
On the Convergence of the Benjamini–Hochberg Procedure


Abstract
:1. Introduction
2. Main Results and Their Proofs
2.1. Some Preliminary Notation
2.2. General Inequalities and Information concerning the Distribution of
2.3. Condition (M)
2.4. Theoretical Bounds on the Distribution of under Condition ( M)
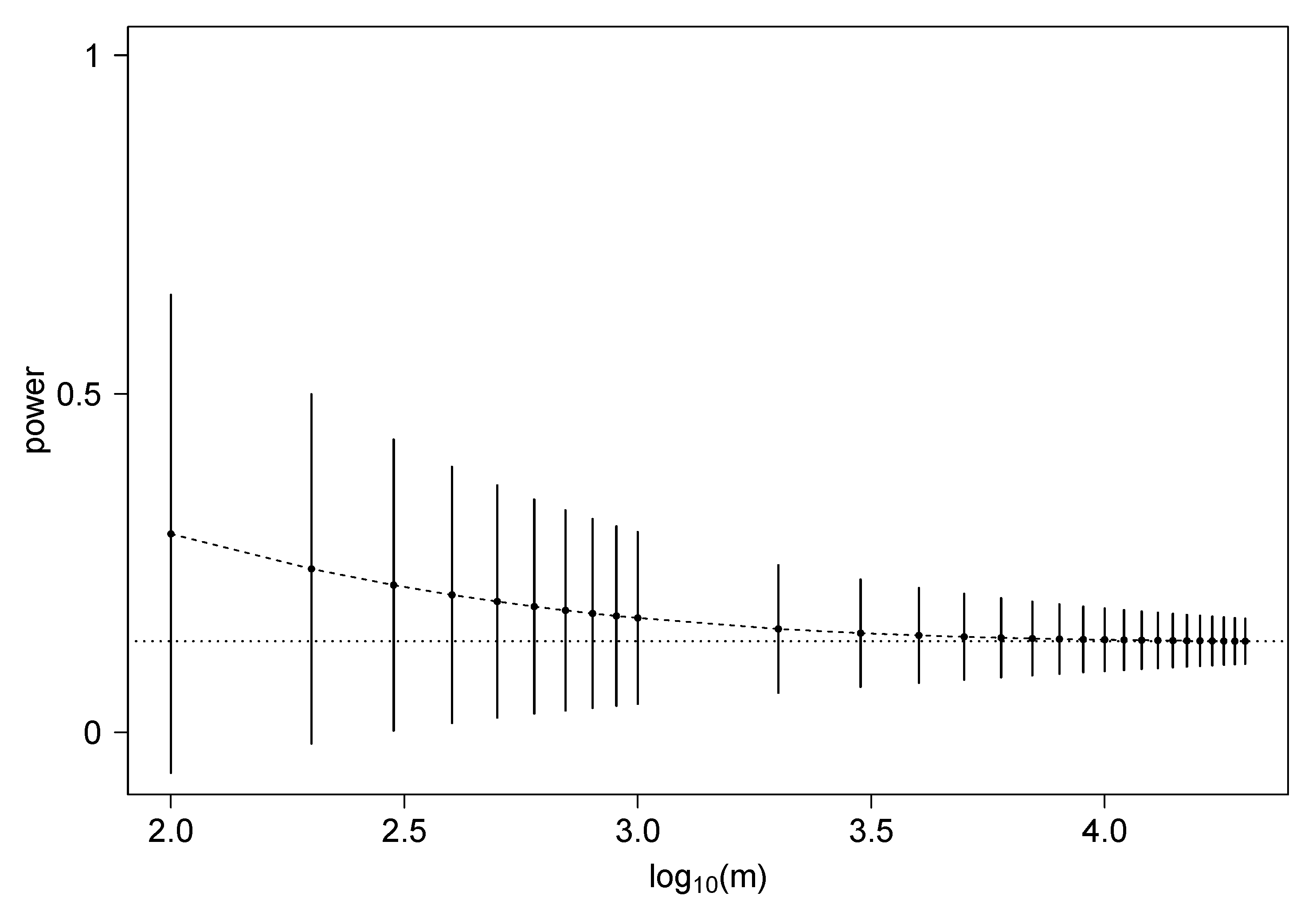
2.5. Exponential Convergence to the Theoretical Limit of the Power of the Benjamini–Hochberg Procedure
3. Workflow
- we calculate by solving numerically Equation (22) wherein ;
- for given , any given and is such that we have an estimate based on (42), that is
- fixing we attempt to solve (numerically) in the equation
- if then (42) represents a valid theoretical lower bound, that iswith
- finally, we optimize in and choose so that the estimated probability bound is the largest, that is
4. Results
5. Discussion
5.1. Related Work
5.2. Considerations about Our Work
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| FDR | False Discovery Rate |
| PET | Positron Emission Tomography |
| CT | Computerized Tomography |
| fMRI | Functional Magnetic Resonance Imaging |
Appendix A. Petrov’s Inequality
References
- Benjamini, Y.; Hochberg, Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Love, M.; Huber, W.; Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014, 15, 550. [Google Scholar] [CrossRef] [Green Version]
- Robinson, M.D.; McCarthy, D.J.; Smyth, G.K. edgeR: A Bioconductor package for differential expression analysis of digital gene expression data. Bioinformatics 2010, 26, 139–140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trapnell, C.; Hendrickson, D.G.; Sauvageau, M.; Goff, L.; Rinn, J.L.; Pachter, L. Differential analysis of gene regulation at transcript resolution with RNA-seq. Nat. Biotechnol. 2012, 31, 46–53. [Google Scholar] [CrossRef]
- Chalkidou, A.; O’Doherty, M.J.; Marsden, P.K. False Discovery Rates in PET and CT Studies with Texture Features: A Systematic Review. PLoS ONE 2015, 10, e0124165. [Google Scholar] [CrossRef] [Green Version]
- Bennett, C.M.; Wolford, G.L.; Miller, M.B. The principled control of false positives in neuroimaging. Soc. Cogn. Affect. Neurosci. 2009, 4, 417–422. [Google Scholar] [CrossRef]
- Miller, C.J.; Genovese, C.; Nichol, R.C.; Wasserman, L.; Connolly, A.; Reichart, D.; Hopkins, A.; Schneider, J.; Moore, A. Controlling the False-Discovery Rate in Astrophysical Data Analysis. Astron. J. 2001, 122, 3492. [Google Scholar] [CrossRef] [Green Version]
- Benjamini, Y.; Yekutieli, D. The Control of the False Discovery Rate in Multiple Testing under Dependency. Ann. Stat. 2001, 29, 1165–1188. [Google Scholar] [CrossRef]
- Storey, J.D.; Taylor, J.E.; Siegmund, D. Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: A unified approach. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2004, 66, 187–205. [Google Scholar] [CrossRef]
- Pollard, K.S.; van der Laan, M.J. Choice of a null distribution in resampling-based multiple testing. J. Stat. Plan. Inference 2004, 125, 85–100. [Google Scholar] [CrossRef]
- Van Noorden, R.; Maher, B.; Nuzzo, R. The top 100 papers. Nature 2014, 514, 550–553. [Google Scholar] [CrossRef] [Green Version]
- Farcomeni, A. Some Results on the Control of the False Discovery Rate under Dependence. Scand. J. Stat. 2007, 34, 275–297. [Google Scholar] [CrossRef]
- Chi, Z. On the performance of FDR control: Constraints and a partial solution. Ann. Statist. 2007, 35, 1409–1431. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, J.A.; Zwinderman, A.H. Approximate Power and Sample Size Calculations with the Benjamini-Hochberg Method. Int. J. Biostat 2006, 2, 8. [Google Scholar] [CrossRef]
- Ferreira, J.A.; Zwinderman, A.H. On the Benjamini—Hochberg method. Ann. Statist. 2006, 34, 1827–1849. [Google Scholar] [CrossRef] [Green Version]
- Dvoretzky, A.; Kiefer, J.; Wolfowitz, J. Asymptotic Minimax Character of the Sample Distribution Function and of the Classical Multinomial Estimator. Ann. Math. Stat. 1956, 27, 642–669. [Google Scholar] [CrossRef]
- Pounds, S.; Morris, S.W. Estimating the occurrence of false positives and false negatives in microarray studies by approximating and partitioning the empirical distribution of p-values. Bioinformatics 2003, 19, 1236–1242. [Google Scholar] [CrossRef] [PubMed]
- Neuvial, P. Asymptotic properties of false discovery rate controlling procedures under independence. Electron. J. Stat. 2008, 2, 1065–1110. [Google Scholar] [CrossRef]
- Finner, H.; Dickhaus, T.; Roters, M. On the false discovery rate and an asymptotically optimal rejection curve. Ann. Statist. 2009, 37, 596–618. [Google Scholar] [CrossRef]
- Gontscharuk, V.; Finner, H. Asymptotic FDR control under weak dependence: A counterexample. Stat. Probab. Lett. 2013, 83, 1888–1893. [Google Scholar] [CrossRef]
- Atanassov, E.; Gurov, T.; Karaivanova, A.; Ivanovska, S.; Durchova, M.; Dimitrov, D. On the parallelization approaches for Intel MIC architecture. AIP Conf. Proc. 2016, 1773, 070001. [Google Scholar] [CrossRef]
- Petrov, V.V. Sums of Independent Random Variables; Brown, A.A., Translator; Ergebnisse der Mathematik und ihrer Grenzgebiete; Springer: Berlin/Heidelberg, Germany, 1975; Volume 82. [Google Scholar]

{kind=link}
| Lower Bound l | Empirical Probability | Theoretical Estimate | |
|---|---|---|---|
| 0.750 | 1.000 | 1.000 | 0.098 |
| 0.760 | 1.000 | 1.000 | 0.097 |
| 0.770 | 1.000 | 1.000 | 0.096 |
| 0.780 | 1.000 | 1.000 | 0.096 |
| 0.790 | 1.000 | 1.000 | 0.095 |
| 0.800 | 1.000 | 1.000 | 0.095 |
| 0.810 | 1.000 | 1.000 | 0.094 |
| 0.820 | 1.000 | 1.000 | 0.094 |
| 0.830 | 1.000 | 1.000 | 0.093 |
| 0.840 | 1.000 | 1.000 | 0.093 |
| 0.850 | 1.000 | 0.999 | 0.085 |
| 0.860 | 1.000 | 0.996 | 0.078 |
| 0.870 | 1.000 | 0.985 | 0.068 |
| 0.880 | 1.000 | 0.952 | 0.058 |
| 0.890 | 1.000 | 0.873 | 0.048 |
| 0.900 | 1.000 | 0.714 | 0.037 |
| 0.910 | 1.000 | 0.476 | 0.027 |
| 0.920 | 1.000 | 0.204 | 0.016 |
| 0.930 | 0.967 | 0.018 | 0.005 |
| 0.940 | 0.550 | 0.000 |
| Lower Bound l | Empirical Probability | Theoretical Estimate | |
|---|---|---|---|
| 0.190 | 1.000 | 0.779 | 0.105 |
| 0.200 | 0.997 | 0.434 | 0.072 |
| 0.210 | 0.972 | 0.000 | 0.001 |
| 0.220 | 0.868 | 0.000 | 0.001 |
| 0.230 | 0.626 | 0.000 | 0.001 |
| Lower Bound l | Empirical Probability | Theoretical Estimate | |
|---|---|---|---|
| 0.500 | 1.000 | 1.000 | 0.119 |
| 0.510 | 1.000 | 1.000 | 0.117 |
| 0.520 | 1.000 | 1.000 | 0.116 |
| 0.530 | 1.000 | 1.000 | 0.115 |
| 0.540 | 1.000 | 0.999 | 0.106 |
| 0.550 | 1.000 | 0.996 | 0.097 |
| 0.560 | 1.000 | 0.979 | 0.081 |
| 0.570 | 1.000 | 0.926 | 0.067 |
| 0.580 | 1.000 | 0.786 | 0.052 |
| 0.590 | 0.994 | 0.521 | 0.036 |
| 0.600 | 0.953 | 0.189 | 0.02 |
| 0.610 | 0.803 | 0.000 | 0.001 |
| 0.620 | 0.511 | 0.000 |
| Lower Bound l | Empirical Probability | Theoretical Estimate | |
|---|---|---|---|
| 0.600 | 1.000 | 1.000 | 0.109 |
| 0.610 | 1.000 | 1.000 | 0.108 |
| 0.620 | 1.000 | 1.000 | 0.107 |
| 0.630 | 1.000 | 1.000 | 0.106 |
| 0.640 | 1.000 | 1.000 | 0.105 |
| 0.650 | 1.000 | 1.000 | 0.105 |
| 0.660 | 1.000 | 1.000 | 0.104 |
| 0.670 | 1.000 | 0.999 | 0.096 |
| 0.680 | 1.000 | 0.995 | 0.085 |
| 0.690 | 1.000 | 0.980 | 0.074 |
| 0.700 | 1.000 | 0.934 | 0.062 |
| 0.710 | 1.000 | 0.821 | 0.049 |
| 0.720 | 0.999 | 0.608 | 0.037 |
| 0.730 | 0.991 | 0.309 | 0.024 |
| 0.740 | 0.924 | 0.048 | 0.009 |
| 0.750 | 0.693 | 0.000 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palejev, D.; Savov, M. On the Convergence of the Benjamini–Hochberg Procedure. Mathematics 2021, 9, 2154. https://doi.org/10.3390/math9172154
Palejev D, Savov M. On the Convergence of the Benjamini–Hochberg Procedure. Mathematics. 2021; 9(17):2154. https://doi.org/10.3390/math9172154
Chicago/Turabian StylePalejev, Dean, and Mladen Savov. 2021. "On the Convergence of the Benjamini–Hochberg Procedure" Mathematics 9, no. 17: 2154. https://doi.org/10.3390/math9172154
APA StylePalejev, D., & Savov, M. (2021). On the Convergence of the Benjamini–Hochberg Procedure. Mathematics, 9(17), 2154. https://doi.org/10.3390/math9172154