
A Hubness Information-Based k-Nearest Neighbor Approach for Multi-Label Learning


Abstract
1. Introduction
2. Related Work
2.1. Multi-Label Classification Algorithms
2.2. Methods Addressing the Hubness Problem
3. The Proposed Method: MLHiKNN
3.1. Label Relevance Score for Query Points
3.2. Fuzzy Measure of Label Relevance for Training Points
| Algorithm 1 k-occurrence counting. |
| Input: |
| D: training set; |
| k: number of nearest neighbors to take into account. |
| Output: |
: the k-occurrence and label k-occurrence with respect to each possible label l of each instance x in D.
|
3.3. Distance and Hubness Weighting
3.4. Learning with Label Relevance Scores
| Algorithm 2 The training process of MLHiKNN. |
| Input: |
| D: training set; |
| k: number of nearest neighbors to take into account; |
| : threshold parameter for computing ; |
| : distance weighting parameter for computing ; |
| s: smoothing parameter for computing . |
| Output: |
trained MLHiKNN classifier;
|
| Algorithm 3 The prediction process of MLHiKNN. |
| Input: |
| trained MLHiKNN classifier: ; |
| t: query instance. |
| Output: |
| : label set prediction of instance t. |
3.5. Complexity Analysis
4. Experimental Results and Discussions
4.1. Experimental Setup
4.1.1. Datasets and Metrics
4.1.2. Compared Approaches
| Algorithm 4 Hubness-reduced BRkNNa. |
| Input: |
| D: training set; |
| : parameters needed for BRkNNa and the hubness reduction technique; |
| : testing set. |
| Output: |
: label predictions of testing set.
|
| Algorithm 5 Hubness-reduced MLKNN. |
| Input: |
| D: training set; |
| : parameters needed for MLKNN and the hubness reduction technique; |
| : testing set. |
| Output: |
: label predictions of testing set.
|
4.2. Comparisons with MLC Algorithms
4.3. Comparisons with Hubness Reduction Techniques
4.4. Ablation Analysis for MLHiKNN
4.5. Parameter Analysis for MLHiKNN
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MLC | Multi-label classification |
| SLC | Single-label classification |
| MLDs | Multi-label datasets |
| SLDs | Single-label datasets |
| kNN | k-nearest neighbor |
| MLHiKNN | Multi-label hubness information-based k-nearest neighbor |
| LS | Local scaling |
| MP | Mutual proximity |
| DSL | Local dissimilarity |
| A set consisting of the k-nearest neighbors of example t | |
| The number of times x appears among the k nearest neighbors of all other points in a dataset | |
| The number of instances relevant to label l in |
Appendix A. Time Costs of the Proposed Method

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | BRkNNa | MLKNN | MLHiKNN-fo | MLHiKNN | ||||
|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |
| birds | 0.02 | 0.05 | 0.05 | 0.59 | 0.59 | 1.14 | 0.59 | |
| CAL500 | 0.03 | 0.60 | 0.30 | 0.11 | 0.12 | 13.01 | 0.17 | |
| emotions | 0.03 | 0.07 | 0.09 | 0.14 | 0.15 | 0.43 | 0.16 | |
| genbase | 0.04 | 0.11 | 0.12 | 0.23 | 0.24 | 0.72 | 0.26 | |
| LLOG | 0.08 | 1.04 | 0.57 | 0.04 | 0.06 | 3.82 | 0.10 | |
| enron | 0.10 | 0.56 | 0.45 | 0.91 | 0.92 | 4.01 | 0.98 | |
| scene | 0.12 | 0.25 | 0.35 | 9.39 | 9.39 | 10.02 | 9.68 | |
| yeast | 0.12 | 0.44 | 0.42 | 1.13 | 1.17 | 2.64 | 1.23 | |
| Slashdot | 0.13 | 0.41 | 0.46 | 0.02 | 0.07 | 0.95 | 0.09 | |
| corel5k | 0.29 | 5.81 | 3.37 | 0.07 | 0.16 | 57.89 | 0.71 | |
| rcv1subset1 | 0.35 | 3.89 | 2.52 | 0.11 | 0.23 | 23.56 | 0.40 | |
| rcv1subset2 | 0.35 | 3.98 | 2.57 | 0.10 | 0.22 | 23.64 | 0.36 | |
| rcv1subset3 | 0.35 | 3.99 | 2.57 | 0.10 | 0.22 | 23.59 | 0.36 | |
| rcv1subset4 | 0.37 | 3.94 | 2.55 | 0.09 | 0.22 | 22.93 | 0.35 | |
| rcv1subset5 | 0.35 | 4.02 | 2.59 | 0.09 | 0.22 | 23.77 | 0.35 | |
| bibtex | 0.42 | 8.95 | 5.16 | 0.12 | 0.27 | 63.46 | 0.81 | |
| Arts | 0.44 | 1.81 | 1.65 | 0.13 | 0.28 | 3.72 | 0.38 | |
| Health | 0.54 | 2.03 | 1.92 | 0.42 | 0.62 | 3.78 | 0.63 | |
| Business | 0.67 | 2.78 | 2.47 | 0.24 | 0.46 | 4.77 | 0.57 | |
| Education | 0.76 | 3.18 | 2.78 | 0.68 | 0.96 | 5.86 | 0.87 | |
| Computers | 0.82 | 3.33 | 2.92 | 0.75 | 1.02 | 9.09 | 1.02 | |
| Entertainment | 0.84 | 2.47 | 2.51 | 0.90 | 1.18 | 4.05 | 1.20 | |
| Recreation | 0.83 | 2.94 | 2.76 | 0.51 | 0.76 | 4.37 | 0.76 | |
| Society | 1.01 | 3.81 | 3.38 | 1.00 | 1.31 | 9.49 | 1.29 | |
| eurlex-dc-l | 1.15 | 29.21 | 16.56 | 1.26 | 1.54 | 90.64 | 2.11 | |
| eurlex-sm | 1.33 | 20.06 | 11.82 | 1.79 | 2.22 | 74.25 | 3.35 | |
| tmc2007-500 | 2.59 | 7.12 | 6.53 | 8.47 | 9.34 | 15.64 | 7.77 | |
| mediamill | 4.52 | 33.90 | 20.46 | 282.61 | 285.35 | 395.58 | 275.31 | |
Appendix B. Experimental Results of Compared MLC Algorithms
| Dataset | AUC Micro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.666(8) ± 0.039 | 0.660(9) ± 0.028 | 0.785(1) ± 0.015 • | 0.761(2) ± 0.011 | 0.676(7) ± 0.025 | 0.736(5) ± 0.014 | 0.659(10) ± 0.013 | 0.730(6) ± 0.016 | 0.736(4) ± 0.014 | 0.746(3) ± 0.019 |
| CAL500 | 0.628(7) ± 0.011 | 0.589(9) ± 0.010 | 0.731(4) ± 0.004 | 0.688(6) ± 0.002 | 0.601(8) ± 0.005 | 0.749(3) ± 0.003 | 0.713(5) ± 0.003 | 0.755(2) ± 0.001 | 0.558(10) ± 0.007 | 0.757(1) ± 0.004 • |
| emotions | 0.693(9) ± 0.022 | 0.688(10) ± 0.019 | 0.837(4) ± 0.008 | 0.812(6) ± 0.009 | 0.697(8) ± 0.014 | 0.852(3) ± 0.005 | 0.747(7) ± 0.011 | 0.828(5) ± 0.007 | 0.856(2) ± 0.007 | 0.862(1) ± 0.005 • |
| genbase | 0.996(7) ± 0.006 | 0.995(8) ± 0.007 | 0.997(1) ± 0.003 • | 0.997(3) ± 0.004 | 0.996(6) ± 0.006 | 0.993(9) ± 0.004 | 0.970(10) ± 0.012 | 0.997(2) ± 0.002 | 0.997(4) ± 0.003 | 0.996(5) ± 0.004 |
| LLOG | 0.771(5) ± 0.002 | 0.670(8) ± 0.021 | 0.682(7) ± 0.027 | 0.659(9) ± 0.008 | 0.618(10) ± 0.023 | 0.788(4) ± 0.005 | 0.791(3) ± 0.002 | 0.805(1) ± 0.003 • | 0.805(2) ± 0.003 | 0.767(6) ± 0.002 |
| enron | 0.764(8) ± 0.007 | 0.760(9) ± 0.011 | 0.851(4) ± 0.005 | 0.823(6) ± 0.005 | 0.751(10) ± 0.009 | 0.801(7) ± 0.012 | 0.825(5) ± 0.004 | 0.863(1) ± 0.003 • | 0.855(3) ± 0.005 | 0.860(2) ± 0.002 |
| scene | 0.747(9) ± 0.019 | 0.744(10) ± 0.020 | 0.928(5) ± 0.005 | 0.902(6) ± 0.003 | 0.755(8) ± 0.012 | 0.934(4) ± 0.003 | 0.885(7) ± 0.004 | 0.940(3) ± 0.004 | 0.945(2) ± 0.003 | 0.950(1) ± 0.002 • |
| yeast | 0.683(8) ± 0.010 | 0.652(10) ± 0.013 | 0.816(5) ± 0.004 | 0.791(6) ± 0.003 | 0.679(9) ± 0.007 | 0.837(3) ± 0.003 | 0.766(7) ± 0.004 | 0.832(4) ± 0.003 | 0.840(2) ± 0.004 | 0.842(1) ± 0.004 • |
| Slashdot | 0.937(5) ± 0.004 | 0.940(4) ± 0.003 | 0.892(10) ± 0.004 | 0.892(9) ± 0.004 | 0.918(7) ± 0.008 | 0.932(6) ± 0.008 | 0.912(8) ± 0.009 | 0.951(1) ± 0.004 • | 0.948(2) ± 0.006 | 0.945(3) ± 0.004 |
| corel5k | 0.776(3) ± 0.004 | 0.744(6) ± 0.003 | 0.573(9) ± 0.008 | 0.558(10) ± 0.003 | 0.714(7) ± 0.006 | 0.713(8) ± 0.008 | 0.772(5) ± 0.004 | 0.802(1) ± 0.003 • | 0.775(4) ± 0.005 | 0.796(2) ± 0.004 |
| rcv1subset1 | 0.788(7) ± 0.006 | 0.727(10) ± 0.008 | 0.814(6) ± 0.004 | 0.748(8) ± 0.005 | 0.746(9) ± 0.008 | 0.894(3) ± 0.004 | 0.866(5) ± 0.003 | 0.913(1) ± 0.002 • | 0.901(2) ± 0.004 | 0.874(4) ± 0.009 |
| rcv1subset2 | 0.803(6) ± 0.007 | 0.736(9) ± 0.009 | 0.800(7) ± 0.004 | 0.730(10) ± 0.005 | 0.762(8) ± 0.009 | 0.895(2) ± 0.003 | 0.874(4) ± 0.003 | 0.914(1) ± 0.003 • | 0.893(3) ± 0.005 | 0.865(5) ± 0.010 |
| rcv1subset3 | 0.797(7) ± 0.005 | 0.712(10) ± 0.009 | 0.808(6) ± 0.004 | 0.727(9) ± 0.005 | 0.763(8) ± 0.009 | 0.893(3) ± 0.003 | 0.871(4) ± 0.003 | 0.912(1) ± 0.003 • | 0.896(2) ± 0.002 | 0.861(5) ± 0.007 |
| rcv1subset4 | 0.818(7) ± 0.007 | 0.730(10) ± 0.010 | 0.819(6) ± 0.004 | 0.732(9) ± 0.005 | 0.783(8) ± 0.006 | 0.906(2) ± 0.004 | 0.884(4) ± 0.002 | 0.922(1) ± 0.002 • | 0.904(3) ± 0.003 | 0.884(5) ± 0.010 |
| rcv1subset5 | 0.809(6) ± 0.009 | 0.756(9) ± 0.009 | 0.807(7) ± 0.005 | 0.743(10) ± 0.004 | 0.768(8) ± 0.006 | 0.891(3) ± 0.003 | 0.871(4) ± 0.002 | 0.914(1) ± 0.002 • | 0.896(2) ± 0.003 | 0.868(5) ± 0.009 |
| bibtex | 0.788(6) ± 0.007 | 0.776(7) ± 0.007 | 0.709(9) ± 0.003 | 0.667(10) ± 0.004 | 0.739(8) ± 0.008 | 0.838(3) ± 0.003 | 0.802(5) ± 0.004 | 0.863(1) ± 0.003 • | 0.821(4) ± 0.007 | 0.863(2) ± 0.006 |
| Arts | 0.789(5) ± 0.006 | 0.787(6) ± 0.005 | 0.765(7) ± 0.004 | 0.689(10) ± 0.004 | 0.722(8) ± 0.023 | 0.818(4) ± 0.003 | 0.713(9) ± 0.004 | 0.840(3) ± 0.003 | 0.845(2) ± 0.004 | 0.851(1) ± 0.003 • |
| Health | 0.864(5) ± 0.005 | 0.862(6) ± 0.008 | 0.857(7) ± 0.004 | 0.819(9) ± 0.003 | 0.817(10) ± 0.010 | 0.893(4) ± 0.004 | 0.827(8) ± 0.004 | 0.910(3) ± 0.003 | 0.912(2) ± 0.003 | 0.919(1) ± 0.002 • |
| Business | 0.908(5) ± 0.004 | 0.895(7) ± 0.002 | 0.869(9) ± 0.004 | 0.853(10) ± 0.003 | 0.882(8) ± 0.006 | 0.927(4) ± 0.002 | 0.908(6) ± 0.002 | 0.945(2) ± 0.002 | 0.943(3) ± 0.001 | 0.947(1) ± 0.001 • |
| Education | 0.830(6) ± 0.004 | 0.840(5) ± 0.005 | 0.823(7) ± 0.004 | 0.746(10) ± 0.003 | 0.757(9) ± 0.022 | 0.876(4) ± 0.002 | 0.822(8) ± 0.003 | 0.900(3) ± 0.002 | 0.900(2) ± 0.002 | 0.906(1) ± 0.002 • |
| Computers | 0.827(5) ± 0.003 | 0.817(8) ± 0.007 | 0.822(6) ± 0.004 | 0.776(10) ± 0.003 | 0.779(9) ± 0.013 | 0.862(4) ± 0.003 | 0.820(7) ± 0.003 | 0.888(3) ± 0.003 | 0.888(2) ± 0.003 | 0.896(1) ± 0.003 • |
| Entertainment | 0.821(6) ± 0.005 | 0.805(7) ± 0.005 | 0.847(5) ± 0.006 | 0.775(9) ± 0.003 | 0.786(8) ± 0.010 | 0.863(4) ± 0.002 | 0.754(10) ± 0.004 | 0.879(3) ± 0.002 | 0.880(2) ± 0.001 | 0.891(1) ± 0.002 • |
| Recreation | 0.810(5) ± 0.004 | 0.796(7) ± 0.004 | 0.800(6) ± 0.004 | 0.717(9) ± 0.004 | 0.756(8) ± 0.019 | 0.839(4) ± 0.005 | 0.697(10) ± 0.004 | 0.859(3) ± 0.004 | 0.863(2) ± 0.004 | 0.874(1) ± 0.004 • |
| Society | 0.805(6) ± 0.003 | 0.812(5) ± 0.003 | 0.772(7) ± 0.004 | 0.722(10) ± 0.002 | 0.738(9) ± 0.018 | 0.829(4) ± 0.003 | 0.753(8) ± 0.004 | 0.858(3) ± 0.002 | 0.860(2) ± 0.002 | 0.869(1) ± 0.002 • |
| eurlex-dc-l | 0.837(6) ± 0.003 | 0.827(7) ± 0.004 | 0.758(9) ± 0.004 | 0.712(10) ± 0.002 | 0.799(8) ± 0.005 | 0.882(3) ± 0.004 | 0.875(4) ± 0.003 | 0.895(2) ± 0.003 | 0.863(5) ± 0.003 | 0.919(1) ± 0.005 • |
| eurlex-sm | 0.871(6) ± 0.003 | 0.866(7) ± 0.004 | 0.837(8) ± 0.002 | 0.806(10) ± 0.001 | 0.831(9) ± 0.005 | 0.919(4) ± 0.002 | 0.917(5) ± 0.002 | 0.936(2) ± 0.002 | 0.932(3) ± 0.002 | 0.952(1) ± 0.002 • |
| tmc2007-500 | 0.842(9) ± 0.003 | 0.845(8) ± 0.004 | 0.920(5) ± 0.001 | 0.907(6) ± 0.001 | 0.832(10) ± 0.004 | 0.928(4) ± 0.001 | 0.891(7) ± 0.002 | 0.942(3) ± 0.001 | 0.942(2) ± 0.001 | 0.958(1) ± 0.001 • |
| mediamill | 0.815(8) ± 0.004 | 0.780(9) ± 0.003 | 0.879(6) ± 0.002 | 0.857(7) ± 0.001 | 0.763(10) ± 0.004 | 0.930(5) ± 0.001 | 0.930(4) ± 0.000 | 0.950(2) ± 0.001 | 0.949(3) ± 0.001 | 0.957(1) ± 0.001 • |
| average rank | 6.43 | 7.86 | 6.18 | 8.18 | 8.39 | 4.14 | 6.39 | 2.29 | 2.89 | 2.25 |
| win/tie/loss | 86/24/142 | 55/22/175 | 97/14/141 | 41/16/195 | 32/22/198 | 161/9/82 | 97/13/142 | 208/14/30 | 189/18/45 | 211/14/27 |
| Dataset | Ranking Loss | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.362(7) ± 0.039 | 0.372(9) ± 0.031 | 0.317(5) ± 0.023 | 0.370(8) ± 0.026 | 0.391(10) ± 0.028 | 0.317(4) ± 0.020 | 0.345(6) ± 0.018 | 0.271(3) ± 0.018 | 0.264(2) ± 0.020 | 0.251(1) ± 0.020 • |
| CAL500 | 0.403(7) ± 0.013 | 0.450(8) ± 0.012 | 0.337(5) ± 0.004 | 0.381(6) ± 0.004 | 0.485(10) ± 0.010 | 0.282(3) ± 0.003 | 0.284(4) ± 0.003 | 0.242(2) ± 0.002 | 0.456(9) ± 0.007 | 0.240(1) ± 0.005 • |
| emotions | 0.385(9) ± 0.021 | 0.385(8) ± 0.024 | 0.213(5) ± 0.011 | 0.230(6) ± 0.010 | 0.432(10) ± 0.014 | 0.184(3) ± 0.011 | 0.241(7) ± 0.015 | 0.185(4) ± 0.011 | 0.158(2) ± 0.007 | 0.153(1) ± 0.007 • |
| genbase | 0.007(6) ± 0.011 | 0.007(5) ± 0.011 | 0.005(3) ± 0.004 | 0.007(4) ± 0.008 | 0.008(7) ± 0.011 | 0.016(9) ± 0.006 | 0.026(10) ± 0.010 | 0.010(8) ± 0.005 | 0.002(1) ± 0.002 • | 0.004(2) ± 0.003 |
| LLOG | 0.186(4) ± 0.002 | 0.283(7) ± 0.023 | 0.481(9) ± 0.060 | 0.536(10) ± 0.020 | 0.368(8) ± 0.028 | 0.229(6) ± 0.005 | 0.186(3) ± 0.002 | 0.186(1) ± 0.002 • | 0.186(2) ± 0.002 | 0.187(5) ± 0.002 |
| enron | 0.225(5) ± 0.009 | 0.231(6) ± 0.013 | 0.243(7) ± 0.010 | 0.301(10) ± 0.010 | 0.260(9) ± 0.011 | 0.260(8) ± 0.018 | 0.165(4) ± 0.005 | 0.130(1) ± 0.003 • | 0.135(3) ± 0.004 | 0.135(2) ± 0.003 |
| scene | 0.321(9) ± 0.018 | 0.302(8) ± 0.021 | 0.115(5) ± 0.007 | 0.138(7) ± 0.004 | 0.360(10) ± 0.018 | 0.102(4) ± 0.005 | 0.121(6) ± 0.004 | 0.078(3) ± 0.004 | 0.076(2) ± 0.004 | 0.071(1) ± 0.003 • |
| yeast | 0.364(8) ± 0.018 | 0.409(9) ± 0.011 | 0.225(5) ± 0.004 | 0.245(7) ± 0.003 | 0.417(10) ± 0.008 | 0.191(4) ± 0.003 | 0.234(6) ± 0.004 | 0.175(3) ± 0.003 | 0.169(2) ± 0.003 | 0.168(1) ± 0.003 • |
| Slashdot | 0.049(5) ± 0.004 | 0.047(4) ± 0.004 | 0.155(10) ± 0.009 | 0.153(9) ± 0.008 | 0.081(7) ± 0.009 | 0.084(8) ± 0.011 | 0.066(6) ± 0.008 | 0.042(1) ± 0.004 • | 0.043(2) ± 0.004 | 0.047(3) ± 0.005 |
| corel5k | 0.227(4) ± 0.004 | 0.256(6) ± 0.003 | 0.848(9) ± 0.017 | 0.879(10) ± 0.006 | 0.293(7) ± 0.006 | 0.452(8) ± 0.011 | 0.228(5) ± 0.003 | 0.199(1) ± 0.003 • | 0.221(3) ± 0.006 | 0.206(2) ± 0.004 |
| rcv1subset1 | 0.205(6) ± 0.006 | 0.265(8) ± 0.009 | 0.315(9) ± 0.009 | 0.457(10) ± 0.011 | 0.254(7) ± 0.008 | 0.143(5) ± 0.005 | 0.120(4) ± 0.003 | 0.077(1) ± 0.002 • | 0.087(2) ± 0.003 | 0.118(3) ± 0.008 |
| rcv1subset2 | 0.182(6) ± 0.009 | 0.257(8) ± 0.011 | 0.326(9) ± 0.008 | 0.479(10) ± 0.010 | 0.231(7) ± 0.012 | 0.141(5) ± 0.005 | 0.112(3) ± 0.002 | 0.072(1) ± 0.003 • | 0.085(2) ± 0.003 | 0.118(4) ± 0.009 |
| rcv1subset3 | 0.188(6) ± 0.008 | 0.277(8) ± 0.008 | 0.314(9) ± 0.007 | 0.481(10) ± 0.010 | 0.231(7) ± 0.010 | 0.147(5) ± 0.004 | 0.115(3) ± 0.001 | 0.075(1) ± 0.002 • | 0.085(2) ± 0.002 | 0.122(4) ± 0.005 |
| rcv1subset4 | 0.163(6) ± 0.008 | 0.250(8) ± 0.011 | 0.284(9) ± 0.007 | 0.469(10) ± 0.008 | 0.206(7) ± 0.007 | 0.125(5) ± 0.006 | 0.100(3) ± 0.001 | 0.064(1) ± 0.002 • | 0.077(2) ± 0.002 | 0.100(4) ± 0.009 |
| rcv1subset5 | 0.177(6) ± 0.011 | 0.239(8) ± 0.012 | 0.322(9) ± 0.010 | 0.461(10) ± 0.011 | 0.225(7) ± 0.007 | 0.150(5) ± 0.006 | 0.115(3) ± 0.002 | 0.072(1) ± 0.001 • | 0.084(2) ± 0.002 | 0.117(4) ± 0.009 |
| bibtex | 0.202(5) ± 0.006 | 0.204(6) ± 0.006 | 0.566(9) ± 0.005 | 0.638(10) ± 0.009 | 0.257(7) ± 0.009 | 0.282(8) ± 0.006 | 0.197(4) ± 0.005 | 0.122(1) ± 0.003 • | 0.182(3) ± 0.006 | 0.147(2) ± 0.004 |
| Arts | 0.189(5) ± 0.007 | 0.186(4) ± 0.004 | 0.330(9) ± 0.011 | 0.545(10) ± 0.009 | 0.285(8) ± 0.022 | 0.206(6) ± 0.004 | 0.266(7) ± 0.004 | 0.136(3) ± 0.003 | 0.135(2) ± 0.003 | 0.129(1) ± 0.003 • |
| Health | 0.119(5) ± 0.005 | 0.118(4) ± 0.007 | 0.209(9) ± 0.007 | 0.285(10) ± 0.006 | 0.185(8) ± 0.011 | 0.125(6) ± 0.004 | 0.146(7) ± 0.005 | 0.076(3) ± 0.002 | 0.076(2) ± 0.002 | 0.070(1) ± 0.002 • |
| Business | 0.066(5) ± 0.003 | 0.076(6) ± 0.002 | 0.174(9) ± 0.006 | 0.198(10) ± 0.004 | 0.098(8) ± 0.006 | 0.081(7) ± 0.003 | 0.066(4) ± 0.001 | 0.037(2) ± 0.001 | 0.038(3) ± 0.001 | 0.037(1) ± 0.001 • |
| Education | 0.167(7) ± 0.004 | 0.156(5) ± 0.004 | 0.261(8) ± 0.006 | 0.441(10) ± 0.007 | 0.265(9) ± 0.022 | 0.156(4) ± 0.003 | 0.162(6) ± 0.002 | 0.093(2) ± 0.002 | 0.094(3) ± 0.002 | 0.089(1) ± 0.002 • |
| Computers | 0.146(5) ± 0.003 | 0.148(6) ± 0.005 | 0.267(9) ± 0.005 | 0.378(10) ± 0.005 | 0.214(8) ± 0.013 | 0.166(7) ± 0.003 | 0.144(4) ± 0.004 | 0.089(2) ± 0.002 | 0.090(3) ± 0.002 | 0.086(1) ± 0.002 • |
| Entertainment | 0.169(4) ± 0.006 | 0.181(6) ± 0.004 | 0.227(8) ± 0.009 | 0.387(10) ± 0.007 | 0.244(9) ± 0.013 | 0.174(5) ± 0.003 | 0.224(7) ± 0.003 | 0.122(3) ± 0.002 | 0.121(2) ± 0.002 | 0.111(1) ± 0.002 • |
| Recreation | 0.164(4) ± 0.006 | 0.172(5) ± 0.004 | 0.283(9) ± 0.008 | 0.499(10) ± 0.009 | 0.255(7) ± 0.020 | 0.197(6) ± 0.006 | 0.277(8) ± 0.005 | 0.127(3) ± 0.003 | 0.126(2) ± 0.004 | 0.115(1) ± 0.004 • |
| Society | 0.168(5) ± 0.004 | 0.152(4) ± 0.003 | 0.326(9) ± 0.008 | 0.448(10) ± 0.007 | 0.248(8) ± 0.017 | 0.189(6) ± 0.004 | 0.216(7) ± 0.004 | 0.112(2) ± 0.002 | 0.112(3) ± 0.002 | 0.105(1) ± 0.002 • |
| eurlex-dc-l | 0.150(5) ± 0.003 | 0.156(6) ± 0.003 | 0.455(9) ± 0.008 | 0.547(10) ± 0.005 | 0.188(7) ± 0.005 | 0.206(8) ± 0.006 | 0.118(3) ± 0.003 | 0.074(1) ± 0.002 • | 0.119(4) ± 0.003 | 0.078(2) ± 0.005 |
| eurlex-sm | 0.127(5) ± 0.003 | 0.130(6) ± 0.003 | 0.307(9) ± 0.003 | 0.372(10) ± 0.003 | 0.169(8) ± 0.006 | 0.138(7) ± 0.003 | 0.084(4) ± 0.001 | 0.053(2) ± 0.001 | 0.064(3) ± 0.001 | 0.050(1) ± 0.002 • |
| tmc2007-500 | 0.148(9) ± 0.004 | 0.145(8) ± 0.003 | 0.121(6) ± 0.003 | 0.144(7) ± 0.002 | 0.179(10) ± 0.004 | 0.092(4) ± 0.001 | 0.105(5) ± 0.001 | 0.059(3) ± 0.001 | 0.057(2) ± 0.001 | 0.044(1) ± 0.001 • |
| mediamill | 0.181(6) ± 0.005 | 0.224(8) ± 0.004 | 0.187(7) ± 0.002 | 0.233(9) ± 0.002 | 0.240(10) ± 0.004 | 0.092(5) ± 0.001 | 0.059(4) ± 0.000 | 0.043(2) ± 0.000 | 0.044(3) ± 0.000 | 0.038(1) ± 0.001 • |
| average rank | 5.86 | 6.57 | 7.79 | 9.04 | 8.21 | 5.75 | 5.11 | 2.18 | 2.61 | 1.89 |
| win/tie/loss | 108/18/126 | 90/19/143 | 57/9/186 | 20/10/222 | 48/10/194 | 115/5/132 | 127/12/113 | 218/8/26 | 203/11/38 | 214/18/20 |
| Dataset | F1 Macro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.368(4) ± 0.040 | 0.367(5) ± 0.030 | 0.385(2) ± 0.030 | 0.409(1) ± 0.035 • | 0.382(3) ± 0.017 | 0.034(10) ± 0.019 | 0.157(8) ± 0.027 | 0.117(9) ± 0.029 | 0.242(7) ± 0.024 | 0.258(6) ± 0.069 |
| CAL500 | 0.170(5) ± 0.007 | 0.195(3) ± 0.006 | 0.141(6) ± 0.006 | 0.191(4) ± 0.005 | 0.215(2) ± 0.003 | 0.083(10) ± 0.002 | 0.103(7) ± 0.003 | 0.084(8) ± 0.002 | 0.229(1) ± 0.007 • | 0.083(9) ± 0.003 |
| emotions | 0.570(8) ± 0.011 | 0.551(10) ± 0.023 | 0.639(2) ± 0.013 | 0.614(4) ± 0.013 | 0.555(9) ± 0.018 | 0.608(5) ± 0.011 | 0.602(6) ± 0.023 | 0.595(7) ± 0.017 | 0.638(3) ± 0.014 | 0.651(1) ± 0.013 • |
| genbase | 0.980(5) ± 0.012 | 0.977(6) ± 0.018 | 0.983(3) ± 0.007 | 0.984(2) ± 0.012 | 0.984(1) ± 0.014 • | 0.639(10) ± 0.058 | 0.913(8) ± 0.030 | 0.820(9) ± 0.080 | 0.980(4) ± 0.009 | 0.954(7) ± 0.017 |
| LLOG | 0.117(2) ± 0.005 | 0.042(10) ± 0.006 | 0.049(9) ± 0.010 | 0.094(8) ± 0.005 | 0.097(7) ± 0.010 | 0.141(1) ± 0.012 • | 0.116(4) ± 0.005 | 0.113(5) ± 0.003 | 0.116(3) ± 0.005 | 0.097(6) ± 0.016 |
| enron | 0.215(5) ± 0.007 | 0.218(2) ± 0.006 | 0.217(4) ± 0.007 | 0.224(1) ± 0.005 • | 0.217(3) ± 0.011 | 0.067(10) ± 0.008 | 0.131(8) ± 0.007 | 0.103(9) ± 0.010 | 0.170(6) ± 0.010 | 0.131(7) ± 0.009 |
| scene | 0.622(8) ± 0.009 | 0.610(9) ± 0.010 | 0.723(5) ± 0.008 | 0.688(6) ± 0.009 | 0.602(10) ± 0.013 | 0.643(7) ± 0.015 | 0.726(3) ± 0.007 | 0.726(4) ± 0.007 | 0.730(2) ± 0.008 | 0.749(1) ± 0.008 • |
| yeast | 0.382(5) ± 0.015 | 0.381(7) ± 0.006 | 0.389(2) ± 0.010 | 0.388(3) ± 0.005 | 0.382(6) ± 0.006 | 0.347(10) ± 0.006 | 0.385(4) ± 0.010 | 0.352(9) ± 0.010 | 0.370(8) ± 0.006 | 0.420(1) ± 0.009 • |
| Slashdot | 0.135(6) ± 0.033 | 0.132(7) ± 0.024 | 0.129(8) ± 0.022 | 0.177(2) ± 0.024 | 0.172(3) ± 0.023 | 0.081(10) ± 0.002 | 0.149(5) ± 0.036 | 0.120(9) ± 0.021 | 0.177(1) ± 0.023 • | 0.163(4) ± 0.025 |
| corel5k | 0.029(4) ± 0.003 | 0.029(6) ± 0.004 | 0.008(8) ± 0.002 | 0.029(5) ± 0.002 | 0.031(3) ± 0.003 | 0.001(10) ± 0.001 | 0.038(2) ± 0.006 | 0.003(9) ± 0.002 | 0.055(1) ± 0.004 • | 0.026(7) ± 0.004 |
| rcv1subset1 | 0.243(3) ± 0.008 | 0.242(4) ± 0.007 | 0.216(6) ± 0.011 | 0.246(2) ± 0.009 | 0.238(5) ± 0.007 | 0.074(10) ± 0.006 | 0.181(7) ± 0.010 | 0.097(9) ± 0.004 | 0.255(1) ± 0.008 • | 0.152(8) ± 0.014 |
| rcv1subset2 | 0.231(3) ± 0.008 | 0.237(2) ± 0.013 | 0.197(6) ± 0.008 | 0.230(4) ± 0.007 | 0.227(5) ± 0.005 | 0.067(10) ± 0.003 | 0.173(7) ± 0.011 | 0.081(9) ± 0.003 | 0.246(1) ± 0.007 • | 0.133(8) ± 0.015 |
| rcv1subset3 | 0.217(3) ± 0.007 | 0.221(2) ± 0.008 | 0.191(6) ± 0.007 | 0.214(5) ± 0.009 | 0.215(4) ± 0.007 | 0.060(10) ± 0.001 | 0.164(7) ± 0.006 | 0.076(9) ± 0.006 | 0.239(1) ± 0.008 • | 0.120(8) ± 0.010 |
| rcv1subset4 | 0.231(3) ± 0.014 | 0.244(2) ± 0.008 | 0.197(6) ± 0.007 | 0.228(4) ± 0.011 | 0.227(5) ± 0.010 | 0.081(10) ± 0.005 | 0.178(7) ± 0.008 | 0.091(9) ± 0.004 | 0.253(1) ± 0.007 • | 0.149(8) ± 0.013 |
| rcv1subset5 | 0.228(2) ± 0.009 | 0.226(3) ± 0.007 | 0.192(6) ± 0.007 | 0.223(4) ± 0.008 | 0.221(5) ± 0.009 | 0.069(10) ± 0.003 | 0.163(7) ± 0.006 | 0.082(9) ± 0.008 | 0.243(1) ± 0.008 • | 0.134(8) ± 0.017 |
| bibtex | 0.213(1) ± 0.007 • | 0.202(4) ± 0.005 | 0.191(5) ± 0.006 | 0.204(3) ± 0.008 | 0.204(2) ± 0.005 | 0.060(9) ± 0.002 | 0.148(8) ± 0.006 | 0.052(10) ± 0.003 | 0.173(7) ± 0.003 | 0.187(6) ± 0.006 |
| Arts | 0.267(2) ± 0.007 | 0.256(6) ± 0.008 | 0.257(5) ± 0.011 | 0.274(1) ± 0.008 • | 0.266(3) ± 0.011 | 0.140(10) ± 0.010 | 0.223(7) ± 0.013 | 0.182(9) ± 0.014 | 0.218(8) ± 0.019 | 0.263(4) ± 0.015 |
| Health | 0.445(4) ± 0.015 | 0.446(3) ± 0.012 | 0.450(2) ± 0.010 | 0.459(1) ± 0.011 • | 0.435(5) ± 0.013 | 0.269(10) ± 0.016 | 0.360(8) ± 0.019 | 0.338(9) ± 0.017 | 0.360(7) ± 0.016 | 0.404(6) ± 0.011 |
| Business | 0.272(1) ± 0.020 • | 0.245(5) ± 0.014 | 0.237(8) ± 0.012 | 0.269(2) ± 0.019 | 0.265(4) ± 0.014 | 0.141(10) ± 0.008 | 0.239(7) ± 0.010 | 0.194(9) ± 0.009 | 0.244(6) ± 0.014 | 0.267(3) ± 0.005 |
| Education | 0.260(4) ± 0.012 | 0.264(3) ± 0.012 | 0.258(5) ± 0.009 | 0.269(2) ± 0.010 | 0.257(6) ± 0.010 | 0.145(10) ± 0.008 | 0.220(8) ± 0.009 | 0.179(9) ± 0.015 | 0.235(7) ± 0.012 | 0.278(1) ± 0.015 • |
| Computers | 0.303(2) ± 0.015 | 0.289(5) ± 0.013 | 0.275(6) ± 0.015 | 0.306(1) ± 0.014 • | 0.296(3) ± 0.014 | 0.142(10) ± 0.011 | 0.255(8) ± 0.014 | 0.211(9) ± 0.011 | 0.257(7) ± 0.011 | 0.294(4) ± 0.010 |
| Entertainment | 0.390(5) ± 0.013 | 0.378(6) ± 0.014 | 0.400(2) ± 0.012 | 0.404(1) ± 0.008 • | 0.393(3) ± 0.012 | 0.257(10) ± 0.008 | 0.347(7) ± 0.012 | 0.304(9) ± 0.012 | 0.327(8) ± 0.012 | 0.390(4) ± 0.008 |
| Recreation | 0.369(4) ± 0.010 | 0.361(6) ± 0.010 | 0.373(3) ± 0.015 | 0.385(2) ± 0.011 | 0.367(5) ± 0.010 | 0.240(10) ± 0.022 | 0.352(7) ± 0.014 | 0.316(9) ± 0.013 | 0.352(8) ± 0.015 | 0.390(1) ± 0.016 • |
| Society | 0.261(4) ± 0.010 | 0.261(5) ± 0.010 | 0.250(6) ± 0.008 | 0.271(2) ± 0.006 | 0.265(3) ± 0.009 | 0.158(10) ± 0.008 | 0.246(7) ± 0.010 | 0.220(9) ± 0.008 | 0.243(8) ± 0.012 | 0.291(1) ± 0.012 • |
| eurlex-dc-l | 0.258(2) ± 0.008 | 0.258(3) ± 0.008 | 0.237(6) ± 0.004 | 0.253(4) ± 0.007 | 0.251(5) ± 0.006 | 0.148(9) ± 0.003 | 0.177(7) ± 0.005 | 0.068(10) ± 0.003 | 0.169(8) ± 0.004 | 0.267(1) ± 0.010 • |
| eurlex-sm | 0.377(3) ± 0.004 | 0.370(6) ± 0.006 | 0.372(5) ± 0.006 | 0.377(2) ± 0.005 | 0.372(4) ± 0.007 | 0.252(9) ± 0.005 | 0.296(8) ± 0.007 | 0.200(10) ± 0.006 | 0.307(7) ± 0.007 | 0.388(1) ± 0.009 • |
| tmc2007-500 | 0.560(4) ± 0.006 | 0.558(5) ± 0.007 | 0.582(2) ± 0.005 | 0.578(3) ± 0.005 | 0.544(6) ± 0.004 | 0.239(10) ± 0.004 | 0.464(7) ± 0.010 | 0.425(9) ± 0.009 | 0.452(8) ± 0.006 | 0.603(1) ± 0.007 • |
| mediamill | 0.172(4) ± 0.006 | 0.156(5) ± 0.004 | 0.128(8) ± 0.005 | 0.196(2) ± 0.004 | 0.180(3) ± 0.005 | 0.085(10) ± 0.002 | 0.137(7) ± 0.006 | 0.088(9) ± 0.002 | 0.155(6) ± 0.005 | 0.293(1) ± 0.005 • |
| average rank | 3.79 | 5.00 | 5.07 | 2.89 | 4.39 | 9.29 | 6.64 | 8.68 | 4.86 | 4.39 |
| win/tie/loss | 140/55/57 | 124/45/83 | 116/39/97 | 175/41/36 | 135/49/68 | 19/5/228 | 80/27/145 | 33/11/208 | 134/23/95 | 143/27/82 |
| Dataset | F1 Micro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.452(3) ± 0.044 | 0.448(4) ± 0.035 | 0.497(1) ± 0.021 • | 0.481(2) ± 0.024 | 0.438(5) ± 0.021 | 0.074(10) ± 0.042 | 0.230(8) ± 0.050 | 0.208(9) ± 0.039 | 0.327(7) ± 0.027 | 0.358(6) ± 0.061 |
| CAL500 | 0.353(4) ± 0.011 | 0.362(3) ± 0.011 | 0.386(1) ± 0.007 • | 0.383(2) ± 0.004 | 0.351(5) ± 0.005 | 0.321(10) ± 0.006 | 0.338(8) ± 0.009 | 0.331(9) ± 0.005 | 0.338(7) ± 0.008 | 0.342(6) ± 0.014 |
| emotions | 0.579(8) ± 0.012 | 0.561(10) ± 0.022 | 0.655(3) ± 0.012 | 0.627(6) ± 0.012 | 0.564(9) ± 0.018 | 0.635(4) ± 0.013 | 0.629(5) ± 0.020 | 0.616(7) ± 0.018 | 0.662(2) ± 0.011 | 0.672(1) ± 0.011 • |
| genbase | 0.987(4) ± 0.008 | 0.986(6) ± 0.010 | 0.990(2) ± 0.005 | 0.990(1) ± 0.007 • | 0.989(3) ± 0.010 | 0.839(10) ± 0.040 | 0.949(8) ± 0.020 | 0.909(9) ± 0.036 | 0.986(5) ± 0.007 | 0.965(7) ± 0.014 |
| LLOG | 0.429(2) ± 0.013 | 0.100(10) ± 0.035 | 0.145(9) ± 0.061 | 0.367(7) ± 0.016 | 0.371(6) ± 0.033 | 0.466(1) ± 0.023 • | 0.427(3) ± 0.013 | 0.421(5) ± 0.008 | 0.427(4) ± 0.012 | 0.363(8) ± 0.059 |
| enron | 0.522(4) ± 0.009 | 0.524(3) ± 0.012 | 0.584(1) ± 0.007 • | 0.565(2) ± 0.009 | 0.514(5) ± 0.008 | 0.219(10) ± 0.022 | 0.476(6) ± 0.011 | 0.450(9) ± 0.014 | 0.454(8) ± 0.015 | 0.460(7) ± 0.013 |
| scene | 0.610(8) ± 0.009 | 0.594(9) ± 0.012 | 0.715(5) ± 0.009 | 0.677(6) ± 0.009 | 0.591(10) ± 0.012 | 0.649(7) ± 0.011 | 0.720(3) ± 0.007 | 0.720(4) ± 0.008 | 0.725(2) ± 0.008 | 0.743(1) ± 0.008 • |
| yeast | 0.573(8) ± 0.011 | 0.539(9) ± 0.010 | 0.637(3) ± 0.006 | 0.609(7) ± 0.002 | 0.538(10) ± 0.005 | 0.628(6) ± 0.004 | 0.635(4) ± 0.006 | 0.628(5) ± 0.006 | 0.641(2) ± 0.003 | 0.643(1) ± 0.006 • |
| Slashdot | 0.845(5) ± 0.007 | 0.846(4) ± 0.007 | 0.846(3) ± 0.007 | 0.849(1) ± 0.008 • | 0.849(2) ± 0.008 | 0.843(7) ± 0.007 | 0.843(6) ± 0.011 | 0.842(10) ± 0.008 | 0.843(9) ± 0.006 | 0.843(8) ± 0.008 |
| corel5k | 0.093(4) ± 0.008 | 0.094(2) ± 0.008 | 0.029(8) ± 0.006 | 0.081(5) ± 0.006 | 0.095(1) ± 0.007 • | 0.003(10) ± 0.003 | 0.094(3) ± 0.013 | 0.007(9) ± 0.004 | 0.075(6) ± 0.004 | 0.050(7) ± 0.011 |
| rcv1subset1 | 0.369(3) ± 0.009 | 0.357(6) ± 0.004 | 0.365(5) ± 0.009 | 0.387(1) ± 0.005 • | 0.366(4) ± 0.006 | 0.203(10) ± 0.007 | 0.345(7) ± 0.011 | 0.261(9) ± 0.007 | 0.374(2) ± 0.007 | 0.296(8) ± 0.021 |
| rcv1subset2 | 0.383(3) ± 0.005 | 0.369(6) ± 0.009 | 0.377(5) ± 0.011 | 0.388(1) ± 0.007 • | 0.382(4) ± 0.006 | 0.275(10) ± 0.008 | 0.367(7) ± 0.016 | 0.288(9) ± 0.007 | 0.385(2) ± 0.007 | 0.334(8) ± 0.012 |
| rcv1subset3 | 0.383(3) ± 0.012 | 0.371(6) ± 0.009 | 0.372(5) ± 0.007 | 0.387(1) ± 0.012 • | 0.381(4) ± 0.006 | 0.258(10) ± 0.007 | 0.362(7) ± 0.013 | 0.279(9) ± 0.009 | 0.386(2) ± 0.006 | 0.333(8) ± 0.009 |
| rcv1subset4 | 0.427(4) ± 0.008 | 0.423(6) ± 0.012 | 0.420(7) ± 0.008 | 0.437(1) ± 0.006 • | 0.426(5) ± 0.009 | 0.336(10) ± 0.007 | 0.430(3) ± 0.007 | 0.362(9) ± 0.005 | 0.434(2) ± 0.007 | 0.394(8) ± 0.019 |
| rcv1subset5 | 0.403(2) ± 0.004 | 0.377(6) ± 0.007 | 0.384(5) ± 0.008 | 0.411(1) ± 0.006 • | 0.398(3) ± 0.008 | 0.284(10) ± 0.010 | 0.369(7) ± 0.009 | 0.303(9) ± 0.010 | 0.397(4) ± 0.005 | 0.348(8) ± 0.014 |
| bibtex | 0.393(1) ± 0.008 • | 0.386(5) ± 0.006 | 0.387(4) ± 0.006 | 0.392(2) ± 0.007 | 0.389(3) ± 0.005 | 0.241(9) ± 0.006 | 0.328(7) ± 0.004 | 0.231(10) ± 0.006 | 0.256(8) ± 0.006 | 0.367(6) ± 0.006 |
| Arts | 0.393(5) ± 0.005 | 0.393(3) ± 0.008 | 0.419(1) ± 0.007 • | 0.410(2) ± 0.008 | 0.393(4) ± 0.010 | 0.263(10) ± 0.016 | 0.340(7) ± 0.017 | 0.296(9) ± 0.022 | 0.316(8) ± 0.018 | 0.369(6) ± 0.014 |
| Health | 0.611(4) ± 0.006 | 0.619(3) ± 0.006 | 0.654(1) ± 0.006 • | 0.634(2) ± 0.006 | 0.608(5) ± 0.008 | 0.491(10) ± 0.012 | 0.531(7) ± 0.017 | 0.519(9) ± 0.016 | 0.530(8) ± 0.013 | 0.574(6) ± 0.011 |
| Business | 0.720(4) ± 0.004 | 0.712(8) ± 0.005 | 0.732(1) ± 0.004 • | 0.730(2) ± 0.003 | 0.717(5) ± 0.005 | 0.705(10) ± 0.005 | 0.714(7) ± 0.006 | 0.707(9) ± 0.004 | 0.716(6) ± 0.004 | 0.722(3) ± 0.004 |
| Education | 0.421(4) ± 0.007 | 0.426(3) ± 0.005 | 0.460(1) ± 0.006 • | 0.440(2) ± 0.003 | 0.414(5) ± 0.005 | 0.288(10) ± 0.012 | 0.357(7) ± 0.013 | 0.307(9) ± 0.019 | 0.321(8) ± 0.014 | 0.378(6) ± 0.014 |
| Computers | 0.514(3) ± 0.004 | 0.502(6) ± 0.007 | 0.551(1) ± 0.004 • | 0.532(2) ± 0.003 | 0.504(5) ± 0.004 | 0.468(10) ± 0.004 | 0.490(7) ± 0.008 | 0.478(9) ± 0.013 | 0.487(8) ± 0.004 | 0.511(4) ± 0.005 |
| Entertainment | 0.534(4) ± 0.006 | 0.507(5) ± 0.009 | 0.572(1) ± 0.007 • | 0.562(2) ± 0.006 | 0.534(3) ± 0.006 | 0.400(10) ± 0.009 | 0.472(7) ± 0.014 | 0.441(9) ± 0.011 | 0.453(8) ± 0.011 | 0.505(6) ± 0.008 |
| Recreation | 0.468(3) ± 0.006 | 0.422(7) ± 0.007 | 0.489(1) ± 0.005 • | 0.484(2) ± 0.007 | 0.466(4) ± 0.006 | 0.345(10) ± 0.018 | 0.428(6) ± 0.017 | 0.402(9) ± 0.017 | 0.406(8) ± 0.015 | 0.454(5) ± 0.012 |
| Society | 0.444(6) ± 0.005 | 0.488(2) ± 0.005 | 0.494(1) ± 0.004 • | 0.470(3) ± 0.002 | 0.447(5) ± 0.003 | 0.385(10) ± 0.014 | 0.433(7) ± 0.010 | 0.415(9) ± 0.020 | 0.432(8) ± 0.009 | 0.468(4) ± 0.010 |
| eurlex-dc-l | 0.483(4) ± 0.005 | 0.484(3) ± 0.006 | 0.494(1) ± 0.007 • | 0.489(2) ± 0.004 | 0.478(6) ± 0.005 | 0.390(8) ± 0.003 | 0.401(7) ± 0.006 | 0.288(9) ± 0.006 | 0.278(10) ± 0.003 | 0.479(5) ± 0.007 |
| eurlex-sm | 0.599(3) ± 0.003 | 0.594(5) ± 0.004 | 0.624(1) ± 0.005 • | 0.616(2) ± 0.004 | 0.596(4) ± 0.004 | 0.504(9) ± 0.006 | 0.533(7) ± 0.006 | 0.481(10) ± 0.006 | 0.510(8) ± 0.006 | 0.589(6) ± 0.007 |
| tmc2007-500 | 0.668(4) ± 0.003 | 0.665(5) ± 0.003 | 0.716(2) ± 0.003 | 0.707(3) ± 0.002 | 0.657(6) ± 0.003 | 0.577(10) ± 0.003 | 0.634(9) ± 0.006 | 0.638(8) ± 0.002 | 0.640(7) ± 0.004 | 0.726(1) ± 0.003 • |
| mediamill | 0.553(8) ± 0.003 | 0.536(10) ± 0.002 | 0.597(3) ± 0.002 | 0.598(2) ± 0.002 | 0.541(9) ± 0.003 | 0.573(6) ± 0.002 | 0.583(4) ± 0.004 | 0.568(7) ± 0.002 | 0.580(5) ± 0.002 | 0.635(1) ± 0.001 • |
| average rank | 4.21 | 5.54 | 2.93 | 2.57 | 5.00 | 8.82 | 6.21 | 8.46 | 5.86 | 5.39 |
| win/tie/loss | 140/41/71 | 108/32/112 | 184/21/47 | 195/20/37 | 121/40/91 | 28/8/216 | 90/30/132 | 41/14/197 | 101/39/112 | 121/17/114 |
| Dataset | Hamming Loss | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.143(4) ± 0.013 | 0.145(7) ± 0.012 | 0.119(1) ± 0.007 • | 0.134(2) ± 0.008 | 0.157(10) ± 0.011 | 0.144(5) ± 0.007 | 0.145(6) ± 0.007 | 0.146(8) ± 0.006 | 0.151(9) ± 0.006 | 0.137(3) ± 0.008 |
| CAL500 | 0.228(7) ± 0.003 | 0.244(8) ± 0.005 | 0.198(5) ± 0.002 | 0.227(6) ± 0.002 | 0.263(9) ± 0.003 | 0.187(2) ± 0.002 | 0.192(4) ± 0.001 | 0.189(3) ± 0.001 | 0.300(10) ± 0.003 | 0.187(1) ± 0.001 • |
| emotions | 0.260(8) ± 0.010 | 0.270(9) ± 0.011 | 0.209(4) ± 0.007 | 0.225(7) ± 0.008 | 0.271(10) ± 0.011 | 0.198(2) ± 0.007 | 0.211(5) ± 0.006 | 0.216(6) ± 0.007 | 0.199(3) ± 0.006 | 0.190(1) ± 0.005 • |
| genbase | 0.002(4) ± 0.001 | 0.002(5) ± 0.002 | 0.002(2) ± 0.001 | 0.002(1) ± 0.001 • | 0.002(3) ± 0.002 | 0.026(10) ± 0.007 | 0.009(8) ± 0.003 | 0.014(9) ± 0.005 | 0.002(6) ± 0.001 | 0.006(7) ± 0.002 |
| LLOG | 0.185(1) ± 0.004 • | 0.206(10) ± 0.007 | 0.202(9) ± 0.009 | 0.187(5) ± 0.004 | 0.187(6) ± 0.005 | 0.192(8) ± 0.004 | 0.185(3) ± 0.004 | 0.185(2) ± 0.004 | 0.185(4) ± 0.004 | 0.188(7) ± 0.006 |
| enron | 0.080(5) ± 0.001 | 0.080(7) ± 0.002 | 0.070(1) ± 0.001 • | 0.074(2) ± 0.001 | 0.083(9) ± 0.002 | 0.090(10) ± 0.001 | 0.080(6) ± 0.001 | 0.078(4) ± 0.001 | 0.082(8) ± 0.002 | 0.075(3) ± 0.001 |
| scene | 0.138(8) ± 0.003 | 0.147(10) ± 0.005 | 0.095(5) ± 0.003 | 0.108(7) ± 0.003 | 0.145(9) ± 0.004 | 0.103(6) ± 0.003 | 0.092(3) ± 0.002 | 0.093(4) ± 0.003 | 0.089(2) ± 0.003 | 0.084(1) ± 0.003 • |
| yeast | 0.255(8) ± 0.007 | 0.277(9) ± 0.005 | 0.212(6) ± 0.003 | 0.234(7) ± 0.003 | 0.280(10) ± 0.004 | 0.199(2) ± 0.003 | 0.204(5) ± 0.002 | 0.202(4) ± 0.002 | 0.198(1) ± 0.002 • | 0.200(3) ± 0.003 |
| Slashdot | 0.028(5) ± 0.001 | 0.028(4) ± 0.001 | 0.028(3) ± 0.001 | 0.027(1) ± 0.001 • | 0.027(2) ± 0.002 | 0.028(8) ± 0.001 | 0.028(6) ± 0.002 | 0.028(7) ± 0.001 | 0.028(9) ± 0.001 | 0.029(10) ± 0.001 |
| corel5k | 0.022(6) ± 0.000 | 0.022(7) ± 0.000 | 0.021(4) ± 0.000 | 0.021(5) ± 0.000 | 0.022(8) ± 0.000 | 0.021(3) ± 0.000 | 0.022(9) ± 0.000 | 0.021(2) ± 0.000 | 0.038(10) ± 0.001 | 0.021(1) ± 0.000 • |
| rcv1subset1 | 0.036(7) ± 0.000 | 0.039(10) ± 0.001 | 0.034(4) ± 0.000 | 0.036(6) ± 0.000 | 0.037(8) ± 0.000 | 0.034(5) ± 0.000 | 0.033(3) ± 0.000 | 0.033(2) ± 0.000 | 0.037(9) ± 0.001 | 0.032(1) ± 0.000 • |
| rcv1subset2 | 0.031(7) ± 0.000 | 0.032(9) ± 0.001 | 0.028(5) ± 0.000 | 0.030(6) ± 0.000 | 0.031(8) ± 0.000 | 0.028(3) ± 0.000 | 0.028(4) ± 0.000 | 0.028(2) ± 0.000 | 0.033(10) ± 0.001 | 0.027(1) ± 0.000 • |
| rcv1subset3 | 0.031(7) ± 0.001 | 0.033(10) ± 0.001 | 0.028(5) ± 0.000 | 0.030(6) ± 0.001 | 0.031(8) ± 0.000 | 0.028(3) ± 0.000 | 0.028(4) ± 0.000 | 0.028(2) ± 0.000 | 0.032(9) ± 0.001 | 0.027(1) ± 0.000 • |
| rcv1subset4 | 0.028(7) ± 0.000 | 0.030(10) ± 0.001 | 0.026(5) ± 0.000 | 0.027(6) ± 0.000 | 0.028(8) ± 0.000 | 0.025(4) ± 0.000 | 0.025(3) ± 0.000 | 0.025(2) ± 0.000 | 0.030(9) ± 0.000 | 0.024(1) ± 0.000 • |
| rcv1subset5 | 0.030(7) ± 0.000 | 0.033(10) ± 0.001 | 0.028(5) ± 0.000 | 0.029(6) ± 0.000 | 0.030(8) ± 0.000 | 0.027(3) ± 0.000 | 0.028(4) ± 0.000 | 0.027(2) ± 0.000 | 0.032(9) ± 0.000 | 0.027(1) ± 0.000 • |
| bibtex | 0.013(4) ± 0.000 | 0.013(7) ± 0.000 | 0.013(1) ± 0.000 • | 0.013(3) ± 0.000 | 0.013(6) ± 0.000 | 0.013(8) ± 0.000 | 0.013(5) ± 0.000 | 0.013(9) ± 0.000 | 0.026(10) ± 0.001 | 0.013(2) ± 0.000 |
| Arts | 0.061(7) ± 0.001 | 0.073(10) ± 0.001 | 0.058(1) ± 0.001 • | 0.059(2) ± 0.001 | 0.063(9) ± 0.001 | 0.061(6) ± 0.001 | 0.061(5) ± 0.000 | 0.061(8) ± 0.000 | 0.060(4) ± 0.000 | 0.059(3) ± 0.001 |
| Health | 0.053(3) ± 0.000 | 0.054(5) ± 0.001 | 0.049(1) ± 0.001 • | 0.050(2) ± 0.001 | 0.054(4) ± 0.001 | 0.061(10) ± 0.001 | 0.059(9) ± 0.001 | 0.059(8) ± 0.001 | 0.057(7) ± 0.001 | 0.055(6) ± 0.001 |
| Business | 0.032(8) ± 0.000 | 0.033(10) ± 0.001 | 0.030(1) ± 0.001 • | 0.031(2) ± 0.000 | 0.032(9) ± 0.001 | 0.032(7) ± 0.001 | 0.031(5) ± 0.001 | 0.032(6) ± 0.001 | 0.031(4) ± 0.001 | 0.031(3) ± 0.000 |
| Education | 0.049(8) ± 0.000 | 0.055(10) ± 0.001 | 0.045(1) ± 0.001 • | 0.046(2) ± 0.000 | 0.050(9) ± 0.001 | 0.047(6) ± 0.001 | 0.047(7) ± 0.001 | 0.047(5) ± 0.001 | 0.047(4) ± 0.001 | 0.046(3) ± 0.001 |
| Computers | 0.045(8) ± 0.000 | 0.049(10) ± 0.001 | 0.042(1) ± 0.000 • | 0.042(2) ± 0.000 | 0.046(9) ± 0.000 | 0.045(7) ± 0.000 | 0.044(5) ± 0.001 | 0.044(6) ± 0.000 | 0.044(4) ± 0.000 | 0.043(3) ± 0.000 |
| Entertainment | 0.062(4) ± 0.001 | 0.077(10) ± 0.001 | 0.058(1) ± 0.002 • | 0.058(2) ± 0.001 | 0.064(6) ± 0.001 | 0.064(9) ± 0.001 | 0.064(7) ± 0.001 | 0.064(8) ± 0.001 | 0.063(5) ± 0.001 | 0.061(3) ± 0.001 |
| Recreation | 0.052(5) ± 0.001 | 0.068(10) ± 0.001 | 0.049(1) ± 0.001 • | 0.050(2) ± 0.001 | 0.053(9) ± 0.001 | 0.053(8) ± 0.001 | 0.052(6) ± 0.001 | 0.052(7) ± 0.001 | 0.051(4) ± 0.001 | 0.050(3) ± 0.001 |
| Society | 0.054(8) ± 0.000 | 0.056(10) ± 0.001 | 0.052(3) ± 0.000 | 0.052(4) ± 0.000 | 0.055(9) ± 0.001 | 0.054(7) ± 0.001 | 0.053(5) ± 0.001 | 0.053(6) ± 0.001 | 0.052(2) ± 0.001 | 0.051(1) ± 0.001 • |
| eurlex-dc-l | 0.005(4) ± 0.000 | 0.005(6) ± 0.000 | 0.004(1) ± 0.000 • | 0.005(3) ± 0.000 | 0.005(5) ± 0.000 | 0.005(8) ± 0.000 | 0.005(7) ± 0.000 | 0.005(9) ± 0.000 | 0.010(10) ± 0.000 | 0.004(2) ± 0.000 |
| eurlex-sm | 0.011(4) ± 0.000 | 0.011(6) ± 0.000 | 0.010(1) ± 0.000 • | 0.010(2) ± 0.000 | 0.011(5) ± 0.000 | 0.012(8) ± 0.000 | 0.012(7) ± 0.000 | 0.012(9) ± 0.000 | 0.013(10) ± 0.000 | 0.011(3) ± 0.000 |
| tmc2007-500 | 0.064(4) ± 0.000 | 0.065(5) ± 0.001 | 0.055(2) ± 0.001 | 0.056(3) ± 0.000 | 0.066(8) ± 0.000 | 0.070(10) ± 0.001 | 0.067(9) ± 0.000 | 0.066(7) ± 0.000 | 0.065(6) ± 0.001 | 0.051(1) ± 0.000 • |
| mediamill | 0.035(8) ± 0.000 | 0.037(9) ± 0.000 | 0.030(2) ± 0.000 | 0.031(7) ± 0.000 | 0.038(10) ± 0.000 | 0.031(3) ± 0.000 | 0.031(5) ± 0.000 | 0.031(6) ± 0.000 | 0.031(4) ± 0.000 | 0.028(1) ± 0.000 • |
| average rank | 5.93 | 8.32 | 2.89 | 3.89 | 7.64 | 6.11 | 5.54 | 5.46 | 6.50 | 2.71 |
| win/tie/loss | 92/32/128 | 34/28/190 | 185/21/46 | 156/20/76 | 55/25/172 | 96/28/128 | 110/34/108 | 113/30/109 | 90/25/137 | 197/21/34 |
Appendix C. Experimental Results of Compared Hubness-Reduced MLC Approaches
| Dataset | AUC Micro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.736(4) ± 0.014 | 0.724(5) ± 0.021 | 0.754(1) ± 0.011 • | 0.738(3) ± 0.009 | 0.659(6) ± 0.013 | 0.565(7) ± 0.029 | 0.545(8) ± 0.014 | 0.532(9) ± 0.024 | 0.746(2) ± 0.019 |
| CAL500 | 0.749(2) ± 0.003 | 0.746(5) ± 0.003 | 0.749(4) ± 0.002 | 0.749(3) ± 0.003 | 0.713(6) ± 0.003 | 0.703(7) ± 0.003 | 0.703(8) ± 0.003 | 0.702(9) ± 0.003 | 0.757(1) ± 0.004 • |
| emotions | 0.852(4) ± 0.005 | 0.841(5) ± 0.008 | 0.861(2) ± 0.007 | 0.859(3) ± 0.007 | 0.747(6) ± 0.011 | 0.731(9) ± 0.015 | 0.734(7) ± 0.013 | 0.731(8) ± 0.013 | 0.862(1) ± 0.005 • |
| genbase | 0.993(4) ± 0.004 | 0.993(3) ± 0.004 | 0.994(2) ± 0.004 | 0.986(5) ± 0.004 | 0.970(6) ± 0.012 | 0.832(7) ± 0.043 | 0.831(8) ± 0.053 | 0.721(9) ± 0.042 | 0.996(1) ± 0.004 • |
| LLOG | 0.788(2) ± 0.005 | 0.782(3) ± 0.006 | 0.781(5) ± 0.004 | 0.782(3) ± 0.006 | 0.791(1) ± 0.002 • | 0.592(9) ± 0.040 | 0.604(8) ± 0.041 | 0.607(7) ± 0.037 | 0.767(6) ± 0.002 |
| enron | 0.801(5) ± 0.012 | 0.828(3) ± 0.005 | 0.830(2) ± 0.005 | 0.801(6) ± 0.007 | 0.825(4) ± 0.004 | 0.714(7) ± 0.005 | 0.711(8) ± 0.005 | 0.708(9) ± 0.006 | 0.860(1) ± 0.002 • |
| scene | 0.934(5) ± 0.003 | 0.943(4) ± 0.002 | 0.948(2) ± 0.002 | 0.948(3) ± 0.003 | 0.885(6) ± 0.004 | 0.868(9) ± 0.009 | 0.871(7) ± 0.009 | 0.870(8) ± 0.009 | 0.950(1) ± 0.002 • |
| yeast | 0.837(4) ± 0.003 | 0.827(5) ± 0.004 | 0.842(2) ± 0.003 | 0.842(3) ± 0.003 | 0.766(6) ± 0.004 | 0.734(9) ± 0.004 | 0.740(8) ± 0.005 | 0.740(7) ± 0.005 | 0.842(1) ± 0.004 • |
| Slashdot | 0.932(5) ± 0.008 | 0.935(3) ± 0.008 | 0.938(2) ± 0.004 | 0.935(4) ± 0.008 | 0.912(6) ± 0.009 | 0.880(9) ± 0.009 | 0.887(8) ± 0.012 | 0.890(7) ± 0.009 | 0.945(1) ± 0.004 • |
| corel5k | 0.713(6) ± 0.008 | 0.747(5) ± 0.008 | 0.752(4) ± 0.008 | 0.752(3) ± 0.009 | 0.772(2) ± 0.004 | 0.668(8) ± 0.005 | 0.668(7) ± 0.005 | 0.666(9) ± 0.004 | 0.796(1) ± 0.004 • |
| rcv1subset1 | 0.894(4) ± 0.004 | 0.911(2) ± 0.003 | 0.912(1) ± 0.003 • | 0.899(3) ± 0.004 | 0.866(6) ± 0.003 | 0.689(7) ± 0.006 | 0.687(8) ± 0.006 | 0.656(9) ± 0.008 | 0.874(5) ± 0.009 |
| rcv1subset2 | 0.895(4) ± 0.003 | 0.912(1) ± 0.003 • | 0.909(2) ± 0.004 | 0.898(3) ± 0.003 | 0.874(5) ± 0.003 | 0.672(8) ± 0.012 | 0.683(7) ± 0.015 | 0.636(9) ± 0.012 | 0.865(6) ± 0.010 |
| rcv1subset3 | 0.893(3) ± 0.003 | 0.908(2) ± 0.003 | 0.909(1) ± 0.006 • | 0.893(4) ± 0.004 | 0.871(5) ± 0.003 | 0.671(7) ± 0.006 | 0.670(8) ± 0.015 | 0.639(9) ± 0.012 | 0.861(6) ± 0.007 |
| rcv1subset4 | 0.906(4) ± 0.004 | 0.918(1) ± 0.003 • | 0.917(2) ± 0.004 | 0.909(3) ± 0.004 | 0.884(5) ± 0.002 | 0.703(8) ± 0.006 | 0.707(7) ± 0.006 | 0.671(9) ± 0.007 | 0.884(6) ± 0.010 |
| rcv1subset5 | 0.891(4) ± 0.003 | 0.907(1) ± 0.002 • | 0.904(2) ± 0.002 | 0.893(3) ± 0.003 | 0.871(5) ± 0.002 | 0.665(8) ± 0.006 | 0.690(7) ± 0.006 | 0.635(9) ± 0.007 | 0.868(6) ± 0.009 |
| bibtex | 0.838(5) ± 0.003 | 0.853(4) ± 0.003 | 0.864(1) ± 0.003 • | 0.853(3) ± 0.003 | 0.802(6) ± 0.004 | 0.489(9) ± 0.007 | 0.524(8) ± 0.006 | 0.541(7) ± 0.005 | 0.863(2) ± 0.006 |
| Arts | 0.818(4) ± 0.003 | 0.822(2) ± 0.004 | 0.819(3) ± 0.003 | 0.810(5) ± 0.004 | 0.713(6) ± 0.004 | 0.592(8) ± 0.006 | 0.603(7) ± 0.004 | 0.511(9) ± 0.015 | 0.851(1) ± 0.003 • |
| Health | 0.893(4) ± 0.004 | 0.896(2) ± 0.003 | 0.895(3) ± 0.002 | 0.884(5) ± 0.004 | 0.827(6) ± 0.004 | 0.717(8) ± 0.007 | 0.724(7) ± 0.003 | 0.546(9) ± 0.023 | 0.919(1) ± 0.002 • |
| Business | 0.927(4) ± 0.002 | 0.929(3) ± 0.002 | 0.930(2) ± 0.002 | 0.925(5) ± 0.002 | 0.908(6) ± 0.002 | 0.824(8) ± 0.005 | 0.825(7) ± 0.005 | 0.797(9) ± 0.007 | 0.947(1) ± 0.001 • |
| Education | 0.876(3) ± 0.002 | 0.876(2) ± 0.002 | 0.876(4) ± 0.002 | 0.868(5) ± 0.002 | 0.822(6) ± 0.003 | 0.744(9) ± 0.004 | 0.747(7) ± 0.003 | 0.746(8) ± 0.004 | 0.906(1) ± 0.002 • |
| Computers | 0.862(4) ± 0.003 | 0.865(2) ± 0.002 | 0.865(3) ± 0.003 | 0.853(5) ± 0.003 | 0.820(6) ± 0.003 | 0.695(8) ± 0.005 | 0.700(7) ± 0.004 | 0.582(9) ± 0.005 | 0.896(1) ± 0.003 • |
| Entertainment | 0.863(3) ± 0.002 | 0.865(2) ± 0.002 | 0.861(4) ± 0.003 | 0.854(5) ± 0.003 | 0.754(6) ± 0.004 | 0.637(8) ± 0.005 | 0.647(7) ± 0.006 | 0.481(9) ± 0.011 | 0.891(1) ± 0.002 • |
| Recreation | 0.839(4) ± 0.005 | 0.840(2) ± 0.005 | 0.839(3) ± 0.004 | 0.824(5) ± 0.004 | 0.697(6) ± 0.004 | 0.534(8) ± 0.010 | 0.541(7) ± 0.007 | 0.443(9) ± 0.013 | 0.874(1) ± 0.004 • |
| Society | 0.829(4) ± 0.003 | 0.830(2) ± 0.003 | 0.830(3) ± 0.002 | 0.823(5) ± 0.004 | 0.753(6) ± 0.004 | 0.646(7) ± 0.004 | 0.645(8) ± 0.004 | 0.553(9) ± 0.012 | 0.869(1) ± 0.002 • |
| eurlex-dc-l | 0.882(4) ± 0.004 | 0.884(2) ± 0.004 | 0.883(3) ± 0.003 | 0.872(6) ± 0.003 | 0.875(5) ± 0.003 | 0.603(7) ± 0.006 | 0.603(8) ± 0.005 | 0.267(9) ± 0.008 | 0.919(1) ± 0.005 • |
| eurlex-sm | 0.919(4) ± 0.002 | 0.921(2) ± 0.002 | 0.920(3) ± 0.002 | 0.914(6) ± 0.002 | 0.917(5) ± 0.002 | 0.704(7) ± 0.005 | 0.699(8) ± 0.005 | 0.692(9) ± 0.004 | 0.952(1) ± 0.002 • |
| tmc2007-500 | 0.928(4) ± 0.001 | 0.939(2) ± 0.001 | 0.937(3) ± 0.001 | 0.925(5) ± 0.001 | 0.891(6) ± 0.002 | 0.783(7) ± 0.004 | 0.775(8) ± 0.004 | 0.733(9) ± 0.011 | 0.958(1) ± 0.001 • |
| mediamill | 0.930(6) ± 0.001 | 0.932(3) ± 0.001 | 0.933(2) ± 0.001 | 0.932(4) ± 0.001 | 0.930(5) ± 0.000 | 0.862(7) ± 0.001 | 0.862(8) ± 0.001 | 0.861(9) ± 0.001 | 0.957(1) ± 0.001 • |
| average rank | 4.04 | 2.80 | 2.54 | 4.16 | 5.36 | 7.86 | 7.54 | 8.61 | 2.11 |
| win/tie/loss | 132/16/76 | 162/16/46 | 171/24/29 | 129/19/76 | 99/3/122 | 25/18/181 | 29/21/174 | 4/13/207 | 187/10/27 |
| Dataset | Ranking Loss | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.317(4) ± 0.020 | 0.325(5) ± 0.022 | 0.292(2) ± 0.016 | 0.310(3) ± 0.014 | 0.345(6) ± 0.018 | 0.441(7) ± 0.030 | 0.462(8) ± 0.017 | 0.469(9) ± 0.026 | 0.251(1) ± 0.020 • |
| CAL500 | 0.282(2) ± 0.003 | 0.285(6) ± 0.004 | 0.282(4) ± 0.003 | 0.282(3) ± 0.003 | 0.284(5) ± 0.003 | 0.293(7) ± 0.003 | 0.294(8) ± 0.002 | 0.294(9) ± 0.003 | 0.240(1) ± 0.005 • |
| emotions | 0.184(4) ± 0.011 | 0.201(5) ± 0.014 | 0.175(2) ± 0.009 | 0.176(3) ± 0.009 | 0.241(6) ± 0.015 | 0.256(9) ± 0.018 | 0.252(7) ± 0.014 | 0.255(8) ± 0.018 | 0.153(1) ± 0.007 • |
| genbase | 0.016(4) ± 0.006 | 0.015(2) ± 0.005 | 0.015(3) ± 0.005 | 0.028(6) ± 0.006 | 0.026(5) ± 0.010 | 0.155(7) ± 0.045 | 0.155(8) ± 0.053 | 0.245(9) ± 0.044 | 0.004(1) ± 0.003 • |
| LLOG | 0.229(3) ± 0.005 | 0.235(4) ± 0.008 | 0.235(6) ± 0.009 | 0.235(4) ± 0.008 | 0.186(1) ± 0.002 • | 0.388(9) ± 0.045 | 0.336(7) ± 0.027 | 0.343(8) ± 0.032 | 0.187(2) ± 0.002 |
| enron | 0.260(6) ± 0.018 | 0.218(4) ± 0.007 | 0.217(3) ± 0.008 | 0.255(5) ± 0.009 | 0.165(2) ± 0.005 | 0.285(7) ± 0.003 | 0.287(8) ± 0.006 | 0.290(9) ± 0.006 | 0.135(1) ± 0.003 • |
| scene | 0.102(5) ± 0.005 | 0.091(4) ± 0.004 | 0.085(2) ± 0.004 | 0.085(3) ± 0.005 | 0.121(6) ± 0.004 | 0.138(8) ± 0.011 | 0.138(9) ± 0.011 | 0.138(7) ± 0.010 | 0.071(1) ± 0.003 • |
| yeast | 0.191(4) ± 0.003 | 0.198(5) ± 0.004 | 0.186(3) ± 0.002 | 0.186(2) ± 0.003 | 0.234(6) ± 0.004 | 0.262(8) ± 0.005 | 0.261(7) ± 0.005 | 0.262(9) ± 0.005 | 0.168(1) ± 0.003 • |
| Slashdot | 0.084(6) ± 0.011 | 0.076(4) ± 0.013 | 0.071(3) ± 0.007 | 0.077(5) ± 0.013 | 0.066(2) ± 0.008 | 0.091(9) ± 0.009 | 0.087(7) ± 0.010 | 0.087(8) ± 0.006 | 0.047(1) ± 0.005 • |
| corel5k | 0.452(9) ± 0.011 | 0.408(8) ± 0.015 | 0.400(7) ± 0.014 | 0.399(6) ± 0.017 | 0.228(2) ± 0.003 | 0.331(4) ± 0.005 | 0.330(3) ± 0.005 | 0.332(5) ± 0.004 | 0.206(1) ± 0.004 • |
| rcv1subset1 | 0.143(6) ± 0.005 | 0.119(3) ± 0.004 | 0.119(2) ± 0.004 | 0.137(5) ± 0.006 | 0.120(4) ± 0.003 | 0.301(7) ± 0.008 | 0.304(8) ± 0.007 | 0.342(9) ± 0.008 | 0.118(1) ± 0.008 • |
| rcv1subset2 | 0.141(6) ± 0.005 | 0.117(2) ± 0.004 | 0.122(4) ± 0.006 | 0.136(5) ± 0.004 | 0.112(1) ± 0.002 • | 0.314(8) ± 0.015 | 0.302(7) ± 0.018 | 0.354(9) ± 0.016 | 0.118(3) ± 0.009 |
| rcv1subset3 | 0.147(6) ± 0.004 | 0.124(4) ± 0.004 | 0.124(3) ± 0.008 | 0.145(5) ± 0.004 | 0.115(1) ± 0.001 • | 0.313(7) ± 0.007 | 0.314(8) ± 0.012 | 0.347(9) ± 0.012 | 0.122(2) ± 0.005 |
| rcv1subset4 | 0.125(6) ± 0.006 | 0.108(3) ± 0.005 | 0.110(4) ± 0.006 | 0.121(5) ± 0.006 | 0.100(1) ± 0.001 • | 0.267(8) ± 0.007 | 0.262(7) ± 0.007 | 0.299(9) ± 0.007 | 0.100(2) ± 0.009 |
| rcv1subset5 | 0.150(6) ± 0.006 | 0.127(3) ± 0.004 | 0.131(4) ± 0.004 | 0.146(5) ± 0.005 | 0.115(1) ± 0.002 • | 0.317(8) ± 0.006 | 0.291(7) ± 0.006 | 0.349(9) ± 0.007 | 0.117(2) ± 0.009 |
| bibtex | 0.282(6) ± 0.006 | 0.256(4) ± 0.007 | 0.240(3) ± 0.007 | 0.257(5) ± 0.007 | 0.197(2) ± 0.005 | 0.493(9) ± 0.007 | 0.456(8) ± 0.006 | 0.447(7) ± 0.006 | 0.147(1) ± 0.004 • |
| Arts | 0.206(4) ± 0.004 | 0.202(2) ± 0.004 | 0.204(3) ± 0.004 | 0.216(5) ± 0.004 | 0.266(6) ± 0.004 | 0.407(8) ± 0.008 | 0.396(7) ± 0.005 | 0.506(9) ± 0.017 | 0.129(1) ± 0.003 • |
| Health | 0.125(4) ± 0.004 | 0.121(2) ± 0.003 | 0.122(3) ± 0.002 | 0.137(5) ± 0.004 | 0.146(6) ± 0.005 | 0.249(8) ± 0.007 | 0.242(7) ± 0.003 | 0.460(9) ± 0.026 | 0.070(1) ± 0.002 • |
| Business | 0.081(5) ± 0.003 | 0.079(4) ± 0.003 | 0.076(3) ± 0.002 | 0.084(6) ± 0.004 | 0.066(2) ± 0.001 | 0.126(8) ± 0.004 | 0.123(7) ± 0.004 | 0.146(9) ± 0.005 | 0.037(1) ± 0.001 • |
| Education | 0.156(3) ± 0.003 | 0.156(2) ± 0.002 | 0.156(4) ± 0.002 | 0.167(6) ± 0.003 | 0.162(5) ± 0.002 | 0.251(9) ± 0.004 | 0.249(8) ± 0.003 | 0.249(7) ± 0.004 | 0.089(1) ± 0.002 • |
| Computers | 0.166(5) ± 0.003 | 0.160(3) ± 0.003 | 0.162(4) ± 0.003 | 0.174(6) ± 0.005 | 0.144(2) ± 0.004 | 0.253(8) ± 0.005 | 0.245(7) ± 0.004 | 0.390(9) ± 0.006 | 0.086(1) ± 0.002 • |
| Entertainment | 0.174(3) ± 0.003 | 0.171(2) ± 0.002 | 0.175(4) ± 0.004 | 0.183(5) ± 0.005 | 0.224(6) ± 0.003 | 0.345(8) ± 0.005 | 0.338(7) ± 0.005 | 0.530(9) ± 0.011 | 0.111(1) ± 0.002 • |
| Recreation | 0.197(4) ± 0.006 | 0.194(2) ± 0.006 | 0.194(3) ± 0.005 | 0.212(5) ± 0.005 | 0.277(6) ± 0.005 | 0.462(8) ± 0.013 | 0.453(7) ± 0.008 | 0.577(9) ± 0.014 | 0.115(1) ± 0.004 • |
| Society | 0.189(4) ± 0.004 | 0.187(2) ± 0.004 | 0.188(3) ± 0.004 | 0.196(5) ± 0.005 | 0.216(6) ± 0.004 | 0.335(8) ± 0.004 | 0.334(7) ± 0.006 | 0.457(9) ± 0.013 | 0.105(1) ± 0.002 • |
| eurlex-dc-l | 0.206(5) ± 0.006 | 0.204(3) ± 0.006 | 0.206(4) ± 0.005 | 0.224(6) ± 0.005 | 0.118(2) ± 0.003 | 0.377(7) ± 0.005 | 0.378(8) ± 0.004 | 0.735(9) ± 0.009 | 0.078(1) ± 0.005 • |
| eurlex-sm | 0.138(5) ± 0.003 | 0.136(3) ± 0.003 | 0.137(4) ± 0.003 | 0.146(6) ± 0.003 | 0.084(2) ± 0.001 | 0.317(7) ± 0.005 | 0.323(8) ± 0.004 | 0.330(9) ± 0.004 | 0.050(1) ± 0.002 • |
| tmc2007-500 | 0.092(4) ± 0.001 | 0.077(2) ± 0.001 | 0.081(3) ± 0.001 | 0.095(5) ± 0.001 | 0.105(6) ± 0.001 | 0.209(7) ± 0.003 | 0.217(8) ± 0.004 | 0.255(9) ± 0.010 | 0.044(1) ± 0.001 • |
| mediamill | 0.092(6) ± 0.001 | 0.087(3) ± 0.001 | 0.088(4) ± 0.001 | 0.088(5) ± 0.001 | 0.059(2) ± 0.000 | 0.120(7) ± 0.002 | 0.120(8) ± 0.001 | 0.121(9) ± 0.001 | 0.038(1) ± 0.001 • |
| average rank | 4.82 | 3.45 | 3.46 | 4.84 | 3.64 | 7.68 | 7.36 | 8.54 | 1.21 |
| win/tie/loss | 106/21/97 | 141/24/59 | 143/29/52 | 105/20/99 | 143/12/69 | 27/20/177 | 34/24/166 | 8/17/199 | 212/11/1 |
| Dataset | F1 Macro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.034(9) ± 0.019 | 0.058(7) ± 0.024 | 0.072(6) ± 0.019 | 0.052(8) ± 0.018 | 0.157(2) ± 0.027 | 0.118(3) ± 0.022 | 0.092(4) ± 0.034 | 0.082(5) ± 0.027 | 0.258(1) ± 0.069 • |
| CAL500 | 0.083(5) ± 0.002 | 0.075(9) ± 0.004 | 0.083(2) ± 0.002 | 0.083(4) ± 0.003 | 0.103(1) ± 0.003 • | 0.080(6) ± 0.005 | 0.080(8) ± 0.005 | 0.080(7) ± 0.004 | 0.083(3) ± 0.003 |
| emotions | 0.608(4) ± 0.011 | 0.544(9) ± 0.009 | 0.626(2) ± 0.011 | 0.624(3) ± 0.013 | 0.602(7) ± 0.023 | 0.604(5) ± 0.023 | 0.595(8) ± 0.024 | 0.603(6) ± 0.020 | 0.651(1) ± 0.013 • |
| genbase | 0.639(8) ± 0.058 | 0.648(7) ± 0.062 | 0.649(6) ± 0.059 | 0.567(9) ± 0.054 | 0.913(2) ± 0.030 | 0.743(3) ± 0.063 | 0.740(4) ± 0.083 | 0.701(5) ± 0.097 | 0.954(1) ± 0.017 • |
| LLOG | 0.141(1) ± 0.012 • | 0.115(5) ± 0.024 | 0.118(3) ± 0.028 | 0.115(5) ± 0.024 | 0.116(4) ± 0.005 | 0.124(2) ± 0.013 | 0.095(9) ± 0.017 | 0.103(7) ± 0.017 | 0.097(8) ± 0.016 |
| enron | 0.067(8) ± 0.008 | 0.084(7) ± 0.008 | 0.090(6) ± 0.006 | 0.067(9) ± 0.008 | 0.131(2) ± 0.007 | 0.100(4) ± 0.009 | 0.101(3) ± 0.005 | 0.092(5) ± 0.007 | 0.131(1) ± 0.009 • |
| scene | 0.643(9) ± 0.015 | 0.664(8) ± 0.010 | 0.696(7) ± 0.010 | 0.699(6) ± 0.011 | 0.726(5) ± 0.007 | 0.738(3) ± 0.012 | 0.739(2) ± 0.012 | 0.734(4) ± 0.009 | 0.749(1) ± 0.008 • |
| yeast | 0.347(6) ± 0.006 | 0.285(9) ± 0.009 | 0.344(8) ± 0.006 | 0.344(7) ± 0.006 | 0.385(2) ± 0.010 | 0.356(3) ± 0.010 | 0.356(5) ± 0.010 | 0.356(4) ± 0.008 | 0.420(1) ± 0.009 • |
| Slashdot | 0.081(8) ± 0.002 | 0.090(7) ± 0.014 | 0.097(6) ± 0.017 | 0.080(9) ± 0.001 | 0.149(2) ± 0.036 | 0.115(5) ± 0.026 | 0.117(4) ± 0.026 | 0.126(3) ± 0.016 | 0.163(1) ± 0.025 • |
| corel5k | 0.001(9) ± 0.001 | 0.006(8) ± 0.001 | 0.007(7) ± 0.001 | 0.007(6) ± 0.001 | 0.038(1) ± 0.006 • | 0.016(4) ± 0.003 | 0.016(5) ± 0.003 | 0.017(3) ± 0.003 | 0.026(2) ± 0.004 |
| rcv1subset1 | 0.074(9) ± 0.006 | 0.091(7) ± 0.005 | 0.097(6) ± 0.006 | 0.078(8) ± 0.004 | 0.181(1) ± 0.010 • | 0.145(4) ± 0.006 | 0.145(3) ± 0.004 | 0.136(5) ± 0.006 | 0.152(2) ± 0.014 |
| rcv1subset2 | 0.067(9) ± 0.003 | 0.077(7) ± 0.003 | 0.083(6) ± 0.003 | 0.073(8) ± 0.002 | 0.173(1) ± 0.011 • | 0.125(3) ± 0.005 | 0.123(4) ± 0.008 | 0.111(5) ± 0.006 | 0.133(2) ± 0.015 |
| rcv1subset3 | 0.060(9) ± 0.001 | 0.074(7) ± 0.002 | 0.081(6) ± 0.010 | 0.067(8) ± 0.003 | 0.164(1) ± 0.006 • | 0.120(3) ± 0.008 | 0.124(2) ± 0.012 | 0.111(5) ± 0.008 | 0.120(4) ± 0.010 |
| rcv1subset4 | 0.081(9) ± 0.005 | 0.094(7) ± 0.006 | 0.099(6) ± 0.006 | 0.086(8) ± 0.005 | 0.178(1) ± 0.008 • | 0.135(3) ± 0.008 | 0.132(4) ± 0.010 | 0.128(5) ± 0.009 | 0.149(2) ± 0.013 |
| rcv1subset5 | 0.069(9) ± 0.003 | 0.075(7) ± 0.004 | 0.081(6) ± 0.003 | 0.072(8) ± 0.004 | 0.163(1) ± 0.006 • | 0.117(3) ± 0.011 | 0.107(5) ± 0.003 | 0.107(4) ± 0.008 | 0.134(2) ± 0.017 |
| bibtex | 0.060(9) ± 0.002 | 0.069(8) ± 0.004 | 0.090(6) ± 0.005 | 0.079(7) ± 0.004 | 0.148(2) ± 0.006 | 0.122(4) ± 0.006 | 0.131(3) ± 0.005 | 0.112(5) ± 0.003 | 0.187(1) ± 0.006 • |
| Arts | 0.140(7) ± 0.010 | 0.140(6) ± 0.011 | 0.148(5) ± 0.010 | 0.112(8) ± 0.011 | 0.223(2) ± 0.013 | 0.188(3) ± 0.009 | 0.178(4) ± 0.015 | 0.004(9) ± 0.006 | 0.263(1) ± 0.015 • |
| Health | 0.269(7) ± 0.016 | 0.278(5) ± 0.015 | 0.278(6) ± 0.011 | 0.216(8) ± 0.012 | 0.360(2) ± 0.019 | 0.336(3) ± 0.009 | 0.311(4) ± 0.017 | 0.026(9) ± 0.003 | 0.404(1) ± 0.011 • |
| Business | 0.141(7) ± 0.008 | 0.147(6) ± 0.010 | 0.154(5) ± 0.010 | 0.124(8) ± 0.007 | 0.239(2) ± 0.010 | 0.192(3) ± 0.010 | 0.172(4) ± 0.011 | 0.039(9) ± 0.001 | 0.267(1) ± 0.005 • |
| Education | 0.145(6) ± 0.008 | 0.146(5) ± 0.008 | 0.144(7) ± 0.008 | 0.114(9) ± 0.012 | 0.220(2) ± 0.009 | 0.167(3) ± 0.012 | 0.164(4) ± 0.014 | 0.137(8) ± 0.009 | 0.278(1) ± 0.015 • |
| Computers | 0.142(7) ± 0.011 | 0.144(6) ± 0.012 | 0.160(5) ± 0.008 | 0.121(8) ± 0.011 | 0.255(2) ± 0.014 | 0.201(3) ± 0.015 | 0.182(4) ± 0.012 | 0.023(9) ± 0.002 | 0.294(1) ± 0.010 • |
| Entertainment | 0.257(7) ± 0.008 | 0.260(6) ± 0.008 | 0.263(5) ± 0.007 | 0.215(8) ± 0.011 | 0.347(2) ± 0.012 | 0.304(3) ± 0.013 | 0.285(4) ± 0.012 | 0.006(9) ± 0.008 | 0.390(1) ± 0.008 • |
| Recreation | 0.240(7) ± 0.022 | 0.247(6) ± 0.018 | 0.254(5) ± 0.018 | 0.191(8) ± 0.016 | 0.352(2) ± 0.014 | 0.315(3) ± 0.015 | 0.297(4) ± 0.024 | 0.002(9) ± 0.003 | 0.390(1) ± 0.016 • |
| Society | 0.158(7) ± 0.008 | 0.161(6) ± 0.008 | 0.164(5) ± 0.008 | 0.117(8) ± 0.013 | 0.246(2) ± 0.010 | 0.230(3) ± 0.013 | 0.216(4) ± 0.013 | 0.021(9) ± 0.003 | 0.291(1) ± 0.012 • |
| eurlex-dc-l | 0.148(3) ± 0.003 | 0.147(4) ± 0.004 | 0.145(5) ± 0.003 | 0.118(8) ± 0.005 | 0.177(2) ± 0.005 | 0.140(6) ± 0.004 | 0.132(7) ± 0.004 | 0.001(9) ± 0.001 | 0.267(1) ± 0.010 • |
| eurlex-sm | 0.252(5) ± 0.005 | 0.253(4) ± 0.005 | 0.250(6) ± 0.005 | 0.234(8) ± 0.004 | 0.296(2) ± 0.007 | 0.259(3) ± 0.004 | 0.248(7) ± 0.006 | 0.232(9) ± 0.006 | 0.388(1) ± 0.009 • |
| tmc2007-500 | 0.239(9) ± 0.004 | 0.289(7) ± 0.002 | 0.291(6) ± 0.004 | 0.248(8) ± 0.006 | 0.464(2) ± 0.010 | 0.443(3) ± 0.009 | 0.429(4) ± 0.005 | 0.395(5) ± 0.008 | 0.603(1) ± 0.007 • |
| mediamill | 0.085(6) ± 0.002 | 0.055(9) ± 0.002 | 0.084(8) ± 0.001 | 0.085(7) ± 0.002 | 0.137(2) ± 0.006 | 0.103(3) ± 0.005 | 0.100(4) ± 0.003 | 0.095(5) ± 0.003 | 0.293(1) ± 0.005 • |
| average rank | 7.11 | 6.77 | 5.61 | 7.48 | 2.11 | 3.46 | 4.54 | 6.32 | 1.61 |
| win/tie/loss | 41/22/161 | 53/20/151 | 78/31/115 | 31/22/171 | 190/10/24 | 137/30/57 | 111/39/74 | 58/34/132 | 196/18/10 |
| Dataset | F1 micro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.074(9) ± 0.042 | 0.130(7) ± 0.058 | 0.159(5) ± 0.034 | 0.112(8) ± 0.037 | 0.230(2) ± 0.050 | 0.205(3) ± 0.035 | 0.164(4) ± 0.054 | 0.146(6) ± 0.045 | 0.358(1) ± 0.061 • |
| CAL500 | 0.321(6) ± 0.006 | 0.311(9) ± 0.007 | 0.316(8) ± 0.005 | 0.317(7) ± 0.006 | 0.338(2) ± 0.009 | 0.330(3) ± 0.009 | 0.327(5) ± 0.009 | 0.330(4) ± 0.009 | 0.342(1) ± 0.014 • |
| emotions | 0.635(6) ± 0.013 | 0.592(9) ± 0.013 | 0.654(2) ± 0.013 | 0.652(3) ± 0.014 | 0.629(8) ± 0.020 | 0.641(4) ± 0.019 | 0.629(7) ± 0.028 | 0.639(5) ± 0.015 | 0.672(1) ± 0.011 • |
| genbase | 0.839(7) ± 0.040 | 0.846(6) ± 0.040 | 0.850(5) ± 0.036 | 0.779(9) ± 0.035 | 0.949(2) ± 0.020 | 0.851(4) ± 0.037 | 0.855(3) ± 0.046 | 0.819(8) ± 0.047 | 0.965(1) ± 0.014 • |
| LLOG | 0.466(1) ± 0.023 • | 0.394(4) ± 0.062 | 0.407(3) ± 0.063 | 0.394(4) ± 0.062 | 0.427(2) ± 0.013 | 0.360(7) ± 0.028 | 0.327(9) ± 0.053 | 0.351(8) ± 0.039 | 0.363(6) ± 0.059 |
| enron | 0.219(8) ± 0.022 | 0.314(7) ± 0.016 | 0.321(6) ± 0.014 | 0.219(9) ± 0.027 | 0.476(1) ± 0.011 • | 0.458(3) ± 0.017 | 0.453(4) ± 0.013 | 0.414(5) ± 0.021 | 0.460(2) ± 0.013 |
| scene | 0.649(9) ± 0.011 | 0.663(8) ± 0.009 | 0.696(7) ± 0.009 | 0.700(6) ± 0.009 | 0.720(5) ± 0.007 | 0.734(3) ± 0.011 | 0.736(2) ± 0.011 | 0.730(4) ± 0.008 | 0.743(1) ± 0.008 • |
| yeast | 0.628(6) ± 0.004 | 0.585(9) ± 0.007 | 0.627(8) ± 0.004 | 0.627(7) ± 0.005 | 0.635(5) ± 0.006 | 0.638(2) ± 0.004 | 0.637(4) ± 0.005 | 0.637(3) ± 0.005 | 0.643(1) ± 0.006 • |
| Slashdot | 0.843(4) ± 0.007 | 0.843(3) ± 0.007 | 0.844(1) ± 0.007 • | 0.843(6) ± 0.008 | 0.843(2) ± 0.011 | 0.833(8) ± 0.014 | 0.832(9) ± 0.012 | 0.835(7) ± 0.009 | 0.843(5) ± 0.008 |
| corel5k | 0.003(9) ± 0.003 | 0.020(8) ± 0.007 | 0.026(7) ± 0.007 | 0.027(6) ± 0.010 | 0.094(1) ± 0.013 • | 0.031(3) ± 0.008 | 0.028(5) ± 0.007 | 0.030(4) ± 0.005 | 0.050(2) ± 0.011 |
| rcv1subset1 | 0.203(9) ± 0.007 | 0.240(7) ± 0.004 | 0.246(6) ± 0.005 | 0.209(8) ± 0.005 | 0.345(1) ± 0.011 • | 0.299(3) ± 0.014 | 0.306(2) ± 0.011 | 0.286(5) ± 0.010 | 0.296(4) ± 0.021 |
| rcv1subset2 | 0.275(8) ± 0.008 | 0.288(7) ± 0.007 | 0.295(6) ± 0.006 | 0.274(9) ± 0.005 | 0.367(1) ± 0.016 • | 0.329(3) ± 0.011 | 0.327(4) ± 0.012 | 0.314(5) ± 0.012 | 0.334(2) ± 0.012 |
| rcv1subset3 | 0.258(9) ± 0.007 | 0.281(7) ± 0.007 | 0.290(6) ± 0.016 | 0.263(8) ± 0.009 | 0.362(1) ± 0.013 • | 0.324(4) ± 0.010 | 0.326(3) ± 0.019 | 0.318(5) ± 0.014 | 0.333(2) ± 0.009 |
| rcv1subset4 | 0.336(9) ± 0.007 | 0.355(7) ± 0.006 | 0.359(6) ± 0.006 | 0.339(8) ± 0.005 | 0.430(1) ± 0.007 • | 0.396(2) ± 0.010 | 0.392(4) ± 0.015 | 0.387(5) ± 0.012 | 0.394(3) ± 0.019 |
| rcv1subset5 | 0.284(8) ± 0.010 | 0.297(7) ± 0.009 | 0.299(6) ± 0.008 | 0.280(9) ± 0.007 | 0.369(1) ± 0.009 • | 0.341(3) ± 0.014 | 0.329(4) ± 0.011 | 0.321(5) ± 0.011 | 0.348(2) ± 0.014 |
| bibtex | 0.241(9) ± 0.006 | 0.252(8) ± 0.006 | 0.295(5) ± 0.006 | 0.272(7) ± 0.006 | 0.328(2) ± 0.004 | 0.312(4) ± 0.004 | 0.323(3) ± 0.008 | 0.292(6) ± 0.007 | 0.367(1) ± 0.006 • |
| Arts | 0.263(7) ± 0.016 | 0.267(5) ± 0.017 | 0.267(6) ± 0.016 | 0.234(8) ± 0.020 | 0.340(2) ± 0.017 | 0.310(3) ± 0.015 | 0.299(4) ± 0.021 | 0.012(9) ± 0.020 | 0.369(1) ± 0.014 • |
| Health | 0.491(7) ± 0.012 | 0.502(5) ± 0.013 | 0.502(6) ± 0.012 | 0.463(8) ± 0.013 | 0.531(2) ± 0.017 | 0.525(3) ± 0.011 | 0.519(4) ± 0.014 | 0.258(9) ± 0.059 | 0.574(1) ± 0.011 • |
| Business | 0.705(7) ± 0.005 | 0.707(4) ± 0.005 | 0.705(6) ± 0.004 | 0.696(8) ± 0.005 | 0.714(2) ± 0.006 | 0.708(3) ± 0.004 | 0.705(5) ± 0.004 | 0.670(9) ± 0.004 | 0.722(1) ± 0.004 • |
| Education | 0.288(7) ± 0.012 | 0.290(5) ± 0.011 | 0.290(6) ± 0.011 | 0.254(9) ± 0.012 | 0.357(2) ± 0.013 | 0.310(3) ± 0.014 | 0.301(4) ± 0.016 | 0.267(8) ± 0.018 | 0.378(1) ± 0.014 • |
| Computers | 0.468(4) ± 0.004 | 0.463(7) ± 0.004 | 0.463(6) ± 0.003 | 0.446(8) ± 0.013 | 0.490(2) ± 0.008 | 0.480(3) ± 0.006 | 0.466(5) ± 0.009 | 0.362(9) ± 0.033 | 0.511(1) ± 0.005 • |
| Entertainment | 0.400(7) ± 0.009 | 0.407(5) ± 0.010 | 0.405(6) ± 0.009 | 0.349(8) ± 0.011 | 0.472(2) ± 0.014 | 0.457(3) ± 0.011 | 0.435(4) ± 0.008 | 0.021(9) ± 0.032 | 0.505(1) ± 0.008 • |
| Recreation | 0.345(7) ± 0.018 | 0.350(6) ± 0.018 | 0.357(5) ± 0.016 | 0.285(8) ± 0.018 | 0.428(2) ± 0.017 | 0.411(3) ± 0.015 | 0.399(4) ± 0.016 | 0.005(9) ± 0.009 | 0.454(1) ± 0.012 • |
| Society | 0.385(7) ± 0.014 | 0.389(5) ± 0.012 | 0.386(6) ± 0.011 | 0.354(8) ± 0.016 | 0.433(2) ± 0.010 | 0.430(3) ± 0.014 | 0.412(4) ± 0.014 | 0.236(9) ± 0.047 | 0.468(1) ± 0.010 • |
| eurlex-dc-l | 0.390(3) ± 0.003 | 0.390(4) ± 0.003 | 0.389(5) ± 0.004 | 0.333(8) ± 0.009 | 0.401(2) ± 0.006 | 0.370(6) ± 0.005 | 0.359(7) ± 0.005 | 0.026(9) ± 0.027 | 0.479(1) ± 0.007 • |
| eurlex-sm | 0.504(6) ± 0.006 | 0.506(4) ± 0.006 | 0.505(5) ± 0.005 | 0.490(8) ± 0.003 | 0.533(2) ± 0.006 | 0.516(3) ± 0.005 | 0.502(7) ± 0.007 | 0.489(9) ± 0.005 | 0.589(1) ± 0.007 • |
| tmc2007-500 | 0.577(8) ± 0.003 | 0.606(7) ± 0.003 | 0.607(6) ± 0.003 | 0.574(9) ± 0.006 | 0.634(5) ± 0.006 | 0.658(2) ± 0.004 | 0.652(3) ± 0.005 | 0.635(4) ± 0.006 | 0.726(1) ± 0.003 • |
| mediamill | 0.573(6) ± 0.002 | 0.548(9) ± 0.002 | 0.571(7) ± 0.002 | 0.571(8) ± 0.002 | 0.583(2) ± 0.004 | 0.577(3) ± 0.003 | 0.575(4) ± 0.003 | 0.574(5) ± 0.005 | 0.635(1) ± 0.001 • |
| average rank | 6.89 | 6.41 | 5.61 | 7.59 | 2.29 | 3.46 | 4.54 | 6.54 | 1.68 |
| win/tie/loss | 46/25/153 | 59/26/139 | 78/36/110 | 30/26/168 | 175/23/26 | 129/44/51 | 103/47/74 | 53/38/133 | 190/25/9 |
| Dataset | Hamming Loss | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.144(7) ± 0.007 | 0.141(3) ± 0.006 | 0.139(2) ± 0.006 | 0.142(5) ± 0.006 | 0.145(8) ± 0.007 | 0.141(4) ± 0.007 | 0.144(6) ± 0.009 | 0.146(9) ± 0.009 | 0.137(1) ± 0.008 • |
| CAL500 | 0.187(3) ± 0.002 | 0.187(2) ± 0.001 | 0.188(5) ± 0.001 | 0.188(4) ± 0.001 | 0.192(9) ± 0.001 | 0.189(7) ± 0.001 | 0.189(6) ± 0.001 | 0.189(8) ± 0.002 | 0.187(1) ± 0.001 • |
| emotions | 0.198(4) ± 0.007 | 0.216(9) ± 0.007 | 0.192(2) ± 0.007 | 0.193(3) ± 0.009 | 0.211(8) ± 0.006 | 0.203(5) ± 0.010 | 0.207(7) ± 0.010 | 0.203(6) ± 0.006 | 0.190(1) ± 0.005 • |
| genbase | 0.026(7) ± 0.007 | 0.024(6) ± 0.006 | 0.024(5) ± 0.006 | 0.035(9) ± 0.006 | 0.009(2) ± 0.003 | 0.023(4) ± 0.005 | 0.022(3) ± 0.006 | 0.027(8) ± 0.006 | 0.006(1) ± 0.002 • |
| LLOG | 0.192(3) ± 0.004 | 0.195(5) ± 0.005 | 0.193(4) ± 0.006 | 0.195(5) ± 0.005 | 0.185(1) ± 0.004 • | 0.253(9) ± 0.037 | 0.215(8) ± 0.021 | 0.213(7) ± 0.021 | 0.188(2) ± 0.006 |
| enron | 0.090(8) ± 0.001 | 0.085(7) ± 0.002 | 0.085(6) ± 0.002 | 0.090(9) ± 0.001 | 0.080(4) ± 0.001 | 0.079(2) ± 0.001 | 0.079(3) ± 0.001 | 0.082(5) ± 0.001 | 0.075(1) ± 0.001 • |
| scene | 0.103(9) ± 0.003 | 0.097(8) ± 0.002 | 0.091(6) ± 0.002 | 0.090(5) ± 0.003 | 0.092(7) ± 0.002 | 0.087(3) ± 0.003 | 0.086(2) ± 0.002 | 0.087(4) ± 0.003 | 0.084(1) ± 0.003 • |
| yeast | 0.199(6) ± 0.003 | 0.208(9) ± 0.002 | 0.197(1) ± 0.002 • | 0.197(3) ± 0.003 | 0.204(8) ± 0.002 | 0.197(2) ± 0.003 | 0.198(4) ± 0.002 | 0.198(5) ± 0.002 | 0.200(7) ± 0.003 |
| Slashdot | 0.028(4) ± 0.001 | 0.028(3) ± 0.001 | 0.028(1) ± 0.001 • | 0.028(5) ± 0.001 | 0.028(2) ± 0.002 | 0.030(7) ± 0.003 | 0.030(9) ± 0.003 | 0.030(8) ± 0.002 | 0.029(6) ± 0.001 |
| corel5k | 0.021(4) ± 0.000 | 0.021(6) ± 0.000 | 0.021(8) ± 0.000 | 0.021(7) ± 0.000 | 0.022(9) ± 0.000 | 0.021(3) ± 0.000 | 0.021(2) ± 0.000 | 0.021(5) ± 0.000 | 0.021(1) ± 0.000 • |
| rcv1subset1 | 0.034(9) ± 0.000 | 0.033(2) ± 0.000 | 0.033(5) ± 0.000 | 0.034(8) ± 0.000 | 0.033(6) ± 0.000 | 0.033(3) ± 0.000 | 0.033(4) ± 0.000 | 0.033(7) ± 0.000 | 0.032(1) ± 0.000 • |
| rcv1subset2 | 0.028(7) ± 0.000 | 0.028(3) ± 0.000 | 0.028(2) ± 0.000 | 0.028(5) ± 0.000 | 0.028(9) ± 0.000 | 0.028(6) ± 0.000 | 0.028(4) ± 0.000 | 0.028(8) ± 0.000 | 0.027(1) ± 0.000 • |
| rcv1subset3 | 0.028(8) ± 0.000 | 0.027(3) ± 0.000 | 0.027(2) ± 0.000 | 0.028(4) ± 0.000 | 0.028(9) ± 0.000 | 0.028(6) ± 0.000 | 0.028(5) ± 0.000 | 0.028(7) ± 0.000 | 0.027(1) ± 0.000 • |
| rcv1subset4 | 0.025(9) ± 0.000 | 0.025(2) ± 0.000 | 0.025(3) ± 0.000 | 0.025(7) ± 0.000 | 0.025(8) ± 0.000 | 0.025(4) ± 0.000 | 0.025(6) ± 0.000 | 0.025(5) ± 0.000 | 0.024(1) ± 0.000 • |
| rcv1subset5 | 0.027(7) ± 0.000 | 0.027(2) ± 0.000 | 0.027(3) ± 0.000 | 0.027(4) ± 0.000 | 0.028(9) ± 0.000 | 0.027(5) ± 0.000 | 0.027(6) ± 0.000 | 0.027(8) ± 0.000 | 0.027(1) ± 0.000 • |
| bibtex | 0.013(9) ± 0.000 | 0.013(8) ± 0.000 | 0.013(1) ± 0.000 • | 0.013(5) ± 0.000 | 0.013(6) ± 0.000 | 0.013(4) ± 0.000 | 0.013(3) ± 0.000 | 0.013(7) ± 0.000 | 0.013(2) ± 0.000 |
| Arts | 0.061(5) ± 0.001 | 0.061(4) ± 0.001 | 0.061(7) ± 0.001 | 0.063(8) ± 0.001 | 0.061(3) ± 0.000 | 0.060(2) ± 0.001 | 0.061(5) ± 0.001 | 0.069(9) ± 0.001 | 0.059(1) ± 0.001 • |
| Health | 0.061(7) ± 0.001 | 0.060(6) ± 0.001 | 0.060(5) ± 0.001 | 0.065(8) ± 0.001 | 0.059(4) ± 0.001 | 0.058(2) ± 0.001 | 0.058(3) ± 0.001 | 0.079(9) ± 0.002 | 0.055(1) ± 0.001 • |
| Business | 0.032(7) ± 0.001 | 0.031(5) ± 0.001 | 0.031(4) ± 0.000 | 0.033(8) ± 0.001 | 0.031(2) ± 0.001 | 0.031(3) ± 0.001 | 0.032(6) ± 0.001 | 0.034(9) ± 0.001 | 0.031(1) ± 0.000 • |
| Education | 0.047(6) ± 0.001 | 0.047(4) ± 0.000 | 0.047(5) ± 0.000 | 0.049(9) ± 0.001 | 0.047(7) ± 0.001 | 0.047(2) ± 0.000 | 0.047(3) ± 0.001 | 0.048(8) ± 0.000 | 0.046(1) ± 0.001 • |
| Computers | 0.045(7) ± 0.000 | 0.045(6) ± 0.000 | 0.044(4) ± 0.000 | 0.046(8) ± 0.000 | 0.044(3) ± 0.001 | 0.044(2) ± 0.000 | 0.045(5) ± 0.000 | 0.055(9) ± 0.002 | 0.043(1) ± 0.000 • |
| Entertainment | 0.064(5) ± 0.001 | 0.064(4) ± 0.001 | 0.065(6) ± 0.001 | 0.067(8) ± 0.001 | 0.064(3) ± 0.001 | 0.063(2) ± 0.001 | 0.065(7) ± 0.001 | 0.083(9) ± 0.002 | 0.061(1) ± 0.001 • |
| Recreation | 0.053(7) ± 0.001 | 0.053(6) ± 0.001 | 0.053(5) ± 0.001 | 0.055(8) ± 0.001 | 0.052(3) ± 0.001 | 0.051(2) ± 0.001 | 0.052(4) ± 0.001 | 0.065(9) ± 0.000 | 0.050(1) ± 0.001 • |
| Society | 0.054(7) ± 0.001 | 0.053(5) ± 0.001 | 0.053(6) ± 0.000 | 0.055(8) ± 0.001 | 0.053(3) ± 0.001 | 0.052(2) ± 0.000 | 0.053(4) ± 0.001 | 0.063(9) ± 0.002 | 0.051(1) ± 0.001 • |
| eurlex-dc-l | 0.005(4) ± 0.000 | 0.005(3) ± 0.000 | 0.005(5) ± 0.000 | 0.005(8) ± 0.000 | 0.005(2) ± 0.000 | 0.005(6) ± 0.000 | 0.005(7) ± 0.000 | 0.006(9) ± 0.000 | 0.004(1) ± 0.000 • |
| eurlex-sm | 0.012(6) ± 0.000 | 0.012(4) ± 0.000 | 0.012(5) ± 0.000 | 0.012(8) ± 0.000 | 0.012(3) ± 0.000 | 0.012(2) ± 0.000 | 0.012(7) ± 0.000 | 0.012(9) ± 0.000 | 0.011(1) ± 0.000 • |
| tmc2007-500 | 0.070(8) ± 0.001 | 0.066(4) ± 0.000 | 0.067(5) ± 0.001 | 0.070(9) ± 0.001 | 0.067(7) ± 0.000 | 0.063(2) ± 0.001 | 0.064(3) ± 0.000 | 0.067(6) ± 0.001 | 0.051(1) ± 0.000 • |
| mediamill | 0.031(7) ± 0.000 | 0.031(9) ± 0.000 | 0.030(4) ± 0.000 | 0.030(6) ± 0.000 | 0.031(8) ± 0.000 | 0.030(2) ± 0.000 | 0.030(3) ± 0.000 | 0.030(5) ± 0.000 | 0.028(1) ± 0.000 • |
| average rank | 6.45 | 4.95 | 4.18 | 6.59 | 5.46 | 3.68 | 4.84 | 7.39 | 1.46 |
| win/tie/loss | 50/46/128 | 92/44/88 | 109/47/68 | 53/36/135 | 80/34/110 | 118/49/57 | 89/56/79 | 34/38/152 | 200/16/8 |
| Metric | # Algorithms | # Datasets | Critical Value | |
|---|---|---|---|---|
| AUC macro | 203.401 | 9 | 28 | 1.981 |
| AUC micro | 181.614 | |||
| Ranking Loss | 172.663 | |||
| F1 macro | 143.012 | |||
| F1 micro | 134.357 | |||
| Hamming Loss | 95.295 |
| AUC micro | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 0.998 | 1.000 | 0.219 | 1.83 | 3.73 | 3.73 | 3.73 | 0.998 |
| BRkNNa-dsl | 0.002 | - | 0.868 | 0.008 | 4.10 | 3.73 | 3.73 | 3.73 | 0.959 |
| BRkNNa-ls | 6.47 | 0.137 | - | 1.23 | 2.05 | 3.73 | 3.73 | 3.73 | 0.925 |
| BRkNNa-mp | 0.788 | 0.992 | 1.000 | - | 5.52 | 3.73 | 3.73 | 3.73 | 0.998 |
| MLKNN | 1.000 | 1.000 | 1.000 | 1.000 | - | 3.73 | 3.73 | 3.73 | 1.000 |
| MLKNN-dsl | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 0.984 | 2.63 | 1.000 |
| MLKNN-ls | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.017 | - | 1.03 | 1.000 |
| MLKNN-mp | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 1.000 |
| MLHiKNN | 0.002 | 0.043 | 0.078 | 0.002 | 1.14 | 3.73 | 3.73 | 3.73 | - |
| Ranking Loss | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 0.999 | 1.000 | 0.315 | 0.842 | 2.61 | 3.28 | 2.05 | 1.000 |
| BRkNNa-dsl | 0.001 | - | 0.593 | 0.002 | 0.558 | 1.23 | 1.23 | 1.23 | 1.000 |
| BRkNNa-ls | 3.37 | 0.416 | - | 5.10 | 0.478 | 7.08 | 7.08 | 3.73 | 1.000 |
| BRkNNa-mp | 0.693 | 0.998 | 1.000 | - | 0.836 | 7.08 | 7.08 | 7.08 | 1.000 |
| MLKNN | 0.164 | 0.451 | 0.531 | 0.169 | - | 3.73 | 3.73 | 3.73 | 1.000 |
| MLKNN-dsl | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 0.984 | 2.63 | 1.000 |
| MLKNN-ls | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.017 | - | 1.14 | 1.000 |
| MLKNN-mp | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 1.000 |
| MLHiKNN | 3.73 | 1.86 | 3.73 | 3.73 | 7.71 | 3.73 | 3.73 | 3.73 | - |
| F1 Macro | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 0.976 | 1.000 | 0.066 | 1.000 | 1.000 | 1.000 | 0.407 | 1.000 |
| BRkNNa-dsl | 0.025 | - | 1.000 | 0.016 | 1.000 | 1.000 | 1.000 | 0.442 | 1.000 |
| BRkNNa-ls | 4.66 | 2.00 | - | 3.28 | 1.000 | 1.000 | 1.000 | 0.284 | 1.000 |
| BRkNNa-mp | 0.937 | 0.984 | 1.000 | - | 1.000 | 1.000 | 1.000 | 0.513 | 1.000 |
| MLKNN | 2.61 | 3.73 | 2.61 | 1.86 | - | 5.22 | 1.12 | 1.86 | 0.999 |
| MLKNN-dsl | 4.10 | 1.86 | 3.28 | 7.08 | 1.000 | - | 5.29 | 6.30 | 1.000 |
| MLKNN-ls | 8.83 | 3.28 | 2.76 | 6.30 | 1.000 | 1.000 | - | 2.76 | 1.000 |
| MLKNN-mp | 0.602 | 0.567 | 0.724 | 0.496 | 1.000 | 1.000 | 1.000 | - | 1.000 |
| MLHiKNN | 2.61 | 1.12 | 2.61 | 1.12 | 0.001 | 1.60 | 1.86 | 1.12 | - |
| F1 Micro | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 0.972 | 1.000 | 0.037 | 1.000 | 1.000 | 1.000 | 0.299 | 1.000 |
| BRkNNa-dsl | 0.030 | - | 1.000 | 0.010 | 1.000 | 1.000 | 1.000 | 0.315 | 1.000 |
| BRkNNa-ls | 5.32 | 1.37 | - | 5.10 | 1.000 | 1.000 | 0.999 | 0.066 | 1.000 |
| BRkNNa-mp | 0.965 | 0.990 | 1.000 | - | 1.000 | 1.000 | 1.000 | 0.433 | 1.000 |
| MLKNN | 2.61 | 3.73 | 1.60 | 7.08 | - | 1.83 | 2.00 | 6.30 | 0.965 |
| MLKNN-dsl | 3.60 | 3.37 | 9.68 | 9.42 | 1.000 | - | 1.09 | 2.61 | 1.000 |
| MLKNN-ls | 2.92 | 1.09 | 9.34 | 2.11 | 1.000 | 1.000 | - | 2.76 | 1.000 |
| MLKNN-mp | 0.709 | 0.693 | 0.937 | 0.576 | 1.000 | 1.000 | 1.000 | - | 1.000 |
| MLHiKNN | 1.67 | 5.22 | 1.60 | 7.08 | 0.037 | 3.73 | 7.08 | 3.73 | - |
| Hamming Loss | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 0.994 | 1.000 | 0.105 | 0.940 | 0.997 | 0.973 | 0.014 | 1.000 |
| BRkNNa-dsl | 0.007 | - | 0.955 | 0.008 | 0.903 | 0.982 | 0.794 | 0.007 | 1.000 |
| BRkNNa-ls | 1.91 | 0.047 | - | 3.37 | 0.261 | 0.836 | 0.323 | 2.42 | 1.000 |
| BRkNNa-mp | 0.899 | 0.992 | 1.000 | - | 0.877 | 0.996 | 0.975 | 0.010 | 1.000 |
| MLKNN | 0.063 | 0.101 | 0.746 | 0.127 | - | 0.998 | 0.907 | 0.030 | 1.000 |
| MLKNN-dsl | 0.004 | 0.019 | 0.169 | 0.004 | 0.002 | - | 0.009 | 5.52 | 1.000 |
| MLKNN-ls | 0.028 | 0.212 | 0.685 | 0.027 | 0.097 | 0.992 | - | 1.09 | 1.000 |
| MLKNN-mp | 0.987 | 0.994 | 1.000 | 0.990 | 0.972 | 1.000 | 1.000 | - | 1.000 |
| MLHiKNN | 7.08 | 1.86 | 5.52 | 9.42 | 2.38 | 2.00 | 4.10 | 2.05 | - |
Appendix D. Results of Ablation Analysis Experiments
| Dataset | AUC Micro | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.737(5) ± 0.022 | 0.743(4) ± 0.025 | 0.744(3) ± 0.018 | 0.737(6) ± 0.015 | 0.784(1) ± 0.019 • | 0.746(2) ± 0.019 |
| CAL500 | 0.751(5) ± 0.007 | 0.722(6) ± 0.010 | 0.759(2) ± 0.004 | 0.758(3) ± 0.003 | 0.764(1) ± 0.002 • | 0.757(4) ± 0.004 |
| emotions | 0.862(1) ± 0.005 • | 0.854(6) ± 0.006 | 0.862(2) ± 0.005 | 0.859(4) ± 0.007 | 0.858(5) ± 0.006 | 0.862(3) ± 0.005 |
| genbase | 0.995(6) ± 0.004 | 0.996(5) ± 0.004 | 0.997(3) ± 0.003 | 0.997(2) ± 0.004 | 0.999(1) ± 0.001 • | 0.996(4) ± 0.004 |
| LLOG | 0.764(6) ± 0.005 | 0.767(5) ± 0.002 | 0.767(2) ± 0.002 | 0.767(4) ± 0.002 | 0.798(1) ± 0.004 • | 0.767(3) ± 0.002 |
| enron | 0.859(4) ± 0.003 | 0.847(6) ± 0.005 | 0.857(5) ± 0.002 | 0.859(3) ± 0.004 | 0.868(1) ± 0.004 • | 0.860(2) ± 0.002 |
| scene | 0.950(1) ± 0.003 • | 0.948(6) ± 0.002 | 0.948(4) ± 0.002 | 0.949(3) ± 0.002 | 0.948(5) ± 0.002 | 0.950(2) ± 0.002 |
| yeast | 0.841(4) ± 0.004 | 0.829(6) ± 0.005 | 0.842(3) ± 0.004 | 0.840(5) ± 0.003 | 0.843(1) ± 0.003 • | 0.842(2) ± 0.004 |
| Slashdot | 0.938(6) ± 0.006 | 0.944(4) ± 0.003 | 0.944(5) ± 0.004 | 0.948(2) ± 0.004 | 0.949(1) ± 0.005 • | 0.945(3) ± 0.004 |
| corel5k | 0.791(5) ± 0.004 | 0.781(6) ± 0.005 | 0.796(3) ± 0.003 | 0.795(4) ± 0.003 | 0.802(1) ± 0.004 • | 0.796(2) ± 0.004 |
| rcv1subset1 | 0.859(6) ± 0.007 | 0.905(2) ± 0.003 | 0.871(5) ± 0.008 | 0.872(4) ± 0.009 | 0.931(1) ± 0.002 • | 0.874(3) ± 0.009 |
| rcv1subset2 | 0.843(6) ± 0.008 | 0.906(2) ± 0.004 | 0.863(5) ± 0.008 | 0.870(3) ± 0.012 | 0.933(1) ± 0.004 • | 0.865(4) ± 0.010 |
| rcv1subset3 | 0.835(6) ± 0.006 | 0.897(2) ± 0.005 | 0.860(5) ± 0.009 | 0.864(3) ± 0.008 | 0.930(1) ± 0.002 • | 0.861(4) ± 0.007 |
| rcv1subset4 | 0.866(6) ± 0.007 | 0.917(2) ± 0.003 | 0.886(4) ± 0.005 | 0.889(3) ± 0.009 | 0.938(1) ± 0.002 • | 0.884(5) ± 0.010 |
| rcv1subset5 | 0.847(6) ± 0.007 | 0.902(2) ± 0.003 | 0.866(5) ± 0.008 | 0.871(3) ± 0.007 | 0.931(1) ± 0.002 • | 0.868(4) ± 0.009 |
| bibtex | 0.820(6) ± 0.008 | 0.869(2) ± 0.004 | 0.860(4) ± 0.006 | 0.859(5) ± 0.005 | 0.883(1) ± 0.004 • | 0.863(3) ± 0.006 |
| Arts | 0.838(6) ± 0.003 | 0.849(4) ± 0.003 | 0.851(3) ± 0.003 | 0.851(2) ± 0.003 | 0.849(5) ± 0.003 | 0.851(1) ± 0.003 • |
| Health | 0.912(6) ± 0.002 | 0.916(5) ± 0.002 | 0.918(3) ± 0.002 | 0.918(2) ± 0.002 | 0.917(4) ± 0.002 | 0.919(1) ± 0.002 • |
| Business | 0.939(6) ± 0.002 | 0.946(4) ± 0.002 | 0.947(2) ± 0.001 | 0.948(1) ± 0.001 • | 0.945(5) ± 0.001 | 0.947(3) ± 0.001 |
| Education | 0.899(6) ± 0.002 | 0.905(4) ± 0.002 | 0.906(3) ± 0.002 | 0.906(2) ± 0.002 | 0.903(5) ± 0.002 | 0.906(1) ± 0.002 • |
| Computers | 0.884(6) ± 0.005 | 0.892(4) ± 0.004 | 0.895(3) ± 0.003 | 0.895(2) ± 0.003 | 0.891(5) ± 0.002 | 0.896(1) ± 0.003 • |
| Entertainment | 0.880(6) ± 0.001 | 0.889(4) ± 0.002 | 0.890(3) ± 0.002 | 0.890(2) ± 0.002 | 0.886(5) ± 0.002 | 0.891(1) ± 0.002 • |
| Recreation | 0.854(6) ± 0.004 | 0.873(3) ± 0.004 | 0.873(4) ± 0.004 | 0.875(1) ± 0.004 • | 0.868(5) ± 0.004 | 0.874(2) ± 0.004 |
| Society | 0.861(5) ± 0.002 | 0.864(4) ± 0.004 | 0.868(2) ± 0.002 | 0.868(3) ± 0.002 | 0.860(6) ± 0.002 | 0.869(1) ± 0.002 • |
| eurlex-dc-l | 0.904(6) ± 0.005 | 0.915(3) ± 0.004 | 0.919(1) ± 0.005 • | 0.905(5) ± 0.006 | 0.909(4) ± 0.003 | 0.919(2) ± 0.005 |
| eurlex-sm | 0.948(3) ± 0.001 | 0.945(5) ± 0.002 | 0.952(2) ± 0.002 | 0.946(4) ± 0.002 | 0.943(6) ± 0.002 | 0.952(1) ± 0.002 • |
| tmc2007-500 | 0.956(3) ± 0.001 | 0.949(6) ± 0.001 | 0.956(4) ± 0.001 | 0.952(5) ± 0.001 | 0.956(2) ± 0.001 | 0.958(1) ± 0.001 • |
| mediamill | 0.958(1) ± 0.001 • | 0.948(6) ± 0.001 | 0.957(3) ± 0.000 | 0.951(5) ± 0.001 | 0.954(4) ± 0.001 | 0.957(2) ± 0.001 |
| average rank | 4.96 | 4.21 | 3.32 | 3.25 | 2.86 | 2.39 |
| win/tie/loss | 19/23/98 | 42/22/76 | 55/46/39 | 54/41/45 | 81/13/46 | 76/41/23 |
| Dataset | Ranking Loss | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.269(6) ± 0.025 | 0.253(3) ± 0.029 | 0.256(4) ± 0.019 | 0.262(5) ± 0.018 | 0.217(1) ± 0.023 • | 0.251(2) ± 0.020 |
| CAL500 | 0.246(5) ± 0.008 | 0.275(6) ± 0.010 | 0.239(2) ± 0.004 | 0.239(3) ± 0.003 | 0.233(1) ± 0.002 • | 0.240(4) ± 0.005 |
| emotions | 0.154(3) ± 0.007 | 0.160(5) ± 0.007 | 0.152(1) ± 0.007 • | 0.156(4) ± 0.010 | 0.161(6) ± 0.009 | 0.153(2) ± 0.007 |
| genbase | 0.005(5) ± 0.003 | 0.006(6) ± 0.003 | 0.004(1) ± 0.002 • | 0.004(2) ± 0.003 | 0.004(3) ± 0.002 | 0.004(4) ± 0.003 |
| LLOG | 0.190(5) ± 0.005 | 0.187(4) ± 0.003 | 0.187(1) ± 0.002 • | 0.187(3) ± 0.002 | 0.195(6) ± 0.003 | 0.187(2) ± 0.002 |
| enron | 0.136(4) ± 0.004 | 0.143(6) ± 0.005 | 0.139(5) ± 0.003 | 0.135(3) ± 0.005 | 0.124(1) ± 0.003 • | 0.135(2) ± 0.003 |
| scene | 0.071(1) ± 0.004 • | 0.074(5) ± 0.002 | 0.073(4) ± 0.003 | 0.072(3) ± 0.003 | 0.074(6) ± 0.003 | 0.071(2) ± 0.003 |
| yeast | 0.168(2) ± 0.003 | 0.180(6) ± 0.004 | 0.168(4) ± 0.003 | 0.170(5) ± 0.003 | 0.167(1) ± 0.003 • | 0.168(3) ± 0.003 |
| Slashdot | 0.051(6) ± 0.005 | 0.048(4) ± 0.003 | 0.048(5) ± 0.004 | 0.044(2) ± 0.004 | 0.042(1) ± 0.005 • | 0.047(3) ± 0.005 |
| corel5k | 0.211(5) ± 0.004 | 0.218(6) ± 0.005 | 0.206(3) ± 0.004 | 0.207(4) ± 0.004 | 0.173(1) ± 0.004 • | 0.206(2) ± 0.004 |
| rcv1subset1 | 0.132(6) ± 0.007 | 0.087(2) ± 0.003 | 0.121(5) ± 0.007 | 0.119(4) ± 0.008 | 0.058(1) ± 0.001 • | 0.118(3) ± 0.008 |
| rcv1subset2 | 0.139(6) ± 0.007 | 0.081(2) ± 0.004 | 0.120(5) ± 0.008 | 0.115(3) ± 0.010 | 0.054(1) ± 0.002 • | 0.118(4) ± 0.009 |
| rcv1subset3 | 0.145(6) ± 0.004 | 0.089(2) ± 0.003 | 0.123(5) ± 0.007 | 0.120(3) ± 0.008 | 0.056(1) ± 0.001 • | 0.122(4) ± 0.005 |
| rcv1subset4 | 0.113(6) ± 0.006 | 0.071(2) ± 0.002 | 0.099(4) ± 0.005 | 0.095(3) ± 0.008 | 0.048(1) ± 0.002 • | 0.100(5) ± 0.009 |
| rcv1subset5 | 0.135(6) ± 0.008 | 0.087(2) ± 0.002 | 0.118(5) ± 0.008 | 0.114(3) ± 0.006 | 0.055(1) ± 0.001 • | 0.117(4) ± 0.009 |
| bibtex | 0.184(6) ± 0.006 | 0.136(2) ± 0.004 | 0.150(4) ± 0.004 | 0.150(5) ± 0.003 | 0.092(1) ± 0.002 • | 0.147(3) ± 0.004 |
| Arts | 0.140(6) ± 0.003 | 0.131(5) ± 0.003 | 0.130(4) ± 0.003 | 0.129(3) ± 0.003 | 0.128(1) ± 0.002 • | 0.129(2) ± 0.003 |
| Health | 0.077(6) ± 0.001 | 0.072(5) ± 0.002 | 0.071(4) ± 0.002 | 0.070(2) ± 0.002 | 0.070(3) ± 0.002 | 0.070(1) ± 0.002 • |
| Business | 0.042(6) ± 0.001 | 0.037(4) ± 0.001 | 0.037(2) ± 0.001 | 0.036(1) ± 0.001 • | 0.038(5) ± 0.001 | 0.037(3) ± 0.001 |
| Education | 0.095(6) ± 0.002 | 0.091(5) ± 0.002 | 0.090(3) ± 0.002 | 0.089(1) ± 0.002 • | 0.090(4) ± 0.002 | 0.089(2) ± 0.002 |
| Computers | 0.093(6) ± 0.003 | 0.089(5) ± 0.002 | 0.086(2) ± 0.002 | 0.087(3) ± 0.002 | 0.087(4) ± 0.002 | 0.086(1) ± 0.002 • |
| Entertainment | 0.119(6) ± 0.002 | 0.114(4) ± 0.003 | 0.113(3) ± 0.003 | 0.112(2) ± 0.002 | 0.114(5) ± 0.002 | 0.111(1) ± 0.002 • |
| Recreation | 0.129(6) ± 0.004 | 0.116(3) ± 0.004 | 0.117(4) ± 0.004 | 0.115(1) ± 0.004 • | 0.118(5) ± 0.004 | 0.115(2) ± 0.004 |
| Society | 0.112(6) ± 0.003 | 0.110(4) ± 0.004 | 0.106(2) ± 0.002 | 0.107(3) ± 0.002 | 0.110(5) ± 0.002 | 0.105(1) ± 0.002 • |
| eurlex-dc-l | 0.092(6) ± 0.004 | 0.081(3) ± 0.004 | 0.078(1) ± 0.005 • | 0.090(4) ± 0.005 | 0.090(5) ± 0.004 | 0.078(2) ± 0.005 |
| eurlex-sm | 0.055(3) ± 0.001 | 0.056(5) ± 0.002 | 0.050(2) ± 0.002 | 0.056(6) ± 0.002 | 0.056(4) ± 0.001 | 0.050(1) ± 0.002 • |
| tmc2007-500 | 0.048(5) ± 0.001 | 0.050(6) ± 0.001 | 0.046(2) ± 0.001 | 0.047(4) ± 0.001 | 0.047(3) ± 0.001 | 0.044(1) ± 0.001 • |
| mediamill | 0.037(1) ± 0.001 • | 0.044(6) ± 0.001 | 0.038(3) ± 0.001 | 0.043(5) ± 0.000 | 0.040(4) ± 0.000 | 0.038(2) ± 0.001 |
| average rank | 5.04 | 4.21 | 3.21 | 3.21 | 2.89 | 2.43 |
| win/tie/loss | 17/23/100 | 40/20/80 | 53/46/41 | 56/42/42 | 78/23/39 | 78/42/20 |
| Dataset | F1 Macro | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.217(5) ± 0.074 | 0.348(1) ± 0.043 • | 0.269(2) ± 0.052 | 0.236(4) ± 0.066 | 0.161(6) ± 0.018 | 0.258(3) ± 0.069 |
| CAL500 | 0.071(6) ± 0.004 | 0.129(1) ± 0.006 • | 0.081(4) ± 0.004 | 0.083(2) ± 0.004 | 0.075(5) ± 0.003 | 0.083(3) ± 0.003 |
| emotions | 0.641(5) ± 0.012 | 0.643(4) ± 0.017 | 0.646(2) ± 0.017 | 0.645(3) ± 0.018 | 0.617(6) ± 0.010 | 0.651(1) ± 0.013 • |
| genbase | 0.969(2) ± 0.014 | 0.927(6) ± 0.018 | 0.957(3) ± 0.019 | 0.970(1) ± 0.013 • | 0.950(5) ± 0.008 | 0.954(4) ± 0.017 |
| LLOG | 0.091(6) ± 0.016 | 0.094(4) ± 0.013 | 0.102(2) ± 0.013 | 0.094(5) ± 0.018 | 0.114(1) ± 0.015 • | 0.097(3) ± 0.016 |
| enron | 0.125(5) ± 0.014 | 0.163(1) ± 0.008 • | 0.120(6) ± 0.006 | 0.128(4) ± 0.008 | 0.155(2) ± 0.009 | 0.131(3) ± 0.009 |
| scene | 0.748(2) ± 0.009 | 0.744(5) ± 0.006 | 0.744(4) ± 0.007 | 0.746(3) ± 0.009 | 0.602(6) ± 0.015 | 0.749(1) ± 0.008 • |
| yeast | 0.371(5) ± 0.010 | 0.435(1) ± 0.008 • | 0.418(3) ± 0.008 | 0.416(4) ± 0.006 | 0.322(6) ± 0.004 | 0.420(2) ± 0.009 |
| Slashdot | 0.156(4) ± 0.028 | 0.144(6) ± 0.019 | 0.152(5) ± 0.027 | 0.179(2) ± 0.032 | 0.182(1) ± 0.017 • | 0.163(3) ± 0.025 |
| corel5k | 0.020(5) ± 0.003 | 0.064(1) ± 0.006 • | 0.028(2) ± 0.004 | 0.025(4) ± 0.004 | 0.016(6) ± 0.004 | 0.026(3) ± 0.004 |
| rcv1subset1 | 0.122(5) ± 0.011 | 0.260(1) ± 0.005 • | 0.149(4) ± 0.011 | 0.154(2) ± 0.012 | 0.114(6) ± 0.008 | 0.152(3) ± 0.014 |
| rcv1subset2 | 0.100(6) ± 0.009 | 0.259(1) ± 0.007 • | 0.129(4) ± 0.013 | 0.143(2) ± 0.022 | 0.112(5) ± 0.005 | 0.133(3) ± 0.015 |
| rcv1subset3 | 0.085(6) ± 0.007 | 0.215(1) ± 0.013 • | 0.114(4) ± 0.010 | 0.126(2) ± 0.008 | 0.097(5) ± 0.005 | 0.120(3) ± 0.010 |
| rcv1subset4 | 0.109(6) ± 0.008 | 0.249(1) ± 0.011 • | 0.147(4) ± 0.009 | 0.158(2) ± 0.013 | 0.118(5) ± 0.005 | 0.149(3) ± 0.013 |
| rcv1subset5 | 0.096(6) ± 0.013 | 0.237(1) ± 0.008 • | 0.130(4) ± 0.015 | 0.140(2) ± 0.012 | 0.108(5) ± 0.003 | 0.134(3) ± 0.017 |
| bibtex | 0.139(5) ± 0.006 | 0.234(1) ± 0.006 • | 0.182(4) ± 0.006 | 0.189(2) ± 0.005 | 0.084(6) ± 0.003 | 0.187(3) ± 0.006 |
| Arts | 0.193(5) ± 0.014 | 0.292(1) ± 0.011 • | 0.260(4) ± 0.018 | 0.271(2) ± 0.013 | 0.170(6) ± 0.013 | 0.263(3) ± 0.015 |
| Health | 0.353(5) ± 0.012 | 0.414(1) ± 0.011 • | 0.399(4) ± 0.011 | 0.407(2) ± 0.015 | 0.309(6) ± 0.012 | 0.404(3) ± 0.011 |
| Business | 0.198(5) ± 0.014 | 0.303(1) ± 0.010 • | 0.266(4) ± 0.005 | 0.289(2) ± 0.011 | 0.180(6) ± 0.008 | 0.267(3) ± 0.005 |
| Education | 0.210(5) ± 0.016 | 0.305(1) ± 0.012 • | 0.274(4) ± 0.016 | 0.283(2) ± 0.011 | 0.182(6) ± 0.011 | 0.278(3) ± 0.015 |
| Computers | 0.228(5) ± 0.018 | 0.322(1) ± 0.015 • | 0.292(4) ± 0.012 | 0.307(2) ± 0.015 | 0.217(6) ± 0.012 | 0.294(3) ± 0.010 |
| Entertainment | 0.325(5) ± 0.010 | 0.398(1) ± 0.011 • | 0.382(4) ± 0.009 | 0.385(3) ± 0.010 | 0.297(6) ± 0.006 | 0.390(2) ± 0.008 |
| Recreation | 0.309(6) ± 0.014 | 0.414(1) ± 0.013 • | 0.382(4) ± 0.018 | 0.407(2) ± 0.014 | 0.310(5) ± 0.017 | 0.390(3) ± 0.016 |
| Society | 0.232(5) ± 0.010 | 0.305(1) ± 0.009 • | 0.285(4) ± 0.012 | 0.298(2) ± 0.013 | 0.204(6) ± 0.011 | 0.291(3) ± 0.012 |
| eurlex-dc-l | 0.240(4) ± 0.006 | 0.266(3) ± 0.008 | 0.267(2) ± 0.011 | 0.233(5) ± 0.008 | 0.194(6) ± 0.003 | 0.267(1) ± 0.010 • |
| eurlex-sm | 0.367(4) ± 0.007 | 0.377(3) ± 0.007 | 0.387(2) ± 0.007 | 0.353(5) ± 0.007 | 0.303(6) ± 0.006 | 0.388(1) ± 0.009 • |
| tmc2007-500 | 0.601(2) ± 0.006 | 0.526(5) ± 0.008 | 0.590(3) ± 0.009 | 0.553(4) ± 0.007 | 0.484(6) ± 0.008 | 0.603(1) ± 0.007 • |
| mediamill | 0.285(3) ± 0.012 | 0.235(4) ± 0.008 | 0.294(1) ± 0.004 • | 0.184(5) ± 0.005 | 0.117(6) ± 0.003 | 0.293(2) ± 0.005 |
| average rank | 4.75 | 2.11 | 3.46 | 2.86 | 5.25 | 2.57 |
| win/tie/loss | 29/21/90 | 105/14/21 | 56/32/52 | 71/26/43 | 19/4/117 | 75/33/32 |
| Dataset | F1 Micro | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.317(5) ± 0.091 | 0.414(1) ± 0.035 • | 0.361(2) ± 0.072 | 0.323(4) ± 0.080 | 0.245(6) ± 0.024 | 0.358(3) ± 0.061 |
| CAL500 | 0.329(6) ± 0.015 | 0.356(1) ± 0.008 • | 0.336(4) ± 0.014 | 0.342(3) ± 0.014 | 0.330(5) ± 0.008 | 0.342(2) ± 0.014 |
| emotions | 0.666(4) ± 0.013 | 0.661(5) ± 0.013 | 0.668(2) ± 0.015 | 0.666(3) ± 0.015 | 0.650(6) ± 0.011 | 0.672(1) ± 0.011 • |
| genbase | 0.976(1) ± 0.011 • | 0.947(6) ± 0.010 | 0.968(3) ± 0.015 | 0.974(2) ± 0.009 | 0.963(5) ± 0.012 | 0.965(4) ± 0.014 |
| LLOG | 0.343(6) ± 0.064 | 0.357(4) ± 0.051 | 0.382(2) ± 0.043 | 0.350(5) ± 0.068 | 0.415(1) ± 0.037 • | 0.363(3) ± 0.059 |
| enron | 0.457(4) ± 0.013 | 0.488(1) ± 0.010 • | 0.446(5) ± 0.013 | 0.472(2) ± 0.010 | 0.437(6) ± 0.005 | 0.460(3) ± 0.013 |
| scene | 0.743(2) ± 0.009 | 0.737(5) ± 0.007 | 0.738(4) ± 0.007 | 0.740(3) ± 0.009 | 0.613(6) ± 0.012 | 0.743(1) ± 0.008 • |
| yeast | 0.644(1) ± 0.004 • | 0.630(5) ± 0.007 | 0.641(3) ± 0.007 | 0.639(4) ± 0.006 | 0.625(6) ± 0.004 | 0.643(2) ± 0.006 |
| Slashdot | 0.839(6) ± 0.010 | 0.844(2) ± 0.008 | 0.843(3) ± 0.007 | 0.847(1) ± 0.007 • | 0.839(5) ± 0.008 | 0.843(4) ± 0.008 |
| corel5k | 0.031(6) ± 0.004 | 0.138(1) ± 0.008 • | 0.056(2) ± 0.007 | 0.049(4) ± 0.009 | 0.032(5) ± 0.009 | 0.050(3) ± 0.011 |
| rcv1subset1 | 0.244(6) ± 0.010 | 0.386(1) ± 0.005 • | 0.290(4) ± 0.017 | 0.300(2) ± 0.022 | 0.245(5) ± 0.009 | 0.296(3) ± 0.021 |
| rcv1subset2 | 0.293(6) ± 0.018 | 0.417(1) ± 0.009 • | 0.326(4) ± 0.010 | 0.338(2) ± 0.017 | 0.305(5) ± 0.006 | 0.334(3) ± 0.012 |
| rcv1subset3 | 0.290(6) ± 0.012 | 0.403(1) ± 0.005 • | 0.325(4) ± 0.011 | 0.337(2) ± 0.015 | 0.291(5) ± 0.008 | 0.333(3) ± 0.009 |
| rcv1subset4 | 0.362(6) ± 0.010 | 0.469(1) ± 0.006 • | 0.394(4) ± 0.017 | 0.400(2) ± 0.018 | 0.368(5) ± 0.006 | 0.394(3) ± 0.019 |
| rcv1subset5 | 0.286(6) ± 0.013 | 0.425(1) ± 0.005 • | 0.346(4) ± 0.019 | 0.357(2) ± 0.022 | 0.320(5) ± 0.006 | 0.348(3) ± 0.014 |
| bibtex | 0.327(5) ± 0.009 | 0.373(1) ± 0.004 • | 0.361(4) ± 0.004 | 0.371(2) ± 0.005 | 0.265(6) ± 0.006 | 0.367(3) ± 0.006 |
| Arts | 0.299(5) ± 0.020 | 0.380(1) ± 0.013 • | 0.365(4) ± 0.015 | 0.372(2) ± 0.013 | 0.285(6) ± 0.018 | 0.369(3) ± 0.014 |
| Health | 0.538(5) ± 0.013 | 0.569(3) ± 0.011 | 0.568(4) ± 0.011 | 0.574(2) ± 0.010 | 0.521(6) ± 0.012 | 0.574(1) ± 0.011 • |
| Business | 0.704(6) ± 0.004 | 0.721(4) ± 0.004 | 0.721(3) ± 0.003 | 0.725(1) ± 0.004 • | 0.711(5) ± 0.004 | 0.722(2) ± 0.004 |
| Education | 0.315(5) ± 0.017 | 0.393(1) ± 0.012 • | 0.374(4) ± 0.013 | 0.379(2) ± 0.014 | 0.299(6) ± 0.014 | 0.378(3) ± 0.014 |
| Computers | 0.475(6) ± 0.007 | 0.513(2) ± 0.005 | 0.508(4) ± 0.005 | 0.514(1) ± 0.005 • | 0.487(5) ± 0.006 | 0.511(3) ± 0.005 |
| Entertainment | 0.454(5) ± 0.010 | 0.508(1) ± 0.006 • | 0.498(4) ± 0.007 | 0.504(3) ± 0.007 | 0.436(6) ± 0.008 | 0.505(2) ± 0.008 |
| Recreation | 0.395(5) ± 0.017 | 0.463(1) ± 0.011 • | 0.447(4) ± 0.014 | 0.455(2) ± 0.010 | 0.392(6) ± 0.019 | 0.454(3) ± 0.012 |
| Society | 0.431(5) ± 0.012 | 0.470(1) ± 0.008 • | 0.465(4) ± 0.011 | 0.467(3) ± 0.009 | 0.420(6) ± 0.013 | 0.468(2) ± 0.010 |
| eurlex-dc-l | 0.466(3) ± 0.007 | 0.453(4) ± 0.006 | 0.479(2) ± 0.008 | 0.447(5) ± 0.004 | 0.420(6) ± 0.005 | 0.479(1) ± 0.007 • |
| eurlex-sm | 0.580(3) ± 0.006 | 0.564(5) ± 0.006 | 0.586(2) ± 0.007 | 0.565(4) ± 0.007 | 0.537(6) ± 0.005 | 0.589(1) ± 0.007 • |
| tmc2007-500 | 0.732(1) ± 0.002 • | 0.679(5) ± 0.003 | 0.721(3) ± 0.003 | 0.679(6) ± 0.002 | 0.687(4) ± 0.003 | 0.726(2) ± 0.003 |
| mediamill | 0.643(1) ± 0.002 • | 0.598(4) ± 0.002 | 0.634(3) ± 0.002 | 0.596(5) ± 0.002 | 0.591(6) ± 0.002 | 0.635(2) ± 0.001 |
| average rank | 4.50 | 2.46 | 3.39 | 2.82 | 5.36 | 2.46 |
| win/tie/loss | 33/26/81 | 93/16/31 | 63/22/55 | 70/30/40 | 12/9/119 | 83/29/28 |
| Dataset | Hamming Loss | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.135(2) ± 0.009 | 0.144(6) ± 0.009 | 0.139(4) ± 0.008 | 0.140(5) ± 0.007 | 0.133(1) ± 0.004 • | 0.137(3) ± 0.008 |
| CAL500 | 0.186(2) ± 0.001 | 0.200(6) ± 0.002 | 0.187(4) ± 0.001 | 0.187(5) ± 0.001 | 0.186(1) ± 0.001 • | 0.187(3) ± 0.001 |
| emotions | 0.193(2) ± 0.007 | 0.199(6) ± 0.006 | 0.193(3) ± 0.007 | 0.193(5) ± 0.007 | 0.193(4) ± 0.006 | 0.190(1) ± 0.005 • |
| genbase | 0.004(1) ± 0.002 • | 0.009(6) ± 0.002 | 0.006(3) ± 0.003 | 0.004(2) ± 0.002 | 0.006(5) ± 0.002 | 0.006(4) ± 0.002 |
| LLOG | 0.190(6) ± 0.007 | 0.188(4) ± 0.005 | 0.187(2) ± 0.005 | 0.189(5) ± 0.006 | 0.187(1) ± 0.004 • | 0.188(3) ± 0.006 |
| enron | 0.076(3) ± 0.001 | 0.078(6) ± 0.001 | 0.076(4) ± 0.001 | 0.075(1) ± 0.001 • | 0.077(5) ± 0.001 | 0.075(2) ± 0.001 |
| scene | 0.083(1) ± 0.003 • | 0.087(5) ± 0.002 | 0.086(4) ± 0.002 | 0.085(3) ± 0.003 | 0.104(6) ± 0.003 | 0.084(2) ± 0.003 |
| yeast | 0.195(1) ± 0.003 • | 0.211(6) ± 0.004 | 0.200(4) ± 0.004 | 0.201(5) ± 0.004 | 0.197(2) ± 0.003 | 0.200(3) ± 0.003 |
| Slashdot | 0.029(5) ± 0.002 | 0.028(2) ± 0.002 | 0.029(3) ± 0.001 | 0.028(1) ± 0.001 • | 0.030(6) ± 0.001 | 0.029(4) ± 0.001 |
| corel5k | 0.021(1) ± 0.000 • | 0.025(6) ± 0.001 | 0.021(3) ± 0.000 | 0.021(5) ± 0.000 | 0.021(2) ± 0.000 | 0.021(4) ± 0.000 |
| rcv1subset1 | 0.033(4) ± 0.000 | 0.035(6) ± 0.001 | 0.032(2) ± 0.000 | 0.033(3) ± 0.000 | 0.033(5) ± 0.000 | 0.032(1) ± 0.000 • |
| rcv1subset2 | 0.027(5) ± 0.000 | 0.029(6) ± 0.000 | 0.027(3) ± 0.000 | 0.027(4) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 |
| rcv1subset3 | 0.027(4) ± 0.000 | 0.029(6) ± 0.000 | 0.027(3) ± 0.000 | 0.027(2) ± 0.000 | 0.027(5) ± 0.000 | 0.027(1) ± 0.000 • |
| rcv1subset4 | 0.025(5) ± 0.000 | 0.026(6) ± 0.000 | 0.024(3) ± 0.000 | 0.024(2) ± 0.000 | 0.025(4) ± 0.000 | 0.024(1) ± 0.000 • |
| rcv1subset5 | 0.027(5) ± 0.000 | 0.028(6) ± 0.000 | 0.027(4) ± 0.000 | 0.027(3) ± 0.000 | 0.027(2) ± 0.000 | 0.027(1) ± 0.000 • |
| bibtex | 0.013(5) ± 0.000 | 0.015(6) ± 0.000 | 0.013(3) ± 0.000 | 0.013(1) ± 0.000 • | 0.013(4) ± 0.000 | 0.013(2) ± 0.000 |
| Arts | 0.062(6) ± 0.001 | 0.060(4) ± 0.001 | 0.059(3) ± 0.000 | 0.059(1) ± 0.000 • | 0.060(5) ± 0.001 | 0.059(2) ± 0.001 |
| Health | 0.057(5) ± 0.001 | 0.056(4) ± 0.001 | 0.055(3) ± 0.001 | 0.055(2) ± 0.001 | 0.058(6) ± 0.001 | 0.055(1) ± 0.001 • |
| Business | 0.032(6) ± 0.000 | 0.031(5) ± 0.000 | 0.031(3) ± 0.000 | 0.031(1) ± 0.000 • | 0.031(4) ± 0.000 | 0.031(2) ± 0.000 |
| Education | 0.048(6) ± 0.001 | 0.046(5) ± 0.001 | 0.046(3) ± 0.001 | 0.046(1) ± 0.001 • | 0.046(4) ± 0.001 | 0.046(2) ± 0.001 |
| Computers | 0.044(6) ± 0.001 | 0.043(5) ± 0.000 | 0.043(3) ± 0.000 | 0.043(1) ± 0.000 • | 0.043(4) ± 0.000 | 0.043(2) ± 0.000 |
| Entertainment | 0.064(6) ± 0.001 | 0.061(4) ± 0.001 | 0.061(3) ± 0.001 | 0.061(2) ± 0.001 | 0.062(5) ± 0.001 | 0.061(1) ± 0.001 • |
| Recreation | 0.053(6) ± 0.001 | 0.050(3) ± 0.001 | 0.050(4) ± 0.001 | 0.050(1) ± 0.001 • | 0.051(5) ± 0.001 | 0.050(2) ± 0.001 |
| Society | 0.053(6) ± 0.001 | 0.051(4) ± 0.001 | 0.051(3) ± 0.001 | 0.051(1) ± 0.001 • | 0.052(5) ± 0.001 | 0.051(2) ± 0.001 |
| eurlex-dc-l | 0.005(3) ± 0.000 | 0.005(6) ± 0.000 | 0.005(2) ± 0.000 | 0.005(5) ± 0.000 | 0.005(4) ± 0.000 | 0.004(1) ± 0.000 • |
| eurlex-sm | 0.011(3) ± 0.000 | 0.011(6) ± 0.000 | 0.011(2) ± 0.000 | 0.011(5) ± 0.000 | 0.011(4) ± 0.000 | 0.011(1) ± 0.000 • |
| tmc2007-500 | 0.050(1) ± 0.000 • | 0.060(6) ± 0.000 | 0.052(3) ± 0.000 | 0.060(5) ± 0.000 | 0.055(4) ± 0.000 | 0.051(2) ± 0.000 |
| mediamill | 0.027(1) ± 0.000 • | 0.031(6) ± 0.000 | 0.028(3) ± 0.000 | 0.030(5) ± 0.000 | 0.029(4) ± 0.000 | 0.028(2) ± 0.000 |
| average rank | 3.82 | 5.25 | 3.11 | 2.93 | 3.86 | 2.04 |
| win/tie/loss | 47/24/69 | 18/11/111 | 63/36/41 | 76/29/35 | 48/24/68 | 90/33/17 |
Appendix E. Results of Parameter Analysis Experiments for MLHiKNN
| Dataset | AUC Macro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.735(1) ± 0.020 • | 0.732(3) ± 0.020 | 0.732(2) ± 0.025 | 0.730(4) ± 0.026 | 0.728(7) ± 0.030 | 0.729(6) ± 0.028 | 0.729(5) ± 0.026 | 0.720(8) ± 0.024 | 0.715(9) ± 0.023 |
| CAL500 | 0.551(9) ± 0.004 | 0.558(8) ± 0.006 | 0.566(7) ± 0.008 | 0.570(6) ± 0.008 | 0.571(5) ± 0.006 | 0.572(4) ± 0.007 | 0.573(1) ± 0.007 • | 0.572(2) ± 0.007 | 0.572(3) ± 0.007 |
| emotions | 0.832(9) ± 0.010 | 0.841(8) ± 0.008 | 0.843(7) ± 0.006 | 0.849(1) ± 0.006 • | 0.846(5) ± 0.005 | 0.848(4) ± 0.007 | 0.849(2) ± 0.007 | 0.848(3) ± 0.007 | 0.846(6) ± 0.006 |
| genbase | 0.992(9) ± 0.005 | 0.995(8) ± 0.004 | 0.996(7) ± 0.004 | 0.997(3) ± 0.003 | 0.997(2) ± 0.003 | 0.997(1) ± 0.003 • | 0.997(4) ± 0.003 | 0.996(5) ± 0.003 | 0.996(6) ± 0.003 |
| LLOG | 0.603(8) ± 0.006 | 0.603(9) ± 0.006 | 0.603(2) ± 0.006 | 0.603(7) ± 0.006 | 0.603(6) ± 0.006 | 0.603(1) ± 0.006 • | 0.603(4) ± 0.006 | 0.603(3) ± 0.006 | 0.603(5) ± 0.006 |
| enron | 0.661(9) ± 0.011 | 0.669(8) ± 0.012 | 0.672(7) ± 0.015 | 0.674(3) ± 0.011 | 0.676(1) ± 0.012 • | 0.675(2) ± 0.010 | 0.674(4) ± 0.011 | 0.673(5) ± 0.009 | 0.673(6) ± 0.009 |
| scene | 0.925(9) ± 0.004 | 0.935(8) ± 0.004 | 0.942(7) ± 0.002 | 0.943(5) ± 0.003 | 0.944(1) ± 0.002 • | 0.944(2) ± 0.002 | 0.943(3) ± 0.002 | 0.943(4) ± 0.002 | 0.943(6) ± 0.002 |
| yeast | 0.682(9) ± 0.009 | 0.695(8) ± 0.009 | 0.707(7) ± 0.008 | 0.711(2) ± 0.007 | 0.711(1) ± 0.006 • | 0.710(3) ± 0.006 | 0.710(4) ± 0.006 | 0.708(5) ± 0.005 | 0.707(6) ± 0.006 |
| Slashdot | 0.720(8) ± 0.015 | 0.713(9) ± 0.017 | 0.722(6) ± 0.020 | 0.724(2) ± 0.016 | 0.723(3) ± 0.021 | 0.723(4) ± 0.020 | 0.732(1) ± 0.019 • | 0.722(5) ± 0.024 | 0.722(7) ± 0.016 |
| corel5k | 0.605(9) ± 0.009 | 0.624(8) ± 0.013 | 0.656(7) ± 0.011 | 0.677(6) ± 0.007 | 0.690(5) ± 0.005 | 0.698(4) ± 0.003 | 0.703(3) ± 0.004 | 0.709(2) ± 0.004 | 0.713(1) ± 0.004 • |
| rcv1subset1 | 0.880(9) ± 0.004 | 0.889(5) ± 0.003 | 0.892(1) ± 0.003 • | 0.892(2) ± 0.005 | 0.891(3) ± 0.004 | 0.890(4) ± 0.004 | 0.888(6) ± 0.004 | 0.887(7) ± 0.004 | 0.886(8) ± 0.004 |
| rcv1subset2 | 0.876(9) ± 0.006 | 0.886(4) ± 0.006 | 0.891(1) ± 0.005 • | 0.890(2) ± 0.005 | 0.888(3) ± 0.005 | 0.886(5) ± 0.006 | 0.885(6) ± 0.006 | 0.885(7) ± 0.005 | 0.884(8) ± 0.005 |
| rcv1subset3 | 0.870(9) ± 0.005 | 0.879(4) ± 0.004 | 0.882(1) ± 0.005 • | 0.882(2) ± 0.004 | 0.880(3) ± 0.004 | 0.877(5) ± 0.003 | 0.876(6) ± 0.003 | 0.875(7) ± 0.004 | 0.874(8) ± 0.003 |
| rcv1subset4 | 0.875(9) ± 0.004 | 0.886(4) ± 0.007 | 0.889(1) ± 0.006 • | 0.888(2) ± 0.008 | 0.887(3) ± 0.007 | 0.885(5) ± 0.008 | 0.884(6) ± 0.007 | 0.883(7) ± 0.007 | 0.883(8) ± 0.008 |
| rcv1subset5 | 0.862(9) ± 0.005 | 0.873(3) ± 0.005 | 0.876(1) ± 0.005 • | 0.874(2) ± 0.005 | 0.873(4) ± 0.005 | 0.870(5) ± 0.005 | 0.869(6) ± 0.005 | 0.869(7) ± 0.005 | 0.868(8) ± 0.005 |
| bibtex | 0.863(9) ± 0.002 | 0.876(8) ± 0.002 | 0.883(7) ± 0.002 | 0.886(2) ± 0.001 | 0.886(1) ± 0.001 • | 0.886(3) ± 0.002 | 0.885(4) ± 0.002 | 0.885(5) ± 0.002 | 0.884(6) ± 0.001 |
| Arts | 0.692(9) ± 0.011 | 0.707(8) ± 0.010 | 0.722(7) ± 0.012 | 0.728(6) ± 0.010 | 0.730(5) ± 0.009 | 0.735(4) ± 0.009 | 0.738(3) ± 0.009 | 0.739(1) ± 0.008 • | 0.739(2) ± 0.008 |
| Health | 0.738(9) ± 0.007 | 0.755(8) ± 0.010 | 0.769(7) ± 0.011 | 0.775(6) ± 0.009 | 0.778(5) ± 0.009 | 0.779(3) ± 0.008 | 0.779(4) ± 0.011 | 0.782(2) ± 0.010 | 0.782(1) ± 0.010 • |
| Business | 0.700(9) ± 0.010 | 0.720(8) ± 0.010 | 0.741(7) ± 0.009 | 0.749(6) ± 0.008 | 0.752(5) ± 0.007 | 0.755(4) ± 0.007 | 0.757(3) ± 0.008 | 0.759(1) ± 0.008 • | 0.758(2) ± 0.006 |
| Education | 0.700(9) ± 0.014 | 0.715(8) ± 0.015 | 0.733(7) ± 0.015 | 0.744(6) ± 0.012 | 0.748(5) ± 0.014 | 0.750(4) ± 0.014 | 0.753(3) ± 0.014 | 0.755(2) ± 0.011 | 0.756(1) ± 0.011 • |
| Computers | 0.706(9) ± 0.008 | 0.720(8) ± 0.008 | 0.736(7) ± 0.005 | 0.744(6) ± 0.005 | 0.750(5) ± 0.005 | 0.752(4) ± 0.006 | 0.753(3) ± 0.005 | 0.755(2) ± 0.006 | 0.755(1) ± 0.004 • |
| Entertainment | 0.744(9) ± 0.008 | 0.757(8) ± 0.007 | 0.770(7) ± 0.006 | 0.777(6) ± 0.003 | 0.782(5) ± 0.004 | 0.784(4) ± 0.004 | 0.785(3) ± 0.005 | 0.787(2) ± 0.004 | 0.789(1) ± 0.005 • |
| Recreation | 0.752(9) ± 0.012 | 0.765(8) ± 0.011 | 0.779(7) ± 0.008 | 0.785(6) ± 0.008 | 0.788(5) ± 0.009 | 0.790(4) ± 0.009 | 0.791(3) ± 0.008 | 0.792(2) ± 0.010 | 0.793(1) ± 0.009 • |
| Society | 0.676(9) ± 0.007 | 0.687(8) ± 0.007 | 0.697(7) ± 0.005 | 0.702(6) ± 0.005 | 0.707(5) ± 0.006 | 0.709(4) ± 0.006 | 0.711(3) ± 0.006 | 0.713(2) ± 0.005 | 0.714(1) ± 0.007 • |
| eurlex-dc-l | 0.865(9) ± 0.005 | 0.882(8) ± 0.007 | 0.895(7) ± 0.005 | 0.899(6) ± 0.005 | 0.900(5) ± 0.004 | 0.903(4) ± 0.004 | 0.904(3) ± 0.004 | 0.904(2) ± 0.004 | 0.905(1) ± 0.004 • |
| eurlex-sm | 0.894(9) ± 0.003 | 0.903(8) ± 0.002 | 0.907(7) ± 0.003 | 0.909(2) ± 0.002 | 0.908(4) ± 0.003 | 0.909(1) ± 0.003 • | 0.909(3) ± 0.003 | 0.908(5) ± 0.003 | 0.907(6) ± 0.003 |
| tmc2007-500 | 0.893(9) ± 0.003 | 0.904(8) ± 0.002 | 0.915(7) ± 0.002 | 0.919(6) ± 0.002 | 0.920(5) ± 0.002 | 0.922(4) ± 0.002 | 0.924(3) ± 0.002 | 0.924(2) ± 0.002 | 0.925(1) ± 0.002 • |
| mediamill | 0.801(9) ± 0.003 | 0.813(8) ± 0.002 | 0.824(4) ± 0.002 | 0.824(3) ± 0.003 | 0.824(2) ± 0.002 | 0.824(1) ± 0.003 • | 0.823(5) ± 0.003 | 0.821(6) ± 0.003 | 0.819(7) ± 0.004 |
| average rank | 8.64 | 7.18 | 5.43 | 4.14 | 3.89 | 3.54 | 3.71 | 3.96 | 4.50 |
| win/tie/loss | 1/22/201 | 36/40/148 | 74/54/96 | 93/72/59 | 104/74/46 | 110/70/44 | 109/72/43 | 107/78/39 | 102/62/60 |
| Dataset | AUC Micro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.752(2) ± 0.017 | 0.754(1) ± 0.014 • | 0.750(3) ± 0.018 | 0.748(5) ± 0.019 | 0.746(6) ± 0.019 | 0.748(4) ± 0.016 | 0.745(7) ± 0.022 | 0.737(8) ± 0.018 | 0.730(9) ± 0.025 |
| CAL500 | 0.754(8) ± 0.003 | 0.754(9) ± 0.005 | 0.757(7) ± 0.004 | 0.758(1) ± 0.005 • | 0.757(4) ± 0.004 | 0.757(5) ± 0.006 | 0.758(2) ± 0.002 | 0.757(6) ± 0.005 | 0.757(3) ± 0.004 |
| emotions | 0.845(9) ± 0.009 | 0.855(8) ± 0.007 | 0.859(7) ± 0.006 | 0.862(4) ± 0.007 | 0.862(5) ± 0.005 | 0.863(3) ± 0.005 | 0.863(1) ± 0.006 • | 0.863(2) ± 0.006 | 0.861(6) ± 0.005 |
| genbase | 0.991(9) ± 0.005 | 0.995(8) ± 0.003 | 0.996(3) ± 0.004 | 0.997(1) ± 0.003 • | 0.996(2) ± 0.004 | 0.996(4) ± 0.003 | 0.995(5) ± 0.004 | 0.995(6) ± 0.004 | 0.995(7) ± 0.004 |
| LLOG | 0.770(2) ± 0.002 | 0.765(9) ± 0.002 | 0.767(8) ± 0.002 | 0.770(1) ± 0.001 • | 0.767(4) ± 0.002 | 0.767(5) ± 0.003 | 0.767(6) ± 0.002 | 0.767(3) ± 0.002 | 0.767(7) ± 0.002 |
| enron | 0.858(7) ± 0.002 | 0.860(1) ± 0.003 • | 0.860(3) ± 0.004 | 0.859(4) ± 0.003 | 0.860(2) ± 0.002 | 0.859(5) ± 0.003 | 0.858(6) ± 0.003 | 0.857(9) ± 0.002 | 0.857(8) ± 0.003 |
| scene | 0.931(9) ± 0.004 | 0.941(8) ± 0.004 | 0.948(7) ± 0.002 | 0.949(4) ± 0.002 | 0.950(1) ± 0.002 • | 0.949(2) ± 0.002 | 0.949(3) ± 0.002 | 0.949(5) ± 0.002 | 0.948(6) ± 0.002 |
| yeast | 0.827(9) ± 0.004 | 0.833(8) ± 0.005 | 0.840(7) ± 0.004 | 0.842(4) ± 0.004 | 0.842(1) ± 0.004 • | 0.842(3) ± 0.004 | 0.842(2) ± 0.003 | 0.841(6) ± 0.003 | 0.841(5) ± 0.003 |
| Slashdot | 0.944(5) ± 0.004 | 0.945(2) ± 0.003 | 0.944(9) ± 0.004 | 0.945(4) ± 0.004 | 0.945(1) ± 0.004 • | 0.944(8) ± 0.004 | 0.945(3) ± 0.004 | 0.944(6) ± 0.004 | 0.944(7) ± 0.004 |
| corel5k | 0.785(9) ± 0.003 | 0.787(8) ± 0.003 | 0.791(7) ± 0.004 | 0.794(6) ± 0.003 | 0.796(4) ± 0.004 | 0.796(5) ± 0.003 | 0.798(3) ± 0.004 | 0.799(2) ± 0.004 | 0.801(1) ± 0.004 • |
| rcv1subset1 | 0.872(9) ± 0.007 | 0.875(1) ± 0.005 • | 0.875(2) ± 0.009 | 0.874(3) ± 0.009 | 0.874(6) ± 0.009 | 0.874(5) ± 0.006 | 0.872(8) ± 0.009 | 0.873(7) ± 0.007 | 0.874(4) ± 0.008 |
| rcv1subset2 | 0.870(3) ± 0.010 | 0.874(1) ± 0.011 • | 0.871(2) ± 0.010 | 0.868(4) ± 0.009 | 0.865(5) ± 0.010 | 0.863(6) ± 0.011 | 0.861(8) ± 0.010 | 0.862(7) ± 0.009 | 0.860(9) ± 0.010 |
| rcv1subset3 | 0.858(5) ± 0.006 | 0.861(2) ± 0.005 | 0.862(1) ± 0.007 • | 0.859(4) ± 0.010 | 0.861(3) ± 0.007 | 0.858(6) ± 0.010 | 0.857(9) ± 0.008 | 0.857(7) ± 0.008 | 0.857(8) ± 0.007 |
| rcv1subset4 | 0.886(4) ± 0.008 | 0.888(2) ± 0.010 | 0.888(1) ± 0.008 • | 0.888(3) ± 0.010 | 0.884(8) ± 0.010 | 0.885(5) ± 0.009 | 0.885(7) ± 0.008 | 0.883(9) ± 0.009 | 0.885(6) ± 0.006 |
| rcv1subset5 | 0.869(4) ± 0.006 | 0.876(1) ± 0.007 • | 0.871(3) ± 0.006 | 0.868(7) ± 0.008 | 0.868(8) ± 0.009 | 0.868(6) ± 0.008 | 0.867(9) ± 0.007 | 0.872(2) ± 0.007 | 0.869(5) ± 0.008 |
| bibtex | 0.838(9) ± 0.005 | 0.850(8) ± 0.008 | 0.859(6) ± 0.009 | 0.862(3) ± 0.004 | 0.863(2) ± 0.006 | 0.862(4) ± 0.007 | 0.863(1) ± 0.005 • | 0.860(5) ± 0.004 | 0.859(7) ± 0.006 |
| Arts | 0.836(9) ± 0.003 | 0.842(8) ± 0.003 | 0.847(7) ± 0.003 | 0.850(6) ± 0.003 | 0.851(5) ± 0.003 | 0.853(4) ± 0.003 | 0.854(2) ± 0.003 | 0.854(3) ± 0.003 | 0.854(1) ± 0.003 • |
| Health | 0.910(9) ± 0.003 | 0.914(8) ± 0.002 | 0.917(7) ± 0.002 | 0.919(6) ± 0.002 | 0.919(5) ± 0.002 | 0.919(4) ± 0.002 | 0.919(3) ± 0.002 | 0.920(2) ± 0.002 | 0.920(1) ± 0.002 • |
| Business | 0.942(9) ± 0.001 | 0.944(8) ± 0.001 | 0.946(7) ± 0.001 | 0.947(6) ± 0.001 | 0.947(5) ± 0.001 | 0.948(4) ± 0.001 | 0.948(3) ± 0.001 | 0.948(2) ± 0.001 | 0.949(1) ± 0.001 • |
| Education | 0.896(9) ± 0.002 | 0.900(8) ± 0.002 | 0.904(7) ± 0.002 | 0.906(6) ± 0.002 | 0.906(5) ± 0.002 | 0.907(4) ± 0.002 | 0.907(3) ± 0.002 | 0.908(2) ± 0.002 | 0.908(1) ± 0.002 • |
| Computers | 0.884(9) ± 0.003 | 0.888(8) ± 0.003 | 0.892(7) ± 0.003 | 0.894(6) ± 0.002 | 0.896(5) ± 0.003 | 0.896(4) ± 0.003 | 0.896(3) ± 0.003 | 0.897(1) ± 0.003 • | 0.896(2) ± 0.003 |
| Entertainment | 0.876(9) ± 0.002 | 0.881(8) ± 0.002 | 0.887(7) ± 0.002 | 0.890(6) ± 0.002 | 0.891(5) ± 0.002 | 0.892(4) ± 0.002 | 0.893(3) ± 0.002 | 0.893(2) ± 0.002 | 0.894(1) ± 0.002 • |
| Recreation | 0.857(9) ± 0.005 | 0.863(8) ± 0.005 | 0.870(7) ± 0.004 | 0.873(6) ± 0.004 | 0.874(5) ± 0.004 | 0.875(4) ± 0.004 | 0.875(3) ± 0.004 | 0.875(2) ± 0.004 | 0.875(1) ± 0.004 • |
| Society | 0.858(9) ± 0.003 | 0.862(8) ± 0.002 | 0.866(7) ± 0.002 | 0.868(6) ± 0.002 | 0.869(5) ± 0.002 | 0.870(4) ± 0.002 | 0.870(3) ± 0.002 | 0.871(2) ± 0.002 | 0.871(1) ± 0.002 • |
| eurlex-dc-l | 0.906(9) ± 0.005 | 0.913(8) ± 0.006 | 0.917(7) ± 0.005 | 0.920(5) ± 0.005 | 0.919(6) ± 0.005 | 0.920(4) ± 0.005 | 0.921(1) ± 0.004 • | 0.921(3) ± 0.004 | 0.921(2) ± 0.005 |
| eurlex-sm | 0.946(9) ± 0.001 | 0.950(8) ± 0.001 | 0.951(7) ± 0.001 | 0.952(5) ± 0.002 | 0.952(6) ± 0.002 | 0.953(1) ± 0.002 • | 0.953(2) ± 0.002 | 0.952(4) ± 0.002 | 0.952(3) ± 0.002 |
| tmc2007-500 | 0.947(9) ± 0.001 | 0.952(8) ± 0.001 | 0.956(7) ± 0.001 | 0.957(6) ± 0.001 | 0.958(5) ± 0.001 | 0.959(4) ± 0.001 | 0.959(3) ± 0.001 | 0.959(1) ± 0.001 • | 0.959(2) ± 0.001 |
| mediamill | 0.955(9) ± 0.001 | 0.957(4) ± 0.001 | 0.958(1) ± 0.001 • | 0.958(2) ± 0.001 | 0.957(3) ± 0.001 | 0.957(5) ± 0.001 | 0.957(6) ± 0.001 | 0.956(7) ± 0.000 | 0.956(8) ± 0.001 |
| average rank | 7.54 | 6.04 | 5.50 | 4.43 | 4.36 | 4.36 | 4.11 | 4.32 | 4.36 |
| win/tie/loss | 13/59/152 | 43/56/125 | 55/81/88 | 82/89/53 | 84/95/45 | 74/111/39 | 85/106/33 | 86/102/36 | 89/95/40 |
| Dataset | Ranking Loss | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.250(2) ± 0.021 | 0.248(1) ± 0.016 • | 0.253(5) ± 0.021 | 0.257(7) ± 0.023 | 0.251(3) ± 0.020 | 0.251(4) ± 0.018 | 0.255(6) ± 0.029 | 0.261(8) ± 0.020 | 0.270(9) ± 0.029 |
| CAL500 | 0.243(8) ± 0.003 | 0.243(9) ± 0.005 | 0.241(6) ± 0.004 | 0.239(1) ± 0.005 • | 0.240(4) ± 0.005 | 0.241(5) ± 0.006 | 0.240(2) ± 0.002 | 0.241(7) ± 0.005 | 0.240(3) ± 0.004 |
| emotions | 0.171(9) ± 0.010 | 0.164(8) ± 0.010 | 0.158(7) ± 0.009 | 0.154(5) ± 0.011 | 0.153(4) ± 0.007 | 0.152(3) ± 0.005 | 0.151(1) ± 0.005 • | 0.152(2) ± 0.007 | 0.155(6) ± 0.007 |
| genbase | 0.010(9) ± 0.005 | 0.006(8) ± 0.003 | 0.004(3) ± 0.003 | 0.004(1) ± 0.003 • | 0.004(2) ± 0.003 | 0.005(4) ± 0.003 | 0.006(6) ± 0.003 | 0.006(7) ± 0.003 | 0.005(5) ± 0.003 |
| LLOG | 0.186(1) ± 0.002 • | 0.189(9) ± 0.003 | 0.187(7) ± 0.002 | 0.186(2) ± 0.002 | 0.187(4) ± 0.002 | 0.187(5) ± 0.002 | 0.187(6) ± 0.002 | 0.187(3) ± 0.002 | 0.188(8) ± 0.003 |
| enron | 0.136(6) ± 0.004 | 0.135(1) ± 0.004 • | 0.135(4) ± 0.003 | 0.135(3) ± 0.004 | 0.135(2) ± 0.003 | 0.136(5) ± 0.003 | 0.136(7) ± 0.003 | 0.137(9) ± 0.003 | 0.137(8) ± 0.004 |
| scene | 0.092(9) ± 0.004 | 0.082(8) ± 0.005 | 0.074(7) ± 0.003 | 0.073(6) ± 0.003 | 0.071(2) ± 0.003 | 0.072(3) ± 0.003 | 0.071(1) ± 0.003 • | 0.072(5) ± 0.002 | 0.072(4) ± 0.003 |
| yeast | 0.183(9) ± 0.004 | 0.178(8) ± 0.004 | 0.172(7) ± 0.004 | 0.169(6) ± 0.004 | 0.168(3) ± 0.003 | 0.168(4) ± 0.004 | 0.168(1) ± 0.003 • | 0.168(5) ± 0.003 | 0.168(2) ± 0.004 |
| Slashdot | 0.048(6) ± 0.004 | 0.047(3) ± 0.004 | 0.048(9) ± 0.004 | 0.048(7) ± 0.005 | 0.047(1) ± 0.005 • | 0.048(8) ± 0.004 | 0.047(2) ± 0.005 | 0.047(4) ± 0.004 | 0.048(5) ± 0.004 |
| corel5k | 0.216(9) ± 0.003 | 0.215(8) ± 0.003 | 0.211(7) ± 0.004 | 0.208(6) ± 0.003 | 0.206(4) ± 0.004 | 0.207(5) ± 0.003 | 0.204(3) ± 0.004 | 0.203(2) ± 0.004 | 0.202(1) ± 0.004 • |
| rcv1subset1 | 0.117(4) ± 0.007 | 0.115(1) ± 0.006 • | 0.116(2) ± 0.009 | 0.117(3) ± 0.009 | 0.118(5) ± 0.008 | 0.118(7) ± 0.006 | 0.119(9) ± 0.009 | 0.119(8) ± 0.007 | 0.118(6) ± 0.008 |
| rcv1subset2 | 0.111(2) ± 0.009 | 0.109(1) ± 0.009 • | 0.113(3) ± 0.009 | 0.116(4) ± 0.008 | 0.118(5) ± 0.009 | 0.119(6) ± 0.010 | 0.122(8) ± 0.009 | 0.121(7) ± 0.008 | 0.123(9) ± 0.009 |
| rcv1subset3 | 0.123(4) ± 0.006 | 0.121(2) ± 0.005 | 0.120(1) ± 0.007 • | 0.125(5) ± 0.009 | 0.122(3) ± 0.005 | 0.125(6) ± 0.007 | 0.125(9) ± 0.005 | 0.125(7) ± 0.006 | 0.125(8) ± 0.006 |
| rcv1subset4 | 0.097(3) ± 0.008 | 0.095(1) ± 0.008 • | 0.096(2) ± 0.007 | 0.097(4) ± 0.009 | 0.100(8) ± 0.009 | 0.099(6) ± 0.008 | 0.100(7) ± 0.007 | 0.101(9) ± 0.008 | 0.099(5) ± 0.006 |
| rcv1subset5 | 0.114(4) ± 0.007 | 0.109(1) ± 0.006 • | 0.114(3) ± 0.007 | 0.117(7) ± 0.008 | 0.117(8) ± 0.009 | 0.117(6) ± 0.008 | 0.118(9) ± 0.007 | 0.114(2) ± 0.007 | 0.116(5) ± 0.007 |
| bibtex | 0.170(9) ± 0.005 | 0.160(8) ± 0.007 | 0.150(7) ± 0.007 | 0.147(3) ± 0.004 | 0.147(2) ± 0.004 | 0.148(4) ± 0.005 | 0.147(1) ± 0.002 • | 0.149(5) ± 0.004 | 0.150(6) ± 0.006 |
| Arts | 0.145(9) ± 0.003 | 0.139(8) ± 0.003 | 0.134(7) ± 0.003 | 0.130(6) ± 0.003 | 0.129(5) ± 0.003 | 0.127(4) ± 0.003 | 0.126(3) ± 0.003 | 0.126(2) ± 0.003 | 0.126(1) ± 0.003 • |
| Health | 0.078(9) ± 0.002 | 0.075(8) ± 0.002 | 0.072(7) ± 0.002 | 0.070(6) ± 0.002 | 0.070(5) ± 0.002 | 0.070(4) ± 0.002 | 0.069(3) ± 0.002 | 0.069(2) ± 0.002 | 0.069(1) ± 0.002 • |
| Business | 0.040(9) ± 0.001 | 0.039(8) ± 0.001 | 0.037(7) ± 0.001 | 0.037(6) ± 0.001 | 0.037(5) ± 0.001 | 0.036(4) ± 0.001 | 0.036(3) ± 0.001 | 0.036(2) ± 0.001 | 0.036(1) ± 0.001 • |
| Education | 0.099(9) ± 0.001 | 0.096(8) ± 0.002 | 0.092(7) ± 0.002 | 0.090(6) ± 0.002 | 0.089(5) ± 0.002 | 0.089(4) ± 0.002 | 0.088(3) ± 0.002 | 0.088(2) ± 0.002 | 0.088(1) ± 0.001 • |
| Computers | 0.094(9) ± 0.002 | 0.091(8) ± 0.002 | 0.089(7) ± 0.002 | 0.087(6) ± 0.002 | 0.086(5) ± 0.002 | 0.086(4) ± 0.002 | 0.085(3) ± 0.002 | 0.085(1) ± 0.002 • | 0.085(2) ± 0.002 |
| Entertainment | 0.124(9) ± 0.002 | 0.120(8) ± 0.003 | 0.116(7) ± 0.002 | 0.113(6) ± 0.003 | 0.111(5) ± 0.002 | 0.111(4) ± 0.002 | 0.110(3) ± 0.003 | 0.109(2) ± 0.003 | 0.109(1) ± 0.003 • |
| Recreation | 0.131(9) ± 0.004 | 0.127(8) ± 0.004 | 0.120(7) ± 0.004 | 0.117(6) ± 0.003 | 0.115(5) ± 0.004 | 0.115(4) ± 0.004 | 0.114(3) ± 0.004 | 0.114(2) ± 0.004 | 0.113(1) ± 0.004 • |
| Society | 0.115(9) ± 0.003 | 0.112(8) ± 0.003 | 0.108(7) ± 0.002 | 0.106(6) ± 0.003 | 0.105(5) ± 0.002 | 0.104(4) ± 0.002 | 0.104(3) ± 0.002 | 0.104(2) ± 0.002 | 0.104(1) ± 0.002 • |
| eurlex-dc-l | 0.090(9) ± 0.005 | 0.084(8) ± 0.005 | 0.080(7) ± 0.004 | 0.078(5) ± 0.005 | 0.078(6) ± 0.005 | 0.077(4) ± 0.004 | 0.076(1) ± 0.003 • | 0.076(3) ± 0.003 | 0.076(2) ± 0.004 |
| eurlex-sm | 0.057(9) ± 0.002 | 0.053(8) ± 0.001 | 0.051(7) ± 0.002 | 0.050(6) ± 0.002 | 0.050(5) ± 0.002 | 0.049(1) ± 0.002 • | 0.049(3) ± 0.002 | 0.049(4) ± 0.002 | 0.049(2) ± 0.002 |
| tmc2007-500 | 0.055(9) ± 0.001 | 0.050(8) ± 0.001 | 0.047(7) ± 0.001 | 0.045(6) ± 0.001 | 0.044(5) ± 0.001 | 0.044(4) ± 0.001 | 0.043(3) ± 0.001 | 0.043(2) ± 0.001 | 0.043(1) ± 0.001 • |
| mediamill | 0.040(9) ± 0.001 | 0.038(6) ± 0.000 | 0.037(1) ± 0.000 • | 0.038(2) ± 0.000 | 0.038(3) ± 0.001 | 0.038(4) ± 0.001 | 0.038(5) ± 0.001 | 0.038(7) ± 0.000 | 0.039(8) ± 0.000 |
| average rank | 7.21 | 6.11 | 5.64 | 4.89 | 4.25 | 4.50 | 4.07 | 4.32 | 4.00 |
| win/tie/loss | 13/62/149 | 49/46/129 | 65/70/89 | 70/91/63 | 76/100/48 | 73/105/46 | 87/100/37 | 91/106/27 | 94/100/30 |
| Dataset | F1 Macro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.316(2) ± 0.059 | 0.324(1) ± 0.046 • | 0.284(3) ± 0.054 | 0.264(4) ± 0.064 | 0.258(6) ± 0.069 | 0.261(5) ± 0.043 | 0.236(7) ± 0.027 | 0.226(8) ± 0.030 | 0.223(9) ± 0.041 |
| CAL500 | 0.087(1) ± 0.008 • | 0.086(2) ± 0.006 | 0.082(4) ± 0.007 | 0.082(5) ± 0.005 | 0.083(3) ± 0.003 | 0.080(7) ± 0.004 | 0.079(9) ± 0.004 | 0.081(6) ± 0.004 | 0.080(8) ± 0.005 |
| emotions | 0.640(9) ± 0.023 | 0.656(1) ± 0.014 • | 0.651(4) ± 0.014 | 0.650(8) ± 0.014 | 0.651(6) ± 0.013 | 0.652(3) ± 0.014 | 0.654(2) ± 0.015 | 0.651(5) ± 0.011 | 0.650(7) ± 0.010 |
| genbase | 0.953(9) ± 0.012 | 0.960(2) ± 0.011 | 0.961(1) ± 0.012 • | 0.957(4) ± 0.017 | 0.954(8) ± 0.017 | 0.955(7) ± 0.013 | 0.956(5) ± 0.016 | 0.956(6) ± 0.017 | 0.957(3) ± 0.017 |
| LLOG | 0.115(1) ± 0.005 • | 0.090(9) ± 0.018 | 0.093(8) ± 0.017 | 0.115(2) ± 0.005 | 0.097(5) ± 0.016 | 0.099(3) ± 0.015 | 0.097(6) ± 0.013 | 0.098(4) ± 0.016 | 0.096(7) ± 0.013 |
| enron | 0.150(1) ± 0.011 • | 0.145(2) ± 0.012 | 0.136(3) ± 0.013 | 0.131(4) ± 0.011 | 0.131(5) ± 0.009 | 0.128(6) ± 0.007 | 0.126(7) ± 0.008 | 0.122(8) ± 0.011 | 0.121(9) ± 0.009 |
| scene | 0.718(9) ± 0.012 | 0.737(8) ± 0.011 | 0.748(3) ± 0.008 | 0.749(1) ± 0.007 • | 0.749(2) ± 0.008 | 0.746(4) ± 0.008 | 0.746(5) ± 0.010 | 0.742(7) ± 0.009 | 0.742(6) ± 0.007 |
| yeast | 0.409(8) ± 0.014 | 0.412(6) ± 0.010 | 0.422(2) ± 0.007 | 0.425(1) ± 0.006 • | 0.420(3) ± 0.009 | 0.415(5) ± 0.006 | 0.415(4) ± 0.007 | 0.412(7) ± 0.009 | 0.406(9) ± 0.012 |
| Slashdot | 0.176(1) ± 0.034 • | 0.169(2) ± 0.020 | 0.157(8) ± 0.023 | 0.168(3) ± 0.033 | 0.163(5) ± 0.025 | 0.158(7) ± 0.030 | 0.165(4) ± 0.029 | 0.158(6) ± 0.026 | 0.147(9) ± 0.037 |
| corel5k | 0.019(9) ± 0.003 | 0.021(8) ± 0.003 | 0.022(7) ± 0.003 | 0.027(5) ± 0.003 | 0.026(6) ± 0.004 | 0.027(4) ± 0.003 | 0.030(3) ± 0.005 | 0.031(2) ± 0.002 | 0.031(1) ± 0.004 • |
| rcv1subset1 | 0.160(2) ± 0.012 | 0.160(3) ± 0.007 | 0.160(1) ± 0.013 • | 0.156(4) ± 0.015 | 0.152(5) ± 0.014 | 0.152(6) ± 0.011 | 0.148(8) ± 0.015 | 0.147(9) ± 0.011 | 0.151(7) ± 0.013 |
| rcv1subset2 | 0.150(2) ± 0.018 | 0.152(1) ± 0.018 • | 0.143(3) ± 0.015 | 0.139(4) ± 0.017 | 0.133(5) ± 0.015 | 0.128(6) ± 0.018 | 0.124(8) ± 0.018 | 0.125(7) ± 0.013 | 0.122(9) ± 0.017 |
| rcv1subset3 | 0.124(3) ± 0.008 | 0.130(1) ± 0.010 • | 0.125(2) ± 0.010 | 0.117(5) ± 0.014 | 0.120(4) ± 0.010 | 0.112(6) ± 0.013 | 0.108(8) ± 0.011 | 0.110(7) ± 0.008 | 0.108(9) ± 0.010 |
| rcv1subset4 | 0.167(1) ± 0.018 • | 0.164(2) ± 0.019 | 0.156(3) ± 0.016 | 0.154(4) ± 0.020 | 0.149(5) ± 0.013 | 0.147(6) ± 0.014 | 0.143(7) ± 0.012 | 0.141(8) ± 0.012 | 0.140(9) ± 0.008 |
| rcv1subset5 | 0.150(2) ± 0.011 | 0.154(1) ± 0.008 • | 0.144(3) ± 0.010 | 0.135(4) ± 0.016 | 0.134(5) ± 0.017 | 0.129(7) ± 0.012 | 0.127(8) ± 0.012 | 0.130(6) ± 0.016 | 0.127(9) ± 0.015 |
| bibtex | 0.172(9) ± 0.006 | 0.182(7) ± 0.006 | 0.189(1) ± 0.007 • | 0.189(2) ± 0.005 | 0.187(5) ± 0.006 | 0.188(4) ± 0.005 | 0.188(3) ± 0.005 | 0.186(6) ± 0.004 | 0.182(8) ± 0.006 |
| Arts | 0.252(9) ± 0.014 | 0.264(3) ± 0.013 | 0.265(2) ± 0.010 | 0.267(1) ± 0.011 • | 0.263(4) ± 0.015 | 0.262(5) ± 0.011 | 0.261(6) ± 0.013 | 0.255(8) ± 0.012 | 0.256(7) ± 0.011 |
| Health | 0.389(9) ± 0.014 | 0.396(8) ± 0.011 | 0.403(3) ± 0.011 | 0.405(1) ± 0.011 • | 0.404(2) ± 0.011 | 0.401(5) ± 0.011 | 0.401(4) ± 0.014 | 0.400(6) ± 0.013 | 0.400(7) ± 0.014 |
| Business | 0.266(5) ± 0.013 | 0.271(3) ± 0.008 | 0.274(2) ± 0.010 | 0.275(1) ± 0.008 • | 0.267(4) ± 0.005 | 0.266(7) ± 0.005 | 0.265(8) ± 0.009 | 0.263(9) ± 0.008 | 0.266(6) ± 0.007 |
| Education | 0.269(9) ± 0.012 | 0.277(2) ± 0.015 | 0.276(3) ± 0.019 | 0.275(4) ± 0.014 | 0.278(1) ± 0.015 • | 0.274(5) ± 0.019 | 0.272(6) ± 0.014 | 0.271(7) ± 0.016 | 0.271(8) ± 0.015 |
| Computers | 0.296(4) ± 0.013 | 0.302(1) ± 0.012 • | 0.301(2) ± 0.010 | 0.297(3) ± 0.011 | 0.294(5) ± 0.010 | 0.294(6) ± 0.015 | 0.290(8) ± 0.012 | 0.292(7) ± 0.014 | 0.288(9) ± 0.012 |
| Entertainment | 0.377(9) ± 0.008 | 0.391(3) ± 0.006 | 0.395(1) ± 0.008 • | 0.394(2) ± 0.009 | 0.390(4) ± 0.008 | 0.388(5) ± 0.008 | 0.386(6) ± 0.012 | 0.384(7) ± 0.007 | 0.381(8) ± 0.009 |
| Recreation | 0.383(6) ± 0.012 | 0.390(4) ± 0.016 | 0.397(2) ± 0.014 | 0.398(1) ± 0.016 • | 0.390(3) ± 0.016 | 0.388(5) ± 0.015 | 0.382(7) ± 0.014 | 0.380(8) ± 0.014 | 0.377(9) ± 0.012 |
| Society | 0.272(9) ± 0.015 | 0.286(6) ± 0.015 | 0.293(1) ± 0.012 • | 0.289(4) ± 0.014 | 0.291(2) ± 0.012 | 0.289(3) ± 0.009 | 0.288(5) ± 0.010 | 0.284(7) ± 0.009 | 0.283(8) ± 0.011 |
| eurlex-dc-l | 0.285(2) ± 0.012 | 0.288(1) ± 0.011 • | 0.279(3) ± 0.011 | 0.274(4) ± 0.010 | 0.267(5) ± 0.010 | 0.266(6) ± 0.008 | 0.264(7) ± 0.008 | 0.259(9) ± 0.007 | 0.260(8) ± 0.006 |
| eurlex-sm | 0.404(2) ± 0.009 | 0.408(1) ± 0.006 • | 0.397(3) ± 0.008 | 0.395(4) ± 0.010 | 0.388(5) ± 0.009 | 0.387(6) ± 0.012 | 0.385(7) ± 0.010 | 0.380(8) ± 0.009 | 0.377(9) ± 0.008 |
| tmc2007-500 | 0.576(9) ± 0.007 | 0.589(8) ± 0.006 | 0.602(4) ± 0.005 | 0.603(3) ± 0.007 | 0.603(2) ± 0.007 | 0.603(1) ± 0.008 • | 0.601(5) ± 0.009 | 0.599(6) ± 0.010 | 0.597(7) ± 0.007 |
| mediamill | 0.326(1) ± 0.006 • | 0.326(2) ± 0.008 | 0.314(3) ± 0.007 | 0.303(4) ± 0.003 | 0.293(5) ± 0.005 | 0.287(6) ± 0.006 | 0.284(7) ± 0.006 | 0.276(8) ± 0.004 | 0.266(9) ± 0.005 |
| average rank | 5.11 | 3.50 | 3.04 | 3.29 | 4.29 | 5.21 | 6.07 | 6.86 | 7.64 |
| win/tie/loss | 77/71/76 | 98/89/37 | 103/95/26 | 101/95/28 | 63/118/43 | 49/120/55 | 36/113/75 | 20/105/99 | 13/90/121 |
| Dataset | F1 Micro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.402(2) ± 0.051 | 0.412(1) ± 0.036 • | 0.384(3) ± 0.044 | 0.362(5) ± 0.061 | 0.358(6) ± 0.061 | 0.367(4) ± 0.037 | 0.337(8) ± 0.036 | 0.338(7) ± 0.031 | 0.332(9) ± 0.032 |
| CAL500 | 0.336(3) ± 0.012 | 0.334(7) ± 0.008 | 0.330(9) ± 0.015 | 0.336(5) ± 0.015 | 0.342(1) ± 0.014 • | 0.336(6) ± 0.012 | 0.333(8) ± 0.011 | 0.337(2) ± 0.010 | 0.336(4) ± 0.015 |
| emotions | 0.656(9) ± 0.020 | 0.672(4) ± 0.013 | 0.671(6) ± 0.013 | 0.672(5) ± 0.011 | 0.672(3) ± 0.011 | 0.673(2) ± 0.010 | 0.675(1) ± 0.013 • | 0.669(8) ± 0.010 | 0.670(7) ± 0.007 |
| genbase | 0.960(7) ± 0.012 | 0.967(2) ± 0.011 | 0.970(1) ± 0.011 • | 0.965(3) ± 0.014 | 0.965(4) ± 0.014 | 0.965(5) ± 0.013 | 0.962(6) ± 0.016 | 0.958(8) ± 0.017 | 0.955(9) ± 0.020 |
| LLOG | 0.425(1) ± 0.012 • | 0.342(9) ± 0.071 | 0.351(8) ± 0.066 | 0.425(2) ± 0.012 | 0.363(6) ± 0.059 | 0.369(3) ± 0.049 | 0.365(5) ± 0.050 | 0.367(4) ± 0.055 | 0.361(7) ± 0.053 |
| enron | 0.466(1) ± 0.009 • | 0.466(2) ± 0.011 | 0.463(3) ± 0.013 | 0.461(4) ± 0.016 | 0.460(5) ± 0.013 | 0.456(8) ± 0.010 | 0.455(9) ± 0.013 | 0.459(6) ± 0.015 | 0.457(7) ± 0.013 |
| scene | 0.710(9) ± 0.012 | 0.731(8) ± 0.010 | 0.742(3) ± 0.008 | 0.743(2) ± 0.008 | 0.743(1) ± 0.008 • | 0.740(4) ± 0.008 | 0.740(5) ± 0.010 | 0.736(7) ± 0.009 | 0.736(6) ± 0.008 |
| yeast | 0.631(9) ± 0.008 | 0.638(8) ± 0.009 | 0.643(6) ± 0.008 | 0.643(5) ± 0.008 | 0.643(3) ± 0.006 | 0.642(7) ± 0.007 | 0.644(2) ± 0.008 | 0.645(1) ± 0.008 • | 0.643(4) ± 0.009 |
| Slashdot | 0.844(1) ± 0.007 • | 0.844(2) ± 0.007 | 0.840(8) ± 0.007 | 0.839(9) ± 0.009 | 0.843(4) ± 0.008 | 0.841(7) ± 0.009 | 0.843(3) ± 0.009 | 0.842(5) ± 0.007 | 0.841(6) ± 0.006 |
| corel5k | 0.037(9) ± 0.006 | 0.038(8) ± 0.009 | 0.040(7) ± 0.007 | 0.050(6) ± 0.010 | 0.050(5) ± 0.011 | 0.055(4) ± 0.010 | 0.058(3) ± 0.014 | 0.064(1) ± 0.008 • | 0.063(2) ± 0.014 |
| rcv1subset1 | 0.313(2) ± 0.017 | 0.314(1) ± 0.012 • | 0.307(3) ± 0.017 | 0.300(4) ± 0.020 | 0.296(5) ± 0.021 | 0.286(8) ± 0.023 | 0.290(6) ± 0.023 | 0.286(7) ± 0.021 | 0.285(9) ± 0.022 |
| rcv1subset2 | 0.356(1) ± 0.011 • | 0.353(2) ± 0.013 | 0.342(3) ± 0.013 | 0.337(4) ± 0.014 | 0.334(5) ± 0.012 | 0.329(6) ± 0.009 | 0.324(8) ± 0.015 | 0.326(7) ± 0.009 | 0.321(9) ± 0.014 |
| rcv1subset3 | 0.349(1) ± 0.009 • | 0.348(2) ± 0.014 | 0.342(3) ± 0.014 | 0.333(5) ± 0.016 | 0.333(4) ± 0.009 | 0.326(8) ± 0.012 | 0.327(6) ± 0.009 | 0.326(7) ± 0.012 | 0.324(9) ± 0.011 |
| rcv1subset4 | 0.425(1) ± 0.017 • | 0.422(2) ± 0.014 | 0.408(3) ± 0.020 | 0.401(4) ± 0.023 | 0.394(5) ± 0.019 | 0.389(6) ± 0.019 | 0.384(7) ± 0.015 | 0.383(8) ± 0.012 | 0.382(9) ± 0.012 |
| rcv1subset5 | 0.364(2) ± 0.014 | 0.369(1) ± 0.014 • | 0.364(3) ± 0.013 | 0.351(4) ± 0.013 | 0.348(5) ± 0.014 | 0.342(7) ± 0.020 | 0.339(8) ± 0.014 | 0.344(6) ± 0.025 | 0.336(9) ± 0.021 |
| bibtex | 0.351(9) ± 0.005 | 0.363(8) ± 0.005 | 0.370(1) ± 0.004 • | 0.369(2) ± 0.004 | 0.367(5) ± 0.006 | 0.368(3) ± 0.005 | 0.367(4) ± 0.007 | 0.366(6) ± 0.006 | 0.363(7) ± 0.006 |
| Arts | 0.353(9) ± 0.012 | 0.364(7) ± 0.012 | 0.369(3) ± 0.012 | 0.372(1) ± 0.014 • | 0.369(2) ± 0.014 | 0.368(4) ± 0.014 | 0.367(5) ± 0.014 | 0.364(6) ± 0.012 | 0.363(8) ± 0.012 |
| Health | 0.557(9) ± 0.013 | 0.567(8) ± 0.010 | 0.576(1) ± 0.009 • | 0.574(3) ± 0.012 | 0.574(2) ± 0.011 | 0.574(4) ± 0.010 | 0.571(5) ± 0.011 | 0.571(6) ± 0.011 | 0.571(7) ± 0.011 |
| Business | 0.717(9) ± 0.003 | 0.721(6) ± 0.003 | 0.723(2) ± 0.003 | 0.723(1) ± 0.003 • | 0.722(3) ± 0.004 | 0.722(4) ± 0.003 | 0.721(5) ± 0.004 | 0.721(7) ± 0.003 | 0.721(8) ± 0.003 |
| Education | 0.368(9) ± 0.012 | 0.380(3) ± 0.011 | 0.383(1) ± 0.012 • | 0.382(2) ± 0.013 | 0.378(4) ± 0.014 | 0.378(5) ± 0.014 | 0.374(6) ± 0.010 | 0.372(7) ± 0.013 | 0.370(8) ± 0.013 |
| Computers | 0.498(9) ± 0.007 | 0.505(8) ± 0.005 | 0.511(4) ± 0.005 | 0.511(3) ± 0.006 | 0.511(1) ± 0.005 • | 0.511(2) ± 0.007 | 0.510(5) ± 0.006 | 0.510(6) ± 0.006 | 0.509(7) ± 0.006 |
| Entertainment | 0.483(9) ± 0.010 | 0.495(8) ± 0.007 | 0.503(7) ± 0.006 | 0.505(3) ± 0.007 | 0.505(6) ± 0.008 | 0.506(1) ± 0.006 • | 0.505(2) ± 0.007 | 0.505(5) ± 0.007 | 0.505(4) ± 0.007 |
| Recreation | 0.446(9) ± 0.012 | 0.455(3) ± 0.012 | 0.457(1) ± 0.012 • | 0.456(2) ± 0.012 | 0.454(4) ± 0.012 | 0.453(5) ± 0.012 | 0.451(6) ± 0.012 | 0.449(7) ± 0.011 | 0.449(8) ± 0.011 |
| Society | 0.450(9) ± 0.011 | 0.461(8) ± 0.010 | 0.469(1) ± 0.009 • | 0.468(3) ± 0.010 | 0.468(2) ± 0.010 | 0.467(4) ± 0.009 | 0.466(5) ± 0.010 | 0.466(6) ± 0.011 | 0.462(7) ± 0.010 |
| eurlex-dc-l | 0.493(2) ± 0.006 | 0.494(1) ± 0.005 • | 0.488(3) ± 0.006 | 0.483(4) ± 0.007 | 0.479(5) ± 0.007 | 0.477(6) ± 0.004 | 0.475(7) ± 0.006 | 0.473(9) ± 0.006 | 0.474(8) ± 0.004 |
| eurlex-sm | 0.603(2) ± 0.007 | 0.606(1) ± 0.006 • | 0.598(3) ± 0.007 | 0.594(4) ± 0.007 | 0.589(5) ± 0.007 | 0.586(6) ± 0.008 | 0.584(7) ± 0.007 | 0.582(8) ± 0.006 | 0.580(9) ± 0.006 |
| tmc2007-500 | 0.701(9) ± 0.003 | 0.713(8) ± 0.003 | 0.722(7) ± 0.003 | 0.725(5) ± 0.003 | 0.726(4) ± 0.003 | 0.727(1) ± 0.003 • | 0.727(2) ± 0.003 | 0.726(3) ± 0.003 | 0.725(6) ± 0.003 |
| mediamill | 0.644(3) ± 0.002 | 0.647(1) ± 0.002 • | 0.644(2) ± 0.002 | 0.639(4) ± 0.002 | 0.635(5) ± 0.001 | 0.631(6) ± 0.002 | 0.628(7) ± 0.002 | 0.625(8) ± 0.002 | 0.623(9) ± 0.002 |
| average rank | 5.54 | 4.61 | 3.75 | 3.71 | 3.93 | 4.86 | 5.39 | 6.00 | 7.21 |
| win/tie/loss | 71/44/109 | 90/68/66 | 102/89/33 | 93/96/35 | 75/107/42 | 59/109/56 | 47/111/66 | 33/107/84 | 23/99/102 |
| Dataset | Hamming Loss | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| k = 3 | k = 5 | k = 10 | k = 15 | k = 20 | k = 25 | k = 30 | k = 35 | k = 40 | |
| birds | 0.140(9) ± 0.008 | 0.138(4) ± 0.006 | 0.135(1) ± 0.005 • | 0.138(6) ± 0.007 | 0.137(3) ± 0.008 | 0.139(8) ± 0.006 | 0.139(7) ± 0.004 | 0.137(2) ± 0.005 | 0.138(5) ± 0.004 |
| CAL500 | 0.189(8) ± 0.001 | 0.189(9) ± 0.002 | 0.188(7) ± 0.002 | 0.187(5) ± 0.001 | 0.187(1) ± 0.001 • | 0.187(3) ± 0.002 | 0.187(2) ± 0.002 | 0.187(4) ± 0.002 | 0.187(6) ± 0.001 |
| emotions | 0.202(9) ± 0.010 | 0.192(7) ± 0.006 | 0.192(5) ± 0.007 | 0.191(4) ± 0.006 | 0.190(2) ± 0.005 | 0.191(3) ± 0.004 | 0.189(1) ± 0.007 • | 0.193(8) ± 0.005 | 0.192(6) ± 0.003 |
| genbase | 0.007(7) ± 0.002 | 0.006(2) ± 0.002 | 0.005(1) ± 0.002 • | 0.006(3) ± 0.002 | 0.006(4) ± 0.002 | 0.006(5) ± 0.002 | 0.007(6) ± 0.003 | 0.007(8) ± 0.003 | 0.008(9) ± 0.003 |
| LLOG | 0.185(1) ± 0.004 • | 0.189(9) ± 0.006 | 0.189(8) ± 0.006 | 0.185(2) ± 0.004 | 0.188(6) ± 0.006 | 0.188(5) ± 0.005 | 0.188(3) ± 0.006 | 0.188(4) ± 0.005 | 0.189(7) ± 0.006 |
| enron | 0.077(9) ± 0.001 | 0.077(8) ± 0.001 | 0.076(7) ± 0.001 | 0.076(6) ± 0.001 | 0.075(4) ± 0.001 | 0.075(3) ± 0.001 | 0.075(5) ± 0.001 | 0.075(1) ± 0.001 • | 0.075(2) ± 0.001 |
| scene | 0.095(9) ± 0.004 | 0.089(8) ± 0.003 | 0.085(3) ± 0.002 | 0.084(2) ± 0.002 | 0.084(1) ± 0.003 • | 0.085(4) ± 0.003 | 0.085(5) ± 0.003 | 0.086(7) ± 0.003 | 0.086(6) ± 0.002 |
| yeast | 0.209(9) ± 0.003 | 0.204(8) ± 0.004 | 0.202(7) ± 0.004 | 0.200(6) ± 0.003 | 0.200(4) ± 0.003 | 0.200(5) ± 0.004 | 0.199(2) ± 0.004 | 0.199(1) ± 0.003 • | 0.200(3) ± 0.005 |
| Slashdot | 0.028(2) ± 0.001 | 0.028(1) ± 0.001 • | 0.029(7) ± 0.001 | 0.030(9) ± 0.002 | 0.029(4) ± 0.001 | 0.029(8) ± 0.002 | 0.029(3) ± 0.002 | 0.029(5) ± 0.001 | 0.029(6) ± 0.001 |
| corel5k | 0.021(8) ± 0.000 | 0.021(9) ± 0.000 | 0.021(7) ± 0.000 | 0.021(6) ± 0.000 | 0.021(5) ± 0.000 | 0.021(4) ± 0.000 | 0.021(2) ± 0.000 | 0.021(3) ± 0.000 | 0.021(1) ± 0.000 • |
| rcv1subset1 | 0.033(9) ± 0.000 | 0.033(8) ± 0.000 | 0.033(7) ± 0.000 | 0.032(6) ± 0.000 | 0.032(3) ± 0.000 | 0.032(2) ± 0.000 | 0.032(5) ± 0.000 | 0.032(1) ± 0.000 • | 0.032(4) ± 0.000 |
| rcv1subset2 | 0.028(9) ± 0.000 | 0.027(8) ± 0.000 | 0.027(6) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(4) ± 0.000 | 0.027(7) ± 0.000 | 0.027(3) ± 0.000 | 0.027(5) ± 0.000 |
| rcv1subset3 | 0.028(9) ± 0.000 | 0.027(8) ± 0.000 | 0.027(7) ± 0.000 | 0.027(3) ± 0.000 | 0.027(5) ± 0.000 | 0.027(6) ± 0.000 | 0.027(4) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 |
| rcv1subset4 | 0.025(9) ± 0.000 | 0.024(4) ± 0.000 | 0.024(2) ± 0.000 | 0.024(1) ± 0.000 • | 0.024(3) ± 0.000 | 0.024(5) ± 0.000 | 0.024(6) ± 0.000 | 0.024(7) ± 0.000 | 0.024(8) ± 0.000 |
| rcv1subset5 | 0.027(9) ± 0.000 | 0.027(4) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(3) ± 0.000 | 0.027(5) ± 0.000 | 0.027(6) ± 0.000 | 0.027(7) ± 0.000 | 0.027(8) ± 0.000 |
| bibtex | 0.013(9) ± 0.000 | 0.013(8) ± 0.000 | 0.013(7) ± 0.000 | 0.013(1) ± 0.000 • | 0.013(2) ± 0.000 | 0.013(3) ± 0.000 | 0.013(4) ± 0.000 | 0.013(5) ± 0.000 | 0.013(6) ± 0.000 |
| Arts | 0.063(9) ± 0.001 | 0.061(8) ± 0.001 | 0.060(7) ± 0.001 | 0.059(6) ± 0.001 | 0.059(5) ± 0.001 | 0.059(1) ± 0.001 • | 0.059(2) ± 0.000 | 0.059(3) ± 0.000 | 0.059(4) ± 0.000 |
| Health | 0.059(9) ± 0.001 | 0.057(8) ± 0.001 | 0.055(7) ± 0.001 | 0.055(6) ± 0.001 | 0.055(2) ± 0.001 | 0.055(1) ± 0.001 • | 0.055(5) ± 0.001 | 0.055(4) ± 0.001 | 0.055(3) ± 0.001 |
| Business | 0.032(9) ± 0.000 | 0.031(8) ± 0.000 | 0.031(2) ± 0.000 | 0.031(1) ± 0.000 • | 0.031(3) ± 0.000 | 0.031(6) ± 0.000 | 0.031(4) ± 0.000 | 0.031(5) ± 0.000 | 0.031(7) ± 0.000 |
| Education | 0.049(9) ± 0.001 | 0.048(8) ± 0.000 | 0.046(7) ± 0.001 | 0.046(6) ± 0.001 | 0.046(5) ± 0.001 | 0.046(4) ± 0.001 | 0.046(3) ± 0.001 | 0.046(1) ± 0.001 • | 0.046(2) ± 0.001 |
| Computers | 0.045(9) ± 0.001 | 0.044(8) ± 0.000 | 0.043(7) ± 0.000 | 0.043(6) ± 0.000 | 0.043(5) ± 0.000 | 0.043(2) ± 0.001 | 0.043(3) ± 0.001 | 0.043(4) ± 0.001 | 0.043(1) ± 0.001 • |
| Entertainment | 0.065(9) ± 0.001 | 0.063(8) ± 0.001 | 0.062(7) ± 0.001 | 0.061(6) ± 0.001 | 0.061(5) ± 0.001 | 0.060(4) ± 0.001 | 0.060(3) ± 0.001 | 0.060(2) ± 0.001 | 0.060(1) ± 0.001 • |
| Recreation | 0.053(9) ± 0.001 | 0.051(8) ± 0.001 | 0.050(7) ± 0.001 | 0.050(5) ± 0.001 | 0.050(1) ± 0.001 • | 0.050(3) ± 0.001 | 0.050(2) ± 0.001 | 0.050(6) ± 0.001 | 0.050(4) ± 0.001 |
| Society | 0.054(9) ± 0.001 | 0.052(8) ± 0.001 | 0.051(7) ± 0.001 | 0.051(6) ± 0.001 | 0.051(5) ± 0.001 | 0.050(3) ± 0.001 | 0.050(2) ± 0.001 | 0.050(1) ± 0.001 • | 0.051(4) ± 0.001 |
| eurlex-dc-l | 0.005(9) ± 0.000 | 0.004(3) ± 0.000 | 0.004(1) ± 0.000 • | 0.004(2) ± 0.000 | 0.004(4) ± 0.000 | 0.005(5) ± 0.000 | 0.005(6) ± 0.000 | 0.005(7) ± 0.000 | 0.005(8) ± 0.000 |
| eurlex-sm | 0.011(7) ± 0.000 | 0.011(1) ± 0.000 • | 0.011(2) ± 0.000 | 0.011(3) ± 0.000 | 0.011(4) ± 0.000 | 0.011(5) ± 0.000 | 0.011(6) ± 0.000 | 0.011(8) ± 0.000 | 0.011(9) ± 0.000 |
| tmc2007-500 | 0.056(9) ± 0.000 | 0.054(8) ± 0.000 | 0.052(7) ± 0.001 | 0.051(6) ± 0.000 | 0.051(4) ± 0.000 | 0.051(1) ± 0.000 • | 0.051(2) ± 0.000 | 0.051(3) ± 0.001 | 0.051(5) ± 0.001 |
| mediamill | 0.028(6) ± 0.000 | 0.028(2) ± 0.000 | 0.028(1) ± 0.000 • | 0.028(3) ± 0.000 | 0.028(4) ± 0.000 | 0.028(5) ± 0.000 | 0.028(7) ± 0.000 | 0.028(8) ± 0.000 | 0.029(9) ± 0.000 |
| average rank | 8.14 | 6.54 | 5.18 | 4.25 | 3.54 | 4.04 | 4.04 | 4.25 | 5.04 |
| win/tie/loss | 12/31/181 | 45/48/131 | 75/80/69 | 89/96/39 | 86/114/24 | 73/124/27 | 69/125/30 | 68/125/31 | 59/121/44 |
| Dataset | AUC Macro | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.723(9) ± 0.033 | 0.722(11) ± 0.027 | 0.722(10) ± 0.031 | 0.727(8) ± 0.031 | 0.728(6) ± 0.030 | 0.730(3) ± 0.029 | 0.729(5) ± 0.030 | 0.729(4) ± 0.029 | 0.730(1) ± 0.029 • | 0.730(2) ± 0.029 | 0.728(7) ± 0.031 |
| CAL500 | 0.564(10) ± 0.007 | 0.569(9) ± 0.008 | 0.571(4) ± 0.007 | 0.572(1) ± 0.006 • | 0.571(2) ± 0.006 | 0.571(3) ± 0.006 | 0.571(5) ± 0.006 | 0.570(6) ± 0.006 | 0.570(7) ± 0.006 | 0.570(8) ± 0.006 | 0.561(11) ± 0.006 |
| emotions | 0.840(11) ± 0.006 | 0.842(10) ± 0.007 | 0.843(9) ± 0.005 | 0.845(8) ± 0.005 | 0.846(6) ± 0.005 | 0.847(4) ± 0.006 | 0.847(3) ± 0.007 | 0.847(5) ± 0.007 | 0.848(2) ± 0.006 | 0.848(1) ± 0.006 • | 0.845(7) ± 0.009 |
| genbase | 0.997(10) ± 0.003 | 0.997(1) ± 0.002 • | 0.997(3) ± 0.002 | 0.997(4) ± 0.003 | 0.997(5) ± 0.003 | 0.997(6) ± 0.003 | 0.997(2) ± 0.003 | 0.997(8) ± 0.003 | 0.997(9) ± 0.003 | 0.997(7) ± 0.003 | 0.996(11) ± 0.004 |
| LLOG | 0.603(2) ± 0.006 | 0.603(5) ± 0.006 | 0.603(1) ± 0.006 • | 0.603(3) ± 0.006 | 0.603(7) ± 0.006 | 0.603(10) ± 0.006 | 0.603(4) ± 0.006 | 0.603(8) ± 0.006 | 0.603(6) ± 0.006 | 0.603(11) ± 0.006 | 0.603(9) ± 0.006 |
| enron | 0.671(10) ± 0.007 | 0.680(1) ± 0.012 • | 0.679(2) ± 0.012 | 0.676(3) ± 0.013 | 0.676(4) ± 0.012 | 0.675(5) ± 0.012 | 0.674(6) ± 0.011 | 0.674(7) ± 0.011 | 0.673(8) ± 0.011 | 0.673(9) ± 0.011 | 0.663(11) ± 0.011 |
| scene | 0.942(11) ± 0.002 | 0.942(10) ± 0.002 | 0.943(9) ± 0.002 | 0.944(8) ± 0.002 | 0.944(7) ± 0.002 | 0.945(6) ± 0.002 | 0.945(5) ± 0.002 | 0.945(3) ± 0.002 | 0.945(2) ± 0.002 | 0.945(1) ± 0.002 • | 0.945(4) ± 0.003 |
| yeast | 0.690(11) ± 0.010 | 0.692(10) ± 0.010 | 0.698(9) ± 0.010 | 0.709(7) ± 0.007 | 0.711(5) ± 0.006 | 0.712(4) ± 0.006 | 0.712(3) ± 0.006 | 0.712(1) ± 0.006 • | 0.712(2) ± 0.006 | 0.711(6) ± 0.007 | 0.699(8) ± 0.004 |
| Slashdot | 0.719(7) ± 0.021 | 0.716(10) ± 0.019 | 0.718(9) ± 0.021 | 0.723(3) ± 0.018 | 0.723(2) ± 0.021 | 0.724(1) ± 0.019 • | 0.722(4) ± 0.019 | 0.720(5) ± 0.019 | 0.719(6) ± 0.020 | 0.719(8) ± 0.019 | 0.686(11) ± 0.016 |
| corel5k | 0.651(11) ± 0.009 | 0.671(9) ± 0.005 | 0.683(8) ± 0.005 | 0.689(7) ± 0.005 | 0.690(2) ± 0.005 | 0.690(1) ± 0.005 • | 0.690(3) ± 0.005 | 0.690(4) ± 0.005 | 0.689(5) ± 0.004 | 0.689(6) ± 0.004 | 0.666(10) ± 0.004 |
| rcv1subset1 | 0.877(11) ± 0.005 | 0.892(3) ± 0.004 | 0.893(1) ± 0.004 • | 0.893(2) ± 0.004 | 0.891(4) ± 0.004 | 0.890(5) ± 0.004 | 0.890(6) ± 0.004 | 0.890(7) ± 0.004 | 0.889(9) ± 0.004 | 0.889(8) ± 0.003 | 0.882(10) ± 0.003 |
| rcv1subset2 | 0.873(11) ± 0.006 | 0.889(1) ± 0.005 • | 0.889(3) ± 0.005 | 0.889(2) ± 0.005 | 0.888(4) ± 0.005 | 0.887(5) ± 0.005 | 0.887(6) ± 0.005 | 0.886(7) ± 0.005 | 0.886(8) ± 0.005 | 0.886(9) ± 0.005 | 0.873(10) ± 0.007 |
| rcv1subset3 | 0.868(10) ± 0.003 | 0.880(4) ± 0.004 | 0.880(1) ± 0.004 • | 0.879(5) ± 0.003 | 0.880(2) ± 0.004 | 0.880(3) ± 0.004 | 0.879(6) ± 0.004 | 0.879(7) ± 0.004 | 0.878(8) ± 0.004 | 0.878(9) ± 0.004 | 0.863(11) ± 0.004 |
| rcv1subset4 | 0.877(10) ± 0.006 | 0.889(1) ± 0.006 • | 0.888(2) ± 0.006 | 0.887(4) ± 0.007 | 0.887(3) ± 0.007 | 0.886(5) ± 0.008 | 0.886(6) ± 0.007 | 0.885(7) ± 0.008 | 0.885(8) ± 0.008 | 0.885(9) ± 0.008 | 0.873(11) ± 0.006 |
| rcv1subset5 | 0.864(10) ± 0.005 | 0.875(1) ± 0.005 • | 0.875(2) ± 0.005 | 0.874(3) ± 0.005 | 0.873(4) ± 0.005 | 0.872(5) ± 0.005 | 0.872(6) ± 0.005 | 0.872(7) ± 0.005 | 0.871(8) ± 0.005 | 0.871(9) ± 0.005 | 0.857(11) ± 0.005 |
| bibtex | 0.862(11) ± 0.004 | 0.878(9) ± 0.003 | 0.883(8) ± 0.002 | 0.885(7) ± 0.001 | 0.886(6) ± 0.001 | 0.886(5) ± 0.001 | 0.887(4) ± 0.001 | 0.887(3) ± 0.001 | 0.887(2) ± 0.001 | 0.887(1) ± 0.001 • | 0.878(10) ± 0.002 |
| Arts | 0.725(10) ± 0.008 | 0.729(7) ± 0.010 | 0.731(2) ± 0.008 | 0.731(1) ± 0.009 • | 0.730(3) ± 0.009 | 0.730(4) ± 0.010 | 0.729(5) ± 0.009 | 0.729(6) ± 0.009 | 0.728(8) ± 0.010 | 0.728(9) ± 0.009 | 0.701(11) ± 0.009 |
| Health | 0.771(10) ± 0.010 | 0.780(1) ± 0.010 • | 0.780(2) ± 0.009 | 0.779(3) ± 0.010 | 0.778(6) ± 0.009 | 0.778(4) ± 0.010 | 0.778(5) ± 0.010 | 0.777(7) ± 0.010 | 0.777(8) ± 0.009 | 0.776(9) ± 0.010 | 0.749(11) ± 0.007 |
| Business | 0.732(10) ± 0.018 | 0.747(9) ± 0.010 | 0.752(4) ± 0.006 | 0.753(1) ± 0.008 • | 0.752(3) ± 0.007 | 0.753(2) ± 0.007 | 0.752(5) ± 0.008 | 0.751(6) ± 0.008 | 0.751(7) ± 0.008 | 0.751(8) ± 0.008 | 0.709(11) ± 0.007 |
| Education | 0.736(10) ± 0.011 | 0.746(5) ± 0.012 | 0.747(3) ± 0.012 | 0.748(1) ± 0.012 • | 0.748(2) ± 0.014 | 0.747(4) ± 0.014 | 0.745(6) ± 0.013 | 0.745(7) ± 0.013 | 0.743(8) ± 0.014 | 0.743(9) ± 0.013 | 0.711(11) ± 0.018 |
| Computers | 0.743(10) ± 0.007 | 0.748(9) ± 0.007 | 0.750(3) ± 0.006 | 0.750(2) ± 0.006 | 0.750(1) ± 0.005 • | 0.750(4) ± 0.006 | 0.749(7) ± 0.006 | 0.749(5) ± 0.006 | 0.749(6) ± 0.006 | 0.748(8) ± 0.006 | 0.716(11) ± 0.008 |
| Entertainment | 0.775(10) ± 0.009 | 0.781(3) ± 0.006 | 0.781(5) ± 0.005 | 0.782(1) ± 0.005 • | 0.782(2) ± 0.004 | 0.781(4) ± 0.004 | 0.780(6) ± 0.004 | 0.780(7) ± 0.003 | 0.780(8) ± 0.003 | 0.779(9) ± 0.004 | 0.757(11) ± 0.005 |
| Recreation | 0.786(10) ± 0.008 | 0.786(6) ± 0.007 | 0.788(3) ± 0.008 | 0.789(1) ± 0.008 • | 0.788(2) ± 0.009 | 0.788(4) ± 0.009 | 0.787(5) ± 0.009 | 0.786(7) ± 0.008 | 0.786(8) ± 0.008 | 0.786(9) ± 0.008 | 0.756(11) ± 0.009 |
| Society | 0.704(10) ± 0.004 | 0.705(9) ± 0.004 | 0.706(7) ± 0.005 | 0.706(4) ± 0.006 | 0.707(1) ± 0.006 • | 0.706(5) ± 0.006 | 0.706(8) ± 0.006 | 0.706(3) ± 0.007 | 0.707(2) ± 0.007 | 0.706(6) ± 0.007 | 0.685(11) ± 0.007 |
| eurlex-dc-l | 0.874(11) ± 0.003 | 0.881(10) ± 0.006 | 0.892(8) ± 0.006 | 0.899(7) ± 0.005 | 0.900(5) ± 0.004 | 0.900(3) ± 0.005 | 0.900(4) ± 0.005 | 0.900(2) ± 0.005 | 0.901(1) ± 0.005 • | 0.900(6) ± 0.005 | 0.883(9) ± 0.007 |
| eurlex-sm | 0.896(11) ± 0.004 | 0.900(9) ± 0.004 | 0.905(8) ± 0.003 | 0.908(7) ± 0.003 | 0.908(6) ± 0.003 | 0.908(2) ± 0.003 | 0.909(1) ± 0.003 • | 0.908(3) ± 0.003 | 0.908(5) ± 0.003 | 0.908(4) ± 0.003 | 0.899(10) ± 0.004 |
| tmc2007-500 | 0.907(11) ± 0.002 | 0.913(10) ± 0.002 | 0.917(8) ± 0.002 | 0.919(7) ± 0.002 | 0.920(6) ± 0.002 | 0.921(5) ± 0.002 | 0.922(4) ± 0.002 | 0.922(3) ± 0.002 | 0.923(1) ± 0.002 • | 0.923(2) ± 0.002 | 0.914(9) ± 0.002 |
| mediamill | 0.791(11) ± 0.003 | 0.803(10) ± 0.003 | 0.812(9) ± 0.003 | 0.822(7) ± 0.002 | 0.824(6) ± 0.002 | 0.825(5) ± 0.002 | 0.826(4) ± 0.002 | 0.826(3) ± 0.002 | 0.827(2) ± 0.002 | 0.827(1) ± 0.002 • | 0.820(8) ± 0.003 |
| average rank | 9.96 | 6.54 | 5.11 | 4.18 | 4.00 | 4.18 | 4.79 | 5.29 | 5.54 | 6.57 | 9.86 |
| win/tie/loss | 13/64/203 | 69/124/87 | 106/103/71 | 129/96/55 | 124/119/37 | 124/124/32 | 109/122/49 | 96/125/59 | 92/114/74 | 86/109/85 | 16/52/212 |
| Dataset | AUC Micr | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.743(10) ± 0.025 | 0.747(7) ± 0.014 | 0.746(8) ± 0.019 | 0.747(6) ± 0.019 | 0.746(9) ± 0.019 | 0.751(1) ± 0.017 • | 0.749(3) ± 0.017 | 0.749(5) ± 0.015 | 0.750(2) ± 0.016 | 0.749(4) ± 0.014 | 0.737(11) ± 0.022 |
| CAL500 | 0.722(11) ± 0.010 | 0.745(10) ± 0.004 | 0.754(8) ± 0.003 | 0.759(1) ± 0.004 • | 0.757(3) ± 0.004 | 0.758(2) ± 0.004 | 0.757(4) ± 0.004 | 0.756(7) ± 0.005 | 0.756(6) ± 0.005 | 0.757(5) ± 0.005 | 0.751(9) ± 0.007 |
| emotions | 0.854(11) ± 0.006 | 0.856(10) ± 0.006 | 0.859(9) ± 0.005 | 0.860(8) ± 0.006 | 0.862(6) ± 0.005 | 0.862(5) ± 0.005 | 0.863(2) ± 0.006 | 0.862(7) ± 0.006 | 0.862(4) ± 0.006 | 0.863(1) ± 0.006 • | 0.862(3) ± 0.005 |
| genbase | 0.996(7) ± 0.004 | 0.996(10) ± 0.003 | 0.996(9) ± 0.003 | 0.996(4) ± 0.004 | 0.996(2) ± 0.004 | 0.997(1) ± 0.004 • | 0.996(3) ± 0.004 | 0.996(6) ± 0.004 | 0.996(5) ± 0.004 | 0.996(8) ± 0.004 | 0.995(11) ± 0.004 |
| LLOG | 0.767(9) ± 0.002 | 0.767(8) ± 0.002 | 0.767(10) ± 0.002 | 0.767(1) ± 0.002 • | 0.767(2) ± 0.002 | 0.767(4) ± 0.002 | 0.767(6) ± 0.003 | 0.767(7) ± 0.003 | 0.767(5) ± 0.002 | 0.767(3) ± 0.002 | 0.764(11) ± 0.005 |
| enron | 0.847(11) ± 0.005 | 0.859(10) ± 0.003 | 0.860(5) ± 0.002 | 0.860(1) ± 0.002 • | 0.860(2) ± 0.002 | 0.860(3) ± 0.002 | 0.860(4) ± 0.002 | 0.860(6) ± 0.002 | 0.860(7) ± 0.002 | 0.859(8) ± 0.002 | 0.859(9) ± 0.003 |
| scene | 0.948(11) ± 0.002 | 0.949(10) ± 0.001 | 0.949(9) ± 0.002 | 0.950(8) ± 0.002 | 0.950(7) ± 0.002 | 0.950(5) ± 0.002 | 0.951(4) ± 0.002 | 0.951(2) ± 0.002 | 0.951(3) ± 0.002 | 0.951(1) ± 0.002 • | 0.950(6) ± 0.003 |
| yeast | 0.829(11) ± 0.005 | 0.830(10) ± 0.005 | 0.833(9) ± 0.005 | 0.839(8) ± 0.004 | 0.842(6) ± 0.004 | 0.844(5) ± 0.003 | 0.844(4) ± 0.003 | 0.845(1) ± 0.004 • | 0.845(2) ± 0.003 | 0.844(3) ± 0.004 | 0.841(7) ± 0.004 |
| Slashdot | 0.944(8) ± 0.003 | 0.944(10) ± 0.003 | 0.944(9) ± 0.003 | 0.945(1) ± 0.004 • | 0.945(2) ± 0.004 | 0.945(4) ± 0.004 | 0.945(3) ± 0.004 | 0.944(7) ± 0.004 | 0.945(5) ± 0.004 | 0.945(6) ± 0.004 | 0.938(11) ± 0.006 |
| corel5k | 0.781(11) ± 0.005 | 0.799(1) ± 0.003 • | 0.797(2) ± 0.004 | 0.796(5) ± 0.004 | 0.796(3) ± 0.004 | 0.796(4) ± 0.004 | 0.795(7) ± 0.003 | 0.795(6) ± 0.003 | 0.795(8) ± 0.003 | 0.795(9) ± 0.003 | 0.791(10) ± 0.004 |
| rcv1subset1 | 0.905(1) ± 0.003 • | 0.896(2) ± 0.005 | 0.887(3) ± 0.009 | 0.876(4) ± 0.009 | 0.874(5) ± 0.009 | 0.871(6) ± 0.009 | 0.871(7) ± 0.007 | 0.869(8) ± 0.008 | 0.869(9) ± 0.008 | 0.869(10) ± 0.007 | 0.859(11) ± 0.007 |
| rcv1subset2 | 0.906(1) ± 0.004 • | 0.894(2) ± 0.008 | 0.878(3) ± 0.012 | 0.869(4) ± 0.012 | 0.865(5) ± 0.010 | 0.861(7) ± 0.008 | 0.861(6) ± 0.008 | 0.860(8) ± 0.008 | 0.859(10) ± 0.008 | 0.859(9) ± 0.007 | 0.843(11) ± 0.008 |
| rcv1subset3 | 0.897(1) ± 0.005 • | 0.882(2) ± 0.006 | 0.871(3) ± 0.009 | 0.863(4) ± 0.007 | 0.861(5) ± 0.007 | 0.858(6) ± 0.007 | 0.855(7) ± 0.008 | 0.855(8) ± 0.008 | 0.853(9) ± 0.008 | 0.851(10) ± 0.008 | 0.835(11) ± 0.006 |
| rcv1subset4 | 0.917(1) ± 0.003 • | 0.908(2) ± 0.008 | 0.897(3) ± 0.009 | 0.888(4) ± 0.009 | 0.884(5) ± 0.010 | 0.884(6) ± 0.008 | 0.883(7) ± 0.008 | 0.883(8) ± 0.008 | 0.883(10) ± 0.007 | 0.883(9) ± 0.007 | 0.866(11) ± 0.007 |
| rcv1subset5 | 0.902(1) ± 0.003 • | 0.885(2) ± 0.007 | 0.877(3) ± 0.006 | 0.870(4) ± 0.007 | 0.868(5) ± 0.009 | 0.867(6) ± 0.009 | 0.866(7) ± 0.008 | 0.864(8) ± 0.007 | 0.864(9) ± 0.008 | 0.863(10) ± 0.008 | 0.847(11) ± 0.007 |
| bibtex | 0.869(3) ± 0.004 | 0.877(1) ± 0.004 • | 0.872(2) ± 0.005 | 0.866(4) ± 0.006 | 0.863(5) ± 0.006 | 0.860(6) ± 0.004 | 0.859(7) ± 0.004 | 0.858(8) ± 0.004 | 0.856(9) ± 0.004 | 0.856(10) ± 0.004 | 0.820(11) ± 0.008 |
| Arts | 0.849(10) ± 0.003 | 0.850(9) ± 0.004 | 0.850(8) ± 0.004 | 0.852(1) ± 0.003 • | 0.851(2) ± 0.003 | 0.851(5) ± 0.004 | 0.851(4) ± 0.004 | 0.851(6) ± 0.004 | 0.851(3) ± 0.003 | 0.851(7) ± 0.004 | 0.838(11) ± 0.003 |
| Health | 0.916(10) ± 0.002 | 0.917(9) ± 0.002 | 0.918(8) ± 0.002 | 0.919(7) ± 0.002 | 0.919(5) ± 0.002 | 0.919(3) ± 0.002 | 0.919(1) ± 0.002 • | 0.919(2) ± 0.002 | 0.919(4) ± 0.002 | 0.919(6) ± 0.002 | 0.912(11) ± 0.002 |
| Business | 0.946(10) ± 0.002 | 0.947(9) ± 0.001 | 0.948(1) ± 0.001 • | 0.947(5) ± 0.001 | 0.947(3) ± 0.001 | 0.947(4) ± 0.000 | 0.947(2) ± 0.001 | 0.947(6) ± 0.001 | 0.947(8) ± 0.001 | 0.947(7) ± 0.001 | 0.939(11) ± 0.002 |
| Education | 0.905(10) ± 0.002 | 0.906(9) ± 0.002 | 0.906(4) ± 0.002 | 0.907(1) ± 0.002 • | 0.906(3) ± 0.002 | 0.906(2) ± 0.002 | 0.906(6) ± 0.002 | 0.906(5) ± 0.002 | 0.906(7) ± 0.002 | 0.906(8) ± 0.002 | 0.899(11) ± 0.002 |
| Computers | 0.892(10) ± 0.004 | 0.893(9) ± 0.004 | 0.895(8) ± 0.003 | 0.896(2) ± 0.003 | 0.896(1) ± 0.003 • | 0.895(4) ± 0.003 | 0.895(5) ± 0.003 | 0.895(3) ± 0.003 | 0.895(6) ± 0.002 | 0.895(7) ± 0.002 | 0.884(11) ± 0.005 |
| Entertainment | 0.889(10) ± 0.002 | 0.890(9) ± 0.002 | 0.891(7) ± 0.002 | 0.891(3) ± 0.002 | 0.891(1) ± 0.002 • | 0.891(2) ± 0.002 | 0.891(4) ± 0.001 | 0.891(5) ± 0.001 | 0.891(6) ± 0.001 | 0.891(8) ± 0.001 | 0.880(11) ± 0.001 |
| Recreation | 0.873(7) ± 0.004 | 0.874(4) ± 0.004 | 0.875(2) ± 0.004 | 0.875(1) ± 0.004 • | 0.874(3) ± 0.004 | 0.874(5) ± 0.004 | 0.873(6) ± 0.004 | 0.873(8) ± 0.004 | 0.873(9) ± 0.004 | 0.872(10) ± 0.004 | 0.854(11) ± 0.004 |
| Society | 0.864(10) ± 0.004 | 0.867(9) ± 0.002 | 0.868(8) ± 0.002 | 0.869(5) ± 0.002 | 0.869(1) ± 0.002 • | 0.869(4) ± 0.002 | 0.869(3) ± 0.002 | 0.869(2) ± 0.002 | 0.869(6) ± 0.002 | 0.869(7) ± 0.002 | 0.861(11) ± 0.002 |
| eurlex-dc-l | 0.915(10) ± 0.004 | 0.916(9) ± 0.005 | 0.918(8) ± 0.006 | 0.920(1) ± 0.005 • | 0.919(2) ± 0.005 | 0.919(3) ± 0.006 | 0.919(7) ± 0.006 | 0.919(6) ± 0.006 | 0.919(4) ± 0.006 | 0.919(5) ± 0.006 | 0.904(11) ± 0.005 |
| eurlex-sm | 0.945(11) ± 0.002 | 0.947(10) ± 0.002 | 0.950(8) ± 0.002 | 0.952(7) ± 0.002 | 0.952(6) ± 0.002 | 0.952(5) ± 0.002 | 0.953(4) ± 0.002 | 0.953(3) ± 0.002 | 0.953(2) ± 0.001 | 0.953(1) ± 0.001 • | 0.948(9) ± 0.001 |
| tmc2007-500 | 0.949(11) ± 0.001 | 0.954(10) ± 0.001 | 0.956(9) ± 0.001 | 0.957(7) ± 0.001 | 0.958(6) ± 0.001 | 0.959(5) ± 0.001 | 0.959(4) ± 0.001 | 0.959(3) ± 0.001 | 0.959(2) ± 0.001 | 0.959(1) ± 0.001 • | 0.956(8) ± 0.001 |
| mediamill | 0.948(11) ± 0.001 | 0.951(10) ± 0.001 | 0.954(9) ± 0.001 | 0.956(8) ± 0.001 | 0.957(7) ± 0.001 | 0.958(5) ± 0.001 | 0.958(4) ± 0.001 | 0.958(3) ± 0.001 | 0.958(2) ± 0.001 | 0.958(1) ± 0.001 • | 0.958(6) ± 0.001 |
| average rank | 8.14 | 7.25 | 6.25 | 4.11 | 4.00 | 4.21 | 4.68 | 5.50 | 5.79 | 6.21 | 9.86 |
| win/tie/loss | 70/43/167 | 95/68/117 | 105/93/82 | 111/108/61 | 110/123/47 | 99/136/45 | 97/130/53 | 90/134/56 | 86/133/61 | 83/132/65 | 21/46/213 |
| Dataset | Ranking Loss | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.253(9) ± 0.029 | 0.252(7) ± 0.020 | 0.254(10) ± 0.025 | 0.251(4) ± 0.021 | 0.251(5) ± 0.020 | 0.248(1) ± 0.020 • | 0.250(3) ± 0.023 | 0.251(6) ± 0.021 | 0.250(2) ± 0.020 | 0.253(8) ± 0.018 | 0.269(11) ± 0.025 |
| CAL500 | 0.275(11) ± 0.010 | 0.253(10) ± 0.005 | 0.243(8) ± 0.003 | 0.238(1) ± 0.004 • | 0.240(3) ± 0.005 | 0.240(2) ± 0.004 | 0.240(4) ± 0.004 | 0.241(7) ± 0.005 | 0.241(6) ± 0.005 | 0.241(5) ± 0.005 | 0.246(9) ± 0.008 |
| emotions | 0.160(11) ± 0.007 | 0.157(10) ± 0.007 | 0.155(9) ± 0.006 | 0.155(8) ± 0.010 | 0.153(3) ± 0.007 | 0.153(2) ± 0.007 | 0.152(1) ± 0.008 • | 0.154(6) ± 0.010 | 0.153(5) ± 0.010 | 0.153(4) ± 0.010 | 0.154(7) ± 0.007 |
| genbase | 0.006(11) ± 0.003 | 0.006(10) ± 0.004 | 0.005(8) ± 0.003 | 0.004(7) ± 0.003 | 0.004(2) ± 0.003 | 0.004(1) ± 0.003 • | 0.004(3) ± 0.003 | 0.004(4) ± 0.003 | 0.004(5) ± 0.003 | 0.004(6) ± 0.003 | 0.005(9) ± 0.003 |
| LLOG | 0.187(5) ± 0.003 | 0.187(6) ± 0.002 | 0.187(8) ± 0.002 | 0.187(1) ± 0.002 • | 0.187(2) ± 0.002 | 0.187(4) ± 0.003 | 0.187(7) ± 0.002 | 0.187(10) ± 0.003 | 0.187(9) ± 0.002 | 0.187(3) ± 0.002 | 0.190(11) ± 0.005 |
| enron | 0.143(11) ± 0.005 | 0.135(4) ± 0.003 | 0.134(2) ± 0.003 | 0.134(1) ± 0.003 • | 0.135(3) ± 0.003 | 0.135(5) ± 0.003 | 0.135(6) ± 0.003 | 0.136(7) ± 0.003 | 0.136(9) ± 0.003 | 0.136(8) ± 0.003 | 0.136(10) ± 0.004 |
| scene | 0.074(11) ± 0.002 | 0.073(10) ± 0.003 | 0.073(9) ± 0.003 | 0.072(8) ± 0.004 | 0.071(7) ± 0.003 | 0.071(5) ± 0.003 | 0.070(1) ± 0.003 • | 0.071(3) ± 0.003 | 0.071(4) ± 0.003 | 0.070(2) ± 0.004 | 0.071(6) ± 0.004 |
| yeast | 0.180(11) ± 0.004 | 0.180(10) ± 0.004 | 0.177(9) ± 0.004 | 0.171(8) ± 0.004 | 0.168(7) ± 0.003 | 0.167(5) ± 0.003 | 0.166(4) ± 0.003 | 0.166(1) ± 0.003 • | 0.166(2) ± 0.003 | 0.166(3) ± 0.003 | 0.168(6) ± 0.003 |
| Slashdot | 0.048(8) ± 0.003 | 0.048(10) ± 0.003 | 0.048(9) ± 0.004 | 0.047(1) ± 0.005 • | 0.047(2) ± 0.005 | 0.047(4) ± 0.005 | 0.047(3) ± 0.004 | 0.048(7) ± 0.004 | 0.047(5) ± 0.004 | 0.047(6) ± 0.004 | 0.051(11) ± 0.005 |
| corel5k | 0.218(11) ± 0.005 | 0.204(1) ± 0.003 • | 0.205(2) ± 0.004 | 0.206(5) ± 0.004 | 0.206(3) ± 0.004 | 0.206(4) ± 0.004 | 0.207(7) ± 0.004 | 0.207(6) ± 0.003 | 0.207(8) ± 0.003 | 0.207(9) ± 0.003 | 0.211(10) ± 0.004 |
| rcv1subset1 | 0.087(1) ± 0.003 • | 0.097(2) ± 0.005 | 0.105(3) ± 0.008 | 0.115(4) ± 0.009 | 0.118(5) ± 0.008 | 0.120(7) ± 0.008 | 0.120(6) ± 0.007 | 0.122(8) ± 0.008 | 0.122(9) ± 0.007 | 0.122(10) ± 0.006 | 0.132(11) ± 0.007 |
| rcv1subset2 | 0.081(1) ± 0.004 • | 0.093(2) ± 0.007 | 0.107(3) ± 0.011 | 0.114(4) ± 0.012 | 0.118(5) ± 0.009 | 0.122(7) ± 0.008 | 0.122(6) ± 0.009 | 0.123(8) ± 0.008 | 0.124(10) ± 0.008 | 0.124(9) ± 0.007 | 0.139(11) ± 0.007 |
| rcv1subset3 | 0.089(1) ± 0.003 • | 0.103(2) ± 0.005 | 0.112(3) ± 0.007 | 0.120(4) ± 0.005 | 0.122(5) ± 0.005 | 0.125(6) ± 0.005 | 0.127(7) ± 0.006 | 0.127(8) ± 0.006 | 0.129(9) ± 0.006 | 0.130(10) ± 0.006 | 0.145(11) ± 0.004 |
| rcv1subset4 | 0.071(1) ± 0.002 • | 0.081(2) ± 0.007 | 0.090(3) ± 0.008 | 0.097(4) ± 0.009 | 0.100(7) ± 0.009 | 0.100(6) ± 0.007 | 0.100(5) ± 0.007 | 0.100(9) ± 0.007 | 0.100(8) ± 0.007 | 0.101(10) ± 0.006 | 0.113(11) ± 0.006 |
| rcv1subset5 | 0.087(1) ± 0.002 • | 0.102(2) ± 0.006 | 0.109(3) ± 0.006 | 0.116(4) ± 0.007 | 0.117(5) ± 0.009 | 0.118(6) ± 0.009 | 0.118(7) ± 0.008 | 0.120(8) ± 0.007 | 0.120(9) ± 0.008 | 0.121(10) ± 0.008 | 0.135(11) ± 0.008 |
| bibtex | 0.136(2) ± 0.004 | 0.133(1) ± 0.003 • | 0.139(3) ± 0.003 | 0.145(4) ± 0.004 | 0.147(5) ± 0.004 | 0.150(6) ± 0.004 | 0.150(7) ± 0.005 | 0.151(8) ± 0.004 | 0.152(9) ± 0.004 | 0.152(10) ± 0.004 | 0.184(11) ± 0.006 |
| Arts | 0.131(10) ± 0.003 | 0.131(9) ± 0.004 | 0.130(8) ± 0.004 | 0.129(1) ± 0.003 • | 0.129(3) ± 0.003 | 0.130(7) ± 0.003 | 0.129(4) ± 0.003 | 0.130(6) ± 0.003 | 0.129(2) ± 0.003 | 0.129(5) ± 0.003 | 0.140(11) ± 0.003 |
| Health | 0.072(10) ± 0.002 | 0.071(9) ± 0.002 | 0.070(8) ± 0.002 | 0.070(6) ± 0.002 | 0.070(4) ± 0.002 | 0.070(3) ± 0.002 | 0.070(1) ± 0.002 • | 0.070(2) ± 0.002 | 0.070(5) ± 0.002 | 0.070(7) ± 0.002 | 0.077(11) ± 0.001 |
| Business | 0.037(10) ± 0.001 | 0.037(6) ± 0.001 | 0.036(1) ± 0.001 • | 0.037(5) ± 0.001 | 0.037(3) ± 0.001 | 0.037(4) ± 0.001 | 0.037(2) ± 0.001 | 0.037(7) ± 0.001 | 0.037(8) ± 0.001 | 0.037(9) ± 0.001 | 0.042(11) ± 0.001 |
| Education | 0.091(10) ± 0.002 | 0.090(9) ± 0.002 | 0.090(6) ± 0.002 | 0.089(2) ± 0.002 | 0.089(3) ± 0.002 | 0.089(1) ± 0.002 • | 0.090(5) ± 0.002 | 0.090(4) ± 0.002 | 0.090(7) ± 0.002 | 0.090(8) ± 0.002 | 0.095(11) ± 0.002 |
| Computers | 0.089(10) ± 0.002 | 0.087(9) ± 0.002 | 0.087(8) ± 0.002 | 0.086(7) ± 0.002 | 0.086(2) ± 0.002 | 0.086(3) ± 0.002 | 0.086(6) ± 0.002 | 0.086(1) ± 0.002 • | 0.086(4) ± 0.002 | 0.086(5) ± 0.002 | 0.093(11) ± 0.003 |
| Entertainment | 0.114(10) ± 0.003 | 0.113(9) ± 0.003 | 0.112(8) ± 0.003 | 0.112(3) ± 0.003 | 0.111(2) ± 0.002 | 0.111(1) ± 0.002 • | 0.112(4) ± 0.002 | 0.112(5) ± 0.002 | 0.112(6) ± 0.002 | 0.112(7) ± 0.002 | 0.119(11) ± 0.002 |
| Recreation | 0.116(10) ± 0.004 | 0.116(6) ± 0.003 | 0.115(3) ± 0.004 | 0.115(1) ± 0.004 • | 0.115(2) ± 0.004 | 0.115(4) ± 0.004 | 0.116(5) ± 0.004 | 0.116(7) ± 0.004 | 0.116(8) ± 0.004 | 0.116(9) ± 0.004 | 0.129(11) ± 0.004 |
| Society | 0.110(10) ± 0.004 | 0.107(9) ± 0.003 | 0.106(8) ± 0.003 | 0.105(4) ± 0.002 | 0.105(1) ± 0.002 • | 0.106(5) ± 0.002 | 0.105(2) ± 0.002 | 0.105(3) ± 0.002 | 0.106(6) ± 0.002 | 0.106(7) ± 0.002 | 0.112(11) ± 0.003 |
| eurlex-dc-l | 0.081(10) ± 0.004 | 0.081(9) ± 0.004 | 0.079(8) ± 0.005 | 0.077(1) ± 0.004 • | 0.078(3) ± 0.005 | 0.078(2) ± 0.005 | 0.078(5) ± 0.005 | 0.078(6) ± 0.005 | 0.078(4) ± 0.005 | 0.078(7) ± 0.005 | 0.092(11) ± 0.004 |
| eurlex-sm | 0.056(11) ± 0.002 | 0.054(9) ± 0.002 | 0.052(8) ± 0.002 | 0.050(7) ± 0.002 | 0.050(6) ± 0.002 | 0.050(5) ± 0.002 | 0.049(3) ± 0.002 | 0.050(4) ± 0.002 | 0.049(2) ± 0.002 | 0.049(1) ± 0.002 • | 0.055(10) ± 0.001 |
| tmc2007-500 | 0.050(11) ± 0.001 | 0.047(9) ± 0.001 | 0.046(8) ± 0.001 | 0.045(7) ± 0.001 | 0.044(6) ± 0.001 | 0.044(5) ± 0.001 | 0.044(4) ± 0.001 | 0.044(3) ± 0.001 | 0.044(2) ± 0.001 | 0.044(1) ± 0.001 • | 0.048(10) ± 0.001 |
| mediamill | 0.044(11) ± 0.001 | 0.043(10) ± 0.001 | 0.041(9) ± 0.001 | 0.038(8) ± 0.001 | 0.038(7) ± 0.001 | 0.037(6) ± 0.001 | 0.037(4) ± 0.001 | 0.037(3) ± 0.000 | 0.037(2) ± 0.000 | 0.037(1) ± 0.000 • | 0.037(5) ± 0.001 |
| average rank | 8.18 | 6.86 | 6.25 | 4.29 | 3.96 | 4.18 | 4.36 | 5.61 | 5.89 | 6.43 | 10.0 |
| win/tie/loss | 69/51/160 | 88/78/114 | 108/100/72 | 112/118/50 | 99/137/44 | 92/141/47 | 85/152/43 | 77/153/50 | 76/153/51 | 73/153/54 | 15/56/209 |
| Dataset | F1 Macro | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.348(1) ± 0.043 • | 0.299(2) ± 0.028 | 0.271(4) ± 0.053 | 0.269(5) ± 0.058 | 0.258(10) ± 0.069 | 0.271(3) ± 0.064 | 0.263(8) ± 0.064 | 0.265(7) ± 0.066 | 0.265(6) ± 0.065 | 0.259(9) ± 0.060 | 0.217(11) ± 0.074 |
| CAL500 | 0.129(1) ± 0.006 • | 0.105(2) ± 0.006 | 0.093(3) ± 0.003 | 0.085(4) ± 0.003 | 0.083(5) ± 0.003 | 0.081(6) ± 0.003 | 0.079(7) ± 0.004 | 0.077(8) ± 0.004 | 0.077(9) ± 0.004 | 0.076(10) ± 0.004 | 0.071(11) ± 0.004 |
| emotions | 0.643(8) ± 0.017 | 0.643(10) ± 0.018 | 0.643(9) ± 0.017 | 0.649(5) ± 0.014 | 0.651(1) ± 0.013 • | 0.649(3) ± 0.014 | 0.647(7) ± 0.017 | 0.648(6) ± 0.015 | 0.649(4) ± 0.014 | 0.650(2) ± 0.015 | 0.641(11) ± 0.012 |
| genbase | 0.927(11) ± 0.018 | 0.939(10) ± 0.016 | 0.942(9) ± 0.013 | 0.951(8) ± 0.018 | 0.954(7) ± 0.017 | 0.955(6) ± 0.017 | 0.958(5) ± 0.016 | 0.962(4) ± 0.011 | 0.962(3) ± 0.010 | 0.962(2) ± 0.010 | 0.969(1) ± 0.014 • |
| LLOG | 0.094(8) ± 0.013 | 0.094(9) ± 0.013 | 0.093(10) ± 0.014 | 0.096(2) ± 0.014 | 0.097(1) ± 0.016 • | 0.095(4) ± 0.018 | 0.095(3) ± 0.018 | 0.095(6) ± 0.019 | 0.095(6) ± 0.019 | 0.095(6) ± 0.019 | 0.091(11) ± 0.016 |
| enron | 0.163(1) ± 0.008 • | 0.140(2) ± 0.008 | 0.134(3) ± 0.006 | 0.133(4) ± 0.007 | 0.131(5) ± 0.009 | 0.129(6) ± 0.010 | 0.129(8) ± 0.009 | 0.128(10) ± 0.009 | 0.128(9) ± 0.010 | 0.129(7) ± 0.010 | 0.125(11) ± 0.014 |
| scene | 0.744(11) ± 0.006 | 0.748(8) ± 0.006 | 0.748(10) ± 0.007 | 0.749(6) ± 0.007 | 0.749(5) ± 0.008 | 0.749(7) ± 0.008 | 0.750(4) ± 0.008 | 0.751(2) ± 0.008 | 0.750(3) ± 0.008 | 0.751(1) ± 0.010 • | 0.748(9) ± 0.009 |
| yeast | 0.435(2) ± 0.008 | 0.435(1) ± 0.009 • | 0.432(3) ± 0.010 | 0.426(4) ± 0.009 | 0.420(5) ± 0.009 | 0.416(6) ± 0.009 | 0.415(7) ± 0.007 | 0.409(8) ± 0.010 | 0.408(9) ± 0.009 | 0.405(10) ± 0.008 | 0.371(11) ± 0.010 |
| Slashdot | 0.144(11) ± 0.019 | 0.148(10) ± 0.021 | 0.154(9) ± 0.026 | 0.163(6) ± 0.029 | 0.163(7) ± 0.025 | 0.164(4) ± 0.026 | 0.163(5) ± 0.024 | 0.166(2) ± 0.023 | 0.168(1) ± 0.025 • | 0.166(3) ± 0.023 | 0.156(8) ± 0.028 |
| corel5k | 0.064(1) ± 0.006 • | 0.031(2) ± 0.003 | 0.028(3) ± 0.005 | 0.026(4) ± 0.003 | 0.026(5) ± 0.004 | 0.026(6) ± 0.004 | 0.025(9) ± 0.003 | 0.025(8) ± 0.004 | 0.025(7) ± 0.004 | 0.025(10) ± 0.003 | 0.020(11) ± 0.003 |
| rcv1subset1 | 0.260(1) ± 0.005 • | 0.203(2) ± 0.013 | 0.179(3) ± 0.017 | 0.158(4) ± 0.017 | 0.152(5) ± 0.014 | 0.149(6) ± 0.013 | 0.149(7) ± 0.013 | 0.147(8) ± 0.014 | 0.145(10) ± 0.014 | 0.146(9) ± 0.014 | 0.122(11) ± 0.011 |
| rcv1subset2 | 0.259(1) ± 0.007 • | 0.188(2) ± 0.017 | 0.154(3) ± 0.020 | 0.139(4) ± 0.021 | 0.133(5) ± 0.015 | 0.127(7) ± 0.013 | 0.127(6) ± 0.012 | 0.125(8) ± 0.013 | 0.122(10) ± 0.013 | 0.123(9) ± 0.012 | 0.100(11) ± 0.009 |
| rcv1subset3 | 0.215(1) ± 0.013 • | 0.149(2) ± 0.009 | 0.132(3) ± 0.013 | 0.120(4) ± 0.011 | 0.120(5) ± 0.010 | 0.116(6) ± 0.010 | 0.111(7) ± 0.010 | 0.110(8) ± 0.008 | 0.108(9) ± 0.011 | 0.106(10) ± 0.010 | 0.085(11) ± 0.007 |
| rcv1subset4 | 0.249(1) ± 0.011 • | 0.192(2) ± 0.014 | 0.167(3) ± 0.014 | 0.153(4) ± 0.013 | 0.149(5) ± 0.013 | 0.146(6) ± 0.010 | 0.145(7) ± 0.010 | 0.143(8) ± 0.010 | 0.142(9) ± 0.010 | 0.142(10) ± 0.011 | 0.109(11) ± 0.008 |
| rcv1subset5 | 0.237(1) ± 0.008 • | 0.166(2) ± 0.013 | 0.150(3) ± 0.011 | 0.139(4) ± 0.014 | 0.134(5) ± 0.017 | 0.131(6) ± 0.018 | 0.130(7) ± 0.018 | 0.126(8) ± 0.014 | 0.126(9) ± 0.014 | 0.125(10) ± 0.014 | 0.096(11) ± 0.013 |
| bibtex | 0.234(1) ± 0.006 • | 0.211(2) ± 0.007 | 0.201(3) ± 0.007 | 0.191(4) ± 0.006 | 0.187(5) ± 0.006 | 0.184(6) ± 0.004 | 0.182(7) ± 0.004 | 0.180(8) ± 0.003 | 0.179(9) ± 0.004 | 0.178(10) ± 0.004 | 0.139(11) ± 0.006 |
| Arts | 0.292(1) ± 0.011 • | 0.280(2) ± 0.014 | 0.275(3) ± 0.012 | 0.268(4) ± 0.014 | 0.263(5) ± 0.015 | 0.258(6) ± 0.017 | 0.255(7) ± 0.017 | 0.255(8) ± 0.016 | 0.253(9) ± 0.014 | 0.251(10) ± 0.016 | 0.193(11) ± 0.014 |
| Health | 0.414(1) ± 0.011 • | 0.412(2) ± 0.013 | 0.409(3) ± 0.012 | 0.406(4) ± 0.010 | 0.404(5) ± 0.011 | 0.404(6) ± 0.011 | 0.402(7) ± 0.011 | 0.402(8) ± 0.011 | 0.398(9) ± 0.009 | 0.398(10) ± 0.009 | 0.353(11) ± 0.012 |
| Business | 0.303(1) ± 0.010 • | 0.293(2) ± 0.009 | 0.282(3) ± 0.011 | 0.274(4) ± 0.007 | 0.267(5) ± 0.005 | 0.263(6) ± 0.006 | 0.262(7) ± 0.006 | 0.260(8) ± 0.008 | 0.259(9) ± 0.009 | 0.259(10) ± 0.010 | 0.198(11) ± 0.014 |
| Education | 0.305(1) ± 0.012 • | 0.302(2) ± 0.015 | 0.293(3) ± 0.017 | 0.283(4) ± 0.017 | 0.278(5) ± 0.015 | 0.276(6) ± 0.014 | 0.271(7) ± 0.010 | 0.270(8) ± 0.012 | 0.267(9) ± 0.012 | 0.266(10) ± 0.011 | 0.210(11) ± 0.016 |
| Computers | 0.322(1) ± 0.015 • | 0.321(2) ± 0.014 | 0.312(3) ± 0.011 | 0.300(4) ± 0.013 | 0.294(5) ± 0.010 | 0.291(6) ± 0.012 | 0.290(7) ± 0.012 | 0.288(8) ± 0.011 | 0.285(9) ± 0.010 | 0.284(10) ± 0.009 | 0.228(11) ± 0.018 |
| Entertainment | 0.398(3) ± 0.011 | 0.400(1) ± 0.013 • | 0.398(2) ± 0.009 | 0.392(4) ± 0.009 | 0.390(5) ± 0.008 | 0.390(6) ± 0.007 | 0.388(7) ± 0.008 | 0.387(8) ± 0.008 | 0.387(9) ± 0.009 | 0.386(10) ± 0.009 | 0.325(11) ± 0.010 |
| Recreation | 0.414(1) ± 0.013 • | 0.409(2) ± 0.012 | 0.407(3) ± 0.012 | 0.399(4) ± 0.014 | 0.390(5) ± 0.016 | 0.387(6) ± 0.017 | 0.384(7) ± 0.019 | 0.382(8) ± 0.018 | 0.379(9) ± 0.015 | 0.376(10) ± 0.015 | 0.309(11) ± 0.014 |
| Society | 0.305(1) ± 0.009 • | 0.303(2) ± 0.010 | 0.300(3) ± 0.010 | 0.295(4) ± 0.009 | 0.291(5) ± 0.012 | 0.287(6) ± 0.013 | 0.285(7) ± 0.011 | 0.284(8) ± 0.010 | 0.281(10) ± 0.009 | 0.281(9) ± 0.010 | 0.232(11) ± 0.010 |
| eurlex-dc-l | 0.266(8) ± 0.008 | 0.257(10) ± 0.010 | 0.259(9) ± 0.009 | 0.267(6) ± 0.009 | 0.267(7) ± 0.010 | 0.269(2) ± 0.012 | 0.269(3) ± 0.010 | 0.269(1) ± 0.010 • | 0.268(4) ± 0.010 | 0.268(5) ± 0.009 | 0.240(11) ± 0.006 |
| eurlex-sm | 0.377(8) ± 0.007 | 0.375(10) ± 0.008 | 0.376(9) ± 0.009 | 0.383(7) ± 0.010 | 0.388(6) ± 0.009 | 0.390(5) ± 0.009 | 0.390(4) ± 0.008 | 0.390(3) ± 0.009 | 0.391(1) ± 0.007 • | 0.390(2) ± 0.007 | 0.367(11) ± 0.007 |
| tmc2007-500 | 0.526(11) ± 0.008 | 0.572(10) ± 0.007 | 0.587(9) ± 0.006 | 0.598(8) ± 0.008 | 0.603(6) ± 0.007 | 0.606(5) ± 0.009 | 0.609(4) ± 0.008 | 0.610(3) ± 0.008 | 0.610(2) ± 0.008 | 0.612(1) ± 0.008 • | 0.601(7) ± 0.006 |
| mediamill | 0.235(11) ± 0.008 | 0.238(10) ± 0.004 | 0.252(9) ± 0.004 | 0.284(8) ± 0.005 | 0.293(6) ± 0.005 | 0.297(5) ± 0.003 | 0.299(4) ± 0.005 | 0.300(3) ± 0.005 | 0.302(1) ± 0.005 • | 0.301(2) ± 0.005 | 0.285(7) ± 0.012 |
| average rank | 3.89 | 4.39 | 5.00 | 4.75 | 5.21 | 5.46 | 6.25 | 6.54 | 6.93 | 7.39 | 10.18 |
| win/tie/loss | 186/40/54 | 167/53/60 | 146/51/83 | 136/66/78 | 121/72/87 | 100/84/96 | 82/97/101 | 69/105/106 | 64/98/118 | 59/87/134 | 14/39/227 |
| Dataset | F1 Micro | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.414(1) ± 0.035 • | 0.388(2) ± 0.032 | 0.361(7) ± 0.058 | 0.363(4) ± 0.056 | 0.358(8) ± 0.061 | 0.366(3) ± 0.057 | 0.357(9) ± 0.056 | 0.362(6) ± 0.057 | 0.363(5) ± 0.056 | 0.357(10) ± 0.053 | 0.317(11) ± 0.091 |
| CAL500 | 0.356(1) ± 0.008 • | 0.345(2) ± 0.008 | 0.340(5) ± 0.012 | 0.341(4) ± 0.010 | 0.342(3) ± 0.014 | 0.339(6) ± 0.015 | 0.336(7) ± 0.015 | 0.334(9) ± 0.016 | 0.335(8) ± 0.016 | 0.332(10) ± 0.013 | 0.329(11) ± 0.015 |
| emotions | 0.661(11) ± 0.013 | 0.662(10) ± 0.013 | 0.664(9) ± 0.014 | 0.669(7) ± 0.013 | 0.672(1) ± 0.011 • | 0.671(3) ± 0.013 | 0.670(6) ± 0.015 | 0.671(5) ± 0.014 | 0.671(4) ± 0.013 | 0.672(2) ± 0.014 | 0.666(8) ± 0.013 |
| genbase | 0.947(11) ± 0.010 | 0.954(10) ± 0.011 | 0.958(9) ± 0.010 | 0.963(8) ± 0.015 | 0.965(7) ± 0.014 | 0.966(6) ± 0.013 | 0.968(5) ± 0.013 | 0.969(4) ± 0.009 | 0.970(3) ± 0.009 | 0.970(2) ± 0.009 | 0.976(1) ± 0.011 • |
| LLOG | 0.357(4) ± 0.051 | 0.357(3) ± 0.050 | 0.351(10) ± 0.051 | 0.362(2) ± 0.051 | 0.363(1) ± 0.059 • | 0.355(6) ± 0.068 | 0.355(5) ± 0.068 | 0.352(8) ± 0.073 | 0.352(8) ± 0.073 | 0.352(8) ± 0.073 | 0.343(11) ± 0.064 |
| enron | 0.488(1) ± 0.010 • | 0.477(2) ± 0.011 | 0.469(3) ± 0.010 | 0.462(4) ± 0.009 | 0.460(5) ± 0.013 | 0.455(8) ± 0.014 | 0.454(9) ± 0.013 | 0.453(10) ± 0.013 | 0.453(11) ± 0.013 | 0.456(7) ± 0.012 | 0.457(6) ± 0.013 |
| scene | 0.737(11) ± 0.007 | 0.742(9) ± 0.007 | 0.742(10) ± 0.008 | 0.743(7) ± 0.007 | 0.743(5) ± 0.008 | 0.743(6) ± 0.008 | 0.744(4) ± 0.009 | 0.745(2) ± 0.009 | 0.745(3) ± 0.008 | 0.745(1) ± 0.010 • | 0.743(8) ± 0.009 |
| yeast | 0.630(10) ± 0.007 | 0.629(11) ± 0.008 | 0.632(9) ± 0.008 | 0.639(8) ± 0.008 | 0.643(7) ± 0.006 | 0.645(5) ± 0.006 | 0.647(4) ± 0.005 | 0.648(3) ± 0.006 | 0.648(2) ± 0.006 | 0.650(1) ± 0.005 • | 0.644(6) ± 0.004 |
| Slashdot | 0.844(1) ± 0.008 • | 0.844(3) ± 0.008 | 0.843(4) ± 0.008 | 0.844(2) ± 0.008 | 0.843(5) ± 0.008 | 0.843(6) ± 0.007 | 0.841(9) ± 0.007 | 0.842(7) ± 0.008 | 0.842(8) ± 0.008 | 0.841(10) ± 0.008 | 0.839(11) ± 0.010 |
| corel5k | 0.138(1) ± 0.008 • | 0.071(2) ± 0.010 | 0.060(3) ± 0.011 | 0.054(4) ± 0.011 | 0.050(5) ± 0.011 | 0.050(6) ± 0.010 | 0.046(9) ± 0.008 | 0.047(8) ± 0.009 | 0.047(7) ± 0.008 | 0.046(10) ± 0.008 | 0.031(11) ± 0.004 |
| rcv1subset1 | 0.386(1) ± 0.005 • | 0.364(2) ± 0.006 | 0.342(3) ± 0.014 | 0.300(4) ± 0.020 | 0.296(5) ± 0.021 | 0.289(6) ± 0.023 | 0.284(7) ± 0.017 | 0.282(8) ± 0.018 | 0.282(9) ± 0.017 | 0.282(10) ± 0.018 | 0.244(11) ± 0.010 |
| rcv1subset2 | 0.417(1) ± 0.009 • | 0.386(2) ± 0.016 | 0.358(3) ± 0.018 | 0.339(4) ± 0.020 | 0.334(5) ± 0.012 | 0.322(6) ± 0.008 | 0.320(7) ± 0.009 | 0.319(8) ± 0.009 | 0.316(10) ± 0.012 | 0.316(9) ± 0.010 | 0.293(11) ± 0.018 |
| rcv1subset3 | 0.403(1) ± 0.005 • | 0.370(2) ± 0.007 | 0.352(3) ± 0.016 | 0.338(4) ± 0.009 | 0.333(5) ± 0.009 | 0.328(6) ± 0.012 | 0.323(8) ± 0.014 | 0.324(7) ± 0.011 | 0.321(9) ± 0.015 | 0.317(10) ± 0.013 | 0.290(11) ± 0.012 |
| rcv1subset4 | 0.469(1) ± 0.006 • | 0.441(2) ± 0.014 | 0.419(3) ± 0.017 | 0.404(4) ± 0.022 | 0.394(5) ± 0.019 | 0.392(6) ± 0.015 | 0.391(7) ± 0.015 | 0.391(8) ± 0.015 | 0.389(9) ± 0.015 | 0.389(10) ± 0.015 | 0.362(11) ± 0.010 |
| rcv1subset5 | 0.425(1) ± 0.005 • | 0.390(2) ± 0.024 | 0.371(3) ± 0.020 | 0.357(4) ± 0.017 | 0.348(5) ± 0.014 | 0.345(6) ± 0.016 | 0.344(7) ± 0.014 | 0.339(8) ± 0.013 | 0.337(9) ± 0.015 | 0.333(10) ± 0.012 | 0.286(11) ± 0.013 |
| bibtex | 0.373(3) ± 0.004 | 0.379(1) ± 0.005 • | 0.375(2) ± 0.005 | 0.371(4) ± 0.004 | 0.367(5) ± 0.006 | 0.365(6) ± 0.005 | 0.364(7) ± 0.004 | 0.363(8) ± 0.004 | 0.362(9) ± 0.004 | 0.361(10) ± 0.004 | 0.327(11) ± 0.009 |
| Arts | 0.380(1) ± 0.013 • | 0.379(2) ± 0.012 | 0.377(3) ± 0.013 | 0.372(4) ± 0.014 | 0.369(5) ± 0.014 | 0.366(6) ± 0.015 | 0.363(7) ± 0.016 | 0.361(8) ± 0.015 | 0.359(9) ± 0.015 | 0.357(10) ± 0.014 | 0.299(11) ± 0.020 |
| Health | 0.569(10) ± 0.011 | 0.571(9) ± 0.011 | 0.573(4) ± 0.011 | 0.574(3) ± 0.012 | 0.574(1) ± 0.011 • | 0.574(2) ± 0.012 | 0.573(5) ± 0.012 | 0.573(6) ± 0.012 | 0.572(7) ± 0.012 | 0.572(8) ± 0.012 | 0.538(11) ± 0.013 |
| Business | 0.721(8) ± 0.004 | 0.722(4) ± 0.004 | 0.722(3) ± 0.004 | 0.723(1) ± 0.004 • | 0.722(2) ± 0.004 | 0.722(6) ± 0.004 | 0.722(5) ± 0.003 | 0.721(7) ± 0.004 | 0.720(9) ± 0.004 | 0.720(10) ± 0.004 | 0.704(11) ± 0.004 |
| Education | 0.393(1) ± 0.012 • | 0.392(2) ± 0.012 | 0.388(3) ± 0.012 | 0.383(4) ± 0.013 | 0.378(5) ± 0.014 | 0.376(6) ± 0.013 | 0.375(7) ± 0.014 | 0.373(8) ± 0.014 | 0.372(9) ± 0.014 | 0.371(10) ± 0.014 | 0.315(11) ± 0.017 |
| Computers | 0.513(4) ± 0.005 | 0.515(1) ± 0.005 • | 0.515(2) ± 0.006 | 0.513(3) ± 0.005 | 0.511(5) ± 0.005 | 0.510(6) ± 0.005 | 0.509(7) ± 0.005 | 0.509(8) ± 0.005 | 0.508(9) ± 0.005 | 0.507(10) ± 0.005 | 0.475(11) ± 0.007 |
| Entertainment | 0.508(3) ± 0.006 | 0.510(1) ± 0.007 • | 0.508(2) ± 0.008 | 0.507(4) ± 0.007 | 0.505(5) ± 0.008 | 0.503(6) ± 0.007 | 0.503(7) ± 0.007 | 0.502(8) ± 0.006 | 0.502(9) ± 0.006 | 0.501(10) ± 0.006 | 0.454(11) ± 0.010 |
| Recreation | 0.463(1) ± 0.011 • | 0.462(2) ± 0.010 | 0.460(3) ± 0.011 | 0.458(4) ± 0.011 | 0.454(5) ± 0.012 | 0.453(6) ± 0.011 | 0.450(7) ± 0.012 | 0.448(8) ± 0.011 | 0.446(9) ± 0.011 | 0.445(10) ± 0.012 | 0.395(11) ± 0.017 |
| Society | 0.470(3) ± 0.008 | 0.471(1) ± 0.009 • | 0.471(2) ± 0.009 | 0.469(4) ± 0.010 | 0.468(5) ± 0.010 | 0.468(6) ± 0.010 | 0.467(7) ± 0.010 | 0.466(8) ± 0.011 | 0.464(9) ± 0.012 | 0.463(10) ± 0.012 | 0.431(11) ± 0.012 |
| eurlex-dc-l | 0.453(11) ± 0.006 | 0.455(10) ± 0.006 | 0.461(9) ± 0.006 | 0.472(7) ± 0.005 | 0.479(6) ± 0.007 | 0.482(5) ± 0.007 | 0.483(4) ± 0.007 | 0.484(3) ± 0.007 | 0.485(1) ± 0.007 • | 0.484(2) ± 0.007 | 0.466(8) ± 0.007 |
| eurlex-sm | 0.564(11) ± 0.006 | 0.568(10) ± 0.007 | 0.574(9) ± 0.007 | 0.585(7) ± 0.007 | 0.589(6) ± 0.007 | 0.591(5) ± 0.007 | 0.592(4) ± 0.007 | 0.592(3) ± 0.007 | 0.593(2) ± 0.007 | 0.593(1) ± 0.007 • | 0.580(8) ± 0.006 |
| tmc2007-500 | 0.679(11) ± 0.003 | 0.705(10) ± 0.002 | 0.715(9) ± 0.002 | 0.723(8) ± 0.003 | 0.726(7) ± 0.003 | 0.729(6) ± 0.003 | 0.730(5) ± 0.003 | 0.732(4) ± 0.003 | 0.732(2) ± 0.003 | 0.733(1) ± 0.003 • | 0.732(3) ± 0.002 |
| mediamill | 0.598(11) ± 0.002 | 0.604(10) ± 0.002 | 0.615(9) ± 0.002 | 0.629(8) ± 0.002 | 0.635(7) ± 0.001 | 0.638(6) ± 0.001 | 0.639(5) ± 0.001 | 0.640(4) ± 0.001 | 0.641(3) ± 0.001 | 0.641(2) ± 0.002 | 0.643(1) ± 0.002 • |
| average rank | 4.82 | 4.54 | 5.14 | 4.68 | 4.86 | 5.61 | 6.43 | 6.57 | 6.86 | 7.29 | 9.21 |
| win/tie/loss | 152/35/93 | 152/54/74 | 134/66/80 | 142/61/77 | 114/78/88 | 96/90/94 | 86/97/97 | 83/94/103 | 74/99/107 | 70/78/132 | 38/46/196 |
| Dataset | Hamming Loss | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| λ = 0.05 | λ = 0.5 | λ = 1 | λ = 2 | λ = 3 | λ = 4 | λ = 5 | λ = 6 | λ = 7 | λ = 8 | λ → +∞ | |
| birds | 0.144(11) ± 0.009 | 0.141(9) ± 0.009 | 0.141(10) ± 0.008 | 0.139(8) ± 0.009 | 0.137(7) ± 0.008 | 0.136(5) ± 0.008 | 0.137(6) ± 0.008 | 0.136(4) ± 0.007 | 0.136(2) ± 0.007 | 0.136(3) ± 0.007 | 0.135(1) ± 0.009 • |
| CAL500 | 0.200(11) ± 0.002 | 0.192(10) ± 0.002 | 0.189(9) ± 0.001 | 0.187(8) ± 0.001 | 0.187(7) ± 0.001 | 0.186(2) ± 0.001 | 0.186(5) ± 0.002 | 0.186(4) ± 0.001 | 0.186(1) ± 0.001 • | 0.186(3) ± 0.002 | 0.186(6) ± 0.001 |
| emotions | 0.199(11) ± 0.006 | 0.197(10) ± 0.006 | 0.196(9) ± 0.007 | 0.192(7) ± 0.006 | 0.190(1) ± 0.005 • | 0.191(5) ± 0.006 | 0.191(6) ± 0.007 | 0.191(4) ± 0.007 | 0.190(3) ± 0.007 | 0.190(2) ± 0.007 | 0.193(8) ± 0.007 |
| genbase | 0.009(11) ± 0.002 | 0.008(10) ± 0.002 | 0.007(9) ± 0.002 | 0.006(8) ± 0.003 | 0.006(7) ± 0.002 | 0.006(6) ± 0.002 | 0.006(5) ± 0.002 | 0.005(4) ± 0.002 | 0.005(3) ± 0.002 | 0.005(2) ± 0.002 | 0.004(1) ± 0.002 • |
| LLOG | 0.188(4) ± 0.005 | 0.188(2) ± 0.005 | 0.189(5) ± 0.005 | 0.188(1) ± 0.005 • | 0.188(3) ± 0.006 | 0.189(7) ± 0.006 | 0.189(6) ± 0.006 | 0.189(9) ± 0.006 | 0.189(9) ± 0.006 | 0.189(9) ± 0.006 | 0.190(11) ± 0.007 |
| enron | 0.078(11) ± 0.001 | 0.075(1) ± 0.001 • | 0.075(2) ± 0.001 | 0.075(3) ± 0.001 | 0.075(4) ± 0.001 | 0.075(5) ± 0.001 | 0.076(7) ± 0.001 | 0.076(10) ± 0.001 | 0.076(9) ± 0.001 | 0.076(8) ± 0.001 | 0.076(6) ± 0.001 |
| scene | 0.087(11) ± 0.002 | 0.085(10) ± 0.002 | 0.085(9) ± 0.002 | 0.085(8) ± 0.002 | 0.084(7) ± 0.003 | 0.084(6) ± 0.002 | 0.084(5) ± 0.003 | 0.084(4) ± 0.002 | 0.084(3) ± 0.002 | 0.083(2) ± 0.003 | 0.083(1) ± 0.003 • |
| yeast | 0.211(10) ± 0.004 | 0.211(11) ± 0.004 | 0.208(9) ± 0.004 | 0.202(8) ± 0.004 | 0.200(7) ± 0.003 | 0.198(6) ± 0.003 | 0.197(5) ± 0.003 | 0.196(4) ± 0.004 | 0.196(3) ± 0.003 | 0.196(2) ± 0.003 | 0.195(1) ± 0.003 • |
| Slashdot | 0.028(1) ± 0.002 • | 0.029(3) ± 0.001 | 0.029(4) ± 0.001 | 0.028(2) ± 0.001 | 0.029(5) ± 0.001 | 0.029(6) ± 0.001 | 0.029(9) ± 0.001 | 0.029(7) ± 0.001 | 0.029(8) ± 0.002 | 0.029(10) ± 0.001 | 0.029(11) ± 0.002 |
| corel5k | 0.025(11) ± 0.001 | 0.021(10) ± 0.000 | 0.021(9) ± 0.000 | 0.021(8) ± 0.000 | 0.021(7) ± 0.000 | 0.021(6) ± 0.000 | 0.021(5) ± 0.000 | 0.021(4) ± 0.000 | 0.021(3) ± 0.000 | 0.021(2) ± 0.000 | 0.021(1) ± 0.000 • |
| rcv1subset1 | 0.035(11) ± 0.001 | 0.033(10) ± 0.000 | 0.033(8) ± 0.000 | 0.033(7) ± 0.000 | 0.032(6) ± 0.000 | 0.032(5) ± 0.000 | 0.032(4) ± 0.000 | 0.032(3) ± 0.000 | 0.032(2) ± 0.000 | 0.032(1) ± 0.000 • | 0.033(9) ± 0.000 |
| rcv1subset2 | 0.029(11) ± 0.000 | 0.028(10) ± 0.000 | 0.027(8) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(7) ± 0.000 | 0.027(5) ± 0.000 | 0.027(6) ± 0.000 | 0.027(4) ± 0.000 | 0.027(3) ± 0.000 | 0.027(9) ± 0.000 |
| rcv1subset3 | 0.029(11) ± 0.000 | 0.028(10) ± 0.000 | 0.027(8) ± 0.000 | 0.027(4) ± 0.000 | 0.027(7) ± 0.000 | 0.027(6) ± 0.000 | 0.027(5) ± 0.000 | 0.027(2) ± 0.000 | 0.027(3) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(9) ± 0.000 |
| rcv1subset4 | 0.026(11) ± 0.000 | 0.025(9) ± 0.000 | 0.024(8) ± 0.000 | 0.024(1) ± 0.000 • | 0.024(6) ± 0.000 | 0.024(7) ± 0.000 | 0.024(4) ± 0.000 | 0.024(2) ± 0.000 | 0.024(5) ± 0.000 | 0.024(3) ± 0.000 | 0.025(10) ± 0.000 |
| rcv1subset5 | 0.028(11) ± 0.000 | 0.027(9) ± 0.000 | 0.027(4) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(3) ± 0.000 | 0.027(5) ± 0.000 | 0.027(6) ± 0.000 | 0.027(7) ± 0.000 | 0.027(8) ± 0.000 | 0.027(10) ± 0.000 |
| bibtex | 0.015(11) ± 0.000 | 0.013(9) ± 0.000 | 0.013(8) ± 0.000 | 0.013(6) ± 0.000 | 0.013(4) ± 0.000 | 0.013(1) ± 0.000 • | 0.013(7) ± 0.000 | 0.013(3) ± 0.000 | 0.013(2) ± 0.000 | 0.013(5) ± 0.000 | 0.013(10) ± 0.000 |
| Arts | 0.060(10) ± 0.001 | 0.059(6) ± 0.001 | 0.059(3) ± 0.000 | 0.059(1) ± 0.000 • | 0.059(2) ± 0.001 | 0.059(4) ± 0.001 | 0.059(5) ± 0.001 | 0.059(7) ± 0.000 | 0.060(8) ± 0.001 | 0.060(9) ± 0.001 | 0.062(11) ± 0.001 |
| Health | 0.056(10) ± 0.001 | 0.055(9) ± 0.001 | 0.055(8) ± 0.001 | 0.055(6) ± 0.001 | 0.055(2) ± 0.001 | 0.055(1) ± 0.001 • | 0.055(3) ± 0.001 | 0.055(4) ± 0.001 | 0.055(5) ± 0.001 | 0.055(7) ± 0.001 | 0.057(11) ± 0.001 |
| Business | 0.031(10) ± 0.000 | 0.031(9) ± 0.000 | 0.031(7) ± 0.000 | 0.031(2) ± 0.000 | 0.031(1) ± 0.000 • | 0.031(4) ± 0.000 | 0.031(3) ± 0.000 | 0.031(5) ± 0.000 | 0.031(6) ± 0.000 | 0.031(8) ± 0.001 | 0.032(11) ± 0.000 |
| Education | 0.046(10) ± 0.001 | 0.046(9) ± 0.001 | 0.046(8) ± 0.001 | 0.046(2) ± 0.001 | 0.046(1) ± 0.001 • | 0.046(3) ± 0.001 | 0.046(4) ± 0.001 | 0.046(5) ± 0.001 | 0.046(6) ± 0.001 | 0.046(6) ± 0.001 | 0.048(11) ± 0.001 |
| Computers | 0.043(10) ± 0.000 | 0.043(9) ± 0.000 | 0.043(3) ± 0.000 | 0.043(1) ± 0.000 • | 0.043(2) ± 0.000 | 0.043(4) ± 0.000 | 0.043(5) ± 0.000 | 0.043(6) ± 0.000 | 0.043(7) ± 0.000 | 0.043(8) ± 0.000 | 0.044(11) ± 0.001 |
| Entertainment | 0.061(10) ± 0.001 | 0.061(9) ± 0.001 | 0.061(4) ± 0.001 | 0.061(2) ± 0.001 | 0.061(1) ± 0.001 • | 0.061(3) ± 0.001 | 0.061(5) ± 0.001 | 0.061(6) ± 0.001 | 0.061(7) ± 0.001 | 0.061(8) ± 0.001 | 0.064(11) ± 0.001 |
| Recreation | 0.050(5) ± 0.001 | 0.050(3) ± 0.001 | 0.050(1) ± 0.001 • | 0.050(2) ± 0.001 | 0.050(4) ± 0.001 | 0.050(6) ± 0.001 | 0.050(7) ± 0.001 | 0.050(8) ± 0.001 | 0.051(9) ± 0.001 | 0.051(10) ± 0.001 | 0.053(11) ± 0.001 |
| Society | 0.051(10) ± 0.001 | 0.051(6) ± 0.001 | 0.051(3) ± 0.001 | 0.051(2) ± 0.001 | 0.051(1) ± 0.001 • | 0.051(4) ± 0.001 | 0.051(5) ± 0.001 | 0.051(7) ± 0.001 | 0.051(8) ± 0.001 | 0.051(9) ± 0.001 | 0.053(11) ± 0.001 |
| eurlex-dc-l | 0.005(11) ± 0.000 | 0.005(10) ± 0.000 | 0.005(9) ± 0.000 | 0.005(8) ± 0.000 | 0.004(6) ± 0.000 | 0.004(5) ± 0.000 | 0.004(4) ± 0.000 | 0.004(1) ± 0.000 • | 0.004(2) ± 0.000 | 0.004(3) ± 0.000 | 0.005(7) ± 0.000 |
| eurlex-sm | 0.011(11) ± 0.000 | 0.011(10) ± 0.000 | 0.011(9) ± 0.000 | 0.011(8) ± 0.000 | 0.011(6) ± 0.000 | 0.011(5) ± 0.000 | 0.011(4) ± 0.000 | 0.011(3) ± 0.000 | 0.011(2) ± 0.000 | 0.011(1) ± 0.000 • | 0.011(7) ± 0.000 |
| tmc2007-500 | 0.060(11) ± 0.000 | 0.055(10) ± 0.000 | 0.053(9) ± 0.000 | 0.052(8) ± 0.000 | 0.051(7) ± 0.000 | 0.051(6) ± 0.000 | 0.050(5) ± 0.000 | 0.050(4) ± 0.000 | 0.050(3) ± 0.000 | 0.050(1) ± 0.000 • | 0.050(2) ± 0.000 |
| mediamill | 0.031(11) ± 0.000 | 0.031(10) ± 0.000 | 0.030(9) ± 0.000 | 0.028(8) ± 0.000 | 0.028(7) ± 0.000 | 0.028(6) ± 0.000 | 0.028(5) ± 0.000 | 0.028(4) ± 0.000 | 0.027(3) ± 0.000 | 0.027(2) ± 0.000 | 0.027(1) ± 0.000 • |
| average rank | 9.89 | 8.32 | 6.86 | 4.68 | 4.36 | 4.79 | 5.14 | 4.86 | 4.77 | 4.88 | 7.46 |
| win/tie/loss | 16/24/240 | 40/61/179 | 77/81/122 | 119/98/63 | 124/113/43 | 120/113/47 | 119/121/40 | 119/124/37 | 111/125/44 | 112/113/55 | 69/62/149 |
| Dataset | AUC Macro | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.734(1) ± 0.026 • | 0.731(2) ± 0.029 | 0.730(3) ± 0.029 | 0.728(4) ± 0.030 | 0.723(6) ± 0.031 | 0.724(5) ± 0.030 | 0.722(7) ± 0.028 | 0.721(8) ± 0.029 |
| CAL500 | 0.570(8) ± 0.008 | 0.571(6) ± 0.007 | 0.572(1) ± 0.007 • | 0.571(3) ± 0.006 | 0.571(2) ± 0.005 | 0.571(4) ± 0.005 | 0.571(5) ± 0.005 | 0.571(7) ± 0.005 |
| emotions | 0.847(1) ± 0.006 • | 0.847(2) ± 0.006 | 0.847(3) ± 0.007 | 0.846(4) ± 0.005 | 0.845(6) ± 0.007 | 0.845(5) ± 0.007 | 0.844(7) ± 0.007 | 0.844(8) ± 0.007 |
| genbase | 0.993(8) ± 0.005 | 0.996(7) ± 0.003 | 0.996(6) ± 0.003 | 0.997(5) ± 0.003 | 0.997(4) ± 0.003 | 0.998(3) ± 0.003 | 0.998(2) ± 0.003 | 0.998(1) ± 0.003 • |
| LLOG | 0.603(7) ± 0.006 | 0.603(4) ± 0.006 | 0.603(1) ± 0.006 • | 0.603(4) ± 0.006 | 0.603(1) ± 0.006 • | 0.603(7) ± 0.006 | 0.603(4) ± 0.006 | 0.603(4) ± 0.006 |
| enron | 0.673(5) ± 0.012 | 0.674(4) ± 0.013 | 0.675(2) ± 0.013 | 0.676(1) ± 0.012 • | 0.675(3) ± 0.013 | 0.673(6) ± 0.011 | 0.672(7) ± 0.011 | 0.672(8) ± 0.011 |
| scene | 0.946(1) ± 0.002 • | 0.945(2) ± 0.002 | 0.945(3) ± 0.002 | 0.944(4) ± 0.002 | 0.944(5) ± 0.002 | 0.944(6) ± 0.002 | 0.943(8) ± 0.002 | 0.943(7) ± 0.002 |
| yeast | 0.718(1) ± 0.007 • | 0.715(2) ± 0.007 | 0.713(3) ± 0.006 | 0.711(4) ± 0.006 | 0.709(5) ± 0.006 | 0.708(6) ± 0.006 | 0.708(7) ± 0.005 | 0.707(8) ± 0.005 |
| Slashdot | 0.713(8) ± 0.026 | 0.721(7) ± 0.022 | 0.722(6) ± 0.022 | 0.723(5) ± 0.021 | 0.724(4) ± 0.020 | 0.724(3) ± 0.019 | 0.724(2) ± 0.020 | 0.724(1) ± 0.020 • |
| corel5k | 0.690(4) ± 0.003 | 0.690(1) ± 0.004 • | 0.690(2) ± 0.004 | 0.690(3) ± 0.005 | 0.690(5) ± 0.005 | 0.689(6) ± 0.005 | 0.689(7) ± 0.005 | 0.689(8) ± 0.005 |
| rcv1subset1 | 0.891(4) ± 0.003 | 0.892(2) ± 0.003 | 0.892(1) ± 0.003 • | 0.891(3) ± 0.004 | 0.890(5) ± 0.004 | 0.889(6) ± 0.004 | 0.888(7) ± 0.004 | 0.888(8) ± 0.004 |
| rcv1subset2 | 0.890(1) ± 0.005 • | 0.890(2) ± 0.005 | 0.888(3) ± 0.004 | 0.888(4) ± 0.005 | 0.887(5) ± 0.005 | 0.886(6) ± 0.005 | 0.885(7) ± 0.005 | 0.884(8) ± 0.006 |
| rcv1subset3 | 0.880(2) ± 0.003 | 0.881(1) ± 0.004 • | 0.880(3) ± 0.004 | 0.880(4) ± 0.004 | 0.879(5) ± 0.004 | 0.879(6) ± 0.004 | 0.878(7) ± 0.002 | 0.877(8) ± 0.002 |
| rcv1subset4 | 0.887(3) ± 0.007 | 0.888(1) ± 0.007 • | 0.888(2) ± 0.007 | 0.887(4) ± 0.007 | 0.885(5) ± 0.007 | 0.884(6) ± 0.007 | 0.884(7) ± 0.007 | 0.883(8) ± 0.007 |
| rcv1subset5 | 0.872(6) ± 0.005 | 0.874(2) ± 0.005 | 0.874(1) ± 0.006 • | 0.873(3) ± 0.005 | 0.872(5) ± 0.005 | 0.872(4) ± 0.006 | 0.871(7) ± 0.005 | 0.871(8) ± 0.005 |
| bibtex | 0.885(5) ± 0.001 | 0.887(1) ± 0.001 • | 0.886(2) ± 0.001 | 0.886(3) ± 0.001 | 0.885(4) ± 0.001 | 0.885(6) ± 0.001 | 0.885(7) ± 0.001 | 0.884(8) ± 0.002 |
| Arts | 0.720(8) ± 0.013 | 0.728(7) ± 0.011 | 0.729(6) ± 0.010 | 0.730(5) ± 0.009 | 0.731(2) ± 0.009 | 0.730(4) ± 0.008 | 0.731(3) ± 0.008 | 0.731(1) ± 0.008 • |
| Health | 0.771(8) ± 0.009 | 0.776(7) ± 0.009 | 0.777(6) ± 0.009 | 0.778(3) ± 0.009 | 0.780(1) ± 0.009 • | 0.779(2) ± 0.010 | 0.778(5) ± 0.010 | 0.778(4) ± 0.010 |
| Business | 0.742(8) ± 0.007 | 0.748(7) ± 0.007 | 0.751(3) ± 0.008 | 0.752(2) ± 0.007 | 0.752(1) ± 0.006 • | 0.750(6) ± 0.008 | 0.750(4) ± 0.007 | 0.750(5) ± 0.008 |
| Education | 0.737(8) ± 0.014 | 0.745(7) ± 0.013 | 0.747(4) ± 0.013 | 0.748(2) ± 0.014 | 0.749(1) ± 0.012 • | 0.747(6) ± 0.012 | 0.747(3) ± 0.014 | 0.747(5) ± 0.013 |
| Computers | 0.742(8) ± 0.006 | 0.749(7) ± 0.005 | 0.749(5) ± 0.005 | 0.750(2) ± 0.005 | 0.751(1) ± 0.007 • | 0.750(3) ± 0.007 | 0.749(6) ± 0.007 | 0.749(4) ± 0.007 |
| Entertainment | 0.773(8) ± 0.005 | 0.778(7) ± 0.005 | 0.780(6) ± 0.004 | 0.782(1) ± 0.004 • | 0.781(3) ± 0.005 | 0.781(2) ± 0.005 | 0.781(4) ± 0.005 | 0.781(5) ± 0.005 |
| Recreation | 0.781(8) ± 0.008 | 0.786(7) ± 0.008 | 0.788(6) ± 0.008 | 0.788(5) ± 0.009 | 0.789(4) ± 0.008 | 0.789(3) ± 0.008 | 0.789(2) ± 0.008 | 0.789(1) ± 0.008 • |
| Society | 0.700(8) ± 0.007 | 0.705(7) ± 0.006 | 0.706(6) ± 0.006 | 0.707(3) ± 0.006 | 0.707(1) ± 0.005 • | 0.707(2) ± 0.005 | 0.706(4) ± 0.005 | 0.706(5) ± 0.004 |
| eurlex-dc-l | 0.896(6) ± 0.005 | 0.900(3) ± 0.005 | 0.900(2) ± 0.005 | 0.900(1) ± 0.004 • | 0.899(4) ± 0.004 | 0.896(5) ± 0.004 | 0.896(7) ± 0.004 | 0.895(8) ± 0.004 |
| eurlex-sm | 0.907(4) ± 0.003 | 0.910(1) ± 0.002 • | 0.909(2) ± 0.003 | 0.908(3) ± 0.003 | 0.906(5) ± 0.002 | 0.905(6) ± 0.002 | 0.904(7) ± 0.003 | 0.904(8) ± 0.002 |
| tmc2007-500 | 0.921(1) ± 0.002 • | 0.921(6) ± 0.002 | 0.920(8) ± 0.002 | 0.920(7) ± 0.002 | 0.921(2) ± 0.002 | 0.921(4) ± 0.002 | 0.921(3) ± 0.002 | 0.921(5) ± 0.002 |
| mediamill | 0.830(1) ± 0.002 • | 0.830(2) ± 0.002 | 0.828(3) ± 0.002 | 0.824(4) ± 0.002 | 0.815(5) ± 0.005 | 0.810(6) ± 0.004 | 0.806(7) ± 0.004 | 0.803(8) ± 0.005 |
| average rank | 5.05 | 4.09 | 3.55 | 3.45 | 3.59 | 4.80 | 5.48 | 5.98 |
| win/tie/loss | 51/62/83 | 77/86/33 | 82/92/22 | 71/102/23 | 64/89/43 | 38/104/54 | 26/93/77 | 17/88/91 |
| Dataset | AUC Micro | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.756(1) ± 0.022 • | 0.751(2) ± 0.017 | 0.750(3) ± 0.019 | 0.746(4) ± 0.019 | 0.744(5) ± 0.018 | 0.741(6) ± 0.016 | 0.740(7) ± 0.017 | 0.739(8) ± 0.018 |
| CAL500 | 0.757(7) ± 0.004 | 0.756(8) ± 0.003 | 0.758(5) ± 0.003 | 0.757(6) ± 0.004 | 0.760(1) ± 0.003 • | 0.759(4) ± 0.003 | 0.759(3) ± 0.003 | 0.759(2) ± 0.003 |
| emotions | 0.862(2) ± 0.004 | 0.862(1) ± 0.005 • | 0.862(4) ± 0.006 | 0.862(3) ± 0.005 | 0.859(7) ± 0.006 | 0.860(5) ± 0.007 | 0.860(6) ± 0.006 | 0.859(8) ± 0.006 |
| genbase | 0.992(8) ± 0.006 | 0.995(7) ± 0.003 | 0.996(6) ± 0.003 | 0.996(4) ± 0.004 | 0.996(5) ± 0.004 | 0.997(2) ± 0.004 | 0.997(3) ± 0.004 | 0.997(1) ± 0.004 • |
| LLOG | 0.767(5) ± 0.002 | 0.767(2) ± 0.002 • | 0.767(7) ± 0.002 | 0.767(2) ± 0.002 • | 0.767(7) ± 0.002 | 0.767(5) ± 0.002 | 0.767(2) ± 0.002 • | 0.767(2) ± 0.002 • |
| enron | 0.858(6) ± 0.003 | 0.858(8) ± 0.004 | 0.859(3) ± 0.004 | 0.860(1) ± 0.002 • | 0.860(2) ± 0.002 | 0.859(4) ± 0.003 | 0.858(5) ± 0.003 | 0.858(7) ± 0.003 |
| scene | 0.952(1) ± 0.002 • | 0.951(2) ± 0.002 | 0.951(3) ± 0.002 | 0.950(4) ± 0.002 | 0.950(5) ± 0.002 | 0.949(7) ± 0.002 | 0.949(8) ± 0.002 | 0.949(6) ± 0.002 |
| yeast | 0.847(1) ± 0.004 • | 0.845(2) ± 0.004 | 0.843(3) ± 0.003 | 0.842(4) ± 0.004 | 0.840(5) ± 0.004 | 0.840(6) ± 0.003 | 0.840(7) ± 0.003 | 0.840(8) ± 0.003 |
| Slashdot | 0.945(2) ± 0.004 | 0.945(4) ± 0.004 | 0.945(1) ± 0.004 • | 0.945(3) ± 0.004 | 0.945(6) ± 0.004 | 0.945(8) ± 0.004 | 0.945(5) ± 0.004 | 0.945(7) ± 0.004 |
| corel5k | 0.796(1) ± 0.002 • | 0.796(3) ± 0.004 | 0.796(4) ± 0.004 | 0.796(2) ± 0.004 | 0.796(5) ± 0.003 | 0.795(6) ± 0.004 | 0.795(8) ± 0.003 | 0.795(7) ± 0.003 |
| rcv1subset1 | 0.867(8) ± 0.007 | 0.872(7) ± 0.007 | 0.873(6) ± 0.008 | 0.874(2) ± 0.009 | 0.875(1) ± 0.008 • | 0.873(3) ± 0.008 | 0.873(5) ± 0.009 | 0.873(4) ± 0.009 |
| rcv1subset2 | 0.865(5) ± 0.010 | 0.864(7) ± 0.007 | 0.862(8) ± 0.007 | 0.865(6) ± 0.010 | 0.868(2) ± 0.012 | 0.866(3) ± 0.010 | 0.866(4) ± 0.010 | 0.868(1) ± 0.010 • |
| rcv1subset3 | 0.850(8) ± 0.007 | 0.856(7) ± 0.010 | 0.856(6) ± 0.008 | 0.861(5) ± 0.007 | 0.864(4) ± 0.008 | 0.865(2) ± 0.009 | 0.866(1) ± 0.007 • | 0.865(3) ± 0.007 |
| rcv1subset4 | 0.881(8) ± 0.010 | 0.885(6) ± 0.010 | 0.886(5) ± 0.010 | 0.884(7) ± 0.010 | 0.887(4) ± 0.009 | 0.888(3) ± 0.009 | 0.889(2) ± 0.009 | 0.889(1) ± 0.009 • |
| rcv1subset5 | 0.862(8) ± 0.006 | 0.868(5) ± 0.006 | 0.870(4) ± 0.008 | 0.868(7) ± 0.009 | 0.868(6) ± 0.009 | 0.871(3) ± 0.009 | 0.872(1) ± 0.009 • | 0.871(2) ± 0.010 |
| bibtex | 0.850(8) ± 0.007 | 0.860(7) ± 0.006 | 0.861(6) ± 0.004 | 0.863(1) ± 0.006 • | 0.862(4) ± 0.004 | 0.863(2) ± 0.005 | 0.862(5) ± 0.005 | 0.862(3) ± 0.005 |
| Arts | 0.846(8) ± 0.004 | 0.850(7) ± 0.003 | 0.851(5) ± 0.003 | 0.851(4) ± 0.003 | 0.852(2) ± 0.003 | 0.852(1) ± 0.003 • | 0.852(3) ± 0.003 | 0.851(6) ± 0.003 |
| Health | 0.917(8) ± 0.002 | 0.919(4) ± 0.002 | 0.919(3) ± 0.002 | 0.919(2) ± 0.002 | 0.919(1) ± 0.002 • | 0.919(5) ± 0.002 | 0.918(6) ± 0.002 | 0.918(7) ± 0.002 |
| Business | 0.945(8) ± 0.001 | 0.947(7) ± 0.001 | 0.947(6) ± 0.001 | 0.947(3) ± 0.001 | 0.948(1) ± 0.001 • | 0.947(4) ± 0.001 | 0.947(5) ± 0.000 | 0.947(2) ± 0.001 |
| Education | 0.904(8) ± 0.002 | 0.906(7) ± 0.002 | 0.906(6) ± 0.002 | 0.906(4) ± 0.002 | 0.907(1) ± 0.002 • | 0.907(2) ± 0.002 | 0.906(3) ± 0.002 | 0.906(5) ± 0.002 |
| Computers | 0.891(8) ± 0.003 | 0.894(7) ± 0.003 | 0.895(3) ± 0.003 | 0.896(1) ± 0.003 • | 0.895(2) ± 0.003 | 0.895(5) ± 0.003 | 0.895(6) ± 0.003 | 0.895(4) ± 0.003 |
| Entertainment | 0.886(8) ± 0.002 | 0.890(7) ± 0.002 | 0.891(6) ± 0.002 | 0.891(2) ± 0.002 | 0.891(1) ± 0.002 • | 0.891(3) ± 0.002 | 0.891(4) ± 0.002 | 0.891(5) ± 0.002 |
| Recreation | 0.868(8) ± 0.004 | 0.872(7) ± 0.004 | 0.873(6) ± 0.003 | 0.874(5) ± 0.004 | 0.875(1) ± 0.004 • | 0.875(2) ± 0.004 | 0.875(3) ± 0.004 | 0.875(4) ± 0.004 |
| Society | 0.866(8) ± 0.002 | 0.868(4) ± 0.002 | 0.869(1) ± 0.002 • | 0.869(2) ± 0.002 | 0.869(3) ± 0.002 | 0.868(5) ± 0.002 | 0.868(6) ± 0.002 | 0.868(7) ± 0.002 |
| eurlex-dc-l | 0.914(7) ± 0.006 | 0.918(3) ± 0.007 | 0.920(1) ± 0.006 • | 0.919(2) ± 0.005 | 0.918(4) ± 0.005 | 0.915(5) ± 0.005 | 0.914(6) ± 0.005 | 0.913(8) ± 0.006 |
| eurlex-sm | 0.951(4) ± 0.002 | 0.953(1) ± 0.001 • | 0.953(2) ± 0.002 | 0.952(3) ± 0.002 | 0.951(5) ± 0.002 | 0.950(6) ± 0.002 | 0.949(7) ± 0.002 | 0.949(8) ± 0.001 |
| tmc2007-500 | 0.958(1) ± 0.001 • | 0.958(8) ± 0.001 | 0.958(7) ± 0.001 | 0.958(5) ± 0.001 | 0.958(2) ± 0.001 | 0.958(4) ± 0.001 | 0.958(3) ± 0.001 | 0.958(6) ± 0.001 |
| mediamill | 0.960(1) ± 0.000 • | 0.959(2) ± 0.001 | 0.958(3) ± 0.001 | 0.957(4) ± 0.001 | 0.955(5) ± 0.001 | 0.953(6) ± 0.001 | 0.952(7) ± 0.001 | 0.952(8) ± 0.001 |
| average rank | 5.59 | 5.09 | 4.41 | 3.52 | 3.48 | 4.20 | 4.70 | 5.02 |
| win/tie/loss | 41/49/106 | 51/91/54 | 56/106/34 | 65/110/21 | 70/103/23 | 49/107/40 | 34/108/54 | 32/98/66 |
| Dataset | Ranking Loss | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.245(1) ± 0.025 • | 0.248(3) ± 0.021 | 0.248(2) ± 0.022 | 0.251(4) ± 0.020 | 0.256(5) ± 0.022 | 0.259(6) ± 0.019 | 0.260(7) ± 0.020 | 0.260(8) ± 0.019 |
| CAL500 | 0.240(7) ± 0.004 | 0.241(8) ± 0.003 | 0.240(5) ± 0.004 | 0.240(6) ± 0.005 | 0.238(1) ± 0.003 • | 0.238(4) ± 0.004 | 0.238(3) ± 0.003 | 0.238(2) ± 0.003 |
| emotions | 0.153(4) ± 0.009 | 0.152(1) ± 0.007 • | 0.152(2) ± 0.007 | 0.153(3) ± 0.007 | 0.155(5) ± 0.009 | 0.156(7) ± 0.010 | 0.156(6) ± 0.010 | 0.156(8) ± 0.010 |
| genbase | 0.009(8) ± 0.005 | 0.006(7) ± 0.003 | 0.005(6) ± 0.003 | 0.004(5) ± 0.003 | 0.004(4) ± 0.002 | 0.004(3) ± 0.004 | 0.004(2) ± 0.003 | 0.003(1) ± 0.003 • |
| LLOG | 0.187(3) ± 0.002 • | 0.187(3) ± 0.002 • | 0.187(7) ± 0.002 | 0.187(3) ± 0.002 • | 0.187(7) ± 0.002 | 0.187(3) ± 0.002 • | 0.187(3) ± 0.002 • | 0.187(3) ± 0.002 • |
| enron | 0.137(6) ± 0.004 | 0.136(5) ± 0.004 | 0.136(4) ± 0.004 | 0.135(1) ± 0.003 • | 0.135(2) ± 0.003 | 0.136(3) ± 0.004 | 0.137(7) ± 0.004 | 0.137(8) ± 0.004 |
| scene | 0.070(1) ± 0.003 • | 0.070(2) ± 0.003 | 0.071(3) ± 0.003 | 0.071(4) ± 0.003 | 0.072(5) ± 0.003 | 0.072(6) ± 0.003 | 0.072(7) ± 0.003 | 0.072(8) ± 0.003 |
| yeast | 0.165(1) ± 0.004 • | 0.167(2) ± 0.004 | 0.168(3) ± 0.003 | 0.168(4) ± 0.003 | 0.169(6) ± 0.003 | 0.169(5) ± 0.003 | 0.170(7) ± 0.003 | 0.170(8) ± 0.003 |
| Slashdot | 0.047(3) ± 0.005 | 0.047(2) ± 0.005 | 0.047(1) ± 0.004 • | 0.047(4) ± 0.005 | 0.047(7) ± 0.004 | 0.047(8) ± 0.005 | 0.047(5) ± 0.004 | 0.047(6) ± 0.004 |
| corel5k | 0.206(1) ± 0.003 • | 0.206(3) ± 0.004 | 0.206(4) ± 0.004 | 0.206(2) ± 0.004 | 0.206(5) ± 0.004 | 0.207(6) ± 0.004 | 0.207(8) ± 0.004 | 0.207(7) ± 0.004 |
| rcv1subset1 | 0.124(8) ± 0.008 | 0.119(7) ± 0.007 | 0.119(6) ± 0.008 | 0.118(3) ± 0.008 | 0.116(1) ± 0.008 • | 0.117(2) ± 0.008 | 0.118(5) ± 0.009 | 0.118(4) ± 0.009 |
| rcv1subset2 | 0.117(3) ± 0.010 | 0.118(5) ± 0.007 | 0.121(8) ± 0.008 | 0.118(6) ± 0.009 | 0.116(1) ± 0.012 • | 0.118(4) ± 0.010 | 0.119(7) ± 0.009 | 0.117(2) ± 0.009 |
| rcv1subset3 | 0.132(8) ± 0.008 | 0.126(6) ± 0.009 | 0.126(7) ± 0.007 | 0.122(5) ± 0.005 | 0.119(4) ± 0.007 | 0.118(2) ± 0.008 | 0.118(1) ± 0.007 • | 0.118(3) ± 0.007 |
| rcv1subset4 | 0.103(8) ± 0.009 | 0.099(6) ± 0.009 | 0.098(5) ± 0.008 | 0.100(7) ± 0.009 | 0.098(4) ± 0.009 | 0.096(3) ± 0.008 | 0.096(2) ± 0.008 | 0.096(1) ± 0.008 • |
| rcv1subset5 | 0.123(8) ± 0.006 | 0.117(5) ± 0.006 | 0.115(4) ± 0.008 | 0.117(7) ± 0.009 | 0.117(6) ± 0.007 | 0.114(3) ± 0.008 | 0.113(1) ± 0.008 • | 0.114(2) ± 0.009 |
| bibtex | 0.158(8) ± 0.005 | 0.149(7) ± 0.004 | 0.148(5) ± 0.003 | 0.147(1) ± 0.004 • | 0.148(3) ± 0.003 | 0.148(2) ± 0.003 | 0.148(6) ± 0.003 | 0.148(4) ± 0.004 |
| Arts | 0.134(8) ± 0.003 | 0.130(7) ± 0.003 | 0.129(4) ± 0.003 | 0.129(5) ± 0.003 | 0.129(1) ± 0.003 • | 0.129(2) ± 0.003 | 0.129(3) ± 0.003 | 0.129(6) ± 0.003 |
| Health | 0.072(8) ± 0.002 | 0.070(5) ± 0.002 | 0.070(3) ± 0.002 | 0.070(2) ± 0.002 | 0.070(1) ± 0.002 • | 0.070(4) ± 0.002 | 0.070(6) ± 0.001 | 0.070(7) ± 0.001 |
| Business | 0.038(8) ± 0.001 | 0.037(7) ± 0.001 | 0.037(6) ± 0.001 | 0.037(5) ± 0.001 | 0.037(2) ± 0.001 | 0.037(3) ± 0.001 | 0.037(4) ± 0.001 | 0.037(1) ± 0.001 • |
| Education | 0.092(8) ± 0.002 | 0.090(7) ± 0.002 | 0.090(6) ± 0.002 | 0.089(4) ± 0.002 | 0.089(1) ± 0.002 • | 0.089(2) ± 0.002 | 0.090(5) ± 0.002 | 0.089(3) ± 0.002 |
| Computers | 0.088(8) ± 0.003 | 0.086(4) ± 0.002 | 0.086(2) ± 0.002 | 0.086(1) ± 0.002 • | 0.086(3) ± 0.002 | 0.087(5) ± 0.002 | 0.087(7) ± 0.002 | 0.087(6) ± 0.002 |
| Entertainment | 0.115(8) ± 0.003 | 0.112(7) ± 0.003 | 0.112(3) ± 0.002 | 0.111(1) ± 0.002 • | 0.112(2) ± 0.003 | 0.112(5) ± 0.003 | 0.112(4) ± 0.002 | 0.112(6) ± 0.002 |
| Recreation | 0.120(8) ± 0.004 | 0.117(7) ± 0.004 | 0.116(6) ± 0.003 | 0.115(5) ± 0.004 | 0.115(1) ± 0.003 • | 0.115(2) ± 0.004 | 0.115(3) ± 0.004 | 0.115(4) ± 0.004 |
| Society | 0.108(8) ± 0.003 | 0.106(4) ± 0.002 | 0.105(1) ± 0.002 • | 0.105(2) ± 0.002 | 0.106(3) ± 0.002 | 0.106(5) ± 0.002 | 0.106(6) ± 0.002 | 0.107(7) ± 0.002 |
| eurlex-dc-l | 0.083(8) ± 0.005 | 0.079(4) ± 0.006 | 0.077(1) ± 0.005 • | 0.078(2) ± 0.005 | 0.078(3) ± 0.004 | 0.081(5) ± 0.004 | 0.082(6) ± 0.004 | 0.083(7) ± 0.005 |
| eurlex-sm | 0.051(5) ± 0.002 | 0.049(1) ± 0.002 • | 0.049(2) ± 0.002 | 0.050(3) ± 0.002 | 0.051(4) ± 0.002 | 0.052(6) ± 0.002 | 0.053(7) ± 0.002 | 0.053(8) ± 0.002 |
| tmc2007-500 | 0.044(1) ± 0.001 • | 0.044(2) ± 0.001 | 0.044(3) ± 0.001 | 0.044(4) ± 0.001 | 0.044(5) ± 0.001 | 0.044(6) ± 0.001 | 0.044(7) ± 0.001 | 0.044(8) ± 0.001 |
| mediamill | 0.036(1) ± 0.000 • | 0.036(2) ± 0.001 | 0.037(3) ± 0.001 | 0.038(4) ± 0.001 | 0.040(5) ± 0.001 | 0.041(6) ± 0.001 | 0.041(7) ± 0.000 | 0.042(8) ± 0.001 |
| average rank | 5.62 | 4.62 | 4.02 | 3.70 | 3.48 | 4.23 | 5.09 | 5.23 |
| win/tie/loss | 37/53/106 | 54/99/43 | 58/109/29 | 57/115/24 | 62/110/24 | 43/114/39 | 28/117/51 | 32/109/55 |
| Dataset | F1 Macro | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.283(1) ± 0.039 • | 0.280(2) ± 0.044 | 0.279(3) ± 0.046 | 0.258(4) ± 0.069 | 0.257(5) ± 0.067 | 0.250(6) ± 0.055 | 0.245(8) ± 0.071 | 0.245(7) ± 0.071 |
| CAL500 | 0.080(8) ± 0.002 | 0.081(7) ± 0.004 | 0.081(6) ± 0.003 | 0.083(4) ± 0.003 | 0.083(5) ± 0.003 | 0.084(3) ± 0.004 | 0.084(2) ± 0.004 | 0.084(1) ± 0.004 • |
| emotions | 0.657(1) ± 0.014 • | 0.653(2) ± 0.015 | 0.650(4) ± 0.015 | 0.651(3) ± 0.013 | 0.646(5) ± 0.018 | 0.645(6) ± 0.019 | 0.644(7) ± 0.019 | 0.644(8) ± 0.018 |
| genbase | 0.956(7) ± 0.013 | 0.957(5) ± 0.012 | 0.956(6) ± 0.015 | 0.954(8) ± 0.017 | 0.961(4) ± 0.012 | 0.967(3) ± 0.011 | 0.969(2) ± 0.010 | 0.971(1) ± 0.012 • |
| LLOG | 0.097(3) ± 0.016 • | 0.097(3) ± 0.016 • | 0.097(7) ± 0.016 | 0.097(3) ± 0.016 • | 0.097(7) ± 0.016 | 0.097(3) ± 0.016 • | 0.097(3) ± 0.016 • | 0.097(3) ± 0.016 • |
| enron | 0.135(1) ± 0.010 • | 0.131(4) ± 0.011 | 0.131(3) ± 0.009 | 0.131(2) ± 0.009 | 0.127(5) ± 0.009 | 0.125(6) ± 0.009 | 0.122(7) ± 0.010 | 0.121(8) ± 0.009 |
| scene | 0.754(1) ± 0.009 • | 0.751(2) ± 0.007 | 0.750(3) ± 0.008 | 0.749(4) ± 0.008 | 0.747(5) ± 0.008 | 0.746(6) ± 0.007 | 0.746(7) ± 0.007 | 0.746(8) ± 0.007 |
| yeast | 0.428(1) ± 0.008 • | 0.424(2) ± 0.007 | 0.421(3) ± 0.008 | 0.420(4) ± 0.009 | 0.415(8) ± 0.009 | 0.415(5) ± 0.008 | 0.415(7) ± 0.008 | 0.415(6) ± 0.007 |
| Slashdot | 0.161(6) ± 0.023 | 0.163(2) ± 0.027 | 0.163(3) ± 0.026 | 0.163(4) ± 0.025 | 0.166(1) ± 0.025 • | 0.162(5) ± 0.032 | 0.160(8) ± 0.030 | 0.160(7) ± 0.031 |
| corel5k | 0.026(2) ± 0.003 | 0.027(1) ± 0.004 • | 0.026(4) ± 0.005 | 0.026(3) ± 0.004 | 0.026(5) ± 0.003 | 0.024(8) ± 0.004 | 0.025(7) ± 0.003 | 0.025(6) ± 0.003 |
| rcv1subset1 | 0.142(8) ± 0.011 | 0.152(7) ± 0.013 | 0.154(5) ± 0.014 | 0.152(6) ± 0.014 | 0.156(1) ± 0.013 • | 0.155(4) ± 0.013 | 0.156(2) ± 0.012 | 0.155(3) ± 0.012 |
| rcv1subset2 | 0.127(6) ± 0.017 | 0.125(7) ± 0.010 | 0.125(8) ± 0.010 | 0.133(5) ± 0.015 | 0.138(2) ± 0.021 | 0.135(4) ± 0.015 | 0.137(3) ± 0.017 | 0.141(1) ± 0.019 • |
| rcv1subset3 | 0.099(8) ± 0.007 | 0.109(7) ± 0.012 | 0.113(6) ± 0.010 | 0.120(5) ± 0.010 | 0.122(4) ± 0.009 | 0.124(3) ± 0.011 | 0.126(1) ± 0.007 • | 0.125(2) ± 0.009 |
| rcv1subset4 | 0.138(8) ± 0.016 | 0.148(7) ± 0.017 | 0.151(4) ± 0.015 | 0.149(6) ± 0.013 | 0.151(5) ± 0.017 | 0.154(3) ± 0.013 | 0.154(1) ± 0.012 • | 0.154(2) ± 0.012 |
| rcv1subset5 | 0.128(8) ± 0.013 | 0.132(7) ± 0.013 | 0.135(4) ± 0.017 | 0.134(5) ± 0.017 | 0.132(6) ± 0.014 | 0.138(2) ± 0.015 | 0.138(1) ± 0.014 • | 0.137(3) ± 0.014 |
| bibtex | 0.176(8) ± 0.006 | 0.187(3) ± 0.004 | 0.187(1) ± 0.005 • | 0.187(2) ± 0.006 | 0.185(5) ± 0.005 | 0.186(4) ± 0.007 | 0.184(6) ± 0.006 | 0.184(7) ± 0.006 |
| Arts | 0.236(8) ± 0.014 | 0.252(7) ± 0.014 | 0.258(6) ± 0.015 | 0.263(5) ± 0.015 | 0.269(3) ± 0.014 | 0.273(1) ± 0.014 • | 0.272(2) ± 0.014 | 0.268(4) ± 0.014 |
| Health | 0.382(8) ± 0.010 | 0.394(7) ± 0.011 | 0.397(6) ± 0.011 | 0.404(4) ± 0.011 | 0.407(2) ± 0.011 | 0.407(1) ± 0.012 • | 0.405(3) ± 0.011 | 0.403(5) ± 0.011 |
| Business | 0.245(8) ± 0.007 | 0.255(7) ± 0.008 | 0.259(6) ± 0.008 | 0.267(5) ± 0.005 | 0.279(3) ± 0.009 | 0.281(1) ± 0.009 • | 0.279(4) ± 0.008 | 0.280(2) ± 0.010 |
| Education | 0.254(8) ± 0.013 | 0.268(7) ± 0.013 | 0.274(6) ± 0.014 | 0.278(5) ± 0.015 | 0.286(1) ± 0.013 • | 0.283(2) ± 0.013 | 0.279(4) ± 0.012 | 0.281(3) ± 0.011 |
| Computers | 0.271(8) ± 0.012 | 0.286(7) ± 0.010 | 0.292(6) ± 0.009 | 0.294(5) ± 0.010 | 0.303(1) ± 0.014 • | 0.301(4) ± 0.015 | 0.302(2) ± 0.017 | 0.302(3) ± 0.014 |
| Entertainment | 0.372(8) ± 0.005 | 0.383(7) ± 0.008 | 0.386(6) ± 0.009 | 0.390(2) ± 0.008 | 0.391(1) ± 0.010 • | 0.389(3) ± 0.010 | 0.388(4) ± 0.011 | 0.387(5) ± 0.011 |
| Recreation | 0.367(8) ± 0.015 | 0.378(7) ± 0.017 | 0.384(6) ± 0.011 | 0.390(5) ± 0.016 | 0.399(3) ± 0.014 | 0.400(1) ± 0.015 • | 0.399(2) ± 0.015 | 0.398(4) ± 0.014 |
| Society | 0.266(8) ± 0.012 | 0.278(7) ± 0.011 | 0.284(6) ± 0.012 | 0.291(5) ± 0.012 | 0.297(1) ± 0.010 • | 0.296(2) ± 0.011 | 0.295(3) ± 0.012 | 0.295(4) ± 0.013 |
| eurlex-dc-l | 0.261(5) ± 0.010 | 0.266(3) ± 0.012 | 0.269(1) ± 0.012 • | 0.267(2) ± 0.010 | 0.265(4) ± 0.012 | 0.257(6) ± 0.011 | 0.251(7) ± 0.010 | 0.247(8) ± 0.011 |
| eurlex-sm | 0.385(4) ± 0.007 | 0.392(1) ± 0.010 • | 0.390(2) ± 0.009 | 0.388(3) ± 0.009 | 0.383(5) ± 0.012 | 0.373(6) ± 0.010 | 0.365(7) ± 0.010 | 0.363(8) ± 0.010 |
| tmc2007-500 | 0.604(4) ± 0.008 | 0.602(8) ± 0.008 | 0.602(7) ± 0.008 | 0.603(6) ± 0.007 | 0.604(5) ± 0.008 | 0.604(1) ± 0.007 • | 0.604(2) ± 0.007 | 0.604(3) ± 0.007 |
| mediamill | 0.332(1) ± 0.005 • | 0.319(2) ± 0.004 | 0.312(3) ± 0.003 | 0.293(4) ± 0.005 | 0.257(5) ± 0.005 | 0.224(6) ± 0.008 | 0.202(7) ± 0.007 | 0.192(8) ± 0.007 |
| average rank | 5.55 | 4.95 | 4.70 | 4.27 | 3.84 | 3.77 | 4.27 | 4.66 |
| win/tie/loss | 42/55/99 | 48/78/70 | 54/83/59 | 65/90/41 | 62/110/24 | 66/90/40 | 52/96/48 | 47/94/55 |
| Dataset | F1 Micro | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.366(3) ± 0.037 | 0.376(1) ± 0.044 • | 0.369(2) ± 0.050 | 0.358(4) ± 0.061 | 0.352(6) ± 0.062 | 0.352(5) ± 0.053 | 0.335(7) ± 0.085 | 0.332(8) ± 0.084 |
| CAL500 | 0.336(7) ± 0.009 | 0.335(8) ± 0.014 | 0.339(6) ± 0.010 | 0.342(4) ± 0.014 | 0.341(5) ± 0.012 | 0.342(2) ± 0.014 | 0.342(3) ± 0.013 | 0.343(1) ± 0.013 • |
| emotions | 0.680(1) ± 0.015 • | 0.675(2) ± 0.013 | 0.672(4) ± 0.013 | 0.672(3) ± 0.011 | 0.668(5) ± 0.016 | 0.665(8) ± 0.015 | 0.666(6) ± 0.016 | 0.665(7) ± 0.015 |
| genbase | 0.956(8) ± 0.015 | 0.962(7) ± 0.014 | 0.965(6) ± 0.012 | 0.965(5) ± 0.014 | 0.970(4) ± 0.012 | 0.974(3) ± 0.011 | 0.976(1) ± 0.010 • | 0.976(2) ± 0.010 |
| LLOG | 0.363(3) ± 0.059 • | 0.363(3) ± 0.059 • | 0.360(7) ± 0.057 | 0.363(3) ± 0.059 • | 0.360(7) ± 0.057 | 0.363(3) ± 0.059 • | 0.363(3) ± 0.059 • | 0.363(3) ± 0.059 • |
| enron | 0.444(8) ± 0.012 | 0.452(7) ± 0.012 | 0.454(6) ± 0.014 | 0.460(5) ± 0.013 | 0.464(4) ± 0.010 | 0.466(3) ± 0.011 | 0.467(1) ± 0.012 • | 0.467(2) ± 0.011 |
| scene | 0.748(1) ± 0.009 • | 0.746(2) ± 0.007 | 0.744(3) ± 0.009 | 0.743(4) ± 0.008 | 0.741(5) ± 0.009 | 0.741(6) ± 0.008 | 0.741(7) ± 0.007 | 0.740(8) ± 0.008 |
| yeast | 0.652(1) ± 0.008 • | 0.647(2) ± 0.008 | 0.645(3) ± 0.006 | 0.643(4) ± 0.006 | 0.641(6) ± 0.007 | 0.641(5) ± 0.007 | 0.640(7) ± 0.006 | 0.640(8) ± 0.006 |
| Slashdot | 0.844(1) ± 0.007 • | 0.844(2) ± 0.007 | 0.843(4) ± 0.008 | 0.843(8) ± 0.008 | 0.843(7) ± 0.007 | 0.843(3) ± 0.007 | 0.843(5) ± 0.007 | 0.843(6) ± 0.007 |
| corel5k | 0.051(4) ± 0.009 | 0.051(1) ± 0.011 • | 0.051(2) ± 0.012 | 0.050(5) ± 0.011 | 0.051(3) ± 0.010 | 0.048(8) ± 0.010 | 0.048(7) ± 0.009 | 0.049(6) ± 0.009 |
| rcv1subset1 | 0.277(8) ± 0.019 | 0.288(7) ± 0.017 | 0.291(6) ± 0.020 | 0.296(5) ± 0.021 | 0.298(4) ± 0.020 | 0.300(3) ± 0.021 | 0.302(2) ± 0.023 | 0.302(1) ± 0.023 • |
| rcv1subset2 | 0.325(7) ± 0.012 | 0.330(6) ± 0.009 | 0.324(8) ± 0.010 | 0.334(3) ± 0.012 | 0.336(1) ± 0.017 • | 0.333(4) ± 0.014 | 0.332(5) ± 0.014 | 0.335(2) ± 0.016 |
| rcv1subset3 | 0.313(8) ± 0.010 | 0.323(7) ± 0.016 | 0.326(6) ± 0.010 | 0.333(5) ± 0.009 | 0.334(3) ± 0.014 | 0.334(4) ± 0.014 | 0.335(2) ± 0.010 | 0.335(1) ± 0.011 • |
| rcv1subset4 | 0.382(8) ± 0.018 | 0.394(6) ± 0.024 | 0.398(3) ± 0.022 | 0.394(7) ± 0.019 | 0.396(5) ± 0.022 | 0.399(1) ± 0.019 • | 0.397(4) ± 0.017 | 0.398(2) ± 0.018 |
| rcv1subset5 | 0.340(8) ± 0.016 | 0.347(7) ± 0.016 | 0.348(6) ± 0.015 | 0.348(5) ± 0.014 | 0.350(4) ± 0.016 | 0.357(2) ± 0.020 | 0.359(1) ± 0.022 • | 0.357(3) ± 0.020 |
| bibtex | 0.360(8) ± 0.007 | 0.367(3) ± 0.006 | 0.368(1) ± 0.006 • | 0.367(2) ± 0.006 | 0.365(4) ± 0.004 | 0.364(5) ± 0.005 | 0.363(7) ± 0.004 | 0.363(6) ± 0.004 |
| Arts | 0.344(8) ± 0.017 | 0.358(7) ± 0.016 | 0.365(6) ± 0.014 | 0.369(5) ± 0.014 | 0.372(1) ± 0.014 • | 0.371(2) ± 0.014 | 0.371(3) ± 0.014 | 0.370(4) ± 0.014 |
| Health | 0.565(8) ± 0.011 | 0.570(7) ± 0.010 | 0.572(6) ± 0.011 | 0.574(2) ± 0.011 | 0.575(1) ± 0.009 • | 0.573(4) ± 0.011 | 0.573(3) ± 0.010 | 0.573(5) ± 0.010 |
| Business | 0.718(8) ± 0.004 | 0.720(7) ± 0.004 | 0.721(6) ± 0.003 | 0.722(5) ± 0.004 | 0.723(1) ± 0.003 • | 0.723(3) ± 0.004 | 0.723(2) ± 0.003 | 0.722(4) ± 0.004 |
| Education | 0.358(8) ± 0.013 | 0.371(7) ± 0.014 | 0.376(6) ± 0.013 | 0.378(5) ± 0.014 | 0.381(1) ± 0.013 • | 0.379(2) ± 0.014 | 0.379(4) ± 0.012 | 0.379(3) ± 0.013 |
| Computers | 0.501(8) ± 0.004 | 0.507(7) ± 0.005 | 0.509(6) ± 0.005 | 0.511(5) ± 0.005 | 0.513(1) ± 0.006 • | 0.512(2) ± 0.006 | 0.512(3) ± 0.006 | 0.512(4) ± 0.005 |
| Entertainment | 0.489(8) ± 0.008 | 0.499(7) ± 0.007 | 0.502(6) ± 0.006 | 0.505(4) ± 0.008 | 0.506(2) ± 0.007 | 0.506(1) ± 0.006 • | 0.505(3) ± 0.006 | 0.504(5) ± 0.006 |
| Recreation | 0.439(8) ± 0.012 | 0.449(7) ± 0.012 | 0.452(5) ± 0.010 | 0.454(3) ± 0.012 | 0.456(1) ± 0.012 • | 0.454(2) ± 0.013 | 0.453(4) ± 0.013 | 0.452(6) ± 0.012 |
| Society | 0.455(8) ± 0.012 | 0.464(7) ± 0.011 | 0.467(4) ± 0.010 | 0.468(3) ± 0.010 | 0.470(1) ± 0.009 • | 0.468(2) ± 0.010 | 0.466(6) ± 0.010 | 0.466(5) ± 0.010 |
| eurlex-dc-l | 0.475(4) ± 0.008 | 0.479(3) ± 0.007 | 0.481(1) ± 0.007 • | 0.479(2) ± 0.007 | 0.474(5) ± 0.005 | 0.467(6) ± 0.005 | 0.462(7) ± 0.006 | 0.459(8) ± 0.005 |
| eurlex-sm | 0.593(2) ± 0.006 | 0.594(1) ± 0.007 • | 0.592(3) ± 0.007 | 0.589(4) ± 0.007 | 0.582(5) ± 0.008 | 0.576(6) ± 0.008 | 0.572(7) ± 0.008 | 0.570(8) ± 0.008 |
| tmc2007-500 | 0.728(1) ± 0.003 • | 0.726(2) ± 0.003 | 0.726(3) ± 0.003 | 0.726(4) ± 0.003 | 0.726(5) ± 0.003 | 0.726(6) ± 0.003 | 0.726(7) ± 0.003 | 0.726(8) ± 0.003 |
| mediamill | 0.655(1) ± 0.001 • | 0.649(2) ± 0.001 | 0.644(3) ± 0.001 | 0.635(4) ± 0.001 | 0.618(5) ± 0.001 | 0.606(6) ± 0.002 | 0.601(7) ± 0.002 | 0.598(8) ± 0.002 |
| average rank | 5.59 | 4.84 | 4.59 | 4.23 | 3.66 | 3.84 | 4.45 | 4.80 |
| win/tie/loss | 47/38/111 | 62/57/77 | 61/74/61 | 72/95/29 | 76/88/32 | 66/85/45 | 48/91/57 | 43/90/63 |
| Dataset | Hamming Loss | |||||||
|---|---|---|---|---|---|---|---|---|
| β = 5/4 | β = 3/2 | β = 5/3 | β = 2 | β = 3 | β = 5 | β = 9 | β = 17 | |
| birds | 0.139(7) ± 0.005 | 0.139(6) ± 0.007 | 0.139(5) ± 0.007 | 0.137(1) ± 0.008 • | 0.137(2) ± 0.006 | 0.137(3) ± 0.007 | 0.138(4) ± 0.007 | 0.139(8) ± 0.007 |
| CAL500 | 0.187(3) ± 0.001 | 0.187(8) ± 0.001 | 0.187(6) ± 0.001 | 0.187(2) ± 0.001 | 0.186(1) ± 0.001 • | 0.187(7) ± 0.001 | 0.187(5) ± 0.001 | 0.187(4) ± 0.001 |
| emotions | 0.186(1) ± 0.008 • | 0.189(2) ± 0.006 | 0.190(4) ± 0.006 | 0.190(3) ± 0.005 | 0.192(5) ± 0.007 | 0.194(8) ± 0.007 | 0.194(6) ± 0.007 | 0.194(7) ± 0.007 |
| genbase | 0.008(8) ± 0.003 | 0.007(7) ± 0.002 | 0.006(6) ± 0.002 | 0.006(5) ± 0.002 | 0.005(4) ± 0.002 | 0.005(3) ± 0.002 | 0.004(1) ± 0.002 • | 0.004(1) ± 0.002 • |
| LLOG | 0.188(3) ± 0.006 • | 0.188(3) ± 0.006 • | 0.188(7) ± 0.005 | 0.188(3) ± 0.006 • | 0.188(7) ± 0.005 | 0.188(3) ± 0.006 • | 0.188(3) ± 0.006 • | 0.188(3) ± 0.006 • |
| enron | 0.076(8) ± 0.001 | 0.076(7) ± 0.001 | 0.075(4) ± 0.001 | 0.075(5) ± 0.001 | 0.075(1) ± 0.001 • | 0.075(6) ± 0.001 | 0.075(2) ± 0.001 | 0.075(3) ± 0.001 |
| scene | 0.083(1) ± 0.003 • | 0.084(2) ± 0.002 | 0.084(3) ± 0.003 | 0.084(4) ± 0.003 | 0.085(5) ± 0.003 | 0.085(6) ± 0.002 | 0.085(7) ± 0.002 | 0.085(8) ± 0.002 |
| yeast | 0.195(1) ± 0.005 • | 0.198(2) ± 0.004 | 0.199(3) ± 0.003 | 0.200(4) ± 0.003 | 0.201(5) ± 0.004 | 0.201(6) ± 0.004 | 0.201(7) ± 0.004 | 0.201(8) ± 0.004 |
| Slashdot | 0.028(1) ± 0.001 • | 0.028(2) ± 0.001 | 0.029(4) ± 0.002 | 0.029(8) ± 0.001 | 0.029(7) ± 0.001 | 0.029(3) ± 0.001 | 0.029(5) ± 0.001 | 0.029(6) ± 0.001 |
| corel5k | 0.021(1) ± 0.000 • | 0.021(2) ± 0.000 | 0.021(7) ± 0.000 | 0.021(4) ± 0.000 | 0.021(3) ± 0.000 | 0.021(6) ± 0.000 | 0.021(5) ± 0.000 | 0.021(8) ± 0.000 |
| rcv1subset1 | 0.033(8) ± 0.000 | 0.033(6) ± 0.000 | 0.033(4) ± 0.000 | 0.032(1) ± 0.000 • | 0.032(3) ± 0.000 | 0.032(2) ± 0.000 | 0.033(5) ± 0.000 | 0.033(7) ± 0.000 |
| rcv1subset2 | 0.027(6) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(3) ± 0.000 | 0.027(2) ± 0.000 | 0.027(5) ± 0.000 | 0.027(4) ± 0.000 | 0.027(7) ± 0.000 | 0.027(8) ± 0.000 |
| rcv1subset3 | 0.027(8) ± 0.000 | 0.027(6) ± 0.000 | 0.027(4) ± 0.000 | 0.027(3) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(5) ± 0.000 | 0.027(7) ± 0.000 |
| rcv1subset4 | 0.024(7) ± 0.000 | 0.024(4) ± 0.000 | 0.024(1) ± 0.000 • | 0.024(2) ± 0.000 | 0.024(5) ± 0.000 | 0.024(3) ± 0.000 | 0.024(8) ± 0.000 | 0.024(5) ± 0.000 |
| rcv1subset5 | 0.027(3) ± 0.000 | 0.027(5) ± 0.000 | 0.027(4) ± 0.000 | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(6) ± 0.000 | 0.027(7) ± 0.000 | 0.027(8) ± 0.000 |
| bibtex | 0.013(1) ± 0.000 • | 0.013(3) ± 0.000 | 0.013(2) ± 0.000 | 0.013(4) ± 0.000 | 0.013(5) ± 0.000 | 0.013(6) ± 0.000 | 0.013(7) ± 0.000 | 0.013(8) ± 0.000 |
| Arts | 0.060(8) ± 0.001 | 0.060(7) ± 0.001 | 0.059(6) ± 0.001 | 0.059(4) ± 0.001 | 0.059(1) ± 0.000 • | 0.059(2) ± 0.000 | 0.059(3) ± 0.000 | 0.059(5) ± 0.000 |
| Health | 0.056(8) ± 0.001 | 0.055(7) ± 0.001 | 0.055(6) ± 0.001 | 0.055(2) ± 0.001 | 0.055(1) ± 0.001 • | 0.055(3) ± 0.001 | 0.055(4) ± 0.001 | 0.055(5) ± 0.001 |
| Business | 0.031(8) ± 0.000 | 0.031(6) ± 0.000 | 0.031(4) ± 0.000 | 0.031(1) ± 0.000 • | 0.031(2) ± 0.000 | 0.031(3) ± 0.000 | 0.031(5) ± 0.000 | 0.031(7) ± 0.000 |
| Education | 0.047(8) ± 0.001 | 0.046(7) ± 0.001 | 0.046(6) ± 0.001 | 0.046(2) ± 0.001 | 0.046(1) ± 0.001 • | 0.046(3) ± 0.001 | 0.046(4) ± 0.001 | 0.046(5) ± 0.001 |
| Computers | 0.043(8) ± 0.000 | 0.043(7) ± 0.000 | 0.043(5) ± 0.000 | 0.043(2) ± 0.000 | 0.043(1) ± 0.001 • | 0.043(3) ± 0.001 | 0.043(6) ± 0.001 | 0.043(4) ± 0.001 |
| Entertainment | 0.062(8) ± 0.001 | 0.061(7) ± 0.001 | 0.061(6) ± 0.001 | 0.061(3) ± 0.001 | 0.061(1) ± 0.001 • | 0.061(2) ± 0.001 | 0.061(4) ± 0.001 | 0.061(5) ± 0.001 |
| Recreation | 0.051(8) ± 0.001 | 0.050(7) ± 0.001 | 0.050(6) ± 0.001 | 0.050(3) ± 0.001 | 0.050(1) ± 0.001 • | 0.050(2) ± 0.001 | 0.050(4) ± 0.001 | 0.050(5) ± 0.001 |
| Society | 0.052(8) ± 0.001 | 0.051(7) ± 0.001 | 0.051(6) ± 0.001 | 0.051(2) ± 0.001 | 0.051(1) ± 0.001 • | 0.051(3) ± 0.001 | 0.051(4) ± 0.001 | 0.051(5) ± 0.001 |
| eurlex-dc-l | 0.005(4) ± 0.000 | 0.004(1) ± 0.000 • | 0.004(2) ± 0.000 | 0.004(3) ± 0.000 | 0.005(5) ± 0.000 | 0.005(6) ± 0.000 | 0.005(7) ± 0.000 | 0.005(8) ± 0.000 |
| eurlex-sm | 0.011(2) ± 0.000 | 0.011(1) ± 0.000 • | 0.011(3) ± 0.000 | 0.011(4) ± 0.000 | 0.011(5) ± 0.000 | 0.011(6) ± 0.000 | 0.011(7) ± 0.000 | 0.011(8) ± 0.000 |
| tmc2007-500 | 0.051(1) ± 0.000 • | 0.051(2) ± 0.000 | 0.051(3) ± 0.000 | 0.051(4) ± 0.000 | 0.051(5) ± 0.000 | 0.051(6) ± 0.000 | 0.051(7) ± 0.000 | 0.051(8) ± 0.000 |
| mediamill | 0.027(1) ± 0.000 • | 0.027(2) ± 0.000 | 0.027(3) ± 0.000 | 0.028(4) ± 0.000 | 0.029(5) ± 0.000 | 0.030(6) ± 0.000 | 0.030(7) ± 0.000 | 0.030(8) ± 0.000 |
| average rank | 4.98 | 4.55 | 4.41 | 3.09 | 3.25 | 4.27 | 5.25 | 6.20 |
| win/tie/loss | 55/69/72 | 53/90/53 | 57/101/38 | 65/108/23 | 57/102/37 | 49/108/39 | 30/115/51 | 23/98/75 |
References
- Huang, A.; Xu, R.; Chen, Y.; Guo, M. Research on multi-label user classification of social media based on ML-KNN algorithm. Technol. Forecast. Soc. Change 2023, 188, 122271. [Google Scholar] [CrossRef]
- George, M.; Floerkemeier, C. Recognizing Products: A Per-exemplar Multi-label Image Classification Approach. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 440–455. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Dai, T.; He, Z. Exploring Weighted Dual Graph Regularized Non-Negative Matrix Tri-Factorization Based Collaborative Filtering Framework for Multi-Label Annotation of Remote Sensing Images. Remote Sens. 2019, 11, 922. [Google Scholar] [CrossRef]
- Chalkidis, I.; Fergadiotis, E.; Malakasiotis, P.; Androutsopoulos, I. Large-Scale Multi-Label Text Classification on EU Legislation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 28 July–2 August 2019; pp. 6314–6322. [Google Scholar] [CrossRef]
- Spyromitros, E.; Tsoumakas, G.; Vlahavas, I. An Empirical Study of Lazy Multilabel Classification Algorithms. In Proceedings of the Artificial Intelligence: Theories, Models and Applications, Syros, Greece, 2–4 October 2008; Darzentas, J., Vouros, G.A., Vosinakis, S., Arnellos, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 401–406. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. ML-KNN: A lazy learning approach to multi-label learning. Pattern Recognit. 2007, 40, 2038–2048. [Google Scholar] [CrossRef]
- Younes, Z.; Abdallah, F.; Denoeux, T. Multi-label classification algorithm derived from K-nearest neighbor rule with label dependencies. In Proceedings of the 2008 16th European Signal Processing Conference, Lausanne, Switzeerland, 25–19 August 2008; pp. 1–5. [Google Scholar]
- Cheng, W.; Hüllermeier, E. Combining instance-based learning and logistic regression for multilabel classification. Mach. Learn. 2009, 76, 211–225. [Google Scholar] [CrossRef]
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Džeroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recognit. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Bogatinovski, J.; Todorovski, L.; Džeroski, S.; Kocev, D. Comprehensive comparative study of multi-label classification methods. Expert Syst. Appl. 2022, 203, 117215. [Google Scholar] [CrossRef]
- Radovanović, M.; Nanopoulos, A.; Ivanović, M. Hubs in space: Popular nearest neighbors in high-dimensional data. J. Mach. Learn. Res. 2010, 11, 2487–2531. [Google Scholar]
- Feldbauer, R.; Flexer, A. A comprehensive empirical comparison of hubness reduction in high-dimensional spaces. Knowl. Inf. Syst. 2019, 59, 137–166. [Google Scholar] [CrossRef]
- Zhang, M.L.; Zhou, Z.H. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef]
- Fürnkranz, J.; Hüllermeier, E.; Mencía, E.L.; Brinker, K. Multilabel classification via calibrated label ranking. Mach. Learn. 2008, 73, 133–153. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Fürnkranz, J.; Cheng, W.; Brinker, K. Label ranking by learning pairwise preferences. Artif. Intell. 2008, 172, 1897–1916. [Google Scholar] [CrossRef]
- Read, J.; Pfahringer, B.; Holmes, G.; Frank, E. Classifier chains for multi-label classification. Mach. Learn. 2011, 85, 333–359. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Katakis, I.; Vlahavas, I. Random k-Labelsets for Multilabel Classification. IEEE Trans. Knowl. Data Eng. 2011, 23, 1079–1089. [Google Scholar] [CrossRef]
- Clare, A.; King, R.D. Knowledge Discovery in Multi-label Phenotype Data. In Proceedings of the Principles of Data Mining and Knowledge Discovery, Freiburg, Germany, 3–5 September 2001; De Raedt, L., Siebes, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 42–53. [Google Scholar] [CrossRef]
- Elisseeff, A.; Weston, J. A Kernel Method for Multi-Labelled Classification. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic, Cambridge, MA, USA, 3–8 December 2001; NIPS’01. pp. 681–687. [Google Scholar]
- Zhang, M.L. Ml-rbf: RBF Neural Networks for Multi-Label Learning. Neural Process. Lett. 2009, 29, 61–74. [Google Scholar] [CrossRef]
- Cuevas-Muñoz, J.M.; García-Pedrajas, N.E. ML-k’sNN: Label Dependent k Values for Multi-Label k-Nearest Neighbor Rule. Mathematics 2023, 11, 275. [Google Scholar] [CrossRef]
- Liu, W.; Wang, H.; Shen, X.; Tsang, I.W. The Emerging Trends of Multi-Label Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7955–7974. [Google Scholar] [CrossRef]
- Tarekegn, A.N.; Giacobini, M.; Michalak, K. A review of methods for imbalanced multi-label classification. Pattern Recognit. 2021, 118, 107965. [Google Scholar] [CrossRef]
- Qian, K.; Min, X.Y.; Cheng, Y.; Min, F. Weight matrix sharing for multi-label learning. Pattern Recognit. 2023, 136, 109156. [Google Scholar] [CrossRef]
- Bakhshi, S.; Can, F. Balancing efficiency vs. effectiveness and providing missing label robustness in multi-label stream classification. Knowl.-Based Syst. 2024, 289, 111489. [Google Scholar] [CrossRef]
- Xie, M.K.; Huang, S.J. Partial multi-label learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 4302–4309. [Google Scholar] [CrossRef]
- Hu, Y.; Fang, X.; Kang, P.; Chen, Y.; Fang, Y.; Xie, S. Dual Noise Elimination and Dynamic Label Correlation Guided Partial Multi-Label Learning. IEEE Trans. Multimed. 2024, 26, 5641–5656. [Google Scholar] [CrossRef]
- Xu, C.; Tao, D.; Xu, C. Robust Extreme Multi-label Learning. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016; KDD ’16. pp. 1275–1284. [Google Scholar] [CrossRef]
- Mittal, A.; Sachdeva, N.; Agrawal, S.; Agarwal, S.; Kar, P.; Varma, M. ECLARE: Extreme Classification with Label Graph Correlations. In Proceedings of the Web Conference 2021, New York, NY, USA, 19–23 April 2021; WWW ’21. pp. 3721–3732. [Google Scholar] [CrossRef]
- Venkatesan, R.; Er, M.J.; Wu, S.; Pratama, M. A novel online real-time classifier for multi-label data streams. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1833–1840. [Google Scholar] [CrossRef]
- Esteban, A.; Cano, A.; Zafra, A.; Ventura, S. Hoeffding adaptive trees for multi-label classification on data streams. Knowl.-Based Syst. 2024, 304, 112561. [Google Scholar] [CrossRef]
- Aucouturier, J.J.; Pachet, F. Improving timbre similarity: How high is the sky. J. Negat. Results Speech Audio Sci. 2004, 1, 1–13. [Google Scholar]
- Hara, K.; Suzuki, I.; Kobayashi, K.; Fukumizu, K.; Radovanovíc, M. Flattening the density gradient for eliminating spatial centrality to reduce hubness. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, AAAI 2016, Phoenix, AZ, USA, 12–17 February 2016; pp. 1659–1665. [Google Scholar] [CrossRef]
- Aryal, S.; Ting, K.M.; Washio, T.; Haffari, G. Data-dependent dissimilarity measure: An effective alternative to geometric distance measures. Knowl. Inf. Syst. 2017, 53, 479–506. [Google Scholar] [CrossRef]
- Tomašev, N.; Mladenić, D. Hubness-aware shared neighbor distances for high-dimensional k-nearest neighbor classification. Knowl. Inf. Syst. 2014, 39, 89–122. [Google Scholar] [CrossRef]
- Pal, A.K.; Mondal, P.K.; Ghosh, A.K. High dimensional nearest neighbor classification based on mean absolute differences of inter-point distances. Pattern Recognit. Lett. 2016, 74, 1–8. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the Surprising Behavior of Distance Metrics in High Dimensional Space. In Proceedings of the Database Theory—ICDT 2001, London, UK, 4–6 January 2001; Van den Bussche, J., Vianu, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 420–434. [Google Scholar] [CrossRef]
- Flexer, A.; Schnitzer, D. Choosing ℓp norms in high-dimensional spaces based on hub analysis. Neurocomputing 2015, 169, 281–287. [Google Scholar] [CrossRef]
- Schnitzer, D.; Flexer, A.; Schedl, M.; Widmer, G. Local and Global Scaling Reduce Hubs in Space. J. Mach. Learn. Res. 2012, 13, 2871–2902. [Google Scholar]
- Feldbauer, R.; Leodolter, M.; Plant, C.; Flexer, A. Fast Approximate Hubness Reduction for Large High-Dimensional Data. In Proceedings of the 2018 IEEE International Conference on Big Knowledge (ICBK), Singapore, 17–18 November 2018; pp. 358–367. [Google Scholar] [CrossRef]
- Suzuki, I.; Hara, K.; Shimbo, M.; Saerens, M.; Fukumizu, K. Centering similarity measures to reduce hubs. In Proceedings of the EMNLP 2013—2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; Proceedings of the Conference. pp. 613–623. [Google Scholar]
- Hara, K.; Suzuki, I.; Shimbo, M.; Kobayashi, K.; Fukumizu, K.; Radovanovic, M. Localized centering: Reducing hubness in large-sample data. Proc. Natl. Conf. Artif. Intell. 2015, 4, 2645–2651. [Google Scholar] [CrossRef]
- Obraczka, D.; Rahm, E. An Evaluation of Hubness Reduction Methods for Entity Alignment with Knowledge Graph Embeddings. Int. Jt. Conf. Knowl. Discov. Knowl. Eng. Knowl. Manag. IC3K Proc. 2021, 2, 28–39. [Google Scholar] [CrossRef]
- Amblard, E.; Bac, J.; Chervov, A.; Soumelis, V.; Zinovyev, A. Hubness reduction improves clustering and trajectory inference in single-cell transcriptomic data. Bioinformatics 2022, 38, 1045–1051. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, B.M.; Hansen, L.K. Hubness Reduction Improves Sentence-BERT Semantic Spaces. Proc. Mach. Learn. Res. 2024, 233. [Google Scholar]
- Radovanović, M.; Nanopoulos, A.; Ivanović, M. Nearest neighbors in high-dimensional data: The emergence and influence of hubs. In Proceedings of the 26th Annual International Conference on Machine Learning, New York, NY, USA, 14–18 June 2009; ICML ’09. pp. 865–872. [Google Scholar] [CrossRef]
- Tomasev, N.; Radovanović, M.; Mladenić, D.; Ivanović, M. A probabilistic approach to nearest-neighbor classification: Naive hubness bayesian kNN. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, New York, NY, USA, 24–28 October 2011; CIKM ’11. pp. 2173–2176. [Google Scholar] [CrossRef]
- Tomašev, N.; Radovanović, M.; Mladenić, D.; Ivanović, M. Hubness-based fuzzy measures for high-dimensional k-nearest neighbor classification. Int. J. Mach. Learn. Cybern. 2014, 5, 445–458. [Google Scholar]
- Tomašev, N.; Mladenić, D. Nearest neighbor voting in high dimensional data: Learning from past occurrences. Comput. Sci. Inf. Syst. 2012, 9, 691–712. [Google Scholar] [CrossRef]
- Buza, K.; Nanopoulos, A.; Nagy, G. Nearest neighbor regression in the presence of bad hubs. Knowl.-Based Syst. 2015, 86, 250–260. [Google Scholar] [CrossRef]
- Tomasev, N.; Radovanovic, M.; Mladenic, D.; Ivanovic, M. The Role of Hubness in Clustering High-Dimensional Data. IEEE Trans. Knowl. Data Eng. 2014, 26, 739–751. [Google Scholar] [CrossRef]
- Radovanović, M.; Nanopoulos, A.; Ivanović, M. Reverse Nearest Neighbors in Unsupervised Distance-Based Outlier Detection. IEEE Trans. Knowl. Data Eng. 2015, 27, 1369–1382. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, S.; Wu, Z.; Li, X. Outlier detection using local density and global structure. Pattern Recognit. 2025, 157, 110947. [Google Scholar] [CrossRef]
- Shigeto, Y.; Suzuki, I.; Hara, K.; Shimbo, M.; Matsumoto, Y. Ridge Regression, Hubness, and Zero-Shot Learning. In Proceedings of the Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; Appice, A., Rodrigues, P.P., Santos Costa, V., Soares, C., Gama, J., Jorge, A., Eds.; Springer: Cham, Switzerland, 2015; pp. 135–151. [Google Scholar] [CrossRef]
- Dinu, G.; Lazaridou, A.; Baroni, M. Improving zero-shot learning by mitigating the hubness problem. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Workshop Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–10. [Google Scholar]
- Zhang, L.; Xiang, T.; Gong, S. Learning a Deep Embedding Model for Zero-Shot Learning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3010–3019. [Google Scholar] [CrossRef]
- Luo, C.; Li, Z.; Huang, K.; Feng, J.; Wang, M. Zero-Shot Learning via Attribute Regression and Class Prototype Rectification. IEEE Trans. Image Process. 2018, 27, 637–648. [Google Scholar] [CrossRef]
- Paul, A.; Krishnan, N.C.; Munjal, P. Semantically Aligned Bias Reducing Zero Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7049–7058. [Google Scholar] [CrossRef]
- Buza, K.; Peška, L. Drug–target interaction prediction with Bipartite Local Models and hubness-aware regression. Neurocomputing 2017, 260, 284–293. [Google Scholar] [CrossRef]
- Wang, D.; Yih, Y.; Ventresca, M. Improving neighbor-based collaborative filtering by using a hybrid similarity measurement. Expert Syst. Appl. 2020, 160, 113651. [Google Scholar] [CrossRef]
- Tian, M.; Giunchiglia, F.; Song, R.; Xu, H. Guiding ontology translation with hubness-aware translation memory. Expert Syst. Appl. 2025, 264, 125650. [Google Scholar] [CrossRef]
- Tsoumakas, G.; Spyromitros-Xioufis, E.; Vilcek, J.; Vlahavas, I. MULAN: A Java Library for Multi-Label Learning. J. Mach. Learn. Res. 2011, 12, 2411–2414. [Google Scholar]
- Read, J.; Reutemann, P.; Pfahringer, B.; Holmes, G. MEKA: A Multi-label/Multi-target Extension to WEKA. J. Mach. Learn. Res. 2016, 17, 1–5. [Google Scholar]
- Sun, L.; Ji, S.; Ye, J. Hypergraph spectral learning for multi-label classification. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2008; KDD ’08. pp. 668–676. [Google Scholar] [CrossRef]
- Zhang, M.L.; Li, Y.K.; Yang, H.; Liu, X.Y. Towards Class-Imbalance Aware Multi-Label Learning. IEEE Trans. Cybern. 2022, 52, 4459–4471. [Google Scholar] [CrossRef] [PubMed]
- Szymański, P.; Kajdanowicz, T. A scikit-based Python environment for performing multi-label classification. arXiv 2017, arXiv:1702.01460. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Feldbauer, R.; Rattei, T.; Flexer, A. scikit-hubness: Hubness Reduction and Approximate Neighbor Search. J. Open Source Softw. 2020, 5, 1957. [Google Scholar] [CrossRef]
- Benavoli, A.; Corani, G.; Mangili, F. Should We Really Use Post-Hoc Tests Based on Mean-Ranks? J. Mach. Learn. Res. 2016, 17, 152–161. [Google Scholar]
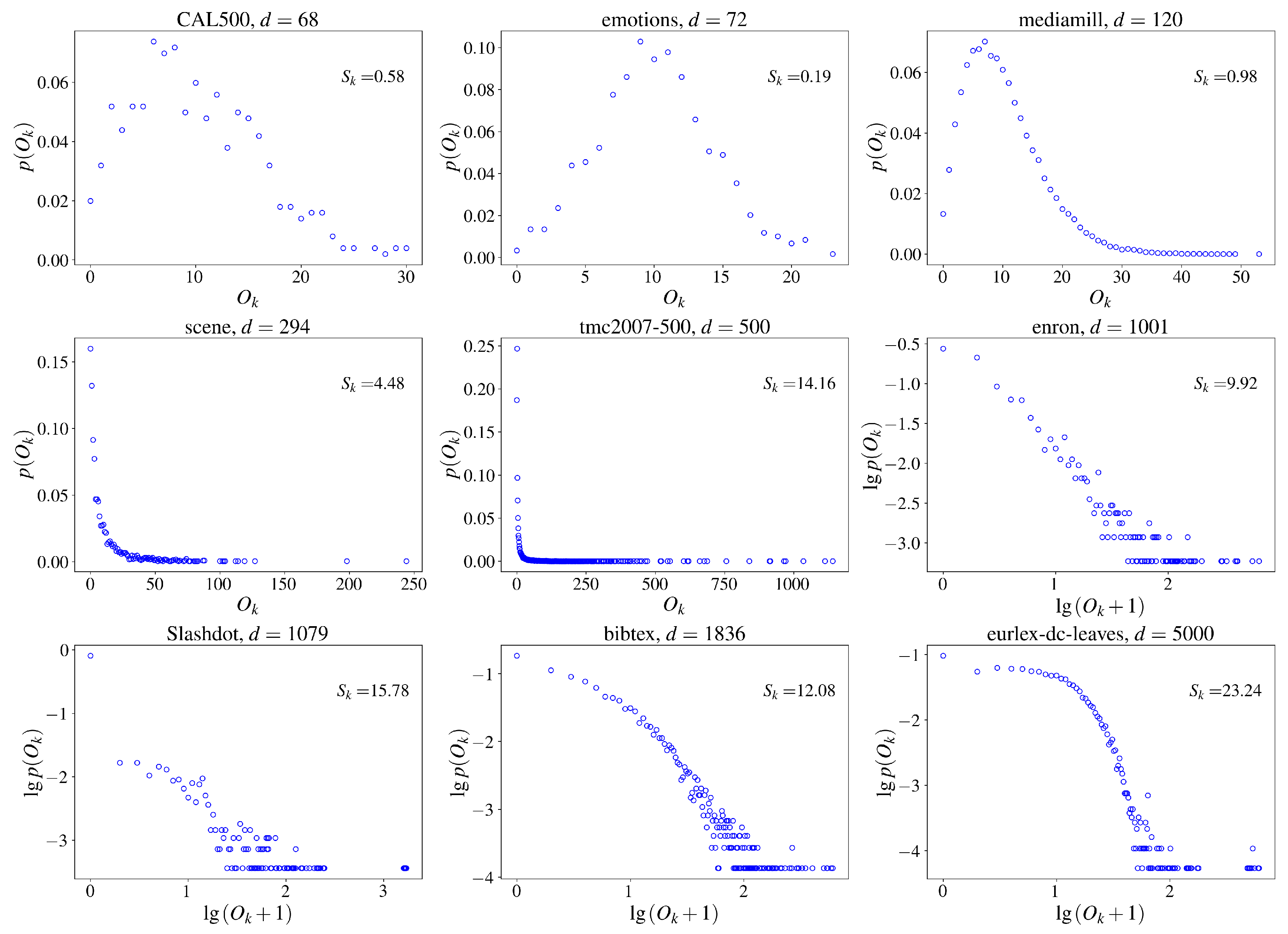
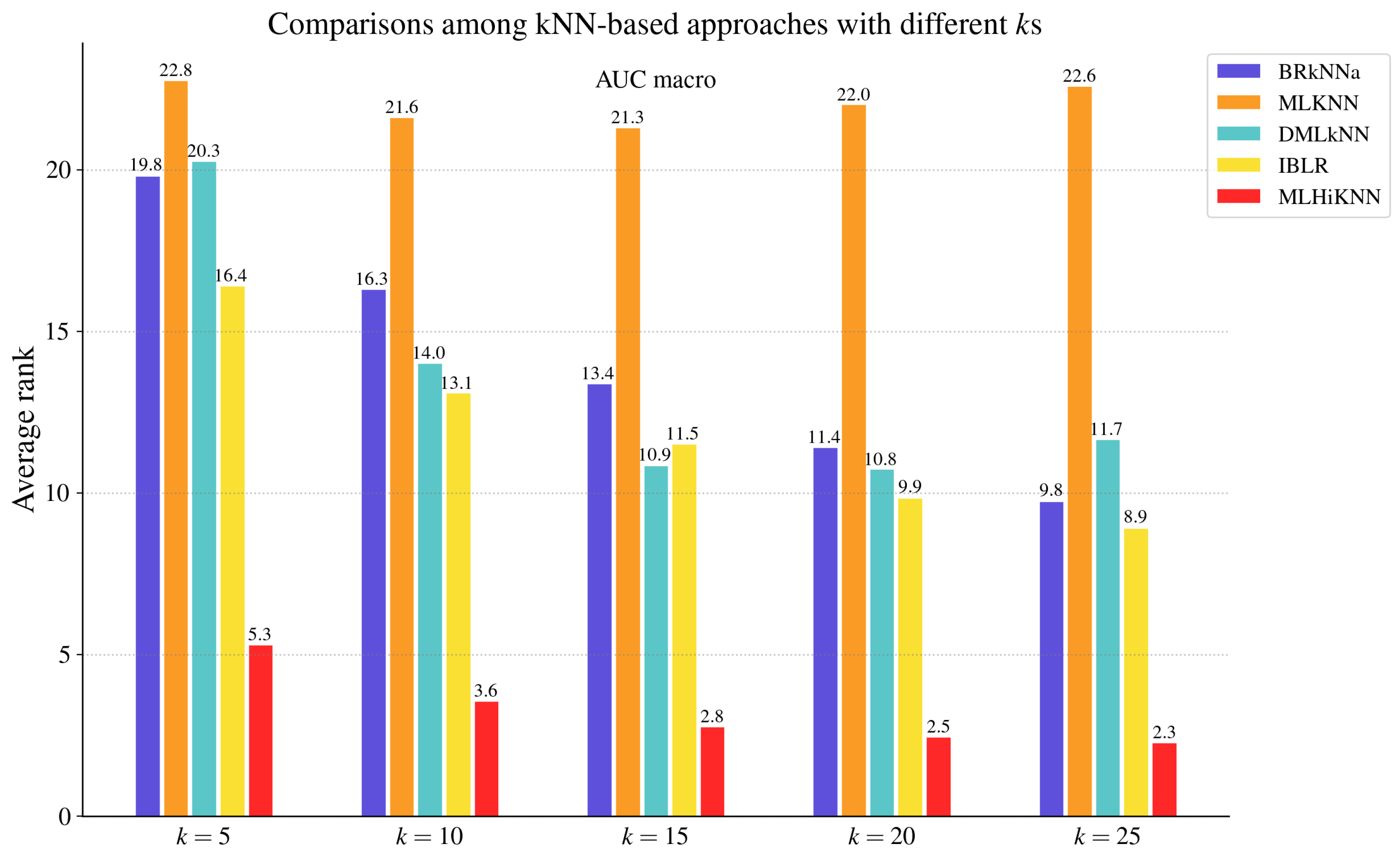
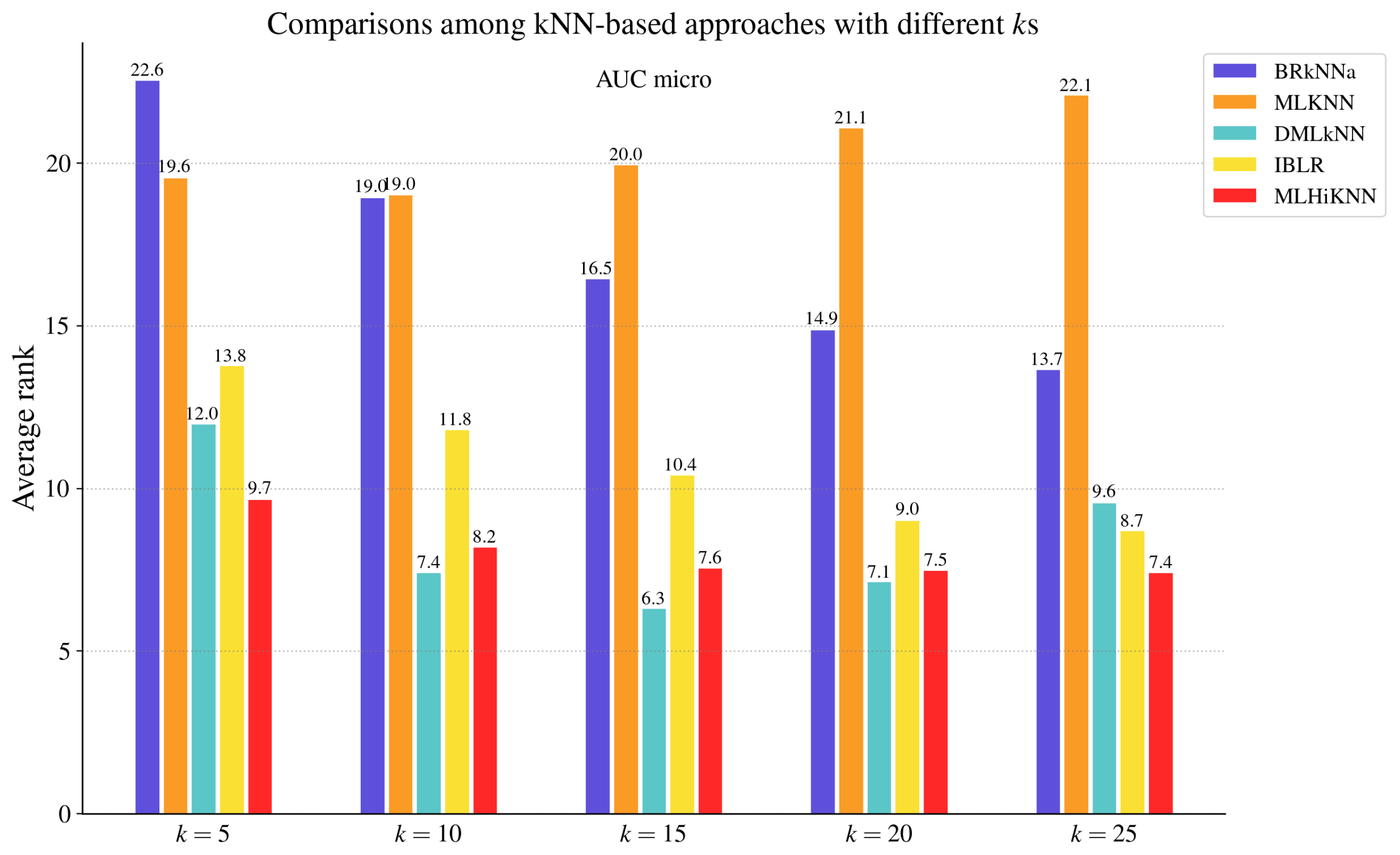
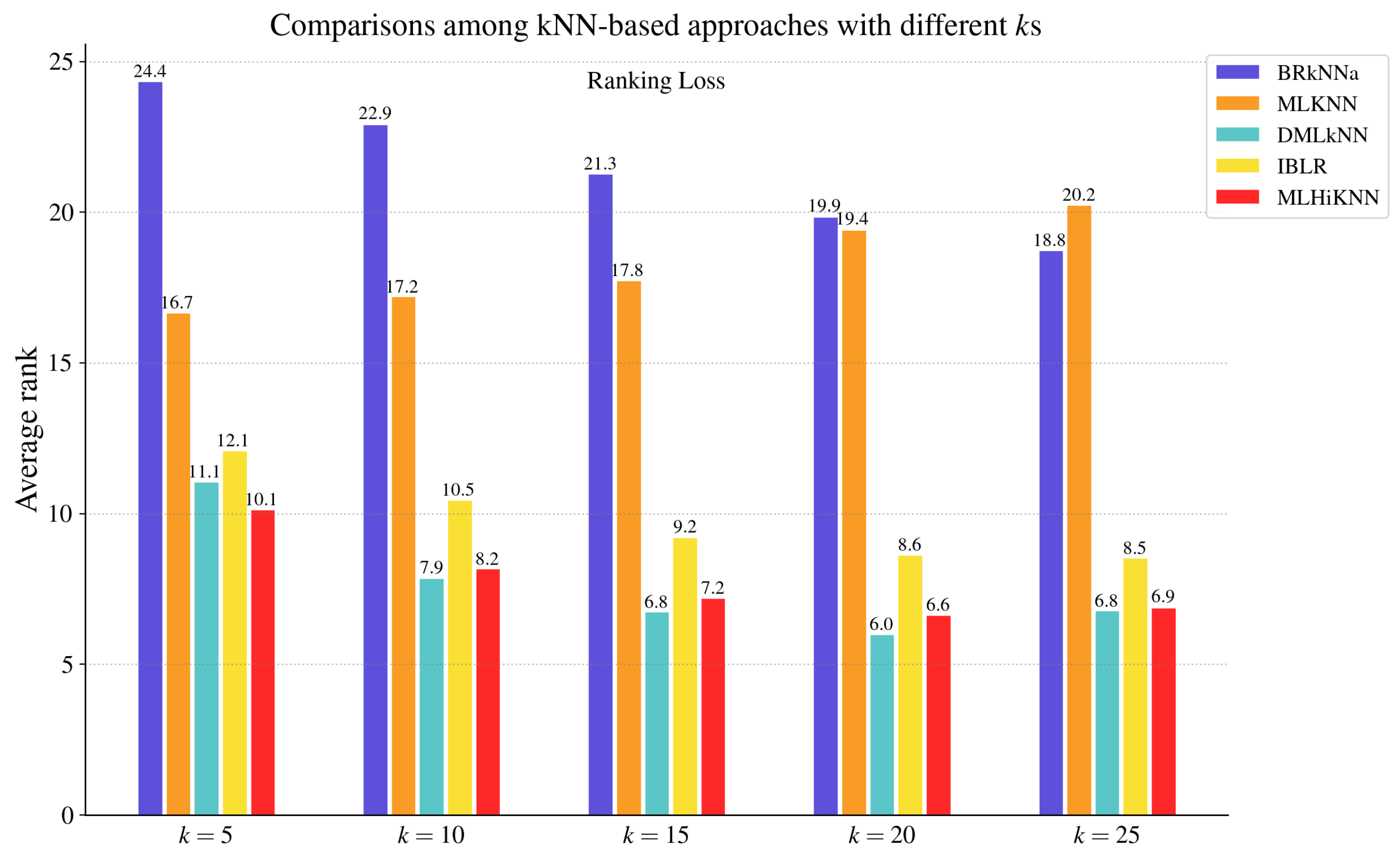
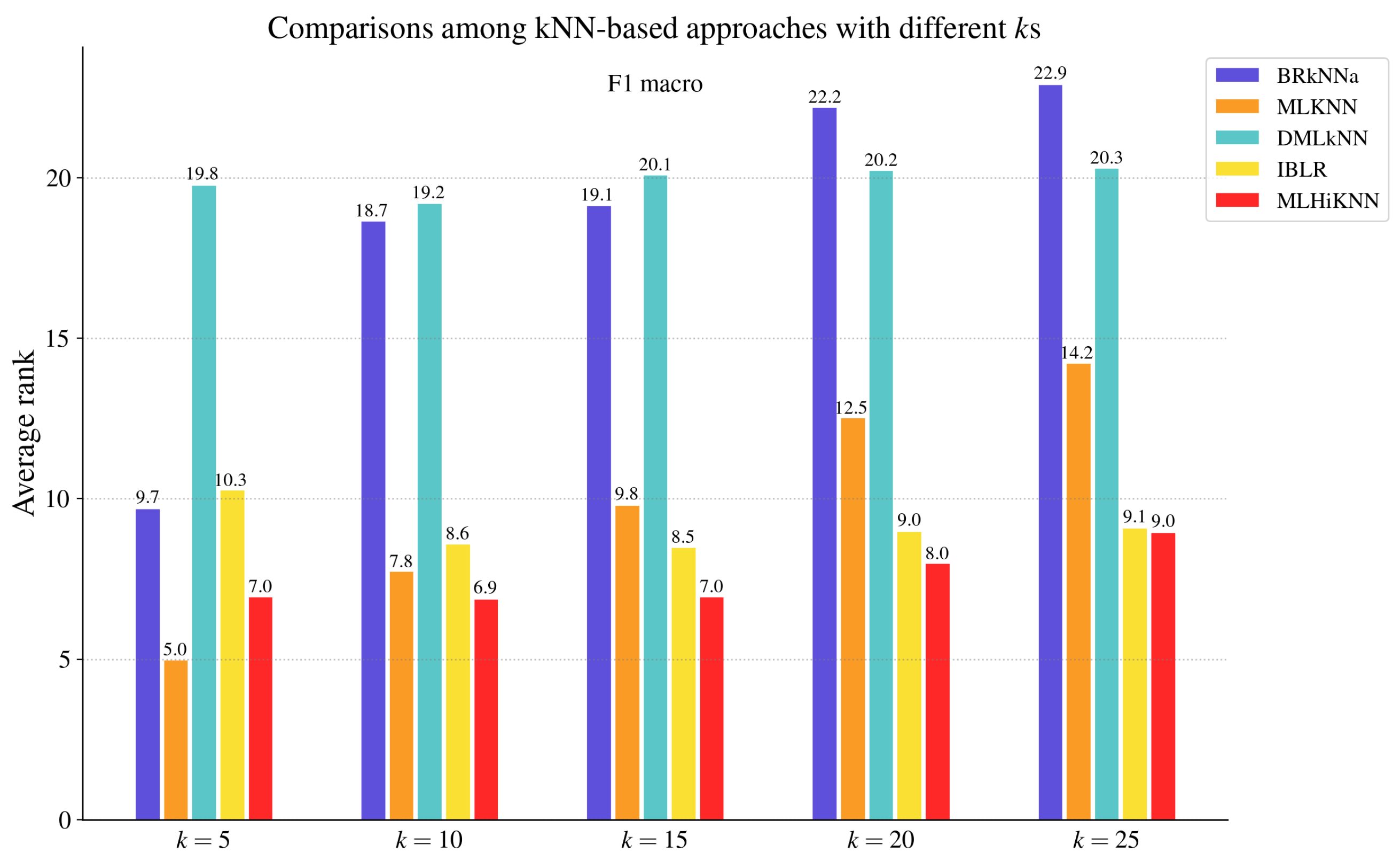

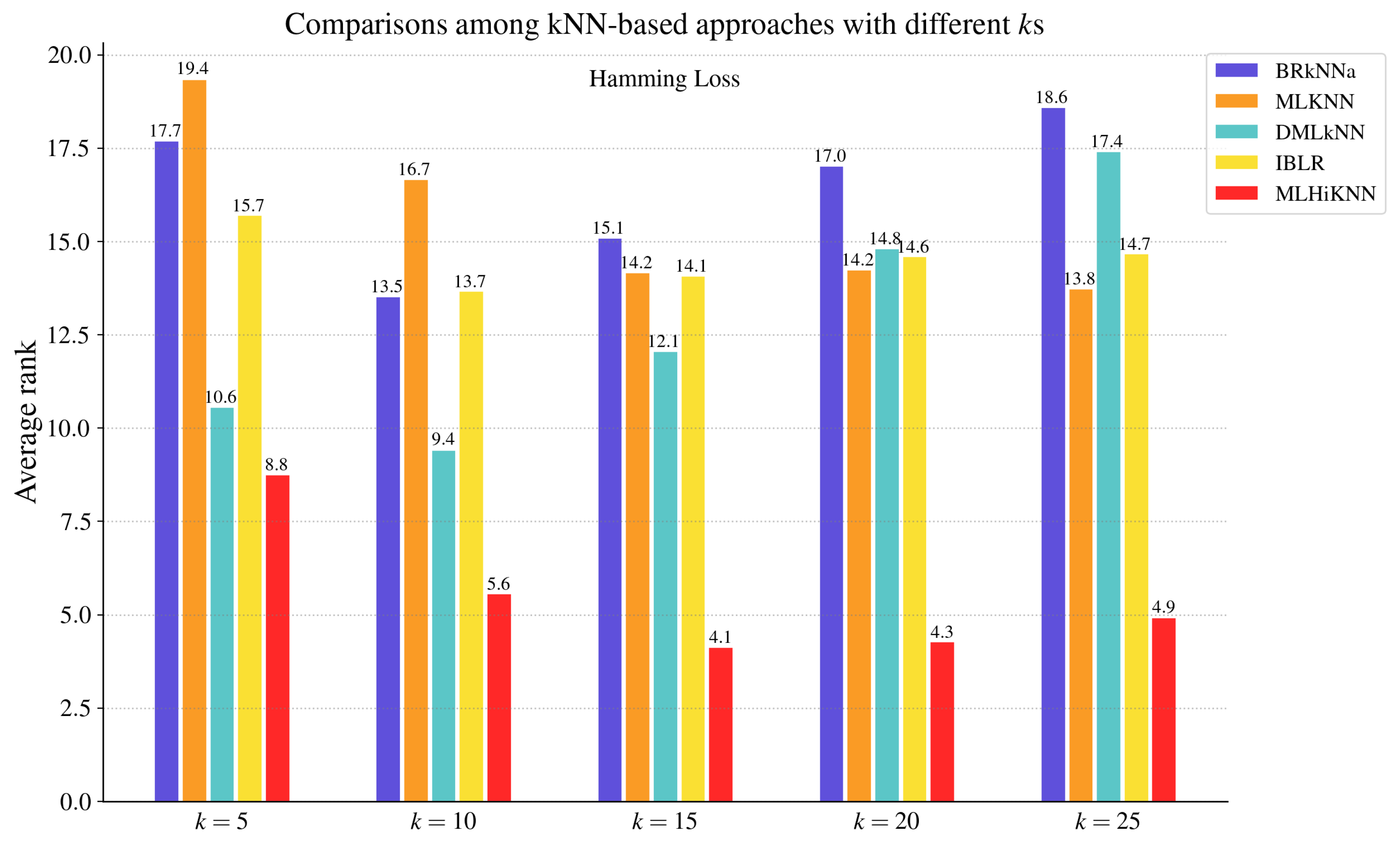


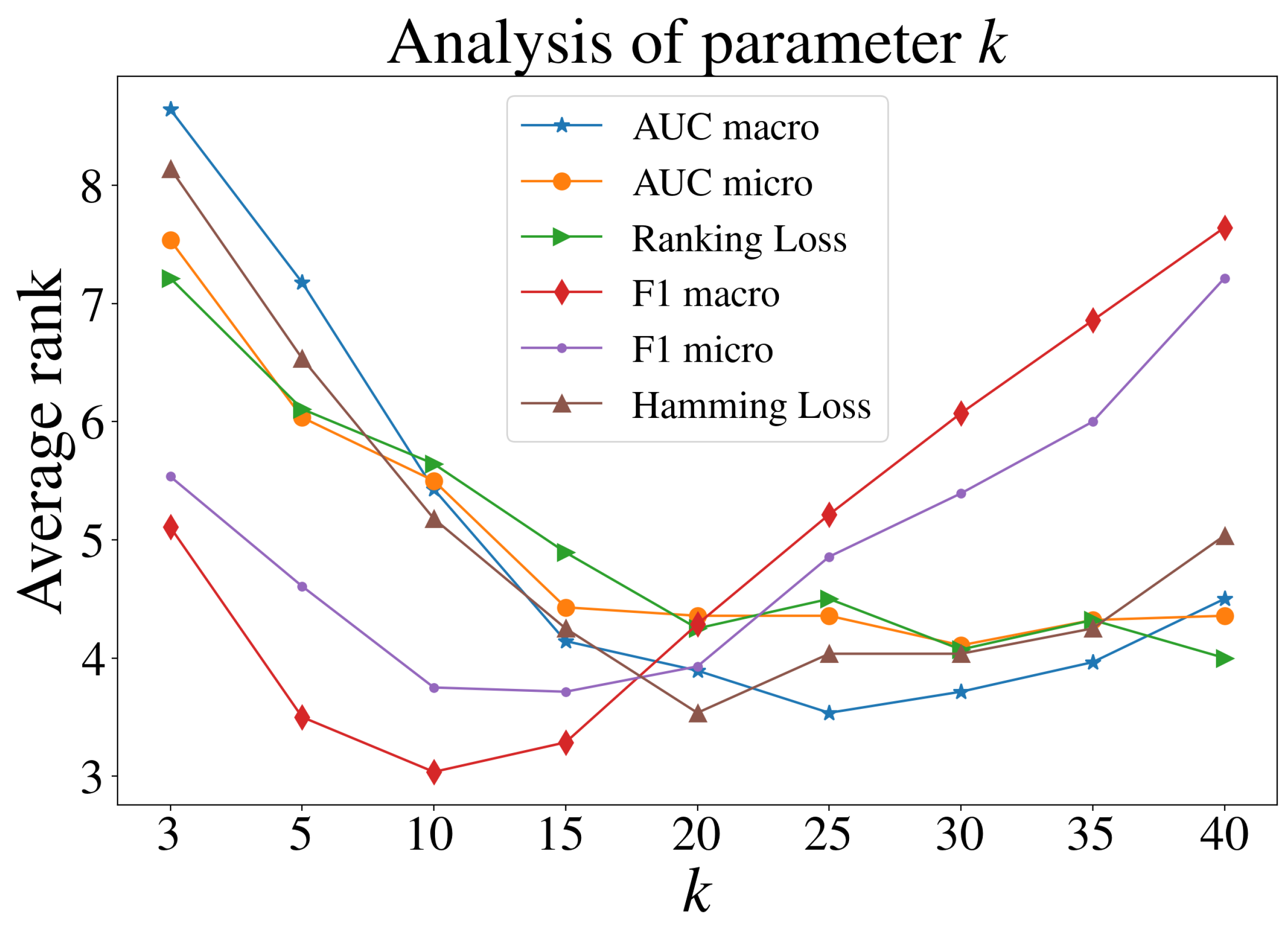
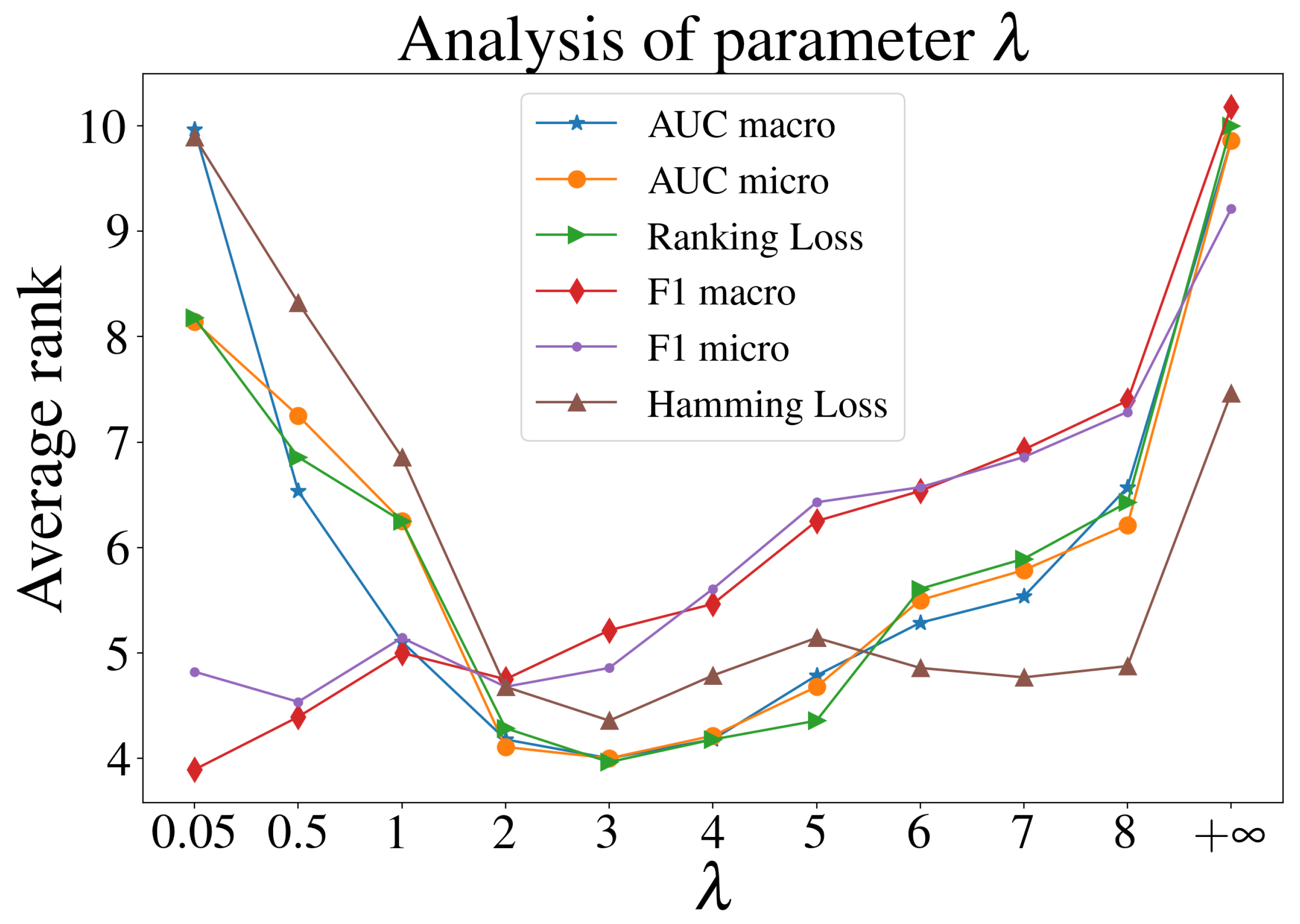
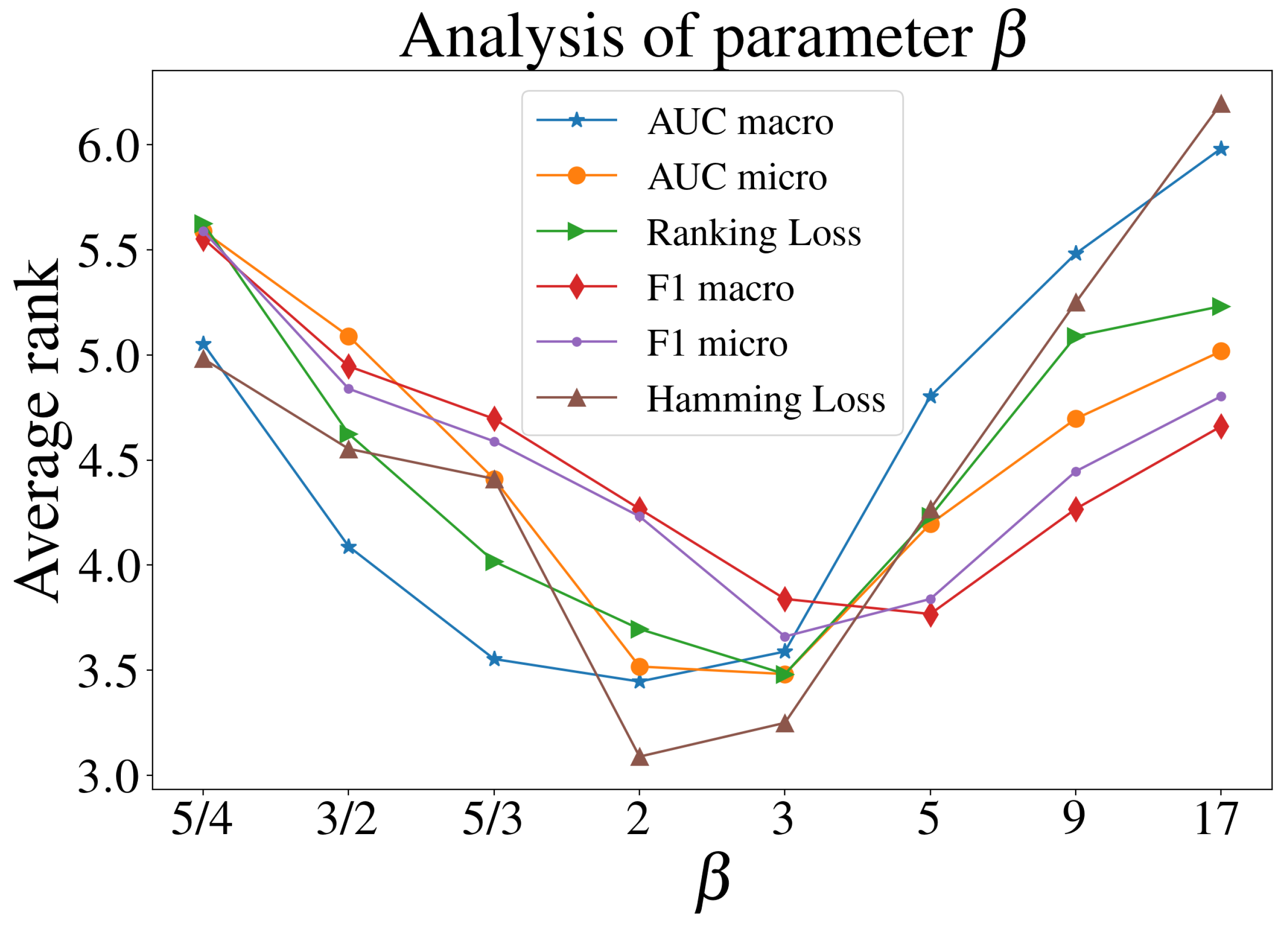
| Dataset | #Samples | #Attr | #Labels | LCard | LDen | LDiv | PLDiv | Domain | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| birds | 327 | 260 | 12 | 1.76 | 0.15 | 92 | 0.28 | -0.22 | 0.01 | 0.0000 | audio |
| CAL500 | 502 | 68 | 124 | 25.06 | 0.20 | 502 | 1.00 | 0.58 | 0.12 | 0.0000 | music |
| emotions | 593 | 72 | 6 | 1.87 | 0.31 | 27 | 0.05 | 0.19 | 0.01 | 0.0000 | music |
| genbase | 662 | 1186 | 13 | 1.13 | 0.09 | 14 | 0.02 | −0.06 | 0.00 | 0.0000 | biology |
| LLOG | 1429 | 100 | 75 | 16.28 | 0.22 | 1213 | 0.85 | 11.38 | 1.00 | 0.9685 | text |
| enron | 1702 | 1001 | 35 | 3.28 | 0.09 | 675 | 0.40 | 9.92 | 0.65 | 0.0000 | text |
| scene | 2407 | 294 | 6 | 1.07 | 0.18 | 15 | 0.01 | 4.48 | 0.52 | 0.0000 | image |
| yeast | 2417 | 103 | 14 | 4.24 | 0.30 | 198 | 0.08 | 1.55 | 0.26 | 0.0000 | biology |
| Slashdot | 2771 | 53 | 12 | 1.18 | 0.10 | 52 | 0.02 | 15.78 | 0.89 | 0.7694 | text |
| corel5k | 4985 | 499 | 153 | 3.18 | 0.02 | 2626 | 0.53 | 24.64 | 0.79 | 0.0000 | images |
| rcv1subset1 | 6000 | 472 | 80 | 2.84 | 0.04 | 977 | 0.16 | 8.21 | 0.42 | 0.0010 | text |
| rcv1subset2 | 6000 | 472 | 83 | 2.60 | 0.03 | 903 | 0.15 | 5.28 | 0.41 | 0.0047 | text |
| rcv1subset3 | 6000 | 472 | 83 | 2.58 | 0.03 | 899 | 0.15 | 6.17 | 0.41 | 0.0048 | text |
| rcv1subset4 | 6000 | 472 | 82 | 2.46 | 0.03 | 762 | 0.13 | 5.42 | 0.40 | 0.0053 | text |
| rcv1subset5 | 6000 | 472 | 84 | 2.61 | 0.03 | 902 | 0.15 | 6.02 | 0.41 | 0.0097 | text |
| bibtex | 7395 | 184 | 159 | 2.40 | 0.02 | 2856 | 0.39 | 12.08 | 0.52 | 0.0368 | text |
| Arts | 7484 | 462 | 24 | 1.65 | 0.07 | 595 | 0.08 | 17.88 | 0.44 | 0.0345 | text |
| Health | 9205 | 612 | 21 | 1.64 | 0.08 | 314 | 0.03 | 14.84 | 0.44 | 0.0214 | text |
| Business | 11,204 | 438 | 25 | 1.60 | 0.06 | 221 | 0.02 | 26.53 | 0.54 | 0.1252 | text |
| Education | 12,016 | 550 | 27 | 1.46 | 0.05 | 488 | 0.04 | 12.24 | 0.43 | 0.0137 | text |
| Computers | 12,434 | 681 | 27 | 1.50 | 0.06 | 403 | 0.03 | 18.04 | 0.46 | 0.0314 | text |
| Entertainment | 12,730 | 640 | 17 | 1.41 | 0.08 | 317 | 0.02 | 23.59 | 0.45 | 0.0324 | text |
| Recreation | 12,828 | 606 | 22 | 1.43 | 0.06 | 530 | 0.04 | 28.08 | 0.46 | 0.0677 | text |
| Society | 14,512 | 636 | 26 | 1.67 | 0.06 | 1053 | 0.07 | 18.50 | 0.45 | 0.0300 | text |
| eurlex-dc-l (In the tables of this paper, the dataset eurlex-dc-leaves is denoted by eurlex-dc-l for short) | 18,593 | 250 | 215 | 1.26 | 0.01 | 1115 | 0.06 | 23.24 | 0.32 | 0.0575 | text |
| eurlex-sm | 19,282 | 250 | 136 | 2.20 | 0.02 | 2314 | 0.12 | 3.68 | 0.28 | 0.0200 | text |
| tmc2007-500 | 28,596 | 500 | 22 | 2.22 | 0.10 | 1172 | 0.04 | 14.16 | 0.62 | 0.0002 | text |
| mediamill | 42,177 | 120 | 101 | 4.56 | 0.05 | 6554 | 0.16 | 0.98 | 0.16 | 0.0000 | video |
| Perspective | Macro-Averaging | Micro-Averaging | Example-Based |
|---|---|---|---|
| Ranking | AUC macro | AUC micro | Ranking Loss |
| Classification | F1 macro | F1 micro | Hamming Loss |
| Dataset | AUC Macro | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN | |
| birds | 0.624(9) ± 0.030 | 0.625(8) ± 0.020 | 0.753(1) ± 0.017 • | 0.723(3) ± 0.016 | 0.651(7) ± 0.014 | 0.702(4) ± 0.016 | 0.606(10) ± 0.019 | 0.684(6) ± 0.021 | 0.691(5) ± 0.017 | 0.728(2) ± 0.030 |
| CAL500 | 0.511(9) ± 0.005 | 0.508(10) ± 0.005 | 0.537(3) ± 0.006 | 0.527(5) ± 0.004 | 0.513(8) ± 0.003 | 0.543(2) ± 0.006 | 0.515(7) ± 0.004 | 0.530(4) ± 0.003 | 0.516(6) ± 0.008 | 0.571(1) ± 0.006 • |
| emotions | 0.690(8) ± 0.018 | 0.680(10) ± 0.016 | 0.818(4) ± 0.008 | 0.793(6) ± 0.009 | 0.689(9) ± 0.014 | 0.834(3) ± 0.005 | 0.723(7) ± 0.013 | 0.805(5) ± 0.009 | 0.836(2) ± 0.010 | 0.846(1) ± 0.005 • |
| genbase | 0.989(8) ± 0.010 | 0.987(9) ± 0.014 | 0.996(4) ± 0.005 | 0.997(2) ± 0.004 | 0.994(7) ± 0.008 | 0.996(5) ± 0.004 | 0.963(10) ± 0.013 | 0.998(1) ± 0.001 • | 0.995(6) ± 0.006 | 0.997(3) ± 0.003 |
| LLOG | 0.526(9) ± 0.002 | 0.525(10) ± 0.004 | 0.539(6) ± 0.006 | 0.531(8) ± 0.002 | 0.536(7) ± 0.005 | 0.598(4) ± 0.006 | 0.588(5) ± 0.006 | 0.602(3) ± 0.006 | 0.602(2) ± 0.006 | 0.603(1) ± 0.006 • |
| enron | 0.580(9) ± 0.008 | 0.576(10) ± 0.004 | 0.646(2) ± 0.005 | 0.631(5) ± 0.005 | 0.585(8) ± 0.009 | 0.627(6) ± 0.012 | 0.596(7) ± 0.011 | 0.634(4) ± 0.014 | 0.641(3) ± 0.017 | 0.676(1) ± 0.012 • |
| scene | 0.761(8) ± 0.015 | 0.752(10) ± 0.014 | 0.921(5) ± 0.004 | 0.894(7) ± 0.003 | 0.760(9) ± 0.011 | 0.937(3) ± 0.003 | 0.898(6) ± 0.007 | 0.932(4) ± 0.004 | 0.940(2) ± 0.003 | 0.944(1) ± 0.002 • |
| yeast | 0.569(8) ± 0.006 | 0.562(10) ± 0.007 | 0.641(5) ± 0.005 | 0.625(6) ± 0.004 | 0.562(9) ± 0.010 | 0.685(3) ± 0.005 | 0.583(7) ± 0.006 | 0.671(4) ± 0.006 | 0.692(2) ± 0.006 | 0.711(1) ± 0.006 • |
| Slashdot | 0.560(8) ± 0.019 | 0.581(6) ± 0.021 | 0.535(10) ± 0.014 | 0.550(9) ± 0.010 | 0.595(5) ± 0.019 | 0.680(3) ± 0.017 | 0.563(7) ± 0.033 | 0.671(4) ± 0.034 | 0.682(2) ± 0.035 | 0.723(1) ± 0.021 • |
| corel5k | 0.522(6) ± 0.002 | 0.516(10) ± 0.002 | 0.520(8) ± 0.002 | 0.516(9) ± 0.001 | 0.522(7) ± 0.002 | 0.582(4) ± 0.004 | 0.569(5) ± 0.004 | 0.587(3) ± 0.007 | 0.603(2) ± 0.008 | 0.690(1) ± 0.005 • |
| rcv1subset1 | 0.642(9) ± 0.008 | 0.614(10) ± 0.005 | 0.728(6) ± 0.004 | 0.661(7) ± 0.005 | 0.649(8) ± 0.011 | 0.819(4) ± 0.006 | 0.766(5) ± 0.006 | 0.835(2) ± 0.005 | 0.834(3) ± 0.005 | 0.891(1) ± 0.004 • |
| rcv1subset2 | 0.645(9) ± 0.007 | 0.595(10) ± 0.009 | 0.721(6) ± 0.005 | 0.652(8) ± 0.003 | 0.653(7) ± 0.006 | 0.819(3) ± 0.008 | 0.770(5) ± 0.007 | 0.841(2) ± 0.006 | 0.810(4) ± 0.007 | 0.888(1) ± 0.005 • |
| rcv1subset3 | 0.635(9) ± 0.007 | 0.584(10) ± 0.008 | 0.718(6) ± 0.005 | 0.646(8) ± 0.004 | 0.648(7) ± 0.006 | 0.816(3) ± 0.007 | 0.767(5) ± 0.007 | 0.834(2) ± 0.008 | 0.816(4) ± 0.005 | 0.880(1) ± 0.004 • |
| rcv1subset4 | 0.643(8) ± 0.012 | 0.600(10) ± 0.007 | 0.714(6) ± 0.004 | 0.642(9) ± 0.005 | 0.652(7) ± 0.010 | 0.816(3) ± 0.006 | 0.769(5) ± 0.006 | 0.840(2) ± 0.007 | 0.811(4) ± 0.007 | 0.887(1) ± 0.007 • |
| rcv1subset5 | 0.640(9) ± 0.010 | 0.594(10) ± 0.007 | 0.714(6) ± 0.005 | 0.647(8) ± 0.003 | 0.649(7) ± 0.008 | 0.810(4) ± 0.006 | 0.758(5) ± 0.005 | 0.834(2) ± 0.006 | 0.812(3) ± 0.008 | 0.873(1) ± 0.005 • |
| bibtex | 0.639(7) ± 0.007 | 0.634(8) ± 0.007 | 0.661(6) ± 0.003 | 0.617(10) ± 0.004 | 0.626(9) ± 0.006 | 0.794(4) ± 0.003 | 0.754(5) ± 0.004 | 0.807(2) ± 0.003 | 0.806(3) ± 0.005 | 0.886(1) ± 0.001 • |
| Arts | 0.598(8) ± 0.005 | 0.594(9) ± 0.007 | 0.650(5) ± 0.004 | 0.631(6) ± 0.004 | 0.601(7) ± 0.004 | 0.695(3) ± 0.009 | 0.545(10) ± 0.007 | 0.685(4) ± 0.009 | 0.704(2) ± 0.013 | 0.730(1) ± 0.009 • |
| Health | 0.687(8) ± 0.008 | 0.686(9) ± 0.009 | 0.731(5) ± 0.006 | 0.713(6) ± 0.005 | 0.687(7) ± 0.011 | 0.745(3) ± 0.008 | 0.606(10) ± 0.008 | 0.737(4) ± 0.010 | 0.754(2) ± 0.011 | 0.778(1) ± 0.009 • |
| Business | 0.609(7) ± 0.010 | 0.597(9) ± 0.007 | 0.641(5) ± 0.009 | 0.628(6) ± 0.005 | 0.609(8) ± 0.010 | 0.701(3) ± 0.009 | 0.589(10) ± 0.008 | 0.704(2) ± 0.009 | 0.699(4) ± 0.011 | 0.752(1) ± 0.007 • |
| Education | 0.601(9) ± 0.011 | 0.607(7) ± 0.011 | 0.648(5) ± 0.005 | 0.635(6) ± 0.006 | 0.606(8) ± 0.015 | 0.698(2) ± 0.009 | 0.595(10) ± 0.006 | 0.683(4) ± 0.010 | 0.696(3) ± 0.014 | 0.748(1) ± 0.014 • |
| Computers | 0.618(8) ± 0.007 | 0.602(10) ± 0.009 | 0.674(5) ± 0.008 | 0.657(6) ± 0.007 | 0.620(7) ± 0.010 | 0.707(4) ± 0.006 | 0.611(9) ± 0.004 | 0.710(3) ± 0.006 | 0.715(2) ± 0.009 | 0.750(1) ± 0.005 • |
| Entertainment | 0.654(9) ± 0.010 | 0.661(8) ± 0.011 | 0.724(5) ± 0.007 | 0.694(6) ± 0.005 | 0.677(7) ± 0.013 | 0.743(4) ± 0.005 | 0.581(10) ± 0.008 | 0.749(3) ± 0.004 | 0.754(2) ± 0.006 | 0.782(1) ± 0.004 • |
| Recreation | 0.648(8) ± 0.008 | 0.647(9) ± 0.009 | 0.709(5) ± 0.006 | 0.678(6) ± 0.006 | 0.658(7) ± 0.011 | 0.752(3) ± 0.006 | 0.559(10) ± 0.012 | 0.751(4) ± 0.010 | 0.762(2) ± 0.009 | 0.788(1) ± 0.009 • |
| Society | 0.593(8) ± 0.006 | 0.585(9) ± 0.004 | 0.636(5) ± 0.004 | 0.622(6) ± 0.004 | 0.594(7) ± 0.006 | 0.675(3) ± 0.005 | 0.554(10) ± 0.007 | 0.673(4) ± 0.005 | 0.683(2) ± 0.006 | 0.707(1) ± 0.006 • |
| eurlex-dc-l | 0.635(8) ± 0.005 | 0.630(10) ± 0.006 | 0.676(6) ± 0.002 | 0.637(7) ± 0.004 | 0.634(9) ± 0.005 | 0.820(2) ± 0.005 | 0.785(4) ± 0.005 | 0.798(3) ± 0.005 | 0.774(5) ± 0.006 | 0.900(1) ± 0.004 • |
| eurlex-sm | 0.686(8) ± 0.005 | 0.683(10) ± 0.007 | 0.736(6) ± 0.003 | 0.707(7) ± 0.004 | 0.685(9) ± 0.006 | 0.852(2) ± 0.005 | 0.814(5) ± 0.004 | 0.842(3) ± 0.006 | 0.841(4) ± 0.006 | 0.908(1) ± 0.003 • |
| tmc2007-500 | 0.761(10) ± 0.005 | 0.765(9) ± 0.006 | 0.847(5) ± 0.003 | 0.837(6) ± 0.003 | 0.770(8) ± 0.010 | 0.863(4) ± 0.002 | 0.799(7) ± 0.003 | 0.888(3) ± 0.002 | 0.891(2) ± 0.002 | 0.920(1) ± 0.002 • |
| mediamill | 0.596(8) ± 0.004 | 0.577(10) ± 0.004 | 0.638(7) ± 0.003 | 0.647(6) ± 0.003 | 0.584(9) ± 0.006 | 0.747(4) ± 0.003 | 0.704(5) ± 0.003 | 0.781(2) ± 0.003 | 0.761(3) ± 0.005 | 0.824(1) ± 0.002 • |
| average rank | 8.29 | 9.29 | 5.29 | 6.57 | 7.64 | 3.39 | 7.18 | 3.18 | 3.07 | 1.11 |
| win/tie/loss | 29/30/193 | 17/20/215 | 128/8/116 | 88/18/146 | 49/32/171 | 175/19/58 | 75/8/169 | 181/16/55 | 184/22/46 | 244/7/1 |
| Metric | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| AUC macro | 8.29 | 9.29 | 5.29 | 6.57 | 7.64 | 3.39 | 7.18 | 3.18 | 3.07 | 1.11 |
| AUC micro | 6.43 | 7.86 | 6.18 | 8.18 | 8.39 | 4.14 | 6.39 | 2.29 | 2.89 | 2.25 |
| Ranking Loss | 5.86 | 6.57 | 7.79 | 9.04 | 8.21 | 5.75 | 5.11 | 2.18 | 2.61 | 1.89 |
| F1 macro | 3.79 | 5.00 | 5.07 | 2.89 | 4.39 | 9.29 | 6.64 | 8.68 | 4.86 | 4.39 |
| F1 micro | 4.21 | 5.54 | 2.93 | 2.57 | 5.00 | 8.82 | 6.21 | 8.46 | 5.86 | 5.39 |
| Hamming Loss | 5.93 | 8.32 | 2.89 | 3.89 | 7.64 | 6.11 | 5.54 | 5.46 | 6.50 | 2.71 |
| Metric | # Algorithms | # Datasets | Critical Value | |
|---|---|---|---|---|
| AUC macro | 200.743 | 10 | 28 | 1.919 |
| AUC micro | 161.135 | |||
| Ranking Loss | 180.210 | |||
| F1 macro | 118.442 | |||
| F1 micro | 114.732 | |||
| Hamming Loss | 95.447 |
| AUC Macro | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 3.23 | 1.000 | 1.000 | 0.996 | 1.000 | 0.986 | 1.000 | 1.000 | 1.000 |
| CC | 1.000 | - | 1.000 | 1.000 | 1.000 | 1.000 | 0.992 | 1.000 | 1.000 | 1.000 |
| ECC | 5.22 | 1.23 | - | 5.10 | 9.42 | 1.000 | 0.113 | 1.000 | 1.000 | 1.000 |
| RAkEL | 4.70 | 5.10 | 1.000 | - | 2.36 | 1.000 | 0.685 | 1.000 | 1.000 | 1.000 |
| RAkELd | 0.004 | 3.28 | 1.000 | 1.000 | - | 1.000 | 0.977 | 1.000 | 1.000 | 1.000 |
| BRkNNa | 3.73 | 3.73 | 2.84 | 7.08 | 3.73 | - | 3.73 | 0.685 | 0.959 | 1.000 |
| MLKNN | 0.015 | 0.009 | 0.891 | 0.323 | 0.024 | 1.000 | - | 1.000 | 1.000 | 1.000 |
| DMLkNN | 3.73 | 3.73 | 1.03 | 7.08 | 3.73 | 0.323 | 3.73 | - | 0.669 | 1.000 |
| IBLR | 3.73 | 3.73 | 2.84 | 9.31 | 3.73 | 0.043 | 1.12 | 0.339 | - | 1.000 |
| MLHiKNN | 3.73 | 3.73 | 1.86 | 7.45 | 3.73 | 3.73 | 3.73 | 1.12 | 3.73 | - |
| AUC Micro | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 1.03 | 0.619 | 0.045 | 3.28 | 1.000 | 0.967 | 1.000 | 1.000 | 1.000 |
| CC | 1.000 | - | 0.980 | 0.323 | 0.024 | 1.000 | 0.997 | 1.000 | 1.000 | 1.000 |
| ECC | 0.390 | 0.021 | - | 1.12 | 1.09 | 1.000 | 0.760 | 1.000 | 1.000 | 1.000 |
| RAkEL | 0.957 | 0.685 | 1.000 | - | 0.478 | 1.000 | 0.999 | 1.000 | 1.000 | 1.000 |
| RAkELd | 1.000 | 0.977 | 1.000 | 0.531 | - | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| BRkNNa | 1.14 | 9.31 | 3.98 | 9.31 | 1.86 | - | 1.83 | 1.000 | 0.999 | 0.998 |
| MLKNN | 0.035 | 0.004 | 0.247 | 0.001 | 1.19 | 1.000 | - | 1.000 | 1.000 | 1.000 |
| DMLkNN | 3.73 | 3.73 | 3.28 | 1.86 | 3.73 | 6.47 | 3.73 | - | 0.055 | 0.746 |
| IBLR | 1.14 | 2.61 | 1.83 | 9.42 | 1.86 | 7.08 | 6.47 | 0.948 | - | 0.937 |
| MLHiKNN | 1.12 | 3.73 | 1.23 | 1.86 | 3.73 | 0.002 | 1.14 | 0.261 | 0.066 | - |
| Ranking Loss | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 0.001 | 0.002 | 2.11 | 3.73 | 0.813 | 0.990 | 1.000 | 1.000 | 1.000 |
| CC | 0.999 | - | 0.010 | 3.60 | 8.61 | 0.957 | 0.998 | 1.000 | 1.000 | 1.000 |
| ECC | 0.998 | 0.990 | - | 1.12 | 0.940 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| RAkEL | 1.000 | 1.000 | 1.000 | - | 0.999 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| RAkELd | 1.000 | 1.000 | 0.063 | 6.45 | - | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| BRkNNa | 0.193 | 0.045 | 5.22 | 7.45 | 3.16 | - | 0.842 | 1.000 | 1.000 | 1.000 |
| MLKNN | 0.010 | 0.002 | 4.70 | 5.22 | 9.31 | 0.164 | - | 1.000 | 1.000 | 1.000 |
| DMLkNN | 1.12 | 7.45 | 7.45 | 7.45 | 7.45 | 7.45 | 3.73 | - | 0.031 | 0.558 |
| IBLR | 2.05 | 1.86 | 1.60 | 2.61 | 3.73 | 4.70 | 7.57 | 0.970 | - | 0.950 |
| MLHiKNN | 7.45 | 3.73 | 3.73 | 3.73 | 3.73 | 3.73 | 7.71 | 0.451 | 0.052 | - |
| F1 Macro | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 0.013 | 0.024 | 0.998 | 0.063 | 9.31 | 4.66 | 9.42 | 0.060 | 0.187 |
| CC | 0.988 | - | 0.137 | 1.000 | 0.899 | 4.10 | 9.34 | 8.83 | 0.169 | 0.451 |
| ECC | 0.977 | 0.868 | - | 1.000 | 0.972 | 1.60 | 1.22 | 3.28 | 0.323 | 0.339 |
| RAkEL | 0.002 | 1.22 | 6.77 | - | 6.77 | 3.73 | 5.10 | 7.08 | 0.007 | 0.055 |
| RAkELd | 0.940 | 0.105 | 0.030 | 1.000 | - | 2.61 | 8.61 | 2.00 | 0.060 | 0.219 |
| BRkNNa | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 1.000 | 0.999 | 1.000 | 1.000 |
| MLKNN | 1.000 | 0.999 | 1.000 | 1.000 | 1.000 | 2.61 | - | 3.73 | 1.000 | 0.999 |
| DMLkNN | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 5.86 | 1.000 | - | 1.000 | 1.000 |
| IBLR | 0.943 | 0.836 | 0.685 | 0.993 | 0.943 | 1.86 | 4.83 | 3.73 | - | 0.701 |
| MLHiKNN | 0.819 | 0.558 | 0.669 | 0.948 | 0.788 | 2.61 | 0.001 | 1.86 | 0.307 | - |
| F1 Micro | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 0.003 | 0.996 | 1.000 | 4.66 | 8.83 | 0.003 | 6.77 | 0.010 | 0.063 |
| CC | 0.997 | - | 1.000 | 1.000 | 0.794 | 1.71 | 0.050 | 0.003 | 0.127 | 0.276 |
| ECC | 0.004 | 6.47 | - | 0.153 | 0.003 | 3.98 | 1.91 | 6.47 | 0.006 | 0.001 |
| RAkEL | 2.42 | 6.30 | 0.853 | - | 5.10 | 7.71 | 7.64 | 9.42 | 2.12 | 0.001 |
| RAkELd | 1.000 | 0.212 | 0.997 | 1.000 | - | 5.29 | 0.020 | 4.83 | 0.043 | 0.101 |
| BRkNNa | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 1.000 | 0.997 | 1.000 | 1.000 |
| MLKNN | 0.998 | 0.953 | 1.000 | 1.000 | 0.981 | 2.61 | - | 1.86 | 0.478 | 0.965 |
| DMLkNN | 1.000 | 0.997 | 1.000 | 1.000 | 1.000 | 0.003 | 1.000 | - | 1.000 | 1.000 |
| IBLR | 0.991 | 0.877 | 0.995 | 1.000 | 0.959 | 1.59 | 0.531 | 1.60 | - | 0.953 |
| MLHiKNN | 0.940 | 0.732 | 0.999 | 0.999 | 0.903 | 1.67 | 0.037 | 1.14 | 0.050 | - |
| Hamming Loss | BR | CC | ECC | RAkEL | RAkELd | BRkNNa | MLKNN | DMLkNN | IBLR | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|---|
| BR | - | 2.61 | 1.000 | 1.000 | 1.38 | 0.788 | 0.934 | 0.948 | 0.132 | 1.000 |
| CC | 1.000 | - | 1.000 | 1.000 | 0.963 | 0.997 | 1.000 | 1.000 | 0.895 | 1.000 |
| ECC | 2.38 | 3.73 | - | 1.19 | 3.98 | 0.013 | 0.013 | 0.016 | 0.004 | 0.753 |
| RAkEL | 6.30 | 3.73 | 1.000 | - | 3.73 | 0.199 | 0.451 | 0.407 | 0.006 | 0.899 |
| RAkELd | 1.000 | 0.039 | 1.000 | 1.000 | - | 0.967 | 0.999 | 0.999 | 0.760 | 1.000 |
| BRkNNa | 0.219 | 0.003 | 0.988 | 0.807 | 0.035 | - | 0.940 | 0.940 | 0.381 | 1.000 |
| MLKNN | 0.069 | 3.96 | 0.988 | 0.558 | 8.52 | 0.063 | - | 0.373 | 0.158 | 1.000 |
| DMLkNN | 0.055 | 2.92 | 0.985 | 0.602 | 6.45 | 0.063 | 0.636 | - | 0.158 | 1.000 |
| IBLR | 0.873 | 0.109 | 0.996 | 0.994 | 0.247 | 0.627 | 0.847 | 0.847 | - | 1.000 |
| MLHiKNN | 5.29 | 7.71 | 0.254 | 0.105 | 8.83 | 7.08 | 2.38 | 2.84 | 2.11 | - |
| Dataset | AUC Macro | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN | |
| birds | 0.702(4) ± 0.016 | 0.701(5) ± 0.028 | 0.728(1) ± 0.009 • | 0.708(3) ± 0.010 | 0.606(6) ± 0.019 | 0.490(7) ± 0.025 | 0.472(8) ± 0.025 | 0.452(9) ± 0.032 | 0.728(2) ± 0.030 |
| CAL500 | 0.543(4) ± 0.006 | 0.539(5) ± 0.007 | 0.545(3) ± 0.004 | 0.546(2) ± 0.006 | 0.515(6) ± 0.004 | 0.494(7) ± 0.005 | 0.494(8) ± 0.004 | 0.491(9) ± 0.004 | 0.571(1) ± 0.006 • |
| emotions | 0.834(4) ± 0.005 | 0.830(5) ± 0.008 | 0.845(2) ± 0.007 | 0.842(3) ± 0.006 | 0.723(6) ± 0.013 | 0.707(7) ± 0.015 | 0.705(8) ± 0.016 | 0.701(9) ± 0.014 | 0.846(1) ± 0.005 • |
| genbase | 0.996(4) ± 0.004 | 0.996(2) ± 0.004 | 0.996(3) ± 0.004 | 0.990(5) ± 0.006 | 0.963(6) ± 0.013 | 0.773(7) ± 0.042 | 0.771(8) ± 0.052 | 0.627(9) ± 0.080 | 0.997(1) ± 0.003 • |
| LLOG | 0.598(2) ± 0.006 | 0.595(3) ± 0.006 | 0.594(5) ± 0.005 | 0.595(3) ± 0.006 | 0.588(6) ± 0.006 | 0.549(7) ± 0.020 | 0.512(9) ± 0.026 | 0.520(8) ± 0.019 | 0.603(1) ± 0.006 • |
| enron | 0.627(4) ± 0.012 | 0.638(3) ± 0.012 | 0.644(2) ± 0.011 | 0.616(5) ± 0.009 | 0.596(6) ± 0.011 | 0.439(7) ± 0.015 | 0.434(8) ± 0.012 | 0.431(9) ± 0.010 | 0.676(1) ± 0.012 • |
| scene | 0.937(5) ± 0.003 | 0.940(4) ± 0.002 | 0.945(1) ± 0.003 • | 0.944(2) ± 0.003 | 0.898(6) ± 0.007 | 0.879(7) ± 0.016 | 0.879(8) ± 0.014 | 0.877(9) ± 0.018 | 0.944(3) ± 0.002 |
| yeast | 0.685(4) ± 0.005 | 0.663(5) ± 0.006 | 0.689(2) ± 0.004 | 0.689(3) ± 0.004 | 0.583(6) ± 0.006 | 0.522(9) ± 0.007 | 0.529(8) ± 0.011 | 0.531(7) ± 0.012 | 0.711(1) ± 0.006 • |
| Slashdot | 0.680(5) ± 0.017 | 0.690(3) ± 0.020 | 0.700(2) ± 0.012 | 0.688(4) ± 0.015 | 0.563(6) ± 0.033 | 0.405(9) ± 0.031 | 0.409(8) ± 0.038 | 0.433(7) ± 0.029 | 0.723(1) ± 0.021 • |
| corel5k | 0.582(5) ± 0.004 | 0.626(2) ± 0.007 | 0.625(4) ± 0.007 | 0.626(3) ± 0.008 | 0.569(6) ± 0.004 | 0.415(7) ± 0.007 | 0.414(8) ± 0.007 | 0.412(9) ± 0.006 | 0.690(1) ± 0.005 • |
| rcv1subset1 | 0.819(5) ± 0.006 | 0.844(3) ± 0.005 | 0.845(2) ± 0.004 | 0.823(4) ± 0.005 | 0.766(6) ± 0.006 | 0.396(7) ± 0.016 | 0.393(8) ± 0.016 | 0.367(9) ± 0.007 | 0.891(1) ± 0.004 • |
| rcv1subset2 | 0.819(5) ± 0.008 | 0.843(2) ± 0.007 | 0.840(3) ± 0.007 | 0.823(4) ± 0.006 | 0.770(6) ± 0.007 | 0.363(8) ± 0.014 | 0.376(7) ± 0.012 | 0.328(9) ± 0.016 | 0.888(1) ± 0.005 • |
| rcv1subset3 | 0.816(4) ± 0.007 | 0.838(3) ± 0.005 | 0.840(2) ± 0.011 | 0.815(5) ± 0.007 | 0.767(6) ± 0.007 | 0.360(7) ± 0.015 | 0.358(8) ± 0.023 | 0.336(9) ± 0.021 | 0.880(1) ± 0.004 • |
| rcv1subset4 | 0.816(5) ± 0.006 | 0.837(2) ± 0.007 | 0.837(3) ± 0.007 | 0.823(4) ± 0.009 | 0.769(6) ± 0.006 | 0.380(8) ± 0.010 | 0.387(7) ± 0.010 | 0.344(9) ± 0.010 | 0.887(1) ± 0.007 • |
| rcv1subset5 | 0.810(4) ± 0.006 | 0.830(2) ± 0.004 | 0.827(3) ± 0.006 | 0.809(5) ± 0.006 | 0.758(6) ± 0.005 | 0.324(8) ± 0.014 | 0.370(7) ± 0.021 | 0.316(9) ± 0.015 | 0.873(1) ± 0.005 • |
| bibtex | 0.794(5) ± 0.003 | 0.813(4) ± 0.003 | 0.826(2) ± 0.002 | 0.814(3) ± 0.003 | 0.754(6) ± 0.004 | 0.352(9) ± 0.012 | 0.400(8) ± 0.007 | 0.432(7) ± 0.007 | 0.886(1) ± 0.001 • |
| Arts | 0.695(4) ± 0.009 | 0.699(2) ± 0.010 | 0.696(3) ± 0.008 | 0.677(5) ± 0.007 | 0.545(6) ± 0.007 | 0.339(9) ± 0.008 | 0.343(8) ± 0.008 | 0.357(7) ± 0.007 | 0.730(1) ± 0.009 • |
| Health | 0.745(4) ± 0.008 | 0.750(2) ± 0.008 | 0.746(3) ± 0.004 | 0.714(5) ± 0.008 | 0.606(6) ± 0.008 | 0.324(9) ± 0.013 | 0.346(7) ± 0.007 | 0.326(8) ± 0.007 | 0.778(1) ± 0.009 • |
| Business | 0.701(4) ± 0.009 | 0.705(3) ± 0.008 | 0.718(2) ± 0.006 | 0.679(5) ± 0.007 | 0.589(6) ± 0.008 | 0.328(8) ± 0.007 | 0.317(9) ± 0.005 | 0.342(7) ± 0.007 | 0.752(1) ± 0.007 • |
| Education | 0.698(4) ± 0.009 | 0.701(2) ± 0.009 | 0.701(3) ± 0.008 | 0.675(5) ± 0.010 | 0.595(6) ± 0.006 | 0.331(9) ± 0.011 | 0.336(8) ± 0.014 | 0.352(7) ± 0.011 | 0.748(1) ± 0.014 • |
| Computers | 0.707(4) ± 0.006 | 0.711(3) ± 0.005 | 0.715(2) ± 0.006 | 0.685(5) ± 0.006 | 0.611(6) ± 0.004 | 0.319(9) ± 0.006 | 0.321(8) ± 0.004 | 0.336(7) ± 0.005 | 0.750(1) ± 0.005 • |
| Entertainment | 0.743(4) ± 0.005 | 0.746(2) ± 0.005 | 0.744(3) ± 0.006 | 0.726(5) ± 0.008 | 0.581(6) ± 0.008 | 0.374(8) ± 0.006 | 0.379(7) ± 0.005 | 0.329(9) ± 0.008 | 0.782(1) ± 0.004 • |
| Recreation | 0.752(4) ± 0.006 | 0.754(2) ± 0.006 | 0.752(3) ± 0.006 | 0.728(5) ± 0.005 | 0.559(6) ± 0.012 | 0.296(9) ± 0.006 | 0.301(8) ± 0.007 | 0.312(7) ± 0.006 | 0.788(1) ± 0.009 • |
| Society | 0.675(4) ± 0.005 | 0.679(2) ± 0.005 | 0.677(3) ± 0.006 | 0.661(5) ± 0.006 | 0.554(6) ± 0.007 | 0.348(9) ± 0.005 | 0.350(8) ± 0.006 | 0.363(7) ± 0.006 | 0.707(1) ± 0.006 • |
| eurlex-dc-l | 0.820(4) ± 0.005 | 0.822(2) ± 0.005 | 0.820(3) ± 0.005 | 0.805(5) ± 0.004 | 0.785(6) ± 0.005 | 0.296(8) ± 0.014 | 0.303(7) ± 0.012 | 0.197(9) ± 0.004 | 0.900(1) ± 0.004 • |
| eurlex-sm | 0.852(3) ± 0.005 | 0.853(2) ± 0.004 | 0.852(4) ± 0.004 | 0.842(5) ± 0.004 | 0.814(6) ± 0.004 | 0.302(9) ± 0.010 | 0.303(7) ± 0.011 | 0.302(8) ± 0.008 | 0.908(1) ± 0.003 • |
| tmc2007-500 | 0.863(4) ± 0.002 | 0.885(2) ± 0.001 | 0.881(3) ± 0.002 | 0.858(5) ± 0.002 | 0.799(6) ± 0.003 | 0.440(7) ± 0.009 | 0.433(8) ± 0.012 | 0.374(9) ± 0.017 | 0.920(1) ± 0.002 • |
| mediamill | 0.747(4) ± 0.003 | 0.747(5) ± 0.003 | 0.752(2) ± 0.003 | 0.752(3) ± 0.004 | 0.704(6) ± 0.003 | 0.326(7) ± 0.005 | 0.323(8) ± 0.005 | 0.322(9) ± 0.007 | 0.824(1) ± 0.002 • |
| average rank | 4.14 | 2.95 | 2.64 | 4.16 | 6.00 | 7.93 | 7.82 | 8.25 | 1.11 |
| win/tie/loss | 129/21/74 | 158/21/45 | 164/27/33 | 127/16/81 | 84/0/140 | 19/16/189 | 23/21/180 | 16/15/193 | 216/7/1 |
| AUC Macro | BRkNNa | BRkNNa-dsl | BRkNNa-ls | BRkNNa-mp | MLKNN | MLKNN-dsl | MLKNN-ls | MLKNN-mp | MLHiKNN |
|---|---|---|---|---|---|---|---|---|---|
| BRkNNa | - | 1.000 | 1.000 | 0.089 | 3.73 | 3.73 | 3.73 | 3.73 | 1.000 |
| BRkNNa-dsl | 5.32 | - | 0.937 | 8.06 | 3.73 | 3.73 | 3.73 | 3.73 | 1.000 |
| BRkNNa-ls | 4.10 | 0.066 | - | 2.05 | 3.73 | 3.73 | 3.73 | 3.73 | 1.000 |
| BRkNNa-mp | 0.915 | 0.999 | 1.000 | - | 3.73 | 3.73 | 3.73 | 3.73 | 1.000 |
| MLKNN | 1.000 | 1.000 | 1.000 | 1.000 | - | 3.73 | 3.73 | 3.73 | 1.000 |
| MLKNN-dsl | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | - | 0.887 | 0.072 | 1.000 |
| MLKNN-ls | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.118 | - | 0.050 | 1.000 |
| MLKNN-mp | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.931 | 0.953 | - | 1.000 |
| MLHiKNN | 3.73 | 3.73 | 3.73 | 7.45 | 3.73 | 3.73 | 3.73 | 3.73 | - |
| Approach | Explanation |
|---|---|
| MLHiKNN-g1 | is fixed at 1 in Equations (9) and (10) |
| MLHiKNN-g0 | is fixed at 0 in Equations (9) and (10) |
| MLHiKNN-h1 | is fixed at 1 in Equation (5) |
| MLHiKNN-d1 | is fixed at 1 in Equation (5) |
| MLHiKNN-fo |
| Dataset | AUC Macro | |||||
|---|---|---|---|---|---|---|
| MLHiKNN-g1 | MLHiKNN-g0 | MLHiKNN-h1 | MLHiKNN-d1 | MLHiKNN-fo | MLHiKNN | |
| birds | 0.728(3) ± 0.031 | 0.723(4) ± 0.033 | 0.718(6) ± 0.032 | 0.719(5) ± 0.028 | 0.755(1) ± 0.019 • | 0.728(2) ± 0.030 |
| CAL500 | 0.561(5) ± 0.006 | 0.564(4) ± 0.007 | 0.573(1) ± 0.006 • | 0.571(3) ± 0.005 | 0.558(6) ± 0.004 | 0.571(2) ± 0.006 |
| emotions | 0.845(2) ± 0.009 | 0.840(6) ± 0.006 | 0.845(3) ± 0.007 | 0.844(4) ± 0.007 | 0.843(5) ± 0.006 | 0.846(1) ± 0.005 • |
| genbase | 0.996(6) ± 0.004 | 0.997(5) ± 0.003 | 0.997(3) ± 0.003 | 0.998(2) ± 0.003 | 0.998(1) ± 0.002 • | 0.997(4) ± 0.003 |
| LLOG | 0.603(5) ± 0.006 | 0.603(1) ± 0.006 • | 0.603(2) ± 0.006 | 0.603(3) ± 0.006 | 0.603(6) ± 0.006 | 0.603(4) ± 0.006 |
| enron | 0.663(6) ± 0.011 | 0.671(4) ± 0.007 | 0.670(5) ± 0.010 | 0.673(2) ± 0.012 | 0.672(3) ± 0.011 | 0.676(1) ± 0.012 • |
| scene | 0.945(1) ± 0.003 • | 0.942(6) ± 0.002 | 0.943(4) ± 0.002 | 0.943(3) ± 0.002 | 0.943(5) ± 0.001 | 0.944(2) ± 0.002 |
| yeast | 0.699(5) ± 0.004 | 0.690(6) ± 0.010 | 0.710(2) ± 0.006 | 0.707(3) ± 0.005 | 0.706(4) ± 0.006 | 0.711(1) ± 0.006 • |
| Slashdot | 0.686(6) ± 0.016 | 0.719(5) ± 0.021 | 0.721(4) ± 0.020 | 0.730(2) ± 0.014 | 0.743(1) ± 0.014 • | 0.723(3) ± 0.021 |
| corel5k | 0.666(4) ± 0.004 | 0.651(5) ± 0.009 | 0.689(2) ± 0.005 | 0.689(3) ± 0.005 | 0.635(6) ± 0.007 | 0.690(1) ± 0.005 • |
| rcv1subset1 | 0.882(4) ± 0.003 | 0.877(5) ± 0.005 | 0.886(3) ± 0.004 | 0.887(2) ± 0.004 | 0.863(6) ± 0.004 | 0.891(1) ± 0.004 • |
| rcv1subset2 | 0.873(4) ± 0.007 | 0.873(6) ± 0.006 | 0.881(3) ± 0.004 | 0.884(2) ± 0.005 | 0.873(5) ± 0.009 | 0.888(1) ± 0.005 • |
| rcv1subset3 | 0.863(6) ± 0.004 | 0.868(4) ± 0.003 | 0.874(3) ± 0.003 | 0.876(2) ± 0.002 | 0.868(5) ± 0.004 | 0.880(1) ± 0.004 • |
| rcv1subset4 | 0.873(5) ± 0.006 | 0.877(4) ± 0.006 | 0.881(3) ± 0.007 | 0.882(2) ± 0.007 | 0.863(6) ± 0.005 | 0.887(1) ± 0.007 • |
| rcv1subset5 | 0.857(6) ± 0.005 | 0.864(5) ± 0.005 | 0.869(4) ± 0.006 | 0.871(2) ± 0.005 | 0.869(3) ± 0.005 | 0.873(1) ± 0.005 • |
| bibtex | 0.878(4) ± 0.002 | 0.862(5) ± 0.004 | 0.882(3) ± 0.002 | 0.885(2) ± 0.002 | 0.841(6) ± 0.005 | 0.886(1) ± 0.001 • |
| Arts | 0.701(6) ± 0.009 | 0.725(4) ± 0.008 | 0.730(2) ± 0.009 | 0.731(1) ± 0.009 • | 0.718(5) ± 0.008 | 0.730(3) ± 0.009 |
| Health | 0.749(6) ± 0.007 | 0.771(5) ± 0.010 | 0.775(3) ± 0.009 | 0.779(1) ± 0.011 • | 0.771(4) ± 0.007 | 0.778(2) ± 0.009 |
| Business | 0.709(6) ± 0.007 | 0.732(5) ± 0.018 | 0.751(3) ± 0.007 | 0.751(4) ± 0.008 | 0.766(1) ± 0.007 • | 0.752(2) ± 0.007 |
| Education | 0.711(6) ± 0.018 | 0.736(4) ± 0.011 | 0.748(2) ± 0.013 | 0.746(3) ± 0.013 | 0.734(5) ± 0.010 | 0.748(1) ± 0.014 • |
| Computers | 0.716(6) ± 0.008 | 0.743(5) ± 0.007 | 0.749(4) ± 0.006 | 0.750(3) ± 0.007 | 0.750(2) ± 0.005 | 0.750(1) ± 0.005 • |
| Entertainment | 0.757(5) ± 0.005 | 0.775(4) ± 0.009 | 0.780(2) ± 0.004 | 0.780(3) ± 0.006 | 0.756(6) ± 0.008 | 0.782(1) ± 0.004 • |
| Recreation | 0.756(6) ± 0.009 | 0.786(4) ± 0.008 | 0.787(3) ± 0.008 | 0.790(1) ± 0.008 • | 0.777(5) ± 0.007 | 0.788(2) ± 0.009 |
| Society | 0.685(6) ± 0.007 | 0.704(4) ± 0.004 | 0.707(2) ± 0.006 | 0.705(3) ± 0.004 | 0.693(5) ± 0.005 | 0.707(1) ± 0.006 • |
| eurlex-dc-l | 0.883(4) ± 0.007 | 0.874(5) ± 0.003 | 0.900(2) ± 0.004 | 0.892(3) ± 0.005 | 0.856(6) ± 0.005 | 0.900(1) ± 0.004 • |
| eurlex-sm | 0.899(4) ± 0.004 | 0.896(5) ± 0.004 | 0.907(2) ± 0.003 | 0.900(3) ± 0.002 | 0.881(6) ± 0.006 | 0.908(1) ± 0.003 • |
| tmc2007-500 | 0.914(4) ± 0.002 | 0.907(6) ± 0.002 | 0.918(3) ± 0.002 | 0.912(5) ± 0.002 | 0.919(2) ± 0.002 | 0.920(1) ± 0.002 • |
| mediamill | 0.820(3) ± 0.003 | 0.791(6) ± 0.003 | 0.824(1) ± 0.002 • | 0.801(4) ± 0.005 | 0.796(5) ± 0.003 | 0.824(2) ± 0.002 |
| average rank | 4.79 | 4.71 | 2.86 | 2.71 | 4.32 | 1.61 |
| win/tie/loss | 22/25/93 | 24/32/84 | 66/46/28 | 66/46/28 | 36/32/72 | 97/37/6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teng, Z.; Tang, S.; Huang, M.; Wang, X. A Hubness Information-Based k-Nearest Neighbor Approach for Multi-Label Learning. Mathematics 2025, 13, 1202. https://doi.org/10.3390/math13071202
Teng Z, Tang S, Huang M, Wang X. A Hubness Information-Based k-Nearest Neighbor Approach for Multi-Label Learning. Mathematics. 2025; 13(7):1202. https://doi.org/10.3390/math13071202
Chicago/Turabian StyleTeng, Zeyu, Shanshan Tang, Min Huang, and Xingwei Wang. 2025. "A Hubness Information-Based k-Nearest Neighbor Approach for Multi-Label Learning" Mathematics 13, no. 7: 1202. https://doi.org/10.3390/math13071202
APA StyleTeng, Z., Tang, S., Huang, M., & Wang, X. (2025). A Hubness Information-Based k-Nearest Neighbor Approach for Multi-Label Learning. Mathematics, 13(7), 1202. https://doi.org/10.3390/math13071202