1. Introduction
In many survival analysis studies, the cause of failure of a product is not determined by a single risk, but by one of several competing risks. With continuous improvements in manufacturing design and technology, modern products have become more reliable and durable. In order to obtain more information regarding the lifetime of products, accelerated life tests (ALT) are taken. ALT is the process of exposing products to higher-than-normal stress conditions, causing products to fail faster than at normal stress levels. Therefore, ALT is an important means of obtaining useful information about product reliability under test time constraints. A widely used accelerated life test is the step-stress test in which the stress level begins to increase at a predetermined point. Ref. [
1] considered the step-stress cumulative exposure model with time constraints when the life distributions of different risk factors are independent exponential distributions. The exact sampling distributions of maximum likelihood estimators were derived. The confidence intervals were constructed using exact distributions, asymptotic distributions, bootstrap method and Bayesian posterior distribution. Ref. [
2] discussed estimation of parameters with truncated normal distribution under step-stress ALT and type-II censoring scheme. Maximum likelihood estimates were performed. The asymptotic confidence intervals were established. Bayesian estimators for three loss functions were studied. The optimal truncation schemes under different criteria were obtained. Ref. [
3] presented the step-stress model with lagged effect and assumed that every test unit follows Weibull distribution. The unknown parameters were estimated by maximum likelihood method and least square method. Bayesian estimation was further discussed. Ref. [
4] proposed a step-stress model for two competing risks with a linear lag period. The lifetime under each of these independent risks follows Weibull distribution. The maximum likelihood estimates asymptotic confidence intervals and percentile bootstrap confidence intervals, and the bias-corrected and accelerated percentile bootstrap confidence intervals were obtained.
1.1. Competing Risks Model
In the analysis of reliability, test units are often exposed to multiple potentially fatal risk factors and their failures are related to one of these factors. Competing risks analysis is the reliability analysis in the existence of other risk factors and has been widely studied in the fields of medicine, actuarial science and biostatistics. In a competing risks model, the observations of a test unit are often in a binary format, that is, the lifetime and the cause of the failure. The multiple causes of test unit failure can be independent or dependent. Ref. [
5] studied the competing risks model of progressive hybrid censoring scheme under Gompertz distribution. They derived the maximum likelihood estimates of the parameters and obtained the confidence intervals of the model using the asymptotic approximation theory and Bootstrap method. As mentioned in Refs. [
6,
7], without any knowledge of the covariates, it is not feasible to test the hypothesis about whether the risks are independent. Competing risk models with independent competing risks have been extensively studied. Ref. [
8] studied Bayesian analysis under Weibull distribution of progressively censored independent competing risks data. When the common shape parameters are already known, Bayesian estimators of scale parameters have closed formal expressions. When the common shape parameters are unknown, MCMC samples are used to compute Bayesian estimates and maximum posterior density confidence intervals. Ref. [
9] considered step-stress ALT under type-I truncation when different risk factors obey independent generalized exponential distributions. Under the cumulative exposure model, point estimates of different parameters were derived by the maximum likelihood method. By using asymptotic distribution and parameter bootstrap method, the construction of parameter confidence intervals was discussed. For other articles in this area, see Refs. [
10,
11,
12], etc.
1.2. Step-Stress Accelerated Life Tests
Three main stress-increasing schemes are used for ALT: constant stress, progressive stress, and step-stress. Constant stress accelerated life test means that every test unit is exposed to a constant selected stress level until the test cell fails or the test is completed. Progressive stress accelerated life test allows stress levels to increase consistently. The step-stress accelerated life test is intermediate between constant stress ALT and progressive stress ALT. Since it allows stress levels to increase at some scheduled point time, this ensures that the step-stress accelerated life test is flexible and adjustable. Step-stress ALT are widely concerned in reliability analysis. A key assumption in accelerated life tests is the cumulative exposure model (CEM). The cumulative exposure model was first proposed in Ref. [
13]. The cumulative exposure model essentially provides the cumulative distribution function of lifetime. The cumulative risk model links the distribution of one stress level to the distribution of the next level, regardless of how the failure accumulated. By now, CEM has been studied extensively. Ref. [
14] proposed a multi-step-stress ALT programming method with independent competition risks under a cumulative exposure model. Ref. [
15] used Bayesian method to optimize step-stress accelerated life tests. Other works on CEM include Refs. [
16,
17,
18], etc.
The hazard function of lifetime at the stress change point is discontinuous under cumulative exposure model, which means that the impact of changes in stress levels is instantaneous. Thus, a cumulative exposure model may not be reasonable in real life. Ref. [
19] proposed a new step-stress model, cumulative risk model (CRM), to improve the cumulative exposure model by establishing a continuous hazard function. The cumulative risk model assumes that there is a lag period before stress changes completely. Moreover, the authors also indicated that as the lagged period is small and proceeds to zero, CEM can be obtained as a limit case of CRM where lifetime distribution follows the exponential distribution. Now, the more realistic CRM is more concerned. Ref. [
20] considered statistical inferences of cumulative risk model under competing risks when the lifetime of each test unit under different risks follows exponential distribution.
1.3. Gompertz Distribution
Although the exponential distributions have many attractive features, assuming a constant hazard function may not always be more realistic in practice. Despite the fact that the Weibull distribution with two parameters is widely used in the survival and reliability literature and provides great flexibility in modeling the hazard function for step-stress tests, the hazard function is not guaranteed to be constantly increasing and may not always be reliable in step-stress accelerated tests. The Gompertz distribution model is a common model used in reliability and life testing and has two parameters, similarly to Weibull distribution. Furthermore, the Gompertz distribution can degenerate to an exponential distribution; thus, it has the superior properties of exponential distribution. Moreover, its hazard function is an increasing function, which is consistent with the conditions of stress increase in step-stress accelerated tests.
Gompertz distribution is a popular one of the popular distributions to model lifetime data with shape parameter and scale parameter. As Ref. [
21] noted, Gompertz distribution was first proposed in 1825. It is widely used in financial data, bioanalytical experiments, actuarial problems, graduating age-specific mortality rates, and preparing life tables. Ref. [
22] provided a theoretical justification that allows it to be employed in cases of accretionary growth. They also summarized the features and the application of Gompertz distribution. Ref. [
23] proposed a Gompertz curve-fitting process, and its benefits include, without knowing the value for forecasting, the stability of the sensitivity of saturation over the sample period. Ref. [
24] established an accurate confidence interval and an accurate joint confidence region for the parameters of the Gompertz distribution. Ref. [
25] discussed the lifetime problem under the step-stress ALT of two independent risks with Gompertz life distribution. In Ref. [
26], the failure time of a product was analyzed by using a constant stress ALT with two independent competitive risks under Gompertz distribution.
The probability density function (PDF) (see
Figure 1) of Gompertz distribution with shape parameter
and scale parameter
is as follows.
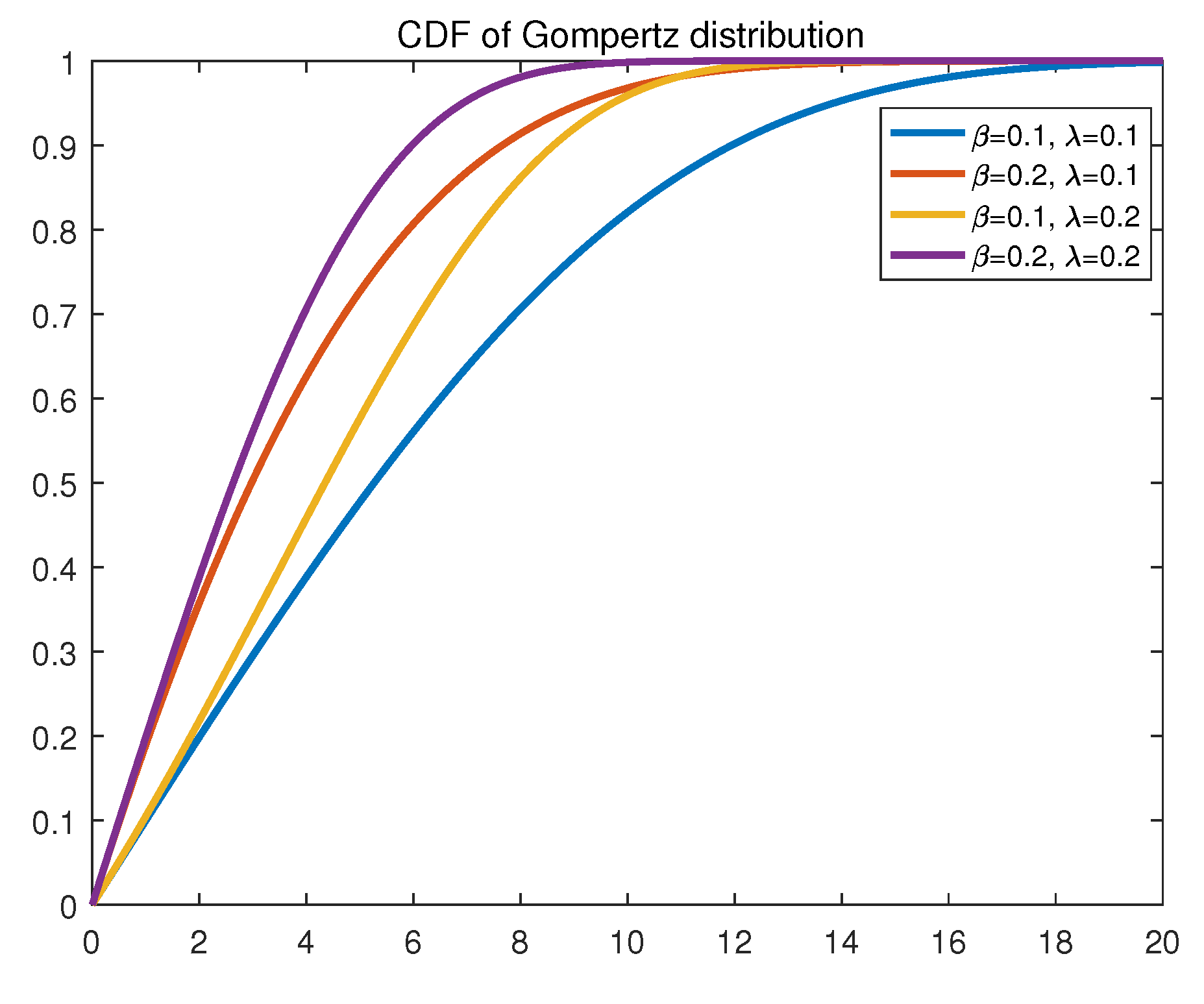
The cumulative distribution function (CDF) (see
Figure 2) is obtained from the following expression.
The corresponding hazard function is shown below.
The hazard function of Gompertz distribution is increasing. When tends to 0, the Gompertz distribution degenerates to the exponential distribution with mean .
Continuous hazard functions reflect the impact of changes in stress levels more realistically; thus, CRM has many applications in survival analysis and solves the major limitation of existing models. The Gompertz distribution has a natural advantage in CRM modeling due to its own nature. In this paper, the Gompertz distribution is first used in CRM modeling, which provides a new method of exploring the step-stress model and addresses the main limitations of existing models.
In this paper, we study the point estimations and interval estimations of a class of step-stress models with competing risks and lagged effect based on Gompertz distribution when different competing risks are independent of each other. We make inferences using Gompertz distributions with different scale parameters and different shape parameters. The organization of the rest of the article is as follows. In
Section 2, the cumulative risk model of step-stress ALT with two independent risks is described. The risk function, cumulative risk function, cumulative distribution function, and probability density function under different risk factors are deducted. In
Section 3, the maximum likelihood estimates of parameters are evaluated by the Newton–Raphson method. In
Section 4, the least square method is used to obtain the estimates of the parameters. In
Section 5, the observed Fisher information matrix is presented. Asymptotic intervals are constructed. In
Section 6, we use the percentile bootstrap method to construct confidence intervals. In
Section 7, by a large number of Monte-Carlo simulations, we compare and assess the performance of estimations and confidence intervals. In
Section 8, a real dataset was analyzed to illustrate the effectiveness of estimation methods.
Section 9 summarizes the entire article and discusses future work in this area.
2. Model Description
Investigating step-stress ALT with
n test units, all of the units come from homogeneous groups. In the initial period, all units are affected by stress level
. At a predetermined time
, the stress level begins to increase. The improvement in stress level is fully realized at
and the stress level proceeds up to
.
=
is known as the lag period. When
, which means
, CRM converges to the CEM, and the proof can be found in
Appendix A.
In real situations, the lifetime of every experimental unit is often affected by several factors. This paper considers that the lifetime of every unit is affected by two risks. The failure time is denoted as , , where is the failure time of i-th item for the the j-th cause.
The data are recorded as
, where
represents failure time,
represents failure cause and
represents the stress level of the
i-th unit,
We denote
,
and
as interval 1, interval 2 and interval 3, respectively.
is the total number of units that fail resulting from the
j-th risk within time interval
k .
is the total number of units that fail within time interval
k .
is the total number of units that fail resulting from the
j-th risk in the entire time range. Considering lagged effect and two potential risks of failure, there is
, where
n is the number of all units observed in the test. Ref. [
25] argued that shape parameters are related to risk factors and scale parameters are related to stress levels. All shape parameters and scale parameters are greater than zero. A similar assumption is used in this article.
and
are associated with risk factors.
and
are associated with stress levels.
We assume that the hazard functions in the cumulative risk model of step-stress ALT increase linearly during the lag period, and Ref. [
4] made the same assumption. By using the CRM of step-stress ALT, we obtained the hazard function
under the Gompertz distribution of the
j-th risk factor for
.
In order to obtain a continuous hazard function over the life span,
and
should satisfy the following conditions.
The cumulative hazard function
for the
j-th failure cause under CRM of step-stress ALT with two risks is as follows.
The cumulative distribution function (CDF)
of the lifetime for the
j-th failure cause is as follows.
The probability density function (PDF)
of the lifetime for the
j-th failure cause is as follows.
Considering two independent competing factors, the cumulative distribution function
of lifetime is shown below.
The PDF of lifetime
is described by the following expression.
The joint probability density function
of lifetime and failure cause, with two independent competing risks, is as shown below.
The explicit expressions of
,
and
are provided in
Appendix B.
3. Maximum Likelihood Estimation
Maximum likelihood estimation (MLE) is one of the most extensively used methods for parameter estimation. In this section, we reparameterize the parameters according to the continuity of the hazard functions, apply the new parameters to the maximum likelihood function and obtain point estimates of the new parameters.
By (
11), the likelihood function
L is as follows:
where
is an indicator function.
The corresponding log-likelihood function
l is the following.
Reparameterization
Continuity conditions in (
5) are used to reparameterize original model terms. New parameters are applied to the maximum likelihood function. This form renders the function simpler when performing subsequent calculations and simulations.
Express the function
l using
,
,
and
.
In order to obtain estimates of
,
,
and
, the partial derivatives of log-likelihood function for
,
,
and
are set to 0. Based on that, we have the following four equations. The concrete equations are provided in
Appendix C.
By solving these equations, we can obtain the maximum likelihood estimates , , and of four parameters. The log-likelihood function can be maximized when the estimates are used as parameters. However, these equations are highly nonlinear, and it is not feasible to obtain analytical solutions. In order to solve this problem, numerical techniques are indispensable. The Newton–Raphson method is used to obtain maximum likelihood estimates of , , and , and the Newton–Raphson method can be implemented by R software.
4. Least Squares Estimation
In this section, we provide least squares estimation (LSE) to estimate and when and are known. Since , , and can be expressed in terms of , , and , estimates of , , and can also be obtained by using this method.
From Equation (
5),
and
can be expressed as follows.
The cumulative hazard function
of lifetime under the two competing risks is shown below:
where
is the cumulative survival function of lifetime under two independent competing risks,
, and
is denoted as follows.
The empirical cumulative risk function
can be derived from the empirical survival function
.
We note that, under CRM, the cumulative risk function is linear for and when and are fixed. Therefore, the estimates of and can be obtained by minimizing and .
The squares distance function
is as follows.
From Equations (
17) and (
19), the expression of function (
20) is as follows.
In order to obtain estimates
and
, the derivatives of the squares distance function for
and
are set to zero. By solving these equations, the least squares estimates
and
are obtained. The squares distance function is minimized when the estimates are used as parameters.
In order to obtain the respective estimates of
and
, we note that the relationship between
and
as follows:
where
indicates the probability that failure is due to risk factor 1.
indicates the derivative of
.
Apply (
24) to function (
22), the least squares estimates of
,
,
and
for given
and
can be obtained as follows.
If and are known in advance, LSE is directly used to obtain the estimates of , , , , and . If and are not known quantities, the estimates of and can be derived by MLE, and the obtained estimates are used as the true values of and . Afterwards, we use LSE to obtain the estimates of , , , , and .
5. Asymptotic Confidence Intervals
As the sample size increases, maximum likelihood estimators have asymptotic normality and the distributions of the estimators approach normal distributions. The means of the normal distributions are the true values of the parameters. The variance–covariance matrix is acquired by inverting Fisher information matrix. Moreover, as the sample size becomes large, the biases of the estimators tend to 0, and the variances reach Cramer–Rao lower bounds. Maximum likelihood estimators are asymptotically unbiased and efficient. In this part, using these properties of maximum likelihood estimation, we obtain the asymptotic intervals of , , and .
6. Percentile Bootstrap Confidence Intervals
Bootstrap method is an effective tool for constructing confidence intervals via resampling, and the percentile bootstrap (Boot-p) method is commonly used. This section presents the construction of the percentile bootstrap confidence intervals utilizing simulated data. The algorithms of simulating sample data and generating Boot-p confidence intervals are demonstrated as follows, and the expression of coverage rates is given.
Algorithm 1 provides a method to simulate failure time by considering two competing risks. For each of the two risks, failure times
and
are simulated. Since only the shortest lifetimes are observed in the analysis of competing risks, the shortest times of
and
and the associated cause of failure are recorded. The specific algorithm is shown below.
| Algorithm 1: Simulating sample data. |
- Step 1:
Generate two independent random variables with identical uniform distribution from 0 to 1, and generate two sets produced by those two random variables, whose capacity is n. - Step 2:
Calculate the CDFs in ( 7) at and . Invert the CDFs of the two causes to generate failure time. - Step 3:
Determine the minimum time of failure generated in Step 2 for each unit and the cause of failure. Denote the failure time as , . If a certain dataset satisfies [ and or ] or [ and or , discard this dataset and generate a new one.
|
The percentile bootstrap is a resampling method. Its details are described in Ref. [
27]. With Algorithm 2, the percentile bootstrap intervals (BPI) under the step-stress ALT taking into account lagged effects and two competing risks are constructed.
| Algorithm 2: Generating Boot-p confidence intervals. |
- Step 1:
Calculate , the MLEs of from the original sample, through the optimization of ( 14). - Step 2:
Using the estimates as Algorithm 1, generate a new dataset of size n, denoting it as , . - Step 3:
Estimate MLEs as Step 1, based on . - Step 4:
Set the amount of simulation times beforehand. Repeat Steps 2–3 times, obtaining a total of s. - Step 5:
Sort each element of s separately. Taking as an example, the Boot-p confidence interval at coverage rate of is expressed in the following. The Boot-p confidence intervals of other parameters are gained in the same way:
|
In order to calculate coverage rates, set the number of repetitions
and run steps 1–5 for
times. The coverage rates of Boot-p confidence intervals are calculated by computing the proportion of true values falling into the confidence intervals. Here, we calculate the coverage rate of
as an example:
where
is an indicator function, and
=
,
=
.
7. Numerical Study
This section uses Monte-Carlo simulations to evaluate the properties of MLE and LSE and ACI and BPI. Here, the R software is used for calculations and simulations. We predetermined four sets of true values for simulation, and the true values are set as follows:
True Values I: = 3, = 6, = 0.2, = 0.1, = 1/10, = 1/5;
True Values II: = 3, = 6, = 0.15, = 0.1, = 1/10, = 1/5;
True Values III: = 4, = 6, = 0.2, = 0.1, = 1/10, = 1/5;
True Values IV: = 4, = 6, = 0.15, = 0.1, = 1/10, = 1/5.
The means and mean square errors (MSE) demonstrate the performance of MLE and LSE. Four sets of data are predetermined as true values using Algorithm 1 to generate random numbers under different true values as samples. When using maximum likelihood estimation, estimates of the unknown parameters based on the samples are obtained by using the
optim command in R software. When using LSE,
and
are considered as known and are the corresponding predefined true values. Due to the randomness of the simulation, sampling is repeated
times, and the average value is taken as the final value. We also calculated the mean square error.
Table 1,
Table 2,
Table 3 and
Table 4 report the means and mean square errors of the maximum likelihood estimates and the least square estimates for different true values.
For interval estimation, the performance of asymptotic confidence intervals and percentile bootstrap confidence intervals is demonstrated by the mean interval lengths (ML) and coverage rates (CR). For ACI, maximum likelihood estimates and the variance–covariance matrix were used to obtain asymptotic confidence intervals. The sampling is repeated
times to calculate the mean interval lengths and the coverage rates of the asymptotic confidence intervals. For BPI, due to a large number of iterations of the Boot-p algorithm, it is time costly to perform too much repetitive sampling in practical applications. In this paper, we show the ML and CR of Boot-p confidence intervals with repeated sampling
.
Table 5 and
Table 6 report ML and CR of asymptotic confidence intervals and Boot-p confidence intervals at
confidence level and
confidence level respectively under True Value I.
Table 7 and
Table 8 report ML and CR of asymptotic confidence intervals and Boot-p confidence intervals at
confidence level and
confidence level respectively under True Value II.
Table 9 and
Table 10 report ML and CR of asymptotic confidence intervals and Boot-p confidence intervals at
confidence level and
confidence level respectively under True Value III.
Table 11 and
Table 12 report ML and CR of asymptotic confidence intervals and Boot-p confidence intervals at
confidence level and
confidence level respectively under True Value IV.
From
Table 1,
Table 2,
Table 3 and
Table 4, the following conclusions can be drawn. Taking
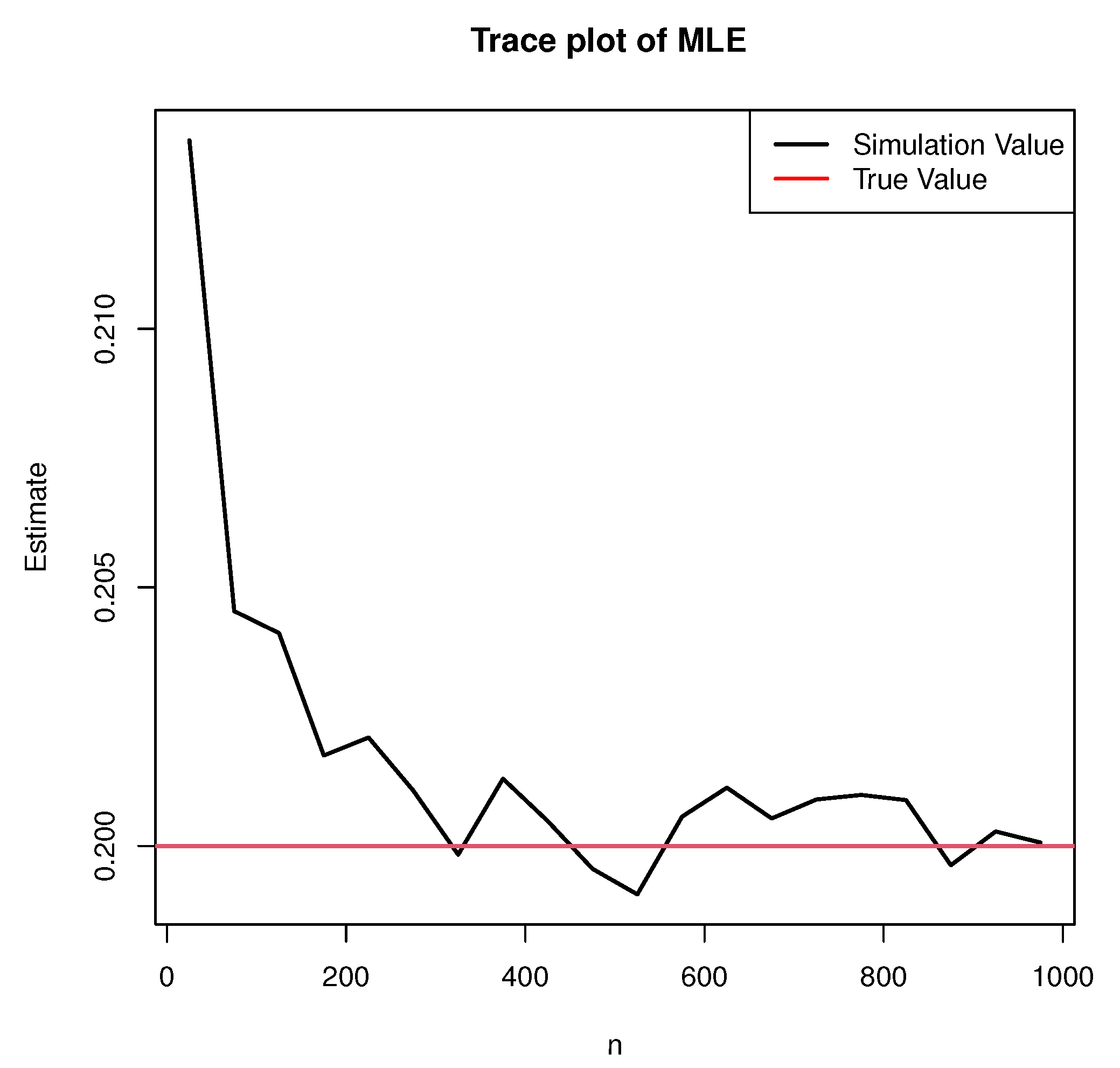
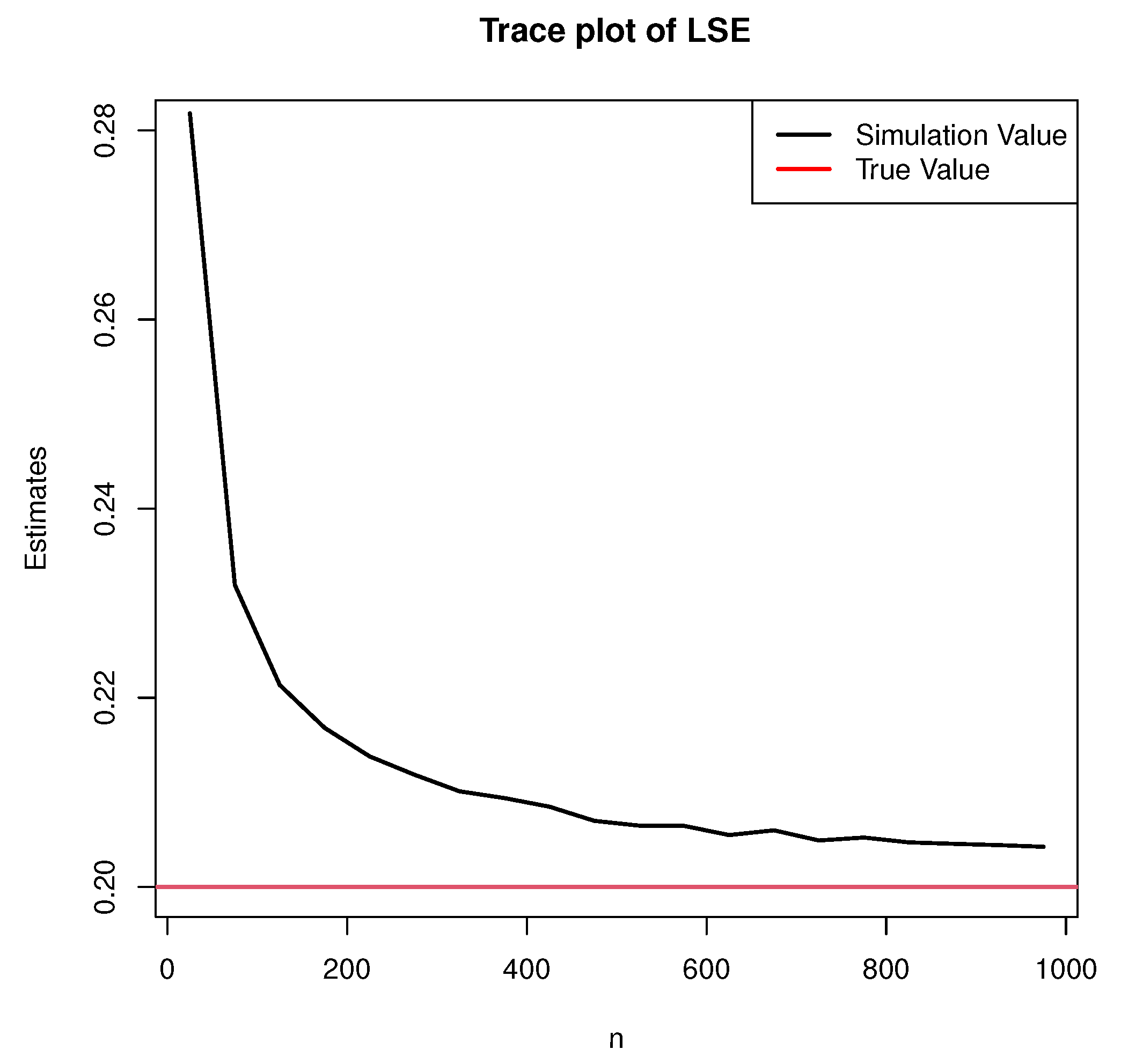
as an example, the estimates using MLE and LSE at different sample sizes
n under the True Value I are shown in
Figure 3 and
Figure 4.
(1) With an increased sample size n, the estimates of both MLE and LSE converge to true values, and the mean square errors gradually reduce and tend to zero.
(2) From the perspective of mean value and mean square error, there is no significant difference between the mean square error of MLE and LSE. However, the maximum likelihood estimates are much closer to the true value than the least squares estimates. This is because the least square method minimizes the sum of the squares of the distances between the observed and estimated points. On the other hand, the maximum likelihood estimation is intended for maximizing the probability of drawing observations from the model. The purpose of the least square estimation method is to obtain the parameters that make the model best fit the sample data. When using LSE in the case of small samples, it produces large errors, which is consistent with simulation results.
(3) For different true values, there is no significant difference in the fitting effect. Moreover, the mean squared errors of and are significantly larger than the MSEs of and , which means that the simulation errors of and are smaller under the same conditions.
(1) With an increasing sample size n, the mean interval lengths of ACI and BPI become slimmer, and the coverage rates of asymptotic credible intervals and Boot-p credible intervals are very close to CL .
(2) For ACI, there is no significant difference in the average interval lengths and no significant difference in coverage for different truth values. The same is true for BPI.
(3) For the same true values, the coverage rates of and are almost the same in asymptotic confidence intervals. Moreover, and have significantly greater coverage rates than and . In the Boot-p interval, there is no significant difference in the coverage of , , and . The simulation results also show that Boot-p confidence intervals have stable coverage rates and narrow average interval lengths at .
The performance of the coverage rates of confidence intervals can be represented by the following formula:
where indicates a higher coverage rate under the same conditions and indicates a similar coverage rate under the same conditions.
8. Real Data Analysis
In this section, a real dataset is used to illustrate the proposed methods. This dataset is also used in Ref. [
9]. It has two main failure risks (capacitor failure and controller failure). The stress element is temperature, and the stress level is in the range of 293 K to 353 K,
= 293 K,
= 353 K and
= 273 K in the standard state. K is the unit of temperature Kelvin. This dataset came from a lifetime test of solar lighting installations. The original dataset defines a sudden stress increase at
. We assume that the two risk factors are independent at arbitrary constant temperature and the stress change time point is 4.7–5.2 (hundred hours). In the dataset, the total number of solar lighting devices tested
and the specific data are shown in
Table 13. The proposed model was used to evaluate the reliability of solar lighting equipment.
From this dataset, we have
= 3,
= 3,
= 7,
= 12,
= 3 and
= 3. The maximum likelihood estimation is carried out according to experimental data, and least square estimation is carried out using
and
obtained from the maximum likelihood estimation. The estimation results are shown in
Table 14.
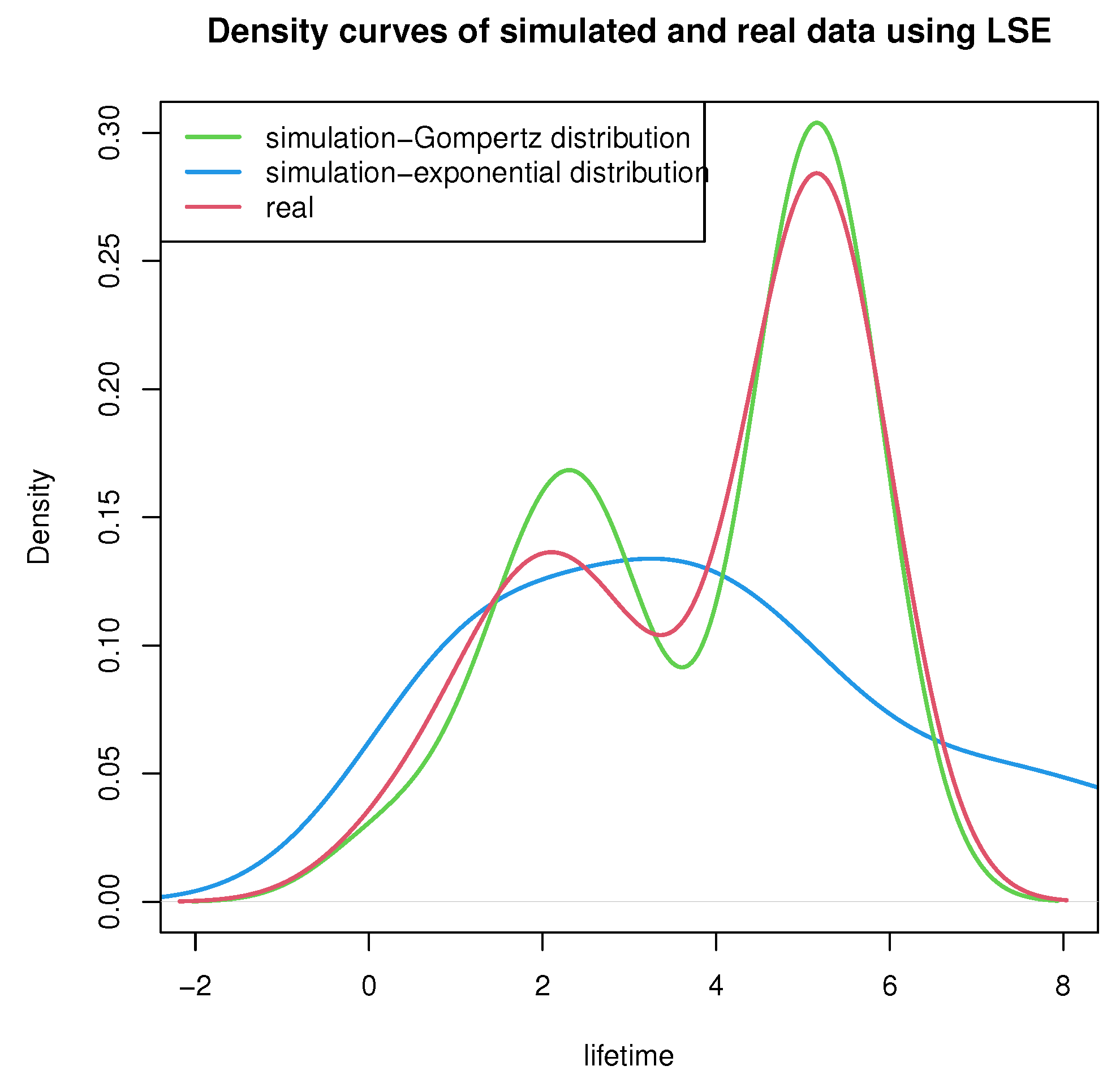
In order to show that the Gompertz distribution has good properties in solving such models, we make statistical inferences using the same methods when the lifetime distribution obeys the exponential distribution under the proposed model and assumptions. Moreover, we compare the results under Gompertz distribution and exponential distribution. Part
C of
Section 1 states that Gompertz distribution with two parameters degenerates to the exponential distribution with one parameter, as scale parameter
tends to zero. Thus, by making
and
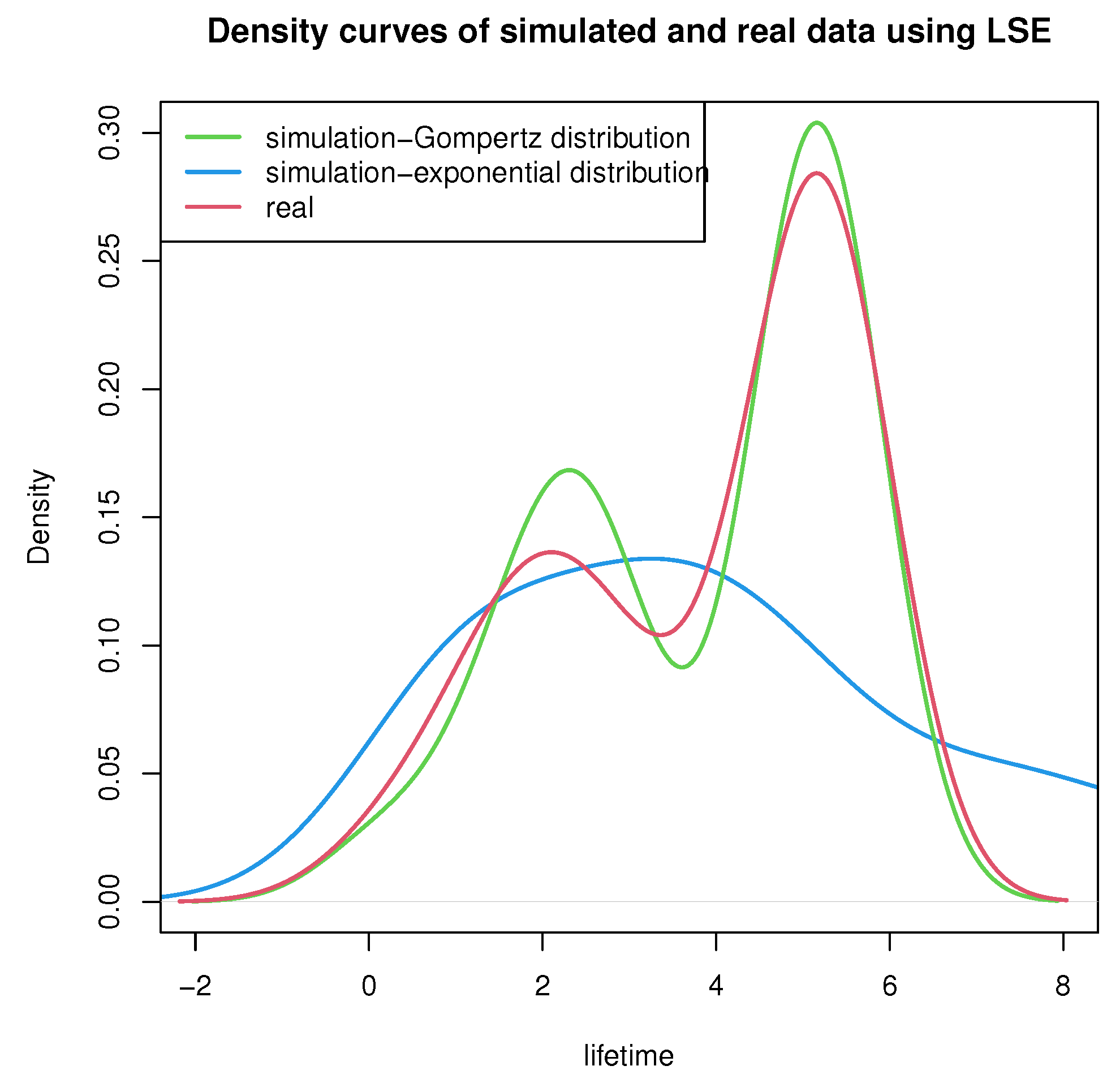
equal to 0.001, the distribution is considered to obey exponential distribution. The density curves of simulated and real data using MLE and LSE based on the Gompertz and exponential distributions are shown in
Figure 5 and
Figure 6.
Based on the real dataset, the results of ACI and BPI at
,
and
confidence levels are shown in
Table 15.
By examining the fitting curves of maximum likelihood estimation and least square estimation, it was observed that the fitting effect of the two point estimation methods is satisfactory, the lengths of the ACI and BPI are approximately equal and the two point estimation values fall into the range of the confidence intervals.
9. Discussion
In this paper, we assume that the hazard function of the lag period is only related to the stress level and is linear with time. If the assumption about the lag period being linear does not hold. The lag period and the subsequent time will be modeled mistakenly. In practice, an assessment of model can help researchers determine if the chosen method is appropriate. Thus, we need to test the hypothesis about the lag period. For nuisance factors, they are classified into three categories in Ref. [
28] as uncontrollable and unknown, uncontrollable and known and controllable and known. For the uncontrollable and unknown nuisance factors, randomization is used by increasing the sample size of the experiment to eliminate the effect. For the uncontrollable and known nuisance factors, it is handled by calculating the covariance. For controllable and known nuisance factors, blocks are conducted for experiments. Considering hypothesis tests where the lags are modeled as linear, Ref. [
29] suggested performing repeated counting and sensitivity analysis to assess the impact of these different inputs.
In our study, all cases can benefit from independently modeling competing risks, except for the strong dependencies between risks. In many cases where dependencies between risks are not considered, reliable conclusions can be drawn, and tedious calculations can be eliminated, which is important in engineering and in practical applications. In practice, some causes do not always satisfy this independence assumption. Considering the dependence structure between competing risks, binary or multivariate distributions can be used to describe the dependence between failure causes. For example, Refs. [
30,
31,
32] used Marshall–Olkin type distribution, Moran–Downton exponential distribution and copula models, respectively, to describe this binary or multivariate relationship. In subsequent studies, we will also carefully consider the impact on this model when risk factors are not independent.
10. Conclusions
The cumulative risk model more realistically reflects the impact of stress changes and addresses the main constraint of existing models. The Gompertz distribution model is a common model used in reliability and life testing and has two parameters and has many satisfactory properties. Taking into account competing risks, the Gompertz cumulative risk model is an extremely flexible step-stress model and is suitable for many applications in survivability analysis.
In this paper, the parameters estimation problems of the step-stress ALT model considering lagged effect and competing risks are studied. The maximum likelihood method and least squares method are used to determine point estimates. The Newton–Raphson algorithm was used to solve the nonlinear equations. The asymptotic confidence intervals and percentile bootstrap confidence intervals are constructed. From the numerical simulation, it can be observed that, with an increased sample size n, the estimates of both maximum likelihood estimation and least squares estimation converge to the true values, and the mean square errors gradually reduce and tend to zero. Moreover, the maximum likelihood estimates are much closer to the true value than the least squares estimates. In interval estimation, with an increasing sample size n, the mean interval lengths of asymptotic confidence intervals and Boot-p confidence intervals become slimmer, and the coverage rates are very close to confidence level . It is also shown that asymptotic confidence intervals have higher coverage rates when estimating , and Boot-p confidence intervals have higher coverage rates when estimating . The simulation results also suggest that the Boot-p confidence intervals have stable coverage rates and narrow average interval lengths for small samples. The model proposed in this paper has been shown to be valuable by simulation in estimating parameters. On the basis of theoretical results, the analysis of the real data was carried out to illustrate this model.
Step-stress models with lagged effect and competing risks are more practical and useful in practical survival analysis and deserve further investigation. In this paper, step-stress accelerated life tests with two stress levels and two risks are considered, which can be extended to models with diverse stress levels and various failure risks. For the next research study, we can further explore this in the case where risk factors are not independent and can also research different stress parameters under different competing risks and propose different truncation methods.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}