1. Introduction
With the rapid advancement of econometric finance, the financial industry faces significant challenges due to the exponential growth of data and the increasing complexity of financial models. To address these issues, numerous mathematical models have been developed and applied in the financial sector. While numerous mathematical approaches address these issues, their computational demands and inherent limitations underscore the need for innovative solutions.
For instance, reference [
1] offers a framework for families to calculate their asset portfolios, serving as a valuable guide for many family asset managers. However, as the volume of data continues to increase, these methods have become somewhat overshadowed in recent years. In response to these challenges, artificial intelligence (AI) and machine learning (ML) [
2,
3] have emerged as powerful tools for navigating the demands of the modern data-driven era. Extensive research has been conducted in this domain. For example, Ayyildiz and Iskenderoglu [
4] introduced ML algorithms to predict movement trends of stock market indices in developed economies. While traditional machine learning methods demonstrate promise in stock index prediction, their scalability is constrained by exponentially growing data volumes. Consequently, quantum computing has emerged as a transformative solution to overcome these limitations by leveraging its computational efficiency advantages.
This paper introduces a novel stock prediction framework that employs a GMM-MVTF (Gaussian mixture models and means and variances to feature) discretization pipeline to overcome the inherent limitations of Gaussian mixture models (GMM) in handling continuous data for stock market predictions. By using the Shanghai Stock Exchange (SSE) and Shenzhen Stock Exchange (SZSE) datasets, this paper evaluates three HQMM variants: one with MVTF-discretized data and another with evenly discretized data, with performance comparisons against classical HMM under distinct processing techniques. This study unlocks a new dimension of quantum-enhanced computing for the industry and provides a valuable reference for further investigating the potential applications of quantum algorithms in other fields.
3. The Comparison Between the Classical HMM and HQMM
3.1. Hidden Markov Model in Stock Forecasting
HMM describes a hidden Markov chain that generates an unobservable sequence of states, where the state probability at time
t,
, is only determined by the previous state
, as (1) shows:
By using the time-independent constant matrices
A and
C to define the transition matrix and the observation matrix, respectively, in the Markov process, the model can be defined as
[
19], which denotes the initial state distribution
[
20]:
where there are the elements at the
i-th row and the
j-th column of the
N ×
N transition matrix and the
N ×
M observation matrix, respectively. The initial state distribution
defines the probability of being in state
i at the first time point. When the HMM is applied to stock market prediction, elements such as the risk-free interest rate, systemic risk, and risk premium are incorporated into the hidden state, and the observation matrix represents the price of each stock. By using historical daily stock prices as input data, the transition matrix
A and observation matrix
C of HMM are trained by using ML techniques. Then, the probability of each subsequent hidden state can be derived from matrix
A, while the probability of the most possible stock price at the next time step [
19,
21] can be calculated using the following equation:
Given model and observation sequence = {1, 2, … T}, is the observation vector at time t + 1, where is the predicted state with the largest probability at time t + 1. Obviously, this model only focuses on the price variations of a single stock over time but ignores other influencing factors. However, in the real stock market, numerous factors have a determinant influence on stock prices, including both external and internal variables, such as risk-free interest rate, systemic risk, and risk premium. This renders HMM-based predictions fundamentally unstable in real environments.
3.2. Hidden Quantum Markov Model
As an extension of the classical HMM framework, HQMM [
22] can be expressed as follows:
where
is the observation state,
is the known state,
is the conditional probability of the observation state at time
t when the density matrix
at time
is known, tr is the trace,
is the Kraus operator corresponding to the observation state at time
, and the superscript
indicates the conjugate.
HQMM is trained using gradient descent or variational inference to optimize quantum operators by density matrix ρ (showing the hidden state) and state update (controlled by the Kraus operator {Km}, following quantum channel constraints, where m is the number of the operator, and I refers to the identity matrix). Through the global information storage of quantum states, interference effects, long-term dependency modeling, and exponentially scalable state space, HQMM breaks through the limitations of HMM, which can only focus on a single stock trend, making it more suitable for multi-asset, market linkage analysis and intricate financial systems.
Both HMM and HQMM are capable of inferring the probability of the next state from the previous state. In a classical HMM, the next hidden state and observation state can be inferred from the transition matrix
A and the state observation matrix
C, respectively. Comparatively, in HQMM, the Kraus operator replaces the matrices
A and
C, serving to predict the next state. Traditional HMMs can only model Markov processes, where the current state depends solely on the previous state, and a fixed probability transition matrix governs transitions. In contrast, Kraus operators in HQMMs leverage density matrices to retain historical information and quantum coherence. Additionally, HQMMs allow the use of multiple Kraus operators, each of which can correspond to different market conditions or trading patterns, providing greater flexibility in capturing complex financial dynamics. A comparison of the two models is presented in
Table 1, and the relevant formulas and characteristics can be found in Ref. [
22].
In classical HMM probability, the vector represents the probability of different market states and is referred to as a probability vector. The belief state reflects the confidence level in the market being in a specific state at a given moment—such as rising, stable, or falling. The joint distribution encodes the combined probability of two or more variables occurring simultaneously. Marginalization refers to the process of ignoring a variable d in order to focus only on the distribution over x. Conditional probability is used to update belief about x, given new information d.
In the HQMM analogue, represents a density matrix, which incorporates not only probabilistic information but also quantum coherence. Density matrix allows for interference between different states, making it more suitable for capturing the complexity of financial markets. A multi-particle density matrix, , models the joint behavior of strongly correlated variables—such as two closely linked sectors—more accurately. A partial trace, , is used when macro-level information (D) is known and focuses on a particular asset (X), obtaining partial trace for the macro-variable (D). Projection+partial trace constitutes the quantum analogue of conditional probability: the system is first projected onto a measured outcome d (e.g., a major policy announcement), and then a partial trace is taken to infer its effect on the market state X (e.g., stock movement).
Fundamentally, HMM and HQMM differ in their modeling approach. HMM forecasts market behavior by learning transition probabilities between historical price states. In contrast, HQMM leverages the principles of quantum mechanics—superposition (interference between rising and falling probabilities) and entanglement (interlinked behavior of assets like U.S. and Chinese stocks)—to potentially capture more intricate market dynamics. This includes nonlinear dependencies, long-range memory effects, and hidden correlations that classical models may fail to represent.
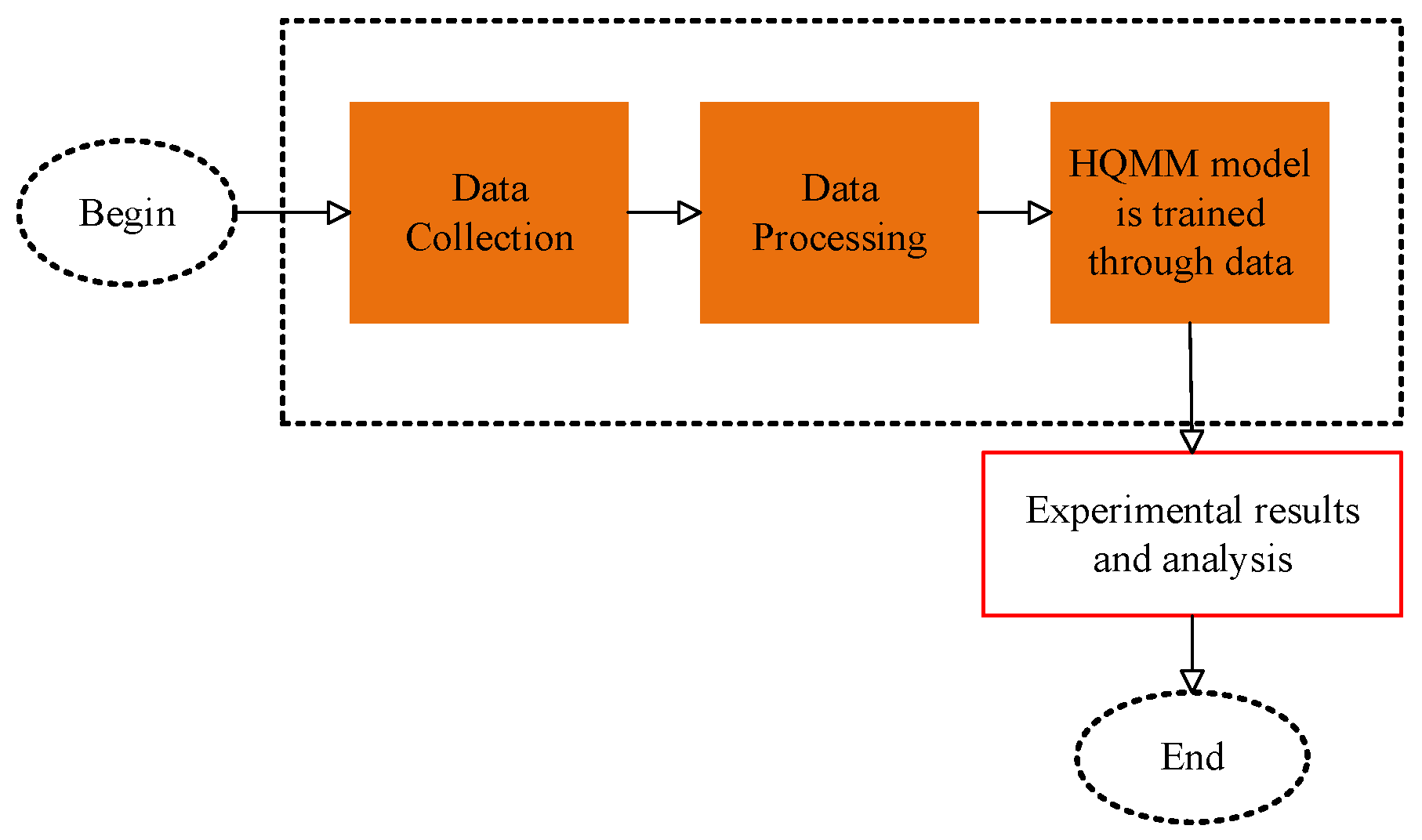
4. Experimental Procedure Introduction
To achieve accurate prediction of the stock market based on HQMM, three main steps should be performed, involving the collection of real-time stock data, conversion of the continuous data into discretized formats, and training of HQMM based on the processed data to predict stock trends, as illustrated in
Figure 1.
4.1. Data Collection
Here, 15 stocks with stock codes of 000901, 000036, 000031, 601318, 600519, 600009, 600004, 600050, 600022, 000623, 000401, 000488, 000518, 000800, and 000895 were taken into consideration. The 5 key indices of these stocks, opening price, highest price, lowest price, closing price, and trading volume, were collected daily from the real-time stock data of SSE and SZSE from June 2018 to June 2021. Financial data were accessed via the Tushare Application Programming Interface (API). The workflow integrates multiple specialized libraries: backtrader and Tushare for stock data acquisition, pandas and NumPy for data preprocessing, hmmlearn and scikit-learn for classical modeling (hidden Markov models and Gaussian methods), and Qiskit for quantum circuit implementation. The following data were split into different time periods: 1 June 2018–26 October 2019 (training period), 30 October 2019–24 August 2020 (validation period), and 24 August 2020–23 June 2021 (testing period).
Each stock has an index number of 5. These indices serve as the evaluation standards for investment performance and the innovation of index derivative products, providing the foundational conditions for index investment.
4.2. Data Processing
As discussed before, the current HQMM-based algorithm can only handle discretized time-series data [
21]; thus, the obtained continuous data from SSE and SZSE cannot be directly used for this hidden quantum Markov prediction. To ensure that the data can be compatible with HQMM, further data processing is required. As for HMMs, when continuous data is applied, integrated algorithms, such as Gaussian HMM, are usually employed. However, an equivalent quantum version of such an approach is not accessible for HQMM, necessitating the exploration of alternative methods. Discretizing continuous data is often considered the first option for HQMM; however, it also faces a significant challenge. The original data may be seriously distorted, having a negative impact on the model’s effectiveness. As a result, another method—integrating the Gaussian mixture model (GMM) with the means and variances to feature (MVTF) model—is proposed and also applied for data processing, aiming at ensuring maximum fidelity in financial data representation and thus enhancing the model performance.
4.2.1. Even Discretization of Continuous Data
In order to better discretize continuous data, the traditional discretization method in
Table 2 is presented, and then the experimental method in
Table 3 is improved to reduce external interference.
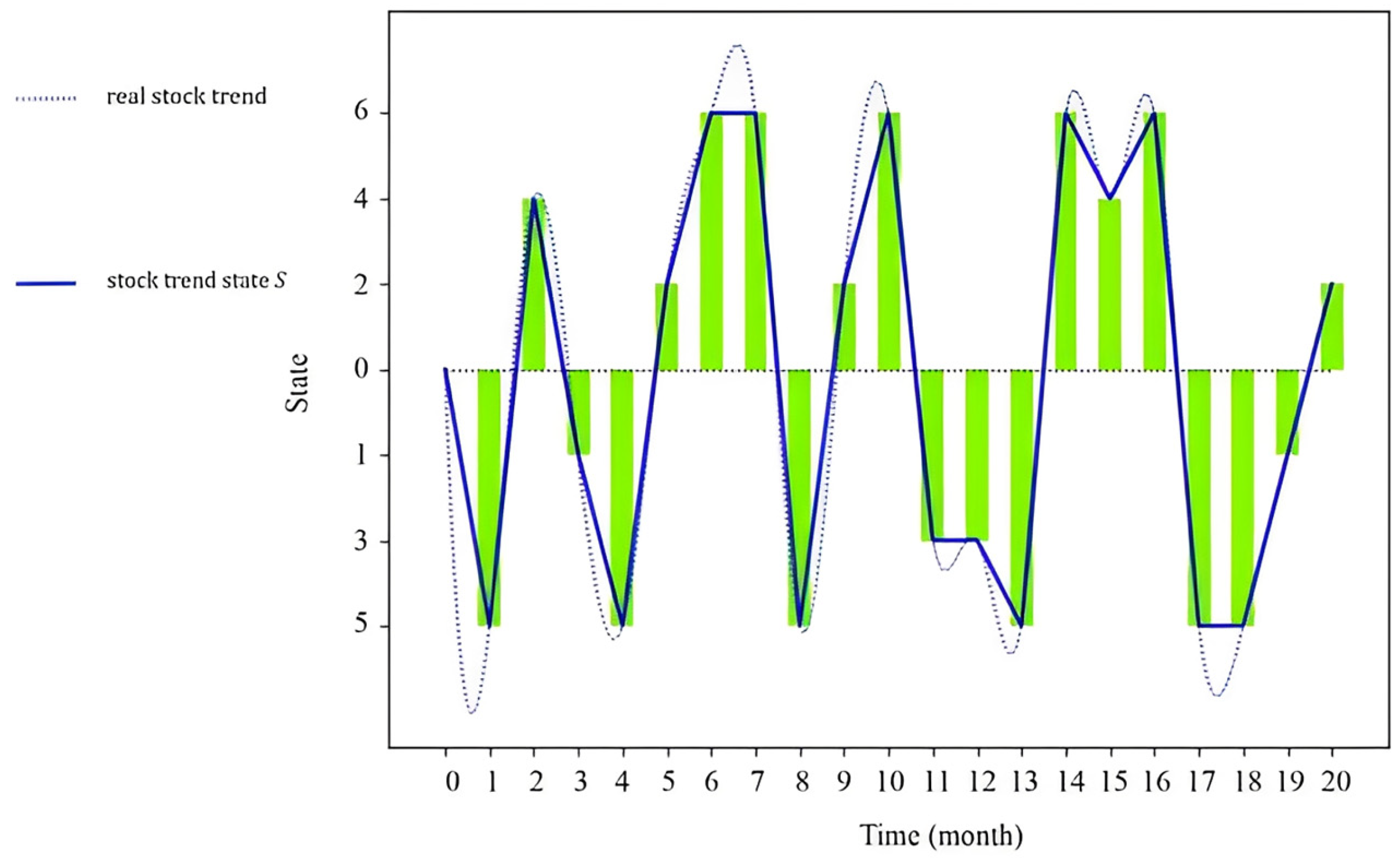
Table 2 demonstrates that the data underwent straightforward processing and were subsequently input into the HQMM model. While the prediction results were generated, they were significantly influenced by external factors, leading to a lack of robustness and vulnerability to artificial interference. To enable a fair comparison with our improved method, the same approach was employed, whereby the obtained data were categorized into three intervals based on stock price fluctuations. These intervals were represented by the integer values 1, 3, 5, 2, 4, and 6, respectively (
Table 3). The value of L is mentioned in formula 8 (through the calculation of GMM mean and variance and MVTF below), and L is converted into the value of
S(Observation status in
Table 3) and then transformed into a bar graph in
Figure 2. The ordinate of the green bar chart is the value of separate
S, the dotted line represents the real stock trend value, and the solid line is the line of the midpoint of the bar chart, indicating that the stock trend obtained through the division of
S is more realistic.
The calculation of stock price fluctuations (increase or decrease) is performed by subtracting the previous day’s closing price from the next day’s closing price. If the resulting value S is positive, it indicates a rise; conversely, a negative S signifies a fall. This approach facilitates the data input into the HQMM model and simplifies the subsequent analysis of experimental results.
4.2.2. Data Discretization with GMM and MVTF
The processing steps of our proposed method, which combines GMM with MVTF to discretize continuous data, are as follows:
(1) The data collected during a certain time period are first inputted into the GMM-based ML algorithm, allowing for the training of multiple Gaussian distributions. The common steps for GMM to process data are as follows: (i) The dataset and the variables to cluster are selected. (ii) The optimal cluster number K is determined based on the characteristics and size of the dataset using the Bayesian Information criterion (BIC) or Akaike Information criterion (AIC) through multiple experiments. The cluster parameter K is empirically determined as 6 in this experimental setup. (iii) Random initialization or k-means algorithm is used to initialize GMM parameters. (iv) The expectation maximization (EM) algorithm is used to assign each sample to the Gaussian distribution with the highest probability, and the probability of each sample belonging to the Gaussian distribution is calculated (posterior probability, E-step). (v) M-step in the EM algorithm is used to find the mean value, method, and weight. (vi) Steps iv and v are repeated until the posterior probability change is less than a certain value. (vii) The mean and variance of each distribution are extracted based on the resulting distribution.
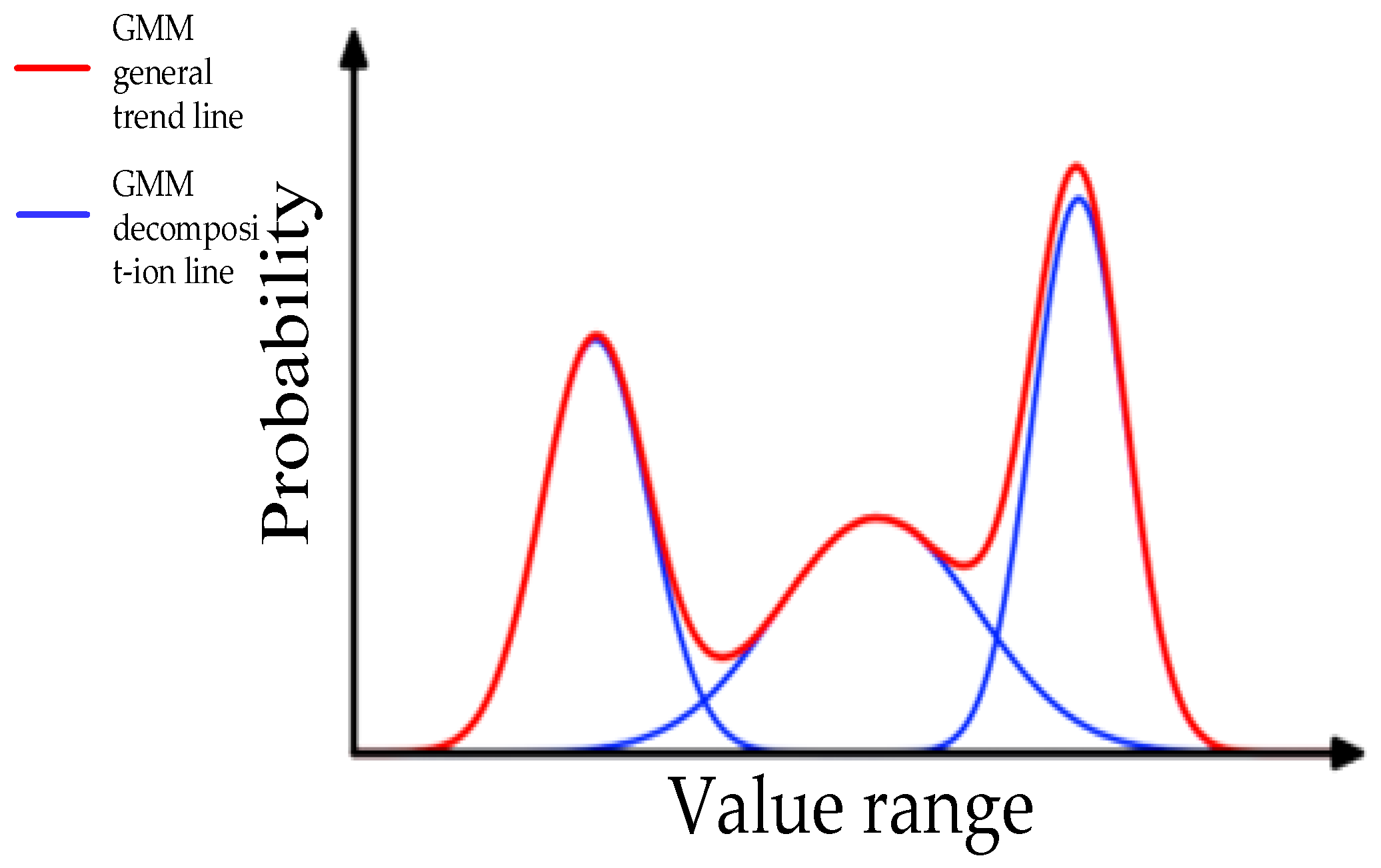
In an experimental model, the collected data is accurately quantified and decomposed into k models based on the Gaussian probability density function, as shown in
Figure 3. (Schematic diagram illustrates GMM, so no scale is required. The red line is the overall trend, which then breaks down into the blue line). Here, a one-dimensional GMM is utilized, the 30-day data is considered and input into a Gaussian mixture model for training, and n is set to 5, where n represents the number of Gaussian mixture components. In order to ensure consistent generalization across all data samples and to avoid the imbalance phenomenon where some data perform exceptionally well while other data significantly deteriorate due to parameter deviations, the above parameters were selected. This means that the GMM model learns five Gaussian distributions and obtains variances (
) and means (
) of these Gaussian distributions.
(2) The means and variances obtained in the previous step are further processed through the MVTF model and then used to determine the trend states of the stocks over the specified period. During this step, how to convert the before-derived means and variances into the stock trend states (indicating a bull or bear market) is crucial because it has a significant effect on the fidelity degree of the experimental data when input into HQMM. To maximize this fidelity, the following conversion processes are performed:
The n variances () obtained from the experimental data are sorted from small to large and assigned to in order, and the mean corresponding to is also assigned to in the same order as .
The L value of each set of data is calculated using the following equation:
represents the mean
corresponding to the
i-th variance
. The trend state
S of stocks can be defined by classifying the value of L (L is a calculated value based on
and a weighting coefficient), based on the classification principle shown in
Table 3. To ensure MVTF fully leverages all information from the GMM-generated Gaussian distributions while accounting for the correlation between experimental results and the number of Gaussians, Formula (8) is derived by using a criterion. As a result, the stock trend state
S is made into tabular data. Correspondingly, the resulting trend state of stock 600519 is shown in
Figure 2.
Besides the above processes involving GMM and MVTF, the whole operation flow of data processing also includes: (i) collecting real-time stock data; (ii) calculating and tabulating the difference between the closing price of each day and that of the previous day; (iii) splitting all collected data into a group of 30 days; (iv) inputting each group of data into GMM and setting the number of Gaussian distributions in GMM to n (n is an integer and n ≥ 1); (v) calculating the means and variances of n Gaussian distributions; and (iv) converting these means and variances into the stock trend state through the MVTF model. After these operations, the collected continuous financial market data is successfully discretized and finally converted into a format accessible to HQMM.
4.3. HQMM Training
In order to accurately predict the stock market with the previous data processing results, the HQMM model is constructed. How to construct the likelihood function and solve the Kraus operator with the gradient descent method is at the core of this model. The historical stock observation data
are used to construct the likelihood function [
23] as follows:
where
is the manually set initial density matrix. In the initial state
under different
K values, it exhibits the advantage of robustness, allowing the model state to evolve from any initial state to a stable state. Additionally, the manually set method for HQMM is the same used in References [
16,
23]. During the HQMM process, when the Markov chain has a long sequence,
will produce a decoherence effect. In the process of evolving the relative state, for the first half of a batch, any initial state undergoes evolution, while the second half undergoes the experiment. In this experiment,
can be set to the following:
.
Then, the likelihood function (9) is used to calculate the derivative of all possible Kraus operators for gradient descent to maximize the value of the likelihood function. Therefore, a matrix solution to the Kraus operator
is obtained, which is the
n-th Kraus operation matrix. Each observation value corresponds to an operation matrix, which is the same at the beginning; the solution of the derived HQMM is transformed into a constrained optimization problem: relational matrix
is the maximum and
[
24], with
m being the number of the operator and
I referring to the identity matrix. Then, the likelihood function is used to conduct derivative processing on all the Kraus algorithms. Subsequently, the gradient descent method is employed to calculate the maximum likelihood function value, thereby enabling the determination of the matrix solution of the first Kraus.
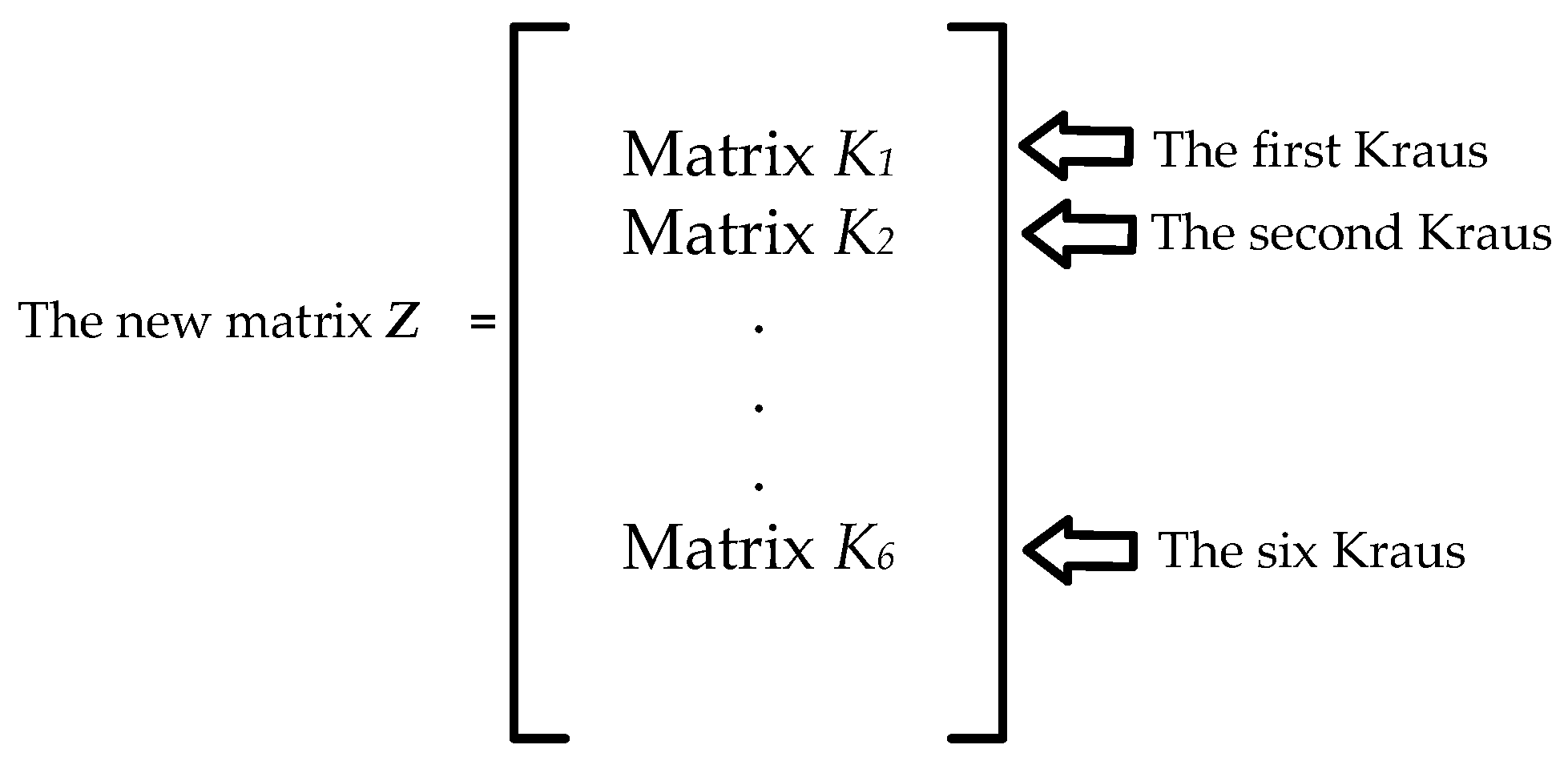
For the convenience of computer operation, a new matrix
Z [
24] is reconstructed by stacking all the
Kraus operator matrices, as shown in
Figure 4. It has a dimension of
, determined by the output number
H, i.e., the number of stock observation states. The constrained optimization problem requires the constructed matrix
Z to satisfy the following:
is the maximum and
[
24]. Since
is on the Stiefel manifold, its constrained optimization problem can be transformed into the following unconstrained problem, which can be solved by the gradient descent algorithm:
[
24] and
[
24]. Here,
G is the partial differential of the likelihood function for
Z;
is the step size of gradient descent (a real number in the interval [0, 1]); and both
and
are the augmented matrices and represented by
and
[
24]. By solving this constrained optimization problem, the Kraus operator can be solved, the latest
is updated, and the whole HQMM is obtained. Finally, the result of reversing
to obtain the Kraus operators is derived, and the quantum hidden Markov model is used to solve and obtain the prediction of the stock’s trend,
, at the next moment, based on the results of the Kraus operators.
To accurately evaluate the model’s performance, the description accuracy (DA) must be obtained. The fundamental principle of DA is to serve as a standardized log-likelihood ratio metric. It achieves likelihood standardization with respect to state-space dimension and length normalization, enabling fair comparison across models of varying complexity. For more detailed explanations, refer to reference [
22]. The algorithm is adopted and defined as follows:
where
r is the length of the sequence,
w is the number of hidden states,
Y is the observation data,
D is the generated model, and
f (·) is a nonlinear function that takes the argument from (−∞, 1] to (−1, 1]:
If DA = 1, the model perfectly predicts the stochastic sequence, while 1 > DA
0 means that the model predicts the sequence better than random [
22]. If DA < 0, the results indicate that the model performs poorly and is inferior to a random baseline. The more DA converges to 1, the better the model functions. It describes the DA as the loss function used to evaluate the quality of the model training. In repeated experiments, DA demonstrates noise resistance in measurement, with its values eventually converging to a stable state [
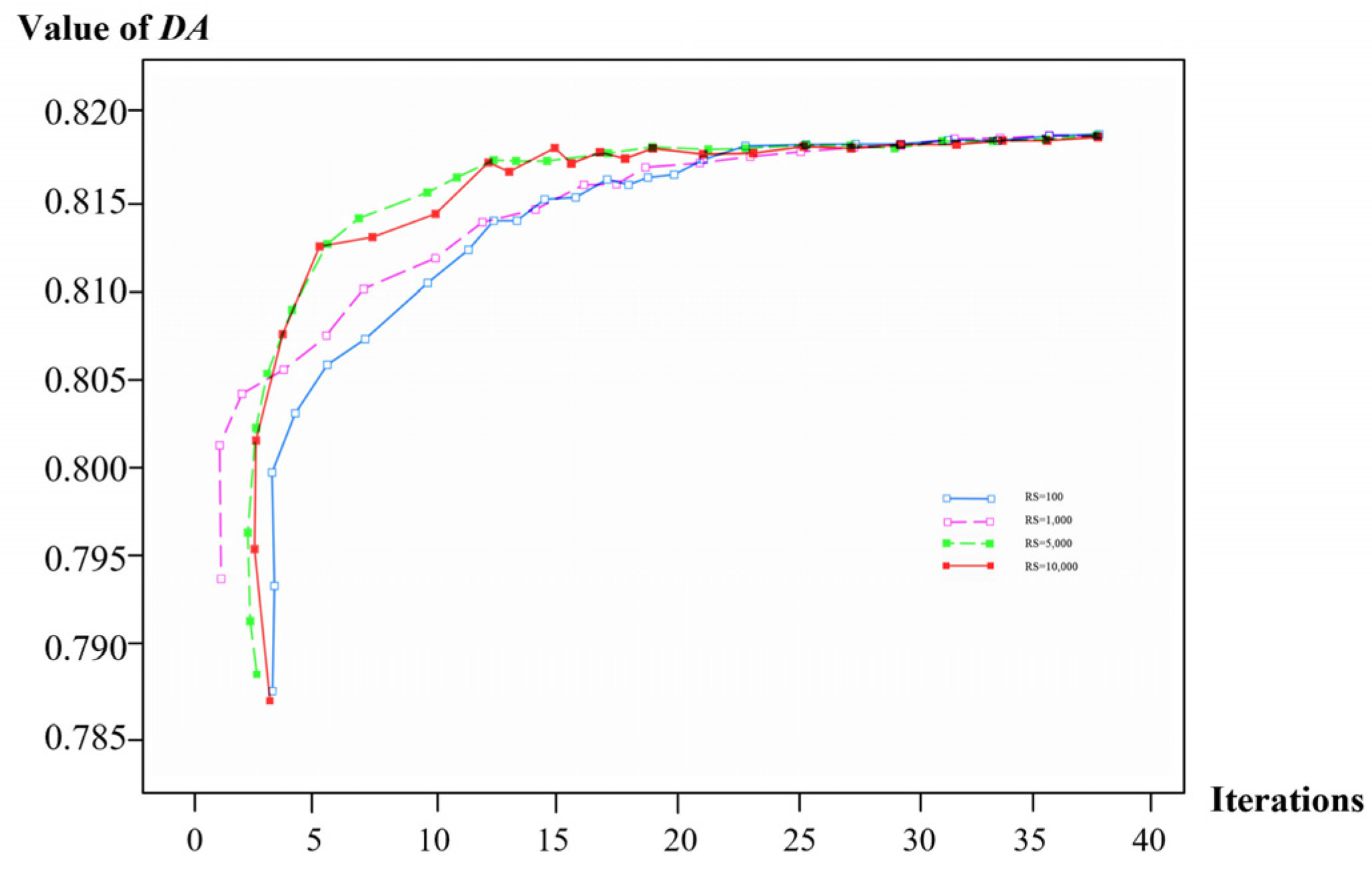
16]. Subsequently, through the model, the influence of different initialization positions of Kraus (equivalent to data noise) on the training results of the model is calculated, as shown in
Figure 5 [
16]. The RS represents the random number seed.
5. Experimental Results and Discussion
Since different stocks and lengths of prediction time would lead to different prediction performances for both HQMM and HMM, 15 distinct stocks were selected for analysis, and the average performance was calculated to evaluate the models’ performance. During the experiment, for the HQMM model constructed in this paper, the number of hidden states was 6, which was derived through global optimization, while the settings for the Kraus operators and density matrices were retained from prior configurations. This methodology ensures robustness and stability across the full dataset, thereby eliminating performance fluctuations induced by data distribution discrepancies. Additionally, the matrix
Z with a dimension of
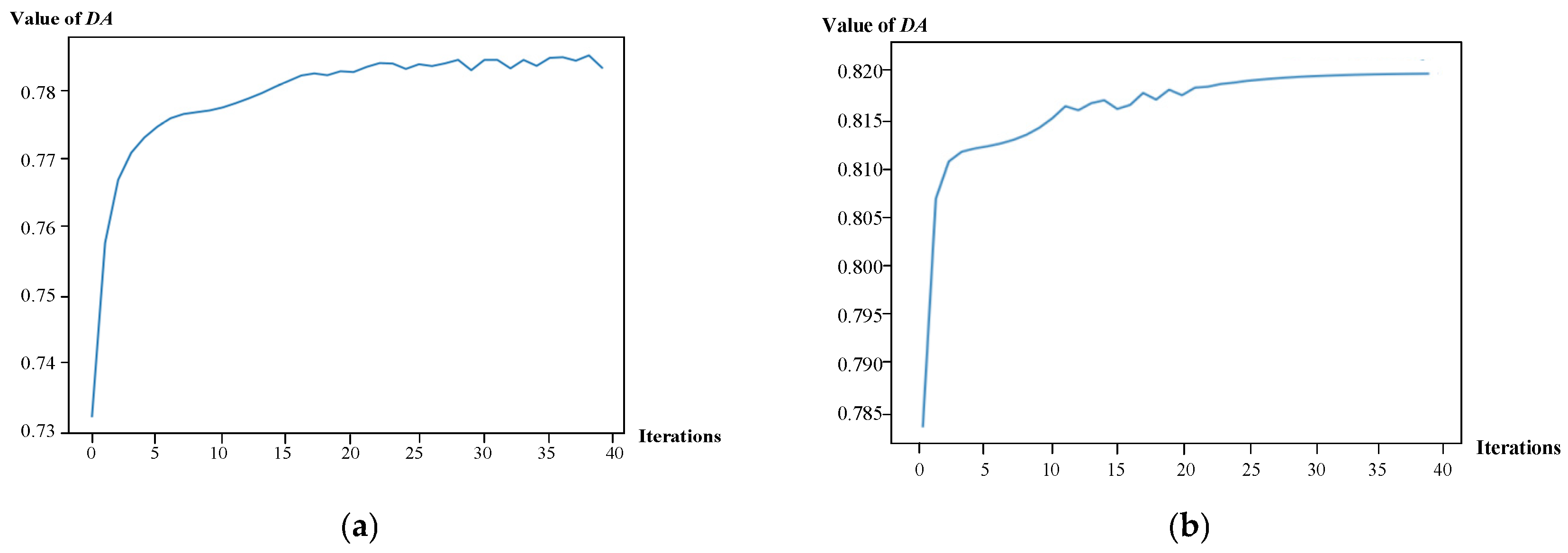
is obtained from the training process. The calculated results of DA for the evenly-discretized continuous data and that processed with MVTF are shown in
Figure 6a,b, respectively. It can be found that when the number of iterations is less than 5, the value of DA increases rapidly, while once the number of iterations exceeds 40, the value of DA tends to converge. At this time, the mode training is completed.
Upon completing model training, the following steps are further conducted to investigate the model’s prediction performance:
Based on the constructed matrix
Z, six matrices
are obtained, and the corresponding prediction values
could be calculated by the following equation:
The minimum value is found among , and thus the subscript is the predicted state at the t time. For example, if the minimum value is , 3 is the most possible next state (E).
By setting the initial capital (IC) to 1,000,000, the trend of each stock is predicted one by one with different methods. If the prediction result of one stock is rising, i.e., is , , or , buy(long) it; otherwise, sell(short) it. if the prediction result is falling ( is , or ). In order to measure the prediction effect, for the following scheme, the final capital (FC) that the operator (including buying and selling at the right time) uses for HQMM can be obtained. It should be noted that the transaction costs in the whole process are neglected. The core function of HQMM is to predict market state evolution by forecasting the most probable range of price fluctuations, and it is decoupled from trade execution. If HQMM needs to be integrated into a trading system for downstream applications, this can be achieved in the future through a portfolio optimization module.
To compare the prediction result of the stock with the natural growth capital (NC), the comparative growth rate (
R) is proposed [
25], formulated as follows:
where IP is the initial price of each stock, FP is the final price of each stock at the time of experiment, SP is the selling price, and BP is the buying price. Obviously, NC can be obtained from the real data of the stock, as shown in
Table 4.
At the beginning, the final capital (FC) is set equal to the initial capital (IC), and then the selling price (SP) and buying price (BP) are defined accordingly. Once the HQMM indicates a buying suggestion, the calculation of (15) is repeatedly performed, leading to the update of the final capital (FC).
Regarding the stock prediction using HMM, the detailed processes can be found in reference [
26]. This involves using classical ML techniques and historical stock data as input to comprehensively train the HMM model, which is then utilized to predict stock trends. Similarly, both FC and R can also be obtained with the same methods in HQMM.
To further investigate the model’s time generalization capabilities, three different prediction periods of 90 days, 180 days, and 360 days were considered to study the impacts of different stocks, time periods, and models on prediction results.
Three randomly selected stocks were taken as an example, and the predicted trends by three different methods were compared with the actual trends over different time periods. The results are shown in
Figure 7 (The grey columns represent an increase, while the red columns represent a decrease). For the stock with code 600519, the predicted trend from August 2020 to July 2021, as determined by HMM, best aligns with the actual trend, as shown in
Figure 7a. For the stocks with codes 601318 and 600022, HQMM performs the best, as shown in
Figure 7b,c. Notably, for all these stocks, the prediction results of HQMM with the data discretized by GMM and MVTF are always superior to those of HQMM with evenly discretized data. This further demonstrates that selecting multiple stocks and various time periods to evaluate the model’s average prediction capability is necessary. By applying similar operations to our selected 15 stocks and considering different time periods, the (FC) and (
R) are calculated by three different prediction methods, and the detailed results are summarized in
Table 4,
Table 5,
Table 6 and
Table 7.
Table 4 presents the (NC) and its variation rate for 15 stocks across different periods (90, 180, and 360 days), serving as the benchmark for evaluating prediction model performance. A model demonstrates practical value if its forecast-guided (FC) exceeds (NC).
Table 5 displays the predictive performance of the classical HMM, with the (
R) as the key metric.
Table 6 presents the prediction results of HQMM with evenly discretized data, also evaluated using (
R).
Table 7 presents HQMM’s performance when employing GMM and MVTF transformation, with
R as the comparative metric. (With an investment of 1,000,000 in 90 days, the natural capital of stock code 000901 is 1732049. The growth rate of this model, compared with that of natural growth capital, is 0.92%.)
(NC) refers to the value attained by initial capital under natural market conditions without model-guided investment, reflecting intrinsic stock value growth and providing a performance baseline. (R) quantifies the difference between model-predicted returns and (NC), calculated as , where (FC) represents final capital. This metric measures the growth rate of return generated by model-driven trading strategies relative to passive market growth.
Experimental validation demonstrates the significant advantages of the quantum-enhanced model over traditional approaches.
Table 8 compares the prediction results and performances of the above-mentioned three prediction methods. (1) Superior predictive performance (average capital with shorting/longing as predicted): 1390860 is realized by classical HMM, 1362922 by HQMM with evenly discretized data, and 1404827 by HQMM with data discretized by MVTF. (2) Average comparative growth rates: 3.73%, 1.59%, and 4.96% (Formula (12)), respectively. (3) Total required time (min): 40, 12, and 12. (4) The computational complexity: HMM =
, HQMM =
[
16]. (
T denotes the prediction sequence length,
n represents the number of hidden states, and
w corresponds to the observable space dimension.) This linear scaling in
w versus HMMs’ quadratic dependence on
n demonstrates HQMMs’ computational advantage for high-dimensional observation spaces.
The MVTF-discretized HQMM approach demonstrates superior performance over comparative methods, with 70% faster computation (12 vs. 40 min), a 4.96% higher comparative growth rate, and a computational advantage. By employing a novel GMM-MVTF framework that converts continuous financial data into discrete time-series sequences, this methodology effectively resolves inherent processing limitations in hidden quantum Markov models.
Practical value discussion: Due to the clear advantages demonstrated by the MVTF-discretized HQMM experiments, it is now necessary to discuss its practical significance. (1) Real-time signal generation identifies bullish, bearish, or range-bound regimes to support pre-trade decisions through predictive alerts. (2) Enhanced quantitative strategies strengthen in-process risk management via automatic stop-loss triggers and maximum drawdown control when hidden state probabilities indicate market deterioration, enabling optimized portfolio hedging. (3) Dynamic optimization of asset allocation thresholds via asset rotation gradually increases exposure to growth stocks during predicted bull markets (shifting to high-dividend companies during bear markets), enabling optimized portfolio hedging. (4) It is supplemented by sector rotation forecasts from HQMM that refine industry heatmaps. (5) Quantum-driven model accelerates processing speeds (70% faster), significantly augmenting human analytical capabilities. (6) Practical implementability is ensured through MVTF-discretized quantum algorithms trained on real-world financial time series. (7) In the future, it can also be integrated with the development of other assessment frameworks in a collaborative manner.
6. Conclusions
To address the limitations of HQMM, which does not apply to continuous data, this paper proposes a data discretization method for stock data while also applying the HQMM approach to forecast stock trends for the first time. A series of experiments were conducted based on the real data collected from SSE and SZSE to evaluate the performance of such quantum-inspired classical algebraic models. Experimental results demonstrate that the HQMM with data discretized by MVTF outperforms both HMM and evenly discretized HQMM in temporal efficiency, time (70% faster), computational complexity, and superior predictive performance (4.96% higher). Furthermore, the model captures nonlinear dependencies and hidden correlations unattainable by classical machine learning methods, confirming its quantum information advantage. While this study demonstrates the significant potential of quantum computing in financial forecasting, several limitations must be acknowledged: (1) data preprocessing has bottlenecks for high-frequency markets, and (2) regulators could leverage quantum-enhanced models for systemic risk monitoring, while financial institutions should establish validation protocols to ensure algorithmic transparency amid quantum adoption. Future research could further enhance model performance by exploring several key directions. These include the advanced design and optimization of quantum circuits, the augmentation of dataset capacity to improve model generalizability, the identification of optimal input cycles tailored to different stock behaviors, the refinement of rule structures within the MVTF model, the development of quantum-specific risk evaluation frameworks, and the standardization of quantum advantage benchmarks in finance. Such advancements would not only contribute to the theoretical evolution of quantum finance but also facilitate its practical implementation within the financial sector. By processing real market data, HQMM enables real-time market regime prediction, automated risk control, and dynamic asset allocation—thus forming an implementable quantum—forming a quantum-enhanced decision system for adaptive portfolio management through accelerated quantum processing.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}