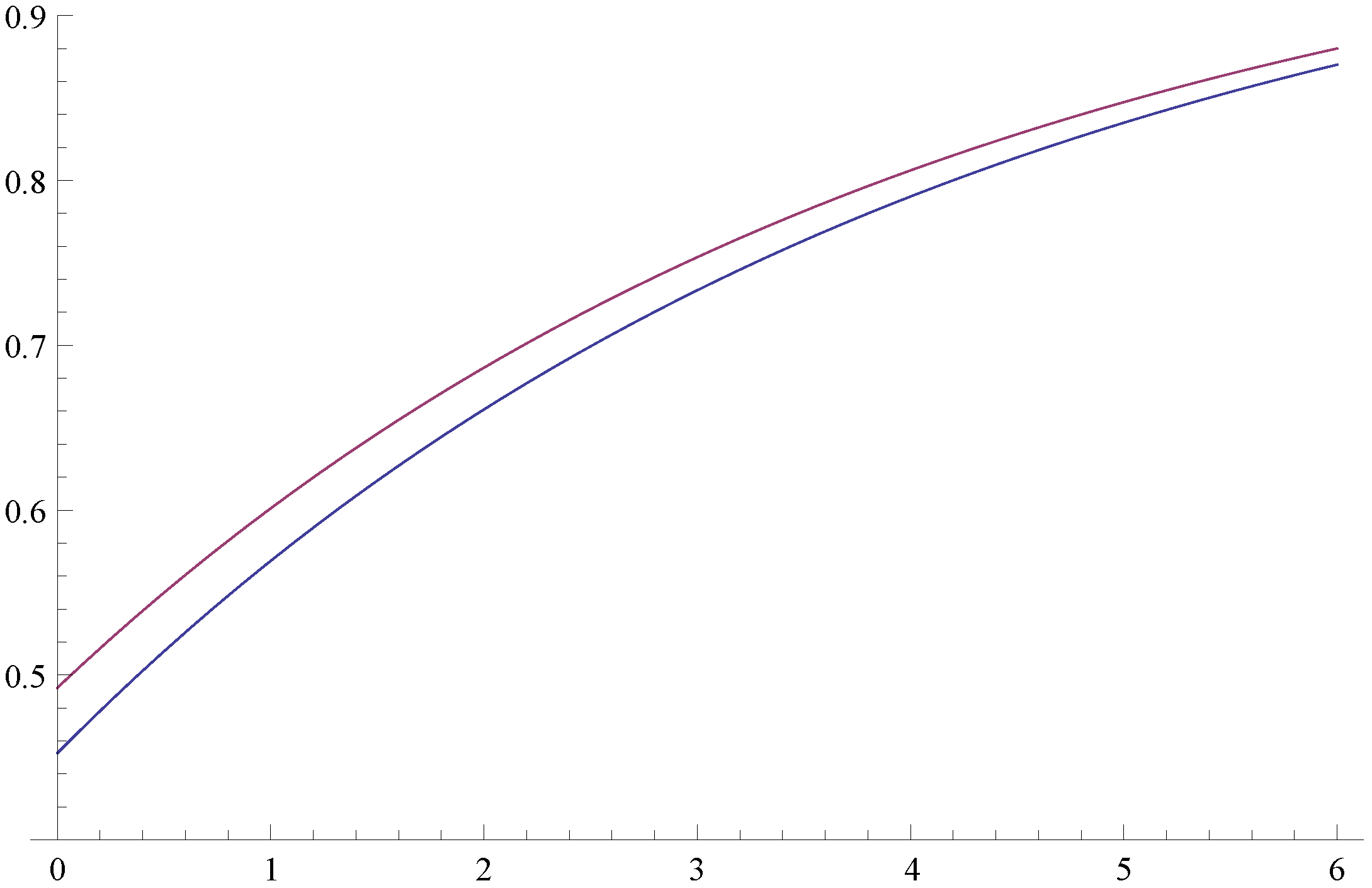1. Introduction
In classical risk theory, the ruin of an insurance portfolio is defined as the event that the surplus process becomes negative. In practice, it may be more reasonable to assume that the surplus value is not checked continuously, but at certain times only. If these times are not fixed deterministically, but are assumed to be epochs of a certain independent renewal process, then one often still has sufficient analytical structure to obtain explicit expressions for ruin probabilities and related quantities; see [
1,
2] for corresponding studies in the framework of the Cramér–Lundberg risk model and Erlang inter-observation times. An alternative ruin concept is studied in [
3], where negative surplus does not necessarily lead to bankruptcy, but bankruptcy is declared at the first instance of an inhomogeneous Poisson process with a rate depending on the surplus value, whenever it is negative. When this rate is constant, this bankruptcy concept corresponds to the one in [
1,
2] for exponential inter-observation times. Yet another related concept is the one of Parisian ruin, where ruin is only reported if the surplus process stays negative for a certain amount of time (see, e.g., [
4,
5]). If this time is assumed to be an independent exponential random variable instead of a deterministic value, one recovers the former models with exponential inter-observation times and a constant bankruptcy rate function, respectively. Recently, simple expressions for the corresponding ruin probability have been derived when the surplus process follows a spectrally-negative Lévy process, see [
6].
In this paper, we extend the above model and allow the surplus process to be a spectrally-negative Markov additive process. The dynamics of such a process change according to an external environment process, modeled by a Markov chain, and changes of the latter may also cause a jump in the surplus process. We assume that the value of the surplus process is only observed at epochs of a Poisson process, and ruin occurs when at any such observation time, the surplus process is negative. We also allow the rate of observations to depend on the current state of the environment (one possible interpretation being that if the environment states refer to different economic conditions, a regulator may increase the observation rates in states of distress). Using an approximation argument and the spectral theory for Markov additive processes, we explicitly calculate for any initial capital the survival probability and the probability to reach a given level before ruin in this model. The resulting formulas turn out to be quite simple. At the same time, these formulas provide information on certain occupation times of the process, which may be of independent theoretical interest.
In
Section 2, we introduce the model and the considered quantities in more detail.
Section 3 gives a brief summary of general fluctuation results for Markov additive processes that are needed later on. In
Section 4, we state our main results and discuss their relation with previous results, and the proofs are given in
Section 5. In
Section 6, we reconsider the classical ruin concept and show how the present results implicitly extend the classical simple formula for the ruin probability with zero initial capital to the case of a Markov additive surplus process. Finally, in
Section 7, we give a numerical illustration of the results for our relaxed ruin concept in a Markov-modulated Cramér–Lundberg model.
2. The Model
Let
be a Markov additive process (MAP), where
is a surplus process and
is an irreducible Markov chain on
n states representing the environment; see, e.g., [
7]. While
,
evolves as some Lévy process
, and
has a jump distributed as
when
switches from
i to
j. Consequently,
has stationary and independent increments given the corresponding states of the environment. We assume that
has no positive jumps and that none of the processes,
, is a non-increasing Lévy process. The latter assumption is not a real restriction, because one can always remove the corresponding states of
and replace non-increasing processes by the appropriate negative jumps. Note that the Markov-modulated Cramér–Lundberg risk model with
is a particular case of the present framework, where
u is the initial capital of an insurance portfolio,
is the premium density in state
i,
is an inhomogeneous Poisson process with claim arrival intensity
in state
i and
are independent claim sizes with distribution function
, if, at the time of occurrence, the environment is in state
i (in this case,
for all
); see [
7].
Write
for a matrix with
th element
, where
Y is an arbitrary random variable, and
for the probability matrix corresponding to an event
A. If
, then we simply drop the subscript. We write
for an identity matrix, a zero matrix, a column vector of ones and a column vector of zeros of dimension
n, respectively. For
, define the first passage time above
x (below
) by:
As in [
2], we assume that ruin occurs when an independent Poissonian observer sees negative
, where, in our setup, the rate of observations depends on the state of
, i.e., the rate is
for given
. Recall that a Poisson process of rate
ω has no jumps (observations) in some Borel set
with probability
. Hence, the probability of survival (non-ruin) in our model with initial capital
u is given by the column vector:
which follows by conditioning on the
s. The
ith component of this vector refers to the probability of survival with initial state
. Define for any
the
matrix:
so
is the matrix of probabilities of reaching level
x without ruin, when starting at level
u.
It is known that
converges to a deterministic constant,
μ (the asymptotic drift of
) a.s. as
, independently of the initial state,
. If
, then
a.s.; so
a.s. for all
j, and consequently, ruin is certain (unless all
). If
, then
a.s. for all
x, and so:
Finally, note that
can be interpreted as a joint transform of the occupation times,
. Moreover, with the definition
, the strong Markov property and the absence of positive jumps give:
for
(see, also, [
8]). Hence,
can be expressed in terms of
and
, given that these matrices are invertible. That is, it suffices to study the matrix-valued function,
.
Remark 2.1. The present framework can be extended to include positive jumps of phase type, cf.
[7]. One can convert a MAP with positive jumps of phase type into a spectrally-negative MAP using the so-called fluid embedding, which amounts to an expansion of the state space of and to putting for each auxiliary state, i;
see e.g., [9] and [10] (Section 2.7). Next, we set for all the new auxiliary states,
i,
and compute the corresponding survival probability vector for the new model, which, when restricted to the original states, yields the survival probabilities of interest. 3. Review of Exit Theory for MAPs
Let us quickly recall the recently established exit theory for spectrally-negative MAPs, which is an extension of the one for scalar Lévy processes (see, e.g., [
11], Section 8). A spectrally-negative MAP,
, is characterized by a matrix-valued function,
, via
for
. We let
π be the stationary distribution of
. It is not hard to see that
is a Markov chain, and thus,
for a certain
transition rate matrix, Λ, which can be computed using an iterative procedure or a spectral method; see [
12,
13] and the references therein. It is easy to see that
is non-defective (with a stationary distribution,
), if and only if
.
The two-sided exit problem for MAPs without positive jumps was solved in [
14], where it is shown that:
for
and
, where
is a continuous matrix-valued function (called the scale function) characterized by the transform:
for sufficiently large
θ. It is known that
is non-singular for
and so is
in the domain of interest. In addition:
where
is a positive matrix increasing (as
) to
L, a matrix of expected occupation times at zero (note that in the case of the Markov modulated Cramér–Lundberg model, Equation (
1),
provides the expected number of times when the surplus is zero in state
j given
and
). If
, then
L has finite entries and is invertible. Finally:
where
is analytic in for fixed
in the domain
.
Importantly, all the above identities hold for defective (killed) MAPs, as well, i.e., when the state space of
is complemented by an absorbing `cemetery’ state; the original states of
then form a transient communicating class, and the (killing) rate from a state,
i, into the absorbing state is
. We refer to [
15] for applications of the killing concept in risk theory.
Note that killed MAPs preserve the stationarity and independence of increments given the environment state. Furthermore, we get probabilistic identities of the following type:
where
and
refer to the killed process, and we are still concerned with the original
n states only. The right-hand side of Equation (
8) is similar to the definition of the matrix,
, in Equation (
3); it is also the joint transform of certain occupation times. However,
is more complicated, as there, the killing is only applied when the surplus process is below zero; so with the setup of this paper, one leaves the class of defective MAPs (the increments now depend on the current value of
). Let us recall the relation between
and its killed analogue
:
Letting
be a diagonal matrix with the stationary distribution vector,
π, of
J on the diagonal, we note that
corresponds to a time-reversed process, which is, again, a spectrally-negative MAP (with no non-increasing Lévy processes as building blocks) with the same asymptotic drift,
μ; see [
7]. Using the characterization Equation (
5), one can see that the corresponding scale function is given by
.
5. Proofs
The proofs rely on a spectral representation of the matrix,
, which we quickly review in the following. Let
be a Jordan chain of
corresponding to an eigenvalue
γ, i.e.,
and
for
. From the classical theory of Jordan chains, we know that:
for any
and
and, in particular,
. Moreover, this Jordan chain turns out to be a generalized Jordan chain of an analytic matrix function
corresponding to a generalized eigenvalue,
γ, i.e., for any
, it holds that:
and, in particular,
; see [
13] for details.
Proof of Proposition 4.1. Observe that
, and so Equation (
5) and Equation (
6) yield:
for large enough
θ. Since
is bounded from above by
L, this equation can be analytically continued to
with non-singular
. Hence, for small enough
, we can write:
where
is an exponentially distributed r.v. with parameter
q. Letting
completes the proof of the first part.
According to Equation (
12), we have
. Next, consider:
where differentiation under the integral sign can be justified using standard arguments. Finally:
because the second sum is
for
. The final step of the proof is the same as in the case of
. ☐
The proof of Theorem 4.1 relies on an approximation idea, which has already appeared in various papers; see, e.g., [
6,
20,
21]. We consider an approximation,
, of the matrix,
. When computing the occupation times, we start the clock when
goes below
(rather than zero), but stop it when
reaches the level of zero. Mathematically, we write, using the strong Markov property:
Using the exit theory for MAPs discussed in
Section 3, we note that the first term on the right is
, and the second, according to Equation (
8), is:
By the monotone convergence theorem, the approximating occupation times converge to
as
, and then, the dominated convergence theorem implies convergence of the transforms:
as
for any
. Hence, we have:
where we also used the continuity of
. We will need the following auxiliary result for the analysis of the above limit.
Lemma 5.1. Let be a Borel function bounded around zero. Then: Proof. Consider a scale function of the time-reversed process:
. It is enough to show that:
but:
which clearly converges to the zero matrix. ☐
Proof of Theorem 4.1. First, we provide a proof under a simplifying assumption, and then, we deal with the general case.
Part I: Assume that
has
n linearly-independent eigenvectors
v:
. Considering Equation (
14), we observe that the integral multiplied by
v is given by:
according to Equation (
7). Hence, the limit in Equation (
14) multiplied by
v is given by:
according to the form of
and Lemma 5.1. Finally, from Equation (
13), we have:
which, under the assumption that there are
n linearly-independent eigenvectors, shows that:
completing the proof.
Part II: In general, we consider a Jordan chain,
, of
corresponding to an eigenvalue,
γ. Using Equation (
12), we see that the integral in Equation (
14) multiplied by
is given by:
where all the terms can be obtained by considering Equation (
7) for
, multiplying it by
and taking derivatives with respect to
γ. Again, Lemma 5.1 allows us to show that:
converges to the zero matrix as
. Hence, the expression on the left of
in Equation (
14) when multiplied by
is equal to:
The definition of
leads to:
Plugging this in Equation (
15), interchanging summation and using Equation (
13), we can rewrite Equation (
15) in the following way:
which is just:
according to Equation (
12). The proof is complete, since there are
n linearly-independent vectors in the corresponding Jordan chains.
Proof of Theorem 4.2. First, we provide a proof under the assumption that both
and
have semi-simple eigenvalues and that the real parts of the eigenvalues of
are large enough. Assume for a moment that every eigenvalue,
γ, of
is such that the transform Equation (
5) holds for
. In the following, we will study the limit of
.
Consider an eigen pair
of
and a left eigen pair
of
, i.e.,
and
. Then, Theorem 4.1 implies:
where
by the above assumption. Note that the expression in brackets converges to a zero matrix, because of Equation (
5) and Equation (
13). Therefore, we can apply L’Hôpital’s rule to get:
where the second equality follows from Equation (
6). Under the assumption that all the eigenvalues of Λ and
are semi-simple (there are
n eigenvectors in each case), this implies that
converges to a finite limit,
U, and:
which yields Equation (
10). Since
is bounded and
U is invertible, we see that the former converges to
.
Jordan chains: When some eigenvalues are not semi-simple, the proof follows the same idea, but the calculus becomes rather tedious. Therefore, we only present the main steps. Consider an arbitrary Jordan chain,
, of
with eigenvalue
γ and an arbitrary left Jordan chain,
of
, with eigenvalue
. We need to show that
has a finite limit,
U, as
, and that this
U satisfies:
where
by convention. For this, we compute
using Equation (
12) and its analogue for the left chain and take the limit using L’Hôpital’s rule, which is applicable because of Equation (
13). This then confirms that:
and the result follows.
Analytic continuation: Finally, it remains to remove the assumption that the real part of every eigenvalue of is large enough. For some , we can define new killing rates by and consider the corresponding new matrices, (note that Λ and L stay unchanged). By choosing large enough q, we can ensure that the real parts of the zeros of (in the right half complex plane) are arbitrarily large. These zeros are exactly the eigenvalues of , and so, the result of our Theorem holds for large enough q.
We now use analytic continuation in
q in the domain
. In this domain,
is analytic for every
x, which follows from its probabilistic interpretation. This and the invertibility of
can be used to show that
is also analytic. Furthermore, one can show that only for a finite number of different
q’s, the matrices, Λ and
, can have common eigenvalues. Now, we express
, where
is formed from the elements of Λ and
; see, e.g., [
22]. Hence,
can be analytically continued to the domain of interest excluding the above finite set of points. Hence, also,
in the latter domain, where
is the unique solution of the corresponding Sylvester equation. In particular, this holds for
, and the proof is complete.
6. Remarks on Classical Ruin
Let us briefly return to the classical ruin concept, i.e., all
. From Equation (
7), the matrix of probabilities to reach level
x before ruin is in this case given by:
which for
reduces to
. It is known that
is a diagonal matrix with
equal to zero or
, according to
having unbounded variation or bounded variation on compacts, and
being the linear drift of
(the premium density in the case of Equation (
1)).
In order to obtain survival probabilities when
, we need to compute:
which, similarly to the proof of Theorem 4.2, is a non-trivial problem. Using recent results from [
23], in particular Lemma 1, Proposition 1 and Lemma 3, we find that this limit is given by:
where
is the stationary distribution associated with
and the latter corresponds to the time-reversed process. Hence, the probability of survival according to the classical ruin concept with zero initial capital and
is given by:
In the case of the classical Cramér–Lundberg model (), this further simplifies to the well-known expression, .
The simplicity of all the terms in Equation (
16) motivates a direct probabilistic argument, which we provide in the following. Assuming that
and
is a bounded variation process with linear drift
, we consider
(with an independent exponentially distributed
), which provides the required vector of survival probabilities upon taking
. According to a standard time-reversal argument, we write:
which yields:
Moreover:
where the last equality follows from the structure of the sample paths (or local time at the maximum). It is known that
as
, which then shows that the above expression converges to
as
, where the interchange of the limit and integral can be made precise using the generalized dominated convergence theorem. Combining this with Equation (
17) yields Equation (
16).
7. A Numerical Example
Let us finally consider a numerical illustration of our results for a Markov-modulated Cramér–Lundberg model Equation (
1) with two states, exponential claim sizes with a mean of one in both states, premium densities
, claim arrival rates
,
, observation rates
and the Markov chain,
, having transition rates of 1, 1, which results in the asymptotic drift
. For this model, we specify the matrix-valued functions,
(see [
7] (Proposition 4.2)) and
,
cf. Equation (
9). Using the spectral method, we determine the matrices Λ and
, and then also the matrix
L according to Proposition 4.1:
We use Theorem 4.2 to compute the vector of survival probabilities for zero initial capital:
Furthermore, Corollary 4.1 yields the vector of survival probabilities for an arbitrary initial capital,
, in terms of a matrix-valued function,
. Due to the exponential jumps, the matrix,
, has an explicit form; see Remark 4.2.
Figure 1 depicts the survival probabilities as a function of the initial capital,
u.
Figure 1.
Survival probabilities, and .
Figure 1.
Survival probabilities, and .
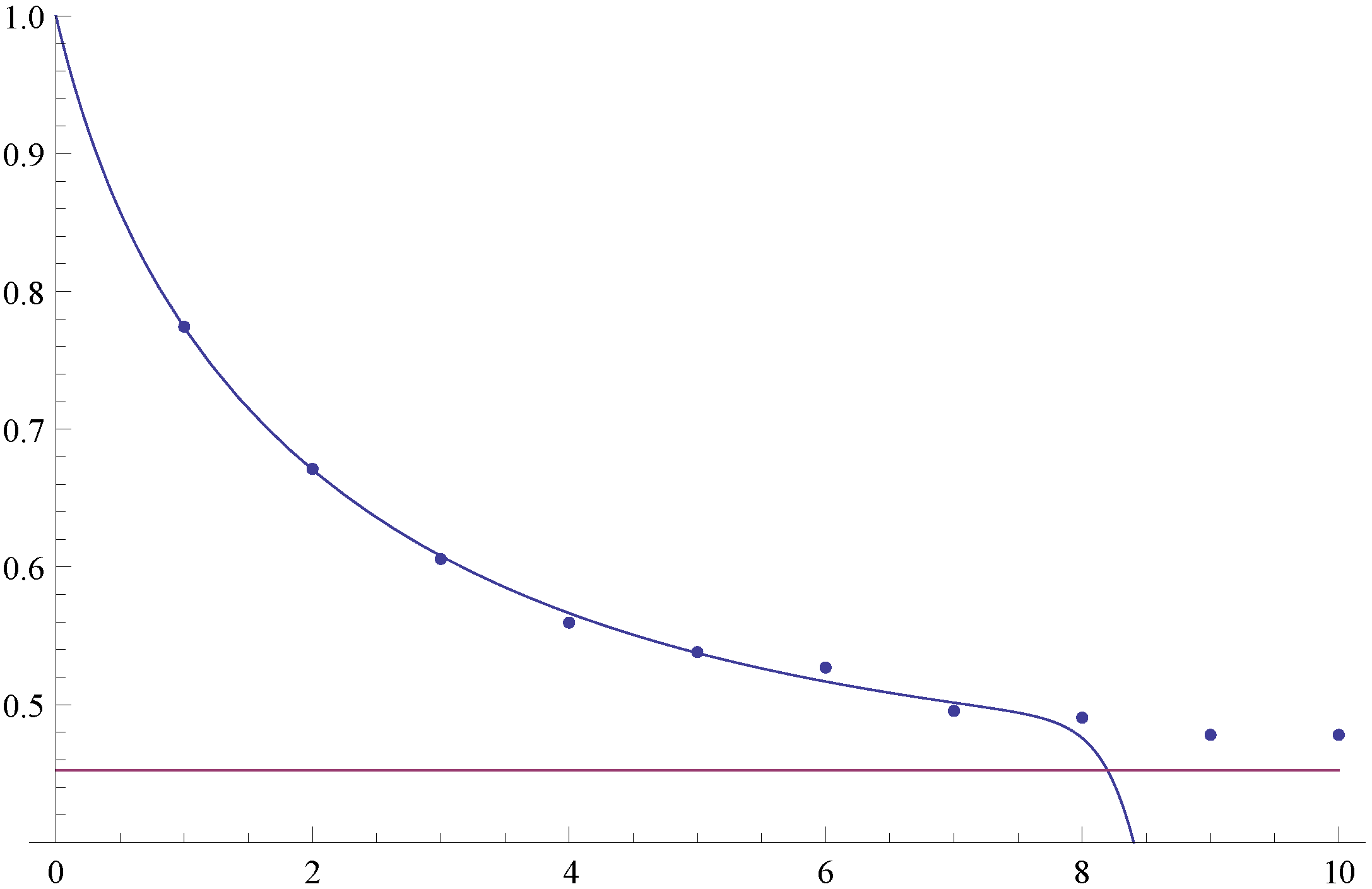
Figure 2 confirms the correctness of our results. It depicts
(i.e., the probability of reaching level
x before being observed as being ruined when starting in State 1 with zero initial capital), and the dots represent Monte Carlo simulation estimates of the same quantity based on 10,000 runs, the horizontal line representing
. One sees that for large values of
x, the numerical determination of
(as well as
) becomes a challenge, which underlines the importance of our limiting result, i.e., Theorem 4.2.
Figure 2.
The probability of reaching level x before ruin for .
Figure 2.
The probability of reaching level x before ruin for .


{kind=link}
{kind=link}