

Domain Adaptation Based on Human Feedback for Enhancing Image Denoising in Generative Models




Abstract
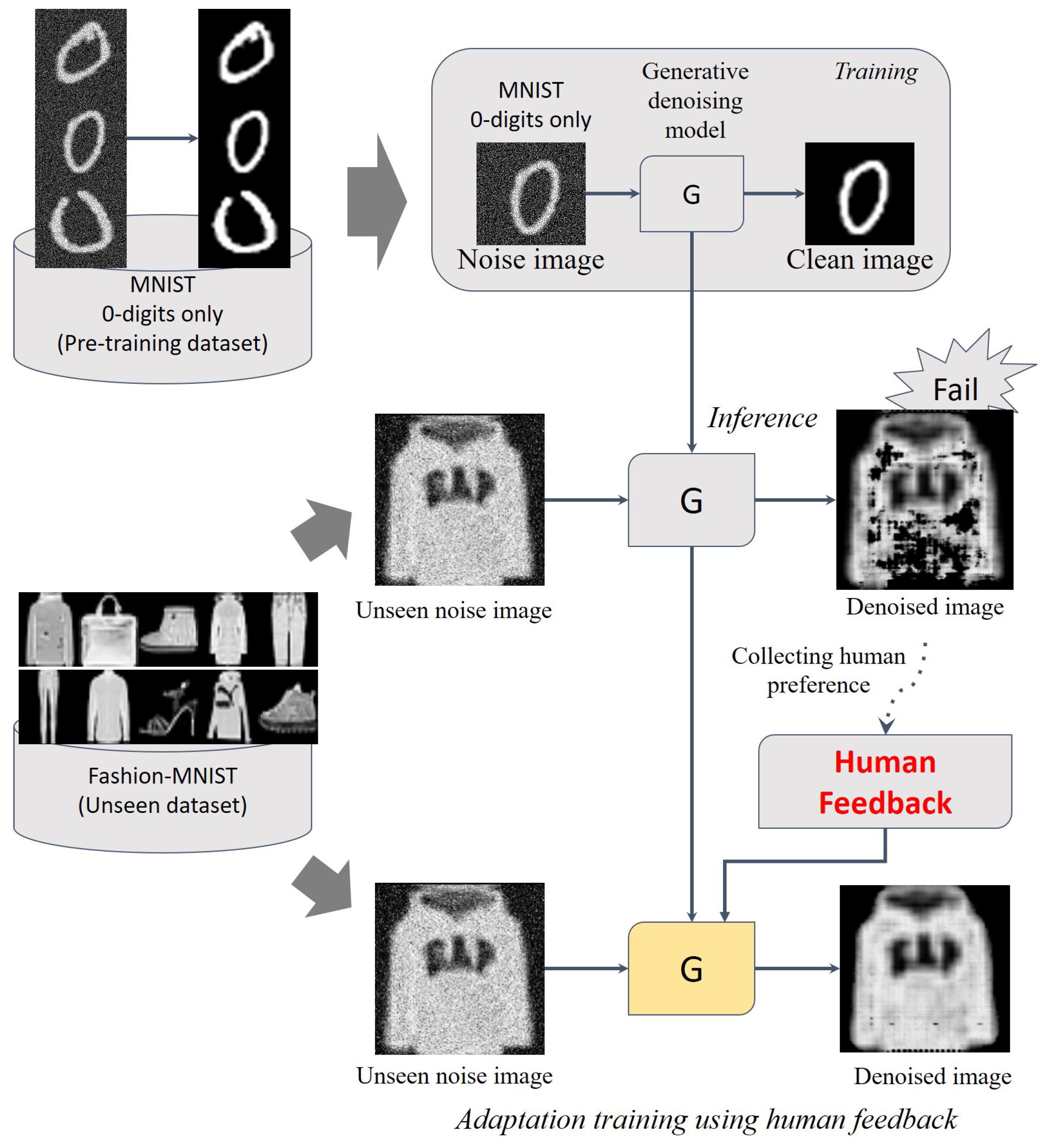
1. Introduction
- We propose an adaptation method for the domain of image-based generative models through human feedback.
- We perform domain adaptation while maintaining the quality of the generated image using an optional loss function with a reward model using human feedback.
- We show that the model can be adapted by human feedback, even in the absence of labeled target data.
2. Methods
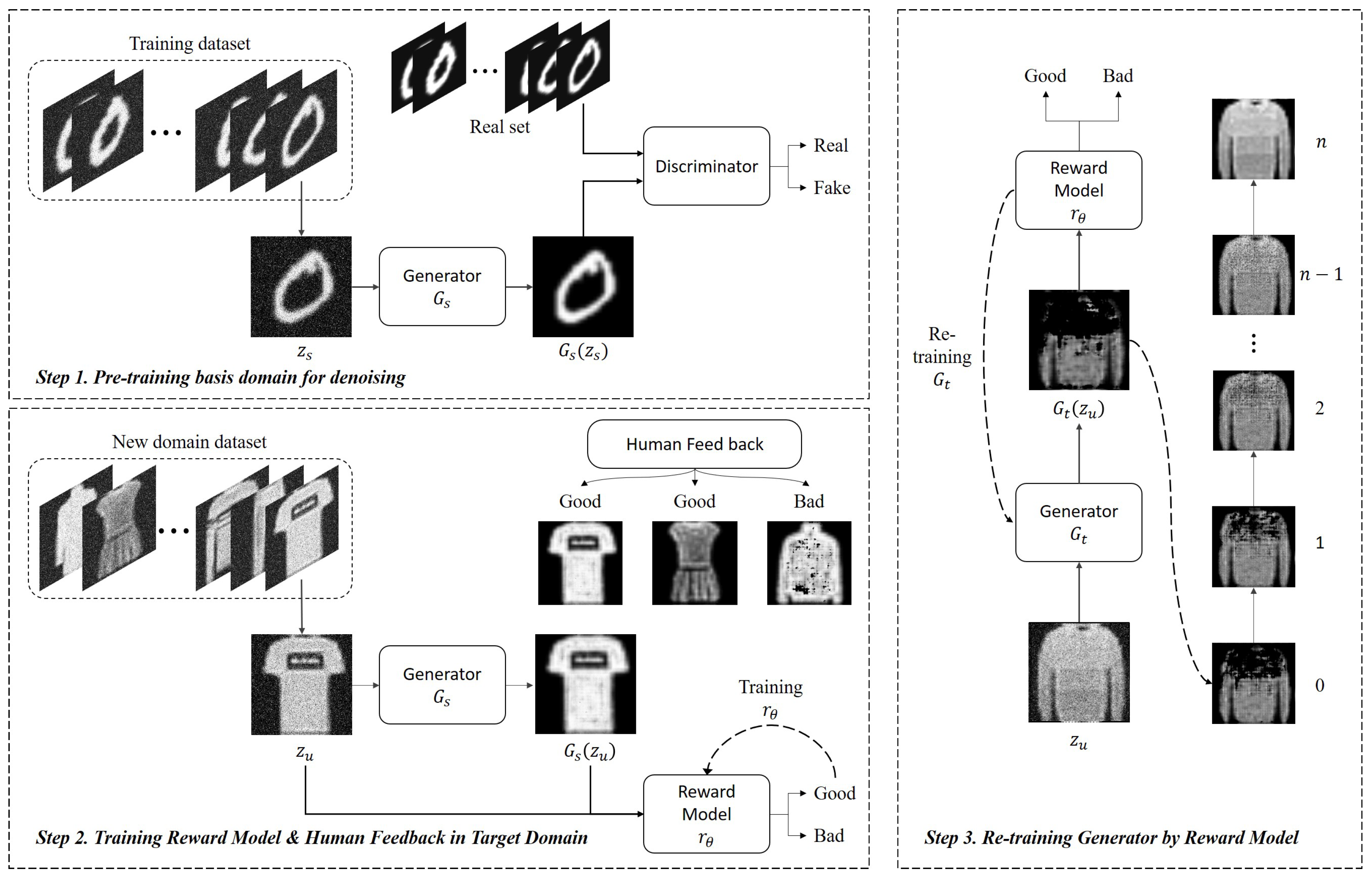
2.1. Pre-Training Basis Domain for Denoising
2.2. Human Feedback and Training Reward Model
2.3. Objective
- Reward Loss : The primary objective of generator is to generate denoised images that are assessed by the reward model as ‘’ (0, indicating clean images). The minimization of aims to train generator to generate clean images. In other words, the reward loss trains to map from the distribution of ‘’ quality images (distribution j) to the distribution of ‘’ quality images (distribution k), .where is a reward model trained on human feedback that has fixed parameters. Thus, only assesses the quality of the generated image from and the input image .
- Consistency Loss : As the model learns from new data, there is a potential issue of the performance of past good results deteriorating due to parameter updates. This is commonly referred to as the problem of catastrophic forgetting. To control this issue, it is necessary to compare the outcomes of the initial parameters with the current results. We present a novel compensatory term, denoted as , which facilitates a comparison between the outputs of the initial frozen generator, , and the target generator . The primary objective of is to minimize the pixel-wise loss between the outcomes generated by and , thereby ensuring that the current model preserves crucial insights acquired from the initial generator throughout the training procedure. By incorporating this approach, we effectively address the issue of neglecting important details and consequently witness a notable enhancement in the overall performance of the current model.where is the step function, and r denotes the result of the reward. is a threshold value ranging from 0 to 1.
- Regularization Loss : We employ a regularization loss term to address the issues of over-fitting and mode collapse. In existing methods, the difference in cosine similarity of feature vectors in the latent space has been compared [21,30]. However, in our approach, we intuitively compare the outputs of the model from the past and the current training stages to suppress excessive variations caused by the model’s learning. calculates the pixel-wise loss between the results of the current generator and the () generator . The generator copies weights from every N steps and then freezes them.
3. Experiments
3.1. Data Sets
3.2. Training Setting
- Pre-training for denoising: “pix2pix” [26] is employed as the baseline model in this experiment. The main objective of most GANs is to establish a mapping . “pix2pix” demonstrated the training approach for pixel-wise mapping between input and output images. Consequently, the generator of “pix2pix" can effectively learn the transformation from the noise space Z to the clean space X. In this experiment, we trained a denoising model, denoted as , using the MNIST data set. was specifically trained using a set of 1000 image pairs consisting of clean digits and their corresponding noisy versions. The clean images used in the training process were specifically selected to represent the digit ‘0’. For optimization, we employed the Adam solver [34] with a batch size of 10, a learning rate of 0.0002, and momentum parameters and . The denoising model was trained for 200 epochs.
- Inference and human feedback: In this paper, our proposed method demonstrates the adaptability of a pre-trained model to a target domain through human feedback. To gather human feedback, the pre-trained generate model is used to infer results in the target domain, which are then manually assessed by human evaluators. In our experiments, we employ Fashion-MNIST as the target domain data set, and we collect human feedback for the 10,000 test images in this data set.
- Training for reward model by human feedback: The reward model, denoted as , is utilized in the auxiliary loss term. The architecture of the reward model is designed to be the same as the discriminator of the “pix2pix" model. The hyperparameters used for training remain consistent with the pre-training setting.
- Adaptive training by human feedback: Note that the adaptive training process implements Equation (10), utilizing the same set of hyperparameters as mentioned above. It is important to note that has trainable parameters, whereas and are untrainable parameters. The constant in Equation (8) is set to 0.2, and the constant in Equation (10) is set to 0.9. In the ablation study, we examine the influence of and as is varied.
3.3. Evaluation
3.4. Results of Domain Adaptive Denoising by Human Feedback
- Comparison of evaluation metrics: In this section, we examine the results of domain adaptive denoising. Our intuition is that, even when presented with unseen data from a target domain, if we provide human feedback to a supervised learning model, the model can adapt to the data effectively. Note that our human feedback is not ground-truth for a denoised image; it shows human preference, consisting of ‘’ and ‘.’ In Table 1, ‘ vs. x’ represents the denoising results of the model before adaptive learning using human feedback. ‘ vs. x’ shows the denoising outcomes of the adapted model based on human feedback. The results obtained from the MNIST data set indicate the performance in the pre-trained domain, while the results from the Fashion-MNIST data set reflect the performance on unseen data. Therefore, we can observe the adaptation progress between the initial model and the updated model . In our experiments, both and demonstrated a significant improvement in PSNR measured on the Fashion-MNIST test set, with an overall increase of 94% over the entire 10K data set. The statistical analysis of the PSNR improvement revealed a mean increase of 1.61 ± 2.78 dB (MAX: 18.21, MIN: 0.0001). Figure 4a shows the images with the most significant increase in PSNR, along with the corresponding metrics between each generator output image and the ground truth image. In addition, for the remaining 6% of cases, there was a decrease in PSNR values, with the statistical analysis showing a mean decrease of 0.12 ± 0.18 dB (MAX: 2.75, MIN: 0.0001) (See Figure 4b). Figure 5 shows the boxplot of PSNR for each generator and on the experimental data set. The images from the same data set exhibit higher PSNR values, indicating improved image quality after adaptation. Particularly noteworthy is that after adaptation, the PSNR and SSIM values of the MNIST test set (10K) from the generator, corresponding to the source domain, show little to no variation or even slight improvement (see Figure 5a). This demonstrates the prevention of the catastrophic forgetting issue for the source domain even after adaptation to the target domain. Furthermore, we apply the model tuned on the Fashion-MNIST test set with the reward model to the Fashion-MNIST training set (60k). This demonstrates that when the reward model is trained in a new domain, it can effectively work without requiring additional training.
- Visual evaluation: Figure 4 illustrates the improvement in denoising and restoration, particularly in addressing image collapse. Notably, trained on the ‘0’ digits of MNIST, exhibits instances where the results suffer from image collapse in several images, indicating a lack of adaptation. However, our approach effectively enhances the image quality by leveraging human feedback, as demonstrated by the results obtained with .
3.5. Ablation Study
- Effect of term: The term compares the image quality between and and is the loss function between images that are well evaluated by human feedback based on the reward function. We examine the effect of the loss on the quality of the output. Typically, the constant alpha of is fixed at 0.9. To evaluate the effect of excluding the term, we vary the alpha value to 0, resulting in the loss equation becoming . Performing the adaptation without an term exhibits low quantitative performance, as demonstrated in the second row of Table 1. Additionally, Figure 6d,e depict the anomaly texture created in the image for reference.
- Effect of term: represents the loss between the ()th and (n)th iterations of G( and ). In terms of quantitative evaluation, it demonstrates comparable performance (Table 1, first and third row). However, in qualitative assessment, it becomes evident that there are limitations in generating the desired image to a satisfactory degree. (See Figure 6d–f). We also examine the effect of loss on the output quality. The role of is to restrict significant parameter changes from the previous model. Given that the function of is to restrict parameter updates between the previous and current models, it becomes apparent that there are limitations in generating the desired image to a satisfactory extent in qualitative evaluation, leading to potential issues such as collapse.
- Effect of term: represents the cross-entropy loss used to distinguish between ‘’ and ‘’ cases. In the experiments where and are ablated, the adaptation relies solely on , resulting in parameter updates exclusively driven by human feedback. Consequently, in the absence of pixel-wise losses, such as and , it is evident that image details and shapes are not preserved, as illustrated in Figure 6d–g.
4. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Tran, L.D.; Nguyen, S.M.; Arai, M. GAN-based noise model for denoising real images. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Vo, D.M.; Nguyen, D.M.; Le, T.P.; Lee, S.W. HI-GAN: A hierarchical generative adversarial network for blind denoising of real photographs. Inf. Sci. 2021, 570, 225–240. [Google Scholar] [CrossRef]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. Adv. Neural Inf. Process. Syst. 2017, 30, 465–476. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30, 700–708. [Google Scholar]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef] [PubMed]
- Volpi, R.; Morerio, P.; Savarese, S.; Murino, V. Adversarial feature augmentation for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5495–5504. [Google Scholar]
- Wang, Y.; Wu, C.; Herranz, L.; Van de Weijer, J.; Gonzalez-Garcia, A.; Raducanu, B. Transferring gans: Generating images from limited data. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 218–234. [Google Scholar]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4893–4902. [Google Scholar]
- Alanov, A.; Titov, V.; Vetrov, D.P. Hyperdomainnet: Universal domain adaptation for generative adversarial networks. Adv. Neural Inf. Process. Syst. 2022, 35, 29414–29426. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Lin, K.; Li, T.H.; Liu, S.; Li, G. Real photographs denoising with noise domain adaptation and attentive generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chen, L.; Chen, H.; Wei, Z.; Jin, X.; Tan, X.; Jin, Y.; Chen, E. Reusing the task-specific classifier as a discriminator: Discriminator-free adversarial domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7181–7190. [Google Scholar]
- Kwon, G.; Ye, J.C. One-shot adaptation of gan in just one clip. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12179–12191. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Volume 30. [Google Scholar]
- Lee, K.; Liu, H.; Ryu, M.; Watkins, O.; Du, Y.; Boutilier, C.; Abbeel, P.; Ghavamzadeh, M.; Gu, S.S. Aligning text-to-image models using human feedback. arXiv 2023, arXiv:2302.12192. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to summarize with human feedback. In Proceedings of the Advances in Neural Information Processing Systems, Online Conference, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Volume 33, pp. 3008–3021. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhang, T.; Cheng, J.; Fu, H.; Gu, Z.; Xiao, Y.; Zhou, K.; Gao, S.; Zheng, R.; Liu, J. Noise adaptation generative adversarial network for medical image analysis. IEEE Trans. Med. Imaging 2019, 39, 1149–1159. [Google Scholar] [CrossRef] [PubMed]
- Park, H.S.; Jeon, K.; Lee, S.H.; Seo, J.K. Unpaired-paired learning for shading correction in cone-beam computed tomography. IEEE Access 2022, 10, 26140–26148. [Google Scholar] [CrossRef]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Zhu, P.; Abdal, R.; Femiani, J.; Wonka, P. Mind the gap: Domain gap control for single shot domain adaptation for generative adversarial networks. arXiv 2021, arXiv:2110.08398. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Fu, B.; Zhao, X.; Song, C.; Li, X.; Wang, X. A salt and pepper noise image denoising method based on the generative classification. Multimed. Tools Appl. 2019, 78, 12043–12053. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MNIST Test (10k) | Fashion-MNIST Test (10k) | Fashion-MNIST Train (60k) | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| Gt(z) vs. x | 29.36 ± 0.92 | 0.95 ± 0.01 | 25.68 ± 3.91 | 0.84 ± 0.11 | 25.75 ± 3.86 | 0.84 ± 0.10 |
| vs. x/wo loss | 24.20 ± 0.65 | 0.66 ± 0.08 | 25.00 ± 2.44 | 0.68 ± 0.10 | 25.07 ± 2.37 | 0.69 ± 0.10 |
| vs. x/wo loss | 29.10 ± 0.98 | 0.95 ± 0.01 | 25.30 ± 4.35 | 0.83 ± 0.12 | 25.41 ± 4.25 | 0.83 ± 0.12 |
| vs. x/only loss | 20.66 ± 0.69 | 0.82 ± 0.03 | 17.97 ± 2.15 | 0.58 ± 0.13 | 18.03 ± 2.14 | 0.58 ± 0.12 |
| vs. x | 29.26 ± 1.04 | 0.94 ± 0.01 | 24.18 ± 5.57 | 0.80 ± 0.16 | 24.27 ± 5.52 | 0.80 ± 0.16 |
| Baseline source (z vs. x) | 14.72 ± 0.06 | 0.12 ± 0.01 | 13.23 ± 0.13 | 0.07 ± 0.13 | 13.23 ± 0.13 | 0.07 ± 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, H.-C.; Ngo, D.; Kang, S.H. Domain Adaptation Based on Human Feedback for Enhancing Image Denoising in Generative Models. Mathematics 2025, 13, 598. https://doi.org/10.3390/math13040598
Park H-C, Ngo D, Kang SH. Domain Adaptation Based on Human Feedback for Enhancing Image Denoising in Generative Models. Mathematics. 2025; 13(4):598. https://doi.org/10.3390/math13040598
Chicago/Turabian StylePark, Hyun-Cheol, Dat Ngo, and Sung Ho Kang. 2025. "Domain Adaptation Based on Human Feedback for Enhancing Image Denoising in Generative Models" Mathematics 13, no. 4: 598. https://doi.org/10.3390/math13040598
APA StylePark, H.-C., Ngo, D., & Kang, S. H. (2025). Domain Adaptation Based on Human Feedback for Enhancing Image Denoising in Generative Models. Mathematics, 13(4), 598. https://doi.org/10.3390/math13040598