1. Introduction
In today’s dynamic global marketplace, optimizing production, administrative, and logistics processes has become essential for organizations seeking not only survival but also growth and prosperity. Competitiveness is continually intensifying, becoming a crucial factor in the viability of any company [
1]. In the realm of production and operations management, effectively scheduling tasks on machines is a critical challenge that directly impacts organizational productivity and competitiveness. A particularly complex issue within this domain is single-machine scheduling with a common due date, where both early and late completions incur significant penalties [
2]. This challenge is known as the single-machine weighted earliness/tardiness (SMWET) problem. It is a fundamental area of study in production scheduling, which provides a framework for optimizing job sequencing, seeking a balance between delivery times and associated costs. Its relevance extends across various industries (manufacturing, logistics, and services), and advancements in optimization algorithms and techniques continue to expand its applications and utility. As modern production environments become increasingly complex, research in this field remains crucial for enhancing efficiency and competitiveness. The use of SMWET to optimize job sequencing on a production line offers several advantages and disadvantages, which depend on the specific characteristics of the environment and the desired objectives.
The main advantages include the following:
Simplicity: Scheduling on a single machine is simpler to model and solve compared to multi-machine environments, making implementation and analysis easier. The model incorporates job durations, enabling more accurate planning.
Flexibility: It allows for the adjustment of penalty weights to prioritize certain tasks, adapting to the specific needs of production or service.
Resource optimization: Proper scheduling can maximize machine capacity usage, minimizing idle time and improving operational efficiency.
Improved customer satisfaction: By minimizing penalties for tardiness and earliness, customer relationships can be enhanced by better meeting delivery deadlines.
Suitable for a critical machine: Optimizes the work sequence in environments where a machine is a key resource.
The main disadvantages include the following:
Computational complexity: It is NP-hard, making it difficult to find optimal solutions for large job sets.
Does not consider multiple machines: It is limited to a single-machine environment, unsuitable for systems with multiple stations.
Effect of penalties: Penalties for early/late completions must be well-defined for the model to function correctly.
Complexity in implementation: Although the problem is conceptually simple, implementing a system that considers all constraints and optimizes performance can be complicated.
Limitation in flexibility: It may not adapt well to dynamic production environments or those with frequent changes.
Scheduling problems are classic discrete combinatorial optimization problems. Most of these belong to the well-known class of just-in-time scheduling, which aims to optimize the supply chain by delivering materials and components precisely when required, minimizing inventory and maximizing operational efficiency [
3]. Common due date assignment and just-in-time scheduling have been extensively researched in recent years [
4,
5].
Due dates are key parameters in scheduling problems. When all jobs share a single due date, it is referred to as a common due date scheduling problem. These dates are determined within the context of the business relationship, considering both client objectives and company goals to ensure customer satisfaction, while minimizing production costs [
6]. In a common due date scheduling problem, some jobs may be completed ahead of schedule, while others may be delayed. Early job completion necessitates storage, incurring additional expenses. Late job delivery results in contractual penalties, profit loss, and damage to the manufacturer’s reputation. Both scenarios are unfavorable due to their associated costs and negative impact on the company [
7].
Generally, problems involving common due dates can be categorized into two types: restrictive and non-restrictive. Specifically, if the optimal common due date is either a decision variable or does not impact the optimal task sequence, the problem is classified as non-restrictive. Conversely, if the common due date is given and can influence the optimal task sequence, the problem is considered restrictive. In this case, the search for an optimal task schedule must be conducted with respect to the due date [
8].
The approaches used in this area are generally categorized into mathematical methods and metaheuristic algorithms [
9]. While mathematical methods are effective in situations where gradients can be calculated, they often encounter significant challenges when solving global optimization problems [
10]. This limitation has motivated the development of nature-inspired algorithms [
11], which have demonstrated remarkable success in addressing optimization complexities on benchmark datasets, such as those published at the IEEE congress on evolutionary computation (CEC).
Widely used across various domains, metaheuristic algorithms have been studied for several decades. These optimization techniques employ nature-inspired simulations and provide high-quality approximate solutions to complex problems that are difficult to solve [
12]. To address scheduling problems, there are primarily two types of methods: exact algorithms and approximate algorithms. Exact algorithms mainly encompass mathematical programming, dynamic programming, and branch-and-bound methods. Approximate algorithms primarily include heuristic and intelligent algorithms [
13]. Specifically, this study proposes the use of the MBO algorithm, categorized as an approximate metaheuristic algorithm. MBO has emerged as a promising approach for tackling complex problems. Its effectiveness lies in its ability to discover optimal solutions by drawing inspiration from the natural mating process of queen honey bees and drones [
14]. There are several algorithms derived from MBO, such as fast marriage in honey-bee optimization (FMHBO), honey-bee mating optimization (HBMO), honey-bee optimization (HBO) and next-generation hybrid algorithms such as hybrid honey-bee simulated annealing (HBSA) [
15], the honey-bee mating-based firefly algorithm (HBMFA) [
16], and others focused on nectar collection, such as the hierarchical learning-based artificial bee colony (HLABC) [
17], the artificial bee colony + particle swarm optimization (ABCPSO) [
18], the one-dimensional binary artificial bee colony (oBABC) [
19], and the artificial bee colony based on a two-dimensional queue structure (KLABC) [
20], among others.
MBO simulates the mating process of honey bees, where queen bees select the most suitable drones to ensure offspring quality. It employs selection and adaptation principles that can be highly effective in optimizing task scheduling [
21]. Benatchba et al. [
22] propose the use of an artificial bee colony-inspired optimization algorithm to tackle a complex data mining problem framed as a Max-SAT problem. The algorithm proved effective in generating high-quality solutions within reasonable computational limits, outperforming several conventional optimization techniques. Palominos et al. [
23] propose an algorithm inspired by honey bee behavior, which incorporates chaotic elements to enhance solution exploration. Empirical results validate the algorithm’s superiority, yielding higher-quality and more efficient solutions than conventional approaches across multiple traveling salesman problem instances. Alotaibi [
24] proposes a hybrid algorithm that combines the behavior of artificial bee colonies with that of spiders to optimize resource allocation in the cloud. This problem has grown increasingly complex due to the escalating demands of cloud services. The findings reveal that, in terms of cost, the proposed method outperforms various bio-inspired optimization algorithms.
Recently, Yogeshwar and Kamalakkannan [
25] proposed a hybrid MBO-rock hyraxes swarm optimization algorithm for efficient key generation in data sanitization and restoration. This approach significantly improved privacy and security in IoT-based systems by effectively concealing sensitive data during transmission. The model achieved 97% effectiveness on the analyzed dataset, outperforming other compared methods. Xiao et al. [
26] introduced an MBO approach for efficient area coverage using swarms of robots, especially in challenging environments. Inspired by bee and ant colonies, the methodology incorporates specific behavioral models for each robot type. The algorithm demonstrated adaptability to dynamic conditions, including unexpected threats, across various experimental scenarios.
The scheduling problem to be solved involves sequencing tasks on a machine to minimize the total penalties associated with early and late deliveries relative to a deadline. The purpose of this study is to develop a schedule that minimizes the objective function value, which represents the cost associated with these penalties. This study adopts the methodology of Abbass [
27,
28,
29], adapted for discrete problems, introducing a novel use of the MBO algorithm that has not been previously explored in this context. The main objective is to evaluate the efficiency of this metaheuristic method in solving NP-hard combinatorial optimization problems, specifically in scheduling.
Related Literature
The general problem of minimizing total penalties for early and late tasks with a common due date has been investigated by different researchers, including Lv et al. [
30], who studied a single-machine scheduling problem with proportional job deterioration, focusing on minimizing the total weighted completion time while considering job release times. Their key contributions include identifying dominance properties and deriving both upper and lower bounds for the problem. Furthermore, they propose a branch-and-bound algorithm and several metaheuristic algorithms, such as tabu search, simulated annealing, and the NEH heuristic. Experimental results show that the branch-and-bound algorithm can solve instances with up to 40 jobs within reasonable timeframes. Additionally, the NEH and simulated annealing algorithms were found to be more accurate than tabu search, providing a comparative analysis of the efficiency and accuracy of the different proposed methods. In addition, Shabtay et al. [
6] investigated the single-machine scheduling problem with assignable due dates or windows. Their findings suggest that if the due window’s location is unrestricted, the problem can be solved efficiently. Moreover, when the due window’s length is unlimited, the computational time is reduced further. Nevertheless, imposing bounds on either parameter dramatically increases problem complexity, necessitating a pseudopolynomial-time algorithm to address this NP-hard challenge.
Zhang and Tang [
31] propose a method for solving the single-machine scheduling problem with flexible delivery dates. They introduced a dynamic scheduling algorithm to address two specific problems. The objective is to minimize a function that considers early work, late work, and flexible delivery dates. For the first issue, they determine the range of delivery dates based on cost coefficients and develop an algorithm that guarantees an optimal solution. For the second issue, they address the allocation of time windows and propose another algorithm that defines the range of delivery dates. Finally, they provide a numerical example to illustrate the feasibility of their proposed algorithms. Li and Chen [
32] investigate the optimization of assigning a common due date to multiple tasks. Their primary contribution lies in formulating and solving a scheduling problem that minimizes penalties for weighted early and late completions. The findings suggest that, under specific conditions, this problem can be resolved using a polynomial-time algorithm.
Atsmony and Mosheiov [
33] propose a pseudo-polynomial dynamic programming algorithm to address the NP-hard problem of common deadline assignment on a machine. The goal is to minimize the maximum lead/lag costs while maintaining a specified bound on the total job rejection cost. The results demonstrate an efficient implementation that reduces computational effort, allowing problems with up to 200 jobs to be solved in reasonable times. Additionally, they introduce an intuitive heuristic that, after numerical testing, shows small error margins compared to the optimal solution. Qian et al. [
34] developed a single-machine scheduling model incorporating important factors like the learning effect, the lead time, and convex resource allocation. Their findings reveal that three distinct objective functions can be formulated and solved, each targeting the minimization of different scheduling costs, including the lead time, delays, and resource expenses. Furthermore, they demonstrate that all the relevant problems can be solved in polynomial time, indicating that efficient algorithms have been developed to address them.
Arik [
2] developed a polynomial-time algorithm to address single-machine scheduling with distinct weights for job preemption and tardiness. The objective is to minimize the total cost resulting from the sum of the weighted anticipation and tardiness, along with the assigned common due date. Leveraging the V-shaped property and machine start time, the proposed heuristic consistently delivers superior solutions within reasonable computational bounds, even as problem complexity increases. Tan and Fu [
3] address a single-machine scheduling problem aiming to minimize the total costs incurred by job preemption, tardiness, and idle time. They propose a hybrid approach that integrates a custom dynamic programming algorithm, designed to handle the nonconvex idle cost function, with a genetic algorithm (GA) enhanced by restarts and early discarding for sequencing. The results underscore the method’s superior performance and adaptability compared to existing solutions.
Furthermore, Lee and Kim [
35] tackled the single-machine SMWET problem using a parallel GA, followed by James [
36], who employed a tabu search (TS) algorithm. Notably, neither study incorporated the third property identified by Biskup and Feldmann [
37], which states that an optimal sequence of tasks does not necessarily start at time zero. Biskup and Feldmann generated a test problem set for the SMWET problem, solving them with two specific heuristics while considering the three properties outlined in
Section 2. The resulting solution values were established as upper bounds for the problem set, providing a benchmark for subsequent research.
Later, Feldmann and Biskup [
8] revisited the SMWET problem, employing five distinct metaheuristic approaches: (i) the evolutionary strategy, (ii) simulated annealing, (iii) threshold-accepting algorithms, (iv) the evolutionary strategy with a destabilizing phase, and (v) threshold-accepting algorithms with stabilized search. They benchmarked these metaheuristics against a subset of test problems from their prior work [
37]. Subsequently, [
38,
39,
40,
41,
42,
43] also explored the SMWET problem, utilizing the Biskup and Feldmann [
37] test suite for a performance comparison.
A literature review reveals a growing diversity of scheduling approaches for single machines, leading to substantial advancements in efficiency optimization and cost reduction. These advancements primarily focus on the lead time (earliness/tardiness) and the assignment of common delivery dates. The reviewed studies address complex problems such as minimizing weighted completion times, assigning flexible delivery windows, and considering factors like task deterioration and learning.
Notable methodological contributions include branch-and-bound algorithms, pseudo-polynomial dynamic programming, and metaheuristics, which have enabled more efficient solutions to NP-hard problems. However, each approach has its limitations and challenges. While some algorithms achieve optimal solutions in reasonable times for small instances, complexity increases significantly with additional constraints or a larger number of tasks, posing an ongoing challenge.
Moreover, despite significant theoretical progress, scalability and the impact of external factors remain areas requiring further attention. The practical application of these methods in real industrial settings has not yet been fully explored. While valuable contributions have been made, it is crucial to focus on testing these methods in more dynamic and complex environments and to explore hybrid approaches that can address some of the current limitations.
The remainder of this document is organized as follows.
Section 2 defines the SMWET problem.
Section 3 details the MBO metaheuristics.
Section 4 outlines the adaptation of the MBO approach to solve the restrictive SMWET problem.
Section 5 presents the computational experiments and discusses the obtained results, evaluating the MBO metaheuristic’s performance on the studied problem set. Finally,
Section 6 provides conclusions of the study and suggests some future work.
2. Problem Formulation
Punctuality is a fundamental requirement for successful just-in-time implementation. By scheduling tasks with minimal tolerance and defining strict time windows, deviations from the production plan are minimized. This strategy helps reduce in-process inventory, cycle times, and material management costs. In this context, the objective is to find an optimal sequence of tasks, σ, that minimizes the weighted sum of lead and lag times for all tasks. In the problem formulation, a set of tasks j = {1,2,…, n} is given, available to be processed at time zero. Each task j has a processing time and a common due date d that applies to the entire set of tasks. Suspending tasks is not allowed. A task is considered early if its completion time is less than the common due date and tardy if its processing finishes after the due date. Therefore, if the completion time of task j deviates from the due date, either earlier or later, a penalty will be incurred. The rest of the nomenclature is defined as follows: a penalty for the early completion of job j per unit of time; a penalty for the tardiness of job j per unit of time; the early completion of job j; and the tardiness of job j.
Earliness and tardiness are calculated as = max{0; −} = max{0; d − } and = max{0; } = max{0; − d}, respectively, for each job j, j = {1,2,…, n}. The unit penalties per unit time of job j for being early or tardy are and , respectively.
The objective is to identify a feasible schedule,
S, that minimizes the aggregate earliness and tardiness penalties given a common due date,
d.
The objective function (Equation (1)) refers to the restrictive case, where the common due date is not a decision variable but is given and can influence optimum task scheduling. It is subject to the following conditions:
| − d, j = 1,2,…n |
| , j = 1,2,…n |
| R), j = 1,2,…n − 1; k = j + 1,…n |
| R·, j = 1,2,…n − 1; k = j + 1,…n |
| ≥ 0, j = 1,2,…n |
| {0, 1}, j = 1,2,…n − 1; k = j + 1,…n |
In the field of operations research and task scheduling theory, it is essential to identify and apply properties that facilitate the optimization of schedules for various types of problems. This study describes key properties of the SMWET problem, which enable the construction of optimal solutions by organizing sequences of tasks under specific conditions and efficiency criteria. Several authors have examined three properties of the non-restrictive version of the SMWET problem [
44,
45,
46,
47,
48,
49,
50]. On the other hand, for the problem with a restrictive due date, properties are identified by the methods proposed in [
48,
50,
51], and they can be formulated in a similar way as that proposed by the authors of [
8].
Property 1: In an optimal schedule, there is no idle time between the processing of two consecutive tasks [
50].
Property 2: An optimal schedule exhibits a V-shaped property in the sense that, within the schedule, the advanced tasks are ordered in decreasing order according to the
ratio, and the tardy tasks are sequenced in the increasing order of the
ratio. The possibility of a straddling job existing in the set of tasks, i.e., a job whose processing starts early and ends tardily, remains open [
37].
Property 3: There exists an optimal schedule in which the following holds true: (i) the first job in the set starts processing at time zero or (ii) a job is completed exactly on its due date [
37].
This research addresses the SMWET problem in its restricted form, considering properties 1 and 3 through the application of the MBO metaheuristic using the Abbass procedure [
27,
28,
29]. The objective is to evaluate the effectiveness of this approach for solving NP-hard combinatorial optimization problems. Specifically, the main contribution of this work is the adaptation of the MBO metaheuristic to address the restrictive SMWET problem, demonstrating its suitability for task scheduling. According to the literature review, and as far as we know, there are no existing studies that apply the MBO algorithm to this area.
To evaluate the performance of the proposed MBO metaheuristic approach for the SMWET problem, a set of standard test problems from the literature, as proposed by Biskup and Feldmann [
37] and accessible through the OR-Library [
52], was solved. In this context, new upper bounds were established for a significant portion of the test instances. Specifically, the adapted MBO algorithm achieved solutions that were at least as good as, or better than, those of the test problem set in 67.14% of cases.
3. MBO Metaheuristics
The MBO metaheuristic was introduced by Abbass in his 2001 paper [
27]. Later, the authors of [
28,
29,
53,
54] presented modifications and improvements to the initially proposed algorithm.
The MBO metaheuristic is inspired by the social behavior of mating in bee colonies. It is an evolutionary algorithm designed to solve complex combinatorial problems. MBO employs strategies based on searching for neighboring solutions, placing it in the same category as GAs and ant colony optimization.
Abbass [
27,
28,
29] pioneered the modeling of bee mating for optimization problem-solving. Bee colonies consist of queens, drones, workers, and offspring. The process begins with the queen’s nuptial flight, where she mates with multiple drones. The queen stores the drones’ genetic material in her spermatheca. Each egg is fertilized with a random combination from this stored material, creating the colony’s offspring. Workers tend to the young.
The MBO metaheuristic simulates the mating process of bees as a series of state transitions. Initially, a queen bee’s genotype is randomly generated. Worker bees, acting as local search heuristics, improve this initial solution. Subsequently, the queen embarks on multiple mating flights. Each flight involves the random initialization of the queen’s energy and speed. As she transitions through different states (potential solutions), she has opportunities to mate with randomly generated drones. Successful matings, determined by factors like the queen’s energy and the drone’s fitness, result in the drone’s genetic material being stored in the queen’s spermatheca. After each flight, the queen generates new offspring by combining her genetic material with randomly selected material from the spermatheca. These offspring are refined by worker bees. The fittest offspring replaces the queen, and the process iterates.
The MBO algorithm comprises three core processes: (i) the queen’s mating flight for parent selection, (ii) the creation of offspring through genetic recombination, and (iii) the refinement of offspring by worker bees using local search heuristics [
53]. Each process is crucial for the algorithm’s performance in finding optimal solutions.
The MBO algorithm in [
27] employs a pure exploration strategy, accepting as many queen paths as possible. Each queen is initially assigned random energy
and speed
values between 0.5 and 1.0 to facilitate an average of 7–17 matings per flight [
27,
28,
29]. During the flight, the queen’s energy and speed diminish according to Equations (2) and (3).
where parameters
and α correspond to the reduction factors of the queen’s energy and speed at instant
t, respectively.
The queen’s energy and speed parameters mimic natural bee behavior. Energy correlates with flight duration, limiting the queen’s search for drones in the solution space. Speed influences mating success, with higher speeds increasing the likelihood of successful mating, especially at the flight’s onset [
27,
28,
29].
The success of a queen’s mating flight depends on the proximity of drones. Drones closer to the queen have a higher mating probability, as defined by Equation (4). These drones are preferentially selected for genetic recombination.
where
l(
q,
d) = dist(
f(
q),
f(
d)) is the distance between the evaluations of the fitness functions of the queen and of the drone, and
s(
t) is the queen’s speed at instant
t.
In Abbass’s MBO algorithm [
27], queen bees randomly select drones for mating. A drone is accepted as a parent if its mating probability exceeds a random value between 0 and 1. Half of the drone’s genetic material is then incorporated into the queen’s spermatheca, signifying a successful mating.
A mating flight concludes when the queen’s energy depletes, i.e., E(t) = 0, or the spermatheca is full. Upon returning to the hive, the queen initiates reproduction by randomly selecting a drone’s genetic material from her spermatheca for crossover. The resulting offspring undergo mutation by worker bees, finalizing the brood-raising process.
The fittest brood replaces the weakest queen. The remaining broods are discarded. The process iterates until the termination criteria are met.
4. MBO Algorithm for Solving the SMWET Problem
There are two commonly used methods to represent solutions to the SMWET problem [
43]. One approach utilizes permutation chains to depict the physical task sequences. Consequently, an SMWET problem with
n tasks yields a solution space comprising
n permutations. Alternatively, solutions can be sought within a smaller solution space exclusively containing those that inherently satisfy property 2 (the V-shaped property).
This work employs permutation chains for solution representation due to their adaptability and guaranteed feasibility. Accordingly, each genotype (queen, drone, and brood) is characterized by a permutation sequence of equal length (n) representing the task order. Furthermore, a starting time is assigned to each genotype’s initial task, addressing property 3 of the SMWET problem, which stipulates that the first processed task may not necessarily commence at time zero.
4.1. Parameters Used for the MBO Algorithm
In the proposed MBO algorithm, the use of fixed parameters was considered for solving all the instances contained in the set of test problems proposed by the authors of [
37], with the purpose of evaluating the effectiveness of the algorithm in the search for good solutions of the problem, and to validate a general solving algorithm in which it would not be necessary to adjust the parameters to solve a particular problem.
The general parameters employed in the proposed algorithm are as follows: (i) The number of queen bees (
Q)—this parameter represents the number of queen bees initiating mating flights. The algorithm utilized four queens, each proposing a distinct solution at every iteration. (ii) The number of drones (
D)—indicating the maximum number of drones a queen can mate with per flight,
D was experimentally fixed at 10. (iii) The spermatheca capacity (
M)—this parameter defines the queen’s genetic material storage capacity post-flight. Based on Abbass’s recommendations [
27,
28,
29] suggesting a range of 7 to 17,
M was set to 10.
Table 1 shows the values of the specific parameters used in the MBO algorithm proposed in this study.
Equation (5) was used to determine the value of parameter 5.
where
=
E(
t = 0) is the initial energy of the queen bee, and
M is the size of the spermatheca. The specification of parameter 5 ensures that each queen mates with the amount of drone-derived material stored in her spermatheca.
The values
= 0.9 and
= 0.9 were chosen for the initial velocity and the queen bee’s energy, respectively, in accordance with the studies [
27,
28,
29,
53,
54].
4.1.1. Obtaining an Initial Population
This paper examines four queen bees, two initialized with random solutions and two derived from the LPT and SPT scheduling rules. Randomizing half the queen bees fosters greater solution diversity, following the guidelines of [
27,
28,
29,
53,
54,
55]. Each generated queen bee is assigned initial energy and speed parameters. To ensure quality solutions, the initial queen bees are refined using worker bees, which are local search algorithms or simple heuristics.
The initial drone population is also generated randomly, adhering to the original MBO algorithm framework by the authors of [
27,
28,
29].
4.1.2. Mutation of Drones
As in [
53], each drone should mutate at the time of coupling with the queen. In the mutation process, each drone possesses a genotype, and an operation called a genotype marker (GM). This marker randomly selects half of the drone’s genes for mutation, ensuring that only these genes participate in the creation of brood due to the haploid nature of drones [
27,
28,
29,
53,
54]. The mutation process involves applying the GM to the drone genotype and then randomly rearranging the marked genes, which will contribute to the offspring.
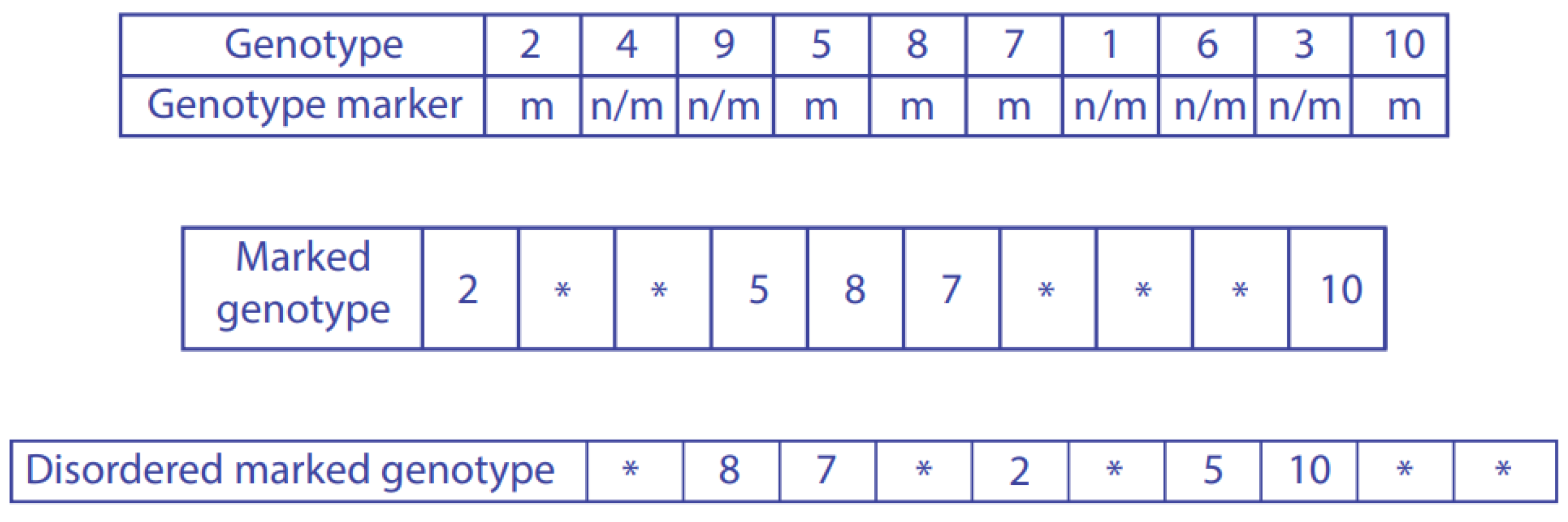
Figure 1 visually depicts the drone genotype, the GM operator, and the mutation process. The symbol m indicates a marked gene, n/m an unmarked gene, and an asterisk * a non-existent gene.
In this way, at each transition, starting with the original drone genotype denoted by , a mutated genotype is obtained. If the fitness of the mutated drone is higher than that of the original drone (i.e., f() < f()), then the mutated drone replaces the original one = .
4.1.3. Selection of the Drone’s Genetic Material
In the implementation of the MBO algorithm for the SMWET problem, it was defined, following [
27,
28,
29,
53,
54], that the queen probabilistically adds drone material to her spermatheca according to the annealing function presented in Equation (4). A random number between 0 and 1 is generated for each queen and then compared to the highest mating probability of any drone with respect to that queen. If the mating probability is greater than the generated number, the queen bee accepts the drone as a parent, meaning that half of the drone’s genetic material (given its haploid donor status) is added to the queen’s spermatheca, resulting in a successful mating.
Furthermore, in this work, the substitution of a queen by a drone was considered if the fitness of any drone was superior to that of a queen.
4.1.4. Crossing of Genetic Material and Offspring Production
During the mating process, the queen bee stores the genetic material of a drone in her spermatheca. This genetic material is then randomly selected to fertilize eggs, resulting in the creation of broods.
A genetic crossover operator is employed to facilitate the exchange of genetic material between the queen and the drone. This operator selects two individuals, referred to as Parent 1 and Parent 2, and performs a genetic crossover between their genotypes.
The crossover process involves combining the genetic information from both parents to generate a new offspring. The head of the offspring’s genotype sequence is inherited from Parent 2, while the tail is inherited from Parent 1.
The genetic crossover operator can be formally defined by the following three steps: (i) a segment of the cord, which carries the genotype of Parent 1, is randomly selected. This segment is defined by its starting position, i, and ending position, j, where 1 < i < j < n. The genes within this segment (i.e., i, j) are stored as a list. (ii) Genes from Parent 2 are selected, ensuring they are not present in the previously chosen segment of Parent 1. These selected genes are stored in a list of length less than n, where n is the total number of tasks. (iii) The genes from Parent 2 stored in the previously generated list, up to position i (the starting point of the Parent 1 segment), are combined with the Parent 1 segment and the remaining genes from Parent 2, thus creating a new offspring.
The queen’s and drone’s genotypes served as Parent 1 and Parent 2. The crossover operator was applied to create broods with (i) queen-dominant genotypes—the majority of genetic material at the beginning of the sequence was from the queen (with the drone’s genotype as Parent 1 and the queen’s as Parent 2)—and (ii) drone-dominant genotypes—the majority of genetic material at the beginning of the sequence was from the drone (with the queen’s genotype as Parent 1 and the drone’s as Parent 2).
Experiments were conducted using the crossover operator with the drone as Parent 1 in 70% of cases and the queen as Parent 1 in 30%. This approach was based on the general superiority of the queen’s genotype (due to prior optimization) and its potential alignment with the solution structure.
4.2. Improvement of Offspring Using Workers
To address the SMWET scheduling problem, the MBO algorithm was used, employing three heuristics as workers. These heuristics were used to enhance the initial queen bee population and the offspring generated through the genetic recombination of the drone and queen. The specific heuristics utilized were hill climbing, simulated annealing, and a local search operator.
4.2.1. Hill-Climbing Heuristic
Beginning with an initial state or solution, a local search algorithm explores the search space by moving to neighboring states, which enhances the value of a specified objective function [
56]. At each iteration, the algorithm modifies one or more elements of the current solution, represented by a vector
x, which can contain continuous and/or discrete data. It then assesses how these changes impact the value of the objective function
f(
x) [
57]. This optimization process continues until no neighboring states yield a better solution, leading to a local maximum or minimum, or until a predetermined termination criterion is fulfilled. Algorithm 1 shows the pseudo-code of the hill-climbing heuristic [
58].
| Algorithm 1. Pseudo code for hill-climbing algorithm | |
| i = initial solution | |
| While f(s) ≤ f(i) for all s Neighbors (i) do | |
| | Generates an s Neighbors (i); |
| | If fitness (s) > fitness (i) then |
| | Replace s with the i; |
| | End If |
| End While | |
| | | | |
This search process was selected as a worker based on the suggestion in [
27,
28,
29] to use local search algorithms as workers. The choice of this heuristic and its representation was influenced by the study of M’Hallah [
59]. This technique, along with simulated annealing, was chosen due to its ease of application to various combinatorial optimization problems. Despite the risk of converging to local optima, it can provide strong initial solutions.
The hill-climbing heuristic consists of the following three steps: (i) Selecting a starting point or current state , which corresponds to the current solution. (ii) Perturbing the current solution (→) and accepting any transition that improves the solution (either upward or downward, depending on the problem’s objective). (iii) Choosing the best successor in the neighborhood of , where = best {}; if there are multiple equally good successors, one is chosen at random.
Transitions are generated by creating neighboring solutions using a task-swapping operator. This operator randomly exchanges tasks within the solution delivered by the brood. If the resulting solution is better than the current one, it is accepted.
4.2.2. Simulated Annealing Heuristic
Stochastic search method inspired by the annealing process in metallurgy, suggested by the authors of [
60], and proposed by the authors of [
61]. While simulated annealing does not guarantee finding an optimal solution, it can effectively escape local minima by exploring the search space through random movements, particularly in complex environments [
62]. This enables suboptimal solutions to improve by employing a decreasing parameter known as “temperature” [
63]. Furthermore, simulated annealing is simple to implement and requires minimal parameter tuning, making it well-suited for a wide range of optimization problems, both combinatorial and continuous ones.
This method was chosen as the second worker heuristic due to its versatility and applicability to combinatorial optimization problems. Its probabilistic acceptance of solutions, even if they are not always superior, allows for the exploration of the solution space and avoids the local optima trap, a significant disadvantage of hill climbing. To adapt simulated annealing to our problem, we followed a similar approach as described in [
8]. The simulated annealing metaheuristic used in this study, both to refine brood solutions and improve initial queens, is outlined below.
Starting from an arbitrary solution (initial)
, a solution
is chosen randomly in the neighborhood of
,. Let
=
f(
) −
f(
) be the difference between the values of the objective function of
and
. If the value of the objective function of the new solution
is less than or equal to the previous
≤ 0, then the new solution,
, becomes the present one and the search process continues from
. On the other hand, if the objective value of the neighboring solution
is greater than the objective value of the previous
> 0 solution, then
is accepted as the present solution with probability
, where
represents the present value of the control parameter of the simulated annealing algorithm, which is the temperature. The algorithm begins with a relatively high temperature value, so at the beginning, most of the lower neighboring solutions are accepted. During the execution of the simulated annealing algorithm,
remains constant over several iterations and then drops, so the probability of accepting neighboring solutions is less in the terminal stage of the search process. The present work considered an initial temperature
= 0.9, which remains constant over several iterations equal to
= 8. A linear type of temperature reduction function and a temperature reduction factor (or cooling factor)
c = 0.8 were also used, so that the temperature after each transition decreased according to the rule
=
c . The simulated annealing algorithm (Algorithm 2) can be outlined as follows.
| Algorithm 2. Pseudo-code for simulated annealing algorithm |
| Step 0: k: = 1, : = , : = , : = |
| Step 1: Select at random N () |
| | If ≤ 0 then: : = and if f() < f() then : = |
| | else: If exp(−/) > random [0, 1) then : = |
| Step 2: After repetitions of Step 1: : = () and k: = k + 1 | |
| Step 3: If stop criterion is not true go to Step 1 |
| | | | |
Like hill climbing, transitions are generated by creating neighboring solutions using a swap operator. This operator randomly exchanges tasks within the solution provided by the brood. Solutions are accepted if they improve the current solution or meet the simulated annealing acceptance criteria, based on a predetermined number of iterations. The best solution found throughout the process is retained and presented as the final output.
4.2.3. Local Search Operator
In addition to the two heuristic workers, it was decided to use a swap operator that works in parallel to these workers. A local search operator makes minimal changes to the current solution with the goal of improving its quality [
64]. This operator is based on the findings of Pan et al. [
39], who also investigated the SMWET problem. To further enhance solution quality, these authors applied an iterative local search to the global best solution
. This search utilizes a simple binary exchange neighborhood. The local search procedure involves swapping two randomly selected tasks, subject to the condition that the first of these tasks is early with respect to the due date and the second is tardy with respect to the due date. This task-swapping operator was also introduced by the authors of [
8]. The iterative local search in Algorithm 3 was based on the simple binary swap neighborhood.
| Algorithm 3. Pseudo-code for Iterated local search algorithm |
| s0 = Gt= |
| s = Local Search () |
| Do{ |
| | = Perturbation (s) |
| | = LocalSearch () |
| | s = AcceptanceCriterion (s, s2) |
| }While (Not Termination) |
| If f(s) < f() then = s |
In this work, both the heuristic and task-swapping operators are initially used to refine the initial queens and later used to enhance the offspring produced through the genetic recombination of the queen and drone. The selection of the candidate heuristic is performed probabilistically in three steps: (i) Each heuristic candidate is assigned a selection probability. The heuristic with the highest probability after each iteration is chosen as the worker. Initially, all heuristics have a probability of 1/w, where w the total number of workers. (ii) The average improvement
achieved by each heuristic h is calculated and stored. This represents the average improvement of the brood solution. (iii) The selection probability is then updated to reflect the impact of the most effective heuristic. The new probability,
, is calculated as the previous probability
p plus the ratio of the average improvement contributed by heuristic
h to the sum of all average improvements and the total number of workers
w. This calculation ensures that the new probability remains between 0 and 1. Formally, the new choice probability is given by Equation (6).
The choice rule defined in Equation (6) is applied after each iteration of the heuristics, selecting the one with the highest choice probability. Once selected, each solution improvement method is executed a specific number of times: 200 iterations for simulated annealing, 50 iterations for hill climbing, and 40 iterations for local search. These iteration values were determined experimentally.
4.3. Population Updating
In each flight, after the broods obtained from crossing operations have been improved through the application of worker heuristics, the fitness of the newly improved broods is evaluated. If the fitness function of an improved brood is better than the fitness function of some queen, f() < f(), then the queen population is updated by removing the least fit queen and replacing her with the brood that has the best fitness, = .
The evaluation function determines whether the newly generated individual (the improved brood) is suitable to be considered a new solution-generating individual (queen bee).
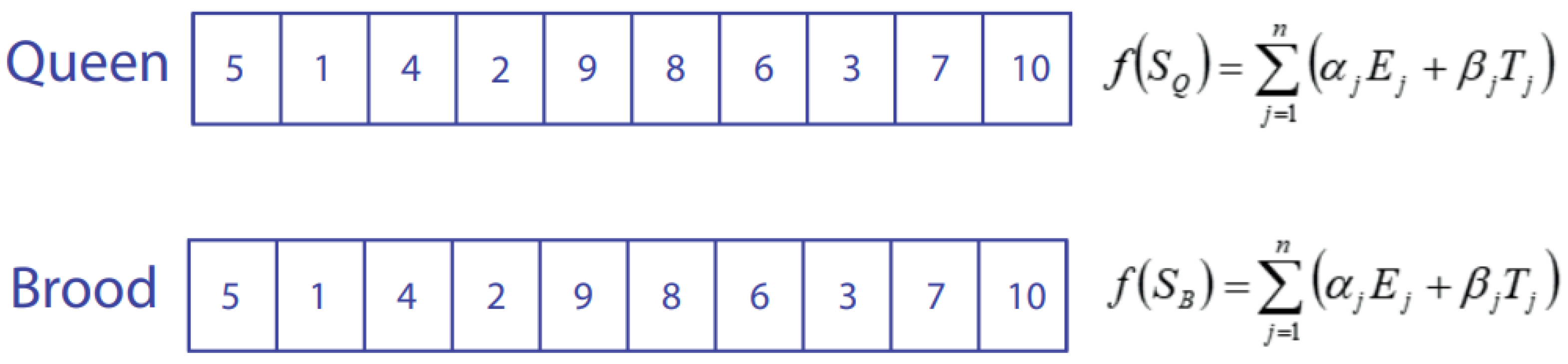
Therefore, the proposed MBO algorithm evaluates both queens and broods using Equation (1), applied to the partial solutions of each:
f(
) for queens and
f(
) for broods.
Figure 2 provides a schematic representation of the fitness evaluation process.
At the end of each flight, the queen population is updated by replacing the queens with the worst fitness with broods that have the best fitness, if any exist. The lists of generated broods and drones are then deleted. A new population of drones is generated for the subsequent flight, resulting in new broods from crossing the genotypes of the queens and the new drones.
This process is repeated until the algorithm’s stopping condition is met. Since queens are updated after each flight, the algorithm iterates through all the previously mentioned stages until the stopping criterion is fulfilled.
4.4. Parameter Updating
During each mating flight, a queen bee experiences a loss of energy, a decrease in flight speed, and a reduction in available space in her spermatheca. To accurately simulate these changes, parameters related to the queen’s energy, speed, and spermatheca capacity must be updated after each flight. The updating procedure follows the methods outlined by the authors of [
27,
28,
29,
53,
54]. In this way, the relevant parameters updated during each flight are as follows.
Updating the queen’s energy: This is completed using Equation (2): E(t + 1) = E(t) − . At each transition t, the energy is reduced by units, where corresponds to the energy reduction factor of the bees, as previously described in Equation (5).
Updating the queen’s speed: This is completed using Equation (3): S(t + 1) = α∙S(t). At each transition t, the speed is progressively reduced by a factor α of the previous speed.
Updating the spermatheca’s capacity: The capacity of the spermatheca is updated based on the number of drones with which the queen mates during each flight. This depends on the acceptance or rejection of the mating event between the queen and the drone, which is represented by the annealing probability described in Equation (4).
4.5. Stopping Conditions
In the implementation of the MBO algorithm, a stopping criterion was established based on reaching a predetermined number of iterations, equivalent to the number of flights. For the scheduling problem examined, it was determined that 20 flights within the MBO algorithm yielded satisfactory solutions for a substantial portion of the 280 problems investigated. Consequently, this number of flights was considered suitable for addressing the SMWET problem. The MBO metaheuristic proposed for the SMWET problem is described in Algorithm 4.
| Algorithm 4. Queen–brood fitness evaluation |
| Define | M, (to be spermatheca size); Q = 4, (queen quantity); α = 0.98, (queen velocity’s reduction step) | | | |
| Define | E(t) and S(t) to be the queen’s energy and speed at time t, respectively | | | |
| Define | maxiter_hc, maxiter_sa, maxiter_ls to be the maximum number of iterations for workers | | | |
| Initialize | workers to be simulated annealing, hill climbing and local search. | | | |
| Initialize | queen genotypes, according to SPT and LPT scheduling rules for the first two queens and randomly | | | |
| | generate the genotypes for the remaining two queens. | | | |
| Randomly use workers to improve initial queen’s genotype | | | |
| while | Flight quantity < 20: | | | |
| | t = 0 | | | |
| | Initialize | = [0.5 E(t)/M] | | |
| | Generate D = 10 drones at random | | | |
| | while | E(t) > 0 and M < 10: (queen still have energy to flight and spermatheca is not full) | | |
| | | Mutate drones genotype → | | |
| | | if, f) | (if mutated drone fitness is better than the original drone fitness, then accept mutated drone genotype as potential drone) | |
| | | | |
| | | | | |
| | | else if, f) | (if mutated drone fitness is better than queen fitness, replace queen genotype by mutated drone genotype) | |
| | | | |
| | | end if | | |
| | | end elseif | | |
| | Select the candidate drone’s genotype to cross it with the queen’s genotype according with annealing probability, (Equation (4)) | | | |
| | | | |
| | | if, rand } for D = {1, 2,…, 10} | | |
| | | (add drone’s genotype to spermatheca) | | |
| | t = t + 1; E(t + 1)=E(t) − ; S(t + 1) = αS(t) | | | |
| | end while | | | |
| | for brood | =1 to total number of broods | | |
| | | select drone material from queen spermatheca at random | | |
| | | if rand(0.1) ≤ 0.3 apply “drone-queen” crossover operator and generate a brood | | |
| | | else, apply “queen drone” crossover operator and generate a brood | | |
| | | endif | | |
| | | use workers to improve brood’s genotype according to the probabilistic rule (Equation (6)) | | |
| | | for workers [hill climbing, simulated annealing and local search] | | |
| | | | , the best election probability associated with a worker | |
| | | | select worker | |
| | | | apply worker to all broods to obtain mutated broods | |
| | | | | |
| | | | | |
| | | end for | | |
| | | if f) | (if mutated brood fitness is better than the original brood fitness, then keep mutated brood as partial solution) |
| | | | |
| | end for | | | |
| | if f) | (if there are broods with better fitness than any queen, replace the queen by broods) | |
| | | | |
| | end if | | | |
| | kill all broods | | | |
| end while | | | | |
| | | | | | | | | | | | | | |
The flowchart of the MBO algorithm, adapted for this study, is provided in
Figure 3.
6. Conclusions
This paper explores the potential of the MBO algorithm to tackle complex NP-hard optimization problems. This study proposes an enhanced MBO heuristic algorithm, introducing modifications to the original algorithm to optimize the objective function and generate high-quality solutions within reasonable computational time. This novel approach has not been previously explored in the context of this research. Specifically, we consider the discrete problem of minimizing the total penalties for the completion of early and late tasks on a single machine with a common due date:
[
49,
51,
65], known as SMWET.
Compared to the
UB values from [
37], our proposed MBO algorithm achieved an average percentage improvement of 0.91% across 280 benchmark problems. It yielded better solutions for 160 problems, a 57% improvement in the total number of problems addressed.
The metaheuristic demonstrated efficient performance on problems with restrictive due date factors of
h = 0.2 and
h = 0.4, achieving an average percentage improvement of 3.71% across 140 evaluated cases. On the other hand, in problems with restrictive due date factors
h = 0.6 and
h = 0.8, also in 140 cases, the metaheuristic achieved an average percentage error of 1.72% compared to the
UBs published by the authors of [
37].
Compared to other metaheuristics in the literature for the same problem set, the MBO metaheuristic demonstrated strong competitiveness. Notably, MBO was consistently applied to all 280 problems without parameter tuning, unlike other metaheuristic approaches. MBO achieved a maximum error of 1.12% compared to the best improvement percentage of 2.15%, resulting in an average efficiency of 98.88% against solutions from well-known metaheuristics like foraging bees [
42], DPSO [
39], and VNS/TS [
41], for the complete set of 280 problems. The proposed MBO algorithm demonstrated competitiveness compared to recent studies, such as those by the authors of [
30,
33,
66,
67]. It achieved comparable optimal values and computation times when applied to a different dataset, addressing the same problem.
Moreover, when comparing average computation times for finding optimal solutions, the adapted MBO metaheuristic exhibited similar behavior to the times reported by the authors of [
8] for 140 problems with restrictive due date factors of
h = 0.2 and
h = 0.4. Similarly, comparable average computation times were observed relative to the DE metaheuristic for all 280 problems. Differences were mainly noted in problems involving a number of tasks
n ≥ 100. However, the computation times are not directly comparable due to inherent differences in programming languages and the capabilities of the systems used.
A statistical analysis of the mean difference relative to the
UB values reported by the authors of [
37] confirms that the adapted MBO algorithm is significantly more efficient for all problems with restrictive due date factors (
h = 0.2 and
h = 0.4). This holds true regardless of the number of tasks to be sequenced and at a 5% significance level (α = 0.05). However, for problems with factors
h = 0.6 and
h = 0.8, the solutions obtained by the MBO metaheuristic do not exhibit statistically significant differences compared to the
UB values.
Direct comparisons with other algorithms are hindered, as execution times were often unavailable or substantially faster due to the use of compiled languages instead of Python. Additionally, the processing power of the hardware significantly impacts the obtained results. The scalability of the system is notably compromised when adding constraints or increasing the number of tasks, highlighting a persistent limitation in its current state. While the methodology employed in this study has shown promising results, further comparative studies are necessary to evaluate its effectiveness in industrial settings and determine its suitability for specific problems.
Future works could focus on advancing the MBO metaheuristic through hybrid approaches with other optimization techniques like ant colony optimization and particle swarm optimization. Aiming to develop hybrid algorithms that combine the strengths of each method to tackle more complex optimization problems.
Finally, it is essential to conduct rigorous studies on the selection and tuning of the parameters of MBO. By identifying optimal configurations, we can significantly improve the algorithm’s performance and stability across diverse applications. A promising approach involves leveraging machine learning techniques to automate this process, reducing manual effort and enhancing the algorithm’s adaptability to various problem types.





{kind=link}
{kind=link}
{kind=link}