LSE,
WLSE | - (1)
Parameters are estimated by minimizing the sum of squared errors. - (2)
In linear regression models, the LSE is unbiased and achieves the minimum variance among all linear unbiased estimators (i.e., it is BLUE, the Best Linear Unbiased Estimator). - (3)
It is sensitive to outliers because its optimization relies on minimizing the sum of squared errors. - (4)
It is suitable for data with linear relationships, offering computational simplicity and ease of implementation.
| Linear regression and curve fitting. If the data distribution is unknown and the model is simple, it is preferable to prioritize LSE. |
| MLE | - (1)
Parameters are estimated by maximizing the likelihood function, relying solely on observed data without considering prior information. - (2)
For large sample sizes, MLE typically exhibits consistency (estimates converge to the true values as the sample size increases). - (3)
The computational complexity is low, and solutions can generally be obtained through analytical methods or numerical optimization. - (4)
MLE is asymptotically efficient when model assumptions hold but may fail when these assumptions are violated.
| Highly versatile and suitable for large samples, but computationally intensive. If the dataset is large and the distribution is known, MLE should be prioritized. |
| MAPE | - (1)
Combines the likelihood of observed data with prior information about parameters, representing a Bayesian estimation method. - (2)
MAPE generally outperforms MLE when prior information is reliable and sample sizes are small. - (3)
MAPE can be interpreted as a regularized version of MLE, where the prior distribution acts as a regularization term. - (4)
Computational complexity may be high, particularly with complex prior distributions or when numerical optimization is required.
| Combines prior information, suitable for small samples, but relies on prior selection. If the sample size is small and there is a need to incorporate prior information, the MAPE is chosen. |
| MVE | - (1)
Among all unbiased estimators, it has the minimum variance, making it the optimal unbiased estimator. - (2)
It typically requires assumptions about the data distribution (e.g., normal distribution), and its optimality is guaranteed under these assumptions. - (3)
It exhibits higher computational complexity, particularly with high-dimensional data.
| In the case where the model is known and unbiased estimation is required, select either the MVE or the LMVE. |
| LMVE | - (1)
It is the estimation method with the minimum variance among all linear estimators. - (2)
It only requires knowledge of the first- and second-order moments of the estimated quantity and measured quantity, making it suitable for stationary processes. - (3)
For non-stationary processes, precise knowledge of the first- and second-order moments at each time instant is required, which significantly constrains its applicability. - (4)
The computational complexity is moderate, but the estimation accuracy critically depends on the accuracy of the assumed moments
|
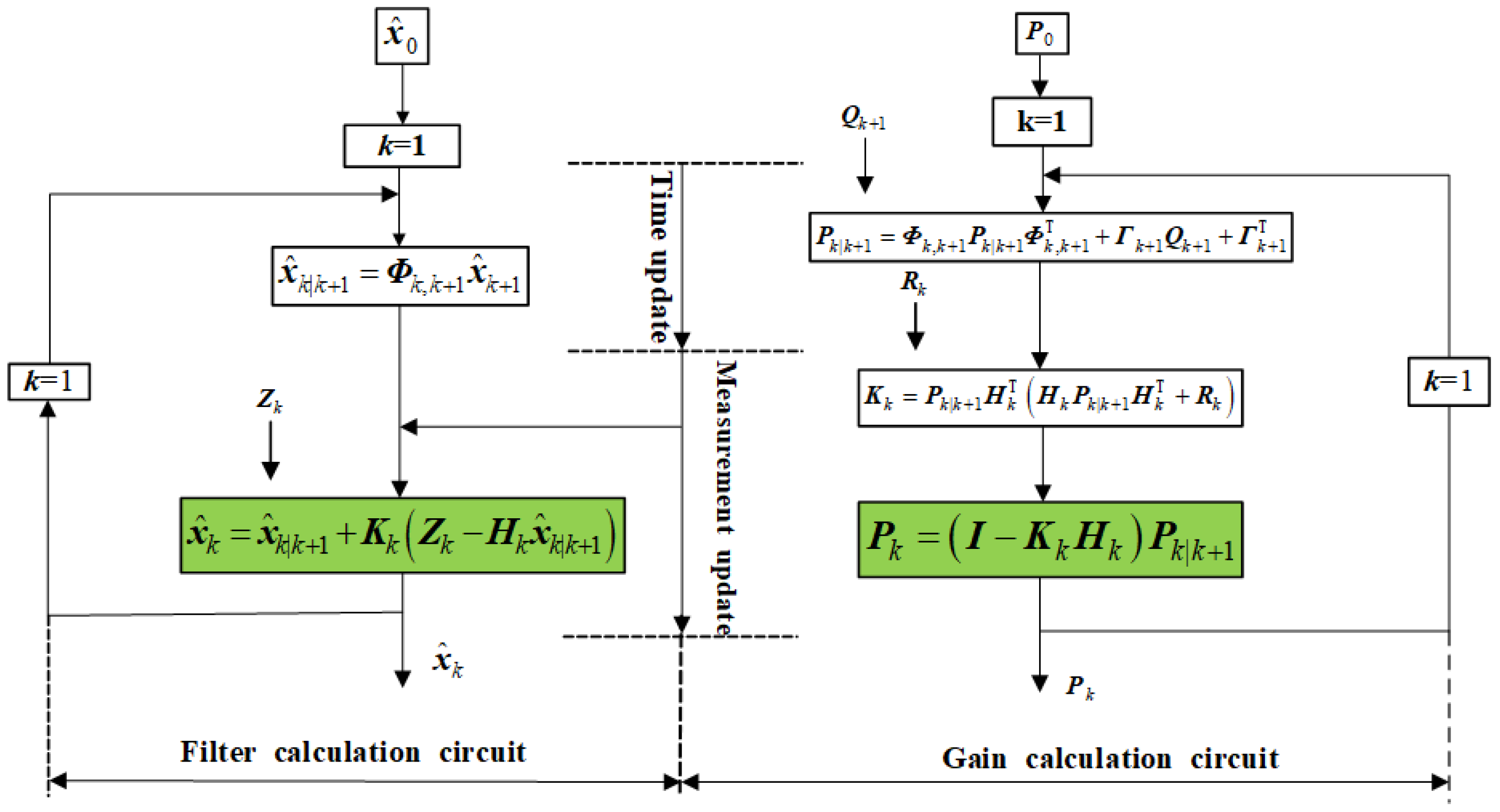
| KF | - (1)
Linear System Assumption: The KF assumes both the system model and observation model are linear, with additive Gaussian noise. This linear–Gaussian assumption theoretically guarantees a globally optimal solution. - (2)
High Computational Efficiency: The KF exhibits low computational complexity (O(n2) for state dimension n), making it well-suited for real-time applications with stringent timing requirements. - (3)
Optimal Estimation Accuracy: Under strict adherence to linear–Gaussian assumptions, the KF provides statistically optimal estimates in the minimum mean-square error sense. - (4)
Limited Applicability: The KF’s strict linearity assumptions lead to significant estimation errors when applied to nonlinear systems, severely constraining its practical application scope.
| It is suitable for scenarios where the system is linear and the noise follows a Gaussian distribution, such as in simple navigation and signal processing. |
| EKF | - (1)
Nonlinear system processing: The EKF approximates nonlinear problems by linearizing the nonlinear system model. - (2)
Moderate computational complexity: The computational complexity of the EKF is higher than the KF but lower than the UKF. - (3)
Limited accuracy: Due to the linearization process, the EKF may experience larger estimation errors in strongly nonlinear systems. - (4)
Jacobian matrix calculation: The EKF requires computation of the Jacobian matrices of the system model and observation model, which increases the algorithm’s complexity. - (5)
Broad applicability: The EKF is a widely used method for handling nonlinear systems and is suitable for moderate nonlinearity.
| It is suitable for scenarios where the nonlinearity is not high and fast real-time processing is required. Due to its lower computational complexity, the EKF is well-suited for use in embedded systems with limited computational resources. When the initial state estimation is relatively accurate, the EKF can converge quickly and provide better estimation results. |
| UKF | - (1)
Strong nonlinear system processing capability: The UKF selects a set of deterministic sampling points (Sigma points) through the UT, enabling a more accurate approximation of the statistical properties of nonlinear systems. - (2)
No Jacobian matrices required: The UKF avoids the complex Jacobian matrix calculations required in the EKF, enhancing the algorithm’s stability and precision. - (3)
Higher computational complexity: The computational complexity of the UKF is higher than that of the EKF, but it generally remains within acceptable limits. - (4)
High accuracy: The UKF outperforms the EKF in strongly nonlinear systems, providing more accurate estimation results.
| Suitable for scenarios involving nonlinear systems with Gaussian noise, such as complex target tracking and robotic navigation |
| PF | - (1)
Strong nonlinear and non-Gaussian adaptability: The PF is a recursive Bayesian estimation technique based on Monte Carlo methods, capable of handling complex nonlinear systems and non-Gaussian noise environments. It approximates the posterior probability distribution through a large number of random samples (particles), thus avoiding the linearity and Gaussian assumptions required by traditional filtering methods (e.g., KF). - (2)
Flexibility and robustness: The PF exhibits high flexibility, adapting to diverse systems and observation models. It demonstrates strong robustness against noise and outliers, making it particularly suitable for dynamic systems in complex environments. - (3)
Parallel computing capability: The computational process of the PF can be parallelized, as the prediction and update operations for each particle are executed independently, significantly improving computational efficiency. - (4)
Handling complex probability distributions: The PF can manage multimodal probability distributions, making it ideal for state estimation in complex scenarios. Through its particle weight updating mechanism, it effectively integrates information from multiple sensors. - (5)
Challenges and optimizations: Despite its adaptability, the PF faces challenges such as particle degeneracy and high computational complexity. To address these issues, researchers have proposed improvements like adaptive PF, combining the UKF to generate proposal distributions, and optimizing resampling strategies.
| Suitable for nonlinear and non-Gaussian systems, such as target tracking, robotic navigation, and signal processing. |
| UPF | - (1)
Adaptability to non-Gaussian noise: When combined with a PF, the UKF further enhances its adaptability to non-Gaussian and multimodal probability distributions. - (2)
Balanced computational efficiency and accuracy: The UKF achieves a good balance between computational efficiency and accuracy. While its computational complexity is higher than that of the traditional KF, the UKF outperforms the EKF in handling high-dimensional state spaces and has lower computational complexity compared to the PF. By integrating a PF, particles are generated and updated via the UT, further improving particle effectiveness and sampling efficiency. - (3)
Mitigation of particle degeneracy: In PFs, particle degeneracy—a common issue where most particle weights approach zero, reducing the number of effective particles—is alleviated when combined with the UKF. Sigma points generated through the UT provide a more accurate description of the state distribution, thereby reducing particle degeneracy. - (4)
Further optimization via PF integration: The UPF combines the strengths of the UKF and the PF. By generating and updating particles through the UKF UT, UPF retains PF’s strong adaptability to nonlinear and non-Gaussian problems while improving sampling efficiency.
| Suitable for nonlinear and non-Gaussian systems where high estimation accuracy is required. |
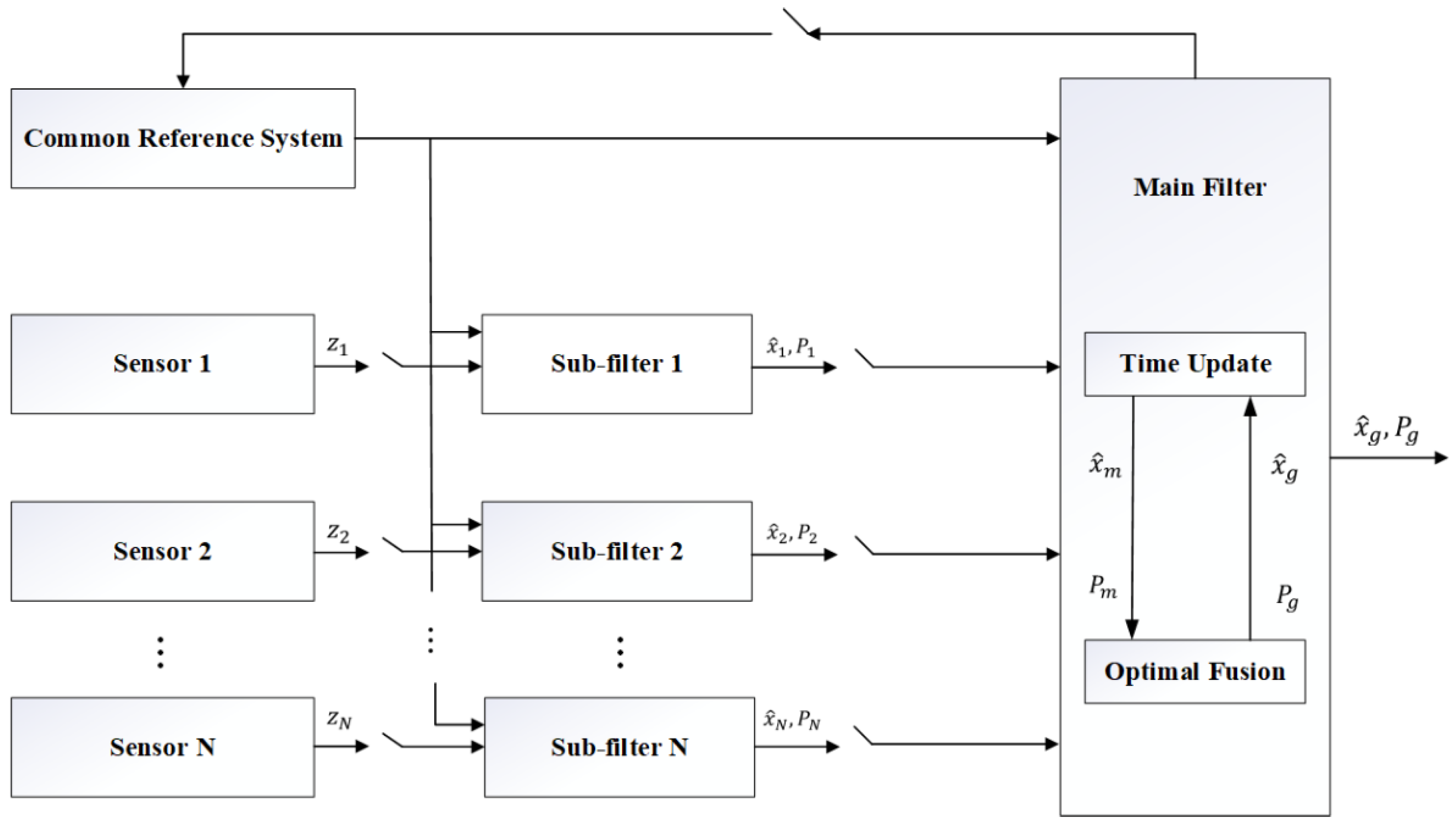
| FF | - (1)
Distributed Structure and Flexibility: The FF adopts a distributed architecture, decomposing data fusion tasks into multiple sub-filters and a master filter. This structural design offers flexibility, allowing the selection of appropriate filtering algorithms (e.g., EKF, UKF) based on the characteristics of different sensors. It also supports dynamic adaptation to sensors joining or leaving the network. - (2)
Fault Tolerance and Fault Isolation Capability: The FF can detect and isolate faulty sensors in real time, preventing erroneous data from degrading global estimation accuracy. This ensures high precision and reliability even when partial sensor failures occur. - (3)
Diversity of Information Allocation Strategies: The FF supports multiple information allocation strategies, including zero-reset mode, variable proportion mode, feedback-free mode, and fusion-feedback mode. These strategies exhibit trade-offs in computational complexity, fusion accuracy, and fault tolerance, enabling flexible selection tailored to specific application scenarios. - (4)
High Computational Efficiency: By distributing data processing among multiple sub-filters, each of which handles only local data, the FF reduces the computational load. This distributed computing approach not only enhances the system’s real-time performance but also lowers the demand for hardware resources. - (5)
Adaptive and Dynamic Adjustment Capability: Integrated with adaptive filtering theory, the FF dynamically adjusts information allocation coefficients based on sensor performance and environmental changes. - (6)
Plug-and-Play Functionality: The FF supports plug-and-play operation for sensors, enabling rapid adaptation to dynamic sensor addition or removal. This feature enhances flexibility and adaptability in complex environments or evolving mission requirements. - (7)
Globally Optimal Estimation: The master filter synthesizes local estimates from sub-filters to achieve a globally optimal estimate. This two-tier architecture preserves local filtering precision while improving overall system performance through global fusion. - (8)
Suitability for Complex Environments: The FF excels in multi-source heterogeneous data fusion scenarios, such as integrating satellite navigation, inertial navigation, and visual navigation in navigation systems. It effectively addresses sensor noise, model biases, and environmental interference challenges.
| Suitable for multi-sensor networks, especially in scenarios where sensors are widely distributed and communication resources are limited. |
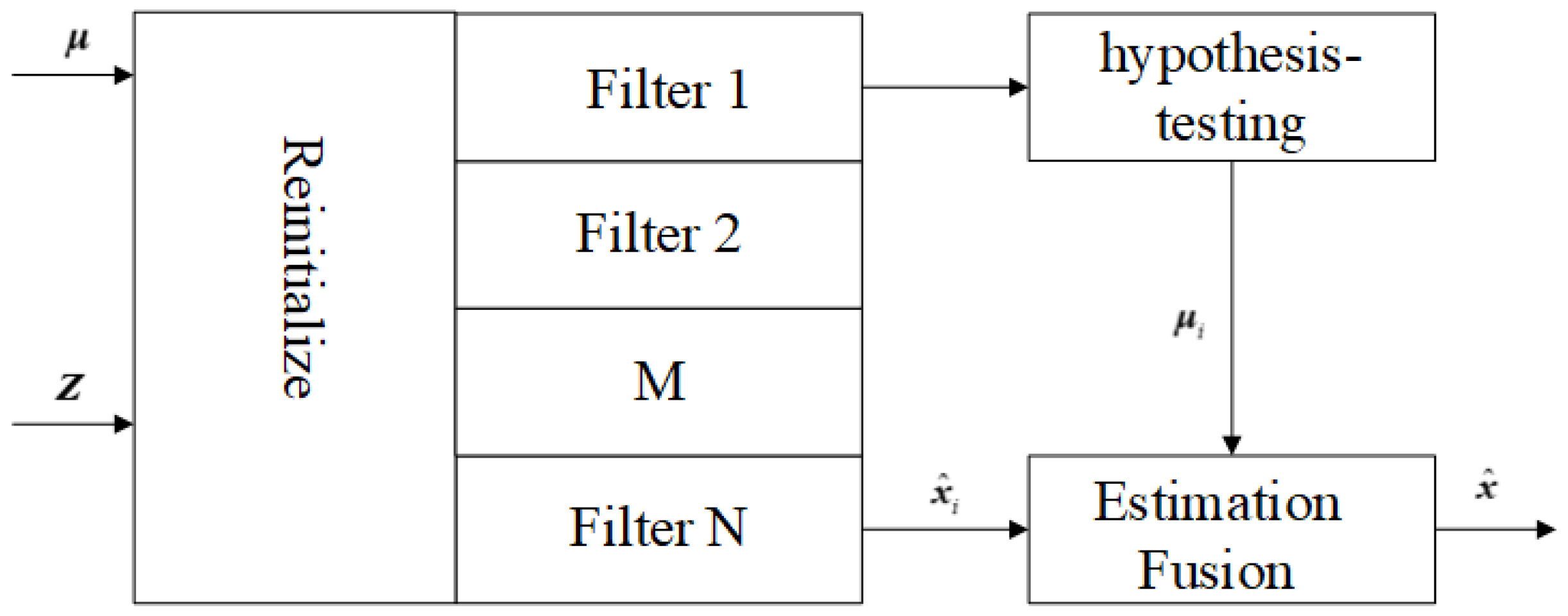
| MME | - (1)
Multimodal Data Processing Capability: MME methods can handle data from different modalities, such as images, text, audio, and video. By mapping multimodal data into a unified feature space or integrating information through fusion techniques, these methods leverage the complementary nature of different modalities to enhance model performance. - (2)
Diversity of Fusion Strategies: MME methods support various fusion strategies, including early fusion (integration at the data level), mid-level fusion (integration at the feature level), late fusion (integration at the decision level), and hybrid fusion (combining multiple strategies). Different strategies are suited to different application scenarios, enabling flexible adaptation to complex data fusion requirements. - (3)
Enhanced Model Robustness: By incorporating multimodal data and multi-model estimation, uncertainties arising from single-modality data can be effectively reduced, improving the model’s robustness against noise and outliers. - (4)
Improved Performance and Generalization Capability: MME methods comprehensively capture target information by fusing multimodal data, thereby boosting both model performance and generalization ability. - (5)
Flexibility in Model Architecture: MME methods typically offer high flexibility, allowing the selection of appropriate model architectures based on specific task requirements. For example, unified embedding-decoder architectures and cross-modal attention architectures can be combined to fully exploit the advantages of different structural designs.
| - (1)
In scenarios such as multi-object tracking and complex trajectory prediction, multi-model estimation methods can effectively deal with the various motion patterns and uncertainties of targets. - (2)
Suitable for integrated navigation systems, such as the fusion of inertial navigation and satellite navigation, multi-model estimation can improve positioning accuracy and reliability. - (3)
In complex industrial scenarios such as power systems and chemical processes, MME methods can be used for modeling and control to address the dynamic changes in system parameters.
|
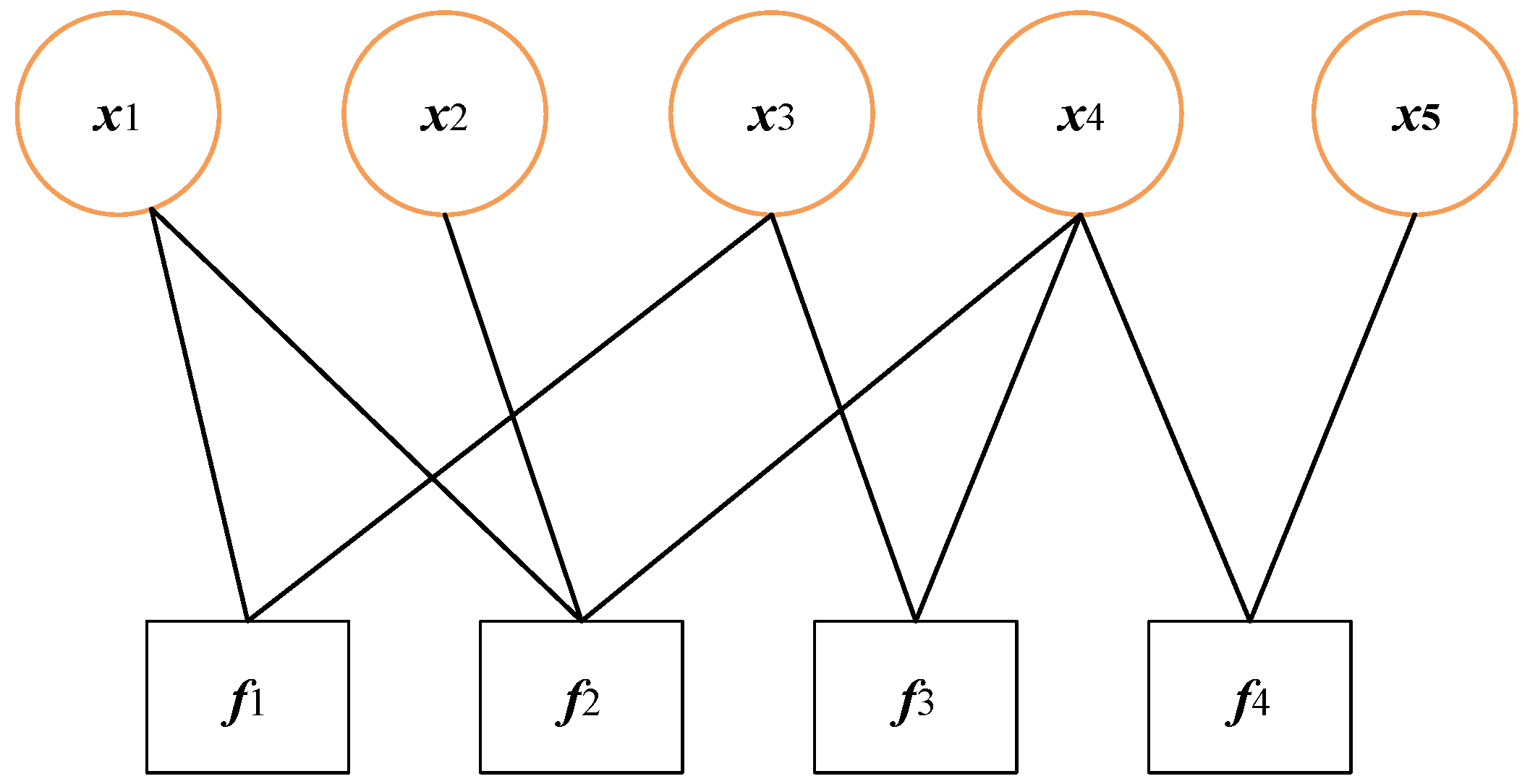
| FG | - (1)
Intuitiveness and Flexibility: FGs visually represent the relationships between variables and factors, making complex probabilistic models more intuitive and easier to understand. Compared to Bayesian networks, FGs can more generally express the decomposition of probability distributions, making them suitable for a wide range of complex probabilistic models. - (2)
Efficient Inference and Optimization Capabilities: FGs excel in algorithms such as variable elimination and message passing, significantly improving inference efficiency. By jointly optimizing the relationships between data from different sensors, FGs can efficiently fuse multi-sensor data. - (3)
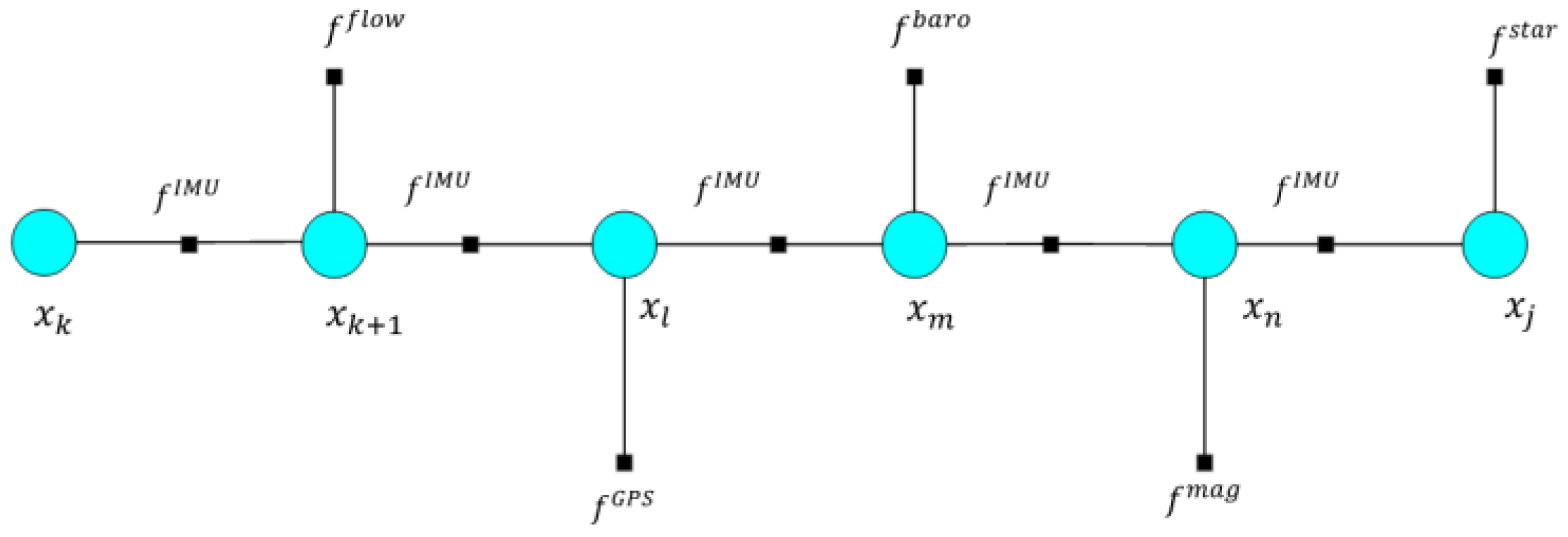
Strong Multi-Source Data Fusion Capability: FGs can effectively integrate data from various sensors (such as cameras, radars, and IMUs). By constructing an FG model, they can jointly optimize heterogeneous multi-source data, thereby enhancing the accuracy and reliability of data fusion. - (4)
Support for Dynamic Data Processing: FG algorithms support techniques such as sliding-window optimization (Sliding-Window FGO), enabling dynamic processing of real-time data streams. This makes them suitable for scenarios with high computational complexity and stringent real-time requirements. - (5)
Robustness and Outlier Resistance: In complex environments (such as urban canyons), FGO demonstrates better robustness and positioning accuracy compared to traditional methods like the EKF.
| - (1)
Autonomous Driving and Robot Navigation: FG methods are widely used in autonomous driving and robot navigation to integrate data from multiple sources such as cameras, radar, LiDAR, and IMU, thereby enhancing the accuracy of localization and mapping. - (2)
Underwater Robot Localization: In complex underwater environments, FG methods can effectively handle abnormal sensor observations, thereby improving the positioning accuracy of Autonomous Underwater Vehicles. - (3)
Industrial Fault Detection and Diagnosis: FG methods can be used to integrate monitoring data from different sensors to achieve early warning and diagnosis of equipment faults. - (4)
Medical Diagnosis: In the medical field, FG methods can integrate patients’ medical records, imaging data, and laboratory test results to improve the accuracy of disease diagnosis. - (5)
Environmental Monitoring: FG methods can integrate data from satellites, ground sensors, and meteorological data to monitor environmental changes in real time, supporting environmental management and decision-making.
|
| AI | - (1)
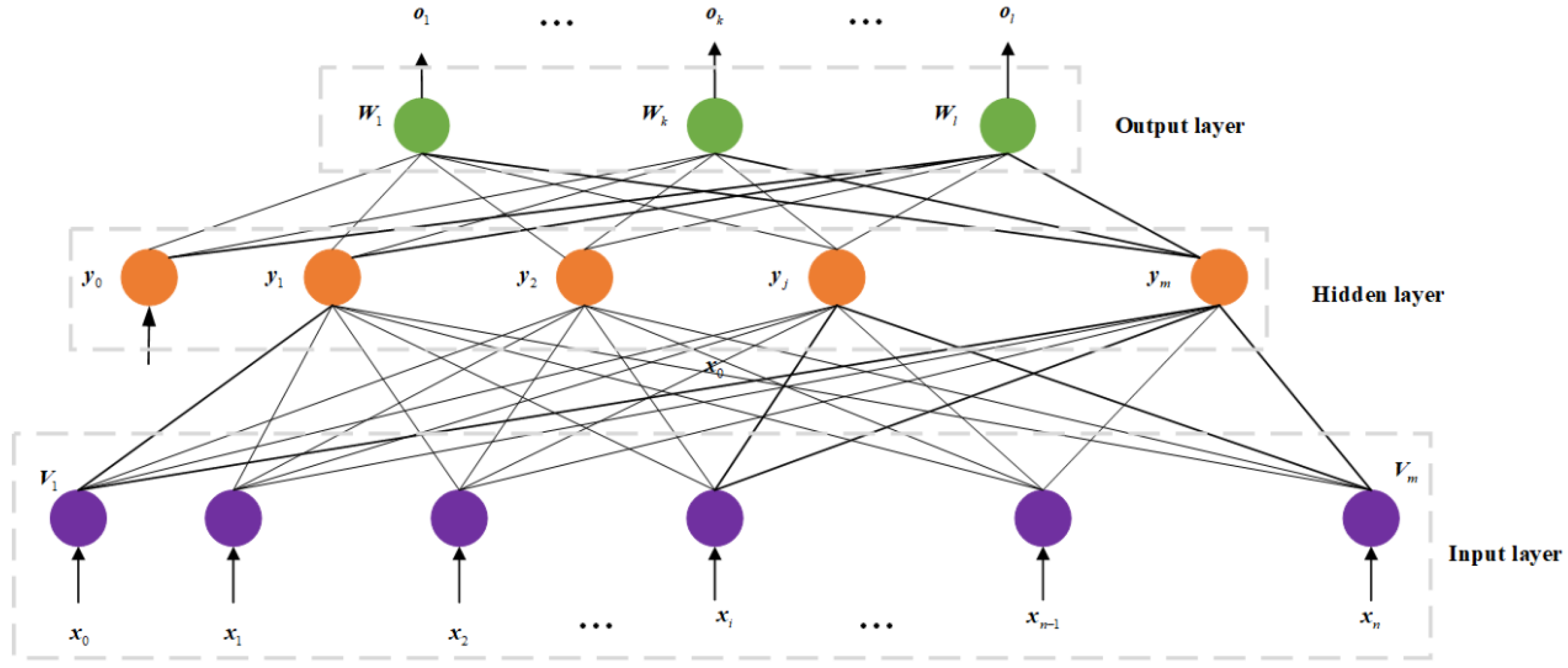
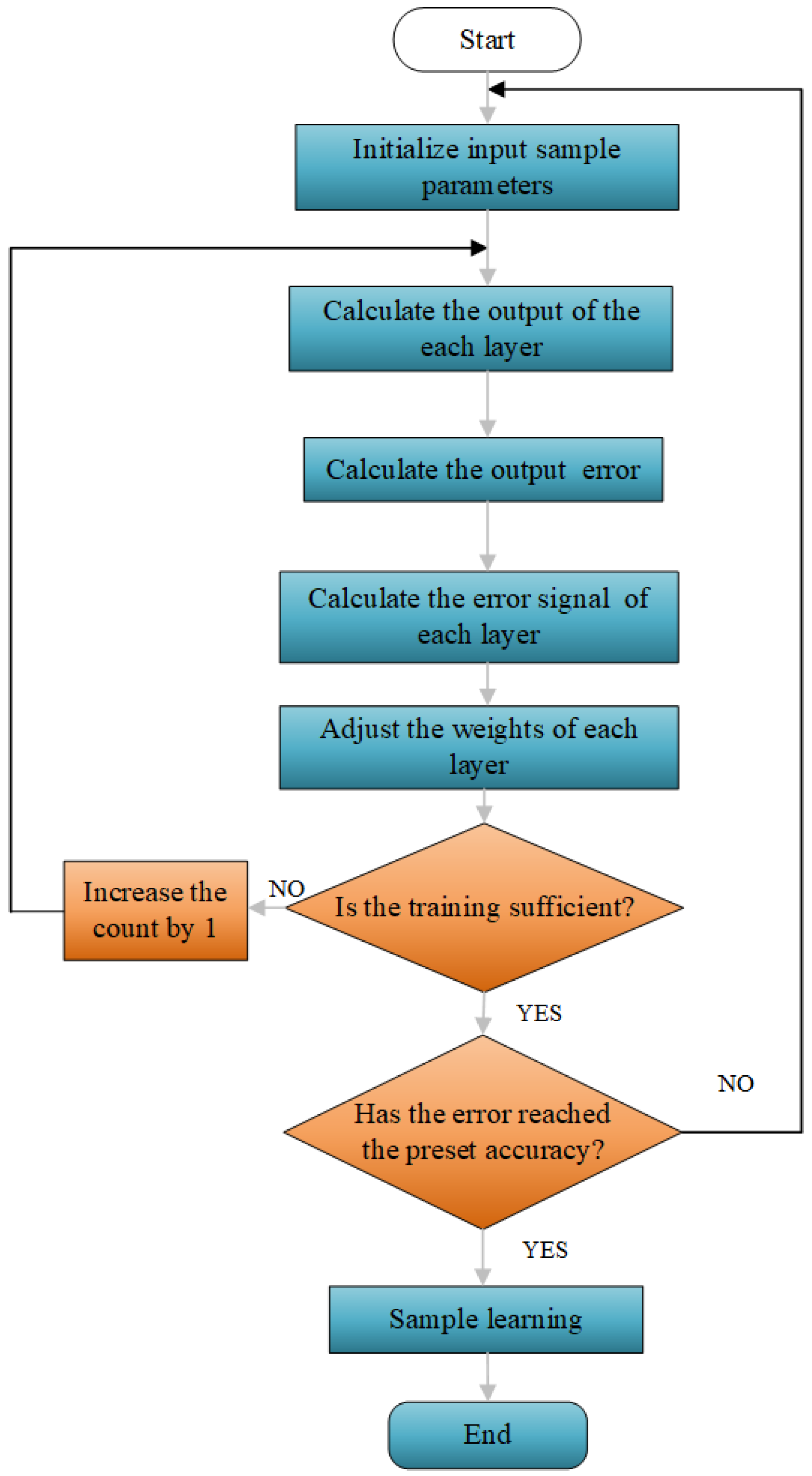
Heterogeneous Data Processing Capability: AI methods can handle data from diverse sources, formats, and structures (such as text, images, and sensor data) through multimodal models (e.g., Transformers, hybrid neural networks) to achieve unified processing. - (2)
Automatic Feature Extraction and Representation Learning: Deep learning models (e.g., autoencoders, BERT) autonomously learn high-level abstract features without manual feature engineering, adapting to the complexity of multi-source data. This reduces reliance on domain-specific knowledge while improving feature expression efficiency and generalization. - (3)
Robustness and Fault Tolerance: AI maintains stability amid data noise, missing values, or conflicts by leveraging adversarial training, data augmentation, and attention mechanisms to filter redundant information. - (4)
Additional capabilities include cross-modal association and reasoning, real-time performance and scalability, and adaptability and dynamic updating.
| - (1)
Autonomous Driving: Integrating data from cameras, radar, and LiDAR helps vehicles understand their surroundings from multiple perspectives, enabling safe navigation. - (2)
Medical Diagnosis: Fusing patient medical records with medical imaging data allows for the rapid and accurate identification of diseases, thereby improving diagnostic efficiency. - (3)
Smart Cities: In real estate management, combining sensor data, social media feedback, and Geographic Information System (GIS) data optimizes urban spatial layout and resource allocation. - (4)
Industrial Internet of Things (IIoT): Analyzing sensor data enables predictive maintenance and optimization of equipment, thereby increasing production efficiency. - (5)
Environmental Monitoring: Integrating satellite data, ground sensor data, and meteorological data allows for real-time monitoring of environmental changes, supporting environmental management and decision-making.
|
| Uncertainty reasoning | - (1)
Strong capability in handling uncertainty: Uncertainty reasoning methods can effectively deal with uncertainty in data, including imprecision, inconsistency, and sensor errors. For example, the Dempster–Shafer theory of evidence can model and fuse uncertain information, while Bayesian methods handle uncertainty through probabilistic updates. - (2)
High flexibility: Uncertainty reasoning methods can flexibly handle different types of data sources and meet the needs of fusing multi-source heterogeneous data. They are capable of integrating symbolic reasoning and numerical reasoning to process various types of information, ranging from qualitative to quantitative. - (3)
Enhanced decision-making reliability: By properly handling uncertainty, uncertainty reasoning methods can improve the reliability of the fusion results and provide support for decision-making in complex environments. - (4)
High computational complexity, high requirements for data preprocessing, difficulty in model construction, and challenges in real-time performance.
| - (1)
Target Recognition and Tracking in Complex Environments: In target recognition and tracking tasks, uncertainty reasoning methods can effectively handle uncertain data from multiple sensors (such as cameras and radars), thereby improving the accuracy and reliability of target detection. - (2)
Medical Diagnosis: In the medical field, by integrating patients’ medical records, imaging data, and laboratory test results, uncertainty reasoning methods can more accurately identify diseases and enhance the accuracy of diagnosis.
|






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}