4.1. Data Selection and Processing
The data in this paper come from the actual sports test values of a university in 2022, and a total of 20,452 records were collected, covering the performance of students in physical fitness, skills, and comprehensive quality. To ensure both the accuracy and generalizability of the model, we systematically divided the dataset. A total of 70% of the data, that is, about 14,316 records, were allocated as the model training set. The remaining 30%, amounting to about 6136 records, were designated as the test set to validate and assess the performance and reliability of the trained model.
The existence of singular sample data in the sample data will affect the accuracy of the classification results to some extent [
35]. In order to influence this part and enhance the precision of classification prediction outcomes, this paper adopts the max-min normalization method to normalize linear variables before establishing the model [
36]. The calculation formula is shown in Equation (
11):
where
x represents the original data value,
is the minimum value in the dataset,
is the maximum value in the dataset, and
Y is the normalized data value ranging from 0 to 1.
4.2. Evaluation Index
In order to further compare the training results of the model and the actual application effect, this paper utilizes model evaluation indexes, such as the accuracy rate, recall rate, accuracy rate, ROC curve, and AUC value. These metrics facilitate a clearer visualization of the model’s predictive performance and generalization capability [
37].
Accuracy rate is defined as the proportion of correctly predicted samples relative to the total number of samples. The higher the value, the better. Its calculation formula is shown in Equation (
12):
where TP is the positive class sample correctly predicted by the model, TN is the negative class sample correctly predicted, FP is the positive class sample incorrectly predicted, and FN is the negative class sample incorrectly predicted.
Recall rate is defined as the proportion of predicted positive samples among those that are actually positive. A higher value indicates better performance. Its calculation formula is shown in Equation (
13):
Accuracy rate refers to the proportion of predicted positive samples and actual positive samples. A higher value indicates better performance. Its calculation formula is shown in Equation (
14):
The F1-score serves as a metric for evaluating classification problems. It represents the harmonic mean of precision and recall, with values ranging from 0 to 1. The calculation formula is shown in Equation (
15):
In the binary classification problem, P is the positive example and N is the negative example. T (true) means true and F (false) means not. TP denotes the count of samples that are genuinely positive and have been predicted as positive; FN signifies the count of samples that are genuinely positive but have been predicted as negative—for example, in the context of physical fitness testing, TP means that the actual physical fitness test result is a pass, and the predicted result is also a pass; FN indicates that the actual physical fitness test result is pass, but the predicted result is fail; FP indicates that the actual physical fitness test result is failing, but the predicted result is passing; TN indicates that the actual physical test result is failing, and the predicted result is also failing. The multi-classification problem can be transformed into the confusion matrix of the binary classification problem, as shown in
Table 3.
The ROC curve, also known as the receiver operating characteristic curve (ROC) [
38], is a comprehensive indicator of the continuous variables of the sensitivity and specificity of the response model. The ordinate TPR (true positive rate) refers to the “true positive rate” of samples. The horizontal coordinate FP (false positive rate) refers to the “false positive rate” of the sample. The coordinate point (0, 0) means that all samples are negative examples, the coordinate point (1, 1) means that all samples are positive examples, and the coordinate (0, 1) means perfect classification. The AUC value is the area enclosed under the ROC curve, and its value is between [0, 1]. The closer to 1, the better the classification effect.
4.3. Algorithm Comparison
In order to verify the performance of the algorithm, the DE-XGBoost model is compared with four models, XGBoost, SVM, GBM, and MLP, for a more comprehensive evaluation.
Table 4 shows the performance comparison of each index of the DE-XGBoost algorithm under different F/Cr reverse combinations, and
Table 5 shows the impact of the Cr value on the performance of the DE-XGBoost model when F = 0.5 is fixed.
Table 6 compares the performance advantages of XGBoost models under different optimization algorithms. The settings of the XGBoost, SVM and other model parameters are shown in
Table 7, and the evaluation index data are shown in
Table 8.
Table 9 shows the Friedman test’s resulting graph, showing each model’s performance ranking. The feature importance diagram of DE-XGBoost is shown in
Figure 3. The ROC curve and AUC values of DE-XGBoost are shown in
Figure 4. The confusion matrix for DE-XGBoost is shown in
Figure 5. The confusion matrix normalization diagram of DE-XGBoost is shown in
Figure 6. The convergence diagram of DE-XGBoost is shown in
Figure 7.
Table 4 shows the impact of different parameter combinations of F and Cr on the performance of the DE-XGBoost model. The data indicate that the overall performance is optimal when F = 0.5 and Cr = 0.5 (accuracy 0.987868, F1-score 0.987829), while the performance is weakest when F = 0.1 and Cr = 0.9 (accuracy 0.984444, F1-score 0.984311). Although parameter adjustments cause fluctuations in the indicators, the maximum difference in accuracy is only 0.34%, and the overall impact is limited, especially when the suboptimal parameters (such as F = 0.3 and Cr = 0.7) have a difference of less than 0.05% compared to the optimal combination. Meanwhile,
Table 5 shows that when F is fixed at 0.5, the parameter combination of F = 0.5 and Cr = 0.5 still performs optimally, while F = 0.5 and Cr = 0.9 performs the weakest (accuracy 0.986357). Notably, when Cr increases from 0.1 to 0.9, the fluctuation range of each indicator is relatively small, with the maximum difference in accuracy being 0.015, indicating that the adjustment of the Cr parameter also has a limited impact on the model performance under the current experimental settings. Therefore, adopting the optimal parameter combination (F = 0.5, Cr = 0.5) as determined in this paper can ensure performance while avoiding the complexity and resource consumption brought by adaptive algorithms.
According to the performance index comparison results presented in
Table 6, the DE-XGBoost model demonstrates significant advantages in all four core evaluation dimensions: its prediction accuracy reaches as high as 0.987868, achieving a 0.2% and 1.7% improvement in accuracy compared to the improved versions based on Particle Swarm Optimization (PSO) and Simulated Annealing (SA), respectively; the recall rate and precision rate indicators both remain consistently above 0.98, reaching excellent performance of 0.987889 and 0.988106, respectively; and the F1 harmonic coefficient even reaches the optimally balanced value of 0.987829. This set of data fully validates the outstanding adaptability of the differential evolution algorithm in the hyperparameter optimization process of XGBoost. Through its efficient swarm intelligence search mechanism, it not only achieves breakthroughs in individual indicators but also significantly outperforms the traditional PSO and SA optimization schemes in the overall improvement of the model’s comprehensive predictive ability.
As shown in
Table 7, DE-XGBoost performs joint optimization of 10 hyperparameters through differential evolution (NP = 15, F = 0.5, Cr = 0.5). Compared with the fixed parameters of traditional XGBoost (100 trees, 0.3 learning rate, depth 6), the accuracy rate of DE-XGBoost in
Table 7 is improved by 3.6%. The advantages of evolutionary algorithms in the intelligent exploration of parameter space are verified. Among other models, SVM’s high regularization (C = 1.0) and RBF kernel are suitable for small samples but have high computational costs. The shallow structure of MLP (single hidden layer 50 nodes) and fixed learning rate (0.001) lead to weak generalization ability. GBM balances model complexity with convergence efficiency and is suitable for medium-scale data. DE-XGBoost’s auto-tuning benefits stand out when high precision and parallel resources are needed.
As evidenced by the evaluation index data presented in
Table 8, there are certain differences in the performance of each model on the test set. The DE-XGBoost model performed best on all metrics, with accuracy, recall, accuracy and F1-scores all close to 0.988. This shows that DE-XGBoost is very effective in handling this task, with high predictive power and stability. The XGBoost model performed second, with accuracy, recall, accuracy, and F1-scores all around 0.952, slightly lower than DE-XGBoost, but still showing strong performance. The indicators of the SVM model are relatively low—all indicators are around 0.908, which represents a significant gap compared with DE-XGBoost. The GBM model was positioned between DE-XGBoost and SVM, with accuracy, recall, and F1-scores around 0.945. This shows that GBM is a relatively reliable model, but not as good as DE-XGBoost. The performance of the MLP is similar to GBM, but slightly lower, with all indicators around 0.938.
Table 9 presents the performance ranking of five algorithms, where DE-XGBoost takes the top spot with an absolute advantage, followed by XGBoost (2nd place) and GBM (3rd place), while MLP (4th place) and SVM (5th place) rank lower. This ranking indicates that DE-XGBoost performs the best in this evaluation. DE-XGBoost, with its optimized ensemble learning framework and feature-processing capabilities, leads to improved prediction accuracy and stability, demonstrating a significant advantage over the traditional tree models XGBoost and GBM in capturing non-linear relationships. In contrast, MLP and SVM, due to their sensitivity to data distribution and generalization limitations, rank at the bottom in this assessment, further highlighting the adaptability advantages of ensemble algorithms in complex tasks.
Figure 3 shows the feature importance scores derived from DE-XGBoost. Including gender (f1), height (f2), weight (f3), lung capacity (f4), 50 m run (f5), standing long jump (f6), sitting forward bend (f7), 800 m run (f8), 1000 m run (f9), 1 min sit-up (f10) and pull-up (f11), and 11 other characteristics. The X-axis represents the importance scores of the feature, and the Y-axis represents the names of the features. It can be intuitively seen from the figure that vital capacity (f4) and body weight (f3) are factors that affect classification accuracy, and the importance scores are 11,367.0 and 10,665.0, respectively. This is consistent with physiological research, which shows that respiratory efficiency and body composition directly affect health levels [
39]. In contrast, sex (f1) showed the smallest effect, with a score of 168.0, suggesting that fitness classifications are less gender-biased in this dataset.
Figure 4 shows the ROC curve and AUC value of the DE-XGBoost model to reflect the characteristics of the model. Curve 1 represents excellent physical fitness, curve 2 indicates good physical fitness test performance, curve 3 indicates passing physical fitness test performance, and curve 4 indicates failing physical fitness test performance. The AUC value (area under the curve) is 0.99, close to 1.0, indicating that the DE-XGBoost model has extremely high accuracy and stability in distinguishing between different classes. The smoothness of the ROC curve and the trend towards the top-left corner further verify the excellent performance of the model in various categories.
Figure 5 is a confusion matrix diagram of DE-XGBoost, showing the classification results of the model on the test set. As depicted in the figure, the classification performance of this model is excellent in most categories, especially categories 0 and 3, where the predicted results exhibit a high degree of consistency with the actual labels. The classification performance of category 1 is slightly weak, and there are some misclassification phenomena, but the overall performance is still good. For category 2, only a very small number of samples was misclassified.
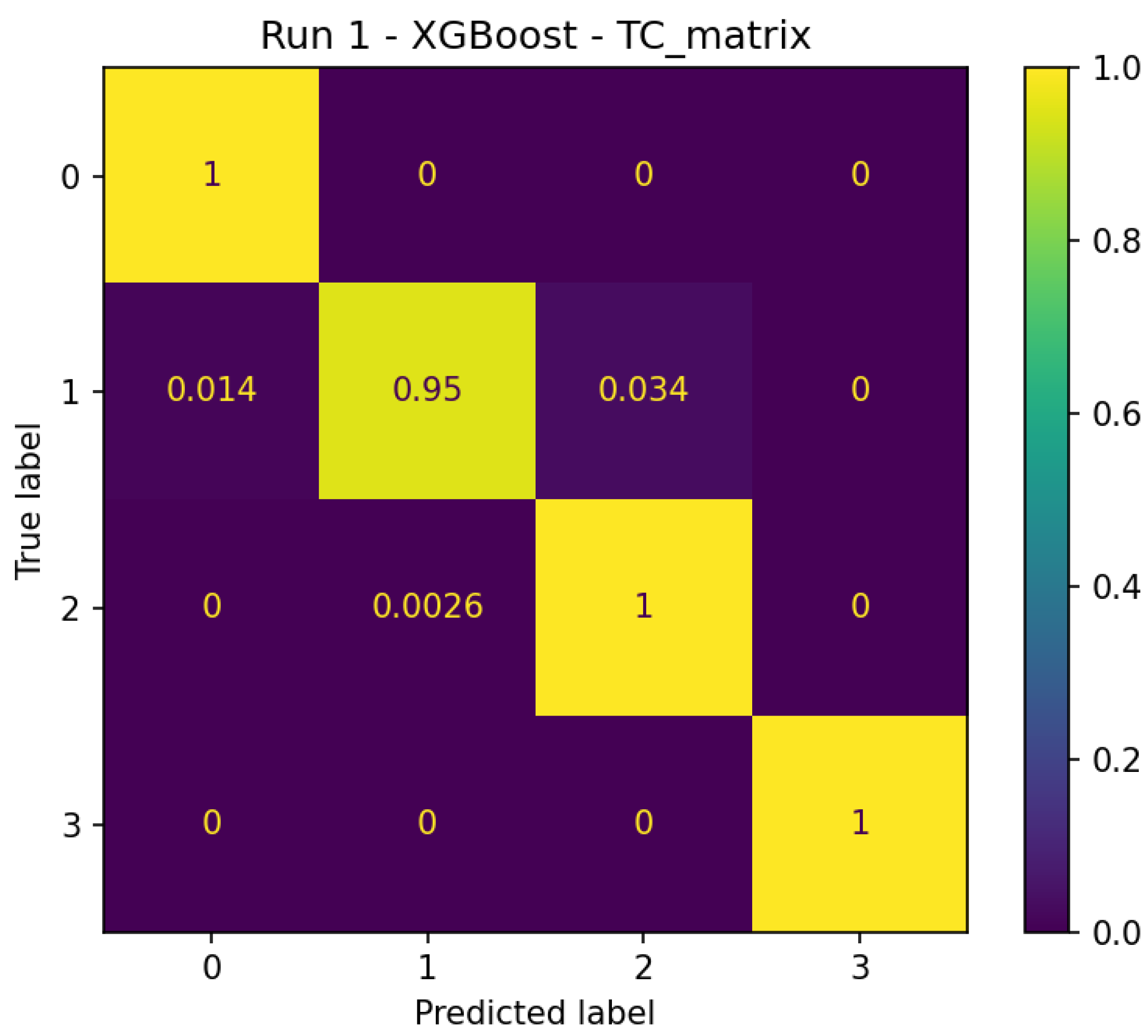
Figure 6 shows the normalized confusion matrix and the proportion of categories, in which 100% of the samples of category 0 are correctly predicted, the accuracy of category 1 is 95%, but there is a phenomenon that 3.4% is misjudged as category 2. Meanwhile, the distribution ratio of samples of categories 1 and 2 in the test set is close, indicating that the high accuracy of the model does not depend on the advantage of sample size, but has stable classification ability.
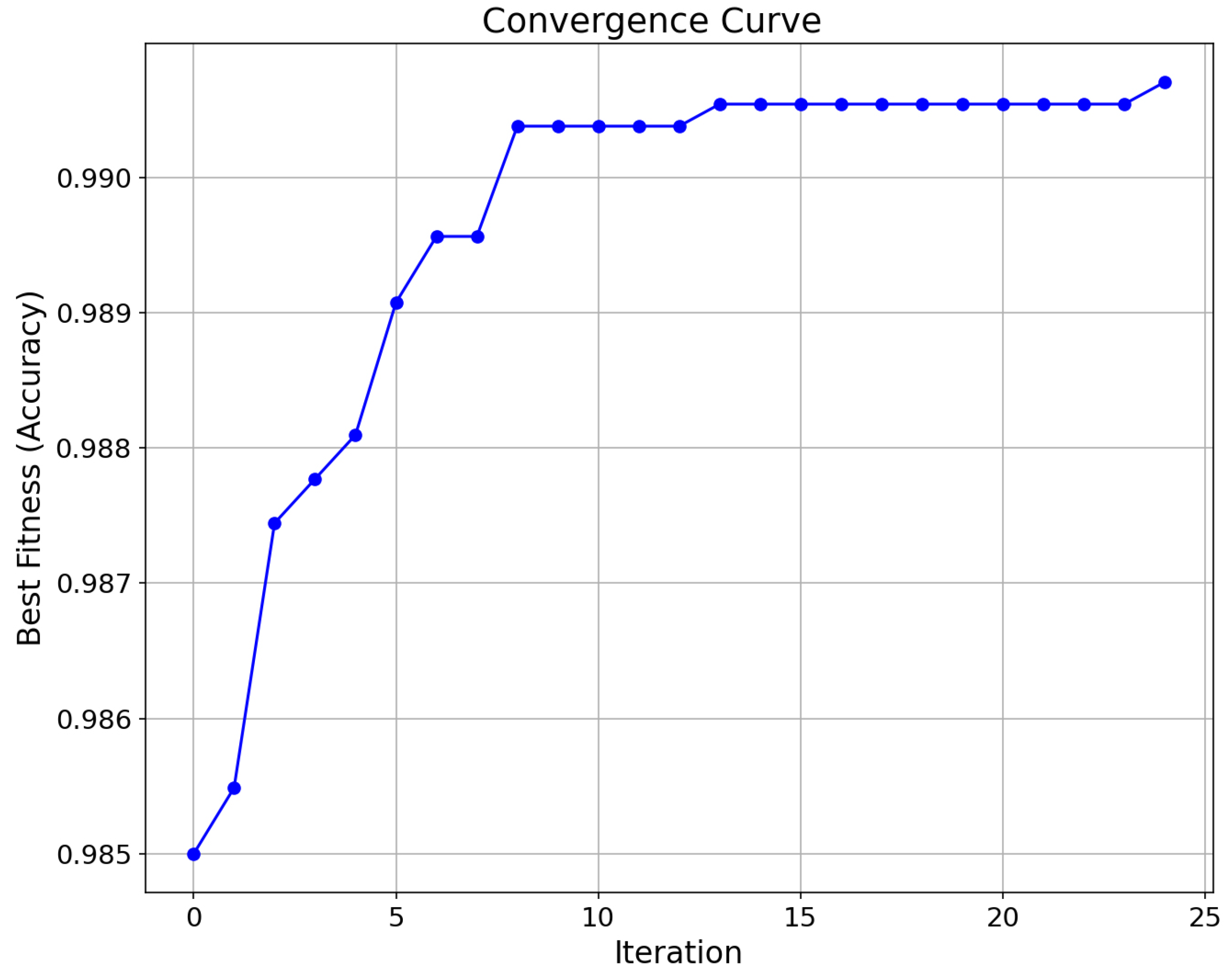
Figure 7 shows the convergence characteristics of the DE-XGBoost algorithm in the first run. The horizontal axis is the number of iterations (0–25), and the vertical axis is the best fitness (based on the classification accuracy index). The convergence curve presents a typical three-stage feature: the accuracy of the initial stage (0–5 iterations) rapidly rises from 0.985 to 0.990, reflecting the efficient exploration ability of the differential evolution mechanism in parameter space. In the middle stage (5–10 iterations), the upward slope is slow and accompanied by a small amount of fluctuation, reflecting the equilibrium process of development and exploration of the algorithm in the local optimal region. In the convergence stage (after 10 iterations), the accuracy rate is stable in the range of 0.990–0.992, and the fluctuation range is very small, which indicates that the hyperparameter combination of XGBoost has reached the approximate optimal configuration after 10 iterations. This convergence mode verifies the optimization efficiency of the DE-XGBoost framework, and only 10 iterations can be completed to optimize parameters while ensuring the model performance, significantly reducing the computational cost.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}