1. Introduction
Everyday commuting in densely populated urban areas is accompanied by repetitive traffic jams, representing an evident violation of urban life quality. Urban motorways, as an integrated part of the urban road network, are consequently affected by congestion. Variable speed limit (VSL) is an efficient traffic control strategy to improve motorways’ Level of service. VSL controls the speed limit in real time by displaying a specific speed limit on variable message signs (VMS). The speed limit value adapts to different traffic situations depending on weather conditions, accidents, traffic jams, etc [
1]. The main objective of VSL is to improve traffic safety and throughput on motorways due to the concept of speed homogenization [
2] and mainstream traffic flow control (MTFC) [
3], respectively. VSL aims to ensure stable traffic flow in motorway areas affected by recurrent bottlenecks. VSL thus has a dual effect: it prevents and alleviates congestion. Typically, problems occur on urban motorways near on-ramps. A higher volume of traffic at the on-ramp can disrupt the main traffic flow and cause a bottleneck activation.
Several VSL control strategies have been suggested in the literature based on different VSL measures and methodologies, such as rule-based VSL activated by predefined threshold values (e.g., flow, speed or density) [
4,
5], the usage of metaheuristics to optimize VSL [
6], optimal control [
7], and model-predictive control [
8]. The most prominent VSL design (among classical controllers) uses feedback control [
3,
9], where the speed limit is calculated based on current measurements of traffic conditions, such as traffic density.
However, in recent years, there has been an increasing interest in improving VSL optimization by taking advantage of machine learning techniques with a focus on reinforcement learning (RL). An overview of the existing literature can be found in [
10]. RL has a proven track record of solving various complex control problems, including transportation and related control optimization problems, and achieving considerable improvements in transportation management efficiency [
11,
12,
13,
14]. In particular, RL provides the ability to solve complex Markov decision processes (MDPs) and find a near-optimal solution for discrete-event stochastic systems while not requiring an analytical model of the system to be controlled [
15]. In addition, RL-based control systems can continuously improve their performance over time by adapting control policies to newly recognized states of the environment (adaptive control).
The majority of studies in RL-VSL are based on a single objective [
16,
17] or multiple objectives implemented as a single control policy (strategy) [
18,
19,
20]. However, large-scale control systems might have various, often conflicting objectives with heterogeneous time and space scales (simultaneous optimization of ramp metering and VSL [
21]) or different levels of priorities (safety contrary to throughput [
22] or throughput contrary to higher traveling speeds [
23]). In practice, VSL is usually applied on several consecutive motorway sections. Thus, the VSL application area should be split into several shorter VSL sections upstream of the bottleneck area to ensure smooth (gradual) spatial adjustment of the speed limits. This can be modelled and solved by multi-agent RL-based control approaches where each agent (VSL controller) sets speed limits on its controlled motorway section [
22,
23,
24].
Although VSL has been extensively studied and some VSL approaches are being used in practice, there are some open questions in the design of the VSL system itself, on which there is very little research. The critical detail for efficient VSL is the design and placement of the VSL zones. In particular, two practical questions arise: how long should the VSL application zone be, and where should it be placed (in other words, how far should the end of the VSL zone be from the bottleneck) to achieve optimal VSL performance. In general, it can be concluded from [
25,
26] that different lengths and positions of the VSL application area for different speed limits and different traffic congestion intensities (the spatial variation of the congestion characteristic) significantly affect VSL performance.
To address this problem, in our previous work [
23], we proposed a distributed spatio-temporal multi-agent VSL control based on RL (DWL-ST-VSL) with dynamic VSL zone allocation. The DWL-ST-VSL controller dynamically adjusts the configuration of VSL zones and speed limits.
In addition to the results and conclusions in [
23], in this study we seek to confirm the extended applicability of DWL-ST-VSL to control longer dynamic VSL application areas with more agents. Therefore, the present study makes the following contributions:
Extension of the applicability and behaviour analysis of DWL4-ST-VSL by increasing the number of learning agents from the original two to four;
Evaluation of the performance of DWL4-ST-VSL in controlling speed limits on a longer motorway segment using collaborative agents;
Assessment of the impact of dynamic VSL zone allocations on traffic flow optimization and comparison to the VSL controllers with static zones in traffic conditions with spatially varying congestion characteristics.
An experimental approach is used to verify suggested solutions using simulation experiments. Thus, the present experiment will give data-based evidence about the potential usefulness of extended DWL4-ST-VSL control with adaptive VSL zones when deployed on longer motorway segments. Results and analysis will provide insights into the modelling of DWL4-ST-VSL and the impact of agents’ collaboration on system performance when used to control traffic flow on a longer motorway segment. This is a crucial aspect for the development of adaptive controllers in particular, but also for research investigating reliable and more efficient RL-based VSL.
We hypothesize that the extension of DWL-ST-VSL will contribute to the ability to dynamically configure VSL zones. The fact that agents can collaborate using remote policies results in a better response to moving congestion because they can collectively assemble a larger number of feasible VSL application areas. A certain number of configurations can more appropriately respond to the current downstream congestion. We anticipate that a DWL-ST-VSL system with more agents will use its additional adaptive feature to adjust VSL zones to resolve congestion as much as possible without suppressing the upstream traffic itself. As a result, we expect a further reduction in the overall travel time of the system, and that a smoother speed transition can be achieved by spatially deploying multiple VSL agents. This is more in line with what the VSL implementation should fulfill to achieve a smooth “harmonized” speed transition. Using an adjustable VSL application area supported by multiple dynamically configurable VSL zones reduces the need for severe speed reduction. Agents in upstream zones can prepare vehicles for conditions in downstream VSL zones by slightly decreasing speed limits. This is necessary since speed limits in downstream zones may be lower due to the proximity of the bottleneck. Therefore, this can help to harmonize traffic flow better in order to avoid undesirable effects, such as shockwaves.
Thus, in this paper, we propose an extended version of the DWL-ST-VSL strategy that allows dynamic spatiotemporal VSL zone allocation on a wider motorway section with four VSL learning-based agents (DWL4-ST-VSL). To provide smoother speed limit control, DWL4-ST-VSL implements two speed limit sets with different granularities on the observed motorway section. DWL4-ST-VSL enables automatic, systematic learning in setting up the sufficiently accurate VSL zone configuration (selection is learnt rather than manually designed) for efficient VSL operation under a fluctuating traffic load. From a technical perspective, the physical VMS could soon be replaced (or enhanced) by advanced technologies (vehicle-to-infrastructure communication, e.g.,an intelligent speed assistance (ISA) system [
27]). Thus, static placement of physical VMSs would no longer be an obstacle to the dynamic adaptation of VSL zone configurations in real motorway applications.
To set up DWL4-ST-VSL, the distributed W-learning (DWL) algorithm is used. DWL is an RL-based multi-agent algorithm for collaborative agent-based self-optimization with respect to multiple policies. It relies only on local learning and interactions. Therefore, no information about the joint state-action space is shared between agents, which means that the complexity of the model does not increase exponentially with the number of agents. DWL was originally proposed in [
28] and successfully applied for controlling traffic signals at multiple urban intersections with different priorities as objectives. It has also been successfully applied for speed limit control on a small urban motorway segment using two agents (DWL2-ST-VSL), as introduced in our previous paper [
23].
Thus, in this study, we investigate the applicability of extended DWL4-ST-VSL in terms of the number of learning agents, their behavior, and their impact on traffic flow control, emphasizing an application on a longer motorway segment.
The proposed DWL4-ST-VSL is evaluated using the microscopic simulator, simulation of urban mobility (SUMO) [
29], in two scenarios with medium and high traffic loads. Its performance is compared with three baselines: no control (NO-VSL), simple proportional speed controller (SPSC) [
30], and W-learning VSL (WL-VSL). The experimental results confirm the feasibility of the proposed extended DWL4-ST-VSL approach with the observed improvement in traffic parameters in the bottleneck area and system travel time of the motorway as a whole. Finally, DWL4-ST-VSL is envisioned as a new approach to dynamically adjust speed limits in space and time, anticipating the practical aspect of vehicle speed control that may be found in the leading-edge of connected and autonomous Vehicles or ISA in general.
The structure of this article is organized as follows:
Section 2 discusses related work in the area of RL application in VSL control.
Section 3 introduces the DWL algorithm.
Section 4 provides insight into the modeling of VSL as a multi-agent DWL problem.
Section 5 describes the simulation set-up, and
Section 6 delivers the results and analysis of our experiments. The discussion can be found in
Section 7.
Section 8 summarizes our results and conclusions.
3. Multi-Agent Based Reinforcement Learning
This section presents the essential elements needed to understand RL-based techniques and the DWL algorithm.
3.1. Reinforcement Learning
RL is a simulation-based technique that is useful in large-scale and complex MDPs [
48]. It combines the principle of the Monte Carlo method with the principle of dynamic programming, which in RL is called the temporal difference method. In RL, simulation can be used to generate samples of the value function of a complex system (rather than finding an explicit model), which are then averaged to obtain the expected value of the value function. Therefore, transition probabilities are not required in RL (model-free technique). This avoids the curse of dimensionality (a potentially large number of states which leads to the well-known curses of dynamic programming: the curse of modeling and the curse of dimensionality) [
15].
3.2. Q-Learning
Q-Learning is an off-policy RL algorithm that perceives and interacts with the environment at each control time step by performing actions and receiving feedback (rewards). Thus, the Q-Learning function
learns to associate an action
with the expected long-term payoff (reward) for performing that action in a given state
[
49]. How good action is in a given state is expressed as a Q-value. Q-function is learned using the following iterative update rule:
The performed action in state stimulates a state transition to the new state , from which an optimal action is . Depending on this transition, the agent receives a reward . The parameter is the learning rate that controls how fast the Q-values are adjusted. The discount factor controls the importance of future rewards. Various exploration/exploitation strategies (e.g., -greedy) are used to search the solution space, i.e., to ensure that the agent sufficiently explores its environment and learns the appropriate action in a given state.
3.3. W-Learning
The WL algorithm proposed in [
43] was designed to manage competition between multiple tasks. In particular, an individual policy is implemented as a separate Q-learning process designed by its own state space. The goal is to learn Q-values for state-action pairs for each policy, where a single policy can be viewed as an agent. At each control time step, each policy nominates an action based on Q-values. Applying WL for each state
x of each of their policies, the agent learns what happens concerning the reward received if the nominated action is not performed (rated using a W-value for a given state
). Thus, an agent only needs local knowledge—what state
it was in, whether the nominated action was obeyed or not, the state transition
, and the received reward
.
Hence, all policies recommend new actions. Nevertheless, only one action is executed (suggested by the “winner policy”) based on the highest W-value (if not, this policy will suffer the highest deviation). Each policy updates its own
function using the winning action
and its own received reward
.
values are updated only for policies that were not obeyed (
) using the following update rule:
where learning rate
and delaying rate
(
) control the convergence of
.
Thus, WL can be seen as a fair resolution of competition. Competition results in fragmentation of the state-space between the different agents, thus allowing any collection of agents. Eventually, they will divide up state-space among them based on the deviations they cause to each other. The winner of a state (determined by highest ) is the agent that is most likely to suffer the highest deviation if it does not win. Eventually, agents are aware of their competition indirectly by the interference they cause.
3.4. Distributed W-Learning
The DWL algorithm proposed in [
28] enables an agent
to learn to select actions that match its local policies while learning how its actions affect its neighbours
, and to give different weights to the preferences of its neighbours when selecting an action. To prompt an agent
to consider the action preference of its neighbours (i.e., to cooperate), each agent implements, in addition to its own local policy
, a “remote” policy
for each of the local policies
used on each of its neighbours. To help neighbour
implement its local policy, remote policy
receives a reward
every time a neighbour’s local policy
receives a reward
(
).
enables heterogeneous agents to collaborate, implement different policies, and have different actions and state spaces. Thus, the DWL scheme lets an agent adapt to the other agents, since their dynamics are generally changeable. Each agent implements its policy as a combination of a Q- and a WL process. Q-values are associated with each of its state-action pairs, while W-values are associated with states. In the learning process, an agent learns Q-values for remote-state/local-action pairs and W-values for local/remote states, through which it learns the influence of its local actions on the states of its neighbours . Thus, DWL does not need a global knowledge or central component. It relies on local learning and interactions with its neighbours, local rewards from the environment, and local actions.
To learn how its actions affect its neighbors, at each control time step, the agent receives information about the current states of its neighbours and the rewards they have received. All local and remote policies nominate an action with an associated W-value. Nominations for actions are treated with full W-values. In contrast, nominations are scaled by a cooperation coefficient C () to enable an agent to weigh the action preferences of its neighbours. indicates a non-cooperative local agent, i.e., it does not consider the performance of its neighbours when picking an action. For , the local agent is entirely cooperative, implying that it cares about its neighbours’ performance as much as its own.
The action performed at the given control time step (one that wins the competition between policies) is selected based on the highest W-value (
) after scaling the remote W-values by
C:
where
and
are W-values nominated by
and
policies of agent
, respectively.
4. Modeling Spatial VSL as a DWL-ST-VSL Problem
So far, DWL has been successfully applied to the problem of controlling urban intersections on a larger scale network with a larger number of agents [
28]. DWL has also proven successful in the VSL control optimization problem [
23] on a smaller motorway segment. Nevertheless, it has never been tested for its extended applicability to motorway traffic control with a higher number of deployed VSL agents. Thus, in our extended DWL4-ST-VSL framework, four neighbouring agents (
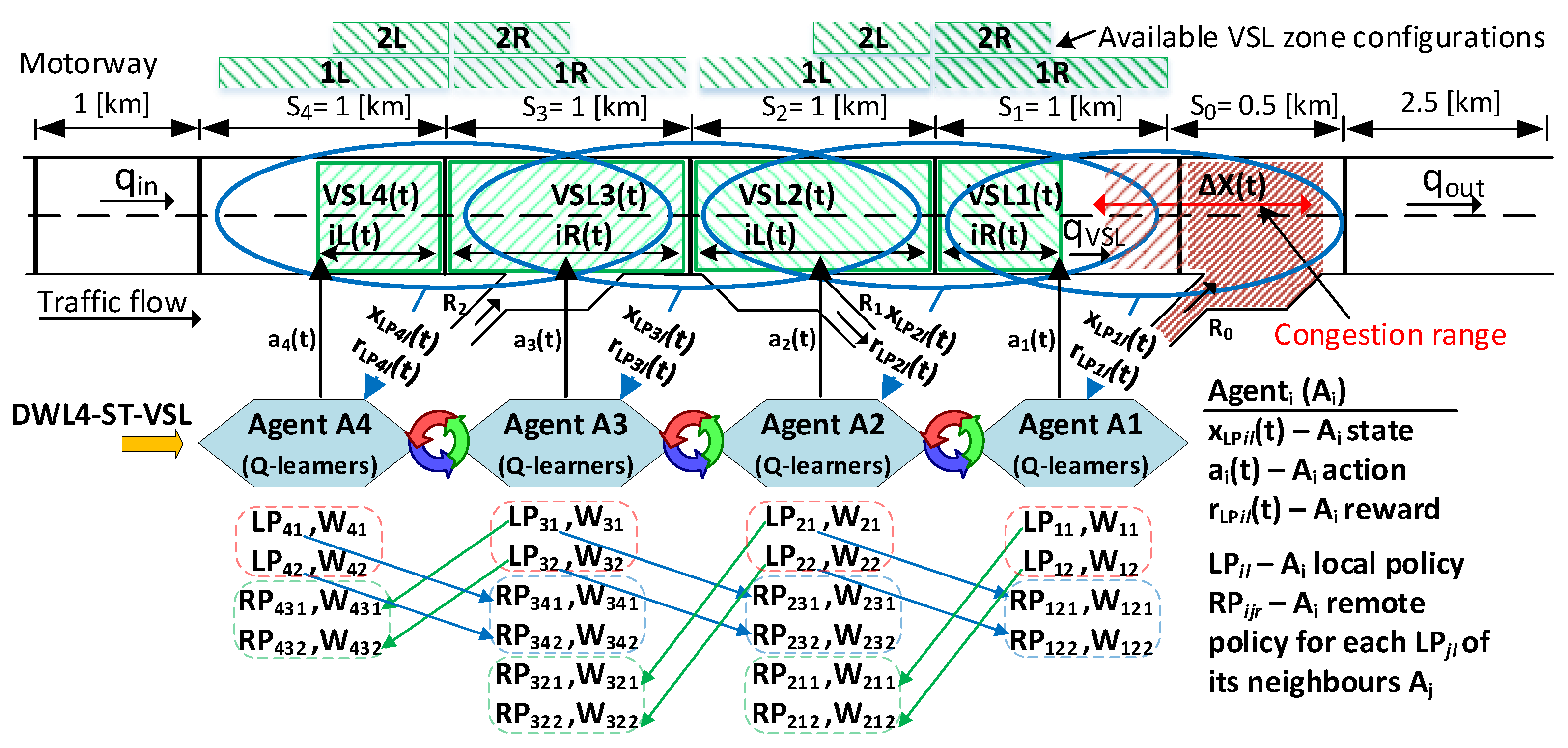
) control the speed limit and VSL zone configuration (length and position) on their own motorway section. Each agent in DWL4-ST-VSL perceives its local environment through agent states and rewards (see
Figure 2). Thus, in the proposed multi-agent control optimization problem, the agent states
, actions
, and reward functions
are modelled as follows.
4.1. State Description
As stated in [
18], defining a compact Markovian state representation for motorways is difficult because many external factors influence traffic flow: e.g., weather conditions, motorway geometry (curvature, slope), etc., which are hard to model precisely. Augmenting the state by additional information, such as observing more sections (e.g., the density measured on the motorway section further upstream from the congestion location and the on-ramp queue length, primarily to provide a predictive component in terms of motorway demand [
21]) or including information from the past in states, may improve the algorithm’s performance. Though this increases solution space, it can be overcome by the function approximation technique [
18,
40]. However, in DWL modelling, the observation of the agent’s neighborhood is available through remote policies. Nevertheless, the observability of the state must be assured. An example of a partially observable state is the usage of flow rate for states. From traffic flow theory, macroscopic variables describe traffic conditions (speed, density, flow). As a result of the nonlinearity of the fundamental diagram (flow-density relationship) [
39], the same traffic flow rate can be observed for a density value below critical density with high speed (stable flow) and a density value above critical density with low speed (unstable flow). Thus, the traffic condition is uniquely determined by using the information of traffic density. Therefore, we use speed and density measurements to omit the agents’ confusion, thus uniquely determining traffic conditions. As a result, the negative effect of imperfect and incomplete perception of agents’ partially observable states in our MDP modeling is reduced.
The inclusion of the speed measurement of the neighboring segments into the state can enhance the learning process, particularly at the beginning of the learning process, when agents cause interference by randomly performing actions (exploration). Besides, low speed indicates traffic flow disruption provoked by congestion. Speeds are encoded in the variable
, which corresponds to the measured average vehicle speed
at time
t in motorway section
(
), as shown in
Figure 2. Each speed measurement can fall into one of four intervals defined with boundary points (
[km/h]).
Current traffic density measured in the motorway section , is stored in the variable . Each measurement can fall into one of twelve intervals defined by the boundary points ( [veh/km/lane]). Additionally, the state space contains information about the agent’s action from the previous control time step, thereby enabling modelling restrictions on the action space by making it state dependent, which is explained in more detail in the following subsection.
Therefore,
’s local policy
at time
t senses state
, while
.
’s
senses state
, while
. Similarly,
’s
senses state
, while
. Finally,
’s
senses state
, while
(see
Figure 2).
4.2. Action Space
Each element in the action sets (4) and (5) consists of two variables. The upper one represents the speed limit [km/h] in section
, while the lower one represents an active VSL zone (indexes for the left (
)/right (
) configuration; see
Figure 2). Agent
controls the speed limit and the length of the VSL zone in section
, while
controls section
, and so on. In this way, the agent’s winning policy (either
or
) will define the speed limit and the VSL zone configuration for a given motorway section.
Q-values in (DWL2 and DWL4)-ST-VSL are stored in a matrix, where X is a finite set containing the indices of the coded states of the Cartesian product of the input traffic variables ( and ). This seems to be a large solution space for learning optimal Q-values using (1). Nevertheless, the feasible solution space was reduced by constraining the action selection in the nomination process explained in the continuation. Thus, Q-matrix can be considered a sparse matrix, and there is no need to search the whole space.
The consecutive speed limit change within a section (n) must satisfy constraint in the case of agents and , which use action set . In the case of and (), the constraint is . This ensures a smooth and safe speed transition between the upstream free-flow and the congested downstream flow characterized by lower vehicle speeds due to the bottleneck. Thus, the final set of actions allowed for the agent at time t depends on the previously executed actions of the agent. This constraint also implies that the next possible action () in the update process of the W- and Q-values (see update rules (1) and (2)) must be bounded based on . Thus, each time the Q-value is updated, a possible subset of the allowed actions is considered. E.g., if , then the available action subset at time t is . Therefore, the previous action in the state space is used to uniquely distinguish between states’ transitions given the constrained subset of actions between control time steps. This constraint is implicitly modelled in the update rule (1). It addresses a unique row in Q-matrix () and the reachable entries in that row, corresponding to a given action index. Feasible entries in the particular row correspond to original indexes of elements from the original action set). Thus, only such entries in are reachable in updating Q- and W-values and in the action nomination process while using “argmax” in Q-learning. Otherwise, the oscillation in the values of elements in a particular state (row) will be present. Thus, Q-values will not converge to a stationary policy, and action nomination in a particular state will constantly switch no matter how long the learning period is. Eventually, a stable agent diminishes the nonstationarity effect in the learning problem of the other agents.
In this way, it is not necessary to model constraints directly in the rewards. It is still ensured that DWL4-ST-VSL operates according to the advised safety rules on maximum allowable speed changes.
It is important to note that the constraints on the spatial difference of speed limit values between two adjacent VSL zones on the motorway are not explicitly considered in this setup. It is assumed that agents communicate information about congestion intensity and locations via remote policies. Thus, the difference in spatial speed limits should be reasonable in terms of optimal traffic flow control. This is also aided by DWL’s ability to implement two sets of speed limits with different granularity simultaneously. Action set (4) is for agents and , which are closer to the bottleneck. The finer action set (5) is for upstream agents and . The finer actions aim to slightly adjust the speeds of the arriving vehicles before they enter the VSL application areas controlled by downstream agents. In this way, agents smooth out the incoming traffic towards the congestion point, thus avoiding the undesirable sudden deceleration of vehicles and effects such as shockwaves.
4.3. Reward Function
In [
18], the minimization of the total time spent (
) of vehicles on the observed motorway segment over a given time interval was successfully used as an objective in RL-VSL control. Therefore, we also use the
measure for reward. The variable
measures
between two control time steps
t and
on the motorway section
n. In this way, an agent receives feedback about how good its action was. Each agent must learn to strike a balance between two conflicting policies. In the case of an inactive bottleneck, the penalty will be lower for a higher speed limit. Contrary, when congestion occurs, it is required to gradually reduce the speed limit in upstream sections to control the incoming traffic towards the congestion point so as to maintain the traffic volume near the operational capacity of the active bottleneck. Thus, each policy seeks to optimize its objective as follows.
4.3.1. Local Policy for Stable-Flow Control
The local policy
of an agent
aims to learn the speed limit to ensure a reduction of
by promoting, when possible, higher traveling speeds in stable-flow conditions. To achieve this goal, the
reward is:
thereby favoring average vehicle speeds above 102 [km/h].
In a certain percentage, is activated in saturated flow during the transition from free-flow to congested flow and vice versa. Therefore, it prepares traffic for the second policy (), which dominates in oversaturated (congested) conditions. After congestion has started to resolve by deploying , and the congestion intensity reduces to a certain level, helps restore traffic to free flow (higher traveling speeds) as soon as possible by gradually increasing the speed limit. Thus, seeks to reduce traffic recovery time. Finally, the states perceived by satisfy the minimum requirements to determine whether the flow in the agent’s neighborhood is a stable flow or deviating from it. Thus, the agent can recognize when the higher speed limits for free flow can be implemented or not.
4.3.2. Local Policy for Unstable-Flow (Congested) Traffic Control
Local policy
aims to reduce
in the downstream motorway section in the case of an active bottleneck. Thus, an agent must learn and apply appropriate speed limits to restrict the inflow into the bottleneck until the discharge capacity is restored. If not, congestion will grow, and consequently, it will increase its penalty in proportion to:
where coefficient
controls the agent’s sensitivity to congestion. Instead of using only downstream congestion information,
uses information about the upcoming traffic flow (current speed and density) from the section
. This can be considered a prediction of the forthcoming traffic flow (how fast and with what volume it will arrive) into the downstream congested section
. In this way, the description of traffic conditions (states) is extended to include more unique traffic characteristics for more efficient congestion control.
4.3.3. Remote Policies
Cooperation between agents is based on remote policies. Thus, an agent
learns additional remote policies (
) that complement its neighbouring agent’s local policies. In order to know how
’s local actions
affect the neighbours’ states, the agent updates the remote policies by the information it receives about its neighbours’ current states and the rewards that neighbour agents have received (
Figure 2). Our experiments consider that agents’ communication is perfect (no loss of information and no breakdown of agents is assumed).
4.4. Winner Action
In DWL4-ST-VSL, an agent
’s experience (Q-values for local-state/action pairs and Q-values for remote-state/local-action pairs) for each policy are respectively stored in
matrices. In the case of agents
and
(
), while for
and
(
). At the same time, for each of the states of each of its policies, an agent learns W-values of what happens in terms of the reward received if the action nominated by that policy is not performed [
43]. This is expressed as a W-value (
) and stored in
matrices in each case. With the knowledge gained from these matrices, all policies (local and remote) propose new actions. The action
that wins the competition between policies at this time step is the one with the highest W-value (
) (computed using (3)) [
28]. After the state transition
, each agent’s local policy receives its unique reward (
,
) and state (
,
) depending on the consequences of the executed action
. The remote policies
obtain rewards and state information from their neighbour agent by querying the neighbour’s local policies states/rewards (
,
,
, and
). Then, all policies update their Q-values (for the winning action
), while only the policies that were not obeyed update their W-value. The above process is repeated for all agents.
6. Simulation Results
The VSL strategies are evaluated using the overall
and measured on the entire simulated motorway segment (including ramps). Traffic parameters, average speed and density are measured in the bottleneck area (section
). The results presented in
Figure 4,
Figure 5,
Figure 6 and
Figure 7 are from the exploitation phase. We analyzed the specific response behavior of the allocation of dynamic VSL zones compared to the case of static zones. The space-time congestion analysis is used to analyze the spatiotemporal behaviour of dynamic VSL zone allocation and its impact on traffic flow control. To assess the benefits of cooperation between agents using DWL’s remote policies, we also evaluate the impact of the cooperation coefficient on agent performance. As a measure of the learning rate of proposed agent-based learning VSL approaches, the convergence curves of overall motorway
during the training (learning) process are shown in
Figure 8.
It is important to note that the purpose of this study is not to show the extent to which DWL4-ST-VSL can improve traffic, but to investigate how the dynamic (spatiotemporal) adaptation of VSL zone configurations and the increased number of learning agents affect the traffic control optimization problem. Thus, an improvement over baseline should be considered primarily as a comparative measure between two different VSL approaches, the commonly used static VSL zones and the new paradigm with dynamic VSL zone allocation, rather than as an absolute measure of performance.
6.1. Comparison of Dynamic VSL Zone Allocation and Static VSL Zones
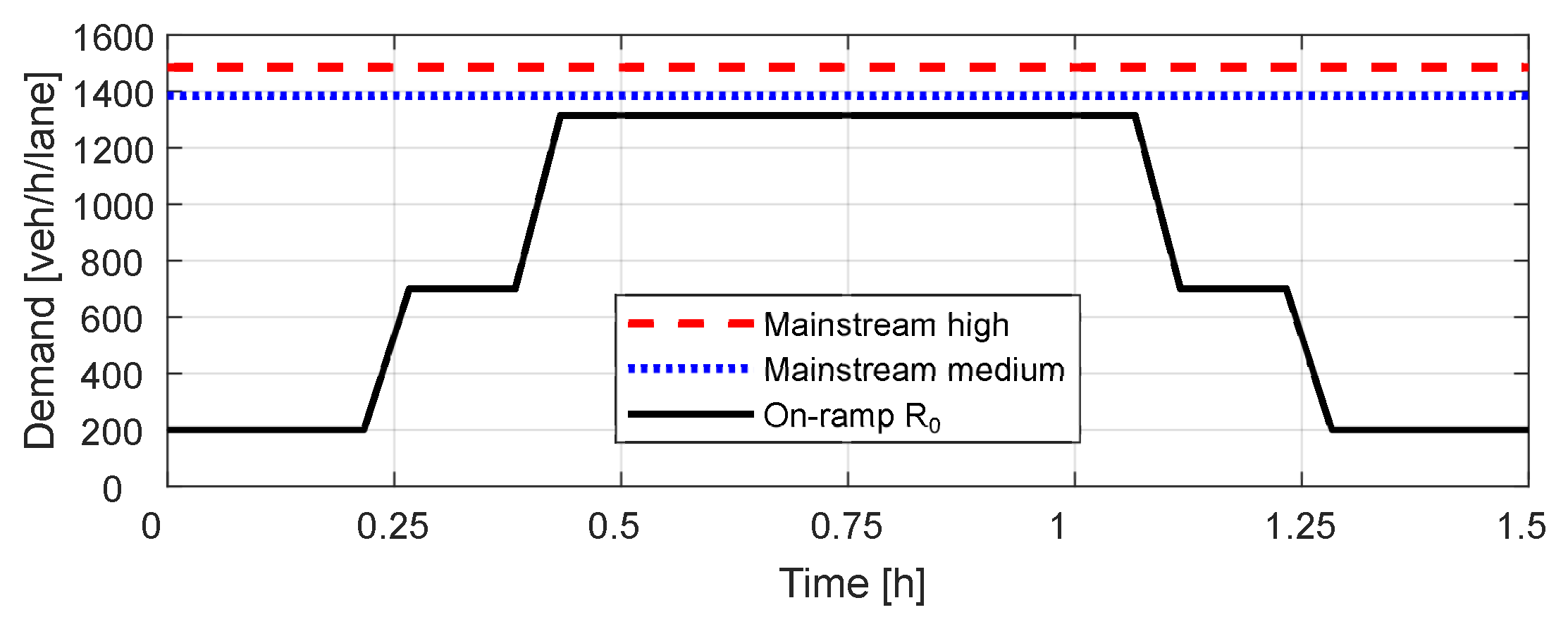
Note that the baselines use the best static VSL zone configuration found for a medium traffic load. Using a medium and a high load in our experimental setup, we simulate significant differences in the spatial displacement of the congestion tail. In this way, we illustrate the benefits and necessity of adaptive spatiotemporal VSL control. Different VSL zone configurations per traffic scenario are learned (without requiring manual setup) and dynamically assigned using DWL4-ST-VSL to better respond to spatially propagating traffic congestion. At the same time, the experiment highlighted the weaknesses of the static VSL zone configuration, which performs suboptimally under high traffic load. Therefore, the VSL zones in VSL with the static VSL zone configuration must be manually set up each time the traffic pattern changes, which is not practical.
6.1.1. Medium Traffic Load
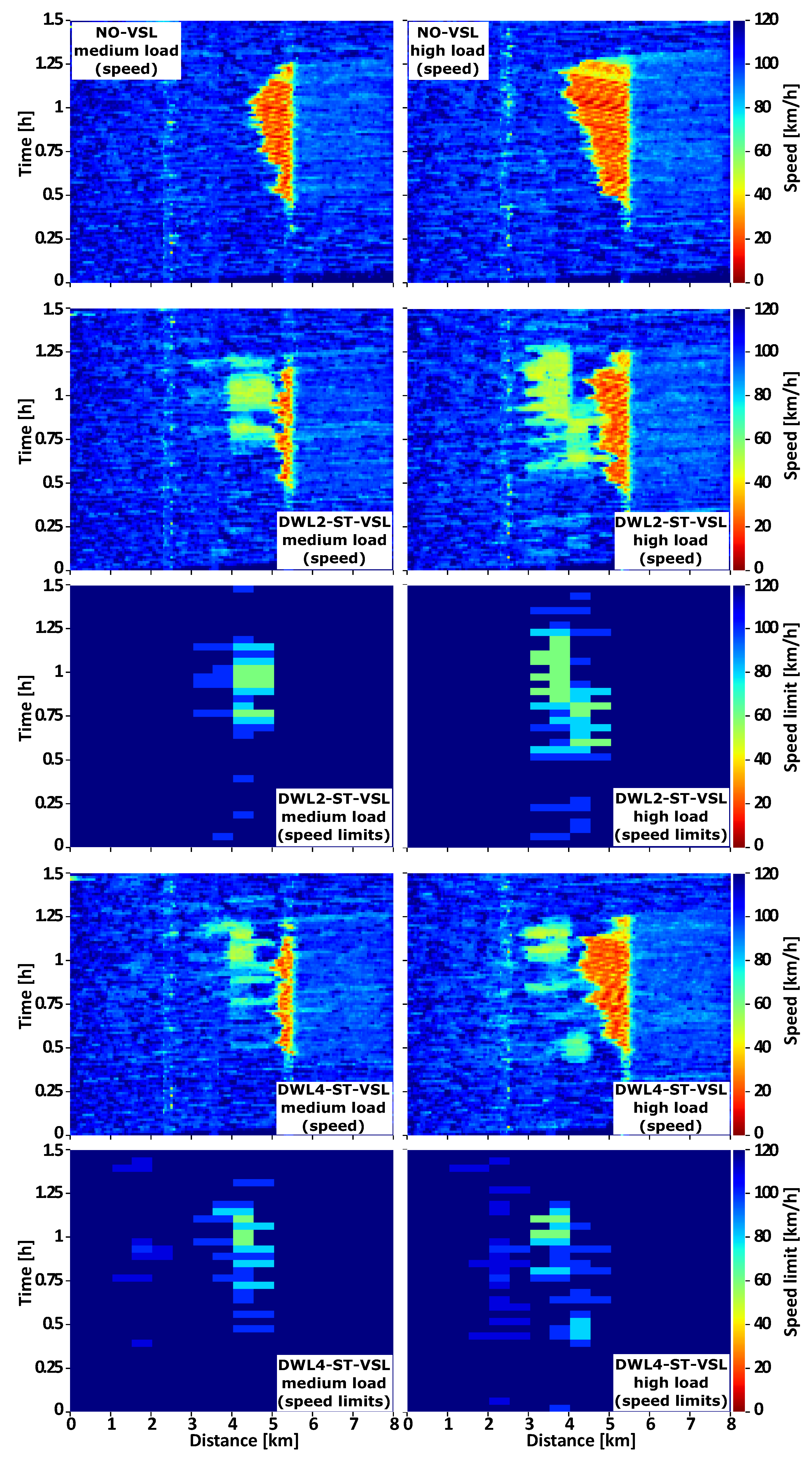
The simulations performed show that the best combination for establishing static VSL zones is . In this case, VSL is able to control congestion in the case of medium traffic load. In DWL2-ST-VSL, by additionally activating VSL zones within the section during the highest congestion peak (around [h]), the agent helps its downstream neighbour , which contributes to an even more effective congestion resolution than the baselines (SPSC and WL-VSL) with static VSL zones. In DWL4-ST-VSL, the agents closest to the congestion ( and ) are assisted by upstream agents ( and ) that activate additional VSL zones within and just before the highest congestion peak ( [h]) (for a shorter period than DWL2-ST-VSL). In this way, agents and help their downstream neighbours. Similar results to those found for DWL2-ST-VSL were observed.
6.1.2. High Traffic Load
The performed simulations indicate that the static VSL zones perform suboptimally in a high traffic scenario. By applying different VSL zone configurations during the simulation within by DWL2-ST-VSL, and within sections in the case of DWL4-ST-VSL, they contribute more notably to congestion clearing than baselines, which results from the gradual adjustment of the VSL application area. In the DWL2-ST-VSL case, agents started with stronger activation of the speed limits and VSL zones in section at the beginning of the congestion. Over time, the congestion starts to propagate upstream through the motorway. The agents begin to use the VSL zones principally in sections and , while finally, for the highest congestion peak, the VSL zones are primarily activated in section .
In the case of DWL4-ST-VSL, VSL zones are activated mainly in all VSL sections at the onset of congestion (somewhat more sparsely for agent
, while agent
was almost not activated at all). Agents
and
preferred a shorter VSL zone configuration, while
preferred a longer one. The application of shorter VSL zones in the downstream sections
and
could be due to the additional support provided by the upstream agents, particularly the speed limits applied by agent
, which reduced the need for longer VSL zones and sudden decreases of the speed limit. As congestion increases, it can be seen in
Figure 5 that the area of inactive VSL zones increases between upstream and downstream sections, primarily due to the use of shorter VSL zones by agent
and sparsely activated VSL zones by
. After
[h], agent
starts applying speed limits again in response to the sudden increase of the queue ahead of the bottleneck (faster propagation of the congestion upstream through the motorway). As congestion intensity approaches its peak, agent
promotes a longer VSL zone, including lower speed limits. Agent
is mostly inactive during this time period, thus forming an additional valuable transition zone [
26] between the active VSL application area and the congestion tail. A somewhat unexpected behavior during the highest congestion peak is observed for agent
, which did not apply speed limits below 120 [km/h] while
was not active for 3 control steps (
Figure 5). In the next section, we will make some arguments that we believe can help explain this unexpected agent behavior.
Nevertheless, both DWL2-ST-VSL and DWL4-ST-VSL adjusted the VSL zones to the spatially moving tail of the resulting congestion. This control strategy is more pronounced in the case of the high congestion scenario, in which agents attempt to create an additional artificial moving bottleneck to reduce the outflow from it and, thus, relieve the congested area. From
Figure 5, it can be seen that the agents aim to create such a VSL configuration that ensures the additional space (without speed limit) between the VSL zones and the congested tail. This can be viewed as an acceleration zone after the VSL zone, allowing vehicles to accelerate to the critical speed (at which capacity is reached) before entering the congested tail, as indicated in [
25]. This feature of DWL-ST-VSL is very useful compared to the static VSL zone (fixed configuration) and confirms the findings that the higher the speed limit, the farther the VSL application zone should be from the bottleneck, which has been recently proven analytically in [
26].
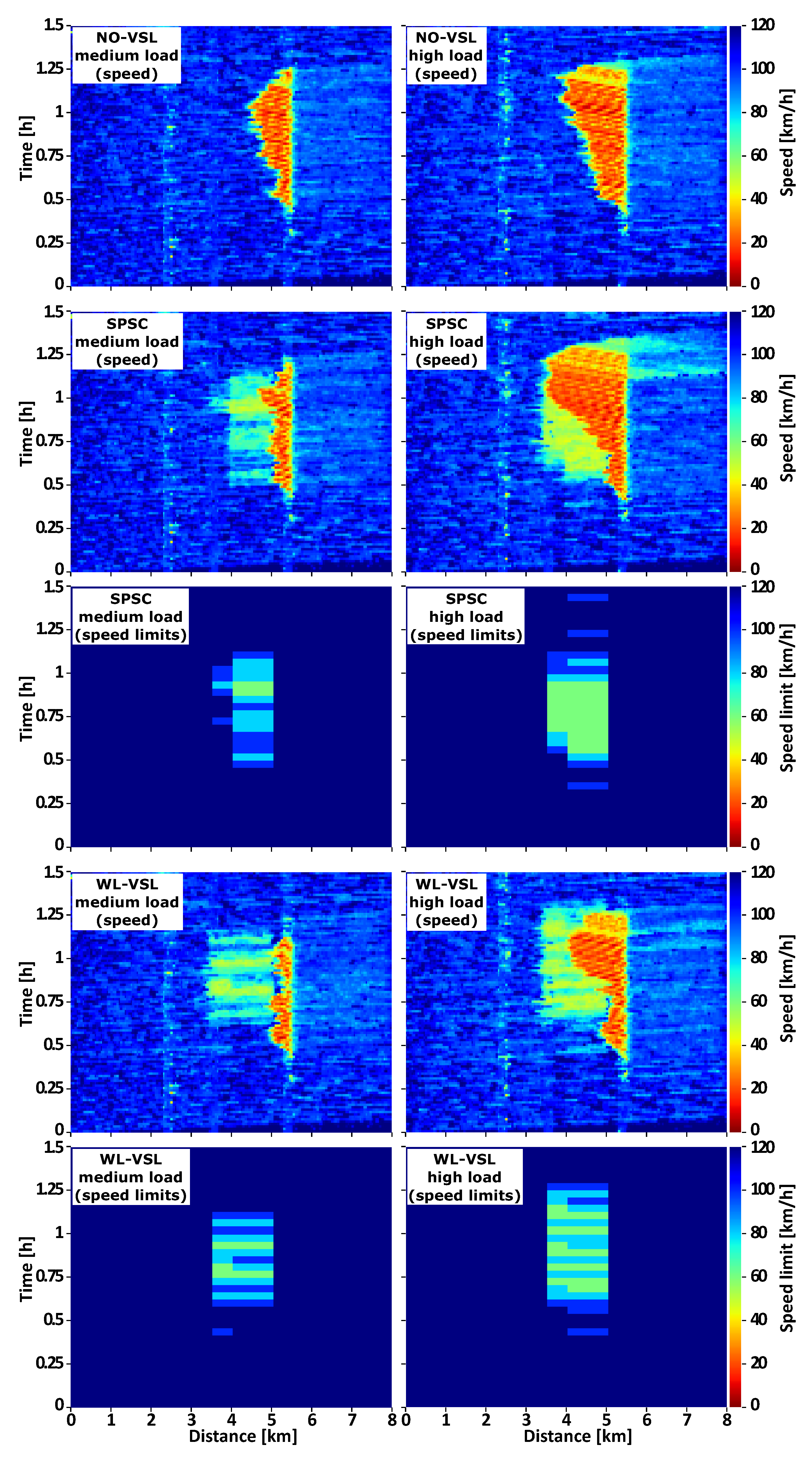
6.2. Space-Time Congestion Analysis
Space-time diagrams are interesting for visualizing how traffic conditions evolve along the observed motorway segment. The on-ramp
in
is located at
[km]. DWL2-ST-VSL ranges from
to
[km], while DWL4-ST-VSL ranges from
to
[km]. The best configuration of the static VSL zones (WL-VSL, SPSC) ranges from
to
[km]. The initial transition area [
26] after the VSL zone starts at
[km] to the on-ramp
and can be changed if the configuration of the VSL zones changes during agents’ operations in DWL-ST-VSL (in particular
and
).
6.2.1. Medium Traffic Load
In
Figure 4 and
Figure 5, the mixed shades of red and orange correspond to congestion where vehicles are traveling at low speeds. The patterns of red stripes represent the propagation of the shock wave upstream through the motorway. Congestion begins at about
[h] in the bottleneck area and propagates upstream. After the demand on the on-ramp
decreases, the congestion decreases and finally dissipates at
[h].
In both DWL-ST-VSL control strategies, the congestion (red) area is much smaller than in the baseline cases. The mixed shades of yellow-green-light blue in front of the congestion area correspond to the speed of vehicles obeying the speed limits (60–100 [km/h]) within active VSL zones. Such an artificially generated moving bottleneck (adaptive VSL area) with a significantly higher average travelling speed than the one measured in the congestion area still reduces inflow into the congestion area, which helps to resolve congestion more efficiently than baselines. In response to spatially varying congestion, both DWL-ST-VSL produce more stable downstream flow than the best baselines with static VSL zones. In the medium load scenario, congestion propagates upstream from the bottleneck to location [km]. In the case of DWL2-ST-VSL and DWL4-ST-VSL, the propagation is reduced to [km], which is an improvement of compared to NO-VSL. Finally, the average density in the congested area (bottleneck and directly affected upstream section ) is reduced from in NO-VSL to [veh/km/lane] in the case of DWL2-ST-VSL, an improvement of . The improvement for simulated DWL4-ST-VSL is .
6.2.2. High Traffic Load
Again, both DWL-ST-VSL versions win the competition. For DWL2-ST-VSL and DWL4-ST-VSL, the congestion area is smaller than for baselines. During the simulated scenario, different combinations of VSL zones were applied to respond to the changing congestion intensities and moving congestion tail. In this way, DWL2-ST-VSL and DWL4-ST-VSL are able to reduce the congestion area much more effectively than the baselines with static VSL zones. In the case of NO-VSL for the high-load scenario, the congestion spreads upstream from the bottleneck to the location [km]. When DWL2-ST-VSL is applied, the propagation is reduced to near [km], an improvement of . Using the extended version with four agents (DWL4-ST-VSL), propagation is reduced to about [km], an improvement of . Finally, the average traffic density in the congested area ( and ) is reduced from the original to [veh/km/lane] by using DWL2-ST-VSL, an improvement of . In the case of DWL4-ST-VSL, the improvement achieved is . Just for comparison, in the case of WL-VSL with static zones, the congestion propagates near [km], resulting in negligible improvement. A similar behavior is observed in the case of SPSC, eventually degrading the system performance.
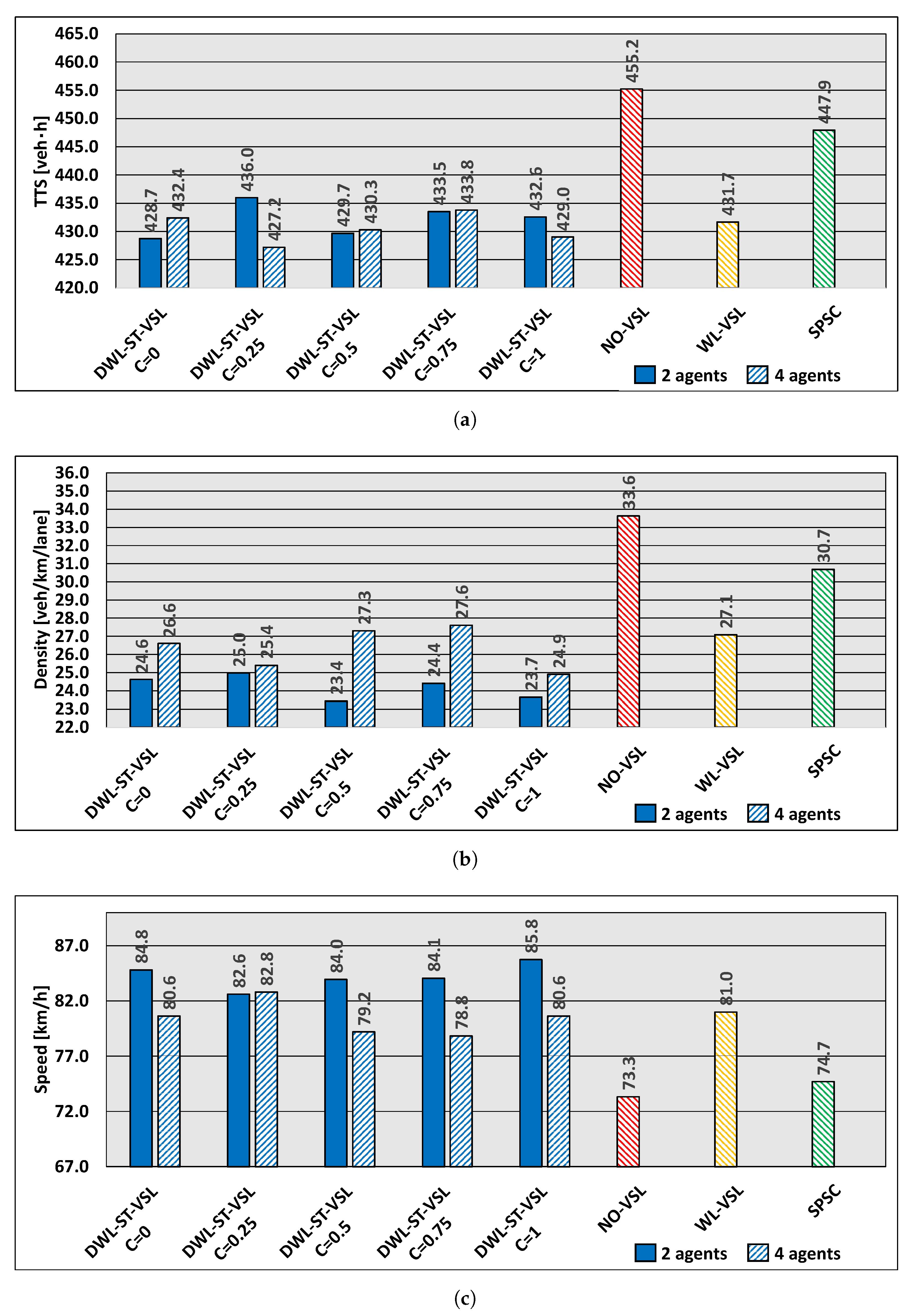
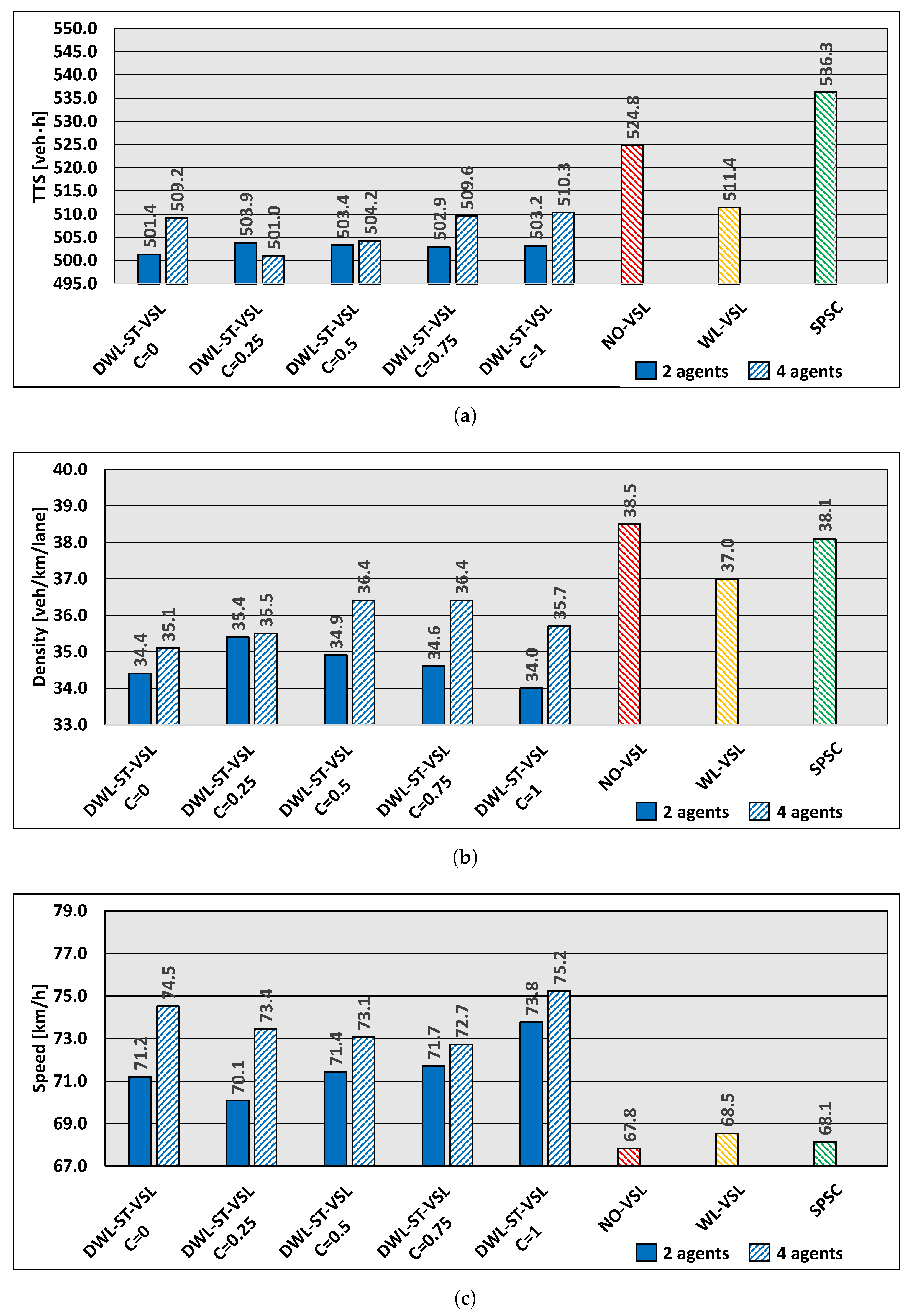
6.3. Level of Cooperation Analysis
To evaluate the benefits of cooperation between agents using the DWL’s concept of remote policies, we also assess the effects of the cooperation coefficient on agent performance. The effects of different levels of agent collaboration on system performance are presented in
Figure 6 and
Figure 7. The analysis was performed for medium and high traffic loads (
Figure 3).
6.3.1. Medium Traffic Load
It can be seen that all DWL-based approaches outperform the baselines used in our experiment. The lowest
value is obtained with DWL4-ST-VSL and is
[veh·h] for
. Compared to the NO-VSL case, (
[veh·h]), a reduction of
(
Figure 6a). The best density is
[veh/km/lane] for
in the case of DWL2-ST-VSL, while it is
for the case of NO-VSL, an improvement of
(
Figure 6b). In particular, the average vehicle speed for
in the case of DWL2-ST-VSL is
[km/h], while the speed in the case of NO-VSL is
[km/h], an improvement of
(
Figure 6c).
6.3.2. High Traffic Load
Similar results were obtained in the high traffic load experiment, where both DWL-ST-VSL configurations outperform the baseline controllers. The lowest
value in the cooperative agent case in DWL4-ST-VSL is
[veh·h] for
. Compared to the NO-VSL case, (
[veh·h]); this is an improvement of
(
Figure 7a). The density is
[veh/km/lane] for DWL2-ST-VSL (
), while in the case of NO-VSL it is
, a reduction of
. The density is reduced by
by using DWL4-ST-VSL (
Figure 7b). In particular, in the case of DWL2-ST-VSL, the average vehicle speed for
is
[km/h], while in the case of NO-VSL the speed is
[km/h], an improvement of
(
Figure 7c). In the case of DWL4-ST-VSL, the average speed is
higher (for
).
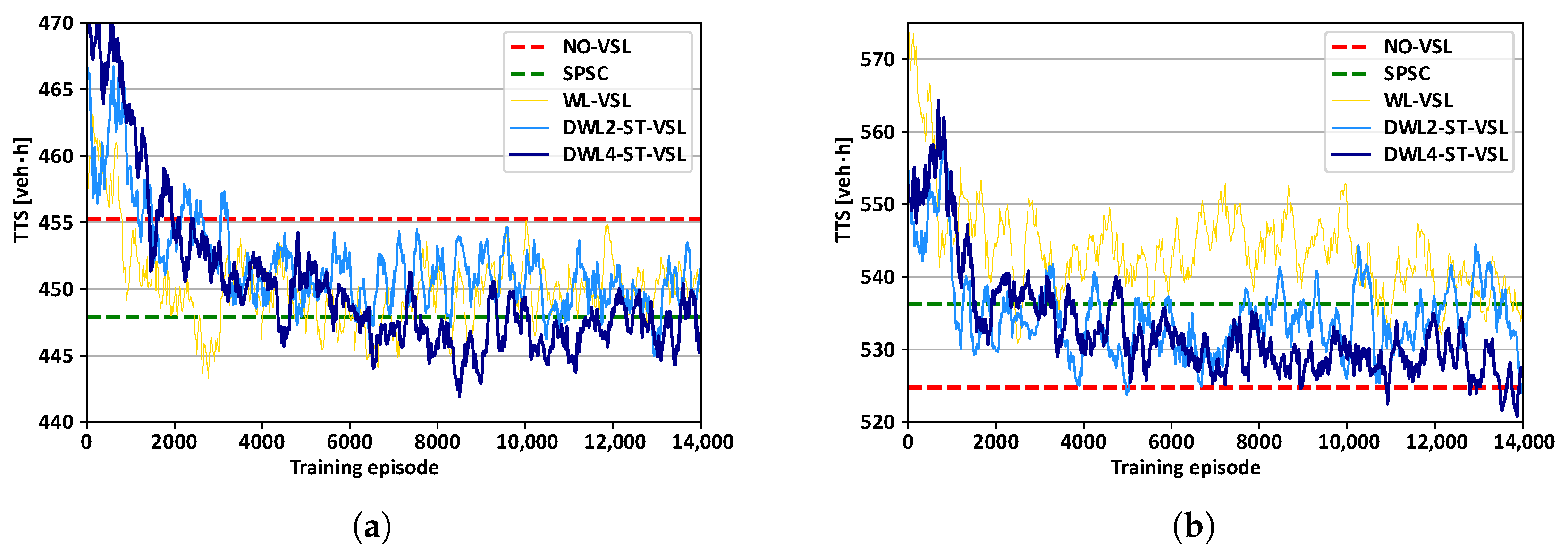
6.4. Convergence of during the Training Process
A comparison of the convergence of
measured per training episode (episode
one simulation) during the learning process is shown in
Figure 8. The graphs are created using the moving average over 10 episodes, while
was measured in the entire motorway network (including all on- and off-ramps). At the beginning of the learning process, all agent-based VSL approaches performed inferiorly compared to NO-VSL, since agents explore the environment by executing random actions with high probability. As simulations progress, the number of random actions taken reduces, and the exploitation of learned experiences increases. Consequently,
decreases, indicating progress in learning. Due to the different complexities of proposed RL-based multi-agent VSL controllers, the different decrease rate of
can be observed throughout the learning process. From
Figure 8a, it can be seen that all approaches have stable decreasing learning curves; generally, DWL4-ST-VSL leads in
reduction over other strategies in the medium traffic scenario.
For the high traffic scenario (
Figure 8b), the static VSL zones used in WL-VSL are prone to performing poorly compared to the dynamic VSL zones. Cases with dynamic VSL zone allocation via DWL2-ST-VSL and DWL4-ST-VSL need a higher number of training episodes to approach lower
values. As the learning process approaches 14,000 episodes,
in the case of DWL2-ST-VSL and DWL4-ST-VSL converges moderately towards and below the
value obtained in NO-VSL. Eventually, compared with the starting values, the overall
is gradually improved for all agent-based VSL strategies, favouring the learning rate of DWL4-ST-VSL in both traffic scenarios.
In the case of the high traffic scenario (
Figure 8b), it can be seen that DWL4-ST-VSL needs a slightly longer time, i.e., higher number of training episodes (around 11,000) to reduce
below the value obtained by NO-VSL. Nevertheless, when converted in real-time, it takes roughly 90 [h] of training in a simulator (on an Intel(R) Core(TM) i7-10750H CPU processor). In case our simulated experiment represents actual recurrent traffic congestion observed online, DWL4-ST-VSL can be trained offline (on simulations) and deployed in a real application in a short period. Thus, DWL4-ST-VSL can be retrained offline to deal with traffic changes in the operating environment to ensure good performance in the newly observed traffic scenarios (similar to the continuous learning scheme for Q-Learning based VSL suggested in [
17]).
The longer time needed for reaching the favorable level may be directly linked to the larger number of agents. They eventually need more training episodes to become aware of the interference they cause by their actions on their immediate neighbours and the controlled motorway system as a whole.
In the second half of the learning process, there are more pronounced oscillations in
. The possible contribution to this might be delaying
W’s convergence until
Q is well known (see
Section 5.4). Thus, W-values are more altered as Q-values are more learned. Consequently, this influences the policies’ nomination (3) in the DWL process and eventually influences the cooperation strategies between agents. As a result, it might cause a change in a learned set of optimal policies, thus resulting in the different system responses during the second half of the learning process. The new policy can induce new rarely seen system states that have not been encountered before, thus affecting agents’ poor decisions. Nevertheless, the function approximation techniques can address this problem by ensuring better generalization (reasonable outputs) for rarely seen states, thus stabilizing the training (learning) process.
7. Discussion
The outermost agents ( and ) do not perceive congestion directly and, therefore, tend to exploit local stable traffic conditions by promoting higher speed limits and, in particular, favoring their local policy . As a result, for small values of the cooperation coefficient C, they do not fully contribute to helping downstream agents to eliminate the congestion. This raises the question of whether C should be scaled differently depending on the spatial location of the agents rather than using uniformly distributed equal values for all agents. It might make sense to increase the coefficients of C the farther agents are from the location of the bottleneck so that they are more sensitive to the preferences of downstream agents and, therefore, give more priority to remote policies in the case of active congestion. The question then arises: to what extent?
The converse is also true, since the actions of the downstream agents affect the state variables (in particular, the measured average vehicle speed) of the upstream agents. The upstream agents always observe the average speed in their immediate downstream area (in the case of local policy ) and, possibly, the actions performed by the downstream agents (lower speed limits) reduce the chance of winning the ; therefore, a penalty by the measured is more likely, even if the local environment is in free-flow conditions. This dependence is implicitly communicated to the downstream neighbouring agent in the form of a higher W-value for remote policy , which complements the local policy of the upstream agents .
The above observation shows the possible trade-off in choosing optimal values for
C. A feasible solution to make
adaptive is to use a scaling scheme used in (2) “learning
Q (somewhat) before learning
W” [
43]. In this scheme, the updates of W-values are weighted differently. The weighting is higher when an agent is sure of what it is doing in a given state. Given that the underlying DWL process (WL algorithm) is considered as a “fair” resolution of competition, this leads to the question: can the W-values of local policies, together with the probability of nominating a particular action in a given state, be communicated between neighbors and used as input for computing
C? This may trigger further research on adaptive cooperation coefficient
C.
Furthermore, the overlapping states of the environment, including the downstream neighbourhood (see
Figure 2), has positive and negative effects on the agent’s learning behavior. The negative effect arises from the nonstationarity caused by the neighbours’ actions, resulting in a moving learning target (particularly during the exploration phase in the training phase) since agents are learning simultaneously. Thus, each time, Ai’s policy changes might cause other agents’ policies to change, too [
50]. The positive effect is the agent’s ability to detect and respond to the early impulse of congestion in downstream traffic. All learning-based approaches were trained with the same number of simulations. However, due to nonstationarity, DWL4-ST-VSL may require more simulations to converge to better control policies for a given traffic scenario due to a higher number of agents. Therefore, DWL4-ST-VSL (and the final results) may be in a slightly unfavorable position compared to DWL2-ST-VSL.
In our experiments, we assumed that all measurements (traffic data) in our experiments are perfect. In reality, sensors are not ideal, and raw data needs to be analyzed and filtered before being used for traffic state estimation. Thus, accurate traffic states are important for real-time traffic control. Raw traffic flow data collected from sensors might be contaminated by different noises caused by the imperfection or damage of sensors. In [
51], the authors introduced data denoising schemes to suppress the potential data outliers from raw traffic data for accurate traffic state estimation and prediction. This presents an open question for further research.
Additionally, the efficiency of DWL-ST-VSL is highly dependent on the learning process performed in traffic simulations. Since simulations themselves depend on the given initial parameters, not all possible relevant traffic conditions can be covered. A possible direction to improve the training process of DWL-ST-VSL by ensuring that all relevant traffic scenarios are covered is to use the idea of structured simulations. Originally proposed in [
52], structured simulations are intended for testing the behavior of complex adaptive systems in general by changing the inputs into the simulations in a structured way. Such a framework might augment existing traffic scenarios (real or synthetic) with unprecedented scenarios that evoke or replicate important aspects of real traffic, such as rarely seen traffic states in which VSL agents performed poorly. Thus, a structured simulations approach can enrich the training data set and consequently minimize unexpected behavior of the RL-based VSL controller in practice.
Even under a medium load scenario, the resulting congestion on the motorway can be classified as a serious traffic problem. However, it has been shown that DWL2-ST-VSL and DWL4-ST-VSL can effectively resolve the congestion in this scenario due to their added ability to dynamically adjust the VSL zone configurations. Since the DWL agents could not fully handle the congestion in the high load scenario (even when using four agents), it might be useful to extend the DWL4-ST-VSL control, e.g., by integrating it with the merge control using the DWL multi-agent framework.
Experimental results confirmed the usefulness of using dynamic VSL zone allocation (the capability to adapt the VSL application area) while optimizing speed limits in traffic conditions with varying congestion. Similarly, in [
42], a VSL strategy able to adjust each control cycle’s length (duration) online, given the changes in traffic conditions, was shown to be superior compared to a fixed cycle length. Thus, integrating dynamic VSL zone allocation and dynamic control cycles can make VSL more adaptive, making VSL’s performance more robust when operating in a nonstationary environment like a motorway. To accomplish the full benefits of adaptivity, the principal time constants of the system should be long enough for the system to ignore false disturbances and yet short enough to respond to indicative changes in the environment (the “stability-plasticity dilemma”) [
53]. Therefore, further research in this direction is desirable in DWL-ST-VSL.
The VSL control approaches with static VSL zone configuration performed poorer in high traffic scenarios than those with dynamic VSL zone allocation. Thus, results strongly indicate the need for the adaptive speed limit system in speed limit, length and position of VSL zones to efficiently cope with the unpredictable spatio-temporal varying congestion, which is more likely to be the case in a real traffic scenario.
8. Conclusions
This paper presented DWL-ST-VSL, a multi-agent RL-based VSL control approach for the dynamic adjustment of VSL zones and speed limits. In addition, an extended version, DWL4-ST-VSL, was analyzed for an urban motorway simulation scenario where four agents learn to jointly control four segments ahead of a congested area using the DWL algorithm on a longer motorway segment. The simulations show that DWL4-ST-VSL and the two-agent based DWL2-ST-VSL consistently perform better than our baseline solutions, WL-VSL and SPSC. The results do not differ significantly between DWL2-ST-VSL and DWL4-ST-VSL in terms of bottleneck parameters. In terms of system travel time, DWL4-ST-VSL gives better results. VSL control is improved by simultaneously adjusting speed limit values and VSL zone configuration in response to spatiotemporal changes in congestion intensity and the congestion’s moving tail. In addition, performance is improved by DWL’s ability to implement multiple different policies simultaneously and to use two sets of actions with different speed limit granularity, as well as to enable collaboration between agents implementing remote policies.
However, the efficiency of DWL-ST-VSL is highly dependent on the training process performed in simulations. To train DWL-ST-VSL in a structured way and ensure that all relevant traffic simulation scenarios are covered, we will use the structured simulations mentioned in the discussion. Using structured simulations and the nonlinear function approximation technique for better generalization together with sensitivity analysis of hyperparameters in DWL may reduce the poor performance of DWL in a nonstationary motorway environment, thus fostering DWL-ST-VSL to be closer to testing in reality. Eventually, this will enable the systematic evaluation of adaptive DWL-ST-VSL control.
Additionally, the results suggest that there may be multiple local optima for different coefficients of cooperation, which requires further analysis. How resilient the learning system would be to the loss of information exchange if one or more agents failed, which is often the case in a real scenario where sensors and equipment are imperfect and may break down, highlights the open research directions. We will consider implementing additional degrees of freedom to allow each agent of DWL-ST-VSL to adjust the length and position of the VSL zone in both directions, considering the constraints on the spatial difference of the speed limit between two adjacent VSL zones. Finally, we will consider integrating DWL-ST-VSL with dynamic control cycles and merge control, as this could further advance the VSL system toward instantaneous vehicle speed control in the presence of emerging vehicle-to-infrastructure technologies and traffic control on motorways in general.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







