1. Introduction
Previous studies have provided important findings about children’s speech production development [
1,
2,
3,
4,
5]. The collective body of information from previous studies has indicated that essentially all aspects of children’s speech demonstrate changes toward more adultlike characteristics of their ambient language over time [
1]. Nevertheless, currently few studies examine the link between children’s production and inexperienced adults’ perception of speech sounds, especially taking into consideration the ongoing sound change such as the raising of the mid-back vowel /o/ [
6].
Research has found that even infants as young as 5 months old rapidly modify their vocalizations in response to audio-visual recordings of vowels produced by an adult on television [
7]. Ten-month-old infants, when they are exposed to different languages produce babbling with some language-specific vowel characteristics when measured acoustically [
8,
9]. These findings suggest that “young children have some ability to process their own vocal output and can link sensory patterns that they have seen and heard with sensory-motor patterns that they are attempting to produce” [
10].
Regarding linguistic attributes of speech sounds, F0 and the lowest two formants (i.e., F1 and F2) are considered the most important acoustic features for linguistic categories and structures, especially for sonorant sounds such as vowels. For example, F0 plays a role in conveying prosodic prominence and phrasing [
11,
12], and the lowest two formants are acoustic cues for vowel types [
13,
14]. Although F0, F1, and F2 are among the most important acoustic features in shaping linguistic categories and structures, researchers have reported that at least for children speaking American English [
15,
16], F0 and the two formants are developed differently based on gender.
As for F0, it seems that both boys and girls speaking American English exhibit a similar F0 range. Because children’s vocal folds are much shorter than those of adults, children’s pitch is much higher than adults’. The non-distinction of gender based on F0 might be due to the influence of caregivers’ modification of speech style toward infants. In many languages, caregivers increase their pitch and expand their vowel spaces when producing infant-directed speech (IDS) [
17,
18]. These acoustic modifications have been shown to attract infant attention. The F0 range typically found in IDS for female adults overlaps with infant speech and IDS, making gender distinction based on F0 difficult [
10]. The F0 differences between gender reportedly begin to emerge around 7 years of age. It is worth testing whether Korean children of both genders show similar developmental trajectories as American children in the F0 range.
The first two lowest formant frequencies have provided essential cues when investigating vowel identification since the study of [
19], whose formant hypothesis has been dominant ever since. This approach has been supported by many subsequent studies and is often mentioned in studies exploring the role of formants and their characteristics in vowel perception. Unlike the lack of F0′s role in gender distinction, the vowel space fails to reveal an overlap between IDS and infant speech with respect to formant patterns [
10]. Thus, formant patterns are shaped based on the children’s vocal tract [
13], and gender differences can result in different formant structures. As the length of the vocal tract of boys is longer than that of girls, the vowel space based on F1 and F2 will be smaller for boys than girls [
15,
20]. The study by [
14] cast doubts on the role of formants in gender discrimination. Their study measured vowel formants (F1 and F2) and vowel space among 3- to 6-year-old Korean children residing on Jeju Island. Despite the expectation that the vowel space for girls would be larger than for boys, Ref. [
14] reported that no differences of vowel space emerged due to gender (
p > 0.05). Thus, it is worth examining whether formants play a role in distinguishing the speech characteristics of boys from those of girls in standard Korean.
Infant-directed speech may also help children form the phonological system of their native language. Regarding the vowel system in Korean, two pairs of vowels are worth noting, as one pair (i.e., [e] and [æ]) completes a merger [
14,
21,
22], and the other (i.e., [o] and [u]) reportedly undergoes a merger [
6]. Thus, in both adults’ and children’s productions the vowel [e] in the Korean word [ke] ’crab’ and the vowel [æ] in [kæ] ’dog’ are now merged into a single (lower) mid-front vowel [e]. As for the non-low back vowels, [o] and [u] in Seoul Korean are undergoing a merger in the F1/F2 space, especially for female speakers [
23]. In studies conducted before 2000, the Korean short vowels [a, ʌ, o, u, ɯ, i] were clearly distinguished in the vowel space, except for [e]–[æ] [
21]. For example, the vowels [o, u] produced by male and female speakers in their 20s, as measured in the study of [
21], maintained a sufficient distance from the vowel space, and the two vowels had a clear difference from the F1 value. On the other hand, more recent phonetics studies have reported changes in formant values implying that the vowel [o] is ascending [
6,
23]. For example, Ref. [
23] examined the difference in the formant values of monophthongal vowels uttered by men and women in their 20s and 30s and found that the vowels [o] and [u] were close in the acoustic space. They also found a gender difference: In the case of men, there was a statistically significant difference in the F1 values of the two vowels, but no statistically significant difference was identified in the F1 and F2 values of female speakers. This implies that the ongoing sound change of [o] raising is led by young female speakers [
24]. Ref. [
6] reported evidence of a chain-like vowel shift possibly being underway in Seoul Korean that has caused [o] to lower its F1 and rise to become more like [u], which in turn might be becoming more fronted (cf. [
25]).
Given the previous research, we hypothesize that children’s vowel production may be similar to adults’ vowel space, resulting in the ongoing sound change of [o]-raising. We also hypothesize that the proximity of [o] and [u] in the children’s vowel space may result in greater misperception by adult listeners. In order to test these hypotheses, this paper conducts acoustic analyses of vowels produced within monosyllabic words by children 2 to 6 years old and perceived by 20 inexperienced adult listeners. In the acoustic analysis, we analyzed boys’ and girls’ voices separately because the acoustic features may be different based on gender [
15].
We aim to answer the following research questions: First, what are the gender-specific acoustic characteristics of vowels produced by Korean children 2 to 6 years old? This question is based on previous research on American children, which showed that children’s gender leads to different formant patterns distinct from F0. Thus, we wanted to see whether the same pattern emerges in Korean children before further acoustic analyses. Second, how correctly would inexperienced listeners transcribe targeted vowels that children produce in monosyllabic words—that is, would inexperienced listeners respond according to the manifested acoustic vowel space when it comes to the recognition of vowels flanked in familiar monosyllabic words? The second question is based on the asymmetric research endeavors of developmental studies. Research on the acquisition of segments tends to be on consonants, not vowels (cf. [
5] and references therein). This study fills the gap by focusing on the perception of children’s vowel production
2. Materials and Methods
2.1. Participants
Data for this study were drawn from a large normative study of speech development being conducted in Korea [
26]. The Hallym University Institutional Review Board approved the normative study and the following perception study. Research flyers were posted at local daycare or preschool communities and on social network sites. Signed consent forms were obtained from children’s caregivers or adult participants.
All the children were native Korean speakers in monolingual environments and attended daycare centers or preschools at the time of data collection The recordings of data were collected from 20 children (10 boys and 10 girls), whose average age was 52.4 months (range = 26~81 months; SD = 17.9 months). All the children were reported to have no diagnosed developmental difficulties as well as no language, hearing, or cognitive concerns by parents or caregivers. The recordings were divided into 5 data sets according to children’s age from 2 to 6 years and each data set consisted of recordings from 4 children.
Twenty adults participated in the study as listeners. They were all undergraduate students (6 males and 14 females) in their early 20s and native Korean speakers. None of the listeners reported any history of speech or hearing problems. The listeners were inexperienced in that they were not familiar with children’s pronunciation patterns and had not taken any phonetic or phonology classes.
2.2. Data Collection
The Korean Articulation and Phonology Profile (K-APP) [
26] was administered to the children in a quiet space in the presence of their caregivers (a parent or a daycare teacher) and audio-recorded using a portable digital voice recorder (Sony ICD-UX400F, Sony Corporation, China).
Eighteen consonant-vowel-consonant (CVC) monosyllables in K-APP were selected for target words to control the effect of different syllable structures and word lengths on children’s articulation proficiency. Seven vowels and 19 consonants in Korean phonology were used for the target monosyllabic words but are not strictly controlled in terms of the consonant types occupying the onsets and codas. The target words are familiar to children. Due to the complete merger between [e] and [æ], we did not consider collecting words with different front mid vowels. The central high vowel [ɯ] is not included on the list due to the lack of familiar monosyllabic words. The target words are listed in
Table 1.
Before recording, the research assistant checked whether children knew the target words. All the target words were familiar to children except for two words, [hak] for ‘crane’ and [ɹiŋ] for ‘ring’. The research assistant presented the pictures and names of the two target words to all children before recording.
Children were asked to look at pictures of the target words, which were presented on a laptop computer screen using PowerPoint, and spontaneously produce them. When a child had difficulty spontaneously producing certain target words, the research assistant presented the target words and then asked his/her to produce them as spontaneously as possible.
To analyze the F0 and formants from children’s vowel production and use auditory stimuli for the perception study, we selected exclusive recording samples in which children correctly produced the vowel of the target words. Praat [
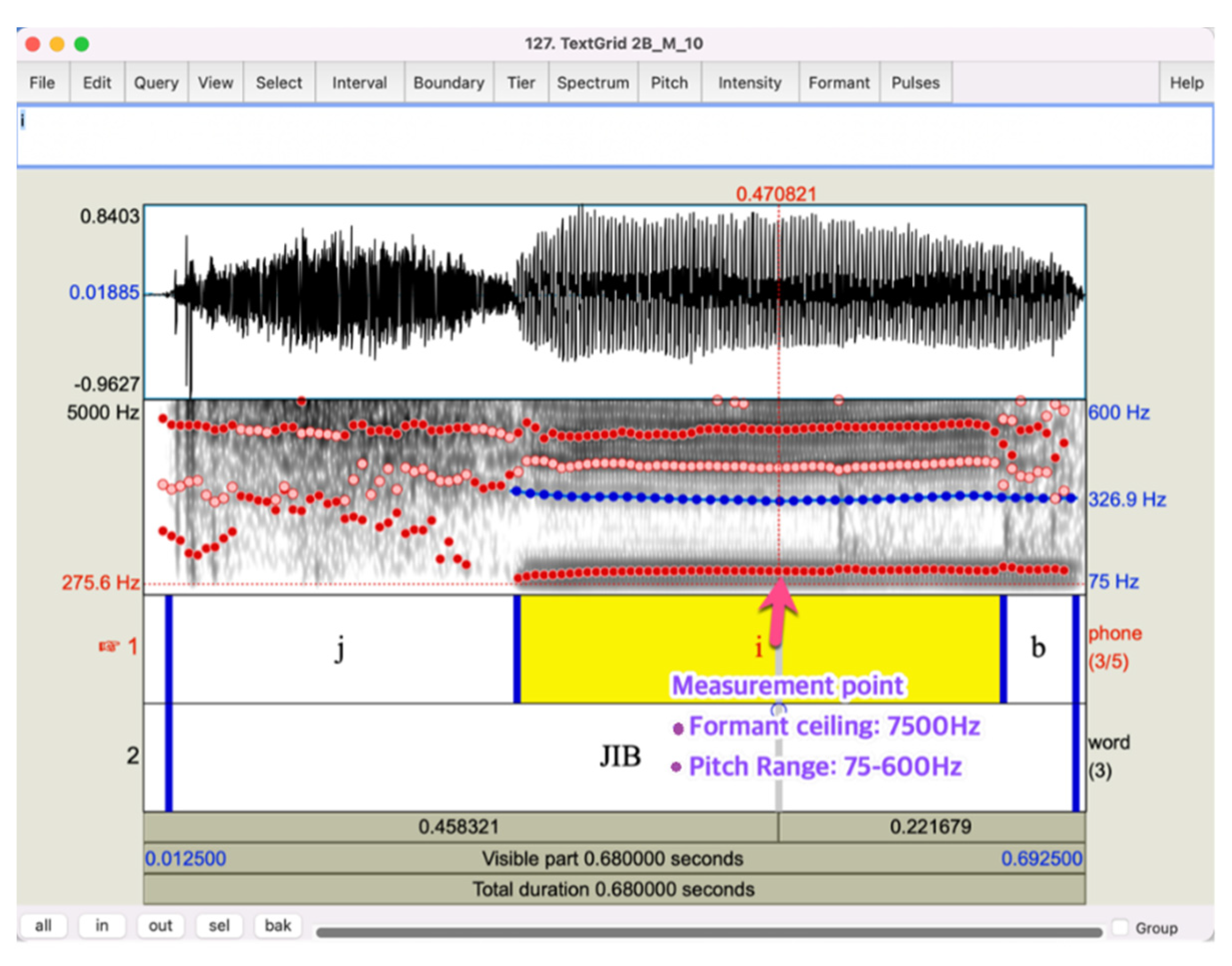
27] was used for the feature extraction. The speech samples were annotated using the TextGrid function in Praat, and a custom-made script was written to extract F0, F1, and F2 at the middle point of the targeted vowels, as shown in
Figure 1. The F0 range was set from 75 to 600 Hz, and the formant ceiling was set to 7500 Hz. The setting was changed from the default values to reflect the shorter length of the vocal tract and vocal folds than those of adults. The exact values in the setting were chosen empirically after visually examining the F0 and formant trajectories of every speech sound.
2.3. Data Analysis
A linear mixed effects model was used to model the acoustic data. The program R (R Development Core Team, 2016, Vienna, Austria) [
28] and the package
lmer [
29] were used for the data analyses. Acoustic properties of interest—that is, F0 (in semitone), F1, and F2 (in Hertz)—were treated as response variables. Linear mixed effects models were fit to each measure of F0, F1, and F2, respectively. Gender was treated as a fixed variable while individual child (Subj as a variable name) and type of vowels were treated as random variables. For F0, the following formula was used with the
lmer package in R:
Formants were modelled using the same formula, but with the different independent acoustic features of F1 and F2.
2.4. Perception Study
The aforementioned 20 listeners were randomly assigned to one of 5 listener groups. Each group was asked to listen to a speech stimulus set containing monosyllabic words produced by 4 children, as shown in
Table 2. The empty cells in
Table 2 indicate where no children’s speech was assigned in the age group. In the tableshows the age and gender distribution of the children. Each age group consisted of 4 children.
All listeners were tested in front of a computer in a quiet room. The stimuli were presented using PowerPoint and played through headphones (Britz W800BT, Britz International Corporation, Seoul, Korea). The listeners were allowed to adjust the audio volume to a comfortable level. The listeners were instructed that they would hear monosyllabic CVC words produced by young children. They were allowed to listen to each stimulus up to 2 times and were instructed to write down the monosyllabic words they understood. Each listener in a group completed the listening task, identifying a total of 288 tokens.
4. Discussion
A newborn baby’s larynx descends from its elevated position at birth over a period of four years. The length of the vocal cords to the lips at birth is approximately 6–8 cm, but grows to 15–18 cm in adulthood [
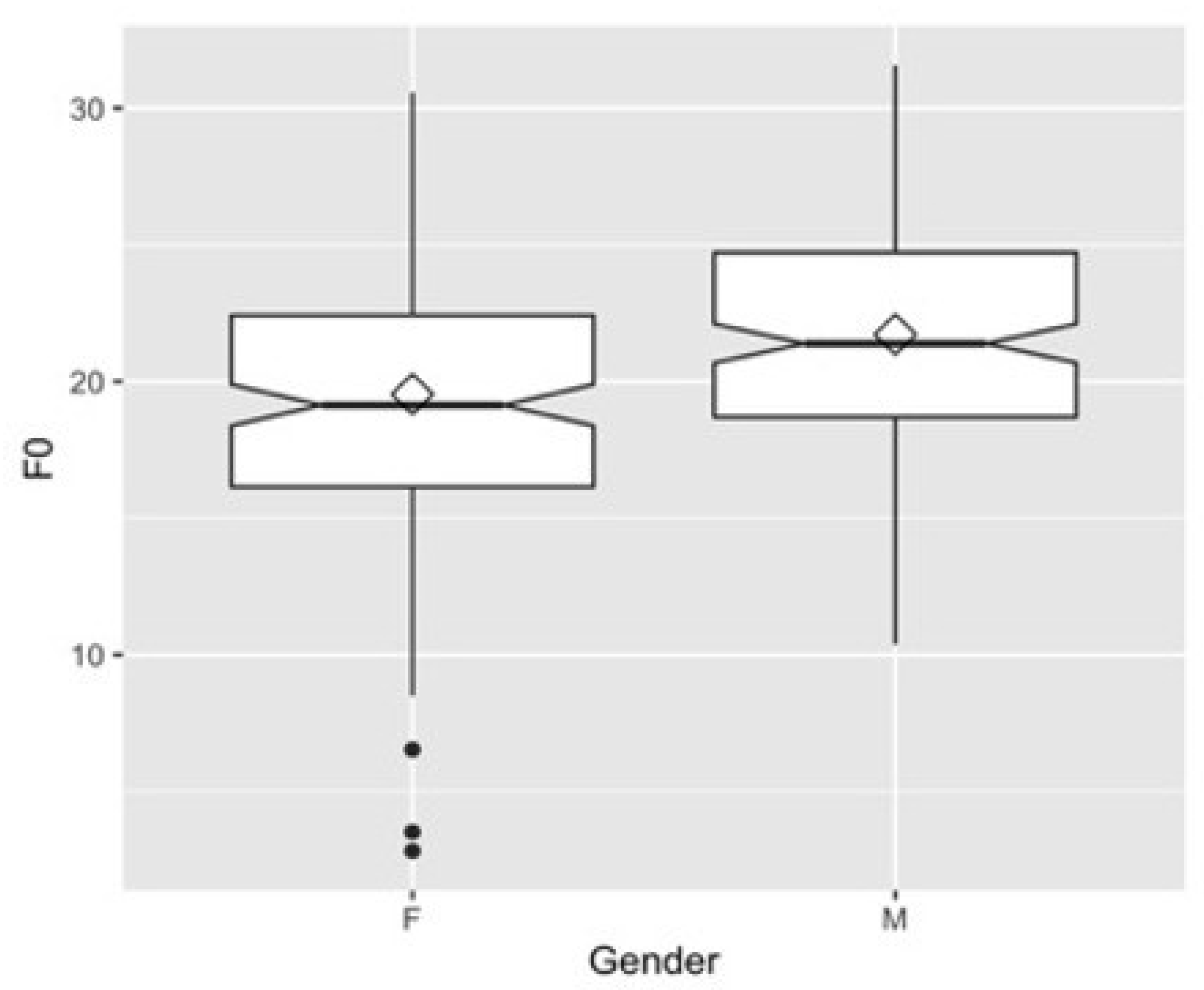
16]. Consequently, children have a higher pitch and formant frequency than adult speakers because the length of the vocal cords and vocal tract is shorter in children than in adults. Similarly, the length from vocal cords to lips is 14–14.5 cm on average for adult women and 17–18 cm on average for adult men, meaning women have a higher formant frequency than men. The present study found that F0 was not significantly different between the genders, which is consistent with previous findings of no gender difference with respect to F0 in children younger than 12 years of age [
15,
31,
32,
33]. Some studies have found that F0 differences do not emerge before the age of 7 [
34]. Nevertheless, since the age of the children in our study fell below age 7, no main effect of gender on F0 corroborated the results of earlier studies [
15]. On the other hand, significant gender effects on vowel formants were found, which is also consistent with previous studies’ findings [
10,
31]. Gender differences in children’s formant frequencies may be attributable to vocal tract size, particularly the pharynx [
10,
31,
35,
36]. Our results are in line with those of previous studies reporting that adults can perceive the gender of children as young as 4 years of age. In
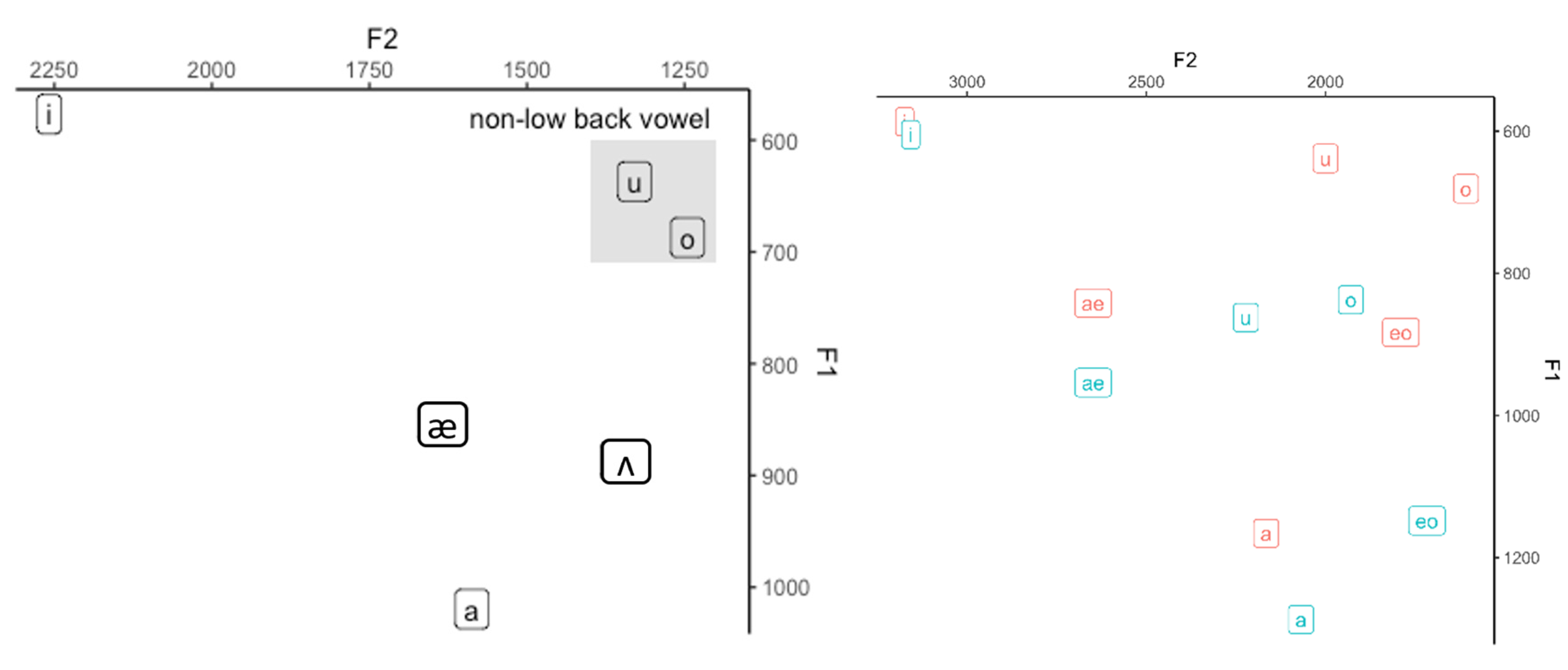
Figure 2, the size of the vowel space is greater for girls than for boys. Thus, adults’ perception of gender from children’s speech sounds is strongly related to formant frequencies.
When it comes to differences based on vowel types, the results of our study diverge from those of previous studies. For example, Ref. [
35] found that the gender effect appeared mostly in non-high and non-back vowels. Girls produce significantly higher F1 for the low-central vowel and higher F2 for the low-central and mid-front vowels. This result was consistent with [
35,
37], in which gender distinctions were reported to be small for high vowels, but large for lower vowels. Ref. [
33] also found that the difference in the F1 value of [a] productions between Korean-speaking boys and girls was the greatest among vowels. However, this study showed that the distance of the high front vowel between boys and girls along the F2 dimension was as long as that of the low vowel along the F1 dimension (
Figure 2). The different formant values between boys and girls could also indicate different articulatory gestures between the two genders. The degree of mouth opening might be a good index for displaying a gender-dependent articulatory gesture. Boys might tend to open their mouths more widely, resulting in a lower F1. In addition, boys might advance their tongues to a more anterior position than girls, especially for high front vowels. The vowel height and frontal quality are differentiated by around 24 months, and the roundness is completed after 36 months. Vowel development is also reported to precede consonant development [
32]. Thus, the perceived vowel by adult listeners agrees with the production by children, as in
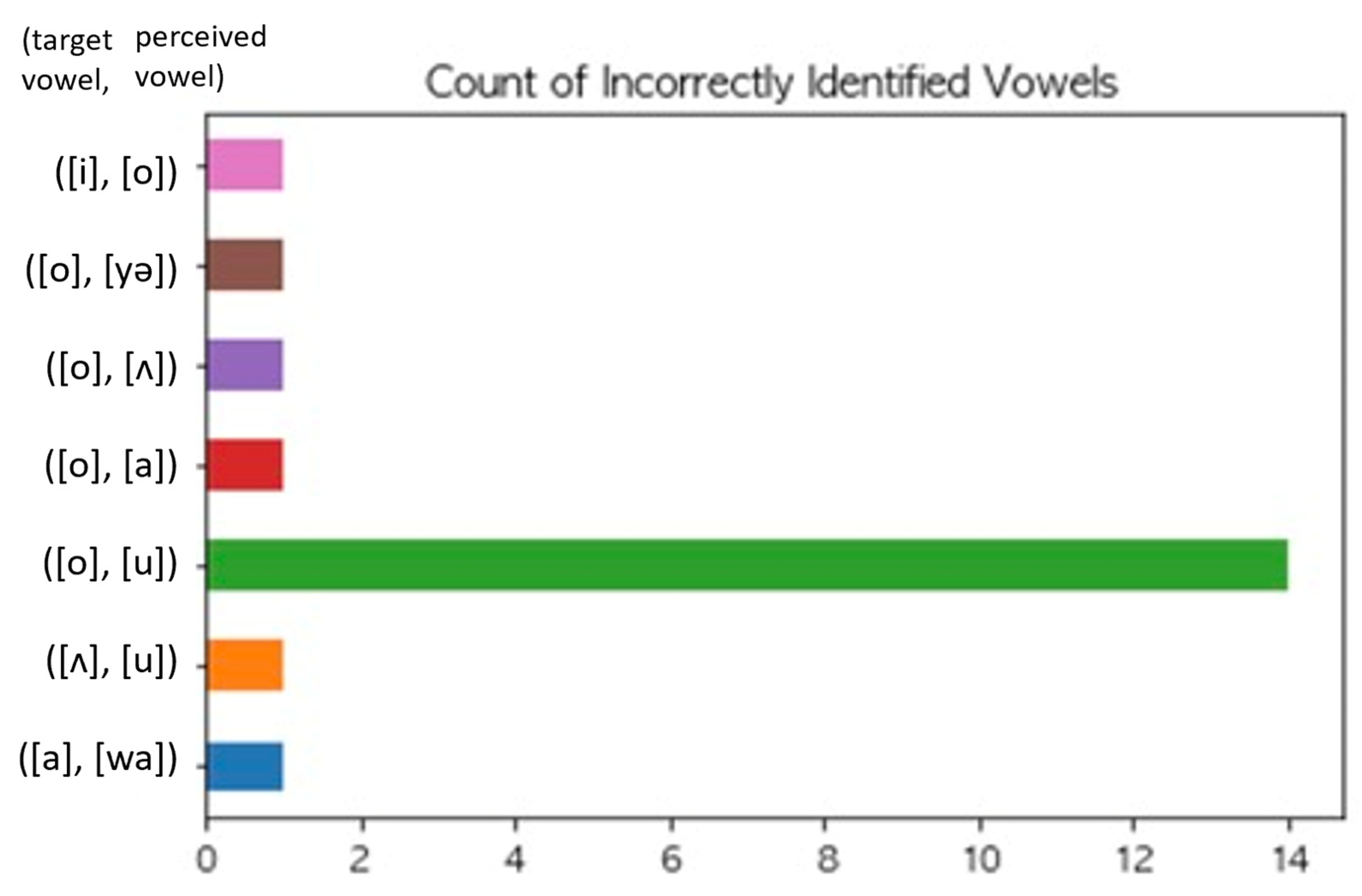
Figure 3, except for [o].
The exceptional case of [o] can be explained if we take the ongoing sound change in Seoul Korean. Acoustic studies in the past decade documented a raised [o] by showing that the lowered first formants (F1) almost overlapped with those of the high back vowel [u] [
6,
24]. The spectral trajectories in [
6] showed that the F1 and F2 between [o] and [u] were differentiated throughout the vowel midpoint although the trajectories gradually merged near the vowel midpoint in older male speakers’ productions. Based on the static spectral examinations in [
6,
24], we can conclude that low F1 values of [o] in our children’s speech confirm the vowel [o] rising, which reflects the ongoing vowel changes of their caregivers.
5. Conclusions
In this paper, we asked whether the acoustic vowel space of children’s speech would reveal gender differences and reflect the phonological patterning of adults’ speech. The results obtained in the present study is in line with the previous findings on American children such as [
16] that F0 of Korean children as young as 6 years old does not serve as a reliable cue for gender distinction, but the formant patterning reflects the physiological difference between Korean girls and boys, functioning reliably as an acoustic cue for gender distinction. This finding for the role of formants in gender distinction differs from that in [
14], in which no differences of vowel space in young Korean children (3- to 6-year-old) emerged due to gender. The present study also suggests that speech perception and production are indeed linked, but the link is not necessarily at the abstract level but rather at the physical level and constrained by phonetic vowel space and indexical information, such as gender.
The current study makes an important contribution to our understanding of the development and perception of children’s speech. Nevertheless, as developmental studies of Korean vowels are very limited, further investigation is necessary to confirm the findings presented herein. Specifically speaking, because we included two children in each age group and 36 vowel tokens (18 words × 2 children per age), it was not possible to conduct fine-grained acoustic analyses based on age group. Instead, we opted to collapse all data points for vowels and ran linear mixed effects models with vowel types and each individual child as random effects and gender as a fixed effect [
29]. In further analyses, we will use an experimental design to assess developmental stages of children’s speech production and perception by including acoustic analyses of varied speech samples beyond the CVC word types across age groups. We will also conduct perception experiments, among others, with more tokens from children and listeners.







{kind=link}
{kind=link}
{kind=link}
{kind=link}