Analysis of SF-6D Health State Utility Scores: Is Beta Regression Appropriate?


Abstract
1. Introduction
2. Materials and Methods
2.1. The SF-6D
2.2. Study Design
2.2.1. Selection of Respondents
2.2.2. Selection of Health States
2.2.3. Interviews
2.3. Study Sample
2.4. Modeling
2.4.1. Model Development
Beta Regression
Linear Regression
2.4.2. Model Estimation
2.4.3. Model Reliability and Validation
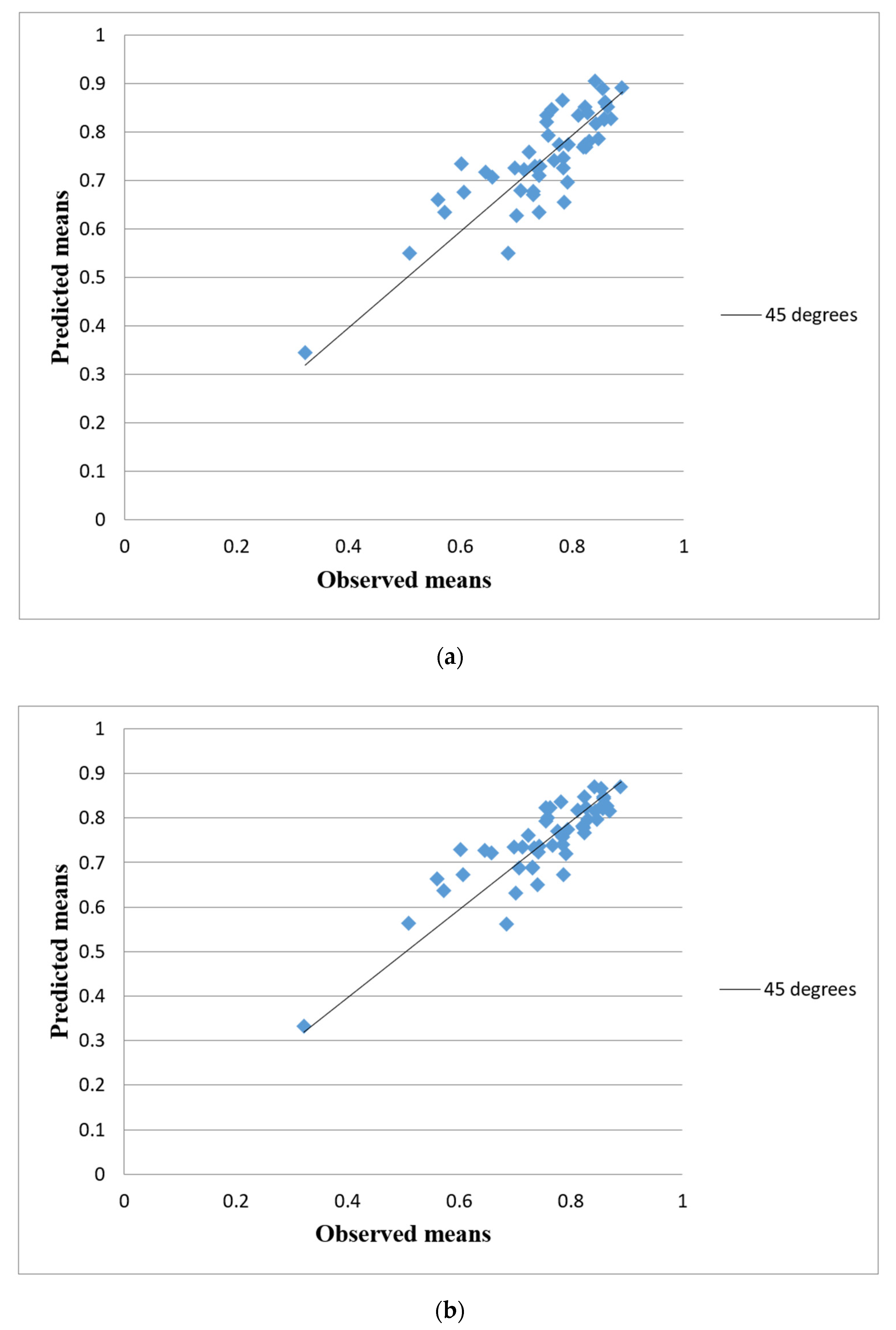
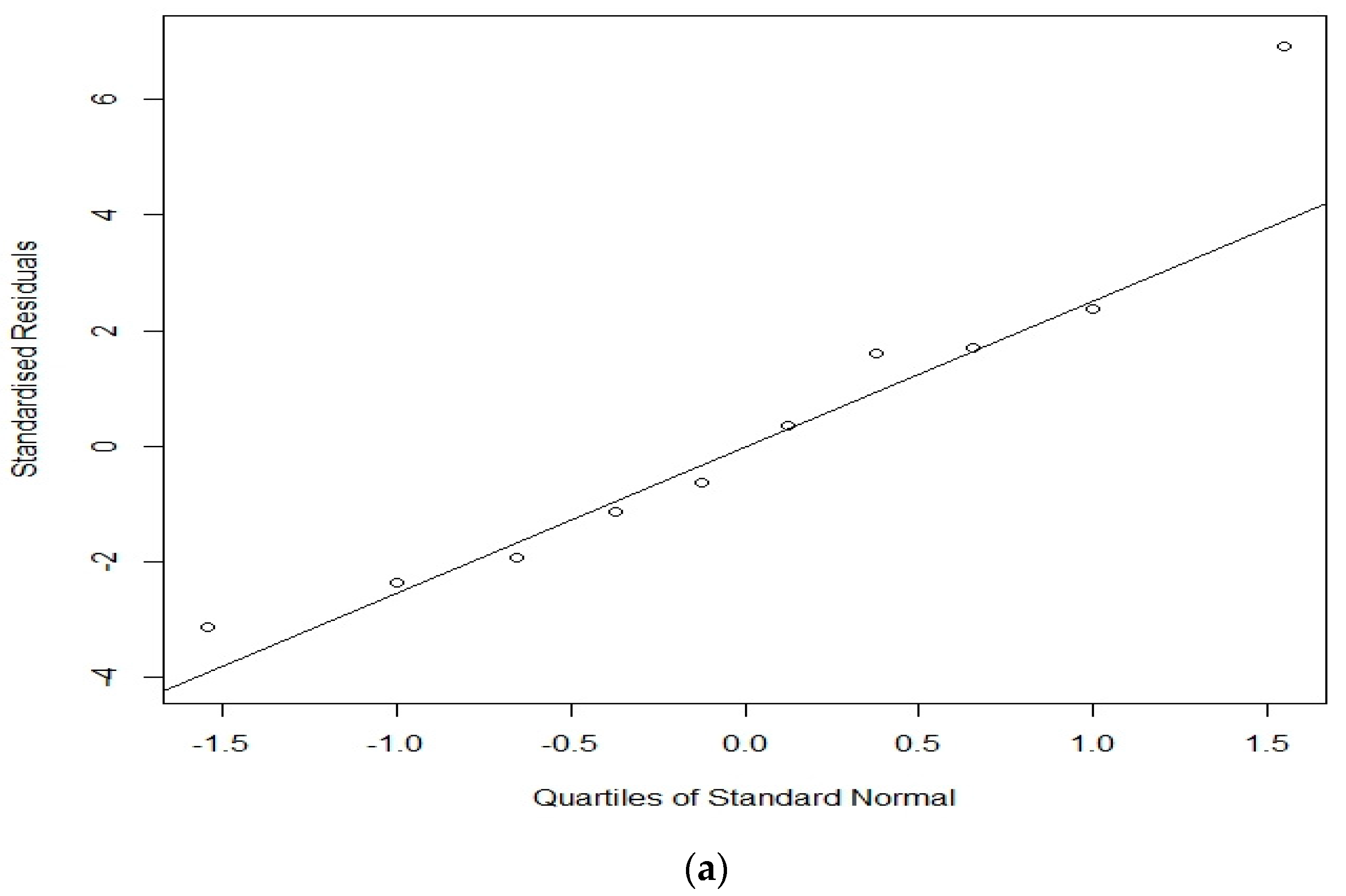
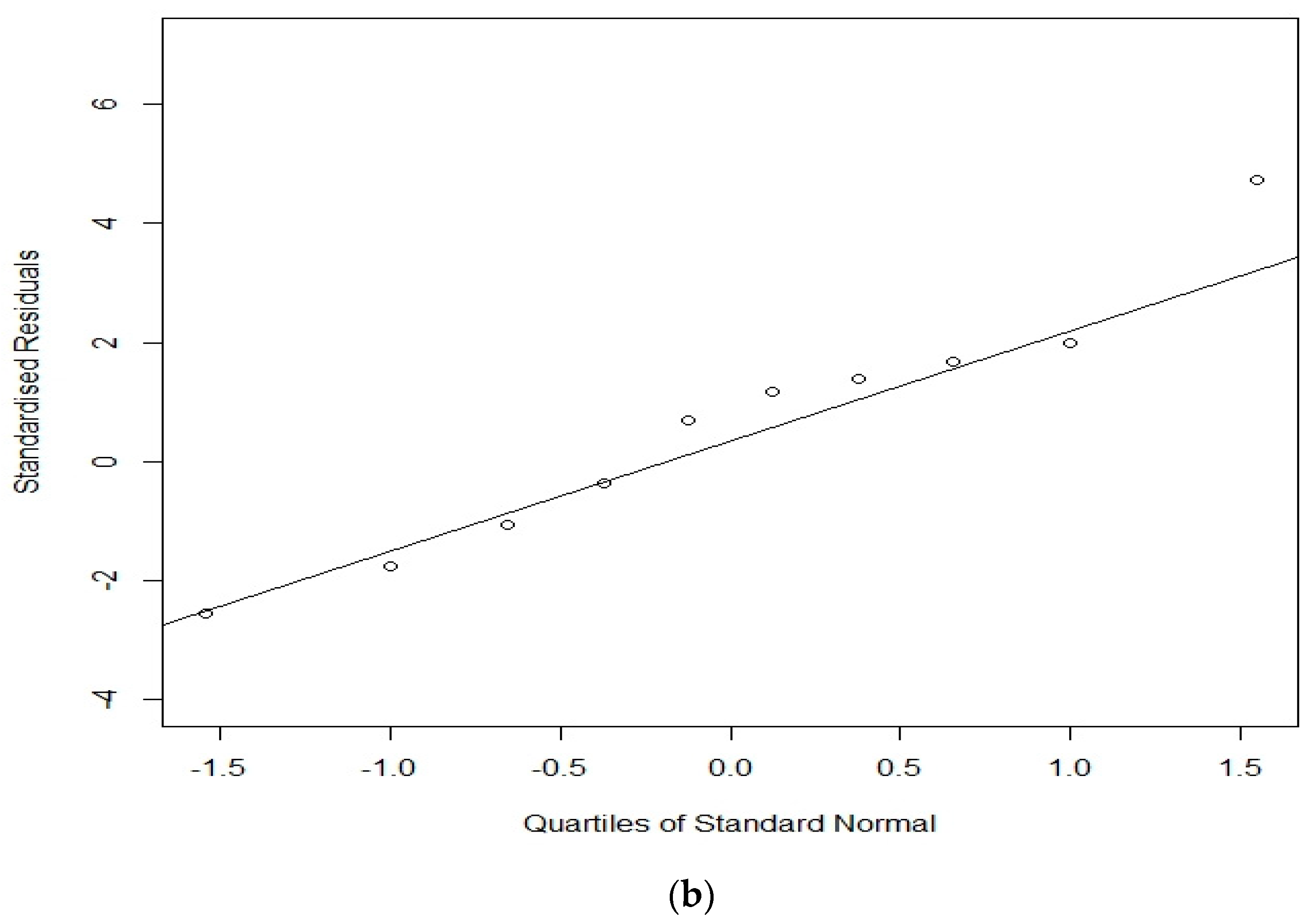
3. Results
3.1. All Models
3.2. BR + RE vs. LR + RE
4. Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Ethics Approval and Consent to Participate
References
- Brooks, R. EuroQol: The current state of play. Health Policy 1996, 37, 53–72. [Google Scholar] [CrossRef]
- Torrance, G.W.; Feeny, D.H.; Furlong, W.J.; Barr, R.D.; Zhang, Y.; Wang, Q.A. Multi-attribute utility function for a comprehensive health status classification system: Health Utilities Index Mark 2. Med. Care 1996, 34, 702–722. [Google Scholar] [CrossRef] [PubMed]
- Feeny, D.H.; Furlong, W.J.; Torrance, G.W.; Goldsmith, C.H.; Zenglong, Z.; Depauw, S.; Denton, M.; Boyle, M. Multi-attribute and single-attribute utility function for the Health Utility Index Mark 3 system. Med. Care 2002, 40, 113–128. [Google Scholar] [CrossRef] [PubMed]
- Hawthorne, G.; Richardson, J.; Day, N.A. A comparison of the Assessment of Quality of Life (AQoL) with four other generic utility instruments. Ann. Med. 2001, 33, 358–370. [Google Scholar] [CrossRef]
- Kaplan, R.M.; Anderson, J.P. A general health policy model: Update and application. Health Serv. Res. 1988, 23, 203–235. [Google Scholar] [PubMed]
- Brazier, J.E.; Roberts, J.; Deverill, M. The estimation of a preference-based measure of health from the SF-36. J. Health Econ. 2002, 21, 271–292. [Google Scholar] [CrossRef]
- Revicki, D.A.; Leidy, N.K.; Brennan-Diemer, F.; Sorenson, S.; Togias, A. Integrating patients’ preferences into health outcomes assessment: The multiattribute asthma symptom utility index. Chest 1998, 114, 998–1007. [Google Scholar] [CrossRef]
- Brazier, J.E.; Czoski-Murray, C.; Roberts, J.; Brown, M.; Symonds, T.; Kelleher, C. Estimation of a preference-based index from a condition specific measure: The King’s Health Questionnaire. Med. Decis. Mak. 2008, 28, 113–126. [Google Scholar] [CrossRef]
- Dolan, P. Modeling valuation for Euroqol health states. Med. Care 1997, 35, 351–363. [Google Scholar] [CrossRef]
- McCabe, C.; Stevens, K.; Roberts, J.; Brazier, J.E. Health state values for the HUI2 descriptive system: Results from a UK Survey. Health Econ. 2005, 14, 231–244. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCollough, B. Regression analysis of variates observed on (0, 1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef]
- Pullenayegum, E.M.; Tarride, J.-E.; Xie, F.; Goeree, R.; Gerstein, H.C.; O’Reilly, D. Analysis of health utility data when some subjects attain the upper bound of 1: Are Tobit and CLAD models appropriate? Value Health 2010, 13, 487–494. [Google Scholar] [CrossRef] [PubMed]
- Austin, P.C. A comparison of methods for analyzing health-related quality-of-life measures. Value Health 2002, 5, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Huang, I.-C.; Frangakis, C.; Atkinson, M.J.; Willke, R.J.; Leite, W.L.; Vogel, W.B.; Wu, A.W. Addressing ceiling effects in health status measures: A comparison of techniques applied to measures for people with HIV disease. Health Serv. Res. 2008, 43, 327–339. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, P.W.; Ghushchyan, V. Mapping the EQ-5D index from the SF-12: US general population preferences in a nationally representative sample. Med. Decis. Mak. 2006, 26, 401–409. [Google Scholar] [CrossRef]
- Li, L.; Fu, A.Z. Some methodological issues with the analysis of preference-based EQ-5D index score. Health Serv. Outcomes Resmethodol. 2009, 9, 162–176. [Google Scholar] [CrossRef]
- Bharmal, M.; Thomas, J., 3rd. Comparing the EQ-5D and the SF-6D descriptive systems to assess their ceiling effects in the US general population. Value Health 2006, 9, 262–271. [Google Scholar] [CrossRef]
- Ferrari, S.L.P.; Cribari-Neto, F. Beta regression for modeling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Hubben, G.A.A.; Bishai, D.; Pechlivanoglou, P.; Cattelan, A.M.; Grisetti, R.; Facchin, C.; Compostella, F.A.; Bos, J.M.; Postma, M.J.; Tramarin, A. The societal burden of HIV/AIDS in Northern Italy: An analysis of costs and quality of life. AIDS Care 2008, 20, 449–455. [Google Scholar] [CrossRef]
- Moberg, C.; Alderling, M.; Meding, B. Hand eczema and quality of life: A population-based study. Br. J. Derm. 2009, 161, 397–403. [Google Scholar] [CrossRef]
- Basu, A.; Manca, A. Regression estimators for quality of life and quality-adjusted life years (QALYs). Value Health 2009, 12, A28. [Google Scholar] [CrossRef]
- Cheung, Y.-B.; Thumboo, J.; Machin, D.; Feng, P.-H.; Boey, M.-L.; Thio, S.-T.; Fong, K.-Y. Modelling variability of quality of life scores: A study of questionnaire version and bilingualism. Qual. Life Res. 2004, 13, 897–906. [Google Scholar] [CrossRef]
- Hunger, M.; Baumert, J.; Holle, R. Analysis of SF-6D Index Data: Is Beta Regression Appropriate? Value Health 2011, 14, 759–767. [Google Scholar] [CrossRef]
- Kharroubi, S.A.; Beyh, Y.; El Harake, M.; Dawoud, D.; Rowen, R.; Brazier, J. Examining the feasibility and acceptability of valuing the Arabic version of SF-6D in a Lebanese population. Int. J. Environ. Res. Public Health 2020, 17, 1037. [Google Scholar] [CrossRef]
- Furlong, W.; Feeny, D.; Torrance, G.W.; Barr, R.; Horsman, J. Guide to design and development of health state utility instrumentation. In Centre for Health Economics and Policy Analysis Paper 90-9; McMaster University: Hamilton, ON, USA, 1990. [Google Scholar]
- Patrick, D.L.; Starks, H.E.; Cain, K.C.; Uhlmann, R.F.; Pearlman, R.A. Measuring preferences for health states worse than death. Med. Decis. Mak. 1994, 14, 9–18. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Zeileis, A. Beta regression in R. J. Stat. Softw. 2010, 34, 1–24. [Google Scholar] [CrossRef]
- Gelman, A. Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 2006, 1, 515–533. [Google Scholar] [CrossRef]
- Natarajan, R.; Kass, R.E. Reference Bayesian methods for generalized linear mixed models. J. Am. Stat. Assoc. 2000, 95, 227–237. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall/CRC: Boca Raton, FA, USA, 1995. [Google Scholar]
- Spiegelhatler, D.J.; Thomas, A.; Best, N.G.; Lunn, D. WinBUGS User Manual: Version 1.4; MRC Biostatistics Unit: Cambridge, UK, 2003. [Google Scholar]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Kharroubi, S.A. Valuations of EQ-5D health states: Could United Kingdom results be used as informative priors for United States. J. Appl. Stat. 2018, 45, 1579–1594. [Google Scholar] [CrossRef]
- Kharroubi, S.A. Valuation of preference-based measures: Can existing preference data be used to generate better estimates? Health Qual. Life Outcomes 2018, 45, 1579–1594. [Google Scholar] [CrossRef]
- Kharroubi, S.A.; Rowen, D. Valuation of preference-based measures: Can existing preference data be used to select a smaller sample of health states? Eur. J. Health Econ. 2018, 20, 245–255. [Google Scholar] [CrossRef]
- Mulhern, B.; Bansback, N.; Norman, R.; Brazier, J. SF-6Dv2 International Project Group. Valuing the SF-6Dv2 Classification System in the United Kingdom Using a Discrete-choice Experiment with Duration. Med. Care 2020, 58, 566–573. [Google Scholar]
- Poder, T.G.; Fauteux, V.; He, J.; Brazier, J.E. Consistency Between Three Different Ways of Administering the Short Form 6 Dimension Version 2. Value Health 2019, 22, 837–842. [Google Scholar] [CrossRef]
- Dufresne, É.; Poder, T.G.; Samaan, K.; Lacombe-Barrios, J.; Paradis, L.; Roches, A.D.; Bégin, P. SF-6Dv2 preference value set for health utility in food allergy. Allergy 2020. [Google Scholar] [CrossRef]
- Brazier, J.; Fukuhara, S.; Roberts, J.; Kharroubi, S.; Yamamoto, Y.; Ikeda, S.; Doherty, J.; Kurokawa, K. Estimating a preference-based index from the Japanese SF-36. J. Clin. Epidemiol. 2009, 62, 1323–1331. [Google Scholar] [CrossRef]
- Perpiñán, J.M.A.; Martínez, F.I.S.; Pérez, J.E.M.; Mendez, I. Lowering the ‘floor’ of the SF-6D scoring algorithm using a lottery equivalent method. Health Econ. 2012, 21, 1271–1285. [Google Scholar] [CrossRef]
- Poder, T.G.; Gandji, E.W. SF-6D value sets: A systematic review. Value Health 2016, 19, A282, ISSN 1098-3015. [Google Scholar] [CrossRef][Green Version]
- Kharroubi, S.A. Status quo on health related quality of life in Lebanon [Éditorial: Statu quo sur la qualité de vie reliée à la santé au Liban]. Int. J. Health Prefer. Res. 2017, 1, 1. [Google Scholar]
- Kharroubi, S.A.; O’Hagan, A.; Brazier, J.A. Comparison of United States and United Kingdom EQ-5D health states valuations using a nonparametric Bayesian method. Stat. Med. 2010, 29, 1622–1634. [Google Scholar] [CrossRef]
- Kharroubi, S.A.; Brazier, J.; McGhee, S. A comparison of Hong Kong and United Kingdom SF-6D health states valuations using a nonparametric Bayesian method. Value Health 2014, 17, 397–405. [Google Scholar] [CrossRef] [PubMed]
- Kharroubi, S.A. A comparison of Japan and United Kingdom SF-6D health states valuations using a nonparametric Bayesian method. Appl. Health Econ. Health Policy 2015, 13, 409–420. [Google Scholar] [CrossRef]
- Pullenayegum, E.M.; Wong, H.S.; Childs, A. Generalized additive for the analysis of EQ-5D utility data. Med. Decis. Mak. 2013, 33, 244–251. [Google Scholar] [CrossRef]
- Hernández Alava, M.; Wailoo, A.J.; Ara, R. Tails from the peak district: Adjusted limited dependent variable mixture models of EQ-5D questionnaire health state utility values. Value Health 2012, 15, 550–561. [Google Scholar] [CrossRef]
- Hawkins, J.D.; Catalano, R.F.; Miller, J.Y. Risk and protective factors for alcohol and other drug problems in adolescence and early adulthood: Implications for substance abuse prevention. Psychol. Bull. 1992, 112, 64–105. [Google Scholar] [CrossRef]
- Wade, J.M. Is it race, sex, gender or all three? Predicting risk for alcohol consumption in emerging adulthood. J. Child. Fam. Stud. 2020. [Google Scholar] [CrossRef]
- Visalli, G.; Cosenza, B.; Mazzu, F.; Bertuccio, M.P.; Spataro, P.; Pellicanò, G.F.; Di-Pietro, A.; Picerno, I.; Facciolà, A. Knowledge of sexually transmitted infections and risky behaviours: A survey among high school and university students. J. Prev. Med. Hyg. 2019, 60, 84–92. [Google Scholar]
- Holte, A.J.; Ferraro, F.R. Anxious, bored, and (maybe) missing out: Evaluation of anxiety attachment, boredom proneness, and fear of missing out (FoMO). Comput. Hum. Behav. 2020, 112, 1–12. [Google Scholar] [CrossRef]
- Fuentes, M.C.; Garcia, O.F.; Garcia, F. Protective and risk factors for adolescent substance use in Spain: Self-esteem and other indicators of personal well-being and ill-being. Sustainability 2020, 12, 5962. [Google Scholar] [CrossRef]
- Walters, S.J.; Brazier, J.E. Comparison of the minimally important difference for two health state utility measures: EQ-5D and SF-6D. Qual. Life Res. 2005, 14, 1523–1532. [Google Scholar] [CrossRef]
- Walters, S.J.; Brazier, J.E. What is the relationship between the minimally important difference and health state utility values? The case of the SF-6D. Health Qual. Life Outcomes 2003, 1, 4. [Google Scholar] [CrossRef] [PubMed]
- Jakovljevic, M.; Sugahara, T.; Timofeyev, Y.; Rancic, N. Predictors of (in)efficiencies of Healthcare Expenditure Among the Leading Asian Economies-Comparison of OECD and Non-OECD Nations. Risk Manag. Healthc. Policy 2020, 13, 2261–2280. [Google Scholar] [CrossRef] [PubMed]
- Jakovljevic, M.; Matter-Walstra, K.; Sugahara, T.; Sharma, T.; Reshetnikov, V.; Merrick, J.; Yamada, T.; Youngkong, S.; Rovira, J. Cost-effectiveness and resource allocation (CERA) 18 years of evolution: Maturity of adulthood and promise beyond tomorrow. Cost Eff. Resour. Alloc. 2020, 18, 15. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Parameter | LR | BR | LR + RE | BR + RE | LR + RE + COV | BR + RE +COV |
|---|---|---|---|---|---|---|
| β | 0.964 (0.916, 1.012) | 2.024 (1.795, 2.254) | 0.938 (0.894, 0.981) | 2.175 (1.941, 2.443) | 0.857 (0.726, 0.998) | 1.666 (1.045, 2.443) |
| β PF2 | −0.043 (−0.079, −0.006) | −0.199 (−0.371, −0.028) | −0.047 (−0.072, −0.022) | −0.255 (−0.410, −0.096) | −0.046 (−0.072, −0.021) | −0.252 (−0.406, −0.098) |
| β PF3 | −0.044 (−0.081, −0.007) | −0.204 (−0.379, −0.025) | −0.046 (−0.072, −0.021) | −0.243 (−0.402, −0.083) | −0.046 (−0.071, −0.020) | −0.238 (−0.395, −0.080) |
| β PF4 | −0.057 (−0.094, −0.020) | −0.276 (−0.447, −0.101) | −0.059 (−0.084, −0.033) | −0.343 (−0.497, −0.187) | −0.059 (−0.084, −0.033) | −0.343 (−0.502, −0.190) |
| β PF5 | −0.094 (−0.131, −0.057) | −0.408 (−0.580, −0.236) | −0.096 (−0.122, −0.071) | −0.515 (−0.667, −0.363) | −0.095 (−0.121, −0.069) | −0.511 (−0.663, −0.359) |
| β PF6 | −0.171 (−0.206, −0.137) | −0.740 (−0.898, −0.582) | −0.165 (−0.189, −0.141) | −0.797 (−0.940, −0.659) | −0.165 (−0.189, −0.141) | −0.796 (−0.934, −0.660) |
| β RL2 | −0.041 (−0.070, −0.011) | −0.190 (−0.326, −0.053) | −0.042 (−0.075, −0.009) | −0.194 (−0.377, −0.006) | −0.042 (−0.075, −0.009) | −0.183 (−0.374, 0.007) |
| β RL3 | 0.005 (−0.025, 0.035) | 0.002 (−0.136, 0.140) | −0.024 (−0.054, 0.006) | −0.118 (−0.294, 0.054) | −0.024 (−0.054, 0.006) | −0.11 (−0.277, 0.063) |
| β RL4 | −0.056 (−0.090, −0.022) | −0.227 (−0.382, −0.072) | −0.109 (−0.141, −0.077) | −0.488 (−0.673, −0.303) | −0.108 (−0.141, −0.076) | −0.475 (−0.657, −0.298) |
| β SF2 | −0.051 (−0.081, −0.021) | −0.216 (−0.360, −0.072) | −0.040 (−0.062, −0.019) | −0.224 (−0.361, −0.086) | −0.040 (−0.062, −0.019) | −0.223 (−0.359, −0.089) |
| β SF3 | −0.094 (−0.131, −0.058) | −0.39 (−0.563, −0.216) | −0.037 (−0.066, −0.009) | −0.224 (−0.397, −0.052) | −0.037 (−0.066, −0.008) | −0.22 (−0.397, −0.045) |
| β SF4 | −0.110 (−0.146, −0.073) | −0.468 (−0.638, −0.296) | −0.058 (−0.088, −0.028) | −0.333 (−0.519, −0.153) | −0.058 (−0.088, −0.028) | −0.331 (−0.514, −0.151) |
| β SF5 | −0.169 (−0.203, −0.135) | −0.724 (−0.883, −0.570) | −0.105 (−0.133, −0.076) | −0.529 (−0.693, −0.369) | −0.105 (−0.133, −0.077) | −0.530 (−0.692, −0.363) |
| β PAIN2 | −0.021 (−0.058, 0.015) | −0.102 (−0.272, 0.072) | −0.003 (−0.029, 0.023) | −0.074 (−0.231, 0.081) | −0.003 (−0.030, 0.023) | −0.078 (−0.234, 0.083) |
| β PAIN3 | −0.006 (−0.043, 0.030) | −0.042 (−0.214, 0.129) | 0.014 (−0.012, 0.040) | 0.002 (−0.156, 0.160) | 0.013 (−0.013, 0.039) | −0.006 (−0.164, 0.157) |
| β PAIN4 | −0.020 (−0.057, 0.016) | −0.091 (−0.263, 0.085) | −0.011 (−0.038, 0.016) | −0.088 (−0.252, 0.073) | −0.011 (−0.038, 0.016) | −0.091 (−0.256, 0.078) |
| β PAIN5 | −0.052 (−0.089, −0.016) | −0.228 (−0.397, −0.057) | −0.010 (−0.039, 0.017) | −0.132 (−0.296, 0.031) | −0.011 (−0.039, 0.018) | −0.139 (−0.303, 0.024) |
| β PAIN6 | −0.107 (−0.142, −0.072) | −0.481 (−0.634, −0.326) | −0.086 (−0.110, −0.061) | −0.428 (−0.572, −0.286) | −0.086 (−0.111, −0.062) | −0.434 (−0.578, −0.293) |
| β MH2 | −0.001 (−0.030, 0.029) | 0.005 (−0.134, 0.148) | −0.001 (−0.023, 0.022) | −0.027 (−0.161, 0.108) | −0.001 (−0.024, 0.022) | −0.028 (−0.163, 0.107) |
| β MH3 | −0.014 (−0.051, 0.022) | −0.086 (−0.253, 0.087) | −0.026 (−0.051, −0.000) | −0.152 (−0.308, 0.005) | −0.026 (−0.052, −0.000) | −0.153 (−0.308, 0.001) |
| β MH4 | −0.088 (−0.124, −0.052) | −0.388 (−0.558, −0.220) | −0.075 (−0.101, −0.048) | −0.392 (−0.548, −0.239) | −0.075 (−0.102, −0.049) | −0.395 (−0.547, −0.241) |
| β MH5 | −0.069 (−0.104, −0.035) | −0.341 (−0.491, −0.187) | −0.076 (−0.102, −0.051) | −0.392 (−0.539, −0.248) | −0.077 (−0.103, −0.051) | −0.397 (−0.544, −0.250) |
| β VIT2 | 0.001 (−0.029, 0.030) | 0.020 (−0.119, 0.16) | 0.011 (−0.011, 0.033) | 0.016 (−0.113, 0.144) | 0.012 (−0.010, 0.033) | 0.023 (−0.109, 0.154) |
| β VIT3 | 0.016 (−0.021, 0.052) | 0.091 (−0.084, 0.264) | −0.001 (−0.027, 0.026) | −0.037 (−0.199, 0.125) | 0.000 (−0.027, 0.027) | −0.030 (−0.191, 0.137) |
| β VIT4 | −0.034 (−0.070, 0.002) | −0.131 (−0.300, 0.040) | −0.017 (−0.043, 0.009) | −0.126 (−0.276, 0.028) | −0.017 (−0.043, 0.009) | −0.127 (−0.284, 0.028) |
| β VIT5 | −0.037 (−0.072, −0.003) | −0.152 (−0.304, 0.002) | −0.051 (−0.077, −0.026) | −0.246 (−0.391, −0.102) | −0.050 (−0.076, −0.024) | −0.240 (−0.391, −0.089) |
| β AGE | NA | NA | NA | NA | 0.001 (−0.002, 0.003) | 0.006 (−0.007, 0.019) |
| β GENDER | NA | NA | NA | NA | −0.025 (−0.072, 0.022) | −0.096 (−0.317, 0.157) |
| β DEGREE | NA | NA | NA | NA | 0.060 (−0.022, 0.139) | 0.298 (−0.025, 0.633) |
| β HOUSING1 | NA | NA | NA | NA | −0.029 (−0.097, 0.041) | −0.083 (−0.426, 0.252) |
| β HOUSING2 | NA | NA | NA | NA | −0.014 (−0.089, 0.060) | −0.006 (−0.382, 0.355) |
| β INCOME1 | NA | NA | NA | NA | 0.003 (−0.086, 0.090) | −0.013 (−0.417, 0.376) |
| β INCOME2 | NA | NA | NA | NA | 0.002 (−0.066, 0.066) | −0.026 (−0.317, 0.243) |
| β MS1 | NA | NA | NA | NA | 0.067 (−0.004, 0.141) | 0.358 (−0.006, 0.715) |
| β MS2 | NA | NA | NA | NA | 0.069 (−0.126, 0.270) | 0.380 (−0.527, 1.338) |
| σ | NA | NA | NA | NA | NA | NA |
| ϕ | NA | 6.924 (6.334, 7.531) | NA | 9.943 (9.793, 9.999) | NA | 9.944 (9.794, 9.999) |
| MPE | 0.128 | 0.126 | 0.089 | 0.084 | 0.089 | 0.084 |
| RMSE | 0.053 | 0.049 | 0.064 | 0.058 | 0.116 | 0.113 |
| DIC | −689.1 | −1069 | −1325 | −1621 | −1306 | −1605 |
| Predicted | |||||
|---|---|---|---|---|---|
| Health | Observed | LR + RE | BR + RE | ||
| State | Mean | Mean | SD | Mean | SD |
| 111,621 | 0.824 | 0.852 | 0.023 | 0.847 | 0.017 |
| 113,411 | 0.854 | 0.890 | 0.023 | 0.865 | 0.016 |
| 115,653 | 0.730 | 0.671 | 0.024 | 0.687 | 0.028 |
| 121,212 | 0.842 | 0.904 | 0.023 | 0.872 | 0.014 |
| 122,233 | 0.869 | 0.826 | 0.024 | 0.816 | 0.021 |
| 122,425 | 0.758 | 0.793 | 0.023 | 0.801 | 0.021 |
| 124,125 | 0.848 | 0.786 | 0.023 | 0.797 | 0.021 |
| 131,542 | 0.828 | 0.841 | 0.022 | 0.824 | 0.019 |
| 132,524 | 0.763 | 0.846 | 0.023 | 0.824 | 0.019 |
| 133,132 | 0.858 | 0.862 | 0.022 | 0.844 | 0.017 |
| 135,312 | 0.756 | 0.835 | 0.024 | 0.824 | 0.019 |
| 142,154 | 0.791 | 0.696 | 0.024 | 0.719 | 0.027 |
| 144,341 | 0.742 | 0.711 | 0.026 | 0.723 | 0.028 |
| 211,111 | 0.890 | 0.891 | 0.021 | 0.872 | 0.014 |
| 212,145 | 0.785 | 0.725 | 0.025 | 0.742 | 0.027 |
| 213,323 | 0.783 | 0.866 | 0.026 | 0.836 | 0.021 |
| 221,452 | 0.824 | 0.773 | 0.025 | 0.778 | 0.024 |
| 224,612 | 0.646 | 0.717 | 0.026 | 0.726 | 0.029 |
| 232,111 | 0.858 | 0.827 | 0.022 | 0.828 | 0.018 |
| 235,224 | 0.767 | 0.741 | 0.026 | 0.739 | 0.028 |
| 241,531 | 0.785 | 0.746 | 0.026 | 0.758 | 0.028 |
| 312,332 | 0.864 | 0.851 | 0.025 | 0.828 | 0.021 |
| 315,515 | 0.698 | 0.726 | 0.027 | 0.735 | 0.029 |
| 321,122 | 0.858 | 0.861 | 0.022 | 0.848 | 0.016 |
| 323,644 | 0.571 | 0.635 | 0.029 | 0.638 | 0.036 |
| 332,411 | 0.844 | 0.817 | 0.024 | 0.817 | 0.021 |
| 334,251 | 0.734 | 0.730 | 0.027 | 0.733 | 0.030 |
| 341,123 | 0.831 | 0.782 | 0.027 | 0.798 | 0.025 |
| 412,152 | 0.793 | 0.774 | 0.024 | 0.773 | 0.023 |
| 414,522 | 0.755 | 0.821 | 0.028 | 0.794 | 0.026 |
| 421,314 | 0.811 | 0.835 | 0.025 | 0.819 | 0.022 |
| 425,131 | 0.658 | 0.707 | 0.026 | 0.722 | 0.029 |
| 431,443 | 0.824 | 0.770 | 0.027 | 0.767 | 0.027 |
| 432,621 | 0.743 | 0.729 | 0.024 | 0.737 | 0.026 |
| 443,215 | 0.731 | 0.679 | 0.027 | 0.689 | 0.032 |
| 511,114 | 0.858 | 0.825 | 0.024 | 0.822 | 0.020 |
| 512,242 | 0.603 | 0.735 | 0.025 | 0.728 | 0.028 |
| 522,321 | 0.777 | 0.773 | 0.023 | 0.771 | 0.022 |
| 523,551 | 0.607 | 0.676 | 0.027 | 0.671 | 0.032 |
| 531,635 | 0.786 | 0.656 | 0.026 | 0.671 | 0.031 |
| 534,113 | 0.723 | 0.759 | 0.025 | 0.763 | 0.026 |
| 545,422 | 0.700 | 0.628 | 0.026 | 0.632 | 0.032 |
| 611,221 | 0.821 | 0.769 | 0.024 | 0.781 | 0.023 |
| 614,434 | 0.561 | 0.661 | 0.028 | 0.663 | 0.034 |
| 622,513 | 0.707 | 0.680 | 0.024 | 0.687 | 0.029 |
| 625,141 | 0.510 | 0.552 | 0.026 | 0.565 | 0.034 |
| 631,355 | 0.741 | 0.636 | 0.025 | 0.650 | 0.031 |
| 633,122 | 0.714 | 0.722 | 0.023 | 0.735 | 0.025 |
| 642,612 | 0.685 | 0.550 | 0.022 | 0.563 | 0.028 |
| 645,655 | 0.322 | 0.346 | 0.015 | 0.331 | 0.017 |
| MPE | 0.032 | 0.027 | |||
| RMSE | 0.059 | 0.053 | |||
| Omitted Health State | Observed Mean | LR + RE | BR + RE | ||||
|---|---|---|---|---|---|---|---|
| Mean | SD | SR | Mean | SD | SR | ||
| 121,212 | 0.842 | 0.876 | 0.032 | −1.129 | 0.849 | 0.024 | −0.368 |
| 132,524 | 0.763 | 0.841 | 0.034 | −2.367 | 0.830 | 0.028 | −2.555 |
| 211,111 | 0.890 | 0.909 | 0.029 | −0.637 | 0.866 | 0.021 | 1.172 |
| 232,111 | 0.858 | 0.805 | 0.033 | 1.705 | 0.798 | 0.031 | 1.983 |
| 321,122 | 0.858 | 0.848 | 0.032 | 0.364 | 0.842 | 0.026 | 0.694 |
| 412,152 | 0.793 | 0.733 | 0.035 | 1.606 | 0.724 | 0.040 | 1.666 |
| 432,621 | 0.743 | 0.647 | 0.039 | 2.385 | 0.664 | 0.054 | 1.388 |
| 523,551 | 0.670 | 0.701 | 0.048 | −1.920 | 0.677 | 0.062 | −1.072 |
| 614,434 | 0.561 | 0.742 | 0.058 | −3.123 | 0.669 | 0.062 | −1.756 |
| 642,612 | 0.685 | 0.458 | 0.032 | 6.924 | 0.462 | 0.046 | 4.728 |
| RMSE | 0.107 | 0.091 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kharroubi, S.A. Analysis of SF-6D Health State Utility Scores: Is Beta Regression Appropriate? Healthcare 2020, 8, 525. https://doi.org/10.3390/healthcare8040525
Kharroubi SA. Analysis of SF-6D Health State Utility Scores: Is Beta Regression Appropriate? Healthcare. 2020; 8(4):525. https://doi.org/10.3390/healthcare8040525
Chicago/Turabian StyleKharroubi, Samer A. 2020. "Analysis of SF-6D Health State Utility Scores: Is Beta Regression Appropriate?" Healthcare 8, no. 4: 525. https://doi.org/10.3390/healthcare8040525
APA StyleKharroubi, S. A. (2020). Analysis of SF-6D Health State Utility Scores: Is Beta Regression Appropriate? Healthcare, 8(4), 525. https://doi.org/10.3390/healthcare8040525