
Watermarking for Large Language Models: A Survey


Abstract
1. Introduction
- We present a comprehensive survey of watermarking techniques for text generated by large language models. The focus is on usage scenarios where models produce natural language outputs—such as open-domain dialogue and content creation—that are especially vulnerable to misuse and thus demand mechanisms for origin verification and ownership attribution.
- We provide a systematic categorization of LLM watermarking approaches, dividing them into training-free and training-based methods. This taxonomy captures key algorithmic differences and reflects the practical implementation strategies observed in recent research.
- From a watermarking perspective, we evaluate existing techniques in terms of robustness, imperceptibility, and capacity. This performance-oriented analysis highlights practical trade-offs and informs the selection and design of watermarking strategies for real-world LLM applications.
2. Preliminaries
2.1. Large Language Models
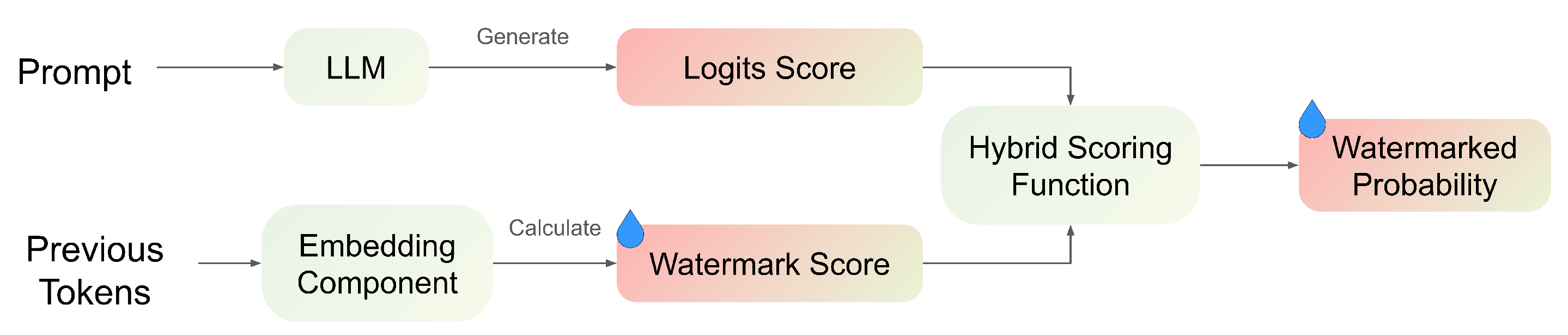
2.2. Watermarking in LLMs
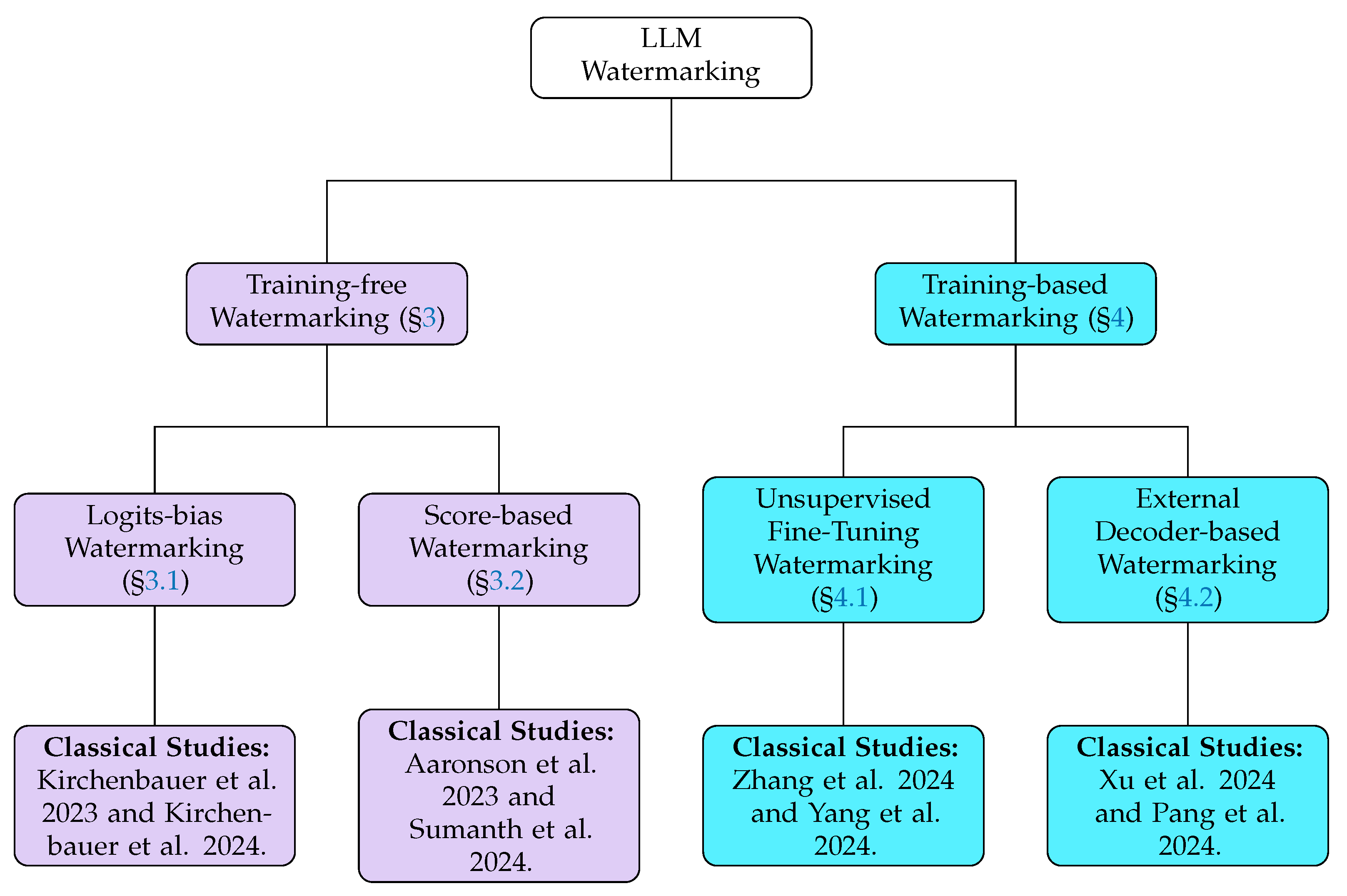
2.3. Taxonomy of LLM Watermarking Algorithms
- Training-free methods, such as logits-bias watermarking and score-based watermarking, operate during the decoding process by adjusting token probabilities. These methods embed statistical patterns into the generated text without modifying the model parameters, making them computationally efficient and easy to integrate with existing models.
- Training-based methods include unsupervised fine-tuning watermarking and external decoder-based watermarking. These approaches either fine-tune the model to generate watermarked outputs intrinsically or introduce an auxiliary decoder. Such methods typically require additional training resources.
3. Training-Free Watermarking
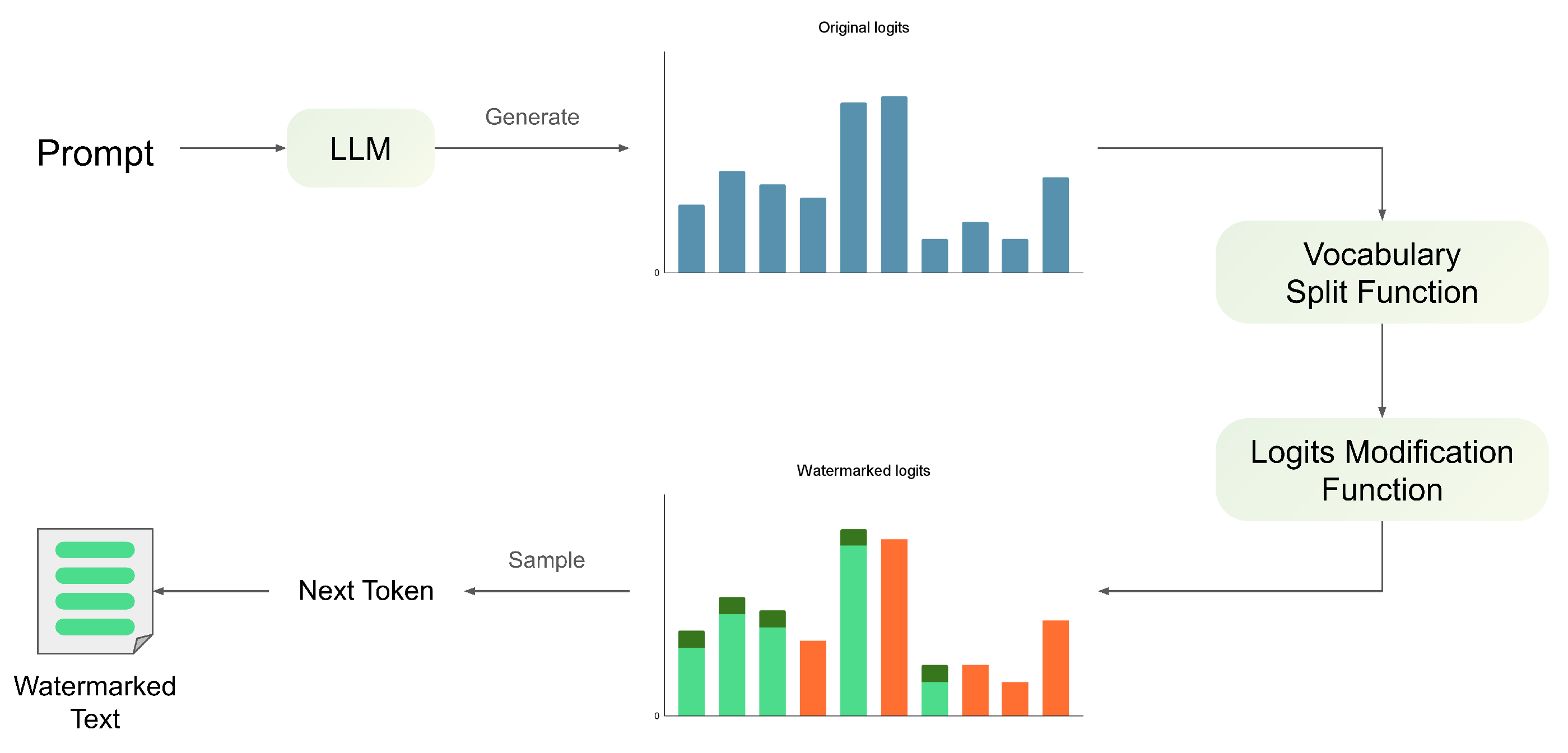
3.1. Logits-Bias Watermarking
3.1.1. Robustness Improvement
3.1.2. Concealment Enhancement
3.1.3. Multi-Bit Watermarking
3.2. Score-Based Watermarking
3.2.1. Concealment Enhancement
3.2.2. Multi-Bit Watermarking
3.2.3. Statistical Analysis
4. Training-Based Watermarking
4.1. Unsupervised Fine-Tuning Watermarking
4.2. External Decoder-Based Watermarking
5. Evaluation Metrics
5.1. Robustness
5.1.1. Token-Level Attacks
5.1.2. Sentence-Level Attacks
5.1.3. Document-Level Attacks
5.2. Imperceptibility
5.2.1. Text Quality
5.2.2. Impact on Downstream Tasks
5.3. Capacity
5.3.1. Single-Bit Watermarking
5.3.2. Multi-Bit Watermarking
6. Challenges and Future Works
6.1. Challenges
6.1.1. Technical and Practical Constraints in LLM Watermarking
6.1.2. Lack of Standardized Benchmarks
6.2. Future Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 4 January 2025).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361v1. [Google Scholar]
- Chiang, W.L.; Zheng, L.; Sheng, Y.; Angelopoulos, A.N.; Li, T.; Li, D.; Zhu, B.; Zhang, H.; Jordan, M.I.; Gonzalez, J.E.; et al. Chatbot arena: An open platform for evaluating LLMs by human preference. In Proceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024, ICML’24, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. In Proceedings of the International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Bengio, Y.; Mindermann, S.; Privitera, D.; Besiroglu, T.; Bommasani, R.; Casper, S.; Choi, Y.; Fox, P.; Garfinkel, B.; Goldfarb, D.; et al. International AI Safety Report. arXiv 2025, arXiv:2501.17805. [Google Scholar]
- van Schyndel, R.; Tirkel, A.; Osborne, C. A digital watermark. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 2, pp. 86–90. [Google Scholar] [CrossRef]
- Baluja, S. Hiding images in plain sight: Deep steganography. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 2066–2076. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Li, F.-F. HiDDeN: Hiding Data With Deep Networks. In Computer Vision–ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Swizterland, 2018; pp. 682–697. [Google Scholar]
- Bassia, P.; Pitas, I.; Nikolaidis, N. Robust audio watermarking in the time domain. IEEE Trans. Multimed. 2001, 3, 232–241. [Google Scholar] [CrossRef]
- Luo, X.; Li, Y.; Chang, H.; Liu, C.; Milanfar, P.; Yang, F. DVMark: A Deep Multiscale Framework for Video Watermarking. IEEE Trans. Image Process. 2023. [Google Scholar] [CrossRef]
- Brassil, J.; Low, S.; Maxemchuk, N.; O’Gorman, L. Electronic marking and identification techniques to discourage document copying. IEEE J. Sel. Areas Commun. 1995, 13, 1495–1504. [Google Scholar] [CrossRef]
- Yang, T.; Wu, H.; Yi, B.; Feng, G.; Zhang, X. Semantic-Preserving Linguistic Steganography by Pivot Translation and Semantic-Aware Bins Coding. IEEE Trans. Dependable Secur. Comput. 2024, 21, 139–152. [Google Scholar] [CrossRef]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S.I. Embedding Watermarks into Deep Neural Networks. In Proceedings of the 2017 ACM International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar] [CrossRef]
- Wu, H.; Liu, G.; Yao, Y.; Zhang, X. Watermarking Neural Networks with Watermarked Images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2591–2601. [Google Scholar] [CrossRef]
- Rizzo, S.G.; Bertini, F.; Montesi, D. Content-preserving Text Watermarking through Unicode Homoglyph Substitution. In Proceedings of the 20th International Database Engineering & Applications Symposium, IDEAS’16, Montreal, Canada, 11–13 July 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 97–104. [Google Scholar] [CrossRef]
- Zhou, W.; Ge, T.; Xu, K.; Wei, F.; Zhou, M. BERT-based Lexical Substitution. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3368–3373. [Google Scholar] [CrossRef]
- Yang, X.; Zhang, J.; Chen, K.; Zhang, W.; Ma, Z.; Wang, F.; Yu, N. Tracing text provenance via context-aware lexical substitution. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 11613–11621. [Google Scholar]
- Atallah, M.J.; Raskin, V.; Crogan, M.; Hempelmann, C.; Kerschbaum, F.; Mohamed, D.; Naik, S. Natural Language Watermarking: Design, Analysis, and a Proof-of-Concept Implementation. In Information Hiding; Moskowitz, I.S., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 185–200. [Google Scholar]
- Abdelnabi, S.; Fritz, M. Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 24–27 May 2021; pp. 121–140. [Google Scholar] [CrossRef]
- Yang, Z.; Wu, H. A Fingerprint for Large Language Models. arXiv 2024, arXiv:2407.01235. [Google Scholar]
- Zhang, J.; Liu, D.; Qian, C.; Zhang, L.; Liu, Y.; Qiao, Y.; Shao, J. REEF: Representation Encoding Fingerprints for Large Language Models. In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025. [Google Scholar]
- Setiadi, D.R.I.M.; Ghosal, S.K.; Sahu, A.K. AI-Powered Steganography: Advances in Image, Linguistic, and 3D Mesh Data Hiding—A Survey. J. Future Artif. Intell. Technol. 2025, 2, 1–23. [Google Scholar] [CrossRef]
- Wu, H.; Yang, T.; Zheng, X.; Fang, Y. Linguistic Steganography and Linguistic Steganalysis. In Adversarial Multimedia Forensics; Nowroozi, E., Kallas, K., Jolfaei, A., Eds.; Springer Nature: Cham, Switzerland, 2024; pp. 163–190. [Google Scholar] [CrossRef]
- Liu, A.; Pan, L.; Lu, Y.; Li, J.; Hu, X.; Zhang, X.; Wen, L.; King, I.; Xiong, H.; Yu, P. A Survey of Text Watermarking in the Era of Large Language Models. ACM Comput. Surv. 2024, 57, 47. [Google Scholar] [CrossRef]
- Lalai, H.N.; Ramakrishnan, A.A.; Shah, R.S.; Lee, D. From Intentions to Techniques: A Comprehensive Taxonomy and Challenges in Text Watermarking for Large Language Models. arXiv 2024, arXiv:2406.11106. [Google Scholar]
- Zhao, X.; Gunn, S.; Christ, M.; Fairoze, J.; Fabrega, A.; Carlini, N.; Garg, S.; Hong, S.; Nasr, M.; Tramèr, F.; et al. SoK: Watermarking for AI-Generated Content. arXiv 2024, arXiv:2411.18479. [Google Scholar]
- Liang, Y.; Xiao, J.; Gan, W.; Yu, P.S. Watermarking Techniques for Large Language Models: A Survey. arXiv 2024, arXiv:2409.00089. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Katz, J.; Miers, I.; Goldstein, T. A Watermark for Large Language Models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; PMLR: Birmingham, UK, 2023; Volume 202, pp. 17061–17084. [Google Scholar]
- Kirchenbauer, J.; Geiping, J.; Wen, Y.; Shu, M.; Saifullah, K.; Kong, K.; Fernando, K.; Saha, A.; Goldblum, M.; Goldstein, T. On the Reliability of Watermarks for Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Aaronson, S.; Kirchner, H. Watermarking gpt Outputs. 2023. Available online: https://www.scottaaronson.com/talks/watermark.ppt (accessed on 4 January 2025).
- Dathathri, S.; See, A.; Ghaisas, S.; Huang, P.S.; McAdam, R.; Welbl, J.; Bachani, V.; Kaskasoli, A.; Stanforth, R.; Matejovicova, T.; et al. Scalable watermarking for identifying large language model outputs. Nature 2024, 634, 818–823. [Google Scholar] [CrossRef]
- Zhang, R.; Hussain, S.S.; Neekhara, P.; Koushanfar, F. REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models. In Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 14–16 August 2024; USENIX Association: Berkeley, CA, USA, 2024; pp. 1813–1830. [Google Scholar]
- Yang, B.; Li, W.; Xiang, L.; Li, B. SrcMarker: Dual-Channel Source Code Watermarking via Scalable Code Transformations. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2024; pp. 4088–4106. [Google Scholar] [CrossRef]
- Xu, X.; Yao, Y.; Liu, Y. Learning to Watermark LLM-generated Text via Reinforcement Learning. arXiv 2024, arXiv:2403.10553. [Google Scholar]
- Pang, K.; Qi, T.; Wu, C.; Bai, M.; Jiang, M.; Huang, Y. ModelShield: Adaptive and Robust Watermark against Model Extraction Attack. IEEE Trans. Inf. Forensics Secur. 2024, 20, 1767–1782. [Google Scholar] [CrossRef]
- Bahri, D.; Wieting, J.M.; Alon, D.; Metzler, D. A Watermark for Black-Box Language Models. arXiv 2024, arXiv:2410.02099. [Google Scholar]
- Baldassini, F.B.; Nguyen, H.H.; Chang, C.C.; Echizen, I. Cross-Attention watermarking of Large Language Models. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 4625–4629. [Google Scholar] [CrossRef]
- Boroujeny, M.K.; Jiang, Y.; Zeng, K.; Mark, B.L. Multi-Bit Distortion-Free Watermarking for Large Language Models. arXiv 2024, arXiv:2402.16578. [Google Scholar]
- Chen, L.; Bian, Y.; Deng, Y.; Cai, D.; Li, S.; Zhao, P.; Wong, K.F. WatME: Towards Lossless Watermarking Through Lexical Redundancy. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 9166–9180. [Google Scholar] [CrossRef]
- Christ, M.; Gunn, S.; Zamir, O. Undetectable Watermarks for Language Models. In Proceedings of the Thirty Seventh Conference on Learning Theory, Edmonton, AB, Canada, 30 June–3 July 2024; Agrawal, S., Roth, A., Eds.; PMLR: Birmingham, UK, 2024; Volume 247, pp. 1125–1139. [Google Scholar]
- Cohen, A.; Hoover, A.; Schoenbach, G. Watermarking Language Models for Many Adaptive Users. In Proceedings of the 2025 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 12–15 May 2025; IEEE Computer Society: Los Alamitos, CA, USA, 2025; p. 84. [Google Scholar]
- Feng, X.; Liu, J.; Ren, K.; Chen, C. A Certified Robust Watermark For Large Language Models. arXiv 2024, arXiv:2409.19708. [Google Scholar]
- Fernandez, P.; Chaffin, A.; Tit, K.; Chappelier, V.; Furon, T. Three Bricks to Consolidate Watermarks for Large Language Models. In Proceedings of the 2023 IEEE International Workshop on Information Forensics and Security (WIFS), Nürnberg, Germany, 4–7 December 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Fu, Y.; Xiong, D.; Dong, Y. Watermarking Conditional Text Generation for AI Detection: Unveiling Challenges and a Semantic-Aware Watermark Remedy. Proc. AAAI Conf. Artif. Intell. 2024, 38, 18003–18011. [Google Scholar] [CrossRef]
- Giboulot, E.; Furon, T. WaterMax: Breaking the LLM watermark detectability-robustness-quality trade-off. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Golowich, N.; Moitra, A. Edit Distance Robust Watermarks via Indexing Pseudorandom Codes. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Guo, Y.; Tian, Z.; Song, Y.; Liu, T.; Ding, L.; Li, D. Context-aware Watermark with Semantic Balanced Green-red Lists for Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 22633–22646. [Google Scholar] [CrossRef]
- He, Z.; Zhou, B.; Hao, H.; Liu, A.; Wang, X.; Tu, Z.; Zhang, Z.; Wang, R. Can Watermarks Survive Translation? On the Cross-lingual Consistency of Text Watermark for Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 4115–4129. [Google Scholar] [CrossRef]
- Hoang, D.C.; Le, H.T.; Chu, R.; Li, P.; Zhao, W.; Lao, Y.; Doan, K.D. Less is More: Sparse Watermarking in LLMs with Enhanced Text Quality. arXiv 2024, arXiv:2407.13803. [Google Scholar]
- Hou, A.; Zhang, J.; He, T.; Wang, Y.; Chuang, Y.S.; Wang, H.; Shen, L.; Van Durme, B.; Khashabi, D.; Tsvetkov, Y. SemStamp: A Semantic Watermark with Paraphrastic Robustness for Text Generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 4067–4082. [Google Scholar] [CrossRef]
- Hou, A.; Zhang, J.; Wang, Y.; Khashabi, D.; He, T. k-SemStamp: A Clustering-Based Semantic Watermark for Detection of Machine-Generated Text. In Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 1706–1715. [Google Scholar] [CrossRef]
- Huo, M.; Somayajula, S.A.; Liang, Y.; Zhang, R.; Koushanfar, F.; Xie, P. Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models. In Proceedings of the ICML, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Jiang, H.; Wang, X.; Yi, P.; Lei, S.; Lin, Y. CredID: Credible Multi-Bit Watermark for Large Language Models Identification. arXiv 2024, arXiv:2412.03107. [Google Scholar]
- Kuditipudi, R.; Thickstun, J.; Hashimoto, T.; Liang, P. Robust Distortion-free Watermarks for Language Models. Trans. Mach. Learn. Res. 2024. [Google Scholar]
- Li, Y.; Wang, Y.; Shi, Z.; Hsieh, C.J. Improving the Generation Quality of Watermarked Large Language Models via Word Importance Scoring. arXiv 2023, arXiv:2311.09668. [Google Scholar]
- Li, L.; Bai, Y.; Cheng, M. Where Am I From? Identifying Origin of LLM-generated Content. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 12218–12229. [Google Scholar] [CrossRef]
- Li, X.; Ruan, F.; Wang, H.; Long, Q.; Su, W.J. A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules. Ann. Stat. 2025, 53, 322–351. [Google Scholar] [CrossRef]
- Liu, Y.; Bu, Y. Adaptive Text Watermark for Large Language Models. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Liu, A.; Pan, L.; Hu, X.; Li, S.; Wen, L.; King, I.; Yu, P.S. An Unforgeable Publicly Verifiable Watermark for Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Niess, G.; Kern, R. Stylometric Watermarks for Large Language Models. arXiv 2024, arXiv:2405.08400. [Google Scholar]
- Pang, Q.; Hu, S.; Zheng, W.; Smith, V. No Free Lunch in LLM Watermarking: Trade-offs in Watermarking Design Choices. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Qu, W.; Yin, D.; He, Z.; Zou, W.; Tao, T.; Jia, J.; Zhang, J. Provably Robust Multi-bit Watermarking for AI-generated Text via Error Correction Code. arXiv 2024, arXiv:2401.16820. [Google Scholar]
- Ren, J.; Xu, H.; Liu, Y.; Cui, Y.; Wang, S.; Yin, D.; Tang, J. A Robust Semantics-based Watermark for Large Language Model against Paraphrasing. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 613–625. [Google Scholar] [CrossRef]
- Ren, Y.; Guo, P.; Cao, Y.; Ma, W. Subtle Signatures, Strong Shields: Advancing Robust and Imperceptible Watermarking in Large Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 5508–5519. [Google Scholar] [CrossRef]
- Song, M.; Li, Z.; Liu, K.; Peng, M.; Tian, G. NLWM: A Robust, Efficient and High-Quality Watermark for Large Language Models. In Web Information Systems Engineering–WISE 2024; Barhamgi, M., Wang, H., Wang, X., Eds.; Springer Nature: Singapore, 2025; pp. 320–335. [Google Scholar]
- Wang, L.; Yang, W.; Chen, D.; Zhou, H.; Lin, Y.; Meng, F.; Zhou, J.; Sun, X. Towards Codable Watermarking for Injecting Multi-Bits Information to LLMs. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Wu, Y.; Hu, Z.; Guo, J.; Zhang, H.; Huang, H. A Resilient and Accessible Distribution-Preserving Watermark for Large Language Models. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Xu, X.; Jia, J.; Yao, Y.; Liu, Y.; Li, H. Robust Multi-bit Text Watermark with LLM-based Paraphrasers. arXiv 2024, arXiv:2412.03123. [Google Scholar]
- Yoo, K.; Ahn, W.; Kwak, N. Advancing Beyond Identification: Multi-bit Watermark for Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 4031–4055. [Google Scholar] [CrossRef]
- Zamir, O. Undetectable Steganography for Language Models. Trans. Mach. Learn. Res. 2024. [Google Scholar]
- Zhao, X.; Ananth, P.V.; Li, L.; Wang, Y.X. Provable Robust Watermarking for AI-Generated Text. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Zhao, X.; Liao, C.; Wang, Y.X.; Li, L. Efficiently Identifying Watermarked Segments in Mixed-Source Texts. In Neurips Safe Generative AI Workshop 2024; NeurIPS: San Diego CA, USA, 2024. [Google Scholar]
- Zhong, X.; Dasgupta, A.; Tanvir, A. Watermarking Language Models through Language Models. arXiv 2024, arXiv:2411.05091. [Google Scholar]
- Zhou, T.; Zhao, X.; Xu, X.; Ren, S. Bileve: Securing Text Provenance in Large Language Models Against Spoofing with Bi-level Signature. In Proceedings of the Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024. [Google Scholar]
- Fairoze, J.; Garg, S.; Jha, S.; Mahloujifar, S.; Mahmoody, M.; Wang, M. Publicly Detectable Watermarking for Language Models. arXiv 2023, arXiv:2310.18491. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, L.; Wu, X.; Wu, Y.; Zhang, H.; Huang, H. Unbiased Watermark for Large Language Models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Zhang, J.; Chen, D.; Liao, J.; Zhang, W.; Feng, H.; Hua, G.; Yu, N. Deep Model Intellectual Property Protection via Deep Watermarking. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 4005–4020. [Google Scholar] [CrossRef]
- Contributors, F.; El-Kishky, A.; Selsam, D.; Song, F.; Parascandolo, G.; Ren, H.; Lightman, H.; Won, H.; Akkaya, I.; Sutskever, I.; et al. OpenAI o1 System Card. arXiv 2024, arXiv:2412.16720. [Google Scholar]
- DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.M.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Red Hook, NY, USA, 2022. [Google Scholar]
- Zhang, H.; Edelman, B.L.; Francati, D.; Venturi, D.; Ateniese, G.; Barak, B. Watermarks in the Sand: Impossibility of Strong Watermarking for Language Models. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Sadasivan, V.S.; Kumar, A.; Balasubramanian, S.; Wang, W.; Feizi, S. Can AI-Generated Text be Reliably Detected? arXiv 2023, arXiv:2303.11156. [Google Scholar]
- Luo, Y.; Lin, K.; Gu, C. Lost in Overlap: Exploring Watermark Collision in LLMs. arXiv 2024, arXiv:2403.10020. [Google Scholar]
- Diaa, A.; Aremu, T.; Lukas, N. Optimizing Adaptive Attacks against Content Watermarks for Language Models. arXiv 2024, arXiv:2410.02440. [Google Scholar]
- Ayoobi, N.; Knab, L.; Cheng, W.; Pantoja, D.; Alikhani, H.; Flamant, S.; Kim, J.; Mukherjee, A. ESPERANTO: Evaluating Synthesized Phrases to Enhance Robustness in AI Detection for Text Origination. arXiv 2024, arXiv:2409.14285. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Piet, J.; Sitawarin, C.; Fang, V.; Mu, N.; Wagner, D. Mark My Words: Analyzing and Evaluating Language Model Watermarks. arXiv 2023, arXiv:2312.00273. [Google Scholar]
- Tu, S.; Sun, Y.; Bai, Y.; Yu, J.; Hou, L.; Li, J. WaterBench: Towards Holistic Evaluation of Watermarks for Large Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 1517–1542. [Google Scholar] [CrossRef]
- Ajith, A.; Singh, S.; Pruthi, D. Downstream Trade-offs of a Family of Text Watermarks. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 14039–14053. [Google Scholar] [CrossRef]
- Molenda, P.; Liusie, A.; Gales, M. WaterJudge: Quality-Detection Trade-off when Watermarking Large Language Models. In Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 3515–3525. [Google Scholar] [CrossRef]
- Guan, B.; Wan, Y.; Bi, Z.; Wang, Z.; Zhang, H.; Zhou, P.; Sun, L. CodeIP: A Grammar-Guided Multi-Bit Watermark for Large Language Models of Code. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 9243–9258. [Google Scholar] [CrossRef]
- Wu, Q.; Chandrasekaran, V. Bypassing LLM Watermarks with Color-Aware Substitutions. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; Ku, L.W., Martins, A., Srikumar, V., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; Volume 1, pp. 8549–8581. [Google Scholar] [CrossRef]
- Creo, A.; Pudasaini, S. SilverSpeak: Evading AI-Generated Text Detectors using Homoglyphs. arXiv 2024, arXiv:2406.11239. [Google Scholar]
- Pang, Q.; Hu, S.; Zheng, W.; Smith, V. Attacking LLM Watermarks by Exploiting Their Strengths. In Proceedings of the ICLR 2024 Workshop on Secure and Trustworthy Large Language Models, Vienna, Austria, 11 May 2024. [Google Scholar]
- Jovanović, N.; Staab, R.; Vechev, M. Watermark stealing in large language models. In Proceedings of the 41st International Conference on Machine Learning. JMLR.org, 2024, ICML’24, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Chang, H.; Hassani, H.; Shokri, R. Watermark Smoothing Attacks against Language Models. arXiv 2024, arXiv:2407.14206. [Google Scholar]
- Chen, R.; Wu, Y.; Guo, J.; Huang, H. De-mark: Watermark Removal in Large Language Models. arXiv 2024, arXiv:2410.13808. [Google Scholar]
- Rastogi, S.; Pruthi, D. Revisiting the Robustness of Watermarking to Paraphrasing Attacks. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2024; pp. 18100–18110. [Google Scholar] [CrossRef]
- Liu, A.; Guan, S.; Liu, Y.; Pan, L.; Zhang, Y.; Fang, L.; Wen, L.; Yu, P.S.; Hu, X. Can Watermarked LLMs be Identified by Users via Crafted Prompts? In Proceedings of the Thirteenth International Conference on Learning Representations, Singapore, 24–28 April 2025.
- Wu, B.; Chen, K.; He, Y.; Chen, G.; Zhang, W.; Yu, N. CodeWMBench: An Automated Benchmark for Code Watermarking Evaluation. In Proceedings of the ACM Turing Award Celebration Conference—China 2024, ACM-TURC ’24, Changsha, China, 5–7 July 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 120–125. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Category | Capacity | Publication Year |
|---|---|---|---|
| Aaronson et al. [35] | Score-based | 1-bit | 2023 |
| Bahri et al. [41] | Score-based | 1-bit | 2024 |
| Baldassini et al. [42] | Unsupervised fine-tuning | Multi-bits | 2024 |
| Boroujeny et al. [43] | Score-based | Multi-bits | 2024 |
| Chen et al. [44] | Logits-based | 1-bit | 2024 |
| Christ et al. [45] | Score-based | 1-bit | 2024 |
| Cohen et al. [46] | Logits-based | Multi-bits | 2025 |
| Dathathri et al. [36] | Score-based | 1-bit | 2024 |
| Feng et al. [47] | Logits-based | 1-bit | 2024 |
| Fernandez et al. [48] | Logits-based | Multi-bits | 2023 |
| Fu et al. [49] | Logits-based | 1-bit | 2024 |
| Giboulot et al. [50] | Score-based | 1-bit | 2024 |
| Golowich et al. [51] | Score-based | 1-bit | 2024 |
| Guo et al. [52] | Logits-based | 1-bit | 2024 |
| He et al. [53] | Logits-based | 1-bit | 2024 |
| Hoang et al. [54] | Logits-based | 1-bit | 2024 |
| Hou et al. [55] | Logits-based | 1-bit | 2024 |
| Hou et al. [56] | Logits-based | 1-bit | 2024 |
| Huo et al. [57] | Logits-based | 1-bit | 2024 |
| Jiang et al. [58] | Logits-based | Multi-bits | 2024 |
| Kirchenbauer et al. [33] | Logits-based | 1-bit | 2023 |
| Kirchenbauer et al. [34] | Logits-based | 1-bit | 2024 |
| Kuditipudi et al. [59] | Score-based | 1-bit | 2024 |
| Li et al. [60] | Logits-based | 1-bit | 2023 |
| Li et al. [61] | Logits-based | Multi-bits | 2024 |
| Li et al. [62] | Score-based | 1-bit | 2025 |
| Liu et al. [63] | Logits-based | 1-bit | 2024 |
| Liu et al. [64] | Logits-based | 1-bit | 2024 |
| Niess et al. [65] | Logits-based | 1-bit | 2024 |
| Pang et al. [66] | Logits-based | 1-bit | 2024 |
| Pang et al. [40] | External decoder-based | 1-bit | 2024 |
| Qu et al. [67] | Logits-based | Multi-bits | 2024 |
| Ren et al. [68] | Logits-based | 1-bit | 2024 |
| Ren et al. [69] | Logits-based | 1-bit | 2024 |
| Song et al. [70] | Logits-based | Multi-bits | 2025 |
| Wang et al. [71] | Logits-based | Multi-bits | 2024 |
| Wu et al. [72] | Score-based | 1-bit | 2024 |
| Xu et al. [39] | External decoder-based | 1-bit | 2024 |
| Xu et al. [73] | External decoder-based | Multi-bits | 2024 |
| Yang et al. [38] | Unsupervised fine-tuning | Multi-bits | 2024 |
| Yoo et al. [74] | Logits-based | Multi-bits | 2024 |
| Zamir et al. [75] | Score-based | Multi-bits | 2024 |
| Zhang et al. [37] | Unsupervised fine-tuning | Multi-bits | 2024 |
| Zhao et al. [76] | Logits-based | 1-bit | 2024 |
| Zhao et al. [77] | Logits-based | 1-bit | 2024 |
| Zhong et al. [78] | External decoder-based | 1-bit | 2024 |
| Zhou et al. [79] | Score-based | 1-bit | 2024 |
| Tailored Strategies | Potential Benefits | Explanation |
|---|---|---|
| Vocabulary Partition | Improved Robustness | Minor modifications that do not alter semantics will not affect vocabulary partitioning. |
| Enhanced Concealment | Minimal impact on downstream tasks, with sufficient watermarked tokens preserving original semantics. | |
| Bias Adjustment | Enhanced Concealment | Reducing the bias of semantically important tokens prevents significant meaning shifts. |
| Improved Robustness | Increasing the bias of less important tokens enhances the probability of watermark presence. | |
| Embedding Token Selection | Enhanced Concealment | Avoids modifying low-entropy text, thus preserving text quality. |
| Method | Imperceptibility | Robustness | Capacity | Resource | |
|---|---|---|---|---|---|
| Paraphrase | Token Substitution | Efficiency | |||
| Aaronson et al. [35] | ++ | ++ | ++ | + | +++ |
| Dathathri et al. [36] | +++ | ++ | ++ | + | +++ |
| Hou et al. [55] | ++ | ++ | ++ | + | +++ |
| Kirchenbauer et al. [33] | ++ | + | + | + | +++ |
| Kirchenbauer et al. [34] | ++ | ++ | ++ | + | +++ |
| Kuditipudi et al. [59] | +++ | ++ | ++ | + | +++ |
| Liu et al. [64] | + | + | + | + | +++ |
| Wang et al. [71] | ++ | + | ++ | ++ | +++ |
| Xu et al. [39] | ++ | ++ | ++ | + | + |
| Xu et al. [73] | ++ | ++ | ++ | ++ | + |
| Zhang et al. [37] | ++ | ++ | ++ | ++ | + |
| Attack Level | Attack Method | Example (Original) | Example (Attack) |
|---|---|---|---|
| Token-level | Synonym Replacement | You just can’t differentiate between a robot and the very best of humans. | You simply cannot distinguish between a machine and the finest of people. |
| Typo Insertion | You just can’t differentiate between a robot and the very best of humans. | You just can’t differntiate between a robot and the very best of humans. | |
| Sentence-level | Paraphrasing | Artificial intelligence has advanced to the point where distinguishing between human and machine-generated text is increasingly difficult. | Distinguishing between human and machine-generated text has become increasingly difficult as artificial intelligence has advanced. |
| Document-level | Paraphrasing | Artificial intelligence has advanced to the point where distinguishing between human and machine-generated text is increasingly difficult. Watermarking techniques are being developed to address this challenge, ensuring the traceability and authenticity of AI-generated content. | As artificial intelligence continues to advance, it is becoming harder to differentiate between human and AI-generated text, prompting the development of watermarking techniques to ensure content authenticity. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Zhao, G.; Wu, H. Watermarking for Large Language Models: A Survey. Mathematics 2025, 13, 1420. https://doi.org/10.3390/math13091420
Yang Z, Zhao G, Wu H. Watermarking for Large Language Models: A Survey. Mathematics. 2025; 13(9):1420. https://doi.org/10.3390/math13091420
Chicago/Turabian StyleYang, Zhiguang, Gejian Zhao, and Hanzhou Wu. 2025. "Watermarking for Large Language Models: A Survey" Mathematics 13, no. 9: 1420. https://doi.org/10.3390/math13091420
APA StyleYang, Z., Zhao, G., & Wu, H. (2025). Watermarking for Large Language Models: A Survey. Mathematics, 13(9), 1420. https://doi.org/10.3390/math13091420