
Recommendation Model Based on Higher-Order Semantics and Node Attention in Heterogeneous Graph Neural Networks

Abstract
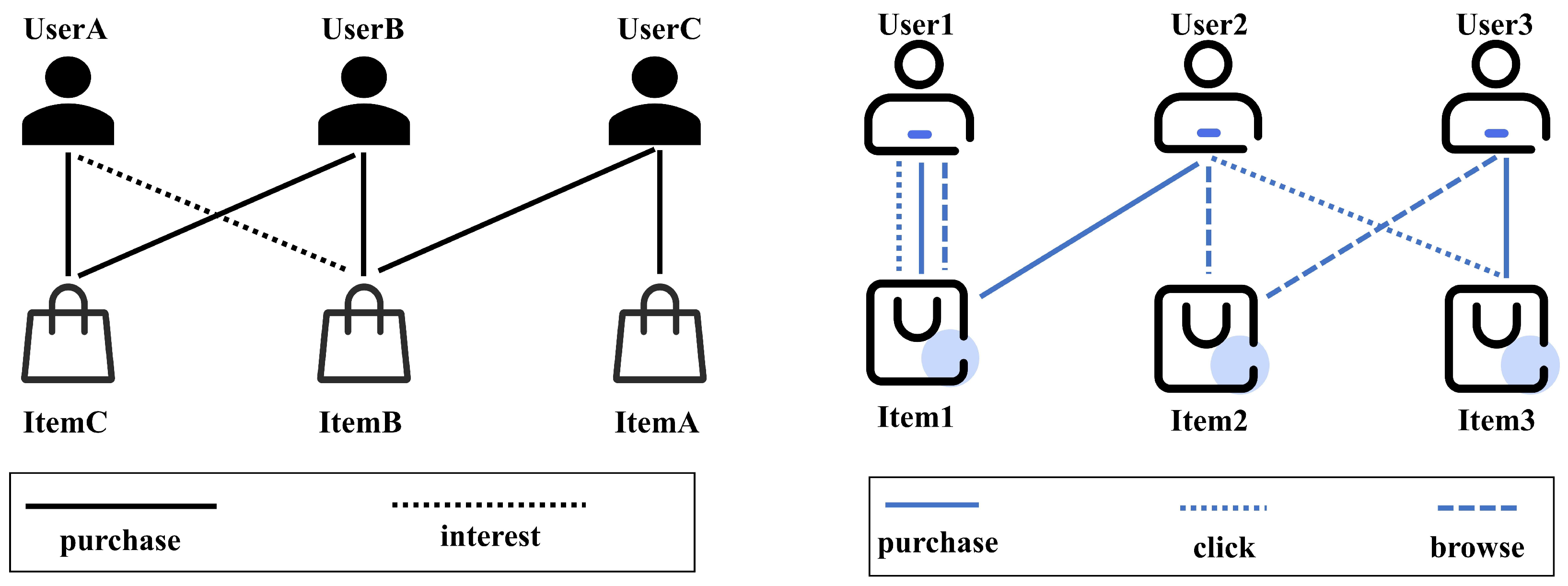
1. Introduction
2. Related Work
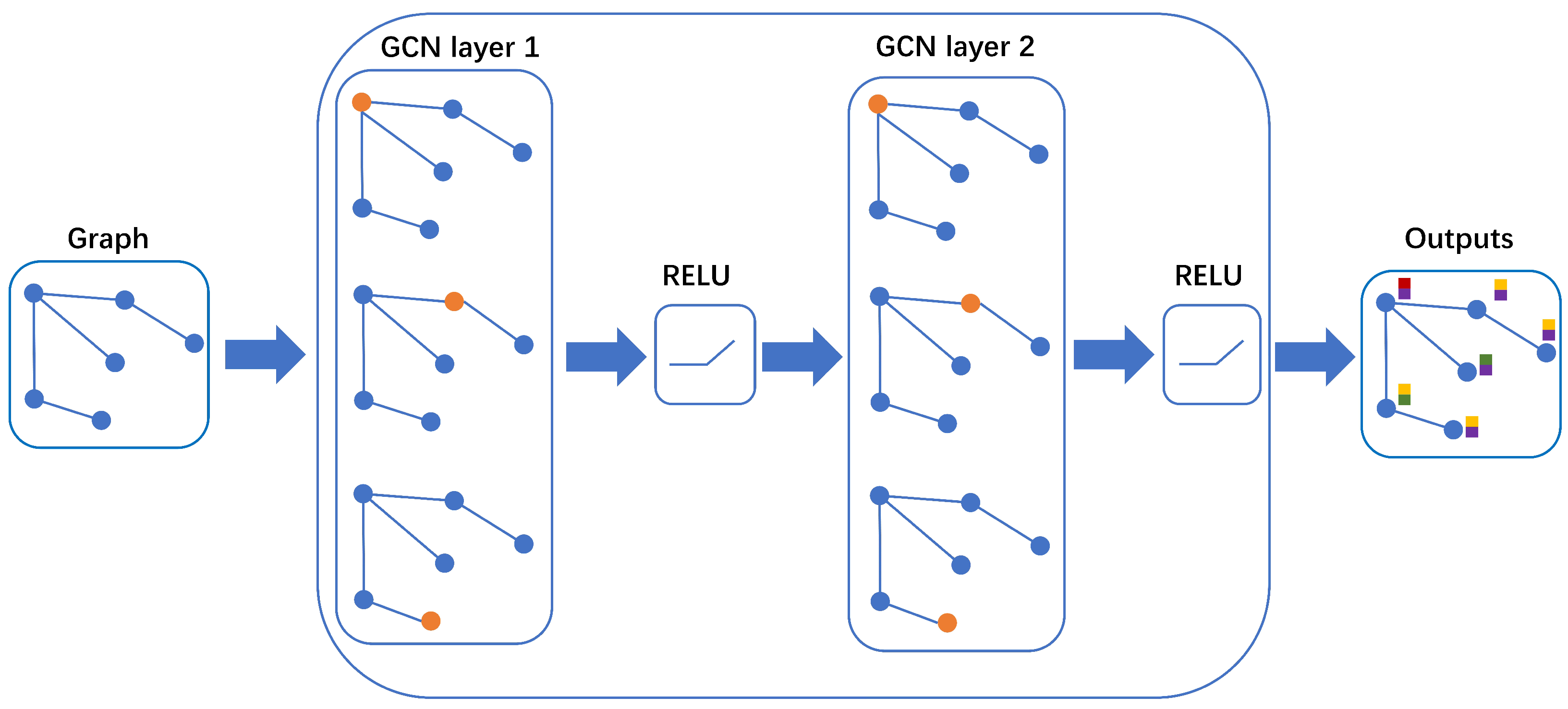
3. Proposed Model
3.1. Interest Aggregation Layer
3.2. Common Interest Feature Capture Layer
3.3. Feature Fusion Layer
4. Experiments
4.1. Dataset
- Amazon-Books: This dataset is derived from Amazon’s product review data, containing user ratings and interaction behaviors for books. The nodes in the dataset include users and books, and the edges represent user ratings or purchase behaviors for books. The characteristic of this dataset is that user–item interactions are relatively sparse, making it suitable for validating model performance under sparse data conditions.
- Yelp: This dataset comes from user review data on the Yelp platform, containing user ratings and reviews for businesses. The nodes in the dataset include users and businesses, and the edges represent user ratings or review behaviors for businesses. The characteristic of this dataset is that user–business interactions are relatively dense, making it suitable for validating model performance under dense data conditions.
- Douban-Movie: This dataset is derived from user rating data on the Douban Movie platform, containing user ratings and reviews for movies. The nodes in the dataset include users and movies, and the edges represent user rating or review actions on movies. The characteristic of this dataset is the diversity of user–movie interactions, making it suitable for validating model performance on diverse data.
4.2. Evaluation Metrics and Baseline Methods
- Precision@K: Measures how many of the top K items in the recommendation list are actually of interest to the user. The higher the precision, the more accurate the recommendation results.
- Recall@K: Measures how many of the user’s actual items of interest are covered by the top K items in the recommendation list. The higher the recall, the more comprehensive the recommendation results.
- GCN (Graph Convolutional Network): A classic graph neural network model that aggregates the features of neighboring nodes through convolution operations to generate node representations.
- GAT (Graph Attention Network): A graph neural network model based on the attention mechanism, which can dynamically adjust the importance of neighboring nodes to enhance the model’s expressive power.
- HAN (Heterogeneous Graph Attention Network): A heterogeneous graph neural network model that captures node and semantic information in heterogeneous graphs through a hierarchical attention mechanism.
- MAGNN (Metapath Aggregated Graph Neural Network): A heterogeneous graph neural network model based on metapath aggregation, capable of capturing high-order semantic information in heterogeneous graphs.
- GTN (Graph Transformer Networks): A model capable of generating new graph structures and learning node representations on these new graphs.
- HGT (Heterogeneous Graph Transformer): An advanced neural network architecture for modeling and processing heterogeneous graph data.
- RippleNet: A knowledge graph-based recommendation model that diffuses user interests by simulating the propagation of ripples.
- KGAT (Knowledge Graph Attention Network): A heterogeneous graph neural network model based on knowledge graphs, which explicitly models high-order connections in the knowledge graph and uses attention mechanisms to distinguish the importance of neighboring nodes.
4.3. Experimental Results
4.4. Ablation Experiments
- HAS-HGNN (Full Model): The complete model including the interest aggregation layer, common interest feature capture layer, and feature fusion layer.
- w/o Interest Aggregation: Removes the interest aggregation layer, using only the common interest feature capture layer and feature fusion layer.
- w/o Common Interest: Removes the common interest feature capture layer, using only the interest aggregation layer and feature fusion layer.
- w/o Attention Fusion: Removes the feature fusion layer, directly concatenating the interest aggregation layer and common interest features.
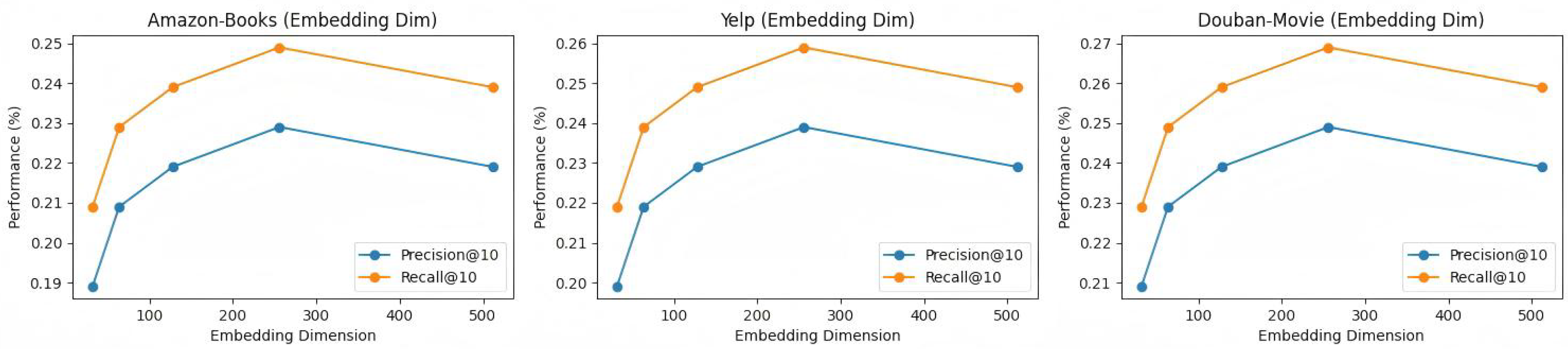
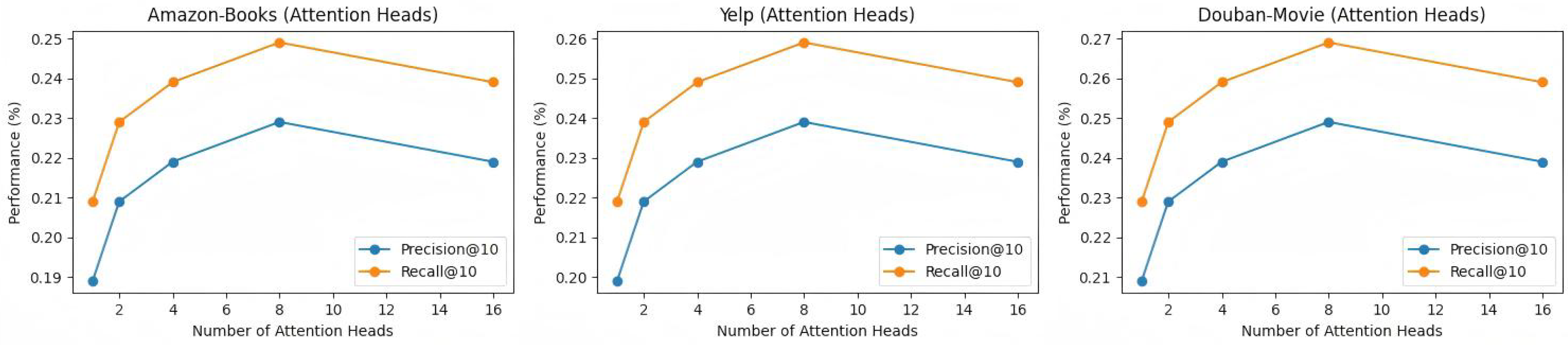
4.5. Hyperparameter Experiment
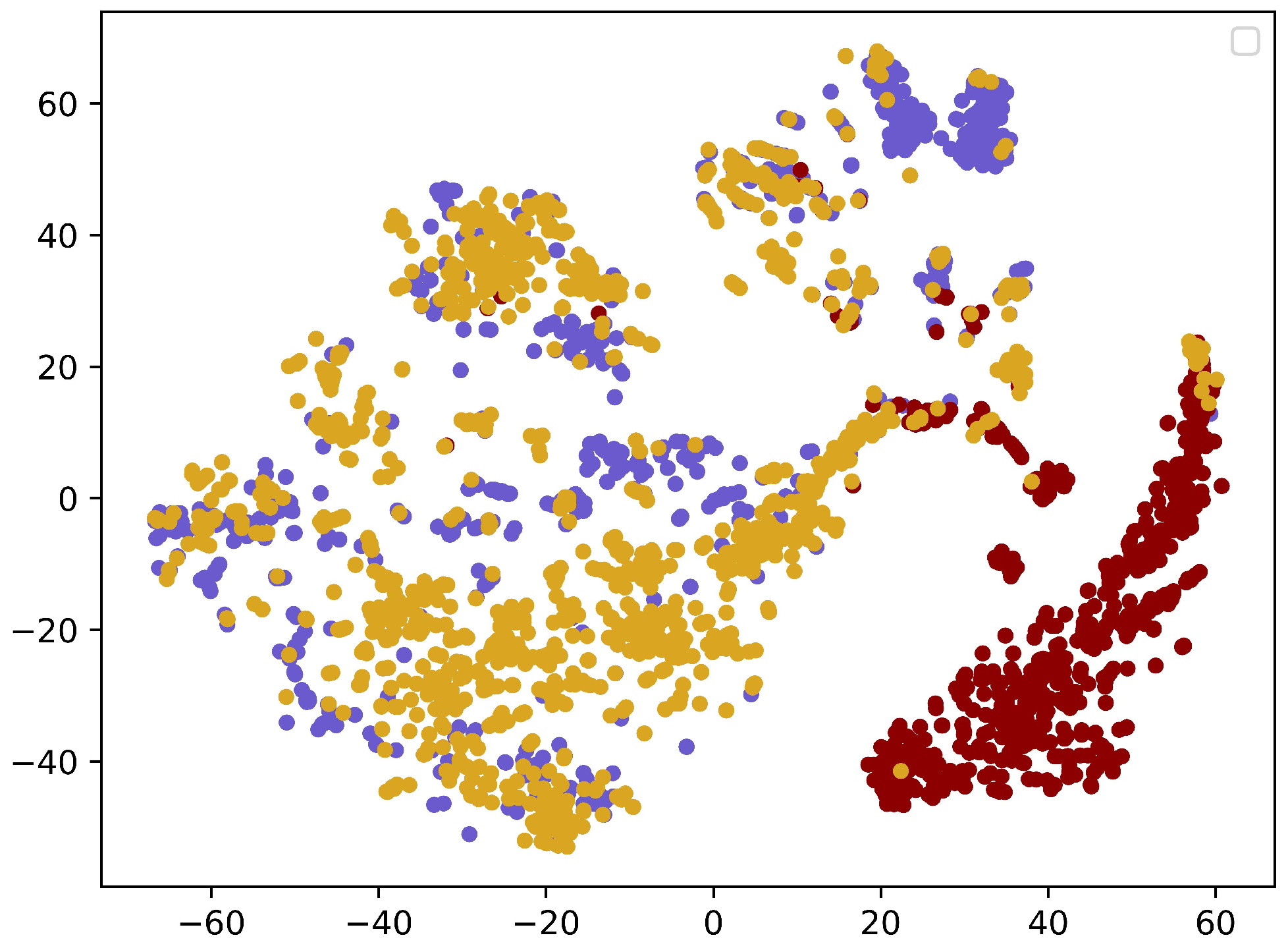
4.6. Visual Experiment
4.7. Robustness Studies
4.8. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Lops, P.; De Gemmis, M.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2011; pp. 73–105. [Google Scholar]
- Zheng, X.; Wang, Y.; Liu, Y.; Li, M.; Zhang, M.; Jin, D.; Yu, P.S.; Pan, S. Graph neural networks for graphs with heterophily: A survey. arXiv 2022, arXiv:2202.07082. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- White, D.R.; Reitz, K.P. Graph and semigroup homomorphisms on networks of relations. Soc. Netw. 1983, 5, 193–234. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, X.; Shi, C.; Hu, B.; Song, G.; Ye, Y. Heterogeneous graph structure learning for graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 4697–4705. [Google Scholar]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous graph attention network. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. Magnn: Metapath aggregated graph neural network for heterogeneous graph embedding. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]
- Wang, H.; Zhang, F.; Wang, J.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Ripplenet: Propagating user preferences on the knowledge graph for recommender systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 417–426. [Google Scholar]
- Jiang, W.; Sun, Y. Social-RippleNet: Jointly modeling of ripple net and social information for recommendation. Appl. Intell. 2023, 53, 3472–3487. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Zhao, Y.; Wang, S.; Duan, H. LSPI: Heterogeneous graph neural network classification aggregation algorithm based on size neighbor path identification. Appl. Soft Comput. 2025, 171, 112656. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, S.; Duan, H. HGNN- BRFE: Heterogeneous Graph Neural Network Model Based on Region Feature Extraction. Electronics 2024, 13, 4447. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, H.; Duan, H. HGNN-GAMS: Heterogeneous Graph Neural Networks for Graph Attribute Mining and Semantic Fusion. IEEE Access 2024, 12, 191603–191611. [Google Scholar] [CrossRef]
- Li, Y.; Liu, K.; Satapathy, R.; Wang, S.; Cambria, E. Recent developments in recommender systems: A survey. IEEE Comput. Intell. Mag. 2024, 19, 78–95. [Google Scholar] [CrossRef]
- Chen, Z.; Gan, W.; Wu, J.; Hu, K.; Lin, H. Data scarcity in recommendation systems: A survey. ACM Trans. Recomm. Syst. 2025, 3, 1–31. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Users | Items | Interactions | Edge Types |
|---|---|---|---|---|
| Amazon-Books | 10,000 | 20,000 | 500,000 | 2 |
| Yelp | 15,000 | 25,000 | 1,000,000 | 3 |
| Douban-Movie | 20,000 | 30,000 | 1,500,000 | 4 |
| Method | Amazon-Books | Yelp | Douban-Movie | |||
|---|---|---|---|---|---|---|
| Precision@10 | Recall@10 | Precision@10 | Recall@10 | Precision@10 | Recall@10 | |
| GCN | 0.1634 ± 0.0023 | 0.1756 ± 0.0018 | 0.1645 ± 0.0031 | 0.1867 ± 0.0025 | 0.1723 ± 0.0027 | 0.1978 ± 0.0032 |
| GAT | 0.1640 ± 0.0025 | 0.1778 ± 0.0021 | 0.1656 ± 0.0029 | 0.1878 ± 0.0028 | 0.1734 ± 0.0030 | 0.1989 ± 0.0026 |
| HAN | 0.1656 ± 0.0032 | 0.1878 ± 0.0027 | 0.1767 ± 0.0035 | 0.1989 ± 0.0031 | 0.1878 ± 0.0029 | 0.2090 ± 0.0034 |
| MAGNN | 0.1767 ± 0.0028 | 0.1989 ± 0.0030 | 0.1878 ± 0.0032 | 0.2090 ± 0.0029 | 0.1989 ± 0.0033 | 0.2190 ± 0.0036 |
| GTN | 0.1878 ± 0.0031 | 0.2090 ± 0.0035 | 0.1989 ± 0.0034 | 0.2190 ± 0.0032 | 0.2090 ± 0.0037 | 0.2290 ± 0.0038 |
| HGT | 0.1989 ± 0.0036 | 0.2190 ± 0.0033 | 0.2090 ± 0.0038 | 0.2290 ± 0.0039 | 0.2190 ± 0.0040 | 0.2395 ± 0.0041 |
| RippleNet | 0.2052 ± 0.0039 | 0.2298 ± 0.0042 | 0.2176 ± 0.0041 | 0.2390 ± 0.0040 | 0.2211 ± 0.0043 | 0.2489 ± 0.0045 |
| KGAT | 0.2114 ± 0.0040 | 0.2311 ± 0.0043 | 0.2204 ± 0.0042 | 0.2455 ± 0.0044 | 0.2296 ± 0.0045 | 0.2549 ± 0.0046 |
| HAS-HGNN | 0.2190 ± 0.0045 | 0.2390 ± 0.0046 | 0.2290 ± 0.0048 | 0.2490 ± 0.0047 | 0.2390 ± 0.0050 | 0.2590 ± 0.0052 |
| Method | Amazon-Books | Yelp | Douban-Movie | |||
|---|---|---|---|---|---|---|
| Precision@10 | Recall@10 | Precision@10 | Recall@10 | Precision@10 | Recall@10 | |
| HAS-HGNN | 0.219 | 0.239 | 0.229 | 0.249 | 0.239 | 0.259 |
| w/o Interest Aggregation | 0.189 | 0.209 | 0.199 | 0.219 | 0.209 | 0.229 |
| w/o Common Interest | 0.199 | 0.219 | 0.209 | 0.229 | 0.219 | 0.239 |
| w/o Attention Fusion | 0.209 | 0.229 | 0.219 | 0.239 | 0.229 | 0.249 |
| Method | Amazon-Books | Yelp | Douban-Movie | |||
|---|---|---|---|---|---|---|
| Precision@10 | Recall@10 | Precision@10 | Recall@10 | Precision@10 | Recall@10 | |
| No noise | 0.219 | 0.239 | 0.229 | 0.249 | 0.239 | 0.259 |
| Noise | 0.191 | 0.212 | 0.207 | 0.219 | 0.214 | 0.227 |
| Metrics | Methods | ||||
|---|---|---|---|---|---|
| GCN | GAT | HAN | KGAT | HAS-HGNN | |
| Times/epoch (s) | 0.425 | 0.484 | 0.537 | 1.65 | 0.87 |
| Memory (GB) | 0.567 | 0.677 | 0.793 | 1.48 | 1.13 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Jin, T.; Luo, H.; Wang, E.; Tao, R. Recommendation Model Based on Higher-Order Semantics and Node Attention in Heterogeneous Graph Neural Networks. Mathematics 2025, 13, 1479. https://doi.org/10.3390/math13091479
Li S, Jin T, Luo H, Wang E, Tao R. Recommendation Model Based on Higher-Order Semantics and Node Attention in Heterogeneous Graph Neural Networks. Mathematics. 2025; 13(9):1479. https://doi.org/10.3390/math13091479
Chicago/Turabian StyleLi, Siyue, Tian Jin, Hao Luo, Erfan Wang, and Ranting Tao. 2025. "Recommendation Model Based on Higher-Order Semantics and Node Attention in Heterogeneous Graph Neural Networks" Mathematics 13, no. 9: 1479. https://doi.org/10.3390/math13091479
APA StyleLi, S., Jin, T., Luo, H., Wang, E., & Tao, R. (2025). Recommendation Model Based on Higher-Order Semantics and Node Attention in Heterogeneous Graph Neural Networks. Mathematics, 13(9), 1479. https://doi.org/10.3390/math13091479