Abstract
Alizadeh et al. introduced a flexible family of distributions, in the so-called Gompertz-G family. In this article, a discrete analogue of the Gompertz-G family is proposed. We also study some of its distributional properties and reliability characteristics. After introducing the general class, three special models of the new family are discussed in detail. The maximum likelihood method is used for estimating the family parameters. A simulation study is carried out to assess the performance of the family parameters. Finally, the flexibility of the new family is illustrated by means of four genuine datasets, and it is found that the proposed model provides a better fit than the competitive distributions.
1. Introduction
In probability and statistics, the Gompertz (Gz) distribution is a continuous probability distribution, named after Benjamin Gompertz. This distribution is a generalization of the exponential (Ex) distribution. The random variable T is said to have the Gz distribution with the shape parameter and scale parameter , if its cumulative distribution function (CDF) is given by
The Gz distribution is often applied to describe the distribution of adult lifespans by demographers and actuaries. Related fields of science such as biology and gerontology also consider the Gz distribution for the analysis of survival. More recently, computer scientists have also started to model the failure rates of computer codes using the Gz distribution. In marketing science, it has been used as an individual-level simulation for customer lifetime value modeling. For more details, see Willemse et al. [1], Preston et al. [2], Melnikov and Romaniuk [3], Ohishi et al. [4], Bemmaor et al. [5], Cordeiro et al. [6], El-Bassiouny et al. [7,8,9], Alzaatreh et al. [10], Roozegar et al. [11], Mazucheli et al. [12], Eliwa et al. [13], among others.
Alizadeh et al. [14] introduced the Gz-G family based on a technique introduced by Alzaatreh et al. [10] in which a general form is used to generate a new family, named the transformed-transformer family. Thus, the random variable X is said to have the Gz-G family if its CDF is given by
where and are two additional parameters, is a vector of parameters (), and is the baseline CDF. The reliability function (RF) of the Gz-G family can be expressed as
The probability density function (PDF) corresponding to Equation (2) can be written as
where is the baseline PDF. Several authors used the technique of Alzaatreh et al. [14] to propose univariate and bivariate families; see for example, El-Morshedy and Eliwa [15], Eliwa and El-Morshedy [16,17], Alizadeh et al. [18], Eliwa et al. [19,20], El-Morshedy et al. [21], and the references cited therein.
Recently, discretizing continuous distributions has received much attention in the statistical literature. The discretization phenomenon generally arises when it becomes impossible or inconvenient to measure the life length of a product or a device on a continuous scale. Such situations may arise when the lifetimes need to be recorded on a discrete scale rather than on a continuous analogue. Therefore, several discrete distributions have been presented in the literature. See for example, Roy [22], Gómez-Déniz [23], Bebbington et al. [24], Nooghabi et al. [25], Nekoukhou et al. [26], Bakouch et al. [27], Nekoukhou and Bidram [28], Chandrakant et al. [29], Para and Jan [30], Mazucheli et al. [31], El-Morshedy et al. [17,20,32], Eliwa and El-Morshedy [33], among others. Although there are a number of discrete distributions in the statistical literature, there is still a lot of space left to develop new discretized distributions that are suitable under different conditions. Therefore, in this paper, we introduce a flexible discrete generator of distributions, in the so-called discrete Gz-G (DGz-G) family. Our reasons for introducing the DGz-G family are the following:
- To generate models with a negatively skewed, a positively skewed, or a symmetric shape;
- To define special models with all types of hazard rate function;
- To propose models which are appropriate for modeling both over- and under-dispersed data;
- To generate models for modeling both lifetime and counting datasets;
- To provide consistently better fits than other generated models under the same baseline distribution and other well-known models in the statistical literature.
The paper is organized as follows. In Section 2, the DGz-G family of distributions is defined. Some statistical and reliability properties of the DGz-G family are obtained in Section 3. In Section 4, three special models of the proposed family are discussed in detail. The family parameters are estimated by maximum likelihood method in Section 5. In Section 6, a simulation study is performed. The usefulness of the DGz-G family is illustrated by means of four genuine datasets, where we prove empirically that the DGz-G family outperforms some well-known distributions in Section 7. Section 8 offers some concluding remarks.
2. The DGz-G Family
Recall Equation (2), the random variable Z is said to have the DGz-G family if its CDF is given by
where , , and . Therefore, the RF of the DGz-G family can be represented as
Let be non-negative independent and identically distributed (IID) integer valued random variables and , then X∼ DGz-G family provided () ∼ DGz-G family where
Further, if , then,
and
The probability mass function (PMF) corresponding to Equation (5) can be expressed as
The hazard rate function (HRF) can be formulated as
where .
3. Different Statistical Properties
3.1. Quantile Function (QF)
For the DGz-G family, the qth QF, say , is the solution of , then
where and represents the baseline QF. Setting , we get the median of the DGz-G family.
3.2. Moments, Dispersion Index, Skewness, Kurtosis, and Cumulants
Assume non-negative random variable DGz-G family, then the rth moment of Z can be expressed as
Using Equation (13), the mean () and variance (Var) can be respectively written as
The dispersion index (DsI) is defined as variance to mean ratio, it indicates whether a certain model is suitable for over- or under-dispersed datasets, and is used widely in ecology as a standard measure for measuring clustering (over dispersion) or repulsion (under dispersion). If DsI (DsI ), the distribution is over-dispersed (under-dispersed). The DsI of the DGz-G family is given by
On the other hand, the moment generating function (MGF) can be represented as
where . The first four derivatives of Equation (16), with respect to t at , yield the first four moments about the origin, i.e., . Moreover, utilizing Equation (13) or (16), the skewness (Sk) and kurtosis (Ku) can be expressed as and , respectively.
In probability theory, the cumulants, say , of a probability model are a set of quantities that provide an alternative to the moments of a probability model. Because in some cases, theoretical treatments of problems in terms of cumulants are simpler than those using moments. The cumulant generating function (CGF) is the logarithm of the MGF. Thus, the can be recovered in terms of moments as follows:
Further, the cumulants are also related to the moments by the following recursion formula:
The first cumulant is the mean, the second cumulant is the variance, and the third cumulant is the same as the third central moment. However, the fourth and higher-order cumulants are not equal to central moments.
3.3. Rényi Entropy
Entropy refers to the amount of uncertainty associated with a random variable Z. It has many applications in several fields such as econometrics, quantum information, information theory, survival analysis, and computer science (see Rényi [34]). The measure of variation of the uncertainty of the random variable Z can be expressed as
where and . The Shannon entropy can be defined by . It is observed that the Shannon entropy can be calculated as a special case of the Rényi entropy when .
3.4. Mean Time to Failure (MTTF), Mean Time between Failure (MTBF), and Availability (Av)
MTTF, MTBF, and Av are reliability terms based on methods and procedures for lifecycle predictions for a product. Customers often must include reliability data when determining what product to buy for their application. MTTF, MTBF, and Av are ways of providing a numeric value based on a compilation of data to quantify a failure rate and the resulting time of expected performance. In addition, in order to design and manufacture a maintainable system, it is necessary to predict the MTTF, MTBF, and Av. If DGz-G, then the MTBF is given as
Whereas, if DGz-G, then the MTTF is given as
The Av is considered as being the probability that the component is successful at time t, i.e., .
3.5. Order Statistics and L-Moment Statistics
3.5.1. Order Statistics (OS)
OS make their appearance in many areas of statistical theory and practice. Let , be a random sample from the DGz-G family of distributions and let ,..., be their corresponding OS. Then, the CDF of the ith OS for an integer value of z can be written as
where . The corresponding PMF of the ith OS can be expressed as
The uth moment of can be written as
3.5.2. L-Moment (LM) Statistics
L-moments (LMs) obtain their name from their construction as linear combinations of OS. Hosking and Wallis [35] defined LMs as summaries of theoretical distribution and observed samples. Therefore, LM statistics are used for computing sample statistics for data at individual regions or for testing for homogeneity/heterogeneity of proposed groupings of sites. Let be ith largest observation in sample of size n, then the LMs can be take the form
From Equation (25), we get , , [], and . Then, we can define some statistical measures such as LM of mean, LM coefficient of variation, LM coefficient of Sk, and LM coefficient of ku in the form , , and , respectively.
4. Special Models
4.1. The DGz-Exponential (DGzEx) Distribution
Consider the CDF of the Ex distribution. Then, the PMF of the DGzEx distribution can be expressed as
where . The PMF in Equation (26) is log-concave for all values of the model parameters, where is a decreasing function in z for all values of the model parameters. Therefore, it is strongly unimodal, it has all its moments, and the HRFs are increasing. Figure 1 and Figure 2 show the PMF and HRF of the DGzEx distribution for various values of the parameters.
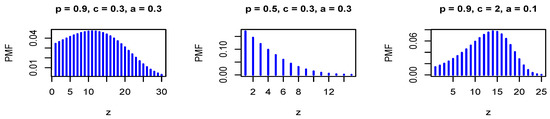
Figure 1.
The probability mass function (PMF) of the discrete Gompertz exponential (DGzEx) distribution for different values of the parameters.
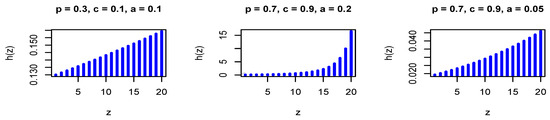
Figure 2.
The hazard rate function (HRF) of the DGzEx distribution for different values of the parameters.
It is not possible to write the rth moment of the DGzE distribution in closed form, and therefore, we use Maple software to discuss some of its statistical properties. Other work such as Para and Jan [30], and Kundu and Nekoukhou [36] did not provide a closed form of the moments. Table 1 lists some descriptive statistics using the DGzEx model for different values of p and c with .

Table 1.
Some descriptive statistics using the DGzEx model.
Regarding Table 1, it is clear that:
- The DGzEx distribution is a flexible distribution and can be used in modeling different types of datasets where
- it is suitable for modeling over- and under-dispersed datasets where DsI ;
- it is appropriate for modeling positive and negative skewness as well as symmetric datasets;
- it can be used to model either platykurtic (Ku ) or leptokurtic (Ku ) data;
- The mean and Var increase whereas the Sk and Ku decrease for fixed values of a and c with ;
- The mean, Var, and Sk decrease for fixed values of a and p with .
Table 2 shows the MTTF and entropy values for fixed values of and with and .
Table 2.
The mean time to failure (MTTF) and entropy using the DGzEx model.
According to Table 2, it is clear that the MTTF and entropy increase for fixed values of and with . Whereas, for fixed values of and with , the MTTF and entropy decrease.
4.2. The DGz-Weibull (DGzW) Distribution
Consider the CDF of the Weibull (W) distribution. Then, the PMF of the DGzW distribution can be expressed as
where . The PMF in Equation (27) is log-concave for some values of the model parameters, where is a decreasing function in z for some values of the model parameters. Figure 3 and Figure 4 show the PMF and HRF of the DGzW distribution for various values of the parameters.
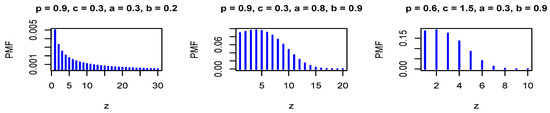
Figure 3.
The PMF of the DGz-Weibull (DGzW) distribution for different values of the parameters.
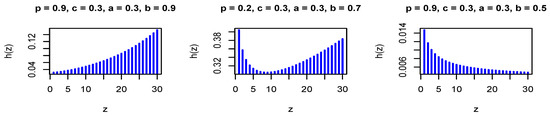
Figure 4.
The HRF of the DGzW distribution for different values of the parameters.
It is immediate that the PMF is unimodal and the HRF can be either increasing, decreasing, or of bathtub shape. Hence, the parameters of the underlying distribution can be adjusted to suit most datasets. Like in the case of the DGzE distribution, it is not possible to write the rth moment in closed form, and consequently, Maple is used to explain some of the statistical properties of the DGzW distribution. Table 3 shows some descriptive statistics utilizing the DGzW distribution for various values of p and c with and .
Table 3.
Some descriptive statistics using the DGzW model.
Regarding Table 3, it is clear that:
- The DGzW distribution is a flexible distribution and can be used for modeling various types of datasets where
- it is suitable for modeling under- and over-dispersed datasets;
- it is appropriate for modeling negative and positive skewness as well as symmetric datasets;
- it can be used to model either platykurtic or leptokurtic data;
- The mean and Var increase for fixed values of and c with ;
- The mean and Var decrease for fixed values of and p with .
Table 4 shows the MTTF and entropy values for fixed values of with and .
Table 4.
The MTTF and entropy using the DGzW model.
According to Table 4, it is clear that the MTTF and entropy increase for fixed values of and with . Whereas, for fixed values of and with , the MTTF and entropy decrease.
4.3. The DGz-Inverse Weibull (DGzIW) Distribution
Consider the CDF of the inverse Weibull (IW) distribution. Then, the PMF of the DGzIW distribution can be expressed as
where . The PMF in Equation (28) is log-concave for some values of the model parameters. Figure 5 and Figure 6 show the PMF and HRF of the DGzIW distribution for various values of the parameters.
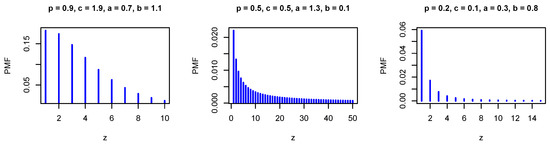
Figure 5.
The PMF of the DGz-inverse Weibull (DGzIW) distribution for different values of the parameters.
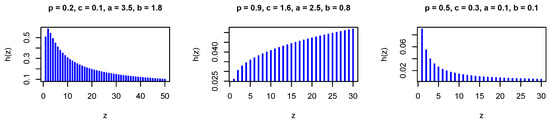
Figure 6.
The HRF of the DGzIW distribution for different values of the parameters.
It is immediate that the PMF is decreasing, whereas the HRF can be either increasing, decreasing, or of unimodal shape. Hence, the parameters of the underlying distribution can be adjusted to suit most datasets.
5. Maximum Likelihood Estimation (MLE)
In this section, we estimate the unknown parameters of the DGz-G family using the maximum likelihood (ML) method. Suppose , is a random sample from the DGz-G family. Then, the log-likelihood function (L) can be expressed as
The MLEs of the parameters and can be derived by solving the nonlinear likelihood equations obtained by differentiating (Equation (29)). The components of the score vector, are
and
where ; , and Setting the Equations (30)–(32) to zero and solving them, immediately yields the MLEs for the DGz-G family parameters. These equations cannot be solved analytically; therefore, an iterative procedure like Newton–Raphson is required to solve them numerically.
6. Simulation Results
In this section, we assess the performance of the MLE with respect to sample size n. The assessment is based on a simulation study which is describes in the following:
- Generate 1000 samples of size from DGzEx, DGzW()and DGzIW(), respectively;
- Compute the MLEs for the 1000 samples, say and for ;
- Compute the biases and mean-squared errors (MSEs), where
The empirical results are shown in Figure 7, Figure 8, Figure 9, Figure 10, Figure 11 and Figure 12.
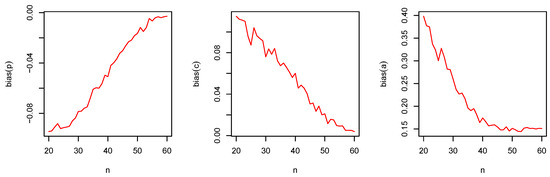
Figure 7.
The bias of and versus for the DGzEx.
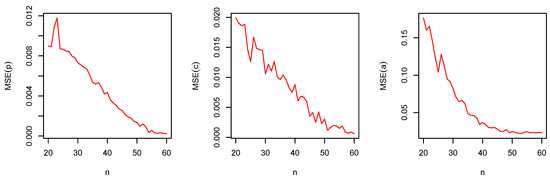
Figure 8.
The MSE of and versus for the DGzEx.
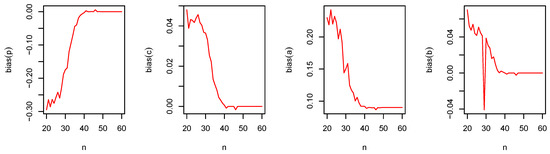
Figure 9.
The bias of and versus for the DGzW().
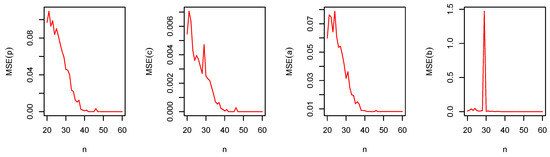
Figure 10.
The MSE of and versus for the DGzW().
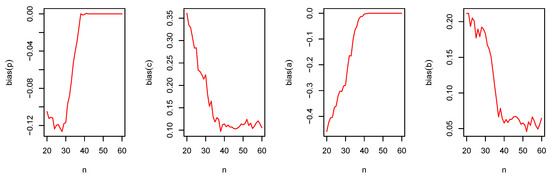
Figure 11.
The bias of and versus for the DGzIW().
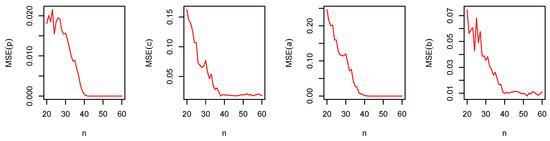
Figure 12.
The MSE of and versus for the DGzIW().
From Figure 7, Figure 8, Figure 9, Figure 10, Figure 11 and Figure 12, the following observations can be noted:
- The magnitude of bias always decreases to zero as ;
- The MSEs always decrease to zero as . This shows the consistency of the estimators;
- Under the MLE method, the estimator of p is slightly negatively biased;
- The MLE method performs quite well for the parameters estimation.
We have presented results only for DGzEx, DGzW(), and DGzIW(). However, the results are similar for other choices for and b.
7. Data Analysis
In this section, we illustrate the empirical importance of the DGzW, DGzEx, and DGzIW distributions using four applications to real data. The fitted models are compared using some criteria, namely, L, Akaike information criterion (AIC), correct Akaike information criterion (CAIC), Chi-square () with degree of freedom (d.f) and its p-value, Kolmogorov-Smirnov (K-S) and its p-value. We shall compare the DGzW, DGzEx, and DGzIW distributions with some competitive models described in Table 5.
Table 5.
The competitive models of the DGzW, DGzEx, and DGzIW distributions.
7.1. Dataset 1
This data represents the failure times (in weeks) of 50 devices put on a life test (see Bebbington et al. [24]). We compare the fits of the DGzW distribution with some competitive models, such as exponentiated discrete Weibull (EDW), discrete Weibull (DW), discrete inverse Weibull (DIW), discrete Lindley type II (DLi-II), exponentiated discrete Lindley (EDLi), discrete log-logistic (DLLc), and discrete Pareto (DPa). The MLEs with their corresponding standard errors (Std-er), and the goodness of fit statistics are reported in Table 6 and Table 7, respectively.
Table 6.
The maximum likelihood estimations (MLEs) with their corresponding standard errors (Std-er) for Dataset 1.
Table 7.
The goodness of fit statistics for Dataset 1.
Regarding Table 7, it is clear that the DW and DLi-II models work quite well for analyzing these data aside from the DGzW model (p-value ). However, we always search for the best model to get the best evaluation of the data, and therefore, concerning the , AIC, CAIC, K-S, and p-values, we can say that the DGzW model provides the best fit among all the tested models because it has the smallest values of , AIC, CAIC, and K-S statistics, as well as having the highest p-value. Figure 13 and Figure 14 support the results of Table 7.
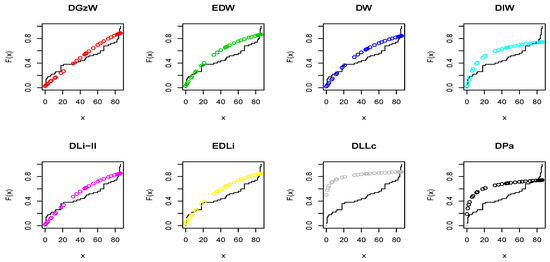
Figure 13.
The estimated CDFs for Dataset 1.
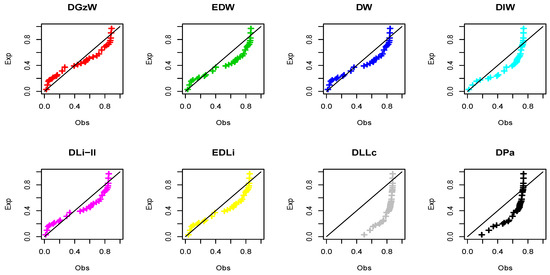
Figure 14.
The probability-probability (P-P) plots for Dataset 1.
It is clear that the dataset plausibly came from the DW and DLi-II models. However, the the DGzW model is the best. Table 8 lists some statistics for Dataset 1 based on the DGzW parameters.
Table 8.
Some statistics for Dataset 1.
Regarding Table 8, it is clear that these data suffer from over-dispersion phenomena. Moreover, these data are moderately skewed to the right: its right tail is longer and most of the distribution is to the left with platykurtic. The MTTF of these data equals whereas the entropyequals . Table 9 lists some numerical values of the reliability properties when using Dataset 1.
Table 9.
Some reliability measures using Dataset 1.
Regarding Table 9, it is clear that the RF decreases with . Further, the HRF is bathtub-shaped, whereas the MTBF has a unimodal shape.
7.2. Dataset 2
These data are reported in Lawless [48] and it gives the failure times for a sample of 15 electronic components in an acceleration life test. For this dataset, we compare the fits of the DGzEx distribution with some competitive models such as discrete exponential (DEx), Discrete generalized exponential type II (DGEx-II), discrete Rayleigh (DR), discrete inverse Rayleigh (DIR), discrete inverse Weibull (DIW), discrete Lomax (DLo), two-parameter discrete Burr type XII (DB-XII), and DPa. The MLEs with their corresponding Std-er, and the goodness of fit statistics are reported in Table 10 and Table 11, respectively.
Table 10.
The MLEs with their corresponding Std-er for Dataset 2.
Table 11.
The goodness of fit statistics for Dataset 2.
Regarding Table 11, it is clear that the DEx, DGEx-II, DR, DIW, and DLo models work quite well for analyzing these data aside from the DGzW model. However, the DGzEx distribution is the best model among all the tested models. Figure 15 and Figure 16 support the results of Table 11.
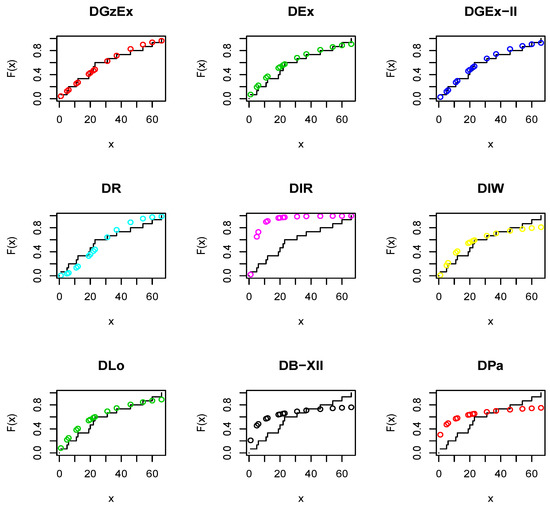
Figure 15.
The estimated cumulative distribution functions (CDFs) for Dataset 2.
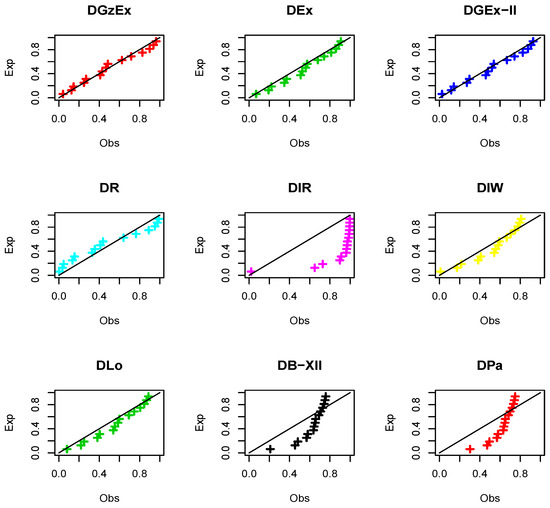
Figure 16.
The P-P plots for Dataset 2.
It is clear that the dataset plausibly came from the the DEx, DGEx-II, DR, DIW, and DLo models. However, the the DGzEx model is the best. Table 12 lists some statistics for Dataset 2 using the DGzEx parameters.
Table 12.
Some statistics for Dataset 2.
Regarding Table 12, it is clear that these data suffer from over-dispersion phenomena. Moreover, these data are moderately skewed to the right with platykurtic. The MTTF of these data equals whereas the entropy equals . Table 13 lists some numerical values of the reliability properties using Dataset 2.
Table 13.
Some reliability measures using Dataset 2.
Regarding Table 13, it is clear that the RF and MTBF decrease, whereas the HRF increases with .
7.3. Dataset 3
These data represent the counts of cysts of kidneys using steroids. This dataset originated from a study Chan et al. [49]. For this dataset, we compare the fits of the DGzW distribution with some competitive models such as DW, DIW, DR, DEx, discrete Lindley (DLi), discrete Lindley type II DLi-II, DLo, and Poisson (Poi). The MLEs with their corresponding Std-er, and the goodness of fit statistics are reported in Table 14 and Table 15, respectively.
Table 14.
The MLEs with their corresponding Std-er for Dataset 3.
Table 15.
The goodness of fit statistics for Dataset 3.
Regarding Table 15, it is clear that, the DW, DIW, and DLo models work quite well for analyzing these data aside from the DGzW model. However, the the DGzW provides the best fit among all the tested models. Figure 17 and Figure 18 support the results of Table 15.
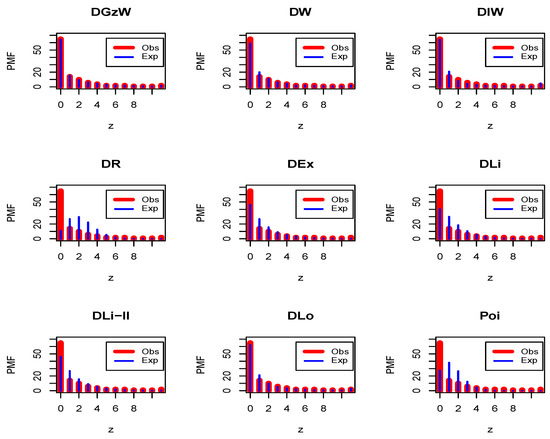
Figure 17.
The fitted PMFs for Dataset 3.
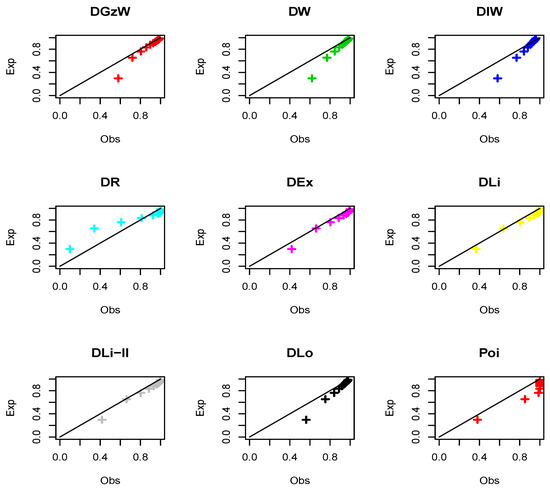
Figure 18.
The P-P plots for Dataset 3.
It is clear that the dataset plausibly came from the DGzW, DW, DIW, and DLo models. However, the DGzW model is the best. Table 16 reports some statistics for Dataset 3 based on the DGzW parameters.
Table 16.
Some statistics for Dataset 3.
According Table 16, it is observed that these data suffer from over-dispersion phenomena. Moreover, these data are moderately skewed to the right with leptokurtic.
7.4. Dataset 4
This dataset is the biological experiment data which represents the number of European corn-borer larvae pyrausta in the field (see Bodhisuwan and Sangpoom [50]). It was an experiment conducted randomly on eight hills in 15 replications, where the experimenter counted the number of borers per hill of corn. We shall compare the fits of the DGzIW distribution with some competitive models such as DIW, DB-XII, DIR, DR, negative binomial (NvBi), DPa, and Poi distributions. The MLEs with their corresponding Std-er as well as goodness of fit statistics for Dataset 4 are listed in Table 17 and Table 18, respectively.
Table 17.
The MLEs with their corresponding Std-er for Dataset 4.
Table 18.
The goodness of fit statistics for Dataset 4.
According to Table 18, it is observed that both the DIW and DB-XII models work quite well aside from the DGzIW model. However, the DGzIW model is the best for these data. Figure 19 and Figure 20 support the results of Table 18.
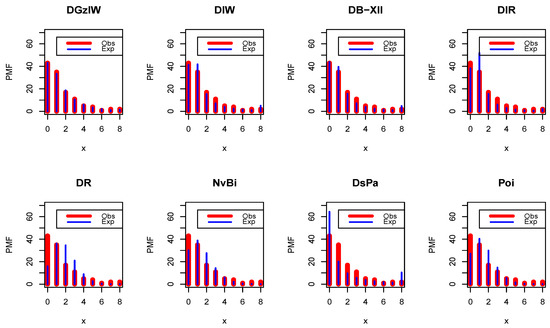
Figure 19.
The fitted PMFs for Dataset 4.
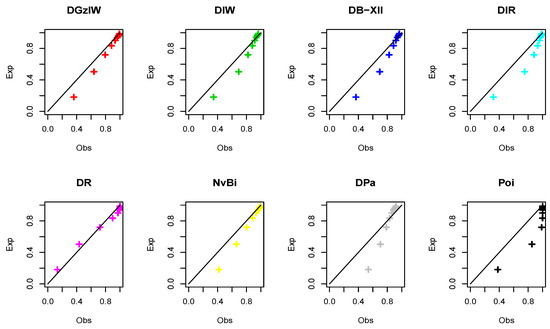
Figure 20.
The P-P plots for Dataset 4.
It is clear that the dataset plausibly came from the DGzIW model. Moreover, it is considered the best model among all the tested models. Table 19 lists some statistics for Dataset 4 based on the DGzIW parameters.
Table 19.
Some statistics for Dataset 4.
Regarding Table 19, it is observed that the data suffers from over-dispersion. Moreover, these data are moderately skewed to the right with leptokurtic.
8. Concluding Remarks
In this article, we propose a new discrete family of distributions, in the so-called DGz-G family. Several of its statistical properties were studied. Three special models of the new family are discussed in detail. It is found that the proposed family is capable of modeling a negatively skewed, a positively skewed, or a symmetric shape, and the HRF can take different shapes. Further, it is appropriate for modeling both over- and under-dispersed data. The proposed family can be used for modeling count and lifetime data. The maximum likelihood method was used for estimating the family parameters. A simulation study was carried out to assess the performance of the family parameters. It is found that the maximum likelihood method performs quite well in estimating the model parameters. Finally, the flexibility of the proposed family was illustrated by means of four distinctive datasets. The aim of the present work is to attract wider applications in medicine, engineering, and other fields of research.
Author Contributions
All authors contributed equally. All authors have read and agreed to the published version of the manuscript.
Acknowledgments
The author would like to thank Deanship of Scientific Research at Majmaah University for supporting this work under Project Number No. R-1441-72.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| Probability density function | |
| CDF | Cumulative distribution function |
| RF | Reliability function |
| QF | Quantile function |
| DGz-G | Discrete Gompertz-G |
| PMF | Probability mass function |
| MGF | Moment generating function |
| HRF | Hazard rate function |
| CGF | Cumulant generating function |
| Var | Variance |
| MTTF | Mean time to failure |
| MTBF | Mean time between failure |
| Av | Availability |
| OS | Order statistics |
| DsI | Dispersion index |
| Sk | Skewness |
| Ku | kurtosis |
| MLE | Maximum likelihood estimation |
| L | Log-likelihood |
| Chi-square | |
| MSE | Mean square error |
| Std-er | Standard error |
| AIC | Akaike information criterion |
| CAIC | Corrected AIC |
| BIC | Bayesian information criterion |
| HQIC | Hannan-Quinn information criterion |
| K-S | Kolmogorov-Smirnov statistic |
| P-P | Probability-Probability |
References
- Willemse, W.J.; Koppelaar, H. Knowledge elicitation of Gompertz’s law of mortality. Scand. Actuar. J. 2000, 2, 168–179. [Google Scholar] [CrossRef]
- Preston, S.H.; Heuveline, P.; Guillot, M. Demography: Measuring and Modeling Population Processes; Blackwell: Oxford, UK, 2001. [Google Scholar]
- Melnikov, A.; Romaniuk, Y. Evaluating the performance of Gompertz, Makeham and Lee-Carter mortality models for risk management with unit-linked contracts. Insur. Math. Econ. 2006, 39, 310–329. [Google Scholar] [CrossRef]
- Ohishi, K.; Okamura, H.; Dohi, T. Gompertz software reliability model: Estimation algorithm and empirical validation. J. Syst. Softw. 2009, 82, 535–543. [Google Scholar] [CrossRef]
- Bemmaor, A.C.; Glady, N. Modeling Purchasing Behavior With Sudden ‘Death’: A Flexible Customer Lifetime Model. Manag. Sci. 2012, 58, 1012–1021. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Alizadeh, M.; Abraao, D.C.; Mahdi, R. The exponentiated Gompertz generated family of distributions: Properties and applications. Chil. J. Stat. 2016, 7, 29–50. [Google Scholar]
- El-Bassiouny, A.H.; Medhat, E.L.; Mustafa, A.; Eliwa, M.S. Characterization of the Generalized Weibull-Gompertz Distribution Based on the Upper Record Values. Int. J. Math. Appl. 2015, 3, 13–22. [Google Scholar]
- El-Bassiouny, A.H.; EL-Damcese, M.; Mustafa, A.; Eliwa, M.S. Exponentiated generalized Weibull-Gompertz distribution with application in survival analysis. J. Stat. Appl. Probab. 2017, 6, 7–16. [Google Scholar] [CrossRef]
- El-Bassiouny, A.H.; EL-Damcese, M.; Mustafa, A.; Eliwa, M.S. Mixture of exponentiated generalized Weibull-Gompertz distribution and its applications in reliability. J. Stat. Appl. Probab. 2016, 5, 1–14. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Lee, C.; Famoye, F. A new method for generating families of continuous distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Roozegar, R.; Tahmasebi, S.; Jafari, A.A. The McDonald Gompertz distribution: Properties and applications. Commun. Stat.-Simul. Comput. 2017, 46, 3341–3355. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Eliwa, M.S.; El-Morshedy, M.; Ibrahim, M. Inverse Gompertz distribution: Properties and different estimation methods with application to complete and censored data. Ann. Data Sci. 2019, 6, 321–339. [Google Scholar] [CrossRef]
- Alizadeh, M.; Cordeiro, G.M.; Luis, G.B.; Indranil, G. The Gompertz-G family of distributions. J. Stat. Theory Pract. 2017, 11, 179–207. [Google Scholar] [CrossRef]
- El-Morshedy, M.; Eliwa, M.S. The odd flexible Weibull-H family of distributions: Properties and estimation with applications to complete and upper record data. Filomat 2019, 33, 2635–2652. [Google Scholar] [CrossRef]
- Eliwa, M.S.; El-Morshedy, M. Bivariate Gumbel-G family of distributions: Statistical properties, Bayesian and non-Bayesian estimation with application. Ann. Data Sci. 2019, 6, 39–60. [Google Scholar] [CrossRef]
- Eliwa, M.S.; El-Morshedy, M. Bivariate odd Weibull-G family of distributions: Properties, Bayesian and non-Bayesian estimation with bootstrap confidence intervals and application. J. Taibah Univ. Sci. 2020, 14, 1–22. [Google Scholar]
- Alizadeh, M.; Afify, A.Z.; Eliwa, M.S.; Ali, S. The odd log-logistic Lindley-G family of distributions: Properties, Bayesian and non-Bayesian estimation with applications. Comput. Stat. 2020, 35, 281–308. [Google Scholar] [CrossRef]
- Eliwa, M.S.; Alhussain, Z.A.; Ahmed, E.A.; Salah, M.M.; Ahmed, H.H.; El-Morshedy, M. Bivariate Gompertz generator of distributions: Statistical properties and estimation with application to model football data. J. Natl. Sci. Found. Sri Lanka 2020, 48, 54–72. [Google Scholar]
- Eliwa, M.S.; El-Morshedy, M.; Afify, A.Z. The odd Chen generator of distributions: Properties and estimation methods with applications in medicine and engineering. J. Natl. Sci. Found. Sri Lanka 2020, 48, 1–23. [Google Scholar]
- El-Morshedy, M.; Alhussain, Z.A.; Atta, D.; Almetwally, E.M.; Eliwa, M.S. Bivariate Burr X generator of distributions: Properties and estimation methods with applications to complete and type-II censored samples. Mathematics 2020, 8, 264. [Google Scholar] [CrossRef]
- Roy, D. Discrete Rayleigh distribution. IEEE Trans. Reliab. 2004, 53, 255–260. [Google Scholar] [CrossRef]
- Gómez-Déniz, E. Another generalization of the geometric distribution. Test 2010, 19, 399–415. [Google Scholar] [CrossRef]
- Bebbington, M.; Lai, C.D.; Wellington, M.; Zitikis, R. The discrete additive Weibull distribution: A bathtub-shaped hazard for discontinuous failure data. Reliab. Eng. Syst. Saf. 2012, 106, 37–44. [Google Scholar] [CrossRef]
- Nooghabi, M.S.; Borzadaran, G.R.; Roknabadi, A.H. Discrete modified Weibull distribution. Metron 2012, 69, 207–222. [Google Scholar] [CrossRef]
- Nekoukhou, V.; Alamatsaz, M.H.; Bidram, H. Discrete generalized exponential distribution of a second type. Statistics 2013, 47, 876–887. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Aghababaei, M.; Nadarajah, S. A new discrete distribution. Statistics 2014, 48, 200–240. [Google Scholar] [CrossRef]
- Nekoukhou, V.; Bidram, H. The exponentiated discrete Weibull distribution. Stat. Oper. Res. Trans. 2015, 39, 127–146. [Google Scholar]
- Chandrakant, K.; Yogesh, M.T.; Manoj, K.R. On a discrete analogue of linear failure rate distribution. Am. J. Math. Manag. Sci. 2017, 36, 229–246. [Google Scholar]
- Para, B.A.; Jan, T.R. Discrete inverse Weibull minimax distribution. J. Stat. Appl. Probab. 2017, 6, 205–218. [Google Scholar] [CrossRef]
- Mazucheli, J.; Bertoli, W.; Oliveira, R.P. On the discrete quasi Xgamma distribution. Methodol. Comput. Appl. Probab. 2019. [Google Scholar] [CrossRef]
- El-Morshedy, M.; Eliwa, M.S.; El-Gohary, A.; Khalil, A.A. Bivariate exponentiated discrete Weibull distribution: Statistical properties, estimation, simulation and applications. Math. Sci. 2019, 1–14. [Google Scholar] [CrossRef]
- Eliwa, M.S.; El-Morshedy, M. A one-parameter discrete distribution for over-dispersed data: Statistical and reliability properties with estimation approaches and applications. J. Appl. Stat. 2020, 47, 184–205. [Google Scholar]
- Rényi, A. On measures of entropy and information. Math. Stat. Probab. 1961, 1, 547–561. [Google Scholar]
- Hosking, J.R.; Wallis, J.R. Regional Frequency Analysis: An Approach Based on L-Moments; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Kundu, D.; Nekoukhou, V. Univariate and bivariate geometric discrete generalized exponential distributions. J. Stat. Theory Pract. 2018, 12, 595–614. [Google Scholar] [CrossRef]
- Nakagawa, T.; Osaki, S. The discrete Weibull distribution. IEEE Trans. Reliab. 1975, 24, 300–301. [Google Scholar] [CrossRef]
- Jazi, A.M.; Lai, D.C.; Alamatsaz, H.M. Inverse Weibull distribution and estimation of its parameters. Stat. Methodol. 2010, 7, 121–132. [Google Scholar] [CrossRef]
- Hussain, T.; Ahmad, M. Discrete inverse Rayleigh distribution. Pak. J. Stat. 2014, 30, 203–222. [Google Scholar]
- Gómez-Déniz, E.; Calderín-Ojeda, E. The discrete Lindley distribution: Properties and applications. J. Stat. Comput. Simul. 2011, 81, 1405–1416. [Google Scholar] [CrossRef]
- El-Morshedy, M.; Eliwa, M.S.; Nagy, H. A new two-parameter exponentiated discrete Lindley distribution: Properties, estimation and applications. J. Appl. Stat. 2020, 47, 354–375. [Google Scholar] [CrossRef]
- Hussain, T.; Aslam, M.; Ahmad, M. A Two parameter discrete Lindley distribution. Rev. Colomb. Estadística 2016, 39, 45–61. [Google Scholar] [CrossRef]
- Para, B.A.; Jan, T.R. Discrete version of log-logistic distribution and its applications in genetics. Int. J. Mod. Math. Sci. 2016, 14, 407–422. [Google Scholar]
- Para, B.A.; Jan, T.R. On discrete three-parameter Burr type XII and discrete Lomax distributions and their applications to model count data from medical science. Biom. Biostat. Int. J. 2016, 4, 1–15. [Google Scholar]
- Krishna, H.; Pundir, P.S. Discrete Burr and discrete Pareto distributions. Stat. Methodol. 2009, 6, 177–188. [Google Scholar] [CrossRef]
- Dougherty, E.R. Probability and Statistics for the Engineering, Computing and Physical Sciences; Prentice Hall: Englewood Cliffs, NJ, USA, 1992; pp. 149–152. ISBN 0-13-711995-X. [Google Scholar]
- Poisson, S.D. Probabilité des Jugements en Matiére Criminelle et en Matiére Civile, Précédées des RéGles Génerales du Calcul des Probabilitiés; Bachelier: Paris, France, 1837; pp. 206–207. [Google Scholar]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Chan, S.; Riley, P.R.; Price, K.L.; McElduff, F.; Winyard, P.J. Corticosteroid-induced kidney dysmorphogenesis is associated with deregulated expression of known cystogenic molecules, as well as Indian hedgehog. Am. J. Physiol.-Ren. Physiol. 2009, 298, 346–356. [Google Scholar] [CrossRef]
- Bodhisuwan, W.; Sangpoom, S. The discrete weighted Lindley distribution. In Proceedings of the International Conference on Mathematics, Statistics, and Their Applications, Banda Aceh, Indonesia, 4–6 October 2016. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).