1. Introduction
Reinforcement learning (RL) has emerged as a cornerstone for training autonomous agents in complex environments, achieving breakthroughs in domains ranging from robotics to game playing [
1,
2]. Despite its success, conventional RL frameworks face a critical limitation in long-horizon task scenarios: they rely on end-to-end policies that must simultaneously handle high-level planning and low-level action execution. This monolithic paradigm imposes significant computational burdens, as agents are forced to explore vast state/action spaces while managing sparse reward signals—a challenge exacerbated in tasks requiring multi-stage reasoning.
Recent advancements in large language models (LLMs), such as GPT [
3] and LLaMA [
4], offer transformative potential for RL through their few-shot reasoning capabilities and structured knowledge representation. Pioneering studies have explored integrating LLMs with RL agents: Carta et al. [
5] demonstrated real-time translation of visual observations into textual descriptions, while Mezghani et al. [
6] designed policies blending language reasoning with physical actions. However, current approaches exhibit two fundamental shortcomings: (1)
Action Generation Dilemma: Directly fine-tuning LLMs to output low-level actions (e.g., discrete motor commands) demands task-specific datasets and extensive retraining, negating LLMs’ generalizability. (2)
Reasoning–Action Discrepancy: Methods coupling small RL models with LLM reasoning (e.g., via API calls) often yield incoherent plans, where LLM-generated subgoals (“turn left”) conflict with environmental affordances (a wall blocks the left path). These limitations stem from a misalignment between LLMs’ abstract reasoning strength and RL agents’ grounded execution capabilities. Attempting to force LLMs into low-level control—or conversely, expecting RL agents to autonomously derive multi-step strategies—results in either computationally prohibitive training or suboptimal policies prone to local minima.
To address these challenges, we propose LGRL, a framework that strategically decomposes complex missions via LLM-based task planning while preserving RL’s proficiency in action execution. Our key insight is threefold:
Decoupling Cognitive Load: By restricting LLMs to generate high-level subgoals rather than atomic actions, we leverage their reasoning capabilities without requiring domain-specific fine-tuning.
Dynamic Adaptation: Through chain-of-thought prompting, LGRL’s LLM component continuously refines subgoals based on real-time environment feedback (e.g., textual state descriptions), enabling recovery from unexpected obstacles.
Reward Scaffolding: We design a subgoal-conditioned reward function that provides dense learning signals, mitigating RL’s exploration inefficiency in sparse-reward settings.
We propose a novel framework, LGRL, whose contributions are summarized as follows:
Hierarchical Task Decomposition: LGRL introduces a bi-level architecture where an LLM planner dynamically generates interpretable subgoals, which a modular RL executor translates into environment-specific actions.
Zero-Shot LLM Utilization: Unlike prior work requiring LLM retraining [
6],
LGRL operates via generic prompts, making it portable across tasks with minimal adaptation.
Progress-Aware Rewards: We introduce a reward mechanism that provides an additional reward for each LLM-generated subgoal upon completion. The reward is scaled by the speed of subgoal completion, so that faster completion yields higher rewards, thereby accelerating exploration and improving model performance.
LGRL is validated on a suite of interactive tasks derived from the Minigrid environment, achieving higher success rates and requiring fewer steps compared to baseline methods.
3. Methods
We introduce the
LGRL framework for interactive environments, which uses LLMs (like DeepSeek V3 [
19]) to decompose high-level missions into manageable subgoals. Our method is evaluated in Minigrid, a two-dimensional grid-based environment where the agent model operates with a discrete action space and receives both visual observations and a textual mission. This setup enables us to demonstrate how language-driven goal decomposition can streamline complex tasks that require multi-step planning and execution.
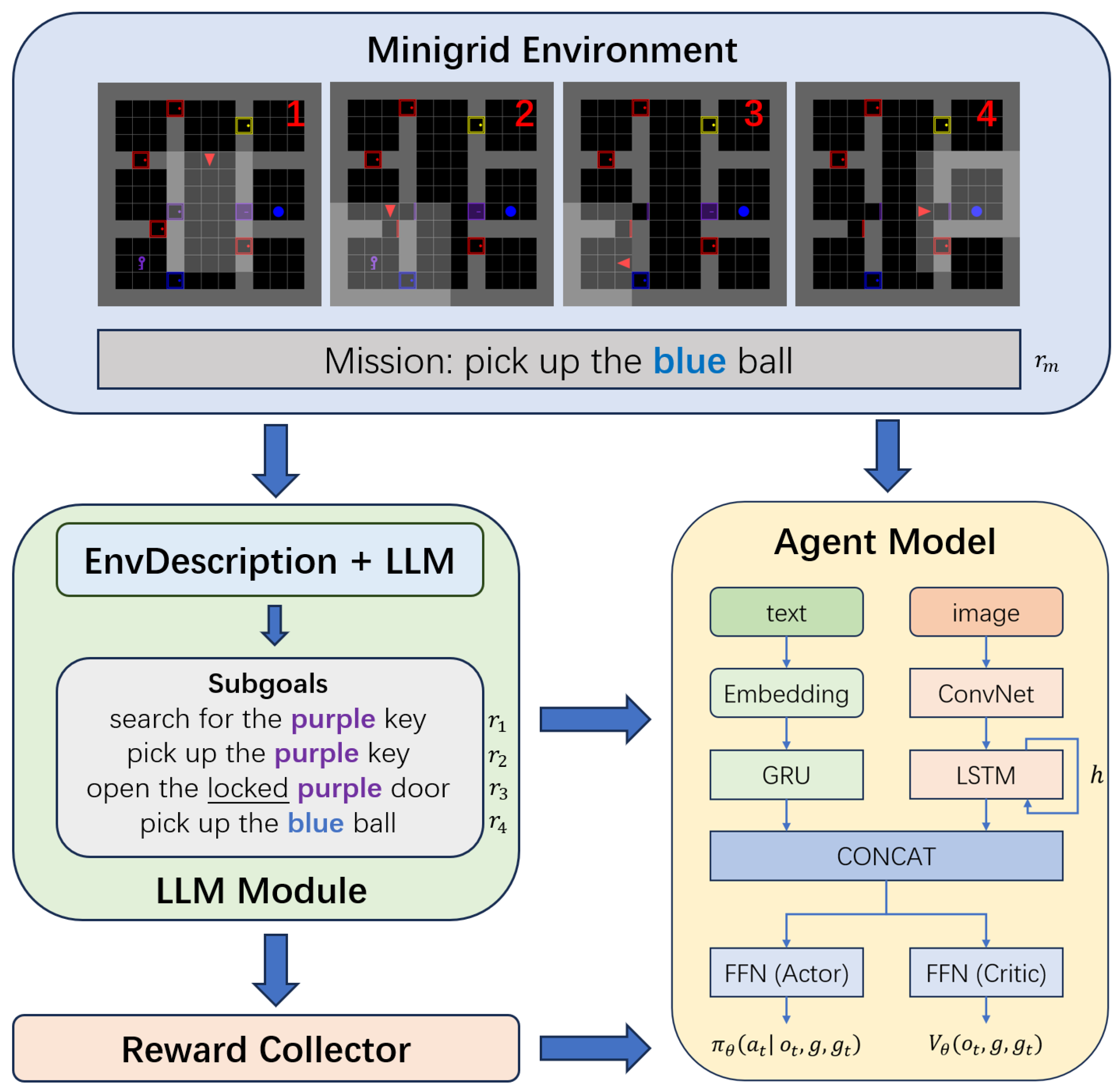
As illustrated in
Figure 1, the environment produces raw observations (for example, the agent’s location, room layouts, and objects) and a high-level mission (for example, “pick up the blue ball”). A rule-based EnvDescription module converts these observations into concise textual summaries. These summaries, together with the mission and any relevant history, are provided to the LLM, which generates a sequence of subgoals. Each subgoal corresponds to a partial objective (for example, “search for the purple key” or “open the locked door”) that guides the agent model’s low-level actions.
To train the agent model, we employed an actor critic architecture with Proximal Policy Optimization (PPO) [
20]. The model receives partial rewards upon completing each subgoal and a mission-level reward upon final task completion. This hierarchical approach allows the LLM to handle a high-level strategy while the agent model focuses on local action execution, thereby enhancing exploration and reducing the complexity of long-horizon tasks.
3.1. Environment Setup and Observation Processing
We conducted our experiments using the Minigrid environment, a 2D grid-world framework designed for goal-oriented tasks. In this setting, the agent is depicted as a triangle operating within a discrete action space.
Table 1 lists the available actions along with their descriptions.
The observation space is defined as a dictionary comprising three components: a direction (Discrete(4)) representing the agent’s current orientation, an image (a Box with pixel values in the range ) that captures the grid layout, and a mission, which is a textual instruction provided by the environment specifying the high-level objective.
The reward function is designed to encourage efficient task completion. Let
denote the maximum achievable reward,
the maximum allowed steps, and
the number of steps taken by the agent to complete the mission. The reward
r is computed as
with a failed mission yielding
. This formulation motivates the agent to complete the mission in as few steps as possible.
3.2. Subgoal Generation via LLM
Our framework decomposes the overall mission into manageable subgoals by employing an LLM. This process consists of two key stages.
3.2.1. Environment-Based Textual Description
Inspired by [
5], the environment converts raw observation data, originally represented as an image matrix, into a human-interpretable textual description
using a predefined rule set. This transformation is expressed as
which captures key aspects of the current state such as object positions, door statuses, and spatial configuration.
3.2.2. LLM Prompt Design for Subgoal Generation
To generate effective subgoals, we designed a prompt as shown in
Figure 2 that is carefully crafted to guide the LLM in producing context-aware subgoals. The prompt incorporates the task, the environment description, and previous subgoal information to guide the LLM in proposing the next relevant subgoal in the Minigrid environment.
Subsequently, the LLM derives the next subgoal
based on the textual description
, the overall mission
m, and the historical context
H of prior reasoning:
Subgoals typically encompass actions such as search for object/door, pickup/drop/move an object, and open/close a door. The LLM is activated only when the previous subgoal has been successfully completed; this approach reduces computational overhead by limiting LLM invocations to critical moments and ensures timely adaptation to significant state changes.
3.3. LLM-RL Integration for Guided Action Selection
Once a new subgoal
is generated (as described in
Section 3.2), it is integrated into the RL agent’s decision-making process. At each time step
t, the agent receives the current observation
, the overall mission
g (for example, “pick up the blue ball”), and the current subgoal
. Here,
g represents the ultimate objective of the episode, while
denotes the immediate subgoal recommended by the LLM. If the current subgoal is not completed at time
t, then the subgoal remains unchanged for the next time step (i.e.,
). The RL agent then selects an action
according to its policy:
By conditioning the policy on both the overall mission and the current subgoal, the agent is guided toward more manageable objectives, thereby improving exploration and accelerating task completion.
3.4. Agent Model Architecture
In our
LGRL framework, the agent model is designed to integrate both textual and visual inputs to inform decision-making. As depicted in the merged framework (
Figure 1), the agent model processes the mission and subgoal information as well as the visual observations from the environment.
The textual inputs, comprising the mission and the current subgoal, are first embedded and then processed by a gated recurrent unit (GRU) to capture semantic and temporal information. In parallel, the visual input, represented as a grid-based image from the Minigrid environment, is passed through a convolutional neural network (ConvNet) to extract spatial features. These visual features are further processed by a long short-term memory (LSTM) network to maintain a temporal context of the agent’s surroundings.
The outputs of these two streams are concatenated and passed through two feed-forward networks (FFNs) that generate the following:
Actor (Policy): , which produces a probability distribution over actions.
Critic (Value Function): , which estimates the expected return given the current state and goals.
By integrating both visual and textual streams, the agent model leverages complementary information: the language stream offers high-level strategic guidance through subgoals, and the visual stream supplies precise spatial context. This fusion enables more effective action selection and contributes to improved exploration and faster task completion.
3.5. Reward Function
The standard Minigrid reward structure heavily penalizes long task completion times, which may discourage the exploration needed for complex tasks. To balance efficiency with extended exploration, we redefine the reward function as follows. Let
denote the maximum reward for the overall mission and
the maximum reward for each subgoal. Define
as the maximum allowed steps and
as the number of steps taken to complete the mission. The mission-level reward is defined as
Furthermore, when the agent completes the
i-th subgoal (out of
n total subgoals), it receives a subgoal reward defined as
where
represents the expected step budget for the
i-th subgoal. To enforce timely completion, if
, the reward for that subgoal is set to
.
The overall reward for an episode is computed as the sum of the mission-level reward and the normalized sum of all subgoal rewards:
This formulation incentivizes the agent to complete subgoals promptly while still rewarding efficient overall mission completion. For our experiments, we set as the default mission reward and use in the modified scheme to maintain a consistent maximum reward.
4. Experiments
We evaluated our proposed LGRL method on a series of tasks based on the Minigrid environment. The experimental setup comprises a multi-step curriculum that progressively increases task complexity, a modified reward function tailored for efficient exploration, and a PPO training procedure. We then present comparative evaluations and convergence analyses to highlight the benefits of our approach.
4.1. Environments and Curriculum Setup
Our experiments are conducted on four key environments derived from Minigrid. In the GoToDoor task, the agent must navigate to a specific door. In GoToObject, the goal is to reach a designated object. The more challenging KeyCorridor task requires the agent to traverse multiple rooms, locate a key in one of the unlocked rooms, open a locked door, and finally retrieve a target object. Finally, in the UnlockPickup task, the agent searches for a key within the current room, unlocks a door, and picks up a target object from the locked room.
To build the necessary skills gradually, the agent is first trained on the simpler GoToDoor and GoToObject tasks to acquire basic navigation abilities. The curriculum then progresses to increasingly larger instances of the KeyCorridor environment, enabling the agent to learn multi-room navigation and sequential interaction tasks such as object manipulation and door toggling.
4.2. PPO Training Procedure
We trained the agent model using PPO within an actor critic framework. The agent’s policy network, , and value network, , were updated jointly using trajectories collected during rollouts. Each trajectory consists of tuples , where is the current observation, g is the overall mission, is the current subgoal, is the action taken, and is the reward received. Advantage estimates, computed via Generalized Advantage Estimation (GAE), guide the gradient updates. Incorporating both mission-level and subgoal rewards into the learning signal encourages steady progress toward subgoal completion and the ultimate mission, resulting in stable and efficient learning even in tasks that demand extensive exploration.
4.3. Implementation Details and Hyperparameter Settings
During training, we first validated the subgoal generation capability of the LLM. In deterministic training environments where states are fully known, a rule-based subgoal generator provided accurate subgoals identical in format to those generated by the LLM. In contrast, during testing, the environment configurations include uncertainty and complexity (such as obstacles that must be moved), and subgoals are generated dynamically via the LLM. To assess robustness, we experimented with multiple LLMs for subgoal generation, including GPT-4o, DeepSeek V3, and DeepSeek R1 [
19,
21]. For efficiency and practicality, we ultimately employ the DeepSeek V3 API to generate subgoals during evaluation.
Our experiments are implemented in Python 3.9 using PyTorch 2.5.1 and employ the PPO algorithm based on the torch_ac 1.4.0 library for training. We train on one or more Minigrid environments with a learning rate of , a batch size of 256, a discount factor of 0.99, and a GAE lambda of 0.95. The PPO clipping parameter is set to 0.2. All training is conducted on an NVIDIA 4090 GPU, with approximately 700 MB of memory allocated.
4.4. Comparative Evaluation in KeyCorridor
We first evaluated the performance in the KeyCorridor environment, where the agent was trained on progressively larger and more complex grid layouts with multiple rooms. The agent was tasked with navigating this environment, locating keys, unlocking doors, and retrieving objects. We compared the following four methods:
Base: Standard RL without subgoal guidance.
Reasoning-Only: RL using language-generated subgoal prompts without subgoal-specific rewards, similar to the approach by Mezghani et al. [
6].
LGRL (Ours): Our proposed method that employs LLM-generated subgoals along with subgoal-specific rewards.
LGRL w/o Guidance: Our proposed method that uses subgoal-specific rewards without LLM-guided subgoal generation.
The agent was trained in the
KeyCorridor environment, with training progressing through smaller grid layouts to more complex configurations. The agent’s performance was then tested across three environments, including two unseen environments,
BabyAI-GoToObject and
UnlockPickup, to assess the generalizability of the learned policy.
Table 2 summarizes the performance across these environments, reporting both success rates and the average number of steps per episode over 1000 test episodes. Higher success rates and fewer steps indicate better performance.
The results in
Table 2 demonstrate that
LGRL (Ours) consistently achieves the highest success rates and the fewest steps across all environments, confirming the effectiveness of our approach. Specifically, in the
KeyCorridor environment,
LGRL outperforms the baseline methods in both success rate and efficiency. This is achieved through LLM-guided subgoal generation and subgoal-specific rewards, which help the agent navigate and complete tasks more efficiently.
In the two additional test environments BabyAI-GoToObject and UnlockPickup (which the model was not explicitly trained on), LGRL still performs excellently, achieving high success rates and low step counts. This demonstrates the generalization ability of LGRL, where the model, despite being trained in KeyCorridor, can transfer its learned policy to solve unseen tasks with comparable efficiency. This highlights the robustness and flexibility of LGRL in handling a variety of tasks with different structures.
When comparing LGRL w/o Guidance, which removes LLM-guided subgoal generation while retaining subgoal-specific rewards, we observe a slight decrease in performance. In KeyCorridor, the success rate drops to 0.936, and the number of steps increases. Similarly, in UnlockPickup, the success rate decreases to 0.837, with the average steps required for task completion also rising. This indicates that, while subgoal-specific rewards alone offer some improvement, the LLM-guided task decomposition is crucial for optimizing task execution and guiding the agent through complex environments efficiently.
Overall, the results show that the combination of LLM-guided subgoal generation and subgoal-specific rewards in LGRL leads to superior performance and generalization across both seen and unseen environments. This reinforces the importance of hierarchical task decomposition and reward scaffolding in achieving both efficient learning and robust task completion in RL agents.
4.5. Single-Step Convergence Analysis
To further analyze convergence behavior, we conducted experiments in the UnlockPickup environment, where the agent must retrieve a key, unlock a door, and pick up the target object within a single room. To enable the agent to learn basic navigation skills and test its ability to handle tasks of varying complexity, we included experiences from the GoToObject task at a 1:3 ratio during training. This Mixed Tasks setting allows the model to simultaneously learn basic navigation while tackling the more complex UnlockPickup task, providing a better evaluation of the model’s capacity to handle multiple tasks at once.
Empirically, only the
LGRL method converges reliably under both the
UnlockPickup and the mixed training regime. In contrast, both the Base and
Reasoning-Only methods exhibit slow or unstable convergence, indicating that explicit subgoal guidance and associated rewards are essential for efficient learning in sequential tasks. The results shown on the left of
Figure 3 highlight that, in the
UnlockPickup environment,
LGRL exhibits faster and more stable convergence compared to the baseline methods. Notably, in the mixed training setup, where the agent is trained on both
UnlockPickup and
GoToObject tasks, all models show a steady increase in average returns in the early stages. This is due to the inclusion of the simpler
GoToObject task, which accelerates the learning process by allowing the agent to quickly master basic navigation skills. However,
LGRL continues to outperform other methods, demonstrating its superior ability to learn more complex tasks while maintaining efficient exploration and faster convergence.
4.6. Discussion
Our experimental results provide strong evidence for the effectiveness of LGRL across two critical dimensions: task performance (accuracy and steps) and training convergence speed.
From the perspective of task performance, LGRL consistently achieves higher success rates and requires fewer steps across all environments. Specifically, in the complex KeyCorridor task, where the agent must sequence multiple interactions (such as locating keys, unlocking doors, and retrieving objects), LGRL significantly outperforms the baseline methods and the Reasoning-Only approach. This improvement is a direct result of LGRL’s ability to decompose tasks into manageable subgoals and provide subgoal-specific rewards, guiding the agent toward efficient exploration and task completion. In the UnlockPickup environment, LGRL similarly demonstrates superior performance, completing the task more efficiently than both the baseline and Reasoning-Only approaches, highlighting the importance of explicit subgoal guidance.
In terms of training convergence, LGRL exhibits the fastest and most stable convergence across all environments. In the UnlockPickup environment, the LGRL approach converges rapidly, outperforming the other methods, including the LGRL w/o Guidance ablation. This faster convergence is especially apparent when LGRL is trained in mixed-task scenarios, where the agent simultaneously learns navigation and object manipulation skills. While the simpler GoToObject task accelerates early learning for all models, LGRL maintains a clear advantage, as its subgoal-guided framework facilitates faster adaptation to complex tasks.
The ablation experiment, LGRL w/o Guidance, further underscores the importance of subgoal guidance for both task performance and training efficiency. When LGRL operates without LLM-generated subgoals, the convergence rate slows down significantly, and the task completion requires more steps. This underlines that the combination of high-level LLM reasoning for subgoal generation and RL’s low-level action execution is essential for achieving both optimal performance and efficient learning in interactive environments.
In summary, LGRL demonstrates superior performance not only in terms of higher success rates and fewer steps but also in faster convergence and improved training stability. This makes it a promising framework for complex, long-horizon tasks and also generalizable to diverse interactive environments.
5. Conclusions
In this paper, we presented LGRL, a novel framework that leverages LLMs to decompose high-level missions into a sequence of manageable subgoals for interactive environments. By converting raw visual observations into textual descriptions and employing a general-purpose prompt to generate subgoals, LGRL effectively separates high-level planning from low-level action execution. This separation enables the agent model to optimize its control policy while the LLM provides accurate, context-aware guidance.
Our experiments on various Minigrid tasks demonstrate that LGRL not only achieves higher success rates and requires fewer steps compared to baseline methods, but also exhibits strong generalization across different environments. In addition, our single-step convergence analysis shows that LGRL converges significantly faster under mixed-task training, highlighting its potential for efficient learning in complex, sequential tasks.
Overall, LGRL offers a scalable and flexible solution for integrating language-based reasoning into RL, paving the way for more robust and generalizable agents in interactive environments. While these findings highlight its promise, several key areas still warrant further development.
Future Work
Although LGRL demonstrates strong performance in the MiniGrid environment, its effectiveness may diminish in previously unseen environments or those requiring more fine-grained action control, especially when guided by LLMs that lack domain-specific experience. This limitation highlights the need for further exploration. We see two main directions to strengthen and extend LGRL:
Enhancing LLM guidance accuracy. Explore lightweight adaptation of the LLM such as LoRA [
22] or prompt-tuning [
23] on a small task-specific corpus and introduce few-shot examples [
3] to improve subgoal validity. We will also investigate combining LLM outputs with simple learned filters to detect and reject invalid subgoals.
Extending LGRL to multi-agent and richer environments. Adapt our framework to multi-agent settings and to more dynamic, realistic domains, including continuous state/action spaces, complex physics, and partial observability. We will ground high-dimensional observations into LLM-compatible inputs by converting sensor or image data into concise text via perception modules (e.g., DETR [
24], CLIP [
25]) or by using vision–language models such as GPT-4V [
26] that accept raw images directly.






{kind=link}
{kind=link}
{kind=link}