1. Introduction
Compressed sensing has revolutionized signal processing and data acquisition by enabling signal reconstruction from fewer measurements, making it crucial for applications such as medical imaging, sensor networks, and wireless communications, where reducing data acquisition costs and time is essential. At its core, compressed sensing relies on sparse recovery, which leverages the fact that many real-world signals have sparse representations. For example, in genomic studies, only a few hundred genes show significant changes among thousands measured. Similarly, communication signals and natural images are often compressible in the Fourier, discrete cosine, or wavelet bases [
1]. Representing signals sparsely enables more efficient processing [
2].
A key aspect of compressed sensing is reconstructing a signal from a small number of random linear measurements, provided that the signal has a sparse representation in some basis. Dictionary learning achieves this sparse representation by learning an overcomplete basis directly from data, capturing essential features of the data with minimal redundancy. However, signal reconstruction remains computationally demanding. Specifically, recovering a signal from reduced measurements requires sophisticated algorithms that are accurate and computationally feasible. This paper focuses on developing an efficient decoding algorithm in the context of compressed sensing.
Recovering sparse representations of a signal using redundant dictionaries can be framed as solving the linear system , where represents m measurements of the n-dimensional signal u, is the sensing matrix, and x is the unknown coefficient vector. When , the system is underdetermined with infinitely many solutions. Assuming that u is sparse, meaning it has only a few nonzero components, the goal is to find the solution with the smallest sparsity. A vector has sparsity level K if it contains at most K nonzero entries.
The problem of recovering a maximally sparse signal can be canonically cast as a combinatorial optimization problem minimizing the number of nonzero entries (the
norm):
where
. However, this problem is non-convex and computationally intractable, as solving it requires an exhaustive search over all possible nonzero component combinations, which scales exponentially with
m and
n.
As another point of departure, sparse recovery based on a non-convex
quasi-norm (
) penalty has been explored:
where
. For
, the
quasi-norm behaves as a quasi-norm rather than a strict norm. The
quasi-norm has become an effective proxy for sparsity, as it provides a closer approximation to
norm than
norm and thus better promotes sparsity. Ref. [
3] demonstrated through numerical simulations that using the non-convex
quasi-norm (
) rather than the
norm requires fewer measurements for exact reconstruction of sparse signals. Additionally, ref. [
4] established sufficient conditions, in terms of the restricted isometry constants of
A, under which the local minimizer of (
2) can exactly recover the original signal.
Despite its advantages, (
2) remains NP-hard and challenging to solve, as no closed-form solution exists when
[
5]. As a result, heuristic methods are required to find local minima. A common approach involves iteratively reweighted schemes, with two notable variants: Iterative Reweighted Least Squares (IRLS) and Iteratively Reweighted
Minimization (IR
) [
6,
7].
The IRLS method for solving (
2) was first studied by [
8], reformulating the non-convex
quasi-norm into a weighted
norm:
where the weights are updated based on the current iterate
. The closed-form update based on (
3) is given by
, where
is a diagonal matrix with entries
. Choosing
causes the objective in (
3) to become a first-order approximation of the
quasi-norm, but it is undefined whenever
. To address this, ref. [
9] introduced
-regularization with
, where
gradually reduces to zero. They numerically validated that this regularization strategy enables exact recovery with fewer measurements for much less sparse signals. Further enhancements include [
10], which sorts absolute solution values to refine nonzero indices and has demonstrated improved recovery with a lower normalized root mean square error. Despite its effectiveness, the IRLS method suffers from costly matrix inversion for each iteration, making it impractical for large-scale datasets.
The IR
approach for solving (
2) replaces the
quasi-norm objective with a weighted
norm:
In the conventional IR
approach by [
11], the weights are defined from the current iterate
as
To keep the solutions from being trapped by local minima,
is typically initialized with a large value and gradually reduced to zero. With (
5), the objective in (
4) serves as a first-order approximation of
Compared to IRLS, IR
generally requires fewer iterations despite its higher per-iteration cost [
12]. It also allows easy integration of additional constraints (e.g., bounded activation or non-negativity constraints) without significantly increasing the computational burden. Although both the standard
minimization and its weighted version (
4) can be formulated as linear programs, IR
tends to be slower than conventional
-based sparsity recovery methods due to iterative reweighting. However, it achieves better performance in sparsity recovery by more effectively penalizing nonzero coefficients in a balanced manner [
11].
In related work, ref. [
12] examined non-separable weight selection for generalized sparsity penalties, which cannot be expressed as a simple summation of functions of individual components. Ref. [
13] proposed a nonuniform sparsity model, where the vector components are divided into two sets with different probabilities of being nonzero, and introduced an
approach based on this sparsity model. Recently, ref. [
14] proposed an adaptively iterative reweighted algorithm for solving generalized non-convex and non-smooth sparse optimization problems; the algorithm extends the weighting strategy from (
5) to construct a weighted
-norm-based convex smooth surrogate for the
quasi-norm sparsity-inducing function.
Despite advancements in
methods for sparse recovery, existing approaches still face key limitations. Conventional reweighting strategy (
5) does not fully exploit the structure of the
quasi-norm and thus provides a relatively loose approximation of the
quasi-norm, which may limit its effectiveness in accurately reconstructing sparse signals. Additionally, existing
methods employ fixed weight update schemes, which fail to dynamically adapt to variations in signal magnitudes during iterations.
To address these limitations, we propose two novel reweighting strategies based on some -approximations of the quasi-norm that offer a more refined approximation under the same perturbation magnitude. Our approaches dynamically adjust weights based on the magnitudes of the solution components. By improving both the accuracy of the weighting scheme and the adaptability of the reweighting process, our proposed methods can improve the performance of sparse recovery.
3. Numerical Validation
In this section, we present numerical results to evaluate and compare the proposed IR
algorithms with the conventional IR
from [
11]. Specifically, we refer to the three IR
algorithms using the reweighting strategies from (
5), (
7), (
12) as IR
-1, IR
-2, and IR
-3, respectively, with IR
-2 and IR
-3 being the newly proposed algorithms. The experiments were conducted on a MacBook Pro running Mac OS Monterey 12.0.1 with 8 GB of memory.
3.1. Experimental Setup and Methodology
We randomly generated a sensing matrix with entries independently drawn from a mean-zero Gaussian distribution. The support of the sparse signal u was randomly selected, with the number of nonzero elements given by the sparsity level K. These nonzero entries were sampled from a Gaussian distribution with mean 0 and standard deviation . We performed experiments for two different values of : , representing relatively small signal magnitudes, and , representing larger signal magnitudes. Within each experiment, the value of remained fixed for all trials to ensure consistency when comparing the three IR algorithms.
The experiments were performed for varying values of p and K, with 100 independent trials conducted for each instance. To examine the effectiveness of the proposed algorithms under different sparsity levels and quasi-norm formulations, we varied the sparsity level K and the quasi-norm parameter p. Specifically, K was set to values in the range between 32 and 54 in increments of 2, and p was varied from 0.1 to 0.9 in increments of 0.1. This ensured a comprehensive evaluation across different sparsity regimes and non-convex formulations.
In every trial, the same sensing matrix A and sparse signal u were used across the three IR algorithms. The regularization parameter was initialized to 0.1, and the starting point was chosen as the minimum -norm solution of , which is explicitly given by the closed-form expression . As the iteration proceeded, whenever the change in -norm between successive iterates was smaller than , was reduced by a factor of 10. This process continued until the relative -norm change was smaller than .
To assess performance, we used the relative error metric, defined as
where
denotes the recovered signal produced by an algorithm. A trial was considered successful recovery if the relative error was below
. We also set the maximum number of iterations at 1000.
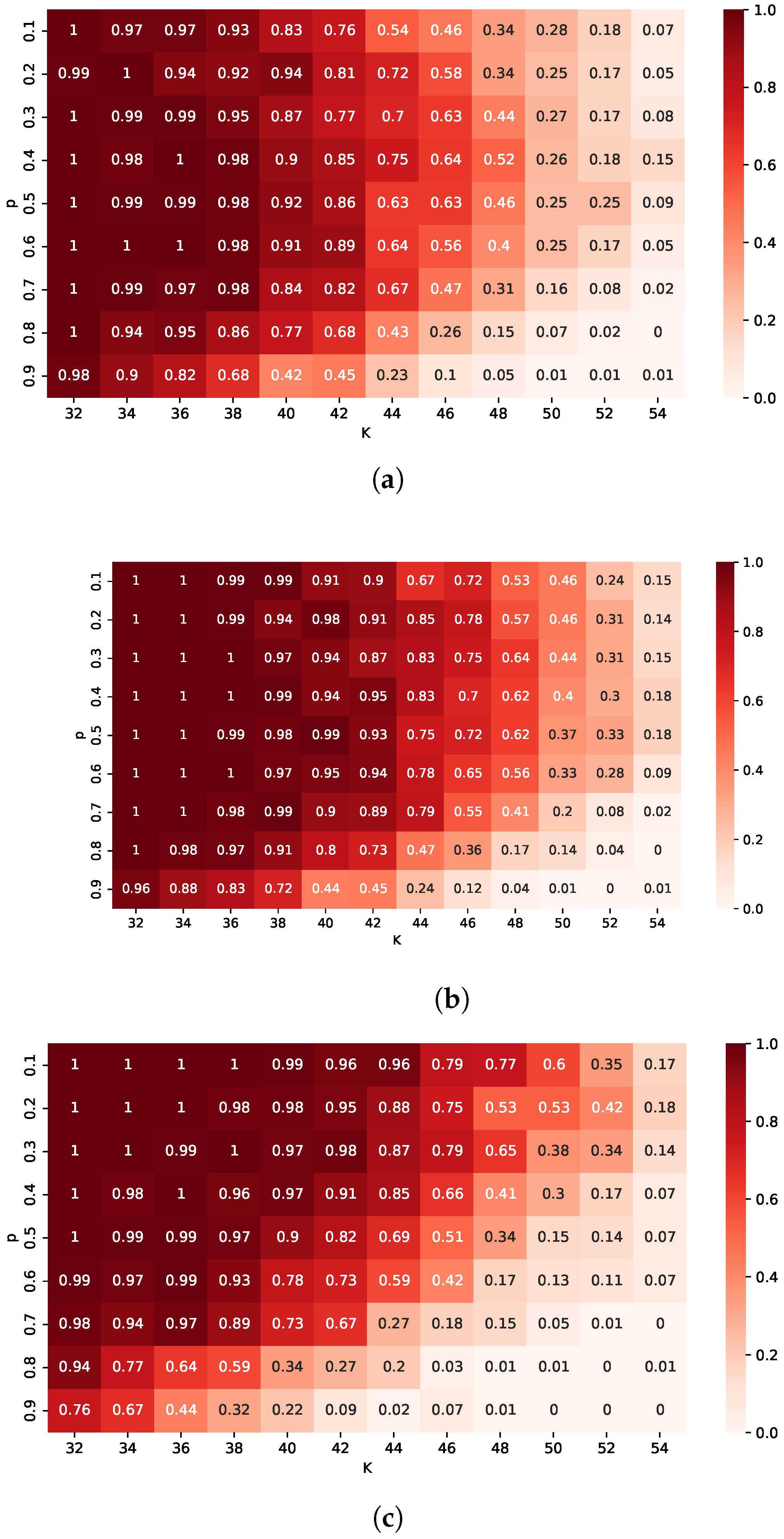
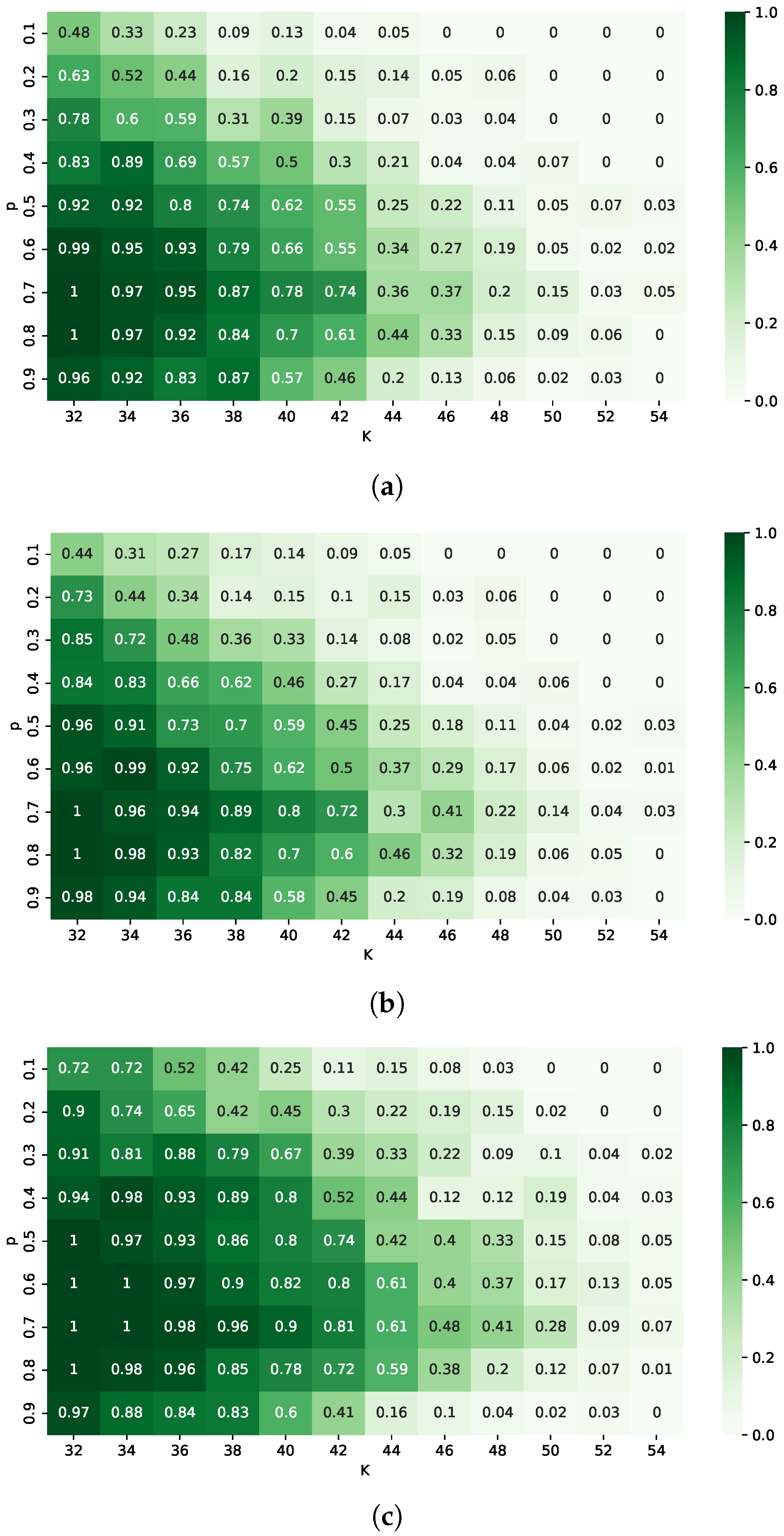
3.2. Discussion of Results
Recovery performance is visualized on the
grid in
Figure 1 and
Figure 2. In these diagrams, the x-axis indicates the sparsity level
K, while the y-axis represents the parameter
p characterizing the quasi-norm. The color at each grid point indicates the recovery success rate averaged over 100 trials. Darker regions denote higher recovery success, while lighter regions indicate failure cases.
The experimental results indicate that the performance of the proposed IR algorithms depends significantly on the signal magnitude and the choice of parameter p. When signal components have small magnitudes (), IR-2 achieves a notably higher success rate than IR-1, especially for smaller values of p. Meanwhile, IR-3 performs best at low p, successfully recovering the broadest range of signals. As p approaches one, the performance of IR-1 and IR-2 converges, whereas that of IR-3 deteriorates.
When signal magnitudes are relatively large (), the recovery behavior changes. IR-3 consistently achieves the highest recovery success, outperforming both IR-1 and IR-2, except at , where the latter two perform slightly better. The advantage of -3 increases as p gets smaller. In this scenario, IR-1 and IR-2 exhibit comparable performance.
To evaluate the robustness of our algorithms to noise, we introduced white noise sampled from a Gaussian distribution with a mean of zero and variance of
into the measurement vector
b.
Table 1 presents the average increase in relative recovery error across 100 trials at
. The results indicate that IR
-2 exhibits noise robustness comparable to that of IR
-1, while IR
-3 is slightly more sensitive to noise, especially when
p is close to one or the noise level is higher.
We also recorded the CPU time for each IR
algorithm at
, as shown in
Figure 3. Each data point on the chart represents the average absolute CPU time over 100 trials. While computational times generally decrease as
p increases, aligning with expectations since the optimization problem becomes closer to a convex formulation, we do not compare computational efficiency across different values of
p. Instead, we focus on evaluating the relative performance of different IR
algorithms under identical parameter settings.
From an efficiency standpoint, IR
-3 generally outperforms the other algorithms, with the performance gap widening as
p decreases. When the signal component magnitudes are small, IR
-2 is consistently faster than IR
-1 but tends to be slightly slower than IR
-3. When the signal magnitudes are relatively large, IR
-1 and IR
-2 exhibit comparable runtimes, while IR
-3 maintains its efficiency advantage. To further assess efficiency, we also examine the average number of iterations required for convergence, which follows a similar trend to
Figure 3. Since each IR
method involves similar per-iteration operations with roughly the same expense, the primary determinant of computational cost is the number of iterations. The observed efficiency improvements in the two newly proposed algorithms stem from more accurate approximations of the original
quasi-norm objective, which accelerates convergence.
To summarize, IR-2 consistently improves recovery success rate and computational efficiency compared to IR when signal magnitudes are small, while maintaining comparable robustness to noise. On the other hand, IR-3 shows the most significant improvements in recovery success rate and efficiency, particularly for large-magnitude signals. However, it is more sensitive to noise in the measurement process, and its performance deteriorates as the sparsity penalty becomes nearly convex (i.e., as p approaches 1).
4. Conclusions
In this paper, we focus on iteratively reweighted -minimization methods for solving the sparse recovery problem based on optimizing the quasi-norm. Specifically, we propose two novel reweighting strategies, with weights derived from -approximations of that provide enhanced approximation under the same perturbation magnitude. Both reweighting strategies dynamically adjust the weights based on the magnitudes of the current iterate, leading to two distinct IR formulations. Each provides a first-order approximation to a tighter surrogate for the original quasi-norm objective, thereby facilitating more effective recovery of sparse signals.
The two proposed IR
algorithms have been shown to converge to the true sparse solution under appropriate conditions on the sensing matrix. Our experimental results demonstrate that the proposed algorithms show significant improvements in terms of signal recovery success rate and computational efficiency compared to the conventional IR
algorithm. The degree of improvement varies depending on the characteristics of the sparse signal. The improvements demonstrated by the proposed IR
algorithms become prominent when the sparsity penalty is highly concave (i.e., for smaller
p, which favors sparsity). In such cases, the recovered signal is highly likely to match the minimum
-norm solution of
as given in (
1).
While our proposed methods improve recovery success and efficiency, they also have certain limitations. One potential drawback is that the performance of our algorithms may be sensitive to noise in the measurement process, which could impact robustness in practical scenarios. Addressing these limitations through adaptive strategies or alternative formulations is an important direction for future research.
Beyond theoretical contributions, our proposed methods have significant practical applications in signal processing, for example, in compressed sensing for efficient signal reconstruction, in medical imaging (MRI and CT) to reduce measurement acquisition while preserving image quality, and in wireless communications for improving channel estimation and reducing interference. By enhancing the accuracy and efficiency of sparse recovery, our algorithms have the potential to contribute to advancements in these critical fields.
This work contributes to the expanding field of sparse recovery by providing more accurate and computationally efficient algorithms for signal reconstruction. Future research may focus on enhancing robustness to noise, and extending these methods to tackle more complex problems in signal processing and machine learning, particularly in applications such as compressed sensing and image recovery.





{kind=link}
{kind=link}
{kind=link}