1. Introduction
Writing accurate chest X-ray reports requires radiologists to meticulously scrutinize image details, which demands a substantial investment of time and technical expertise. Recently, radiologists have been confronted with the formidable task of reviewing a substantial volume of medical images and composing diagnostic reports that possess precise content, standardized structure, and coherent semantics due to the burgeoning patient population, which presents significant challenges for them. In this situation, there is a growing demand for automated generation of chest X-ray reports, which has garnered increasing attention from the medical community [
1,
2,
3].
Chest X-ray report generation refers to discovering and locating lesions through computer vision and natural language processing technology and describing them through a text report to lighten the workload of radiologists. Recently, drawing inspiration from image captioning techniques [
4,
5], the prevailing models for chest X-ray report generation [
6,
7] have predominantly embraced the conventional encoder–decoder architecture. Within this framework, a CNN-based visual feature extractor, such as ResNet [
8] or DenseNet [
9], is employed to distill visual characteristics from the provided images. Subsequently, a report generation module, often based on the Transformer model [
10], is utilized to translate these extracted visual features into a coherent paragraph that accurately depicts the input images. While these CNN–Transformer-based models have demonstrated impressive performance, they are not without their shortcomings, which include the following issues: (1) Lack of effective visual feature extraction methods. The traditional CNN-based methods fail to effectively model the relationships between different regions due to their limited perceptual field. (2) Difficulty in generating long sentences. The direct application of traditional image caption models to chest X-ray report generation is inadequate due to the lengthy nature of these reports. (3) Disregarding of the inter-word connections. Most models [
11,
12] employ cross entropy for optimization, which solely focuses on word-level errors.
To tackle the aforementioned issues, we propose the Reinforced Memory-driven Pure Transformer (RMPT) model. Specifically, to address the first problem, we construct a Transformer–Transformer framework, which eliminates the requirement for CNN. Compared with most existing models [
13,
14], our Transformer–Transformer framework considers the relationship among image regions. To solve the second problem, we introduce the memory-driven Transformer (MemTrans). In implementation, our MemTrans leverages a relational memory to capture vital information throughout the generation process. Furthermore, it incorporates Memory-driven Conditional Layer Normalization (MCLN), seamlessly integrating this information into the Transformer decoder. Compared with the vanilla Transformer, our MemTrans exhibits the capability of generating long reports. To solve the third problem, we propose a policy-based RL to exploit the inter-word connections. Compared with Self-Critical Sequence Learning (SCST) [
15], our RL is adept at steering the model to focus more intently on challenging examples. This targeted emphasis not only elevates the model’s overall performance but also ensures robustness across both general and complex scenarios. The effectiveness of our RMPT is evaluated through experiments conducted on the IU X-ray dataset, demonstrating superior performance across various NLG metrics. In summary, our contributions are:
We propose a Pure Transformer framework for automatic chest X-ray report generation, which eliminates the requirement for CNN.
We introduce the MemTrans to augment the model’s capacity to generate long reports.
We introduce a novel RL-based training strategy to enhance the model’s performance by exploiting the inter-word connections.
Evaluations on the IU X-ray dataset reveal that our proposed RMPT outperforms other models across various NLG metrics. Moreover, generalizability tests on the MIMIC-CXR dataset further validate its effectiveness.
The subsequent sections are structured as follows:
Section 2 offers an extensive overview of pertinent literature.
Section 3 initially outlines our RMPT, subsequently providing an in-depth examination of the Pure Transformer framework, MCLN, and the RL. For detailed information on the experiments, please refer to the
Section 4, while the
Section 5 emphasizes the key points.
3. Proposed Method
The pipeline of our RMPT is shown in
Figure 1.
As shown in
Figure 1, our RMPT model consists of four major components. (1) Visual extractor: we employ a pre-trained Swin Transformer [
25] to extract visual features from input images. For a fair comparison, we utilize both the lateral and frontal view chest X-ray images as input. (2) Encoder: following most chest X-ray report generation models [
1,
2,
3], we adopt a three-layer Transformer encoder for modeling the relationship between different targets. (3) Memory-driven Transformer: we integrate the MCLN into the Transformer decoder to generate long reports, which can model similar patterns in different radiology reports. (4) Reinforcement learning: we introduce an RL-based fine-tuning method to further improve the model performance.
3.1. Transformer–Transformer Framework
In this paper, we first construct a Transformer–Transformer-based framework. Instead of employing the traditional CNN-based models, such as ResNet [
8] or DenseNet [
9], our framework adopts the Swin Transformer [
25] as the visual extractor, which has a larger perceptual field to better model the relationships between different regions. The Swin Transformer draws on the strengths of both CNN and Transformer, which combines a sliding window and a multi-headed attention mechanism.
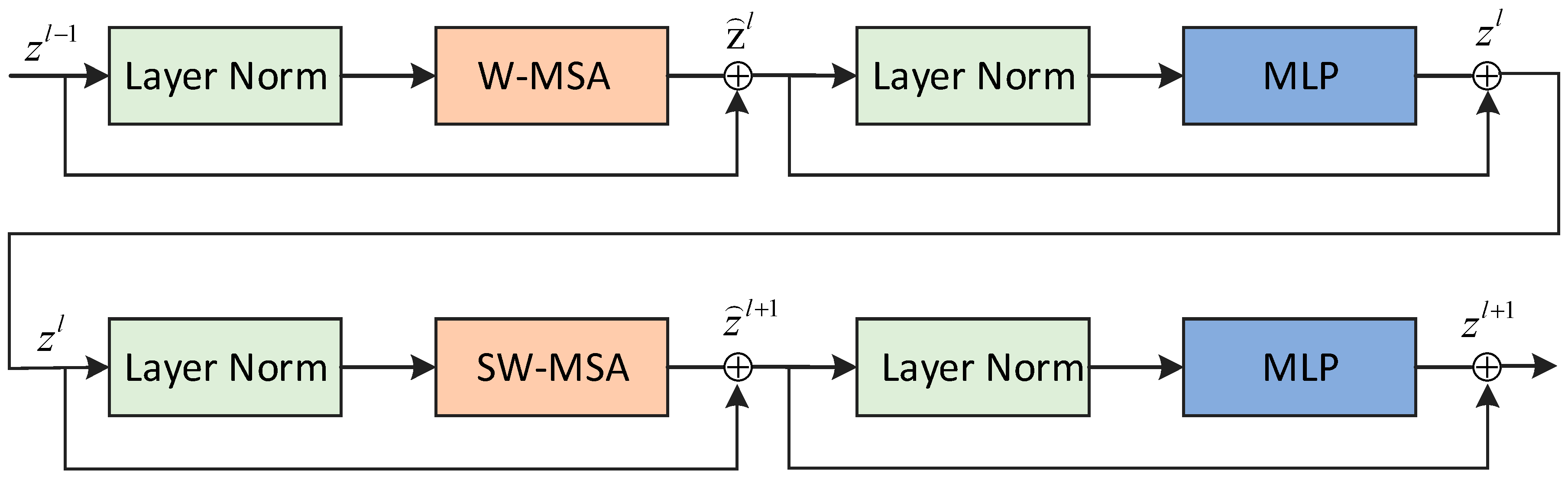
Figure 2 shows two consecutive Swin Transformer blocks.
In the Swin Transformer, the traditional multi-head self-attention (MSA) module within each Transformer block is replaced with a novel shifted-window module, with all other layers preserved. As
Figure 2 shows, each block in the Swin Transformer comprises layer normalization, a multi-head attention mechanism, a residual connection, and a two-layer MLP featuring GELU non-linearity. The block’s structure can be represented as:
where
and
are the outputs of the (S)WMSA module and the MLP module on the
block. Similar to the previous works, self-attention is calculated using the following equation:
where
is derived from the bias matrix.
The strategy of partitioning with shifted windows effectively enhances interactions between adjacent, non-overlapping windows from the preceding layer, showcasing its broad utility across a variety of computer vision tasks. This proven efficacy has inspired us to incorporate it as a visual extractor. To our knowledge, our work represents the pioneering effort in applying the Swin Transformer to the field of radiology report generation.
3.2. MemTrans
Building upon the Transformer architecture [
14], our MemTrans incorporates two key modules. We first introduce relational memory to harness similar patterns across diverse reports. A memory matrix is employed to capture essential pattern information, with its states dynamically propagated throughout the generation phases:
where
refers to the forget gate,
refers to the input gate, and
refers to the temp state.
where
refers to the sigmoid function,
refers to the previously generated word,
,
,
,
are learnable parameters, and
refers to the previous memory.
where
refers to the MLP.
where
,
,
.
Based on the relational memory, we further propose the mcln to incorporate the relational memory to enhance the decoding of the Transformer. The calculation process can be formulated as follows:
where
and
are the standard and mean deviation of
.
where
refers to the MLP, and
and
are two major parameters, which are used to scale and translate features.
3.3. Reinforcement Learning
Our RL, grounded in policy gradients, is a reinforcement learning approach designed to enhance our model’s overall performance. Within our RL framework, the memory-driven Transformer we propose acts as an agent engaging with the external environment. Consequently, the parameters
θ of our proposed memory-driven Transformer delineate a policy that prompts an action. Upon producing the end token, the agent receives a reward,
r. The training process aims to maximize the expected reward.
where
refers to the generated words. In implementation, we typically adopt a single sample drawn from
to estimate the
:
Next, we employ the reinforcement algorithm to compute the gradient:
We employ a single Monte Carlo sample to estimate the gradient:
Furthermore, we introduce a reference reward
to reduce the high variance:
Therefore, the final gradient is estimated by utilizing a single sample:
Different from the SCST, we employ three representative NLG metrics as the initial reward:
where
refer to the weight of the corresponding metric.
B,
M, and
R refer to the BLEU-4 [
31], METEOR [
32], and ROUGE-L [
33] evaluation metrics, respectively. Furthermore, we introduce a factor to adjust the initial reward, which can be formulated as follows:
where
refers to the tanh function. The final reward is formulated as follows:
4. Experiments
4.1. Datasets and Evaluation Metrics
Our RMPT model is experimentally validated on the IU X-ray dataset [
34]. The statistics of the IU X-ray dataset are illustrated in
Table 1. In alignment with the prevalent methods [
1,
13], we have partitioned the dataset into training, validation, and testing subsets in a ratio of 7:1:2. We employ the traditional NLG evaluation metrics, including BLEU [
31], METEOR [
32], and ROUGE-L [
33], to verify the effectiveness of our RMPT.
4.2. Experimental Settings
Datasets pre-processing details. In the image pre-processing stage, we filter out images lacking corresponding reports and standardize their dimensions to 224 × 224 pixels. During the report pre-processing phase, we convert all words to lowercase through tokenization, subsequently eliminating special tokens and words that appear less than three times.
Model details. For feature extracting, we employ the Swin Transformer-B to extract visual features from given images. The proposed MemTrans is based on the Transformer with randomly initialized parameters, where the number of encoder–decoder layers is set to three, and the dimension of the model is set to 512. The memory slot in our MemTrans is set to three.
Training details. The RMPT model is initially trained for a duration of 100 epochs, using CE loss, with a mini-batch of 16. We employ the Adam optimizer [
35], and the learning rate is set to 5 × 10
−5. Subsequently, the RMPT model undergoes fine-tuning with our proposed RL for an additional 100 epochs, this time utilizing a mini-batch size of 10. We set the max length of generated reports to 60. We use both the frontal and lateral images as input. The weight combination for BLEU-4/METEOR/ROUGE-L in our proposed RL is set to 5:1:5, and the penalty factor is set to 2.0.
4.3. Comparison with Previous Studies
We compare our RMPT with 15 recent methods to assess the efficacy of our proposal. The compared models include image caption models: Grounded [
36], M2Transformer [
37]; CNN-LSTM-based chest X-ray report generation models: Co_Att [
18], mDiTag(-) [
19], SentSAT + KG [
20], CMAS-RL [
38]; CNN–Transformer-based chest X-ray report generation models: R2Gen [
13], CMN [
12], METransformer [
7], Align Transformer [
23], PPKED [
39], MMTN [
17], RL-CMN [
29], GSKET [
40], CECL [
41], CmEAA [
42] and Transformer–Transformer based chest X-ray report generation Models: PureT [
43]. Experimental results are presented in
Table 2. There are four major observations.
Firstly, compared to conventional image captioning models, Grounded [
36] and M2Transformer [
37], which are designed to generate a short sentence to describe the major content of given images, the RMPT model achieves greater scores on all evaluation metrics. This observation confirms that designing a specific model for generating long sentences is necessary.
Secondly, compared to CNN-LSTM-based chest X-ray report generation models, Co_Att [
18], mDiTag(-) [
19], SentSAT + KG [
20], and CMAS-RL [
38], which utilize LSTM as the report generator, our RMPT achieves greater scores on all evaluation metrics. This observation confirms the influence of Transformer architecture.
Thirdly, compared to CNN–Transformer-based chest X-ray report generation models—R2Gen [
13], CMN [
12], METransformer [
7], Align Transformer [
23], PPKED [
39], MMTN [
17], RL-CMN [
29], GSKET [
40], CECL [
41], and CmEAA [
42]—our RMPT achieves greater scores on most evaluation metrics. This observation confirms the effectiveness of the Transformer–Transformer framework.
Fourthly, compared to the Transformer–Transformer-based chest X-ray report generation model, PureT [
43], which utilizes the Vision Transformer [
44] as the visual extractor, our RMPT achieves greater scores on all evaluation metrics. This observation confirms the effectiveness of the Swin Transformer and our proposed RL.
4.4. Ablation Study
We conducted ablation studies on the IU X-ray dataset to validate the effectiveness of our MemTrans and RL. The experimental results are displayed in
Table 3.
In this paper, we design a Transformer–Transformer-based framework, serving as our base model. Based on this framework, we first introduce the MemTrans to help to generate long reports. As
Table 3 shows, compared to the base model, the incorporation of our MemTrans can dramatically enhance the quality of generated reports, which results in an average performance improvement of 6.6%. The experimental results demonstrate the effectiveness of MemTrans. Furthermore, we propose an RL training strategy designed to effectively steer the model towards allocating greater attention to challenging examples. As
Table 2 shows, compared to the base model, the incorporation of our RL can dramatically enhance the quality of generated reports, which results in an average performance improvement of 10.5%. The experimental results demonstrate the effectiveness of RL.
4.5. Discussion
In this section, we undertake a series of experiments on the IU X-ray dataset to examine the impact of various settings on model performance. These include different configurations of the Swin Transformer, diverse visual extractors, varied reinforcement learning training strategies, and distinct memory slot arrangements.
4.5.1. Effect of Different Configurations of Swin Transformer
To better validate the impact of different configurations of Swin Transformer on model performance, we use four different configurations of Swin Transformer as visual feature extractors, Swin-T, Swin-S, Swin-B, and Swin-L. The experimental results obtained using the above four visual feature extraction models are shown in
Table 4. As shown in
Table 4, our model performs better and better as the number of model parameters increases, and when Swin-B is used as the visual feature extractor, the best effect is achieved. However, when the number of model parameters continues to increase, the model performance deteriorates dramatically. The reason behind this might be that the IU X-ray dataset is relatively small. Therefore, we select the Swin-B as our visual extractor.
4.5.2. Effect of Different Visual Extractors
To further validate the impact of Swin Transformer, we compare it with traditional CNN-based extractors, including Vgg-16 [
45], Vgg-19 [
45], GoogLeNet [
46], ResNet-18 [
8], ResNet-50 [
8], ResNet-101 [
8], ResNet-152 [
8], and DenseNet-121 [
9]. The experimental results are shown in
Table 5. As shown in
Table 5, our model achieves better performance when Swin-B is used as the visual feature extractor, which demonstrates the effectiveness of our pure transformer-based framework.
4.5.3. RL vs. SCST
To rigorously evaluate the effectiveness of our RL, we have conducted a comparative analysis against the established conventional SCST method [
15]. In this vein, we have separately fine-tuned our model using our novel RL strategy and the traditional SCST technique [
15]. The comparative performance outcomes are detailed in
Table 6. As
Table 6 shows, compared to the SCST, our RL achieves superior performance on all NLG evaluation metrics, which demonstrates its effectiveness.
4.5.4. Effect of Different Memory Slots
We also conduct experiments to validate the impact of the quantity of memory slots. To this end, we train our model with varying memory slots. The comparative results are detailed in
Table 7. As evidenced in
Table 7, our RMPT achieves superior performance across most evaluation metrics when the memory slot is set to 3, except BLEU-1 and METEOR scores. Accordingly, the memory slot will be uniformly maintained at 3 for the rest of this study.
4.6. Generalizability Analysis
To validate our method’s robustness and ensure its practical applicability, we evaluate our method on MIMIC-CXR dataset. As
Table 8 shows, compared to the base model, the incorporation of our MemTrans and RL can dramatically enhance the quality of generated reports, which results in an average performance improvement of 6.8% and 14.0%, respectively. The experimental results demonstrate the effectiveness of method.
5. Conclusions
In this paper, we propose a novel Reinforced Memory-driven Pure Transformer model. In implementation, instead of employing CNN-based models, our RMPT employs the Swin Transformer, which has a larger perceptual field to better model the relationships between different regions, to extract visual features from given X-ray images. Moreover, we adopt MemTrans to effectively model similar patterns in different reports, which can facilitate the model to generate long reports. Furthermore, we develop an innovative policy-driven RL training strategy that efficiently steers the model to focus more on some challenging samples, thereby uplifting its comprehensive performance across both typical and complex situations. Experimental results on the IU X-ray dataset show that our proposed RMPT achieves superior performance on various NLG evaluation metrics. Further ablation study results demonstrate that our RMPT model achieves 10.5% overall performance compared to the base mode. In our future research, we will extend our experiments to include a diverse range of additional datasets to thoroughly assess the robustness and generalizability of our proposed method.





{kind=link}
{kind=link}