Abstract
The tail value at risk at level p, with is a risk measure that captures the tail risk of losses and asset return distributions beyond the p quantile. Given two distributions, it can be used to decide which is riskier. When the tail values at risk of both distributions agree, whenever the probability level about which of them is riskier, then the distributions are ordered in terms of the increasing convex order. The price to pay for such a unanimous agreement is that it is possible that two distributions cannot be compared despite our intuition that one is less risky than the other. In this paper, we introduce a family of stochastic orders, indexed by confidence levels that require agreement of tail values at risk only for levels . We study its main properties and compare it with other families of stochastic orders that have been proposed in the literature to compare tail risks. We illustrate the results with a real data example.
1. Motivation and Preliminaries
In actuarial and financial sciences, risk managers and investors dealing with insurance losses and asset returns are often concerned with the right-tail risk of distributions, which is related to large deviations due to the right-tail losses or right-tail returns (see Wang []). To compare the risk associated to different models, they use risk measures typically based on quantiles, such as the value at risk, the tail value at risk and some generalizations of these measures (see the book by Guégan and Hassani [] for a recent review on the topic of risk measurement). Comparisons of two quantile-based risk measures made for a particular confidence level p are not very informative (they are based on two single numbers) and a change in the confidence level may produce different conclusions. An alternative method to compare two risks X and Y is to use stochastic orderings, which conclude that X is smaller than Y when a family of risk measures (rather than a single risk measure) agrees in the conclusion that X is less risky than For example, the increasing convex order (which is formally defined below) requires agreement of tail values at risk for any confidence level . An advantage of this method is, obviously, its robustness toward changes in the confidence level, which can be interpreted in terms of a common agreement of different decision-maker’s attitudes. By robustness, we understand how sensitive the comparison procedure to different values of p is. For other interpretations of robustness in risk measurement, see Zhelonkin and Chavez-Demoulin []. However, this approach has the drawback that some distributions cannot be compared despite our intuition that one is less risky than the other.
One way to increase the number of distributions that can be compared without losing robustness is to reduce the range of values of the confidence level p required to reach an agreement. For example, an investor concerned with right-tail risks may think that X is less risky than Y if the respective tail values at risk agree in the conclusion that X is less risky than Y for any confidence level p such that where is chosen to suit his/her specific preferences. The aim of this paper is precisely to study a family of stochastic orders based on such an agreement.
Let X be a random variable describing losses of a financial asset and let F be its distribution function (as usual, negative losses are gains). The value at risk of X at level or p-quantile, is defined by
For a given , represents the maximum loss the investor can suffer with confidence over a certain period of time. Despite being widely used in practice, VaR has two major drawbacks. First, it does not describe the tail behavior beyond the confidence level. Second, VaR is not, in general, subadditive (except in some special cases; for example, when the underlying distribution belongs to the elliptical family of distributions, the estimator of VaR is subadditive). The literature offers different possible alternatives to overcome the limitations of VaR (see, for example, Ahmadi-Javid []). One of the most important is the tail value at risk or , defined by
TVaR is subadditive (that is, for all losses X and Y). Given and X continuous, represents the average loss when losses exceed .
In this paper, we study the following family of stochastic orders indexed by confidence levels
Definition 1.
Let X and Y be two random variables and . Then, X is said to be smaller than Y in the -tail value at risk order, denoted by , if
When (2) holds for , then we have the usual increasing convex order (see Lemma 2.1 in Sordo and Ramos []) and we denote . The books by Shaked and Shanthikumar [] and Belzunce et al. [] collect many properties and applications of the increasing convex order. If , then X is both smaller (in fact, implies ) and less variable than In finance and insurance, the increasing convex order is often interpreted in terms of stop-loss contracts and it is also called stop-loss order. Specifically, it holds that if, and only if,
where , if and , if , or, equivalently, if
provided the integrals exist, where and are the tail functions of X and Y, respectively. One purpose of this paper is to study how these characterizations change when the order is replaced by the weaker for some .
We provide an analytical example to motivate the study of the new family of stochastic orders. Let us consider two Pareto loss distributions and . The value at risk of a Pareto distribution , with shape parameter and scale parameter , is given by
and, if the expectation is . Figure 1 shows the plot of the quantile functions for X and Y. Since , then .
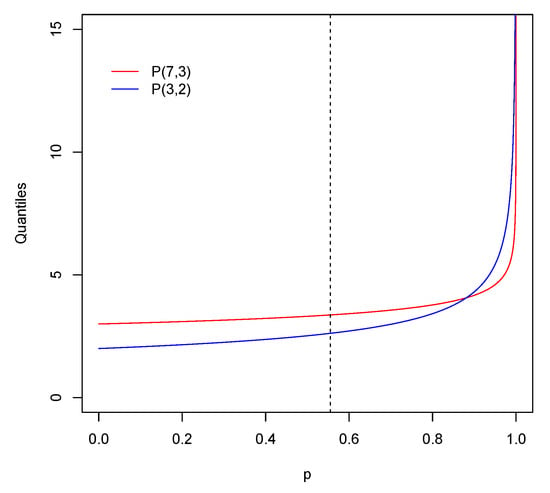
Figure 1.
Quantile functions for and .
However, it can be checked that , for all where here is the minimum value such that ( is represented with a dashed line in Figure 1). An investor concerned with large deviations due to the right-tail losses may make decisions based on the tail value at risk for large values of p. If this is the case, he/she will evaluate X as less dangerous than despite and .
The idea of limiting the number of comparisons to weaken the increasing convex order is not new. Given two random variables X and Y with the same mean, Cheung and Vanduffel [] say that X is smaller than Y in the tail convex order with index (denoted by ) if
According to (3), if X and Y have the same mean, then is the same as It is natural to wonder, when , about the relationship between and We address this issue below.
For other recent studies of orders based on tail comparisons see Sordo et al. [], Mulero et al. [] and Belzunce et al. [].
The rest of the work is organized as follows. In Section 2, we study the main properties of the order and find sufficient conditions under which it holds. We also investigate its relationships with other well-known stochastic orders and compare parametric families of distributions. In particular, we relate the order to the notion of pure tail order as considered by Rojo []. In Section 3 we illustrate the applicability of the new family of orders using a real dataset. Section 4 contains conclusions.
Throughout the paper, “increasing” means “non-decreasing” and “decreasing” means “non-increasing”. Random variables are assumed to have finite means. Given a function h, denotes the number of sign changes of h on its support, where zero terms are discarded.
2. Properties and Relationships with Other Stochastic Orders
It is trivially verified that for all and that for implies , for all . It is also obvious that if X, Y and Z are three random variables such that and with , then with . Finally, if and , with , then , for all , where is defined as before.
Next, we provide some closure properties. In particular, we point out the closure under convergence in distribution and under increasing convex transformations. First of all, recall that given a sequence of random variables with distribution functions and F, respectively, then is said to converge in distribution to X, denoted by , if for all x at which F is continuous.
Proposition 1.
Let and be two sequences of positive continuous random variables such that and . Assume that and X have a common interval support for all and (and, analogously, for and Y and their expectations). If for , then .
Proof.
From Definition 1, it is clear that if, and only if,
Integration by parts in (6) shows that
Now, from , we have that
for all point p where is continuous, where and F are the distribution functions of and X, respectively (see, for example, Chapter 21 in Van der Vaart []). Moreover, from Theorem 2.3 in Müller [], it holds that
The closure under strictly increasing convex transformations require the following lemma taken from page 120 in Barlow and Proschan [].
Lemma 1.
Let W be a measure on the interval , not necessarily nonnegative. Let h be a nonnegative function defined on . If for all and if h is increasing, then .
Proposition 2.
Let X and Y be two random variables and let ϕ be a strictly increasing and convex function. If for , then .
Proof.
Let and denote the distribution functions of and , respectively. Since is strictly increasing we see that and , for all . Since is convex, we know (see, for example, Theorem 10.11 in Zygmund []) that there exists an increasing function such that
Moreover, since is strictly increasing, the function is positive (in fact, it is the derivative of except, perhaps, at some singular points). Observe that if , then
and, if , then
Therefore, we have that
where the last inequality follows from (6) and Lemma 1 using the fact that the function is positive and increasing. Consequently,
for all , which means . □
Next, we give the following relationship among the new order and the icx order of certain random variables.
Proposition 3.
Let X and Y be two random variables. If
then .
Proof.
Given a random variable X with distribution function F, let
and let be its corresponding quantile function, given by
A straightforward computation gives
We obtain similarly where is analogously defined to . It is clear than for all implies for , which proves the result. □
Remark 1.
A stop-loss order is defined as the maximum loss that an investor assumes on a particular investment. Given a loss random variable X, the random variable can be interpreted as a stop-loss order at
Next we discuss the connections between the -tail value at risk order and the tail convex order defined by (5). Observe that if and
With our notation, given X and Y such that Theorem 4 of Cheung and Lo [] shows that for implies and that for implies and .
Remark 2.
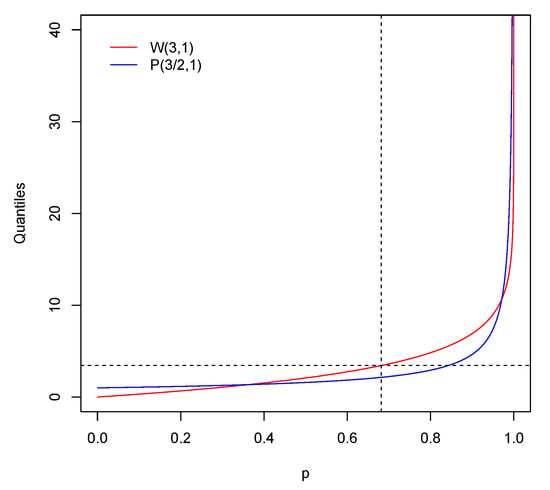
Given X and Y with the same mean, a natural question is whether for implies for . In general, the answer is no. Let us assume that for such that and
Under these assumptions, . Let us consider such that
Then we have
From (14), (15) and (16), it holds that
and . A similar reasoning shows that, in general, does not imply for . Figure 2 illustrates this situation for and , where X is Weibull and Y Pareto with distribution functions F and G, respectively. Recall that if then
for . Note that . It can be checked that with (vertical line in Figure 2) and with (horizontal line). However, since and (14) holds, for any .
Figure 2.
Quantile functions for and .
Now consider two general random variables (not necessarily with the same mean). The following result connects the -tail value at risk order and the stochastic order defined by (13).
Proposition 4.
Let X and Y be two random variables with distribution functions F and G, respectively.
- (i)
- If , then , for all .
- (ii)
- If , for all , then .
Proof.
We prove (i) (the proof of (ii) is similar). Assume . From (7) we know that
Fixed , the function
reachs its minimum at (see Theorem 3.2 in Dhaene et al. []). From this fact and (17) it follows that
or, equivalently,
which concludes the proof. □
Corollary 1.
Let X and Y be two random variables with distribution functions F and G, respectively, and such that . Then, if, and only if, one of the following equivalent conditions holds:
- (i)
- , for all .
- (ii)
- , for all .
Proof.
Clearly, (i) and (ii) are equivalent. From and (ii) we have
Using Proposition 4(ii) it follows that . Conversely, if , (ii) follows from Proposition 4(i). □
The following result shows that two random variables, in which distribution functions cross a finite number of times, are ordered in the -tail value at risk order for some . The proof is straightforward and it is omitted.
Theorem 1.
Let X and Y be two random variables with distribution functions F and G, respectively. If is finite, nonzero and the last sign change occurs from − to +, then , where denotes the last crossing point.
A random variable X is said to be smaller than Y in the univariate dispersive ordering (denoted by ) if for all . It is well-known (see Theorem 2.6.7 in Belzunce et al. []) that if and (which, in particular, implies that ), then . This observation, together with Theorem 1, allows to find many parametric distributions such that for some and . Next, we provide some examples.
Example 1.
The following examples follow from Theorem 1 using results that are well-known for the dispersive order. Note that .
- (i)
- Let and be two normal random variables such that and . Then, , where and .
- (ii)
- Let and be two logistic random variables such that and . Then, , where and .
- (iii)
- Let and be two Weibull random variables such that and . Then, , where , , and .
- (iv)
- Let and be two Pareto random variables such that and . Then, , where , , and .
Remark 3.
From Proposition 2 it is apparent that (i) and (ii) in Example 1 are also valid for the log-normal and log-logistic distribution families, respectively.
Remark 4.
The tail value at risk is a special case of distortion risk measure. Recall that a distortion function is a continuous, and nondecreasing function such that and . Given a random variable X with finite mean, the distorted random variable induced by h has a tail function given by
for all x in the support of X. It is known that given two random variables X and Y such that and a concave distortion h, entonces (see Theorem 13 in Sordo et al. []). It is straightforward to show (although the proof is notationally cumbersome, so we omit it) that if for and h is a concave distortion function, then where .
Before ending this section, we emphasize that, given , the order is a pure tail order in the sense of Rojo []. This is shown in the following result, which shows that if , then the density function of X decreases faster than the density function of Y.
Proposition 5.
Let X and Y be two random variables with distribution functions F and G and density functions f and g, respectively. Let . Then
Proof.
Just applying the L’Hôpital’s rule and using Proposition 4(i), we see that
□
3. A Real Data Example
In this section, we provide a financial application with a real dataset, involving two random variables of −log returns (recall that if denotes the price of an asset at day t, the corresponding −log return is defined by ). Data are of public access and can be obtained from the Yahoo! Finance site. In order to eliminate the time dependent effect, data are related to the weekly close of trading.
We consider two national stock market indexes: the Mexican IPC, denoted by MXX, that measures the performance of the largest and most liquid stocks listed on the Mexican Stock Exchange, and the Hang Seng Index, denoted by HSI, which is the main indicator of the performance of the 50 largest companies of the Hong Kong Stock Exchange. For each index, we have obtained samples of size corresponding to the weekly closings from 1st February 2016 until 31st January 2018. Let us denote by and the −log returns of MXX and HSI, respectively. We will obtain empirical evidence to conclude that but there exists such that .
Before testing the orderings we test the randomness by a classic runs test to and and we obtain the p-values and , respectively. At this point, we plot in Figure 3 the empirical probability distributions of and .
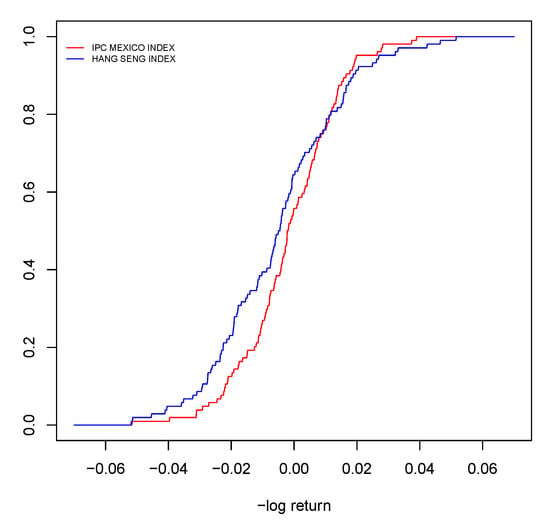
Figure 3.
The empirical distribution functions of and .
From Theorem 1 it is apparent that Figure 3 shows reasonable empirical evidence that for a certain value . In order to see that we just need to check the expectations. For such a purpose, we first test the symmetry by performing the M, and tests described in the lawstat R package. The minimum p-value of the three tests is greater than , therefore, we cannot reject the hypothesis that both distributions, and , are symmetric. Next we compare the medians by a classical Wilcoxon signed-rank test for paired samples. We obtain that the median of is greater than the corresponding of , p-value. Therefore, since data are assumed to be symmetric, we conclude that , which implies that .
The previous non-parametric study suggests to fit a distribution function to greater than in terms of order (with bigger tail risk). Two classical distributions for log returns are the normal and logistic distributions, where the latter better reflects an excess of kurtosis. Table 1 summarizes the p-values of the classical K-S goodness of fit test for both distribution families and Figure 4 provides the histograms of the log returns together with normal and logistic density estimates using the maximum likelihood estimates (MLE) for the location and scale parameters given in Table 2.

Table 1.
The p-values for fitting normal and logistic distributions.
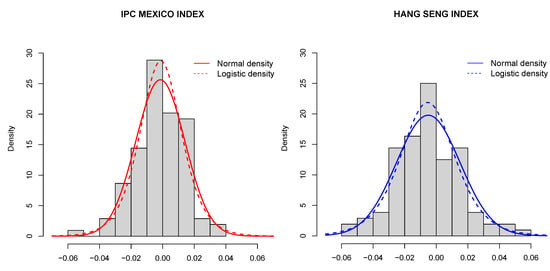
Figure 4.
Histograms of the log returns with a normal density estimate (solid line) and a logistic density estimate (dashed line) superimposed. The left-hand panel corresponds to and right-hand panel corresponds to .
Table 2.
The maximum likelihood estimates (MLE) for normal and logistic distributions.
Although Table 1 suggests than normal distributions fit better than logistics, both can be appropriate. From Example 1 there is enough evidence to assume that and the crossing point can be computed from a parametric point of view. In conclusion, a decision maker concerned by the tail value at risk for large values of p will evaluate as less dangerous than despite and .
4. Conclusions
In this paper, we have introduced a family of stochastic orders indexed by confidence levels , which are useful when we are concerned with right-tail risks. Once is fixed to suit our preferences, we say that X is less risky than Y if the tail value at risk of X is smaller than the tail value at risk of Y for any confidence levels p such that We have studied the properties of this family of orders as well as its relationships with other stochastic orders, in particular with the tail convex order introduced by Cheung and Vandulfel []. We have illustrated the results with a real financial dataset involving log returns.
Author Contributions
Conceptualization, A.J.B., J.M., M.A.S. and A.S.-L.; formal analysis, A.J.B., J.M., M.A.S. and A.S.-L.; investigation, A.J.B., J.M., M.A.S. and A.S.-L.; software, A.J.B., J.M., M.A.S. and A.S.-L.; validation, A.J.B., J.M., M.A.S. and A.S.-L.; visualization, A.J.B., J.M., M.A.S. and A.S.-L.; writing—original draft, A.J.B., J.M., M.A.S. and A.S.-L.; writing—review and editing, A.J.B., J.M., M.A.S. and A.S.-L. All authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
Julio Mulero was supported by the Ministerio de Ciencia e Innovación (Spain), with grant number PID2019-103971GB-I00 (AEI/ FEDER, UE). Alfonso J. Bello, Miguel A. Sordo and Alfonso Suárez-Llorens were partially supported by the Ministerio de Economía y Competitividad (Spain), with grant number MTM2017-89577-P, by the 2014-2020 ERDF Operational Programme, by the Consejería de Economía, Conocimiento, Empresas y Universidad (Junta de Andalucía), with project reference FEDER-UCA18-107519, and by the Universidad de Cádiz through its Programa de Fomento e Impulso de la actividad de Investigación y Transferencia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, S. An actuarial index of the right-tail risk. N. Am. Actuar. J. 1998, 2, 88–101. [Google Scholar] [CrossRef]
- Guégan, D.; Hassani, B.K. Risk Measurement; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zhelonkin, M.; Chavez-Demoulin, V. A note on the statistical robustness of risk measures. J. Oper. Risk 2017, 12, 47–68. [Google Scholar] [CrossRef]
- Ahmadi-Javid, A. Entropic value-at-risk: A new coherent risk measure. Eur. J. Oper. Res. 2019, 279, 225–241. [Google Scholar] [CrossRef]
- Sordo, M.A.; Ramos, H.M. Characterization of stochastic orderings by L-functionals. Stat. Pap. 2007, 48, 249–263. [Google Scholar] [CrossRef]
- Shaked, M.; Shanthikumar, J.G. Stochastic Orders; Springer Series in Statistics; Springer: New York, NY, USA, 2007. [Google Scholar]
- Belzunce, F.; Martínez-Riquelme, C.; Mulero, J. An Introduction to Stochastic Orders; Academic Press, Elsevier Ltd.: London, UK, 2016. [Google Scholar]
- Cheung, K.C.; Vanduffel, S. Bounds for sums of random variables when the marginal distributions and the variance of the sum are given. Scand. Actuar. J. 2013, 2, 103–118. [Google Scholar] [CrossRef]
- Sordo, M.A.; de Souza, M.C.; Suárez-LLorens, A. A new variability order based on tail-heaviness. Statistics 2015, 49, 1042–1061. [Google Scholar] [CrossRef]
- Mulero, J.; Sordo, M.A.; de Souza, M.C.; Suárez-Llorens, A. Two stochastic dominance criteria based on tail comparisons. Appl. Stoch. Model. Bus. Ind. 2017, 33, 575–589. [Google Scholar] [CrossRef]
- Belzunce, F.; Franco-Pereira, A.M.; Mulero, J. New stochastic comparisons based on tail value at risk measures. Commun. Stat. Theory Methods 2020. [Google Scholar] [CrossRef]
- Rojo, J. A pure tail ordering based on the ratio of the quantile functions. Ann. Stat. 1992, 20, 570–579. [Google Scholar] [CrossRef]
- Van der Vaart, A.W. Asymptotic Statistics; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Müller, A. Orderings of Risks: A comparative study via stop-loss transforms. Insur. Math. Econ. 1996, 17, 215–222. [Google Scholar] [CrossRef]
- Barlow, R.E.; Proschan, F. Statistical Theory of Reliability and Life Testing; Holt, Rinehart and Winston, Inc.: New York, NY, USA, 1975. [Google Scholar]
- Zygmund, A. Trigonometric Series; Cambridge University Press: Cambridge, UK, 1959. [Google Scholar]
- Cheung, K.C.; Lo, A. Characterizations of counter-monotonicity and upper comonotonicity by (tail) convex order. Insur. Math. Econ. 2013, 53, 334–342. [Google Scholar] [CrossRef]
- Dhaene, J.; Vanduffel, S.; Goovaerts, M.; Kaas, R.; Tang, Q.; Vyncke, D. Risk measures and comonotonicity: A review. Stoch. Model. 2006, 22, 573–606. [Google Scholar] [CrossRef]
- Sordo, M.A.; Suárez-Llorens, A.; Bello, A.J. Comparisons of conditional distributions in portfolios of dependent risks. Insur. Math. Econ. 2015, 61, 62–69. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).