1. Introduction
The use of bivariate distributions where the marginals are one continuous and the other one discrete are extremely rare in statistics and more specifically in applied statistics. Some examples in which these types of distributions have been previously considered are [
1,
2,
3]. The latter work was applied in tourism settings and the first two papers were applied in actuarial context. Conditional specification structure has also been applied in insurance framework when both marginal distributions are continuous. See [
4] for details.
The statistical literature contains numerous methods to obtain bivariate distributions, some of them within the copula framework. These are functions that enable us to separate the marginal distributions from the dependency structure of a given multivariate distribution (see [
5,
6], among others). Several flexible approaches based on different bivariate copula families such as [
7,
8,
9] have been proposed in the literature, including the Plackett and Frank copulas. The methodology proposed in this work allows us to build a bivariate distribution based on a conditional specification technique (see for instance [
10,
11]). In general, although the models obtained through this methodology rely on formulations that incorporate many parameters, this requirement can be relaxed, as it will be shown below, to obtain simple and practical expressions. The major advantage of this methodology, as compared to copula approach, is that the latter one incorporates a parameter that controls the correlation which is difficult to estimate, since it is restricted to a range of allowed values.(In practice, this can often be solved by choosing a suitable parametrization (e.g., using the logit or arctan of the correlation as parameter)).
In this work, we jointly model amount of expenditure for outpatient visits and number of outpatient visits by taking into account both dependence and simultaneity. It is noted that both variables are important inputs in the structure of health budgets and in health insurance. More specifically, on the one hand, we model dependence by proposing a bivariate structural model that describes both variables specified in terms of their conditional distributions [
10,
11]. In fact, the model proposed here is a special case of the one obtained in [
3]. On the other hand, simultaneity is implemented into the bivariate distribution, by making two assumptions:
the conditional expectation expenditure for outpatient visits with respect to the number of outpatient visits is linear; and
the conditional expectation of outpatient visits with respect to the expenditure for outpatient visits is also linear. Thus, we assume that more expenditure implies that the considered health system is capable of handling more visits (note that we are not assuring that more expenditure involves a greater number of visits, which is difficult to sustain in practice); on the other hand, more visits obviously imply more expense.
Furthermore, one of the conditional distributions obtained in our study is used to calculate Bayesian premiums which take into account both the number of claims and the size of the correspondent claim. A credibility expression for the Bayesian premium in which the credibility factor obeys the classical expression provided in [
12] is also derived. This type of premiums can be useful in automobile insurance contract to take into consideration both the number of claims and the severity of claim.
The second major contribution of this work is based on the fact that the proposed model enables us to evaluate the effect of covariates on both expenditure and number of visits. Thus, we can distinguish between the effects of these explanatory variables on both responses and, therefore, we can determine which covariates simultaneously affect both expenditure and the number of visits.
The proposed model is empirically evaluated by using data of health care use taken from Medical Expenditure Panel Survey (MEPS), conducted by the U.S. Agency of Health Research and Quality. This set of data can be downloaded from the web page of Professor E. Frees. We jointly model the number of outpatient visits and the amount of expenditure of outpatient visits. Some factors affecting these two random variables will be considered.
The rest of this paper is organized as follows.
Section 2 provides the general motivation of this study and the main results. The proposed model for number of visits and expenditure is introduced here. A bivariate model allowing for the implementation of fixed effects is provided in
Section 3. Some methods of estimation are shown in
Section 4. Next, an empirical analysis of these models is performed in
Section 5 and finally
Section 6 summarizes the main conclusions drawn from this work.
2. Motivation and Results
In this section, we propose a non-linear bivariate model of amount of expenditure for outpatient visits and number of outpatient visits. The model is a special case of the one provided in [
3] which was built by using a characterization via conditional expectations. In this case it was constructed through a class of bivariate distributions such that the conditional distributions belong to a specified exponential family.
As is well known, multivariate distributions can be specified in terms of their conditional distributions rather than directly. In this case, the dependence structure can be modeled using bivariate copulas or other mathematical or statistical methods such as conditional distributions or mixing distributions. By assuming that the conditional distributions belong to certain parametric families of distributions, the joint distribution can be obtained as described in [
10] (see also [
11] for an introduction to this topic). For applied works in this setting, see [
1,
3,
13], among others. To obtain the joint distribution, it is first necessary to determine the solution of certain functional equations, which facilitates the derivation of highly flexible multiparametric distributions. As [
11] pointed out, when we wish to specify a bivariate distribution it is sometimes convenient to visualize conditional distributions rather than marginal or joint distributions. In this context, it is useful in statistical modeling to have tractable multivariate distributions with given marginals to quantify the dependence effect of the variables in the model.
Accordingly, let us assume that the amount of expenditure for outpatient visits is represented as a random variable X and that the number of outpatients visits to the hospital is also random, and denoted by N. We now wish to obtain the more general bivariate distribution whose conditional distributions satisfy the following conditions based on expenditure, conditional on the number of visits and on the number of visits to the hospital conditional to expenditure.
On the one hand, the expenditure for outpatient visits depends on the number of outpatient visits, i.e., if
is the expenditure conditional to
visits is directly proportional to the number of outpatient visits. Hence,
According to expression (
1), assuming that
n takes values within the set of integer numbers
there is a minimum expense given by
in the case of no outpatient visits. Then, it seems coherent to assume that the expense increases as the number of visits increases.
On the other hand, it also seems logical to believe that the number of outpatient visits will depend on the expenditure, i.e., the number of outpatient visits that the health care system can assist will depend on its capacity, which in turn is conditioned by the budget (in terms of expenditure) available. Hence,
Although Equation (
1) includes an intercept since some expenditure would be necessary even for zero visits, pointing out that the health system must be prepared for any future visit, this is not the case of Equation (
2). This is mainly due to two reasons:
On the one hand, this modelization facilitates the construction of the mathematical model obtained from Equation (
2); and
it seems obvious that an initial expenditure of near-zero monetary units implies that the health system is unable to absorb patients and, therefore, the mean of visits, and therefore the conditional mean, will be close to zero.
In some circumstances it is certain that this linear dependence relationship is not easily to be assumed. For example, an increase in the number of patient visits to the hospital might be caused by the suffering of more serious diseases that, in turn, incur in more expensive treatments. In this case, it is likely that a non-linear or logarithmic polynomial relationship could be more realistic. Obviously, the modeling in this case would be different from the one considered in this work.
In this work, we propose the use of a bivariate distribution that satisfies the conditions (
1) and (
2). We will consider the case where one of the conditional random variable is Gamma and the other one Poisson. A discrete random variable is said to follow a Poisson distribution with parameter
if its probability mass function (pmf) is given by
In the following,
will denote a random variable following a Poisson distribution with pmf given by (
3). Moreover, a continuous random variable follows a gamma distribution with shape parameter
and rate parameter
if its probability density function (pdf) is expressed as
We will write in this case,
. By searching for the bivariate conditional distribution, let us now assume that
for given functions
,
and
. Then, the conditional distributions given in (
5) and (
6) have pdfs given by
i.e., they are members of the exponential family of distributions. Ref. [
3] (see also [
10], Chapter 4, p. 98) studied the most general bivariate distribution with conditionals given by (
7) and (
8) and concluded that this has pdf given by,
with
,
where
,
,
and
. The parameter
is a normalizing constant, a function of the remaining parameters, satisfying
which can be obtained from one of the conditional distributions given in (
5) and (
6), where
Certainly, the major limitation of this type of models, built by conditional specification, lies in the difficulty that both the marginal distributions and the joint distribution depend on a normalization constant that in most cases is very difficult or even impossible to calculate in closed form (see for example [
14]). Obviously, the difficulty grows when the two variables on which the model depends have different support or it is even more complicated when one variable is discrete and the other one is continuous, as the case considered here. However, from a numerical point of view, this is not an issue of relative importance since there exist integration and summation techniques (more difficult in the latter case) that allow us to compute the constant term. The reader is referred to [
15] for more details on how to proceed in these cases.
For practical purposes, an appropriate choice of the parameter could enable us to obtain a closed-form expression for the normalizing constant. For example, the case
corresponds to that one where
N and
X are independent and the marginal distributions are Poisson and gamma as in (
3) and (
4), respectively. The cases
,
,
and
,
provide a closed-form model with conditional means of the type of (
1) and (
2) and thus suitable for our purpose. This latter model that includes an additional parameter as compared to the previous one will be considered here. Then, the bivariate distribution given in (
9) can be rewritten as
Please note that the bivariate distribution (
13) has a marginal distribution with continuous support and the other one with discrete support. This type of bivariate distribution is uncommon in theoretical and applied statistical literature, allowing us to model phenomena that are not usual in practical situations but sometimes occur, as it is the case described in this paper. See for example [
1,
16,
17].
2.1. Marginal Distributions
The marginal distributions of
X and
N are given by
where
refers to the negative binomial distribution, i.e.,
The marginal distribution of
N is obtained by integrating (
13) with respect to
x over
and the marginal distribution of
X is calculated by summing (
13) with respect to
n in the support
.
Furthermore, it is readily apparent that the marginal means and variances are given by
while the cross moment of
X and
N is
Simple calculations provide the covariance and the coefficient of correlation. These are given by
respectively, which are always positive. The coefficient of correlation is bounded between 0 (
) and 1 (
). Thus, parameter
controls the dependence structure of the model.
If the researcher wanted to work with a model that allows for positive and negative correlations, it would be enough to choose in (
9) a less restrictive model.
2.2. Conditional Distributions
The conditional distribution of
X given
N, shown in (
5), is gamma with the parameters given in (
10) and (
11) and the conditional distribution of
N given
X, see (
6), is Poisson with parameter given in (
12). Thus, the conditional distribution of
X given
is
, where
and the conditional distribution of
N given
is
, with
. Observe that under these conditional distributions, expressions (
1) and (
2) are guaranteed.
Both the moments and maximum likelihood methods are feasible ways of estimating the vector of parameters of the distribution through sample observations.
2.3. Hypothesis Testing
By using bivariate data, hypothesis testing can be performed with the parameters
,
and
. We may also be interested in determining, via the likelihood ratio test, when the model might depend only on two parameters, e.g., when
. In this case, the vector
can be estimated with the constraint that
. If we denote the new vector by
, the critical region for the null hypothesis
is determined from the test statistic
which asymptotically has a
-squared distribution with one degree of freedom.
3. Allowing for Covariates
In this section, we introduce a more practical model where covariates may be easily implemented. The bivariate linear regression model, which makes no distributional assumptions, is likely to be unsatisfactory because certain combinations of parameters and regressors could violate the non-negative restriction of the mean of both variables and therefore prediction could give non-realistic values. To avoid this situation, we propose a parametric model based on the distributional assumptions presented in the previous section when the researcher wishes to examine the factors or covariates that can affect simultaneously both means.
For our regression analysis, we reparameterized (
13) as a function of its marginal means
and
, then
is replaced by
and
is replaced by
, where
and
. Then, the pdf (
13) can be rewritten as
for
and
After this reparameterization we also obtain the cross moment, the covariance and the correlation, which are given by
Thus, parameter controls the dependence or independence of the model. As , while , .
Therefore, the model provided in (
14) is suitable for including covariates since the marginal means are given by
and
. The expression
is used to denote a bivariate random variable
that follows the distribution given in (
14), with marginals gamma and negative binomial. Graphs of the density function for different parameter values and their corresponding contour plots are shown in
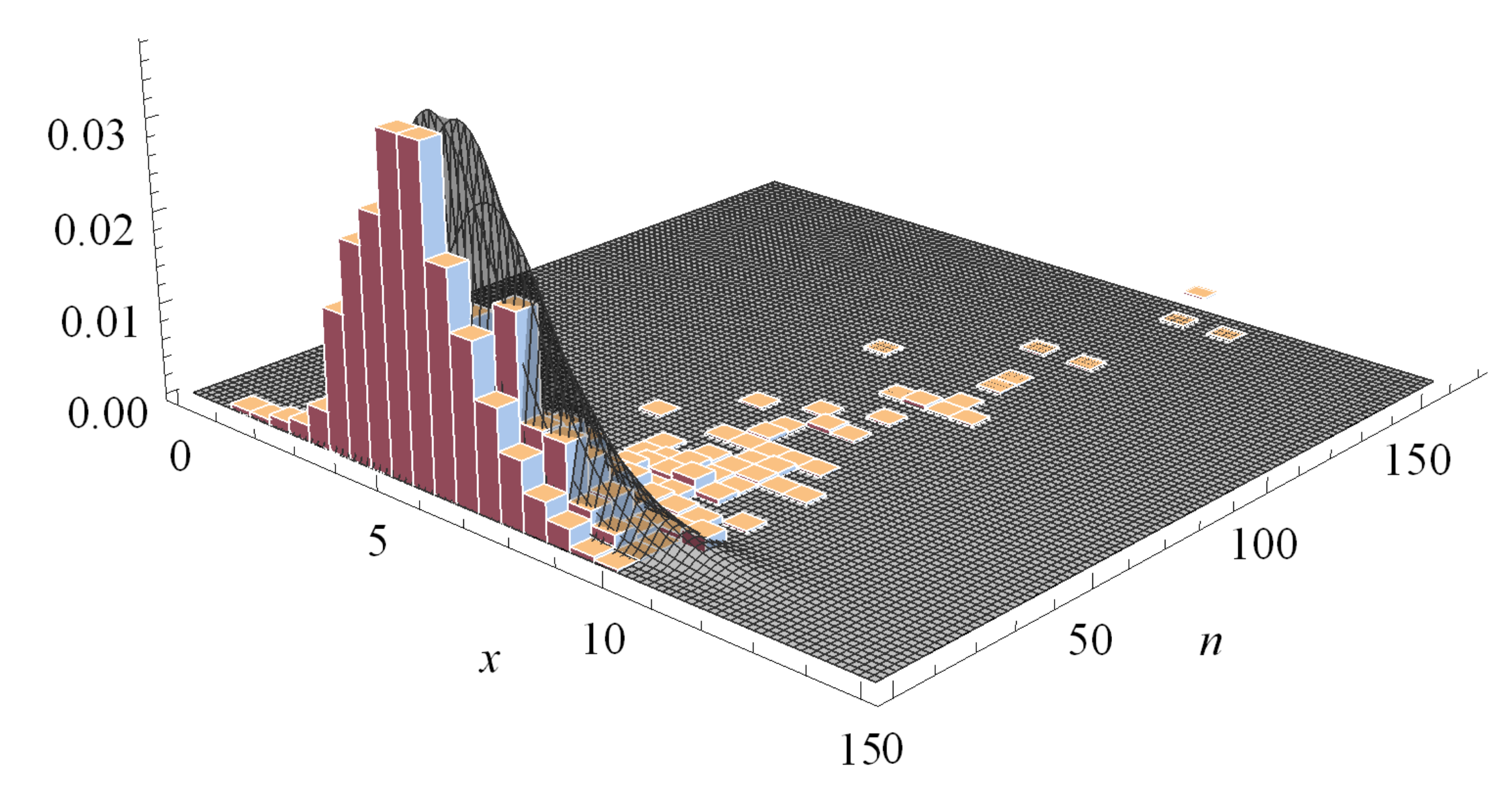
Figure 1, revealing that the density seems to be unimodal for different values of its parameters.
Now, let
and
be two vectors of
k covariates associated with the
ith observation. They are two vectors of linearly independent regressors that are thought to determine
. For the
ith observation, the model takes the form
for
and where
t denotes the number of observations and
and
the corresponding vectors of regression coefficients.
Moreover, each of the variables, X and N, can be influenced by different factors, hence the explanatory variables that are taken to explain , , could not be the same. Furthermore, observe that the log link assumed ensures that falls within the interval and within the interval . Furthermore, in practice the model can handle factors that are only related to just one outcome and not to the other one.
In this study, all estimation computations were implemented by using the Wolfram Mathematica (v. 12.0, Wolfram Research Inc., Champaing, IL, USA) and RATS (v. 7.00 Estima, Evanston, IL, USA) software. In the latter case, the approximation given in (
16) was used, obtaining the same results as those ones computed with Mathematica. For further information on these software packages, the reader is referred to [
18,
19].





{kind=link}
{kind=link}