

Watermark and Trademark Prompts Boost Video Action Recognition in Visual-Language Models


Abstract
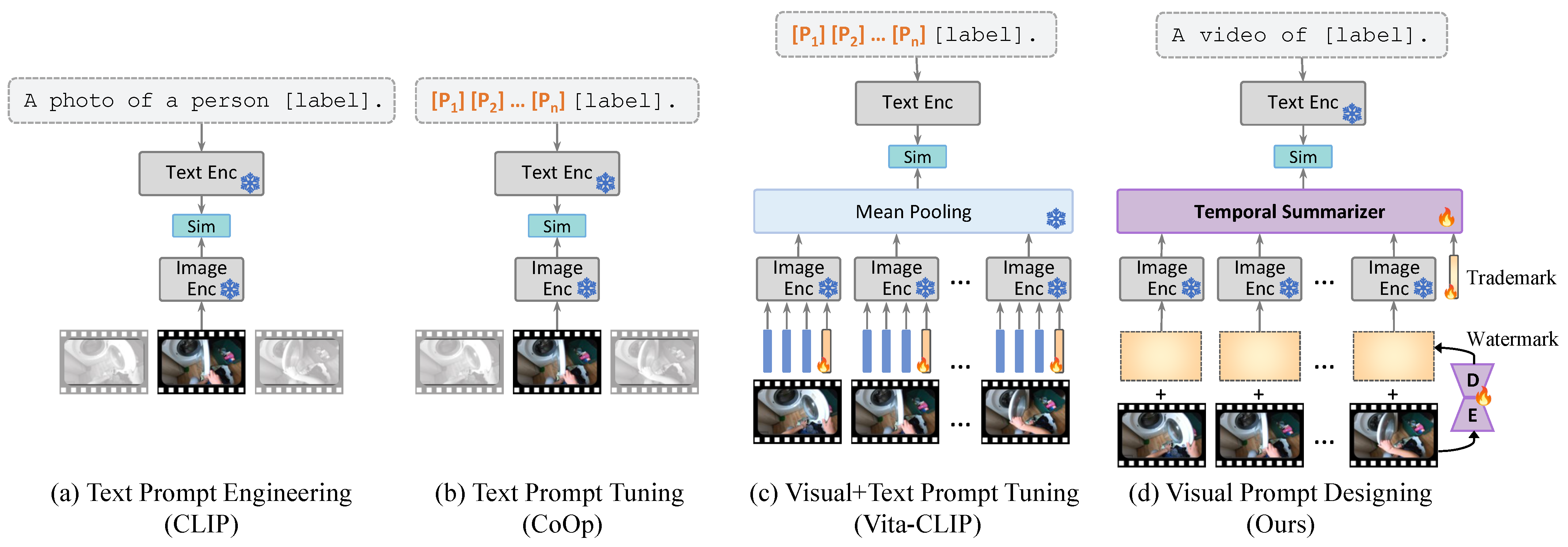
1. Introduction
2. Related Work
2.1. Generalizability, Transferability, and Adaptability
2.2. Video Adaptation in VLMs
3. Methodology
3.1. Watermark Prompts Generation
3.1.1. Prompt Encoder: Mapping Latent Features
3.1.2. Prompt Decoder: Designing Watermark Prompts
3.2. Trademark Prompts Summarization
3.3. Natural Language Supervision
4. Experiments
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Quantitative Results
4.2.1. Main Results
4.2.2. Comparison with State-of-the-Art Methods
4.3. Ablation Studies
4.3.1. Prompt Encoder Design
4.3.2. Prompt Decoder Design
4.3.3. Temporal Aggregation Design
4.3.4. CLIP Image Encoder
4.4. Qualitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VLMs | Visual-Language Models |
| ViT | Vision Transformer |
| CLIP | Contrastive Language–Image Pre-training |
| ALIGN | A Large-scale ImaGe and Noisy-text embedding |
| OCR | Optical Character Recognition |
| CNN | Convolutional Neural Network |
| RGB | Red, Green, Blue (color channels) |
| LSTM | Long Short-Term Memory |
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Birmingham, UK, 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.V.; Sung, Y.; Li, Z.; Duerig, T. Scaling Up Visual and Vision-Language Representation Learning with Noisy Text Supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR: Birmingham, UK, 2021; Volume 139, pp. 4904–4916. [Google Scholar]
- Lv, G.; Sun, Y.; Nian, F.; Zhu, M.; Tang, W.; Hu, Z. COME: Clip-OCR and Master ObjEct for text image captioning. Image Vis. Comput. 2023, 136, 104751. [Google Scholar] [CrossRef]
- Rasheed, H.; Khattak, M.U.; Maaz, M.; Khan, S.; Khan, F.S. Fine-tuned CLIP Models are Efficient Video Learners. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6545–6554. [Google Scholar]
- Wang, M.; Xing, J.; Liu, Y. ActionCLIP: A New Paradigm for Video Action Recognition. arXiv 2021, arXiv:2109.08472. [Google Scholar]
- Zhou, Z.; Zhang, B.; Lei, Y.; Liu, L.; Liu, Y. ZegCLIP: Towards Adapting CLIP for Zero-shot Semantic Segmentation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 11175–11185. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to Prompt for Vision-Language Models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional Prompt Learning for Vision-Language Models. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Luo, H.; Ji, L.; Zhong, M.; Chen, Y.; Lei, W.; Duan, N.; Li, T. CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing 2022, 508, 293–304. [Google Scholar] [CrossRef]
- Ni, B.; Peng, H.; Chen, M.; Zhang, S.; Meng, G.; Fu, J.; Xiang, S.; Ling, H. Expanding Language-Image Pretrained Models for General Video Recognition. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 1–18. [Google Scholar]
- Wasim, S.T.; Naseer, M.; Khan, S.; Khan, F.S.; Shah, M. Vita-CLIP: Video and text adaptive CLIP via Multimodal Prompting. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 23034–23044. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Elsayed, G.F.; Goodfellow, I.; Sohl-Dickstein, J. Adversarial Reprogramming of Neural Networks. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Bahng, H.; Jahanian, A.; Sankaranarayanan, S.; Isola, P. Exploring Visual Prompts for Adapting Large-Scale Models. arXiv 2022, arXiv:2203.17274. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Furnari, A.; Kazakos, E.; Ma, J.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100. Int. J. Comput. Vis. 2022, 130, 33–55. [Google Scholar] [CrossRef]
- Ju, C.; Han, T.; Zheng, K.; Zhang, Y.; Xie, W. Prompting Visual-Language Models for Efficient Video Understanding. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 105–124. [Google Scholar]
- Lin, K.Y.; Ding, H.; Zhou, J.; Peng, Y.X.; Zhao, Z.; Loy, C.C.; Zheng, W.S. Rethinking CLIP-based Video Learners in Cross-Domain Open-Vocabulary Action Recognition. arXiv 2024, arXiv:2403.01560. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Weng, Z.; Yang, X.; Li, A.; Wu, Z.; Jiang, Y.G. Open-VCLIP: Transforming CLIP to an Open-Vocabulary Video Model via Interpolated Weight Optimization. In Proceedings of the International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 36978–36989. [Google Scholar]
- Liu, R.; Huang, J.; Li, G.; Feng, J.; Wu, X.; Li, T.H. Revisiting Temporal Modeling for CLIP-based Image-to-Video Knowledge Transferring. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6555–6564. [Google Scholar]
- Lin, Z.; Geng, S.; Zhang, R.; Gao, P.; de Melo, G.; Wang, X.; Dai, J.; Qiao, Y.; Li, H. Frozen CLIP Models are Efficient Video Learners. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Pan, J.; Lin, Z.; Zhu, X.; Shao, J.; Li, H. ST-Adapter: Parameter-efficient Image-to-Video Transfer Learning. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 November–9 December 2022; pp. 26462–26477. [Google Scholar]
- Park, J.; Lee, J.; Sohn, K. Dual-Path Adaptation from Image to Video Transformers. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 2203–2213. [Google Scholar]
- Wu, W.; Sun, Z.; Ouyang, W. Revisiting Classifier: Transferring Vision-Language Models for Video Recognition. In Proceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7–14 February 2023; pp. 2847–2855. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girdhar, R.; Singh, M.; Ravi, N.; van der Maaten, L.; Joulin, A.; Misra, I. Omnivore: A Single Model for Many Visual Modalities. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16102–16112. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Layer | Channel | Kernel 1 | Output Shape 2 | Activation |
|---|---|---|---|---|---|
| Shape of input video V: | |||||
| Prompt Encoder | Depthwise 3D Convolution | 3 | GELU | ||
| Pointwise 3D Convolution | 8 | GELU | |||
| 3D Max Pooling | |||||
| Depthwise 3D Convolution | 8 | GELU | |||
| Pointwise 3D Convolution | 16 | GELU | |||
| 3D Max Pooling | |||||
| Depthwise 3D Convolution | 16 | GELU | |||
| Pointwise 3D Convolution | 32 | GELU | |||
| 3D Max Pooling | |||||
| Depthwise 3D Convolution | 32 | GELU | |||
| Pointwise 3D Convolution | 64 | GELU | |||
| 3D Max Pooling | |||||
| Depthwise 3D Convolution | 64 | GELU | |||
| Pointwise 3D Convolution | 128 | GELU | |||
| 3D Max Pooling | |||||
| Shape of prompt encoder output : | |||||
| Spatial Decoder | Depthwise 3D Upconvolution | 128 | GELU | ||
| Pointwise 3D Upconvolution | 64 | GELU | |||
| 3D Adaptive Max Pooling | |||||
| Depthwise 3D Upconvolution | 64 | GELU | |||
| Pointwise 3D Upconvolution | 32 | GELU | |||
| 3D Adaptive Max Pooling | |||||
| Depthwise 3D Upconvolution | 32 | GELU | |||
| Pointwise 3D Upconvolution | 16 | GELU | |||
| 3D Adaptive Max Pooling | |||||
| Depthwise 3D Upconvolution | 16 | GELU | |||
| Pointwise 3D Upconvolution | 8 | GELU | |||
| 3D Adaptive Max Pooling | |||||
| Depthwise 3D Upconvolution | 8 | GELU | |||
| Pointwise 3D Upconvolution | C | GELU | |||
| Shape of spatial decoder output : | |||||
| Mask Decoder | Depthwise 3D Upconvolution | 128 | GELU | ||
| Pointwise 3D Upconvolution | 64 | GELU | |||
| Depthwise 3D Upconvolution | 64 | GELU | |||
| Pointwise 3D Upconvolution | 32 | GELU | |||
| Depthwise 3D Upconvolution | 32 | GELU | |||
| Pointwise 3D Upconvolution | 16 | GELU | |||
| Depthwise 3D Upconvolution | 16 | GELU | |||
| Pointwise 3D Upconvolution | 8 | GELU | |||
| Depthwise 3D Upconvolution | 8 | GELU | |||
| Pointwise 3D Upconvolution | 1 | GELU | |||
| Shape of mask decoder output : | |||||
| Case | HMDB-51 | UCF-101 | EK-100 | Trainable | |||
|---|---|---|---|---|---|---|---|
| Top-1 | Top-5 | Top-1 | Top-5 | Top-1 | Top-5 | Params. | |
| CLIP (mid frame) | 38.8 | 67.1 | 65.9 | 88.3 | 1.0 | 3.6 | 0 M |
| CLIP (multi frame) | 40.7 | 69.9 | 68.2 | 90.9 | 5.4 | 15.7 | 0 M |
| + watermark prompts | 44.1 | 71.4 | 71.7 | 91.4 | 8.3 | 23.6 | 0.04 M |
| + trademark prompts (temporal summarizer) | 51.2 | 78.3 | 77.9 | 93.4 | 12.1 | 26.3 | 1.05 M |
| + both prompts | 55.6 | 83.3 | 84.3 | 96.8 | 14.8 | 31.4 | 1.09 M |
| Method | Frames | Views | Fine Tuning | Prompt Tuning | HMDB-51 | UCF-101 | Trainable Params. | |
|---|---|---|---|---|---|---|---|---|
| Text | Visual | |||||||
| Post-Pretraining on Kinetics-400 and Zero-Shot Transfer | ||||||||
| ActionCLIP [5] | 32 | ✓ | - | - | M | |||
| X-CLIP [11] | 8 | ✓ | - | - | M | |||
| ViFi-CLIP [4] | 16 | ✓ | - | - | M | |||
| A5 [18] | 16 | - | - | ✓ | - | M | ||
| Vita-CLIP [12] | 8 | - | ✓ | ✓ | M | |||
| Data Efficient Fine-Tuning for Few-Shot Adaptation | ||||||||
| ActionCLIP [5] | 32 | ✓ | - | - | M | |||
| X-CLIP [11] | 32 | ✓ | - | - | M | |||
| ViFi-CLIP [4] | 16 | ✓ | - | - | M | |||
| A5 [18] | 16 | - | - | ✓ | - | 5 M | ||
| Ours | 16 | - | - | ✓ | M | |||
| Visual | Text | Params. | Top-1 | Top-5 |
|---|---|---|---|---|
| ✓ | - | 1.09 M | 84.3 | 96.8 |
| - | ✓ | 1.06 M | 81.5 | 96.0 |
| ✓ | ✓ | 1.10 M | 82.4 | 96.4 |
| Model | Params. | Frozen | Top-1 | Top-5 |
|---|---|---|---|---|
| CNN (d = 128) | 0.15 M | - | 84.3 | 96.8 |
| CNN (d = 256) | 0.23 M | - | 83.6 | 96.7 |
| Omnivore (S) | 49.51 M | ✓ | 82.8 | 96.3 |
| Omnivore (B) | 86.66 M | ✓ | 83.0 | 96.3 |
| Spatial | Mask | Top-1 | Top-5 | Params. |
|---|---|---|---|---|
| - | - | 81.3 | 96.1 | 2.25 M |
| ✓ | - | 82.0 | 96.3 | 1.08 M |
| ✓ | ✓ | 84.3 | 96.8 | 1.09 M |
| Case | Top-1 | Top-5 | Throughput |
|---|---|---|---|
| average pooling | 71.7 | 91.4 | 190/s |
| attention + pooling | 83.8 | 96.6 | 162/s |
| temporal summarizer | 84.3 | 96.8 | 171/s |
| Model | Top-1 | Top-5 | GPU Memory Usage |
|---|---|---|---|
| ViT-B/32 | 78.5 | 95.2 | 25.8 G |
| ViT-B/16 | 84.3 | 96.8 | 51.6 G |
| ViT-L/14 | 88.1 | 98.6 | 153.8 G |
| ResNet-50 | 65.7 | 88.2 | 38.0 G |
| ResNet-101 | 67.7 | 89.9 | 51.8 G |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, L.; Jung, H.; Jon, H.J.; Kim, E.Y. Watermark and Trademark Prompts Boost Video Action Recognition in Visual-Language Models. Mathematics 2025, 13, 1365. https://doi.org/10.3390/math13091365
Jin L, Jung H, Jon HJ, Kim EY. Watermark and Trademark Prompts Boost Video Action Recognition in Visual-Language Models. Mathematics. 2025; 13(9):1365. https://doi.org/10.3390/math13091365
Chicago/Turabian StyleJin, Longbin, Hyuntaek Jung, Hyo Jin Jon, and Eun Yi Kim. 2025. "Watermark and Trademark Prompts Boost Video Action Recognition in Visual-Language Models" Mathematics 13, no. 9: 1365. https://doi.org/10.3390/math13091365
APA StyleJin, L., Jung, H., Jon, H. J., & Kim, E. Y. (2025). Watermark and Trademark Prompts Boost Video Action Recognition in Visual-Language Models. Mathematics, 13(9), 1365. https://doi.org/10.3390/math13091365