
Bibliometrics of Machine Learning Research Using Homomorphic Encryption



Abstract
:1. Introduction
- An analysis of the literature of homomorphic encryption in machine learning (HEML) was studied by various researchers.
- An approach to the application of bibliometric statistics to the field of homomorphic encryption.
- Analysis of the application and development of homomorphic encryption in the field of machine learning from a literature perspective.
2. Literature Classification and Comparison
3. Research Methodology and Data Extraction
3.1. Literature Databases
- How many papers related to Homomorphic Encryption Machine Learning (HEML) have been published each year in recent years?
- What is the citation status of such papers?
- What are the topics of HEML papers?
- What is the relationship between machine learning and homomorphic encryption?
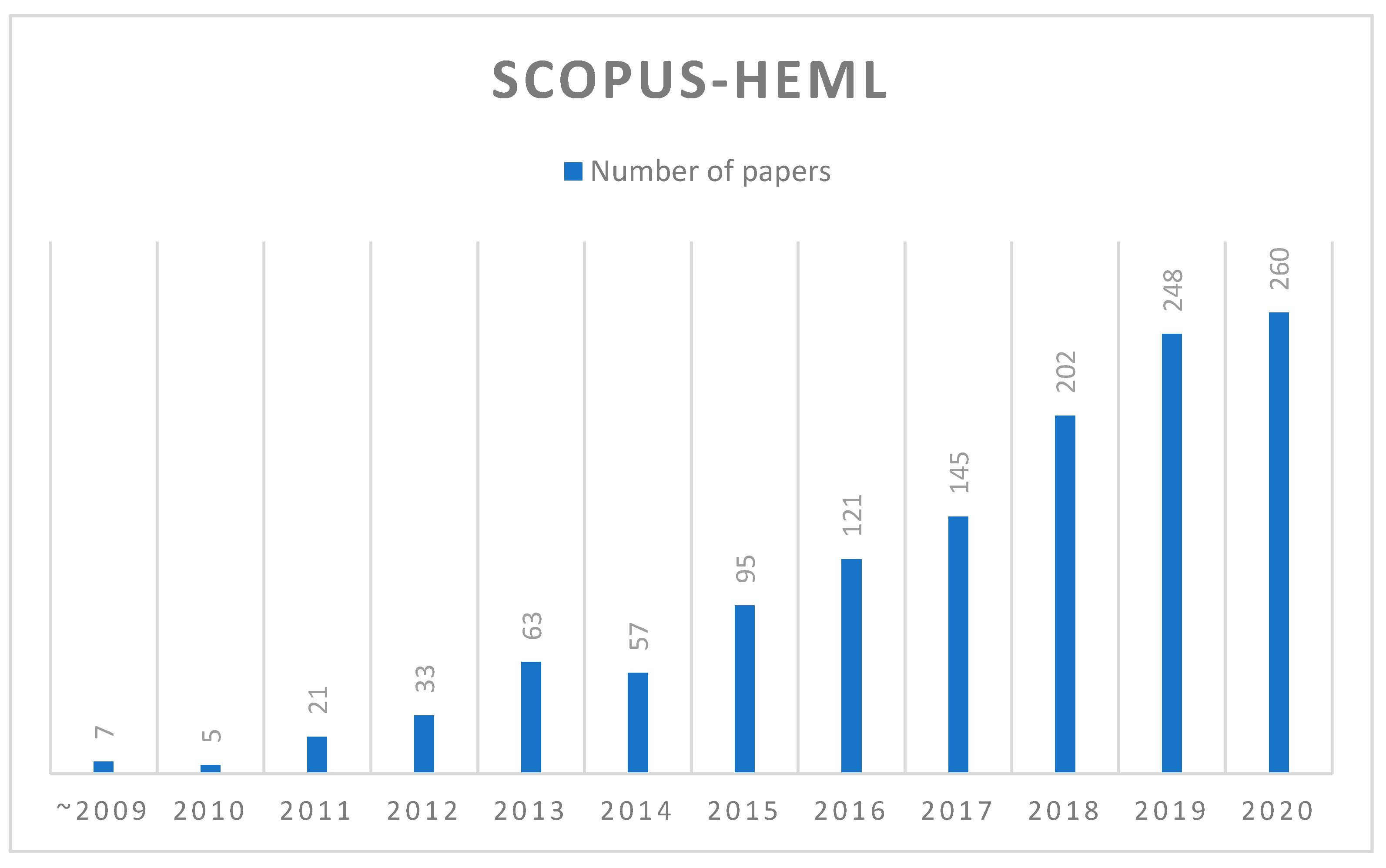
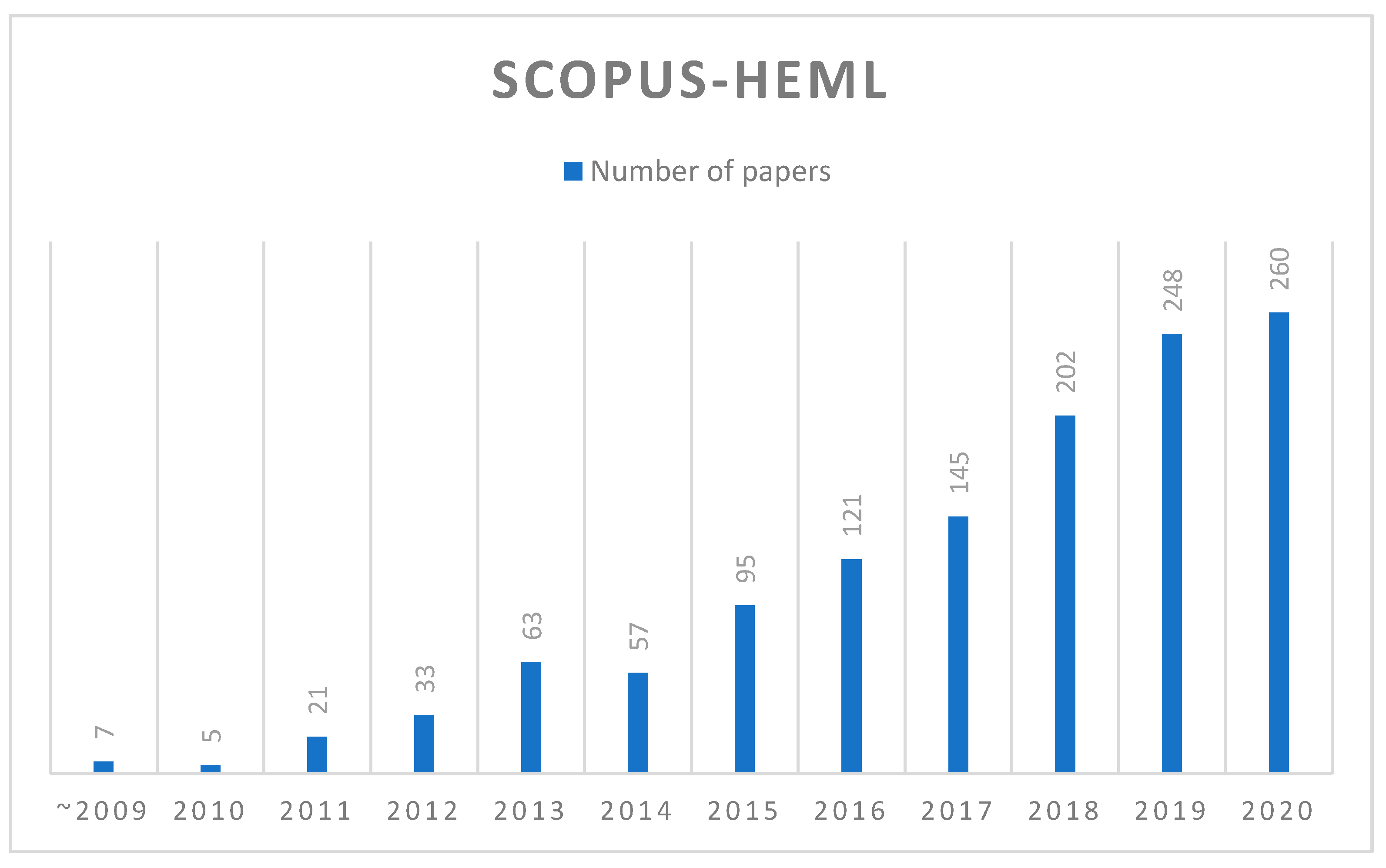
3.2. Extracting HEML Papers from Scopus
4. Analysis and Discussion
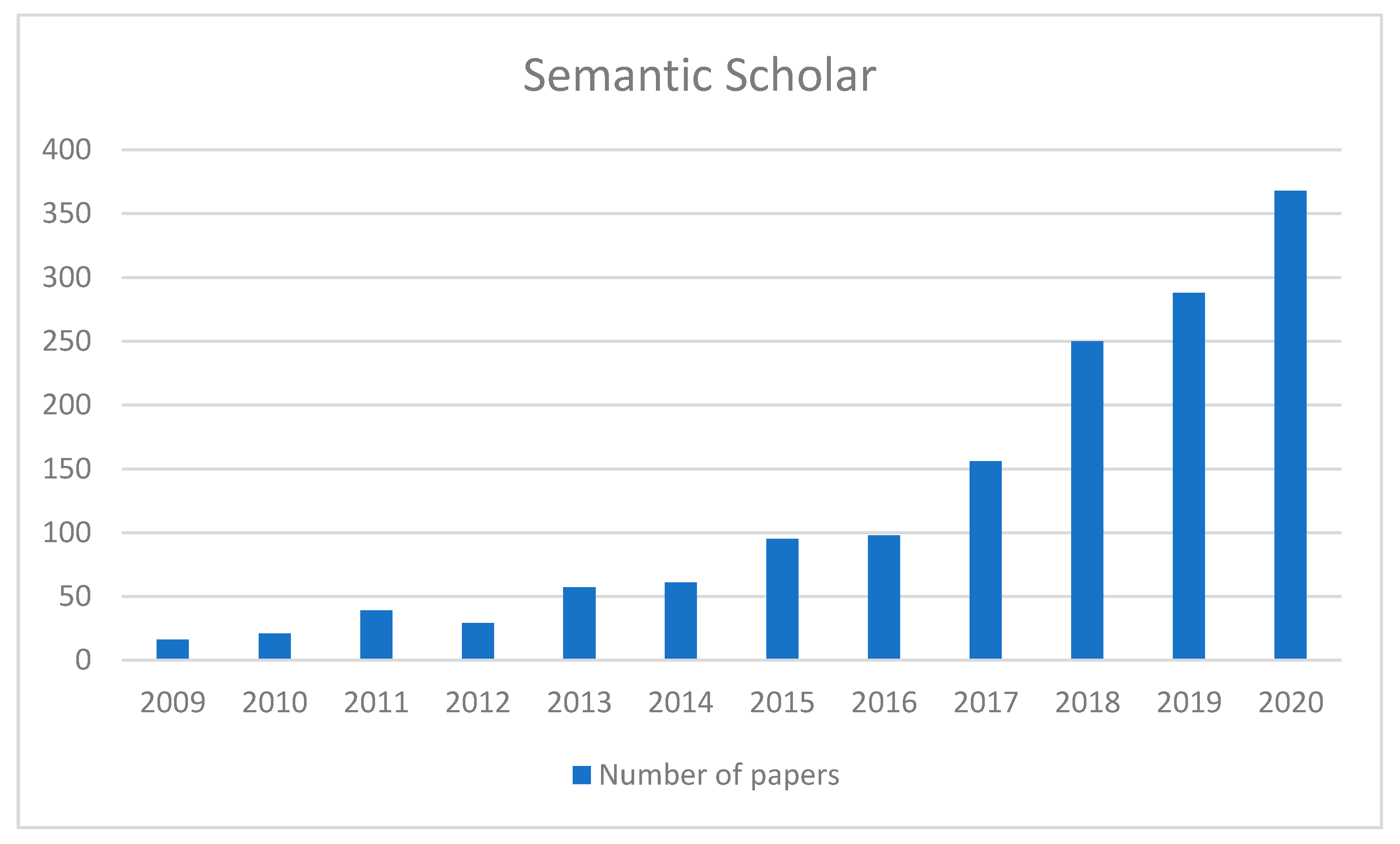
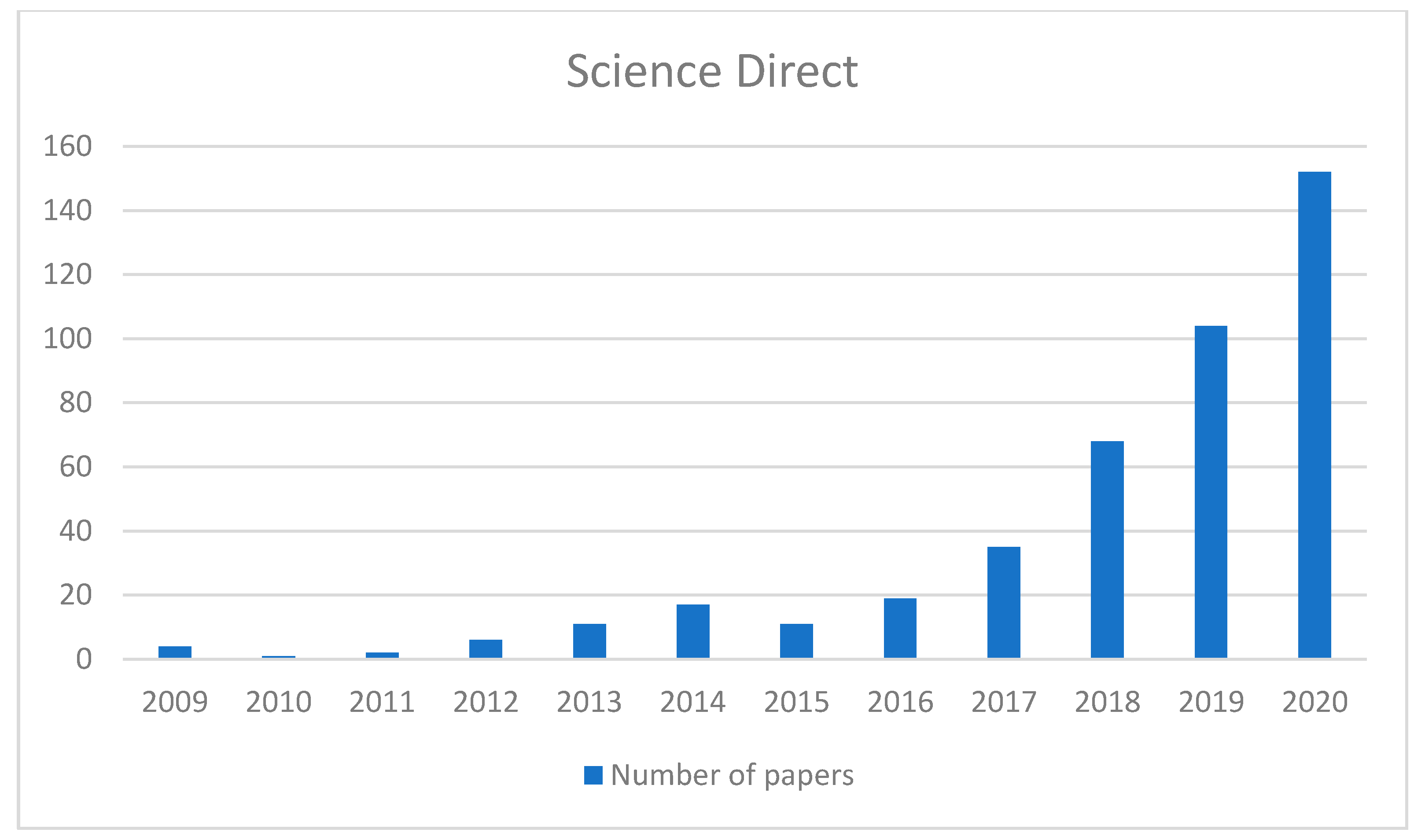
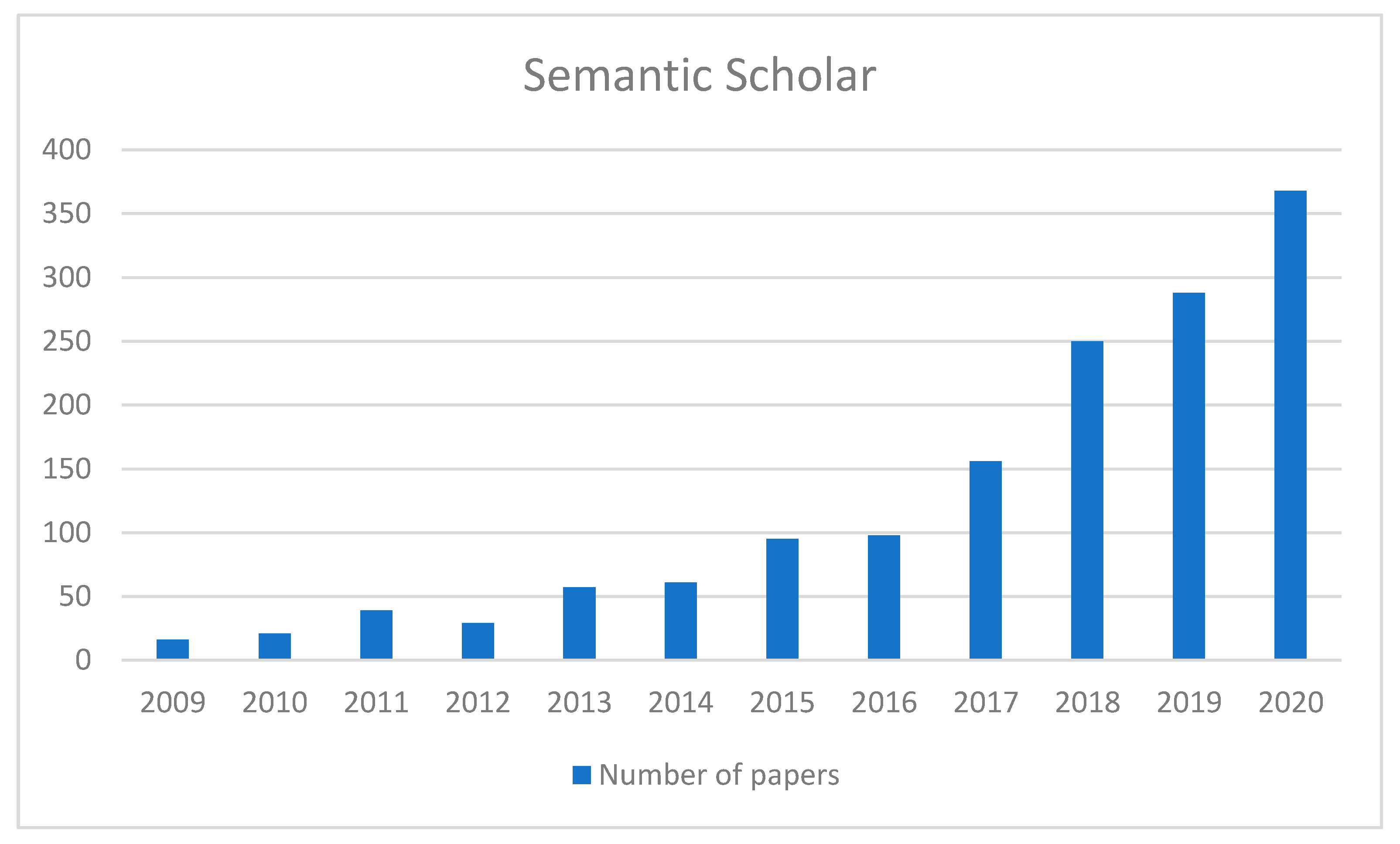
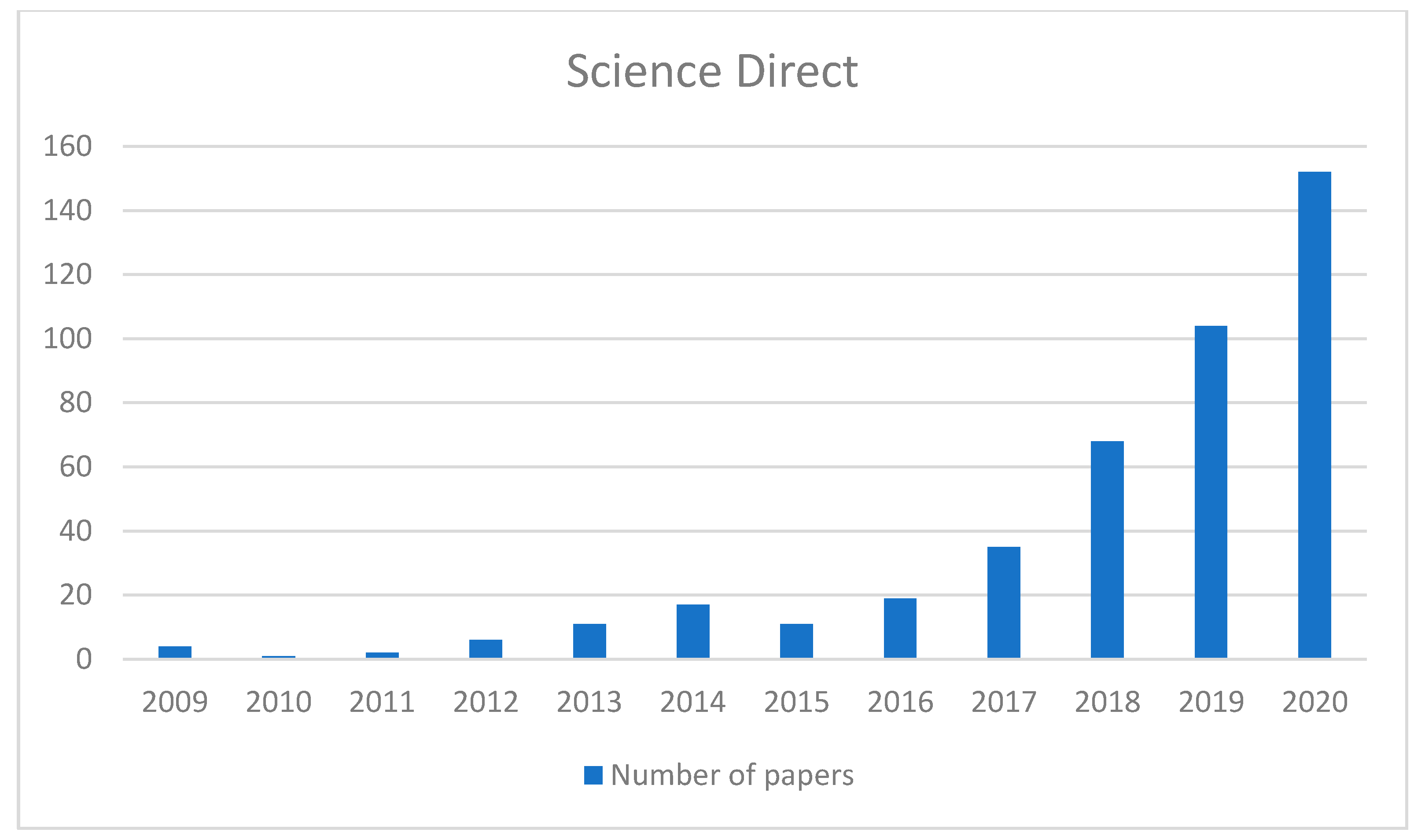
4.1. Literature Databases
4.2. Citation Analysis
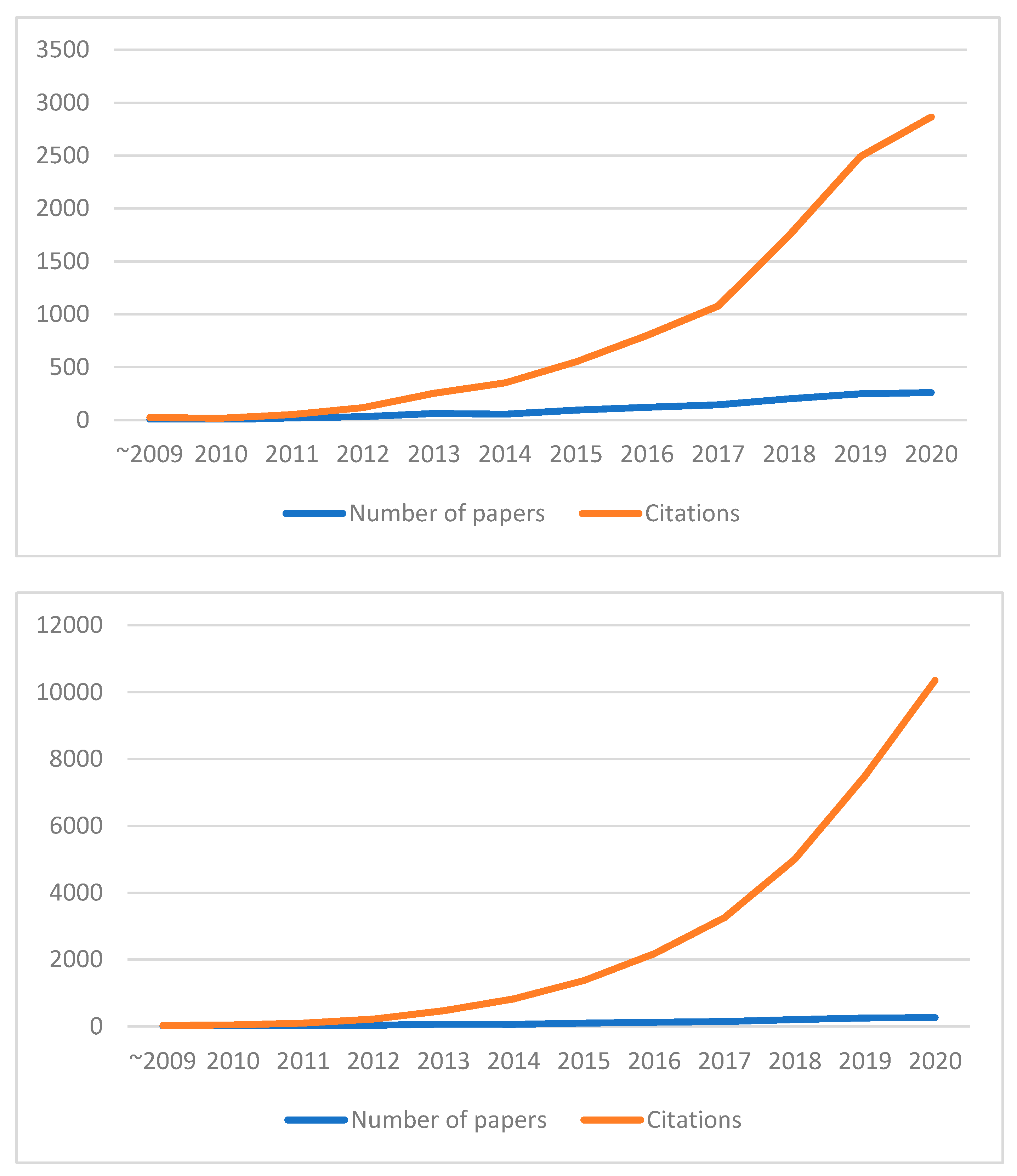
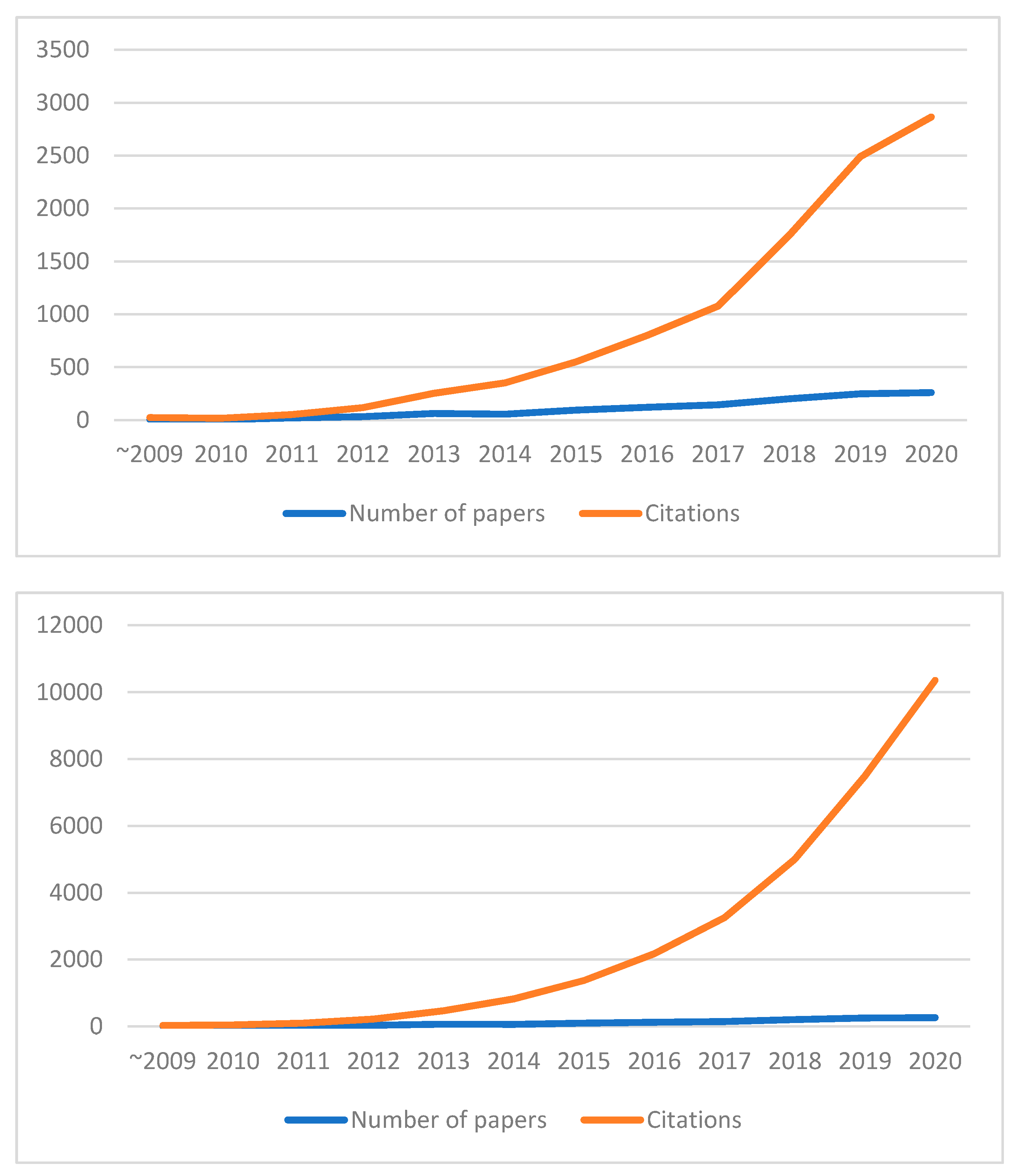
4.2.1. The Overall Situation of Citations
 Blue: Security and Privacy for Cloud-Based IoT: Challenges
Blue: Security and Privacy for Cloud-Based IoT: Challenges Pink: Multi-key privacy-preserving deep learning in cloud computing
Pink: Multi-key privacy-preserving deep learning in cloud computing Red: Can homomorphic encryption be practical?
Red: Can homomorphic encryption be practical? Brown: On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption
Brown: On-the-fly multiparty computation on the cloud via multikey fully homomorphic encryption Grey: Computing arbitrary functions of encrypted data
Grey: Computing arbitrary functions of encrypted data Green: Privacy preserving error resilient DNA searching through oblivious automata
Green: Privacy preserving error resilient DNA searching through oblivious automata4.2.2. Highly Cited Papers
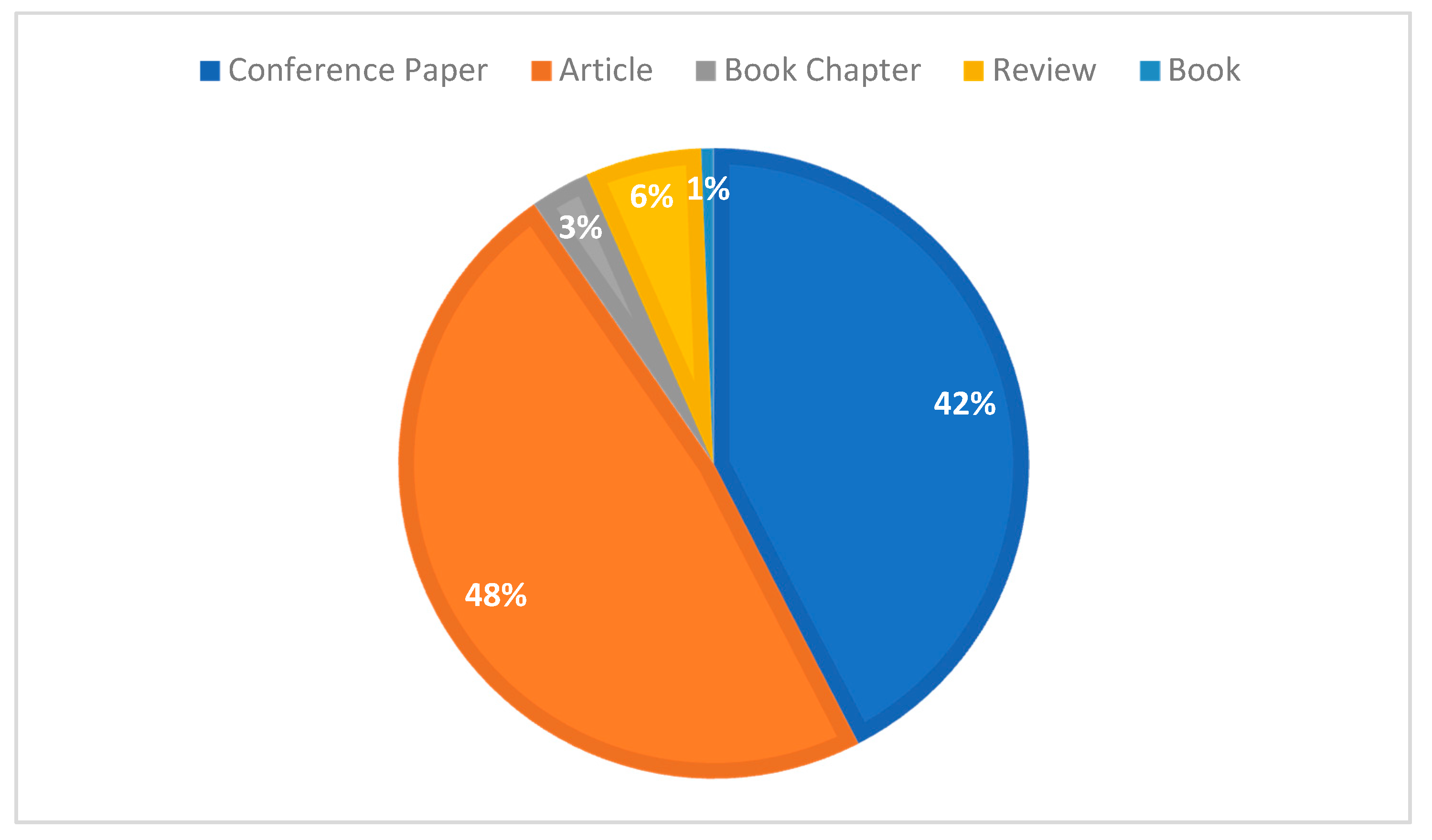
4.2.3. Statistics on the Number and Citations of Different Publication Types
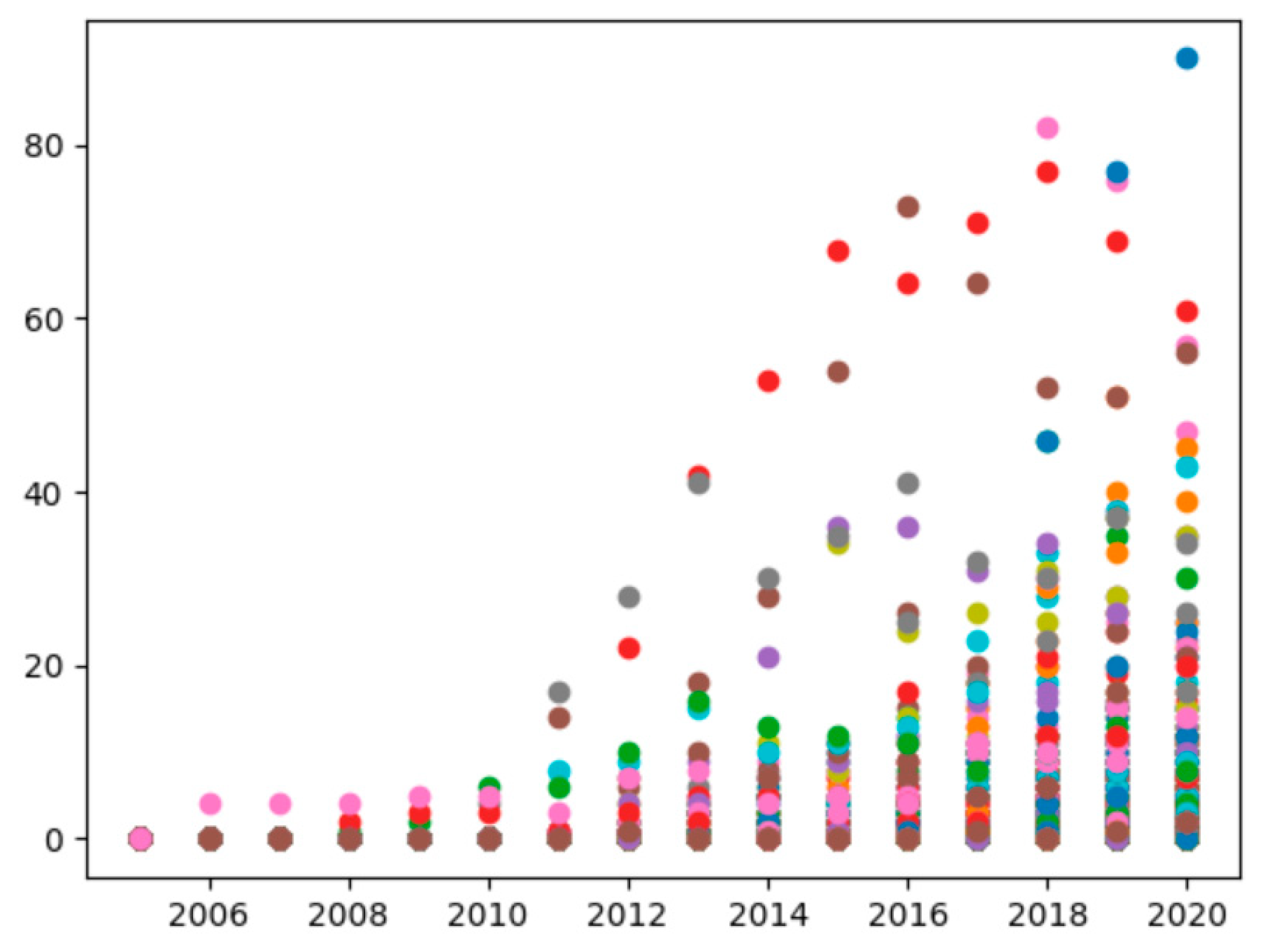
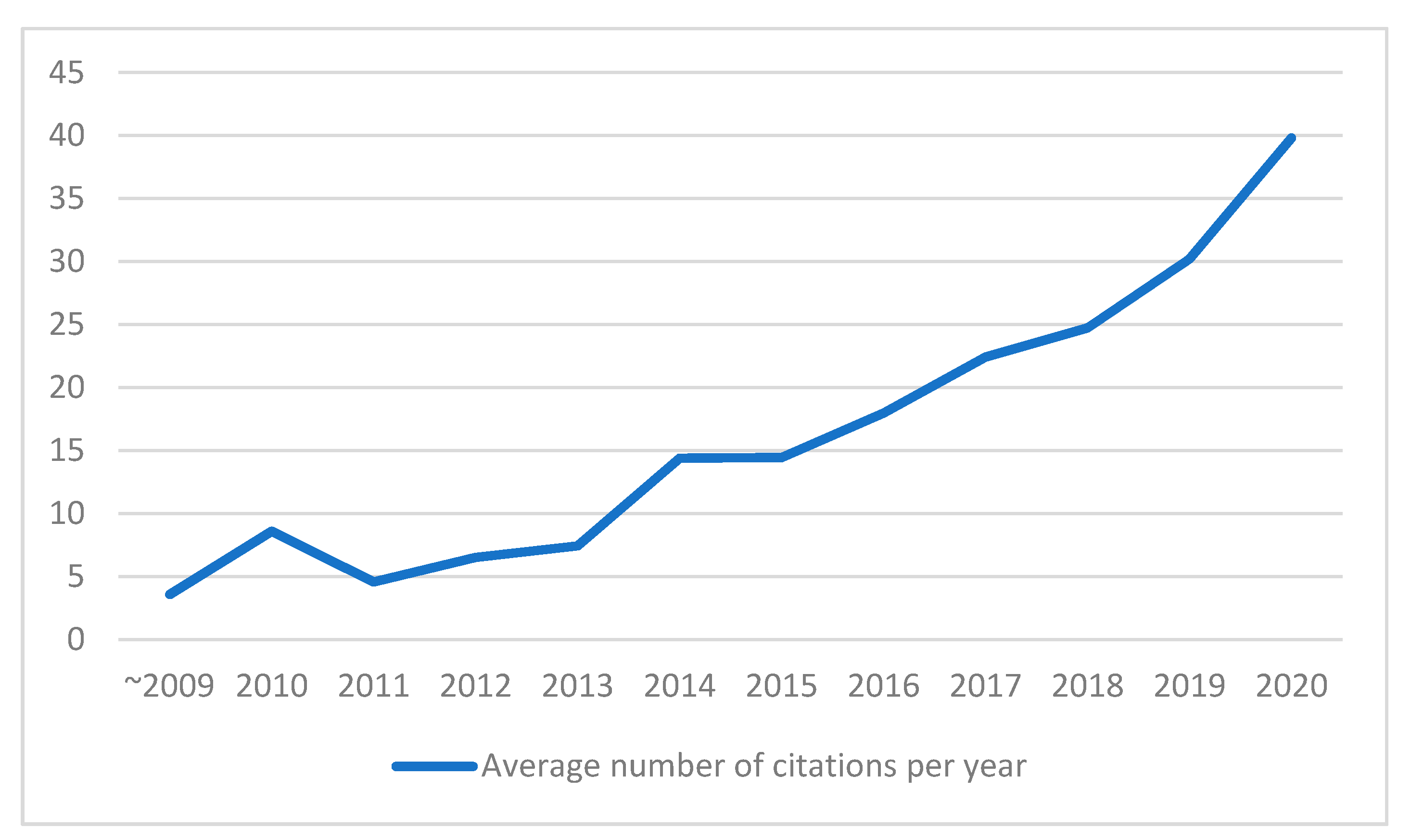
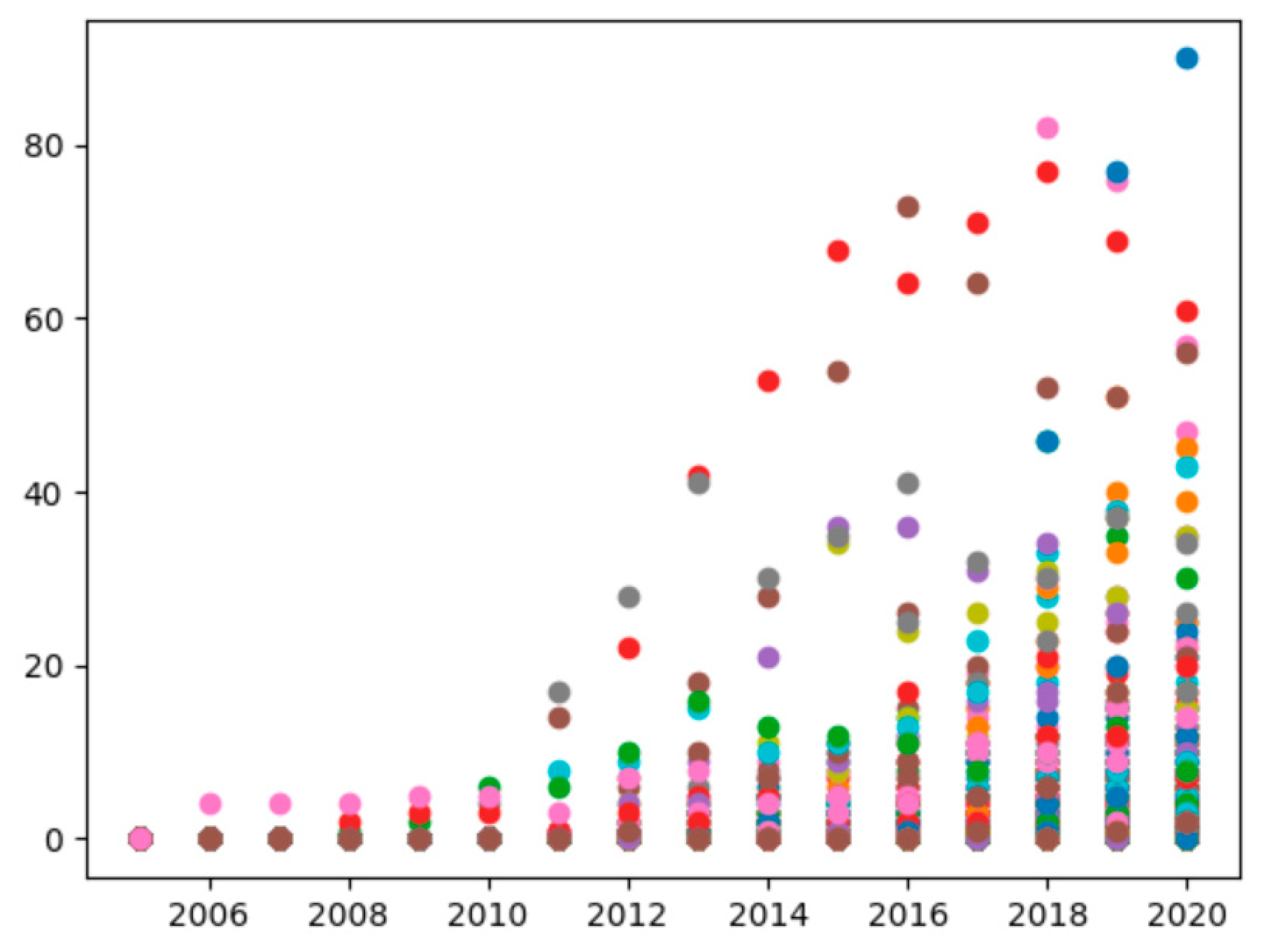
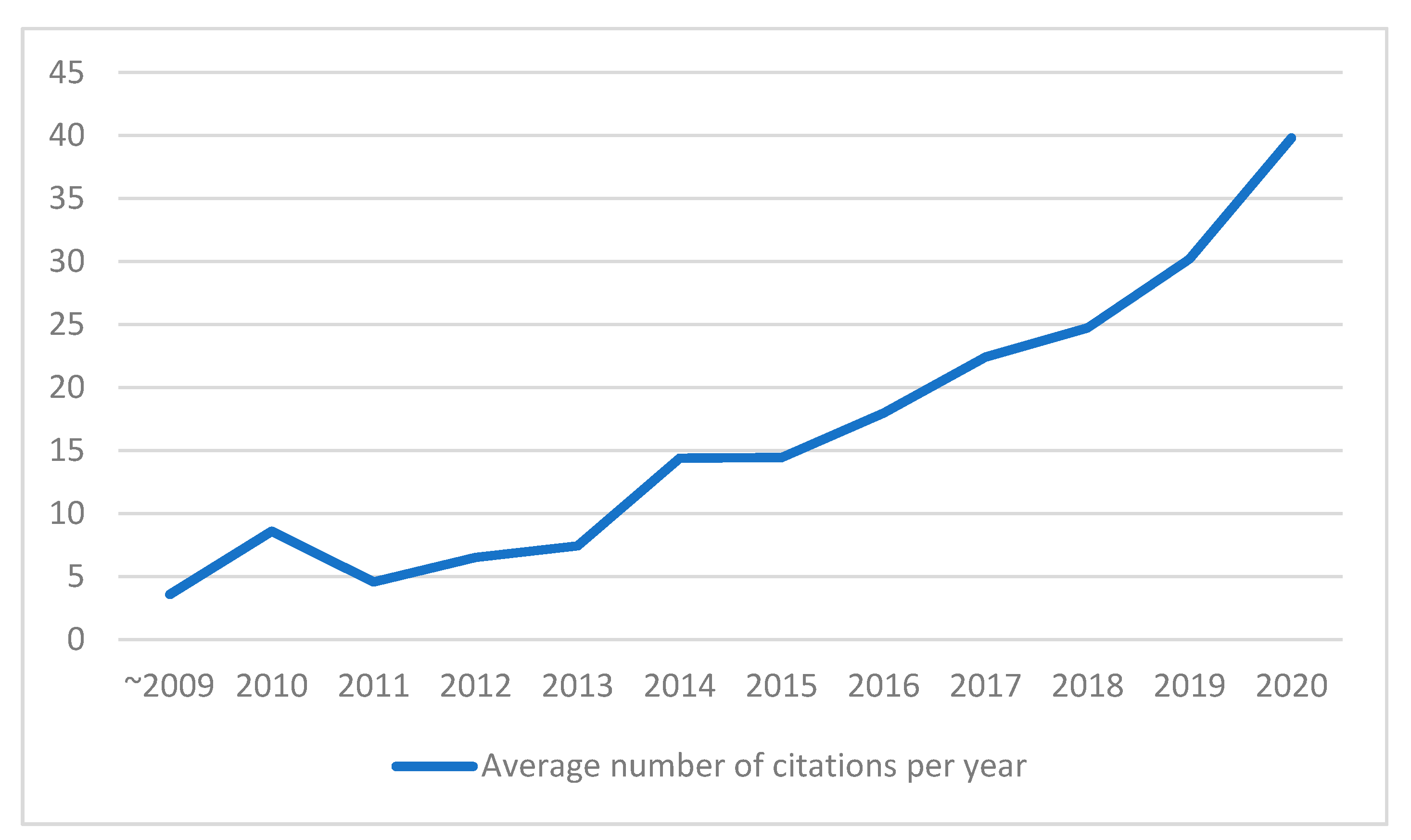
4.2.4. Annual Citation Analysis
4.2.5. Number of Papers and Citations in the HEML Subfield
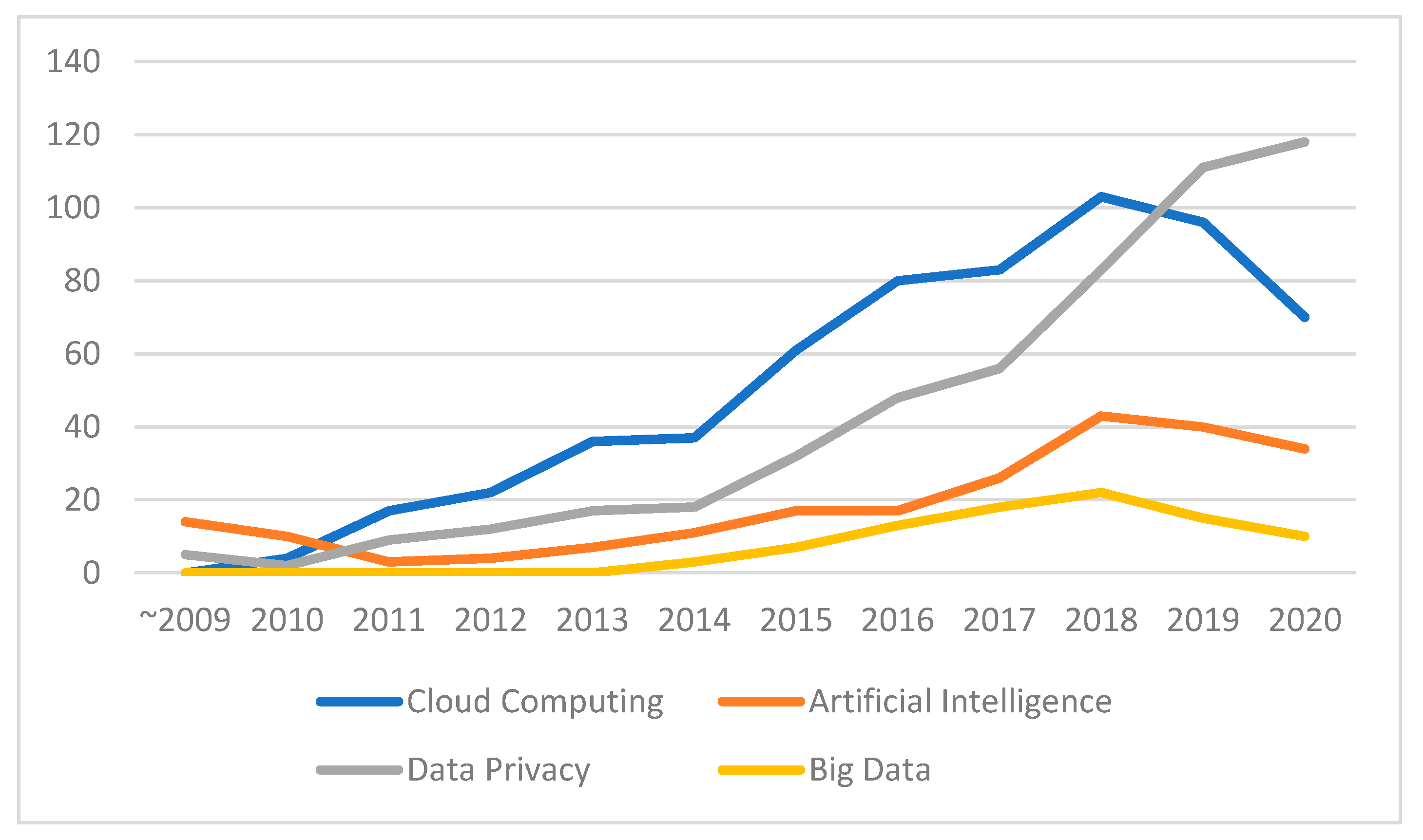
4.3. Focused Keywords
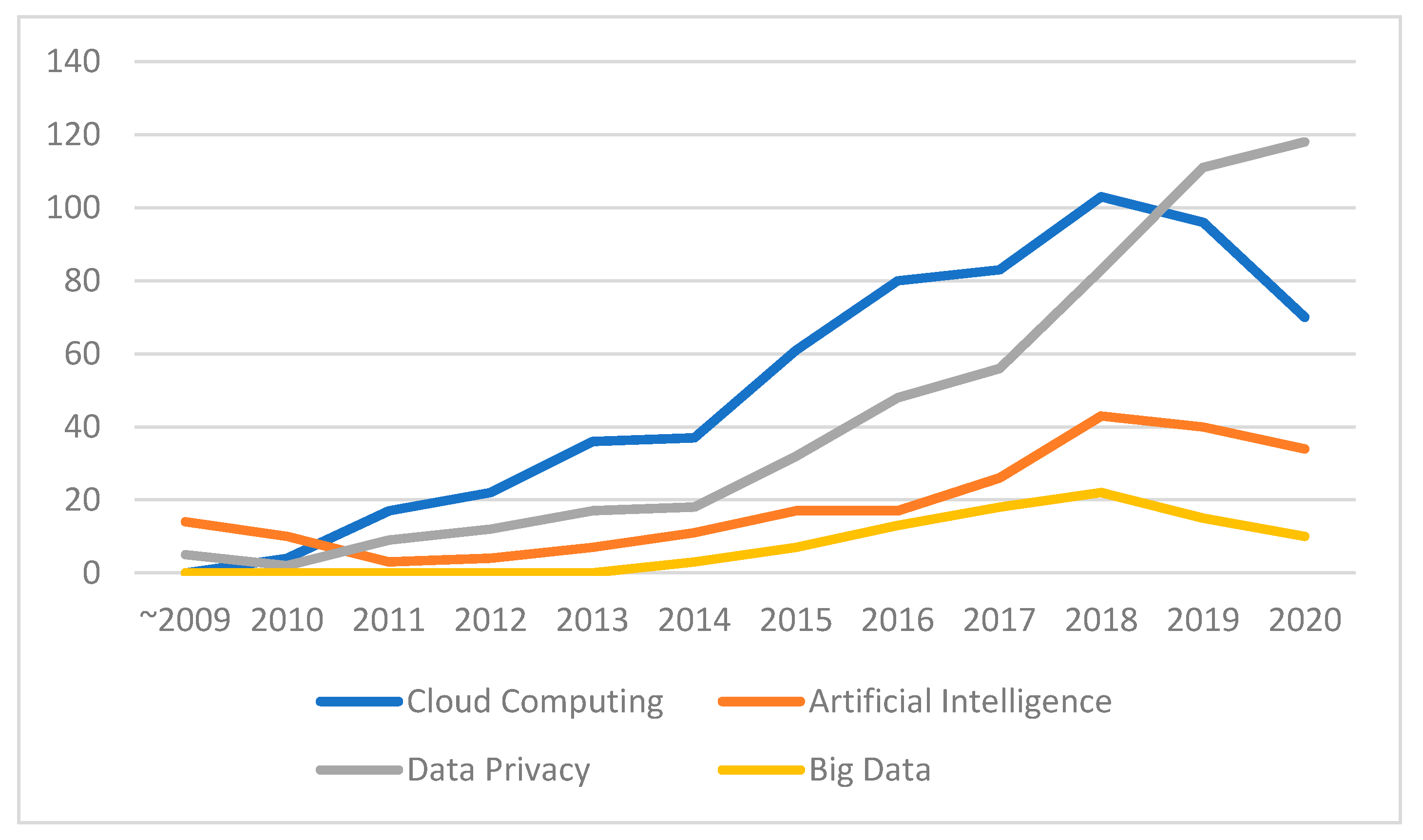
4.4. Theme Analysis
4.5. In-Depth Discussion
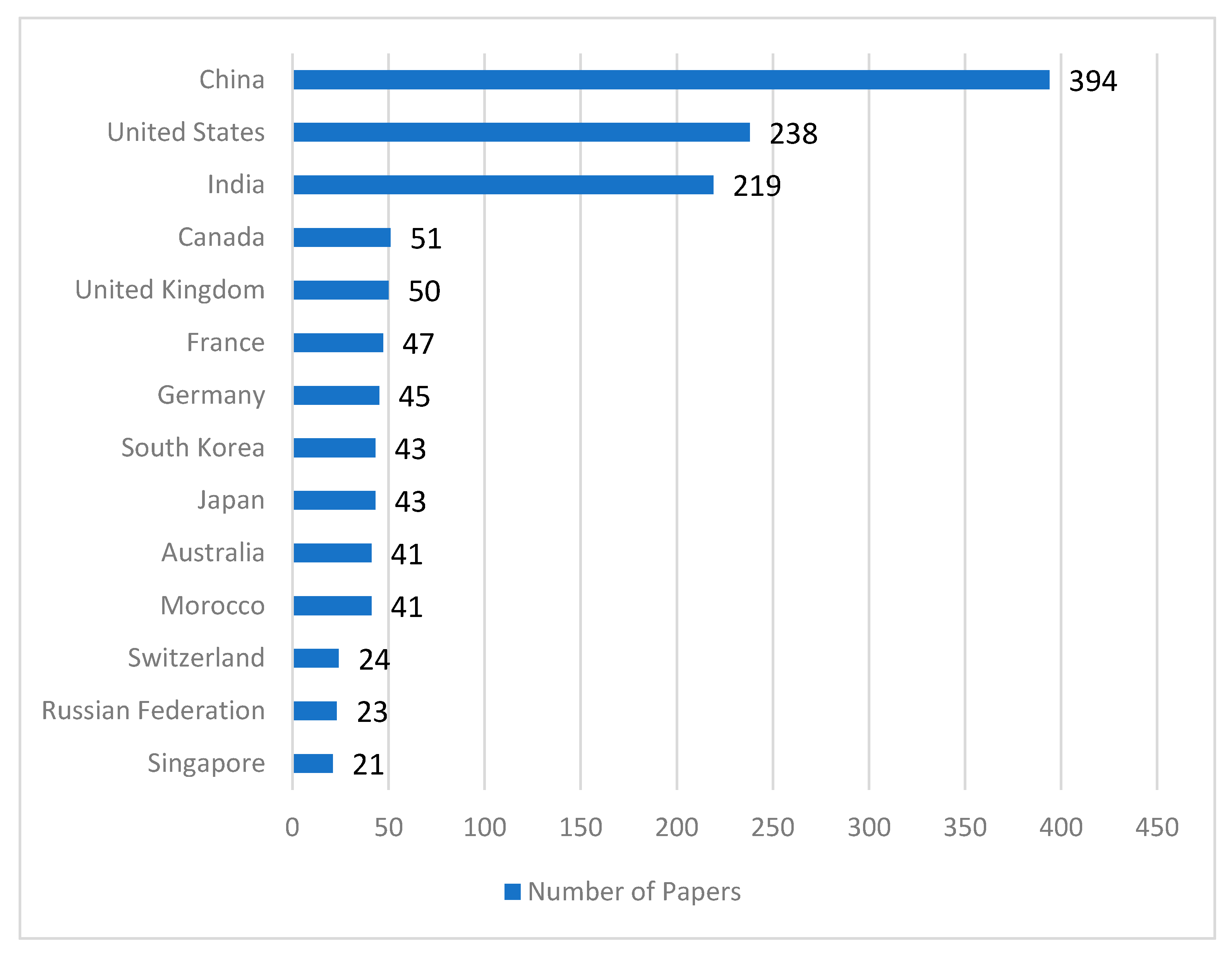
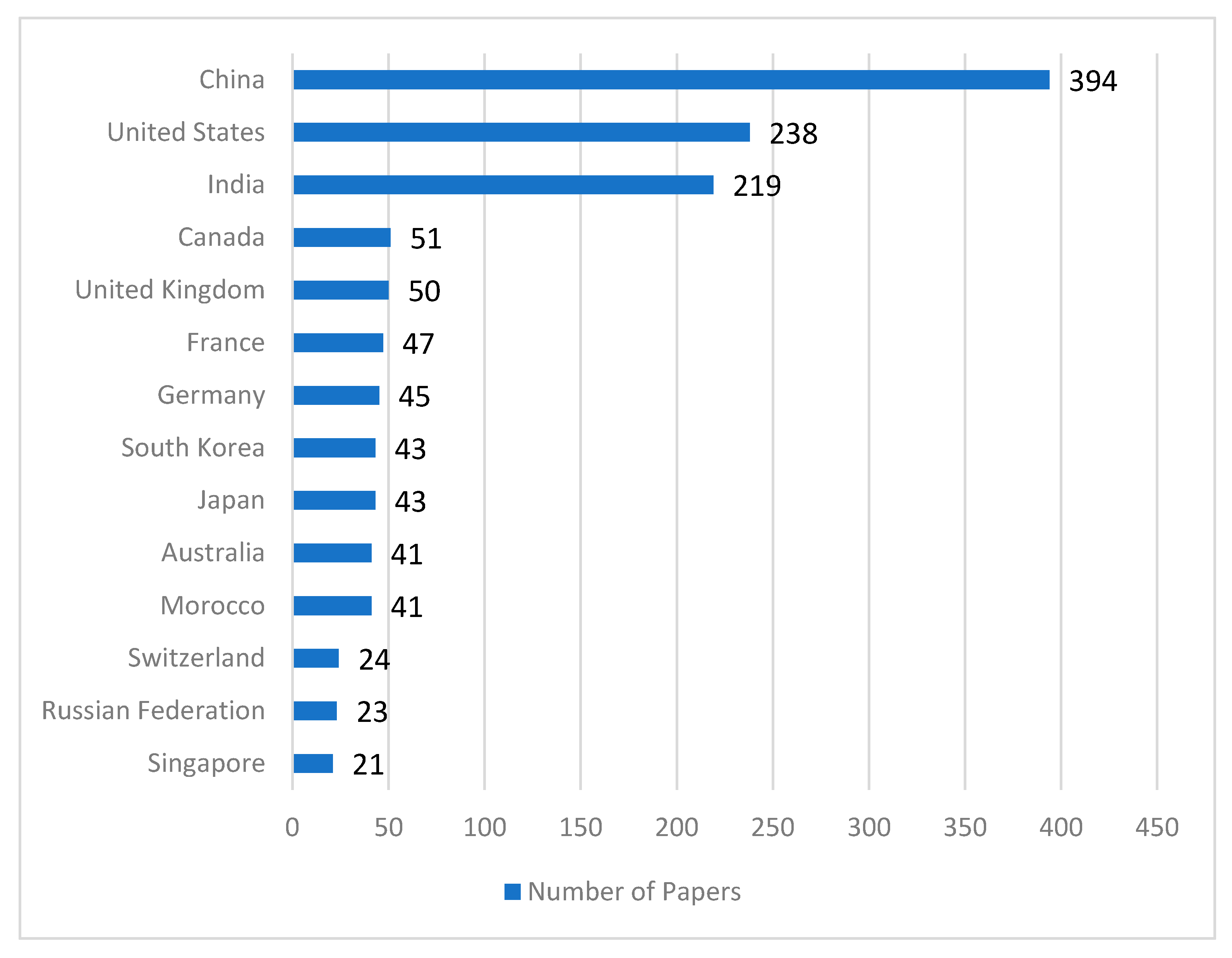
4.6. Number of Contributed Papers by Country
5. Further Discussion
5.1. Research Findings, Trends, and Insights
5.2. Potential Limitations and Effectiveness
6. Conclusions and Future Work
Funding
Data Availability Statement
Conflicts of Interest
References
- Microsoft Azure, AI. Available online: https://azure.microsoft.com/zh-cn/services/machine-learning/ (accessed on 20 December 2020).
- Google Prediction API. Available online: https://cloud.google.com/ai-platform (accessed on 20 December 2020).
- Low, Y.; Gonzalez, J.; Kyrola, A.; Bickson, D.; Guestrin, C.; Hellerstein, J. GraphLab: A new framework for parallel machine learning. In Proceedings of the 26th Conference on Uncertainty in Artificial Intelligence, UAI 2010, Catalina Island, CA, USA, 8–11 July 2010; pp. 340–349. [Google Scholar]
- Ersatz Labs. Available online: https://www.ersatzlabs.com/ (accessed on 1 February 2021).
- Kim, A.; Song, Y.; Kim, M.; Lee, K.; Cheon, J.H. Logistic Regression Model Training based on the Approximate Homomorphic Encryption. In Proceedings of the 6th iDASH Privacy and Security Workshop 2017, Orlando, FL, USA, 14 October 2017. [Google Scholar]
- Han, K.; Hong, S.; Cheon, J.H.; Park, D. Efficient Logistic Regression on Large Encrypted. In Proceedings of the 33th AAAI Conference on Artificial Intelligence, AAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9466–9471. [Google Scholar]
- Han, K.; Hong, S.; Cheon, J.H.; Park, D. Logistic regression on homomorphic encrypted data at scale. In Proceedings of the 9th AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 28–29 January 2019; pp. 9466–9471. [Google Scholar]
- Kim, M.; Lee, J.; Ohno-Machado, L.; Jiang, X. Secure and Differentially Private Logistic Regression for Horizontally Distributed Data. IEEE Trans. Inf. Forensics Secur. 2019, 15, 695–710. [Google Scholar] [CrossRef]
- Kim, M.; Song, Y.; Wang, S.; Xia, Y.; Jiang, X. Secure logistic regression based on homomorphic encryption: Design and evaluation. JMIR Med. Inform. 2018, 6, e8805. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, R.; Joshi, J.; Li, C. CryptoNN: Training Neural Networks over Encrypted Data. In Proceedings of the International Conference on Distributed Computing Systems 2019, Dallas, TX, USA, 7–9 July 2019; Volume 8885038, pp. 1199–1209. [Google Scholar]
- Lou, Q.; Feng, B.; Fox, G.C.; Jiang, L. Glyph: Fast and Accurately Training Deep Neural Networks on Encrypted Data. In Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020. arXiv 2020, arXiv:1911.07101. [Google Scholar]
- Jiang, X.; Lauter, K.; Kim, M.; Song, Y. Secure outsourced matrix computation and application to neural networks. In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1209–1222. [Google Scholar]
- Dowlin, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In Proceedings of the 33th International Conference on Machine Learning, ICML 2016, New York, NY, USA, 19–24 June 2016; Voume 1, pp. 342–351. [Google Scholar]
- SEAL. Available online: https://github.com/microsoft/SEAL (accessed on 25 September 2021).
- HElib. Available online: https://github.com/homenc/HElib (accessed on 7 February 2021).
- TFHE. Available online: https://tfhe.github.io/tfhe/ (accessed on 5 May 2021).
- Brutzkus, A.; Elisha, O.; Gilad-Bachrach, R. Low Latency Privacy Preserving Inference. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 1295–1304. [Google Scholar]
- Boura, C.; Gama, N.; Georgieva, M.; Jetchev, D. CHIMERA: Combining Ring-LWE-based Fully Homomorphic Encryption Schemes. J. Math. Cryptol. 2020, 14, 316–338. [Google Scholar] [CrossRef]
- Li, Z.; Sun, M. Privacy-Preserving Classification of Personal Data with Fully Homomorphic Encryption: An Application to High-Quality Ionospheric Data Prediction. In 2020 Lecture Notes in Computer Science 12486 LNCS; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 437–446. [Google Scholar]
- Li, P.; Li, J.; Huang, Z.; Li, T.; Gao, C.; You, S.; Chen, K. Multi-key privacy-preserving deep learning in cloud computing. In Future Generation Computer Systems; Elesiver: Amsterdam, The Netherlands, 2017; Volume 74, pp. 76–85. [Google Scholar]
- Nandakumar, K.; Ratha, N.; Pankanti, S.; Halevi, S. Towards Deep Neural Network Training on Encrypted Data. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops; CVF: Long Beach, CA, USA, 2019; pp. 40–48. [Google Scholar]
- Sirichotedumrong, W.; Maekawa, T.; Kinoshita, Y.; Kiya, H. Privacy-Preserving Deep Neural Networks with Pixel-Based Image Encryption Considering Data Augmentation in the Encrypted Domain. In Proceedings of the International Conference on Image Processing, ICIP, Taipei, Taiwan, 22–25 September 2019; pp. 674–678. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. CryptoDL: Deep Neural Networks over Encrypted Data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. Deep Neural Networks Classification over Encrypted Data. In Proceedings of the 9th ACM Conference on Data and Application Security and Privacy (CODASPY), Dallas, TX, USA, 25–27 March 2019; pp. 97–108. [Google Scholar]
- Boemer, F.; Costache, A.; Cammarota, R.; Wierzynski, C. nGraph-HE2: A High-Throughput Framework for Neural Network Inference on Encrypted Data. In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 45–56. [Google Scholar]
- Boemer, F.; Lao, Y.; Wierzynski, C. NGRAPH-HE: A Graph Compiler for Deep Learning on Homomorphically Encrypted Data. arXiv 2018, arXiv:1810.10121v1. [Google Scholar]
- Izabachène, M.; Sirdey, R.; Zuber, M. Practical fully homomorphic encryption for fully masked neural networks. In Lecture Notes in Computer Science 11829 LNCS; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 24–36. [Google Scholar]
- Boddeti, V. Secure Face Matching Using Fully Homomorphic Encryption. In Proceedings of the 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems, BTAS, Radondo Beach, CA, USA, 22–25 October 2018; Volume 8698601. [Google Scholar]
- Suh, J.; Tanaka, T. Reinforcement Learning over Fully Homomorphic Encryption, 7 pages, 2 figures, submitted to SICE ISCS 2021. arXiv 2020, arXiv:2002.00506. [Google Scholar]
- Shortell, T.; Shokoufandeh, A. Secure Convolutional Neural Networks using FHE. arXiv 2018, arXiv:1808.03819. [Google Scholar]
- Garousi, V.; Mäntylä, M.V. Bibliometrics of SE literature. Computer Science Review. J. Inf. Sci. 2016, 19, 56–77. [Google Scholar]
- Lauter, K.; Naehrig, M.; Vaikuntanathan, V. Can homomorphic encryption be practical? In Proceedings of the ACM Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; 2011; pp. 113–124. [Google Scholar]
- HEML. Available online: https://drive.google.com/file/d/1IwD8Pr6Fs4LeUW7WJcGukJfv02zf6Gg1/view?usp=sharing (accessed on 9 May 2021).
- Gentry, C. Computing arbitrary functions of encrypted data. In Communications of the ACM; ACM: New York, NY, USA, 2010; Volume 53, pp. 97–105. [Google Scholar]
- Nikolaenko, V.; Weinsberg, U.; Ioannidis, S.; Joye, M.; Boneh, D.; Taft, N. Privacy-preserving ridge regression on hundreds of millions of records. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 334–348. [Google Scholar]
- Phong, L.T.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. In IEEE Transactions on Information Forensics and Security; IEEE: Piscataway, NJ, USA, 2017; Volume 13, pp. 1333–1345. [Google Scholar]
- Graepel, T.; Lauter, K.; Naehrig, M. ML confidential: Machine learning on encrypted data. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 7839 LNCS; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 1–21. [Google Scholar]
- Yu, J.; Lu, P.; Zhu, Y.; Xue, G.; Li, M. Toward secure multikeyword top-k retrieval over encrypted cloud data. In IEEE Transactions on Dependable and Secure Computing; IEEE: Piscataway, NJ, USA, 2017; Volume 10, pp. 239–250. [Google Scholar]
- Li, P.; Li, J.; Huang, Z.; Gao, C.-Z.; Chen, W.-B.; Chen, K. Privacy-Preserving Outsourced Classification in Cloud Computing, Cluster Computing; Springer: Berlin/Heidelberg, Germany, 2017; Volume 21, pp. 277–286. [Google Scholar]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. GAZELLE: A low latency framework for secure neural network inference. In Proceedings of the 27th USENIX Security Symposium, Baltimore, Maryland, 15–17 August 2018; pp. 1651–1668. [Google Scholar]
- Shen, M.; Ma, B.; Zhu, L.; Mijumbi, R.; Du, X.; Hu, J. Cloud-Based Approximate Constrained Shortest Distance Queries over Encrypted Graphs with Privacy Protection. In IEEE Transactions on Information Forensics and Security; IEEE: Piscataway, NJ, USA, 2017; Volume 13, pp. 940–953. [Google Scholar]
- Riazi, M.; Weinert, C.; Tkachenko, O.; Songhori, E.M.; Schneider, T.; Koushanfar, F. Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, New York, NY, USA, 4 June 2018. [Google Scholar]
- Noorden, R.V.; Maher, B.; Nuzzo, R. The top 100 papers. Nature 2014, 514, 550–553. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Topic Model. Available online: https://en.wikipedia.org/wiki/Topic_model (accessed on 18 April 2021).
- LDA. Available online: https://en.wikipedia.org/wiki/Latent_Dirichlet_allocation (accessed on 18 April 2021).
- Khilji, I.Q.; Saha, K.; Shonon, J.A.; Hossain, M.I. Application of homomorphic encryption on neural network in prediction of acute lymphoid Leukemia. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 350–360. [Google Scholar] [CrossRef]
- Doröz, Y.; Shahverdi, A.; Eisenbarth, T.; Sunar, B. Toward practical homomorphic evaluation of block ciphers using prince. In Lecture Notes in Computer Science 8438; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 208–220. [Google Scholar]
- Çetin, G.S.; Doröz, Y.; Sunar, B.; Savaş, E. Depth optimized efficient homomorphic sorting. In Lecture Notes in Computer Science 9230; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 61–80. [Google Scholar]
- Wu, W.; Liu, J.; Wang, H.; Tang, F.; Xian, M. PPolyNets: Achieving High Prediction Accuracy and Efficiency with Parametric Polynomial Activations. In IEEE Access 6; IEEE: Piscataway, NJ, USA, 2018; pp. 72814–72823. [Google Scholar]
- Song, X.; Chen, Z. A general design method of constructing fully homomorphic encryption with ciphertext matrix. In KSII Transactions on Internet and Information Systems 13; Elsevier: Amsterdam, The Netherlands, 2019; pp. 2629–2650. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Overview |
|---|---|
| Logistic Regression | Logistic regression is a very common regression model, such as the CKKS scheme in articles [5,7], which achieves good training capability on large data sets and achieves 96.4% accuracy at MNIST. The paper [6] achieves high accuracy and efficiency based on good data packing and the logistic regression algorithm optimized for ciphertext, which further improves the processing capability of large datasets based on the former. Similar to the previous two, the paper [9] implements least-squares approximation of logistic functions to improve accuracy and efficiency (i.e., reduce computational cost), as well as applies new packing and parallelization techniques. The paper [8] proposes a new strategy that combines differential privacy methods and homomorphic encryption to achieve the best of both, achieving a good variance of less than 1%. In addition, we also find that the articles published by related authors in this field are all relatively similar and are based on the CKSS scheme. The paper [19] differs from all the above papers in that it implements a logistic regression prediction process between the cloud and the client based on the semi-honest assumption and the BGV scheme. |
| DNN, NN | Traditional neural networks, called fully connected layers as the last layer in CNNs, are relatively well implemented and therefore, have a lot of relevant applications. The paper [20] relies mainly on multi-key and coding algorithms (MK-FHE), chunking cryptographic computations before handing them over to the cloud, with high network throughput and latency. The IBM paper [21] makes a considerable contribution by using low polynomial approximation functions in the BGV scheme, averaging pools instead of max pools, and using homomorphic lookup tables, which also take a longer time. The paper [22] uses cryptographic data augmentation for neural network DNN computation and does not use a homomorphic encryption scheme. It is more of an image encoding improvement to achieve privacy protection and high accuracy is achieved on different datasets. |
| CNN | Convolutional neural networks are now the basis of image-related artificial intelligence, so the research here is numerous and outstanding. Differing from articles [23,24] that provide a polynomial approximation to the ReLU activation function, article [10] uses a hybrid network structure that uses homomorphic encryption for the first propagation and final evaluation computations, with the intermediate process still being conventionally explicit training. Article [25] achieves very high efficiency with the help of batch processing and special data processing packaging. Article [11] uses the BGV scheme of the HElib library and the TFHE scheme to implement complete HEML. The common computations, such as ciphertext multiplication and addition are performed in the BGV scheme, while numerical comparisons (activation functions, such as ReLU) are computed in TFHE by a special ciphertext conversion algorithm. The paper [12] implements the matrix computation of homomorphic ciphertext vectors by a special matrix encoding method, and the paper [13] proposes a scheme of the average pool instead of the maximum pool, polynomial approximation of activation function, and parallel encoding of data. |
| Improved CNN | These models are based on DNNs and CNNs with different degrees of improvement. The article [26] builds a bridge between homomorphic encryption and common machine learning libraries and improves processing power with SIMD batching. Combined with TensorFlow, it has good performance in 213 and 214 dimensions. The article [17] proposes two solutions to solve the high latency problem of HEML. The first is a special information representation (LoLa) after encoding pixel points, which can significantly reduce latency and memory usage and the second is a deep neural network through transfer learning. Although the accuracy is slightly lower than other models of the same class, the latency is far better than other models, with only single-digit latency, with the LoLa-Small model having a latency of only 0.29. The paper [27] implements cryptographic computation on arbitrary neural networks through the TFHE and TLWE schemes. The core lies in the ciphertext conversion of the two schemes, and the data encoding method. The performance on the ciphertext face dataset is good, and the total time for one update is less than 0.2 s. The paper [28] uses the NTL library to build the FHE scheme and implements face template matching on facenet, which is more efficient because of the shallow ciphertext depth. The paper [29] puts the computation process that can be linearized into homomorphic encryption, and the computation that cannot be linearized and has high overhead is still performed locally. In the paper [18], TFHE and CKKS are ciphertexts transformed with the BGV scheme, and finally, a fully homomorphic encrypted neural network is trained. All computations that cannot be linearized can be performed by binary circuits because of the properties of TFHE. The accuracy of the encrypted ResNet-34 is even higher than that of the classical ResNet-34. |
| Schemes | Articles with High Relevance |
|---|---|
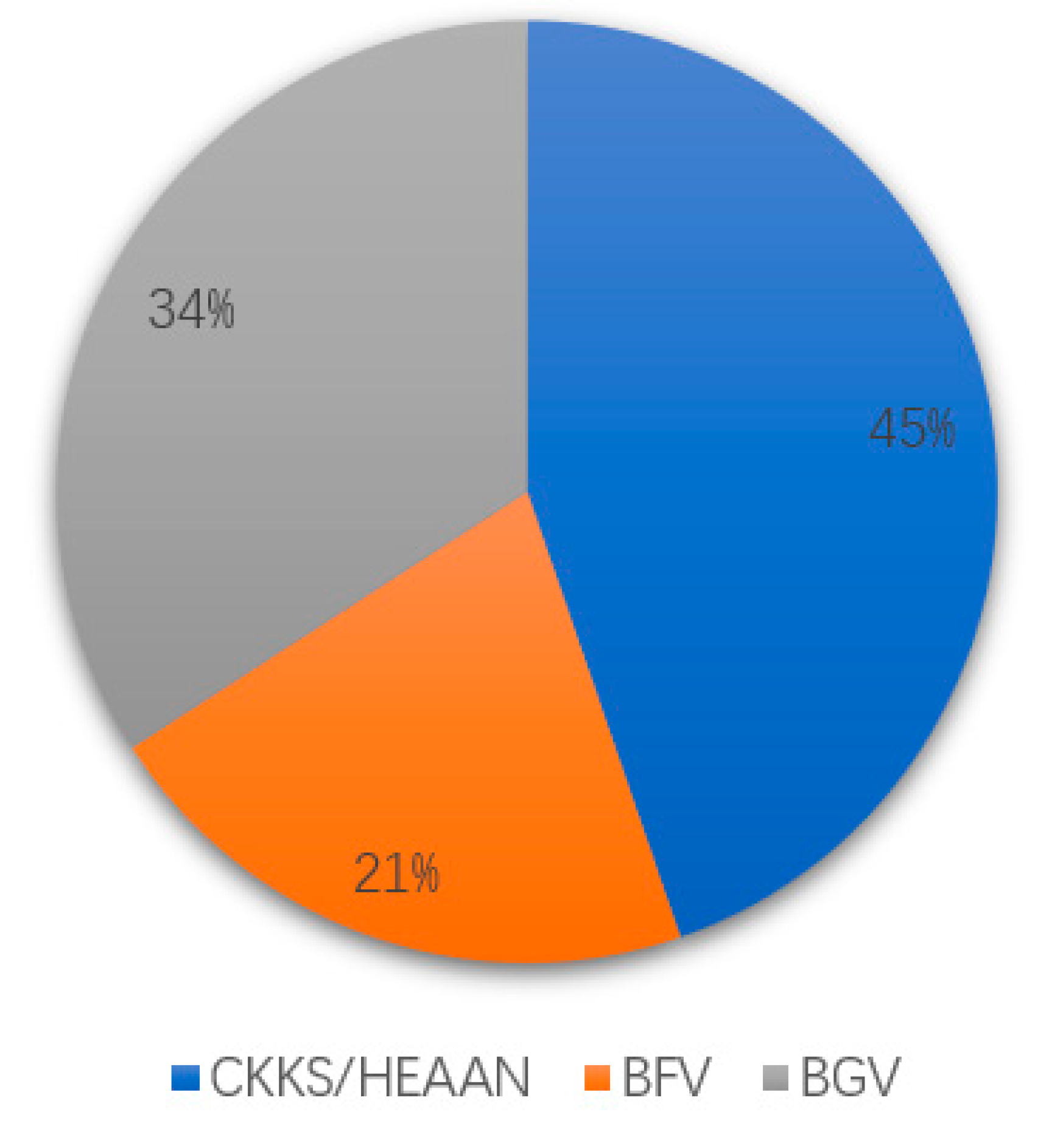
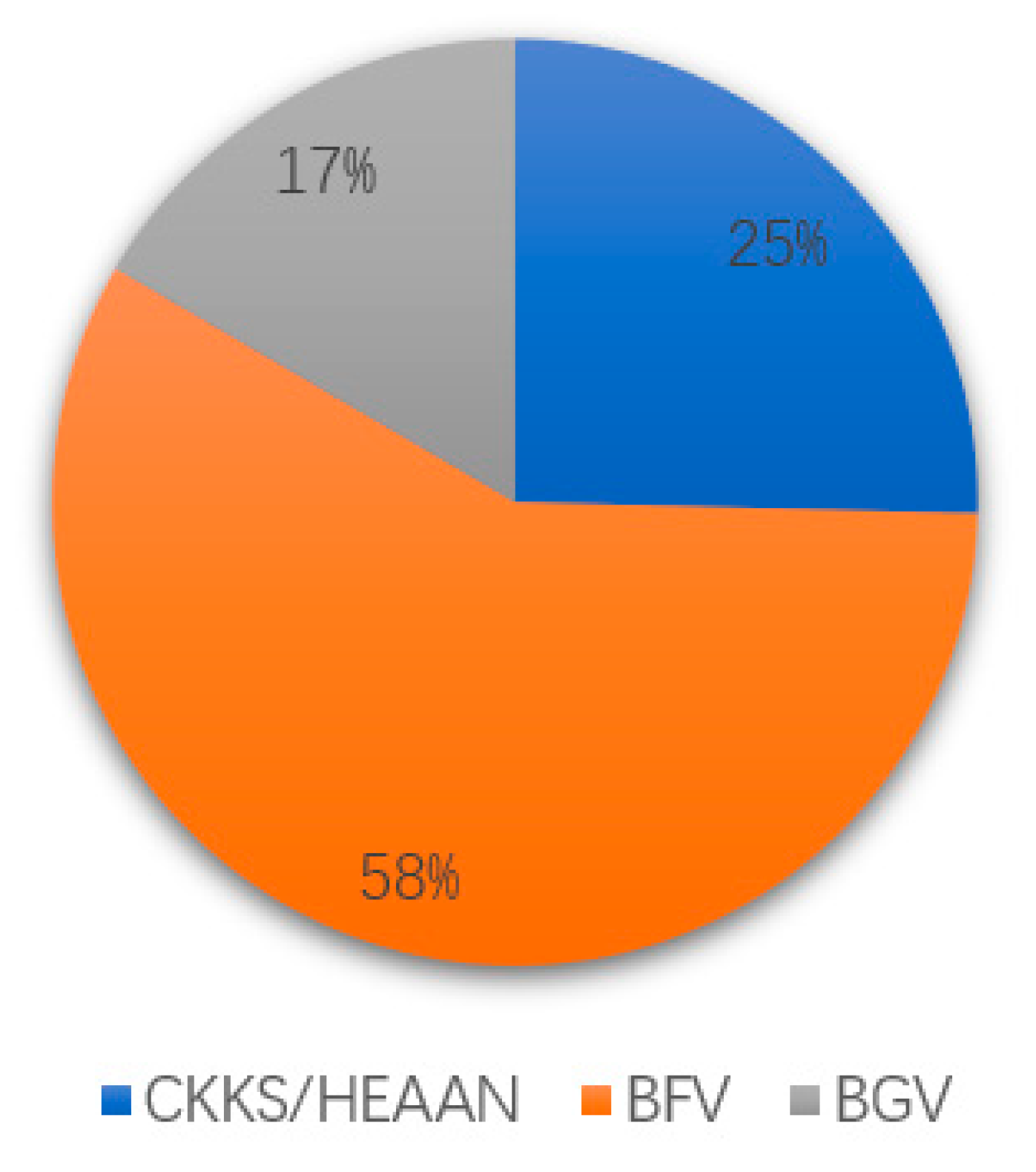
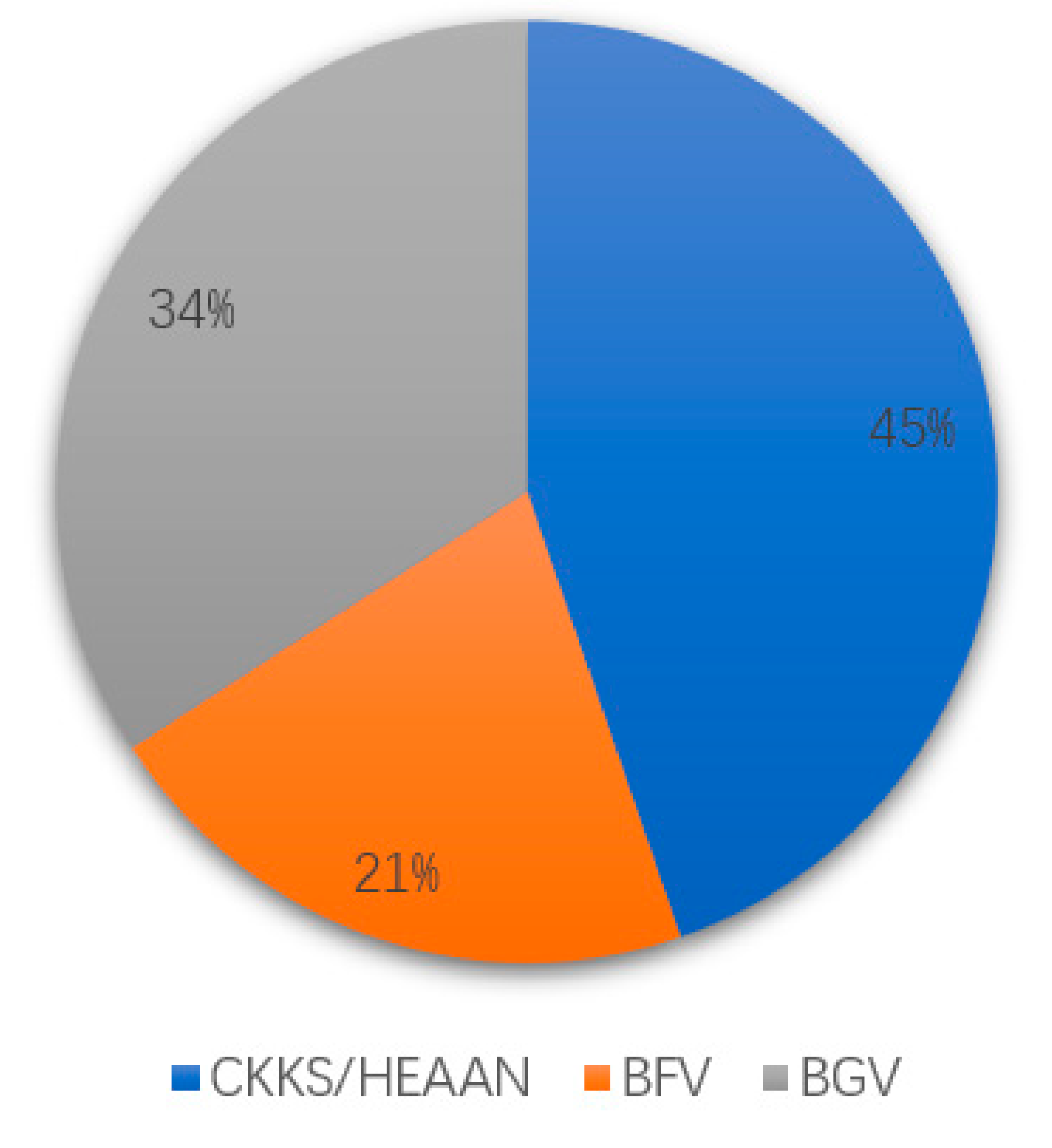
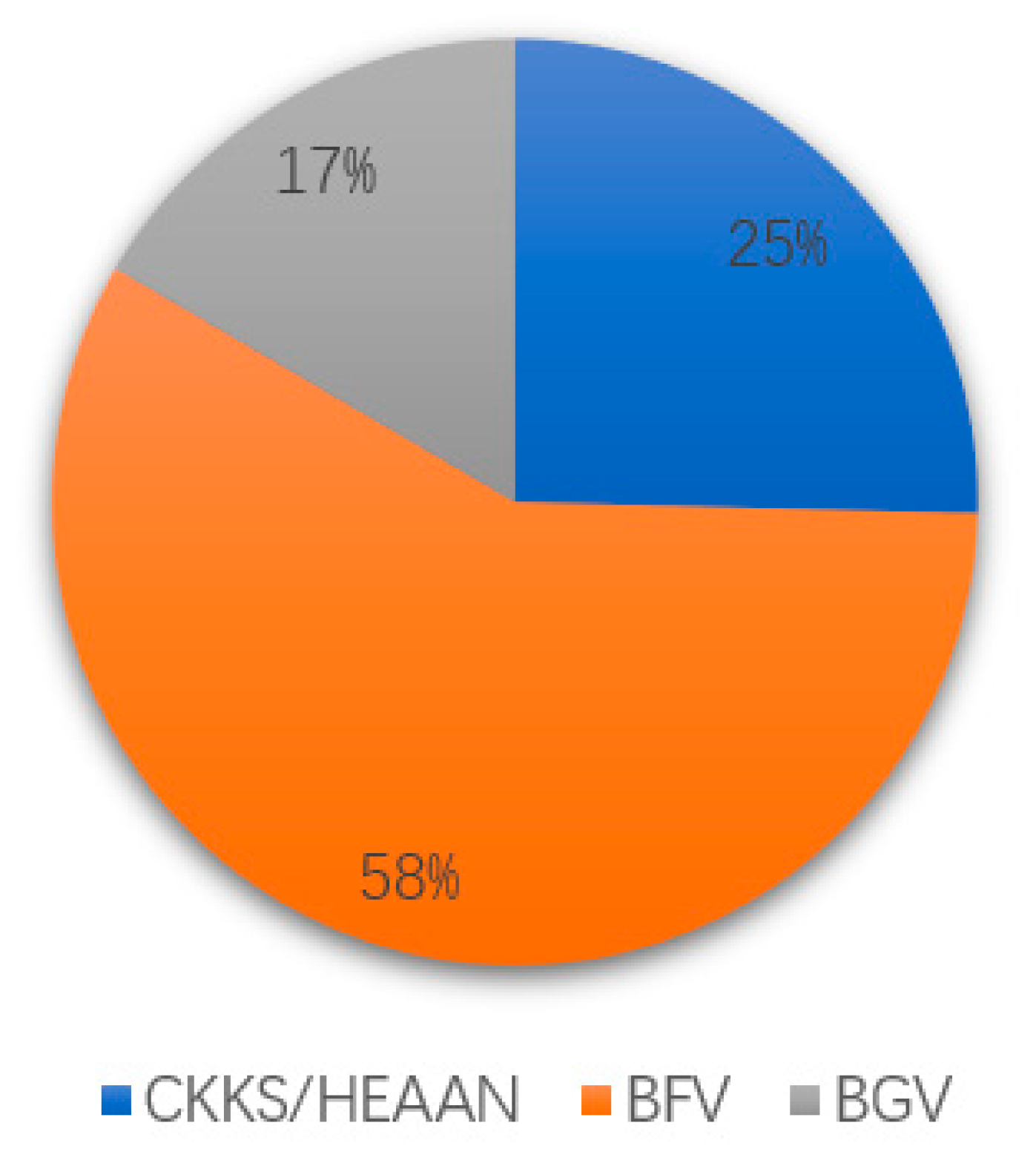
| BGV | [11,18,21,23] |
| CKKS | [5,6,12,13,17,18,24,25,26,29] |
| TFHE | [11,25,27,29] |
| Other HE Schemes | [10,20,22,28,30] |
| Criteria | Literature Databases | |||
|---|---|---|---|---|
| Scopus | Web of Science | Google Scholar | Semantic Scholar | |
| Quality and reliability | Thanks to Scopus’ feature of searching by “source name” (location name), full coverage quality and reliability of search results can be achieved to a large extent. | Given the nature of homomorphic encryption papers, the quality and reliability of the search results cannot be guaranteed within the full coverage. | Based on Google’s powerful engine, we can search a wide range of literature, but the sources are complicated and duplicated, and the quality is not guaranteed. | There is a good range of literature collection in homomorphic encryption, and the statistics of citation data are clear. |
| Citation data | Yes | Yes | Yes | Yes |
| Search interface and output export | Allow saving all exported papers to CSV files | Only allow saving up to 500 results at a time | No | No |
| # | Paper Title | Publishing Year | Number of Citations |
|---|---|---|---|
| 1 | Can homomorphic encryption be practical? [32] | 2011 | 542 |
| 2 | Computing arbitrary functions of encrypted data [34] | 2010 | 332 |
| 3 | Multi-key privacy-preserving deep learning in cloud computing [20] | 2017 | 222 |
| 4 | Privacy-preserving ridge regression on hundreds of millions of records [35] | 2013 | 174 |
| 5 | Privacy-Preserving Deep Learning via Additively Homomorphic Encryption [36] | 2018 | 168 |
| 6 | ML confidential: Machine learning on encrypted data [37] | 2013 | 152 |
| 7 | Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy [13] | 2016 | 123 |
| 8 | Toward secure multi-keyword top-k retrieval over encrypted cloud data [38] | 2013 | 122 |
| 9 | Privacy-preserving outsourced classification in cloud computing [39] | 2018 | 114 |
| 10 | GAZELLE: A low latency framework for secure neural network inference [40] | 2018 | 103 |
| # | Paper Title | Publishing Year | Average Number of Citations | Total Number of Citations |
|---|---|---|---|---|
| 1 | Privacy-Preserving Deep Learning via Additively Homomorphic Encryption [36] | 2018 | 56 | 168 |
| 2 | Multi-key privacy-preserving deep learning in cloud computing [20] | 2017 | 55.5 | 222 |
| 3 | Can homomorphic encryption be practical? [32] | 2011 | 54.2 | 542 |
| 4 | Privacy-preserving outsourced classification in cloud computing [39] | 2018 | 40.3 | 121 |
| 5 | GAZELLE: A low latency framework for secure neural network inference [40] | 2018 | 34.3 | 103 |
| 6 | Cloud-Based Approximate Constrained Shortest Distance Queries over Encrypted Graphs with Privacy Protection [41] | 2018 | 27.3 | 82 |
| 7 | Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy [13] | 2016 | 24.6 | 123 |
| 8 | Chameleon: A hybrid secure computation framework for machine learning applications [42] | 2018 | 22.3 | 67 |
| 9 | Privacy-preserving ridge regression on hundreds of millions of records [35] | 2013 | 21.8 | 174 |
| 10 | ML confidential: Machine learning on encrypted data [37] | 2013 | 18.5 | 152 |
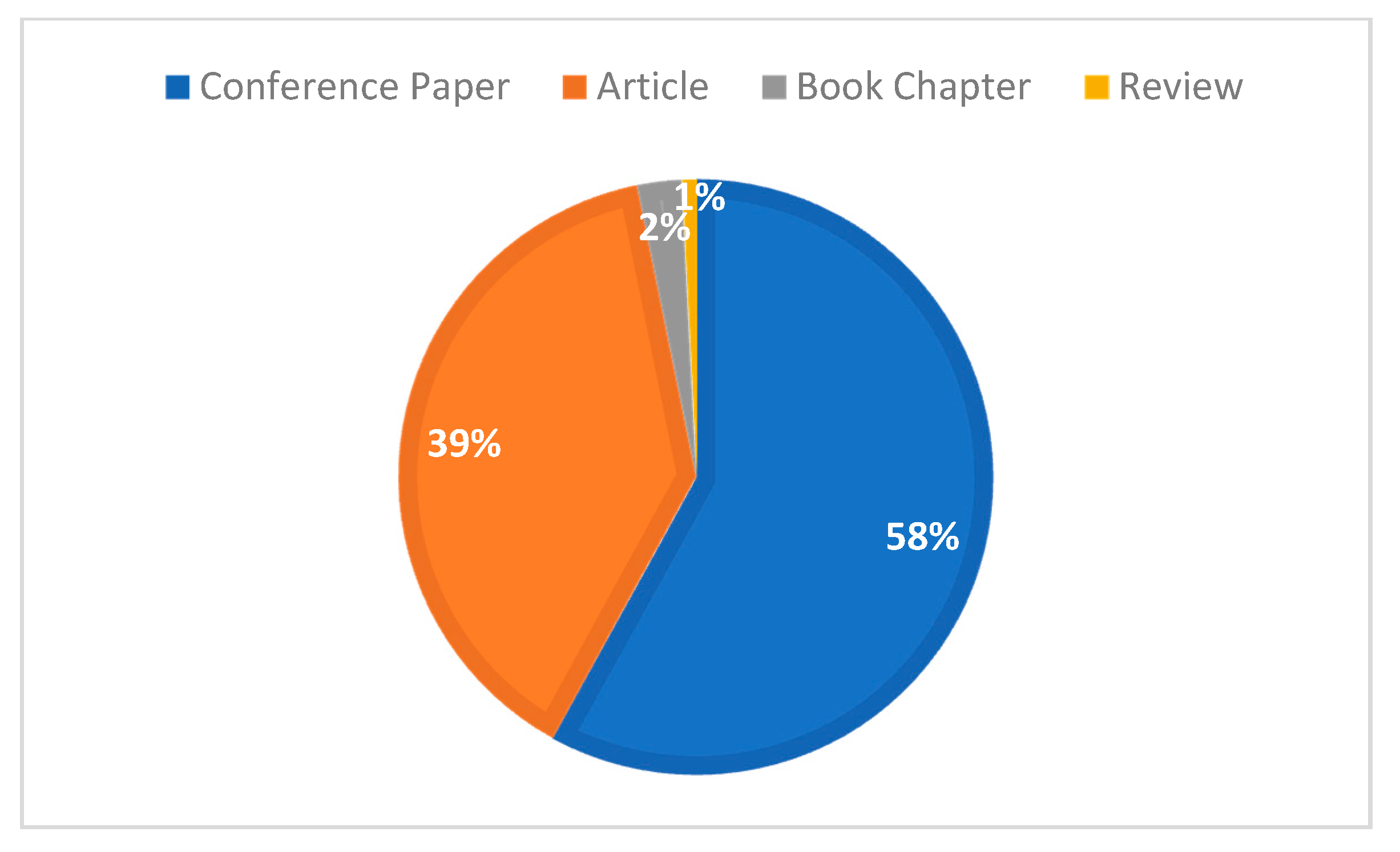
| Data Statistics | Publication Types | |||
|---|---|---|---|---|
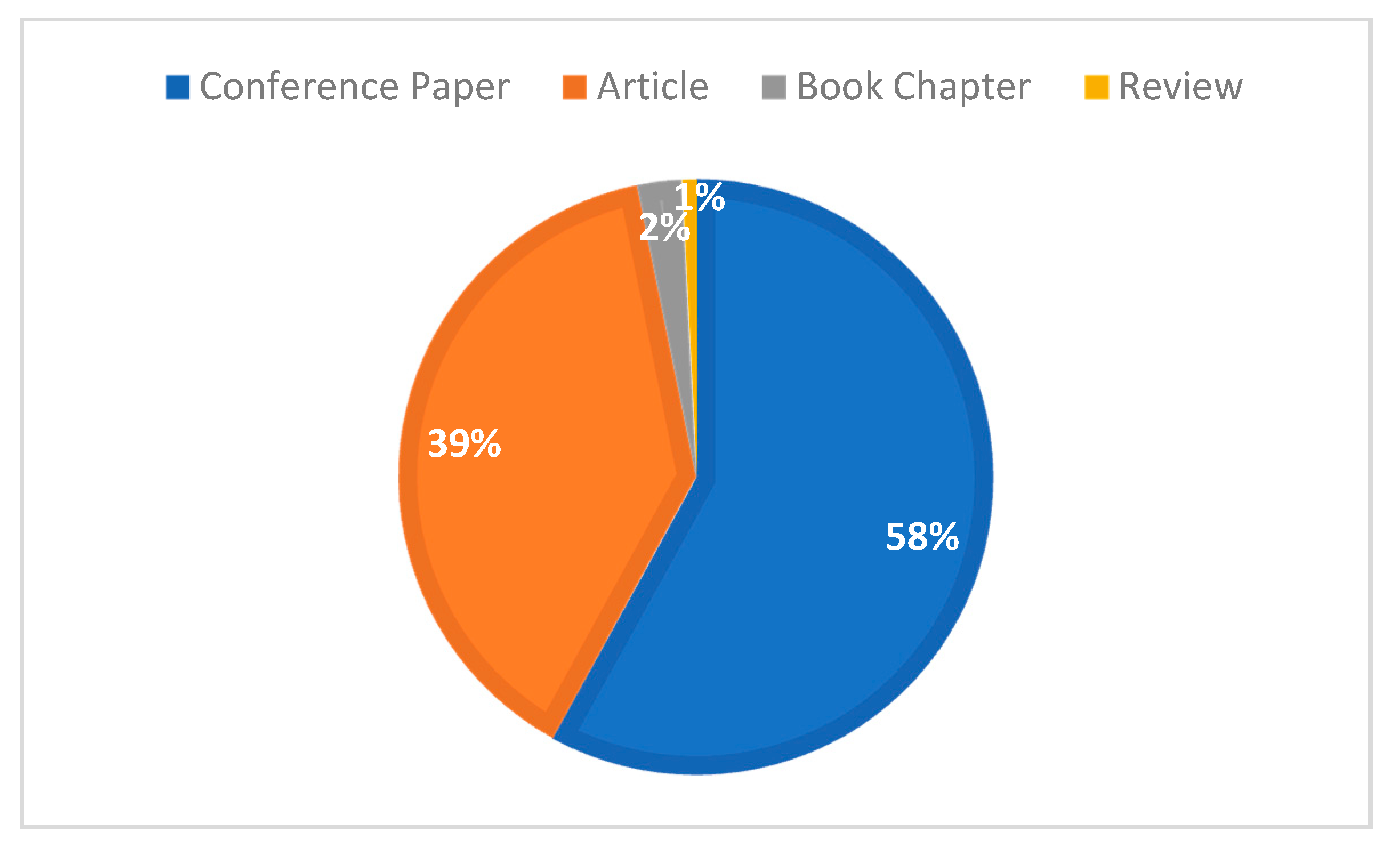
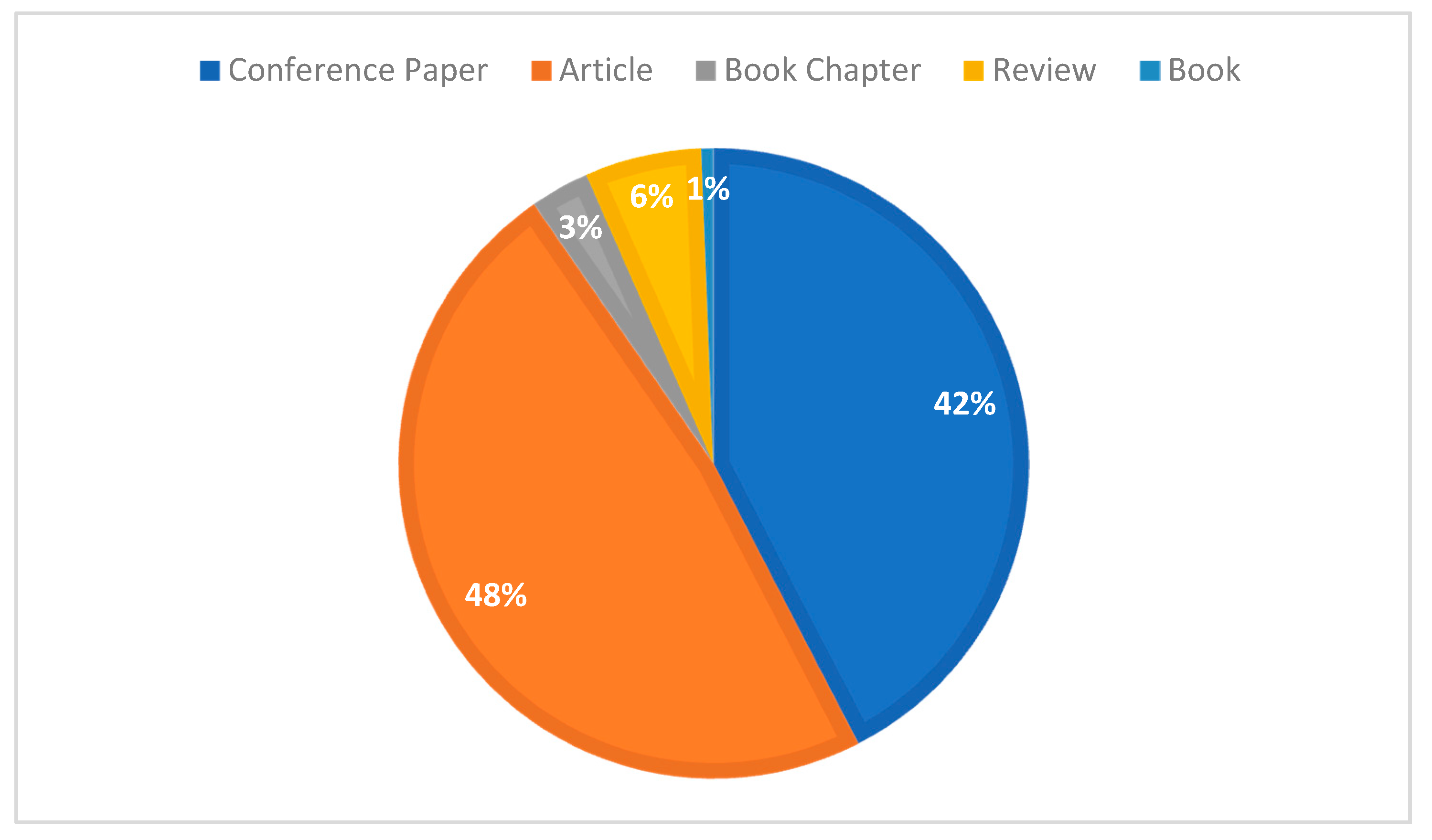
| Conference Paper | Article | Book Chapter | Review | |
| Total number of articles | 729 | 488 | 30 | 10 |
| Percentage% | 58.0 | 38.8 | 2.4 | 0.8 |
| Total number of citations | 6202 | 4912 | 59 | 14 |
| Average number of citations | 8.5 | 10.0 | 3.9 | 1.4 |
| Number of never cited | 236 | 142 | 15 | 5 |
| At least one citation % | 67.6% (493) | 70.9% (346) | 50% (15) | 50% (5) |
| Keywords | Number of Occurrences |
|---|---|
| Encrypt | 1095 |
| Homomorphic | 867 |
| Computer | 677 |
| Cloud | 615 |
| Privacy | 462 |
| Secure | 439 |
| Data | 363 |
| Preserve | 213 |
| Learning | 201 |
| Machine | 110 |
| Cryptography | 104 |
| Network | 82 |
| … | … |
| Keywords | Number of Occurrences |
|---|---|
| Cryptography | 983 |
| Homomorphic Encryption | 720 |
| Cloud Computing | 609 |
| Data Privacy | 422 |
| Privacy-Preserving | 257 |
| Digital Storage | 202 |
| Security Of Data | 177 |
| Encrypted Data | 113 |
| Learning Systems | 112 |
| Network Security | 111 |
| Machine Learning | 110 |
| Big Data | 88 |
| Deep Learning | 67 |
| Internet Of Things | 59 |
| Outsourcing | 56 |
| Neural Networks | 39 |
| Deep Neural Networks | 26 |
| Logistic Regression | 24 |
| Bioinformatics | 23 |
| # | Theme Model |
|---|---|
| 1 | 0.013*”ml” + 0.012*”data” + 0.010*”service” + 0.009*”security” + 0.009*”solution” + 0.008*”privacy” |
| 2 | 0.042*”data” + 0.020*”cloud” + 0.017*”encryption” + 0.015*”image” + 0.015*”homomorphic” + 0.013*”algorithm” |
| 3 | 0.038*”learning” + 0.029*”model” + 0.024*”network” + 0.019*”privacy” + 0.019*”neural” + 0.017*”machine” |
| 4 | 0.038*”cloud” + 0.028*”data” + 0.026*”computing” + 0.017*”security” + 0.011*”paper” + 0.009*”encryption” |
| 5 | 0.041*”scheme” + 0.039*”homomorphic” + 0.032*”encryption” + 0.027*”fhe” + 0.021*”fully” + 0.014*”implementation” |
| 6 | 0.017*”information” + 0.009*”security” + 0.007*”encryption” + 0.007*”content” + 0.005*”codeword” + 0.005*”homomorphic” |
| 7 | 0.022*”scheme” + 0.020*”homomorphic” + 0.013*”image” + 0.013*”encryption” + 0.011*”secure” + 0.009*”algorithm” |
| 8 | 0.032*”voting” + 0.022*”electronic” + 0.013*”scheme” + 0.012*”homomorphic” + 0.009*”encryption” + 0.008*”proposed” |
| 9 | 0.011*”fhe” + 0.009*”computation” + 0.009*”problem” + 0.008*”tree” + 0.008*”private” + 0.008*”character” |
| 10 | 0.050*”data” + 0.049*”cloud” + 0.025*”encryption” + 0.021*”user” + 0.018*”security” + 0.018*”computing” |
| 11 | 0.031*”data” + 0.024*”encryption” + 0.021*”homomorphic” + 0.020*”cloud” + 0.017*”scheme” + 0.013*”computing” |
| 12 | 0.053*”data” + 0.013*”encrypted” + 0.012*”privacy” + 0.012*”cloud” + 0.010*”encryption” + 0.009*”homomorphic” |
| 13 | 0.030*”image” + 0.018*”encryption” + 0.014*”privacy” + 0.011*”homomorphic” + 0.010*”cloud” + 0.010*”proposed” |
| 14 | 0.012*”crm” + 0.007*”device” + 0.006*”city” + 0.005*”stealthy” + 0.005*”edge” + 0.005*”deeper” |
| 15 | 0.048*”data” + 0.022*”cloud” + 0.014*”encrypted” + 0.014*”scheme” + 0.014*”search” + 0.013*”encryption” |
| 16 | 0.021*”data” + 0.010*”cloud” + 0.009*”log” + 0.008*”solution” + 0.007*”privacy” + 0.007*”algorithm” |
| 17 | 0.022*”encryption” + 0.014*”data” + 0.012*”homomorphic” + 0.010*”privacy” + 0.009*”scheme” + 0.008*”network” |
| 18 | 0.032*”learning” + 0.029*”privacy” + 0.026*”data” + 0.019*”model” + 0.013*”machine” + 0.008*”federated” |
| 19 | 0.023*”data” + 0.019*”computation” + 0.016*”query” + 0.015*”encrypted” + 0.013*”cloud” + 0.012*”scheme” |
| 20 | 0.035*”computation” + 0.026*”protocol” + 0.017*”secure” + 0.017*”scheme” + 0.016*”cloud” + 0.014*”client” |
| # | Paper Title | Publishing Year | Number of Citations |
|---|---|---|---|
| 1 | Secure and Differentially Private Logistic Regression for Horizontally Distributed Data [8] | 2020 | 4 |
| 2 | Logistic regression on homomorphically encrypted data at scale [7] | 2019 | 3 |
| 3 | Privacy-Preserving Classification of Personal Data with Fully Homomorphic Encryption: An Application to High-Quality Ionospheric Data Prediction [19] | 2020 | 0 |
| 4 | Secure logistic regression based on homomorphic encryption: Design and evaluation [9] | 2018 | 42 |
| 5 | Secure outsourced matrix computation and application to neural networks [12] | 2018 | 42 |
| # | Paper Title | Publishing Year | Number of Citations |
|---|---|---|---|
| 1 | Application of homomorphic encryption on neural network in the prediction of acute lymphoid Leukemia [46] | 2020 | 0 |
| 2 | Toward practical homomorphic evaluation of block ciphers using prince [47] | 2014 | 23 |
| 3 | Depth optimized efficient homomorphic sorting [48] | 2015 | 18 |
| 4 | PPolyNets: Achieving High Prediction Accuracy and Efficiency with Parametric Polynomial Activations [49] | 2018 | 4 |
| 5 | A general design method of constructing fully homomorphic encryption with ciphertext matrix [50] | 2019 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Hu, G.; Zheng, M.; Song, X.; Chen, L. Bibliometrics of Machine Learning Research Using Homomorphic Encryption. Mathematics 2021, 9, 2792. https://doi.org/10.3390/math9212792
Chen Z, Hu G, Zheng M, Song X, Chen L. Bibliometrics of Machine Learning Research Using Homomorphic Encryption. Mathematics. 2021; 9(21):2792. https://doi.org/10.3390/math9212792
Chicago/Turabian StyleChen, Zhigang, Gang Hu, Mengce Zheng, Xinxia Song, and Liqun Chen. 2021. "Bibliometrics of Machine Learning Research Using Homomorphic Encryption" Mathematics 9, no. 21: 2792. https://doi.org/10.3390/math9212792
APA StyleChen, Z., Hu, G., Zheng, M., Song, X., & Chen, L. (2021). Bibliometrics of Machine Learning Research Using Homomorphic Encryption. Mathematics, 9(21), 2792. https://doi.org/10.3390/math9212792