Assessing Efficiency of Public Poverty Policies in UE-28 with Linguistic Variables and Fuzzy Correlation Measures




Abstract
1. Introduction
- Periodic assessment of public policies is a must for their improvement. That explains the existence of a wide literature on social policy evaluation, which has been summarized in above paragraphs. Our analysis complement these papers by showing a different perspective on this topic since we cover a different period and in some cases we use a different sample of countries and database. Likewise, we also use a novel (in this kind of analysis) mathematical instruments. Likewise, our results are compared with those from precedent literature.
- The methodology proposed to deal with the variability in longitudinal data supposes a novelty in the field of public policy evaluation. To the best of our knowledge in this field, there is a scarcity of papers that model uncertainty in data by using soft computing tools as fuzzy sets. In most of the studies on this topic, when an observation is given by a set of crisp results, these are reduced to a real number (e.g., the arithmetical mean) to model the observation. Hence, subsequent analysis is done ignoring actual data uncertainty. The use of fuzzy numbers lets modeling and structuring observed uncertainty and also provides a developed mathematical core that allows handling these data linked with their uncertainty in similar way to we do with real numbers.
- The literature on productivity measurement under fuzziness is built up by adapting conventional data envelopment analysis to fuzzy mathematics, and then so-called fuzzy data envelopment analysis (FDEA) methods reach. Our paper also uses a fuzzy efficient frontier to evaluate productivity, but it is built over the basis of the Debreu–Farrell index that is fitted with a regression method. This way to fit efficient frontier is very common in economics (see [24]) but supposes a novel approach from fuzzy sets literature perspective.
2. Concepts of Fuzzy Set Mathematics
2.1. Fuzzy Numbers
- TFNs are well-adapted to how humans think about imprecise quantities. For example, a prediction as “I expect that for the next two years the GPD growth rate will be 1.5% and deviations no greater than 0.05%” may be quantified in a very natural way as (0.015, 0.005, 0.005). Notice that it is not needed to be a fuzzy set practitioner to interpret and understand the information provided by that FN;
- When the information about a variable is vague and imprecise, as that in this paper, representing the information as simple as possible is desirable, and the linear shape of TFNs meets that requirement;
- TFNs are easier to handle arithmetically than other more complex shapes. From a soft-computing perspective, they provide a good balance between precision on one hand and computational effort and interpretability of results on the other. This fact explains the great deal of literature about approximating triangular shapes to non-TFNs.
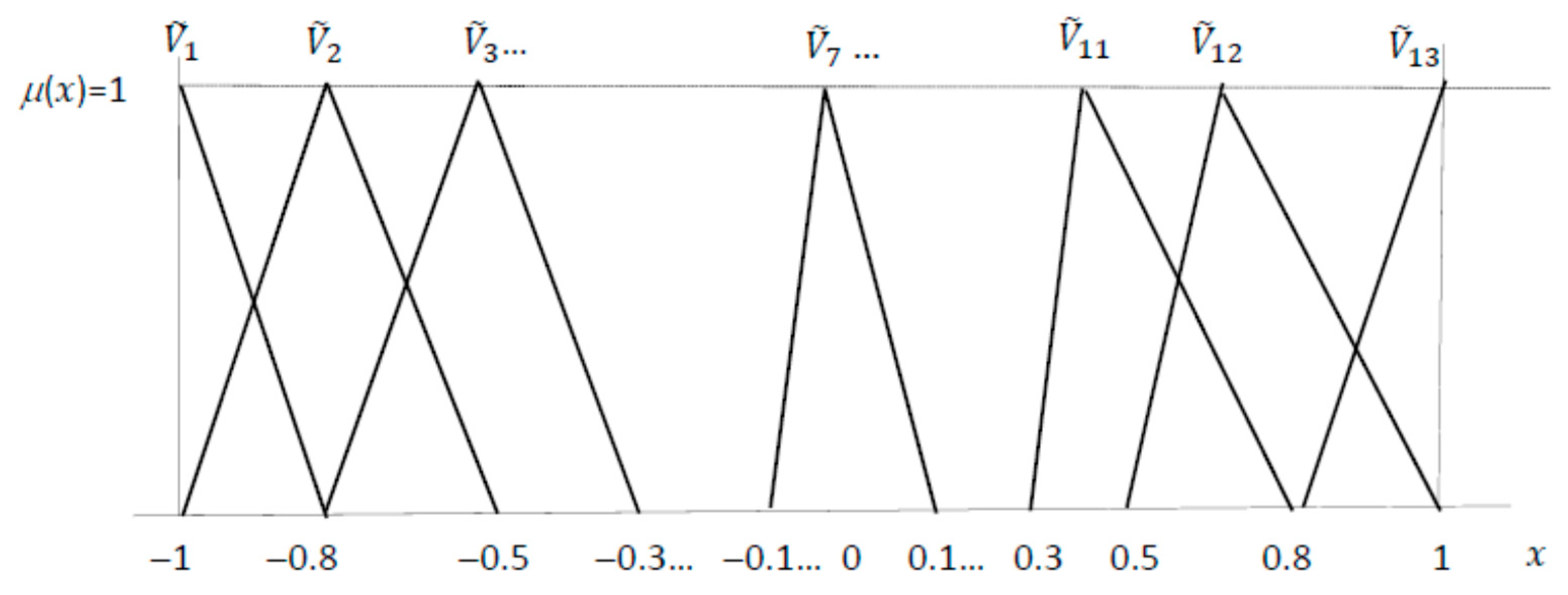
2.2. Modeling the Value of the Pearson Correlation Coefficient as a Linguistic Variable
2.3. Aggregating Crisp Observations by Means of a Triangular Fuzzy Number
- Tools as intuitionistic fuzzy sets (IFSs) or neutrosophic fuzzy sets (NFSs) provide an analytical framework to quantify uncertainty more precisely than FNs. Therefore, they are able to capture more nuances from data and its imprecision. For example, NFS state for any element not only a truth membership degree but also an indeterminacy and a falsity degree. However, their estimation implies a greater cost since the number of parameters to fit for each uncertain observation is three times that number than in the case of FNs. On the other hand, gray numbers (GNs) provide a simpler representation of uncertain quantities than FNs. To define a GN is enough to fit its kernel and a grayness measure. Hence, in several circumstances GNs may oversimplify information. For example, GNs suppose a symmetrical structure for a uncertain quantity when perhaps available information does not suggest so. TFNs balances capturing much of the uncertainty in available information (less than, e.g., NFS, but more than GNs), but with a smooth shape (less than GNs, but more than NFSs).
- In many circumstances, rough sets also could provide accurate quantification of uncertainty. However, as we will explain below, our problem is more linked to vagueness in observations than with their indiscernibility.
- Our analysis needs implementing arithmetical operations with uncertain variables, ranking them and evaluating Pearson’s correlation with uncertain observations. Fuzzy sets literature has developed these questions widely, and so the use of TFNs allows making these analyses similar to real numbers. Likewise, fuzzy arithmetic allows results conserving the triangular shape as well as the uncertainty within data throughout calculations.
Numerical Application 1
2.4. Correlation Coefficients for Fuzzy Data
Numerical Application 2
2.5. Literature Revision
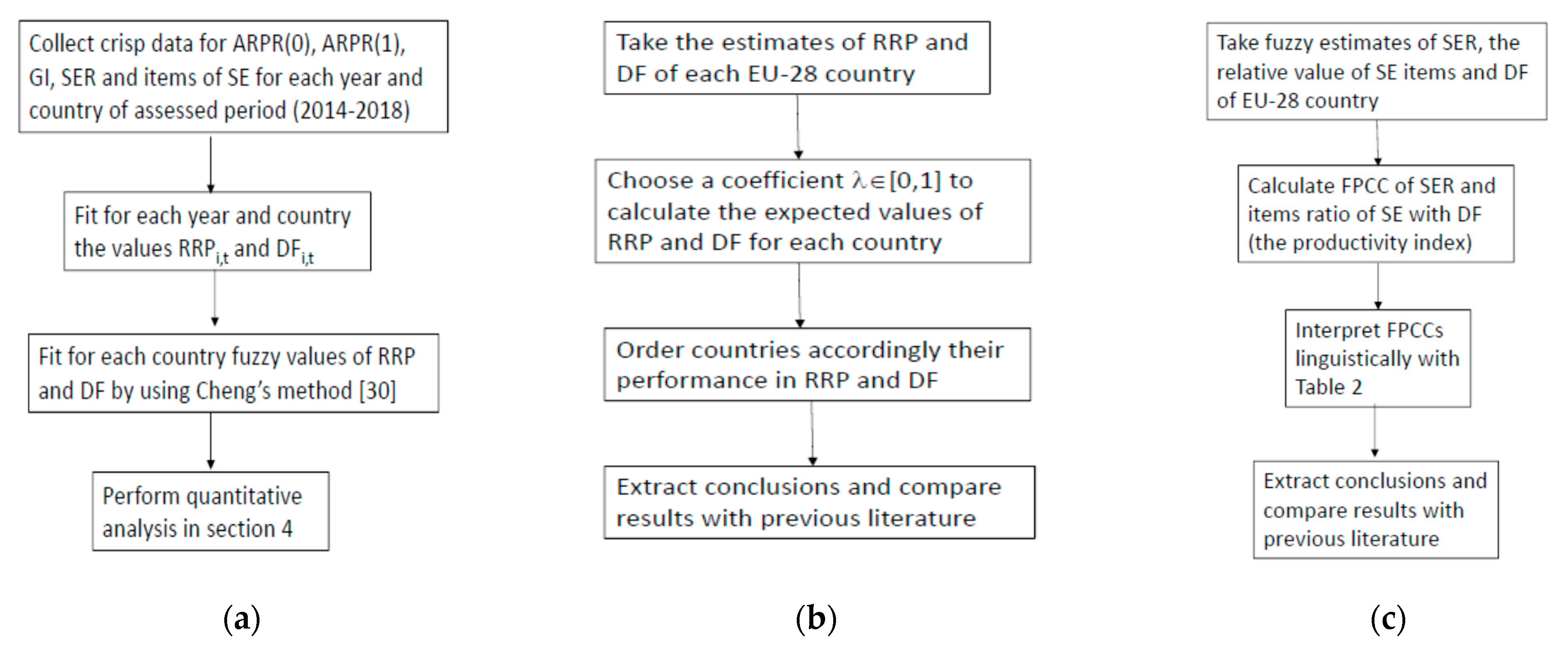
3. Data and Methodology
3.1. Data Description
- ARPR(0)i,t = At-risk-of-poverty rate before social transfers including pensions for the ith country at year t;
- ARPR(1)i,t = At-risk-of-poverty rate after social transfers for the ith country at year t;
- GIi,t = Income inequality (measured as the Gini index) before social transfers for the ith country at year t;
- SERi,t = Ratio social expenses/GDP before social transfers for the ith country at year t.
- Sickness/healthcare benefits (Sicki,t)—Include, for example, medical assistance or the provision of pharmaceutical products;
- Disability benefits (Disi,t)—Pensions, goods and services for disabled persons;
- Old age benefits (Oldi,t)—Basically retirement pensions;
- Survivors’ benefits (Survi,t)—An example are survivors’ pensions;
- Family/children benefits (Fami,t)—Support programs linked to pregnancy assistance, childbirth, etc.;
- Unemployment benefits (Unei,t)—Include unemployment in-cash benefits, but also vocational training services provided by public agencies;
- Housing benefits (Houi,t)—Interventions and programs from public agencies to help households reaching housing expenses;
- Social exclusion benefits not elsewhere classified (n.e.c.) (SocEi,t)—A miscellanea of public interventions that may include, e.g., rehabilitation of drug abusers, etc.
3.2. Methodology
4. Results
4.1. Ranking Public Poverty Policies by the EU-28 States
4.2. Fuzzy Assessment of the Relation between Social Expense Effort and Efficiency in Poverty Reduction
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Sickness/Healthcare | Disability | Old Age | Survivors | Family/Children | Unemployment | Housing | Social Exclusion | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | Center | Left | Right | Center | Left | Right | Center | Left | Right | Center | Left | Right | Center | Left | Right | Center | Left | Right | Center | Left | Right | Center | Left | Right |
| Belgium | 27.019 | 0.097 | 1.07 | 8.458 | 1.18 | 0.755 | 38.439 | 4.508 | 5.208 | 6.525 | 0.306 | 0.206 | 7.498 | 0.177 | 0.22 | 5.492 | 1.221 | 0.939 | 1.51 | 0.017 | 0.037 | 2.425 | 0.543 | 0.371 |
| Denmark | 21.282 | 1.172 | 0.708 | 16.181 | 0.733 | 0.197 | 38.731 | 0.81 | 1.333 | 0.783 | 0.13 | 0.257 | 11.139 | 0.252 | 0.156 | 2.625 | 0.24 | 0.408 | 1.345 | 0.522 | 0.289 | 5.165 | 0.626 | 0.386 |
| Germany | 35.144 | 0.089 | 0.166 | 8.207 | 0.56 | 0.986 | 32.301 | 0.113 | 0.174 | 6.312 | 0.314 | 0.505 | 11.403 | 0.182 | 0.246 | 4.681 | 1.027 | 0.766 | 2.173 | 0.041 | 0.021 | 0.979 | 0.401 | 0.262 |
| Ireland | 36.908 | 3.55 | 2.537 | 5.443 | 0.248 | 0.41 | 31.465 | 0.824 | 1.301 | 2.723 | 0.077 | 0.022 | 9.053 | 0.873 | 0.61 | 2.792 | 0.254 | 0.164 | 0.335 | 0.363 | 0.204 | 0.769 | 0.056 | 0.085 |
| Greece | 19.421 | 0.883 | 1.824 | 4.371 | 0.086 | 1.028 | 55.4 | 0.986 | 2.994 | 10.107 | 0.418 | 1.121 | 4.874 | 1.626 | 2.953 | 10.12 | 5.252 | 3.744 | 3.534 | 0.673 | 0.99 | 1.285 | 1.358 | 0.538 |
| Spain | 26.683 | 0.711 | 1.001 | 7.174 | 0.071 | 0.208 | 41.002 | 3.669 | 2.356 | 9.84 | 0.049 | 0.12 | 5.368 | 0.162 | 0.261 | 3.736 | 0.197 | 0.332 | 0.054 | 0.148 | 0.096 | 0.999 | 0.028 | 0.013 |
| France | 28.564 | 0.39 | 0.258 | 6.449 | 0.048 | 0.021 | 40.17 | 0.02 | 0.194 | 5.384 | 0.192 | 0.262 | 7.68 | 0.229 | 0.368 | 8.345 | 2.059 | 3.276 | 0.443 | 0.045 | 0.027 | 3.068 | 0.239 | 0.347 |
| Italy | 23.132 | 0.086 | 0.276 | 5.713 | 0.2 | 0.175 | 48.987 | 0.093 | 0.039 | 9.492 | 0.123 | 0.31 | 4.1 | 0.192 | 0.057 | 2.895 | 0.45 | 1.114 | 0.106 | 0.032 | 0.019 | 2.728 | 0.967 | 0.627 |
| Luxembourg | 24.977 | 0.575 | 0.855 | 10.857 | 0.568 | 0.856 | 31.362 | 2.845 | 1.614 | 7.743 | 0.672 | 0.457 | 15.439 | 0.174 | 0.25 | 3.581 | 1.412 | 0.963 | 0.396 | 0.129 | 0.081 | 2.257 | 0.106 | 0.064 |
| Netherlands | 33.766 | 1.342 | 1.998 | 9.16 | 0.846 | 0.081 | 38.346 | 0.294 | 0.196 | 3.933 | 0.548 | 0.34 | 3.977 | 0.853 | 0.486 | 2.61 | 1.117 | 0.766 | 0.858 | 0.422 | 0.357 | 4.941 | 0.818 | 0.293 |
| Austria | 25.528 | 0.546 | 1.059 | 6.516 | 0.426 | 0.644 | 44.421 | 0.186 | 0.263 | 5.871 | 0.365 | 0.507 | 9.523 | 0.15 | 0.094 | 4.641 | 2.304 | 1.592 | 1.641 | 0.196 | 0.1 | 1.989 | 0.292 | 0.698 |
| Portugal | 24.994 | 2.525 | 1.759 | 7.223 | 0.417 | 0.293 | 50.339 | 0.655 | 0.994 | 7.6 | 0.063 | 0.154 | 4.834 | 0.519 | 0.347 | 1.235 | 0.309 | 0.472 | 0.224 | 0.102 | 0.146 | 0.905 | 0.125 | 0.073 |
| Finland | 23.023 | 1.057 | 1.958 | 9.943 | 0.814 | 1.393 | 40.985 | 3.512 | 4.921 | 2.702 | 0.083 | 0.135 | 10.02 | 0.319 | 0.52 | 2.887 | 0.122 | 0.073 | 0.253 | 0.066 | 0.109 | 2.926 | 0.15 | 0.404 |
| Sweden | 26.145 | 0.396 | 0.685 | 10.241 | 0.661 | 1.302 | 43.582 | 0.801 | 1.188 | 1.091 | 0.207 | 0.315 | 10.386 | 0.281 | 0.394 | 7.816 | 2.316 | 1.193 | 2.452 | 0.778 | 1.093 | 3.278 | 1.379 | 1.034 |
| United Kingdom | 32.463 | 0.775 | 0.427 | 6.324 | 0.762 | 0.518 | 42.446 | 0.469 | 0.724 | 0.311 | 0.023 | 0.033 | 9.968 | 0.399 | 0.54 | 3.623 | 0.238 | 0.104 | 1.498 | 0.126 | 0.177 | 2.318 | 0.217 | 0.162 |
| Bulgaria | 28.053 | 1.645 | 2.532 | 7.451 | 0.271 | 0.44 | 43.932 | 1.386 | 0.951 | 5.422 | 0.128 | 0.167 | 10.631 | 0.573 | 0.264 | 8.919 | 6.385 | 4.871 | 0.847 | 0.046 | 0.068 | 1.47 | 0.517 | 0.282 |
| Czechia | 32.281 | 2.131 | 1.574 | 6.464 | 0.323 | 0.399 | 43.783 | 0.265 | 0.373 | 3.312 | 0.277 | 0.377 | 8.811 | 0.102 | 0.343 | 3.005 | 0.309 | 0.215 | 0 | 0 | 0 | 1.332 | 0.705 | 0.503 |
| Estonia | 29.601 | 1.311 | 0.65 | 11.503 | 0.281 | 0.525 | 42.104 | 2.793 | 4.276 | 0.352 | 0.065 | 0.098 | 12.929 | 2.022 | 1.362 | 3.545 | 0.413 | 0.579 | 1.969 | 0.111 | 0.046 | 0.554 | 0.083 | 0.202 |
| Croatia | 32.987 | 1.502 | 0.516 | 11.046 | 1.498 | 2.377 | 33.636 | 0.464 | 0.179 | 8.981 | 0.809 | 1.221 | 8.79 | 0.304 | 0.57 | 6.132 | 0.219 | 0.11 | 2.55 | 0.176 | 0.097 | 1.498 | 0.704 | 0.453 |
| Cyprus | 17.912 | 2.278 | 1.598 | 4.116 | 1.522 | 1.059 | 48.577 | 1.015 | 1.585 | 7.227 | 0.11 | 0.081 | 6.816 | 0.28 | 0.496 | 5.723 | 0.423 | 0.679 | 0.13 | 0.049 | 0.026 | 6.696 | 1.184 | 0.696 |
| Latvia | 25.047 | 1.514 | 2.511 | 9.071 | 0.255 | 0.322 | 48.129 | 2.182 | 3.453 | 1.258 | 0.049 | 0.084 | 10.755 | 0.88 | 0.078 | 6.681 | 3.123 | 2.625 | 1.83 | 0.351 | 0.212 | 0.741 | 0.099 | 0.174 |
| Lithuania | 30.315 | 2.63 | 1.584 | 9.3 | 0.336 | 0.117 | 43.377 | 3.021 | 4.716 | 2.718 | 0.54 | 0.348 | 8.026 | 1.122 | 2.132 | 4.318 | 0.693 | 0.451 | 0.534 | 0.19 | 0.26 | 2.005 | 0.616 | 1.132 |
| Hungary | 27.18 | 2.944 | 1.617 | 6.364 | 1.235 | 1.77 | 44.766 | 0.64 | 1.243 | 5.518 | 0.859 | 0.604 | 11.949 | 0.114 | 0.174 | 5.949 | 1.157 | 1.669 | 1.585 | 0.501 | 0.342 | 0.565 | 0.109 | 0.169 |
| Malta | 33.927 | 2.388 | 1.649 | 3.647 | 0.235 | 0.34 | 43.323 | 1.827 | 1.161 | 8.274 | 0.107 | 0.19 | 5.963 | 1.002 | 1.743 | 1.785 | 0.198 | 0.341 | 1.894 | 1.02 | 1.514 | 1.302 | 0.318 | 0.558 |
| Poland | 22.952 | 0.65 | 1.455 | 7.553 | 1.217 | 0.845 | 47.42 | 4.599 | 1.978 | 9.328 | 1.08 | 1.8 | 11.102 | 8.806 | 5.041 | 5.668 | 0.101 | 0.245 | 0.379 | 0.149 | 0.082 | 0.623 | 0.158 | 0.219 |
| Romania | 27.116 | 0.806 | 1.307 | 6.907 | 1.606 | 1.212 | 50.284 | 0.694 | 0.065 | 4.467 | 0.319 | 0.526 | 9.513 | 2.525 | 1.649 | 3.954 | 1.788 | 2.842 | 0 | 0 | 0 | 1.056 | 0.466 | 0.248 |
| Slovenia | 33.015 | 3.168 | 1.867 | 5.309 | 1.698 | 1.314 | 41.847 | 0.631 | 0.486 | 6.169 | 0.9 | 0.614 | 7.963 | 0.667 | 1.008 | 0.591 | 0.396 | 0.615 | 0.103 | 0.039 | 0.05 | 3.103 | 0.157 | 0.253 |
| Slovakia | 31.739 | 0.838 | 2.036 | 8.809 | 0.282 | 0.189 | 40.67 | 0.362 | 0.477 | 4.996 | 0.238 | 0.356 | 9.088 | 0.374 | 0.14 | 2.598 | 0.432 | 0.664 | 0.107 | 0.016 | 0.005 | 1.56 | 0.54 | 0.808 |
| Relative Reduction of Poverty (RRP) | Debreu–Farrell Ratio (DF) | |||||
|---|---|---|---|---|---|---|
| Country | λ = 1 | λ = 0.5 | λ = 0 | λ = 1 | λ = 0.5 | λ = 0 |
| Belgium | 39.91 | 38.62 | 37.34 | 0.577 | 0.576 | 0.575 |
| Denmark | 50.88 | 49.93 | 48.99 | 0.722 | 0.713 | 0.705 |
| Germany | 33.54 | 33.39 | 33.25 | 0.53 | 0.52 | 0.51 |
| Ireland | 54.58 | 53.10 | 51.62 | 1 | 1 | 1 |
| Greece | 17.20 | 16.61 | 16.02 | 0.318 | 0.302 | 0.287 |
| Spain | 26.29 | 24.78 | 23.28 | 0.398 | 0.391 | 0.384 |
| France | 43.38 | 43.14 | 42.91 | 0.629 | 0.600 | 0.570 |
| Italy | 20.91 | 20.88 | 20.86 | 0.299 | 0.291 | 0.283 |
| Luxembourg | 39.41 | 39.03 | 38.66 | 0.669 | 0.653 | 0.637 |
| Netherlands | 43.21 | 41.57 | 39.92 | 0.608 | 0.594 | 0.581 |
| Austria | 43.59 | 42.92 | 42.25 | 0.641 | 0.627 | 0.614 |
| Portugal | 25.54 | 24.27 | 23.00 | 0.469 | 0.456 | 0.444 |
| Finland | 55.99 | 54.87 | 53.75 | 0.764 | 0.741 | 0.719 |
| Sweden | 45.26 | 44.72 | 44.17 | 0.748 | 0.745 | 0.741 |
| United Kingdom | 41.03 | 40.44 | 39.85 | 0.669 | 0.659 | 0.650 |
| Bulgaria | 22.51 | 20.92 | 19.32 | 0.423 | 0.396 | 0.370 |
| Czechia | 40.38 | 40.01 | 39.65 | 0.672 | 0.654 | 0.637 |
| Estonia | 25.64 | 24.14 | 22.63 | 0.433 | 0.428 | 0.424 |
| Croatia | 30.37 | 28.45 | 26.53 | 0.488 | 0.464 | 0.440 |
| Cyprus | 37.70 | 37.06 | 36.42 | 0.645 | 0.627 | 0.610 |
| Latvia | 19.35 | 18.68 | 18.01 | 0.365 | 0.351 | 0.337 |
| Lithuania | 25.13 | 24.14 | 23.15 | 0.501 | 0.481 | 0.461 |
| Hungary | 46.10 | 44.38 | 42.66 | 0.824 | 0.804 | 0.785 |
| Malta | 31.25 | 30.82 | 30.40 | 0.505 | 0.493 | 0.481 |
| Poland | 31.05 | 28.80 | 26.56 | 0.504 | 0.477 | 0.449 |
| Romania | 15.35 | 14.13 | 12.90 | 0.288 | 0.268 | 0.249 |
| Slovenia | 43.25 | 42.75 | 42.26 | 0.652 | 0.625 | 0.598 |
| Slovakia | 33.92 | 31.83 | 29.75 | 0.508 | 0.486 | 0.464 |
References
- Bárcena-Martín, E.; Blanco-Arana, M.; Pérez-Moreno, S. Social Transfers and Child Poverty in European Countries: Pro-poor Targeting or Pro-child Targeting? J. Soc. Policy 2018, 1–20. [Google Scholar] [CrossRef]
- Marchal, S.; Marx, I.; Van Mechelen, N. The Great Wake-Up Call? Social Citizenship and MinimumIncome Provisions in Europe in Times of Crisis. J. Soc. Policy 2014, 43, 247–267. [Google Scholar] [CrossRef]
- Smith, K.D.; Shone, B. Progressive State Taxes and Welfare. Poverty Public Policy 2016, 8, 430–437. [Google Scholar] [CrossRef]
- Afonso, A.; St Aubyn, M. Non-parametric Approaches to Education and Health Efficiency in OECD Countries. J. Appl. Econ. 2005, 8, 227–246. [Google Scholar] [CrossRef]
- Clements, B. How efficient is education spending in Europe? Eur. Rev. Econ. Financ. 2002, 1, 3–26. [Google Scholar]
- Kapsoli, J.; Teodoru, I.R. Benchmarking Social Spending Using Efficiency Frontiers, International Monetary Fund Working Paper 17/197; International Monetary Fund: Washington, DC, USA, 2017. [Google Scholar]
- Herrmann, P.; Tausch, A.; Heshmati, A.; Bajalan, C. Efficiency and Effectiveness of Social Spending; IZA Discussion Papers, No. 3482; Institute for the Study of Labor (IZA): Bonn, Germany, 2008; Available online: http://nbn-resolving.de/urn:nbn:de:101:1-2008052722 (accessed on 10 September 2020).
- Afonso, A.; Schuknecht, L.; Tanzi, V. Income distribution determinants and public spending efficiency. J. Econ. Inequal. 2010, 8, 367–389. [Google Scholar] [CrossRef]
- Lefebvre, M.; Coelli, T.; Pestieau, P. On the Convergence of Social Protection Performance in the European Union. CESifo Econ. Stud. 2010, 56, 300–322. [Google Scholar] [CrossRef]
- Valls Fonayet, F.; Belzunegui Eraso, Á.; De Andrés Sánchez, J. Efficiency of Social Expenditure Levels in Reducing Poverty Risk in the EU-28. Poverty Public Policy 2020, 12, 43–62. [Google Scholar] [CrossRef]
- Antonelli, M.A.; De Bonis, V. Social Spending, Welfare and Redistribution: A Comparative Analysis of 22 European Countries. Mod. Econ. 2017, 8, 1291–1313. [Google Scholar] [CrossRef]
- Andrés-Sánchez, J.; Belzunegui-Eraso, Á.; Valls-Fonayet, F. Pattern recognition in social expenditure and social expenditure performance in EU 28 countries. Acta Oeconomica 2020, 70, 37–61. [Google Scholar] [CrossRef]
- Ferrarini, T.; Nelson, K.; Palme, J. Social transfers and poverty in middle- and high-income countries—A global perspective. Glob. Soc. Policy 2016, 16, 22–46. [Google Scholar] [CrossRef]
- Oxley, H.; Dang, T.-T.; Förster, M.; Pellizari, M. Income inequalities and poverty among children and households with children in selected OECD countries. In Child Well-Being, Child Poverty and Child Policy in Modern Nations: What Do We Know; Vleminckx, K., Smeeding, T., Eds.; Policy Press: Bristol, UK, 2001; pp. 371–405. [Google Scholar]
- Cantillon, B.; Marx, I. Van den Bosch, K. The Puzzle of Egalitarianism: About the Relationships between Employment, Wage Inequality, Social Expenditures and Poverty; Working Papers No 337; Luxembourg Income Study: Luxembourg, 2002. [Google Scholar]
- Wade, R.H. On the causes of increasing world poverty and inequality, or why the Matthew effect prevails. New Political Econ. 2004, 9, 163–188. [Google Scholar] [CrossRef]
- European Economy. Report on Public Finances in EMU; Publications Office of the European Union: Luxemburg, 2018. [Google Scholar]
- Cantillon, B. The Paradox of the Social Investment State. Growth, Employment and Poverty in the Lisbon Era; Working Paper No. 11/03; University of Antwerp: Antwerp, Belgium, 2011. [Google Scholar]
- Cincinnato, S.; Nicaise, I. Minimum Income Schemes: Panorama and Assessment. A Study of National Policies (Belgium); European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Bogdanov, G.; Zahariev, B. Analysis of the Situation in Relation to Minimum Income Schemes in Bulgaria. A Study of National Policies; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Ruoppila, S.; Lamminmäki, S. Minimum Income Schemes. A Study of National Policies; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Legros, M. Minimum Income Schemes. From Crisis to Another, The French Experience of Means-Tested Benefits; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Radu, M. Analysis of the Situation in Relation to Minimum Income Schemes in Romania. A Study of National Policies; European Commission: Brussels, Belgium, 2009. [Google Scholar]
- Greene, W.H. The econometric approach to efficiency analysis. In The Measurement of Productive Efficiency and Productivity Growth; Fried, H.O., Knox Lovell, C.A., Schmidt, S.S., Eds.; Oxford Scholarship: Oxford, UK, 2008; pp. 92–250. [Google Scholar]
- Brunelli, M.; Mezei, J. How different are ranking methods for fuzzy numbers? A numerical study. Int. J. Approx. Reason. 2013, 54, 627–639. [Google Scholar] [CrossRef]
- Campos, L.M.; González, A. A subjective approach for ranking fuzzy numbers. Fuzzy Sets Syst. 1989, 29, 145–153. [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Akoglu, H. User’s guide to correlation coefficients. Turk. J. Emerg. Med. 2018, 18, 91–93. [Google Scholar] [CrossRef]
- Cheng, C.B. Group opinion aggregation based on a grading process: A method for constructing triangular fuzzy numbers. Comput. Math. Appl. 2004, 48, 1619–1632. [Google Scholar] [CrossRef]
- Liu, S.; Fang, Z.; Zang, Y.; Forrest, J. General grey numbers and their operations. Grey Syst. Theory Appl. 2012, 2, 341–349. [Google Scholar] [CrossRef]
- Liu, S.T.; Kao, C. Fuzzy measures for correlation coefficient of fuzzy numbers. Fuzzy Sets Syst. 2002, 128, 267–275. [Google Scholar] [CrossRef]
- Dong, W.; Shah, H.C. Vertex method for computing functions of fuzzy variables. Fuzzy Sets Syst. 1987, 24, 65–78. [Google Scholar] [CrossRef]
- Mesiar, R. Shape preserving additions of fuzzy intervals. Fuzzy Sets Syst. 1997, 86, 73–78. [Google Scholar] [CrossRef]
- Hong, D.H. Fuzzy measures for a correlation coefficient of fuzzy numbers under TW (the weakest t-norm-based fuzzy arithmetic operations. Inf. Sci. 2006, 176, 150–160. [Google Scholar] [CrossRef]
- Ban, A.I.; Ban, O.I.; Tuse, D.A. Derived fuzzy importance of attributes based on the weakest triangular norm-based fuzzy arithmetic and applications to the hotel services. Iran. J. Fuzzy Syst. 2016, 13, 65–85. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, Z. An Overview of the Fuzzy Data Envelopment Analysis Research and Its Successful Applications. Int. J. Fuzzy Syst. 2020, 22, 1037–1055. [Google Scholar] [CrossRef]
- Wu, D.S.; Yang, Z.J.; Liang, L. Efficiency analysis of crossregion bank branches using fuzzy data envelopment analysis. Appl. Math. Comput. 2006, 181, 271–281. [Google Scholar] [CrossRef]
- Lee, S.K.; Mogi, G.; Hui, K.S. A fuzzy analytic hierarchy process (AHP)/data envelopment analysis (DEA) hybrid model for efficiently allocating energy R&D resources: In the case of energy technologies against high oil prices. Renew. Sustain. Energy Rev. 2013, 21, 347–355. [Google Scholar]
- Gupta, P.; Mehlawat, M.K.; Aggarwal, U.; Charles, V. An integrated AHP–DEA multi-objective optimization model for sustainable transportation in mining industry. Resour. Policy 2018, 101180. [Google Scholar] [CrossRef]
- Aydin, N.; Zortuk, M. Measuring efficiency of foreign direct investment in selected transition economies with fuzzy data envelopment analysis. Econ. Comput. Econ. Cybern. Stud. Res. 2014, 48, 273–286. [Google Scholar]
- Kaya, İ.; Çolak, M.; Terzi, F. A comprehensive review of fuzzy multi criteria decision making methodologies for energy policy making. Energy Strategy Rev. 2019, 24, 207–228. [Google Scholar] [CrossRef]
- Sengar, A.; Sharma, V.; Agrawal, R.; Dwivedi, A.; Dwivedi, P.; Joshi, K.; Barthwal, M. Prioritization of barriers to energy generation using pine needles to mitigate climate change: Evidence from India. J. Clean. Prod. 2020, 275, 123840. [Google Scholar] [CrossRef]
- Kumar, A.; Wasan, P.; Luthra, S.; Dixit, G. Development of a framework for selecting a sustainable location of waste electrical and electronic equipment recycling plant in emerging economies. J. Clean. Prod. 2020, 122645. [Google Scholar] [CrossRef]
- Rani, P.; Mishra, A.R.; Mardani, A.; Cavallaro, F.; Alrasheedi, M.; AlRashidi, A. A novel approach to extended fuzzy TOPSIS based on new divergence measures for renewable energy sources selection. J. Clean. Prod. 2020, 257, 120352. [Google Scholar] [CrossRef]
- Büyüközkan, G.; Çifçi, G. A combined fuzzy AHP and fuzzy TOPSIS based strategic analysis of electronic service quality in healthcare industry. Expert Syst. Appl. 2012, 39, 2341–2354. [Google Scholar] [CrossRef]
- Teresa, L.; Liern, V.; Pérez-Gladish, B. A multicriteria assessment model for countries’ degree of preparedness for successful impact investing. Manag. Decis. 2019, 58, 2455–2471. [Google Scholar] [CrossRef]
- Chen, Y.; Yoo, S.; Hwang, J. Fuzzy multiple criteria decision-making assessment of urban conservation in historic districts: Case study of Wenming Historic Block in Kunming City, China. J. Urban Plan. Dev. 2017, 143, 105016008. [Google Scholar] [CrossRef]
- Zyoud, S.H.; Fuchs-Hanusch, D. An Integrated Decision-Making Framework to Appraise Water Losses in Municipal Water Systems. Int. J. Inf. Technol. Decis. Mak. (IJITDM) 2020, 19, 1293–1326. [Google Scholar] [CrossRef]
- Sari, I.U.; Behret, H.; Kahraman, C. Risk governance of urban rail systems using fuzzy AHP: The case of Istanbul. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2012, 20 (Suppl. 01), 67–79. [Google Scholar] [CrossRef]
- Perez-Arellano, L.A.; Blanco-Mesa, F.; León-Castro, E.; Alfaro-García, V. Bonferroni Prioritized Aggregation Operators Applied to Government Transparency. Mathematics 2021, 9, 24. [Google Scholar] [CrossRef]
- González, A.; Ortigoza, E.; Llamosas, C.; Blanco, G.; Amarilla, R. Multi-criteria analysis of economic complexity transition in emerging economies: The case of Paraguay. Socio-Econ. Plan. Sci. 2019, 68, 100617. [Google Scholar] [CrossRef]
- Zmeškal, Z. Value at risk methodology of international index portfolio under soft conditions (fuzzy-stochastic approach). Int. Rev. Financ. Anal. 2005, 14, 263–275. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Gordon-Brown, L.; Khosravi, A.; Creighton, D.; Nahavandi, S. Fuzzy portfolio allocation models through a new risk measure and fuzzy sharpe ratio. IEEE Trans. Fuzzy Syst. 2014, 23, 656–676. [Google Scholar] [CrossRef]
- Tsao, C.T. Fuzzy net present values for capital investments in an uncertain environment. Comput. Oper. Res. 2012, 39, 1885–1892. [Google Scholar] [CrossRef]
- Wu, B.; Sha, W.-S.; Chen, J.-C. Correlation Evaluation with Fuzzy Data and its Application in the Management Science. In Econometrics of Risk; Springer: Cham, Switzerland, 2015; pp. 273–285. [Google Scholar] [CrossRef]
- Wu, B.; Lai, W.; Wu, C.L.; Tienliu, T.K. Correlation with fuzzy data and its applications in the 12-year compulsory education in Taiwan. Commun. Stat.-Simul. Comput. 2016, 45, 1337–1354. [Google Scholar] [CrossRef]
- Chang, D.-F. Student Mobility in Higher Education Explained by Cultural and Technological Awareness in Taiwan. Multicultural Awareness and Technology in Higher Education: Global Perspectives. IGI Glob. 2014, 66–85. [Google Scholar] [CrossRef]
- Kumar, M. Evaluation of the intuitionistic fuzzy importance of attributes based on the correlation coefficient under weakest triangular norm and application to the hotel services. J. Intelligent Fuzzy Syst. 2019, 36, 3211–3223. [Google Scholar] [CrossRef]
- Yuan, J.; Li, X.; Shi, Y.; Chen, F.T.S.; Ruan, J.; Zhu, Y. Linkages Between Chinese Stock Price Index and Exchange Rates—An Evidence From the Belt and Road Initiative. IEEE Access 2020, 8, 95403–95416. [Google Scholar] [CrossRef]
- Eurostat. Social Protection Statistics. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Archive:Social_protection_statistics&direction=next&oldid=503877#Expenditure_on_pensions (accessed on 10 September 2020).


| Correlation Coefficient | Dancey and Reidy (Psychology) | Quinnipiac University (Politics) | Chan (Medicine) | |
|---|---|---|---|---|
| −1 | 1 | Perfect | Perfect | Perfect |
| −0.9 | 0.9 | Strong | Very Strong | Very Strong |
| −0.8 | 0.8 | Strong | Very Strong | Very Strong |
| −0.7 | 0.7 | Strong | Very Strong | Moderate |
| −0.6 | 0.6 | Moderate | Strong | Moderate |
| −0.5 | 0.5 | Moderate | Strong | Fair |
| −0.4 | 0.4 | Moderate | Strong | Fair |
| −0.3 | 0.3 | Weak | Moderate | Fair |
| −0.2 | 0.2 | Weak | Weak | Poor |
| −0,1 | 0.1 | Weak | Negligible | Poor |
| 0 | 0 | Zero | None | None |
| Negative Correlation | Positive Correlation | ||
|---|---|---|---|
| Fuzzy Number | Linguistic Label | Fuzzy Number | Linguistic Label |
| Perfect (−) | Perfect (+) | ||
| Very strong (−) | Very strong (+) | ||
| Strong (−) | Strong (+) | ||
| Moderate (−) | Moderate (+) | ||
| Weak (−) | Weak (+) | ||
| Negligible (−) | Negligible (+) | ||
| No correlation | No correlation | ||
| Year | 2014 | 2015 | 2016 | 2017 | 2018 |
|---|---|---|---|---|---|
| SER | 30 | 29.8 | 29.2 | 28.8 | 28.8 |
| 2014 | 2015 | 2016 | 2017 | 2018 | |
|---|---|---|---|---|---|
| 2014 | 0 | 0.2 | 0.8 | 1.2 | 1.2 |
| 2015 | 0.2 | 0 | 0.6 | 1 | 1 |
| 2016 | 0.8 | 0.6 | 0 | 0.4 | 0.4 |
| 2017 | 1.2 | 1 | 0.4 | 0 | 0 |
| 2018 | 1.2 | 1 | 0.4 | 0 | 0 |
| 2014 | 2015 | 2016 | 2017 | 2018 | |
|---|---|---|---|---|---|
| 2014 | 1 | 0.824 | 1.294 | 0.765 | 0.765 |
| 2015 | 1.214 | 1 | 1.571 | 0.929 | 0.929 |
| 2016 | 0.773 | 0.636 | 1 | 0.591 | 0.591 |
| 2017 | 1.308 | 1.077 | 1.692 | 1 | 1 |
| 2018 | 1.308 | 1.077 | 1.692 | 1 | 1 |
| Country | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Belgium | 29.29 | 1.09 | 1.66 | 41.43 | 8.19 | 5.15 | 0.590 | 0.030 | 0.003 |
| Denmark | 32.82 | 2.10 | 3.22 | 51.86 | 5.74 | 3.77 | 0.728 | 0.046 | 0.033 |
| Germany | 29.52 | 0.82 | 0.51 | 33.36 | 0.23 | 0.59 | 0.538 | 0.056 | 0.040 |
| Ireland | 15.82 | 2.38 | 3.95 | 53.42 | 3.61 | 5.92 | 1.000 | 0.000 | 0.000 |
| Greece | 25.67 | 1.72 | 0.88 | 16.13 | 0.23 | 2.36 | 0.295 | 0.017 | 0.063 |
| Spain | 24.09 | 1.34 | 2.36 | 25.09 | 3.63 | 6.03 | 0.399 | 0.031 | 0.028 |
| France | 34.22 | 0.60 | 0.36 | 44.15 | 2.49 | 0.95 | 0.607 | 0.074 | 0.118 |
| Italy | 29.28 | 0.85 | 1.29 | 21.37 | 1.02 | 0.09 | 0.302 | 0.038 | 0.031 |
| Luxembourg | 22.19 | 0.74 | 1.03 | 40.35 | 3.39 | 1.50 | 0.656 | 0.039 | 0.064 |
| Netherlands | 29.59 | 1.00 | 1.54 | 42.73 | 5.62 | 6.58 | 0.599 | 0.037 | 0.054 |
| Austria | 29.66 | 0.94 | 0.49 | 44.28 | 4.07 | 2.69 | 0.623 | 0.019 | 0.054 |
| Portugal | 25.19 | 1.65 | 2.56 | 24.65 | 3.30 | 5.08 | 0.454 | 0.020 | 0.049 |
| Finland | 31.24 | 2.21 | 1.18 | 54.51 | 1.52 | 4.48 | 0.774 | 0.110 | 0.089 |
| Sweden | 28.98 | 1.04 | 0.64 | 45.71 | 3.08 | 2.18 | 0.767 | 0.052 | 0.014 |
| UK | 26.62 | 1.01 | 1.68 | 42.18 | 4.67 | 2.36 | 0.680 | 0.060 | 0.037 |
| Bulgaria | 17.39 | 1.45 | 1.29 | 21.12 | 3.60 | 6.38 | 0.400 | 0.061 | 0.106 |
| Czechia | 18.90 | 0.51 | 0.82 | 41.84 | 4.38 | 1.45 | 0.661 | 0.049 | 0.071 |
| Estonia | 16.00 | 0.46 | 0.91 | 24.94 | 4.62 | 6.02 | 0.456 | 0.065 | 0.019 |
| Croatia | 21.76 | 0.21 | 0.10 | 29.59 | 6.13 | 7.69 | 0.485 | 0.090 | 0.095 |
| Cyprus | 19.39 | 2.47 | 1.71 | 36.53 | 0.22 | 2.55 | 0.637 | 0.055 | 0.070 |
| Latvia | 14.93 | 0.22 | 0.51 | 20.57 | 5.13 | 2.69 | 0.386 | 0.099 | 0.057 |
| Lithuania | 15.47 | 0.58 | 0.86 | 23.33 | 0.36 | 3.96 | 0.464 | 0.007 | 0.080 |
| Hungary | 18.76 | 1.97 | 1.36 | 44.72 | 4.12 | 6.88 | 0.817 | 0.065 | 0.079 |
| Malta | 16.66 | 2.22 | 1.69 | 30.64 | 0.49 | 1.71 | 0.517 | 0.072 | 0.047 |
| Poland | 19.79 | 1.29 | 1.02 | 29.95 | 6.79 | 8.98 | 0.497 | 0.096 | 0.110 |
| Romania | 14.73 | 0.23 | 0.41 | 14.56 | 3.32 | 4.90 | 0.303 | 0.109 | 0.079 |
| Slovenia | 23.20 | 2.21 | 1.43 | 42.85 | 1.19 | 1.99 | 0.636 | 0.077 | 0.108 |
| Slovakia | 18.17 | 0.59 | 0.39 | 32.42 | 5.35 | 8.34 | 0.492 | 0.057 | 0.088 |
| Max–Min Correlation | Max-Tw Correlation | |||
|---|---|---|---|---|
| α | ||||
| 0 | −0.0643 | 0.7635 | 0.4196 | 0.4819 |
| 0.25 | 0.0762 | 0.7040 | 0.4294 | 0.4761 |
| 0.5 | 0.2140 | 0.6332 | 0.4391 | 0.4702 |
| 0.75 | 0.3427 | 0.5511 | 0.4488 | 0.4644 |
| 1 | 0.4585 | 0.4585 | 0.4585 | 0.4585 |
| Linguistic Label | Max–Min | Max-Tw | Crisp | Linguistic Label | Max–Min | Max-Tw | |
|---|---|---|---|---|---|---|---|
| 1 Perfect (−) | 0 | 0 | 0 | 8 Negligible (+) | 0.42 | 0 | 0 |
| 2 Very strong (−) | 0 | 0 | 0 | 9 Weak (+) | 0.58 | 0 | 0 |
| 3 Strong (−) | 0 | 0 | 0 | 10 Moderate (+) | 0.78 | 0.21 | 0.21 |
| 4 Moderate (−) | 0 | 0 | 0 | 11 Strong (+) | 0.92 | 0.79 | 0.79 |
| 5 Weak (−) | 0.0 | 0 | 0 | 12 Very strong (+) | 0.44 | 0 | 0 |
| 6 Negligible (−) | 0.1 | 0 | 0 | 13 Perfect (+) | 0 | 0 | 0 |
| 7 No correlation | 0.26 | 0 | 0 | Strong (+) correlation | Strong (+) correlation | Strong (+) correlation |
| EU-28 | 23.190 | 0.088 | 0.141 | 34.796 | 0.292 | 0.321 | 0.563 | 0.004 | 0.004 |
| Non EU-15 | 18.089 | 0.190 | 0.131 | 30.236 | 0.522 | 0.691 | 0.519 | 0.008 | 0.008 |
| EU-15 | 27.612 | 0.165 | 0.263 | 38.748 | 0.546 | 0.598 | 0.601 | 0.007 | 0.008 |
| Criteria | Relative Reduction of Poverty (RRP) | Debreu–Farrell Ratio (DF) | ||||||
|---|---|---|---|---|---|---|---|---|
| Country | λ = 1 | λ = 0.5 | λ = 0 | V–F | λ = 1 | λ = 0.5 | λ = 0 | V–F |
| Belgium | 12 | 13 | 13 | 13 | 14 | 14 | 13 | 19 |
| Denmark | 3 | 3 | 3 | 5 | 5 | 5 | 5 | 7 |
| Germany | 16 | 15 | 15 | 14 | 15 | 15 | 15 | 10 |
| Ireland | 2 | 2 | 2 | 10 | 1 | 1 | 1 | 3 |
| Greece | 27 | 27 | 27 | 21 | 26 | 26 | 26 | 21 |
| Spain | 20 | 20 | 20 | 25 | 24 | 24 | 23 | 28 |
| France | 7 | 6 | 5 | 4 | 12 | 12 | 14 | 14 |
| Italy | 25 | 25 | 24 | 19 | 27 | 27 | 27 | 27 |
| Luxembourg | 13 | 12 | 12 | 11 | 7 | 8 | 7 | 5 |
| Netherlands | 9 | 9 | 9 | 3 | 13 | 13 | 12 | 8 |
| Austria | 6 | 7 | 8 | 8 | 11 | 9 | 9 | 16 |
| Portugal | 22 | 21 | 22 | 17 | 21 | 21 | 20 | 18 |
| Finland | 1 | 1 | 1 | 6 | 3 | 4 | 4 | 11 |
| Sweden | 5 | 4 | 4 | 12 | 4 | 3 | 3 | 6 |
| United Kingdom | 10 | 10 | 10 | 15 | 8 | 6 | 6 | 17 |
| Bulgaria | 24 | 24 | 25 | 27 | 23 | 23 | 24 | 26 |
| Czechia | 11 | 11 | 11 | 1 | 6 | 7 | 7 | 1 |
| Estonia | 21 | 23 | 23 | 26 | 22 | 22 | 22 | 23 |
| Croatia | 19 | 19 | 19 | 22 | 20 | 20 | 21 | 22 |
| Cyprus | 14 | 14 | 14 | 20 | 10 | 9 | 10 | 25 |
| Latvia | 26 | 26 | 26 | 28 | 25 | 25 | 25 | 24 |
| Lithuania | 23 | 22 | 21 | 23 | 19 | 18 | 18 | 15 |
| Hungary | 4 | 5 | 6 | 2 | 2 | 2 | 2 | 2 |
| Malta | 17 | 17 | 16 | 18 | 17 | 16 | 16 | 20 |
| Poland | 18 | 18 | 18 | 16 | 18 | 19 | 19 | 13 |
| Romania | 28 | 28 | 28 | 24 | 28 | 28 | 28 | 12 |
| Slovenia | 8 | 8 | 7 | 9 | 9 | 11 | 11 | 9 |
| Slovakia | 15 | 16 | 17 | 7 | 16 | 17 | 17 | 4 |
| RRP (λ = 1) | RRP (λ = 0.5) | RRP (λ = 0) | RRP (V–F) | DF (λ = 1) | DF (λ = 0.5) | DF (λ = 0) | DF (V–F) | |
|---|---|---|---|---|---|---|---|---|
| RRP (λ = 1) | 1 | |||||||
| RRP (λ = 0.5) | 0.996 | 1 | ||||||
| RRP (λ = 0) | 0.991 | 0.997 | 1 | |||||
| RRP (V–F) | 0.830 | 0.831 | 0.824 | 1 | ||||
| DF (λ = 1) | 0.943 | 0.947 | 0.941 | 0.784 | 1 | |||
| DF (λ = 0.5) | 0.939 | 0.944 | 0.937 | 0.757 | 0.994 | 1 | ||
| DF (λ = 0) | 0.935 | 0.939 | 0.932 | 0.761 | 0.992 | 0.997 | 1 | |
| DF (V–F) | 0.642 | 0.652 | 0.642 | 0.795 | 0.718 | 0.680 | 0.692 | 1 |
| EU-28 | Non-EU-15 Countries | EU-15 Countries | |||||||
|---|---|---|---|---|---|---|---|---|---|
| RRP | 0.459 | 0.039 | 0.023 | 0.715 | 0.100 | 0.078 | 0.125 | 0.075 | 0.091 |
| DF | 0.194 | 0.062 | 0.038 | 0.569 | 0.086 | 0.078 | −0.204 | 0.131 | 0.079 |
| EU-28 | Non-EU-15 | EU-15 | ||||
|---|---|---|---|---|---|---|
| Linguistic Label | SER vs. RRP | SER vs. DF | SER vs. RRP | SER vs. DF | SER vs. RRP | SER vs. DF |
| Perfect (−) | 0 | 0 | 0 | 0 | 0 | 0 |
| Very Strong (−) | 0 | 0 | 0 | 0 | 0 | 0 |
| Strong (−) | 0 | 0 | 0 | 0 | 0 | 0 |
| Moderate (−) | 0 | 0 | 0 | 0 | 0 | 0.267 |
| Weak (−) | 0 | 0 | 0 | 0 | 0 | 0.970 |
| Negligible (−) | 0 | 0 | 0 | 0 | 0 | 0.207 |
| No corr | 0 | 0 | 0 | 0 | 0 | 0 |
| Negligible (+) | 0 | 0.065 | 0 | 0 | 0.750 | 0 |
| Weak (+) | 0 | 0.935 | 0 | 0 | 0.250 | 0 |
| Moderate (+) | 0.207 | 0 | 0 | 0 | 0 | 0 |
| Strong (+) | 0.793 | 0 | 0.283 | 0.771 | 0 | 0 |
| Very Strong (+) | 0 | 0 | 0.717 | 0.229 | 0 | 0 |
| Perfect (+) | 0 | 0 | 0 | 0 | 0 | 0 |
| argmax | Strong (+) | Weak (+) | Very strong (+) | Strong (+) | Negligible (+) | Weak (−) |
| EU-28 | Non-EU-15 | EU-15 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Item | |||||||||
| Sick | 0.234 | 0.038 | 0.034 | −0.008 | 0.078 | 0.115 | 0.443 | 0.053 | 0.041 |
| Dis | 0.117 | 0.037 | 0.026 | −0.434 | 0.133 | 0.093 | 0.361 | 0.022 | 0.041 |
| Old | −0.529 | 0.039 | 0.032 | −0.128 | 0.133 | 0.140 | −0.645 | 0.050 | 0.051 |
| Surv | −0.429 | 0.032 | 0.028 | 0.229 | 0.097 | 0.085 | −0.811 | 0.052 | 0.049 |
| Fam | 0.333 | 0.052 | 0.063 | −0.090 | 0.166 | 0.108 | 0.590 | 0.058 | 0.105 |
| Une | −0.202 | 0.133 | 0.094 | −0.202 | 0.205 | 0.165 | −0.209 | 0.246 | 0.176 |
| Hou | −0.083 | 0.041 | 0.061 | −0.068 | 0.103 | 0.098 | −0.140 | 0.077 | 0.113 |
| SocE | 0.273 | 0.053 | 0.024 | 0.277 | 0.052 | 0.045 | 0.209 | 0.116 | 0.052 |
| Sick | Dis | Old | Surv | Fam | Une | Hou | SocH | |
|---|---|---|---|---|---|---|---|---|
| Perfect (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Very strong (−) | 0.000 | 0.000 | 0.096 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Strong (−) | 0.000 | 0.000 | 0.904 | 0.647 | 0.000 | 0.000 | 0.000 | 0.000 |
| Moderate (−) | 0.000 | 0.000 | 0.000 | 0.353 | 0.000 | 0.261 | 0.000 | 0.000 |
| Weak (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.984 | 0.000 | 0.000 |
| Negligible (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.230 | 0.828 | 0.000 |
| No corr | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.172 | 0.000 |
| Negligible (+) | 0.000 | 0.830 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Weak (+) | 0.663 | 0.170 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.265 |
| Moderate (+) | 0.337 | 0.000 | 0.000 | 0.000 | 0.836 | 0.000 | 0.000 | 0.735 |
| Strong (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.164 | 0.000 | 0.000 | 0.000 |
| Very strong (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Perfect (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Argmax | Weak (+) | Negligible (+) | Strong (−) | Strong (−) | Moderate (+) | Weak (−) | Negligible (−) | Moderate (+) |
| Sick | Dis | Old | Surv | Fam | Une | Hou | SocH | |
|---|---|---|---|---|---|---|---|---|
| Perfect (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Very strong (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Strong (−) | 0.000 | 0.668 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Moderate (−) | 0.000 | 0.332 | 0.000 | 0.000 | 0.000 | 0.520 | 0.000 | 0.000 |
| Weak (−) | 0.000 | 0.000 | 0.461 | 0.000 | 0.337 | 0.992 | 0.000 | 0.000 |
| Negligible (−) | 0.079 | 0.000 | 0.788 | 0.000 | 0.940 | 0.505 | 0.691 | 0.000 |
| No corr | 0.921 | 0.000 | 0.037 | 0.000 | 0.456 | 0.018 | 0.336 | 0.000 |
| Negligible (+) | 0.063 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Weak (+) | 0.000 | 0.000 | 0.000 | 0.705 | 0.000 | 0.000 | 0.000 | 0.233 |
| Moderate (+) | 0.000 | 0.000 | 0.000 | 0.295 | 0.000 | 0.000 | 0.000 | 0.767 |
| Strong (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Very strong (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Perfect (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Argmax | No corr | Strong (−) | Negligible (−) | Weak (+) | Negligible (−) | Weak (−) | Negligible (−) | Moderate (+) |
| Sick | Dis | Old | Surv | Fam | Une | Hou | SocH | |
|---|---|---|---|---|---|---|---|---|
| Perfect (−) | 0.000 | 0.000 | 0.000 | 0.055 | 0.000 | 0.000 | 0.000 | 0.000 |
| Very strong (−) | 0.000 | 0.000 | 0.483 | 0.945 | 0.000 | 0.000 | 0.000 | 0.000 |
| Strong (−) | 0.000 | 0.000 | 0.517 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Moderate (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.633 | 0.000 | 0.000 |
| Weak (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.961 | 0.395 | 0.000 |
| Negligible (−) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.556 | 0.605 | 0.000 |
| No corr | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.150 | 0.000 | 0.000 |
| Negligible (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.062 |
| Weak (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.912 |
| Moderate (+) | 0.284 | 0.694 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.088 |
| Strong (+) | 0.716 | 0.306 | 0.000 | 0.000 | 0.700 | 0.000 | 0.000 | 0.000 |
| Very Strong (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.300 | 0.000 | 0.000 | 0.000 |
| Perfect (+) | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Argmax | Strong (+) | Moderate (+) | Strong (−) | Very Strong (−) | Strong (+) | Weak (−) | Negligible (−) | Weak (+) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Andrés-Sánchez, J.; Belzunegui-Eraso, A.; Valls-Fonayet, F. Assessing Efficiency of Public Poverty Policies in UE-28 with Linguistic Variables and Fuzzy Correlation Measures. Mathematics 2021, 9, 128. https://doi.org/10.3390/math9020128
de Andrés-Sánchez J, Belzunegui-Eraso A, Valls-Fonayet F. Assessing Efficiency of Public Poverty Policies in UE-28 with Linguistic Variables and Fuzzy Correlation Measures. Mathematics. 2021; 9(2):128. https://doi.org/10.3390/math9020128
Chicago/Turabian Stylede Andrés-Sánchez, Jorge, Angel Belzunegui-Eraso, and Francesc Valls-Fonayet. 2021. "Assessing Efficiency of Public Poverty Policies in UE-28 with Linguistic Variables and Fuzzy Correlation Measures" Mathematics 9, no. 2: 128. https://doi.org/10.3390/math9020128
APA Stylede Andrés-Sánchez, J., Belzunegui-Eraso, A., & Valls-Fonayet, F. (2021). Assessing Efficiency of Public Poverty Policies in UE-28 with Linguistic Variables and Fuzzy Correlation Measures. Mathematics, 9(2), 128. https://doi.org/10.3390/math9020128