1. Introduction
Markov-type polynomial inequalities (or inverse inequalities) [
1,
2,
3,
4,
5,
6], similarly to Bernstein-type inequalities [
1,
5,
6,
7,
8,
9], are often found in many areas of applied mathematics, including popular numerical solutions of differential equations. Proper estimates of optimal constants in both types of inequalities can help to improve the bounds of numerical errors. They are often used in the error analysis of variational techniques, including the finite element method or the discontinuous Galerkin method used for solving partial differential equations (PDEs) [
10]. Moreover, Markov’s inequality can be found in constructions of polynomial meshes, as it is a representative sampling method, and is used as a tool for studying the uniform convergence of discrete least-squares polynomial approximations or for spectral methods for the solutions of PDEs [
11,
12,
13]. Generally, finding exact values of optimal constants in a given compact set
E in
is considered particularly challenging. In this paper, an approach to determining the upper estimation of the constant in a Markov-type inequality on a simplex is proposed. The method aims to provide a greater value than that estimated by L. Bialas-Ciez and P. Goetgheluck [
4].
For an arbitrary algebraic polynomial
P of
N variables and degree not greater than
n, Markov’s inequality is expressed as
where
,
E is a convex compact subset of
(with non-void interior), and
The exponent 2 in (1) is optimal for a convex compact set
E (with non-void interior) [
2,
4].
In 1974, D. Wilhelmsen [
14] got an upper estimate for the constant
in Markov’s inequality (1), where
is the width of
E. The width of
is defined as
[
4], where
G is the set of all possible couples of parallel planes
and
such that
E lies between
and
Furthermore, for any convex compact set
, the author proposed the hypothesis that
M. Baran [
3,
7] and Y. Sarantopoulos [
15] independently proved that Wilhelmsen’s conjecture is true for centrally symmetric convex compact sets. In turn, L. Bialas-Ciez and P. Goetgheluck [
4] showed that the hypothesis is false in the simplex case and proved that the constant
The best constant in Markov’s inequality (1) for a convex set was also studied by D. Nadzhmiddinow and Y. N. Subbotin [
6] and by A. Kroó and S. Révész [
16]. It is worth mentioning that for any triangles in
, A. Kroó and S. Révész [
16] generalized the result for a simplex given in [
4], considering an admissible upper bound for
, and received an upper estimate value of constant
C in (1):
where
with
being a triangle with the sides
and the angles
, respectively, such that
and
In the recent literature, many works have considered Markov inequalities. For example, S. Ozisik et al. [
10] determined the constants in multivariate Markov inequalities on an interval, a triangle, and a tetrahedron with the
-norm. They derived explicit expressions for the constants on all above-mentioned simplexes using orthonormal polynomials. It is worth noticing that exact values of the constants are the key for the correct derivation of both a priori and a posteriori error estimates in adaptive computations. F. Piazzon and M. Vianello [
11] used the approximation theory notions of a polynomial mesh and the Dubiner distance in a compact set to determine error estimates for the total degree of polynomial optimization on Chebyshev grids of the hypercube. Additionally, F. Piazzon and M. Vianello [
12] constructed norming meshes for polynomial optimization by using a classical Markov inequality on the general convex body in
. A. Sommariva and M. Vianello [
13] used discrete trigonometric norming inequalities on subintervals of the period. They constructed norming meshes with optimal cardinality growth for algebraic polynomials on the sections of a sphere, a ball, and a torus. Moreover, A. Kroó [
17] studied the so-called optimal polynomial meshes and O. Davydov [
18] presented error bounds for the approximation in the space of multivariate piecewise polynomials admitting stable local bases. In particular, the bounds apply to all spaces of smooth finite elements, and they are used in the finite element method for general fully nonlinear elliptic differential equations of the second order. L. Angermann and Ch. Heneke [
19] proved error estimates for the Lagrange interpolation and for discrete
-projection, which were optimal on the elements and almost optimal on the element edges. In another study, M. Bun and J. Thaler [
5] reproved several Markov-type inequalities from approximation theory by constructing explicit dual solutions to natural linear programs. Overall, these inequalities are a basis for proofs of many approximated solutions that can be found in the literature.
In this paper, an approach to determining an approximation of the constant in Markov’s inequality using introduced minimal polynomials is proposed. Then, the polynomials are used in the formulated bilevel optimization problem. Since many optimization techniques could be employed to find the constant, three popular meta-heuristics are applied and their results are investigated.
The rest of this paper is structured as follows. In
Section 2, minimal polynomials are introduced. Then, in
Section 3, their application in the approximation of the constant in a Markov-type inequality is considered. In
Section 4, in turn, the approximation is defined as an optimization problem and the problem is solved using three meta-heuristics. Finally, in
Section 5, the study is summarized and directions for future work are indicated.
4. Optimization Problem in a Markov-Type Inequality
The estimation of the constant
C in Markov’s inequality can be improved by considering a minimal polynomial and an equilibrium measure. The exemplary calculations of minimal polynomials and their corresponding Markov inequalities on the simplex are shown in
Table 2. In the first example of the polynomial, the obtained constant is equal to the value reported by L. Bialas-Ciez and P. Goetgheluck [
4]. In the remaining two polynomials, the constants are improved. However, a slight change in the coefficients decreases the constant, as is shown in the fourth example. Therefore, in this paper, the polynomial is proposed as a result of a nontrivial optimization problem in which an improvement of the estimate of the constant
C is considered.
In this paper, the constant in Markov’s inequality on the simplex for the proposed minimal polynomials is estimated. Assuming that
where
P is one of the following minimal polynomials:
and
, in order to determine the greatest value of the function
an optimization problem is formulated.
R. M. Aron and M. Klimek [
27] gave explicit formulas for supremum norms:
and
where
The vectors
and
are regarded as decision variables in the optimization problem. Consequently,
and
denote the vectors that maximize the
. Considering the relationship between
and
or
and
only the coefficients that maximize their corresponding
and
need to be found, i.e., they are then applied to the remaining polynomials. For polynomials
and
The calculation of Equation (2) requires finding the extrema of the polynomial
P inside the simplex limited by values
. Therefore, the following bilevel optimization problem is solved. Here, one optimization task is nested within the other, i.e., the decision variables of the upper problem are the parameters in the lower one, and the lower problem is a constraint to the upper problem, limiting the feasible
u values to those that are lower-level optimal [
28].
The problem is given by
where
denotes the arguments of the function that maximize its value.
Finally, the values of
and
are found as the solutions to the optimization problem. In order to determine the greatest value of
C, the nonlinearity of the considered objective function, as well as the existence of multiple local optima, must be taken into account. Here, different values of
u can lead to the same value of
C, or close values of
u can result in a large difference between the corresponding values of
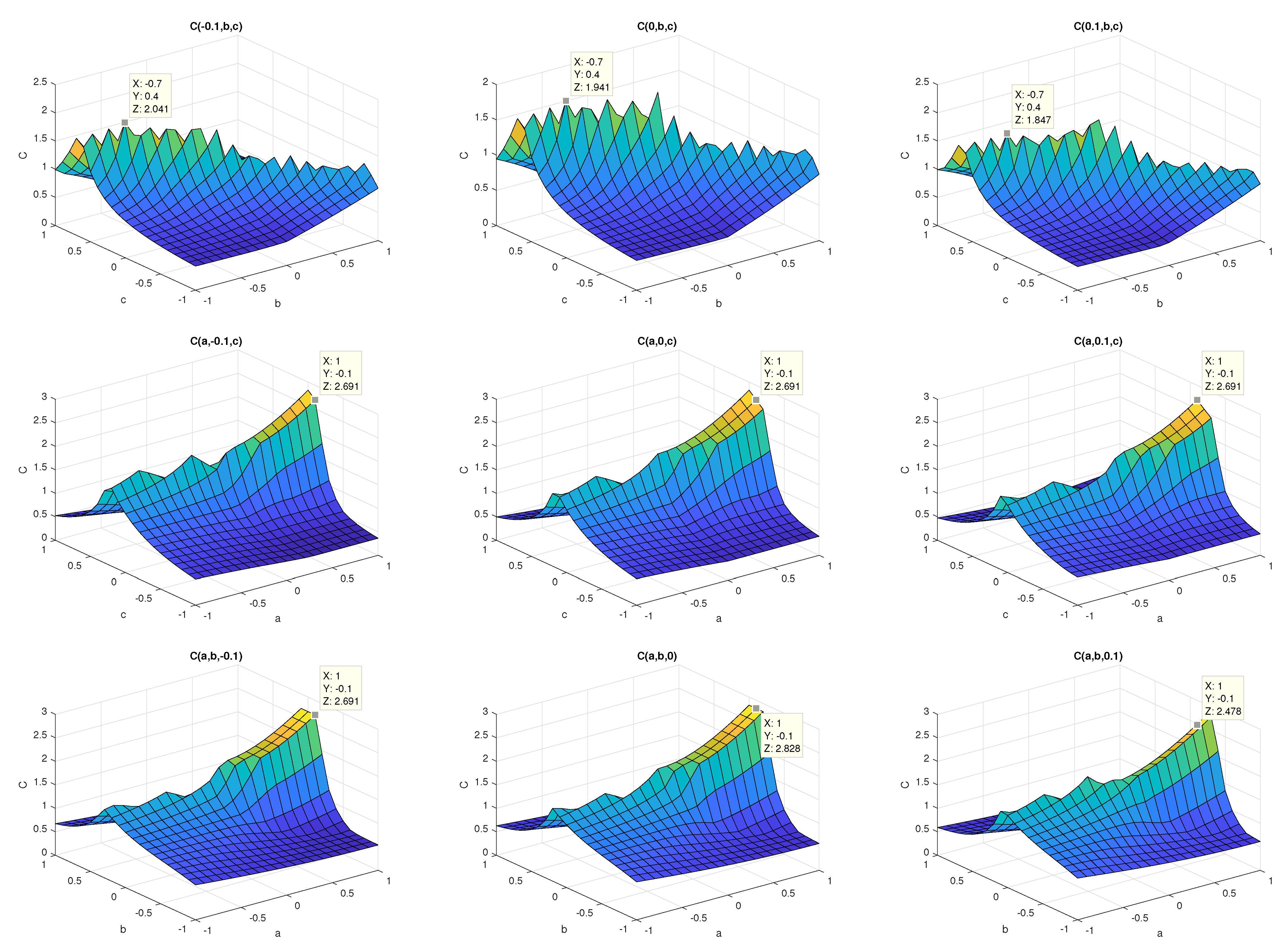
This can be seen in
Figure 1, in which only a small part of the search space is visualized. For the visualization,
C is calculated, keeping one coefficient constant and selecting the remaining one from the range
with the step
. The coefficients are selected from the set
The difference between the values of the constant is purposely small to show the changes of values of
Each subplot in
Figure 1 contains a marker to additionally highlight such changes.
To solve the defined optimization problem, a suitable method should be determined. Therefore, in this paper, a hybrid approach is proposed. It is justified by the need to find the extrema of the polynomial
P inside the simplex for the computation of
C. Such extrema are found using the Interior Point Algorithm (IPT) [
29,
30], i.e.,
is found for an examined
u from the upper level. The upper-level optimization is more difficult. Since the considered problem has not been formulated and solved in the literature, it cannot be determined in advance which method should be used to determine the solution. Therefore, taking into account possible time-consuming computations, three popular meta-heuristics are used and compared: the Particle Swarm Optimization method (PSO) [
31,
32,
33], Genetic Algorithm (GA) [
34,
35], and Simulated Annealing technique (SA) [
36,
37]. The application of population-based algorithms for solving different bilevel problems is popular (e.g., [
28]).
The PSO is a global evolutionary method based on swarm intelligence. It finds the optimal solution by exploring the search space using a set of particles. Each particle represents a candidate solution to the problem. The PSO mimics the movement of a bird flock or a fish school; hence, the dynamics of the set of particles in the solution space are iteratively governed by the following equations [
31]:
where
and
are the position and the velocity of the
i-th particle at time
;
is the best position of the
i-th particle, while
is the best position of the swarm at
n.
w is the inertia weight, and
and
are coefficients constraining the parts of the equation that simulate cognitive and social factors of the swarm [
31,
32,
33]);
and
are random numbers drawn from the range
. The termination criterion of the algorithm is the number of iterations
N or the violation of the minimal acceptable difference in the objective function
C between consecutive iterations. Both criteria are commonly used in most heuristic optimization algorithms. Finally, the PSO returns
.
The GA uses a population of individuals (called chromosomes), representing candidate solutions [
34,
35]. In the GA, at each generation (iteration), a population of individuals is assessed to select the best solutions, which are then used to create the population in the next generation. The assessment is based on the values of the objective function, while new individuals are obtained using crossover and mutation operators. The crossover combines the information carried by two selected parents in one solution by mixing values of their vector representations. The mutation, in turn, introduces random changes to the individual. After the predefined number of generations, the algorithm returns the best individual
.
The simulated annealing, unlike the population-based PSO and GA, uses much fewer resources and requires fewer objective function computations, since it processes only one solution at each iteration [
36,
37]. The SA mimics the process of heating a metal and slowly lowering its temperature. The algorithm starts from a random solution, which is iteratively modified. At each iteration, reflecting a temperature drop, the algorithm modifies the current solution and compares the values of the objective function before and after the modification. If a new solution is better or the difference between their values is within a predefined range, the modification is accepted. The acceptance of a slightly worse solution helps the method to escape local minima [
36,
37].
All of these methods are commonly used for solving nonlinear optimization problems with local optima. However, their suitability for a given problem is mostly determined experimentally. In this paper, they are used to determine
. However, in order to calculate
C for any
u, the lower-level optimum
must be solved each time. In this paper, it is obtained using the IPT algorithm [
29,
30]. Finally, the considered problem is solved using the hybrid approach [
28]. In the IPT algorithm, an optimization problem is defined as
where
is objective function to be minimized and
h and
g are equality and inequality constraints, respectively. The solved approximate problem is defined as
where
are slack variables and
is a barrier parameter. As
converges to zero, the sequence of approximate solutions converges to the minimum of
f [
29,
30].
In the numerical experiments, the solution processed by heuristic algorithms was represented by a five-dimensional vector of floating-point values, since
, and the IPT used a two-dimensional vector
. To ensure a fair comparison of meta-heuristics, each technique was run 50 times, and a maximum of 25,000 objective function calls were performed in each run. The number of function calls was achieved by selecting a large-enough population size, aiming at the best performance of the PSO and GA. The implementations of the algorithms that can be found in the Matlab Optimization Toolbox are used. Algorithms were run with their default parameters: the PSO (
w = [01, 1.1],
,
), the GA (
EliteCount = 0.05 of the population size,
CrossoverFraction = 0.8, the scattered crossover, Gaussian mutation, and stochastic uniform selection), and the SA (
InitialTemperature = 100, temperature is equal to
InitialTemperature * 0.95
). Note that the values in
u were not bounded (i.e.,
), and the GA and PSO, unlike the SA, did not require the specification of the starting point of the optimization, as the initial populations of the solutions were selected randomly. For this reason, the SA started from
. As demonstrated in
Table 3, the PSO was able to determine the best
C for each polynomial. The algorithms explored the solution space in different ways, obtaining different results.
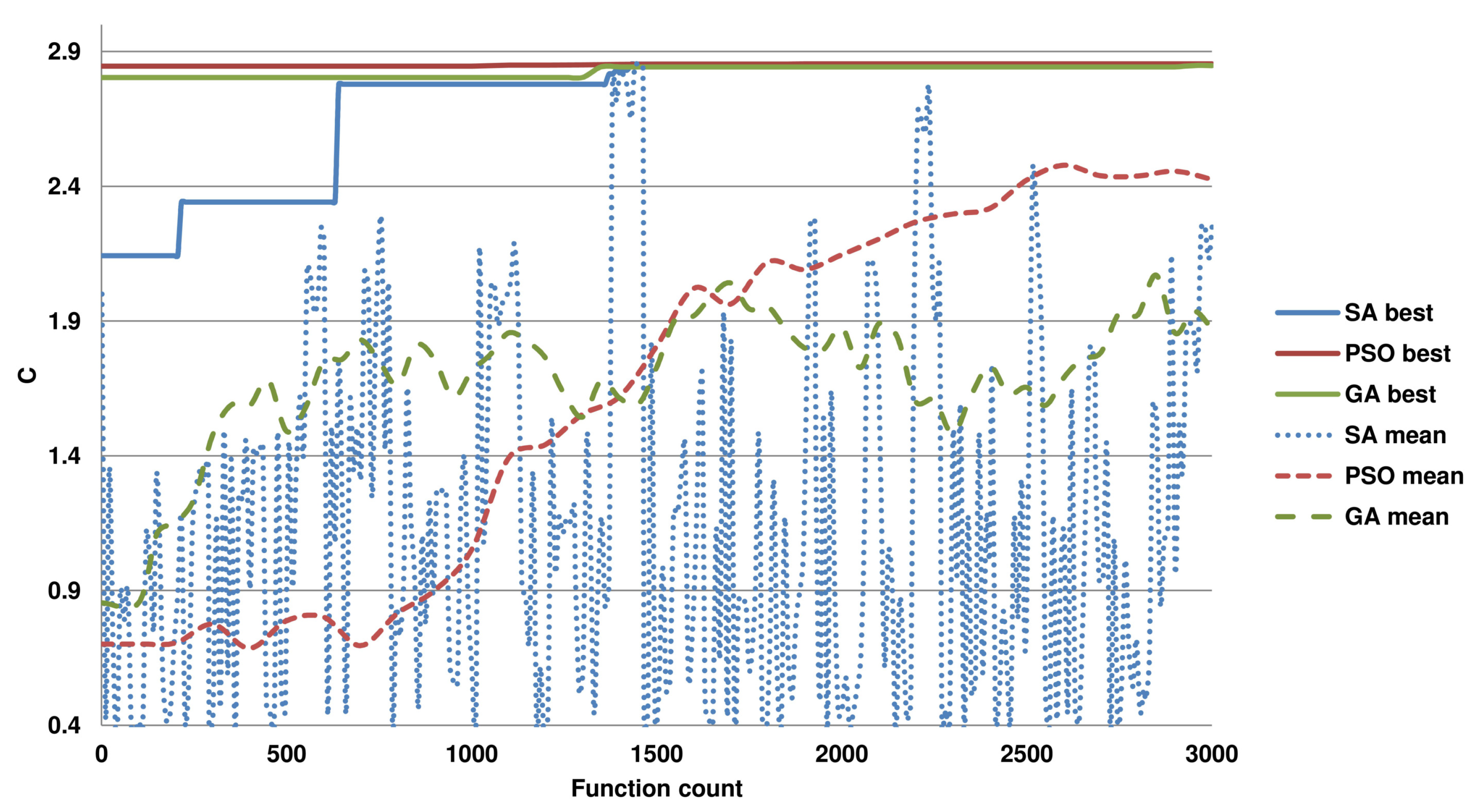
To further show the difficulty of the optimization task for the used algorithms,
Figure 2 presents the convergence of the algorithms towards the optimum. Here, the progress of the set of solutions at each calculation of the objective function is reported. As presented, the approaches with the PSO and GA quickly converge, and most of the time is spent on the exploration of the solution space near the optimum. The SA, unlike the population-based methods, processes one solution at each iteration, which influences its convergence rate. The results reveal that the PSO is better suited to the problem than the GA, since it can determine a better
C (see
Table 3), and it finds it with fewer function calls. Interestingly, the set of solutions in the first function call is more diverse for the PSO, which may contribute to its superior performance, as in the remaining computation time, it is more focused on escaping the local optima. Similarly, it can be seen that the solutions emerging in the run of the SA exhibit large variability. Note that the number of runs (50) and the maximal number of function calls in these experiments (25,000) are purposely greater than could be concluded from the convergence plots to give the methods enough resources to find better solutions. However, the methods often terminate the computations if the change in the best function value is too small.
This experiment indicates that the proposed approach with the PSO can provide the best
C. Therefore, in the second experiment, the parameters of this algorithm were set to conduct an even better search of the solution space. By increasing the number of particles and generations, the maximal number of function calls was set to 25 million, and the method was run 100 times. Note that the estimated time to finish one run of the PSO with 25 million function calls in Matlab on the i7-6700 K 4 GHz with 64 GB RAM CPU is 335 h. The calculations were run in a parallel manner, and the methods were allowed to terminate the optimization if a function value change was small. They are presented in
Table 4. The second experiment improved the already obtained values for
(or
) and
(or
) at the fifth and eighth decimal places, respectively (see
Table 3). The run in which the best
was obtained required 720 thousand function calls, and
was found in a run after the objective function was calculated 1570 thousand times.







{kind=link}
{kind=link}