1. Introduction
Non-response in sample surveys presents a significant obstacle, as it has the potential to create bias and affect the dependability of survey findings. A sample may contain missing data due to factors such as illness, language barriers, participant reluctance, or unavailability during data collection. When conducting surveys on sensitive subjects such as drug use, abortion, or sexually transmitted diseases, non-response (NR) becomes more noticeable, as respondents may opt not to reveal information or decline to participate in the survey entirely. An NR has consequences that go beyond simply missing data. It can result in either underestimating or overestimating demographic metrics, affecting survey results’ reliability. Conventional methods frequently fail to address NR problems or assume that survey data are both complete and unbiased, disregarding the difficulties presented by individuals who do not respond.
Stratified random sampling is an important methodological strategy in survey research that helps deal with the complications caused by NR. Stratified sampling involves dividing the population into homogeneous subgroups, or strata, based on relevant criteria. This method assures that each subgroup is sufficiently represented in the sample. Stratification enhances the accuracy of estimates and allows researchers to customise tactics to minimise NR effects in each stratum. Within each stratum, it is possible to use particular tactics such as targeted follow-ups, alternate contact methods, or weighting adjustments to increase response rates and make up for missing data. These customised approaches are crucial for preserving the accuracy of survey findings, especially when addressing delicate topics that often have higher rates of NR. Furthermore, stratified random sampling allows for incorporating additional data pertaining to each stratum, such as demographic characteristics or past records. By utilising additional data, researchers can more effectively account for bias caused by NR, thus improving the accuracy and dependability of estimates for population parameters.
Many researchers worked on NR. This issue was initially addressed by [
1]. Auxiliary information is essential in statistical estimation, as it offers supplementary data that can enhance the accuracy and precision of estimates. It plays a crucial role in decreasing the variability of estimators and correcting for biases, making it extremely beneficial in a wide range of sampling and estimation procedures. Accurately estimating the population mean is crucial in survey sampling, as it offers valuable insights about the population’s mean. Methods such as ratios, regression estimators, etc., utilise additional information to improve the accuracy and reliability of these estimations. When there is a lack of response, it is very crucial to use supplementary information. By including relevant auxiliary variables, researchers can mitigate biases caused by non-respondents. This application guarantees the resilience of the population mean estimation, even in the presence of missing data in the sample. As a result, the study’s conclusions maintain their integrity and validity. Various authors have addressed the NR issue in stratified random sampling. The authors of [
2] suggested estimators for the population mean that combine different types of estimators. A two-phase sampling method was used to estimate the population mean when there is NR [
3]. Moreover, ref. [
4,
5] proposed a family of estimators in the presence of NR, while [
6] focused on estimating the population mean by using additional information. An estimator for stratified sampling using a single auxiliary variable was developed by [
7].
Moreover, the importance of using bivariate or dual auxiliary information has been highlighted, because it can improve estimation accuracy and reduce biases caused by NR. By employing two correlated variables, dual auxiliary information provides a more precise approach that enables improved adjustments and minimises estimation mistakes. Several researchers investigated NR by utilising dual auxiliary information. In the non-response scenario, ref. [
8] estimated the population mean and [
9] developed a generalised exponential-type estimator under a stratified sampling scheme. The authors of [
10] suggested a family of ratio estimators in the presence of NR issues and addressed them well. An efficient method was introduced by [
11] to estimate the population mean based on bivariate auxiliary information. The authors of [
12] have studied the problem of NR under simple random sampling. NR and measurement error are significant concerns in survey sampling, which can result in biased and inaccurate results if not well-handled. To address the issues of both the measurement error and NR, ref. [
13] proposed some techniques. Further, ref. [
14] introduced a ratio estimator in the presence of NR; also, ref. [
15] developed a new estimator to estimate population mean, and [
16] developed a generalised class of estimators for estimating population means in the presence of such conditions, specifically inside stratified random sampling frameworks. The authors of [
17,
18] proposed various methods in order to identify the optimum strata boundaries in stratified random sampling, [
19] proposed ratio estimators by using regression methods, and [
20] developed a modified regression estimator by incorporating regression techniques. Later, ref. [
21] proposed a robust regression-type estimator, and [
22,
23] emphasised the formulation and use of robust regression-based ratio and regression estimators for population mean and variance, utilising auxiliary variables and advanced statistical methodologies in both simple and stratified random sampling. Recently, ref. [
24] proposed exponential ratio and regression type estimators by using past sample means, and [
25] suggested power and log-transformed ratio estimators. Later, refs. [
26,
27] proposed calibrated estimators for the issue of NR.
Few studies exist on log-type estimators that cover different situations, such as Optional Randomised Response Technique (ORRT) models, calibration estimators in stratified random sampling, population variance estimation, and information from a single auxiliary variable. There is a significant gap for studies that address various important factors like non-response, the use of bivariate auxiliary information, log-type families of estimators, and stratified random sampling. To fill this gap, we conducted research to develop families of log-type estimators that use dual auxiliary information in the context of stratified random sampling with different non-response rates.
The paper is organised as follows:
Section 1 provides notations and procedures for estimating the population mean in the presence of NR.
Section 2 presents the proposed classes of log-type estimators for all four cases.
Section 3 uses four real datasets to conduct an empirical investigation and demonstrate the results.
Section 4 of our study involves conducting a simulation to improve the accuracy of our results and showing the results by using trace plots. In
Section 5, we provide an explanation of the results and discussion. Finally,
Section 6 provides our study’s conclusions.
Procedure for Estimation of Population Mean When NR Occurs
Notations are as follows:
the total population size;
no. of strata;
population size of the stratum;
= sample size of the stratum ;
and = the number of respondent and non-respondent persons in the sample of stratum, such that;
= sub-sampled units from non-respondent group;
denotes the stratum weight;
denotes the NR unit weight.
A finite population of size
is stratified into
homogeneous strata and the size of the
stratum is
,
Let
represent the observations of the study variable
(auxiliary variables
and
) on the
unit of
stratum. Let
represent the sample mean of the
stratum corresponding to the population mean of
. In order to choose a subset of n elements from
, we employ the simple random sampling without replacement (SRSWOR) method. We choose
units from the
stratum such that
Following [
1],
units are selected from the non-respondent group
, which is random, and the selection is a proportion of the NR sampled units. Consequently, we choose
, such that
, where
or
Thus,
is treated as a constant chosen priorly.
To obtain the estimates of the stratum population mean, we combine the initial response and the response group
and the data obtained from the NR group
, i.e.,
sub-sampled units. The estimators for the population means of the study and auxiliary variables in the NR stratum are as follows:
is the sample mean of the study variable (auxiliary variables) based on response units in the stratum and is the sample mean of the study variable ((auxiliary variables) based on response units in the stratum, where ).
The estimator
is unbiased for the population mean
of the study (auxiliary variables) in the
stratum. The variances of these estimators, as described by [
1], are given by the following:
where
is the population variance of the study variable (auxiliary variables) based on all units of
in the
stratum.
is the population’s variance of the study variable (auxiliary variables) based on NR
units in the
stratum, and their weight is given as
. The covariances of the estimators are given (in Equation (1)) by the following:
In the stratum, is the population covariance of the study (auxiliary variables) based on response units and is the population covariance of the study (auxiliary variables) based on NR units .
Without using the auxiliary information, the NR-stratified estimator of the population mean of the study variable is given by the following:
The variances of the estimators are given as follows:
A modified Hansen and Hurwitz [
1] unbiased estimator for stratified sampling may be given as follows:
where
.
Here,
is the mean of
respondents on the first call,
is the mean of
units of respondents on the second call, and
denotes the unbiased Hansen–Hurwitz estimator [
1] of
for stratum h. The variance of this estimator is presented in the Equation (3).
The variance of Equation (2) is given as follows:
where
,
.
5. Results and Discussion
This study extensively examines various NR rates and their effects on the bias and MSE (both combined and separate) in the context of stratified sampling. Our discussion mostly focused on four scenarios (case (i)–(iv)), where we developed theorems and proofs for all four estimators proposed in each case. In addition, we conducted this study for comparisons on several factors, including MSE increases with an increase rate in NR (proved through
Table 1 and
Table 2) and the efficiency of separate-type estimators compared to combined-type estimators (using
Table 3 and
Table 4). We also conducted a comparison with the MSE. The efficiency is high when NR occurs in both study and auxiliary variables and it is lower when NR occurs only in a study variable (proved by using
Table 5 and
Table 6). This is discussed further in this section.
In the numerical study, for all four real datasets, as we mentioned earlier, the values of constants
, and
are chosen in between 0 and 1,
In our study, we consider the values of constants
and
and
and
and
for
Table 5, and the values of constants
and
and
and
and
By utilising
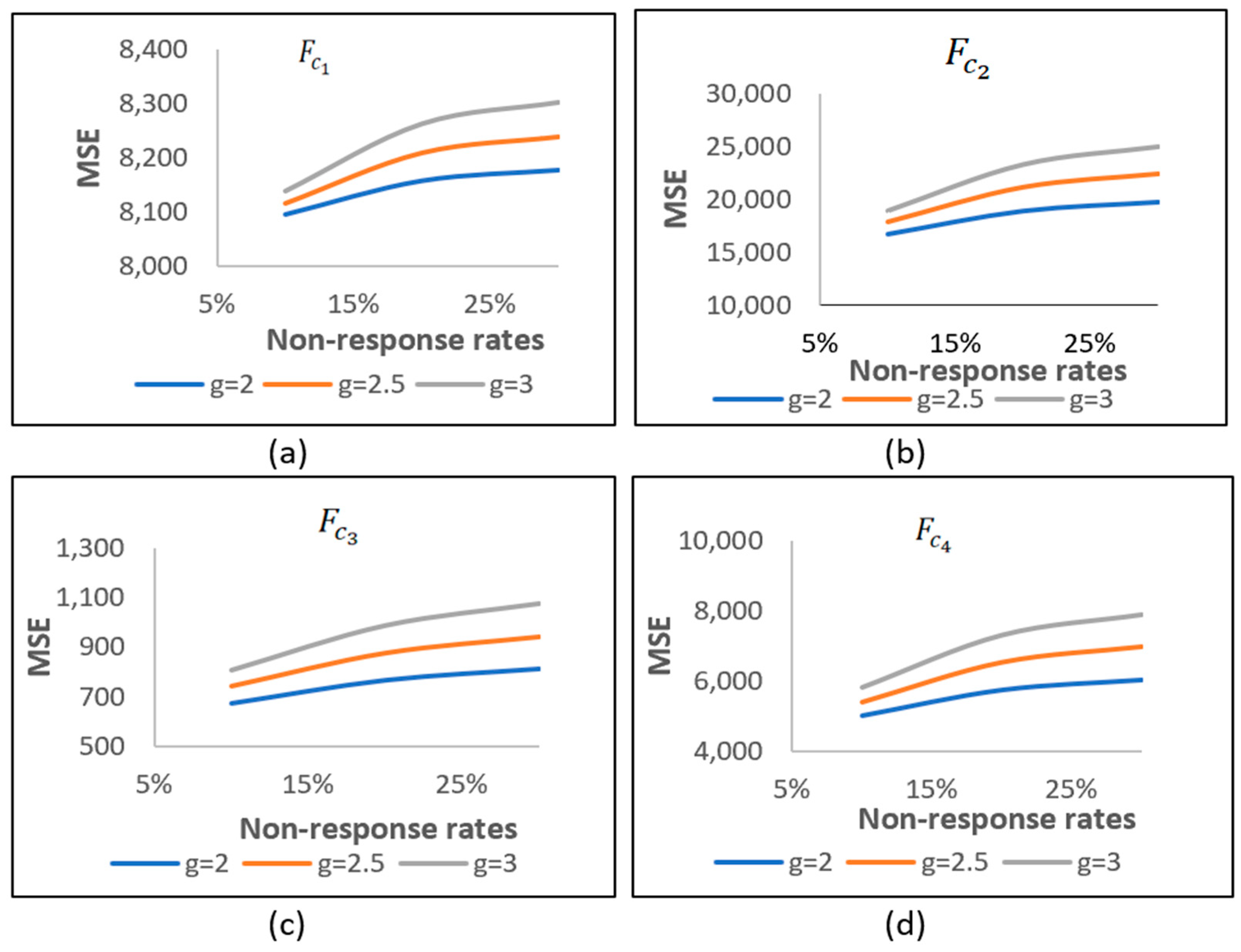
Table 1, we place a specific emphasis on case (i), where NR occurs in both the study and auxiliary variables.
Table 1 clearly demonstrates that the MSE values rise in parallel with the growth in both the NR rates and the values of the constant
. In addition, we displayed this information visually in
Figure 1 and
Figure 2. The estimators
are denoted collectively as (a), (b), (c), and (d) in
Figure 1. In
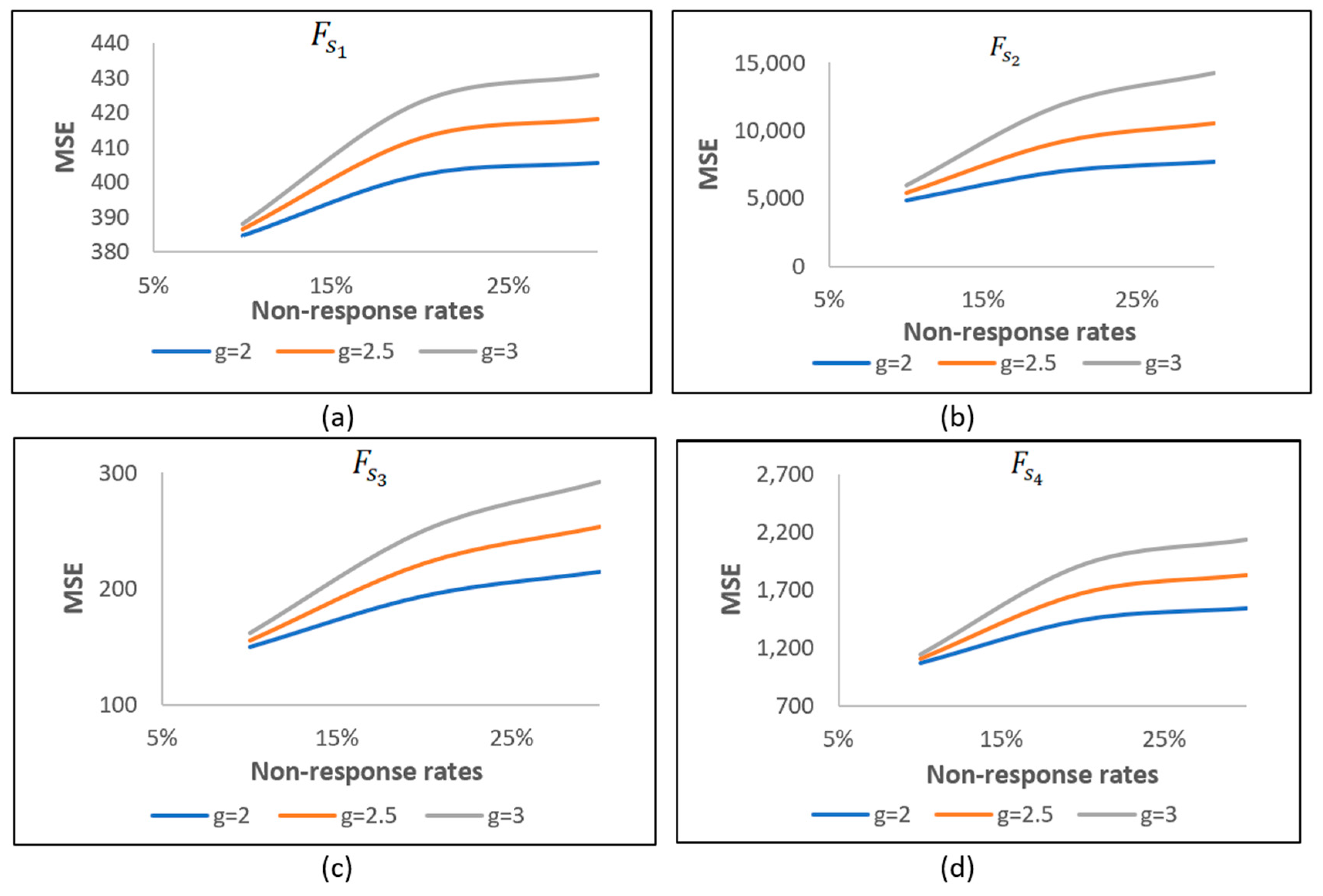
Figure 2, the separate estimators
are labelled separately as (a), (b), (c), and (d). It is observed that the MSE values consistently increase with the NR rates.
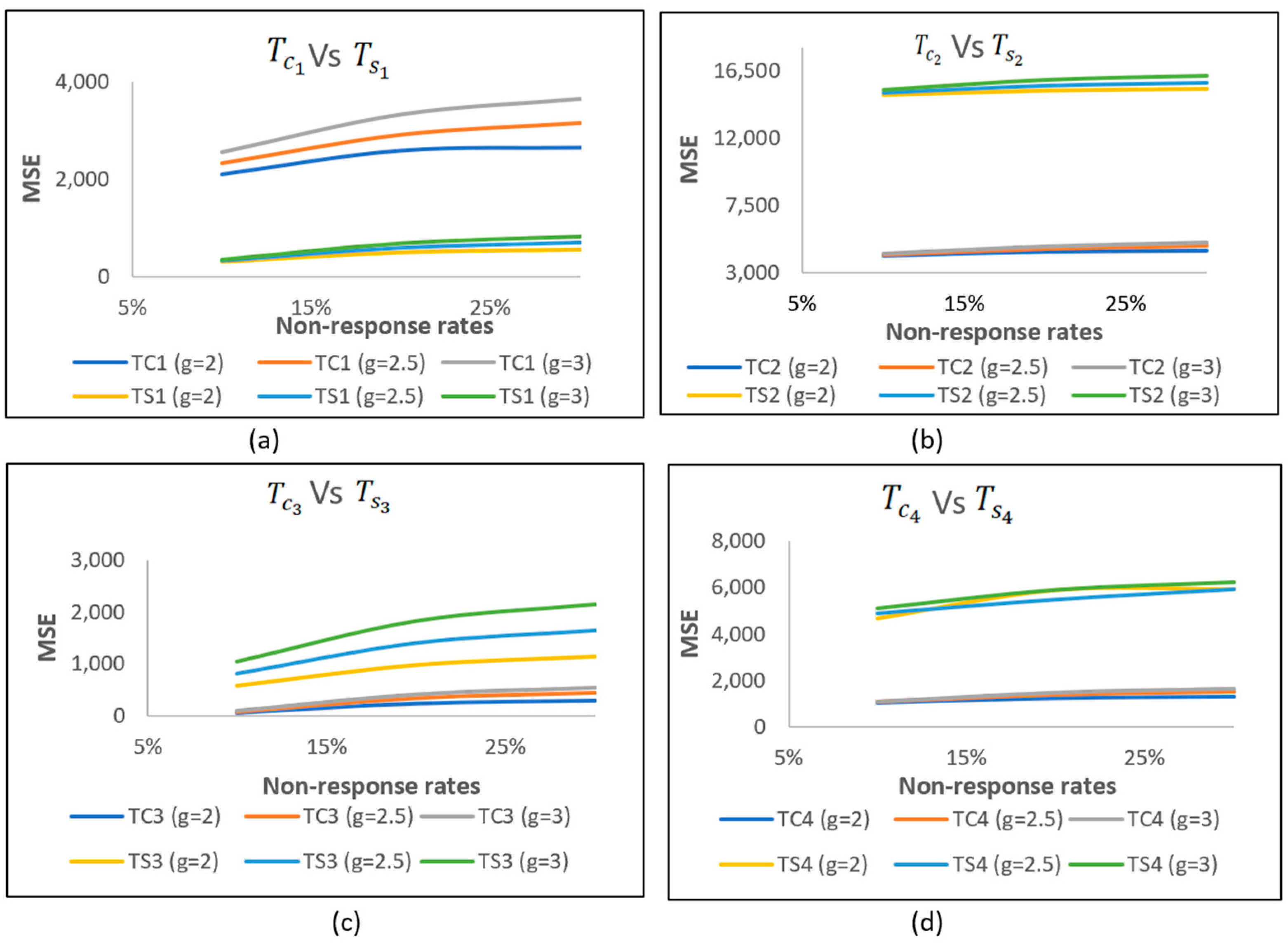
The efficiencies of combined and separate estimators were compared using the results from
Table 2, focusing on case (ii), where NR occurs only in the study variable. It was observed that separate estimators generally exhibit greater efficiency than combined estimators when they are evaluated using MSE metrics.
Figure 3a–d illustrate comparisons between the estimators
, respectively. The observed differences in MSE values between combined and separate estimators may depend on the nature and properties of the datasets.
Table 3 and
Table 4 demonstrate that MSE values are higher when NR occurs in both variables compared to when it only affects the study variable. For example, with a 10% NR rate and
= 2, the MSE of
is greater than
(58.93 > 34.37), emphasising the significance of response rates in data analysis. Similarly, at
= 2.5, the MSE of
surpasses
(60.04 compared to 34.67), and at
= 3,
exceeds
(61.14 compared to 34.98).
The analysis indicates that the NR rates significantly impact the bias and MSE of the cost of living plus rent index estimation. Higher NR rates generally lead to an increased bias and MSE (presented in
Table 5 and
Table 6), indicating the importance of addressing NR in survey designs to ensure accurate and reliable estimates. Overall, the stratification by the cost of living index and the use of Neyman allocation provided a robust framework for sampling. The auxiliary variables (cost of living index and rent index) were effective in improving the estimation of the study variable
. The same results are observed in the fouth population, which predicts the solar UV radiation from
Table 7 and
Table 8. Further investigations into specific
values and their effects on the bias and MSE could provide more insights for optimising sampling strategies in future studies. As the sample size increases, the efficiency of the proposed estimators increases as well.
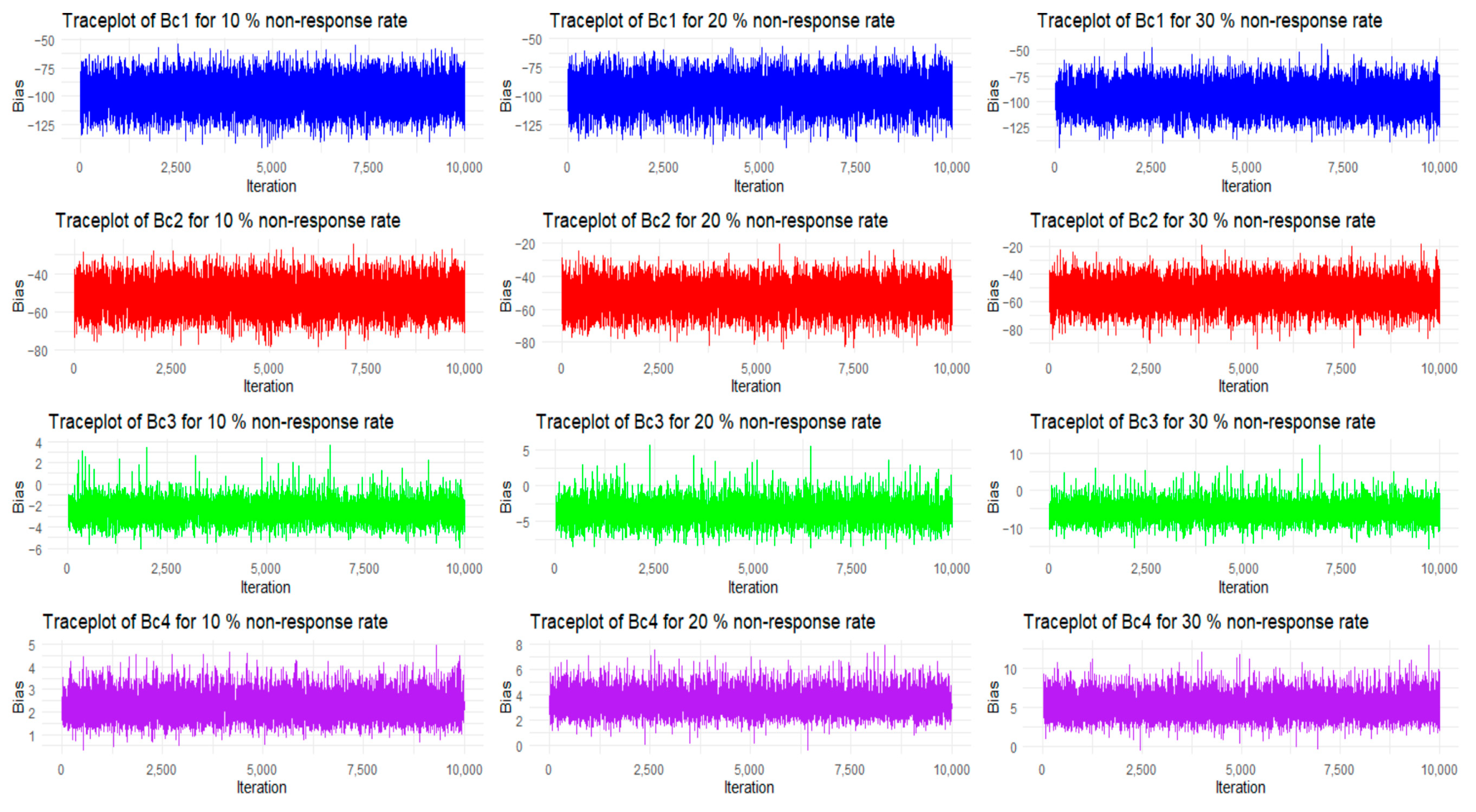
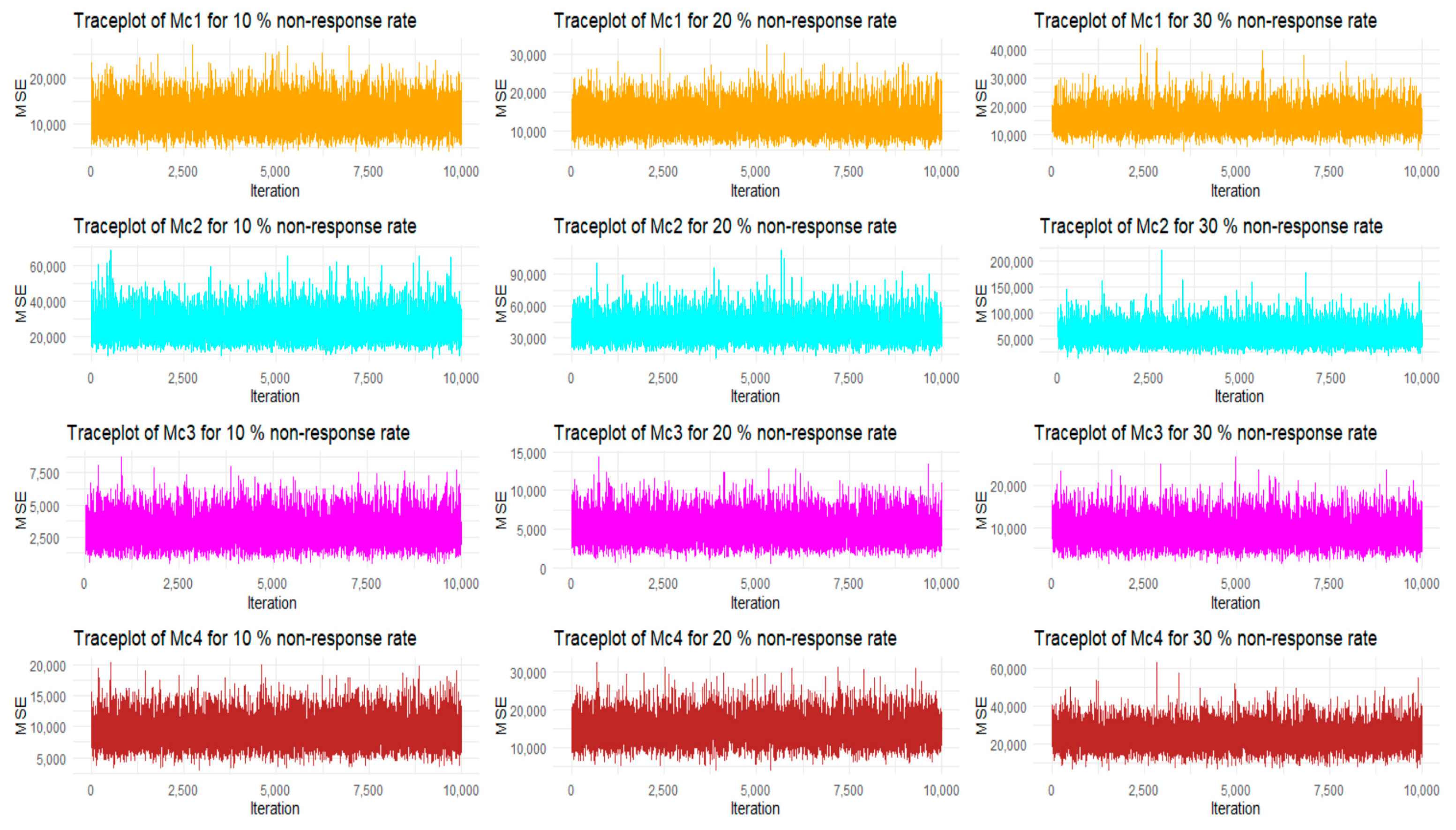
In the simulation study, we carried out 10,000 iterations to obtain the best values for the bias and MSE; we depict the bias and MSE values for each iteration in
Figure 4 and
Figure 5. Here, in graphs 4 and 5, we consider the combined-type estimators from
Table 9, and the plots are taken for the bias and MSE values of
(in graph, bias is denoted by Bc1, Bc2, Bc3, and Bc4, and MSEs are denoted by Mc1, Mc2, Mc3, and Mc4) under 10%, 20%, 30% of NR rates.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}