1. Introduction
In recent decades, the proliferation of the internet, particularly social media platforms, has enabled information to spread at an unprecedented speed and scale. The controversial text has emerged as a pervasive phenomenon in online discourse [
1]. Controversial content can be broadly defined as information that generates substantial positive or negative feedback [
2]. Such text typically contains intense expressions of opinion, emotionally charged rhetoric, or extreme perspectives that can readily provoke opposition and conflict between different groups [
3]. With the ubiquitous presence of online forums, social media, news commentary sections, and blogs, the dissemination of controversial text not only rapidly expands within the digital sphere, but may also extend into real-world contexts, profoundly affecting people’s cognition, emotions, and even social stability. The precise detection of controversial conflicts serves a valuable purpose. For instance, users can receive warnings before viewing such posts, protecting them from the influence of subjective commentary. From a platform perspective, the timely identification of controversial text is crucial for maintaining content ecosystem health and preventing misinformation [
4]. Societally, such detection can mitigate social fragmentation and emotional polarization, ultimately promoting social harmony. Consequently, the development of efficient controversial text-detection systems has become an essential task to address these modern information challenges.
Controversy detection has been studied on web pages and social media for decades [
5]. For standard web pages, the existing methods primarily leverage controversy detection on Wikipedia, Reddit, and some political blogs [
6]. Early controversy-detection methods were mostly based on statistical analysis, such as user editing history, user revision time, and contextual information in Wikipedia [
7]. Unlike web pages, online social media consists of more diverse topics and intense discussions between users. There are many controversial comments under non-controversial topics or posts. This makes controversy detection on social media more challenging.
Early controversy detection predominantly utilized the statistical data from Wikipedia [
8], targeted comments, posts, or topics to reflect controversial discussions. Yasseri et al. [
9] calculated a controversy metric,
M, for Wikipedia articles, revealing that edit conflicts typically manifest as highly bursty editing behaviors, long-range memory effects, and “edit wars” primarily dominated by a minority of editors. Philipp Koncar et al. [
10] analyzed Reddit comments across six language environments, using lexical, stylistic, sentiment, and engagement indicators to predict comment controversy. By extracting 23 features and applying statistical hypothesis testing, they found that controversial discussions elicit higher user engagement, with comments showing increased complexity and more negative sentiments. User engagement features emerged as the most reliable predictors of controversy, consistently across multilingual contexts. However, such results may be biased for complex social media platforms, as some controversial topics might show reduced explicit conflicts due to “editing fatigue” or strategic avoidance of reverts, leading to underestimated controversy levels. Additionally, some entries may be “misclassified” as highly controversial due to individual user behaviors when certain users are abnormally active or prone to conflicts with others.
Recent advances in machine learning have made tremendous contributions to text analysis, including fake news detection, email classification, and claim detection. Ahmed et al. [
11] extracted linguistic features, such as n-grams, from articles and trained multiple ML models, including k-nearest neighbors (KNNs), support vector machines (SVMs), logistic regression (LR), linear support vector machines (LSVMs), decision trees (DTs), and stochastic gradient descent (SGD), achieving the highest accuracy through SVMs and logistic regression. Poddar et al. [
12] evaluated vectorization techniques for fake news detection, comparing the count vectorizer and TF-IDF with various classifiers. Their study found the SVM with TF-IDF to be the most accurate approach. Siddique Z B [
13] utilized the existing machine learning algorithms, including naive Bayes, convolutional neural networks (CNNs), SVMs, and long short-term memory networks (LSTMs) to detect and classify email content. The results indicate that the LSTM model outperforms other models, achieving the highest accuracy at 98.4%. While the extant text-classification literature predominantly concentrates on domain-specific datasets, particularly political texts [
14], the inherent variability of textual structures challenges the development of universal machine learning algorithms. Recent deep learning approaches, including CNNs and bidirectional encoder representations from transformers (BERTs), have demonstrated promising cross-domain capabilities in natural language processing and related computational tasks.
The primary concept of deep learning techniques is to automatically learn and extract complex features rather than manually crafting them as in classical machine learning [
15]. Elnagar et al. [
16] applied the CNN, gated recurrent unit (GRU), and LSTM to two different datasets for Arabic text classification. Murfi et al. [
17] proposed a novel BERT-based hybrid deep learning approach for Indonesian sentiment analysis, demonstrating that integrating BERT representations with LSTM-CNN architecture significantly enhances sentiment classification accuracy by capturing contextual word embeddings more effectively than the traditional methods. Hantom and Rahman [
18] investigated LSTM for detecting Arabic spam tweets, with the results showing the LSTM classifier achieved 94.56% accuracy. Sadiq et al. [
19] designed a traditional CNN architecture utilizing FastText word embeddings to accomplish the task of identifying deep fake tweets, demonstrating its applicability for the efficient and effective classification of tweet data with accuracy rates up to 93%. However, despite deep learning showing significant advantages in text-classification tasks, deep learning models have numerous parameters and easily memorize specific patterns in training data rather than generalizing principles, particularly evident when the data volume is insufficient. Furthermore, minor modifications to text, such as synonym substitution and the addition of irrelevant words, can potentially cause significant changes in model prediction results, indicating that models may be learning the surface features of a text rather than deeper semantics.
To address the challenges posed by tasks involving texts from different domain topics and varying styles, ensemble learning significantly enhances the predictive performance. It strengthens model generalization capabilities and stability by integrating the advantages of multiple models, which demonstrates an exceptional performance, particularly in complex tasks, making it a powerful and efficient method in machine learning. Ensemble learning has been widely applied to common text-classification tasks, such as sentiment classification [
20] and spam detection [
21]. Mohammed and Kora [
22] proposed a novel two-level meta-classifier fusion deep learning benchmark model meta-learning ensemble approach. They demonstrated through experiments on six public benchmark datasets that this method significantly improved the classification accuracy of benchmark deep models and outperformed other state-of-the-art ensemble methods. This was achieved particularly by leveraging the probability distribution of each class label from deep benchmark models to further enhance the ensemble method’s performance.
Motivated by the abovementioned observations, this paper proposes a controversial text-detection framework based on stacked ensemble learning by combining the generalization performance of different machine learning methods to improve the effectiveness of text detection [
23]. First, a framework is built upon feature-engineered data, comprehensively considering metrics, such as sentiment [
24] and comment tree structure [
25], and employs multiple feature selection methods, including lassonet, i.e., a neural network with feature sparsity. Then, stacking ensemble techniques are used to integrate numerous base models of machine learning algorithms, including gradient-boosted decision trees (GBDTs), random forest (RF), extreme gradient boosting (XGBoost), GRU, and LSTM, with SVM as the second-level classifier to obtain the final results after the sparrow search algorithm (SSA) optimization of first-level classifiers. This feature-based approach enables efficient and precise classification when processing texts from multiple domains. The main contributions of this paper are summarized as follows:
We design and implement a multi-level stacked ensemble learning architecture that combines the strengths of traditional machine learning algorithms, e.g., GBDT, RF, and XGBoost, with deep learning models, e.g., GRU and LSTM, in first-level classifiers, conducting meta-learning through logistic regression as the second-level classifier, significantly enhancing model classification performance and generalization capability.
We propose a novel hyperparameter optimization method that utilizes SSA for tuning the first-level classifier, and provide a comprehensive comparison with traditional approaches. The SSA-based method improves computational efficiency, maintains high accuracy, reduces training time, and overcomes the local optima limitations of gradient-based techniques.
We propose an innovative text-classification feature engineering framework that integrates multidimensional metrics, including sentiment analysis and comment tree structure, and employs various advanced feature selection methods, e.g., variance filtering (VF), recursive feature elimination (RFE), and lassonet, for feature screening.
We conduct comprehensive testing on multiple datasets from different topics and domains, systematically evaluating model performance using various assessment metrics, including accuracy, precision, recall, and F1 score. We further extend our study by conducting explainability analysis, addressing scalability challenges with optimization strategies, and exploring cross-platform applicability.
The remainder of this paper is organized as follows:
Section 2 systematically introduces the machine learning framework based on the proposed stacked ensemble model.
Section 3 presents the experimental results. Finally,
Section 4 concludes the paper.
2. Materials and Methods
Based on stacked learning, we proposed a controversy detection framework, as shown in
Figure 1. First, the dataset underwent preprocessing, followed by feature extraction and feature selection. Various feature selection techniques, e.g., VF, RFE, and lassonet, were applied to enhance the quality of the features used for model training. Next, a K-fold cross-validation approach was employed to evaluate and optimize the performance of each base learner. The base learners included models like RF, GBDT, GRU, XGBoost, and LSTM. These learners were trained and their parameters were optimized to improve prediction accuracy. Finally, a SVM was used to make the final prediction based on the outputs from the base learners. The model’s performance was evaluated using several metrics, such as accuracy, precision, recall, and F1 score.
We employed Python 3.13.3 web crawling techniques to collect 20,211 tweets from Reddit, covering multiple topics, including music, shopping, war, and firearms. Human annotation was conducted on these tweets using Ant Crowdsourcing, a reliable Chinese platform. Each tweet was annotated by five annotators who previously participated in English-language tasks and received specific training for this project. We implemented quality control through randomly inserted control samples and measured the inter-annotator agreement (Cohen’s Kappa = 0.79) to ensure annotation reliability. Additionally, we collected 2,422,241 reply data points, linking these replies to original tweets through to construct complete comment interaction scenarios. By matching the reply data with tweet data to extract features, we could comprehensively identify comment characteristics from multiple perspectives.
After obtaining the textual data, we conducted text cleaning procedures. First, HTML tags, JavaScript code, and other non-text content were removed to extract clean text. Next, special characters, line breaks, and excessive spaces were eliminated to standardize text formats. Second, duplicate sentences or paragraphs were identified and deleted to ensure content uniqueness. Third, keyword filtering was utilized to remove irrelevant information, such as contact details or advertising content. Finally, clean, structured textual data were obtained to improve data quality and usability.
2.1. Feature Extraction
Subsequently, we performed feature engineering on the acquired text content. Referencing the historical research, the extracted structural features were categorized into four types: word frequency features, statistics-based features, tree structure features, and sentiment features.
2.1.1. Word Frequency Features
First, comment word frequency features were extracted. Word frequency-based features primarily represent text content by counting the occurrence frequency of different words in the text. Term frequency–inverse document frequency (TF-IDF) was implemented as our statistical method for text feature extraction, as it effectively measures the importance of words in controversial discussions while accounting for their distribution across the entire corpus [
26]. Moreover, it effectively reduces the weight of frequently occurring but less distinctive words across all documents, such as stopwords, while enhancing the weight of key vocabulary. Afterward, principal component analysis (PCA) dimensionality reduction was applied to the resulting matrix.
2.1.2. Statistics-Based Features
In the controversial text-detection framework, a comprehensive statistical feature extraction process was implemented to identify linguistic patterns associated with controversy. The procedure encompasses multiple dimensions of textual characteristics: (1) Lexical density features, including character count to assess text volume, word count to determine content scale, and sentence count to measure structural complexity; (2) Morphological indicators, such as average word-length calculation to reflect lexical sophistication and vocabulary complexity; (3) Stylometric markers, comprising punctuation ratio analysis to identify emotional tendencies and stylistic patterns, and capitalization ratio quantification to detect emphasis patterns or specialized naming conventions; and (4) Content-based metrics, involving the stopword ratio measurement to evaluate the proportion of functional versus semantic text elements, which significantly influences stylistic representation across different text genres [
27], along with the detection of repeated words or phrases to identify redundancy patterns and assess the overall cohesion and quality of the textual content [
28]. These statistical features collectively provide a multidimensional representation of the textual data’s structural, stylistic, and semantic properties for controversial content classification.
2.1.3. Tree Structure Features
Next, tree structure features were extracted from the text content. To represent the hierarchical system of comments and their replies, comment trees were constructed based on submission ID using unique identifiers (submission ID in the submission data and parent ID in the comment data). Specifically, comment trees were built by traversing comment records, categorizing comments according to their parent IDs, and generating them in a nested manner. To analyze comment interaction patterns in controversial Reddit topics, key interaction features were extracted from the comment tree structure. Each post’s comments and replies are modeled as a tree T = (W,E), where
V represents the set of nodes (all comments), and E ⊆
V × V represents the set of edges (parent–child comment relationships). The root node, T ∈
V, represents the post itself, while all other nodes,
v ∈
V, represent user comments or replies to the post. Comment count, defined as the number of all nodes in the tree, is written as:
First-level comment count,
N1, is defined as the number of comments directly replying to the post, corresponding to the number of child nodes of the root node, r. It is formally represented as:
where (
r,
v) ∈
E indicates that an edge from the root node, r, to node, v, exists.
To characterize the hierarchical structure of the comments, the maximum depth,
, and average depth,
, were defined. Maximum depth,
, represents the longest path length from the root node, r, to any leaf node:
where
v ⊆
L represents the set of all leaf nodes, and
dist(
r,
v) represents the path length from root node r to node v. This feature reflects the maximum hierarchical depth of the comment tree.
Average depth,
, is defined as the average path length of all nodes:
This feature captures the hierarchical distribution of the comment tree. Combining the above definitions, the proposed structural feature set is represented as:
where each element corresponds to a specific structural feature, measuring the scale and hierarchical complexity of the comment tree. The above features are modeled from the scale (
N,
N1) and layer complexity (
Dmax,
Davg), which completely illustrate the interaction of nodes in the poster.
The scale feature reflects the degree of user participation and direct interaction intensity, while the layer complexity feature shows the depth and expansion of the discussed topics. By extracting these features, the behavior model of controversial topics is obtained through arguments, which provides a solid data foundation for further quantitative analysis and model building.
2.1.4. Sentiment Features
In order to quantify the sentiment intensity in user reviews, we designed a method to extract sentiment features based on the text content of reviews. Specifically, by calculating the average sentiment score of each review, the average sentiment score was used as the sentiment feature.
Given a set of reviews for post p,
, the sentiment score,
, for each review, ci, was calculated using the TextBlob tool. The sentiment score method in TextBlob is based on a dictionary of sentiment words, outputting a sentiment score, S, in the range of [−1, 1]. The sentiment intensity is defined as:
The average sentiment score,
for post p, defined as the mean of the sentiment scores of all reviews for post p, is expressed as:
To compute the average sentiment score for all reviews of a post, we first obtained the review set for each post, then calculated the sentiment score, , for each individual review. Finally, the average sentiment score for the post was computed. If a post had no reviews, the sentiment score was set to NaN. The average sentiment score is a quantitative representation of the sentiment in reviews, providing important insights into the opinions of users regarding controversial topics. In summary, the language used in this model helps reflect sentiment transitions between different layers of the interaction.
The positive-like ratio, denoted as
, is defined as the ratio of the number of positive likes to the total number of reviews for a post. The formula is expressed as:
where
represents the number of reviews with positive likes, N denotes the total number of reviews for the post, and c is the set of all reviews for the post. The function likes(c) provides the number of likes for review c.
2.2. Feature Selection
Feature selection plays a crucial role in machine learning as it enhances model performance, reduces dimensionality, accelerates training speed, and improves data interpretability. In our feature selection process, we employed an intersection method, combining VT, RFE, and lassonet approaches to ensure that the selected features possessed both the statistical robustness and the ability to enhance model generalization capabilities. The feature selection process is outlined in Algorithm 1.
| Algorithm 1 Feature Selection |
| Require: Feature matrix; label vector ; |
| 1: Predefined variance threshold τ; desired number of features k for RFE; |
| 2: Lassonet parameters: sparsity control λ, learning rate η, epochs T. |
| Ensure: Final selected feature set S. |
| 3: Step 1: Variance Thresholding |
| 4: for each feature in X do |
5: Compute variance:
// Var measures how much feature varies across samples; is the mean of |
| 6: if Var() > τ then |
| 7: Retain |
| 8: end if |
| 9: end for |
| 10: Let be the set of features retained by VT. |
| 11: Step 2: Recursive Feature Elimination |
| 12: Initialize current feature set |
| 13: while |
| 14: Train a base model (e.g., ridge regression) on |
| 15: Compute importance scores (e.g., |
| 16: Remove feature(s) with lowest importance |
17: end while
//Result: contains the top k features based on importance |
| 18: Step 3: Lassonet-based Feature Selection |
19: Initialize parameters θ (neural net), M (feature mask)
//M is a vector that masks features; initially, all entries are typically 1 |
| 20: for t = 1 to T do |
| 21: Apply input masking: |
| 22: Forward pass: h() = |
| 23: Compute total loss: (θ, M) = L(θ, M) + λ‖M‖1 |
24: Update
//Update neural network weights using gradient descent. |
25: Update
//Update the feature mask using gradient descent. |
26: Apply soft-thresholding: M ← sign(M) · (max(‖M‖ − λ, 0)
//Shrinks small values in M to zero, promoting sparsity |
| 27: end for |
| 28: Select features where |
29: Output: Final feature set
//S is the intersection of features selected by all three methods |
2.2.1. Variance Filtering
For controversy-detection tasks, VF serves as an unsupervised feature selection method that evaluates feature variance to identify the most discriminative indicators. High-variance features more effectively capture opinion differences and expression diversity in controversial content, providing the model with more distinguishing input variables and thereby improving the accuracy of controversy detection. For a feature with n observations, the variance is calculated as:
where
is the mean value of the feature, f. Features are selected if their variance exceeds a predefined threshold:
.
2.2.2. Recursive Feature Elimination
RFE is a wrapper-based feature selection method that iteratively removes the weakest features based on their importance in a predictive model. The algorithm follows these steps:
Train a model using the current feature set.
Compute feature importance scores.
Remove the least-important feature(s).
Repeat until the desired number of features is achieved.
For linear models, feature importance is often measured by the absolute coefficient value, . The ridge regression objective function can be written as .
2.2.3. Lassonet
As shown in
Figure 2, Lassonet [
29] combines neural networks with lasso regularization for feature selection in complex, high-dimensional datasets. Its objective function is:
where
is the loss function,
represents neural network parameters,
is the feature selection vector, and
controls sparsity. The model modifies inputs as
, where
denotes element-wise multiplication.
The penalty on encourages sparsity and eliminates features by setting their corresponding elements in to zero. Lassonet creates a feature selection path by decreasing gradually, providing insights into feature importance. This method excels at capturing non-linear relationships and adapts well to different data types.
2.3. Model Construction
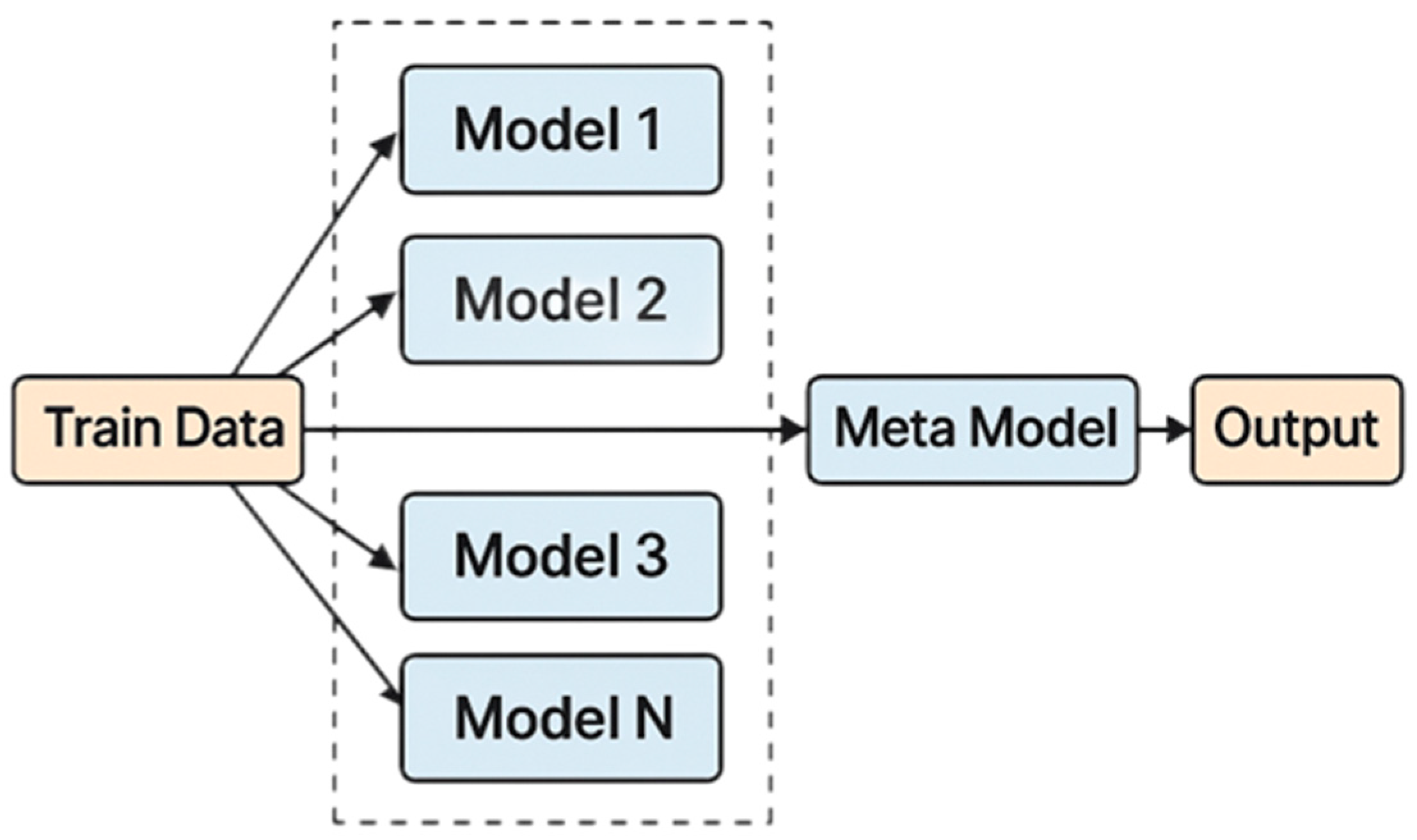
2.3.1. Stacking
Stacking is a powerful ensemble learning method that is widely used in various complex tasks [
30]. This method combines the predictions of multiple base models (weak learners) as input and uses a meta-model to weight and optimize these predictions, thereby generating more accurate final predictions. As shown in
Figure 3, the core idea of stacking is to integrate the outputs of different models and use a meta-model to learn the optimal combination strategy. After multiple base models independently model the data, their predictions are fed into the meta-model for further learning, effectively improving the overall performance of the model. Since social media texts often exhibit characteristics such as short length, irregular grammar, and high noise, a single model often struggles to capture the full range of textual features. Stacking effectively addresses this challenge by combining the predictions of different models, leveraging their respective strengths in feature extraction and semantic understanding. Moreover, stacking reduces the risk of overfitting and improves generalization performance. Due to the rapidly changing distribution of social media data, individual models may overfit specific features, whereas stacking mitigates this risk by using a meta-model to weight and learn from multiple base models, thereby enhancing the model’s ability to generalize to unseen data. The ensemble model we developed, SSA-ControStack, is outlined in Algorithm 2, with the component models described individually in
Section 2.3.
| Algorithm 2 Stacked Ensemble for Binary Classification |
| Require: Labeled dataset, feature matrix X, label vector y; |
| Selected feature set S (via VT, RFE, Lassonet); |
| 2: Base learners: GBDT, RF, XGBoost, GRU, LSTM; |
| Meta-classifier: SVM; optimization algorithm (e.g., SSA); |
| 4: Number of stacking folds K. |
| Ensure: Final stacked classification model |
|
Step 1: Feature Preparation |
| 6: Apply selected feature set S to construct reduced input matrix |
| Normalize and encode features as needed for model input |
| 8: Step 2: Base Model Optimization |
| for each base model m in {GBDT, RF, XGBoost, GRU, LSTM} do |
| 10: Use optimization algorithm (e.g., SSA) to tune hyperparameters of m |
| end for |
| 12: Step 3: Meta-feature Generation via K-fold Stacking |
Initialize meta-feature matrix where M = number of base models
//Create a matrix Z with n rows (number of samples) and M columns (number of base models) to store predictions |
| 14: Split training data into K folds |
| for each base model m do |
| 16: for k = 1 to K do |
| Train m on K − 1 folds |
| 18: Predict on k-th held-out fold and store in corresponding column of Z |
|
end for |
20: end for
//Result: Z contains the out-of-fold predictions from all base models for all samples |
| Step 4: Second-level Classifier Training |
| 22: Train SVM on meta-feature matrix Z and labels y |
| Step 5: Inference for New Samples |
| 24: For new input , extract features using S |
Obtain predictions from each base model →
//Generate predictions for using each base model, resulting in a prediction vector |
26: Feed into trained SVM to obtain final label ŷ
//Input into the trained SVM to compute the final predicted label ŷ |
2.3.2. RF Regression
The RF [
31] method is an integrated learning technique that generates multiple decision trees. Unlike traditional decision tree methods, the RF algorithm reduces the risk of overfitting by randomly selecting a portion of the features of each decision tree. During training, the bootstrap sampling method generates a random subset corresponding to the base tree model. At the end of training, the predicted values are calculated as follows:
where
refers to the anticipated output, N indicates the overall number of trees in the forest, and
refers to the set of the iii-th random tree learners, where x denotes the vector of input variables.
2.3.3. XGBoost
XGBoost is an algorithm based on GBDT to construct advanced tree models [
32]. Unlike GBDT, XGBoost adds regularization terms to the objective function to suppress overfitting. Its strong performance stems from the integration of multiple weak models to improve prediction accuracy and is widely recognized. The predicted value is calculated using the following formula:
where
represents the final tree,
denotes the previously generated tree models,
refers to the features corresponding to the sample i,
is the newly created tree model, and T is the overall number of tree models.
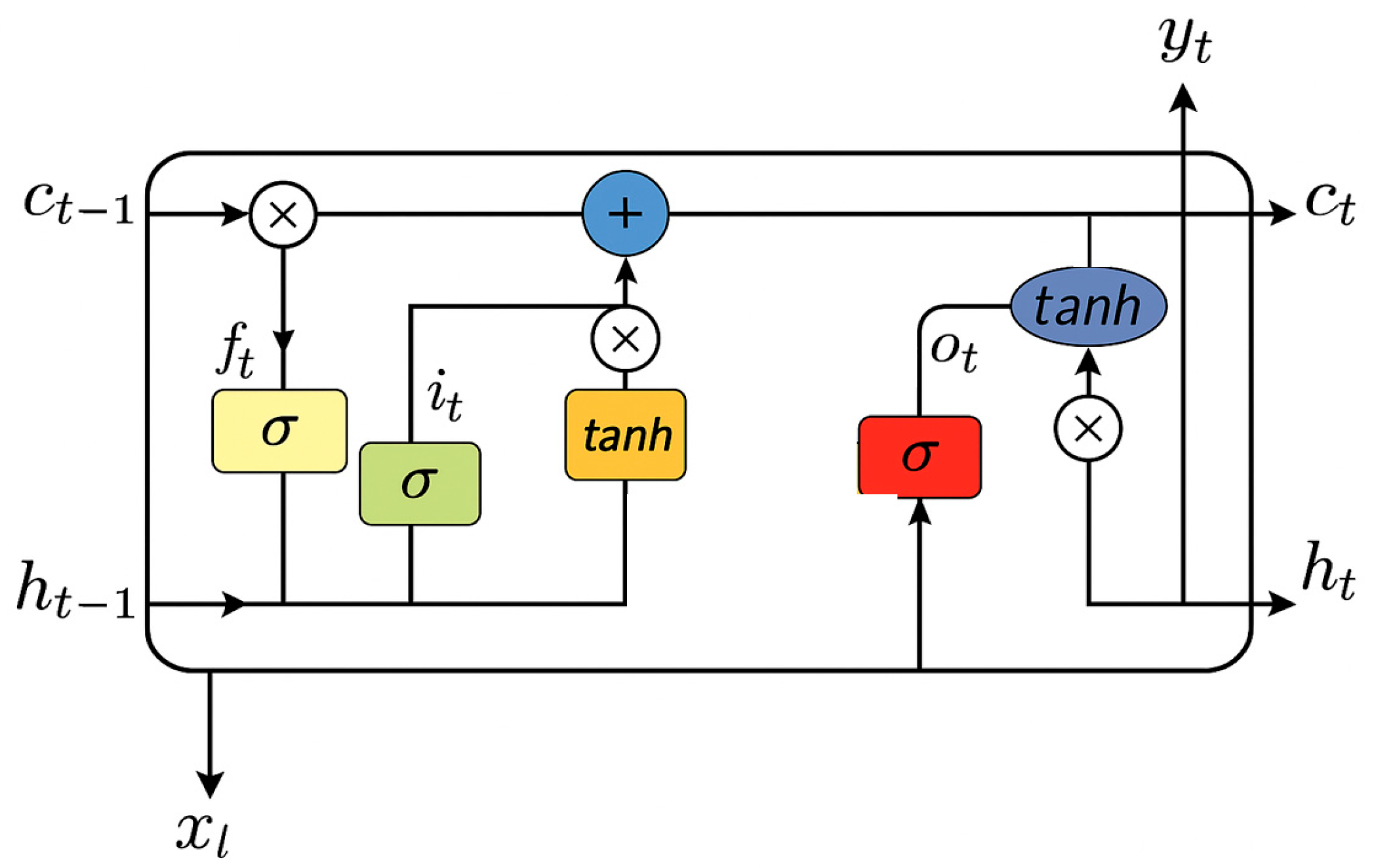
2.3.4. LSTM
The LSTM [
33] network is a specialized recurrent neural network architecture designed to address the vanishing gradient problem in traditional recurrent neural networks (RNNs). As shown in
Figure 4, LSTM incorporates memory cells with three gating mechanisms: input, forget, and output gates. These gates regulate information flow, allowing the model to selectively remember or forget information over long sequences. LSTM has proven particularly effective for complex sequential data with long-term dependencies [
34]. The core formula for the LSTM cell is defined as:
where
and
represent the forget and input gates, respectively;
is the candidate cell state;
is the cell state; and
denotes element-wise multiplication.
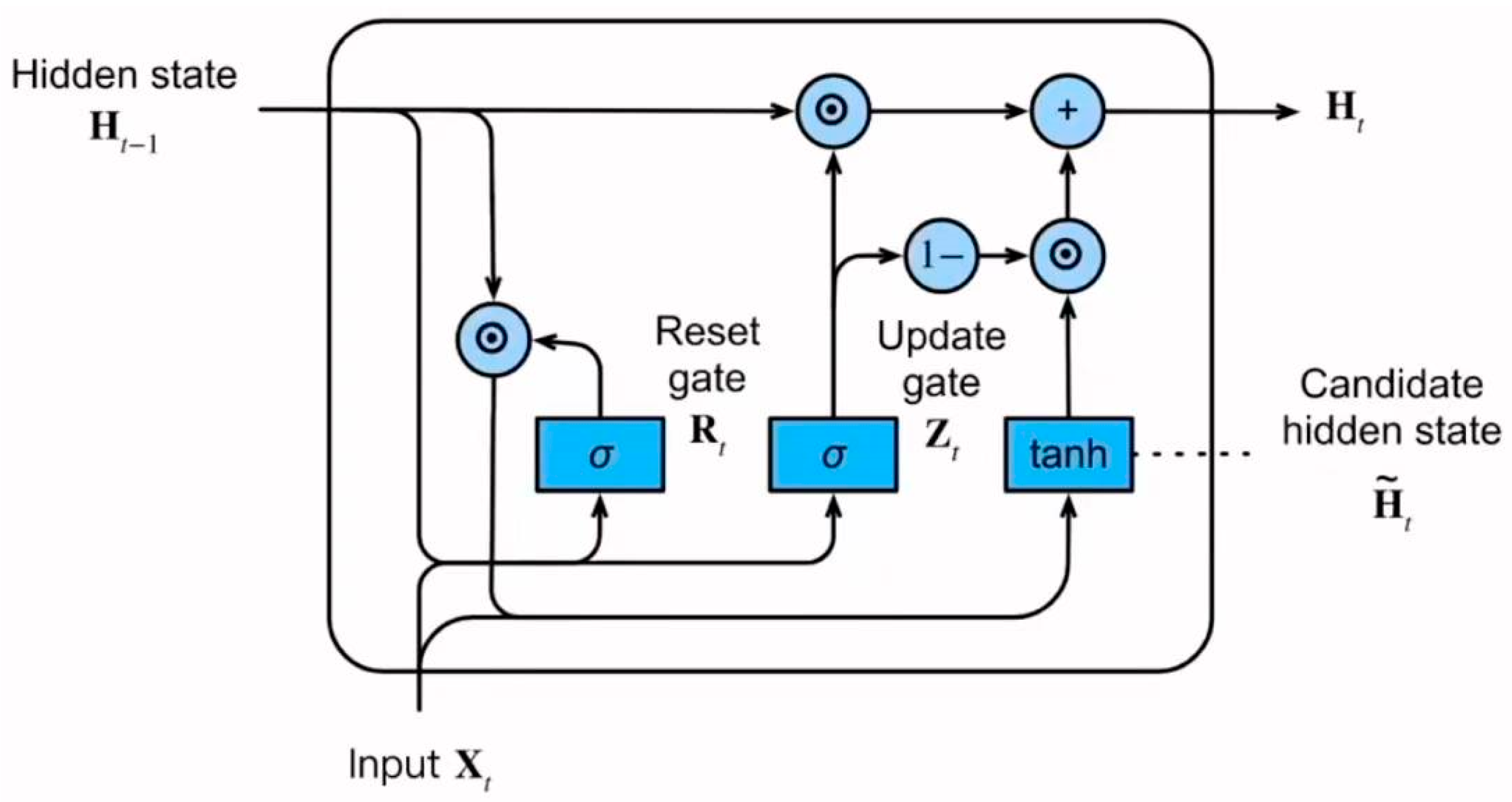
2.3.5. GRU
The GRU [
35] is a simplified variant of the LSTM architecture designed to solve the vanishing gradient problem in recurrent neural networks. As illustrated in
Figure 5, GRU uses update and reset gates to control information flow through the network, making it effective for sequential data analysis while requiring fewer parameters than LSTM. This model demonstrates a strong performance in capturing temporal dependencies in time-series forecasting tasks.
where
represents the update gate,
is the candidate activation,
is the final hidden state, and
denotes element-wise multiplication.
2.3.6. GBDT
GBDT is an ensemble machine learning technique that combines multiple weak decision trees to form a strong predictor. GBDT builds trees sequentially, with each new tree correcting errors made by the previous ensemble. This approach leverages gradient descent optimization to minimize a differentiable loss function. Unlike neural network models, such as GRU and LSTM, GBDT excels at handling tabular data with mixed feature types and missing values, offering strong predictive performance with relatively less preprocessing.
The core formula for GBDT can be expressed as:
where
is the prediction at iteration
,
is the prediction from the previous iteration,
represents the
-th decision tree, and
is the weight assigned to the
-th tree.
2.3.7. SVM
SVM [
36] is a key algorithm in the field of machine learning, demonstrating exceptional classification performance and solid mathematical foundations across various pattern recognition problems. This method achieves structural risk minimization by identifying an optimal classification hyperplane in feature space, providing an elegant and efficient solution for classification tasks.
The core concept behind SVM is to construct a maximum-margin classifier that maximizes the distance between different class samples, thereby enhancing the model’s generalization ability and robustness. This approach is particularly effective when handling high-dimensional data, successfully avoiding overfitting phenomena. For linearly separable binary classification problems, the SVM mathematical model can be formulated as:
where (w, b) determines the classification hyperplane, while the constraints ensure all samples are correctly classified with a functional margin of at least 1. By introducing Lagrangian multipliers, we transform the original problem into its dual form:
After solving this dual problem, the classification hyperplane parameters are:
An important characteristic of SVM is its sparsity—only the Lagrangian multipliers corresponding to support vectors (samples on the maximum margin boundary) are non-zero, significantly improving computational efficiency and model conciseness.
For more complex nonlinear classification problems, SVM employs the kernel trick, using kernel functions
to map data into a higher-dimensional space, transforming nonlinear problems into linearly separable ones. Common kernel functions include linear, polynomial, and Gaussian RBF kernels. With the kernel function, the decision function becomes:
To address noise and outliers in real-world data, SVM adopts a soft margin strategy, balancing margin maximization and classification accuracy through a penalty parameter, C, enhancing the algorithm’s adaptability and robustness.
2.3.8. PSO
PSO is a global optimization algorithm based on swarm intelligence, used for solving continuous and discrete optimization problems. It simulates the behavior of bird flocks or fish schools searching for optimal paths, utilizing cooperation and competition mechanisms among individuals in the swarm to find optimal solutions in the search space.
PSO operates with a population of candidate solutions (particles) that move through the search space. Each particle’s movement is influenced by its local best-known position and the global best-known position discovered by the entire swarm.
For a particle,
, its position,
, and velocity,
, are updated at iteration
as follows:
where
is the inertia weight,
and
are acceleration coefficients,
and
are random numbers in the range [0, 1],
is the personal best position found by particle
, and
is the global best position found by the entire swarm.
2.3.9. SSA
The SSA [
37] is a novel population-based optimization algorithm inspired by the foraging and predator-avoidance behaviors of sparrows. In the SSA, the sparrow population is divided into two types: foraging sparrows and observing sparrows. The foraging sparrows actively explore the search space, while the observing sparrows adjust their positions based on the behavior of the foraging sparrows to accelerate convergence. The position update of the foraging sparrows is given by
where
is the current position of the sparrow,
is the global best solution,
is a step size factor,
is a random factor, and
is a random number in the range [0, 1]. The observing sparrows update their positions similarly, influenced by the foraging sparrows. To simulate predator-avoidance behavior, the algorithm incorporates a predator-avoidance mechanism with the following update rule:
where
is the avoidance factor, controlling the sparrow’s behavior to escape from the predator. Through this mechanism, the SSA not only performs global search but also adapts to avoid local optima, making it an effective tool for solving complex optimization problems.
2.3.10. Bayesian Optimization (BO)
BO is a probabilistic approach to automatically tuning the hyperparameters of machine learning models by leveraging Bayesian inference. The core idea is to model the unknown objective function, typically the model’s performance as a function of its hyperparameters, using a surrogate model, such as a Gaussian Process (GP). In this framework, the optimization process balances the exploration of unknown areas in the hyperparameter space and exploitation of known good regions. The objective function is approximated by the surrogate model, which is iteratively updated with new observations. The next hyperparameter configuration is selected by optimizing an acquisition function, such as Expected Improvement (EI) or Upper Confidence Bound (UCB). The update step can be mathematically described as:
where
is the previous hyperparameter configuration,
is a scaling factor, and Acquisition(x) is the acquisition function that guides the search for the next optimal configuration. By iteratively evaluating the objective function at the new hyperparameter configurations and refining the surrogate model, Bayesian optimization effectively minimizes the number of evaluations required to find optimal hyperparameters, making it a powerful method for complex and expensive optimization tasks.
2.4. Evaluation Metrics
To comprehensively assess our controversial text-detection framework, we employed multiple performance indicators:
Accuracy evaluates the overall classification performance by measuring the proportion of correctly identified instances relative to the total observations, calculated as:
Precision measures the proportion of correct positive predictions among all positive predictions. It is important when the cost of false positives is high, calculated as:
Recall measures the proportion of actual positives that were correctly identified. It is important when the cost of false negatives is high, calculated as:
F1 Score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is particularly useful for imbalanced datasets, calculated as:
where TPs refers to True Positives (correctly predicted positives), TNs stands for True Negatives (correctly predicted negatives), FPs represents false positives (incorrectly predicted as positive), and FNs stands for false negatives (incorrectly predicted as negative).
2.5. SHAPley Additive exPlanations (SHAP)
Machine learning models achieve precise predictions for time-series variables but often lack interpretability, limiting their widespread application. SHAP quantifies each feature’s contribution to the prediction outcome, providing a systematic framework for interpreting complex model outputs. The SHAP interpretation expression for the model is presented below:
where
denotes the index of the inputs,
represents the total number of input features,
is the SHAPley value,
symbolizes the constant value in case when no input factors are present,
refers to the SHAP value for the i-th feature,
is the vector of features, and
prime indicates whether a feature is observed (
= 1) or unknown (
= 0).
where
denotes the set of all features,
represents the input features in subset
; with
being a subset of features that excludes feature
;
refers to the machine learning model used for interpretation;
is the model trained with the feature present; and
is the model trained without the inclusion of the withheld feature.
3. Experiment and Numerical Results
3.1. Dataset and Experimental Setup
Data Sources: Following the extraction of raw textual data from the Reddit platform utilizing Python-based web-scraping methodologies, we implemented comprehensive data cleansing protocols and expert human annotation procedures. This rigorous processing yielded a high-fidelity dataset comprising 18,392 valid entries.
Data Description: The corpus encompasses multiple thematic domains, including firearms, military conflict, musical content, shopping, and additional miscellaneous categories. Controversial content constitutes 5932 entries (32.3% of the corpus), while non-controversial content accounts for 12,460 entries (67.7%).
Data Processing: Notably, distinct controversy distribution patterns emerge across thematic categories. Firearms and military conflict domains exhibit approximately equidistributed controversial and non-controversial content (ratio 1:1), whereas musical content and consumer behavior domains demonstrate predominance of non-controversial material. These distributional characteristics provide a robust foundation for subsequent analytical investigations. To address the inherent class imbalance observed particularly in musical content and consumer behavior domains, we implemented the synthetic minority over-sampling technique (SMOTE) [
38] for resampling. This approach was selected due to its computational efficiency, straightforward implementation, and proven reliability in handling textual data imbalances. The SMOTE algorithm generates synthetic samples for the minority class (controversial content) by interpolating between the existing instances in feature space.
When implementing the SMOTE algorithm for resampling, our objective is to achieve a perfect balance, i.e., a ratio of 1:1, between controversial and non-controversial content. To accomplish this, the resampling procedure was executed independently for each thematic domain, where the minority class, i.e., controversial content, was up-sampled to match the exact quantity of the majority class, i.e., non-controversial content.
Specifically, as shown in
Figure 6, controversial entries in the music domain were increased from 1073 to 2377; similarly, shopping-related controversial entries were augmented from 827 to 2573; and controversial content in the miscellaneous category was expanded from 1148 to 2394. The firearms and military conflict domains, which initially exhibited near-balanced distributions, required only minor adjustments (from 1378 to 1622 for firearms and from 1473 to 1527 for military) to achieve the precise 1:1 ratio.
Following SMOTE implementation, the resulting dataset comprises approximately 20,986 entries with a perfectly balanced 1:1 ratio between controversial and non-controversial content. This completely balanced distribution provides an ideal foundation for subsequent machine learning model training, effectively eliminating potential model bias that might arise from class imbalance, while still preserving the essential characteristics of content within each domain.
3.2. Feature Selection Results
In our feature selection process, we implemented a tripartite filtration methodology to identify variables with an optimal predictive capacity from an initial set of 21 features. The sequential approach proceeded as follows:
Initially, VT filtering was applied to eliminate features exhibiting insufficient variability, reducing the feature dimensionality from 20 to 15 variables. Subsequently, RFE was employed, utilizing RF algorithms to quantify feature importance metrics, further constraining the feature space to 10 variables. In the final phase, lasssonet’s L1 regularization framework was implemented to capture complex non-linear feature interactions while simultaneously enforcing sparse representation, ultimately yielding eight critical features. The resultant parsimonious feature subset maintained high predictive performance while substantially reducing model complexity, thereby enhancing both the interpretability and computational efficiency of the predictive framework.
3.3. Results of All the Dataset
In the experimental setup, the integrated model employed a stacking ensemble approach, where each base classifier, e.g., GBDT, RF, XGBoost, GRU, and LSTM, was assigned specific weights based on its performance. The second-level classifier, which was a SVM, combined the predictions of the base classifiers. Before integrating the individual models into the ensemble, we evaluated different optimization algorithms, including PSO, SSA, and BO, to enhance hyperparameter tuning. Among these methods, SSA demonstrated superior performance in our experimental context, delivering the most effective hyperparameter configuration. We carefully adjusted the learning rates and selected appropriate training epochs for each model to balance computational efficiency with model accuracy.
As shown in
Table 1, individual models exhibit varying performance across metrics. Among the single models, XGBoost demonstrates the strongest performance with 84.95% accuracy and 83.16% precision, along with F1 score and recall rates of 80.82% and 76.88%, respectively. The GRU model follows closely behind with good performance in accuracy (83.53%) and F1 score (81.05%). In comparison, GBDT and RF models show a relatively weaker performance, while LSTM performs at an intermediate level.
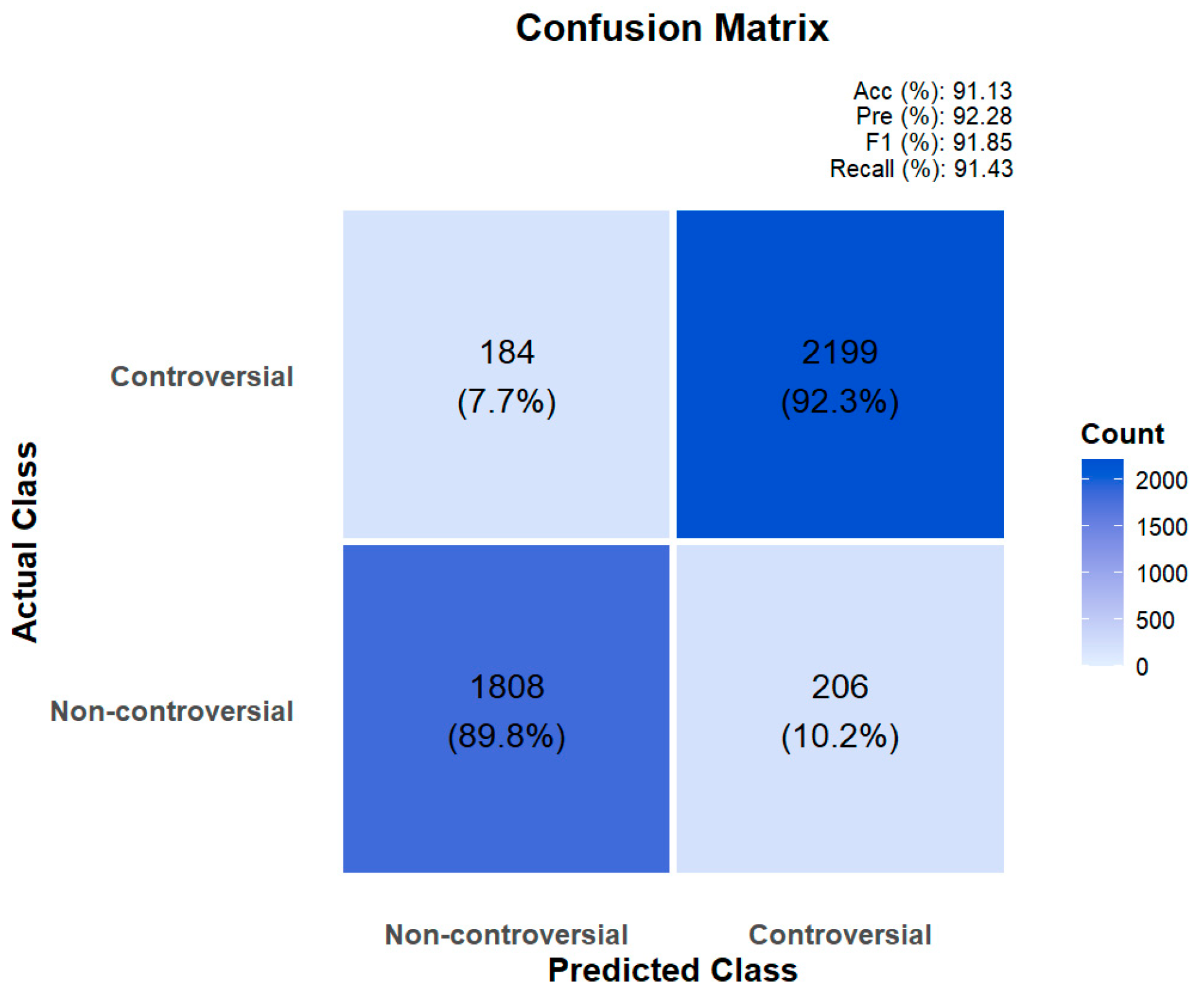
When these models are integrated through different optimization algorithms, their performance improves significantly. Among the three optimization methods tested, the SSA ensemble model demonstrates superior performance across all evaluation metrics: 91.13% accuracy, 92.27% precision, 91.84% F1 score, and 91.47% recall. The confusion matrix of the SSA ensemble model is shown in
Figure 7. The BO ensemble method ranks second, while the PSO ensemble, though showing a clear improvement over single models, performs relatively worse among the three optimization ensemble approaches. These results conclusively demonstrate that the SSA-optimized ensemble strategy effectively combines the complementary strengths of machine learning algorithms, e.g., GBDT, RF, and XGBoost, and deep learning models, e.g., GRU and LSTM, significantly enhancing the overall predictive capability.
As shown in
Table 2, the proposed inheritance-based text-classification model demonstrates superior performance compared to several state-of-the-art approaches. With an accuracy of 91.63%, precision of 92.27%, F1-score of 93.85%, and recall of 91.42%, our model outperforms the previous methods. Mohammed and Kora [
22] achieved high precision (93.45%) but lower overall accuracy (90.21%) and F1-score (92.15%). Chen et al. [
39] showed a strong F1-score performance (93.48%) but the lowest accuracy among the compared models (89.04%). Khurana and Verma [
40] attained balanced metrics with notable recall (92.88%) but lower precision (90.16%). Lin et al. [
41] demonstrated competitive accuracy (91.53%) and precision (92.76%) but fell short in recall compared to our approach. The proposed inheritance-based text-classification model achieves the highest F1-score among all compared methods, which indicates its effectiveness in balancing precision and recall while maintaining high accuracy. It also suggests that the inheritance learning mechanism effectively captures both semantic and contextual information in classification tasks.
3.4. Results of Datasets with Different Themes
To evaluate the adaptability of our inheritance-based text-classification model across diverse topics, we conducted tests on specialized datasets covering firearms, war, music, shopping, and others.
Table 3 illustrates the F1 scores for each model across these domains. The proposed model demonstrates a superior overall performance with the highest average F1 score (91.84%) across all topics. The confusion matrices of our model under different topics are shown in
Figure 8.
Examining the individual domains, our model achieves the best performance in firearms (91.80%) and shopping (92.30%) categories. In the war category, Chen et al. [
39] show slightly better results (93.5%) compared to our approach (92.81%), while Lin et al. [
41] marginally outperform in the others category (92.65% versus our 91.59%). Mohammed and Kora [
22] exhibit a strong performance in firearms (92.54%) but struggle with music (87.12%). Chen et al. [
39] demonstrate an inconsistent performance with the lowest overall F1 score (89.04%) despite strong results in specific categories. Khurana and Verma [
40] and Lin et al. [
41] show a balanced performance across categories but still fall short of our model’s overall consistency. These results confirm that the proposed inheritance-based ensemble learning model maintains a robust classification performance across varied topics, demonstrating a superior generalization capability and topic adaptability compared to the existing approaches.
3.5. Explainability Analysis
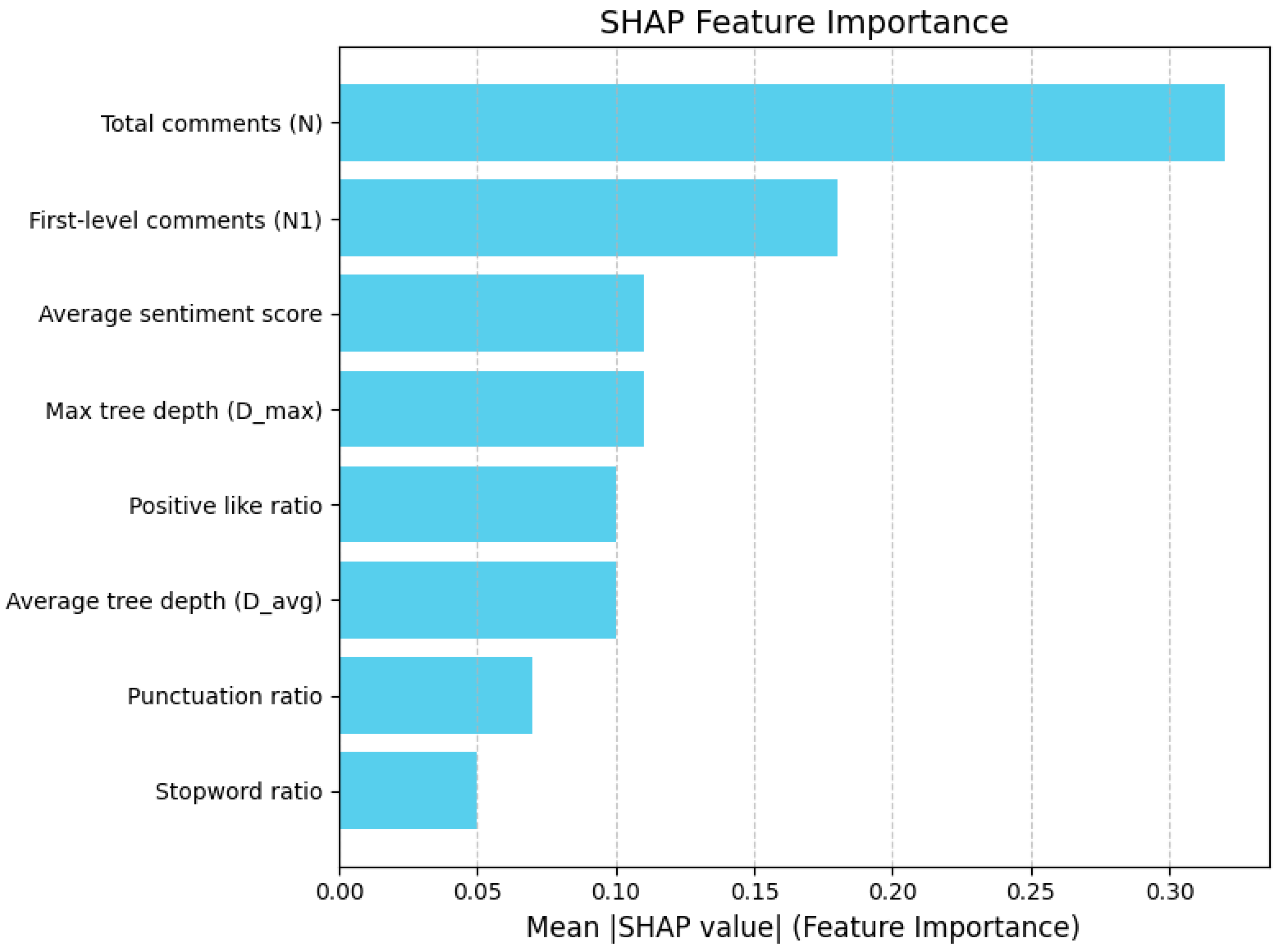
Figure 9 reveals that the classifier’s decision-making hierarchy is overwhelmingly governed by interaction structure. The mean absolute SHAP value of total comments (N) dwarfs that of all other variables, indicating that sheer discussion volume is the primary signal of controversy; as conversation threads attract larger audiences, the model’s posterior probability of the “controversial” class increases almost monotonically. First-level comments (N
1) rank second, suggesting that an intense burst of immediate replies is a strong—though secondary—proxy for dispute emergence. Depth-related indicators provide an additional structural lens: both maximum tree depth (
) and average depth (
) occupy the next positions, underscoring that elongated rebuttal chains and a generally multi-layered dialog architecture jointly exacerbate perceived contentiousness. By comparison, content-oriented features exhibit a more modest but still non-negligible influence. Extreme polarities in the average sentiment score and bifurcated community endorsement captured by the positive-like ratio each contribute meaningful explanatory power, implying that affective divergence and divided approval help refine, rather than dominate, the controversy signal. Finally, stylistic markers—punctuation ratio and stopword ratio—receive the lowest SHAP magnitudes, indicating that rhetorical flourish or lexical density modulates model confidence only at the margins. Collectively, these patterns substantiate a sequential interpretive schema in which the model first attends to participation scale, then to dialogic depth, and only thereafter to emotional tone and surface style when adjudicating whether a Reddit post is contentious.
3.6. Scalability Challenges and Optimization Strategies
Social media platforms generate vast volumes of data every day, and detecting controversial content requires models capable of processing these data streams rapidly while maintaining high accuracy. Contemporary technologies—such as distributed computing frameworks (e.g., Apache Flink) and cloud-based infrastructures—support real-time processing and dynamic scalability. Furthermore, hardware accelerators, like GPUs, markedly improve the efficiency of both model training and inference. By leveraging these technologies, ensemble learning models can attain scalability in social media environments, albeit with the need for the careful optimization of inference latency and memory footprint.
Owing to their inherent complexity, ensemble learning approaches often incur increased inference times and elevated memory requirements. Techniques such as quantization and pruning can alleviate these burdens by reducing computational load and model size, thereby enhancing the real-time performance. Moreover, employing compact model architectures and efficient memory-management strategies (for example, PagedAttention) can further foster scalability [
42]. These methods have proven effective in analogous tasks, including sentiment analysis and fake news detection.
Future research avenues include exploring edge computing paradigms to enable on-device, real-time processing that minimizes latency, and investigating quantum computing solutions for handling the intricacies of social media data. Additionally, the development of AutoML toolkits and explainable AI frameworks specifically tailored to social media moderation will help to improve both the efficiency and transparency of these systems. Federated learning also stands out as a promising direction, offering distributed model training capabilities while safeguarding user privacy.
3.7. Cross-Platform Applicability
In practical applications, cross-platform applicability represents a critical indicator of model generalization capability. The current controversial text-detection framework is primarily constructed using data from the Reddit platform. Different social media platforms exhibit unique interaction mechanisms, user behavioral patterns, and content organizational structures, which significantly impact the manifestation of controversial content.
Primarily, fundamental structural differences exist across major social media platforms. Reddit employs a topic-based community (subreddit) structure, where users engage in discussions around specific subjects, forming deeply nested comment trees. In contrast, Twitter/X predominantly features brief posts (tweets) with limited replies, constituting a flattened interaction network. YouTube’s comment system supports reply chains of limited depth, closely associated with video content. Facebook and Instagram content tend toward social circle propagation, with controversies often manifesting between different social groups. These structural variations necessitate the potential redefinition or weight adjustment of our tree structure features across different platforms. Additionally, user behavioral patterns exhibit platform-specific characteristics. Reddit users tend to develop arguments through lengthy comments and deep reply chains, whereas Twitter/X users more frequently express positions through retweets, quotes, and brief replies. On audiovisual platforms, like YouTube and TikTok, controversies are more frequently reflected in the relationship between comments and video content. Consequently, when transferring the model to alternative platforms, a reassessment of the importance weights for sentiment and interaction features becomes necessary [
43].
To enhance cross-platform applicability, we propose the following strategies: Establish feature equivalence mapping mechanisms for major platforms, such as mapping Reddit’s comment tree depth features to Twitter’s retweet-comment chains or quoted tweet relationships. Design specific knowledge transfer mechanisms utilizing the knowledge learned from the source platform (Reddit) to adapt to feature distributions of target platforms. Specifically, domain adaptation techniques can be employed to adjust the SSA-ControStack model’s weights for features across different platforms. For platforms with limited resources, develop model fine-tuning methods based on minimal annotated data, enhancing model adaptability in sparse sample environments through meta-learning and contrastive learning approaches.
Future work will involve constructing multi-platform datasets to further validate the model’s cross-platform generalization capability and explore more efficient knowledge transfer mechanisms. This aims to realize a “universal” framework for controversial text detection, providing consistent and efficient content analysis tools across diverse social media platforms.
4. Conclusions and Future Directions
This paper proposed a novel controversial text-detection framework based on stacked ensemble learning, which effectively combined feature engineering, machine learning models, and hyperparameter optimization techniques. By incorporating various features, such as sentiment analysis and comment tree structures, along with advanced feature selection methods, like lassonet, the framework successfully addressed challenges like dimensionality reduction and improved both model interpretability and computational efficiency. The multi-level stacked ensemble approach, combining traditional machine learning models with deep learning networks, significantly enhanced classification performance and generalization capability. Additionally, the application of SSA optimization for hyperparameter tuning improved the efficiency of parameter exploration, outperforming the traditional search methods. Comprehensive testing across various datasets and topics demonstrated the robustness and adaptability of the framework, with performance metrics, such as accuracy, precision, recall, and F1 score, showing impressive results (Acc: 91.13%, Pre: 92.27%, F1: 91.84%, and Recall: 91.42%) and a consistently strong performance across multiple domains. These results highlight the framework’s potential as a universal and efficient solution for controversial text detection in diverse contexts.
Although the proposed framework demonstrates significant advancements, several future research directions warrant exploration to further enhance its applicability and impact. First, incorporating multimodal data into model features, such as images, video, audio, or emojis in combination with textual content, provides a more comprehensive understanding of contested discourse. Integrating such data requires adapting the feature engineering process and exploring additional image-recognition techniques. Second, investigating the scalability and real-time performance of the framework on larger and more dynamic datasets, such as social media streams, addresses the challenges in practical deployment. Validating the model’s accuracy variations in real-time changing data is further effective in detecting contention. Third, cross-platform validation, such as testing on Twitter/X, YouTube, Weibo, or emerging decentralized platforms, further evaluates the generality and robustness of the framework to platform-specific linguistic and structural changes. In addition, exploring the interpretability of stacked sets, i.e., potentially through the integration of interpretable AI techniques, such as SHAPley’s additional interpretation or locally interpretable models—agnostic interpretation—improves transparency, allows stakeholders to understand controversial features, and provides deeper insights into the rule-making process.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}