
Marginalized Two-Part Joint Modeling of Longitudinal Semi-Continuous Responses and Survival Data: With Application to Medical Costs

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Conventional Two-Part Model for Joint Analysis of Longitudinal Semi-Continuous Data and Survival Data
2.2. Marginalized Two-Part Joint Model for Longitudinal Semi-Continuous Data and Survival Data
2.2.1. Marginalized Two-Part Model for Longitudinal Semi-Continuous Data
2.2.2. Parameter Estimation of the Marginalized Two-Part Joint Model (MTJM)
3. Results
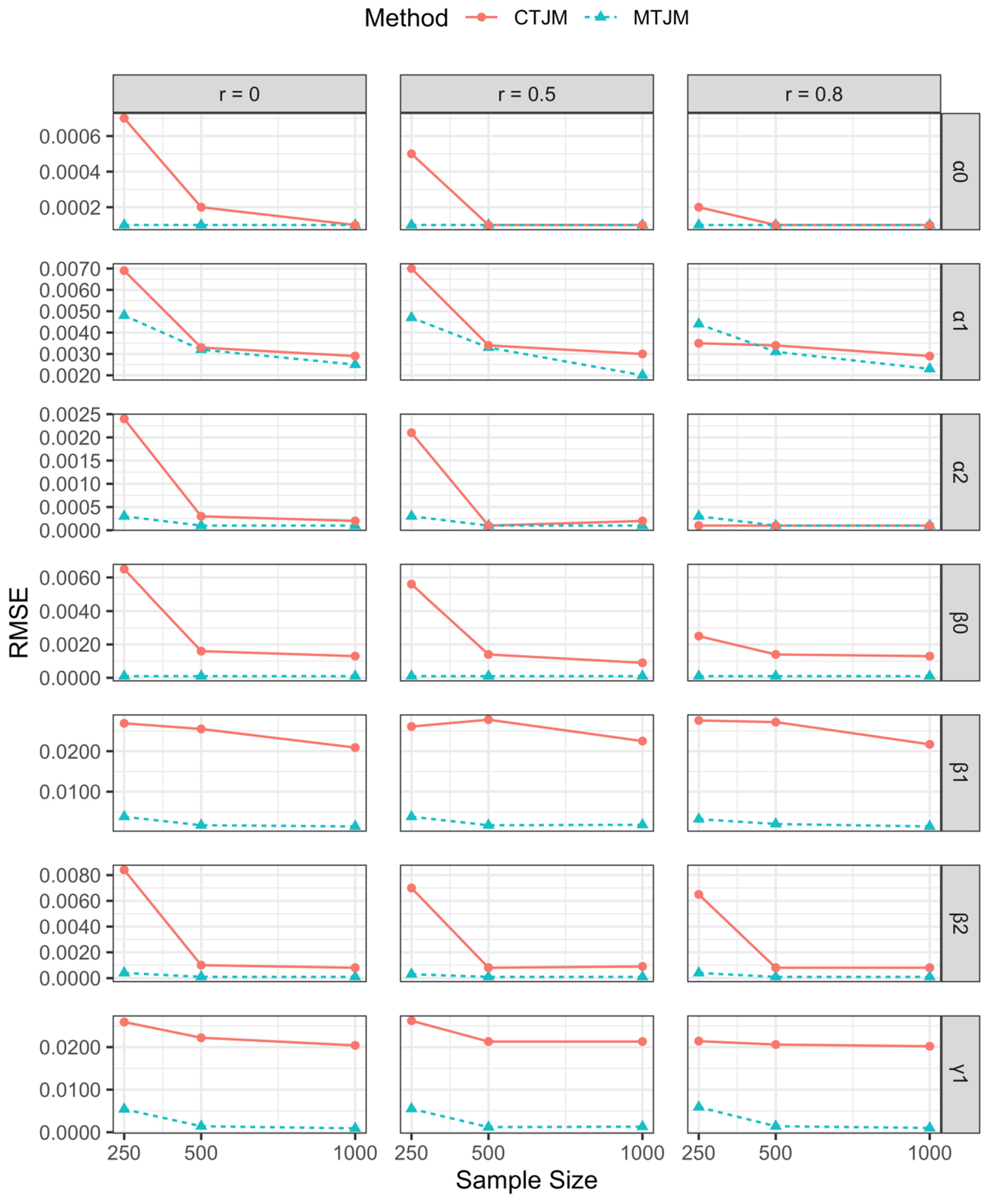
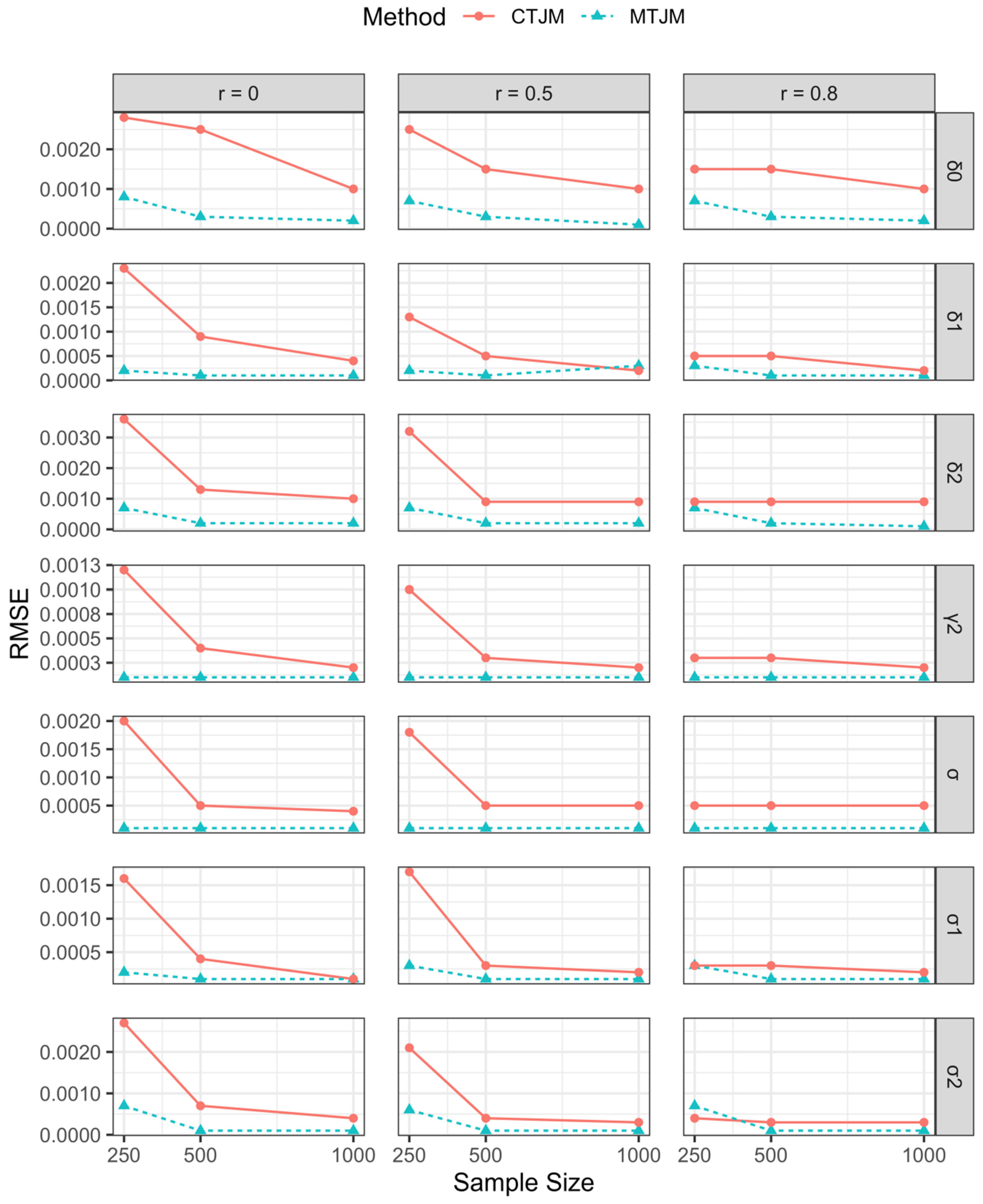
3.1. Simulation Study
3.2. Analysis of HDK Data
3.2.1. Data Description
3.2.2. Detailed Explanations of Variable Selection
3.2.3. Fitting the CTJM and MTJM to the Data
3.2.4. Parameter Estimation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. SAS Procedures for Data Generation and Parameter Estimation
Appendix B. SAS Procedures for Real Data Analysis
References
- Rustand, D.; Briollais, L.; Tournigand, C.; Rondeau, V. Two-part joint model for a longitudinal semicontinuous marker and a terminal event with application to metastatic colorectal cancer data. Biostatistics 2020, kxaa012. [Google Scholar] [CrossRef] [PubMed]
- Olsen, M.K.; Schafer, J.L. A two-part random-effects model for semicontinuous longitudinal data. J. Am. Stat. Assoc. 2001, 96, 730–745. [Google Scholar] [CrossRef]
- Liu, L.; Strawderman, R.L.; Johnson, B.A.; O’Quigley, J.M. Analyzing repeated measures semi-continuous data, with application to an alcohol dependence study. Stat. Methods Med. Res. 2016, 25, 133–152. [Google Scholar] [CrossRef] [PubMed]
- Smith, V.A.; Maciejewski, M.L.; Olsen, M.K. Modeling semicontinuous longitudinal expenditures: A practical guide. Health Serv. Res. 2018, 53, 3125–3147. [Google Scholar] [CrossRef] [PubMed]
- Tran, V.; Liu, D.; Pradhan, A.K.; Li, K.; Bingham, C.R.; Simons-Morton, B.G.; Albert, P.S. Assessing risk-taking in a driving simulator study: Modeling longitudinal semi-continuous driving data using a two-part regression model with correlated random effects. Anal. Methods Accid. Res. 2015, 5, 17–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tian, L.; Huang, J. A two-part model for censored medical cost data. Stat. Med. 2007, 26, 4273–4292. [Google Scholar] [CrossRef]
- Smith, V.A.; Preisser, J.S.; Neelon, B.; Maciejewski, M.L. A marginalized two-part model for semicontinuous data. Stat. Med. 2014, 33, 4891–4903. [Google Scholar] [CrossRef]
- Tooze, J.A.; Grunwald, G.K.; Jones, R.H. Analysis of repeated measures data with clumping at zero. Stat. Methods Med. Res. 2002, 11, 341–355. [Google Scholar] [CrossRef]
- Smith, V.A.; Neelon, B.; Preisser, J.S.; Maciejewski, M.L. A marginalized two-part model for longitudinal semicontinuous data. Stat. Methods Med. Res. 2017, 26, 1949–1968. [Google Scholar] [CrossRef] [PubMed]
- Smith, V.A.; West, B.T.; Zhang, S. Fitting marginalized two-part models to semicontinuous survey data arising from complex samples. Health Serv. Res. 2021, 56, 558–563. [Google Scholar] [CrossRef]
- Smith, V.A.; Preisser, J.S. A marginalized two-part model with heterogeneous variance for semicontinuous data. Stat. Methods Med. Res. 2019, 28, 1412–1426. [Google Scholar] [CrossRef]
- Efendi, A.; Molenberghs, G.; Njagi, E.N.; Dendale, P. A joint model for longitudinal continuous and time-to-event outcomes with direct marginal interpretation. Biom. J. 2013, 55, 572–588. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Daggy, J.; Yu, D.; Craig, B.A.; Sands, L. Joint modeling of medical cost and survival in complex sample surveys. Stat. Med. 2013, 32, 1509–1523. [Google Scholar] [CrossRef]
- Liu, L. Joint modeling longitudinal semi-continuous data and survival, with application to longitudinal medical cost data. Stat. Med. 2009, 28, 972–986. [Google Scholar] [CrossRef] [PubMed]
- Rizopoulos, D. Joint Models for Longitudinal and Time-to-Event Data: With Applications in R, 1st ed.; Chapman and Hall/CRC: Stanford, CA, USA, 2012; pp. 1–100. [Google Scholar]
- Henderson, R.; Diggle, P.; Dobson, A. Joint modelling of longitudinal measurements and event time data. Biostatistics 2000, 1, 465–480. [Google Scholar] [CrossRef]
- Basu, A.; Manning, W.G. Issues for the next generation of health care cost analyses. Med. Care 2009, 47, S109–S114. [Google Scholar] [CrossRef]
- Tom, B.D.; Su, L.; Farewell, V.T. A corrected formulation for marginal inference derived from two-part mixed models for longitudinal semi-continuous data. Stat. Methods Med. Res. 2016, 25, 2014–2020. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Strawderman, R.L.; Cowen, M.E.; Shih, Y.-C.T. A flexible two-part random effects model for correlated medical costs. J. Health Econ. 2010, 29, 110–123. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Roman, C.L.; George, A.M.; Walter, W.S.; Russell, D.W.; Oliver, S. Nonlinear Mixed Models. In SAS for Mixed Models, 2nd ed.; Stephenie, J., Ed.; SAS Institute Inc.: Cary, NC, USA, 2007; Volume 1, p. 569. [Google Scholar]
- Voronca, D.C.; Gebregziabher, M.; Durkalski-Mauldin, V.; Liu, L.; Egede, L.E. MTPmle: A SAS Macro and Stata Programs for Marginalized Inference in Semi-Continuous Data. J. Stat. Softw. 2018, 87, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Hatmi, Z.; Tahvildari, S.; Motlag, A.G.; Kashani, A.S. Prevalence of coronary artery disease risk factors in Iran: A population based survey. BMC Cardiovasc. Disord. 2007, 7, 32. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fabozzi, F.J.; Focardi, S.M.; Rachev, S.T.; Arshanapalli, B.; Hoechstoetter, M. Appendix E: Model selection criterion: AIC and BIC. In The Basics of Financial Econometrics: Tools, Concepts, and Asset Management Applications; John Wiley & Sons: Hoboken, NJ, USA, 2014; pp. 399–403. [Google Scholar]
- Sousa, I. A review on joint modelling of longitudinal measurements and time-to-event. Revstat. Stat. J. 2011, 9, 57–81. [Google Scholar]
- Bolboaca, S.D.; Jäntschi, L. Comparison of quantitative structure-activity relationship model performances on carboquinone derivatives. Sci. World J. 2009, 9, 1148–1166. [Google Scholar] [CrossRef] [PubMed] [Green Version]

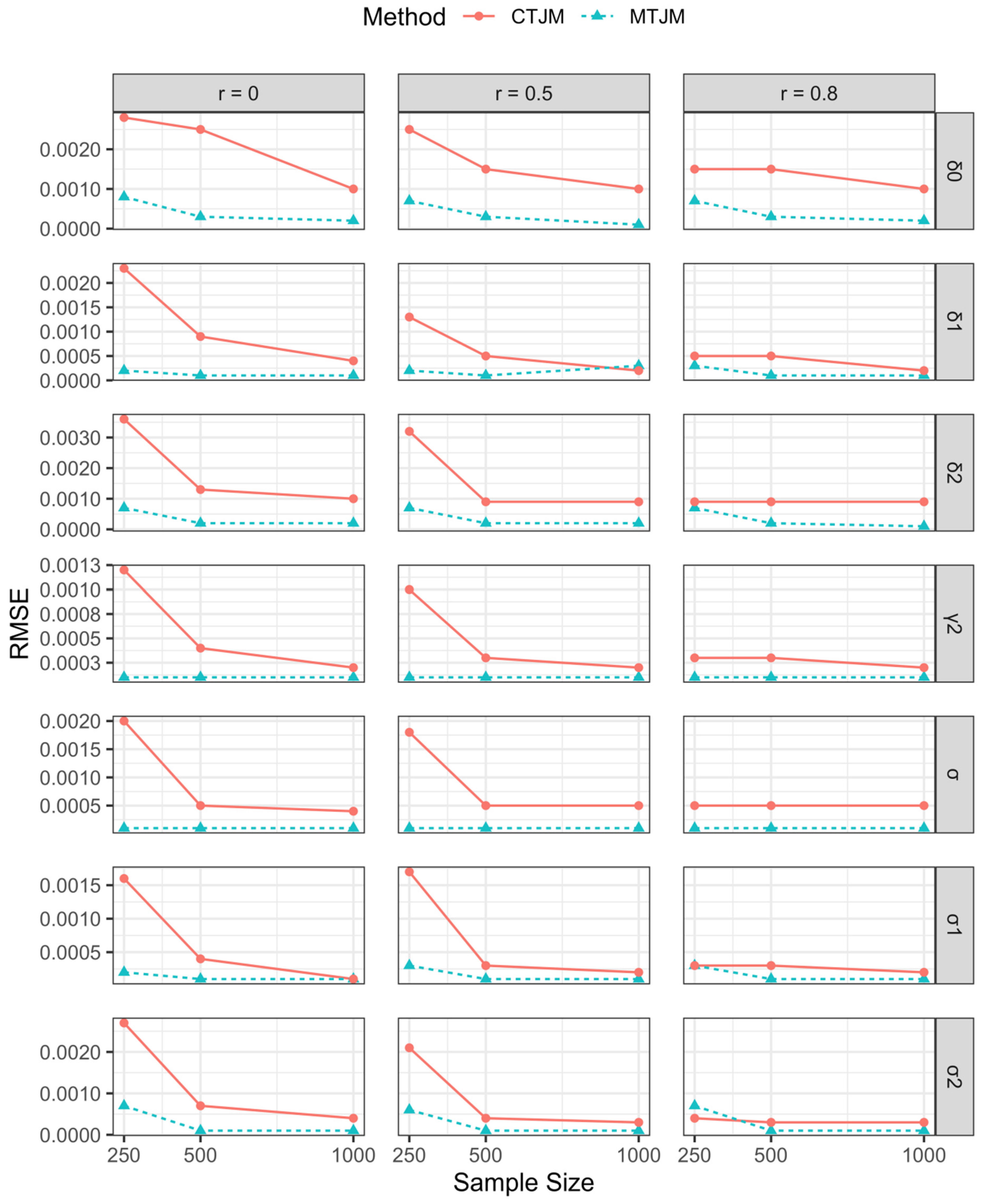

{kind=link}
{kind=link}
| Parameter | True Value | r = 0.0 | r = 0.5 | r = 0.8 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTJM | CTJM | MTJM | CTJM | MTJM | CTJM | ||||||||||||||
| Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | ||
| 14.4 | 14.4000 | 0.0001 | 0.0001 | 14.4003 | 0.0005 | 0.0007 | 14.4000 | 0.0001 | 0.0001 | 14.4003 | 0.0004 | 0.0005 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0002 | |
| −0.3 | −0.3007 | 0.0047 | 0.0048 | −0.2965 | 0.0059 | 0.0069 | −0.3001 | 0.0044 | 0.0047 | −0.2962 | 0.0059 | 0.0070 | −0.3007 | 0.0042 | 0.0044 | −0.2975 | 0.0025 | 0.0035 | |
| 1.6 | 1.6000 | 0.0003 | 0.0003 | 1.6009 | 0.0023 | 0.0024 | 1.6000 | 0.0003 | 0.0003 | 1.6008 | 0.0019 | 0.0021 | 1.6000 | 0.0003 | 0.0003 | 1.5999 | 0.0001 | 0.0001 | |
| 5 | 5.0000 | 0.0001 | 0.0001 | 4.9963 | 0.0054 | 0.0065 | 5.0000 | 0.0001 | 0.0001 | 4.9967 | 0.0045 | 0.0056 | 5.0000 | 0.0001 | 0.0001 | 4.9986 | 0.0014 | 0.0025 | |
| 0.05 | 0.0496 | 0.0038 | 0.0038 | 0.0240 | 0.0066 | 0.0269 | 0.0494 | 0.0031 | 0.0038 | 0.0241 | 0.0066 | 0.0261 | 0.0496 | 0.0033 | 0.0032 | 0.0225 | 0.0029 | 0.0276 | |
| 1.1 | 1.0999 | 0.0004 | 0.0004 | 1.0960 | 0.0075 | 0.0084 | 1.1000 | 0.0004 | 0.0003 | 1.0967 | 0.0065 | 0.0070 | 1.1000 | 0.0004 | 0.0004 | 1.0992 | 0.0003 | 0.0065 | |
| 0.1 | 0.0981 | 0.0051 | 0.0054 | 0.1226 | 0.0126 | 0.0259 | 0.0982 | 0.0057 | 0.0055 | 0.1228 | 0.0128 | 0.0262 | 0.0977 | 0.0058 | 0.0059 | 0.1203 | 0.0067 | 0.0214 | |
| −1 | −1.0000 | 0.0001 | 0.0001 | −0.9999 | 0.0012 | 0.0012 | −1.0000 | 0.0001 | 0.0001 | −0.9999 | 0.0010 | 0.0010 | −1.0000 | 0.0002 | 0.0001 | −0.9998 | 0.0002 | 0.0003 | |
| 1 | 0.9999 | 0.0008 | 0.0008 | 0.9982 | 0.0022 | 0.0028 | 0.9998 | 0.0007 | 0.0007 | 0.9982 | 0.0018 | 0.0025 | 0.9995 | 0.0006 | 0.0007 | 0.9988 | 0.0009 | 0.0015 | |
| 2 | 2.0000 | 0.0002 | 0.0002 | 2.0008 | 0.0022 | 0.0023 | 1.9998 | 0.0002 | 0.0002 | 2.0002 | 0.0013 | 0.0013 | 1.9999 | 0.0003 | 0.0003 | 2.0002 | 0.0005 | 0.0005 | |
| 3 | 3.0001 | 0.0007 | 0.0007 | 3.0014 | 0.0033 | 0.0036 | 3.0000 | 0.0007 | 0.0007 | 3.0014 | 0.0029 | 0.0032 | 3.0002 | 0.0008 | 0.0007 | 3.0008 | 0.0004 | 0.0009 | |
| 3 | 2.9999 | 0.0002 | 0.0002 | 2.9990 | 0.0012 | 0.0016 | 2.9998 | 0.0002 | 0.0003 | 2.9988 | 0.0012 | 0.0017 | 2.9996 | 0.0003 | 0.0003 | 2.9998 | 0.0002 | 0.0003 | |
| 3 | 3.0002 | 0.0006 | 0.0007 | 2.9999 | 0.0027 | 0.0027 | 3.0000 | 0.0007 | 0.0006 | 2.9988 | 0.0021 | 0.0021 | 3.0001 | 0.0007 | 0.0007 | 3.0001 | 0.0003 | 0.0004 | |
| 4 | 4.0000 | 0.0001 | 0.0001 | 4.0009 | 0.0018 | 0.0020 | 4.0000 | 0.0001 | 0.0001 | 4.0008 | 0.0016 | 0.0018 | 4.0000 | 0.0002 | 0.0001 | 4.0003 | 0.0004 | 0.0005 | |
| Parameter | True Value | r = 0.0 | r = 0.5 | r = 0.8 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTJM | CTJM | MTJM | CTJM | MTJM | CTJM | ||||||||||||||
| Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | ||
| 14.4 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0002 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0001 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0001 | |
| −0.3 | −0.3005 | 0.0031 | 0.0032 | −0.2976 | 0.0023 | 0.0033 | −0.3000 | 0.0033 | 0.0033 | −0.2975 | 0.0024 | 0.0034 | −0.3002 | 0.0031 | 0.0031 | −0.2975 | 0.0024 | 0.0034 | |
| 1.6 | 1.6000 | 0.0001 | 0.0001 | 1.5998 | 0.0002 | 0.0003 | 1.6000 | 0.0001 | 0.0001 | 1.5999 | 0.0001 | 0.0001 | 1.6000 | 0.0001 | 0.0001 | 1.5999 | 0.0001 | 0.0001 | |
| 5 | 5.0000 | 0.0001 | 0.0001 | 4.9985 | 0.0004 | 0.0016 | 5.0000 | 0.0001 | 0.0001 | 4.9986 | 0.0005 | 0.0014 | 5.0000 | 0.0001 | 0.0001 | 4.9986 | 0.0005 | 0.0014 | |
| 0.05 | 0.0503 | 0.0017 | 0.0017 | 0.0227 | 0.0030 | 0.0255 | 0.0503 | 0.0017 | 0.0017 | 0.0224 | 0.0029 | 0.0278 | 0.0501 | 0.0020 | 0.0020 | 0.0224 | 0.0029 | 0.0272 | |
| 1.1 | 1.1000 | 0.0001 | 0.0001 | 1.0991 | 0.0003 | 0.0010 | 1.1000 | 0.0001 | 0.0001 | 1.0992 | 0.0002 | 0.0008 | 1.1000 | 0.0001 | 0.0001 | 1.0992 | 0.0002 | 0.0008 | |
| 0.1 | 0.1002 | 0.0014 | 0.0014 | 0.1211 | 0.0067 | 0.0222 | 0.0999 | 0.0012 | 0.0012 | 0.1202 | 0.0068 | 0.0213 | 0.1007 | 0.0012 | 0.0014 | 0.1202 | 0.0068 | 0.0206 | |
| −1 | −1.0000 | 0.0001 | 0.0001 | −0.9997 | 0.0002 | 0.0004 | −1.0000 | 0.0001 | 0.0001 | −0.9997 | 0.0002 | 0.0003 | −1.0000 | 0.0001 | 0.0001 | −0.9998 | 0.0002 | 0.0003 | |
| 1 | 1.0000 | 0.0003 | 0.0003 | 0.9982 | 0.0018 | 0.0025 | 1.0000 | 0.0003 | 0.0003 | 0.9988 | 0.0009 | 0.0015 | 1.0000 | 0.0003 | 0.0003 | 0.9988 | 0.0009 | 0.0015 | |
| 2 | 2.0000 | 0.0002 | 0.0001 | 2.0006 | 0.0006 | 0.0009 | 1.9999 | 0.0001 | 0.0001 | 2.0003 | 0.0005 | 0.0005 | 1.9999 | 0.0001 | 0.0001 | 2.0003 | 0.0005 | 0.0005 | |
| 3 | 3.0001 | 0.0002 | 0.0002 | 3.0011 | 0.0007 | 0.0013 | 3.0001 | 0.0001 | 0.0002 | 3.0008 | 0.0004 | 0.0009 | 3.0001 | 0.0001 | 0.0002 | 3.0008 | 0.0004 | 0.0009 | |
| 3 | 3.0000 | 0.0002 | 0.0001 | 2.9999 | 0.0002 | 0.0004 | 3.0000 | 0.0001 | 0.0001 | 2.9999 | 0.0002 | 0.0003 | 3.0000 | 0.0001 | 0.0001 | 2.9999 | 0.0002 | 0.0003 | |
| 3 | 3.0001 | 0.0002 | 0.0001 | 3.0004 | 0.0003 | 0.0007 | 3.0000 | 0.0001 | 0.0001 | 3.0001 | 0.0003 | 0.0004 | 3.0000 | 0.0001 | 0.0001 | 3.0001 | 0.0003 | 0.0003 | |
| 4 | 4.0000 | 0.0001 | 0.0001 | 4.0003 | 0.0006 | 0.0005 | 4.0000 | 0.0001 | 0.0001 | 4.0003 | 0.0004 | 0.0005 | 4.0000 | 0.0001 | 0.0001 | 4.0003 | 0.0004 | 0.0005 | |
| Parameter | True Value | r = 0.0 | r = 0.5 | r = 0.8 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MTJM | CTJM | MTJM | CTJM | MTJM | CTJM | ||||||||||||||
| Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | Estimate | S.E. | RMSE | ||
| 14.4 | 14.4000 | 0.0001 | 0.0001 | 14.4000 | 0.0001 | 0.0001 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0001 | 14.4000 | 0.0001 | 0.0001 | 14.4001 | 0.0001 | 0.0001 | |
| −0.3 | −0.3001 | 0.0025 | 0.0025 | −0.2981 | 0.0021 | 0.0029 | −0.3000 | 0.0020 | 0.0020 | −0.2971 | 0.0027 | 0.0030 | −0.3004 | 0.0022 | 0.0023 | −0.2971 | 0.0028 | 0.0029 | |
| 1.6 | 1.6000 | 0.0001 | 0.0001 | 1.6001 | 0.0002 | 0.0002 | 1.6001 | 0.0002 | 0.0001 | 1.6000 | 0.0002 | 0.0002 | 1.6000 | 0.0001 | 0.0001 | 1.6000 | 0.0002 | 0.0001 | |
| 5 | 5.0000 | 0.0001 | 0.0001 | 4.9989 | 0.0005 | 0.0013 | 5.0000 | 0.0001 | 0.0001 | 4.9988 | 0.0005 | 0.0009 | 5.0000 | 0.0001 | 0.0001 | 4.9988 | 0.0005 | 0.0013 | |
| 0.05 | 0.0501 | 0.0015 | 0.0014 | 0.0235 | 0.0028 | 0.0209 | 0.0507 | 0.0015 | 0.0018 | 0.0299 | 0.0015 | 0.0225 | 0.0491 | 0.0011 | 0.0014 | 0.0309 | 0.0018 | 0.0217 | |
| 1.1 | 1.1000 | 0.0002 | 0.0001 | 1.0993 | 0.0002 | 0.0008 | 1.1000 | 0.0001 | 0.0001 | 1.0992 | 0.0004 | 0.0009 | 1.1000 | 0.0001 | 0.0001 | 1.0993 | 0.0004 | 0.0008 | |
| 0.1 | 0.1002 | 0.0008 | 0.0009 | 0.1197 | 0.0048 | 0.0204 | 0.1005 | 0.0010 | 0.0013 | 0.1137 | 0.0015 | 0.0213 | 0.0994 | 0.0008 | 0.0010 | 0.1134 | 0.0010 | 0.0202 | |
| −1 | −1.0000 | 0.0001 | 0.0001 | −0.9998 | 0.0001 | 0.0002 | −1.0000 | 0.0001 | 0.0001 | −0.9998 | 0.0001 | 0.0002 | −1.0000 | 0.0001 | 0.0001 | −0.9998 | 0.0001 | 0.0002 | |
| 1 | 1.0000 | 0.0003 | 0.0002 | 0.9991 | 0.0005 | 0.0010 | 1.0005 | 0.0001 | 0.0001 | 0.9991 | 0.0005 | 0.0010 | 0.9998 | 0.0003 | 0.0002 | 0.9991 | 0.0004 | 0.0010 | |
| 2 | 2.0000 | 0.0001 | 0.0001 | 2.0004 | 0.0001 | 0.0004 | 1.9998 | 0.0003 | 0.0003 | 2.0002 | 0.0001 | 0.0002 | 1.9999 | 0.0001 | 0.0001 | 2.0001 | 0.0002 | 0.0002 | |
| 3 | 3.0000 | 0.0004 | 0.0002 | 3.0007 | 0.0007 | 0.0010 | 3.0003 | 0.0004 | 0.0002 | 3.0006 | 0.0008 | 0.0009 | 3.0000 | 0.0001 | 0.0001 | 3.0007 | 0.0008 | 0.0009 | |
| 3 | 3.0000 | 0.0001 | 0.0001 | 3.0000 | 0.0001 | 0.0001 | 3.0000 | 0.0001 | 0.0001 | 2.9999 | 0.0001 | 0.0002 | 3.0000 | 0.0001 | 0.0001 | 2.9998 | 0.0001 | 0.0002 | |
| 3 | 3.0001 | 0.0003 | 0.0001 | 3.0002 | 0.0003 | 0.0004 | 3.0002 | 0.0002 | 0.0001 | 3.0001 | 0.0003 | 0.0003 | 3.0000 | 0.0001 | 0.0001 | 3.0001 | 0.0003 | 0.0003 | |
| 4 | 4.0000 | 0.0002 | 0.0001 | 4.0003 | 0.0003 | 0.0004 | 4.0001 | 0.0002 | 0.0001 | 4.0003 | 0.0003 | 0.0005 | 4.0000 | 0.0001 | 0.0001 | 4.0003 | 0.0004 | 0.0005 | |
| Variables | Description | Type | Participation |
|---|---|---|---|
| Gender | Male */Female | Time-independent | Part II and survival |
| Age | Age that they entered | Time-independent | Part II and survival |
| Place of residence | Kerman */Other city | Time-independent | Survival |
| Type of hospitalization | Outpatient */Inpatient | Time-dependent | Part I and part II |
| Variables | Category | n (%) | Positive Cost (%) | Mean Positive Cost (USD) | Died (%) |
|---|---|---|---|---|---|
| Gender | Male | 835 (50.2) | 92.1 | 633 | 16.3 |
| Female | 829 (49.8) | 87.7 | 463 | 6.2 | |
| Age | <75 years | 1002 (60.2) | 88.2 | 542 | 10.4 |
| ≥75 years | 662 (39.8) | 92.5 | 551 | 12.5 | |
| Place of residence | Kerman | 1587 (95.4) | 89.6 | 542 | 10.6 |
| Other | 77 (4.6) | 97.8 | 660 | 24.7 |
| Visit Time | Type of Hospitalization | n (%) | Positive Cost (%) | Mean Positive Cost (USD) |
|---|---|---|---|---|
| 1 | Outpatient | 933 (56.1) | 80.9 | 62 |
| Inpatient | 731 (43.9) | 99.7 | 1477 | |
| 2 | Outpatient | 459 (27.6) | 54.9 | 24 |
| Inpatient | 1205 (72.4) | 99.5 | 931 | |
| 3 | Outpatient | 188 (11.3) | 31.9 | 13 |
| Inpatient | 1476 (88.7) | 98.8 | 506 | |
| 4 | Outpatient | 61 (9.7) | 29.5 | 11 |
| Inpatient | 565 (90.3) | 99.3 | 372 | |
| 5 | Outpatient | 23 (8.4) | 8.7 | 26 |
| Inpatient | 251 (91.6) | 98.4 | 327 | |
| 6 | Outpatient | 7 (5.2) | 0.0 | 0 |
| Inpatient | 127 (94.8) | 98.4 | 297 | |
| 7 | Outpatient | 4 (5.6) | 0.0 | 0 |
| Inpatient | 67 (94.4) | 97.0 | 260 | |
| 8 | Outpatient | 2 (4.3) | 0.0 | 0 |
| Inpatient | 45 (95.7) | 97.7 | 231 | |
| 9 | Outpatient | 1 (3.7) | 0.0 | 0 |
| Inpatient | 26 (96.3) | 100.0 | 195 | |
| 10 | Outpatient | 0 (0.0) | 0.0 | 0 |
| Inpatient | 14 (100.0) | 92.9 | 188 | |
| 11 | Outpatient | 0 (0.0) | 0.0 | 0 |
| Inpatient | 7 (100.0) | 100.0 | 127 |
| Parameter | MTJM | CTJM | ||||
|---|---|---|---|---|---|---|
| Est | SE | p-Value | Est | SE | p-Value | |
| Longitudinal: Part I | ||||||
| Intercept | 5.299 | 0.136 | <0.0001 | 2.059 | 0.078 | <0.0001 |
| Outpatient | 1.300 | 0.364 | 0.0004 | 1.366 | 0.105 | <0.0001 |
| Longitudinal: Part II | ||||||
| Intercept | 14.298 | 0.126 | <0.0001 | 15.037 | 0.212 | <0.0001 |
| Male | 2.497 | 0.331 | <0.0001 | 2.109 | 0.037 | <0.0001 |
| Age | 0.027 | 0.002 | <0.0001 | 0.297 | 0.065 | <0.0001 |
| Outpatient | 0.001 | 0.081 | 0.8950 | 0.012 | 0.003 | 0.0004 |
| Survival | ||||||
| Male | 1.100 | 0.767 | 0.1520 | 1.142 | 0.209 | <0.0001 |
| Age | 0.499 | 0.378 | 0.1880 | 0.479 | 0.256 | 0.1603 |
| −0.135 | 0.004 | <0.0001 | −0.182 | 0.016 | <0.0001 | |
| Other | ||||||
| 1.010 | 0.122 | <0.0001 | 1.382 | 0.042 | <0.0001 | |
| 1.999 | 0.309 | <0.0001 | 1.870 | 0.319 | <0.0001 | |
| 3.000 | 0.072 | <0.0001 | 3.131 | 0.310 | <0.0001 | |
| 1.005 | 0.033 | <0.0001 | 0.786 | 0.018 | <0.0001 | |
| AIC | 211,965 | 222,610 | ||||
| BIC | 212,035 | 222,680 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahrokhabadi, M.S.; Chen, D.-G.; Mirkamali, S.J.; Kazemnejad, A.; Zayeri, F. Marginalized Two-Part Joint Modeling of Longitudinal Semi-Continuous Responses and Survival Data: With Application to Medical Costs. Mathematics 2021, 9, 2603. https://doi.org/10.3390/math9202603
Shahrokhabadi MS, Chen D-G, Mirkamali SJ, Kazemnejad A, Zayeri F. Marginalized Two-Part Joint Modeling of Longitudinal Semi-Continuous Responses and Survival Data: With Application to Medical Costs. Mathematics. 2021; 9(20):2603. https://doi.org/10.3390/math9202603
Chicago/Turabian StyleShahrokhabadi, Mohadeseh Shojaei, (Din) Ding-Geng Chen, Sayed Jamal Mirkamali, Anoshirvan Kazemnejad, and Farid Zayeri. 2021. "Marginalized Two-Part Joint Modeling of Longitudinal Semi-Continuous Responses and Survival Data: With Application to Medical Costs" Mathematics 9, no. 20: 2603. https://doi.org/10.3390/math9202603
APA StyleShahrokhabadi, M. S., Chen, D.-G., Mirkamali, S. J., Kazemnejad, A., & Zayeri, F. (2021). Marginalized Two-Part Joint Modeling of Longitudinal Semi-Continuous Responses and Survival Data: With Application to Medical Costs. Mathematics, 9(20), 2603. https://doi.org/10.3390/math9202603