1. Introduction
The paper deals with a two-way analysis of variance, in the presence of two two-level factors and a numeric response. The motivating example of this work concerns the US population’s medical insurance cost, and the effect on it of age and being a smoker. Recently, the actuarial modelling of insurance claims has emerged as a significant research topic in the health insurance industry and is primarily used for establishing appropriate premiums [
1]. This is crucial for enticing and keeping insured individuals, as well as for effectively managing current plan members. Nevertheless, because of the numerous elements influencing medical insurance expenses and the complexities involved, there are challenges in precisely developing a predictive model for it. Elements such as demographic data, health conditions, access to healthcare based on location, lifestyle habits, and characteristics of providers can significantly influence the anticipated expenses of medical insurance. Additional important aspects such as the extent of coverage, the kind of plan, the deductible amount, and the customer’s age at the time of enrollment also significantly influence the possible expenses associated with medical insurance [
2].
In some countries, such as the United States, it is nowadays essential for the population to have health insurance [
3,
4]. One of the largest yearly expenses individuals face is their health insurance coverage. Health insurance represents a third of the GDP, and medical care is necessary for everyone at different levels. Shifts in medical practices, trends in pharmaceuticals, and political influences are just some of the numerous factors that create yearly variations in healthcare expenses [
5]. Some research indicates that insurance companies ought to adjust their policies based on the smoking habits, BMI, and age of their clients in order to offer insurance plans that cater to the public’s needs [
6].
Grasping the factors that impact an individual’s health insurance premium is essential for insurance companies to set appropriate prices. When making informed decisions, the premium should always be the primary focus for users. Several empirical works in the literature investigate the main factors that significantly correlate with health insurance costs. Charges are positively related to smoking and age. The importance of health insurance is growing as individuals’ lifestyles and health issues evolve. Since a medical condition can affect anyone unexpectedly and can have significant psychological and financial repercussions, it is challenging to determine when these issues will arise. Given this context, some authors [
7] aimed to predict health insurance costs based on the following factors: age, sex, geographical location, smoking status, body mass index (BMI), and number of children [
8,
9]. Age, BMI, chronic diseases, and family history of cancer have been shown to be the most influential factors determining the premium price [
10,
11].
One of the goals of the paper is that the empirical findings of this study will assist policymakers, insurers, and prospective medical insurance purchasers in making informed choices about selecting policies that fit their individual requirements. To study the effect of age and smoking on insurance costs, we use sample data. The problem under study can be traced back to a two-way ANOVA layout. We are interested in testing the significance of both the main effect of each factor and the interaction between the two. Some solutions have been carried out in the methodological literature for the ANOVA problem. Some researchers have examined the two-way ANOVA model with varying cell frequencies without assuming equal error variances. By employing a generalized approach to calculate
p-values, the traditional F-tests on the interaction and main effects are expanded to accommodate heteroscedasticity. The generalized F-tests introduced in the aforementioned study can be applied in significance testing or in fixed level testing according to the Neyman–Pearson framework. Simulation studies reveal that, although the method shows enhanced power in the presence of heteroscedasticity, the size of the test does not surpass the predetermined significance level [
12]. Another work states that determining the a priori power for univariate repeated measures (RM) ANOVA designs with two or more factors is currently difficult due to the lack of accurate methods for estimating the error variances used in power calculations. Hence, Monte Carlo simulation procedures have been used to estimate power under different experimental conditions [
13]. The main problem remains that this method provides only an estimate and not an adequate procedure for the statistical problem. In another study by Toothaker and Newman (1994) [
14], the ANOVA F-test and several non-parametric competitors for two-way design were compared in terms of empirical
and power. Through a simulation study, they confirmed that the ANOVA F-test suffers from conservative
and power for the mixed normal distribution.
As said, in this work, the goal is to investigate the main and interaction effects of crucial factors, such as being a smoker (yes or no) and age (less than 50 years old and greater than or equal to 50 years old) in an experimental framework where the response variable is the charges of medical insurance costs. The proposed methodological approach is based on a non-parametric inference. The problem is framed within the context of a regression analysis, and the resolution relies on a permutation method. The suggested test, in contrast to parametric methods, does not necessitate the assumption that the response distribution adheres to a particular set of probability distributions. This type of test is highly effective, particularly when the usual assumptions of parametric methods (like data normality) are unmet and the validity of parametric tests is compromised [
15]. Moreover, the proposed approach demonstrates greater flexibility and robustness compared to parametric tests, and it can be viewed in opposition to stepwise regression [
16]. Actually, it is based on a permutation test to evaluate the goodness-of-fit of a multiple regression model. This solution is based on a multiple testing approach, that jointly assesses the significance of all single regression coefficients, including both main effects and interaction effects. The method consists of combining the
p-values of the partial tests on the regression coefficients. The approach of combined permutation tests has been effectively implemented across various contexts [
17,
18]. In particular, it has been widely applied in empirical studies [
19], with numeric variables but also categorical data [
20], for big data problems [
21], in regression analysis [
22,
23], to test directional and non-monotonic hypotheses [
24,
25], with count data [
24] and in many other problems.
Permutation goodness-of-fit assessments, using partial sums or cumulative sums of residuals, have been suggested for linear regression models [
26]. In order to evaluate the influence of covariates, the authors of [
27] introduced the concept of combining non-parametric permutation tests. The notion of treating the test for the validity of a multivariate linear model as a simultaneous test was put forward by [
28] within the context of rotation tests. Moreover, in the literature, several recent articles discuss approaches for assessing goodness-of-fit through the permutation approach in linear regression models, as well as the use of non-parametric permutation tests to evaluate the influence of covariates. For instance, ref. [
29] proposes a non-parametric test to assess the effect of covariates on the cure rate in mixture cure models, employing a bootstrap method to approximate the null distribution of the test statistic. On the other hand, a previous study generalizes the metric-based permutation test for the equality of covariance operators to multiple samples of functional data, utilizing a non-parametric combination methodology to merge pairwise comparisons into a global test [
30].
The rest of the paper is organized as follows.
Section 2 presents the statistical problem. The methodological proposed solution is explained in
Section 3.
Section 4 contains the Monte Carlo simulation study. The case study is described in
Section 5 and
Section 6 includes the overall conclusions.
2. Statistical Problem
Let us consider a model with binary variables as predictors, to represent the main effects and the interaction effects of two factors with two levels. This situation was first considered by [
31] because it is typical of experimental designs where subjects are first divided into homogeneous subgroups (blocks) and then randomly assigned to various treatment levels. Under the null hypothesis, all the treatment effects are null. On the other hand, in the alternative hypothesis, at least one effect is not equal to zero.
Let
denote the
i-th observation of the response variable related to the combination of levels
, that is the value observed on the
i-th unit (
i-th replication) when factor 1 is at level
k and factor 2 is at level
j (
;
). Data are assumed to be realizations of random variables
which behave according to the following linear model:
where
and
are the main effects of factor 1 at level
k and factor 2 at level
j, respectively,
is the interaction effect related to factor 1 at level
k and factor 2 at level
j and
are exchangeable errors, with zero mean and unknown continuous distribution [
15]. In this situation, without loss of generality, for ease of interpretation, it is also possible to consider the usual constraints:
Typically, three potential testing problems could be examined independently:
, against (significance of main effect of factor 1);
, against (significance of main effect of factor 2);
, against (significance of interaction effect).
Under the null hypothesis related to one of the three problems, exchangeability is applicable only among certain data blocks (determined by the
combinations of levels), and thus only synchronized permutations are permitted [
32]. For instance, if we want to compare two treatments of factor 1, corresponding to levels
and
of the factor, where
, we can shuffle data between blocks having the same level of factor 2, one featuring factor 1 at level
and the other at level
. In other words, by representing the data block with
as having factor 1 at level
k and factor 2 at level
j, we can interchange data between
and
for each
j, ensuring that the permutations between the
C pairs of blocks remain synchronized. These synchronized permutations are a valid alternative because it is among the permutation methods used for the two-way (M)ANOVA. However, this method only works when the aim is to test only one factor and consider the others as confounders. This is different from our proposal because we want to verify the significance of the estimates of all the single coefficients jointly considered.
The data can be alternatively represented using a different notation. Let
be the observed data of the response, where
n is the total number of observations and
is the
i-th observation of the response, with
. If we consider the case of two factors at two levels, i.e.,
, and assume
to be a realization of the random variable
, an alternative linear model in the framework of the linear regression analysis is the following:
where
is a dummy variable that takes the value 0 if the
i-th observation is associated to the
v-th factor at level 1, and takes the value 1 if the
i-th observation is related to the
v-th factor at level 2, with
and
. In the regression model,
are exchangeable random errors and
are unknown parameters, with
as the expected value of the response corresponding to the baseline (both the factors at level 1),
and
as the main effects of factor 1 and factor 2, respectively, and
as the interaction effect.
3. Permutation Solution
Regarding the regression coefficients of the reparameterized model (
3), we are interested in the following system of hypotheses:
Given that we aim to determine which coefficients have significant estimates when the null hypothesis is rejected, our approach involves conducting multiple tests to assess the significance of the single regression coefficients. A solution to the aforementioned statistical problem concerns the use of a combined permutation test (CPT) [
33]. The overall testing problem can be considered a multiple test, composed by the partial tests on the significance of the regression coefficients’ estimates [
34].
The system of hypotheses of the partial test concerning the main effect of the
vth factor is
with
. Similarly, the system of hypotheses of the partial test concerning the interaction effect of the two factors is
Therefore, the null and alternative hypotheses of the overall problem can be represented as follows:
where the intersection symbols mean that all the partial null hypotheses are true under
, and the union symbols indicate that, under
, at least one partial alternative hypothesis is true.
The proposed solution consists of the application of permutation tests on the significance of the single coefficients and then a CPT to solve the overall testing problem by combining the inferential results of the partial tests. Reasonable test statistics for the partial tests on the single coefficients are the absolute values of suitable estimators of the parameters. Formally, an appropriate partial test statistic for the main effect of the
vth factor is
with
. Therefore, a suitable partial test statistic for the interaction effect is
The null distribution of the test statistics is obtained by permuting the rows of the design matrix, keeping the vector of observed values of the response fixed, and recalculating for each permutation the estimates of the coefficients and, consequently, the values of the test statistics. This non-parametric method is very useful for solving complex problems and the main advantage with respect to parametric methods is that the multivariate distribution of the trivariate test statistic does not need to be known, and in particular, the dependence structure between variables does not need to be explicitly modelled or specified [
35]. Permutation tests are distribution-free, hence they are flexible and robust with respect to the departure from normality [
32].
The core concept of a combined permutation test is to identify an appropriate statistic for each partial test and to aggregate the permutation
p-values from these tests to address the overall problem [
33]. In our case, the absolute values of the least squares estimators of the regression coefficients serve as suitable and effective test statistics for the partial tests. The procedure follows these steps:
Computation of the vector of observed values of the test statistics ;
B independent random permutations of the rows of the X matrix: ;
Computation of the values of the test statistic vector for the B dataset permutations and the corresponding vector of p-values with ;
Computation of the value of the combined test statistic for each permutation and for the observed dataset through the combination of the partial p-values with a suitable function : ;
Computation of the p-value of the combined test according to the null permutation distribution.
The dependence of the partial tests is implicitly taken into account through the permutation of the rows of the design matrix. Since each partial null hypothesis is rejected for large values of the test statistic, without loss of generality, we assume the same rejection rule for the combined test statistic of the overall problem. Therefore, a suitable combined test statistic
is:
where
,
and
are the
p-values of the partial tests. Equation (
6) represents Fisher’s combination function which, among the various combination functions available in the literature, exhibits a good power behavior regardless of the proportion of true partial alternative hypothesis [
36,
37]. Since such a permutation ANOVA for the linear regression models is defined as a multiple tests, in the case of a rejection of the null hypothesis in favor of the alternative and, in order to attribute the overall significance to specific partial tests (i.e., to specific coefficient estimates), the control of the family-wise error (FWE) is necessary [
38,
39]. Family-wise error rate (FWE) refers to the probability of making at least one type I error (false positive) when performing multiple statistical tests on the same dataset [
40]. It is a key concept in multiple comparisons and hypothesis testing, particularly when testing multiple hypotheses simultaneously. When conducting multiple statistical tests, the likelihood of incorrectly rejecting at least one true null hypothesis (type I error) increases. In other words, to avoid the inflation of the type I error of the overall test, we must adjust the partial
p-values. A suitable method is the one based on the Bonferroni–Holm rule [
41]. This correction procedure works as follows. Given a set of
m partial
p-values:
all p-values are sorted in order of smallest to largest;
if the smallest p-value is greater than or equal to , the procedure is stopped and no p-value must be considered significant. Otherwise, go to step three;
the smallest p-value is considered significant, then the second smallest p-value is compared to . If the second smallest p-value is greater than or equal to , the procedure is stopped and no other p-value is considered significant. Otherwise, go to step four;
repeat steps 2 and 3 on the remaining p-values until you find the first non-significance.
The method’s application to the real data of the case study, along with the simulation analysis, was conducted using original R scripts developed by the authors. Actually, for the regression model, the R function lm() was carried out. The graphs were created with the corresponding R functions plot(), hist() and boxplot().
4. Monte Carlo Simulation Study
A Monte Carlo simulation analysis was conducted to assess the power behavior of the non-parametric test discussed in the paper (CPT) in comparison to the traditional parametric
F-test for the ANOVA and to the bootstrap combined test (TBC), also present in the literature concerning this statistical problem. The previously mentioned competitor, TBC, was implemented by taking inspiration from the technique reported in [
42,
43]. In practice, this method, unlike CPT, generates the
B simulated datasets by resampling the original data with replacement. Once the bootstrapped datasets are generated, the technique for combining the partial
p-values, related to the significance of the individual regression coefficients, remains the same as in the CPT procedure.
Let
n and
q denote the sample size and the number of binary factors of the model, respectively (in our specific case
). The binary data were simulated by randomly generating values from normal distributions and then transforming such values into binary data. Specifically,
matrix
was simulated by randomly generating
n observations from a
q-variate normal distribution with null mean vector and variance–covariance matrix
, i.e.,
. We assumed that the variance of each component of the underlying bivariate normal distribution was constant and equal to
and the correlation between each couple of components
. Consequently,
, where
denotes the
all-ones matrix and
is the
identity matrix. In our simulations, we set
and
. According to the extensive notation, we have:
Then, the model design matrix
was obtained by transforming the elements of
into binary data and adding the column of ones and the products between factors to take into account the constant of the model and the interaction, respectively. As said, we focused on the case
. Let
and
denote the probability of success (or population proportion of ones) of the underlying Bernoulli random variables corresponding to the first and the second factors, respectively. The binary simulated value
corresponding to the
ith observation of the
vth factor was computed as follows:
where
is the indicator function of the set
A,
is the cumulative distribution function of the standard normal distribution, and
its inverse, that is the Gaussian quantile function, with
. In the simulations, we considered the realistic values
and
. Hence, the simulated matrix of predictors is the following:
In order to simulate the values of the numeric response, we assumed three different distributions for the model random errors, mainly to evaluate the effect of the distribution skewness on the inferential results. The n i.i.d. errors, simulated from probability distributions with different skewness, were rescaled to respect a distribution variance of , very similar to that of the case study, and centred on the mean value 0. Let and denote the error randomly generated and the transformed one (rescaled and centered), respectively. The three cases are:
, i.e., errors generated from a normal distribution, such that , then ;
, i.e., errors generated from a chi-square distribution with 13 degrees of freedom, such that (moderate asymmetry), then ;
, i.e., errors generated from a chi-square distribution with 2 degrees of freedom, such that (high asymmetry), then .
The values of the dependent variable were obtained by adding the simulated deterministic part of the model and the transformed simulated errors, according to the regression model reported in Equation (
3). Hence, the vector of
n simulated values of the response is computed as follows:
where
,
, and
.
For every simulation setting, the total number of datasets created for power estimation was 1000, and the count of random permutations to establish the null distribution of the test statistics was
. The approximation would certainly improve with
B = 10,000, which is the choice we made in the case study. Nevertheless, using 1000 permutations in the conditional Monte Carlo method is adequate to achieve a satisfactory level of approximation, ensuring reliable outcomes from the simulations [
15,
33] and computational efficiency. To address the computational limit of the permutation approach and guarantee both robustness and feasibility of the procedure, either Monte Carlo approximations or parallel computing techniques could be also considered [
44,
45]. In the simulations, a comparative performance analysis of the CPT method and the classic F-test of the parametric approach was carried out.
The setting parameters which vary in the simulations are the following:
n is the sample size,
, , and are the coefficients of the regression equation.
, where represents the degrees of freedom of the chi-square distribution of errors (→∞ in case of normality)
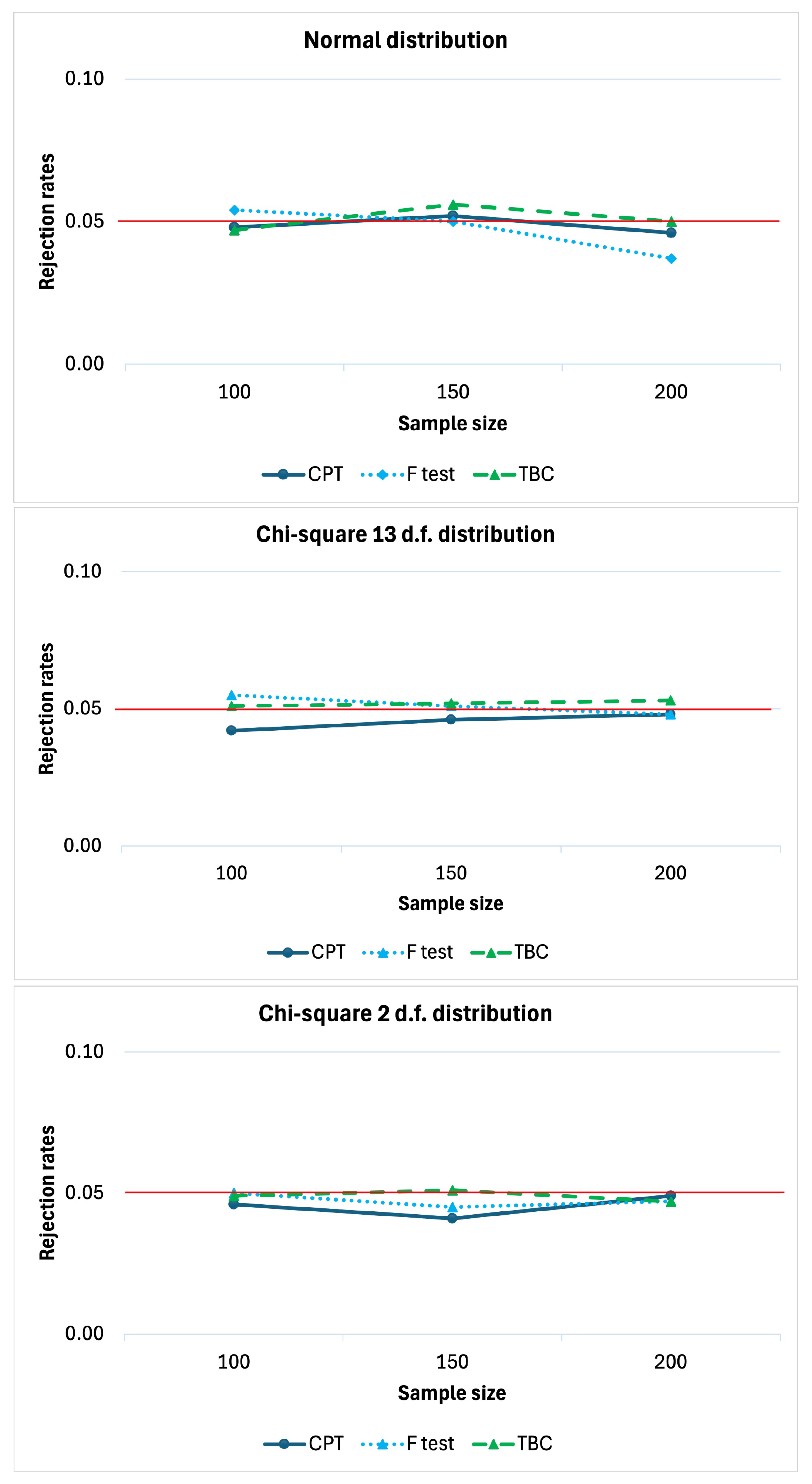
Firstly, simulations were carried out under the null hypothesis (
), with
and
.
Figure 1 reports the rejection rates of the compared tests as a function of the sample size
n. The rejection rate refers to the proportion of times
is rejected in a simulation. Indeed, under
, these values should remain below the predefined significance level
to prove that the tests are well approximated. It is evident that all three tests are well approximated because the rejection rates are all under or very close to the significance level
. Even though the competitor TBC is often above or close to the reference value
.
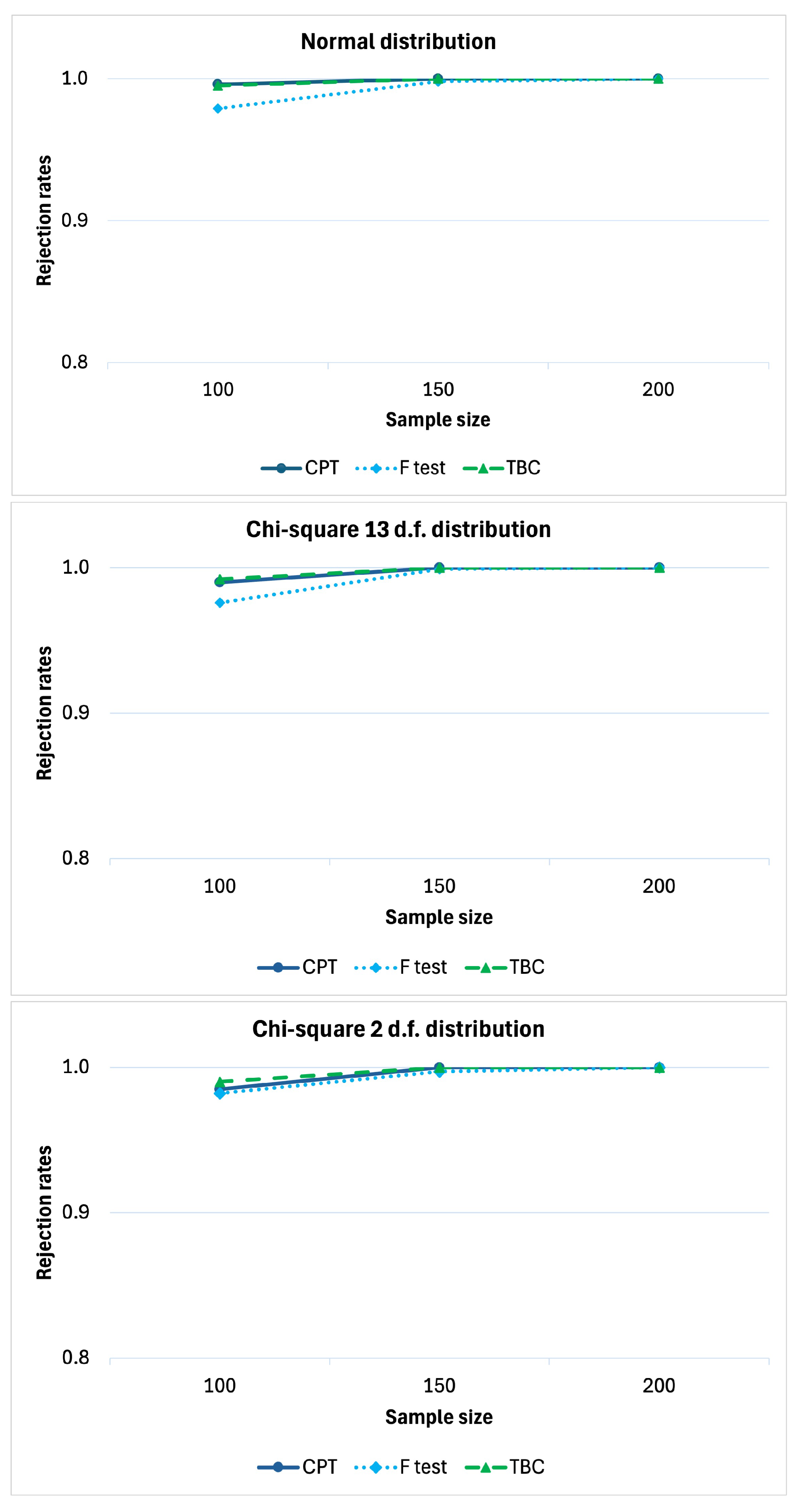
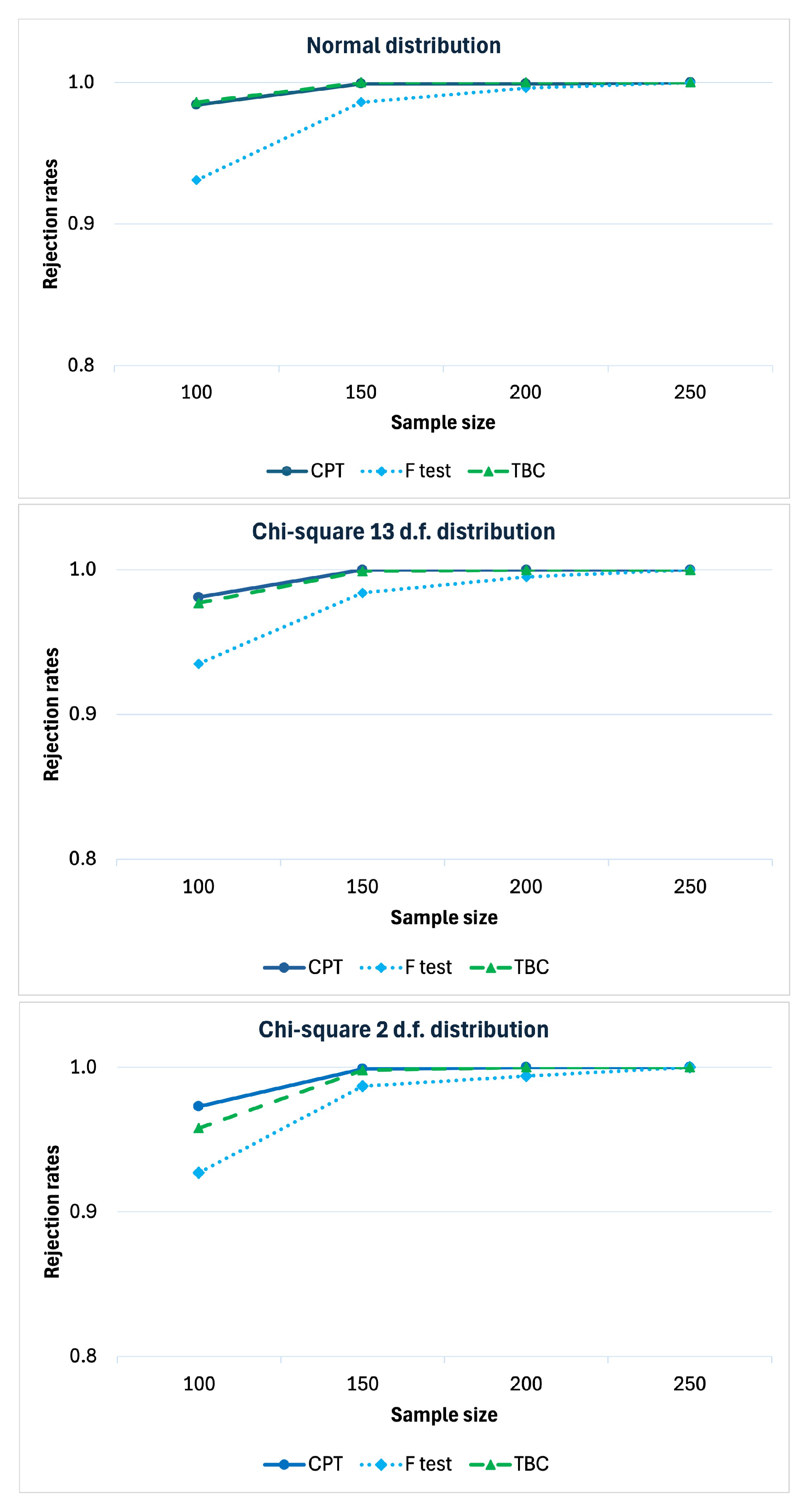
We studied the power behavior under
in the scenario with positive main effects of the two factors and null interaction effect, similarly to the empirical results of the case study. The power of a statistical test is the probability of rejecting the null hypothesis when the alternative hypothesis is true. This probability is typically represented by a curve that illustrates the test’s power as a function of sample size, number of partial tests, or other parameters of interest. The power under such a scenario, as a function of the sample size, is reported in
Figure 2 to evaluate the consistency of the test. In general, all the three tests are consistent. The power of the proposed method is slightly greater than that of the parametric F-test and also the non-parametric method based on a bootstrap approach (TBC). Furthermore, when
n diverges, the proposal tends to infinity faster. We carried out the simulations under the same scenarios except
(to consider the case of positive interaction effect as well). The results confirm that the CPT is more powerful than the parametric F-test and than the TBC approach. Additionally both of them are consistent (see
Appendix A).
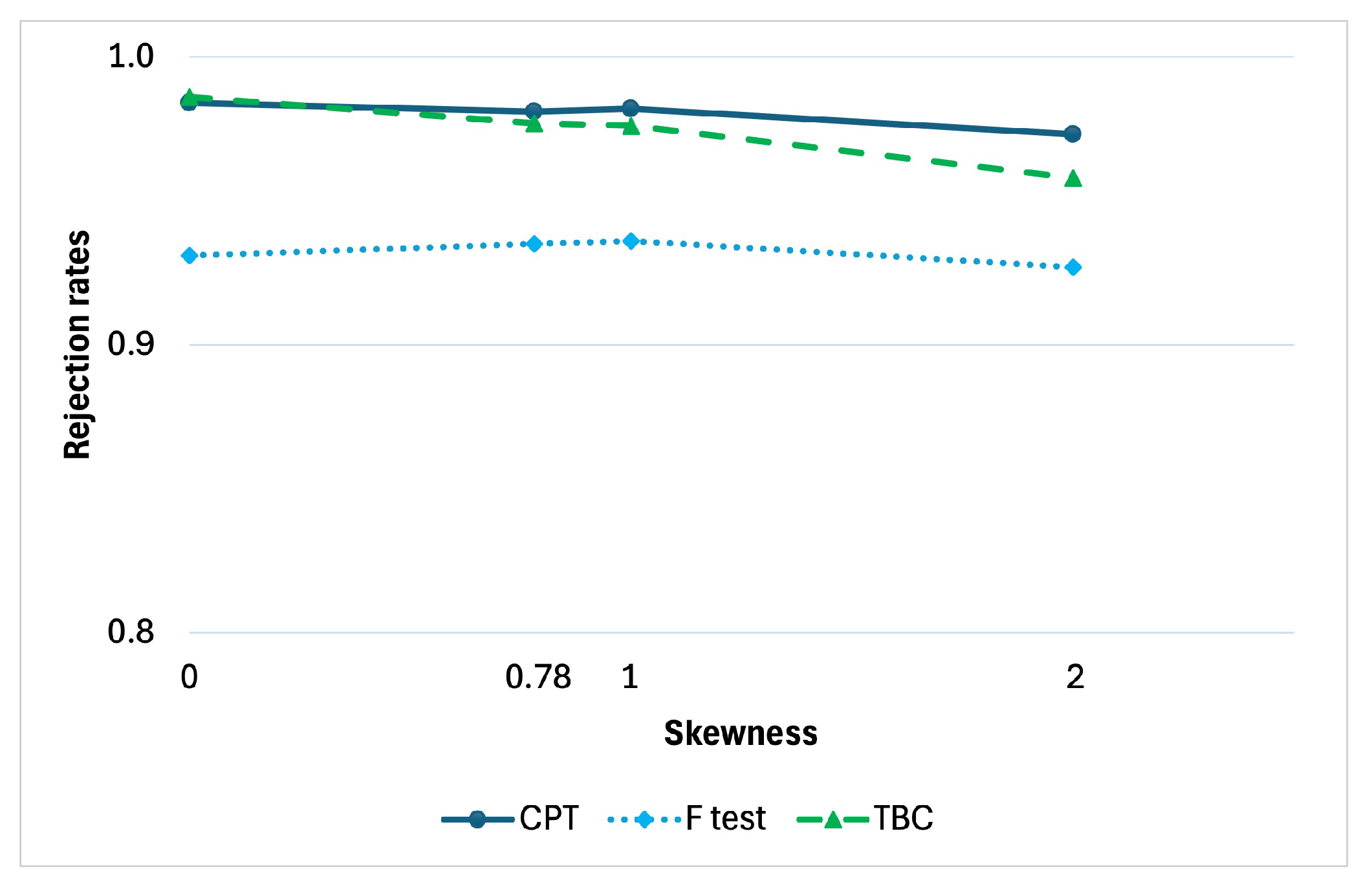
Furthermore, in
Figure 3, the effect of skewness can be assessed when
. The rejection rates of the three tests are represented as a function of the asymmetry of the error term distribution. We remind that the skewness is null when the errors are simulated under normality, and corresponds to
when the assumed error distribution is chi-square with
degrees of freedom. We considered four scenarios, by simulating under normality and under
,
, and
, corresponding to the skewness values 0,
, 1 and 2, respectively. Again, the CPT method seems to be more powerful regardless of the departure of the distribution skewness from the symmetric case typical of normality.
5. Application to Real Data
As said, the application example concerns the study of the effect of age and smoking habit on the medical insurance cost in the USA. Data relate to a small random sample of the American population selected for a survey on the topic. We observed from [
46] that attributes such as being a smoker, BMI, and age are the most important factors in determining medical insurance costs. However, since BMI in our dataset exhibits limited variability, resulting in a generally homogeneous patient population in this regard, we decided not to include it among the factors and instead considered only smoking status and age. The data source is Kaggle (
https://www.kaggle.com/datasets/mirichoi0218/insurance, accessed on 20 December 2024).
The regression model under consideration for such a case study is the following:
where
is the charge of medical insurance costs for the
i-th person,
is the dummy variable that takes the value 1 if the
i-th person is a smoker and 0 otherwise,
is a dummy variable that takes the value 1 if the
i-th person is at least 50 years old and 0 otherwise, and
is the product between
and
, hence it takes the value 1 if both the dummy variables take the value 1, in other words, if the level of both factors changes with respect to the baseline (from no-smoker under 50 y.o. to smoker over 50 y.o.).
In the literature, the concept that the allocation of health care expenses is significantly influenced by age is widespread, a trend that becomes increasingly important as the baby boom generation grows older. After the first year, health-care costs are at their lowest for children, gradually rise throughout adulthood, and surge dramatically after the age of 50 [
47]. It was proved that the annual costs for older adults are roughly four to five times higher than those for individuals in their early teenage years [
48]. For this reason, we took 50 years as a threshold to define
age as a dummy variable [
49]. The considered sample was obtained with a random selection from the American adult population, composed of 1338 people. This random selection implies that the exchangeability of statistical units under the null hypothesis holds.
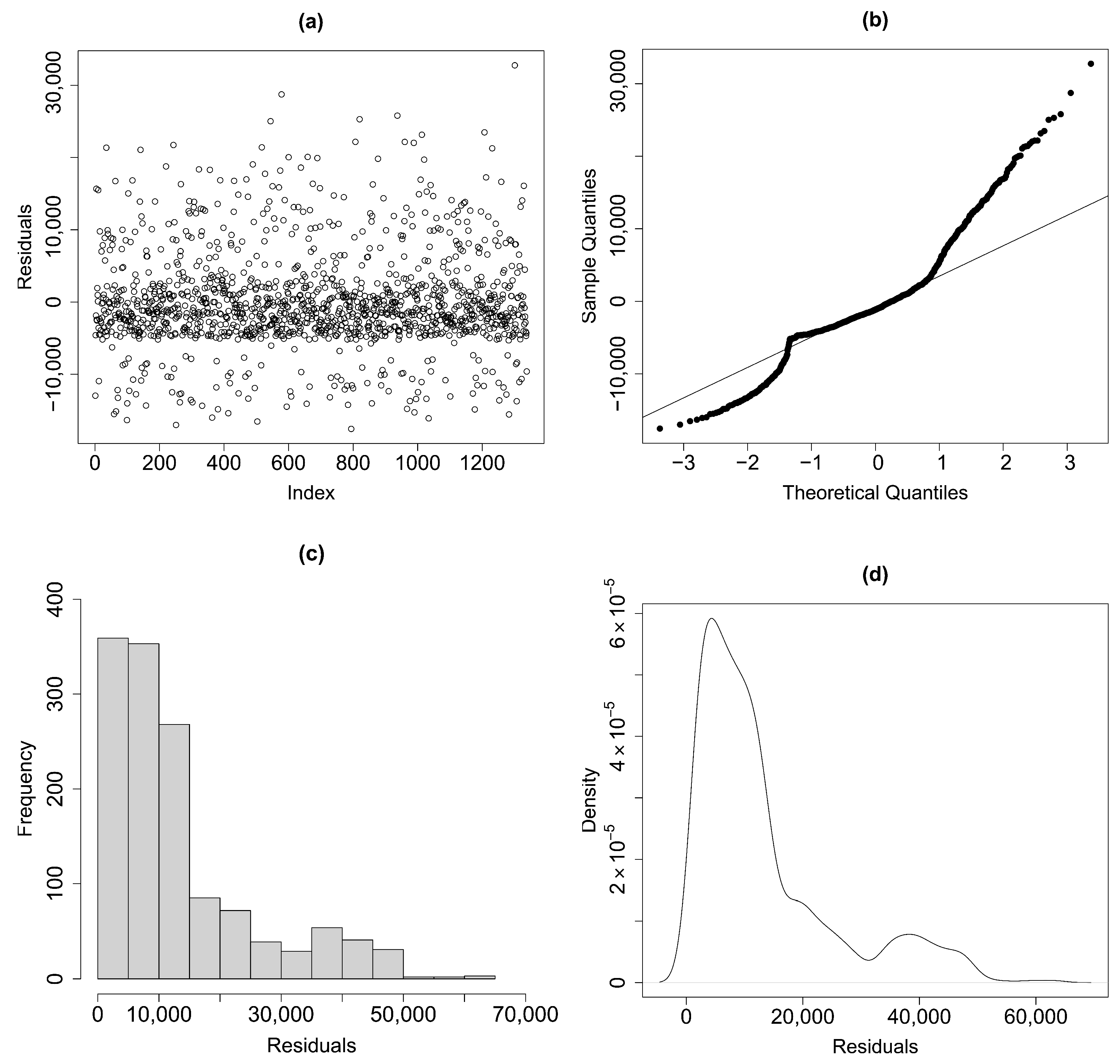
Figure 4 shows the scatter diagram, the normal Q–Q plot, the histogram and the density plot of the residuals. According to such plots, the assumptions of uncorrelated, homoskedastic, zero-mean errors seem to be plausible, but the distributions of the errors could be asymmetric. In particular, by examining the histogram and the density plot of the residuals, it can be observed that the distribution appears asymmetric, suggesting that the data are skewed to the left. This violates one of the typical assumptions of classic linear regression according to which errors follow a normal distribution. On the other hand, the same conclusion can be drawn from the normal Q–Q plot of residuals. In fact, the dots deviate from the straight line, indicating that the data may not follow the assumed theoretical distribution and therefore violate the normality assumption of the residuals. As a result, the assumption of normality for the model errors appears to be unmet and the use of the CPT test is preferable [
50]. Indeed, as previously mentioned, the CPT method allows for the relaxation of the normality assumption, and there is no requirement to assume a specific family of probability distributions for the model error terms.
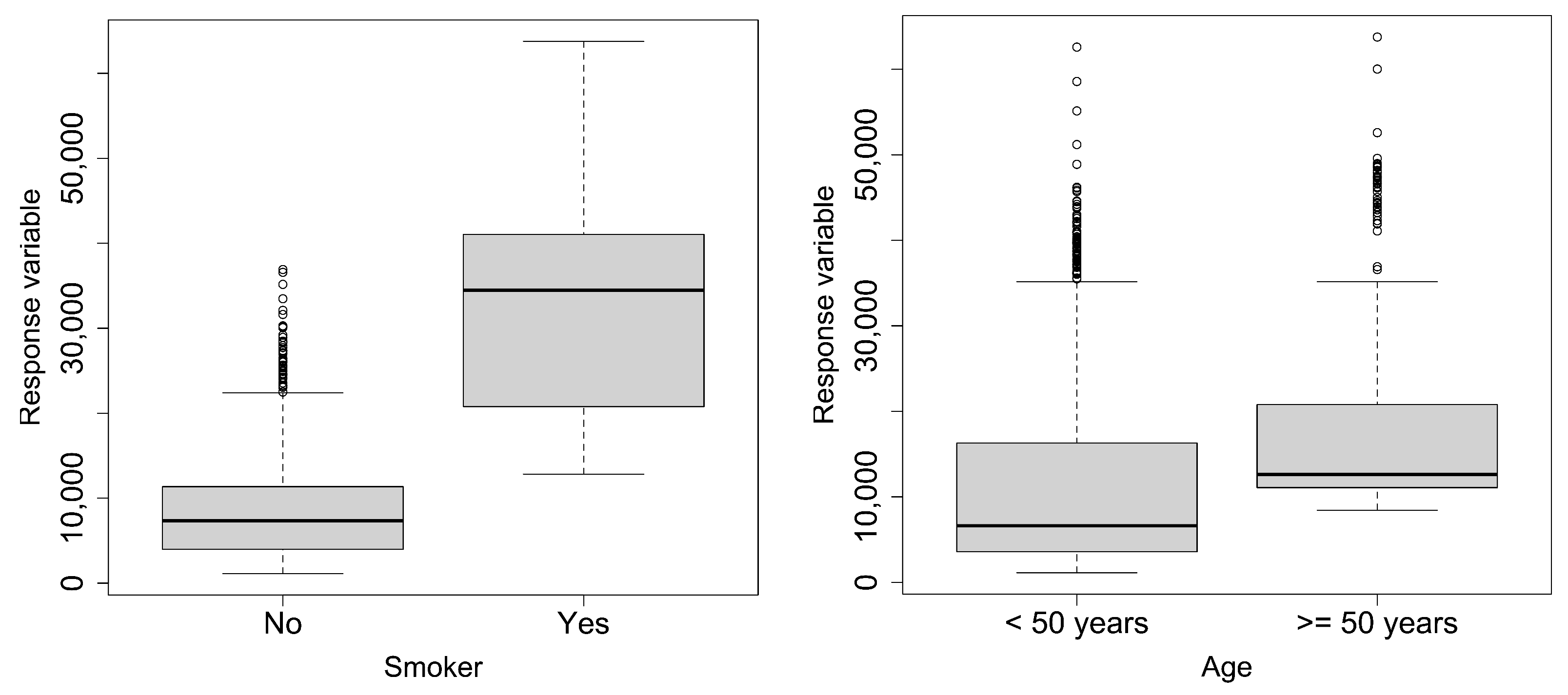
The boxplots of the response versus age and of the response versus being a smoker are reported in
Figure 5. Such plots confirm the previous statements concerning the distribution asymmetry.
In
Figure 6, the main effect plots and the interaction plot are represented. From a descriptive point of view, a variation in the means in both the main effect plots is shown, which is much more evident in the case of being a smoker. Conversely, in the interaction plot, the two segments tends to be parallel so there may not be an interaction between the two factors.
The goal of the analysis is to test the system of hypotheses defined in
Section 3. To this aim, the non-parametric test presented was applied to such data. The significance level was set to
. The overall
p-value of the CPT is equal to
. This is less than the significance level
which leads to the rejection of the null hypothesis of no effect. The partial
p-values related to the tests on the significance of the coefficient estimates adjusted with the Bonferroni–Holm correction are shown in
Table 1. According to such adjusted
p-values, the significance of the overall test can be attributed to the regression coefficients related to being a smoker and age but not to the interaction. Since the estimates of the regression coefficients are positive in both cases, we can state that being a smoker and being at least 50 years old positively influence medical insurance costs.
6. Concluding Remarks
This work is inspired by the study of the effects of age and smoking status on the insurance cost for the population in the USA. The main scientific contribution of the work consists of the application of an innovative non-parametric method, based on the CPT approach, to jointly test the main effects of the two binary factors and their interaction effect. The proposed method involves using permutation tests to assess the significance of individual coefficients, and combining the p-values of such partial tests to address the two-way ANOVA problem. The good power performance of the CPT compared to the F-test was shown in the Monte Carlo simulation study. The test was proved to be powerful, unbiased and consistent, regardless of the skewness of the error distribution.
The application of the proposed method to the interesting case study of medical insurance costs led to empirical evidence in favor of the hypothesis that age and being a smoker, each has a positive effect, whilst there is not an interaction effect. The findings of this research will practically support policymakers, insurance providers, and potential medical insurance buyers in making conscious decisions about choosing policies that meet their specific needs. A future extension of this work could explore the method’s performance on datasets with more complex dependence structures or alternative parametric models.
Possible future developments related to this work may involve the implementation of parallel computing techniques. These techniques serve as valuable tools for accelerating a wide range of algorithms, including Monte Carlo simulations. Indeed, the use of parallel computing can significantly enhance the efficiency of Monte Carlo simulations. Furthermore, the proposed method could be expanded in future work to cases of ANOVA with higher-order interactions or multi-level factors. For instance, in a three-way ANOVA (i.e., with three factors), it would be necessary to examine three main effects, three two-way interactions, and one three-way interaction.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}