Optimal Dynamic Portfolio with Mean-CVaR Criterion

Abstract
:1. Introduction
2. The Structure of the Optimal Portfolio
2.1. Main Problem
- Step 1: minimization of expected shortfall
- Step 2: minimization of conditional value-at-risk
- Step 1: minimization of expected shortfall
2.2. Main Result
2.3. Example: Exact Calculation in the Black–Scholes Model

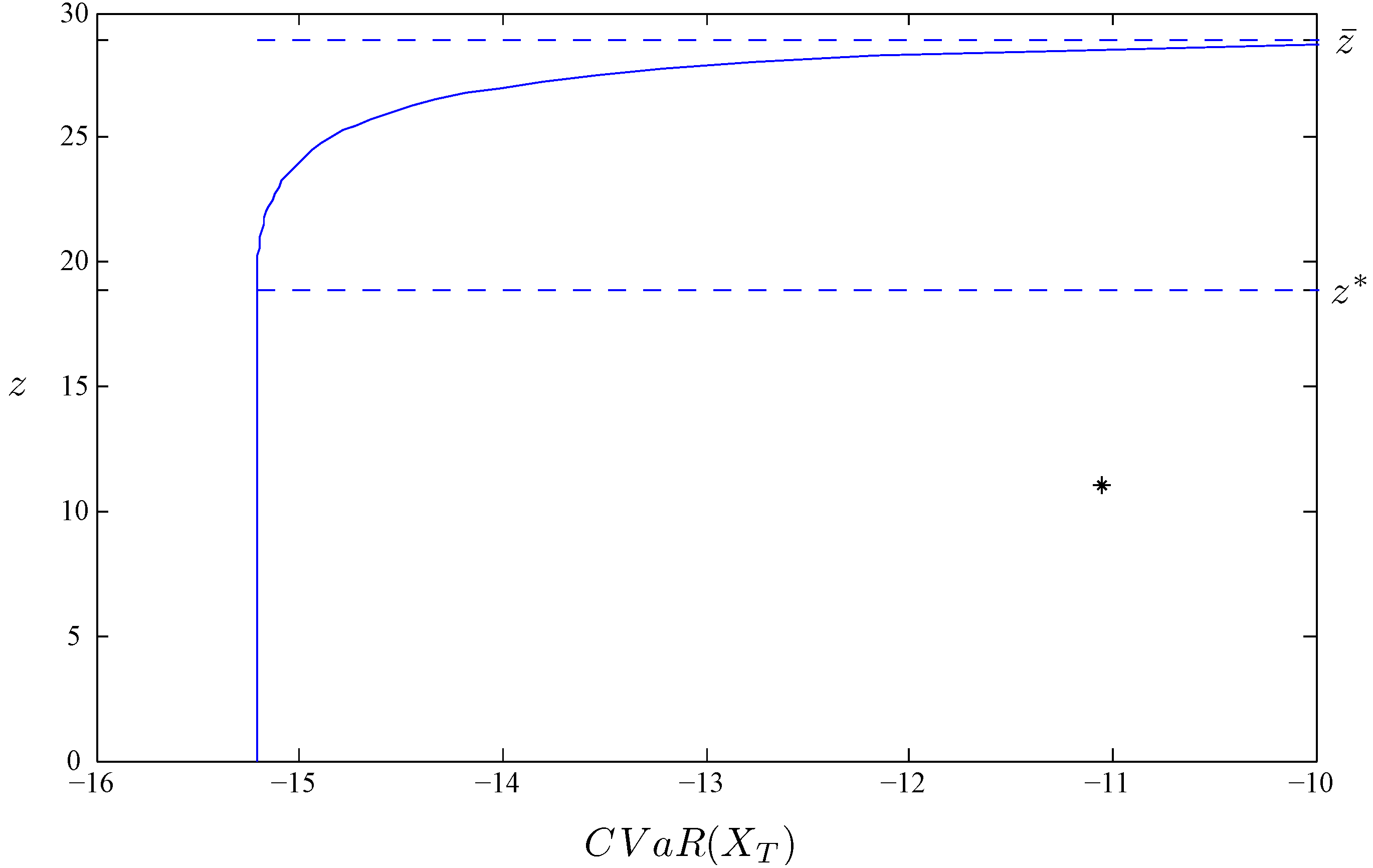{kind=link}
| One-Constraint Problem | Two-Constraint Problem | ||||||
|---|---|---|---|---|---|---|---|
| 30 | 50 | 30 | 30 | 50 | |||
| z | 20 | 25 | 25 | ||||
| 19.0670 | 19.0670 | 19.1258 | 19.5734 | 19.1434 | |||
| 14.5304 | 14.5304 | 14.3765 | 12.5785 | 14.1677 | |||
| 0.0068 | 0.1326 | 0.0172 | |||||
| −15.2118 | −15.2118 | −15.2067 | −14.8405 | −15.1483 | |||
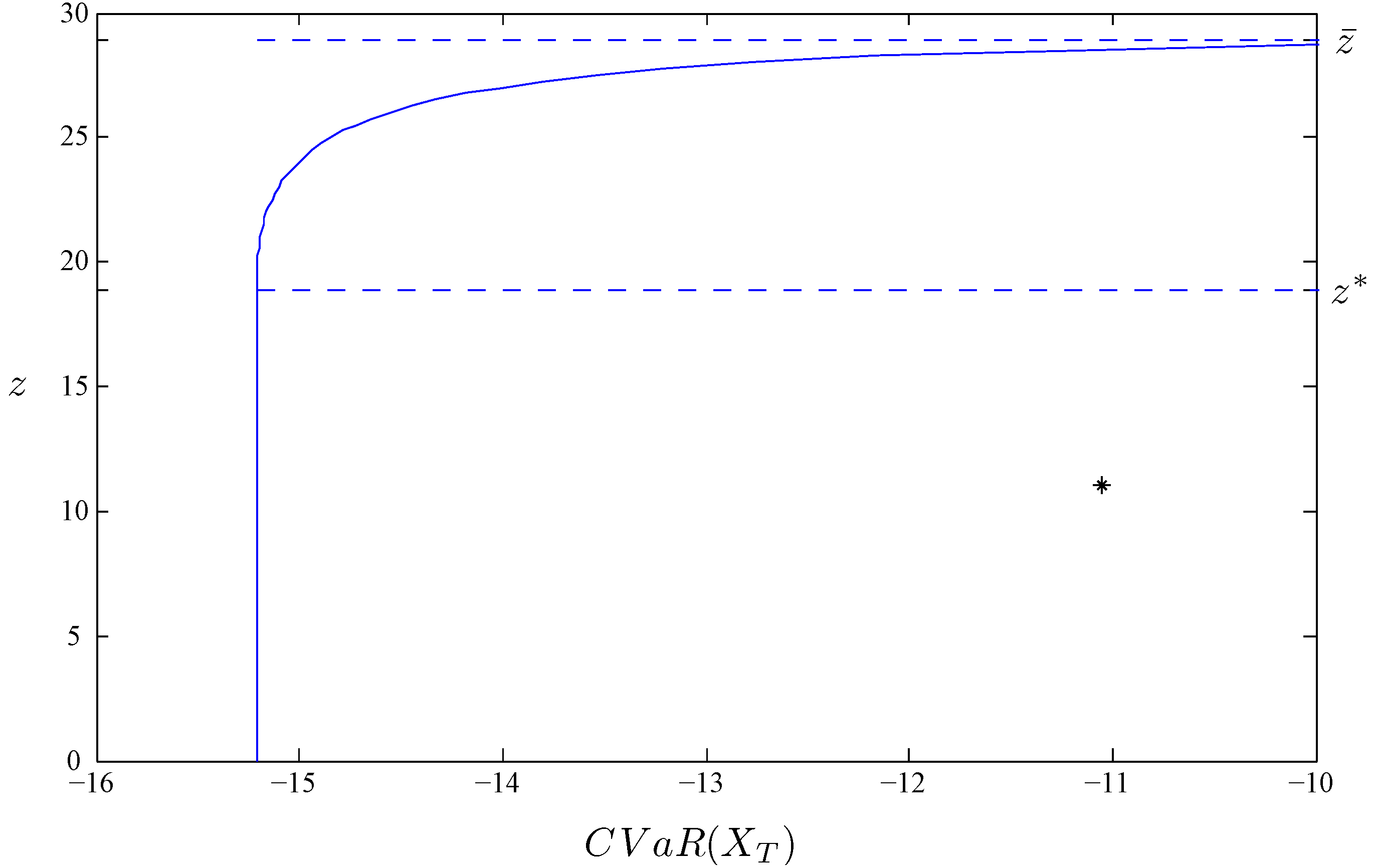
3. Analytical Solution to the Portfolio Selection Problem
3.1. Case : Finite Upper Bound
- 1.
- Any three-line configuration has the structure .
- 2.
- The two-line configuration is associated with the above definition in the case , and .The two-line configuration s associated with the above definition in the case , , and .The two-line configuration is associated with the above definition in the case , , and .
- 1.
- General constraints are the capital constraint and the equality part of the expected return constraint for a three-line configuration :
- 2.
- Degenerated Constraints 1 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :Degenerated Constraints 2 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :Degenerated Constraints 3 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :
- 1.
- Given any , let b be a solution to the capital constraint in Degenerated Constraints 1 for the two-line configuration . Define the expected return of the resulting two-line configuration as .5 Then is a continuous function of x and decreases from to as x increases from to .
- 2.
- Given any , let a be a solution to the capital constraint in Degenerated Constraints 2 for the two-line configuration . Define the expected return of the resulting two-line configuration as . Then, is a continuous function of x and increases from to as x increases from to .
- 1.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 1, satisfies the expected return constraint: ;
- 2.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 1, fails the expected return constraint: ;
- 3.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 2, fails the expected return constraint: ;
- 4.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 2, satisfies the expected return constraint: .
- 1.
- If we fix , then there exists a two-line configuration which is the optimal solution to Step 1 of the two-constraint problem;
- 2.
- If we fix , then there exists a two-line configuration , which is the optimal solution to Step 1 of the two-constraint problem.
- 1.
- When from Definition 3.2 of a bar-system, the three-line configuration degenerates to and .
- 2.
- When and , decreases continuously as b decreases and a increases.
- 3.
- In the extreme case when , the three-line configuration becomes the two-line configuration ; in the extreme case when , the three-line configuration becomes the two-line configuration . In either case, the expected value is below z by Lemma 3.6.
- : any random variable with values in satisfying both the capital constraint and the return constraint .
- : any random variable with values in satisfying both the capital constraint and the return constraint .
- : , where are determined by and as in (17) satisfying the general constraints: and .
- : , where are determined by as in Definition 3.1 satisfying both the capital constraint and the return constraint .
- : , where are associated to as in Definition 3.2 satisfying both the capital constraint and the return constraint .
- 1.
- Suppose . is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- 2
- Suppose .
- If (see Definition 3.2 for the bar-system), then is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- Otherwise, let be the solution to the equation . Associate sets and to level . Define , so that configurationsatisfies the capital constraint .6, and the associated minimal risk is:
- 1.
- Suppose and . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 2.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
- 3.
- Suppose and (see Definition 3.12 for ).
- If (see Definition 3.2), then the bar-system is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- Otherwise, the star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- (4)
- Suppose and . The double-star-system defined in Proposition 3.14 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
3.2. Case : No Upper Bound
- 1.
- Suppose . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- 2.
- Suppose . The star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- 1.
- Suppose and . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 2.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
- 3.
- Suppose and . The star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 4.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
4. Future Work
Acknowledgments
Conflicts of Interest
A. Appendix
A.1. Proof of Lemma 3.3
A.2. Proof of Lemma 3.4
A.3. Proof of Lemma 3.8
A.4. Proof of Proposition 3.9
A.5. Proof of Lemma 3.13
A.6. Proof of Proposition 3.14
- Case 1
- Case 2
- Case 3
- Case 4
- Case 5
A.7. Proof of Theorem 3.15
References
- H. Markowitz. “Portfolio selection.” J. Financ. 7 (1952): 77–91. [Google Scholar]
- T. Bielecki, H. Jin, S.R. Pliska, and X.Y. Zhou. “Continuous-time mean-variance portfolio selection with bankruptcy prohibition.” Math. Financ. 15 (2005): 213–244. [Google Scholar] [CrossRef]
- R.T. Rockafellar, and S. Uryasev. “Optimization of conditional value-at-risk.” J. Risk 2 (2000): 21–51. [Google Scholar]
- R.T. Rockafellar, and S. Uryasev. “Conditional value-at-risk for general loss distributions.” J. Bank. Financ. 26 (2002): 1443–1471. [Google Scholar] [CrossRef]
- C. Acerbi, and D. Tasche. “On the coherence of expected shortfall.” J. Bank. Financ. 26 (2002): 1487–1503. [Google Scholar] [CrossRef]
- P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath. “Thinking coherently.” Risk 10 (1997): 68–71. [Google Scholar]
- P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath. “Coherent measures of risk.” Math. Financ. 9 (1999): 203–228. [Google Scholar] [CrossRef]
- C. Acerbi, and P. Simonetti. Portfolio Optimization with Spectral Measures of Risk. Working Paper; Milan, Italy: Abaxbank, 2002. [Google Scholar]
- A. Adam, M. Houkari, and J.P. Laurent. “Spectral risk measures and portfolio selection.” J. Bank. Financ. 32 (2008): 1870–1882. [Google Scholar] [CrossRef]
- A.S. Cherny. “Weighted V@R and its properties.” Financ. Stoch. 10 (2006): 367–393. [Google Scholar] [CrossRef]
- A. Ruszczyński, and A. Shapiro. “Conditional risk mapping.” Math. Oper. Res. 31 (2006): 544–561. [Google Scholar] [CrossRef]
- R. Gandy. “Portfolio Optimization With Risk Constraints.” Ph.D. Thesis, University of Ulm, Ulm, Germany, July 2005. [Google Scholar]
- H. Zheng. “Efficient frontier of utility and CVaR.” Math. Methods Oper. Res. 70 (2009): 129–148. [Google Scholar] [CrossRef]
- A.G. Quaranta, and A. Zaffaroni. “Robust optimization of conditional value at risk and portfolio selection.” J. Bank. Financ. 32 (2008): 2046–2056. [Google Scholar] [CrossRef]
- J.Y. Gotoh, K. Shinozaki, and A. Takeda. “Robust portfolio techniques for mitigating the fragility of CVaR minimization and generalization to coherent risk measures.” Quant. Financ. 13 (2013): 1621–1635. [Google Scholar] [CrossRef]
- D. Huang, S. Zhu, F.J. Fabozzi, and M. Fukushima. “Portfolio selection under distributional uncertainty: A relative robust CVaR approach.” Eur. J. Oper. Res. 203 (2010): 185–194. [Google Scholar] [CrossRef]
- N. El Karoui, A.E.B. Lim, and G.Y. Vahn. “Performance-Based Regularization in Mean-CVaR Portfolio Optimization.” Working Paper. 2012. Available online: http://arxiv.org/abs/1111.2091 (accessed on 6 August 2013).
- V. Acharya, L. Pedersen, T. Philippon, and M. Richardson. Measuring Systemic Risk. Working Paper; Cleveland, OH, U.S.A.: Federal Reserve Bank of Cleveland, 2010. [Google Scholar]
- C. Chen, G. Iyengar, and C.C. Moallemi. “An axiomatic approach to systemic risk.” Manag. Sci. 59 (2013): 1373–1388. [Google Scholar] [CrossRef]
- T. Adrian, and M.K. Brunnermeier. CoVaR. Working Paper No. w17454; Princeton, NJ, USA: National Bureau of Economic Research, 2011. [Google Scholar]
- J. Sekine. “Dynamic minimization of worst conditional expectation of shortfall.” Math. Financ. 14 (2004): 605–618. [Google Scholar] [CrossRef]
- J. Li, and M. Xu. “Risk minimizing portfolio optimization and hedging with conditional value-at-risk.” Rev. Futures Mark. 16 (2008): 471–506. [Google Scholar]
- A. Melnikov, and I. Smirnov. “Dynamic hedging of conditional value-at-risk.” Insur.: Math. Econ. 51 (2012): 182–190. [Google Scholar] [CrossRef]
- A. Schied. “On the Neyman–Pearson problem for law-invariant risk measures and robust utility functionals.” Ann. Appl. Probab. 14 (2004): 1398–1423. [Google Scholar] [CrossRef]
- X.D. He, and X.Y. Zhou. “Portfolio choice via quantiles.” Eur. J. Oper. Res. 203 (2011): 185–194. [Google Scholar] [CrossRef]
- H. Föllmer, and P. Leukert. “Efficient hedging: Cost versus shortfall risk.” Financ. Stoch. 4 (2000): 117–146. [Google Scholar]
- F. Delbaen, and W. Schachermayer. “A general version of the fundamental theorem of asset pricing.” Math. Ann. 300 (1994): 463–520. [Google Scholar] [CrossRef]
- P. Krokhmal, J. Palmquist, and S. Uryasev. “Portfolio optimization with CVaR objective and constraints.” J. Risk 4 (2001): 43–68. [Google Scholar]
- M. Xu. “Minimizing shortfall risk using duality approach—An application to partial hedging in incomplete markets.” Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, April 2004. [Google Scholar]
- D. Kramkov. “Optional decomposition of supermartingales and hedging contingent claims in incomplete security markets.” Probab. Theory Relat. Fields 105 (1996): 459–479. [Google Scholar] [CrossRef]
- H. Föllmer, and Y.M. Kabanov. “Optional decomposition and Lagrange multipliers.” Financ. Stoch. 2 (1998): 69–81. [Google Scholar]
- B. Rudloff. “Convex hedging in incomplete markets.” Appl. Math. Financ. 14 (2007): 437–452. [Google Scholar] [CrossRef]
- 1.Krokhmal et al. [28] showed conditions under which the problem of maximizing expected return with the CVaR constraint is equivalent to the problem of minimizing CVaR with the expected return constraint. In this paper, we use the term mean-CVaR problem for both cases.
- 2.It is straight-forward to generalize the calculation to the multi-dimensional Black–Scholes Model. Since we provide in this paper an analytical solution to the static CVaR minimization problem, calculation in other complete market models can be carried out as long as the dynamic hedge can be expressed in a simple manner.
- 3. coincides with the dynamic value of a European option with payoff , and coincides with its delta-hedge.
- 4.Note that since the solution, , is binary and the solution, , takes three values, they share the practical difficulty as all digital options do near expiration, namely, the hedge ratio can be very big in magnitude at the boundary near expiration, which makes it impractical to do the hedging properly. We point out that this property is not shared by the optimal solution to the mean-variance type of problems.
- 5.Threshold b and, consequently, sets B and D are all dependent on x through the capital constraint; therefore, is not a linear function of x.
- 6.Equivalently, can be viewed as the solution to the capital constraint and the first order Euler condition in Equation (10) and (11). Then, (what we call the ‘star-system’) is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Li, J.; Xu, M. Optimal Dynamic Portfolio with Mean-CVaR Criterion. Risks 2013, 1, 119-147. https://doi.org/10.3390/risks1030119
Li J, Xu M. Optimal Dynamic Portfolio with Mean-CVaR Criterion. Risks. 2013; 1(3):119-147. https://doi.org/10.3390/risks1030119
Chicago/Turabian StyleLi, Jing, and Mingxin Xu. 2013. "Optimal Dynamic Portfolio with Mean-CVaR Criterion" Risks 1, no. 3: 119-147. https://doi.org/10.3390/risks1030119
APA StyleLi, J., & Xu, M. (2013). Optimal Dynamic Portfolio with Mean-CVaR Criterion. Risks, 1(3), 119-147. https://doi.org/10.3390/risks1030119