Abstract
This paper analyzes the exponential convergence properties of Symmetric Stochastic Bernstein Polynomials (SSBPs), a novel approximation framework that combines the deterministic precision of classical Bernstein polynomials (BPs) with the adaptive node flexibility of Stochastic Bernstein Polynomials (SBPs). Through innovative applications of order statistics concentration inequalities and modulus of smoothness analysis, we derive the first probabilistic convergence rates for SSBPs across all () norms and in pointwise approximation. Numerical experiments demonstrate dual advantages: (1) SSBPs achieve comparable errors to BPs in approximating fundamental stochastic functions (uniform distribution and normal density), while significantly outperforming SBPs; (2) empirical convergence curves validate exponential decay of approximation errors. These results position SSBPs as a principal solution for stochastic approximation problems requiring both mathematical rigor and computational adaptability.
Keywords:
concentration inequality; modulus of continuity; order statistics; stochastic quasi-interpolation MSC:
41A63; 42B08; 60H30
1. Introduction
Modern engineering systems increasingly rely on function approximation from irregular measurements, for example, medical imaging reconstruction [1], robotic sensor networks [2], and shape design problems [3], to name a few. During various approximation methods, classical Bernstein polynomials exhibit excellent properties and have broad applications [4,5,6,7]. For a function , the degree n Bernstein polynomial is constructed as follows:
where , and represents the binomial coefficient. This polynomial approximates the function f in the Banach space , and the approximation error is bounded by the inequality (see, e.g., [8]):
where the second-order modulus of smoothness is defined as:
However, as Wu et al. [9] pointed out, their performance may be limited when handling scattered or noisy data. They can also face challenges in accurately approximating complex functions in high-dimensional spaces. In many real-world problems, data at equally spaced points may not be available, and even when it appears evenly distributed, it may suffer from random errors caused by signal delays or measurement inaccuracies.
Let X be the random variable uniformly distributed on . Let be independent copies of X, which we list in ascending order (Here, we have ignored the event: some of the random variables take the same value, which has probability zero).
to obtain ordered statistics [10]. For brevity of notation, we suppress the asterisks in the displayed inequalities above, and stick with the notations for order statistics.
To mitigate uncertainties brought on by unreliable sampling sites, Wu et al. [9] introduced a class of SBP:
and proved the following result: Let and suppose that Then,
in which denotes the modulus of continuity of f defined by
Sun et al. [11,12,13] analyzed the polynomial error of the classical SBP method. Adell and Cárdenas-Morales [14,15,16] have recently introduced a type of SBPs which enhance probabilistic error estimates for smooth functions. On that basis, Gao et al. [17,18] constructed a series of stochastic quasi-interpolations for scattered data problems, which showed efficiency in computation and high accuracy in approximation. Gal et al. [19] examined efficient approximation methods for random functions using stochastic Bernstein polynomials within capacity spaces. Bouzebda [20] combined k-nearest neighbors with single index modeling to handle high-dimensional functional mixing data through dimension reduction, effectively mitigating the curse of dimensionality. These estimates are similar to those established in the learning theory paradigm advocated by Cucker and Smale [21] and Cucker and Zhou [22].
Moreover, Wu et al. [12] analyzed the exponential convergence of SBP, which is crucial for stochastic problems in practice, such as probability density estimation, numerical solutions to stochastic differential equations, and denoising problems. Taking these factors into account, Sun [12] conducted an analysis of the exponential convergence of the classical SBP method. In order to analyze the overall error of SBPs, Sun [12] introduced the concept of “-probabilistic convergence” for SBP: For and , we define
On that basis, they gave the power and exponential convergence rates using the modulus of continuity and established Gaussian tail bounds , and the case . The pointwise exponential error estimate is also given.
In order to improve the approximation power of SBPs and let it possess the same approximation power of the classical Bernstein polynomials given by Equation (1), Gao et al. [23] introduced a family of symmetric stochastic Bernstein polynomials (SSBPs) which is called optimal in the sense that it possess the same order of error estimates as classical Bernstein polinomials. The SSBPs is defined as
in which . SSBPs are stochastic variants of classical Bernstein polynomials. Among other flexible features, SSBPs allow the underlying sampling operation to take place at scattered sites, which is a more practical way of collecting data for many real world problems. Ref. [23] established the order of convergence in probability in terms of modulus of smoothness, which epitomizes an optimal pointwise error estimate for the classical Bernstein polynomial approximation. Given and assume that . Then, for any , the following probabilistic estimate holds true:
where the second-order Ditzian–Totik -modulus of smoothness is defined by
which characterizes the approximation order of to f in the Banach space .
Motivated by the method in [12], this paper studies the exponential convergence of SSBP. By employing concentration inequalities for order statistics and properties of the modulus of smoothness, we establish probabilistic convergence rates for SSBPs in both the norm, for , and pointwise. Numerical experiments approximating two standard functions demonstrate that SSBPs achieve approximation errors comparable to those of classical Bernstein polynomials while outperforming SBPs. SSBPs present a promising tool for function approximation in stochastic settings, particularly when dealing with scattered and noisy data, and open new avenues for research in stochastic approximation theory and numerical solutions of stochastic partial differential equations.
The paper is structured as follows: Section 2 covers the necessary preliminaries. Section 3 presents error estimates for the exponential convergence in the norm, while Section 4 addresses pointwise exponential convergence estimates. In Section 5, numerical examples are provided to validate the theoretical findings. Finally, Section 6 concludes the paper with a summary of the key results and potential directions for future research.
2. Preliminaries
2.1. Concentration Inequalities for Order Statistics
For a given , let
be the order statistics of independent copies of the random variable X uniformly distributed in . The following is a standard result in order statistics (e.g., [10,24]).
Theorem 1.
If X is a random variable that has density function and distribution function , and if
are the order statistics of the n sample values of X, then the density function of is given by
Proposition 1.
The random variables (as described in (6)) have, respectively, density functions: . That is, obeys the law , the beta distribution with parameters and
Order statistics are intrinsically dependent random variables, and must be studied as such. Direct calculation gives
For , the covariance of the two random variables is
The last equation can be found in [10]. Recall that . It then follows that
2.2. Extension and Modulus of Continuity
It is noted that, the construct of an SSBP (4) requires that a target function be defined on . If a target function is already defined on , then nothing needs to be done. If a target function f is only defined on , then we extend it to be a continuous function on in such a way that the graph of f on the interval is symmetric to that on the interval with respect to the point . Precisely, we define the extension as follows:
In [23], is bounded from above by an (absolute) constant multiple of in the following lemma.
Lemma 1.
Let and be the extension of f as defined in Equation (9), . Then a central secnd-order finite difference of on : is bounded above by that of f on . Moreover, the following inequality holds true:
3. Exponential Decay Rate of the -Probabilistic Convergence
For consistency with contemporary literature, we adopt the functional norm definition initially introduced by Sun [12]. For and , Sun [12] defined
3.1. -Probabilistic Convergence
Lemma 2
([12]). If , then
Lemma 3
([4]). If and , then
In what follows, we will denote for each and ,
Our primary objective in this study is to establish rigorous upper bounds for the probability quantities:
where is a fixed error tolerance and represents the polynomial degree. To derive these estimates, we first require the following foundational lemma:
Lemma 4.
Let and be given. Suppose that . Then the following inequality holds true:
Proof.
For a fixed , we first use the -space triangle inequality to write
The second term can be estimated deterministically based on Equation (1):
For the first term , based on Equation (4) and the definition of norm, we have
where the last two inequalities are based on the definition of norm (Equation (2)). Then taking out, according to the Minkowski inequality and Lemma 1, we have:
Using the assumption that , we have
Thus, in order for to hold true, it is necessary that
which is the desired result. □
We are now in a position to present the first primary result of this work.
Theorem 2.
Let and be given. Suppose that , then the following inequality holds true:
Proof.
Let and be given. Making use of Lemma 4 (for the case , we have
This completes the proof. □
3.2. -Probabilistic Convergence
For the case where , the result exhibits stronger properties. To establish the main theorem, we require the following preparatory lemmas:
Lemma 5
([12]). Let . Then
Lemma 6.
For each , we have
Proof.
We begin by noting that for each ,
By applying Fubini’s theorem to interchange the order of integration between the Lebesgue integral over and the expectation operator E, and leveraging the convexity of the function , we derive the following:
We then apply Lemma 5 to get the desired result. □
Building upon the preceding lemmas, we now present the second principal result of this paper.
Theorem 3.
Let and be given. Suppose that satisfies
Then, the following inequality holds true:
Proof.
For each in the range , and , we first recall the notation defined in Equation (13) and then use Lemma 6 to write
where we have used the Markov inequality and Lemma 6.
This completes the proof. □
4. Exponential Decay of Pointwise Convergence in Probability
Sun and Wu [9] studied pointwise convergence in probability of the stochastic Bernstein polynomials defined in Equation (3) and proved the following result:
In this section, we will prove the following theorem which is the third principal result of the paper.
Theorem 4.
Let , and be given. Suppose that
Then we have the following inequality
We need the following Lemmas to prove Theorem 4.
Lemma 7
([12]).
Lemma 8.
Let and be given. Suppose that
Then for each fixed , the following inequality holds true.
Proof.
Now we apply Markov inequality to give the proof of the Theorem 4.
Proof of Theorem 4.
This completes the proof of Theorem 4. □
5. Numerical Experiments
In this section, we present the results of numerical experiments utilizing SBP and SSBP methods to approximate two test functions: the uniform distribution function and the normal density function. Both functions have widespread applications in stochastic problems, and accurately simulating these functions is crucial for applying SSBPs to various stochastic challenges.
These functions were specifically chosen due to their significantly different smoothness properties. The uniform distribution function is continuous but non-differentiable, while the normal density function is infinitely differentiable but exhibits large variations when the variance is small. This contrast in behavior makes them ideal candidates for evaluating the performance of approximation methods. For these examples, we first show the error in a single random trial, then we show the exponential convergence property of SSBPs.
To approximate high-degree Bernstein polynomials, we employ the De Casteljau algorithm (see, e.g., [25,26]). De Casteljau’s algorithm approximates high-degree Bernstein polynomial curves through the principle of recursive linear interpolation, enabling efficient modeling without directly handling complex high-order formulas. Its core process consists of three steps: recursive subdivision, segment approximation, and dynamic optimization. Its main advantages are: numerical stability, enhanced efficiency, and high flexibility.
5.1. Simulations of Uniform Distribution Functions

Table 1.
Maximal approximation errors given by BPs, SBPs, and SSBPs.
Figure 1 illustrates the approximations of the uniform distribution function using BPs, SBPs, and SSBPs with different polynomial degrees. The left columns in the figures display the graphs of the approximations, while the right columns show the corresponding approximation errors for . These plots are generated using 100 equally spaced points from the interval . The figures clearly demonstrate that SSBPs provide a much more accurate approximation than SBPs, with minimal additional computational cost. The data presented are based on a single random trial.
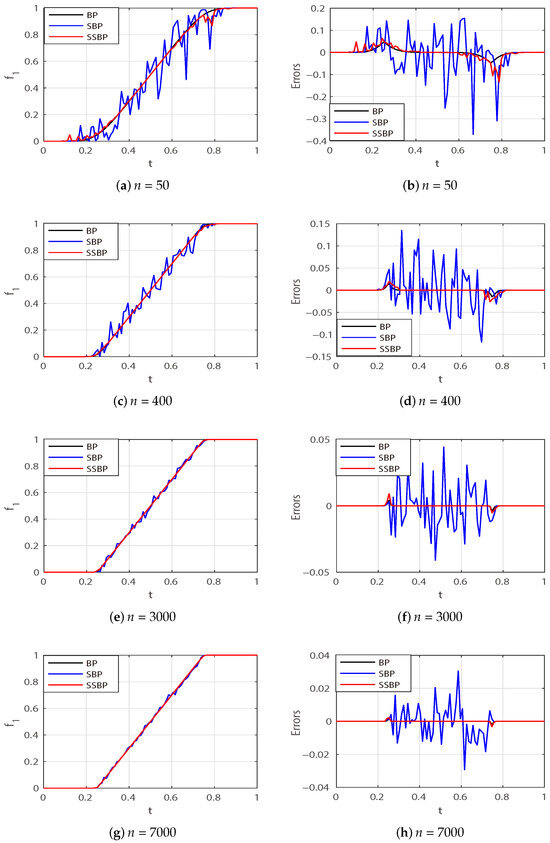
Figure 1.
Pointwise approximation errors (to ) given by BPs, SBPs, and SSBPs in one trial.
In Figure 2, the horizontal axes represent the degrees of SBPs and SSBPs, while the vertical axes represent the probabilities of certain events occurring, which we will elaborate on below. When approximating , we set the tolerance and selected nine equally spaced points, denoted as , from the interval , starting from . The total set of these points is denoted by . At each point , we ran 1000 trials and computed the probabilities of the events and .
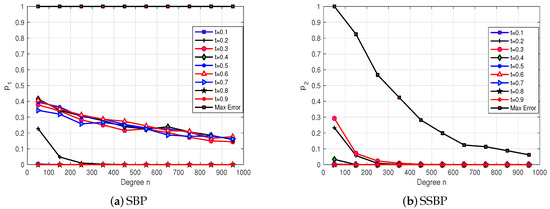
Figure 2.
: Simulations of probabilistic convergence of SBPs and SSBPs in 1000 trials.
Furthermore, we conducted 1000 trials to compute the probabilities of the events and . Figure 2 demonstrates that the probabilities of events associated with SSBPs decay exponentially as the polynomial degree n increases. In contrast, the probabilities of events associated with SBPs do not decay as rapidly as those for SSBPs.
5.2. Simulations of Normal Distribution Functions
In this subsection, we approximate another commonly used function, the normal density function:
where , . The normal density function is widely applied, not only in probability theory but also in areas like kernel approximation, neural networks, and deep learning. Therefore, accurately approximating this function is of great importance. Although the function is infinitely smooth, it presents a challenge due to its significant curvature changes, which can lead to substantial errors if the approximation method is inadequate.
As shown in the Table 2 and Figure 3, the error obtained from the approximation using SSBPs is acceptable, while the error from SBPs becomes so large that it distorts the function’s shape. This demonstrates that SSBPs offer a superior approximation performance for this function. Figure 3 shows the approximation results for polynomial degrees , corresponding to the results summarized in Table 2.
Table 2.
Maximal approximation errors given by BPs, SBPs, and SSBPs.
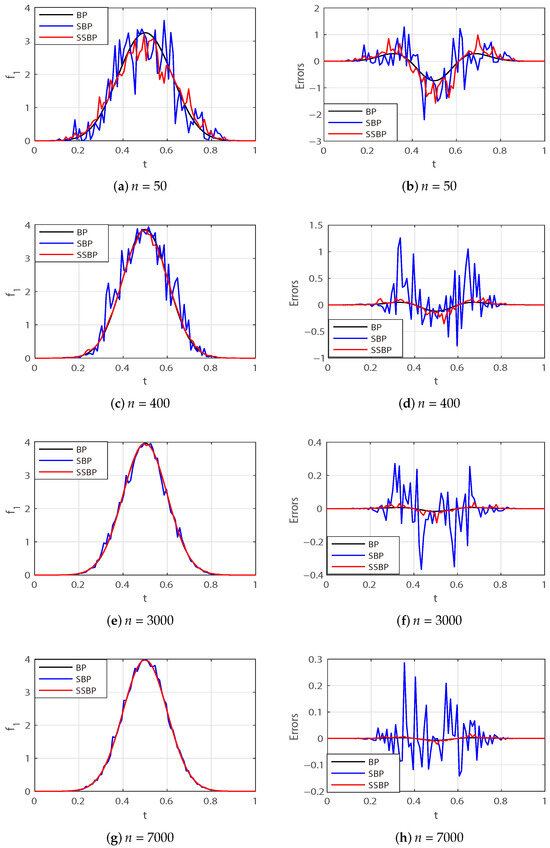
Figure 3.
Pointwise approximation errors (to ) given by BPs, SBPs, and SSBPs in one trial.
In Figure 4, the horizontal axes represent the polynomial degrees for SBPs and SSBPs, while the vertical axes represent the probabilities of certain events occurring. Here, the specific event is defined as the approximation error exceeding 0.5. The probability of the error exceeding 0.5 decreases exponentially as n increases for SSBPs. In contrast, the probability associated with SBPs does not decay as rapidly. This indicates that SBPs are not as effective in approximating functions with large curvature variations, and their performance degrades further as the standard deviation of the normal density function increases.
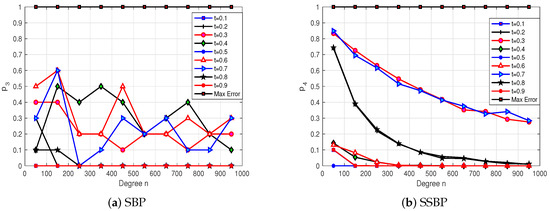
Figure 4.
: Simulations of probabilistic convergence of SBPs and SSBPs in 1000 trials.
Thus, we can observe that SSBPs are well-suited for approximating functions with large curvature changes, as the error remains manageable. From the comparison of these two very different functions—the uniform distribution and the normal density function—it becomes evident that SSBPs can handle noisy data effectively while providing approximation results comparable to classical BPs. Therefore, we conclude that SSBPs are highly reliable for these types of approximations.
6. Conclusions
This paper demonstrates the exponential convergence of SSBPs under the () norm. Theoretical analysis shows that the -error bound of SSBPs is comparable to that of classical BPs and significantly outperforms the SBPs, while maintaining an computational complexity. It is worth mentioning that we establish probabilistic convergence rates for the general norm (Theorem 3), with explicit dependence on the parameter p. However, the numerical experiments in this study exclusively validate the and exponential convergence. While control provides a theoretical upper bound for errors, the actual convergence behavior for finite p values may exhibit distinct characteristics. Although the current study is limited to the univariate case, these findings provide new research directions for the field of stochastic computation, particularly in the extension to multivariate cases and the optimization of computational complexity, which are of significant exploratory value.
Author Contributions
Validation, software and writing, S.Z.; Conceptualization and methodology, Q.G. and C.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (Nos. 12471358, 12071057), the Fundamental Research Funds for the Central Universities (No. DUT23LAB302), and the Characteristic & Preponderant Discipline of Key Construction Universities in Zhejiang Province (Zhejiang Gongshang University-Statistics).
Data Availability Statement
The original contributions presented in this study are included in the article. For further inquiries, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lin, D.; Johnson, P.; Knoll, F.; Lui, Y. Artificial intelligence for MR image reconstruction: An overview for clinicians. J. Magn. Reson. Imaging 2021, 53, 1015–1028. [Google Scholar] [CrossRef] [PubMed]
- Al-Quayed, F.; Ahmad, Z.; Humayun, M. A situation based predictive approach for cybersecurity intrusion detection and prevention using machine learning and deep learning algorithms in wireless sensor networks of industry 4.0. IEEE Access 2024, 12, 34800–34819. [Google Scholar] [CrossRef]
- El, Y.; Ellabib, A. A fuzzy particle swarm optimization method with application to shape design problem. RAIRO-Oper. Res. 2023, 57, 2819–2832. [Google Scholar]
- Lorentz, G. Bernstein Polynomials; American Mathematical Society: Providence, RI, USA, 2012. [Google Scholar]
- Cheney, E.W.; Light, W. A Course in Approximation Theory; American Mathematical Society: Providence, RI, USA, 2009; Volume 101. [Google Scholar]
- Ditzian, Z.; Totik, V. Moduli of Smoothness; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 9. [Google Scholar]
- Chung, K. Elementary Probability Theory with Stochastic Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Paltanea, R. Approximation Theory Using Positive Linear Operators; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Wu, Z.; Sun, X.; Ma, L. Sampling scattered data with Bernstein polynomials: Stochastic and deterministic error estimates. Adv. Comput. Math. 2013, 38, 187–205. [Google Scholar] [CrossRef]
- David, H.; Nagaraja, H. Order Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Sun, X.; Wu, Z. Chebyshev type inequality for stochastic Bernstein polynomials. Proc. Am. Math. Soc. 2019, 147, 671–679. [Google Scholar] [CrossRef]
- Sun, X.; Wu, Z.; Zhou, X. On probabilistic convergence rates of stochastic Bernstein polynomials. Math. Comput. 2021, 90, 813–830. [Google Scholar] [CrossRef]
- Sun, X.; Zhou, X. Stochastic Quasi-Interpolation with Bernstein Polynomials. Mediterr. J. Math. 2022, 19, 240. [Google Scholar] [CrossRef]
- Adell, J.; Cárdenas-Morales, D. Stochastic Bernstein polynomials: Uniform convergence in probability with rates. Adv. Comput. Math. 2020, 46, 16. [Google Scholar] [CrossRef]
- Adell, J.; Cárdenas-Morales, D. Random linear operators arising from piecewise linear interpolation on the unit interval. Mediterr. J. Math. 2022, 19, 223. [Google Scholar] [CrossRef]
- Adell, J.; Cárdenas-Morales, D.; López-Moreno, A. On the rates of pointwise convergence for Bernstein polynomials. Results Math. 2025, 80, 1–10. [Google Scholar] [CrossRef]
- Gao, W.; Sun, X.; Wu, Z.; Zhou, X. Multivariate Monte Carlo approximation based on scattered data. SIAM J. Sci. Comput 2020, 42, A2262–A2280. [Google Scholar] [CrossRef]
- Gao, W.; Fasshauer, G.; Sun, X.; Zhou, X. Optimality and regularization properties of quasi-interpolation: Deterministic and stochastic approaches. SIAM J. Numer. Anal. 2020, 58, 2059–2078. [Google Scholar] [CrossRef]
- Gal, S.; Niculescu, C. Approximation of random functions by stochastic Bernstein polynomials in capacity spaces. Carpathian J. Math. 2021, 37, 185–194. [Google Scholar] [CrossRef]
- Bouzebda, S. Uniform in number of neighbor consistency and weak convergence of k-nearest neighbor single index conditional processes and k-nearest neighbor single index conditional u-processes involving functional mixing data. Symmetry 2024, 16, 1576. [Google Scholar] [CrossRef]
- Cucker, F.; Smale, S. On the mathematical foundations of learning. Bull. Am. Math. Soc. 2002, 39, 1–49. [Google Scholar] [CrossRef]
- Cucker, F.; Zhou, D. Learning Theory: An Approximation Theory Viewpoint; Cambridge University Press: Cambridge, UK, 2007; Volume 24. [Google Scholar]
- Gao, Q.; Sun, X.; Zhang, S. Optimal stochastic Bernstein polynomials in Ditzian-Totik type modulus of smoothness. J. Comput. Appl. Math. 2022, 404, 113888. [Google Scholar] [CrossRef]
- Casella, G.; Berger, R. Statistical Inference; CRC Press: Boca Raton, FL, USA, 2024. [Google Scholar]
- Farin, G. Handbook of Computer Aided Geometric Design; Elsevier: Amsterdam, The Netherlands, 2002; Volume 2, pp. 577–580. [Google Scholar]
- Prautzsch, H.; Boehm, W.; Paluszny, M. Bézier and B-Spline Techniques; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).