1. Introduction
Unsupervised domain adaptation (UDA) performs an adaptive classification from the source domain to a different but related target domain. In this setting, the labeled source data and unlabeled target data are both available during the whole transfer phase. So, we can explicitly align the two domains by well-established domain alignment, such as adversarial learning [
1] and metric learning [
2].
Due to the recent increasing demands of information security and privacy protection, accessing the source data becomes more acute. As a result, in many real scenarios, adapting a model (e.g., the source model) pre-trained on the source data to the unlabeled target domain becomes a natural requirement and solution. For example, in medical image diagnosis applications, some works try to transfer the U-Net [
3] or V-Net [
4], e.g., transfer the source model, pre-trained on images containing lung cancer, to the task of chest organ segmentation for surgery planning. In these cases, during the transfer process, these lung cancer images are unavailable for access owing to patient information protection, whilst the architecture and parameters of the source model are both accessible.
In machine learning, the necessity of using the source data in UDA is also questioned [
5,
6,
7]. With this background, the source-data-free domain adaptation (SFDA) problem, with access to only a source model (pre-trained on the source domain) and the target domain during adaptation, has attracted an increasing amount of research attention [
8,
9,
10,
11].
The key to solving SFDA is to mine adequate and accurate semantic supervision to relieve the lack of semantic supervision caused by both the absences of the source domain and labels on the target domain, thus converting SFDA to a supervised scenario despite the mined supervision being noisy. Compared with the early feature-based work such as subspace alignment [
6], recent end-to-end methods have shown an advantage on this topic. According to the type difference of the mined semantic supervision, we divide these end-to-end approaches into two groups. The first group [
9,
12] faked a source domain as implicit supervision using adversarial learning, where the pre-trained source model was used as a domain classifier. Although the faked data partly bypass the unavailability of the source domain, these low-quality generated data cannot provide sufficient credible semantic information like real source data. The faking operation will additionally lead to the negative transfer problem. Therefore, many works tend to mine the semantic supervision from the target domain, as conducted in the second group [
13,
14,
15]. This kind of method constructed the supervision, such as pseudo-labels and augmentation data, to facilitate entropy regularization. Regarding geometry, these methods essentially perform clustering in the feature space under the regulation of semantic supervision mined from the target domain. However, the supervision mining in these methods only focuses on individual data; the implicit knowledge hidden in the local geometry of target data has not been sufficiently mined and utilized.
Most recently, knowledge distillation was applied regarding SFDA [
16,
17,
18], and the adaptation was modeled as a knowledge transfer from the pre-trained source model (teacher model). These methods provided a natural solution for SFDA that is more in line with our cognitive experience. However, the existing methods did not carefully design the knowledge distillation skeleton to fit SFDA.
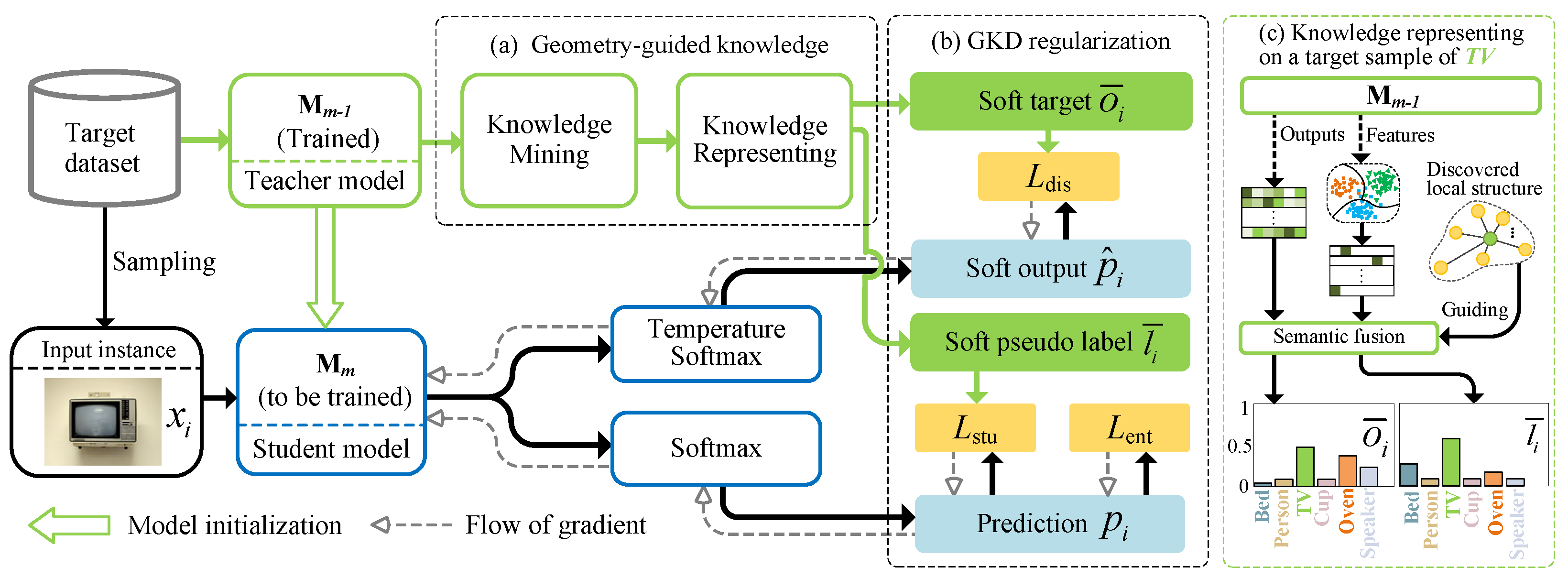
First, the fixed source model is only in charge of predicting the semantic labels (
Figure 1a), as conducted in [
16,
17]. The semantic supervision generated in this static way is also frozen during the whole transfer phase such that the power of the semantic guidance will gradually weaken, namely the semantic guidance degradation.
Second, a dynamic tracking model, e.g., momentum network [
18], was taken as the teacher model for conforming to the composition of a classic knowledge distillation framework (
Figure 1b). Although this scheme solves the first problem above, the teacher model cannot well represent the semantic information to be transferred, namely semantic deviation, due to the semantic noise caused by the inherent discrepancy between the teacher model and the student model.
Third, under the knowledge distillation framework, how to achieve better SFDA by exploiting the local geometry of target data is still an open problem.
Aiming at the limitations mentioned above, we develop a novel knowledge-distillation-based method for SFDA named
Gradual Geometry-Guided Knowledge Distillation (G2KD). At the global level, G2KD slices the whole adaptation into a sequence of (
N) stages/epochs, as shown in
Figure 1c. There are two reasons for adopting this gradual strategy. First, it can resist the aforementioned semantic guidance degradation. Second, due to the model updating after each epoch, the data features change correspondingly, leading to variations in the local structure. Therefore, we need to construct the local structure for each epoch to realize knowledge distillation by this gradual strategy. At the epoch-level, inspired by the self-distillation methods [
19,
20], G2KD adopts the self-guided strategy to minimize the aforementioned semantic deviation. Specifically, the student model
shares the same structure with the teacher model
and is initiated by
at the beginning of the epoch. After that, for utilizing the local geometry, we adopt geometry-guided knowledge distillation (G2KD) to train
. As shown in the right side of
Figure 1c, G2KD works in a “
refining–distilling” manner. Firstly, G2KD mines the geometry-guided knowledge by building local geometry of the neighborhood for any target data. Then, semantic fusion converts it to soft semantic supervision based on semantic estimation using k-means clustering and a teacher model’s output (
refining). Secondly, G2KD performs knowledge distillation. In particular, we introduce an entropy loss with neighbor context for meeting the unsupervised requirement of SFDA (
distilling).
Essentially, G2KD provides an implicit domain aligning approach without reliance on the source domain training data, as assumed in UDA, but only the need to access the pre-trained source model. To be concrete, the epoch-wise adaptation at the global level converts the large domain shift reduction, between the source domain (implicitly represented by the source model) and the target domain, into several successive easy tasks with a small shift. Furthermore, at the local (per-epoch) level, by integrating the local structure information based on the most discriminative up-to-date features (), the obtained geometry-guided knowledge is more credible/accurate than the original outputs of . Empowered by the guidance of them, the performance of can be enhanced further.
Our contributions cover the following three areas.
(1) We develop a novel gradual knowledge distillation framework G2KD for SFDA, exploiting the geometry-guided knowledge, i.e., the self-supervision dynamically mined from the target data’s local geometry, and a new entropy-regularized knowledge distillation method, G2KD. Unlike the existing distillation frameworks, it mitigates the problems of guidance degradation and guidance deviation.
(2) We propose a generation method for geometry-guided knowledge.
The data neighborhood, discovered by similarity comparison, is taken as the local geometry in our approach. Through semantic fusion based on semantic evaluation pre-obtained by both clustering and model outputs, the knowledge is generated.
(3) We carry out extensive experiments on four challenging datasets. The experiments show that our method achieves state-of-the-art results. In addition to the ablation study, we perform a careful investigation for analysis.
The remainder of the paper is organized as follows.
Section 2 introduces the related work.
Section 3 details the proposed method, followed by the experimental results and analyses in
Section 4.
Section 5 comprises the conclusion.
3. Methodology
This section first formulates the SFDA problem and then presents the overview of G2KD. Following that, we present the components of our method in detail, respectively.
3.1. Source-Data-Free Domain Adaptation Problem Formulation
Given two different but related domains, i.e., source domain and target domain , contains labeled samples, while has n unlabeled data. Both labeled and unlabeled samples share the same K categories. Let and be the source samples and the corresponding labels, where is the label of . Similarly, we denote the target samples and their labels by and , respectively. Conventional UDA intends to conduct a K-way classification on the target domain, and the labeled source data and the unlabeled target data are both available as the cross-domain transfer process. In contrast, SFDA tries to build a target model for the same classification task, whilst only and a source model pre-obtained on the source domain are available during the whole transfer process.
Remark 1. In conventional UDA, the domain shift is expressed by the data from the two domains explicitly. In SFDA, as above, the source probability distribution is presented (parameterized) to the source model implicitly such that the shift is reflected in the classification accuracy of the source model on the target domain. Also, SFDA is a “white-box” case; that is, the pre-trained source model is accessible during the adaptation phase, and details, such as architecture and weight parameters, are known. In case the source model only outputs prediction and its details are absent, it is formulated to the topic named “black-box” source-data-free domain adaptation [43,44]. 3.2. Approach Overview
This paper presents SFDA as a model adaptation consisting of sequential sub-transfers, as presented in
Figure 1. Specifically, the whole adaptation from
to
is sliced to
N epochs and learns an intermediate model in each epoch such that the domain shift might be reduced smoothly since the sequential sub-transfers can capture the dynamics in the adaptation process. Formally, we give this progressive process a simple form presented by
where
N is the maximal training epoch number, and notation
denotes a single sub-transfer regulated by the G2KD method from model
A to model
B.
Without loss of generality,
Figure 2 depicts any sub-transfer driven by G2KD, i.e.,
. We can see that the sub-transfer contains two steps. Firstly, we initialize the current
by
, which is trained in the last epoch and fixed during
training. Following this step, we train
by G2KD. In this design,
is the student model, while
is the teacher model. The transfer learning for
is driven by G2KD regularization (
Figure 2b) consisting of three regulators: the entropy loss
, distillation loss
, and student loss
. In the entropy loss, except for classic entropy minimization [
45], we integrate the neighbor context of input instance. Another important component is the geometry-guided knowledge block (
Figure 2a), which plays a central role in our distillation scheme. It provides the soft target and soft pseudo-label to supervise the distillation loss and student loss, respectively. Knowledge mining is achieved by local geometry discovery, which outputs the neighborhood geometry for the input instance. The followed knowledge representation transforms this knowledge into two supervision aspects, including a soft target and a soft pseudo-label. To this end, we perform semantic clustering and fusion based on the deep features and final outputs mapped by the teacher model
, as shown in
Figure 2c. In the following, we present these components in detail.
3.3. Structure of Intermediate Model
To account for classification in SFDA, the source model
is divided into a feature extractor and a classifier, whose details are known according to the SFDA setting. In order to conduct the chain-like training starting with
, formulated by Equation (
1), in the epoch-wise adaptation process of G2KD, all intermediate models
have the same structure as
. Specifically, we use a deep network to specify any intermediate model
;
also consists of a feature extractor
and a classifier
. Thus,
can be parameterized to
, where
collects the model parameters.
3.4. Geometry-Guided Knowledge
In this section, we first introduce the method to discover neighborhood representing the geometry-guided knowledge using the teacher model . Then, we present the semantic information extraction method to represent the mined knowledge regulating our knowledge distillation.
Knowledge mining. As mentioned above, we deem the local geometric relationship of any target data to be the knowledge. To implement this insight, we propose local geometry of the neighborhood to portray this relationship. The feature extractor in the teacher model maps all target samples
to deep features
, denoted by
collectively, where
. We extract the knowledge from this deep feature space.
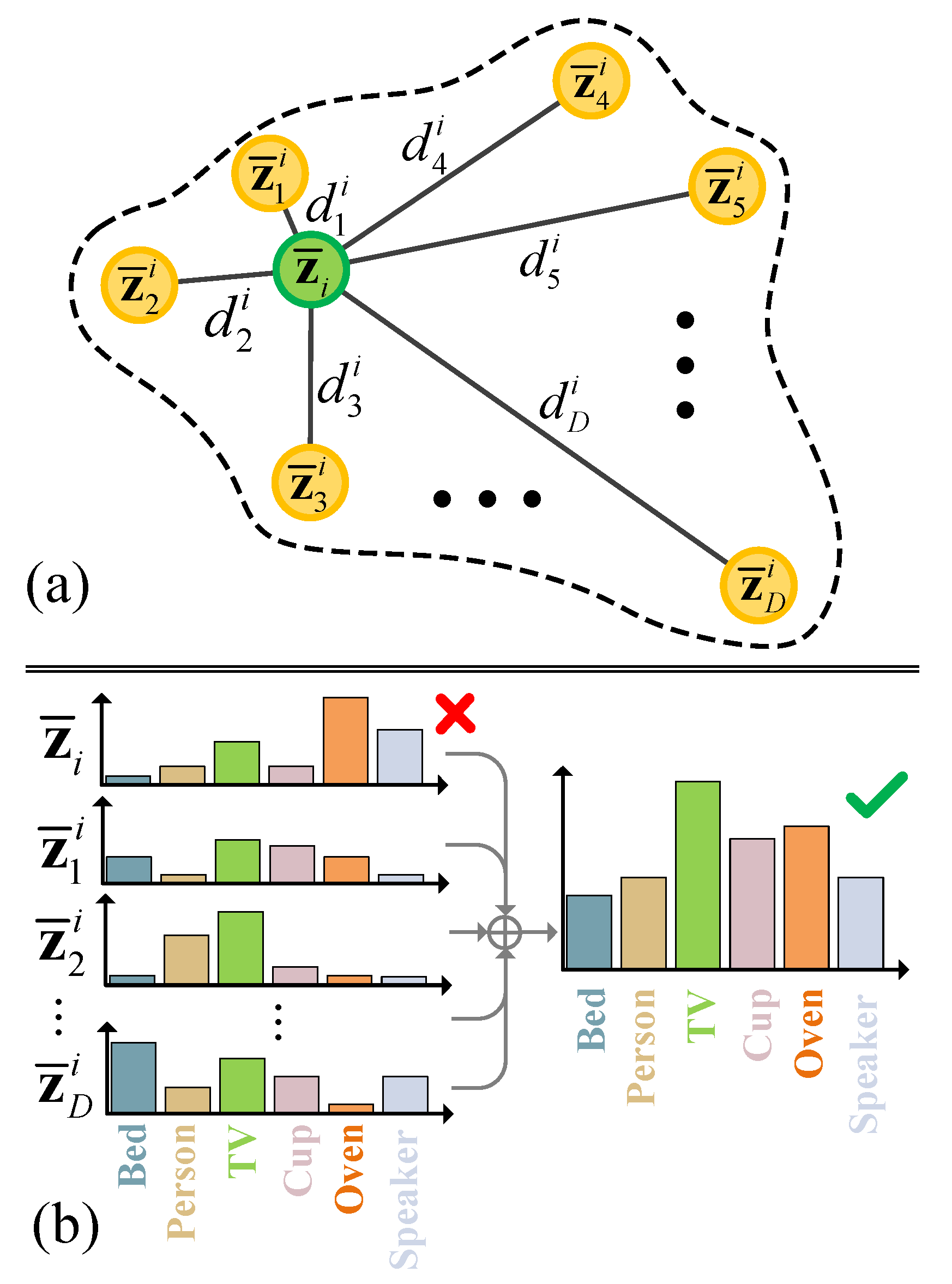
Figure 3 presents the composition of this local structure, whose edge is marked by dotted line. The green circle located in the center stands for a feature sample of any target data, i.e.,
. The orange circles stand for
D feature samples on the edge of the neighborhood, i.e.,
. In practice, we use the cosine similarity in the feature space to identify these neighbor samples
. The similarities between the center sample and the edge samples are represented by the length of solid lines, i.e.,
.
Obviously, if the constructing information
is given, we can definitively determine the neighborhood of
. We specify the neighborhood constructing information of any target sample
by a simple strategy as follows. We first perform a similarity comparison of
over the whole target dataset in the deep space and obtain a similarity measure set
, where function
calculates the cosine similarity of
and
. After that, we choose
D feature samples closest to
and the corresponding distance (the similarity measure value) to form the neighborhood structure. This operation can be formulated by
where function
returns the indices of elements ranking in the first
m in set
.
Knowledge representing. By the above discovery method, we mine the knowledge from the teacher model. However, this knowledge cannot directly support the knowledge distillation. We therefore need to convert it to semantic information compatible with knowledge distillation learning. Corresponding to classic knowledge distillation, we propose (1) soft target and (2) soft pseudo-label to supervise the distillation loss and the student loss for the student model. The generation methods of them are presented in the remainder of this sub-section.
(1) Soft target. Unlike the classic distillation method that directly takes the teacher model’s output as the knowledge to guide the student learning, we use the soft target building on the constructed neighborhood to supervise the distillation part. Suppose
and
are the probability vectors of
and
, respectively, under the mapping of
. Equation (
3) formulates our construction procedure.
(2) Soft pseudo-label. In classic knowledge distillation, the student loss is used to regulate the supervision learning on the given ground truth. However, due to the unavailable truth labels in SFDA, we use pseudo-labels instead. Moreover, we soften pseudo-labels to enhance knowledge transfer by absorbing the semantic information hidden in the neighborhood. To this end, we first extract essential semantic representation through cluster-based classification, the same as [
13], and then perform semantic fusion based on the discovered local geometry. This process includes the following three steps.
(1) Weighted k-means clustering. For the deep features
, the teacher model
predicts, after the Softmax operation, the probability vectors
, where
. We find the
k-th cluster centroid by Equation (
4), where
is the
k-th element of vector
.
(2) Semantic extraction. We obtain the hard pseudo-labels of all feature samples constructing the neighborhood, including
and
, using max-similarity-based classification formulated by Equation (
5), where
is also a cosine similarity function, and
D is the number of neighbor features.
(3) Semantic fusion. Let
be the soft pseudo-label of any target data
; we formulate its generation by Equation (
6), where
is the
k-th element of
,
is the function of the indicator,
is pre-obtained as we model adaptation knowledge via the neighborhood geometry, and
K is the number of categories shared by the source and target domains.
3.5. Geometry-Guided Knowledge Distillation Regularization
Our knowledge distillation is a particular case of self-distillation since, at the beginning of each training epoch, we use the historical model pre-trained in the latest epoch to accomplish knowledge mining in the current epoch. Its objective also consists of two components, the distillation loss and the student loss, as in most previous work on knowledge distillation. However, compared with this other work, our regularization builds on the semantic information mined from the geometry-guided knowledge.
I. Entropy regulator with neighbor context
Entropy-based regularization is widely used in unsupervised classification scenarios [
46,
47], leading to the aggregation of samples without semantic supervision. However, this aggregation only relying on model’s prediction will amplify the prediction errors in a positive feedback way. Therefore, the single use of entropy minimization is always regulated further. In this work, we develop entropy minimization with neighbor relation, focusing on utilizing geometry-based semantic context. In the absence of real supervision in the SFDA setting, the semantic relations between these neighbor samples are not reliable. To bypass this limitation, we take the augmentation data with a slight transformation as the neighbor. Thus, we can use the category consistency constraint on the data before and after augmentation to enhance feature discrimination. To this end, in addition to the classic entropy item, we introduce another entropy regulator [
48], which maximizes the mutual information entropy between the input instance and its augmentation data.
During the
m-th training epoch, given any input instance
and its augmentation data
, obtained by rotating
with a small angle selected from
randomly,
converts
and
to probability vectors
and
over all classes, respectively. The proposed entropy loss on the instance
can be expressed by
where
is the entropy measure;
is the mutual information measure [
49] whose computation is the same as [
48];
is a trade-off hyper-parameter. In this equation, the first term is the classic entropy minimization loss to regulate the individual data. The second term introduces the semantic constraint in the augmentation-based neighbor context for discriminative features.
II. Knowledge distillation regulator
With the notation mentioned above, corresponding to the input instance
, its logit is
, which is mapped through the student model. Using the temperature Softmax formulated by Equation (
8) where
is the temperature scaling parameter, we map
to the soft target
.
Combining the soft target in Equation (
3), we express the distillation loss in the form of the Kullback–Leibler (KL) divergence
Combining the soft pseudo-label in Equation (
6), we express the student loss by Equation (
10), where
is a mean in the
k-th dimension over all target data. In this loss, the first term in cross-entropy form is similar to the classic student loss used in the traditional knowledge distillation framework. The difference between them is that we replace the ground truth by our constructed soft pseudo-label. Due to the errors in the pseudo-labels, the first regularization cannot guide semantic learning absolutely correctly. To relieve the negative impact from the pseudo-labels, like [
13,
50,
51], we introduce the category balance loss as the second regularization term. The
and
are hyper-parameters.
Thus, we have the following loss with knowledge-distillation-like structure.
Based on the regularizers represented in Equations (
7) and (
11), we have our final objective for the G2KD method
3.6. Model Training
Algorithm 1 summarizes the training overview for the model adaptation from
to
based on G2KD.
| Algorithm 1 Overall training of G2KD |
Input: The trained source model , target data , max epoch number N, iteration number of each epoch .
Output: The target model .
- 1:
Let . - 2:
for epoch-index = 1 to N do - 3:
Initialize the student model by the trained teacher model , i.e., . - 4:
Refine geometry-guided knowledge, i.e., local geometry, by teacher model according to Equation ( 2). - 5:
for iter-index = 1 to do - 6:
Sample a mini-batch from . - 7:
Generate soft target for this batch by Equation ( 3). - 8:
Generate soft pseudo-label for this batch by Equation ( 6). - 9:
Update , where the objective is represented by Equation ( 12). - 10:
end for - 11:
end for - 12:
return: .
|
4. Experiments and Analyses
This section first provides the experimental settings, including the dataset introduction, details on implementation, and the baseline for comparison. After that, experimental results on four benchmarks are presented, followed by an analysis and ablation study, respectively.
4.1. Datasets
In this paper, we evaluate G2KD on four widely used benchmarks, i.e., Office-31, Office-Home, VisDA and DomainNet. Among them, Office-31 and VisDA are only used for the task of vanilla closed-set domain adaptation, whilst Office-Home and DomainNet are adopted for both vanilla closed-set domain adaptation tasks and multi-source-domain adaptation tasks.
Office-31 [
52]. Office-31 is a small-scale dataset that is widely used in visual domain adaptation including three domains, i.e., Amazon (A), Webcam (W), and Dslr (D), all of which are taken from real-world objects in various office environments. The dataset has 4652 images of 31 categories in total. Images in (A) are online e-commerce pictures. (W) and (D) consist of low-resolution and high-resolution pictures.
Office-Home [
53]. Office-Home is a medium-scale dataset that is mainly used for domain adaptation, containing 15,000 images belonging to 65 categories from working or family environments. The dataset has four distinct domains, i.e., artistic images (Ar), clip art (Cl), product images (Pr), and real-world images (Rw).
VisDA [
54]. VisDA is a challenging large-scale dataset with 12 types of synthetic to real transfer recognition tasks. The source domain contains 152,000 synthetic images, while the target domain has 55,000 real object images from Microsoft COCO.
DomainNet [
55]. DomainNet is the most challenging large-scale dataset, with 0.6 million images of 345 classes from 6 domains of different image styles: clip art (C), infograph (I), painting (P), quickdraw (Q), real (R), and sketch (S).
4.2. Implementation Details
Network structure. We design and implement our network architecture based on Pytorch. We can divide the above datasets into two types, vanilla closed-domain adaptation and multi-source-domain adaptation, for the vanilla closed-set domain adaptation task. In our model, the feature extractor contains a heavy-weight deep architecture and a compression layer consisting of a batch-normalization layer and a full-connect layer with a size of 2048 × 256. Specifically, for the deep architecture, like [
2,
18,
56], we use ResNet-50 pre-trained on ImageNet as the feature extractor in the experiments on Office-31, Office-Home, and DomainNet. At the same time, on VisDA, we adopt ResNet-101 to replace ResNet-50 used in the methods without the VIT module, whilst methods with VIT, i.e., TDA, SHOT + VIT, and G2KD + VIT, still keep ResNet-50 as the backbone. The classifier consists of a weight-normalization layer and a full-connect layer with a size of 256 ×
K, in which
K differs from one dataset to another.
Source model training. For all evaluation datasets, the source model
was pre-trained with the standard protocol [
7,
8,
13,
15]. We split the labeled source data into two parts of 90%:10% for model pre-training and validation.We set the training epochs on Office-31, Office-Home, VisDA, and DomainNet to 100, 50, 10, and 20, respectively.
Parameter settings. For Office-31, Office-Home, and DomainNet, we set the learning rate and epochs to 0.01 and 15, respectively; for VisDA, the learning rate is set to 0.001 and the same epochs. For hyper-parameters, we set , , , , and . Additionally, the batch size for all tasks is set to 64. All the experiments were run on a single GPU of NVIDIA RTX TITAN.
4.3. Competitors
To verify the effectiveness of our method, we select 24 competing methods in three groups, as shown below.
- (1)
The first group includes two deep models, i.e., ResNet-50 and ResNet-101 [
57]. They are used to initiate the feature extractor of the source model.
- (2)
The second group includes 12 current state-of-the-art UDA methods with access to the source data. They are CDAN [
2], SWD [
58], DMRL [
59], BSP [
60], TN [
61], TPN [
22], IA [
62], BNM [
63], MCC [
64], A2LP [
31], CGDM [
65], CaCo [
66], SUDA [
67],
[
68], CMSDA [
69], DRT [
70], and STEM [
71].
- (3)
The third group includes 10 current state-of-the-art SFDA methods. They are SFDA [
10], 3C-GAN [
9], SHOT [
13], BAIT [
15], HMI [
7], PCT [
34], GPGA [
8], AAA [
12], PS [
35], VDM [
11], DECISION [
72], NRC [
73], and GKD [
74].
To extensively evaluate G2KD, we further introduce two variants: G2KD++ and G2KD + ViT. Specifically, G2KD++ is an enhanced version with semi-supervised learning (MixMatch) [
75], whilst SHOT + ViT is a feature-empowered version with a VIT module [
76]. For comparison, SHOT++ [
77], SHOT + ViT, and TDA [
18] are adopted as the baselines, where SHOT++ and SHOT + ViT are implemented in the same way to G2KD++ and G2KD + ViT, respectively. In practice, these methods with ViT, SHOT + ViT, TDA, and G2KD+ViT implement the feature extractor using ResNet50 + ViT instead of ResNet50 (on Office-31, Office-Home, and DomainNet) and ResNet101 (on VisDA), adopted in SHOT and G2KD. We inject the transformer layer, similar to [
18], between the ResNet-50 architecture and the compression layer.
4.4. Quantitative Results
Vanilla closed-set domain adaptation.
Table 1,
Table 2 and
Table 3 present the experimental results of the object recognition. On the Office-31 dataset (see
Table 1), among these methods without extending, namely saving SHOT++, TDA, and SHOT+VIT, G2KD obtains the best results on the tasks A→D and W→D. Compared with the previous best method, GPGA and AAA, G2KD improves 0.1% on average due to the gap of 1.3% on task W→A, along with slight improvement on other tasks. For the methods with MixMatch, G2KD++ beats SHOT++ on all tasks, improving by 1.0% in average accuracy. For the ViT methods, G2KD + ViT obtains the best results in half tasks. In average accuracy, G2KD + ViT improves by 0.2% as opposed to the second-best method, SHOT + ViT.
On the Office-Home dataset (see
Table 2), in the method group without MixMatch and ViT, G2KD obtains the best results on half tasks and improves 0.3% in average accuracy compared with the second-best method, NRC and GKD. When MixMatch and ViT are introduced, the performance of our method further improves. G2KD++ surpasses SHOT++ in 8 out of 12 tasks, whilst G2KD + ViT achieves the best results in 10 out of 12 tasks. Correspondingly, G2KD++ and G2KD + VIT improve the average accuracy by 0.2% and 0.9%, respectively, over the second-best method, SHOT++ and SHOT + VIT.
On the VisDA dataset (see
Table 3), G2KD achieves the best results in three classes, “skrbrd” and “train’,’ and beats the second-best method, VDM and NRC, by a 0.3% improvement on average. With semi-supervised learning, G2KD++ obtains the best results on 8 out of 12 tasks compared to SHOT++, leading to 0.5% increase in average accuracy. As for the ViT-based methods, the advantages of our method become more evident. G2KD + ViT ranks first in average accuracy, with the best results regarding 10 out of 12 classes. It improves by 3.8% in average accuracy compared to the second-best method, SHOT + ViT.
From
Table 1 to
Table 3, the extensive versions of G2KD, i.e., G2KD++ and G2KD + VIT, defeat other methods, including G2KD. It indicates that both semi-supervised learning and stronger features can boost our method further. From Office-31 to VisDA, G2KD++ surpasses G2KD by 0.7% on average, whilst SHOT++ surpasses SHOT by 1.7% on average. In contrast, on the same three datasets, both G2KD + ViT and SHOT + ViT beat G2KD and SHOT by 5.0% on average. These results show that enhancing feature extraction is a better choice for elevating G2KD compared with semi-supervised learning.
On the most challenging large-scale dataset, Domain-Net (see
Table 4), the advantage of G2KD is further extended. Compared with the second-best method, CGDM, G2KD improves by 6.8% in average accuracy over the whole 30 tasks.
Multi-source-domain adaptation. As reported in the left side of
Table 5, on the DomainNet dataset, G2KD has a 7.9% gap compared with the best UDA method, STEM. Note that STEM is specially designed for the multi-source-domain adaptation task, with access to labeled source data, whilst G2KD adopts the intuitive combination strategy of source models as in [
55]. However, for these SFDA methods, G2KD obtains the best results for 4 out of 6 tasks and improves by 2.9% over SHOT and 0.4% over DECISION. As DECISION is also proposed for multi-source-domain adaptation, the smaller gap on G2KD is sensible. As reported in the right side of
Table 5, on the Office-Home dataset, the gap between G2KD and the best UDA method, CMSDA, is 1.1%. Compared to these SFDA methods, G2KD obtains the best results on 3 out of 4 transfer tasks, achieving the best performance of 75.5% in average accuracy. These results indicate that G2KD is competitive regarding multi-source-domain adaptation despite no specialized design involved.
4.5. Further Analysis
Confusion matrices. To show that our method is category-balanced, we draw the confusion matrices based on the 31-way classification results of symmetrical tasks W→A and A→W.
Figure 4 provides the confusion matrices of the source model and G2KD. As shown in
Figure 4a,b, on task A→W, G2KD is much more accurate than the source model only on all categories. Regarding task W→A, as shown in
Figure 4c,d, G2KD has better results, and the improvements are scattered over all categories. We also observe that G2KD improves significantly in some hard categories on the two tasks. For example, for the fifth category calculator on task A→W, G2KD improves the accuracy from 48.0% to 100.0%. For the 13th category bookcase on task W→A, G2KD improves the accuracy from 46.0% to 80.0%.
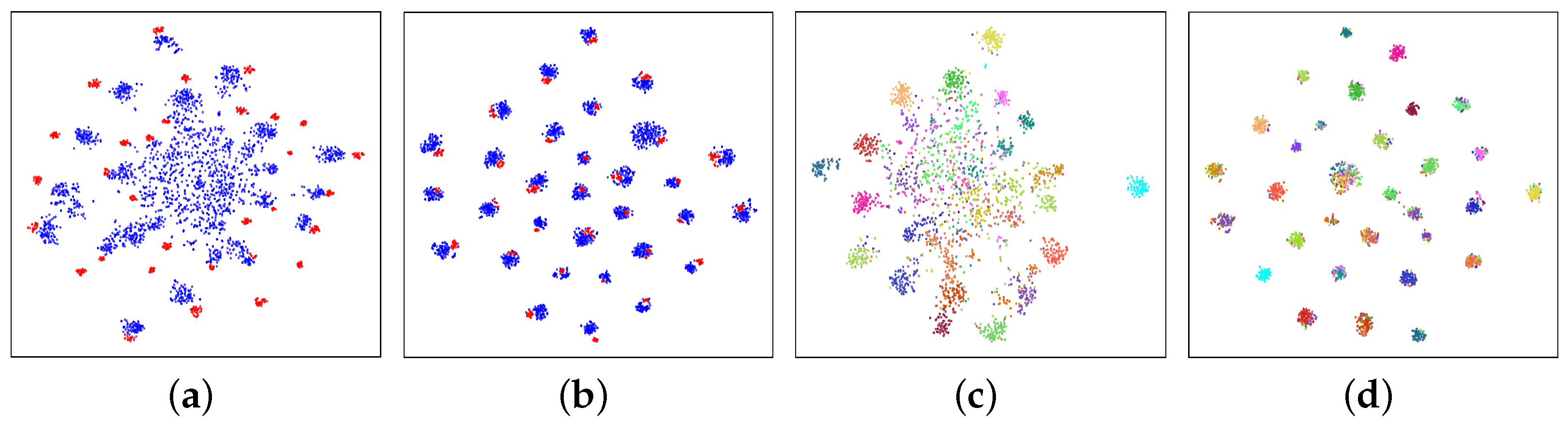
Feature visualization. For intuitively using the tool of t-SNE [
78], we provide a feature analysis that visualizes the 31-way classification results of task W→A on Office-31.
Figure 5a,b present the cluster distribution in the deep feature space defined by function
, i.e., the feature extractor. Our method apparently leads to an implicit alignment from the target domain to the source domain.
Figure 5c,d present distribution details. After model adaptation, the target data in the deep feature space satisfy a distribution with evident semantic meaning.
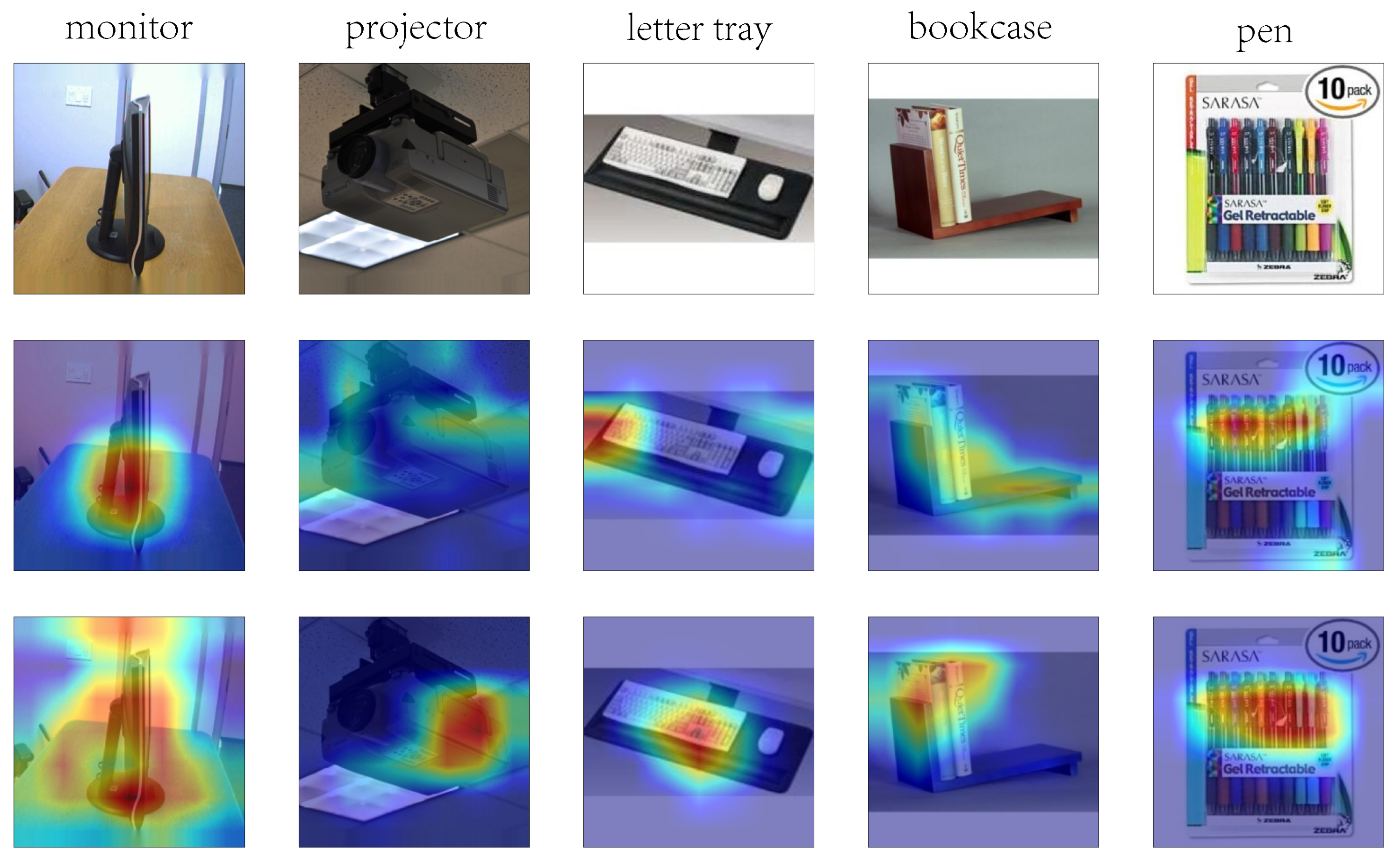
Grad-CAM visualization. To explain why our method works, we conduct a visualization analysis from the perspective of attention using the gradient-weighted class activation map (Grad-CAM) method [
79]. As shown in the first row of
Figure 6, we present some original images randomly selected from Office-31 and provide their Grad-CAM images from the source model and our method in the remaining two rows. As we are using the source model, we cannot clearly observe the attention phenomenon. For the projector, the active area representing attention is weak. For the bookcase, the red area representing strong attention covers the whole image. These attention patterns do not always lead to good results. In contrast, based on our method, attention occurs and focuses on the key components of these objects.
Geometry-guided knowledge visualization. For our method, the constructed geometry-guided knowledge plays a central role. To show the working mechanism of it, we visualize the proposed neighborhood modeling the knowledge in
Figure 7. From the misclassified images on the three datasets for object recognition, we randomly choose 15 example images, as shown in the first row of
Figure 7, and arrange the samples in their neighborhood in the other rows. It emerges that most of the neighborhood samples have the same categories as the corresponding original images. Thus, these neighborhood samples can provide comprehensive semantic information to correct the wrong classification on these original images.
We implement the correction mentioned above by the semantic fusion formulated in Equation (
3) and (
6). Here, we plot the classification accuracies of soft pseudo-labels on Office-31 during the training phase in
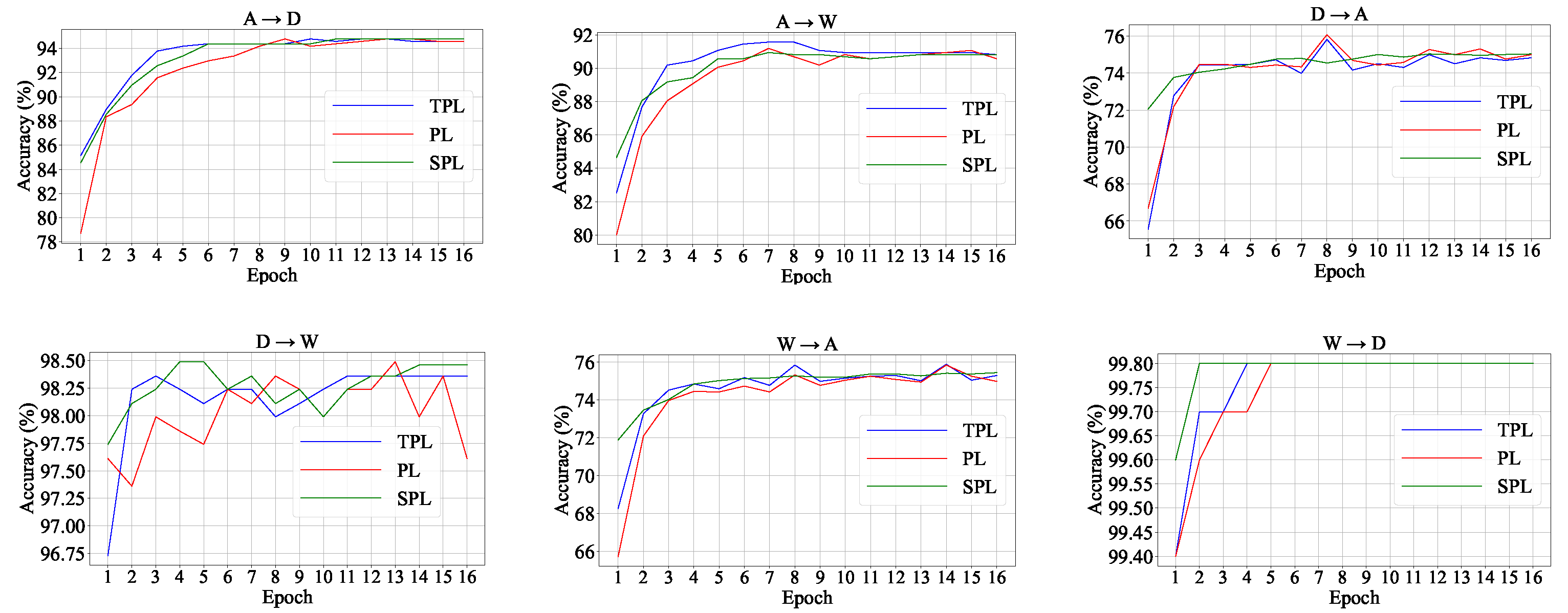
Figure 8. As a comparison, we also present the classification accuracies of pseudo-labels without the semantic fusion and the classification accuracy of pseudo-labels of the teacher model. For clarity, we denote the three methods as SPL, PL, and TPL, respectively. On all six adaptation tasks on Office-31, SPL consistently demonstrates superior performance compared to PL and TPL. This accuracy gap in
Figure 8 also explains the performance decrease caused by canceling the soft pseudo-label that we discussed in the ablation study (see the fourth row and the last row in
Table 6).
Training resource demands. In order to more objectively evaluate the required training resources, we selected three representative SFDA methods, SHOT, AaD, and NRC, as comparison baselines. Experimental comparisons were conducted on the Ar → Cl migration task of the Office-Home dataset under the same test conditions, and the relevant results are shown in
Table 7. Despite the need to recalculate the neighborhood geometry and perform clustering and semantic fusion operations at each stage, the experimental results show that our method remains within a reasonable range in terms of memory usage and training time per epoch, and the computational overhead is controllable.
Sensitivity to hyper-parameters. In G2KD,
D is the neighborhood size, and
in
(Equation (
7)) is the trade-off parameters. We test their sensitivity of performance on the symmetric transfer tasks Cl→Ar and Ar→Cl in Office-Home. Specifically, as shown in
Figure 9, the performance achieves the best result as
D takes an intermediate value. A smaller value leads to insufficient information, whilst a larger value introduces more noise. The results are consistent with our expectations. As for
, it is seen that our method is highly robust to its settings.
4.6. Ablation Study
In this part, we isolate the effect of the critical components in G2KD. These components include (1) the gradual distillation strategy, (2) the geometry-guided knowledge, and (3) the regularization losses in our objective.
Effect of gradual distillation strategy. As noted, for G2KD, the teacher model
provides the supervision for the distillation, i.e., soft target
in
and soft pseudo-label
in
. To verify the effect of the gradual distillation strategy, we cancel this strategy from the training process by imposing a replacement operation on the supervision. Specifically, for a supervision,
or
, we generate it by the source model
, then fix it during the whole adaptation phase. In this way, we have three evaluation cases, as reported in
Table 8.
As shown in the first row in
Table 8, when both
and
are replaced, there is large gap of 14.3% compared to the full version shown in the fourth row. As shown in the following two rows, when
or
is replaced, the average accuracy has evident improvement (increase by 10.4% at least). The comparison indicates that the gradual distillation strategy has a great influence on the final result. This progressive process can well capture the dynamics of data geometric structure during the transfer phase.
Effects of geometry-guided knowledge. G2KD takes the soft target and the soft pseudo-label, based on geometry-guided knowledge, to regulate the distillation loss
and the student loss
, respectively. To present the advantages of introducing geometry-guided knowledge, we use the raw information without the semantic fusion as the supervision. Correspondingly, we rewrite the two knowledge distillation losses as the following raw form.
where
and
are the raw target and the raw pseudo-label, respectively, and the other notations are the same as the ones in Equations (
9) and (
10). Here, we present three primary cases to evaluate the geometry-guided knowledge effect. The first is G2KD without the soft target where we replace
with
, while the second is G2KD without the soft pseudo-label where we replace
with
. The third is G2KD without both soft target and soft pseudo-label. Also, we evaluate the three component losses in our objective
, i.e.,
,
, and
.
Table 6 reports the ablation study results. Comparing the results in the last row with the results from the second row to fourth row, we observe that geometry-guided knowledge can lead to evident improvement on the three datasets. G2KD with geometry-guided knowledge beats the three G2KD variations without geometry-guided knowledge. This comparison indicates the importance of the geometry-guided knowledge distillation that this paper develops. In the fifth row, G2KD with standard k-means refers to applying standard
k-means clustering without the weighting mechanism described in Equation (
4). It is seen that standard k-means leads to noticeable drops on all three datasets, confirming the effect of our weighting strategy.
Effects of regularization losses. We adopt an incremental way to evaluate these losses. We take the variation method trained by only
as baseline and then add losses
and
one by one. As shown in
Table 9, the objective combining
with
or
obtains much better results than merely using
as the objective. We achieve the best results on the three datasets when
,
, and
work simultaneously. These ablation results show that our losses positively affect the final performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}