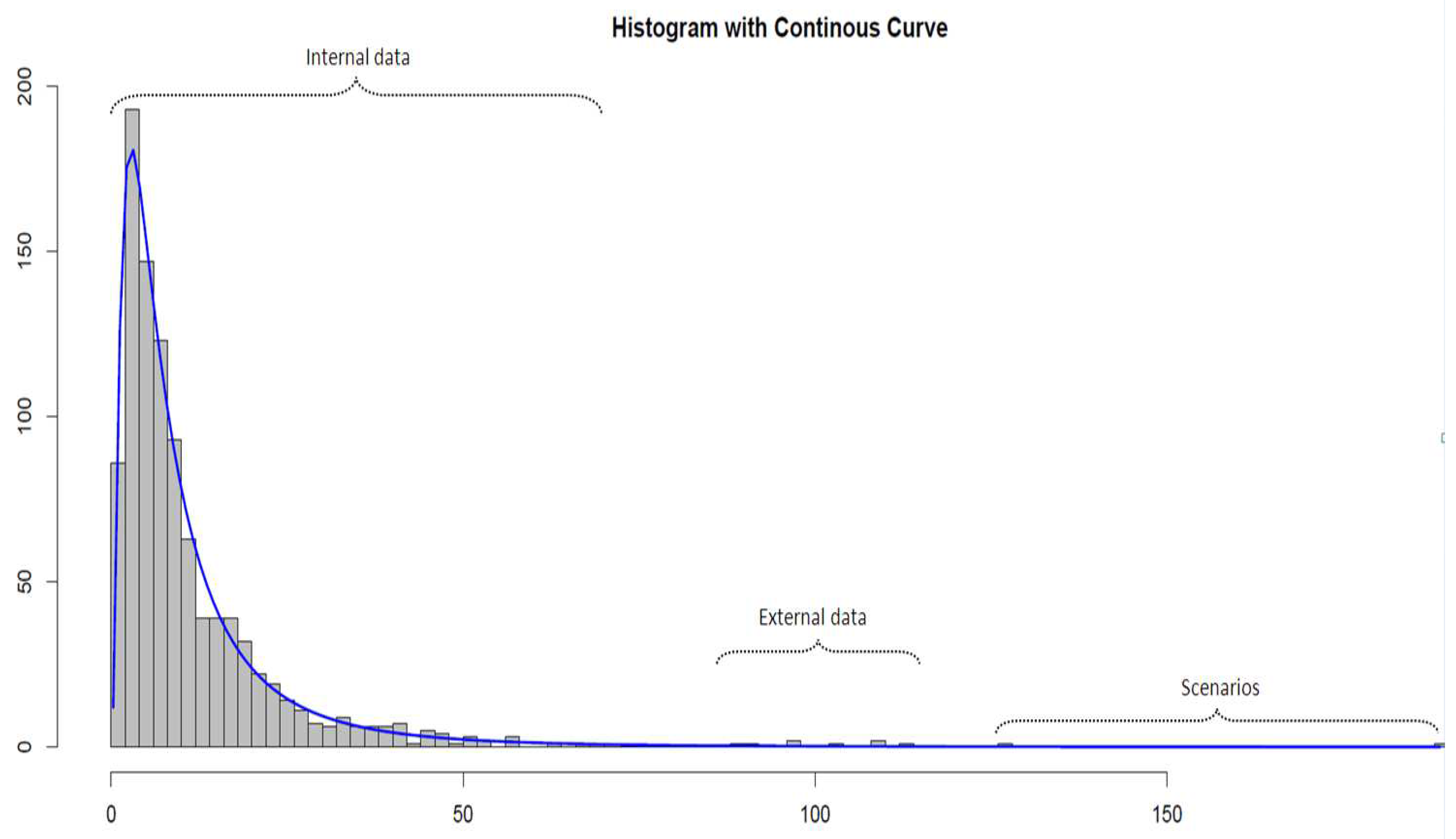{kind=link}
{kind=link}
{kind=link}
| Level 1 | Level 2 | NB Used | Min | Median | Mean | Max | sd | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|
| Internal Fraud | Global | 665 | 4137 | 28,165 | 261,475 | 46,779,130 | 1.9 × 106 | 21.4 | 407.1 |
| External Fraud | Payments | 1567 | 4091 | 12,358 | 36,133 | 1,925,000 | 9.2 × 104 | 11.7 | 185.2 |
| Execution, Delivery & Process Management | Other | 3602 | 4084 | 10,789 | 96,620 | 30,435,400 | 9.5× 105 | 24.8 | 653.8 |
| Level 1 | Level 2 | NB Used | Min | Median | Mean | Max | sd | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|---|---|
| Internal Fraud | Global | 2956 | 20,001 | 88,691 | 697,005 | 130,715,800 | 4.5 × 106 | 17.6 | 387.6 |
| External Fraud | Payments | 1085 | 20,006 | 36,464 | 326,127 | 106,772,200 | 4.3 × 106 | 20.8 | 461.2 |
| Execution, Delivery & Process Management | Other | 31,126 | 20,004 | 47,428 | 271,974 | 585,000,000 | 4.1 × 106 | 107.2 | 14,068.6 |
| Level 1 | Level 2 | 1 in 10 | 1 in 40 |
|---|---|---|---|
| Internal Fraud | Global | 6.0 × 106 | 5.2 × 107 |
| External Fraud | Payments | 1.5 × 106 | 2.5 × 107 |
| Execution, Delivery & Process Management | Other | 2.5 × 107 | 5.0 × 107 |
| Label | Density | Parameters |
|---|---|---|
| Beta | , | |
| Gamma | , | |
| Gaussian | , |
| Label | Scenarios | External Data | Internal Data | |||||
|---|---|---|---|---|---|---|---|---|
| Size | Size | |||||||
| Internal Fraud | 10.616031 | 2.024592 | 8.707405 | 2.693001 | 2956 | 9.347693 | 2.485755 | 665 |
| (Global)—Lognormal | ||||||||
| External Fraud | 0.37642 | 4.6951 × 104 | 1.644924 | 5.4293 × 104 | 1085 | 0.292442 | 976.922586 | 1567 |
| (Payments)—Weibull | ||||||||
| Execution, Delivery, | 0.4705893 | 1.5309 × 106 | 0.732526 | 1.1532 × 106 | 31126 | 0.82231 | 7.0388 × 105 | 3602 |
| and Product Management | ||||||||
| (Financial Instruments)—GPD | ||||||||
| Label | Scenarios Severity from Priors | Intermediate Severity (Scenarios + External Data) | Final Severity (Scenarios + External Data + Internal Data) | |||
|---|---|---|---|---|---|---|
| Internal Fraud (Global)—Lognormal | 10.616031 | 2.024592 | 9.123964 | 2.539844 | 8.727855 | 2.684253 |
| (95% Bayesian Credibility Interval) | - | - | - | - | [7.98176; 9.95824] | [1.23225; 4.42314] |
| External Fraud (Payments)—Weibull | 0.3761 | 46942 | 0.38873 | 49,942 | 0.39910 | 46,622 |
| (95% Bayesian Credibility Interval) | - | - | - | - | [0.23127; 0.50673] | [37,632; 58,981] |
| Execution, Delivery, and Product Management | 0.4705893 | 1.5309 × 106 | 0.4452626 | 1.5109 × 106 | 0.6021 | 6.05 × 105 |
| (Financial Instruments)—GPD | ||||||
| (95% Bayesian Credibility Interval) | - | - | - | - | [0.3313; 0.9089] | [4.52 × 105; 8.30 × 105] |
| Event Type | ||
|---|---|---|
| Execution, Delivery, | 8.092849 | 1.882122 |
| and Product Management | ||
| (Financial Instruments)—Lognormal body |
| Event Type | Initial | Corrected | ||
| Internal Fraud | 133 | 261.5885 | ||
| (Global)—Lognormal | ||||
| External Fraud | 313.4 | 485.0353 | ||
| (Payments)—Weibull | ||||
| Event Type | Initialbody | Initialtail | Initial Global | Corrected Global |
| Execution, Delivery, | 144.08 | 9.2 | 153.28 | 1882.327 |
| and Product Management | ||||
| (Financial Instruments)—GPD |
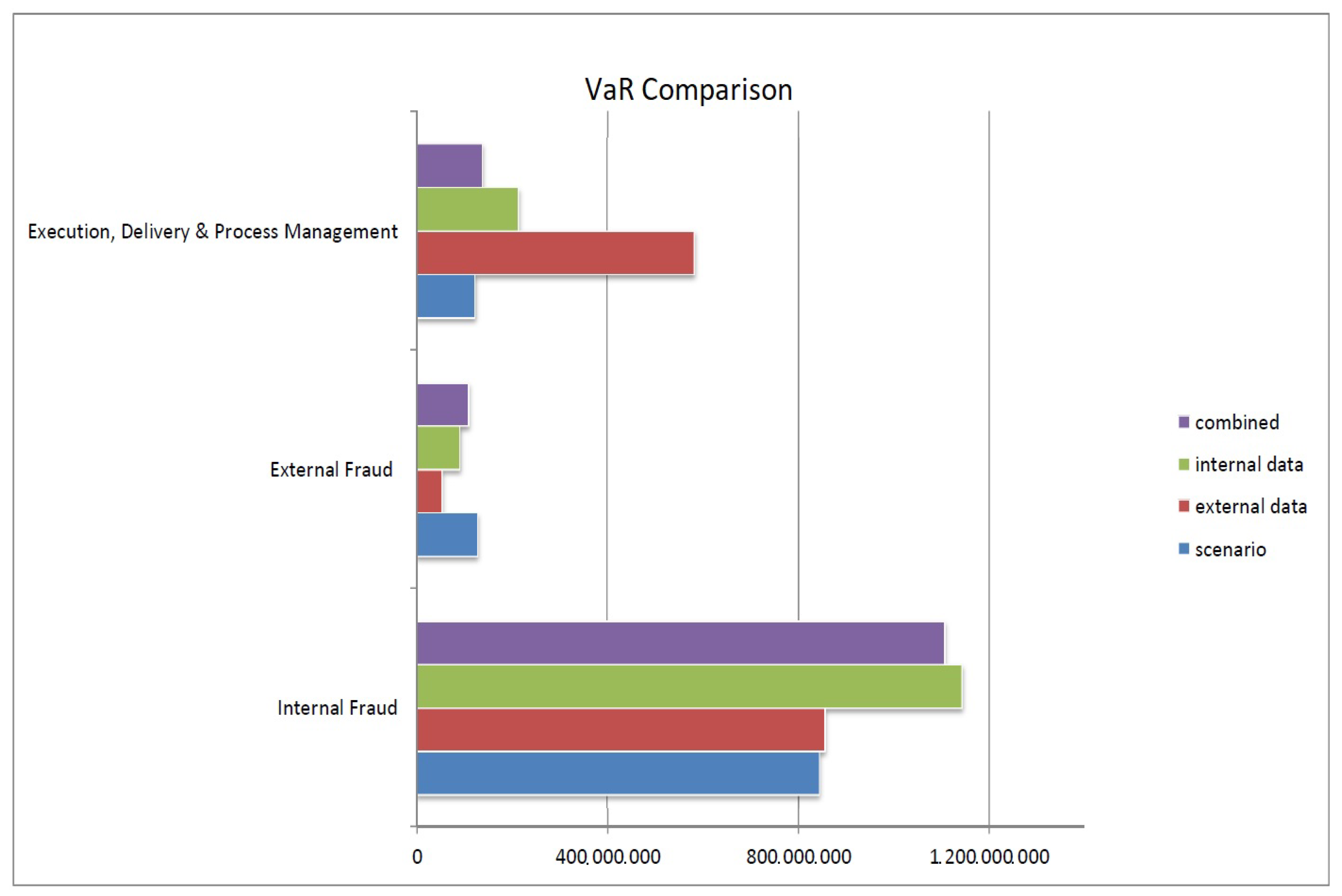
| Label | Scenarios | External Data | Internal Data | Combination | |
|---|---|---|---|---|---|
| VaR | VaR | VaR | VaR | ES | |
| Internal Fraud | 843,445,037 | 855,464,158 | 1,143,579,396 | 1,106,692,211 | 2,470,332,812 |
| (Global) | |||||
| External Fraud Payments | 128,243,367 | 13,664,057 | 3,945,116 | 119,637,592 | 126,935,364 |
| (Payments) | |||||
| Execution, Delivery, and Product Management | 122,544,708 | 583,519,888 | 137,456,938 | 213,982,300 | 281,157,384 |
| (Financial Instruments) | |||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, B.K.; Renaudin, A. The Cascade Bayesian Approach: Prior Transformation for a Controlled Integration of Internal Data, External Data and Scenarios. Risks 2018, 6, 47. https://doi.org/10.3390/risks6020047
Hassani BK, Renaudin A. The Cascade Bayesian Approach: Prior Transformation for a Controlled Integration of Internal Data, External Data and Scenarios. Risks. 2018; 6(2):47. https://doi.org/10.3390/risks6020047
Chicago/Turabian StyleHassani, Bertrand K., and Alexis Renaudin. 2018. "The Cascade Bayesian Approach: Prior Transformation for a Controlled Integration of Internal Data, External Data and Scenarios" Risks 6, no. 2: 47. https://doi.org/10.3390/risks6020047
APA StyleHassani, B. K., & Renaudin, A. (2018). The Cascade Bayesian Approach: Prior Transformation for a Controlled Integration of Internal Data, External Data and Scenarios. Risks, 6(2), 47. https://doi.org/10.3390/risks6020047