
MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation

Abstract
1. Introduction
- We propose an innovative MLKGC framework, which combines multimodal data and LLMs for KGC tasks. This is the first work to integrate multimodal information with triple-based LLMs methods, offering a novel solution for complex knowledge graph completion tasks.
- We designed three novel supplementary sets: the the head set, the relationship set, and the tail set. By incorporating multi-modal data, such as images and audio, this approach enhances the knowledge representation and reasoning capabilities of the model.
- Empirical results on three benchmark datasets demonstrate the effectiveness of MLKGC, showing that it significantly outperforms state-of-the-art baselines.
2. Related Work
3. Methodology
3.1. Problem Formulation
3.2. Overall Method
3.2.1. Information Set
- Head Set: The head set consists of triples designed to enhance the understanding of query semantics through the analogy of the LLMs. The training KG triples and validation KG triples are sampled from different distributions and respectively. Formally, , where includes triples that share the same head entity as the query .
- Tail Set: Similar to the head set, the training and validation triples are sampled from distinct distributions. Formally, , where includes triples that share the same tail entity as the query .
- Relationship Set: The relationship set S comprises triples that offer more information about the query’s entity g. Specifically, S includes all triples, where g appears as either the head or the tail entity in the training and validation datasets. Formally, .
3.2.2. Prompt Engineering with Large Language Models
3.2.3. Multimodal Information Supplement
4. Experiment
4.1. Setup
4.2. Experimental Results
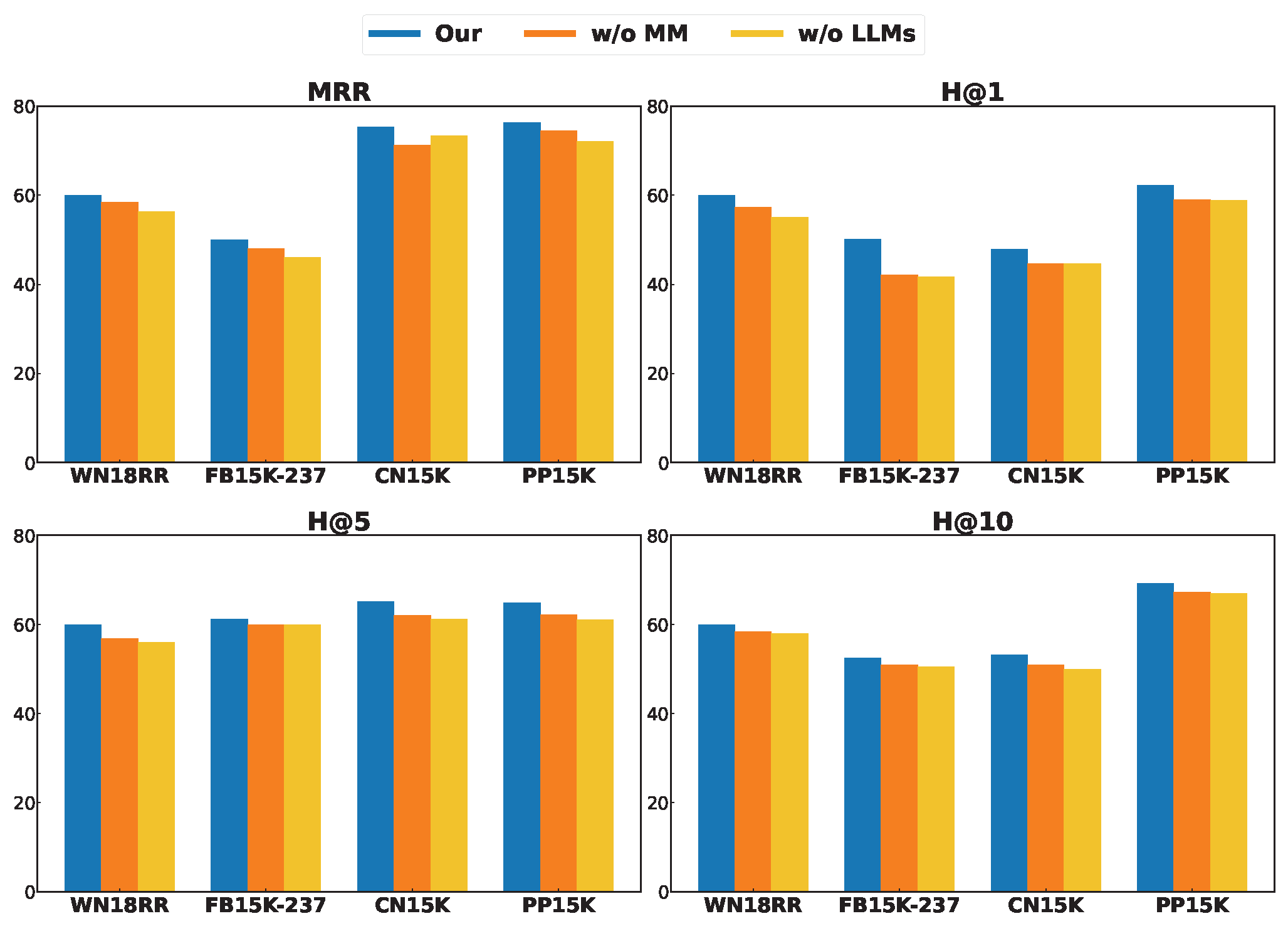
4.3. Ablation Study
5. Conclusions
6. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, C.; Yu, H.; Wan, F. Information retrieval technology based on knowledge graph. In Proceedings of the 2018 3rd International Conference on Advances in Materials, Mechatronics and Civil Engineering (ICAMMCE 2018), Hangzhou, China, 13–15 April 2018; Atlantis Press: Dordrecht, The Netherlands, 2018; pp. 291–296. [Google Scholar]
- Yang, Z.; Wang, Y.; Gan, J.; Li, H.; Lei, N. Design and research of intelligent question-answering (q&a) system based on high school course knowledge graph. Mob. Netw. Appl. 2021, 26, 1884–1890. [Google Scholar]
- Guo, Q.; Zhuang, F.; Qin, C.; Zhu, H.; Xie, X.; Xiong, H.; He, Q. A survey on knowledge graph-based recommender systems. IEEE Trans. Knowl. Data Eng. 2020, 34, 3549–3568. [Google Scholar] [CrossRef]
- Cao, E.; Wang, D.; Huang, J.; Hu, W. Open knowledge enrichment for long-tail entities. In Proceedings of the Web Conference 2020, WWW ’20, Taipei, Taiwan, 20–24 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 384–394. [Google Scholar]
- Zheng, D.; Song, X.; Ma, C.; Tan, Z.; Ye, Z.; Dong, J.; Xiong, H.; Zhang, Z.; Karypis, G. Dgl-ke: Training knowledge graph embeddings at scale. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, China, 25–30 July 2020; pp. 739–748. [Google Scholar]
- Li, X.; Lyu, M.; Wang, Z.; Chen, C.-H.; Zheng, P. Exploiting knowledge graphs in industrial products and services: A survey of key aspects, challenges, and future perspectives. Comput. Ind. 2021, 129, 103449. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Kg-bert: Bert for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Bosselut, A.; Rashkin, H.; Sap, M.; Malaviya, C.; Celikyilmaz, A.; Choi, Y. Comet: Commonsense transformers for automatic knowledge graph construction. arXiv 2019, arXiv:1906.05317. [Google Scholar]
- Sun, Z.; Vashishth, S.; Sanyal, S.; Talukdar, P.; Yang, Y. A re-evaluation of knowledge graph completion methods. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5516–5522. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Rae, J.W.; Borgeaud, S.; Cai, T.; Millican, K.; Hoffmann, J.; Song, F.; Aslanides, J.; Henderson, S.; Ring, R.; Young, S.; et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv 2021, arXiv:2112.11446. [Google Scholar]
- Chen, X.; Zhang, N.; Li, L.; Deng, S.; Tan, C.; Xu, C.; Huang, F.; Si, L.; Chen, H. Hybrid transformer with multi-level fusion for multimodal knowledge graph completion. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 904–915. [Google Scholar]
- Shi, B.; Weninger, T. Open-world knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozi, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Lan, Y.; He, S.; Liu, K.; Zeng, X.; Liu, S.; Zhao, J. Path-based knowledge reasoning with textual semantic information for medical knowledge graph completion. BMC Med. Informatics Decis. Mak. 2021, 21, 1–12. [Google Scholar] [CrossRef]
- Jagvaral, B.; Lee, W.-K.; Roh, J.-S.; Kim, M.-S.; Park, Y.-T. Path-based reasoning approach for knowledge graph completion using cnn-bilstm with attention mechanism. Expert Syst. Appl. 2020, 142, 112960. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2013; Volume 26. [Google Scholar]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A review of relational machine learning for knowledge graphs. Proc. IEEE 2015, 104, 11–33. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.-T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Chen, S.; Liu, X.; Gao, J.; Jiao, J.; Zhang, R.; Ji, Y. Hitter: Hierarchical transformers for knowledge graph embeddings. arXiv 2020, arXiv:2008.12813. [Google Scholar]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. One-shot relational learning for knowledge graphs. arXiv 2018, arXiv:1808.09040. [Google Scholar]
- Chen, M.; Zhang, W.; Zhang, W.; Chen, Q.; Chen, H. Meta relational learning for few-shot link prediction in knowledge graphs. arXiv 2019, arXiv:1909.01515. [Google Scholar]
- Sadeghian, A.; Armandpour, M.; Ding, P.; Wang, D.Z. DRUM: End-To-End Differentiable Rule Mining on Knowledge Graphs; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]
- Wei, Y.; Huang, Q.; Kwok, J.T.; Zhang, Y. KICGPT: Large language model with knowledge in context for knowledge graph completion. In Findings of the Association for Computational Linguistics: EMNLP 2023; Association for Computational Linguistics: Singapore, 2023; pp. 8667–8683. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2901–2908. [Google Scholar]
- Yao, L.; Peng, J.; Mao, C.; Luo, Y. Exploring large language models for knowledge graph completion. arXiv 2023, arXiv:2308.13916. [Google Scholar]
- Saxena, A.; Kochsiek, A.; Gemulla, R. Sequence-to-sequence knowledge graph completion and question answering. arXiv 2022, arXiv:2203.10321. [Google Scholar]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Liu, T.; et al. A survey on in-context learning. arXiv 2022, arXiv:2301.00234. [Google Scholar]
- Zhang, Y.; Chen, Z.; Guo, L.; Xu, Y.; Hu, B.; Liu, Z.; Zhang, W.; Chen, H. Native: Multi-modal knowledge graph completion in the wild. In SIGIR; ACM: New York, NY, USA, 2024; pp. 91–101. [Google Scholar]
- Chen, M.; Tian, Y.; Yang, M.; Zaniolo, C. Multilingual knowledge graph embeddings for cross-lingual knowledge alignment. arXiv 2016, arXiv:1611.03954. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML 2021), Online, 18–24 July 2021. [Google Scholar]
- Toutanova, K.; Chen, D.; Pantel, P.; Poon, H.; Choudhury, P.; Gamon, M. Representing text for joint embedding of text and knowledge bases. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1499–1509. [Google Scholar]
- Chen, X.; Chen, M.; Shi, W.; Sun, Y.; Zaniolo, C. Embedding Uncertain Knowledge Graphs; ser. AAAI’19/IAAI’19/EAAI’19; AAAI Press: Washington, DC, USA, 2019. [Google Scholar]
- AlMousa, M.; Benlamri, R.; Khoury, R. A novel word sense disambiguation approach using wordnet knowledge graph. Comput. Speech Lang. 2022, 74, 101337. [Google Scholar] [CrossRef]
- Nickel, M.; Tresp, V.; Kriegel, H.-P. A three-way model for collective learning on multi-relational data. ICML 2011, 11, 3104482–3104584. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Sun, Z.; Deng, Z.-H.; Nie, J.-Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based multi-relational graph convolutional networks. arXiv 2020, arXiv:1911.03082. [Google Scholar]
- Wang, B.; Shen, T.; Long, G.; Zhou, T.; Wang, Y.; Chang, Y. Structure-augmented text representation learning for efficient knowledge graph completion. In Proceedings of the Web Conference 2021, WWW’21, Ljubljana, Slovenia, 12–23 April 2021; ACM: New York, NY, USA, 2021; pp. 1737–1748. [Google Scholar]
- Xie, X.; Zhang, N.; Li, Z.; Deng, S.; Chen, H.; Xiong, F.; Chen, M.; Chen, H. From discrimination to generation: Knowledge graph completion with generative transformer. In Proceedings of the Web Conference 2022, WWW’22; Lyon, France, 25–29 April 2022, Association for Computing Machinery: New York, NY, USA, 2022; pp. 162–165. [Google Scholar]
- Chen, C.; Wang, Y.; Li, B.; Lam, K.-Y. Knowledge is flat: A seq2seq generative framework for various knowledge graph completion. arXiv 2022, arXiv:2209.07299. [Google Scholar]
- Chen, C.; Wang, Y.; Sun, A.; Li, B.; Lam, K.-Y. Dipping plms sauce: Bridging structure and text for effective knowledge graph completion via conditional soft prompting. arXiv 2023, arXiv:2307.01709. [Google Scholar]
- Zhu, Y.; Wang, X.; Chen, J.; Qiao, S.; Ou, Y.; Yao, Y.; Deng, S.; Chen, H.; Zhang, N. Llms for knowledge graph construction and reasoning: Recent capabilities and future opportunities. World Wide Web 2024, 27, 58. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| h | Head entity |
| r | Relationship |
| t | Tail entity |
| ? | Unknown variable |
| Train and validation distribution | |
| Entity and relationship set | |
| Head, tail and relationship set |
| Entities | Relations | Triples | |
|---|---|---|---|
| WN18RR [25] | 40,943 | 11 | 86,835 |
| FB15K-237 [38] | 14,541 | 237 | 272,115 |
| CN15K [39] | 15,000 | 36 | 241,1,58 |
| WN18RR | FB15k-237 | CN15K | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 | |
| TransE [19] | 27.9 | 23.1 | 46.6 | 51.4 | 25.4 | 19.2 | 36.9 | 45.0 | 29.5 | 39.0 | 48.9 | 57.8 |
| DistMult [20] | 35.5 | 24.5 | 45.4 | 50.9 | 26.5 | 20.1 | 36.7 | 37.6 | 30.2 | 39.6 | 38.9 | 56.6 |
| ComplEx [42] | 45.6 | 43.8 | 41.5 | 56.4 | 39.1 | 20.4 | 25.1 | 31.2 | 41.5 | 49.6 | 37.8 | 42.9 |
| ConvE [25] | 37.5 | 23.7 | 32.8 | 51.3 | 20.6 | 13.5 | 27.2 | 47.6 | 33.9 | 42.2 | 47.9 | 53.9 |
| RotatE [43] | 55.2 | 60.6 | 53.9 | 65.7 | 32.0 | 23.2 | 34.8 | 46.0 | 19.2 | 31.5 | 44.5 | 56.1 |
| CompGCN [44] | 29.6 | 12.2 | 39.8 | 55.9 | 27.9 | 19.6 | 25.4 | 40.0 | 40.1 | 52.9 | 34.9 | 52.5 |
| MTL-KGC [45] | 40.4 | 40.4 | 54.5 | 50.2 | 29.3 | 19.7 | 24.2 | 30.1 | 18.0 | 35.7 | 43.1 | 57.2 |
| StAR [45] | 21.1 | 14.1 | 30.3 | 52.4 | 20.5 | 23.9 | 20.3 | 40.3 | 17.4 | 32.1 | 32.9 | 53.4 |
| KG-BERT [7] | 30.3 | 16.5 | 25.2 | 60.3 | 25.2 | 17.9 | 26.5 | 45.6 | 28.7 | 35.3 | 65.3 | 32.6 |
| GenKGC [46] | – | 28.6 | 44.4 | 52.4 | – | 18.7 | 27.2 | 33.7 | – | 34.9 | 45.1 | 57.9 |
| KG-S2S [47] | 57.6 | 52.9 | 60.5 | 65.4 | 35.4 | 28.5 | 38.8 | 49.3 | 28.0 | 23.7 | 47.8 | 43.2 |
| CSProm-KG [48] | 55.2 | 50.1 | 57.2 | 65.7 | 36.0 | 28.1 | 39.5 | 51.1 | 12.3 | 45.6 | 50.3 | 60.2 |
| [49] | – | 23.7 | – | – | – | 19.0 | – | – | – | 45.7 | – | – |
| [49] | – | 27.5 | – | – | – | 20.7 | – | – | – | 48.3 | – | – |
| MMKICGPT w/o GPT (Ours) | 57.9 | 58.5 | 68.8 | 67.1 | 44.7 | 44.8 | 41.7 | 59.5 | 46.0 | 58.7 | 64.0 | 64.1 |
| MMKICGPT w/o MM (Ours) | 58.4 | 59.2 | 68.0 | 69.1 | 45.7 | 45.1 | 42.0 | 59.3 | 47.2 | 59.0 | 63.9 | 65.2 |
| MMKICGPT (Ours) | 59.9 | 60.2 | 70.8 | 70.1 | 47.2 | 49.3 | 45.2 | 62.5 | 47.3 | 60.3 | 64.9 | 65.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, P.; Tang, H.; Li, W.; Zhang, W.; Yan, B. MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation. Mathematics 2025, 13, 1463. https://doi.org/10.3390/math13091463
Yue P, Tang H, Li W, Zhang W, Yan B. MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation. Mathematics. 2025; 13(9):1463. https://doi.org/10.3390/math13091463
Chicago/Turabian StyleYue, Pengfei, Hailiang Tang, Wanyu Li, Wenxiao Zhang, and Bingjie Yan. 2025. "MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation" Mathematics 13, no. 9: 1463. https://doi.org/10.3390/math13091463
APA StyleYue, P., Tang, H., Li, W., Zhang, W., & Yan, B. (2025). MLKGC: Large Language Models for Knowledge Graph Completion Under Multimodal Augmentation. Mathematics, 13(9), 1463. https://doi.org/10.3390/math13091463