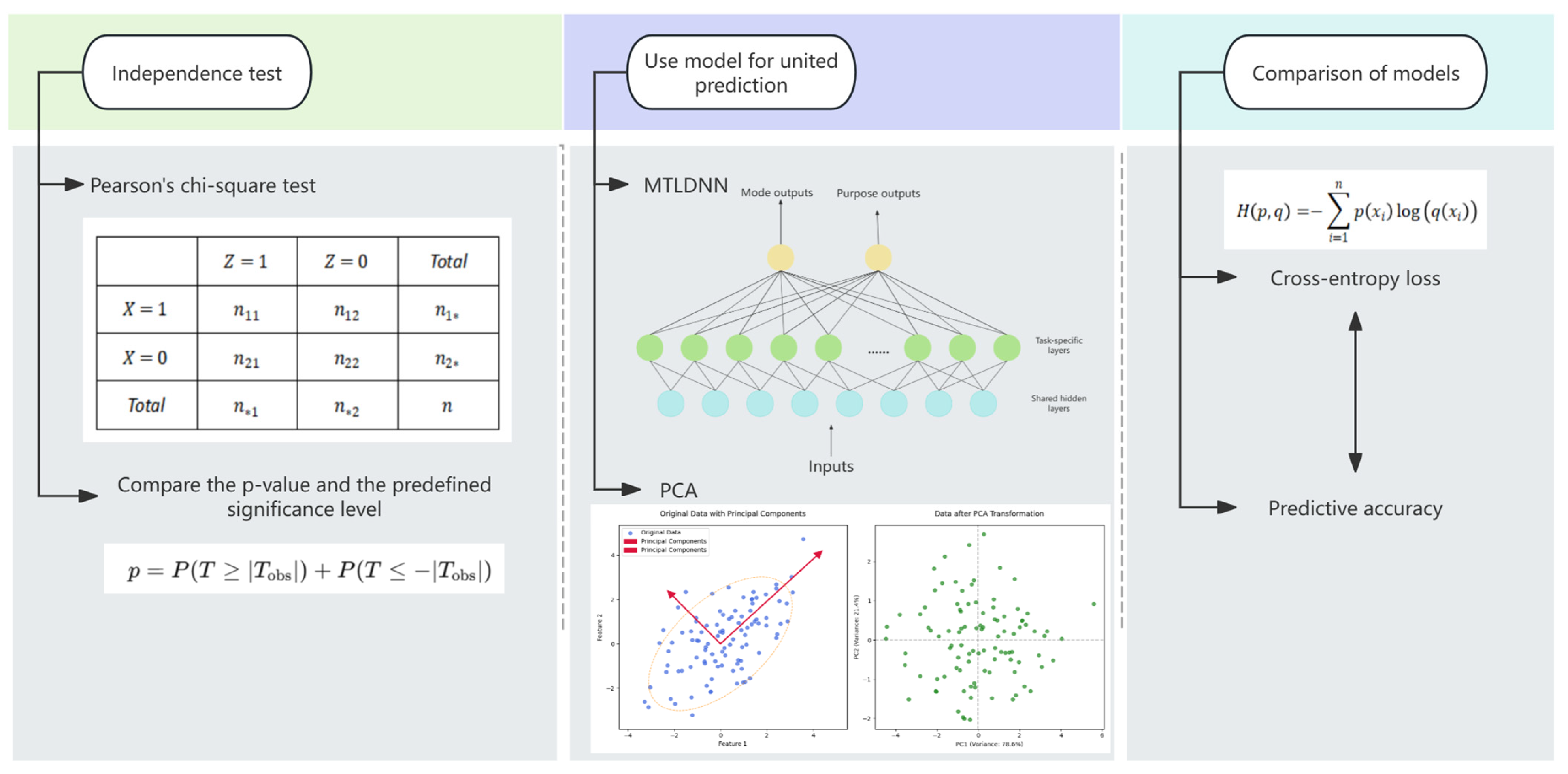
Subsequently, data analysis is conducted using the MTLDNN framework along with other relevant models. The application of the MTLDNN framework and related models enables a deeper understanding of the underlying patterns and characteristics within the data, thereby providing robust support for subsequent predictive tasks. Additionally, the model-based analysis facilitates the identification of potential anomalies and inconsistencies in the data, allowing for targeted adjustments and refinements.
Finally, comparing the prediction results through cross entropy loss and accuracy measurements can comprehensively evaluate the performance of the model. Cross entropy loss reflects the loss situation of the model in the prediction process, while accuracy directly reflects the prediction accuracy of the model. Combining these two indicators can provide a more comprehensive understanding of the performance of the model.
3.2. Multitask Learning Deep Neural Network for the Mode and Purpose
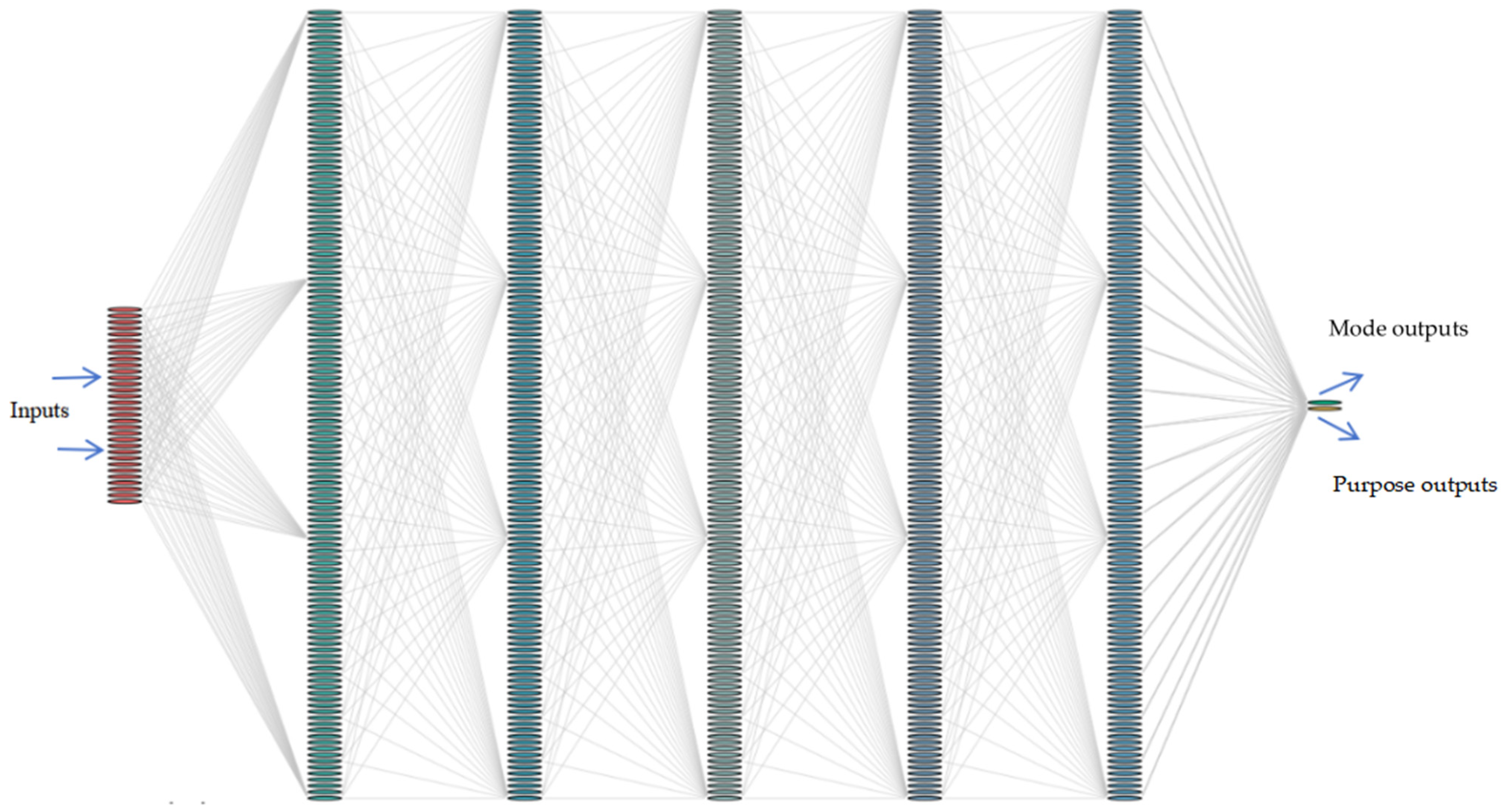
The structure of the MTLDNN model is shown in
Figure 2.
The MTLDNN model is optimized using empirical risk minimization (ERM), incorporating both classification errors and regularization terms:
The MTLDNN framework for analyzing mode and purpose is structured as follows. Let
represent the input variables associated with mode and purpose, where
indexes the observations and
denotes the input dimension. The respective output choices for the mode and purpose are denoted as
and
, with
and
referring to the mode and purpose, respectively. Here,
and
define the dimensions of mode and purpose choices, respectively, and both
and
are expressed as binary vectors. Given the constraint that only one alternative for mode or purpose selection can be valid at a time, their feature transformations are formulated in Equations (3) and (4):
where
denotes the depth of shared layers, while
denotes the depth of the task-specific (non-shared) layers for each individual task. The transformation of a single shared layer is denoted as
, whereas
and
correspond to the transformations of individual layers in the mode and purpose tasks, respectively. With the exception of the output layer, all transformation functions—including
,
, and
—consist of a ReLU activation followed by a linear transformation, expressed as
. The overall MTLDNN architecture is outlined in Equations (2) and (3) and visually represented in
Figure 1, where
signifies the shared layers, and
and
correspond to the task-specific layers for mode and purpose analyses, respectively. The probability distributions for mode and purpose choices are determined using a standard softmax activation function, which is widely applied in multi-class classification, as shown below.
where
and
represent the task-specific parameters in
and
; and
represents the shared parameters in
. Equation (5) computes the choice probability for each of the
mode alternatives, and Equation (6) computes the probability of each of the
travel purposes, given the input data.
The main equation consists of four parts. The first two parts are shown as follows:
These terms represent the empirical risk associated with predicting the mode and purpose, both formulated as cross-entropy loss functions. The third component, , corresponds to the L1-class regularization term with an associated weight , where . Similarly, the fourth component, , denotes the L2-class regularization term, weighted by , where . Equation (5) integrates four hyperparameters , subject to the constraint . Specifically, and control the relative importance assigned to mode and purpose prediction, while and regulate the overall magnitudes of the layer weights. Larger and result in greater weight decay during the Deep Neural Network training process.
When analyzing multivariate data, the complexity of variable correlations and the increased effort required for data collection often make it challenging to isolate individual indicators in a way that fully captures the inherent relationships between variables, potentially leading to incomplete or biased conclusions. On the other hand, overly simplifying the analysis by reducing the number of indicators, while convenient, may result in the loss of critical information, ultimately leading to inaccurate conclusions. Thus, it is imperative to maintain a balance between analytical efficiency and the retention of the original information.
3.3. Integrating Principal Component Analysis (PCA) and RFM (Recency, Frequency, Monetary)
In this study, Principal Component Analysis (PCA) is employed to systematically transform highly correlated variables into a smaller set of uncorrelated variables. These newly derived variables serve as comprehensive indicators, independently representing different aspects of the original data, thereby simplifying the dataset while maximizing the preservation and utilization of key information. If the dataset is n-dimensional and consists of m data points , the dimensionality of these m data is expected to be reduced from n-dimensional to k-dimensional, hoping that these m k-dimensional datasets can represent the original dataset as much as possible.
From the above two sections, we can see that finding the n-dimensional principal components of sample is actually finding the covariance matrix of the sample set, where the first n’ eigenvalues correspond to the eigenvector matrix , and then for each sample , perform the following transformation to achieve the PCA goal of dimensionality reduction.
The following is the specific algorithm process (Algorithm 1):
| Algorithm 1: Principal Component Analysis (PCA) |
| 1. Initialize centered data matrix , where is the mean vector. |
| 2. for each feature pair do |
|
| 4. end for |
| 5. Compute eigenvalue decomposition of : |
|
| 7. Sort eigenvectors in by descending eigenvalues . |
| 8. for to do |
| 9. (Select top components) |
| 10. end for |
| 11. for each sample do |
Input—n-dimensional sample set , the dimensions are to be reduced to n’.
Output—reduced dimensional sample set ;
(1) Centralize all samples;
(2) Calculate the covariance matrix of the sample;
(3) Perform eigenvalue decomposition on matrix ;
(4) Extract the eigenvectors corresponding to the largest n’ eigenvalues, standardize all eigenvectors, and form the eigenvector matrix ;
(5) Convert each sample in the sample set into a new sample ;
(6) Obtain the output sample set .
The Recency, Frequency, Monetary (RFM) model is a widely utilized analytical framework in marketing and customer relationship management (CRM) for assessing customer value and behavioral characteristics [
44]. By incorporating three key dimensions—Recency (R), Frequency (F), and Monetary (M)—the model enables businesses to segment customers based on their purchasing behavior and engagement patterns. The underlying assumption of the RFM model is that customers who have made recent purchases, buy frequently, and spend more are more valuable and likely to continue engaging with the business. Consequently, RFM analysis serves as a fundamental approach for customer segmentation, personalized marketing, customer churn prediction, and strategic decision-making in various industries such as retail, e-commerce, finance, and telecommunications.
The RFM model is based on three distinct yet interrelated metrics. Recency (R) measures the time elapsed since a customer’s most recent purchase, typically expressed in days, weeks, or months. A lower recency value suggests a more active customer, whereas a higher value may indicate disengagement or potential churn. It is calculated as follows:
Frequency (F) represents the number of purchases made by a customer within a specified time period, serving as an indicator of customer loyalty and engagement. Higher frequency values suggest that a customer has a strong relationship with the business. This metric is computed as follows:
Monetary (M) quantifies the total expenditure of a customer over a given timeframe, reflecting their overall contribution to revenue. Customers with high monetary values are typically prioritized for retention and targeted promotions. It is calculated as follows:
To facilitate customer segmentation, RFM scores are often assigned to each dimension, ranking customers into quartiles or percentile groups. These scores are then combined to categorize customers into distinct groups, such as high-value loyal customers, at-risk customers, and low-engagement customers.
Sometimes, we do not specify the value of n’ after dimensionality reduction, but instead specify a principal component weight threshold t for dimensionality reduction. This threshold
is between
. If n eigenvalues are
, then n’ can be obtained by the following equation:
The RFM model offers several advantages. First, it is computationally simple and relies solely on transaction data, making it easy to implement and interpret. Second, it provides strong explanatory power for customer behavior by segmenting customers based on tangible purchasing patterns. Third, it is widely applicable across multiple industries, including retail, banking, and subscription-based services. However, the model also has limitations, such as its static nature and its reliance solely on transaction history, excluding behavioral attributes like product preferences or browsing history. To enhance its effectiveness, the RFM model can be integrated with machine learning techniques such as clustering algorithms (e.g., K-Means) for more granular segmentation or extended to a dynamic RFM (d-RFM) approach, incorporating time-weighted recency metrics to track changes in customer behavior over time. Overall, the RFM model remains a valuable tool for businesses seeking to optimize customer engagement strategies, predict churn, and enhance targeted marketing campaigns.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}