1. Introduction
From 2020 to 2022, during the peak of the COVID-19 pandemic, governments worldwide implemented travel restrictions, lockdowns, and social distancing measures to limit virus transmission. As COVID-19 transitioned into an endemic phase, restrictions eased; however, the pandemic’s prolonged effects continue to shape finance, the economy, and daily life. This extended period of lockdowns has had lasting social and economic consequences, prompting significant research into its wide-ranging impacts across sectors, including healthcare [
1], education [
2], financial markets [
3], mental health [
4], and tourism [
5]. Researchers have sought to understand the systemic transformations triggered by the pandemic, underscoring the importance of studying its effects on societal structures. For example, Ref. [
6] examined COVID-19’s effects on Ghana’s insurance industry, employing a comparative methodology to identify parallels with previous pandemics. However, the global response to COVID-19—characterized by its unprecedented scale and the absence of clear geographical or temporal boundaries—has introduced new challenges for insurers, particularly in risk diversification. Unlike previous pandemics or natural disasters, COVID-19 represents a unique global event with few historical precedents, necessitating a focused study of its impact on the auto insurance sector and the broader socio-economic landscape.
In auto insurance rate regulation, the analysis and design of territories present ongoing challenges, particularly due to spatial contiguity requirements. To address these complexities, both traditional clustering methods, such as
K-means and fuzzy clustering [
7,
8,
9], and advanced spatial clustering techniques [
10,
11] have been employed. These methods help create homogeneous groups of spatial risk exposures, enabling the identification of spatial patterns and supporting actuarial fairness in insurance premiums. However, clustering approaches are inherently unsupervised and lack predictive capabilities, limiting their effectiveness in forecasting future losses based on historical data. This limitation highlights the need for predictive models that enhance spatial loss analysis. Accordingly, this study shifts the focus of territory risk analysis from clustering to predictive modeling, aiming to uncover spatial patterns and forecast future territory risks based on key spatial rating units. Prior research has explored spatial patterns in insurance losses [
9,
12,
13], affirming the value of spatial clustering as a complementary approach to predictive modeling. This study extends these efforts by investigating potential shifts in territory risk patterns before and during the COVID-19 pandemic. It aims to identify underlying spatial trends and assess the pandemic’s impact on auto insurance risk. Additionally, it advances the application of spatial data science techniques in insurance pricing, enhancing our ability to analyze and manage territory risks.
To assess the impact of COVID-19, loss data can be analyzed by incorporating time as a covariate or by associating it with spatial locations in the predictive models. These factors can be treated as external variables influencing loss patterns. Model-based approaches offer significant advantages for examining the effects of such external factors. While previous studies have explored the broader economic and financial consequences of COVID-19 on the insurance industry [
6,
14,
15,
16], there remains a gap in understanding how the pandemic has influenced spatial patterns of insurance losses and premiums. Given the critical role of geographic location in auto insurance pricing, a detailed analysis of spatial variations in loss and premium data is essential for understanding the pandemic’s effects. This study aims to fill this gap by providing insights that can inform future global health crisis preparedness and improve industry-wide auto insurance rate regulation.
To explore the impact of COVID-19 on auto insurance loss metrics, this paper introduces an innovative approach leveraging spatial models for feature extraction from spatial loss data. Key loss metrics, such as loss cost, are analyzed using spatial models to extract informative parameters that reveal temporal shifts in loss patterns. The spatial models [
17,
18] used in this study provide a sophisticated statistical framework, incorporating both fixed and random effects within basic rating units, Forward Sortation Areas (FSAs). Grounded in a Bayesian statistical paradigm and inspired by Gaussian mixture random field models, this approach characterizes the stochastic behavior of spatial autocorrelations among FSAs and their neighboring regions using a Gaussian Markov random field. Implemented through Generalized Linear Mixed Models, this additive structure effectively captures both fixed and random spatial effects.
The remainder of this paper is structured as follows:
Section 2 reviews existing research on the effects of the COVID-19 pandemic.
Section 3 details the spatial models and their application to insurance loss data.
Section 4 presents the findings of the analysis. Finally,
Section 5 concludes the study and outlines directions for future research.
2. Related Work
In this section, we review key research on the broader economic impact of the COVID-19 pandemic on the insurance industry. The pandemic disrupted both supply and demand in insurance markets, prompting critical responses from insurers and regulators. For example, Ref. [
19] provides an extensive overview of the risks posed by COVID-19 and the regulatory measures implemented in response. A surge in claims for life, medical, business interruption, and event cancellation insurance created significant challenges. However, the primary concern for insurers and regulators was financial market instability and the resulting global economic downturn. Ref. [
20] supports this perspective, emphasizing that poor investment performance posed a greater risk to insurers than the increase in claims. Both [
19,
20] discuss how the pandemic strained healthcare systems, leading to delays in non-urgent medical treatments. These delays, in turn, mitigated the immediate impact on life and medical insurance claims. Additionally, the decline in auto insurance claims during lockdowns partially offset the increased losses in life insurance, reflecting an unexpected shift in risk exposure across different insurance lines.
Regulatory interventions during the pandemic aimed to preserve capital while ensuring insurers remained financially stable to meet future obligations [
19]. Transparency in insurer responses was critical in maintaining public trust and preventing adverse selection [
20]. These studies highlight the necessity of proactive regulatory strategies that balance financial stability, clear communication, and consumer protection. Further regulatory discussions are presented in [
21], which examines the National Association of Insurance Commissioners (NAIC) response to the pandemic, particularly regarding catastrophic risk management and health insurance policy changes in a post-pandemic environment. Similarly, Ref. [
22] investigates the operational impact of COVID-19 on insurance businesses in the Gulf region, focusing on conduct-of-business regulations. The study highlights how the insurance sector’s shift toward business survival during the crisis may have led to a reduced emphasis on ensuring fair treatment of policyholders.
The COVID-19 pandemic significantly influenced auto insurance pricing, as insurers adjusted loss ratios to maintain actuarial fairness amid shifting driving behaviors. Lockdowns, remote work policies, and social distancing led to a substantial decline in vehicle usage, initially reducing auto insurance claims. However, with the pandemic persisting longer than anticipated, its long-term effects on auto insurance remain uncertain due to complex behavioral and economic factors. Ref. [
23] projected changes in U.S. auto insurance by modeling various scenarios based on two key parameters: duration and extent of economic contraction and attitudes and behavioral adaptations. Their study estimated combined ratios of total losses and expenses to earned premiums, providing industry forecasts over an 18-month period. While this scenario-based approach facilitated accessibility, it relied on simplifying assumptions that may not fully capture the evolving nature of driver behavior during the COVID-19 pandemic. Recognizing this limitation, Ref. [
24] advocated for a more quantitative approach to assess behavioral shifts in driving patterns. Their study highlighted that government restrictions, hybrid work models, and decreased public transportation use led to significant reductions in road traffic volume and pedestrian movement. However, the study also noted that urban centers experienced a rise in speeding, street racing, and aggressive driving, complicating risk assessment. These findings emphasize that determining the long-term impact of COVID-19 on auto insurance remains challenging, as existing research often simplifies human behavioral responses by relying on subjective assumptions.
Our work advances the literature on auto insurance rate-making by integrating regulatory datasets with predictive spatial modeling, explicitly accounting for spatial autocorrelation in insurance loss analysis. This approach enhances the understanding of spatial loss patterns, offering a more comprehensive perspective than studies that rely solely on individual insurers’ data. By leveraging spatial dependencies, our methodology improves territorial risk assessments, leading to more accurate and equitable premium-setting practices. Furthermore, we extend existing research by examining the impact of COVID-19 on auto insurance pricing and regulation through a spatial lens. The pandemic has reshaped driving behaviors, claim frequencies, and regulatory responses, yet its spatial implications remain underexplored. By applying spatial data science techniques to this emerging challenge, our study contributes to the development of more adaptive and resilient rate-making frameworks that account for dynamic risk factors across different regions.
4. Results
In this section, we analyze the temporal evolution of spatial patterns in loss metrics including insurance loadings and loss costs using Local Moran’s I to capture spatial autocorrelation. Insurance loadings are used to capture how insurers adjust their pricing in response to significant shifts in insurance losses during the pandemic, while loss costs reflect changes in the underlying cost of providing coverage. By applying Moran’s I statistic, we can assess the spatial structure of risk, identifying whether it exhibits homogeneity or heterogeneity across different regions. Regions with high positive values of Local Moran’s I indicate consistent insurance loadings, suggesting that FSAs within these areas form homogeneous clusters in terms of pricing adjustments. Conversely, low or negative values signify variability in insurance loading, indicating inconsistencies across the region. The primary goal of this illustration is to demonstrate how spatial autocorrelation, as measured by Moran’s I, can be utilized to identify spatial patterns influenced by key factors of interest. This approach highlights not only the geographical patterns of loss metrics but also how they evolve over time, reflecting changes in the underlying insurance loss dynamics. These findings support our further exploration of spatio-temporal models to more accurately capture these underlying changes.
Examining spatial autocorrelation in insurance loading is particularly relevant in the context of COVID-19, which significantly disrupted insurance pricing dynamics. Insurance loading encompasses factors beyond pure premiums (i.e., loss costs), including administrative expenses, profit margins, and market adjustments, all of which were influenced by pandemic-induced shifts in driving behavior, claim frequency, and economic uncertainty. Unlike direct loss metrics such as loss cost, frequency, and severity, loading reflects insurers’ strategic responses to these disruptions across different regions. Investigating its spatial patterns helps identify regional disparities, assess pricing fairness, and refine risk adjustment models by incorporating spatial dependencies. Furthermore, this analysis supports regulatory decision-making by determining whether regional pricing variations align with actual risk differences or reflect market distortions exacerbated by the pandemic. However, to gain deeper insights into the spatial patterns of other relevant loss metrics, we also included results based on loss costs. This allows for a better understanding of the temporal evolution of clustering behavior in territorial risk.
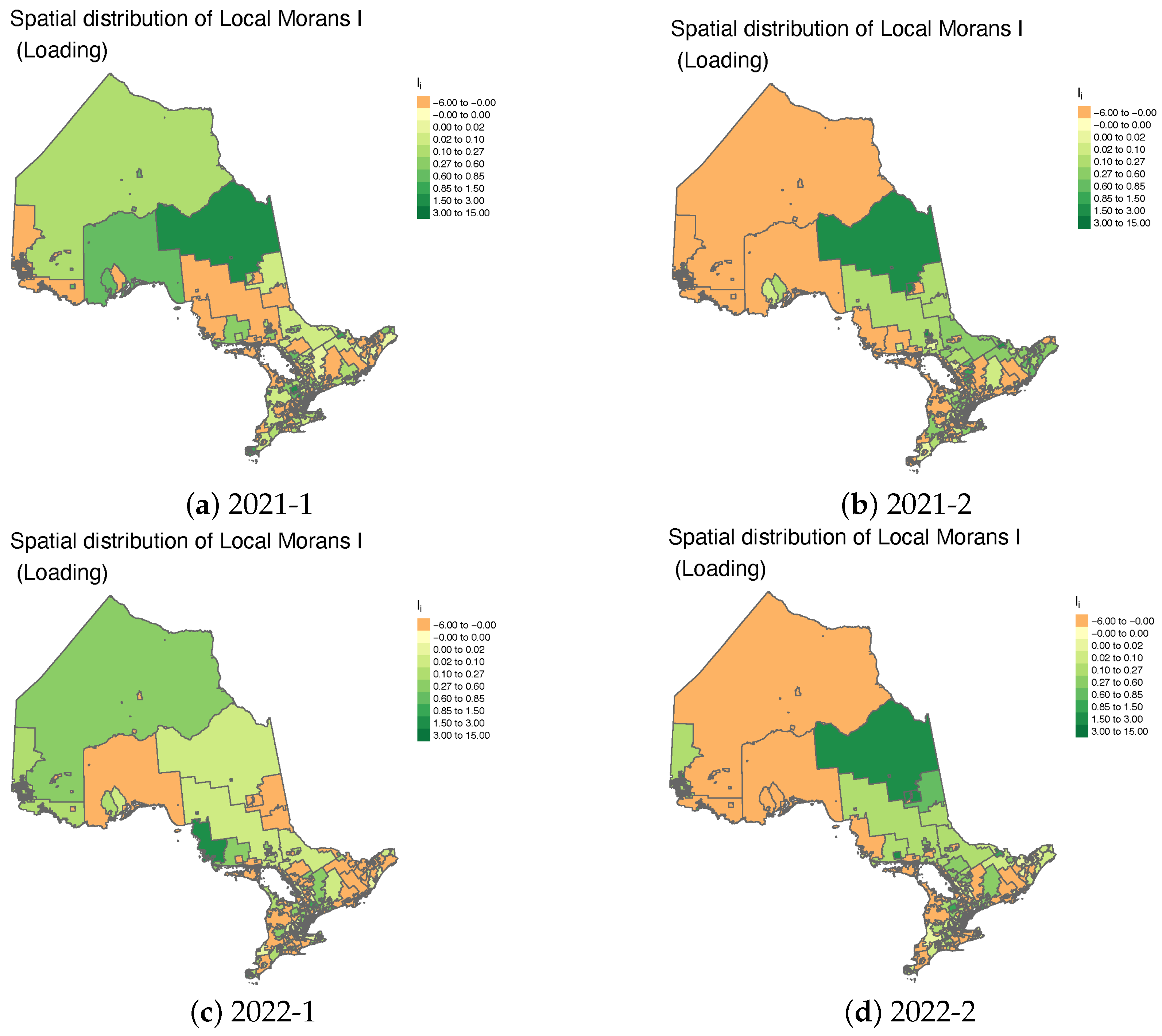
We first present results for the entire province of Ontario before narrowing our focus to southern Ontario, a key economic region. The heat maps in
Figure 1 and
Figure 2, which depict the spatial distribution of Local Moran’s I, show that spatial autocorrelation in insurance loading remained relatively stable before and at the onset of the COVID-19 pandemic, specifically during 2019-1, 2019-2, and 2020-1. A notable observation is the stronger consistency of insurance loading in northern Ontario, in contrast to the greater heterogeneity observed in southern Ontario during these periods. This spatial inconsistency worsened in 2020-2, coinciding with the implementation of lockdown measures, and has persisted through 2022.
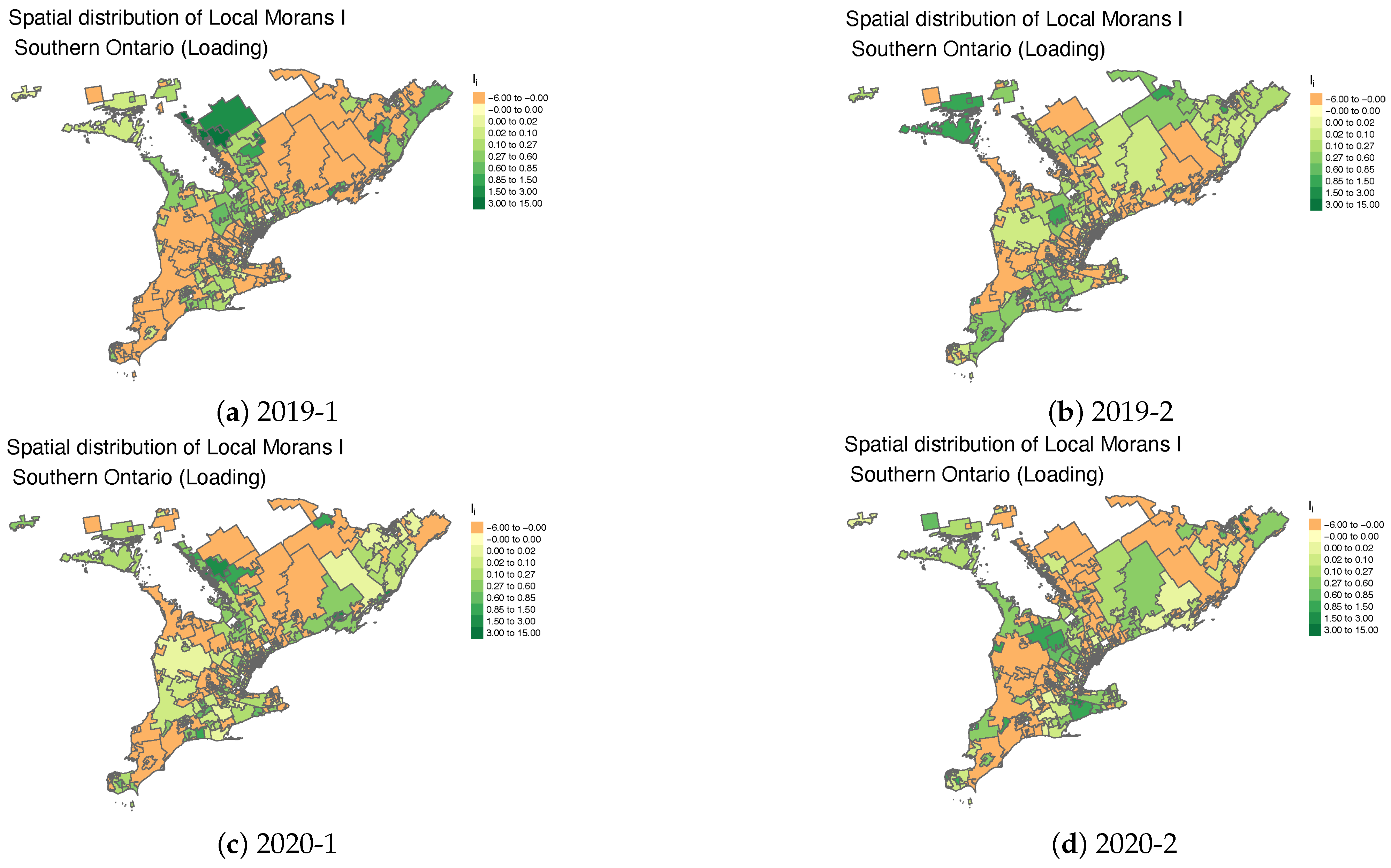
Figure 3 and
Figure 4 illustrate the temporal evolution of spatial autocorrelation in southern Ontario. A notable prevalence of regions with negatively large Local Moran’s I values is observed, particularly in 2019-1, with this pattern persisting both before and throughout the pandemic. This indicates sustained spatial heterogeneity in insurance loading, suggesting inconsistencies in pricing adjustments across neighboring regions. When insurance loading is used to compute Local Moran’s I, negatively large values indicate strong spatial heterogeneity, where FSAs with high loading are surrounded by those with low loading or vice versa. This pattern reflects pricing discontinuities that may arise from market inefficiencies, regulatory interventions, or localized risk misestimations. Conversely, small or near-zero values suggest weak or no significant spatial autocorrelation, implying that insurance loading is more randomly distributed across regions. In such cases, pricing adjustments are likely driven by individual underwriting decisions rather than broader regional trends. Identifying these spatial patterns is essential for evaluating pricing fairness, regulatory compliance, and the alignment of insurance premiums with actual risk factors.
As discussed earlier, analyzing the temporal evolution of spatial patterns in loss cost is crucial for understanding the dynamics of territorial risk. This is especially important when examining the impact of extraordinary events, such as the COVID-19 pandemic, on insurance costs.
Figure 5,
Figure 6,
Figure 7 and
Figure 8 illustrate how spatial autocorrelation patterns in loss cost vary across different accident half years throughout Ontario. Notably, during the pandemic period, the spatial patterns become more heterogeneous, particularly in the southern regions of the province. This spatial variability may be attributed to a significant decline in claim frequency due to lockdown policies, which in turn reduces the dependence of loss costs on neighboring areas.
From an insurance rate regulation perspective, these findings have important implications. They suggest that traditional territorial rating models, which often rely on spatial stability and correlation, may require re-evaluation during periods of systemic disruption. The diminished spatial dependence observed during the pandemic indicates that using historical spatial relationships as a basis for territorial classification could lead to inaccuracies in risk assessment and unfair pricing. As such, regulatory frameworks should consider incorporating dynamic spatial models that account for temporal shifts in risk patterns, especially under conditions of societal or economic stress.
Table 1,
Table 2,
Table 3 and
Table 4 summarize the model output using Besag’s spatial model applied to claim frequency, severity, loss cost, and loading. For each model covariate, the first three quantiles, mean, and standard deviation are reported. Our primary focus is on the sign of each parameter estimate, as it indicates whether a covariate has a positive or negative impact on the response variable.
In
Table 1, all parameter estimates for covariates associated with the highest absolute values of COVID_label are negative, suggesting a strong influence of COVID-19 in reducing overall claim frequency. Additionally, spatial location variables also exhibit negative effects on claim frequency, which may indicate a significant territorial shift in risk during the pandemic. However, the impact of COVID_label on claim severity is not as pronounced. While vehicle density and estimated COVID-19 cases contribute to a decrease in severity, spatial location as a risk factor has a positive effect, further reinforcing the notion of shifting territorial risk patterns during the pandemic. As expected, accident year, as a temporal factor, is associated with an increasing trend in severity.
Examining the combined effects of claim frequency and severity, as reflected in loss cost (
Table 3), we find that COVID_label, est_case, and centroid_lat, all have negative effects on loss cost, whereas vehicle density within an FSA and accident year contribute to an increase. Notably, when analyzing the impact on insurance loading, all covariates except accident year exhibit a positive influence, suggesting that insurers adjusted their pricing strategies by incorporating spatial and pandemic-related factors into their premium structures.
To determine the most suitable spatial model for each loss metric, we fit the data to various models (see Equation (
11)) while assuming different distributional forms for the response variable. Model performance is evaluated using multiple goodness-of-fit metrics, including Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Deviance Information Criterion (DIC), and Watanabe–Akaike Information Criterion (WAIC). The results, summarized in
Table 5, indicate that the Gamma distribution, when combined with the M3 model, provides a strong fit for most loss metrics. However, for claim frequency, the Poisson distribution emerges as a more appropriate choice, reflecting the discrete nature of frequency data. Additionally, within claim frequency modeling, the M3 model is preferred due to its consistently lower DIC and WAIC values, suggesting better model parsimony and predictive accuracy. These findings underscore the importance of selecting an appropriate distributional assumption and spatial model structure when modeling different components of insurance risk. By leveraging the Gamma distribution for continuous loss metrics and the Poisson distribution for frequency data, insurers can improve predictive accuracy and enhance the robustness of auto insurance pricing models.
The analysis of covariate effects on loss metrics in the Besag spatial model provides insights into overall trends for the accident years 2018 to 2022. However, the obtained results offer a limited perspective on the direct impact of the COVID-19 pandemic. To address this limitation, we further examine the temporal evolution of estimated loss metrics using spatial models and compare them to empirical estimates. This approach allows us to identify potential structural changes or significant shifts within each time period. To capture these temporal dynamics, we compare the first (Q1), second (Q2), and third (Q3) quantiles of the estimated loss metrics for each half-year accident period across various spatial models. The results, presented in
Figure 9, reveal a significant drop in claim frequency during the peak of the COVID-19 pandemic. Claim frequency begins to recover after the second half of 2021, coinciding with the Ontario government’s removal of stay-at-home policies.
In contrast, claim severity exhibits a gradual upward trend over time, suggesting a more moderate and sustained impact. When examining loss cost, which reflects the combined effects of claim frequency and severity, the temporal pattern closely aligns with that of claim frequency. This finding implies that the pandemic’s influence on claim frequency was the dominant driver of changes in loss cost. Furthermore, the observed peak in insurance loading during the pandemic period suggests that insurers adopted a more conservative approach to premium adjustments, likely as a response to heightened uncertainty. This raises potential concerns regarding actuarial fairness in pricing during the pandemic, as higher loading may have disproportionately affected certain policyholders.
We further analyze the role of spatial location in predictive modeling by comparing two scenarios: one where spatial location is included as a covariate and another where it is omitted. This comparison allows us to assess the impact of spatial factors on the estimation of loss metrics. The results are presented in
Figure 10 and
Figure 11. Additionally, we compare these trends with the pre-pandemic period (i.e., 2017–2019), which serves as a baseline to isolate the effects of the pandemic. This comparison reveals that prior to the pandemic, loss metrics were relatively stable, with no significant upward or downward trends. The disruption caused by the pandemic (2020–2021) is more pronounced in claim frequency, loss cost, and loading, highlighting the distinct impact of COVID-19.
In
Figure 10, where spatial locations are excluded, the spatial models primarily capture broad trends or local averages within specific time periods, but they fail to account for finer spatial variations. This limitation is particularly evident in periods where the loss metric patterns exhibit significant fluctuations. In contrast, when spatial location is incorporated into the model (
Figure 11), the predicted loss metrics align much more closely with observed values, highlighting the crucial role of spatial information in refining model accuracy.
This finding underscores the importance of incorporating spatial dependencies in auto insurance pricing, as it enhances the ability to capture localized risk variations and improves the predictive performance of loss metrics. Given the inherently geographic nature of insurance risk—where factors such as traffic density, road conditions, and regional economic activity influence claim patterns—spatial modeling provides a more precise and equitable framework for premium adjustments.
5. Conclusions and Future Work
In this study, we analyzed spatial loss patterns in auto insurance before and during the COVID-19 pandemic, applying advanced spatial models to capture and interpret these patterns comprehensively. This approach provides a deeper understanding of how the pandemic influenced auto insurance losses across different regions, underscoring the critical role of spatial risk assessment in insurance pricing and regulation. Our results reveal clear spatial heterogeneity in key loss metrics, with notable reductions observed in urban centers during the pandemic, while some rural and suburban regions exhibited more stable patterns. Such geographic variations are precisely the kind that spatially structured models are designed to capture. Our findings highlight that incorporating spatial dependencies into loss modeling enhances predictive accuracy and facilitates more equitable risk-based pricing strategies.
Despite the growing relevance of spatial data science, its application in auto insurance remains largely underexplored. This study contributes to the field by integrating spatial modeling techniques within the context of insurance rate regulation and insurance pricing, introducing a novel framework for assessing the geographic distribution of risk. Through a rigorous analysis of key loss metrics—including claim frequency, severity, loss cost, and insurance loading—we identify distinct spatial trends and shifts between before and during pandemic periods. These insights are critical for insurers, regulators, and policymakers aiming to refine territorial risk classification and pricing fairness in response to external disruptions. The impact of this research extends beyond COVID-19, providing a robust methodology for analyzing spatial variations in insurance losses under evolving economic and behavioral conditions. By demonstrating the effectiveness of spatial modeling in capturing geographic disparities, this work lays the foundation for more adaptive and resilient insurance pricing frameworks.
To build on these findings, we recommend that the auto insurance industry invest in the development of dynamic, spatially aware pricing systems that integrate real-time geographic and behavioral data. This requires moving beyond static territorial classifications toward adaptive models that account for evolving mobility patterns, infrastructure changes, and socio-economic shifts. Insurers should also collaborate with urban planners and transportation agencies to proactively assess emerging risk landscapes, particularly in the context of climate change, increasing telematics adoption, and autonomous vehicle deployment. By embedding more spatial intelligence into pricing and regulatory frameworks, the industry can better anticipate future disruptions, promote fairness, and support data-driven policy interventions.
Future research will extend this framework to analyze long-term post-pandemic effects and incorporating machine learning techniques for spatial–temporal pattern detection could offer new insights into emerging risk landscapes. As autonomous vehicles and usage-based insurance gain prominence, future studies should also investigate how spatial dependencies interact with these innovations, shaping the next generation of auto insurance risk assessment models.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}