1. Introduction
Mahalanobis distance (MD) is a fundamental statistic in multivariate analysis. It is used to measure the distance between two random vectors or the distance between a random vector and its center of distribution. MD has received wide attention since it was proposed by Mahalanobis [
1] in the 1930’s. After decades of development, MD has been applied as a distance metric in various research areas, including propensity score analysis, as well as applications in matching [
2], classification and discriminant analysis [
3]. In the former case, MD is used to calculate the propensity scores as a measurement of the difference between two objects. In the latter case, the differences among the clusters are investigated based on MD. The applications of MD are also related to multivariate calibration [
4], psychological analysis [
5] and the construction of multivariate process control charts [
6]; it is a standard method to assess the similarity between the observations.
As an essential scale for distinguishing objects from each other, the robustness of MD is important for guaranteeing the accuracy of an analysis. Thus, the properties of MD have been investigated in the last decade. Gath and Hayes [
7] investigated the bounds for extreme MDs. Dai et al. [
8] derived a number of marginal moments of the sample MD and showed that it behaves unexpectedly when
p is relatively larger than
n. Dai and Holgersson [
9] examined the marginal behavior of MDs and determined their density functions. With the distribution derived by Dai and Holgersson [
9], one can set the inferential boundaries for the MD itself and acquire robust criteria. Beside the developments above, some attention has been paid to the Fisher matrix (F-matrix) and Beta matrix which can be considered as the generalizations of MD.
We provide the definition of the Fisher matrix (see [
10]) which is essential here. The Fisher matrices, or simply
F -matrices, are an ensemble of matrices with two components each. Let
be either both real or both complex random variable arrays. For
and
, let
be the arrays, with column vectors
. The
corresponds to the
ith observation in
. This observation is isolated from the rest of the observations, so that
and
are two independent samples. We determine the following matrices:
where
stands for complex conjugate transpose. These two matrices are both of size
Then the Fisher matrix (or
F -matrix) is defined as
Pillai [
11], Pillai and Flury [
12] and Bai et al. [
13] have studied the spectral properties of the F-distribution. Johansson [
14] investigated the central limit theorem (CLT) for the random Hermitian matrices, including the Gaussian unitary ensemble. Guionnet [
15] established the CLT for the non-commutative functional of Gaussian large random matrices. Bai et al. [
16] obtain the CLT for the linear spectral statistics of the Wigner matrix. Zheng [
10] extends the moments of the F-matrix into non-Gaussian circumstances with the assumption that the two components
and
of an F-matrix
are independent. Gallego et al. [
17] extended the MD into the condition of a multidimensional Normal distribution and studied the properties of MD for this case.
However, to the best of our knowledge, the properties of MDs with non-Gaussian complex random variables have not been studied much in the literature. In this paper, we derive the CLT for an MD with complex random variables under a more general circumstance. The common restrictions on the random vector, such as independent and identically distributed (i.i.d.) for the random sample, are not required. The independence between the two components and of the F-matrix is relaxed. We investigate the distributional properties of complex MD without assuming normal distribution. The fourth moments of the MDs are allowed to be an arbitrary value.
This paper is organized as follows. In
Section 2, we introduce the basic definitions concerning different types of complex random vectors, their covariance matrix, and the corresponding MDs. In
Section 3, the first moments of different types of MDs and their distribution properties are given. The connection of leave-one-out MD and classical MD is derived, and their respective asymptotic distributions under general assumptions are investigated. We end up this paper by giving some concluding remarks and discussions in
Section 4.
Some Examples of Mahalanobis Distance in Signal Processing
MD has been applied in different research areas. We give two examples that are related to the applications of MD in signal processing.
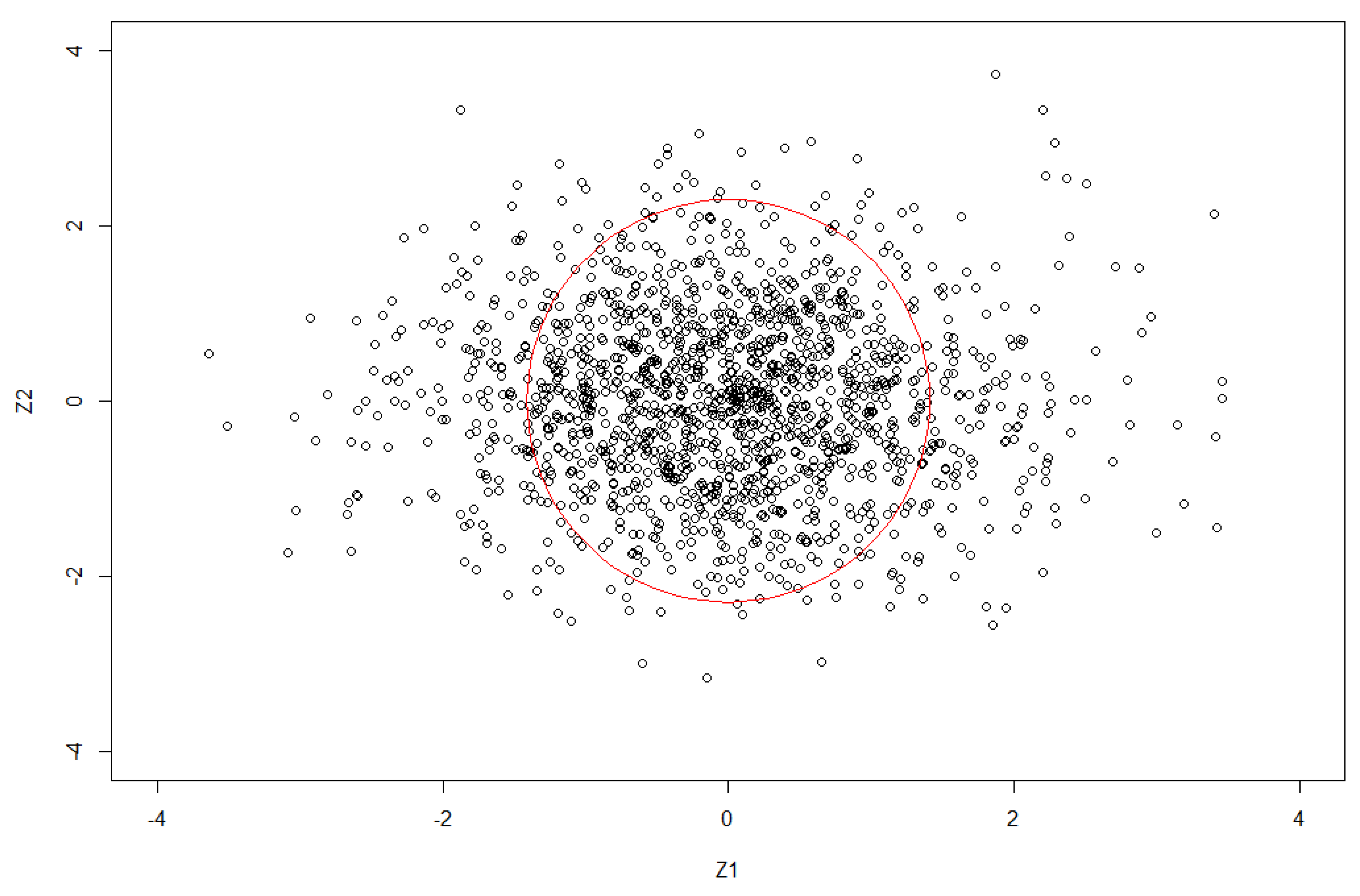
Example 1. We illustrate our idea by using an example. In Figure 1, each point corresponds to the real and comlex part of an MD. The circle in red is an inferential boundary with the radius calculated based on MDs. The points that are outside the boundary are considered to be signals, while the points that are lying inside the circle are detected as noise. This example has been used in some research; for example, in evaluating the capacity of multiple-input, multiple-output (MIMO) wireless communication systems (see [18] for more details). Denote the number of inputs (or transmitters) and the number of outputs (or receivers) of the MIMO wireless communication system by and respectively, and assume that the channel coefficients are correlated at both the transmitter and the receiver ends. Then the MIMO channel can be represented by an complex random matrix with corresponding covariance matrices and . For most of the cases, and should be replaced by the sample covariance matrices and to represent the channel correlations at the receiver and transmitter ends, respectively. The information processed by this random channel is a random quantity which can be measured by MD. Example 2. Zhao et al. [19] use MD in a fuzzy clustering algorithm in order to reduce the effect of noise on image segmentation. They compare the boundaries of clusters calculated by both the Euclidean distance and MD. The boundaries calculated by the Euclidean distance are straight lines which misclassify the observations that diverge far from their cluster center, while the boundaries based on the MDs are curves that fit better with the covariance of the cluster. This example implies that the MD is more accurate with regards to the measure of dissimilarity for image segmentation. It can be extended to the application of clustering when the channel signals are complex random variables. 2. Preliminaries
In this section, some important definitions of complex random variables and related concepts are introduced, including the covariance matrix of a complex random vector and the corresponding MDs.
We first define the covariance matrix of a general complex random vector on an
dimension complex random variable
where
p is the number of variables and
n is the sample size of the dataset, as given in [
20]:
Definition 1. Let , be a complex random vector with known mean where , and . Let be the covariance matrix and be the relation matrix of respectively. Then and are defined respectively as follows:where is the transpose. Definition 1 shows a general presentation of the complex random variables without imposing any distributional assumption on . If we set the components of , the random variables and , as normally distributed, then we are in a more familiar context in the complex space: circular symmetricity. The circular symmetricity of a complex normal random variable is an assumption that is used for the standardized form of complex Gaussian-distributed random variables. The definition of circular symmetricity is the following.
Definition 2. A p-dimensional complex random variable is a circularly symmetric complex normal one if the vector is normally distributed, i.e.,where and , “” stands for the real part and “” stands for the imaginary part. The circularly symmetric normally distributed complex random variable can be used in the circumstance of a standard normal distribution in real space to simplify the derivations on complex random variables. Based on this condition, we acquire a simplified probability density function (hereinafter p.d.f.) on a complex normal random vector which is presented in the following example.
Example 3. The circularly symmetric complex random vector with mean vector and relation matrix has the p.d.f. as follows:where is the covariance matrix of and “” is the determinant. Based on Example 3, one can see the possibility of transforming the expression of a complex random vector into a form consisting of vector multiplication between a complex constant vector and a real random vector. Let
be a complex random variable; then, the transformation between a complex random variable and its real random variables can be presented as follows:
The transformation offers a different way of inspecting the complex random vector [
21]. The complex random vector can be considered as the bivariate form of a real random vector pre-multiplied by a constant vector. This transformation offers another way to present the complex covariance matrix in the form of real random vectors. The idea is presented by the example as follows.
Define matrices
,
,
and
. The covariance matrix
of a
p-dimensional complex random vector can be represented in the form of real random vectors
and
, as follows:
3. MD on Complex Random Variables
In this section, we introduce two types of MDs given in Definitions 5 and 6. We start with the classical MD which is based on a known mean and a known covariance matrix. The definition is given as follows.
Definition 3. The MD of the complex random vector with known mean μ and known covariance matrix is defined as follows: There are both real and complex parts for a complex random vector. Thus, we define the corresponding MDs of the two components in a complex random variable.
Definition 4. The MDs on the real part and imaginary part of a complex random vector with known mean μ and known covariance matrix are defined as follows: Under the definitions above, we can derive the distribution of the MDs on a complex random vector with known mean and covariance. We present the distribution as follows.
Proposition 1. Let be an row-wise double array of i.i.d. complex normally distributed random variables with , and complex positive definite Hermitian covariance matrix . Then we have the distribution of the MD in (1) as .
Proof. For the proof of this proposition, the reader can refer to reference [
22]. □
The result of Proposition 1 is employed here to derive the moments of the MDs on the real and complex parts below.
Proposition 2. The first moment of defined in (1) is given as follows: Proof. The result follows Proposition 1. □
Theorem 1. Set the random variables and to be normally distributed, and the covariance of and as given in (2) and (3). Then their distributions are given as follows:where ⊗
is the tensor product, and stands for trace. Proof. Proposition 1 shows
and
In order to derive the covariance of these two MDs, we need to first derive their cross moments.
Thus, the covariance is given as follows:
which completes the proof. □
The results presented so far concern a complex random vector with known mean and known covariance matrix. In practice, the mean and covariance matrix are not available all the time. Thus, some alternative statistics such as sample mean and sample covariance are used as substitutions of the population mean and variance when building the MDs.
We introduce the definitions of MDs with sample mean and sample covariance matrix in the following.
Definition 5. Let , be a complex normally distributed random sample. The MD on the complex random vector with sample mean and sample covariance matrix is defined as follows: For the purpose of deriving further distributional properties, we give an alternative definition of an MD: the leave-one-out case. Leave-one-out here means that we remove one observation each time and use the rest of the observations for constructing the MD.
Definition 6. Let the leave-one-out sample mean of a complex random vector be and the corresponding leave-one-out sample covariance matrix . The leave-one-out MD on the complex random vector is defined as follows: The advantage of leaving one observation out of the dataset is the achieved independence between the removed observation and the sample covariance matrix of the other observations. The similarity in structure between the estimated and the leave-one-out MDs can be explored in theorems on their distributions. The distribution of the leave-one-out MD is derived as in the following theorem.
Theorem 2. given in (4) follows a Beta distribution .
The proofs of this theorem and others are relegated to
Appendix A, so that readers can perceive the results more smoothly. The distribution of a leave-one-out MD can be used to derive the distribution of an estimated MD. We show this in Theorems 3 and 4.
We present the main results of this paper in the following two theorems. The assumption of a normal distribution on the complex random variable is released. Instead, we introduce two more general assumptions. Assume:
- (i)
The entries of complex random matrix are independent complex random variables, but not necessarily identically distributed with mean 0 and variance 1. Let the 4th moment of the entries have arbitrary value . The limiting ratio of their dimensions is .
- (ii)
For any
,
where
is the indicator function. This assumption is a standard Linderberg-type condition that guarantees the convergence of the random variable without the assumption of identical distribution.
Theorem 3. Under the assumptions (i) and (ii), set the 4th moment of the complex random vector . Then the asymptotic distribution of in (5) is:where ,and By using the results above, we derive the asymptotic distribution of the estimated MD in (4).
Theorem 4. The asymptotic distribution of in (4) is given as follows:where τ and υ are given in Theorem 3.
In the F-matrix , the two component and are assumed to be independent. Theorem 3 is derived under this restriction, while the results in Theorem 4 extend the circumstance and release the assumption of independence in Theorem 3.
4. Summary and Conclusions
This paper defines different types of MDs on complex random vectors with either known or unknown mean and covariance matrix. The MDs’ first moments and the distributions of MD with known mean and covariance matrix are derived. Further, some asymptotic distributions of the estimated and leave-one-out MDs under complex non-normal distribution are investigated. We have relaxed several assumptions from our previous work [
9]. The random variables in the MD are required to be independent but not necessarily identically distributed. The fourth moment of our random variables can be of arbitrary value. The independence between the two components
and
of the F-matrix
can be ignored in our results.
In conclusion, the MDs on complex random vectors are useful tools when dealing with complex random vectors in many situations, for example, robust analysis with signal processing [
23,
24]. The asymptotic properties of MDs can be used in some inferential studies for finance theory [
25]. Further studies could develop upon the real and imaginary parts of MDs over a complex random sample.



{kind=link}
