1. Introduction
Social media are web-based services that allow people, publics, and organizations to cooperate, link, network, and form communities. Such services allow users to easily generate, co-generate, adapt, share, and participate in web contents created by users [
1]. In the past few years, social media have become a dominant part of daily life for most people, with enormous implications and impacts on regional, national, and global economies and political situations [
1]. At the moment when the impacts of conventional media lessened, social media rapidly diffused into the world.
Social media breaks down the borders between the physical world and the virtual world. In the past several years, scholars have started to integrate social theories with algorithms to investigate how people (also referred to as social atoms) interact with each other and how communities (also referred to as social molecules) are formulated [
2]. The exclusivity of the data retrieved from social media requires new data mining techniques; these social media mining techniques can effectively manipulate user-created content with rich social relationships [
2]. Typical relationships include homophilic relationships (such as friendships on Facebook and following/follower relationships on Twitter) and relationships based on value homophily (such as retweets on Twitter, +1 on Google+, and “likes” on Facebook) [
3]. These novel techniques are within the scope of social media mining, a rapidly evolving sub-domain of data mining. Generally speaking, social media mining refers to the analytic procedure of demonstrating, visualizing, analyzing, and deriving patterns from social media data [
2].
Nowadays, social media have become the emphasis of numerous academic studies, basically because they touch the majority of people worldwide who can access mobile devices like cellular phones, tablets, and notebook computers [
4]. Social media are a good source of data for big data analytics [
5], so scholars or practitioners can have deeper understanding of user preferences, discover significant trends, analyze user behaviors, or investigate people’s lifestyles [
4]. In general, social media can provide the data required to analyze preferences, states, texts, images, etc. [
4].
The exceptional accessibility of big data about human behaviors has significantly altered the world [
6]. However, the data retrieved from social media sites are huge, related, noisy, extremely unstructured, and incomplete [
7]. The scale and characteristics of the data retrieved from social media differ significantly from the data traditionally adopted by social scientists to develop theories [
7]. Scholars also have to think about the feasibility of applying social theories on social media data [
7]. Thus, investigators as well as practitioners are aggressively inventing and testing novel analytic techniques and decision-making methods to obtain insights into anthropological behavior and afford decision supports to handle important social problems [
6].
The algorithmic revolution, which includes automatic data processing, machine learning, and natural language processing (NLP) techniques, has made it feasible to apply these big data. In spite of the impression one may get from the social media, much data processing has not been uncovered by existing techniques of data engineering and processing [
8]. Therefore, investigations into the integration of social media, NLP, and other methods of data analytics will be very important for deriving novel implications of data retrieved from social media in general, and those data related to some specific theoretical framework in particular. Some scholars (e.g., Yang et al. [
9]) have already adopted NLP with structural equation models and given insights into data retrieved from social media. Though the partial least squares structural equation modeling (PLS-SEM) based approach indeed derives meaningful results, the influence relationships among aspects and criteria can further be derived to give more meaningful insights.
Several multiple criteria decision making (MCDM) methods have been developed in the past few decades. These include the analytic hierarchy process (AHP) [
10], the analytic network process (ANP), decision-making trial and evaluation laboratory (DEMATEL) [
10], and the DEMATEL-based analytic network process (DANP) [
11,
12]. The AHP and the ANP have been used to measure the weights of the components of the structure by pairwise comparisons, and then to rank the alternatives in the decision. AHP structures a decision problem into a hierarchy with a goal, decision criteria, and alternatives, while the ANP structures it as a network. DEMATEL is a comprehensive method for building and analyzing a structural model involving causal relationships among complex factors. These methods have been applied widely to numerous decision-making problems, which include economics, management, engineering, environmental science, etc. These methods were adopted to derive the weights associated with certain aspects or criteria. Meanwhile, the influence relationships, as well as the influence weights, have further been proposed and widely adopted. These MCDM-based methods can actually give insights into decision-making problems, e.g., the influence relationships and influence weights, which statistical methods-based analytic frameworks cannot afford. The integration of MCDM methods with big data analytics in general, and social media mining in particular, has been rare. However, their integration can indeed derive very different results compared to those methods that integrate big data analytics with a statistical analysis method, e.g., social media mining with PLS-SEM.
Data retrieved from social media usually contain meaningful information. However, few scholars have tried to analyze these data based on decision-making methods. A document usually contains numerous topics; according to Chen et al. [
13], even a short document may contain multiple topics. These topics can serve as the criteria for a decision-making problem, and the problem is, by nature, a MCDM one. The influence relationships among the major variables in the social media data and the weights associated with these variables can be derived in order to provide meaningful insights. However, based on the authors’ limited knowledge, very few scholars have tried to mine social media using MCDM methods. Although MCDM methods can potentially provide specific insights into the data retrieved from big data in general, and social media data in particular, few scholars have tried to propose analytic frameworks to address this research gap. Furthermore, almost no scholars have tried to propose an integrated framework to derive the influence relationships among the aspects of a theoretical framework. Thus, it is necessary to integrate information retrieved from social media sites into an established theoretical framework.
Therefore, in this paper, we aim to propose an analytical framework to mine a social network, analyze the meaningful information using decision-making methods based on a specific theoretical framework (e.g., the technology acceptance model or the value–belief–norm theory [
14]), derive causal relationships among the aspects of the theoretical framework, and, finally, compare the causal relationships with a social theory.
First, social media sites will be trawled. The user-generated contents related to some specific social issue(s) will be retrieved. Then, the Latent Dirichlet allocation (LDA) technique will be adopted to derive topic models based on those data retrieved from social media. According to the probability associated with each topic, the topics will be clustered. Then, these topics will be classified into a specific aspect of a model of a social theory. To feed the probability of data into the computation, the probability associated with each aspect of the model of the social theory will be normalized using a Likert-type 5-point scale. Afterwards, for every topic, the random forest (RF) algorithm will be adopted to derive the feature importance of all other topics. The feature importance matrix will be transformed into the initial influence matrix of DEMATEL. The influence relationships can be derived, along with the influence weight versus each criterion, by using DANP. The consistency between the influence relation map (IRM) and the social theory model will be checked. Discrepancies will be derived, which can provide further insights regarding social phenomena. The contents generated by Taiwanese users regarding attitudes toward the air pollution problem will be retrieved from Dcard (
www.dcard.tw, access on 1 July 2021) to verify the feasibility of applying social media data to the value–belief–norm theory proposed by Stern et al. [
14]. For readers’ convenience, a list of abbreviations and symbols introduced in this work are listed in
Table A1 and
Table A2 in
Appendix A.
The remainder of this paper is organized as follows:
Section 2 reviews the relevant literature regarding the emergence of social media, the mining of social media, data-driven decision-making (DDD), past works on the integration of data analytics and MCDM methods, and research gaps. Research methods, which include the analytic process, topic modeling, RF, DEMATEL, and DANP, will be reviewed in
Section 3.
Section 4 presents the analytic results of text mining, topic modeling, cluster analysis, DEMATEL, and DANP. Finally, the results are discussed in
Section 5.
Section 6 concludes the whole work.
2. Literature Review
According to Kaplan and Haenlein [
15], social media are the set of internet-based applications which are built upon the concepts and technology of Web 2.0; social media enable the generation and exchange of content generated by users [
2]. Numerous classes of social media sites have been created. Typical examples include Facebook (for social networking), Twitter (for microblogging), YouTube (for video sharing), etc. [
2]. Social media mining is an emerging interdisciplinary research field whose arena includes techniques from computer science, statistics, sociology, and ethnography [
2]. DDD is a practice of decision-making, where decisions are based on data analytics instead of on intuitions only [
8]. Better data provide more chances for enhanced decision-making results [
16]. During the past few decades, MCDM methods have been developed and adopted for numerous applications. However, in the age of big data analytics, DDD based on MCDM methods has seldom been adopted in manipulating big data in general and social media data in particular. Thus, in this section, past works on the emergence of social media, social media mining, DDD, MCDM-based DDD, and research gaps will be reviewed. The literature will serve as the basis for developing the integrated framework consisting of social media mining and MCDM methods.
Social media is not based on a single technology. Instead, social media integrate wide-ranging techniques, which include numerous online services that augment the capability of mutual communication in the social environment that forms the organization [
17]. The kernel of social media is grounded on the provision of high visibility and open participation [
17]. For practical applications, social media provide features which allow seamless sharing, commenting, responding, syndicating and interacting with content (text, voice and video) and connecting with others, and following and interacting with their activity streams [
15,
18]. Thus, social media offer a flexible platform which is fundamentally organic, free-flowing, and constructed to enable dynamic and emergent feedback loops of communication within a social group [
17].
Nowadays, social media platforms are typically applied in expressing opinions or viewpoints regarding social events, news, etc., everywhere, without any limitation of time. Future prediction is the great wish of mankind [
19]. In order to meet this forecasting demand, many studies have correctly proven the importance of social media data (e.g., [
10,
20,
21,
22]). Therefore, during the past several years, scholars (e.g., [
23,
24]) have demonstrated numerous applications in the related fields of social science [
19].
Social media mining refers to the process of characterizing, analyzing, and deriving important patterns from data retrieved from social media, which are the result of social interaction [
2]. Social media mining is a multidisciplinary domain which includes techniques from computer science, data engineering, social science, and mathematics [
5]. The exploration of social media by the above-mentioned techniques helps us understand the mutual interactions of users [
2]. Further, interesting patterns, information diffusion, influence relationships, effective and efficient recommendations, as well as novel social behavior can be explored on social media sites [
2]. DDD refers to data analytics-based decisions [
8]. Good sources of data imply better opportunities for good decisions [
16]. Novel digital techniques have greatly enhanced the quality and quantity of data available for decision-makers [
16].
The advantages of DDD have been verified convincingly [
8]. Brynjolfsson et al. have demonstrated how companies’ performance can be enhanced by using DDD [
8]. DDD is also related to better financial results [
8]. DDD has been broadly applied in numerous domains such as medical science, environmental engineering, education, energy management, policy definitions, etc. [
20].
Nowadays, people are facing complicated decision-making problems that are filled with tremendous information, which can describe diverse aspects of problems via different methods. For decision-makers, uncovering an idea solution to a decision-making problem is not easy [
20]. A rational method to tackle this kind of problem is to analyze various aspects and then integrate the analyses to create final solutions to the problems [
20]. This choice is called MCDM [
20]. During the past few decades, numerous works based on MCDM have been conducted to assist people in solving complicated problems [
20].
Traditional MCDM methods such as the AHP, the ANP, DEMATEL, and the DANP have been widely adopted for many decision-making problems. The AHP proposed by Saaty [
10] aims to derive the weights relating to each aspect and criterion of a decision-making method by assuming independence among these aspects and criteria. Saaty also proposed the ANP [
21], which can derive the weights being associated with the aspects and criteria of a decision-making problem by releasing the assumptions of independence. DEMATEL, proposed by Gabus and Fontela [
22] of the Battelle Geneva Institute, has been widely adopted to construct the influence relationships among the aspects and criteria of a MCDM problem. The DANP, a fusion of DEMATEL and the ANP, can easily derive the influence weights of each aspect and criterion of a MCDM problem based on the results of DEMATEL. The DANP simplifies the analytic procedure of the ANP-based methods and considers every influence relationship, while deriving the influence weights. In ANP-based methods, a threshold value is usually defined to avoid too much complexity in the structure of decision-making problems to be solved. From a traditional perspective, it is very reasonable to adopt these methods. However, in the era of big data, decision makers can further consider the possibility of incorporating big data into the decision-making process instead of relying on a very limited number of experts. In the age of big data analytics, data fill the whole analytic process of MCDM [
20]. Therefore, generating reasonable solutions based on contemporary observations and past data has turned out to be a dominant and fascinating matter [
20]. To resolve this problem, Fu et al. [
20] proposed a DDD framework based on the MCDM method, which has become the focus.
Few scholars have tried to integrate machine learning algorithms and MCDM methods to tackle big data in general and social media data in particular. Recently, Yang et al. [
23] used text mining methods to retrieve papers adopting deep learning—a subset of machine learning—algorithms, and MCDM methods in using big data. Limited results were retrieved from major academic databases, including ScienceDirect, ACM, IEEE, Springer, Taylor & Francis, and Wiley Online Library. Some of these works use the AHP to assess risks [
24], such preparing a flood hazard susceptibility map [
25]. However, as mentioned in the prior paragraph, the assumptions of independence among the aspects and criteria bias the results. Yasmin et al. [
26] used intuitionistic fuzzy DEMATEL (IF-DEMATEL) and the ANP to analyze the capabilities of big data analytics for firms. However, they are not really dealing with big data. Meanwhile, the framework faces problems similar to those mentioned in the prior paragraph—the complicated survey procedure and the loss of valuable information due to the threshold definition.
Muruganantham and Gandhi [
27] provide one of the few studies to incorporate social media data into a MCDM method. In their study, the Technique for Order Performance by Similarity to Ideal Solution (TOPSIS) was introduced to rank influencers in a given social media data set. However, no influence relationships, weights, or confirmation with theoretical frameworks could be provided due to the natural limitation of the TOPSIS, which aims to rank the alternatives only.
In general, in spite of the impression one may get from the media, much data processing that has not been uncovered by existing techniques of data engineering and processing. Therefore, investigations on the integration of social media, NLP, and other methods of data analytics will be very important for deriving novel implications of the data retrieved from social media in general, and the data related to a specific theoretical framework in particular. However, very few scholars have tried to do so, especially from the perspective of MCDM, which can derive influence relationships, which can hardly be achieved by traditional data analytics and statistical approaches. Therefore, in this paper, we aim to propose an analytic framework to mine social network, feed the meaningful information to MCDM methods based on a theoretical framework, derive causal relationships amongst the aspects of the theoretical framework, and finally compare the causal relationships with a social theory.
5. Discussion
In this work, a novel analytic framework, which consists of social media mining, RF, and MCDM techniques, was proposed. Further, the Taiwanese social media platform, Dcard, was used to retrieve data and validate the feasibility of the analytic framework. Meanwhile, influence relationships and influence weights were derived using the novel analytic framework. In the following section, the theoretical implications and advances in research methods presented in this study will be discussed.
5.1. Theoretical Implications
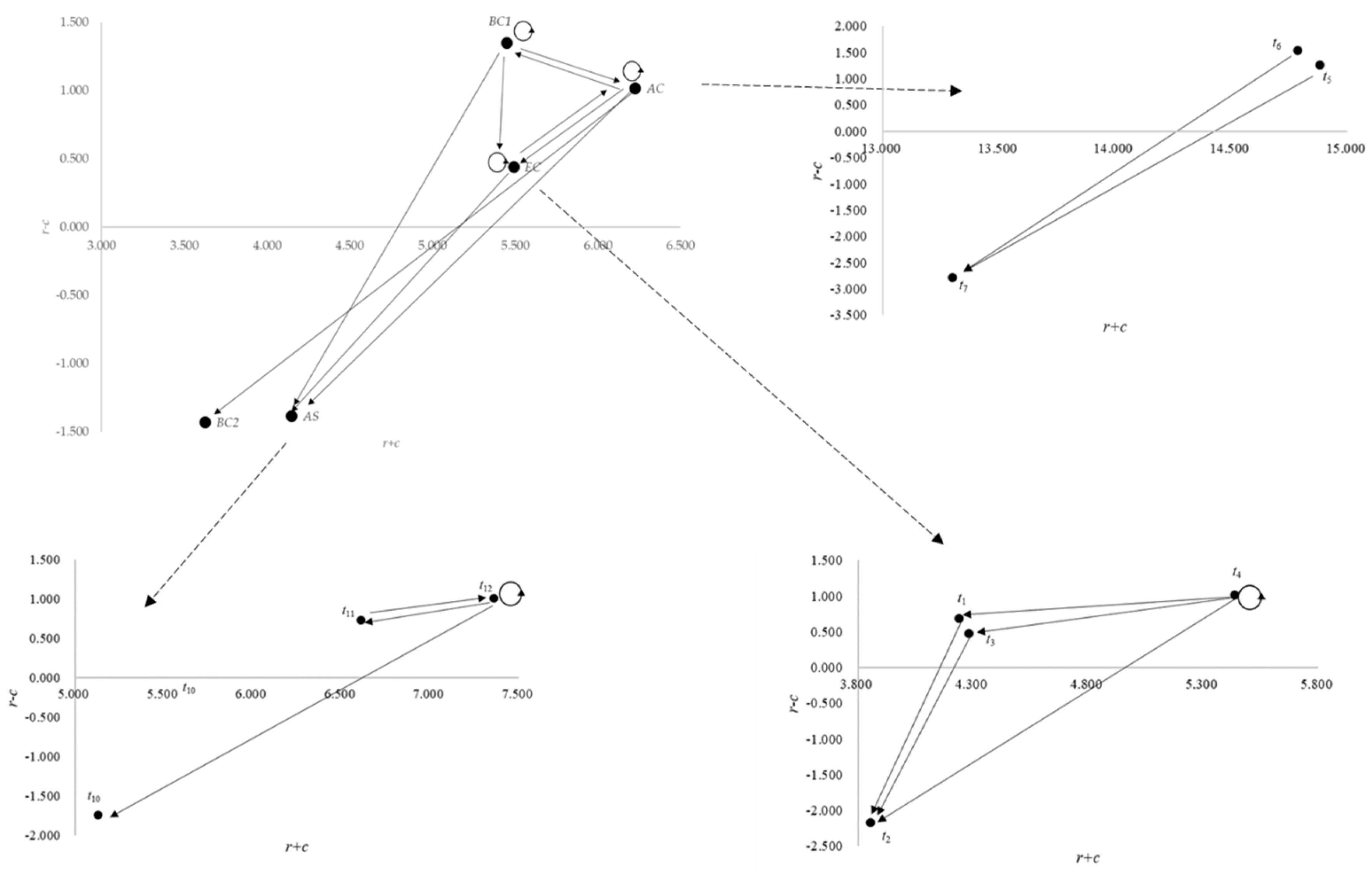
First, the mutual influence relationships among the three aspects from the VBN theory, i.e., altruistic, egoistic, and biosphere concerns, will be discussed. Based on the analytic results, the altruistic concerns influence both the egoistic and biosphere concerns. Furthermore, the biosphere concern influences the egoistic concern. The influence relationships are fully consistent with the original theoretical framework proposed by Stern et al. [
14], which argues that the three environmental concerns—egoistic, altruistic, and biosphere—are mutually correlated. Environmental concern is the extent to which individuals are conscious of environmental issues and/or harms and support efforts to resolve those problems and/or point out an intention to contribute to the solution themselves [
44]. According to Helm et al. [
45], the three aspects are highly correlated. The less important influence relationships from egoistic concerns to biosphere concerns were not demonstrated in the IRM. This may be due to the lower value of total influence from egoistic concerns to the BC
1 aspect; thus, the influence was not demonstrated in
Figure 2. The possible reason for this phenomenon may be the separation analysis of BC
1 and BC
2 aspects, which is limited by the infeasibility of deriving correct DEMATEL results based on the feature importance derived by using the RF algorithm, when there is only one dependent variable and one predictor. The unity feature importance derived will finally cause an IDRM with the same elements, for example,
in this case, where correct results cannot be derived by DEMATEL.
The influence relationships from egoistic concerns to adaptation strategies are consistent with past works. The adaptation strategy is a response strategy to environmental problems in general, and the air pollution problem in particular [
46]. Adaptation strategies can provide possible adaptation plans/actions to facilitate the adjustment of human society and ecological systems to address environmental disasters by increasing a system’s ability or reducing its vulnerability [
51]. Effective adaptation strategies are vital for the long-term success of an organization [
46]. Egoistic concerns are expressed as functional benefits and emotional benefits [
52]. A person with egoistic concerns seeks individual economic benefits and emotional benefits [
52]. Individuals with higher egoistic concerns will particularly think about the expenses and advantages of an environmental behavior for themselves [
53]. Because air pollution is a local environmental problem that directly influences personal welfare, people may adopt adaptation strategies for individual benefit. According to the earlier work by the authors [
9], egoistic concerns have significant correlations with adaptation strategies toward air pollution problems. When egoistic concerns are higher, more people are directly concerned with specific local environmental issues that directly impact them, rather than being stressed by global problems such as climate change [
54]. We believe that people may adopt adaptation strategies for air pollution if air pollution problems are anticipated to influence the benefits of themselves. Based on the influence relationships being derived, i.e., EC→AS, people will adopt adaptation strategies such as supporting wind power generation policies (
), taking medical treatment (
), and purchasing air purifier products (
).
The influence relationships from altruistic concerns to adaptation strategies are also consistent with past works. Altruistic concern is a willingness to take action even in the face of the free rider problem [
14], which means that individual self-interest is not sufficient to produce a collective good [
55]. According to Stern et al. [
14], although some people will possibly anticipate sufficient individual advantages or benefits to rationalize provision of the collective good on egoistic grounds, most are also inspired by a more extensive, altruistic concern. Altruistic concern is a willingness to take action even in the face of the free rider problem [
14], which means that individual self-interest is not sufficient to produce collective good [
55]. Previous studies show that altruistic concerns may lead people to experience environmental stress and coping and then engage in pro-environmental activities [
45]. Based on past works, altruistic concerns impact clients’ purchase intentions regarding ecologically-friendly products [
56]. According to the IRM in
Figure 2, AC→AS, which means the influences from altruistic concerns are very important for the development of adaptation strategies. From the topics belonging to altruistic concerns, coal-fired power generation (
) and refuse combustion (
) are more important issues of concern to Taiwanese people. These air pollution-related problems influence consumer behavior toward purchasing air purifiers (
; 9.260%) and taking medical treatment (
; 8.855%). Though adopting wind power generation (
; 7.053%) is an alternative for reducing the threats caused by air pollution, the replacement of coal-fired or gas-fired power generation plants with green power needs long-term planning over many years. Therefore, wind power generation (
; 7.053%) is the least important strategy from Taiwanese social media users’ perspective.
The influence relationship from biosphere concerns to adaptation strategies is also consistent with past works. Bio-spheric values reflect an individual’s concerns/perception regarding the biosphere and highlight the quality of the natural environment, distinctly from its benefits to humans. Several studies have found that bio-spheric concerns are connected with pro-environmental behavior intention. According to Helm et al. [
49], individuals with more bio-spheric concerns (for example, concern for living creatures and the environment) related to concerns about harmful impacts for all animals and plants on Earth might value the risks of climate change as more severe and stressful, and therefore will probably respond to them [
57]. Thus, bio-spheric environmental concern is dominant in affecting psychological adaptation [
45]. Nguyen et al. [
58] pointed out that biosphere values stimulate active involvement in ecological consumption by enhancing clients’ attitudes toward environmental protection and reducing problems related to environmentally-friendly products. Based on the work by Kiatkawsin et al. [
59], bio-spheric values have more impact on customers’ chances of purchasing sustainable merchandise. According to the IRM in
Figure 2, the BC
1 (policy ambiguity) has more influence on the adaptation strategies than the BC
2 (climate change). The answer is very reasonable. First, based on the recognition of social media users, the influence of policy ambiguity (BC
1) is indeed stronger than that of climate change (BC
2). The terms associated with the only criterion (
) in BC
1, including the terms associated with the topic (green, nuclear, vote, government in
Table 2), are those which have more influence on wind power generation policy (
). The stronger influence relationship can be observed from the TRM of topics in
Table 7. The influence from
to
(0.195) is indeed much higher than the influence from
to
and
, which are 0.061 and 0.066, respectively. Further, the influence of climate change (
) on the three criteria in the AS aspect is 0.088, 0.041, 0.039, respectively. This means that policy ambiguity (BC
1) is indeed the major topic influencing the definition of wind power generation (AS).
Finally, according to the result of the DANP in
Table 10, the influence weight for environmental concerns and adaptation strategies are prioritized as EC
AS
AC
BC
1 BC
2. Many environmental issues are considered social dilemmas; that is, when individuals pursue their own self-interest, this results in damaging consequences for the collective. For example, Knes [
60] proposed that promoting pro-environmental behavior is recognized as a moral issue by altruistic individuals but not by egoistic ones in the context of climate change. However, our study proposes that egoist concerns have a greater influence weight than altruistic and bio-spheric concerns in the context of air pollution. This may be why air pollution is one of the most pressing environmental and health issues, which can cause respiratory illnesses and allergies ranging from coughs to asthma, cancer, or emphysema. Related research by Vyver et al. [
61] revealed that people who perceived higher health threats were also more likely to engage in a range of pro-environmental behaviors in the case of turning off idling engines to reduce air pollution.
5.2. Advance in Research Method
The analytical framework which integrates the method of NLP, RF, and MCDM is a novel one which crosses the gap between social media mining and MCDM research. Numerous scholars have developed works using these methods individually. Very few scholars have tried to integrate the NLP methods with SEM. However, according to the authors’ limited knowledge, this work is the first which tries to integrate these methods and derive meaningful results.
First, the RF algorithm can transform data retrieved from any database into the IDRM, which is required by DEMATEL. Traditionally, the MCDM method required opinions to be provided by experts. However, data retrieved from the database or the mass population (i.e., big data) can also provide very meaningful information. Thus, scholars have started to propose method(s) which tried to integrate the RF algorithm and the MCDM method, like DANP (e.g., the work by Liu et al. [
62] and Lo et al. [
63]), which provide insights into management problems based on real data. In this paper, the NLP-based social media mining techniques are further integrated and advance the existing RF and DANP-based method. Big data retrieved from social media can serve as the basis for uncovering social phenomena by using MCDM methods, which were difficult to achieve. However, the influence relationships can provide more meaningful information than traditional MCDM or statistical methods-based research.
Second, the social media mining-based MCDM framework can provide more insights into social phenomena or social theories. Traditionally, scholars used statistical sampling-based methods such as covariance-based SEM or PLS-SEM to verify the theoretical framework. The social media mining-based MCDM framework provides new opportunities for verifying causal relationships and deriving new influence relations and the importance of aspects belonging to the theoretical frameworks.
In general, the proposed analytical framework advances both the MCDM-based analytical framework and the methods for verifying social theories. The analytical framework can be further adopted in big data analytics, uncovering real problems and confirming social theories by using big data.
5.3. Limitations and Future Research Possibilities
From the aspect of limitations, the analytic results are derived based on the Taiwanese social media site. The results may be controversial when mining social media sites from other regions or economies. Meanwhile, the empirical results are based on the VBN theoretic framework. Whether the analytic framework can derive satisfactory results, which can be fully consistent with other social theories, is worth future study.
Further, as already mentioned in
Section 5.1, when the number of criteria of some specific aspect is less than three, the RF based DANP may not be feasible. The unity feature importance will cause an IDRM with same elements, for example,
. In this case, correct results cannot be derived by DEMATEL. Though this kind of situation will not really occur in research which refers to prior academic works, e.g., the confirmatory analyses based on SEM, which usually contain more than three to five criteria based on the questionnaires, the phenomenon actually constrains the development of some MCDM problems containing aspects with fewer than three criteria.
In the future, the novel analytic framework consisting of social media mining, RF, and MCDM methods can be used to retrieve more information from social media websites in general, and validate social theories regarding social phenomenon in particular. The newly derived influence relationships between altruistic and egoistic concerns and altruistic and biosphere concerns are also worth further research and investigation.
6. Conclusions
During the past decade, social media has emerged as one of the major sources for mining opinions from users in major and emerging economies. Though numerous scholars and practitioners have dedicated attention to mining useful information from social media, a lot more can be retrieved from the available data. The MCDM theories and methods have been well developed and widely applied to numerous economic, management, and engineering problems. However, very few scholars have tried to integrate the MCDM method with social media mining techniques. However, interesting results, such as influence relationships and valuable insights, can be retrieved from social media data. Thus, the authors proposed an analytic framework that integrates the LDA, RF, DEMATEL, and DANP. In this study, Dcard users’ attitudes and adaptation strategies regarding air pollution problems were retrieved and analyzed based on the value–belief–norm theory proposed by Stern et al. [
14].
Based on the analytic results, the influence relationships are fully consistent with the value-belief-norm theory. That is, altruistic concerns influence both egoistic and biosphere concerns. Furthermore, biosphere concerns influence egoistic concerns. Moreover, all three aspects—altruistic, egoistic, and biosphere concerns—influence adaptation strategies. The mutual influences between altruistic concerns and egoistic concerns, as well as altruistic concerns and biosphere concerns, were seldom discussed in past works. Whether these two influence loops are self-enhancing or self-attenuating is worth investigating further.
According to the results derived by the DANP, the most important aspects of the analytic framework include egoistic concerns and altruistic concerns, which had influence weights of 31.613% and 24.394%, respectively. The results are fully consistent with the authors’ earlier work using the PLS-SEM to analyze the VBN theoretic framework [
9], in which these two aspects were the ones most closely correlated with the adaptation strategies. That is, the influence relationships are consistent with statistical results.
The analytic results presented here were derived based on the Taiwanese social media site Dcard. The results may be controversial when mining social media sites from other regions or economies. Meanwhile, the empirical results were based on the VBN theoretical framework. Whether this analytic framework can derive satisfactory results that can be fully consistent with other social theories is a question worth further study. In the future, this novel analytic framework can be used to retrieve more information from social media websites in general, and validate social theories regarding social phenomenon in particular.




{kind=link}
{kind=link}

