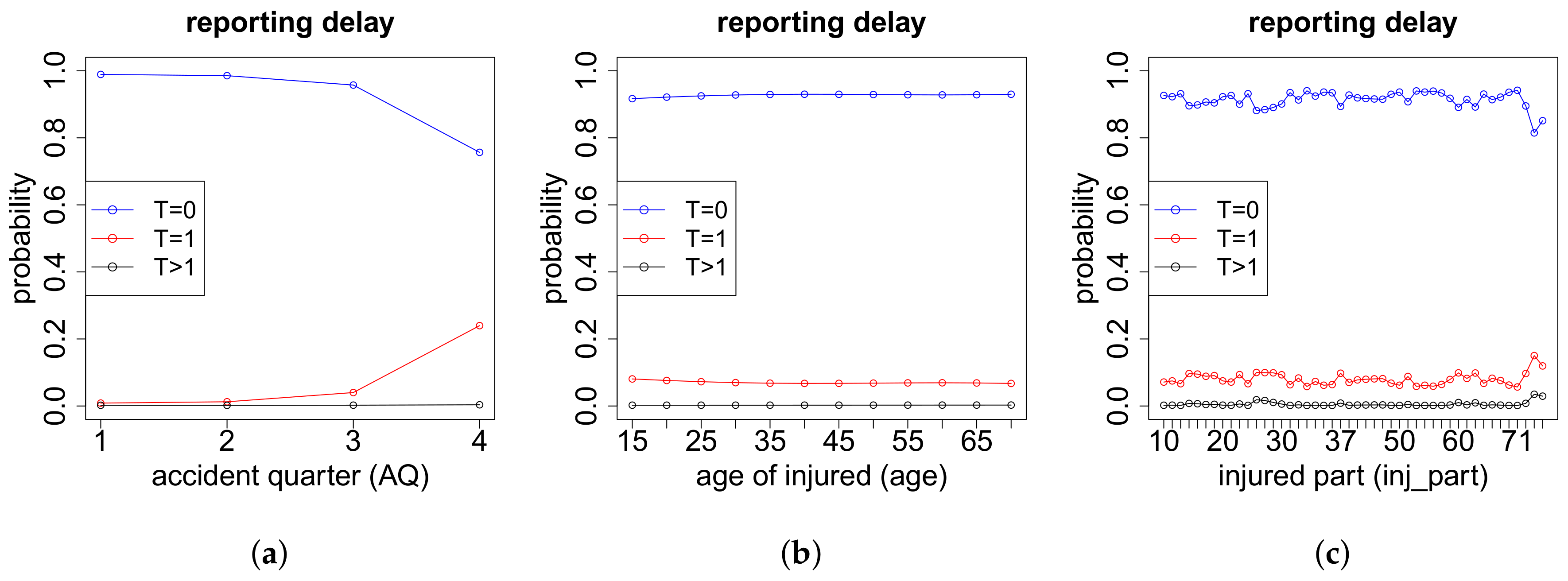
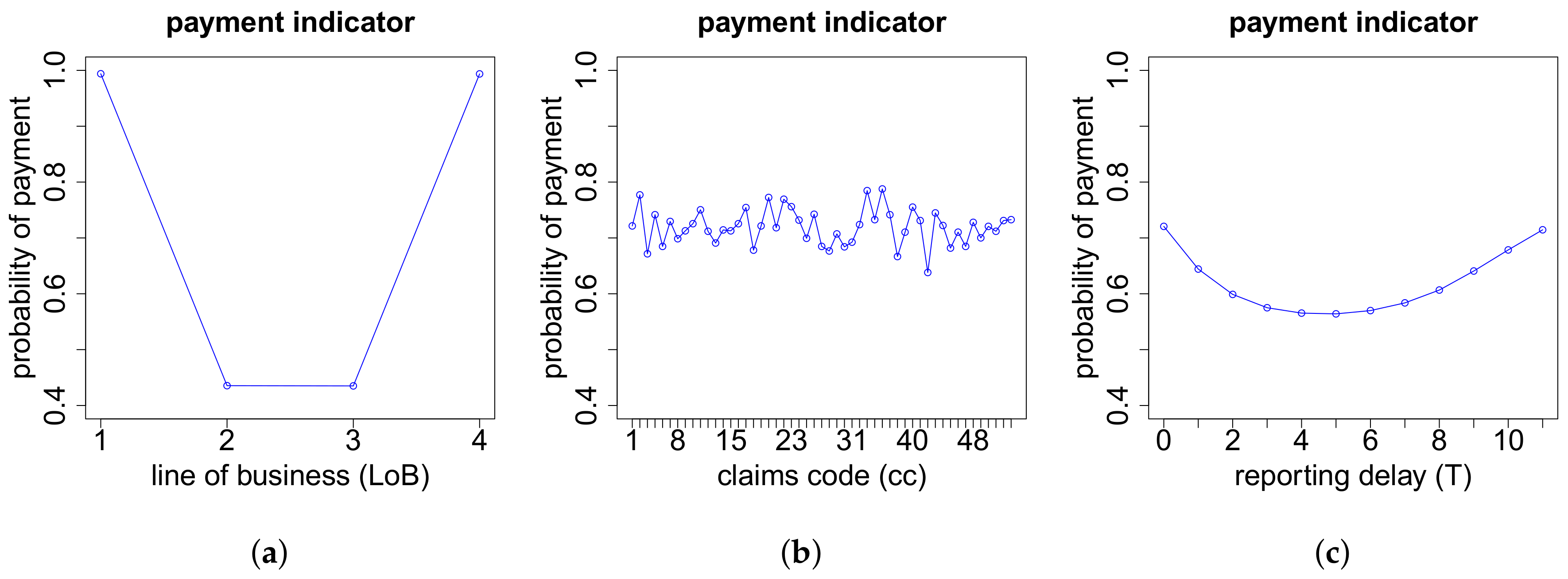
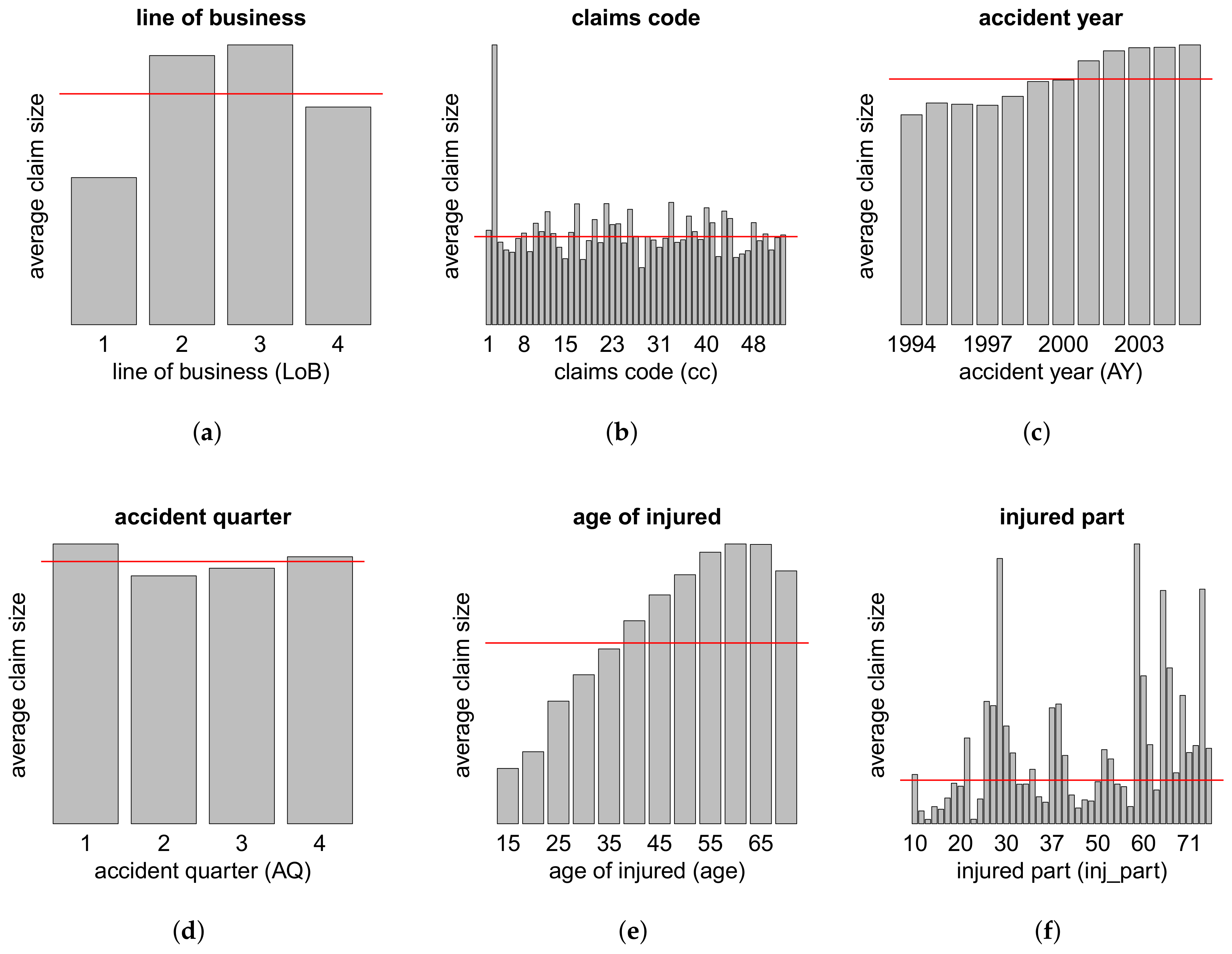
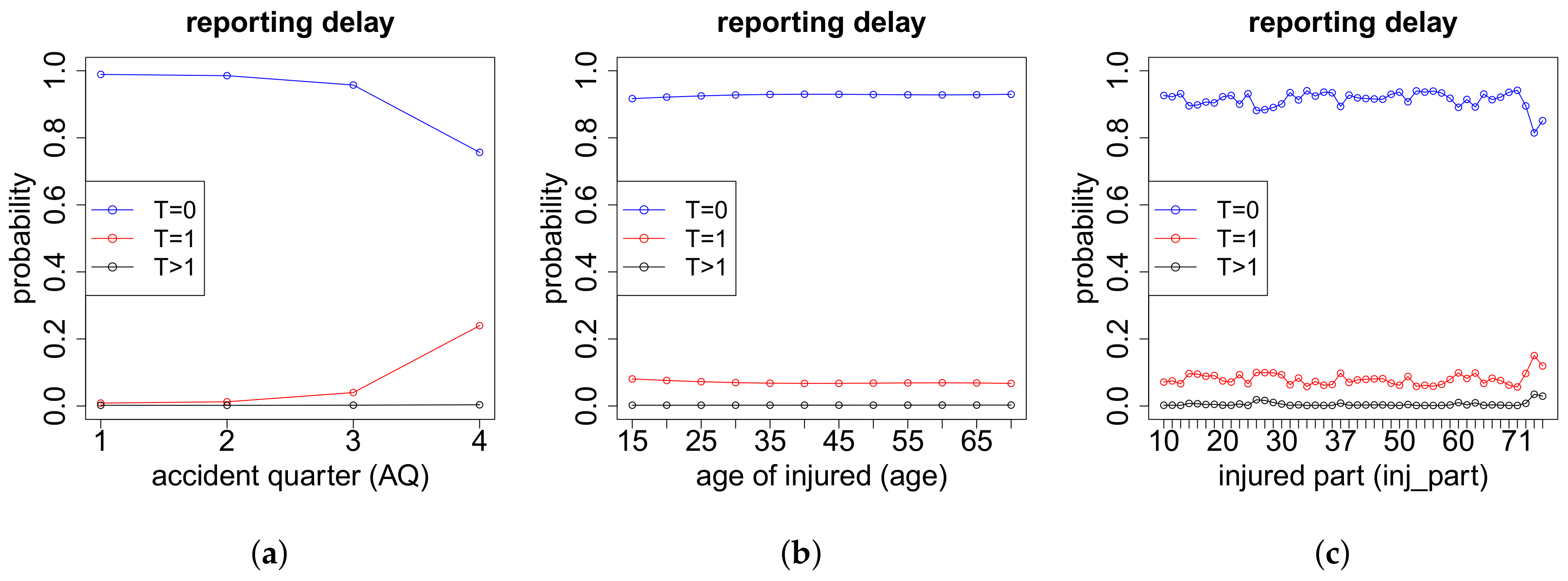
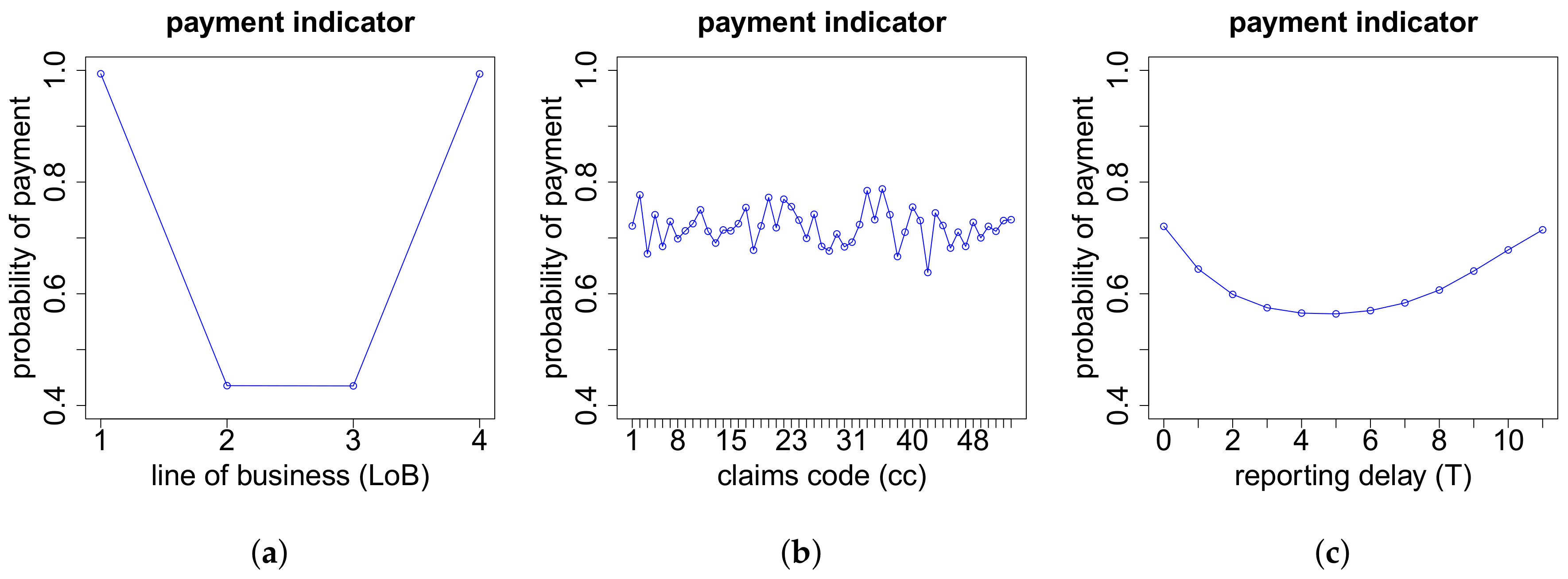
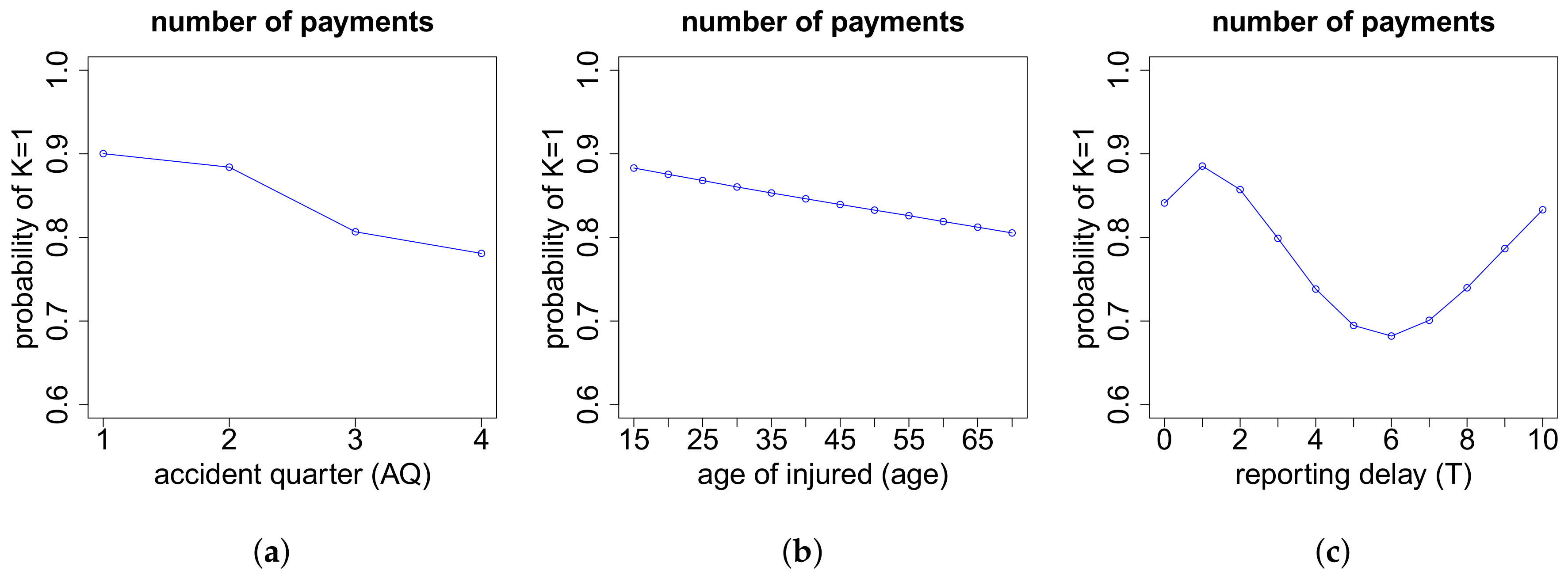
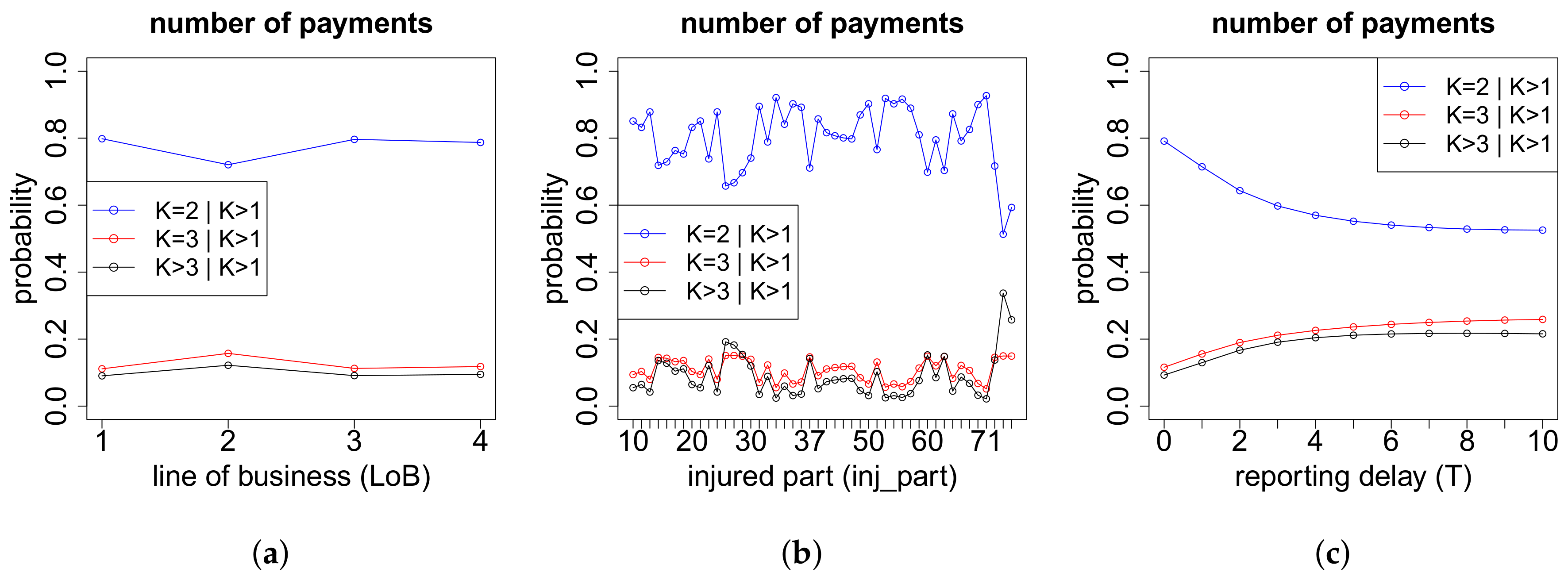
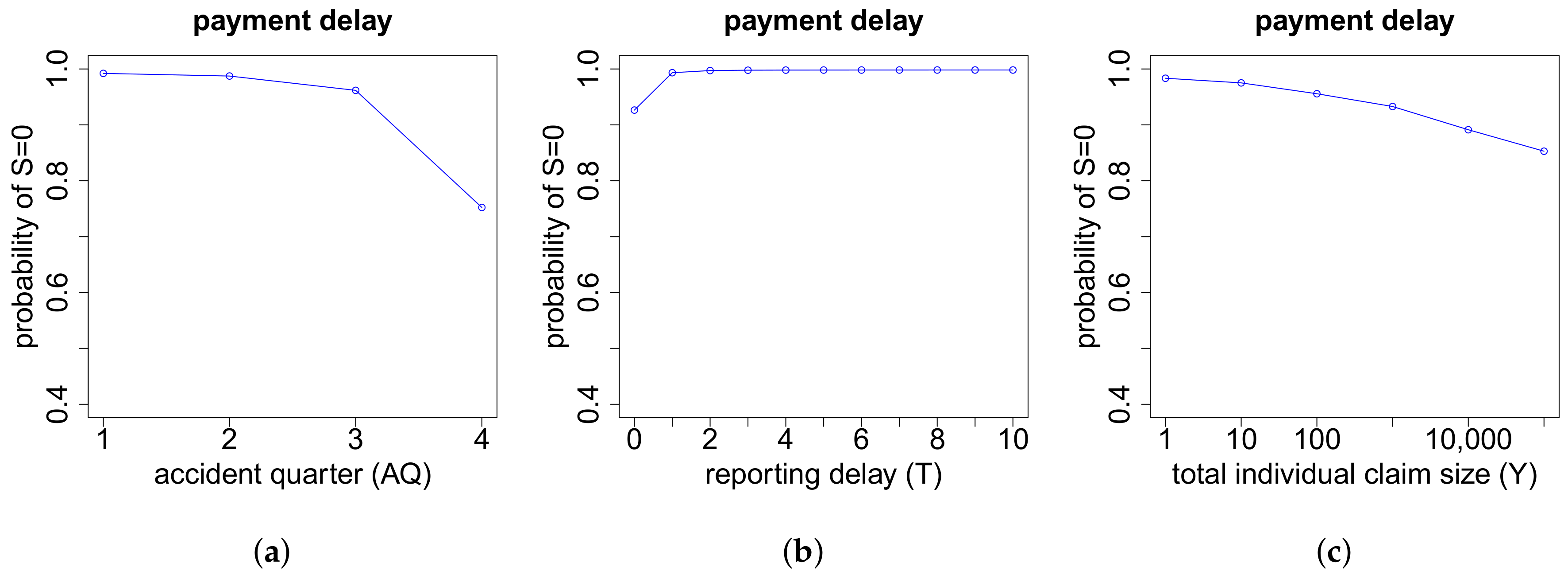
The modeling of the cash flow pattern is more involved, and we need to distinguish different cases. This distinction is done according to the total number of payments , the number of positive payments as well as the number of recovery payments .
2.7.2. Cash Flow for Two Payments
Now we consider claims with exactly two payments. Here we distinguish further between the two cases: (1) both payments are positive, and (2) one payment is positive and the other one negative.
(a) Two Positive Payments
We first consider the case where both payments are positive, i.e.,
and
. In this case, we have to model the time points of the two payments as well as the split of the total individual claim size to the two payments. For both models, we use the
dimensional feature space
, see (
16). We define
to be the number of claims with exactly two positive payments and no recovery and order them appropriately in
i such that
and
for all
. The time points
and
of the two payments are given by
for all
. Then, we modify the two-dimensional vector
to a one-dimensional categorical variable
by setting
for all
. This leads us to the data
Note that
is categorical with
possible values. That is, we are in the same setup as in
Section 2.1—with 66 different classes. Once again, the calibration is done in an analogous fashion as above.
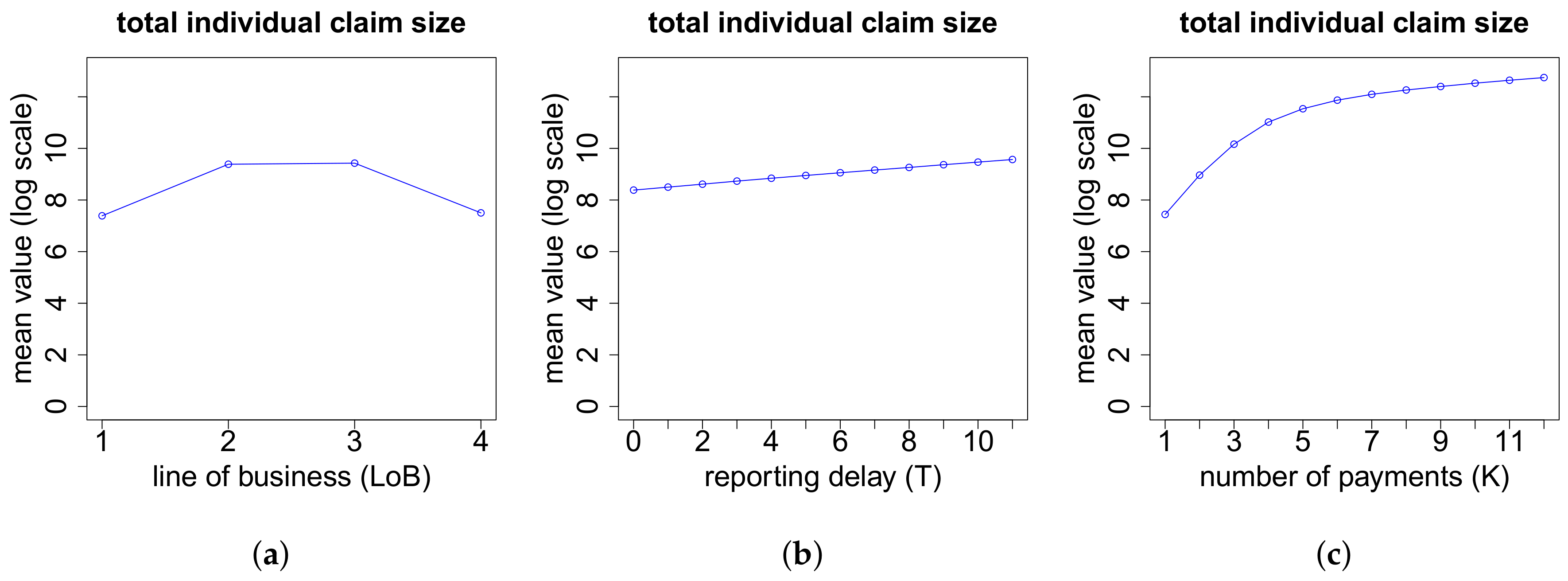
Next, we model the split of the total individual claim size for claims with
. Let
,
, see (
16), and define the proportion
of the total individual claim size
that is paid in the first payment by
for all
. This gives us the data
For a claim with feature
and
, the corresponding proportion of its total individual claim size
Y that is paid in the first payment is for simplicity modeled by a deterministic function
. Note that one could easily randomize
using a Dirichlet distribution. However, at this modeling stage, the resulting differences would be of smaller magnitude. Hence, we directly fit the proportion function
Similarly to the calibration in
Section 2.2, we assume a regression function
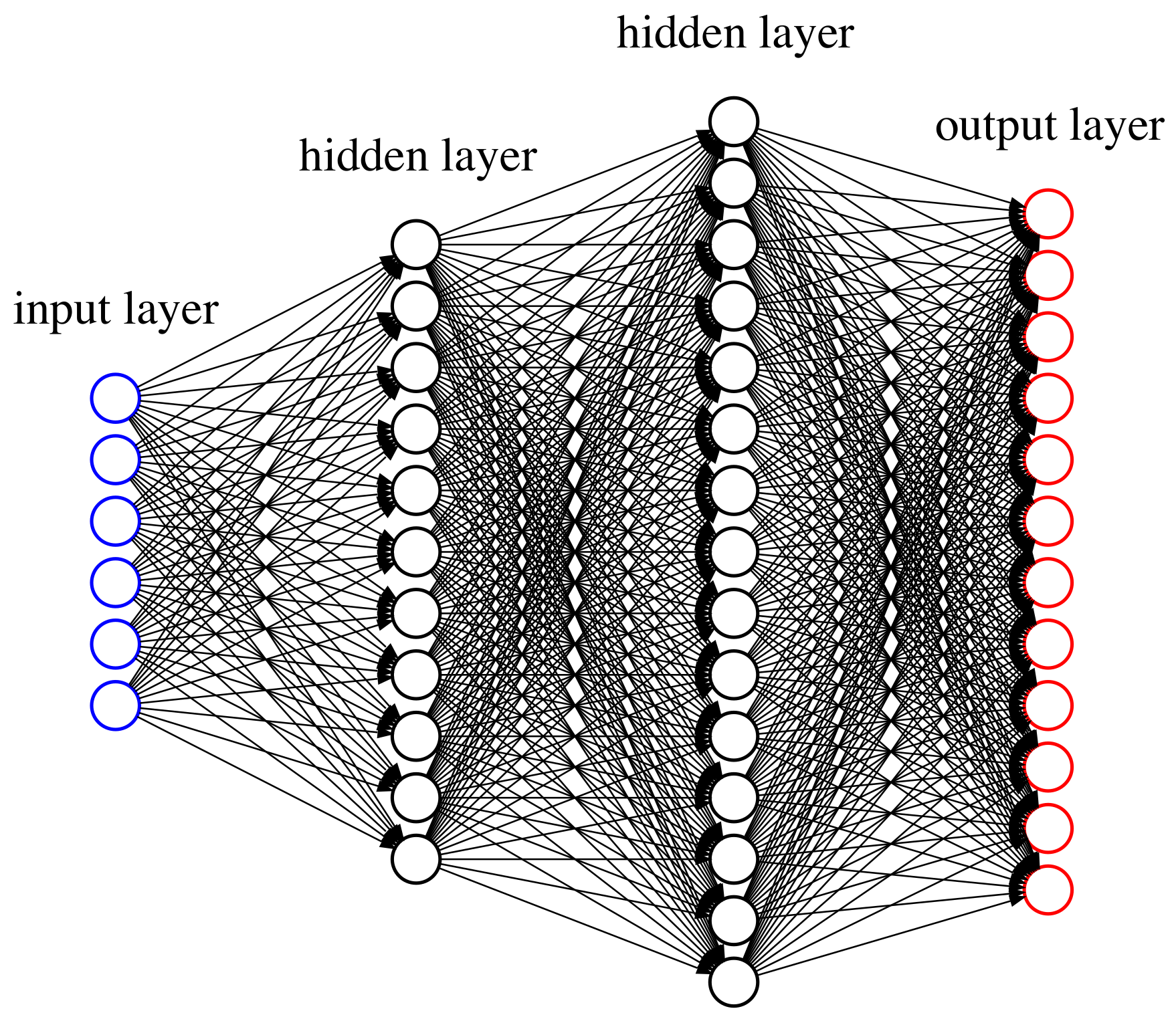
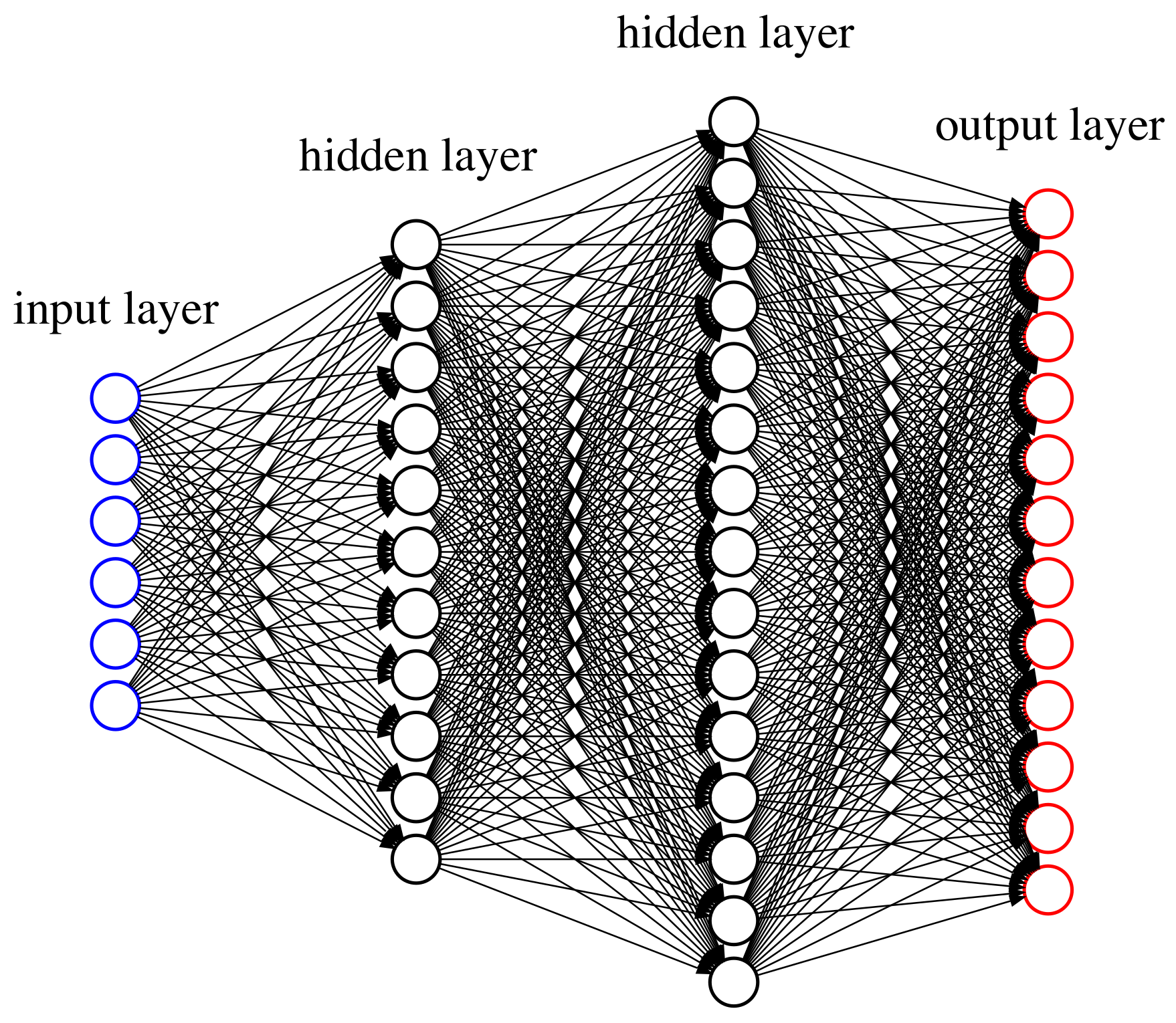
of type (10) for a neural network with two hidden layers. Then, for the output layer, we use
and as loss function the cross entropy function, see also (
11),
where
is the network parameter containing all the weights of the neural network.
From this model, we can then simulate the cash flow for a claim with
. First, we simulate
. If
, we have
and
. If
, we have
The cash flow is given by
with
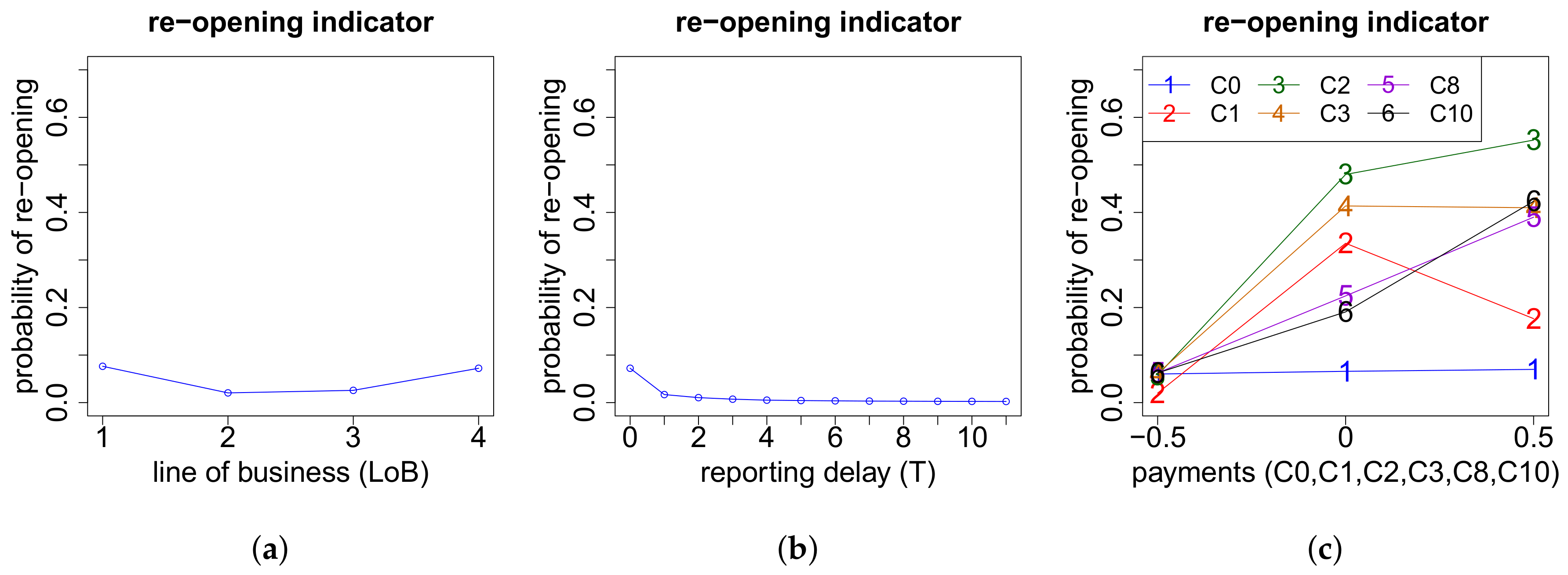
(b) One Positive Payment, One Recovery Payment
Now we focus on the case where we have
positive and
negative payment. Here we only have to model the time points of the two payments, since we know the total individual claim size as well as the total individual recovery and we assume that the positive payment precedes the recovery payment. The modeling of the time points of the two payments is done as above, except that this time we use the
dimensional feature space
where we include the information of the total individual recovery
. Moreover, we define
to be the number of claims with exactly one positive payment and one recovery payment and order the claims appropriately in
i such that
and
for all
. This provides us with the data
with
defined as in (
17). The rest is done as above. We obtain the cash flow
with
Remark that we again have combinatorial complexity of for the time points of the two payments. Since data is sparse, for this calibration we restrict to the 35 most frequent distribution patterns. More details on this restriction are provided in the next section.
2.7.3. Cash Flow for More than Two Payments
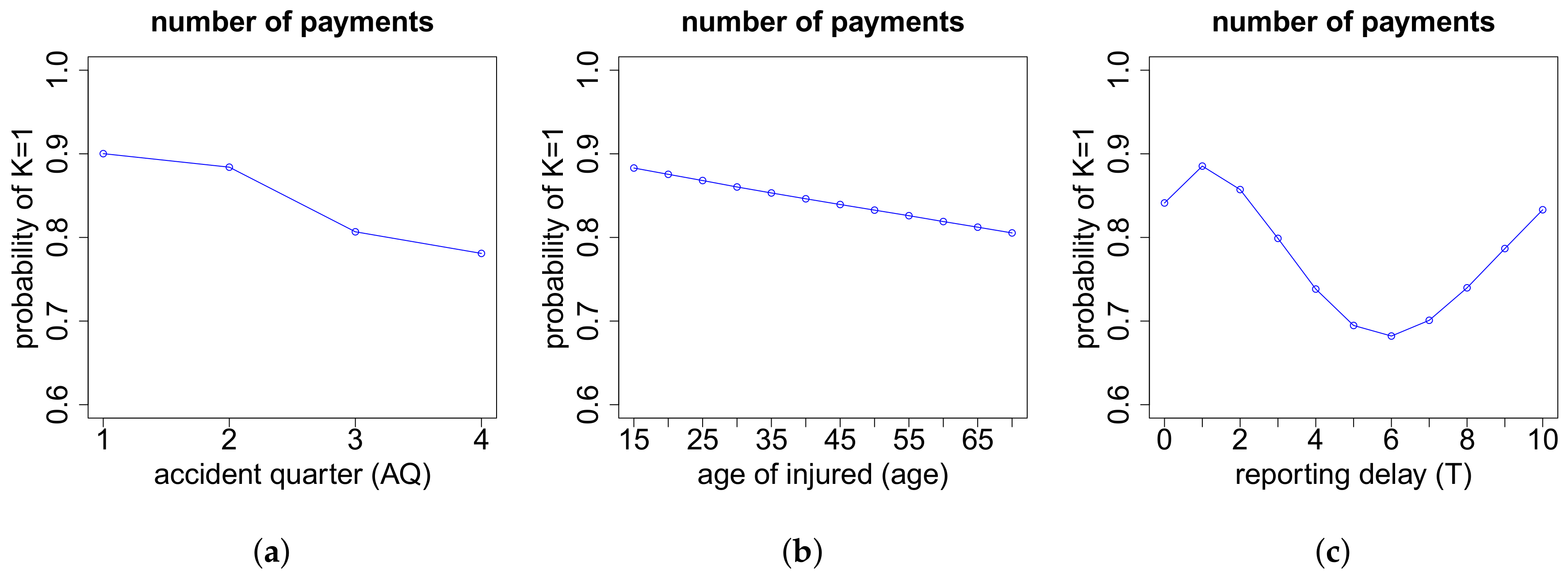
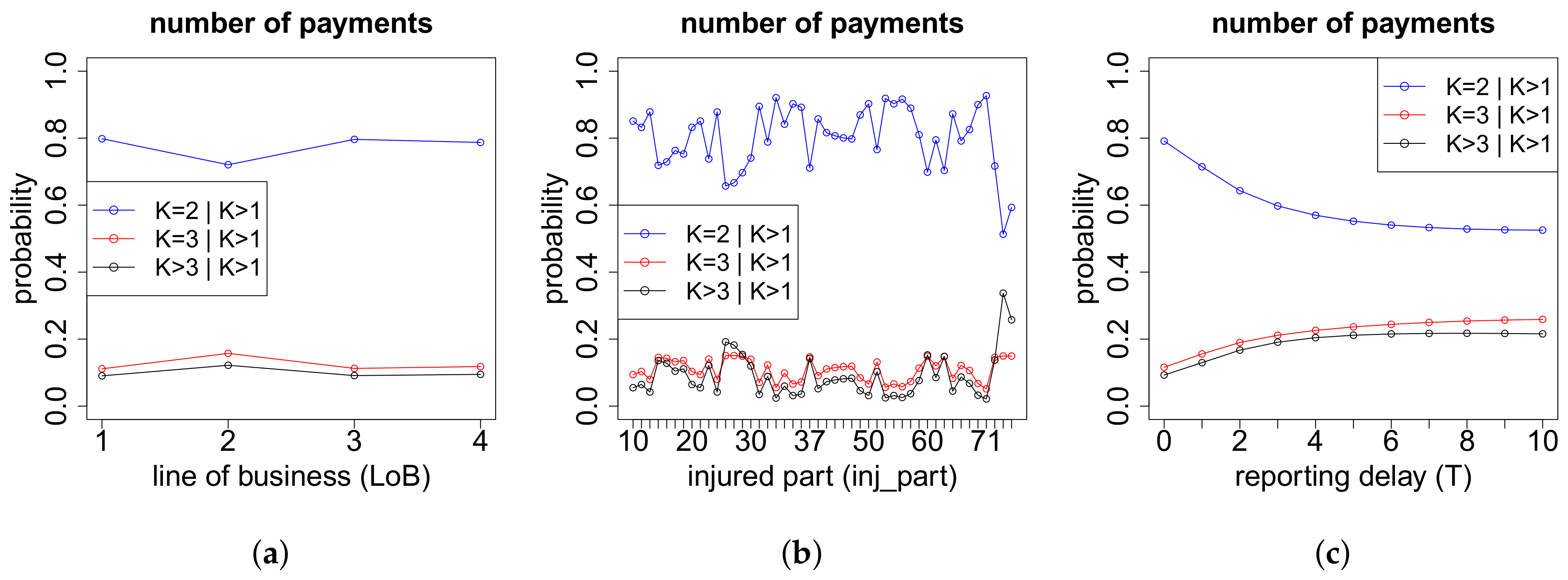
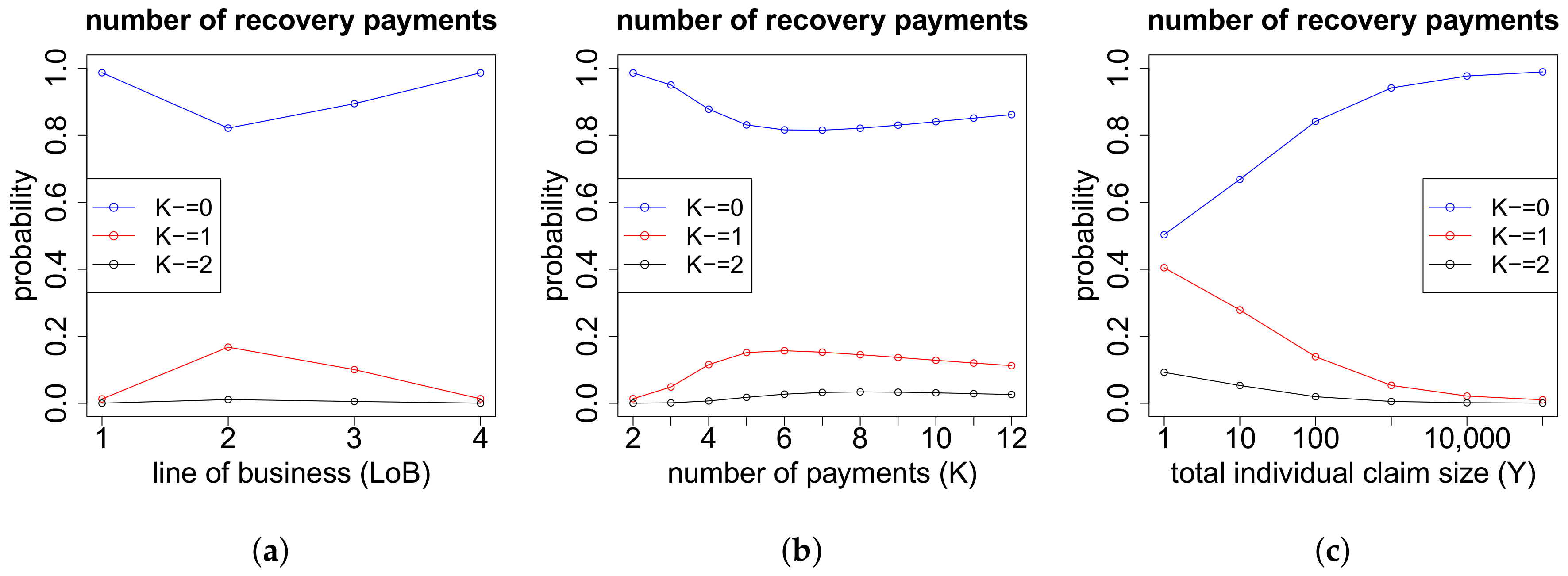
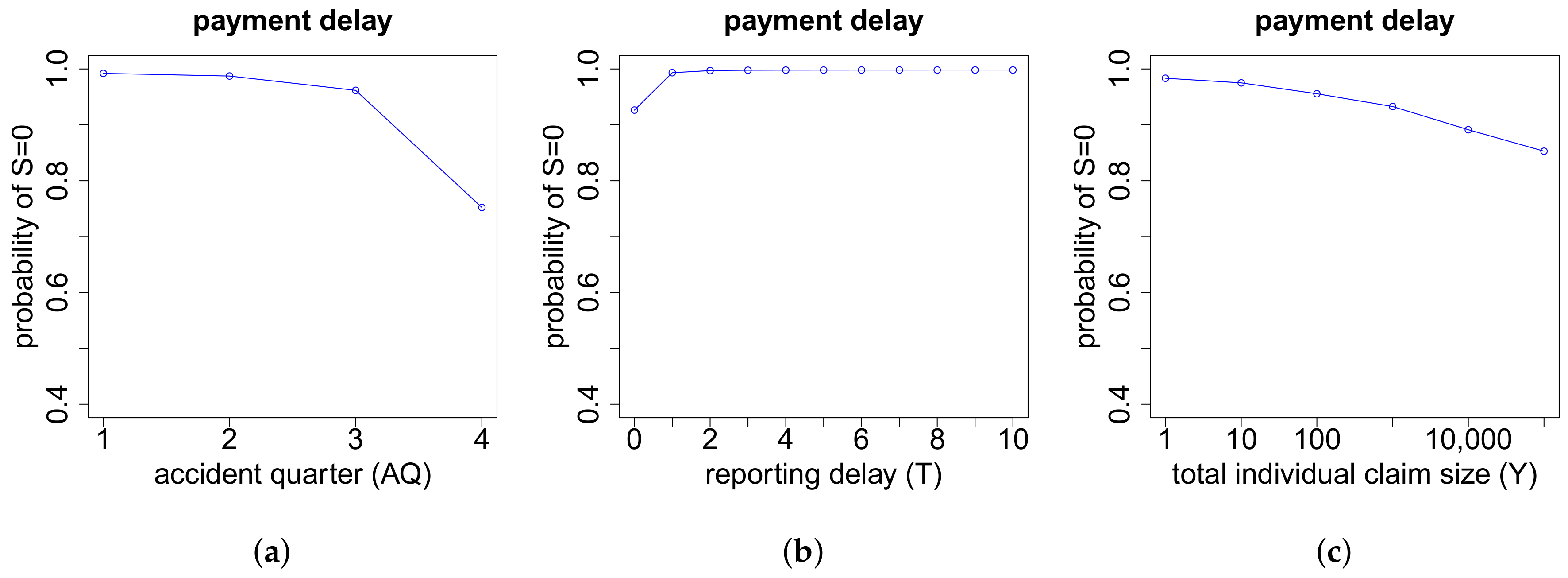
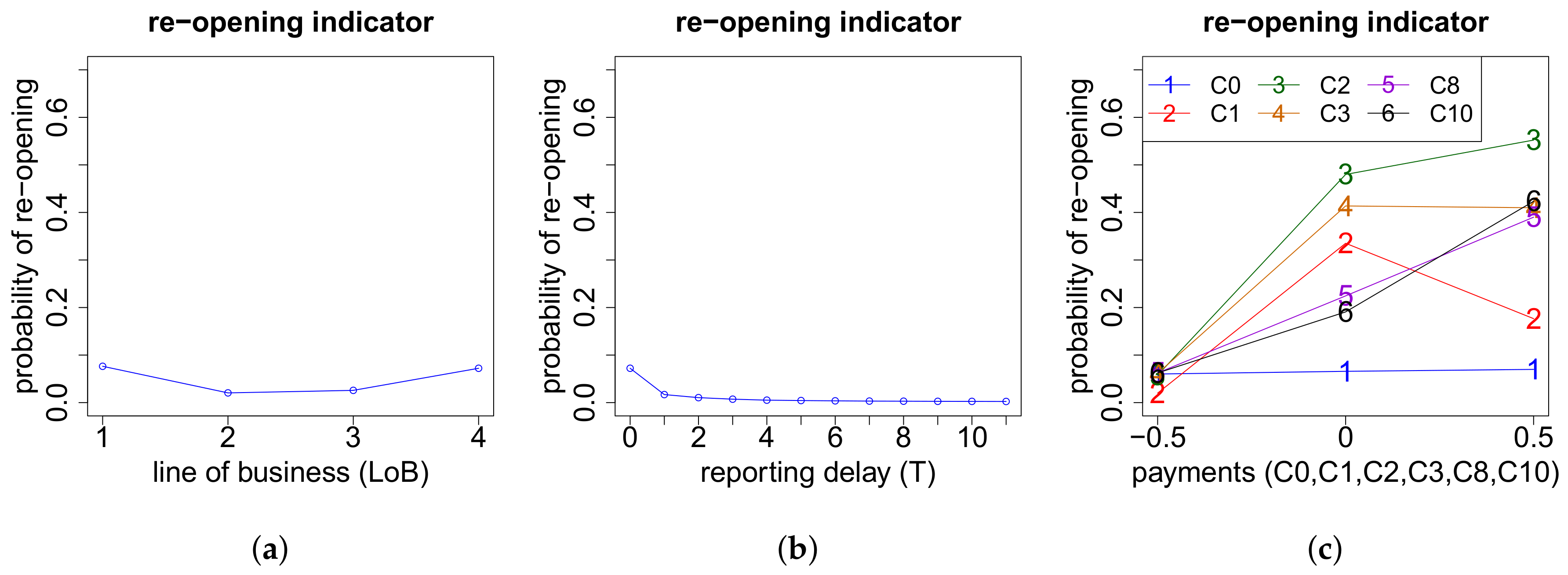
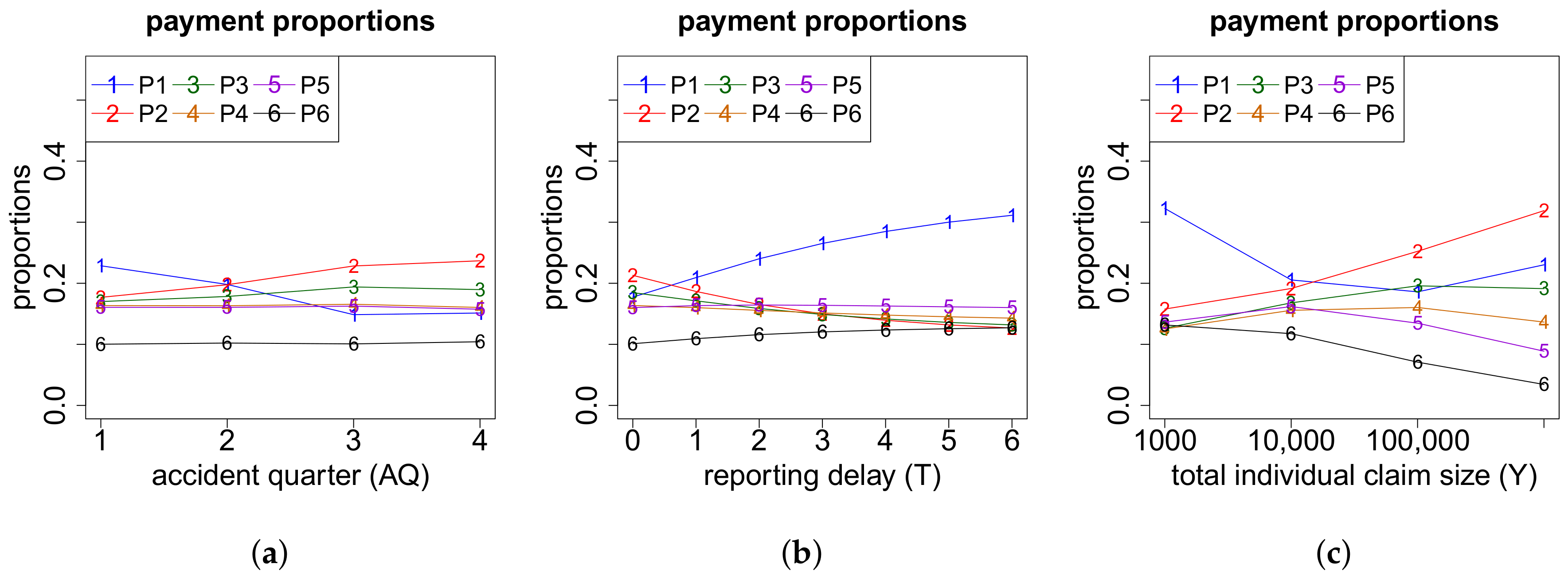
On the one hand, the models for the cash flows in the case of more than two payments depend on the exact number of payments K. On the other hand, they also depend on the respective numbers of positive payments and negative payments . If we have zero or one recovery payment (), then we need to model (a) the time points where the K payments occur and (b) the proportions of the total gross claim amount paid in the positive payments. If , then there are no recovery payments and, thus, . If , the recovery payment is always set at the end. In the case of recovery payments, in addition to (a) and (b), we use another neural network to model (c) the proportions of the total individual recovery paid in the two recovery payments. The time point of the first recovery payment is for simplicity assumed to be uniformly distributed on the set of time points of the 2nd up to the -st payment. The second recovery payment is always set at the end. The time point of the first payment is excluded for recovery in our model since we first require a positive payment before a recovery is possible. The three neural networks considered in this modeling part are outlined below in (a)–(c). Afterwards, we can model the cash flow for claims with payments, see item (d) below.
(a) Distribution of the K Payments
If we have payments, then the distribution of these payments to the 12 development years is trivial, as we have a payment in every development year. Since the model is pretty much the same in all other cases , we present here the case as illustration.
For the modeling of the distribution of the payments to the development years, we slightly simplify our feature space by dropping the categorical feature components
and
. Moreover, we simplify the feature
with its four categorical classes: since the lines of business one and four as well as the lines of business two and three behave very similarly w.r.t. the cash flow patterns, we merge these lines of business in order to get more volume (and less complexity). We denote this simplified lines of business by
. Thus, we work with the
dimensional feature space
Let
be the number of claims with exactly six payments and order the claims appropriately in
i such that
for all
. The time points
of the six payments are given by
for all
and
. Then, we use the following binary representation
for all
, for the time points of the six payments. This leads us to the data
where
and
for some set
. Since there are
possibilities to distribute the
payments to the 12 development years, we have
distribution patterns. To reduce complexity (in view of sparse data), we only allow for the most frequently observed distributions of the payments to the development years. For
, we work with 21 different patterns, which cover
of all claims with
. We denote the set containing these 21 patterns by
. See
Table 1 for an overview, for each
, of the number of possible different patterns, the number of allowed different patterns and the percentage of all claims covered with this choice of allowed distribution patterns.
Note that for
, we allow for all the 12 possible distribution patterns. Going back to the case
, we denote by
the number of claims with exactly
payments and with a distribution of these six payments to the 12 development years contained in the set
. Then, we modify the data
accordingly to
by only considering the relevant observations in
. This provides us with a classification problem similar to the one in
Section 2.1—with
classes.
(b) Proportions of the Positive Payments
If the number of positive payments is equal to one, then the amount paid in this unique positive payment is given by the total gross claim amount . That is, we do not need to model the proportions of the positive payments. Since the model is basically the same in all other cases , we present here the case as illustration.
As in the previous part, we use the
dimensional feature space
. Let
be the number of claims with exactly six positive payments and order the claims appropriately in
i such that
for all
. We define
for all
and
, to be the time points of the six positive payments. Then, we can define
to be the proportion of the total gross claim amount
that is paid in the
k-th positive, annual payment, for all
and
. This equips us with the data
For a claim with feature
and
positive payments, the corresponding proportions
of the total gross claim amount
that are paid in the six positive payments are for simplicity assumed to be deterministic. Note that we could randomize these proportions by simulating from a Dirichlet distribution, but—as in
Section 2.7.2—we refrain from doing so. Hence, we consider the proportion functions
for all
, with normalization
, for all
. We use the same model assumptions as in (
7) by setting for
for appropriate regression functions
resulting as output layer from a neural network with two hidden layers. As in (
19), we consider the cross entropy loss function
where
is the corresponding network parameter. This model is calibrated as described in
Section 2.1. Remark that if
, the model (
20) simplifies to the binomial case, see (
18).
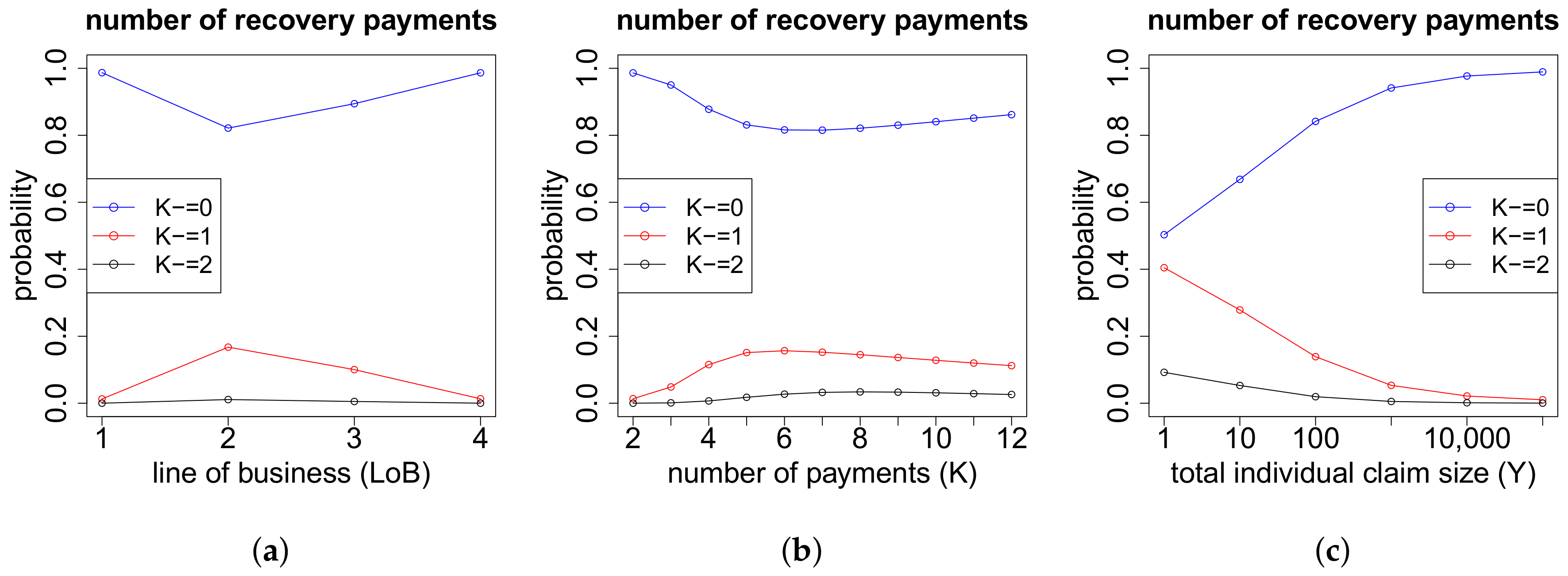
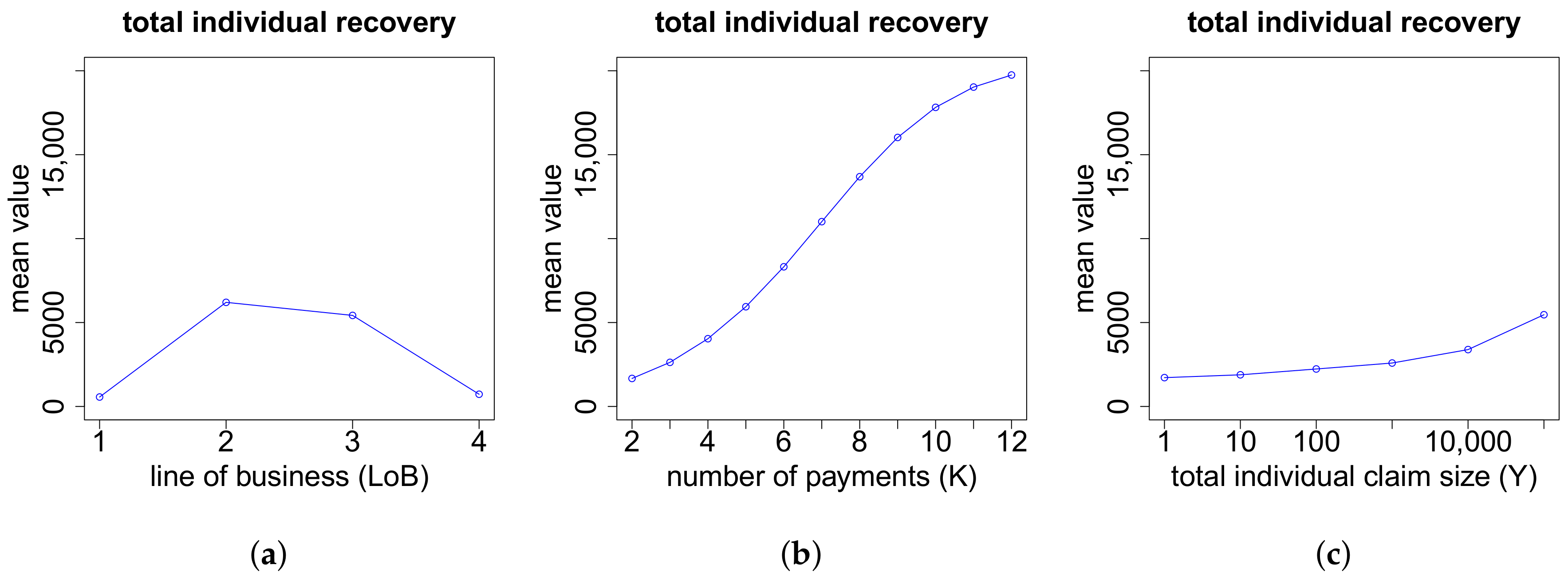
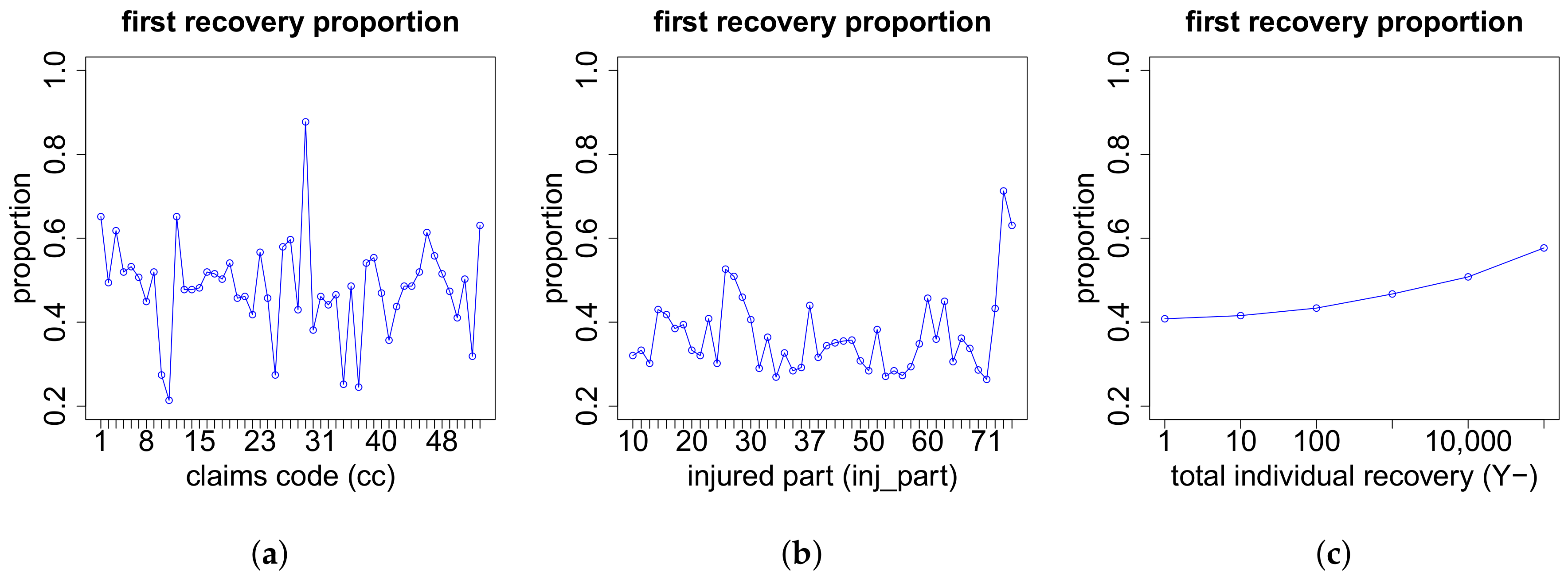
(c) Proportions of the Recovery Payments if
In the case of
recovery payments, we need to model the proportion of the total individual recovery
that is paid in the first recovery payment. For this, we work with the
dimensional feature space
We denote by
the number of claims with exactly two recovery payments and order the claims appropriately in
i such that
for all
. Recall that we set
for all claims
i with two or more recovery payments, see (
15). Moreover, we add all the amounts of the recovery payments done after the second recovery payment to the second one. Let
denote the time point of the first recovery payment, for all
. Then, the proportion
of the total individual recovery
that is paid in the first recovery payment is given by
for all
. This provides us with the data
The remaining modeling part is then done completely analogously to the second part of the two positive payments case (a) in
Section 2.7.2.
(d) Cash Flow Modeling
Finally, using the three neural network models outlined above, we can simulate the cash flow for a claim with more than two payments and with feature
, see (5). We illustrate the case
. Note that we only allow for cash flow patterns in
that are compatible with the reporting delay
T. We start by describing the case
. In this case, there is no difficulty and we directly simulate the cash flow pattern
. This provides us six payments in the time points
For reporting delay , the set of potential cash flow patterns becomes smaller because some of them have to be dropped to remain compatible with . For this reason, we simulate with probability a pattern from , and with probability the six time points are drawn in a uniform manner from the remaining possible time points in . For , the potential subset of patterns in becomes (almost) empty. For this reason, we simply simulate uniformly from the compatible configurations in .
Having the six time points for the payments, we distinguish the three different cases :
Case : we calculate the proportions
according to point (b) above and we receive the cash flow
with
Case : we have five positive payments with proportions
modeled according to point (b) above. This provides the cash flow
with
Case : we have four positive payments with proportions
according to point (b) above and two negative payments with proportions
and
according to point (c) above. The time point of the first recovery
is simulated uniformly from the set of time points
. Note that the time point
is reserved for the first positive payment and the time point
for the second recovery payment. We write
for the time points of the four positive payments. Summarizing, we get the cash flow
with
Of course, if and , we do not need to simulate the proportions of the positive payments, as there is only one positive payment, which occurs in the beginning. Similarly, if , we do not need to simulate the time points of the payments, since there is a payment in every development year.

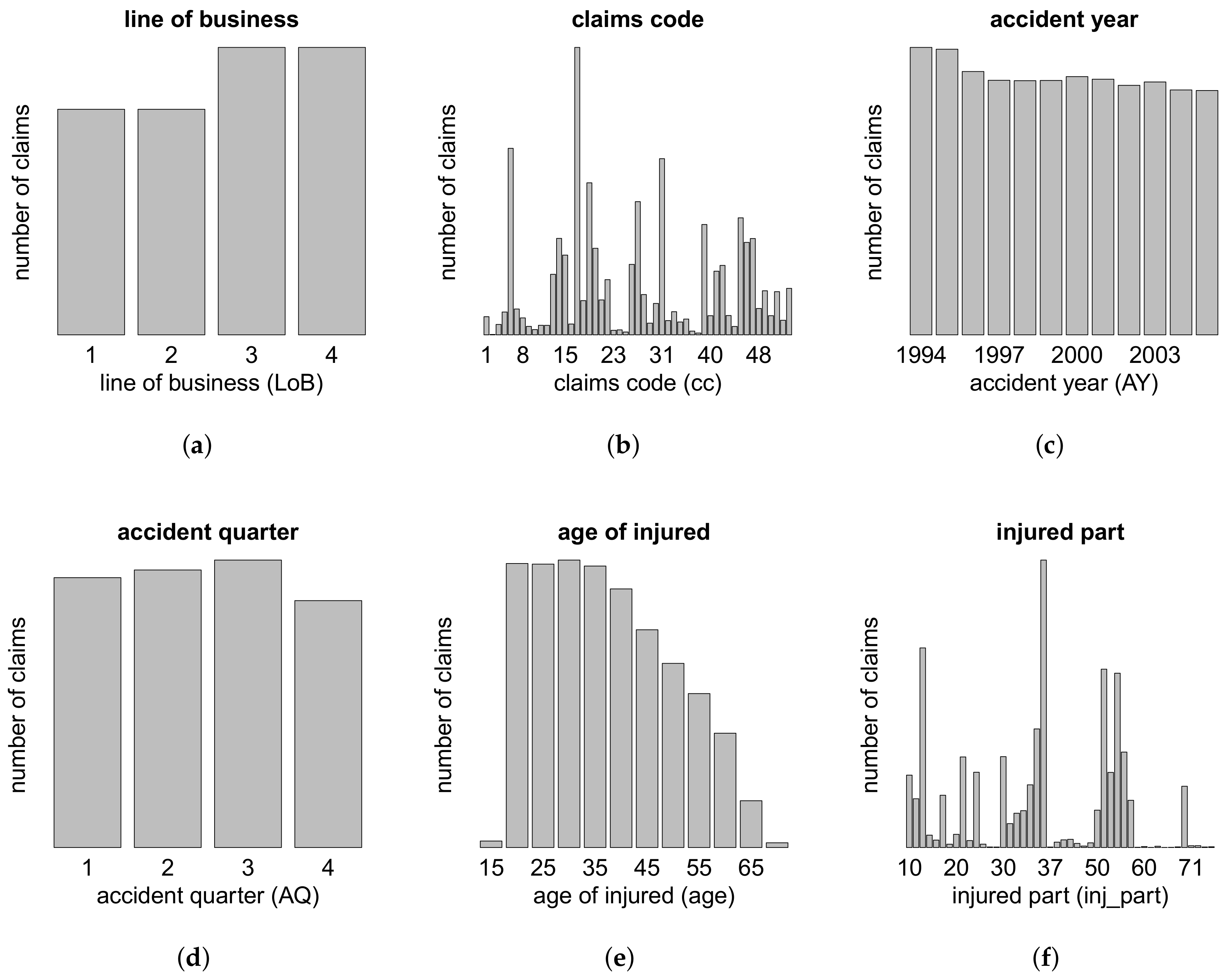
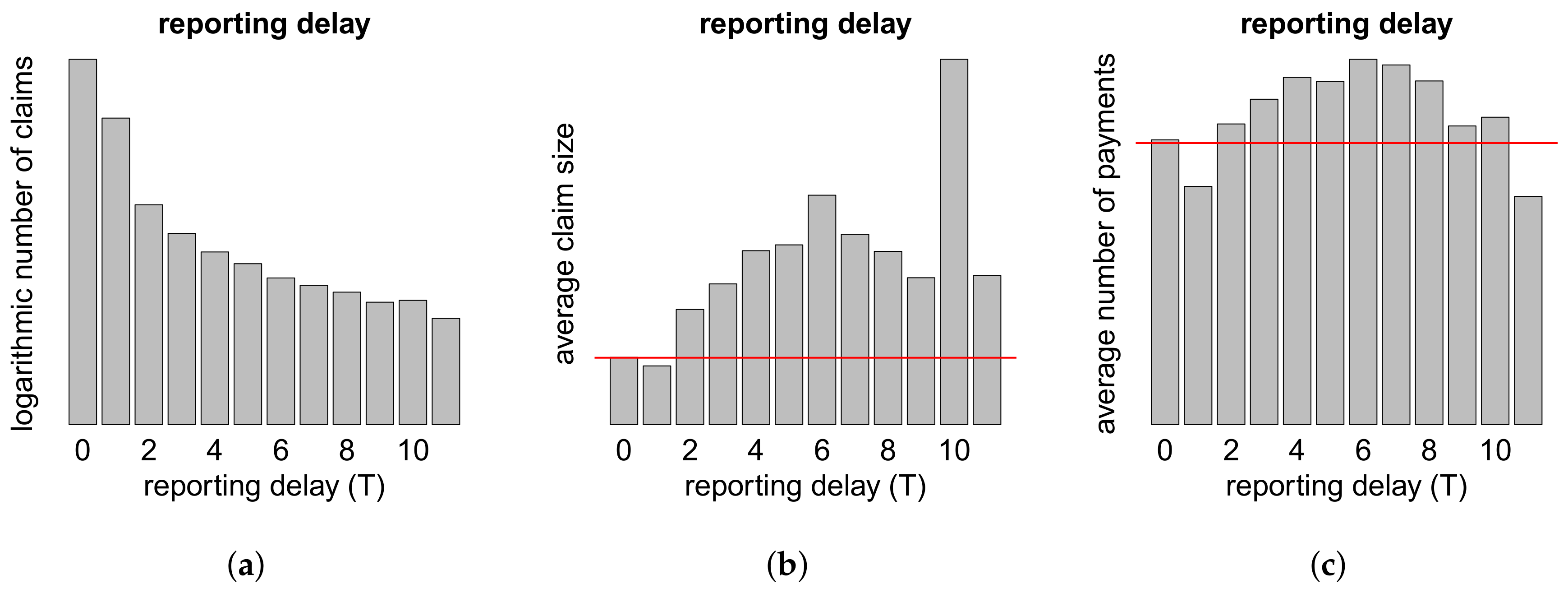
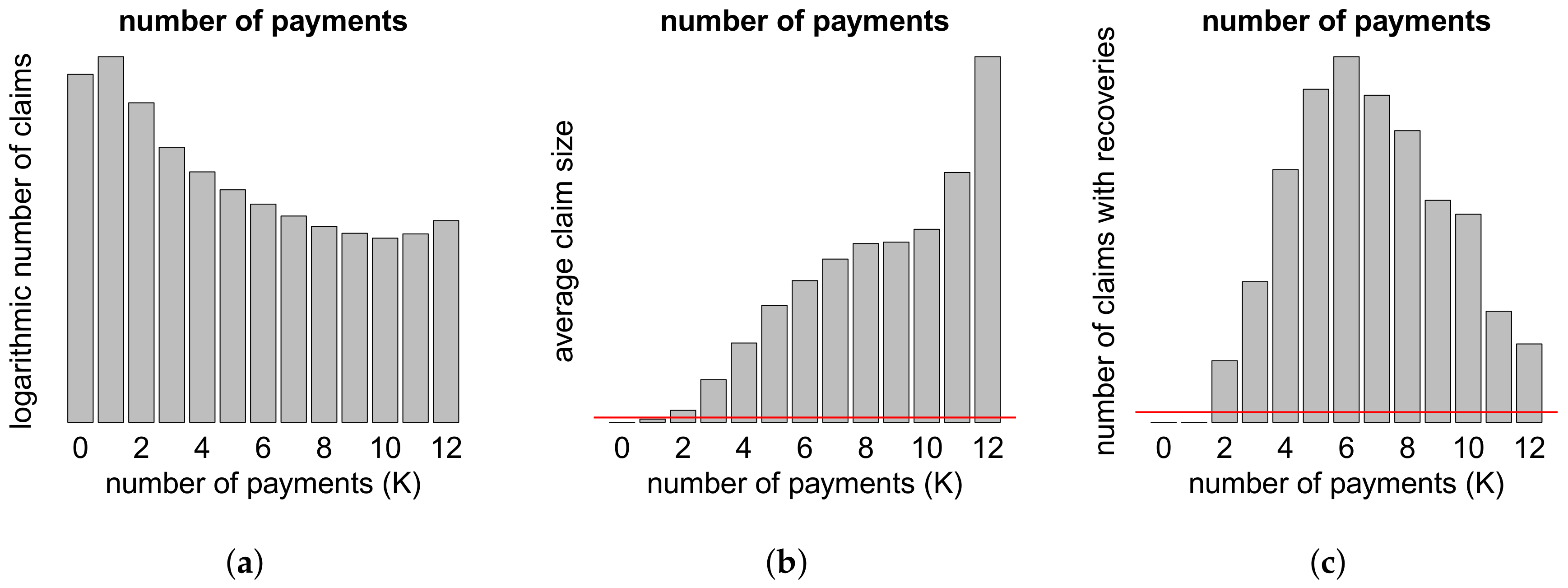
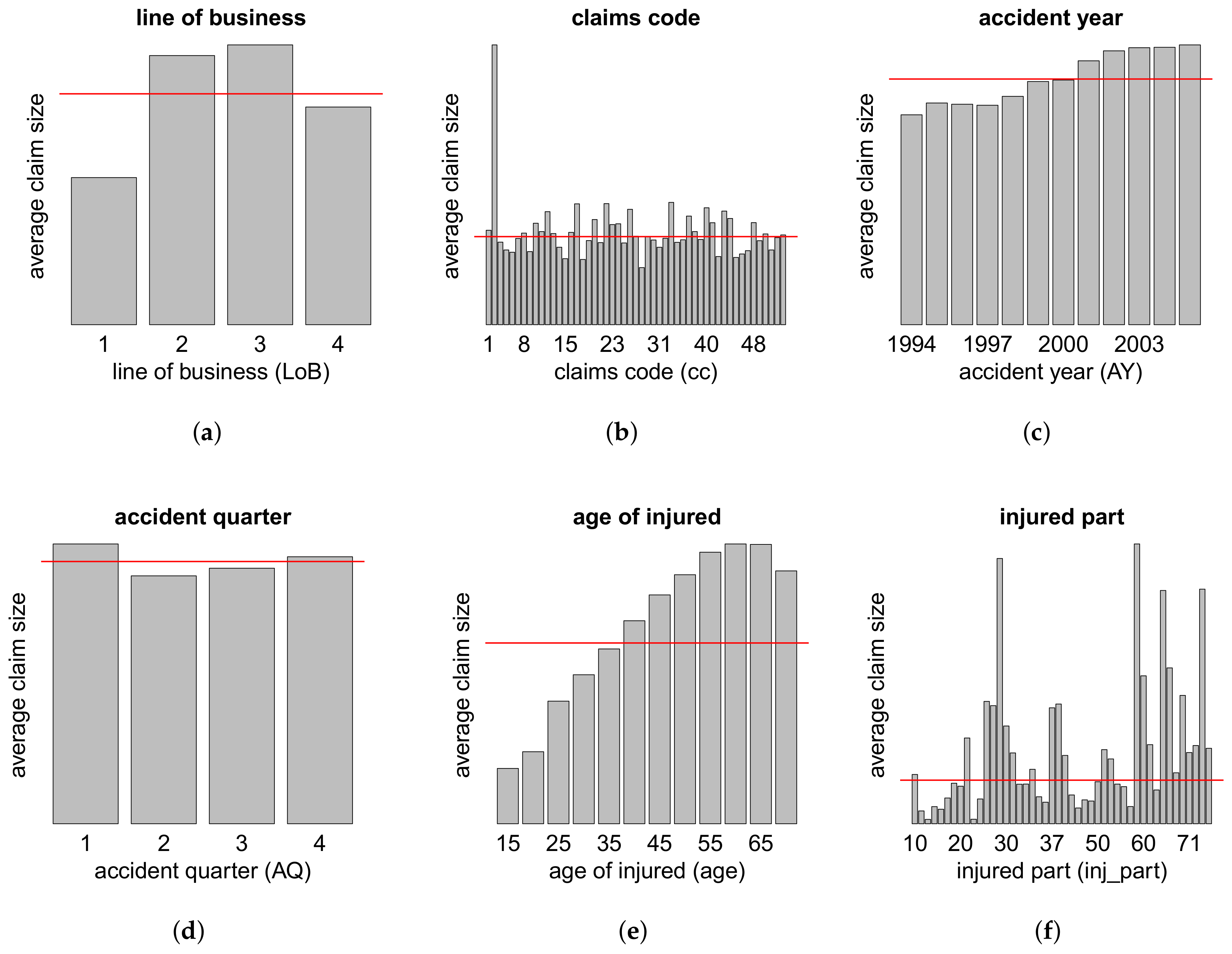





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}