
Machine Learning Algorithms for Predicting Stunting among Under-Five Children in Papua New Guinea

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Source
2.2. Outcome Variable and Potential Risk Factors
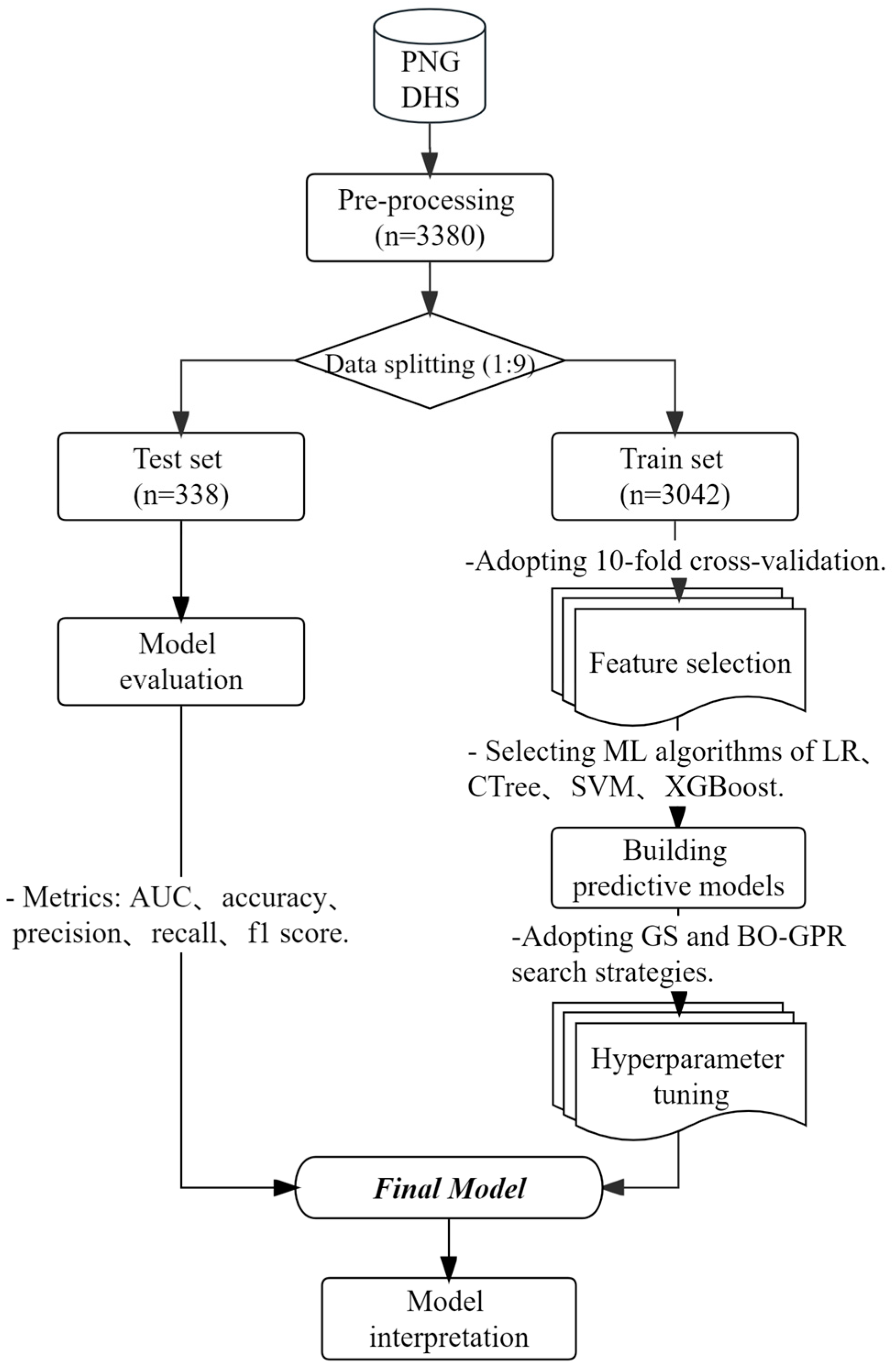
2.3. Analytic Strategy
2.3.1. Preprocessing
2.3.2. Feature Selection
2.3.3. Machine Learning Algorithms and Hyperparameter Tuning
2.3.4. Model Performance Evaluation
3. Results
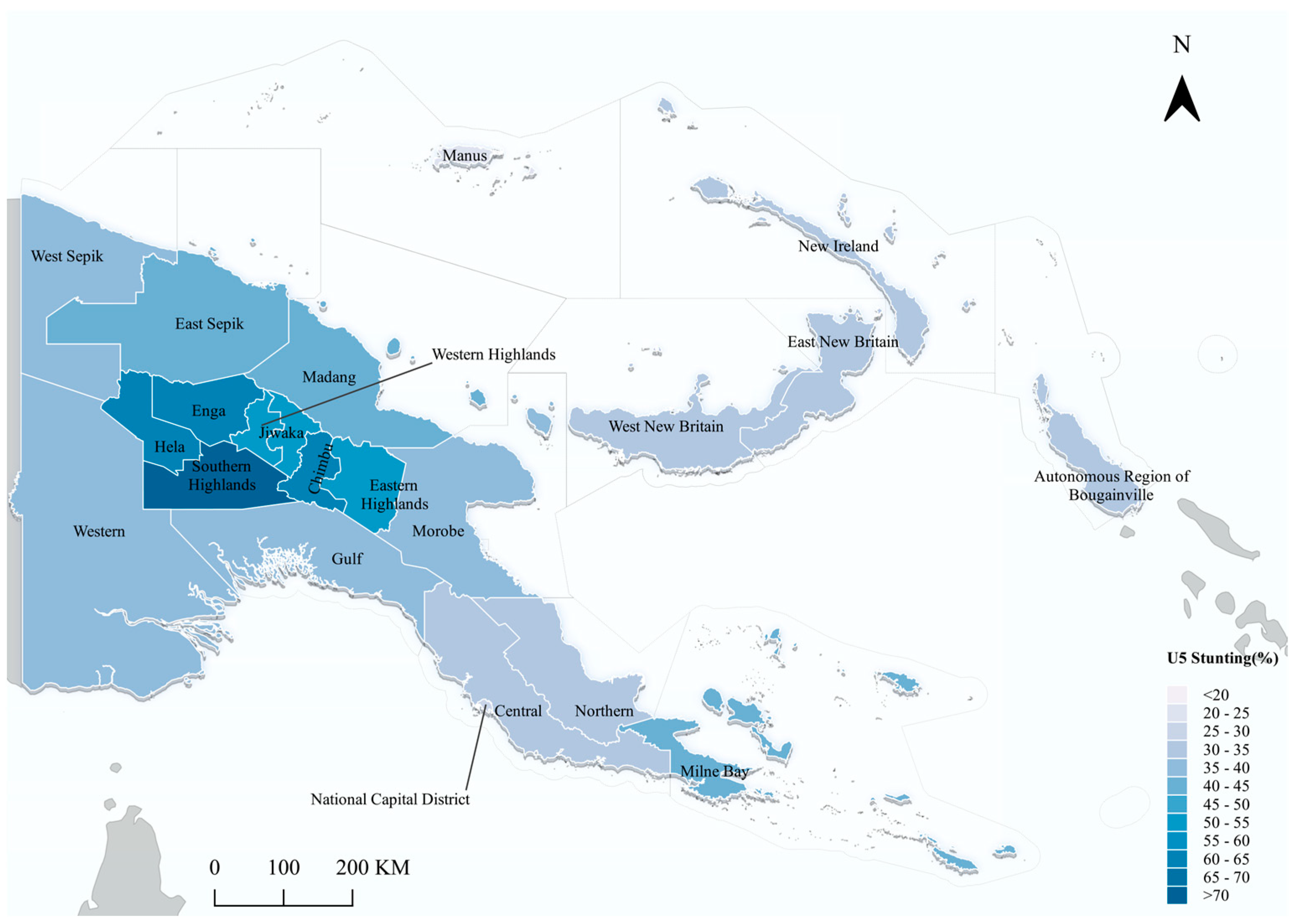
3.1. Descriptive Results
3.2. Feature Selection Results
3.3. Hyperparameter Tuning Results
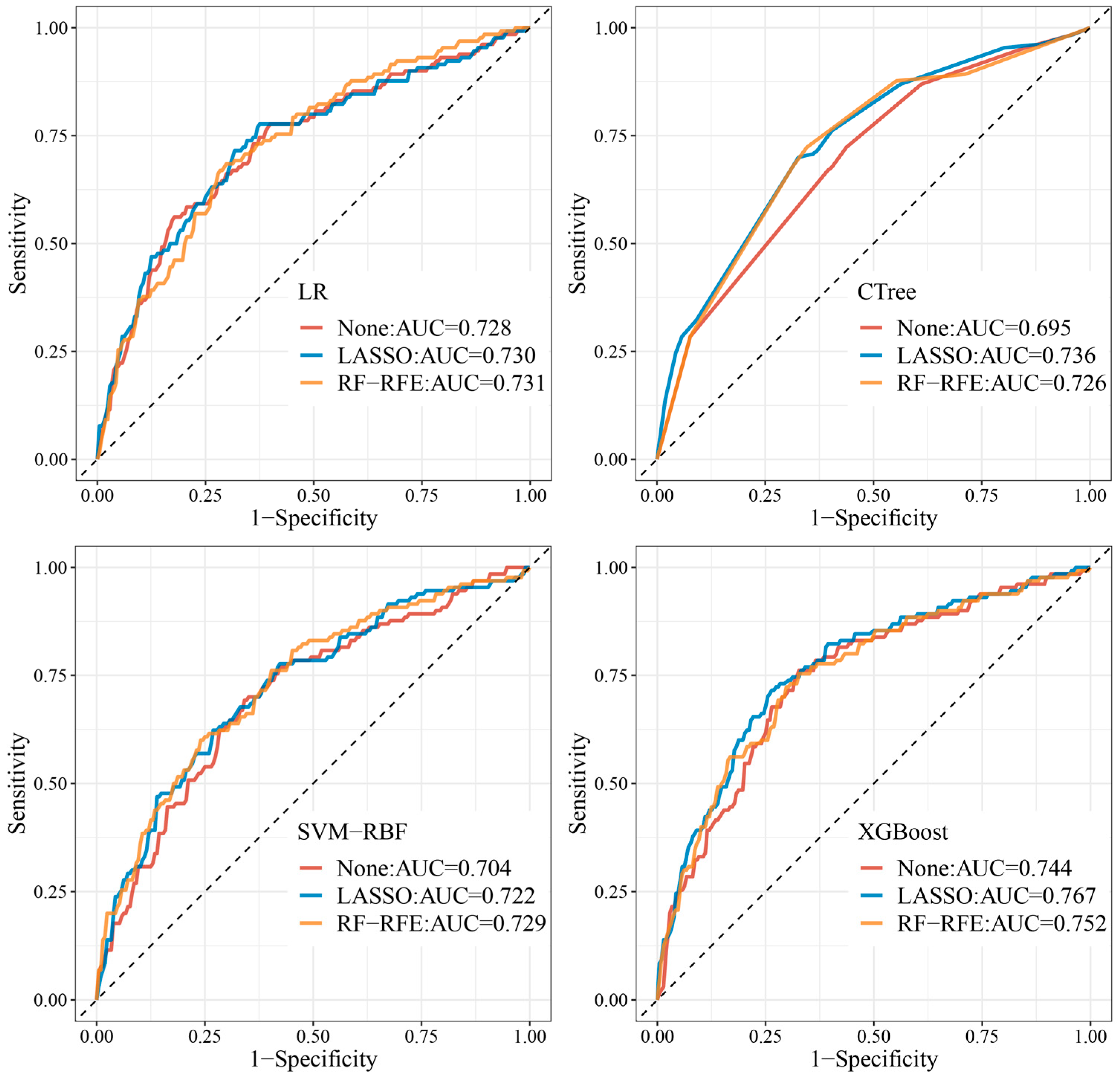
3.4. Evaluation of the Prediction Models
3.5. Model Interpretation
3.5.1. SHAP Summary Plots
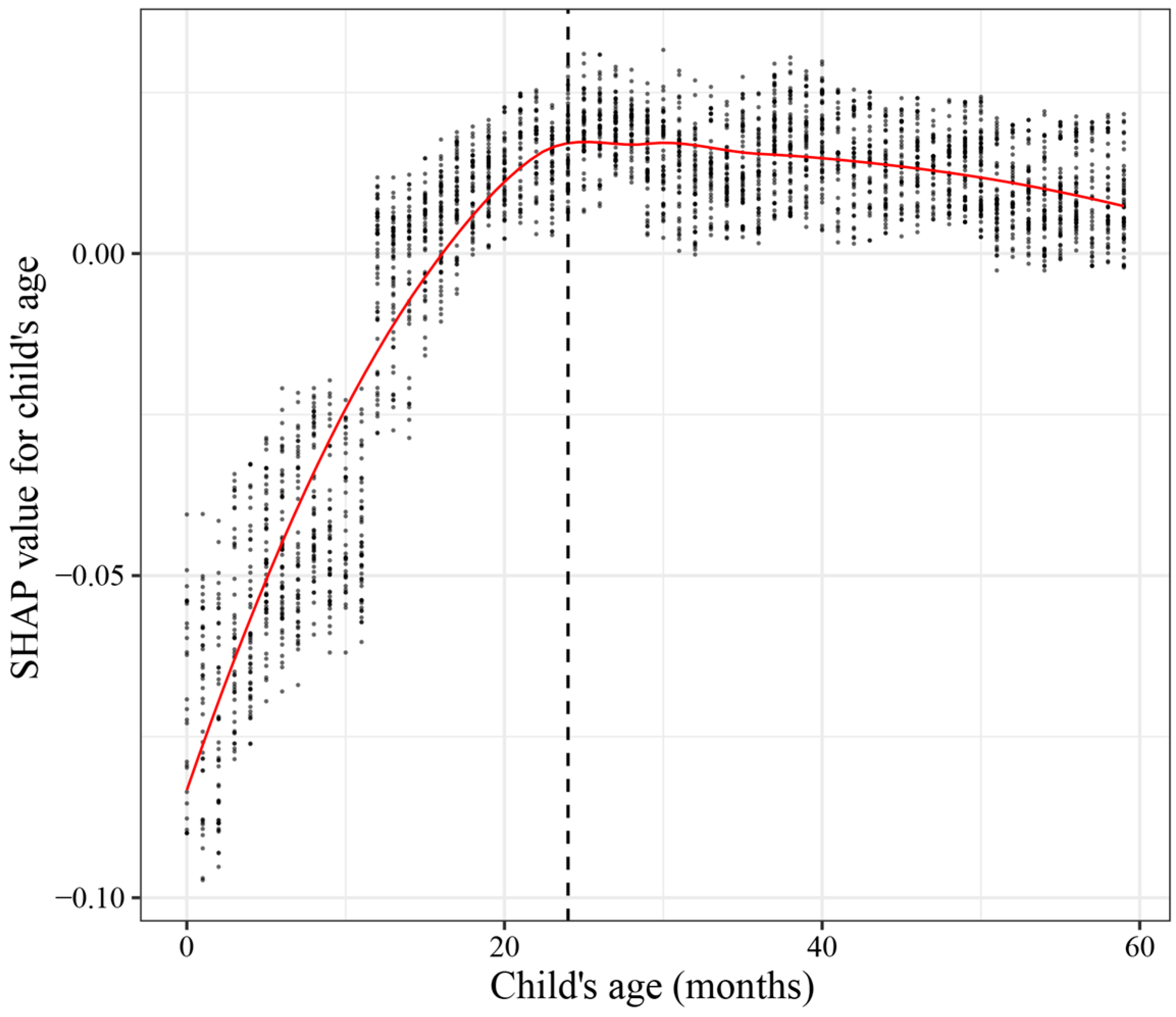
3.5.2. SHAP Dependence Plot of Child’s Age
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. WHO Child Growth Standards: Length/Height-for-Age, Weight-for-Age, Weight-for-Length, Weight-for-Height and Body Mass Index-for-Age: Methods and Development; World Health Organization: Geneva, Switzerland, 2006. [Google Scholar]
- De Onis, M.; Branca, F. Childhood stunting: A global perspective. Matern. Child Nutr. 2016, 12, 12–26. [Google Scholar] [CrossRef] [PubMed]
- Victora, C.G.; De Onis, M.; Hallal, P.C.; Blössner, M.; Shrimpton, R. Worldwide timing of growth faltering: Revisiting implications for interventions. Pediatrics 2010, 125, e473–e480. [Google Scholar] [CrossRef] [PubMed]
- Black, M.M.; Walker, S.P.; Fernald, L.C.; Andersen, C.T.; DiGirolamo, A.M.; Lu, C.; McCoy, D.C.; Fink, G.; Shawar, Y.R.; Shiffman, J. Early childhood development coming of age: Science through the life course. Lancet 2017, 389, 77–90. [Google Scholar] [CrossRef] [PubMed]
- Leroy, J.L.; Ruel, M.; Habicht, J.-P.; Frongillo, E.A. Linear growth deficit continues to accumulate beyond the first 1000 days in low-and middle-income countries: Global evidence from 51 national surveys. J. Nutr. 2014, 144, 1460–1466. [Google Scholar] [CrossRef]
- Prendergast, A.J.; Humphrey, J.H. The stunting syndrome in developing countries. Paediatr. Int. Child Health 2014, 34, 250–265. [Google Scholar] [CrossRef]
- Leroy, J.L.; Frongillo, E.A.; Dewan, P.; Black, M.M.; Waterland, R.A. Can children catch up from the consequences of undernourishment? Evidence from child linear growth, developmental epigenetics, and brain and neurocognitive development. Adv. Nutr. 2020, 11, 1032–1041. [Google Scholar] [CrossRef]
- Leroy, J.L.; Frongillo, E.A. Perspective: What does stunting really mean? A critical review of the evidence. Adv. Nutr. 2019, 10, 196–204. [Google Scholar] [CrossRef]
- World Health Organization. Levels and Trends in Child Malnutrition: UNICEF; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Osborn, D.; Cutter, A.; Ullah, F. Universal sustainable development goals. Underst. Transform. Chall. Dev. Ctries. 2015, 2, 1–25. [Google Scholar]
- World Health Organization. The Health-Related Sustainable Development Goals: Progress Report of the Western Pacific Region, 2020; World Health Organization: Geneva, Switzerland, 2021. [Google Scholar]
- Hou, X. Stagnant stunting rate despite rapid economic growth in Papua new guinea. In Factors Correlated with Malnutrition Among Children Under Five; World Bank Policy Research Working Paper; World Bank: Washington, DC, USA, 2015. [Google Scholar]
- Banks, G. Papua New Guinea National Human Development Report; United Nations Development Programme: New York, NY, USA, 2014. [Google Scholar]
- Pham, B.N.; Silas, V.D.; Okely, A.D.; Pomat, W. Measuring wasting and stunting prevalence among children under 5 years of age and associated risk factors in Papua New Guinea: New evidence from the Comprehensive Health and Epidemiological Surveillance System. Front. Nutr. 2021, 8, 622660. [Google Scholar] [CrossRef]
- Samiak, L.; Emeto, T.I. Vaccination and nutritional status of children in Karawari, East Sepik Province, Papua New Guinea. PLoS ONE 2017, 12, e0187796. [Google Scholar] [CrossRef]
- Wand, H.; Lote, N.; Semos, I.; Siba, P. Investigating the spatial variations of high prevalences of severe malnutrition among children in Papua New Guinea: Results from geoadditive models. BMC Res. Notes 2012, 5, 288. [Google Scholar] [CrossRef] [PubMed]
- Hall, J.; Walton, M.; Van Ogtrop, F.; Guest, D.; Black, K.; Beardsley, J. Factors influencing undernutrition among children under 5 years from cocoa-growing communities in Bougainville. BMJ Glob. Health 2020, 5, e002478. [Google Scholar] [CrossRef] [PubMed]
- van der Meulen Rodgers, Y.; Kassens, A.L. Women’s asset ownership and children’s nutritional status: Evidence from Papua New Guinea. Soc. Sci. Med. 2018, 204, 100–107. [Google Scholar] [CrossRef] [PubMed]
- Hou, X. Stagnant Stunting Rate despite Rapid Economic Growth—An Analysis of Cross Sectional Survey Data of Undernutrition among Children under Five in Papua New Guinea. AIMS Public Health 2016, 3, 25. [Google Scholar] [CrossRef]
- Juarez-Orozco, L.E.; Martinez-Manzanera, O.; Storti, A.E.; Knuuti, J. Machine learning in the evaluation of myocardial ischemia through nuclear cardiology. Curr. Cardiovasc. Imaging Rep. 2019, 12, 5. [Google Scholar] [CrossRef]
- Khourdifi, Y.; Bahaj, M. Heart disease prediction and classification using machine learning algorithms optimized by particle swarm optimization and ant colony optimization. Int. J. Intell. Eng. Syst. 2019, 12, 242–252. [Google Scholar] [CrossRef]
- Kino, S.; Hsu, Y.-T.; Shiba, K.; Chien, Y.-S.; Mita, C.; Kawachi, I.; Daoud, A. A scoping review on the use of machine learning in research on social determinants of health: Trends and research prospects. SSM-Popul. Health 2021, 15, 100836. [Google Scholar] [CrossRef]
- Khan, J.R.; Tomal, J.H.; Raheem, E. Model and variable selection using machine learning methods with applications to childhood stunting in Bangladesh. Inform. Health Soc. Care 2021, 46, 425–442. [Google Scholar] [CrossRef]
- Talukder, A.; Ahammed, B. Machine learning algorithms for predicting malnutrition among under-five children in Bangladesh. Nutrition 2020, 78, 110861. [Google Scholar] [CrossRef]
- Haris, M.S.; Anshori, M.; Khudori, A.N. Prediction of stunting prevalence in east java province with random forest algorithm. J. Tek. Inform. Jutif 2023, 4, 11–13. [Google Scholar] [CrossRef]
- Rahman, S.J.; Ahmed, N.F.; Abedin, M.M.; Ahammed, B.; Ali, M.; Rahman, M.J.; Maniruzzaman, M. Investigate the risk factors of stunting, wasting, and underweight among under-five Bangladeshi children and its prediction based on machine learning approach. PLoS ONE 2021, 16, e0253172. [Google Scholar] [CrossRef] [PubMed]
- Lucy Lawrence, S. Predicting Stunting Status among Children under Five Years: The Case Study of Tanzania. Ph.D. Thesis, University of Rwanda, Kigali, Rwanda, 2021. [Google Scholar]
- Fenta, H.M.; Zewotir, T.; Muluneh, E.K. A machine learning classifier approach for identifying the determinants of under-five child undernutrition in Ethiopian administrative zones. BMC Med. Inform. Decis. Mak. 2021, 21, 291. [Google Scholar] [CrossRef] [PubMed]
- Gutkin, M.; Shamir, R.; Dror, G. SlimPLS: A method for feature selection in gene expression-based disease classification. PLoS ONE 2009, 4, e6416. [Google Scholar] [CrossRef] [PubMed]
- Abiodun, E.O.; Alabdulatif, A.; Abiodun, O.I.; Alawida, M.; Alabdulatif, A.; Alkhawaldeh, R.S. A systematic review of emerging feature selection optimization methods for optimal text classification: The present state and prospective opportunities. Neural Comput. Appl. 2021, 33, 15091–15118. [Google Scholar] [CrossRef] [PubMed]
- Venkatesh, B.; Anuradha, J. A review of feature selection and its methods. Cybern. Inf. Technol. 2019, 19, 3–26. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- National Statistical Office; ICF. Papua New Guinea Demographic and Health Survey 2016-18; ICF: Rockville, MD, USA, 2019. [Google Scholar]
- Akanji, O.O. UNICEF: The State of the World’s Children 1998. Econ. Financ. Rev. 1998, 36, 6. [Google Scholar]
- World Health Organization. Indicators for Assessing Infant and Young Child Feeding Practices: Part 1: Definitions: Conclusions of a Consensus Meeting Held 6–8 November 2007 in Washington DC, USA; World Health Organization: Geneva, Switzerland, 2008. [Google Scholar]
- Campos, A.P.; Vilar-Compte, M.; Hawkins, S.S. Association between breastfeeding and child stunting in Mexico. Ann. Glob. Health 2020, 86, 145. [Google Scholar] [CrossRef]
- Fatema, K.; Lariscy, J.T. Mass media exposure and maternal healthcare utilization in South Asia. SSM Popul. Health 2020, 11, 100614. [Google Scholar] [CrossRef]
- WHO/UNICEF Joint Water Supply; Sanitation Monitoring Programme. Progress on Drinking Water and Sanitation: 2014 Update; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- World Health Organization. Burning Opportunity: Clean Household Energy for Health, Sustainable Development, and Wellbeing of Women and Children; World Health Organization: Geneva, Switzerland, 2016. [Google Scholar]
- Berrar, D. Cross-validation. In Encyclopedia of Bioinformatics and Computational Biology; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 65. [Google Scholar] [CrossRef]
- Liashchynskyi, P.; Liashchynskyi, P. Grid search, random search, genetic algorithm: A big comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Hothorn, T.; Hornik, K.; Zeileis, A. Unbiased recursive partitioning: A conditional inference framework. J. Comput. Graph. Stat. 2006, 15, 651–674. [Google Scholar] [CrossRef]
- Hothorn, T.; Hornik, K.; Zeileis, A. ctree: Conditional inference trees. Compr. R Arch. Netw. 2015, 8, 1–34. [Google Scholar]
- Hothorn, T.; Hornik, K.; Strobl, C.; Zeileis, A.; Hothorn, M.T. Package ‘party’. Packag Ref Man Party, Version 0.9-998. 2015; Volume 16, 37.
- Sarda-Espinosa, A.; Subbiah, S.; Bartz-Beielstein, T. Conditional inference trees for knowledge extraction from motor health condition data. Eng. Appl. Artif. Intell. 2017, 62, 26–37. [Google Scholar] [CrossRef]
- Mantovani, R.G.; Horváth, T.; Cerri, R.; Junior, S.B.; Vanschoren, J.; de Carvalho, A.C.P.d.L.F. An empirical study on hyperparameter tuning of decision trees. arXiv 2018, arXiv:1812.02207. [Google Scholar]
- Nembrini, S. Prediction or interpretability? Emerg. Themes Epidemiol. 2019, 16, 4. [Google Scholar] [CrossRef]
- Ghosh, S.; Dasgupta, A.; Swetapadma, A. A study on support vector machine based linear and non-linear pattern classification. In Proceedings of the 2019 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 21–22 February 2019; pp. 24–28. [Google Scholar]
- Han, S.; Qubo, C.; Meng, H. Parameter selection in SVM with RBF kernel function. In Proceedings of the World Automation Congress 2012, Puerto Vallarta, Mexico, 24–28 June 2012; pp. 1–4. [Google Scholar]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei City, China, 2003. [Google Scholar]
- Thombre, A.M. Effect of outlier removal on grid search and distance between two classes (the techniques to find hyperparameter, sigma of support vector machine). In Proceedings of the 2019 IEEE Pune Section International Conference (PuneCon), Pune, India, 18–20 December 2019; pp. 1–8. [Google Scholar]
- Duarte, E.; Wainer, J. Empirical comparison of cross-validation and internal metrics for tuning SVM hyperparameters. Pattern Recognit. Lett. 2017, 88, 6–11. [Google Scholar] [CrossRef]
- Dong, W.; Huang, Y.; Lehane, B.; Ma, G. XGBoost algorithm-based prediction of concrete electrical resistivity for structural health monitoring. Autom. Constr. 2020, 114, 103155. [Google Scholar] [CrossRef]
- Ogunleye, A.; Wang, Q.-G. XGBoost model for chronic kidney disease diagnosis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 17, 2131–2140. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Teke, A. Advanced hyperparameter optimization for improved spatial prediction of shallow landslides using extreme gradient boosting (XGBoost). Bull. Eng. Geol. Environ. 2022, 81, 201. [Google Scholar] [CrossRef]
- Anggoro, D.A.; Mukti, S.S. Performance Comparison of Grid Search and Random Search Methods for Hyperparameter Tuning in Extreme Gradient Boosting Algorithm to Predict Chronic Kidney Failure. Int. J. Intell. Eng. Syst 2021, 14, 198–207. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de Las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Ruopp, M.D.; Perkins, N.J.; Whitcomb, B.W.; Schisterman, E.F. Youden Index and optimal cut-point estimated from observations affected by a lower limit of detection. Biom. J. J. Math. Methods Biosci. 2008, 50, 419–430. [Google Scholar] [CrossRef]
- Food Assistance to El-Niño Affected Populations in Papua New Guinea; World Food Programme: Rome, Italy, 2016.
- Gwatirisa, P.R.; Pamphilon, B.; Mikhailovich, K. Coping with drought in rural Papua New Guinea: A western highlands case study. Ecol. Food Nutr. 2017, 56, 393–410. [Google Scholar] [CrossRef]
- Jacka, J.K.; Posner, S. How the Enga Cope with Frost in the 21st Century: Food Insecurity, Migration, and Development in the Papua New Guinea Highlands. Hum. Ecol. 2022, 50, 273–286. [Google Scholar] [CrossRef]
- Benjamin, A.; Mopafi, I.; Duke, T. A Perspective on Food and Nutrition in the PNG Highlands. Food Secur. Papua New Guin. 2001, 11, 94. [Google Scholar]
- Schmidt, E.; Dorosh, P.; Gilbert, R. Impacts of COVID-19 induced income and rice price shocks on household welfare in Papua New Guinea: Household model estimates. Agric. Econ. 2021, 52, 391–406. [Google Scholar] [CrossRef]
- Jayanthan, J.; Irava, W.; Anuranga, C.; Rannan-Eliya, R. Impact of out-of-pocket expenditures on families and barriers to use of maternal and child health services in Papua New Guinea: Evidence from the Papua New Guinea household survey 1996 and household income and expenditure survey 2009–2010. In Country Brief; ADB RETA-6515 Country Brief Series; 2012; Available online: https://www.adb.org/sites/default/files/publication/30344/impact-oop-expenditures-mnch-services-png.pdf (accessed on 13 August 2023).
- Schmidt, E.; Mueller, V.; Rosenbach, G. Rural households in Papua New Guinea afford better diets with income from small businesses. Food Policy 2020, 97, 101964. [Google Scholar] [CrossRef]
- Mueller, I.; Vounatsou, P.; Allen, B.; Smith, T. Spatial patterns of child growth in Papua New Guinea and their relation to environment, diet, socio-economic status and subsistence activities. Ann. Hum. Biol. 2001, 28, 263–280. [Google Scholar] [CrossRef]
- Stephenson, L.S.; Latham, M.C.; Ottesen, E. Malnutrition and parasitic helminth infections. Parasitology 2000, 121, S23–S38. [Google Scholar] [CrossRef] [PubMed]
- Thame, M.; Wilks, R.J.; McFarlane-Anderson, N.; Bennett, F.I.; Forrester, T.E. Relationship between maternal nutritional status and infant’s weight and body proportions at birth. Eur. J. Clin. Nutr. 1997, 51, 134–138. [Google Scholar] [CrossRef] [PubMed]
- Barker, D.J.; Godfrey, K.M.; Gluckman, P.D.; Harding, J.E.; Owens, J.A.; Robinson, J.S. Fetal nutrition and cardiovascular disease in adult life. Lancet 1993, 341, 938–941. [Google Scholar] [CrossRef] [PubMed]
- Victora, C.G.; Villar, J.; Barros, F.C.; Ismail, L.C.; Chumlea, C.; Papageorghiou, A.T.; Bertino, E.; Ohuma, E.O.; Lambert, A.; Carvalho, M. Anthropometric characterization of impaired fetal growth: Risk factors for and prognosis of newborns with stunting or wasting. JAMA Pediatr. 2015, 169, e151431. [Google Scholar] [CrossRef] [PubMed]
- Decaro, J.A.; Decaro, E.; Worthman, C.M. Sex differences in child nutritional and immunological status 5–9 years post contact in fringe highland Papua New Guinea. Am. J. Hum. Biol. 2010, 22, 657–666. [Google Scholar] [CrossRef]
- Frost, M.B.; Forste, R.; Haas, D.W. Maternal education and child nutritional status in Bolivia: Finding the links. Soc. Sci. Med. 2005, 60, 395–407. [Google Scholar] [CrossRef]
- Haile, D.; Azage, M.; Mola, T.; Rainey, R. Exploring spatial variations and factors associated with childhood stunting in Ethiopia: Spatial and multilevel analysis. BMC Pediatr. 2016, 16, 49. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range | Type |
|---|---|---|
| Eta | (0.01, 0.3) | Real |
| Gamma | (0, 0.2) | Real |
| Subsample | (0.1, 1) | Real |
| Colsample bytree | (0.1, 1) | Real |
| Nrounds | [1, 200] | Integer |
| Maxdepth | [1, 20] | Integer |
| Min child weight | [1, 20] | Integer |
| Stunted | |||||
|---|---|---|---|---|---|
| Variables | N | Frequency (%)/Mean (SD) | No (%) | Yes (%) | p-Values |
| Individual characteristics | |||||
| Child’s age (months) | 3380 | 29.73 | <0.001 | ||
| Child’s gender | <0.01 | ||||
| Male | 1795 | 53.11 | 57.83 | 42.17 | |
| Female | 1585 | 46.89 | 63.09 | 36.91 | |
| Birth size | <0.001 | ||||
| Average | 1215 | 38.36 | 65.93 | 34.07 | |
| Large | 1337 | 42.22 | 60.13 | 39.87 | |
| Small | 615 | 19.42 | 51.22 | 48.78 | |
| Birth order | 3380 | 3.15 | 0.069 | ||
| Duration of breastfeeding | <0.001 | ||||
| Never breastfed | 168 | 7.19 | 60.71 | 39.29 | |
| <6 months | 367 | 15.71 | 76.02 | 23.98 | |
| ≥6 months | 1801 | 77.10 | 59.74 | 40.26 | |
| Early breastfeeding | 0.280 | ||||
| No | 919 | 41.81 | 63.87 | 36.13 | |
| Yes | 1279 | 58.19 | 61.61 | 38.39 | |
| Had diarrhea in the past 2 weeks | 0.925 | ||||
| No | 2683 | 84.74 | 60.27 | 39.73 | |
| Yes | 483 | 15.26 | 60.04 | 39.96 | |
| Had fever in the past 2 weeks | 0.867 | ||||
| No | 2489 | 78.72 | 60.39 | 39.61 | |
| Yes | 673 | 21.28 | 60.03 | 39.97 | |
| Maternal characteristics | |||||
| Maternal age (years) | 3380 | 30.16 | 0.848 | ||
| Partner’s age (years) | 2961 | 35.03 | 0.547 | ||
| Maternal employment status | <0.001 | ||||
| Not employed | 2101 | 62.59 | 57.45 | 42.55 | |
| Employed | 1256 | 37.41 | 64.81 | 35.19 | |
| Partner’s employment status | <0.001 | ||||
| Not employed | 1328 | 43.60 | 55.72 | 44.28 | |
| Employed | 1718 | 56.40 | 63.50 | 36.50 | |
| Maternal occupation | <0.001 | ||||
| No occupation | 2124 | 63.46 | 57.63 | 42.37 | |
| Professional/technical/managerial | 161 | 4.81 | 78.88 | 21.12 | |
| Clerical | 66 | 1.97 | 69.70 | 30.30 | |
| Sales | 161 | 4.81 | 72.67 | 27.33 | |
| Agricultural | 560 | 16.73 | 56.43 | 43.57 | |
| Services | 257 | 7.68 | 68.87 | 31.13 | |
| Skilled manual | 7 | 0.21 | 85.71 | 14.29 | |
| Unskilled manual | 11 | 0.33 | 54.55 | 45.45 | |
| Maternal marital status | 0.456 | ||||
| Never Married/divorced/separated | 274 | 8.11 | 62.41 | 37.59 | |
| Married/living together | 3106 | 91.89 | 60.11 | 39.89 | |
| Maternal religion | 0.843 | ||||
| Non-Christian/no religion | 29 | 0.86 | 58.62 | 41.38 | |
| Christian | 3343 | 99.14 | 60.42 | 39.58 | |
| Maternal education level | <0.001 | ||||
| No education | 647 | 19.14 | 48.53 | 51.47 | |
| Primary education | 1704 | 50.41 | 59.10 | 40.90 | |
| Secondary education | 918 | 27.16 | 69.17 | 30.83 | |
| Higher education | 111 | 3.28 | 73.87 | 26.13 | |
| Partner’s education level | |||||
| No education | 458 | 15.17 | 46.72 | 53.28 | |
| Primary education | 1371 | 45.40 | 58.35 | 41.65 | |
| Secondary education | 953 | 31.56 | 64.85 | 35.15 | |
| Higher education | 238 | 7.88 | 76.05 | 23.95 | |
| Exposure to mass media | <0.001 | ||||
| No | 1646 | 49.03 | 53.95 | 46.05 | |
| Yes | 1711 | 50.97 | 66.69 | 33.31 | |
| Maternal age of first birth (years) | 3380 | 21.17 | <0.01 | ||
| Household characteristics | |||||
| Sex of househead | 0.061 | ||||
| Male | 2892 | 85.56 | 59.65 | 40.35 | |
| Female | 488 | 14.44 | 64.14 | 35.86 | |
| Household wealth | <0.001 | ||||
| Poorest | 556 | 16.45 | 46.40 | 53.60 | |
| Poorer | 531 | 15.71 | 49.91 | 50.09 | |
| Middle | 653 | 19.32 | 60.49 | 39.51 | |
| Richer | 809 | 23.93 | 61.80 | 38.20 | |
| Richest | 831 | 24.59 | 74.61 | 25.39 | |
| Number of under-5 children | 3380 | 3.35 | <0.05 | ||
| Number of household members | 3380 | 6.93 | <0.05 | ||
| Type of toilet facility | <0.001 | ||||
| No facility | 683 | 20.47 | 61.35 | 38.65 | |
| Unimproved | 1579 | 47.33 | 54.40 | 45.60 | |
| Improved | 1074 | 32.19 | 68.53 | 31.47 | |
| Source of drinking water | <0.001 | ||||
| Unimproved | 1558 | 46.18 | 54.36 | 45.64 | |
| Improved | 1816 | 53.82 | 65.42 | 34.58 | |
| Type of cooking fuels | <0.001 | ||||
| Polluting fuels | 3058 | 91.64 | 58.70 | 41.30 | |
| Clean fuels | 279 | 8.36 | 78.85 | 21.15 | |
| Distance to health facility | <0.001 | ||||
| Not a big problem | 1509 | 45.14 | 64.88 | 35.12 | |
| Big problem | 1834 | 54.86 | 56.32 | 43.68 | |
| Community characteristics | |||||
| Region | <0.001 | ||||
| Southern Region | 663 | 19.62 | 65.68 | 34.32 | |
| Highland Region | 1043 | 30.86 | 41.03 | 58.97 | |
| Momase Region | 799 | 23.64 | 59.32 | 40.68 | |
| Islands Region | 875 | 25.89 | 69.37 | 30.63 | |
| Area | <0.001 | ||||
| Rural | 2581 | 76.36 | 56.95 | 43.05 | |
| Urban | 799 | 23.64 | 71.09 | 28.91 | |
| Trainset (Cross-Validation) | ||
|---|---|---|
| Models | Optimal Hyperparameters | AUC |
| None | ||
| CTree | maxdepth = 5, mincriterion = 0.950 | 0.639 |
| XGBoost | nrounds = 12, eta = 0.153, gamma = 0.091, subsample = 0.807, colsample bytree = 0.995, maxdepth = 6, min child weight = 5 | 0.644 |
| SVM-RBF | C = 2−5, σ = 2−15 | 0.658 |
| LASSO | ||
| CTree | maxdepth = 7, mincriterion = 0.900 | 0.642 |
| XGBoost | nrounds = 12, eta = 0.012, gamma = 0.199, subsample = 0.694, colsample bytree = 0.811, maxdepth = 7, min child weight = 13 | 0.653 |
| SVM-RBF | C = 215, σ = 2−15 | 0.671 |
| RF-RFE | ||
| CTree | maxdepth = 4, mincriterion = 0.990 | 0.646 |
| XGBoost | nrounds = 19, eta = 0.149, gamma = 0.058, subsample = 0.909, colsample bytree = 1, maxdepth = 20, min child weight = 18 | 0.666 |
| SVM-RBF | C = 2−1, σ = 2−5 | 0.666 |
| Models | Test Set | |||||
|---|---|---|---|---|---|---|
| Metric | AUC (95% CI) | Accuracy | Precision | Recall | F1 Score | Threshold |
| None | ||||||
| LR | 0.728 (0.672–0.785) | 0.675 | 0.731 | 0.559 | 0.633 | 0.370 |
| CTree | 0.695 (0.639–0.750) | 0.630 | 0.669 | 0.515 | 0.582 | 0.426 |
| XGBoost | 0.744 (0.690–0.798) | 0.707 | 0.762 | 0.593 | 0.667 | 0.400 |
| SVM-RBF | 0.704 (0.646–0.761) | 0.672 | 0.692 | 0.559 | 0.619 | 0.363 |
| LASSO | ||||||
| LR | 0.730 (0.674–0.787) | 0.692 | 0.708 | 0.582 | 0.639 | 0.391 |
| CTree | 0.736 (0.682–0.789) | 0.683 | 0.700 | 0.572 | 0.630 | 0.459 |
| XGBoost | 0.767 (0.714–0.819) | 0.728 | 0.715 | 0.628 | 0.669 | 0.487 |
| SVM-RBF | 0.722 (0.666–0.778) | 0.672 | 0.677 | 0.561 | 0.613 | 0.346 |
| RF-RFE | ||||||
| LR | 0.731 (0.676–0.785) | 0.695 | 0.685 | 0.589 | 0.633 | 0.394 |
| CTree | 0.726 (0.672–0.781) | 0.681 | 0.723 | 0.566 | 0.635 | 0.343 |
| XGBoost | 0.752 (0.698–0.806) | 0.710 | 0.723 | 0.603 | 0.657 | 0.388 |
| SVM-RBF | 0.729 (0.674–0.785) | 0.692 | 0.615 | 0.597 | 0.606 | 0.367 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shen, H.; Zhao, H.; Jiang, Y. Machine Learning Algorithms for Predicting Stunting among Under-Five Children in Papua New Guinea. Children 2023, 10, 1638. https://doi.org/10.3390/children10101638
Shen H, Zhao H, Jiang Y. Machine Learning Algorithms for Predicting Stunting among Under-Five Children in Papua New Guinea. Children. 2023; 10(10):1638. https://doi.org/10.3390/children10101638
Chicago/Turabian StyleShen, Hao, Hang Zhao, and Yi Jiang. 2023. "Machine Learning Algorithms for Predicting Stunting among Under-Five Children in Papua New Guinea" Children 10, no. 10: 1638. https://doi.org/10.3390/children10101638
APA StyleShen, H., Zhao, H., & Jiang, Y. (2023). Machine Learning Algorithms for Predicting Stunting among Under-Five Children in Papua New Guinea. Children, 10(10), 1638. https://doi.org/10.3390/children10101638