
Efficient Post-Quantum Cross-Silo Federated Learning Based on Key Homomorphic Pseudo-Random Function


Abstract

1. Introduction
- 1.
- We introduce a novel post-quantum secure aggregation scheme with low communication overhead, low communication rounds, and no TTP. This approach provides a new entry point for constructing privacy-preserving federated learning systems. Furthermore, our scheme is adaptable to various application domains, including smart grids and sensor networks.
- 2.
- We construct privacy-preserving cross-silo federated learning using the aforementioned secure aggregation scheme based on secret sharing scheme and KHPRF. By exploiting the key homomorphism property of KHPRF, we optimize the mask-based secure aggregation mechanism, significantly reducing the round complexity compared to classical double-masking schemes. Our approach achieves the minimal round complexity of just one round (the same round complexity as federal learning without privacy protection) in the aggregation phase. Additionally, it supports multiple aggregations, without requiring repeated initialization, making it highly efficient for cross-silo federated learning.
2. Related Works
2.1. Classical Secure Federated Learning
- Differential Privacy: Differential privacy introduces noise into data or model updates to provide formal privacy guarantees. Wang et al. [3] introduced a local differential privacy mechanism transforming user data into randomized bit strings, reconstructed later by an edge server. While safeguarding user privacy and maintaining data usability to some extent, this method incurs significant computational complexity for data reconstruction. Similarly, Tran et al. [4] proposed a privacy-preserving FL framework employing differential privacy techniques (including DP-GANs) and optimized model-agnostic meta-learning algorithms. Their goal was to achieve client instance-level privacy and support personalized model training. However, this framework suffers from high computational and communication overheads, and faces difficulties in optimally balancing privacy guarantees with model performance.
- Homomorphic Encryption: Homomorphic encryption allows computations on encrypted data, enabling secure aggregation, without exposing raw model updates. Zhang et al. [5] designed BatchCrypt for cross-silo federated learning, utilizing quantization, encoding, and batch encryption to reduce encryption and communication overheads, accelerate training, and maintain model quality. Nonetheless, BatchCrypt has limitations regarding synchronization requirements, scalability to very large models, and applicability in vertical-federated learning settings. Liu et al. [7] introduced the DHSA scheme, which integrates multi-key homomorphic encryption with a seeded homomorphic pseudo-random number generator. DHSA offers strong security guarantees, notably defending against collusion threats involving up to participants and the aggregator. While minimizing the computational/communication overhead and reducing round complexity, DHSA is limited by its inability to support one-time initialization and its applicability being restricted to specific scenarios. Zhang et al. [14] proposed the QPFFL framework, integrating functional encryption and homomorphic encryption techniques alongside a privacy-preserving reputation mechanism. This aimed to achieve privacy preservation, fairness guarantees, and robustness enhancement. However, QPFFL relies on a TTP, incurs high computational and communication overheads, and makes certain idealized assumptions.
- Secret Sharing Schemes: A secret sharing scheme distributes shares of a secret (e.g., model updates) among multiple parties, such that only authorized subsets can reconstruct it. This technique is often used for secure aggregation. Building upon the classic double-mask scheme proposed by Bonawitz et al. [8], Bell et al. [15] introduced BBGLR, which employs graph-theory based communication structures, multiple cryptographic primitives, and secret sharing for efficient and secure aggregation. Despite its advancements, BBGLR’s overheads offer room for improvement, it does not handle adaptive adversaries, and requires re-initialization for each aggregation round. Kadhe et al. [16] proposed FastSecAgg, aiming for low-overhead secure aggregation using an SSS based on the Fast Fourier Transform and Chinese Remainder Theorem, combined with authenticated encryption. However, it exhibits lower resistance to collusion compared to certain other schemes and faces practical deployment challenges. So et al. [17] presented LightSecAgg, a lightweight protocol that reconfigures one-time aggregation masks using encoding/decoding techniques. This significantly reduces server-side computation, while preserving privacy and fault-tolerance guarantees similarly to existing protocols. However, its design and implementation are relatively complex, it introduces additional communication overhead, and relies on an ‘honest-but-curious’ threat model, potentially limiting its security in the face of malicious attackers. Tran and Hu et al. [18] utilized a secret sharing scheme to develop a two-layer encryption scheme, avoiding reliance on a TTP or multiple non-colluding servers. Their approach supports dynamic client participation but requires five communication rounds for aggregation and lacks support for one-time initialization.
2.2. Quantum-Resistant Federated Learning
3. Preliminaries
3.1. Key-Homomorphic Pseudo-Random Functions (KHPRFs)
3.1.1. PRF and KHPRF
- 1.
- F is a secure PRF.
- 2.
- For every , and every .
3.1.2. LWE-Based and LWR-Based KHPRF
3.1.3. Ring-LWR-Based KHPRF
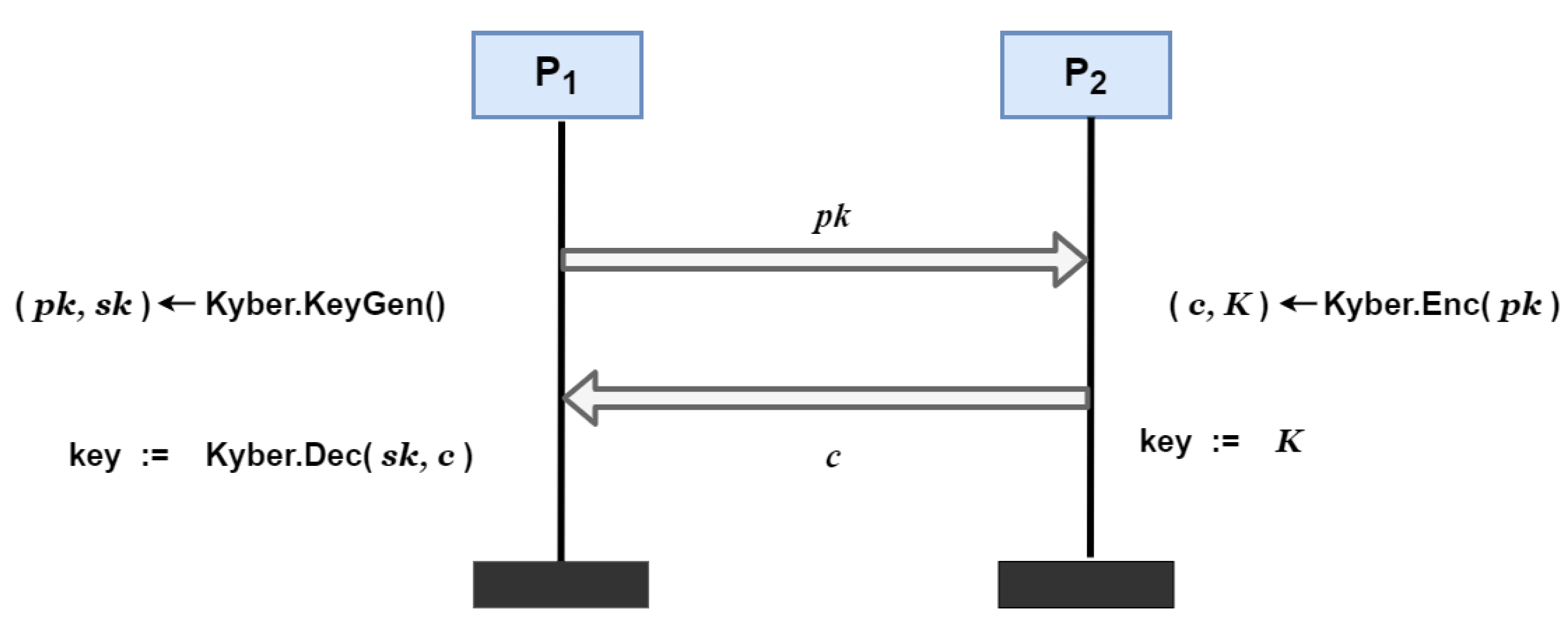
3.2. Key Exchange Protocol
3.3. Lagrange Interpolation
- 1.
- A degree-t polynomial is generated with as the secret.
- 2.
- n shares are distributed to participants ().
- 3.
- Secret recovery requires at least shares to reconstruct :
3.4. Threshold Secret Sharing Scheme
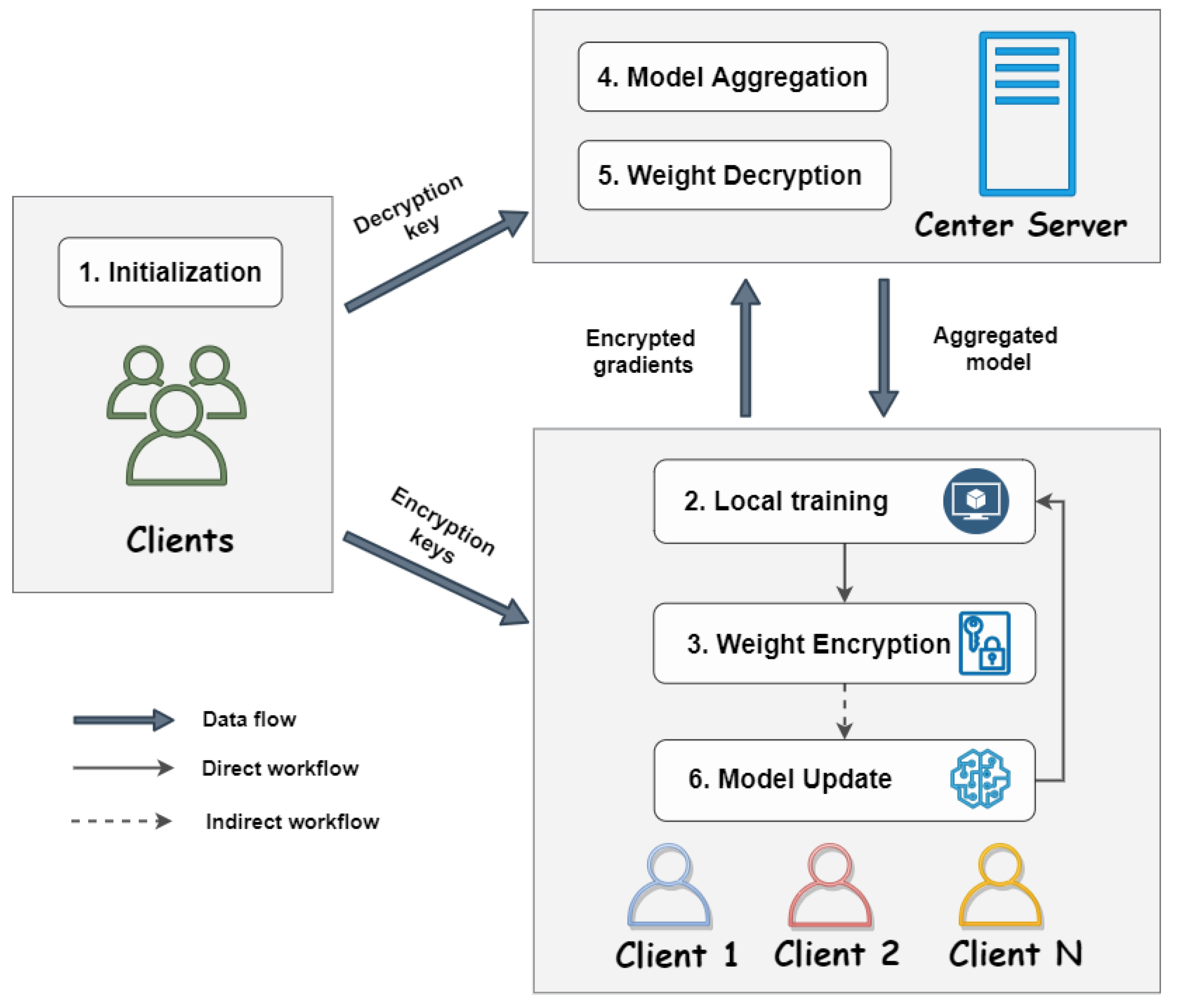
4. Methods
4.1. Overview
| Algorithm 1 Proposed Post-Quantum Cross-Silo federated learning Algorithm. |
|
- 1.
- Reusable PRF Key FactorsOne of our primary objectives is to eliminate the need for a separate initialization in each aggregation round. This is achieved by reusing the materials generated during the initial setup across the subsequent aggregation phases. The KHPRF provides the necessary functionality to accomplish this objective. During the initialization phase, we generate and distribute the key factors , along with the decryption key required for the server side. These values are then persistently used in all subsequent aggregation rounds. In particular, the output of the KHPRF serves as a masking to blind (or encrypt) the data on the client side before aggregation. To ensure fresh masking in each round, we use time-dependent random values as inputs to the KHPRF. Regarding the PRF key structure, part of it is fixed as , while the remaining portion is a constant associated with the current set of online clients. The fixed component , which is a reusable part of the PRF key, is referred to as the key factor.
- 2.
- Non-interactive mask elimination Another main objective of our research on secure aggregation is to minimize the number of communication rounds required between the client and the server in a single aggregation process. The implementation of the KHPRF plays a pivotal role in achieving this goal, as its key-homomorphic property helps to construct a mask removal mechanism that does not require communication and interaction among the participating entities. Analogous to classical double-masking, we can implement KHPRF-based dual masks via a single mechanism, where both masks are derived from the same KHPRF but serve distinct functions. Our scheme achieves equivalent security guarantees with a single-mask design, halving the computational overhead for both clients and servers. During aggregation, the server efficiently eliminates dual masks through lightweight computations, provided all clients remain active. In the context of cross-silo federated learning, given the relatively limited number of participating entities and the absence of variability in this parameter, the scenario of client disconnections is not a concern.
4.2. Initialization
- 1.
- Public Parametersgenerates the necessary parameters: , determine the composition of a client full set A, denote as the clients’ unique position to share the secret; choose a RLWR based KHPRF , where the hash function is as follows , . Then, the publishes as public parameters.
- 2.
- Key Exchange and Secure Channel EstablishmentTo facilitate secure communication throughout the protocol, we employ the quantum-resistant key exchange mechanism Kyber, which is based on the Kyber KEM detailed in Section 3.2. The standard execution details of Kyber are omitted for brevity. Secure channels are established as follows:
- (a)
- Client-Server Channels: Each client executes the Kyber.KE protocol with the CS. This ensures confidential and authenticated communication for exchanging parameters, submitting aggregated results, and potentially other server interactions.
- (b)
- Client–Client Channels: Crucially, for the subsequent secret sharing phase (Step 3), each pair of distinct clients (, ) must also establish a pairwise secure channel. This is achieved by executing Kyber.KE between them. These channels are essential to protect the confidentiality and integrity of the secret shares () exchanged directly between clients.
- 3.
- Computing Key Factors:
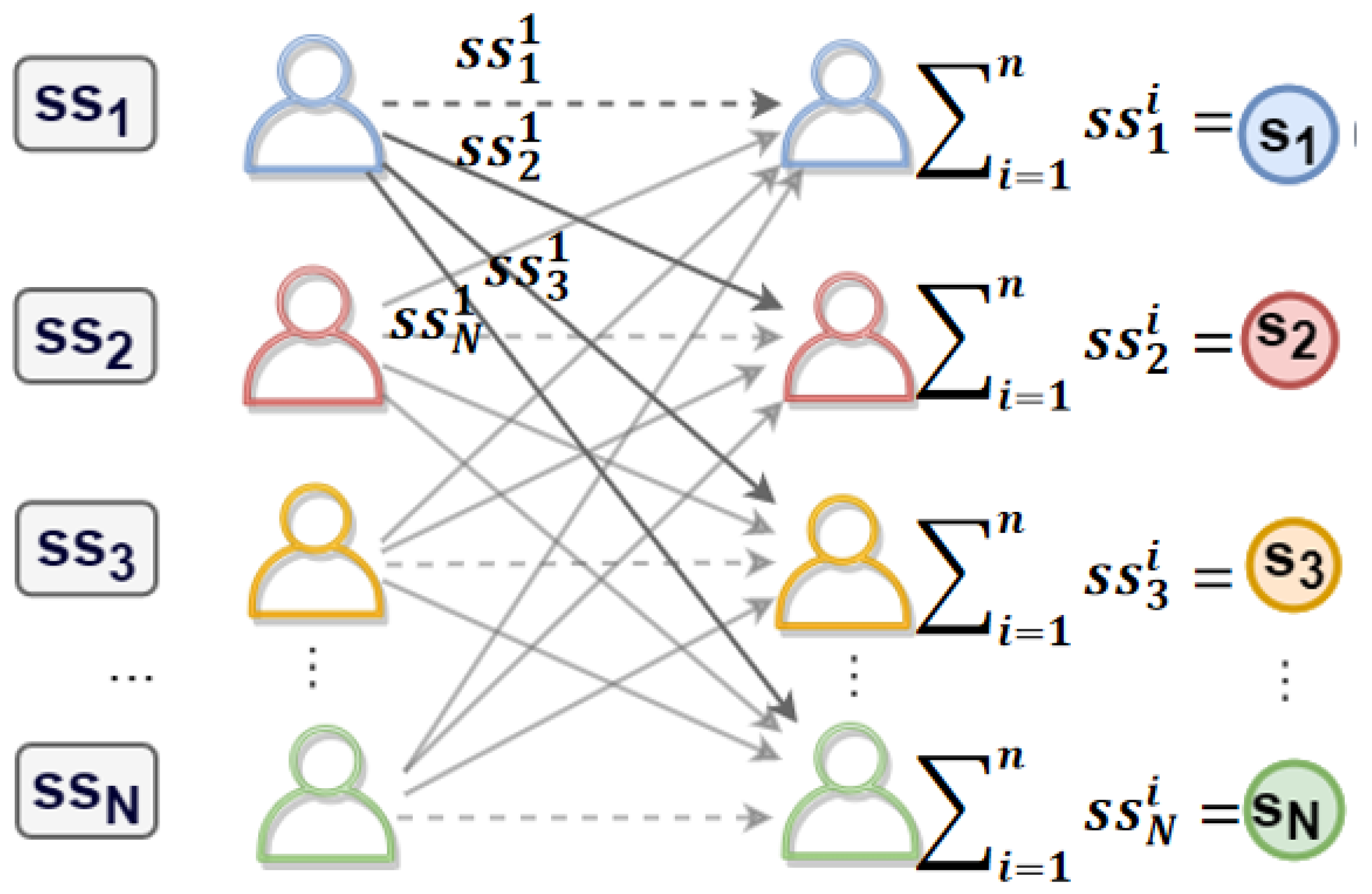
- (a)
- For each client , a random number is chosen and used as the secret value for the secret sharing scheme. Specifically, additional random numbers are selected to generate the following polynomial:where the constant term is the previously chosen random secret value .
- (b)
- Subsequently, the client can calculate the share values for the remaining participants, where , and also holds . Then, the client transmits the value to , where is at a specific sharing position denoted by .
- (c)
- After that, the client receives values from other clients and calculatesthereby obtaining the KHPRF key factor of client , and then locally computing
The schematic diagram for calculating the key factor is shown in Figure 3. As shown in the figure, each client locally generates a random number and then performs secret sharing with the remaining clients (including themselves). The client adds up all the shared values received and the resulting sum is , which is used to compute the KHPRF key. - 4.
- Computing the Decryption Key:Since we do not consider client drops during the aggregation process, the server needs to subtract the total mask from all the received ciphertexts. To calculate the total mask, the server needs to obtain the total PRF key, using the following relation:Each client can send the random number generated at the start of the initialization process to the server-side. The server then calculates the decryption key S according to Equation (11). That is, the PRF key required to calculate the total mask can be obtained in this way without revealing the key factor of any client.Due to the additive homomorphic property of the secret sharing scheme, after using the secret sharing scheme on , the sum of the share values held by each client, is the share value of S. Therefore, we have
4.3. Aggregation Phase
4.3.1. Encryption
- 1.
- Following the initialization phase, the client is required to calculate the mask using the key of the KHPRF, which is obtained during the initialization phase and is formed by multiplying by :then, follow the steps below to encrypt:
- 2.
- A mask is computed for each client participating in the current aggregation round:we use a synchronization timestamp as a random input to the PRF, and the above computation of the mask ensures the reusability of the PRF key factor at each round of subaggregation.
- 3.
- Merge the calculated mask into the plain-text update data to complete the blinding process, which is also the encryption process within the scheme. After the encryption phase is completed, each participant obtains the ciphertext form of the client-side updated data, as follows:
4.3.2. Aggregation
4.3.3. Decryption
5. Security Analysis
5.1. Security Proof
- 2.
- Hybrid (Key Replace)Sim replace with random values . Clients compute , then CS aggregates . The secret key is generated based on the Shamir secret sharing scheme. Since the secret sharing scheme performed during the initialization phase is based on randomly generated polynomials for the distribution of the shared value, as long as the adversary corrupts less than t clients, the key is indistinguishable from the random number . Therefore, and are computationally indistinguishable.
- 3.
- Hybrid (Mask Replace)Sim replace with random masks . Clients compute , then CS aggregates . Since F is a KHPRF based on the RLWR problem, the security of the KHPRF used in this paper can be reduced to the RLWR problem. According to the properties of the PRF, for any polynomial-time predicate D, the probability of distinguishing from a random vector is negligible. Therefore, and are computationally indistinguishable.
- 4.
- Hybrid (Result Replace)CS returns random vector instead of Since the sum of the ciphertexts is also a random number, we cannot distinguish the sum of the ciphertexts from another random number V; therefore, and are computationally indistinguishable.
5.2. Correctness
6. Performance Analysis
6.1. Asymptotic Performance
- 1.
- Client Computation
- Initialization: .The primary overhead in the initialization phase is determined by the computations during secret sharing scheme. Each client locally selects a polynomial of degree and then computes the values of l polynomials for the remaining clients. In total, it needs to calculate the values of polynomials.When computing the value of a single polynomial, multiplications and additions are required. Since the value of t is restricted by N, the overall complexity of computing the value of a single polynomial is . Consequently, the complexity of computing the values of polynomials is , and the average complexity per client is .Key generation and encapsulation for Kyber-512 requires operations, and decapsulation requires , where , n is the polynomial dimension. Therefore, the computational overhead of key negotiation using Kyber is a fixed 8196.
- Aggregation: .During the aggregation phase, the computational overhead of RLWR-KHPRF depends on the polynomial multiplication, which is nlogn under NTT acceleration with an n of 256, and this results in a constant of 2048, which is much smaller than the length of the model parameter l in cross-silo scenarios, and thus can be ignored. Each client only needs to perform one addition operation between the mask and the original data, with a complexity of . Therefore, the total computational overhead generated is .
- 2.
- Client Communication:
- Initialization: .Each client shares the share values (i.e., polynomial values) computed during the initialization phase with every other client, generating a communication volume of in this process.Kybey-512’s communication overhead is fixed at 1568 bytes.
- Aggregation: .The overhead of sending the encrypted vectors is , and the output size of RLWR-KHPRF is , and p is the RLWR output modulus.
- 3.
- Server Computation:
- Initialization: .When computing the decryption key, addition operations are required, which incurs a computation overhead on the server side.Key generation and encapsulation for Kyber-512 requires operations, and decapsulation requires , where k = 2. Therefore, the computational overhead for key negotiation using Kyber is a fixed 8196.
- Aggregation: .Summing up the ciphertext vectors from N clients incurs an overhead of .
- 4.
- Server Communication:
- Initialization: .Receiving a total of random values from N clients generates a communication volume of .Kybey-512’s communication overhead is fixed at 1568 bytes.
- Aggregation: .Receiving the ciphertext vectors from N clients also results in a communication volume of , and the output size of RLWR-KHPRF is , and p is the RLWR output modulus.
6.2. Experimental Performance
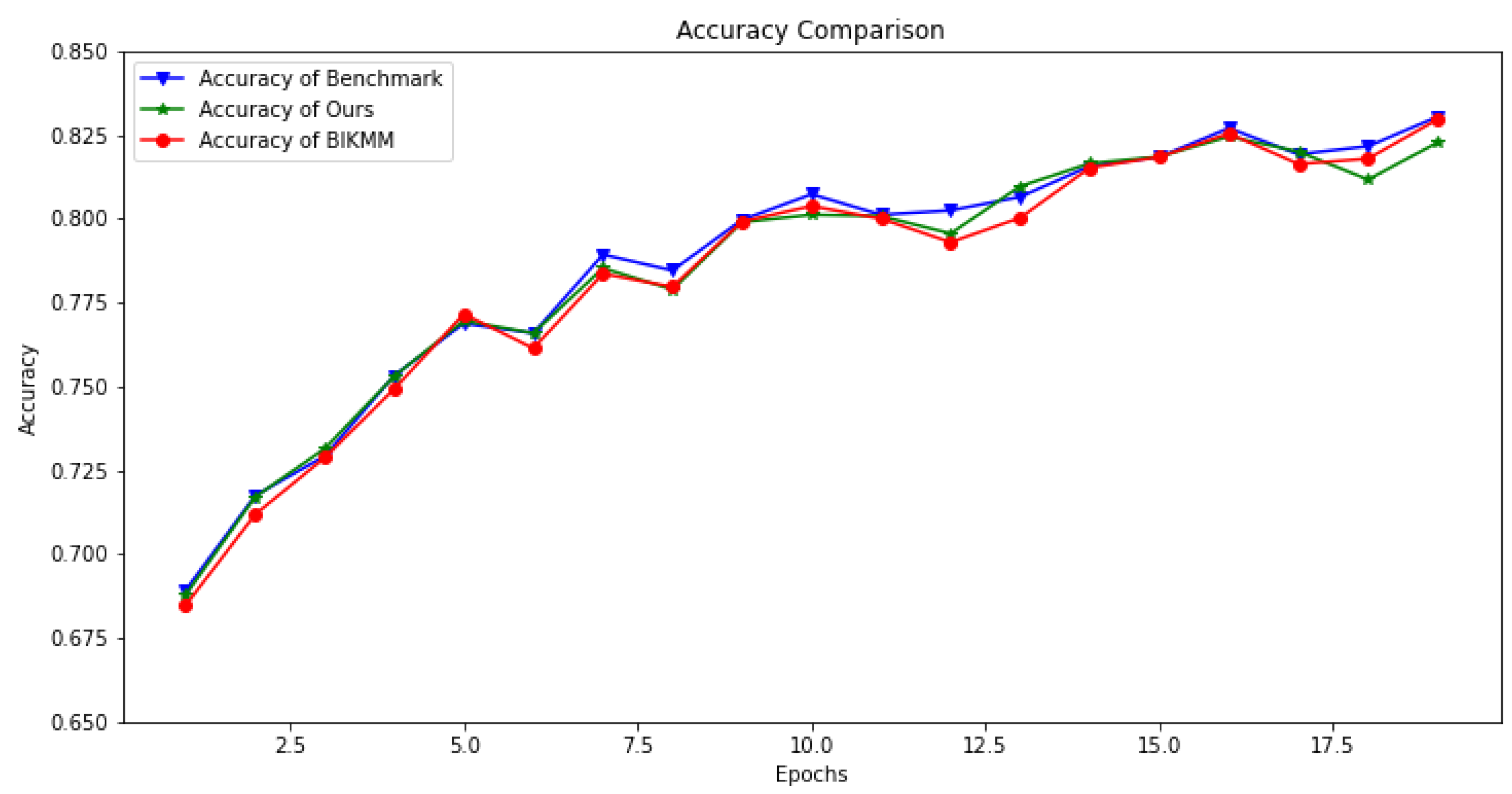
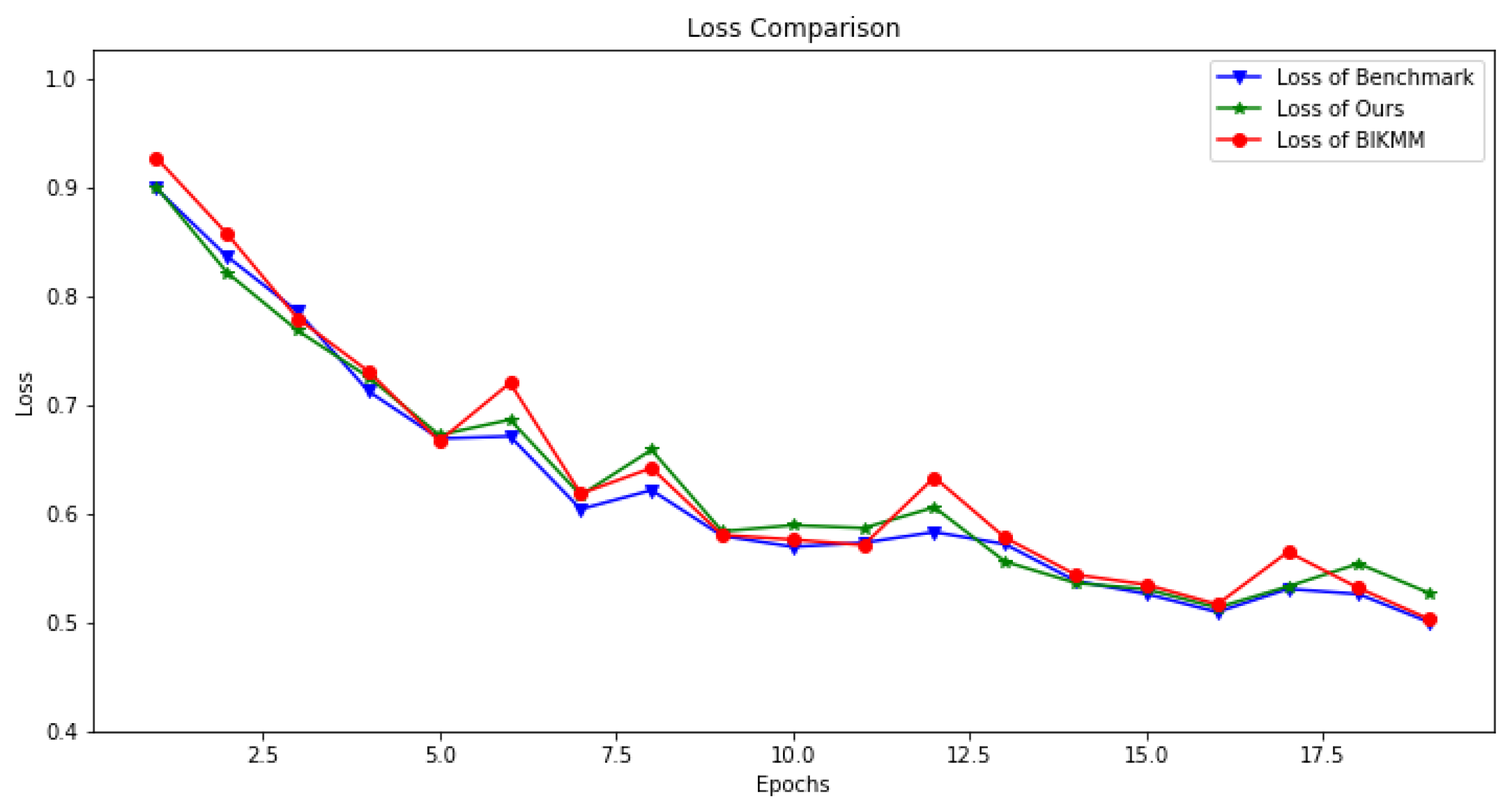
6.2.1. Accuracy and Loss
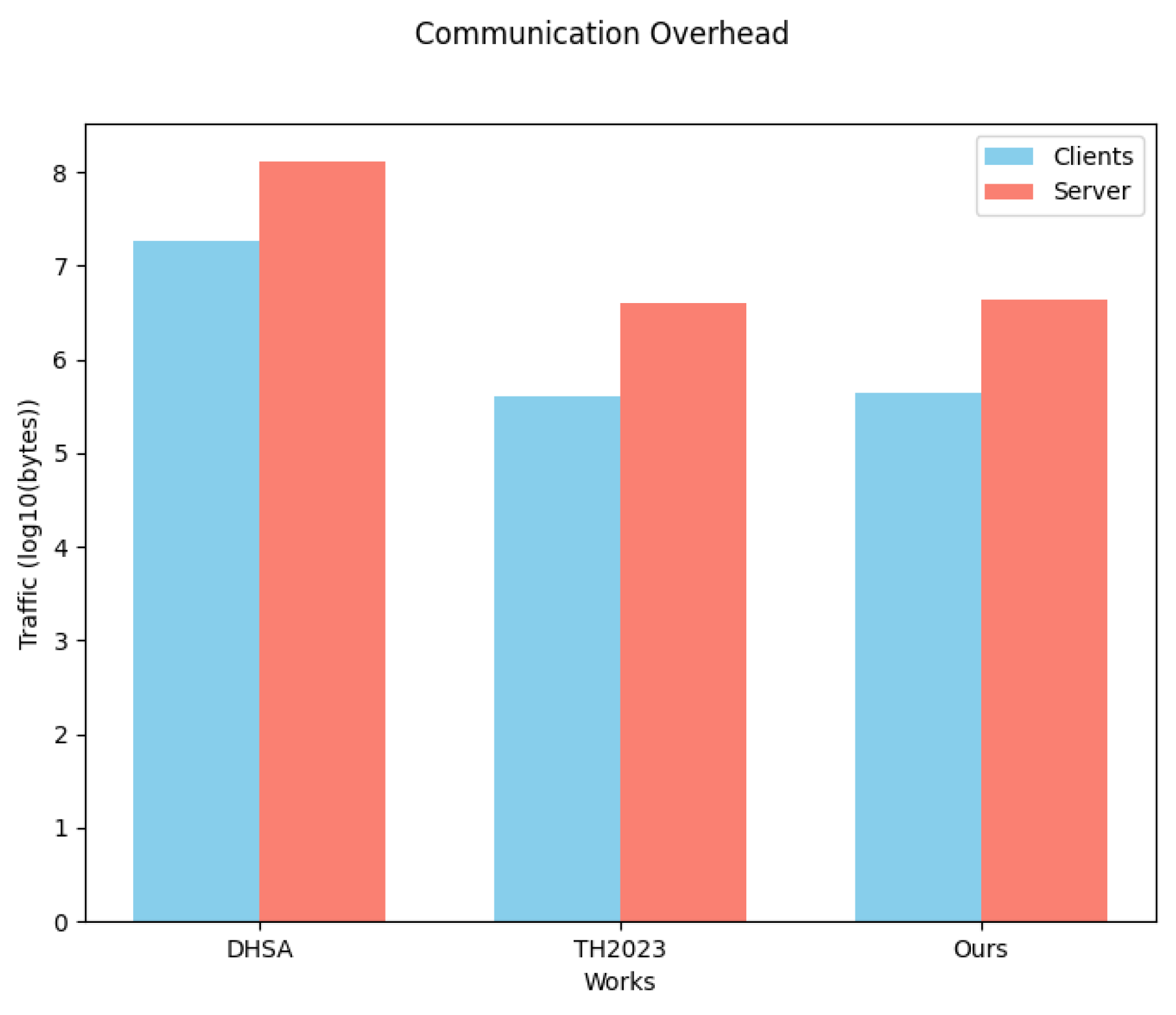
6.2.2. Communication Costs
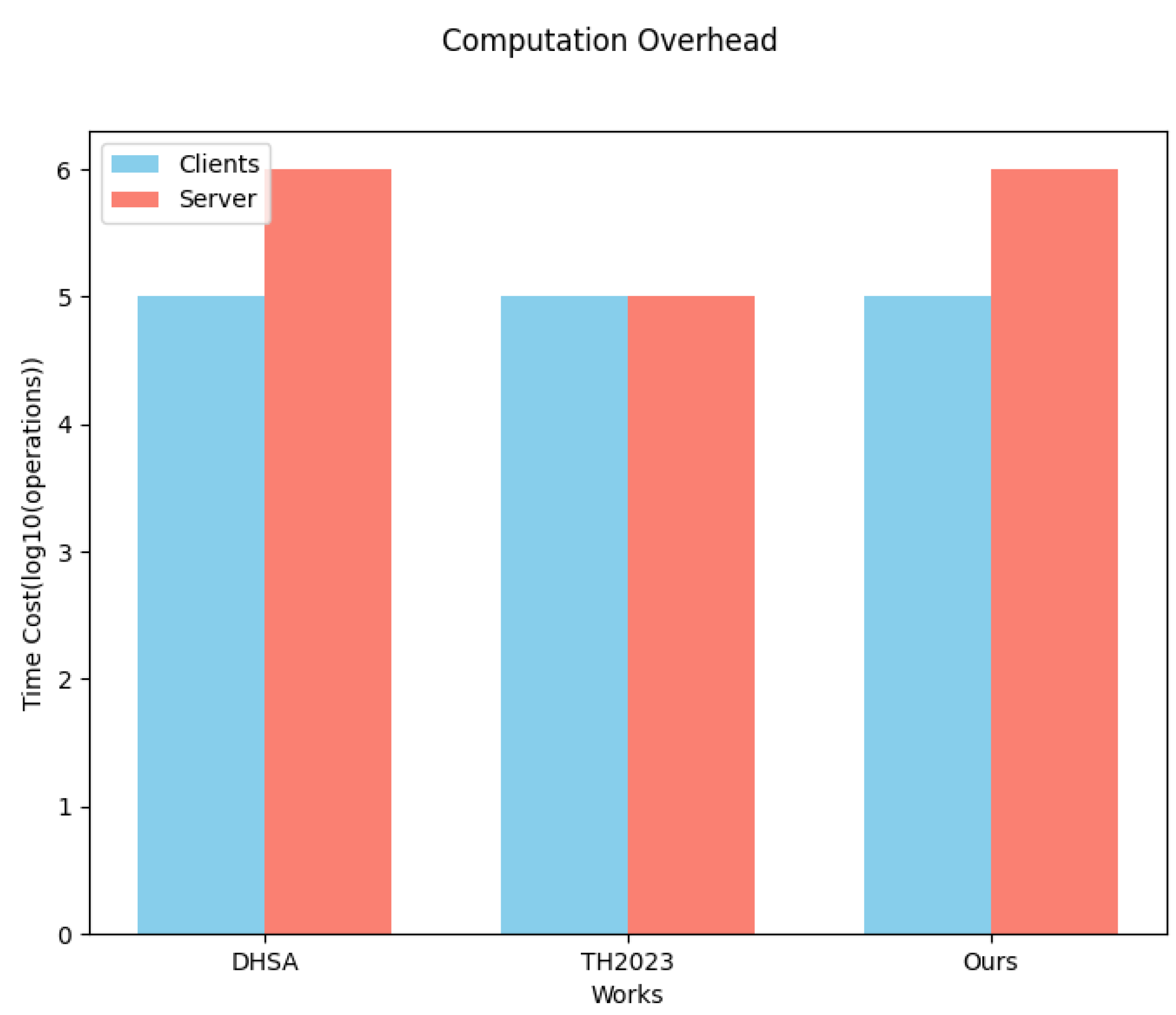
6.2.3. Computation Costs
7. Discussion
- Security Assumptions: The protocol’s security relies on a semi-honest (“honest but curious”) server model and assumes reliable network connectivity; its current design offers limited resilience to client dropouts during aggregation rounds.
- Computational Overhead: While communication-efficient, the necessary cryptographic operations, especially the RLWR-based (for the sake of quantum resistance) KHPRF evaluation, introduce computational costs exceeding those of non-secure FL protocols, potentially impacting resource-constrained settings.
- Scenario Specificity: The current design is optimized for cross-silo deployments and would require adaptation to effectively handle the scale and frequent client dropouts characteristic of cross-device scenarios.
8. Conclusions and Future Work
- Strengthening Server Trust Model: Extend the security framework beyond the current semi-honest server assumption to defend against actively malicious adversaries, potentially by incorporating verifiable computation techniques or other cryptographic primitives.
- Enabling Dynamic Client Participation: Develop mechanisms to smoothly handle client dropouts and support dynamic client availability during the learning process. While the core cryptographic components offer potential extension points, robust management of varying client sets requires dedicated design and analysis.
- Developing Lightweight Protocols: Address the computational overhead for highly resource-constrained environments. This involves exploring and integrating lightweight cryptographic primitives and potentially leveraging hardware acceleration to minimize latency and energy consumption, without compromising security guarantees.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| The i′th client in a specific training phase | |
| Center Server, the party that gets the aggregate result | |
| A | The set of all clients |
| q | key modulus, prime |
| p | mask modulus, prime who less than q |
| Random number locally chosen by client , secret for secret sharing scheme | |
| Share values of , held by client | |
| The product factor of KHPRF key, is the sum of the shared values of | |
| all other clients | |
| S | The decryption key |
| The KHPRF used in this work | |
| Lagrange basis | |
| Lagrangian interpolation coefficient, a constant value related to the client set A | |
| Encrypted data of | |
| N | Total number of clients(length of A) in full federated learning training |
| T | Total number of summations/epochs in full federated learning training |
| Summation of all encrypted data for the round of training | |
| Random input to KHPRF for the round of training | |
| t | The threshold of secret sharing scheme for our scheme |
References
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10. [Google Scholar]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 2019, 32, 14747–14756. [Google Scholar]
- Wang, C.; Wu, X.; Liu, G.; Deng, T.; Peng, K.; Wan, S. Safeguarding cross-silo federated learning with local differential privacy. Digit. Commun. Netw. 2022, 8, 446–454. [Google Scholar] [CrossRef]
- Tran, V.T.; Pham, H.H.; Wong, K.S. Personalized privacy-preserving framework for cross-silo federated learning. IEEE Trans. Emerg. Top. Comput. 2024, 12, 1014–1024. [Google Scholar] [CrossRef]
- Zhang, C.; Li, S.; Xia, J.; Wang, W.; Yan, F.; Liu, Y. BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), Online, 15–17 July 2020; pp. 493–506. [Google Scholar]
- Jiang, Z.; Wang, W.; Liu, Y. Flashe: Additively symmetric homomorphic encryption for cross-silo federated learning. arXiv 2021, arXiv:2109.00675. [Google Scholar]
- Liu, Z.; Chen, S.; Ye, J.; Fan, J.; Li, H.; Li, X. DHSA: Efficient doubly homomorphic secure aggregation for cross-silo federated learning. J. Supercomput. 2023, 79, 2819–2849. [Google Scholar] [CrossRef]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Pleshakova, E.; Osipov, A.; Gataullin, S.; Gataullin, T.; Vasilakos, A. Next gen cybersecurity paradigm towards artificial general intelligence: Russian market challenges and future global technological trends. J. Comput. Virol. Hacking Tech. 2024, 20, 429–440. [Google Scholar] [CrossRef]
- Moody, D.; Perlner, R.; Regenscheid, A.; Robinson, A.; Cooper, D. Transition to Post-Quantum Cryptography Standards; Technical report; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2024.
- Guo, Y.; Polychroniadou, A.; Shi, E.; Byrd, D.; Balch, T. MicroSecAgg: Streamlined Single-Server Secure Aggregation. Cryptology ePrint Archive. 2022. Available online: https://eprint.iacr.org/2022/714 (accessed on 30 September 2024).
- Ma, Y.; Woods, J.; Angel, S.; Polychroniadou, A.; Rabin, T. Flamingo: Multi-round single-server secure aggregation with applications to private federated learning. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–24 May 2023; pp. 477–496. [Google Scholar]
- Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Kyber: A CCA-secure module-lattice-based KEM. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 353–367. [Google Scholar]
- Zhang, R.; Li, H.; Qian, X.; Liu, X.; Jiang, W. QPFFL: Advancing Federated Learning with Quantum-Resistance, Privacy, and Fairness. In Proceedings of the GLOBECOM 2024—2024 IEEE Global Communications Conference, Cape Town, South Africa, 8–12 December 2024; pp. 4994–4999. [Google Scholar]
- Bell, J.H.; Bonawitz, K.A.; Gascón, A.; Lepoint, T.; Raykova, M. Secure single-server aggregation with (poly) logarithmic overhead. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 1253–1269. [Google Scholar]
- Kadhe, S.; Rajaraman, N.; Koyluoglu, O.O.; Ramchandran, K. Fastsecagg: Scalable secure aggregation for privacy-preserving federated learning. arXiv 2020, arXiv:2009.11248. [Google Scholar]
- So, J.; He, C.; Yang, C.S.; Li, S.; Yu, Q.; E Ali, R.; Guler, B.; Avestimehr, S. Lightsecagg: A lightweight and versatile design for secure aggregation in federated learning. Proc. Mach. Learn. Syst. 2022, 4, 694–720. [Google Scholar]
- Tran, H.Y.; Hu, J.; Yin, X.; Pota, H.R. An efficient privacy-enhancing cross-silo federated learning and applications for false data injection attack detection in smart grids. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2538–2552. [Google Scholar] [CrossRef]
- Xu, P.; Hu, M.; Chen, T.; Wang, W.; Jin, H. LaF: Lattice-Based and Communication-Efficient Federated Learning. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2483–2496. [Google Scholar] [CrossRef]
- Gharavi, H.; Granjal, J.; Monteiro, E. PQBFL: A Post-Quantum Blockchain-based Protocol for Federated Learning. arXiv 2025, arXiv:2502.14464. [Google Scholar]
- Zhang, X.; Deng, H.; Wu, R.; Ren, J.; Ren, Y. PQSF: Post-quantum secure privacy-preserving federated learning. Sci. Rep. 2024, 14, 23553. [Google Scholar] [CrossRef] [PubMed]
- Goldreich, O.; Goldwasser, S.; Micali, S. How to construct random functions. J. ACM (JACM) 1986, 33, 792–807. [Google Scholar] [CrossRef]
- Regev, O. On lattices, learning with errors, random linear codes, and cryptography. J. ACM (JACM) 2009, 56, 1–40. [Google Scholar] [CrossRef]
- Boneh, D.; Lewi, K.; Montgomery, H.; Raghunathan, A. Key homomorphic PRFs and their applications. In Annual Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 410–428. [Google Scholar]
- Banerjee, A.; Peikert, C.; Rosen, A. Pseudorandom functions and lattices. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2012; pp. 719–737. [Google Scholar]
- Banerjee, A.; Peikert, C. New and Improved Key-Homomorphic Pseudorandom Functions. Cryptology ePrint Archive, Paper 2014/074. 2014. Available online: https://eprint.iacr.org/2014/074 (accessed on 30 September 2024).
- Lyubashevsky, V.; Peikert, C.; Regev, O. On ideal lattices and learning with errors over rings. In Proceedings of the Advances in Cryptology–EUROCRYPT 2010: 29th Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; pp. 1–23. [Google Scholar]
- Hellman, M. New directions in cryptography. IEEE Trans. Inf. Theory 1976, 22, 644–654. [Google Scholar]
- Shamir, A. How to share a secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Blakley, G.R. Safeguarding cryptographic keys. In Proceedings of the 1979 International Workshop on Managing Requirements Knowledge (MARK), New York, NY, USA, 4–7 June 1979; pp. 313–318. [Google Scholar] [CrossRef]
- Ball, M.; Çakan, A.; Malkin, T. Linear threshold secret-sharing with binary reconstruction. In Proceedings of the 2nd Conference on Information-Theoretic Cryptography (ITC 2021), Schloss Dagstuhl–Leibniz-Zentrum für Informatik, Virtual, 24–26 July 2021. [Google Scholar]
- Yang, Q.; Huang, A.; Liu, Y.; Chen, T. Practicing Federated Learning; Publishing House of Electronics and Industry: Beijing, China, 2021. [Google Scholar]
| Schemes | Time | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|
| BIKMM [8] | 2017 | × | × | × | |||
| BBGLR [15] | 2020 | × | × | × | |||
| FastSecAgg [16] | 2020 | × | × | × | − | ||
| LightSecAgg [17] | 2022 | × | × | × | − | ||
| MicroSecAgg [11] | 2022 | × | ✓ | × | − | ||
| Flamingo [12] | 2023 | × | ✓ | × | |||
| TH [18] | 2023 | × | × | ✓ | − | ||
| DHSA [7] | 2023 | × | × | ✓ | − | ||
| PQSF [21] | 2024 | ✓ | ✓ | × | − | ||
| QPFFL [14] | 2024 | ✓ | ✓ | × | |||
| Ours | 2025 | ✓ | ✓ | ✓ | − |
| Works | Stage | Round | Clients | Server | ||
|---|---|---|---|---|---|---|
| Computation | Communication | Computation | Communication | |||
| INIT | - | - | - | - | - | |
| BIKMM [8] | T AGG | 5T | ||||
| INIT | - | - | - | - | - | |
| BBGLR [15] | T AGG | 6T | ||||
| INIT | - | - | - | - | - | |
| TH [18] | T AGG | 5T | ||||
| INIT | - | - | - | - | - | |
| DHSA [7] | T AGG | |||||
| INIT | 5 | - | ||||
| Flamingo [12] | T AGG | 3T | ||||
| INIT | 2 | |||||
| PQSF [21] | T AGG | 2T | ||||
| INIT | 1 | |||||
| Ours | T AGG | T | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, X.; Xu, R. Efficient Post-Quantum Cross-Silo Federated Learning Based on Key Homomorphic Pseudo-Random Function. Mathematics 2025, 13, 1404. https://doi.org/10.3390/math13091404
Qin X, Xu R. Efficient Post-Quantum Cross-Silo Federated Learning Based on Key Homomorphic Pseudo-Random Function. Mathematics. 2025; 13(9):1404. https://doi.org/10.3390/math13091404
Chicago/Turabian StyleQin, Xiaoyuan, and Rui Xu. 2025. "Efficient Post-Quantum Cross-Silo Federated Learning Based on Key Homomorphic Pseudo-Random Function" Mathematics 13, no. 9: 1404. https://doi.org/10.3390/math13091404
APA StyleQin, X., & Xu, R. (2025). Efficient Post-Quantum Cross-Silo Federated Learning Based on Key Homomorphic Pseudo-Random Function. Mathematics, 13(9), 1404. https://doi.org/10.3390/math13091404