1. Introduction
The relationship between temperature and mortality has been widely studied in epidemiology, with numerous studies emphasizing the critical impacts of extreme temperatures on human health [
1,
2,
3,
4]. Both high and low temperatures have been linked to increased mortality, with vulnerable populations such as the elderly, young children, and individuals with preexisting health conditions being disproportionately affected [
5]. Despite this robust body of research, much of it assumes a static relationship over time, overlooking the potential for temporal variations due to changes in environmental conditions, population characteristics, and adaptive responses. This static assumption could obscure evolving vulnerabilities or resilience within populations, particularly in the context of climate change.
Regression analysis plays a vital role in statistical modeling, particularly in understanding the influence of explanatory variables on a response variable. Nonparametric regression, which does not assume a predefined functional form, allows for flexible modeling of complex relationships. This study focuses on estimating and making inferences about the nonparametric function that describes the relationship between temperature and mortality, specifically analyzing whether the mortality-temperature functions remain consistent over time and whether they share common change points in their structure.
The articles studied the relationship between temperature and mortality, particularly in the context of climate change and extreme weather events, found that the relationship takes the form of a U-shaped or J-shaped association, where mortality rates rise at both low and high temperatures [
6,
7,
8]. Research by [
9,
10] has shown that both heatwaves and cold spells significantly increase mortality, with the elderly and individuals with preexisting health conditions being particularly vulnerable. Similarly, ref. [
11] found a strong correlation between high temperatures and mortality in London, particularly from cardiovascular and respiratory diseases. These findings underscore the public health risks posed by temperature extremes.
Despite this extensive research, most studies assume a static relationship between temperature and mortality, overlooking potential temporal variations. As climate change progresses, factors such as environmental shifts, population dynamics, and adaptive responses may alter the mortality-temperature relationship. The increasing frequency and intensity of extreme weather events, compounded by urban heat islands and demographic transitions, further complicate this association. Studies such as those by [
1,
4] highlight that both high-temperature variability and extreme temperatures contribute to mortality risk. Still, few studies rigorously examine whether this relationship evolves or changes over time.
Existing research often focuses on short-term studies or specific geographic regions, leaving gaps in understanding the long-term evolution of temperature-related mortality. Addressing these gaps is critical, particularly for developing countries and areas with limited healthcare infrastructure. Studies such as those by [
12] project substantial increases in temperature-related mortality, particularly in vulnerable regions. Without significant mitigation and adaptation measures, the global burden of temperature-related mortality is expected to rise, as highlighted by [
13].
Examining the stability of the temperature-mortality relationship is crucial for several reasons. First, it can indicate whether populations are becoming more resilient or more vulnerable to temperature extremes, providing critical insights for public health planning. Second, identifying temporal variations may help pinpoint factors driving these changes, such as improvements in adaptive capacity or increased exposure due to urbanization. Lastly, understanding these dynamics can enhance predictive modeling for future mortality trends under various climate scenarios.
The methodology employed in this study focuses on advanced statistical modeling techniques, including semiparametric methods, to assess whether the temperature-mortality functions have remained consistent over the years 1987–2000 for Chicago City, USA. By leveraging local linear polynomial kernel smoothing, the study aims to detect nonlinear and nonstationary patterns, enabling a more nuanced understanding of how temperature impacts mortality over time. Additionally, a test will be proposed and applied to Chicago data to determine if there is a significant change over time in the temperature-mortality relationship. Another test will examine whether the change points in the mortality-temperature nonparametric function are consistent over time.
This study contributes to the growing field of environmental epidemiology by systematically evaluating how the temperature-mortality relationship changes over time. The findings will offer actionable insights for climate adaptation, public health strategies, and mortality risk mitigation. Given the projected rise in extreme temperature events due to climate change, there is an urgent need for coordinated global efforts to understand and reduce temperature-related mortality. Future research should continue exploring regional vulnerabilities and developing targeted interventions to protect public health in an era of increasing climate instability.
The remainder of this paper is organized as follows. In
Section 2, the nonparametric temperature-mortality function estimation is introduced. In
Section 3, the procedure for testing the equality of the nonparametric function over the years is displayed. Intensive simulation studies are conducted in
Section 4 to evaluate the proposed approaches and compare them to the traditional F test. The real data application is analyzed in
Section 5.
Section 6 includes a discussion, conclusion, and future research.
5. Real Application
In the National Morbidity, Mortality, and Air Pollution Study (NMMAPS), daily data were collected from 1 January 1987 to 31 December 2000 across 108 U.S. cities to investigate the effects of air pollution on health in the United States [
18]. The dataset includes numerous variables, such as temperature, deaths, nitrogen dioxide, relative humidity, ozone, PM10, and others. Many articles studied these data, such as [
19], in which the association between cardiovascular mortality and temperature has been investigated by estimating the nonparametric temperature-mortality function. However, no study has studied the relationship between temperature and mortality over the years to find whether the function curve changed over the years or whether the nonparametric functions have the same change points.
Daily mortality counts were sourced from the National Center for Health Statistics, while pollution data originated from the U.S. national air monitoring network, provided by the EPA Aerometric Information Retrieval System database. Weather data were obtained from the National Climatic Data Center. The dataset was publicly available from June 2004 until 2011, when it was removed due to privacy concerns. However, data from Chicago remain accessible through the R 4.2.1 package “dlnm” which was utilized in this study.
The study starts by exploring the Chicago mortality and temperature data before applying the tests introduced in
Section 3.
Table 5 displays the numerical summary of temperature and mortality for the first three years (1987–1989) and the last three years (1998–2000). The table indicates that mortality decreased while temperature increased.
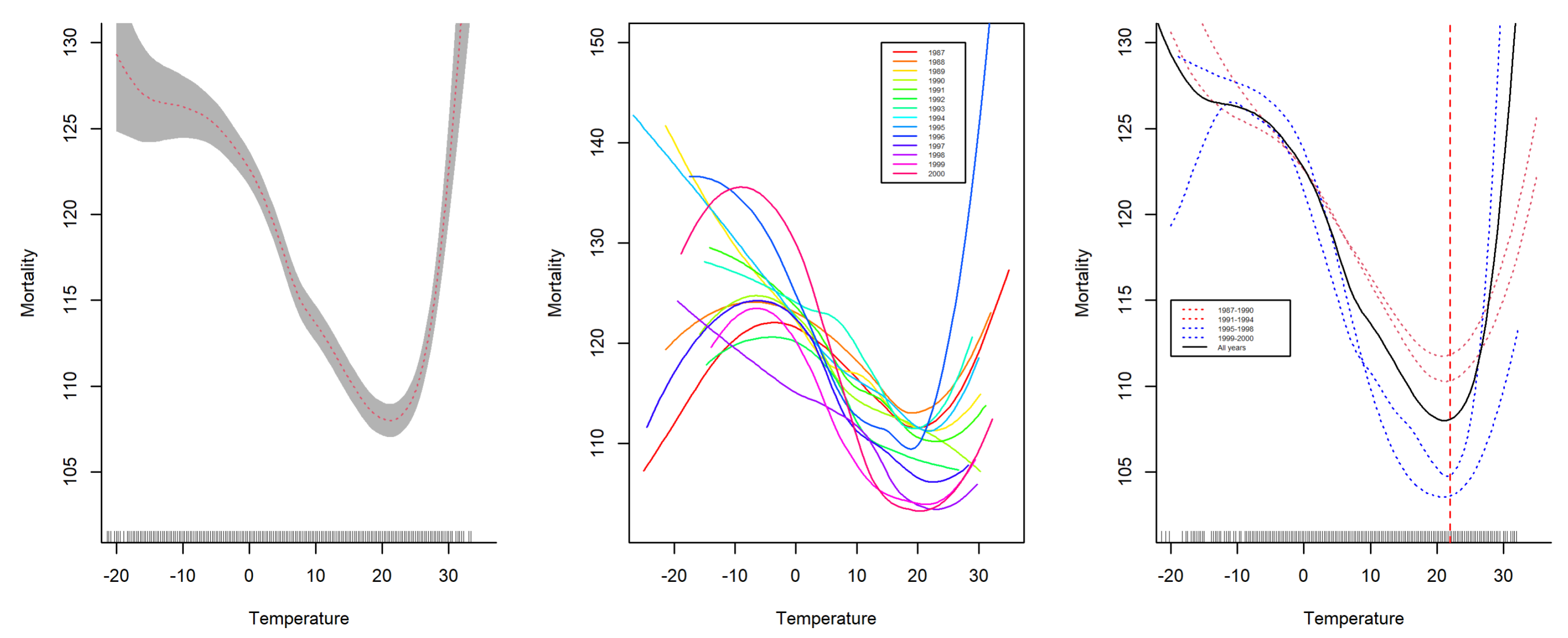
Figure 2 (left) displays the smoothed nonparametric temperature-mortality function for all years combined,
Figure 2 (middle) displays the smoothed nonparametric temperature-mortality function for each year, and
Figure 2 (right) displays the smoothed function for each consecutive four-year period. The figure suggests that the function evolves, with higher years corresponding to a lower mortality function curve, particularly around the temperature change point of approximately 20 °C.
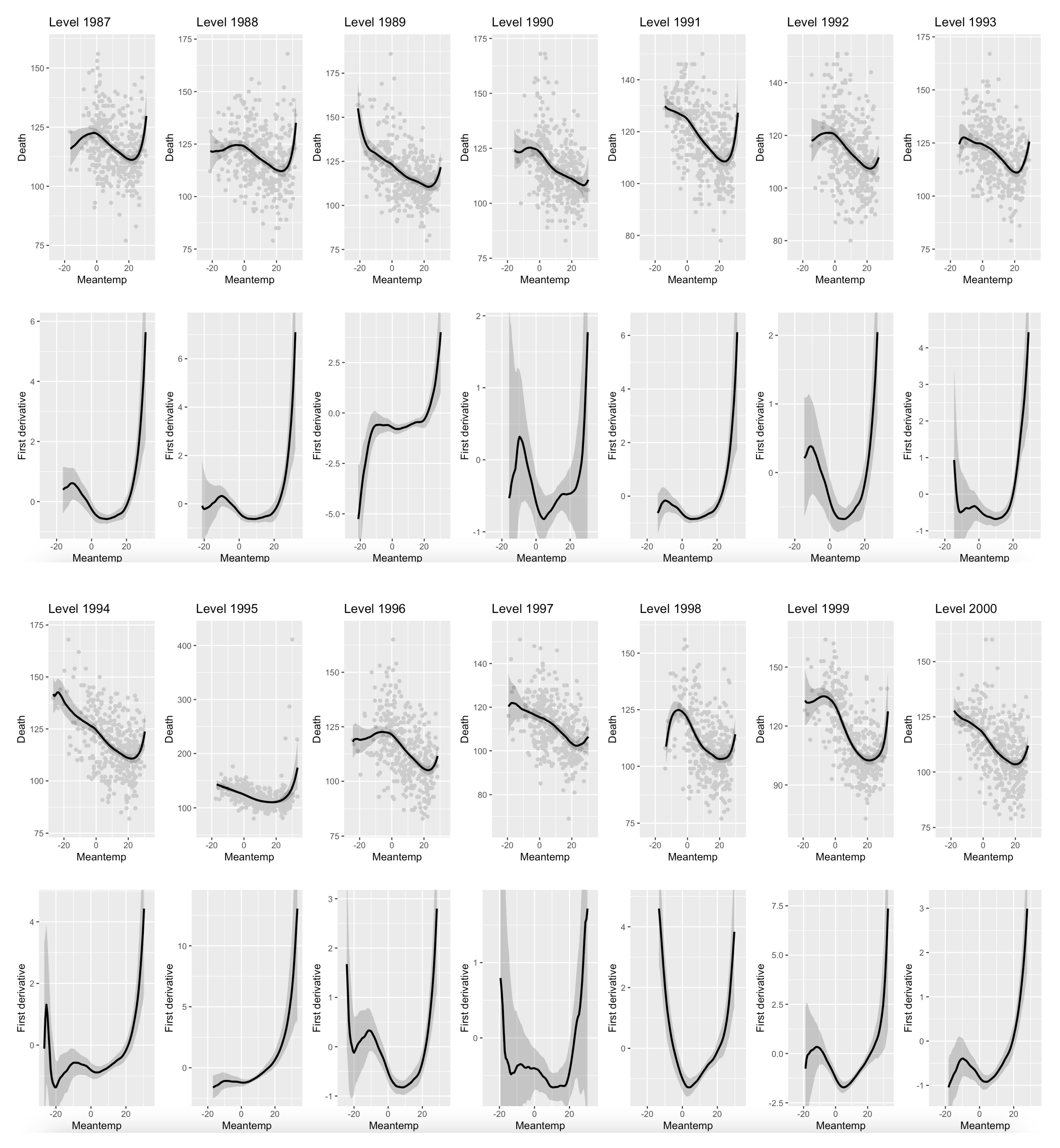
Figure 3 displays the smoothed nonparametric temperature-mortality function for each of the 14 years and its first derivative along with the 95% confidence interval.
The test for equality of the nonparametric functions described in
Section 3.1 and the test for equality of the change points in the mortality-temperature functions described in
Section 3.2 are applied to the Chicago data.
Table 6 shows the change points of the mortality-temperature function for each year with the lower limit (LL) and the upper limit (UL) of the 95% confidence intervals. It also displays the change points in the derivative functions with lower and upper limits of the 95% confidence intervals. It reveals that all the change points in the nonparametric functions are significant because the lower and upper limits have positive signs. However, some of the change points in the derivative functions are not significant.
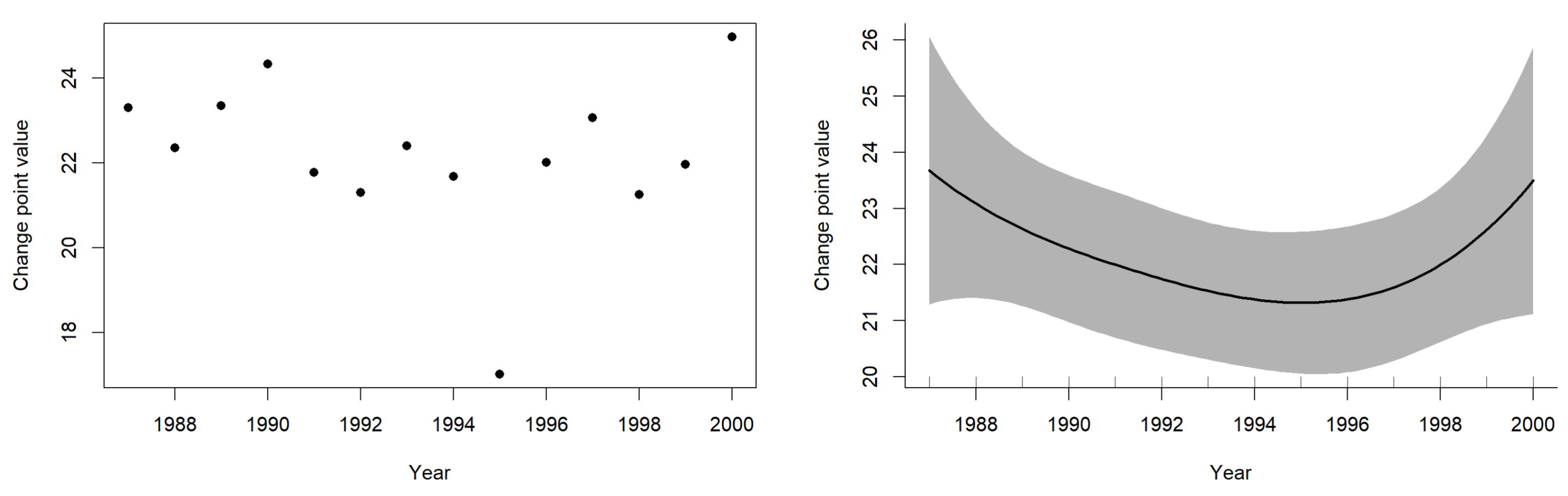
Figure 4 (left) reveals that there is no trend in the change point values; there is no relationship between the year and the change point value, however, the smoothed faction displayed in
Figure 4 (right) reveals that there is a pattern of decreasing change point value and then increasing; however, that is because of one change point of the year 1997 which is considered an outlier.
To find whether the mortality functions of all 14 years have the same shape, it is found that
p-value < 0.001 for testing equal mortality-temperature nonparametric functions. As a result, the null hypothesis was rejected and it was concluded that the temperature-mortality functions do not have the same shapes at all 14 years at 5% significance level. As a follow-up analysis to see whether the change points in the mortality-temperature nonparametric functions for all 14 years have the same change point values, the test described in
Section 3.2 was run. It is found that
p-value = 0.048, which means that the functions do not have the same change points for all 14 years as displayed in
Table 6. However, there is no pattern in the change point values over the years. The programs used in the paper are available upon request.
6. Conclusions and Future Research
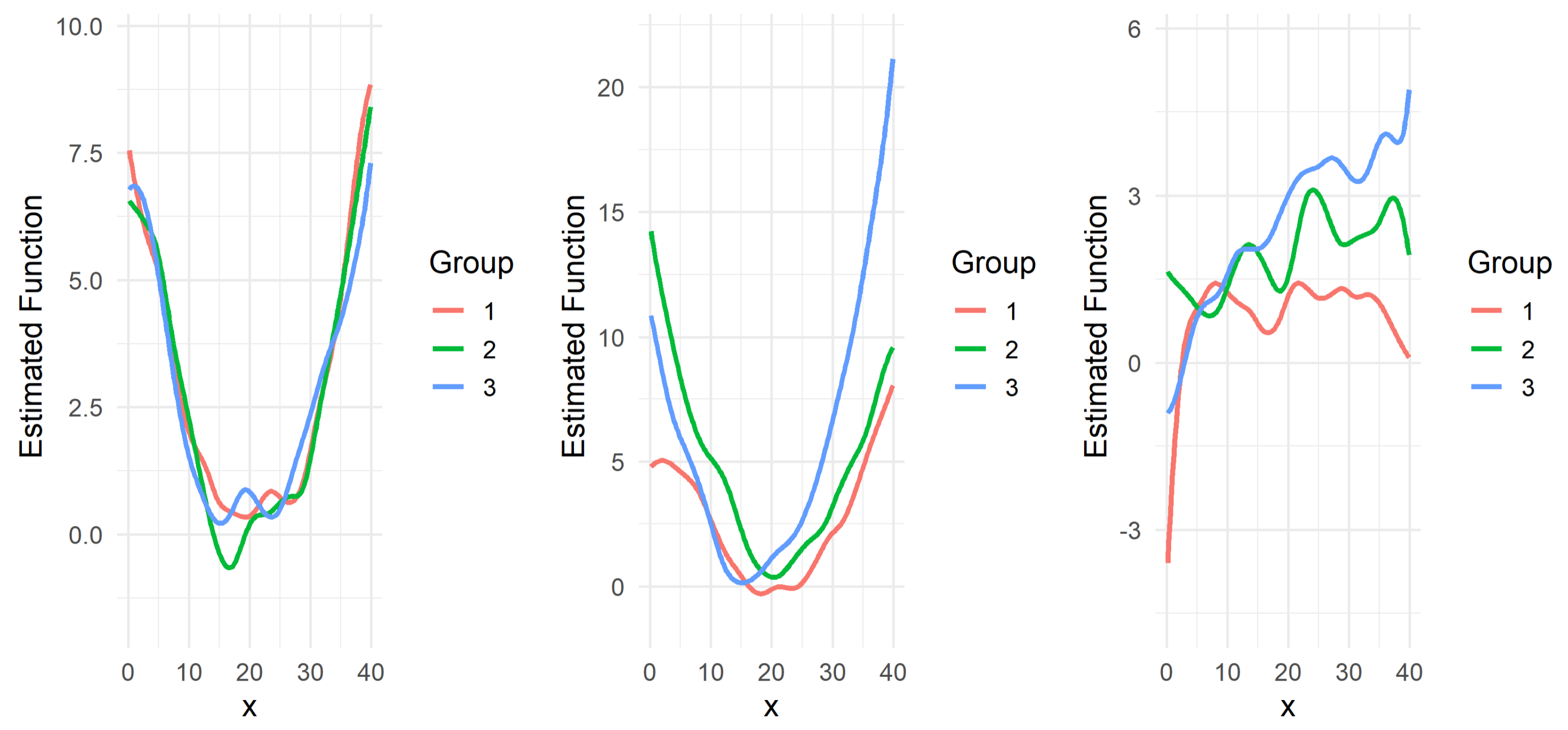
In this article, an approach is presented to test the change in regression functions between groups or levels of a categorical variable, and to explore whether the change points are equal. An intensive simulation study was conducted to systematically evaluate the finite-sample performance of the proposed test procedures under various scenarios, such as different levels of noise, sample sizes, and functional shapes. Based on the empirical Type I error and power, it is found that the testing procedures are effective in detecting functional change and testing the equality of the change points. The proposed tests are compared with F tests and it was found that the proposed tests outperform the traditional functional F test in all scenarios evaluated.
Additionally, this study examined the temporal evolution of the temperature-mortality relationship in Chicago from 1987 to 2000 using nonparametric regression techniques. By applying local linear polynomial kernel smoothing and rigorous inference procedures, we found that the functional form of the temperature-mortality relationship significantly varies across years, indicating dynamic changes in population vulnerability or adaptation to temperature extremes. However, the analysis revealed that the change points, the temperatures at which mortality is highest, remain consistent over time, suggesting a stable threshold of critical risk despite structural changes in the overall relationship.
These findings underscore the importance of modeling strategies that accommodate temporal heterogeneity when assessing climate-sensitive health outcomes. Static models may overlook important variations that have implications for public health interventions and climate resilience planning.
Future research should extend this analysis to other geographic regions and periods to evaluate the generalizability of the observed patterns. Incorporating additional environmental and sociodemographic covariates, such as air pollution, urban heat island effects, and healthcare access, may further elucidate the mechanisms underlying the changing mortality response. Furthermore, developing methods that jointly model change in both the function shape and threshold behavior across space and time will be valuable for advancing epidemiological and environmental risk assessments in a changing climate. Simulation studies are conducted to evaluate the proposed tests; however, another direction for future research is theoretical work that could explore the asymptotic distribution and power properties of the proposed test statistics to formally establish their performance guarantees and limitations.





{kind=link}
{kind=link}
{kind=link}
{kind=link}